

Пока некоторые "лидеры рынка" внезапно «изобретают гиперконвергентность», Nutanix просто вот уже пять лет как ее выпускает и продает на рынке. И вот пару недель назад Nutanix выкатывает большое и важное обновление, тянущее на мажорный релиз, но так как у нас в планах еще более крупное и важное обновление впереди, у нас поскромничали, и это — версия 4.6
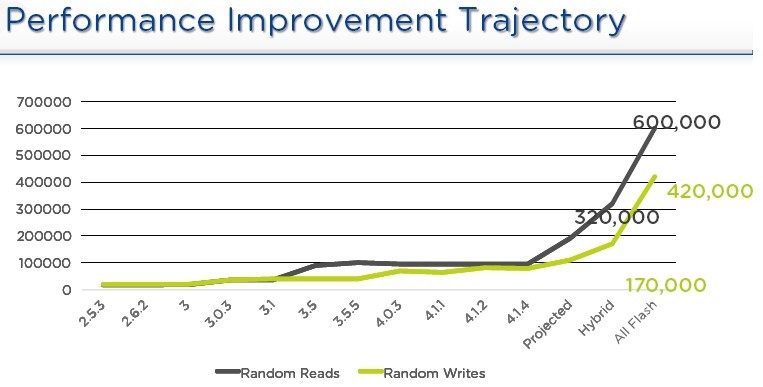
Прежде всего стоит рассказать про резкое и значительное увеличение производительности В РАЗЫ. Нет, не «убрали забытый отладочный sleep 10 в коде», не надо грязи ;) Разработчики назвали следующие причины такого впечатляющего прироста:
- Уменьшение числа dynamic memory allocations
- Снижение locking overhead
- Снижение оверхеда на переключении контекстов
- Использование новых языковых фич и оптимизаций компилятора C++ v11
- Более гранулярное вычисление чексумм
- Более быстрая категоризация ввода-вывода для его дальнейшей оптимизации
- Улучшенное кэширование метаданных
- Улучшенные алгоритмы кэширования записи.
А результаты, чтобы не быть голословным, вот такие. Это наша тестовая система NX-3460-G4, в топовой конфигурации, на 4 ноды. 2x E5-2680v3б 512GB DDR4 RAM на ноду, 2x SSD 1,2TB, 4x SATA 2TB на ноду, всего нод — 4, данные наш тест дает на весь кластер, суммарные по всем четырем нодам, для производительности одной ноды результаты по IOPS делятся на 4.
Вывод — результат работы нашего встроенного теста. На каждой ноде разворачивается VM в конфигурации CentOS, 1x vCPU 1GB RAM, 7 vDisk и на шести из них гоняется fio в режиме секвентальное чтение и запись большими блоками (1MB), рандомное чтение и запись маленькими блоками (4K).
Результаты:
Waiting for the hot cache to flush …………. done.
2016-02-24_05-36-02: Running test «Sequential write bandwidth» …
1653 MBps, latency(msec): min=9, max=1667, median=268
Average CPU: 10.1.16.212: 36% 10.1.16.209: 48% 10.1.16.211: 38% 10.1.16.210: 39%
Duration fio_seq_write: 33 secs
*******************************************************************************
Waiting for the hot cache to flush ……. done.
2016-02-24_05-37-15: Running test «Sequential read bandwidth» …
3954 MBps, latency(msec): min=0, max=474, median=115
Average CPU: 10.1.16.212: 35% 10.1.16.209: 39% 10.1.16.211: 30% 10.1.16.210: 31%
Duration fio_seq_read: 15 secs
*******************************************************************************
Waiting for the hot cache to flush ……… done.
2016-02-24_05-38-22: Running test «Random read IOPS» …
115703 IOPS , latency(msec): min=0, max=456, median=4
Average CPU: 10.1.16.212: 73% 10.1.16.209: 75% 10.1.16.211: 74% 10.1.16.210: 73%
Duration fio_rand_read: 102 secs
*******************************************************************************
Waiting for the hot cache to flush ……. done.
2016-02-24_05-40-44: Running test «Random write IOPS» …
113106 IOPS , latency(msec): min=0, max=3, median=2
Average CPU: 10.1.16.212: 64% 10.1.16.209: 65% 10.1.16.211: 65% 10.1.16.210: 63%
Duration fio_rand_write: 102 secs
*******************************************************************************
Стало после обновления (AHV NOS 4.6):
Waiting for the hot cache to flush …………. done.
2016-03-11_03-50-03: Running test «Sequential write bandwidth» …
1634 MBps, latency(msec): min=11, max=1270, median=281
Average CPU: 10.1.16.212: 39% 10.1.16.209: 46% 10.1.16.211: 42% 10.1.16.210: 47%
Duration fio_seq_write: 33 secs
*******************************************************************************
Waiting for the hot cache to flush ……… done.
2016-03-11_03-51-13: Running test «Sequential read bandwidth» …
3754 MBps, latency(msec): min=0, max=496, median=124
Average CPU: 10.1.16.212: 22% 10.1.16.209: 37% 10.1.16.211: 23% 10.1.16.210: 28%
Duration fio_seq_read: 15 secs
*******************************************************************************
Waiting for the hot cache to flush ………… done.
2016-03-11_03-52-24: Running test «Random read IOPS» …
218362 IOPS, latency(msec): min=0, max=34, median=2
Average CPU: 10.1.16.212: 80% 10.1.16.209: 91% 10.1.16.211: 80% 10.1.16.210: 82%
Duration fio_rand_read: 102 secs
*******************************************************************************
Waiting for the hot cache to flush ……… done.
2016-03-11_03-54-43: Running test «Random write IOPS» …
156843 IOPS, latency(msec): min=0, max=303, median=2
Average CPU: 10.1.16.212: 69% 10.1.16.209: 72% 10.1.16.211: 64% 10.1.16.210: 74%
Duration fio_rand_write: 102 secs
*******************************************************************************
Причем для Allflash конфигураций рост еще более значительный.
И этот прирост вы получаете просто за счет оптимизации и рефакторинга кода нашими программистами, на уже существующей у вас, работающей системе! Без какого-либо аппаратного апгрейда. Бесплатно. Автоматическим обновлением из GUI в течение получаса. Nutanix — это такая Tesla, залил новую прошивку — поехало быстрее и появился автопилот. :)
По моему такие кейсы — лучшая иллюстрация силы Software-defined решений.
Что еще нового, простым перечислением (подробнее, наверное, стоит написать про каждую из этих фич отдельную заметку):
Встроенный в Nutanix распределенный scale-out, single namespace файловый сервис SMB 2.1, называющийся у нас внутри Project Minerva. С ним Nutanix может работать как NAS для внешних потребителей, отдавая файлы «наружу». Многие просили такое, потому что все еще есть области, когда хотелось бы файловое хранилище для внешних пользователей, простейший пример — хранилище пользовательских профилей для рабочих мест VDI. Теперь мы можем делать это в рамках только Nutanix.
Project Minerva это отдельная VM (NVM, «NAS VM») с сервисом NAS в ней, то есть, если вам он не нужен, вы его не устанавливаете, он не занимает место на диске и память, нужен — разворачиваете и устанавливаете изнутри Nutanix. В настоящее время сделан SMB 2.1, в будущем вероятно добавится NFS. Занимается им один из разработчиков SAMBA, однако Minerva — это не SAMBA, это «с нуля» написанный файловый сервис, написанный так, чтобы уметь быть распределенным по неограниченному число нодов в кластере с сохранением на нем единого «пространства имен», single namespace.
О Project Minerva и всех технических его деталях я еще расскажу детально в отдельной статье, когда он дойдет до релиза, но смотреть можно уже сейчас, он опубликован в статусе Technology Preview.
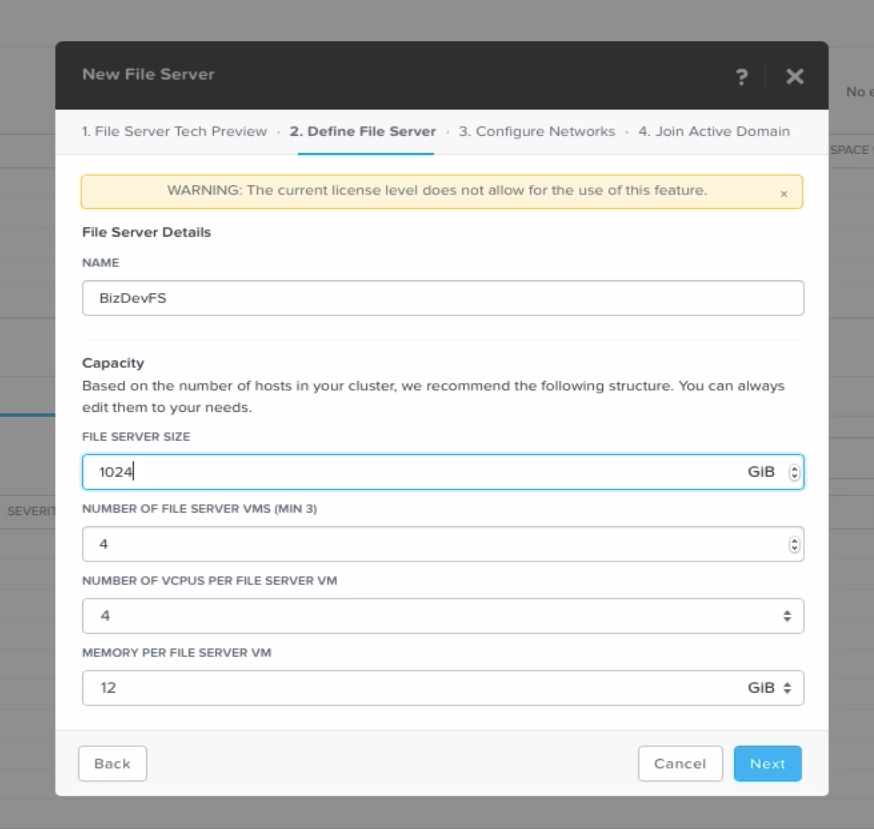
Volume Groups, появившиеся в 4.5 и конфигурировавшиеся там в CLI, теперь управляются из Prism GUI. Volume Groups — это тома с блочным доступом по iSCSI, доступные для VM, в том случае, если вам нужно отдать в VM, работающую внутри Nutanix, раздел с блочным доступом. Примеры таких приложений это Microsoft Exchange на ESXi, Windows 2008 Guest Clustering, Microsoft SQL 2008 Clustering и Oracle RAC.
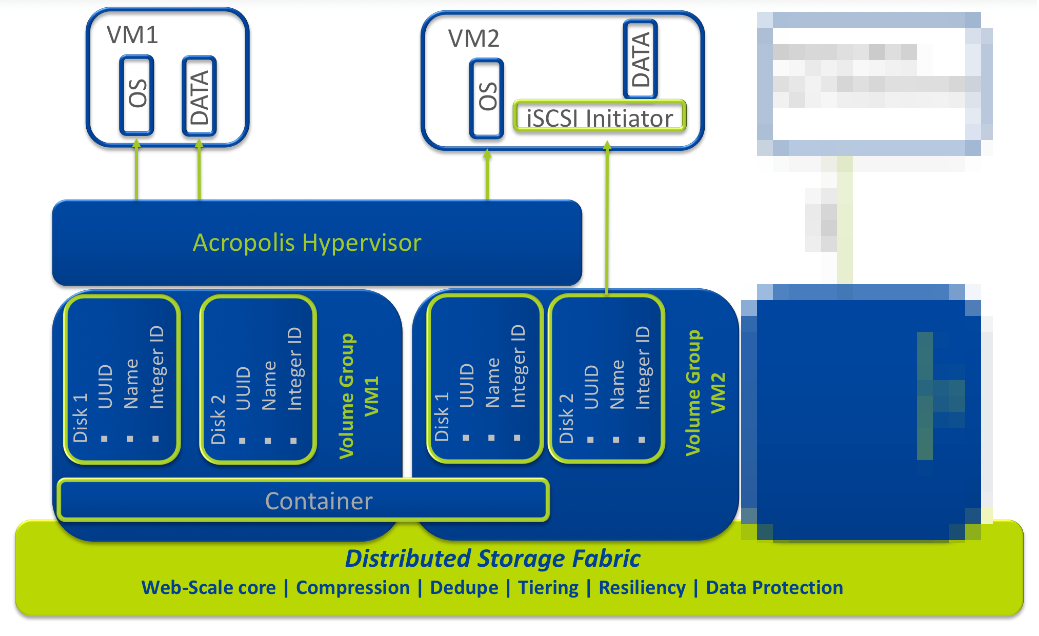
Заблурил на скриншоте некоторые пока не выпущенные в релиз фичи.
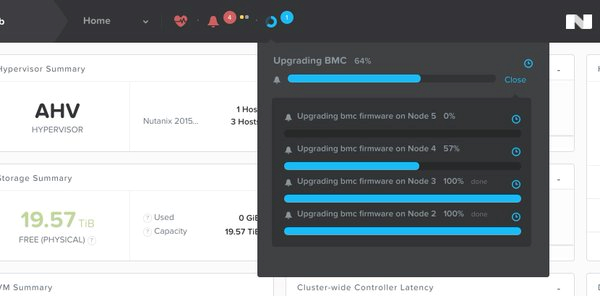
Обновление 1-Click Upgrade теперь работает в том числе и для BMC и BIOS платформы. Без остановки работы вы можете обновить BIOS серверной платформы нашим штатным обновляльщиком. Полностью автоматически хост-платформа мигрирует с себя VM на соседей, перейдет в Maintenance Mode, обновит BIOS, перезагрузится с новым, и вернет на себя свои VM, после чего это проделается по очереди и с остальными хостами кластера, без вмешательства админа.
Также обновляется и встроенный теперь в Nutanix наш сервис прошивки и заливки образов гипервизора и CVM — Foundation. Теперь сам пользователь может добавить встроенным Foundation новую ноду в кластер, без привлечения инженеров Nutanix. С завода приходит сервер-нода с залитым на нее Acropolis Hypervisor и встроенным Foundation. У пользователя есть маленький Java-апплет, запускаемый с компьютера админа, который самостоятельно обнаруживает включенный в сеть сервер-ноду не в кластере (у каждого Nutanix есть уникальный IPv6 адрес из сегмента link local, генерирующийся из его серийника), позволяет залить в него нужный вам гипервизор, например ESXi и включить добавляемую ноду в ваш кластер. Удобно и быстро.
Metro Availability получил долгожданную возможность не перезагружать VM после их миграции на DR-сайт. Раньше это требовалось из-за необходимости переключить NFS-дескрипторы на новый сайт и его хранилище (сами данные синхронно реплицировались), теперь VM работают через NFS proxy, и могут мигрировать «наживую», продолжая работать.
Еще одна долгожданная функция — Self-Service Restore. Теперь пользователь VM может самостоятельно восстановить данные, сохраненные в снэпшоте его VM. Для этого в VM устанавливается так называемый Nutanix Guest Tool, и с его помощью VM коммуницирует с Nutanix, позволяя смонтировать снэпшот как отдельный диск внутри VM, откуда простым копированием можно извлечь данные снэпшота. Пользователи, которые часто «откатываются» в снэпшоты, например, это часто используют разные Test/Dev системы, могут это проделывать сами, не дергая ради этого админа, и не восстанавливая целиком VM, а только нужные отдельные файлы.
Появилась интеграция с OpenStack, новые драйвера для Nova, Cinder, Glance и Neutron. Интеграция работает через специальную Server VM (SVM), образ которой доступен для скачивания и установки в Nutanix. Таким образом, Nutanix видится из Open Stack как hypervisor. Про интеграцию с OpenStack я еще расскажу подробнее позже.
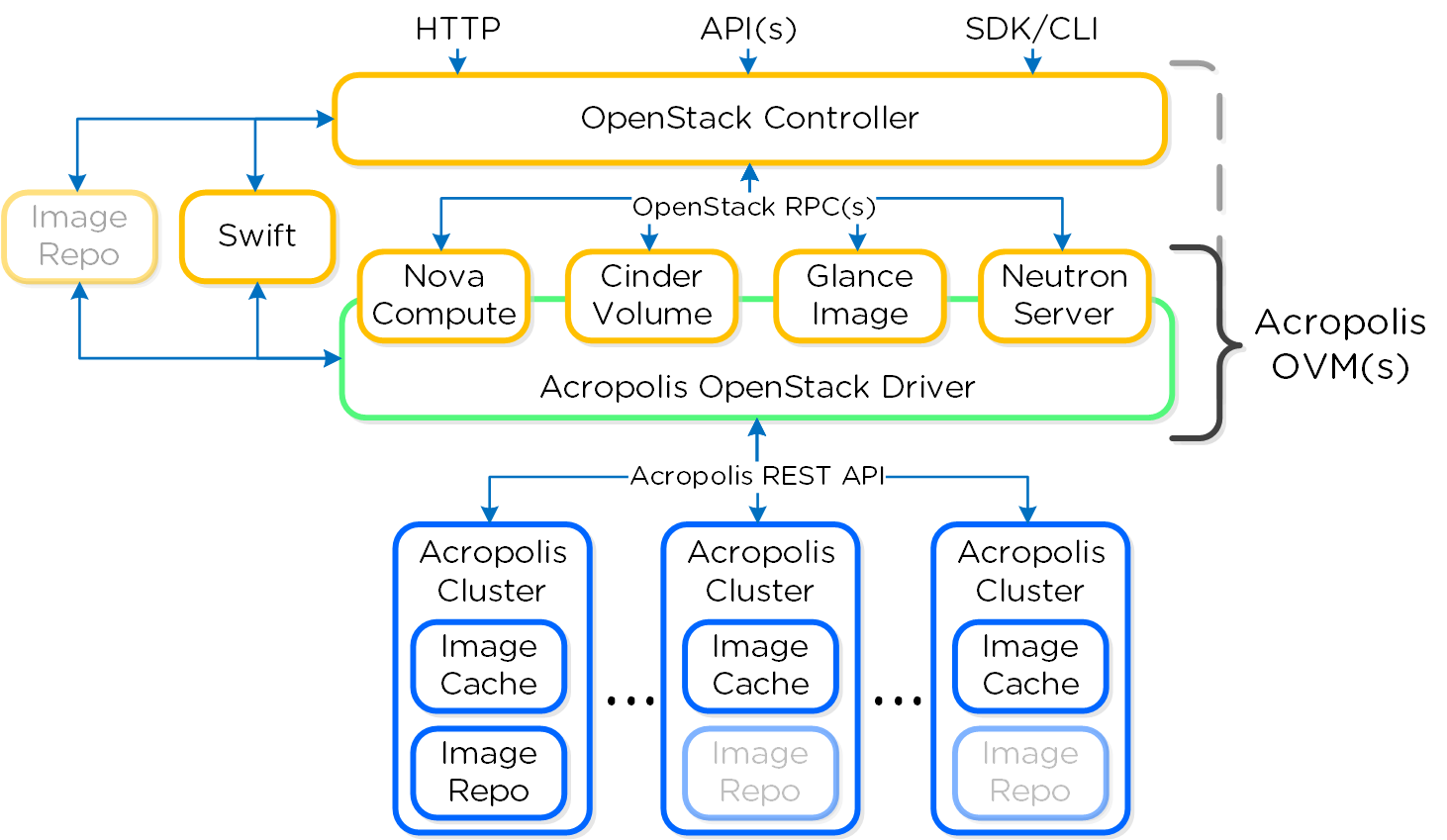
Появилась поддержка cloudinit и скриптов sysprep. Давно просили, сделано. Теперь можно для создаваемой или клонированной машины задать скрипт пост-конфигурирования, и получить на выходе готовую к использованию VM с индивидуальными настройками. Тысячи их. :)
Репликация между кластерами теперь возможна и между разными гипервизорами. Например, продакшновый кластер под ESXi может реплицировать свои данные на кластер в резервном датацентре, под Acropolis Hypervisor. Нравится ESXi, но не нравится платить лицензии за сокеты хостов в DR, используемом от силы пару раз в год — ОК, используйте наш AHV для него.
В статусе Tech Preview опубликован Project Dial — 1-click in-place hypervisor conversion, миграция всего кластера с ESXi на AHV. Автоматически конвертируются гипервизоры кластера, его CVM, а также VM пользователя. Разумеется, все это будет проделываться без остановки работы системы (но VM рестартуются). Релиз GA в ближайших версиях NOS. Но это уж точно стоит отдельного большого рассказа.
Итак, у кого уже есть Nutanix — обновляйтесь, у кого еще нет — завидуйте :)
Для экспериментирующих с Nutanix CE — обновление для CE
Комментарии (20)

navion
14.03.2016 14:25+1Для экспериментирующих с Nutanix CE — обновление для CE будет готово в ближайшее время, я рассчитываю, что даже до конца марта.
Его разве не выпустили 3-го марта (ce-2016.03.03-stable)? И в этот раз вы правильно написали про "эксперементирующих", ведь для продакшена её запрещает использовать EULA.
shapa
14.03.2016 21:25Да, выпустили.
ce-2016.03.03-stable:
Acropolis File Services
Provides file server capability within a Nutanix AHV cluster, as one or more network-attached VMs, to form a virtual file server.
Acropolis App Mobility Fabric — Windows or Linux Guest Customization
Customize or clone Windows or Linux guest VMs hosted by AHV. Includes automated OS installation and custom ISOs by using sysprep (Windows) or cloudinit (Linux).
Acropolis Drivers for OpenStack
These drivers facilitate consuming the Nutanix Acropolis infrastructure as a cloud service or for use in a data center. For example, an OpenStack implementation might require using features such as single sign-on, orchestration, role based access control, and so on. Drivers include Acropolis compute, image, volume, and network drivers.
Volume Group Support Improved
REST API and intuitive Prism web console support has been added, as well as including Acropolis command line support.
Guest VM VLAN Trunking
AHV supports guest VM VLAN tagging, where the tag passes through a single port from the physical network to a VM. It allows the VLAN ID tags to be included in an Ethernet packet to be passed to the guest VM. Guest VM operating systems can use this feature to enable Virtual Guest Tagging (VGT) and simulate multiple virtual NICs.
Nutanix Guest Tools
Nutanix Guest Agent (NGA) service. Communicates with the Nutanix Controller VM. File Level Restore (FLR) CLI. Performs self-service file-level recovery from the VM snapshots. VSS requestor and hardware provider for Windows VMs. Enables application-consistent snapshots of Windows VMs. Application-consistent snapshot for Linux VMs. Supports application-consistent snapshots for Linux VMs by running specific scripts on VM quiesce.
Self-Service Restore
Self-service restore allows a user to restore a file within a virtual machine from the Nutanix protected snapshot with minimal Nutanix administrator intervention. To perform these operations, you need to install and configure NGT on the VMs.
AHV Security Updates
New users or anyone performing a fresh install will already have an updated glibc and openssl packages. Existing users should "yum update" on the host and update at least these two packages, preferably everything that yum will offer updates for.

KorP
14.03.2016 15:23Я то ли не так что то понял, то ли у вас описаочка
всего нод — 4
На каждой ноде разворачивается VM в конфигурации CentOS, 1x vCPU 1GB RAM, 7 vDisk и на шести из них гоняется fio

{kind=link}

Alex_Ig
17.03.2016 12:42А что значит в тесте строчка "Waiting for the hot cache to flush …………. done." Правильно ли я понимаю, что вы вначале все данные в кэш на SSD считали и уже потом тесты запускали?
shapa
17.03.2016 15:09Ждет пока все кэши станут чистыми (0%), и только после этого начать тесты, дабы было максимально объективно. Если брать устаревшие технологии, то это аналог сброса кэшей RAID адаптеров / контроллеров СХД.
nutanix
21.03.2016 15:32Э-э… Даже, честно говоря, затрудняюсь понять, как еще иначе можно было прочитать совершенно однозначную фразу "Waiting for the hot cache to flush ", кроме как "ждем опустошенния кэша" ;)
lovecraft
Очень интересно. Это, видимо, возможно только в том случае, если AHV умеет притворяться ESX'ом, чтобы ESX смигрировал на него свои ВМ?
navion
Или сделали аналог Veeam Quick Migration, когда мигрируется снепшот, потом виртуалка суспендится и поднимается на новом железе.
shapa
Я уже попросил коллегу написавшему статью точнее сформулировать описание фичи.
В целом да, виртуалка запускается на новом железе — старый хост надо переинсталлировать на AHV с ESXi (или наоборот, ибо переход с AHV на ESXi тоже поддерживается).
Нет, это не "аналог" Veeam.
Нам не надо мигрировать снепшоты, ввиду того что формат данных на распределенной СХД идентичен для AHV и ESXi — VM просто запускается на другом аппаратном хосте ровно с того-же виртуального диска.
Все процессы совместимости (чтобы VM могла нормально работать на новом виртуальном железе) — у нас есть Nutanix Guest Tools (о которых надо бы отдельную статью сделать, например они дают возможность делать консистентные снапшоты для Windows / Linux guests на ESXi и AHV)
p.s. Технически уже много лет поддерживаем это, просто сейчас оформили в "фичу". Например, наши Capacity Nodes всегда работают под AHV, независимо от того на каком гипервизоре основной кластер.
navion
Логично, а нет проблем с форматами дисков (родной qemu-img вроде не умеет тонкие диски) или дискриптор хранится где-то отдельно?
Будет интересно, особенно как там сделан запуск sysprep и cloudinit. VMware для этого использует
анально огороженныйприватный API, который нигде толком не описан.shapa
"Логично, а все форматы дисков поддерживаются? " — отличное замечание.
Да, требуются flat диски на ESXi, поэтому если тонкие — надо сначала конвертировать во flat
"Будет интересно, особенно как там сделан запуск sysprep и cloudinit. "
У нас все открыто — тулзы работают на Python внутри гостей.
Например для Linux и скажем MySQL / Postgre перед снятием снапшота и после снятия вызываются pre и post скрипты, а уже там можно автоматизировать что угодно.
"Having the tools enabled unlocks advanced features like: File Level Restore, Volume Shadow Copy Service (VSS), and Cross-Hypervsor DR. The process covers Windows and Linux VMs."
http://next.nutanix.com/t5/Nutanix-Education-Blog/Steps-to-enable-Nutanix-Guest-Tools-NGT-in-your-4-6-cluster/ba-p/8405
http://vcdx56.com/2016/02/26/nutanix-guest-tools/
navion
Хорошая ссылка, тут вместо VMCI для общения с гостем используется виртуальный CD-ROM и сеть.
Это не есть хорошо (ESXi и Hyper-V от сети не зависят), но и катастрофой не назвать учитывая наличие внешней консоли в Prism.
shapa
А чего-же плохого-то?
Наоборот — мы везде где можно используем оборудование стандартное эмуляцию — за счет этого даже без гостевых утилит работает например корректный ребут и прочее (через ACPI).
Сеть? Ну так нет сети — нет Nutanix, у нас все через сеть работает. Это примерно как жаловаться на то что ESXi завязана на внешние хранилки… Лежит FC SAN — лежит все.
navion
Плохо, что виртуалка должна иметь доступ к NGT по сети (пусть и в одну сторону). Наверняка найдётся параноидальное окружение (PCI, DISA и т.п.), где такое не любят.
Ну и всегда хорошо иметь выделенный интерфейс для оркестрирование, которое может затрагивать настройки сети в ВМ.
shapa
"выделенный интерфейс для оркестрирование" учитывая что единственный способ его сделать — это пачка грязных хаков и внедрения в ОС, не думаю что это реально "всегда хорошо".
проблемы с vmware tools — крайне частое и распространенное явление...
впрочем тут у каждого свое мнение.
по поводу PCI и прочих — у нас common criteria сертификация (+ пачка других), работает спец. команда над секьюрити. Учитывая что нас использует например Mastercard, Paypal и прочие Nasdaq — вы все сами понимаете.
navion
Грязным хаком это трудно назвать и Microsoft в итоге тоже к этому пришел — значит фича востребованная.
shapa
При всем уважении к MS (наши очень важные партнеры), в случае виртуализации не стоит их приводить в пример "новизны подхода" — долгое время просто догоняли / копировали функционал ESXi.
Если бы нам говорили "как жить" и мы бы слушали, то Nutanix не было бы вообще, так же как AHV. Еще несколько лет назад крупные вендоры над гиперконвергентностью смеялись, теперь судорожно пытаются вскочить на поезд.
Позиция инженеров компании — использовать стандартные протоколы везде, где можно. Работа с "СХД" — NFS3, iSCSI, SMB3. Если MS может себе позволить поменять ядро Windows Server / Desktop, то с линуксами что делать? VMware tools с которыми извечные проблемы и надо перекомпилировать при малейшей смене ядра?
Работа "утилит" — IP. И т.д.