

А обнаружена она была на серверах Twitter
Ядро Linux имеет ошибку, причиной которой являются контейнеры. Чтобы не проверять контрольные суммы TCP, для сетевой маршрутизации контейнеры используют veth-устройства (такие как Docker на IPv6, Kubernetes, Google Container Engine и Mesos). Это приводит к тому, что в ряде случаев приложения ошибочно получают поврежденные данные, как это происходит при неисправном сетевом оборудовании. Мы проверили, что эта ошибка появилась, по крайней мере, три года назад и до сих пор «сидит» в ядрах. Наш патч был проверен и введен в ядро, и в настоящее время обеспечивает ретроподдержку стабильного релиза 3.14 в различных дистрибутивах (таких как Suse и Canonical). Если Вы в своей системе используете контейнеры, я рекомендую Вам воспользоваться этим патчем или установить ядро вместе с ним, когда это станет доступным.
Примечание: это не относится к сетям с NAT, по умолчанию используемых для Docker, так как Google Container Engine практически защищен от ошибок «железа» своей виртуализированной сетью. Еще Джейк Бауэр (Jake Bower) считает, что эта ошибка очень похожа на ошибку Pager Duty, обнаруженную ранее.
Как это все началось
В один из выходных ноября группа саппорт-инженеров Твиттера просматривала логи. Каждое неработающее приложение выдавало «невероятные» ошибки в виде строк странных символов или пропусков обязательных полей. Взаимосвязь этих ошибок не была очевидна из-за природы распределенной архитектуры Твиттера. Вся ситуация осложнялась еще и тем, что в любой распределенной системе данные, когда-то испорченные, могут вызвать ошибки еще довольно продолжительное время (они сохраняются в кэшах, записываются на дисках, в журналах и т.д.).
После суток непрерывной работы по поиску неисправности на уровне приложений, команде удалось локализовать проблему до отдельных рэковых стоек. Инженеры определили, что значительное увеличение числа выявленных ошибок контрольной суммы TCP произошло непосредственно перед тем, как они дошли до адресата. Казалось, что этот результат «освобождал от вины» софт: приложение может вызвать перегрузку сети, а не повреждение пакета!
Примечание:
упоминание эфемерной «команды» может скрыть от читателя, сколько людей работало над этой проблемой. Над диагностикой этих странных неисправностей работала масса инженеров из всей компании. Трудно перечислить всех, но основной вклад внесли: Брайан Мартин (Brian Martin), Дэвид Робинсон (David Robinson), Кен Коэмото (Ken Kawamoto), Махак Пайтидар (Mahak Patidar), Мануэль Кэбэлкуинто (Manuel Cabalquinto), Сэнди Стронг (Sandy Strong), Зак Киль (Zach Kiehl), Уилл Кэмпбелл (Will Campbell), Рэмин Хатиби (Ramin Khatibi), Яо Юэ (Yao Yue), Берк Демир (Berk Demir), Дэвид Барр (David Barr), Гопал Рейпуроухит (Gopal Rajpurohit), Джозеф Смит (Joseph Smith), Рохис Менон (Rohith Menon), Алекс Ламберт (Alex Lambert) и Иэн Доунес (Ian Downes), Цун Ван (Cong Wang).)
Как только эти стойки были отключены, ошибки в работе приложений исчезли. Конечно, повреждения данных на уровне сети могут произойти по многим причинам: самым причудливым образом могут отказывать коммутаторы, могут повредиться провода, может часто отказывать питание и т.п. Контрольные суммы в TCP и IP предназначены для защиты от таких неисправностей. И действительно, собранная по оборудованию статистика показывала, что ошибки присутствовали. Итак, отчего набор разнообразных приложений начал давать сбои?
После изоляции определенных коммутаторов, были сделаны попытки воспроизвести эти ошибки (главным образом благодаря колоссальной работе старшего инженера по надежности Брайана Мартина). Оказалось, что относительно просто воспроизвести поврежденные данные, отослав на эти стойки некоторое количество пакетов данных. На некоторых коммутаторах оказались поврежденными до 10% отправленных пакетов. Однако, повреждения всегда выявлялись ядром с помощью контрольных сумм TCP (сообщения типа TcpInCsumErrors netstat-a), и никогда не доходили до приложений. (В Linux с помощью недокументированной опции SO_NO_CHECK можно отсылать пакеты IPv4 UDP с отключенными контрольными суммами – в таком случае мы сможем увидеть, что пакет поврежден.)
Эван Джонс (Evan Jones) предположил, что поврежденные данные имеют правильную контрольную сумму TCP. Если в том же самом 16-битном слове два бита зеркально «перевернуть» (например, 0>1 и 1>0), их влияния на контрольную сумму TCP уравновесят друг друга (контрольная сумма TCP – простое сложение битов). Хотя повреждение данных в сообщении (32 байта по модулю) всегда заключалось в изменении одной и той же битовой позиции, факт, что был «залипающий бит» (0>1), исключающий такую возможность. С другой стороны, поскольку сама контрольная сумма перед сохранением инвертируется, «переворот» бита в контрольной сумме вместе с «переворотом» бита в данных могут уравновесить друг друга. Однако, битовая позиция, которую мы наблюдали измененной, не могла касаться контрольной суммы TCP, и поэтому это оказалось невозможным.
Вскоре команда поняла, что наши тесты проводились на стандартной системе Linux, а большинство сервисов на Твиттере работает на Mesos, который для изолирования различных приложений использует контейнеры Linux. В частности, в конфигурации Твиттера созданы виртуальные Ethernet-устройства (veth-устройства) и все пакеты для приложений передаются через них. Конечно же, после запуска нашего тестового приложения в контейнере Mesos немедленно появились поврежденные данные, поступающие через подключение по TCP, не смотря на то, что контрольные суммы TCP были ошибочными (и определялись как неправильные: число TcpInCsumErrors увеличивалось). Кто-то предложил изменение настроек «checksum offloading» на виртуальном Ethernet-устройстве, что решило проблему, приведя к соответствующему удалению поврежденных данных.
Теперь перед нами встала серьезная задача. Команда Твиттера по Mesos быстро передала информацию open source-проекту «Mesos» и изменила настройки на всех рабочих контейнерах Твиттера.
Копаем дальше
Когда мы с Эваном обсуждали эту ошибку, мы решили, что, поскольку протокол TCP/IP нарушался ОС, возможно, что она была не результатом неправильного конфигурирования Mesos, а, скорее всего, – результатом ранее необнаруженной ошибки в сетевом стеке ядра.
Чтобы продолжить это наше расследование, мы создали как можно более простую тестовую систему:
- простой клиент, который открывает сокет и раз в секунду посылает очень простое, длинное сообщение.
- простой сервер (мы фактически использовали сетевой компьютер в режиме прослушивания), который прослушивает сокет и, когда на него поступает информация, выводит ее на экран.
- сетевое устройство, контроллер передачи, который позволяет пользователю произвольно повреждать пакеты перед тем, как они будут отосланы по проводу.
- Один раз соединив клиента и сервер, мы использовали сетевое устройство для повреждения всех отправленных за 10 секунд пакетов.
Мы управляли клиентом с одной машины, а сервером – с другой. Компьютеры подключили через коммутатор. Когда мы запускали тестовую систему без контейнеров, она вела себя точно так, как и ожидалось. Никаких оповещений о поврежденных пакетах не поступало. Фактически, те десять секунд, что передавались поврежденные данные, мы вообще не получали никаких сообщений. После того, как клиент прекратил повреждать пакеты, все 10 сообщений (которые не были доставлены), сразу пришли. Это подтвердило, что TCP на Linux без контейнеров работает так, как и положено: плохие пакеты TCP задерживаются и постоянно повторно передаются до тех пор, пока не смогут быть приняты без ошибок.
Так это должно работать в теории: поврежденные данные не доставляются; TCP повторно передает их.
Linux и контейнеры
В этом месте полезно (как мы это сделали при диагностике проблемы) вернуться назад и кратко описать, как работает сетевой стек в контейнерной среде Linux. Контейнеры были разработаны, чтобы разрешить обслуживающим пользователей приложениям совместно работать на компьютерах? и таким образом предоставить много преимуществ виртуализированной среды (уменьшить или полностью устранить возможность влияния приложений друг на друга, обеспечить возможность нескольким приложениям работать в различных средах или с различными библиотеками) при меньших затратах на виртуализацию. Идеально, чтобы все объекты, конфликтующие между собой, были изолированы. Примерами могут служить очереди запросов к дискам, кэши и работа сети.
В Linux veth-устройства используются для изоляции одних работающих на компьютере контейнеров от других. Сетевой стек Linux достаточно сложный, но по существу veth-устройство представляет собой интерфейс, который с точки зрения пользователя должен выглядеть точно так, как «обычное» Ethernet-устройство.
Чтобы создать контейнер с виртуальным Ethernet-устройством, надо (первое) создать контейнер, (второе) создать veth, (третье) привязать один конец veth к контейнеру, (четвертое) назначить для veth IP-адрес и (пятое) настроить маршрутизацию, как правило, с помощью Linux Traffic Control, для того, чтобы контейнер мог получать и отсылать пакеты.
Почему все это виртуальное хозяйство «падает»
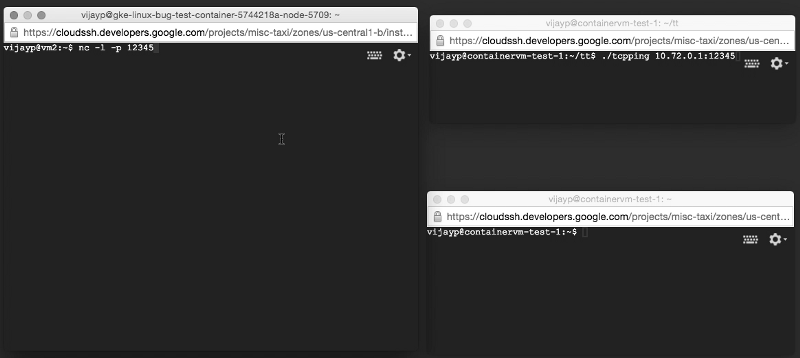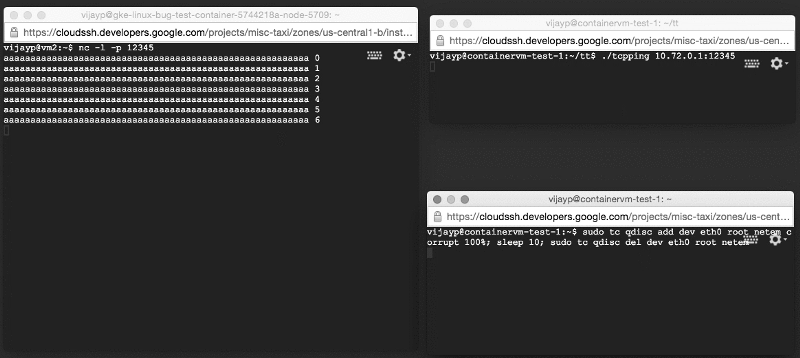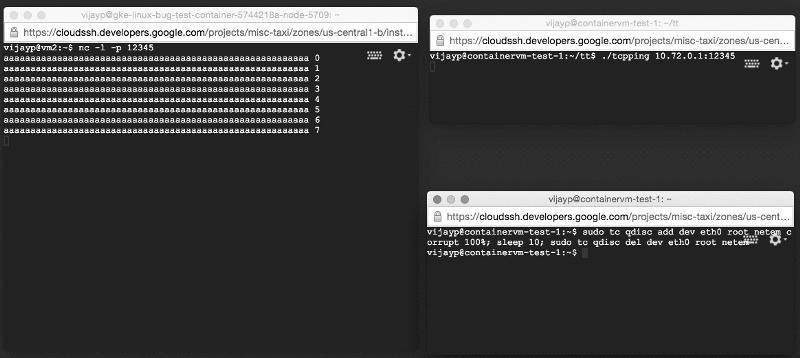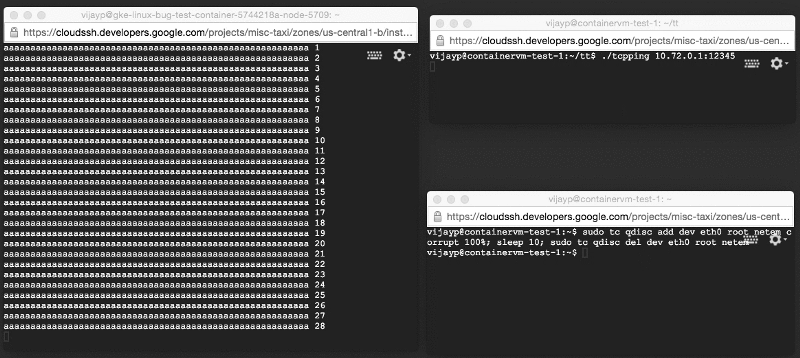
Мы вновь создали описанную выше тестовую систему за исключением того, что теперь сервер работал внутри контейнера. Однако, когда мы ее запустили, мы увидели абсолютно противоположную картину: поврежденные данные не задерживались, а доставлялись приложениям! Мы воспроизвели ошибку на очень простой тестовой системе (две машины на столе и две очень простые программы).
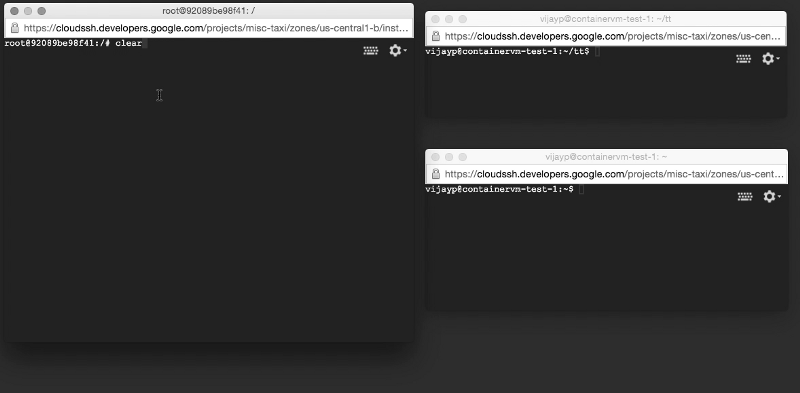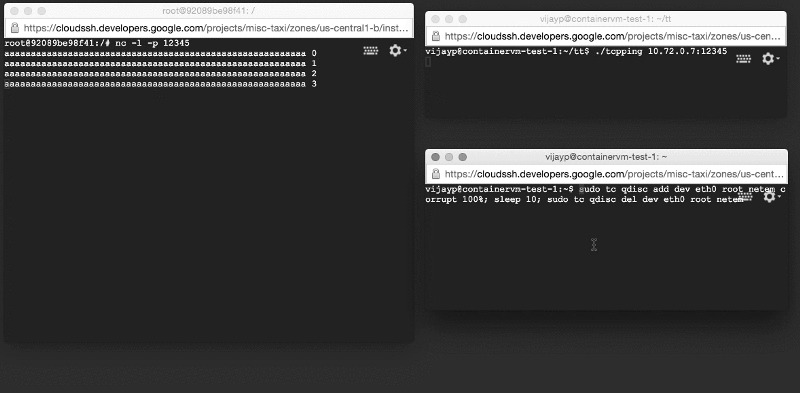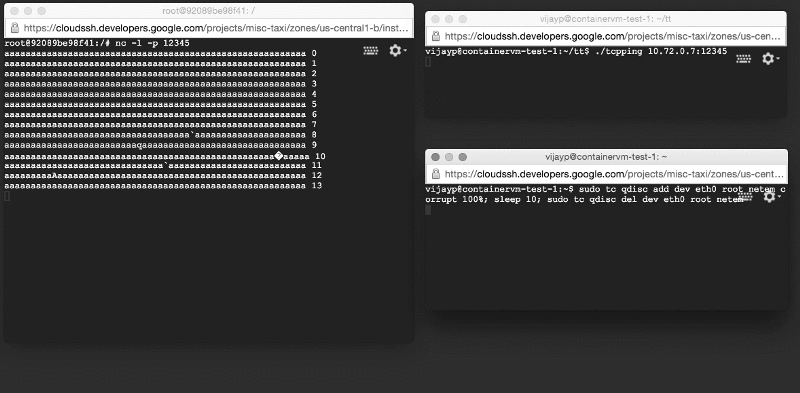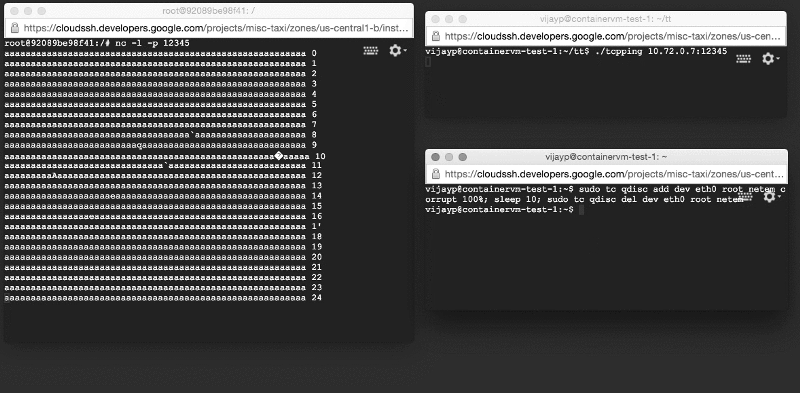
Поврежденные данные доставляются приложению: посмотрите на окно слева!
Мы также смогли воспроизвести эту тестовую систему на облачных платформах. Конфигурация Kubernetes по умолчанию показывает такую же картину (например, при использовании Google Container Engine). Конфигурация Docker’а по умолчанию (с NAT) – безопасна, а конфигурация Docker’а на IPv6 – нет.
Устраняем ошибку
После изучения сетевого кода ядра стало ясно, что эта ошибка в veth-модуле ядра. В ядре в пакетах, которые приходят от реальных устройств сети, параметрам ip_summed присваивается значение CHECKSUM_UNNECESSARY, если «железо» проверило контрольные суммы, или CHECKSUM_NONE, если пакет плохой или не было возможности проверить его.
Код в veth.c заменял CHECKSUM_NONE на CHECKSUM_UNNECESSARY. Это приводило к тому, что контрольные суммы, которые должны были быть проверены и отклонены программным обеспечением, просто молча игнорировались. После удаления этого кода пакеты стали передаваться от одного стека к другому неизмененными (как и ожидалось, tcpdump показывал неверные контрольные суммы на обеих сторонах), и корректно доставлялись (или задерживались) приложениям. Мы не проверили все возможные конфигурации сети, только несколько общих, таких как Bridge-соединение контейнеров, использующее NAT между хостом и контейнером, и маршрутизация от реальных устройств к контейнерам. Мы эффективно внедрили это в работу Твиттера (отключив вычисление контрольной суммы при приеме и разгрузив veth-устройства).
Мы точно не знаем, почему код был написан именно так, но мы полагаем, что это попытка оптимизации. Часто veth-устройства используются для подключения контейнеров на той же физической машине. Логично, что пакеты, передаваемые между контейнерами (или виртуальными машинами) внутри одного физического хоста, не должны вычислять или проверять контрольные суммы: единственный возможный источник повреждений – это собственная RAM хоста, поскольку пакеты никогда не передаются по проводу. К сожалению, эта оптимизация не работает даже так, как было задумано: у локально передаваемых пакетов параметр ip_summed задан как CHECKSUM_PARTIAL, а не как CHECKSUM_NONE.
Этот код был написан для первого релиза драйвера (commit e314dbdc1c0dc6a548ecf [NET]: Virtual ethernet device driver). Релиз Commit 0b7967503dc97864f283a net/veth: Fix packet checksumming (от декабря 2010 года) установил это для пакетов, создаваемых локально и передаваемых на реальные устройства, не изменив CHECKSUM_PARTIAL. Тем не менее, эта проблема все еще не решена для пакетов, передаваемых от реальных устройств.
Ниже приведен патч для ядра:
diff — git a/drivers/net/veth.c b/drivers/net/veth.c
index 0ef4a5a..ba21d07 100644
— — a/drivers/net/veth.c
+++ b/drivers/net/veth.c
@@ -117,12 +117,6 @@ static netdev_tx_t veth_xmit(struct sk_buff *skb, struct net_device *dev)
kfree_skb(skb);
goto drop;
}
- /* don’t change ip_summed == CHECKSUM_PARTIAL, as that
- * will cause bad checksum on forwarded packets
- */
- if (skb->ip_summed == CHECKSUM_NONE &&
- rcv->features & NETIF_F_RXCSUM)
- skb->ip_summed = CHECKSUM_UNNECESSARY;
if (likely(dev_forward_skb(rcv, skb) == NET_RX_SUCCESS)) {
struct pcpu_vstats *stats = this_cpu_ptr(dev->vstats);
Выводы
В целом, я действительно впечатлен netdev-группой и специалистами по ядру Linux. Инспекция кода прошла достаточно быстро, наш патч был подключен в течение нескольких недель, а через месяц обеспечил ретроподдержку старой, стабильной версии (3.14 +) с различными дистрибутивами ядра (Canonical, Suse). При всех преимуществах контейнерной среды, для нас действительно стало большой неожиданностью, что эта ошибка просуществовала много лет незамеченной. Интересно, какое количество отказов и другого непредсказуемого поведения прикладных программ могло быть ею вызвано!
Комментарии (5)

MasMaX
10.03.2016 07:18Не понял в каком ядре это ошибка была и когда она была исправлена? Или пофикшена после 3.14? Так давно уже 4.4 существует.
blind_oracle
10.03.2016 16:23В ядре разрабатываются и поддерживаются сразу много веток, в том числе "старые", с долговременной поддержкой, см. https://www.kernel.org/
Багфиксы бэкпортируются во все причастные версии, находящиеся на поддержке.

csa
15.03.2016 11:18Наткнулся на баг связанный со сбоем на loopback (как предполагаю): https://bugs.openvz.org/browse/OVZ-6684
Суть в том, что в какой-то момент перестает работать tcp на 127.0.0.1, а пинги ходят без проблем. Проявлялось на нескольких разных машинах, рестарт контейнера не помогал.
ragequit
Как всегда, обо всех ошибках, неточностях и прочих "перлах" перевода прошу сообщать в ЛС или при помощи контактов, указанных в профиле. Спасибо.