
Происходят (успешные или не очень — отдельный вопрос) попытки импортозамещения в IT, появилось множество продуктов «made in Russia», особые списки и прочее.
Мы не хотим и не будем говорить о политике, но поговорим о технологиях и ценообразовании.
Сегодня бы хотелось поговорить об одной из наиболее «нагретых» в мире и РФ тематик (крайне выгодной для производителей) — «облачные» платформы для хранения и обработки данных — иными словами СХД, виртуализация, облака и прочее.

Для рассмотрения были выбраны три варианта — массово рекламируемые в РФ импортозаместительные продукты и Nutanix, как лидер (или один из лидеров) мирового рынка HCI.
Подавляющее большинство «стеков сделанных в РФ» укладываются в «Openstack + Ceph».
Перефразируя, мы говорим о современном подходе к построению IT инфрастуктур по принципу как делает Amazon, Google, Facebook и другие, но с локальными особенностями.
Как небольшое отступление, еще в 2014 году Gartner сделал прогноз о том, что в 2017 большинство крупнейших / ключевых компаний будут использовать webscale решения, и они оказались правы.
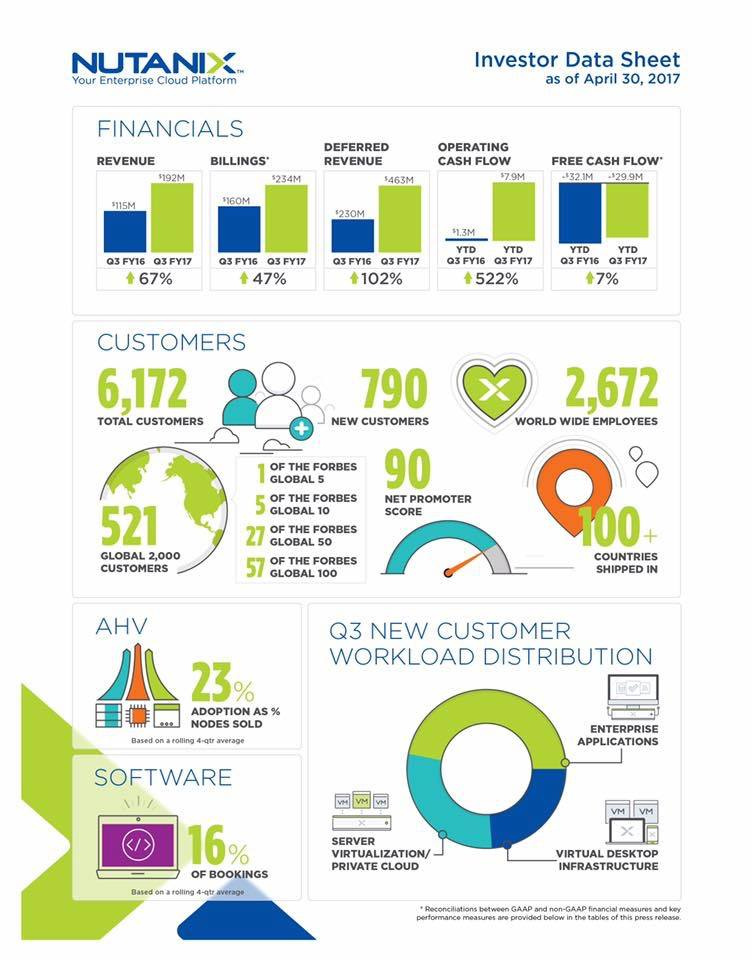
Более половины крупнейших мировых компаний (из Global 100) уже используют WebScale (инфографика — ниже).
Gartner Says By 2017 Web-Scale IT Will Be an Architectural Approach Found Operating in 50 Percent of Global Enterprises

Аналитики в целом сходятся в том, что традиционные подходы к построению инфраструктур изживают себя (так называемые «трех-уровневые инфраструктуры» базирующиеся на СХД), причем пере-раздел рынка происходит крайне быстро.
Крайне интересная инфографика и аналитика:

Теперь вы понимаете, почему рынок так сильно нагрет даже в РФ и почему «импортозаместители» ведут себя как в анекдоте «тушите свет, они на свет лезут», при этом (мое личное мнение) реальная ситуация с технологиями очень напоминает вот это:

На самом деле, речь идет о переразделе многомиллиардных (не в рублях) доходов даже в РФ:
обработка и хранение данных сейчас является ключевой проблемой практически любых бизнесов и организаций в мире, а публичные IT закупки российских компаний составляют сотни миллионов долларов.
Безусловно, существуют другие конкурентные коммерческие западные вендоры, о них мы можем поговорить отдельно.
Суть статьи — понять что реально могут предложить технологически клиенту «российские продукты», является ли импортозамещение в данном случае реальным или бумажным, насколько это все дорого или дешево.
Многие профессионалы знают, что в подавляющем количестве случаев все эти продукты реально не разрабатывались в России, и либо используют ceph + openstack (по ощущению — >95% «импортозамещений»), либо делают вид, что разрабатывают продукт локально, но в реалиях это вполне себе западный программный код.
Один из интересных примеров — как «Лёгким движением руки брюки превращаются в шорты».
Американская компания (бывшая Parallels) Virtuozzo > "Росплатформа" > "СКАЛА-Р"
Дабы избежать любых кривотолков — привожу ссылку на выступление топ-менеджера «Росплатформа», где речь фактически идет о «получении преференций на закупки для российских компаний».
Программный код Virtuozzo принадлежит американской компании.
Версионирование / документация полностью совпадает.
Как вы думаете, какая компания реально продолжает разрабатывать программный код, а какая просто использует выделенный билд-сервер?

Если говорить о суммах, то речь идет обычно о проектах от сотен тысяч до многих миллионов долларов, но решения применимы и небольшими компаниями — порог входа в «новый прекрасный мир» (для РФ) — где-то 35$k.
IBS ориентирует свою «Скала-Р» как «с экономической точки зрения платформа СКАЛА-Р может быть интересна компаниям с ИТ-бюджетом от $500 тыс.», что конечно мягко говоря несколько удивляет.
…
Кстати, позитивные исключения (из массы «готового американского кода») однозначно есть — например хранилища данных Raidix, которые создали специализированное решение для записи и воспроизведения медиа-потоков, причем весьма успешное, но реально не подходящее ни для серьезных проектов построения «корпоративных облаков», ни для хранения generic данных (коллегам просьба не обижаться — но это реально так, если будет желание можем провести сравнение функционала — объясню каких базовых «фич» у вас нет для того чтобы серьезно говорить про облачные enterprise применения).
…
Сегодня хотелось бы затронуть хотя бы базовые вопросы о технической части решений, но немного поговорим и про ценообразование.
Замечу также, что основным аргументов «импортозамещателей» по сути зачастую является наличие волшебной бумажки (сертификаций), но опять-же большинству понятно что все это является по сути профанацией.
Невозможно проверить (за обозримое время) на предмет ошибок или закладок программный код (миллионы строк) современного ядра Linux и всего типового окружения (на базе которого работают практически все «замещатели»), не говоря о массе дополнительного кода (ceph, openstack, virtuozzo и тд).
Только ядро Linux приблизилось к 20 миллионам строк кода.
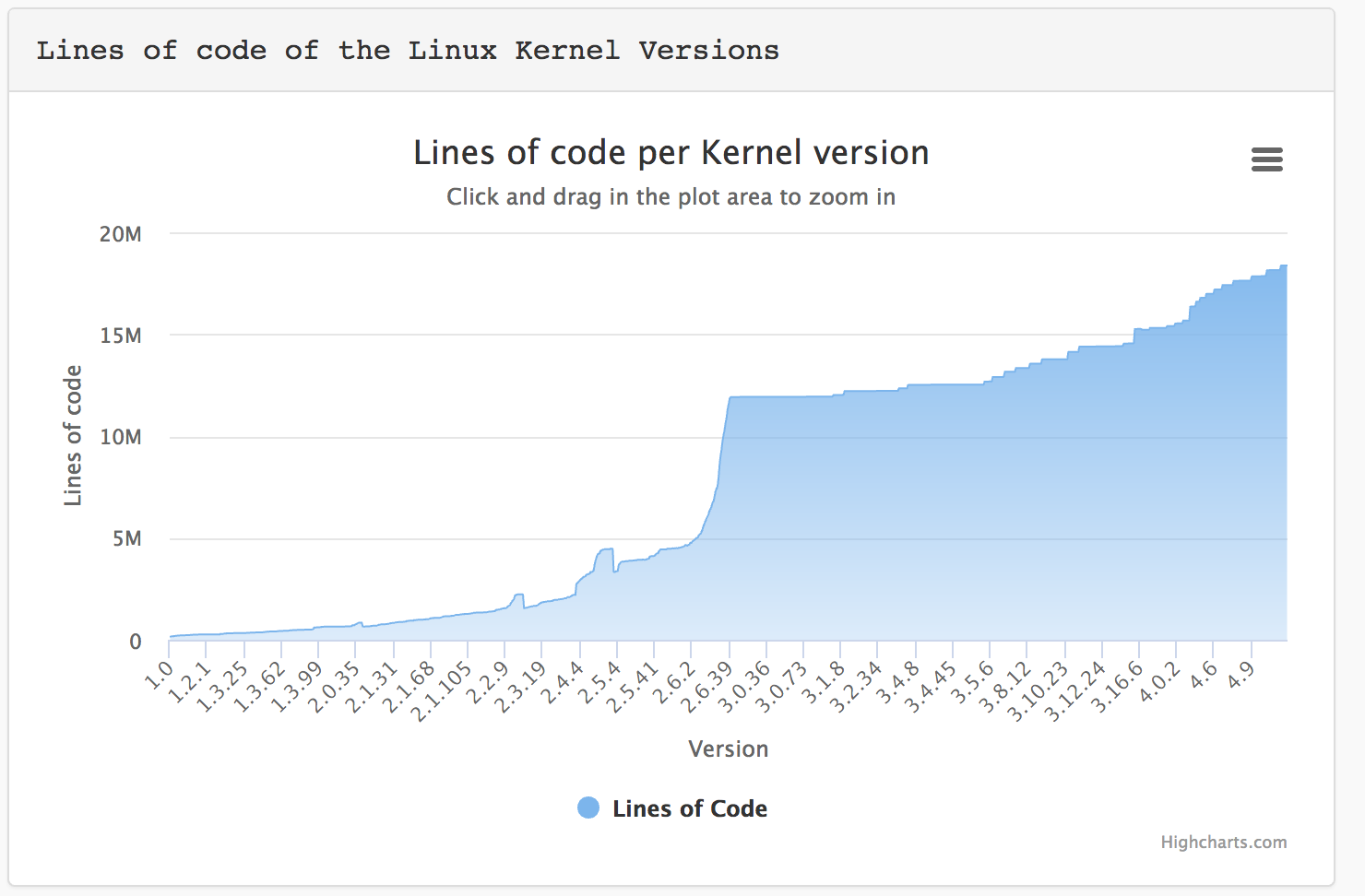
Как показывает жизнь, практически все крупнейшие / скандальные дыры в программном коде Linux и типовых библиотек были обнаружены и исправлены не в РФ (включая heartbleed и прочее) — кому интересно, по сути можно взять и посмотреть когда были выпущены патчи к «русским линукс».
Учитывая что ceph и virtuozzo работают на уровне хоста / ядра ОС, это реально является серьезнейшей проблемой надежности и безопасности.
Итак, поехали. Пока — о базовых вещах.
Ceph + Openstack.
Единый продукт как таковой отсутствует, есть масса разрозненных проектов (компонентов Опенстак) в разном статусе — от достаточно качественной разработки до целиком заброшенных.
Ситуация напоминает «рак+лебедь+щука» — коммерческие провайдеры OS любой ценой стараются привязать клиента к своему решению, безболезненная миграция даже между продуктами одного вендора крайне тяжела, между различными — практически нереальна.

Основной гипервизор (и фактически единственный применимый для использования в случае ceph) — KVM.
В качестве SDS (программного хранения данных) — реальный вариант для использования — только ceph, отдельный opensource проект.
Теоретически можно использовать ESXi и HyperV через iSCSI, но на практике ввиду отсутствия поддержки VAAI / ODX это является как максимум лабораторным вариантом.
Как отступление, я искренне не понимаю как можно запускать любые проекты на ceph для серьезного применения — достаточно изучить баг-трекер.
Например, для последнего «стабильного» релиза Jewel — около 200 критичных (immediate, urgent, high) ошибок.
Все это мне очень напоминает хождение по минному полю.
Баг Тракер ceph
Напомню, что в конце 2016 года ceph.com «лежал» два дня ввиду падения хранилища на базе ceph. Весьма иронично.

Рассказы про то, как «мощные команды русских программистов» (обычно речь идет реально про максимум 3-10 человек) исправили все ошибки ceph и создали русский продукт — оставим на совести продавцов таких решений, но у грамотного IT специалиста должны возникнуть вопросы — почему сотни / тысячи разработчиков основного ceph «не смогли», но у микро-команд из РФ все получилось.
Технологически, в архитектуру заложена масса узких мест — выделенные сервера метаданных, крайне высокие требования к RAM и т.д.
Интересная и актуальная статья на эту тему (как надо устанавливать костыли):
Ceph RBD performance issues
Cудьба Openstack как проекта в целом тоже вызывает много вопросов.
Для начала — пара цитат из блога Мирантис (при том что в 2016 году они например внедряли Опенстак в крупнейшем банке РФ, уже прекрасно осознавая что OS реально «не жилец»):
"Infrastructure Software is Dead"
«Now I’d love to tell you that it’s all because Mirantis OpenStack software is so much better than everybody else’s OpenStack software, but I’d be lying. Everybody’s OpenStack software is equally bad. It’s also as bad as all the other infrastructure software out there – software-defined networking, software-defined storage, cloud management platforms, platforms-as-service, container orchestrators, you name it. It’s all full of bugs, hard to upgrade and a nightmare to operate. It’s all bad.»
На сегодняшний день, практически все ведущие «драйверы» отказались от развития — «Мирантис» уволил массу сотрудников из OpenStack подразделения и открыто признает, что надо уходить на микросервисы, HPE продали полностью подразделение, Rackspace как одна из икон опенстак-движения сделал делистинг с биржи — остался, пожалуй, только RedHat.
Далее поговорим о «бесплатности» таких решений.
Цена на поддержку коммерческого openstack в РФ — в среднем 4-5 тысяч $ (тех самых американских долларов) в год за каждый сервер.
Стоимость OpenStack
Это совпадает с тем, что нам называли в РФ наши клиенты, когда к ним приходил тот же «Мирантис», поэтому можем взять как базу для рассчетов.
Также всегда есть вариант нанять инженеров в свою команду, но для обеспечения нормального функционирования проекта обычно идет речь о нескольких десятках человек минимум — которым надо платить зарплаты. Дополнительная проблема — специалистов найти практически невозможно, даже те кто был (возьмем тот-же Мирантис) уже многие не в РФ (ввиду закрытия московского офиса).
Кстати, коммерческая поддержка openstack обычно не включает в себя поддержку ceph, за нее надо платить отдельно.
Сертификация решений — разброд и шатание, часть локализованных вариантов имеет сертификацию.
Стартовый ПАК — от 45 тысячи долларов США — минимум 6 серверов (3 под ceph, 3 под KVM и OS). Конфигурация реально лабораторная, для промышленного использования требуется разносить сервисы ceph.
Каждый сервер около 5$k (30$k за сервера), плюс поддержка OpenStack (около 5$k за сервер в год).
Virtuozzo / Росплатформа / СКАЛА-Р.
Parallels -> Virtuozzo — по сути, уважаемое, достаточно распространённое решение в узких кругах сервис-провайдеров, заточенное под конкретные задачи (обеспечение работы SP, обычно — недорогих массовых хостингов).
В качестве стека виртуализации ранее использовали свой гипервизор, но в 7-й версии приняли решение переходить на KVM, который при этом "работает на 40% быстрее чем обычный KVM" (сразу вспомнил рекламу про «обычный стиральный порошок :) „)
Частью решения является virtuozzo storage, он же “р-хранилище» — фактически распределенная СХД с массой ограничений (об этом ниже) и минимумом функционала, заточенная конкретно под нужды сервис-провайдинга, о чем упоминается в том числе в документации (на этом фоне крайне интересно позиционирование решения в РФ как универсального).
Готовый ПАК (программно-аппаратный комплекс) из 4-х простых серверов стартует минимально от 7.8 миллионов рублей (~130 тысяч долларов США — за импортозамещение надо платить)
«Cкала-Р» и «Росплатформа» — не совсем ясно, с официального сайта — «Безопасность продукта обеспечивается комплексом средств ИБ и готовностью к сертификации во ФСТЭК.»
Кстати, интересный момент о работе маркетологов в РФ — «Скала» это компьютер, который стоял на Чернобыльской АЭС и в целом участвовал в процессах контроля. Интересно, специально такое название выбрали?
Update: как и ожидалось, пришел представитель «Росплатформа» и начал утверждать, что все выводы неверные, документация старая, никакой связи с американской компанией (параллелс / виртуозо) не осталось.
Господин из «Росплатформа» видимо не в курсе, что у любого документа можно посмотреть PDF теги.
Итого — май 2017 года, документацию делают сотрудники Parallels и Virtuozzo, документация при этом конечно-же свежая.



Nutanix
Создатели рынка HCI / WebScale, лидеры по продажам, масса реализованных проектов практически в любых индустриях.
Как уже писал выше, более половины крупнейших мировых компаний (из Global 100) уже используют Nutanix.
Сертификация в РФ возможна, существуют процедуры, как минимум для одного из крупнейших проектов в РФ был получен ФСТЭК на «периметр».
Получены практически все ключевые сертификации безопасности в мире.
Готовый ПАК в РФ стартует от 35 тысяч долларов США, минимум 3 сервера.
Фактически, вся основная инфографика приложена:
…
Основной технический функционал был собран в сравнительную таблицу, которую в том числе я давал на рассмотрение в «Росплатформа» и IBS. Комментарии они делать отказались, хотя поначалу проявили интерес.
Таблицу по OpenStack + ceph сверял с представителями OpenStack и ceph коммьюнити в РФ.
Говорим только о стабильном функционале, никаких «бета версий» и «технических превью».
В таблице могут быть неточности или ошибки, пишите в комментариях — обязательно или поправим или объясним.
Есть ли какие-то выводы? Их я делать не буду, делайте сами. Информация у вас есть.
| СКАЛА-Р / Росплатформа / Virtuozzo |
Nutanix | CEPH + OpenStack | |
|---|---|---|---|
| Программная архитектура В случае работы на уровне хоста / ядра ОС, потенциальные проблемы безопасности и отказоустойчивости. |
Ядро / хост | Изолированный виртуальный контроллер | Ядро / хост |
| “Заточенность” решения | Сервис провайдеры | Энтерпрайз (корпорации), правительственные службы, военные, медицина, промышленность, ресурсодобывающие компании, финансовые структуры. |
Сервис провайдеры |
| HCI (гиперконвергентное) решение. Дата сервисы и виртуализация работают на серверах одновременно. |
да | да | нет |
| Отсутствие узких мест / точек отказа (централизованные сервисы, например cервера метаданных или сервера управления) |
нет | да | нет |
| STIG политики (Security Technical Implementation Guide) | Отсутствуют, рекомендация производителя — ручной поиск rootkit и обнаружение взломов | да | Отсутствуют, есть масса разрозненных рекомендаций и методик |
| Расположение компании, разрабатывавшей основную часть ПО | США (Parallels -> Virtuozzo -> Росплатформы->”СКАЛА-Р”) |
США | США (основная разработка), производится множеством компаний. Публично доступны полные исходные коды |
| Встроенный полноценный мониторинг (все аппаратные и программные компоненты) и самодиагностика | Частично, Скала-Р применяет дополнительные средства мониторинга |
да | Частично |
| Интеллектуальный автоматический Data Tiering — перемещение блоков данных между холодным и горячими уровнями в случае изменения частоты запросов к этим данным (“нагрев” или “охлаждение”) | нет | да | нет |
| Встроенный портал самообслуживания | нет | да | да |
| Локализация данных VM (data locality) — активные данные VM находятся на том-же сервере где работает виртуальная машина. Кардинальное ускорение операций чтения и снижение нагрузки на сеть в разы. |
нет | да | нет |
| Репликация на уровне VM | нет | да | нет |
| Восстановление целостности данных | Ручной запуск в случае потери крупного домена | Автоматический старт | Автоматический старт |
| Дедупликация данных | нет | да | нет |
| Компрессия данных | нет | да | нет |
| Erasure Code (помехоустойчивое кодирование) | нет | да | да |
| Поддержка All Flash | нет | да | да |
| Микс All Flash и Hybrid в едином кластере | нет | да | да |
| Обработка отказов SSD дисков с метаданными | Временная потеря части узлов с данными и долгое восстановление | Автоматическая отработка, не влияет на производительность кластера, все узлы с данными продолжают работу | Автоматическая отработка, может влиять на производительность кластера |
| Поддержка VAAI и ODX (протоколы «разгрузки» операций ввода-вывода на систему хранения данных) | нет | да | нет |
| Поддержка Application Consistent Snapshots (провайдер VSS для Windows Server и имплементация для Linux) | нет | да | нет |
| Неограниченное количество снапшотов VM, без влияния на производительность и возможностью манипуляций (в т.ч. удаления) снапшотов на любом уровне | нет | да | нет |
| Теневые клоны (shadow disk) — создание локальной копии дисков VM для кардинальной акселерации загрузки и работы | нет | да | нет |
| Встроенный бэкап на Amazon / Azure | нет | да | нет |
| Наличие Best Practice для ключевых типовых приложений (Oracle RAC, MSSQL, Postgres, SAP NetWeaver, MongoDB, Microsoft Exchange, Cisco Unified Communications и другие) | нет | да | нет |
| Распределенный отказоустойчивый cтек управления (management plane) без использования централизованных баз данных | нет | да | нет |
| Не требуются выделенные сервера управления | нет | да | нет |
| Автоматические апгрейды аппаратных прошивок (биос, прошивки дисков и флеш, контроллеры и тд) | нет | да | нет |
| Прозрачное обновление без перезапуска клиентских сервисов при смене основной версии ПО | нет | да | да |
| Поддержка гипервизоров | KVM (несертифицированные патчи), Virtuozzo (устарел, в новой версии перешли на KVM) | AHV (KVM совместим, сертифицирован Microsoft, SAP и другими), XenServer, vSphere, HyperV | KVM Возможно использование vSphere и HyperV с подключением через iSCSI, не рекомендуется для продуктива ввиду отсуствия поддержки VAAI / ODX. Не является HCI решением. |
| Поддержка основных стеков виртуализации рабочих мест (VDI) – Citrix, VMware | нет | Citrix, VMware, Workspot и другие | нет |
| Возможность запуска Microsoft Windows Server с полной поддержкой от Microsoft (SVVP — Server Virtualization Validation Program) | Нет, SVVP сертификация присутствует для старой версии американского продукта с другим гипервизором. Виртуализация Windows Server — на свой страх и риск |
Полная SVVP сертификация | Есть для RedHat OpenStack и Canonical (Ubuntu) OpenStack, отсутствует для большинства других вариантов. |
| Контейнерная виртуализация | Virtuozzo | Docker | Docker, LXD |
| Встроенные бэкапы (без применения стороннего ПО) с пофайловым восстановлением и самообслуживанием | нет | да | нет |
| Метро кластер (распределённый гео-кластер с синхронной репликацией данных) | нет | да | нет |
| Встроенная поддержка аварийного мульти-цод восстановления (many to many DR) | нет | да | нет |
| Поддержка кросс-гипервизорного DR | нет | да | нет |
| Автоматическая конвертация гипервизора и всех VM на кластере (например, ESXi->AHV/KVM) | нет | да | нет |
| Встроенный SDN стек с интеграцией в аппаратное сетевое обеспечение | нет | да | да |
| Поддержка Affinity / Anti-Affinity, для оптимизации лицензирования ПО. При отсутствии поддержки необоснованные лицензионные затраты могут составлять миллионы долларов |
нет | да | да |
| Поддержка RESTful API (стандарт индустрии) | нет | да | да |
| Бесплатный апгрейд ПО на новые версии (минорные и глобальные обновления версий) при наличии действующей базовой техподдержки |
Скала-Р — платно Росплатформа — бесплатно Virtuozzo — платно |
да | да |
| Ценообразование (для РФ) на готовые коммерческие решения (ПАК — программно аппаратный комплекс) | Стартовая цена от 136000$ Кластер минимум из 4-х узлов |
Стартовая цена от 35000$ Кластер минимум из 3-х узлов |
Стартовая цена от 45000$ Необходимый минимум: 3 сервера ceph, 3 сервера виртуализации, ~5$k в год за каждый сервер виртуализации (поддержка OpenStack). Поддержка ceph не учтена. |
| Рейтинг удовлетворенности клиентов работой компании | Не опубликовано | 95%, NPS score 92 | Не применимо, масса вендоров |
Комментарии (89)

omnimod
20.06.2017 23:47+2Спасибо за познавательную статью. Однако отмечу некую однобокость сравнения. OpenStack — это про частные облака, автоматизацию развертывания, учет потребления, самообслуживание, в то время, как Nutanix — это, действительно, HCI, но с базовыми возможностями по автоматизации и простым порталом. Понятно, что сравнение только на поле HCI будет явно не в пользу OpenStack.
Невозможно проверить (за обозримое время) на предмет ошибок или закладок программный код (миллионы строк) современного ядра Linux и всего типового окружения (на базе которого работают практически все «замещатели»), не говоря о массе дополнительного кода (ceph, openstack, virtuozzo и тд).
Но разве CVM и AHV не работают на базе современного ядра Linux?
shapa
21.06.2017 00:08«но с базовыми возможностями по автоматизации» — нет, уже не так. Nutanix Calm уже готов к релизу.
Плюс встроен мощнейший API — автоматизировать можно уже давно было что угодно.
В любом случае, мы говорим про то что в РФ выдают как «импортозамещение», и речь идет конкретно про то что делают — ceph + OpenStack в подавляющем количестве случаев.
shapa
21.06.2017 00:13Мы пошли разными путями — максимально облегчаем ядро / KVM, вся программная логика в VM.
ceph и виртуозо — драйвера / user-space программы работающие на уровне хоста.
Ну и нигде не кричим про «импортозамещение» и «российскую разработку».
lostinfuture
21.06.2017 12:21Не раз уже встречал фразу «вся программная логика в VM», можете пояснить что это значит?

AntonVirtual
21.06.2017 12:41Вся логика находится в контроллерной виртуальной машине. Она не работает на уровне ядра гипервизора — меньше привилегированного кода, меньше влияние на продуктивные ВМ, четкое ограничение доступных ресурсов.
Arxitektor
21.06.2017 09:15-1На самом деле задачи уровня 3-4 сервера и хранение данных либо на серверах либо на выделенной СХД.
Встречаются довольно часто.
У меня в компании возникла задача:
Под проект нужно было несколько серверов. С виртуалками для пользователей и пилотника под кад.
Сначала хотели все сделать на Ceph + OpenStack. Но как в статьеСтартовый ПАК — от 45 тысячи долларов США
все это стоит каких-то не реальных денег.
Хорошо что не было задачи импортозамещения Пока остановились на VMWARE.
Это с учетом то вдруг придётся использовать VDI с видео картами NVIDIA.
А есть ли в России компании которые реализуют на OpenStack и дополнительных решениях
Продукт на уровне VMWARE Horizon.
Задачка примерно такая есть 30-35 пользователей. 10 из них будут работать с графикой карточка tesla m60.
10 пользователей обычные виртуалки через RDP а остальные на терминальном сервере.
AntonVirtual
22.06.2017 00:0835 пользователей через RDP — это продукт уровня VMware Horizon, которая машстабируется до тысяч клиентов? o_O


IBS_habrablog
21.06.2017 11:57Коллеги, внимательно прочитали пост. «Анализ» Скалы-Р вызывает очень много вопросов – готовим развернутый комментарий.
AlexBin
21.06.2017 12:39Рекламная статья, рекламная таблица с удобными критериями сравнения, молодцы. Таблица кстати содержит ошибки, например:
Интеллектуальный автоматический Data Tiering — перемещение блоков данных между холодным и горячими уровнями в случае изменения частоты запросов к этим данным (“нагрев” или “охлаждение”)
В колонке Ceph стоит «нет», хотя на самом деле «да». Тут в конце статьи подробнее описано с анимацией.
Дальше вообще читать не стал.AntonVirtual
21.06.2017 12:43>Тут в конце статьи подробнее описано с анимацией.
Интеллектуальности не видно.AlexBin
21.06.2017 12:52Интеллектуальности не видно.
На интеллектуальность претендовал автор статьи. Я никакой интеллектуальности в этом механизме не вижу.AntonVirtual
22.06.2017 00:05-1Тиринг сделать штука нехитрая. Он даже у IBM есть.
Правда смысла в таком тиринге нет.
А ведь они его тоже интеллектуальным называют.
>Я никакой интеллектуальности в этом механизме не вижу.
Ну это то и понятно, если не смотреть ни на что, кроме ceph.AlexBin
23.06.2017 17:45Опишите «интеллектуальность» тиринга в Nutanix или исправьте таблицу.
AntonVirtual
23.06.2017 18:35AlexBin
28.06.2017 13:43+1Хрен с ней с интеллектуальностью. Чем дата-тиринг Nutanix выгодно отличается от Ceph, что у первого в таблице стоит «Да», у второго — «Нет»?

Vasily_Pechersky
21.06.2017 18:21А почему уважаемый автор не упомянул ProxMox?
Тамошняя интеграция Ceph вполне стабильна. Год в продакшене и выпадения нод по электричеству были.
Летим дальше…
Хотя кластер в 4 ноды можно считать маленьким, относительно OpenStack направленности. Но это не говорит, что Ceph не стабилен…AntonVirtual
23.06.2017 18:38Это значит, Василий, что для вашей нагрузки вам повезло и вы еще не успели за год словить веселостей.
CloudMouse не повезло, и они словили.
IBS_habrablog
21.06.2017 18:26+1Коллеги, с сожалению, таблица изобилует ошибочными оценками и давать ответы на каждый из них в комментариях к этому посту будет не очень удобно. Поэтому мы сделаем отдельный пост у нас в блоге со своей табличкой :).
А пока несколько важных замечаний по сути.
Об импортозамещении
Нас несколько смущает, что Скалу-Р включают в этот контекст. Мы представили наш готовый продукт в мае 2015 года. Разработка, естественно, началась значительно раньше – еще до известных событий и санкций. В основе этого проекта лежало понимание глобального тренда и наша вера в будущее гиперконвергентных платформ как основы современной ИТ-инфраструктуры. Наше решение появилось не ситуативно и конкурирует с мировыми образцами. Тем не менее, сейчас на нашем домашнем рынке действуют определенные правила, которые устанавливает государство. Мы им соответствуем и делаем продукт защищённый от санкционных рынков. Это наше неоспоримое преимущество, которое актуально для многих клиентов. Тем не менее, это только одно из многих достоинств нашей разработки.
Аппаратное обеспечение
У всех производителей HCI примерно одинаковое железо. НО, в состав стандартного комплекса Скала-Р входит дублированный интерконнект на коммутаторах 56gbps.
Функциональные возможности (соответствие запросам Enterprise-рынка)
Все основные функциональные возможности, необходимые для полноценной работы в корпоративном сегменте, у Скалы-Р присутствуют: полноценный мониторинг входящих в состав Скалы-Р компонентов; отсутствие единой точки отказа; локализация данных; автоматический перезапуск; Erasure Coding; поддержка All-Flash и микс с Hybrid в едином кластер; неограниченное количество снапшотов и многое другое (подробнее напишем у себя в блоге). Частично мы уже писали об этом тут. С тех пор есть уже существенные изменения и вскоре мы сделаем большой анонс об этом.
Некорректная оценка стоимости
Надо сравнивать равнозначные комплексы, а не минимальные. Nutanix называет комплекс идеальным для SMB и тут же сравнивает его с комплексом уровня Enterprise. Мы работаем в сегменте Enterprise и нашим заказчикам не нужны вот такие starter kit, которые невозможно будет масштабировать в дальнейшем и для функционирования которых заказчик должен приобрести еще сетевое железо. Наше решение это «инфраструктура под ключ» с дублированными коммутаторами 56gbps, одним коммутатором сети управления, минимально разумным числом узлов (4), всем необходимым ПО и с возможностью дальнейшей практически неограниченной масштабируемостью.
Пункт в таблице про стоимость апгрейда: при наличии действующей технической поддержки Скалы-Р, переход на новую версию ПО абсолютно бесплатен.
Перспективы
Мы уверены, что Скала-Р – одно из лучших решений на своем рынке. У нас есть чёткое видение и план развития, которые корректируется практикой работы продукта у заказчиков. Что-то из упомянутого в таблице появится уже этим летом (гео-репликация на уровне Object Storage). К концу года добавим гео-репликацию на уровне VM и компрессию данных. Но часть функциональных возможностей для Скалы-Р в контексте запросов российского клиента из Enterprise-сегмента пока не актуальна, например, встроенный бэкап на Amazon/Azure. Да и зачем VAAI и ODX в гиперконвергентном решении, в котором предусмотрен только собственный гипервизор и собственный storage?
В общем, следите за анонсами :)shapa
22.06.2017 00:18-1«Коллеги, с сожалению, таблица изобилует ошибочными оценками » — не надо пытаться обмануть публику.
Об импортозамещении
можно сколько угодно говорить «халва», слаще от ээтого не станет. код разрабатывается даже сейчас американской компанией «виртуозо». Ваши же инженеры в приватных разговорах говорили о крайне низком качечестве кода (выше люди уже отзывались) и массе открытых багов в параллелсе (вполне себе западной компании с сингапурским владельцем)
Аппаратное обеспечение
Вы серьезно гордитесь тем то ставите IB, между тем как практически все конкурентные решения работают нормально на 10G ethernet?
Причина — крайне кривая архитектура, вы постоянно «таскаете» данные между серверами / узлами и убиваете сеть.
Вот цитата из вашей документации («Росплатформа»)
«Распределение данных
Чтобы повысить производительность ввода-вывода серверов фрагментов в кластере, ПК Р-Хранилище автоматически распределяет загрузку серверов фрагментов, перемещая „горячие“ фрагменты данных с „горячих“ серверов фрагментов на „холодные“.
Сервер фрагментов считается „горячим“, если глубина его очереди запросов превосходит среднее значение в кластере на 40% или более (см. пример ниже). В отношении фрагментов данных, „горячие“ означает “часто запрашиваемые”.»
Откровенно — это ужасно криво.
«Функциональные возможности (соответствие запросам Enterprise-рынка)»
Опять вы обманываете — неужели не стыдно такое писать на публику?
EC-X в стадии technical preview (документация виртуозо)
Локализация данных — откровенная чушь (смотрите выше цитату) или вы просто не понимаете о чем речь.
Поддержка All-Flash и микс с Hybrid в едином кластер — это неправда, даже инженеры виртуозо признают что нормально это не работает.
Автоматический перезапуск — обман — «Приотказе и выключении крупной области отказов ПКР-Хранилищепоумолчанию не выполняет восстановление данных, так как репликация большого объема данных может занять больше времени, чем восстановление области отказов. '»
Что мешало сделать как на Нутаникс (при восстановлении оборудования отменяется процесс ребилда) — я даже спрашивать не буду.
Вы понимаете разницу в COW и ROW снапшотах? И массу ограничений текущих в вашей имплементации? И что такое per VM снапшот а не per LUN?
Ну и вот такие смешные вещи:
«Переключение между снапшотами возможно только при выключенном LUN.
Удаление возможно только для выключенных снапшотов.
Удаление снапшота, который имеет несколько дочерних элементов, на текущий момент не поддерживается.
» — это вообще пять баллов.
Некорректная оценка стоимости
«же сравнивает его с комплексом уровня Enterprise.» в чем там заключается «enterprise»? Наличие InfiniBand? :)
Расстрою — если подсчитать решение на Нутаникс за 130 тысяч долларов — оно однозначно обойдет и по производительности и тем более по функциональности.
Перспективы
Я не разделяю вашу уверенность. От неимения возможностей сделать что-то самим, IBS схватились за «то что было». При этом решение что выбрано — никоим образом не заточено под энтерпрайз применения, и даже в документации постоянно торчат уши «сервис провайдинга».
Например этот перл:
«Однако в реальных приложениях и виртуальных средах последовательный ввод-вывод используется нечасто (в основном, для резервного копирования), и большинство операций ввода-вывода выполняются в произвольном порядке. Таким образом, обычная пропускная способность жесткого диска значительно ниже, около 10-20 Мб/с, согласно статистике, собранной рядом крупных провайдеров хостинга от сотен серверов.»
Вы серьезно? Не в курсе что в энтерпрайзе — основной I/O это random?
К нам кстати вы тоже приходили и просили исходные коды :))
«Да и зачем VAAI и ODX в гиперконвергентном решении» — затем, что глупо доверять гипервизору, никем реально не сертифицированным, при этом «на 40% быстрее обычного KVM».

vrubanov
22.06.2017 21:17+2Дорогие коллеги из Нутаникс, а какая версия ПО Росплатформа использовалась для указанного тестирования и на какой конфигурации железа?
К сожалению, в текущем посте количество некорректных данных в колонке «Росплатформа» столь велико, что наводит на мысль о предвзятости автора, пытающегося дешевым способом очернить конкурента фантазиями, не связанными с реальным положением вещей. Но поверить в столь грязный «наброс» сложно — поэтому, по всей видимости, была просто использована какая-то старая/промежуточная версия плюс допущены банальные опечатки с перепутыванием да/нет при составлении таблицы. Опечатки прошу исправить самостоятельно, а по поводу остального мои коллеги помогут и опишут реальность в отдельном посте, чтобы вы могли из него актуализировать ваши данные.
Я лишь отмечу, что в текущей версии ПО Росплатформа большинство указанных «нет» — уже отлично работающие «да», включая erasure coding, all flash, Docker, динамическую балансировку данных в зависимости от их локальности и нагрузки на диски, обновление основного ПО без перезагрузки и т.д. Кроме того, ряд строк о наших функциях в таблице почему-то вообще не упомянут (то ли потому что их не поддерживает Нутаникс, то ли потому что таблица не нацелена на объективное исследование).AntonVirtual
22.06.2017 21:22-1Уважаемый коллега из Росплатформы. Ваш комментарий прямо как иллюстрацию можно использовать к «Пособию по ведению газетных дискуссий» Карела Чапека.
«2. Прием второй, или Termini (терминология — лат.). Этот прием заключается в использовании специальных полемических оборотов. Если вы, например, напишете, что господин Икс, по вашему мнению, в чем-то неправ, то господин Икс ответит, что вы „вероломно обрушились на него“. Если вы считаете, что, к сожалению, в чем-то не хватает логики, то ваш противник напишет, что вы „рыдаете“ над этим или „проливаете слезы“. Аналогично этому говорят „брызжет слюной“ вместо „протестует“, „клевещет“, вместо „отмечает“, „обливает грязью“ вместо „критикует“, и так далее.»
IBS / Росплатформе предлагалось перед публикацией пройтись и прокомментировать, был дан отказ. Основано частично на чтении документации, частично на ответах представителей IBS / Росплатформы в публичной дискуссии в «клубном» чате Nutanix вокруг ИТ в Телеграме.vrubanov
22.06.2017 21:43+1Антон, можешь плз переслать мне ответы «представителей IBS / Росплатформы в публичной дискуссии в «клубном» чате Nutanix вокруг ИТ в Телеграме» (в почту). Хочу разобраться, что за ерунда. И в следующий раз прошу запрашивать инфо официально. Документацию я уже попросил проверить на предмет косяков с устаревшей инфой. За это спасибо.
Про отказ — мне показывали неделю назад какую-то бредовую таблицу с красными крестами в одной колонке и красочными зелеными галочками у Нутаникса — в другой. Я подумал, что это шутка, комментировать там было несерьезно что-либо. Когда мне сказали, что вы реально опубликовали это «творение», я весьма удивился — с ума что ли посходили. Но во всем есть польза — надеюсь, благодаря вам, наконец, наши на хабре теперь нормально напишут о своих достижениях) А если найдутся реальные пробелы у нас, то и продакт менеджерам будет подмога в приоретизации scope.
shapa
22.06.2017 21:29Владимир, ну зачем же так неразумно подставляться.
Зная вашу страсть к демагогии и подтасовке фактов, я использовал именно что документацию с сайта «Росплатформа».
Ответственно заявляю, что табличка целиком корректная. То что «спорно» — EC-X, который был выпущен реально весной этого года — мягко говоря неразумно заявлять как production ready функционал.
http://rosplatforma.ru/upload/howto_R_virtualization_quick_start.pdf
http://rosplatforma.ru/upload/howto_install_R_virtualization.pdf
http://rosplatforma.ru/upload/howto_R_storage_admin_guide.pdf
Повторюсь — все цитаты и выводы — из вашей документации, которую вы Владимир похоже не читали :)
p.s. удалять / подчищать следы бесполезно — все скопировано.vrubanov
22.06.2017 21:48Максим, документацию я уже попросил проверить на предмет косяков с устаревшей инфой. Допускаю, что могли что-то не заапдейтить при выпуске новой мажорной версии. Насчет «зачищать» — не совсем понял, если там устаревшие версии, то их нужно просто исправить. Привести в соответствие с реальностью. Это вы запрещаете нам сделать?)
shapa
22.06.2017 22:38Нет, но есть нюанс © (как в анекдоте про Чапаева).
Я точно так-же проверил текущую версию документации Virtuozzo — все ограничения точно так-же присутствуют.
Вы уж их тогда тоже попросите проапдейтить.
Кстати, а почему вы до сих пор представляетесь как работник Parallels и Acronis? Запутались?
shapa
22.06.2017 22:44Владимир, я реально предлагал вам успокоиться и прекратить топить свою компанию.
Вы даже не догадываетесь, что можно посмотреть теги PDF документа.
2017 года, документацию «Росплатформа» делает Parallels. Давайте, расскажите что не успели поменять емейлы, что документы старые и т.д.
Артему Павленко — привет.
vrubanov
22.06.2017 21:23Тем временем, лично меня вы заинтриговали нетехническими пунктами. Здесь ложные данные точно не объяснишь устаревшим источником. Откуда вы взяли про позиционирование и расположение разработки? Решения Росплатформы ориентированы на корпоративный и гос рынок. Да и продукты Virtuozzo работают по всему миру далеко не только в сервис-провайдерах. Впрочем, доверие крупнейших сервис-провайдеров к этим технологиям лично мне дополнительно внушает, так как для них каждая минута простоя — это легко подсчитываемые прямые убытки. Что касается разработки, то Росплатформа владеет полными исходными кодами своих продуктов, все разработки идут в локальной инфраструктуре, в штате — российские специалисты. Если же вы говорите о наших партнерах Virtuozzo, то, хотя их продавцы и разбросаны по всему миру, вся разработка испокон веков находится в Москве.
И смысл российских продуктов простой (кроме того, что деньги остаются в экономике страны) — Росплатформа юридически и технически готова обеспечить непрерывность поддержки и обновления своих продуктов даже в условиях самых жестких санкций вплоть до полной международной изоляции (не дай Б-г, конечно, дожить до такого). Не для всех, но для многих заказчиков это важный фактор. Как у Нутаникс обстоят дела с этим?shapa
22.06.2017 21:34Я ценю попытку увести в сторону разговор :)
Но даже ваши работники (да и ex-parallels ребята многие общаются и делятся — рынок тесный) признают что все что делает «Росплатформа» — это отдельный билд сервер. Все.
Факт N1: код разрабатывается виртуозо, принадлежит американской компании.
Факт N2: ввиду грязного вмешательства в ядро линукс («сотни патчей»), плюс работу кода (предполагаю — миллионы строк кода) на уровне ядра / хоста, решение «виртуозо->росплатформа» может иметь массу «незадекларированных возможностей» и просто проблем безопасности.
Факт N3: очевидно, что заявления " Росплатформа юридически и технически готова обеспечить непрерывность поддержки и обновления своих продуктов" это профанация. Я знаю сколько у вас работает людей.

avagin
27.06.2017 20:25-1То что вы называете «грязным вмешательством» имеет хороший выхлоп в upstream. Кроме того, что мы добавляем новую функциональность, мы регулярно находим баги в апстримном ядре и фиксим их. К слову о том, кто тут может обеспечить поддержку своих продуктов, я не поленился и посмотрел сколько раз ваша компания упоминается в ядре. Ровно два раза! Это нам говорит, что ядро не входит в вашу поддержку. Может проверим и остальные компоненты?
Вы не совсем понимаете, как работает opensource, иначе вас бы не удивляло, что наш kvm для некоторых типов нагрузок работает быстрее. Приведу простой пример. Нами была реализована хостовая часть драйверов hyper-v, что позволило виндовым гостям взлетать с нативными драверами и использовать все прелести паравиртуализации. Вся эта функциональность тут же ушла в апстрим, но в rhel она появится в следующем мажорном релизе, а у нас уже все работает, и до следующего релиза будут новые фишки.AntonVirtual
29.06.2017 10:39>имеет хороший выхлоп в upstream.
В этом между нами разница. Мы работаем на пользователя, чтобы у заказчика было все хорошо. Вы работаете за идею, на апстрим.Dmitriy-Rosplatforma
29.06.2017 14:58Во первых, это не так, мы также работаем на пользователя.
А во вторых, вы противоречите сами себе (своему директору). Сначала называете «грязным вмешательством», а когда вам указали что с нашей стороны все сделано грамотно, тут же переобуваетесь и называете это работой за идею = бесполезным занятием.
avagin
29.06.2017 17:27Приходит к вам пользователь, говорит: «У меня ядро падает на вашей платформе». А вы ему: «Это бага в апстриме, мы не работаем за идею!».
AntonVirtual
29.06.2017 17:32Вы на чьей стороне, Nutanix? ;)
Если к нам приходит пользователь с проблемой — мы решаем ее вне зависимости от апстрима или чьих она рук. Настаивать на коммит в апстрим даже не будем. Решим в кратчайшее время и сделаем патч для 1-click-upgrade, чтобы остальные заказчики смогли обновиться в один клик.avagin
29.06.2017 18:54Т е вы без опыта разработки ядра, полезете и все там пофиксити? Извините, не верю, что из этого что-то хорошее получится. Одна из идей работы с апстримом — это подтверждение свой компетенции. Если вы ничего не делаете с ядром, а потом вдруг решаете там что-то пофиксить, скорей всего ничего хорошего не получится. И вот такие вот фиксы, я бы называл грязным вмешательством без кавычек.
avagin
29.06.2017 18:57Да, и вы опять противоречите себе. То у вас нет своего ядра, то вы там что-то фиксите и накатываете? Где можно посмотреть ваши фиксы к вашему же ядру? Вы же знаете, что их надо выкладывать в публичный доступ?
shapa
22.06.2017 21:38Владимир, я искренне рекомендую подугомониться и изучить все-же (вместо совершенных глупостей на фейсбуке про Нутаникс) нашу степень осведомленности.
Мирантис тоже очень много выступал по моему поводу, хотя за 2 года вперед уже было ясно что все разваливается, в том числе бизнес в РФ. Недавно они закрыли офис в Москве.
Ваши «успехи» нам тоже вполне известны — полностью проваленная «Роса», только что исключили из списка докладчиков на конференции ядерщиков, и т.д.
Отмечу, что очень зря вы писали те самые публичные глупости на фейсбуке, в отличии от вас мы не оскорблениями занимаемся а делаем детальные технические сравнения.vrubanov
22.06.2017 22:24Максим, мне сложно вести дискуссию в таком тоне. Какие то сбивчивые домыслы и недомолвки. Давайте как-то конкретнее. Я, к сожалению, не знаю вас лично, имел лишь опыт общения в фейсбуке, где вы пришли в мой пост с какими-то фантазиями, не имеющими отношения к тому, что я говорил. На мои уточняющие вопросы не ответили. Пропали. Я тогда лишь пожал плечами с немым вопросом «что это было, у человека день что ли тяжелый».
И вот сейчас опять не совсем понятно. Вы много написали, но смысл не ясен. Куча мала какая-то — Мирантис, Роса, атомщики)) Это вы «осведомленность» так пытались демонстрировать? Боюсь, получилось наоборот)
Но давайте хотя бы с одним чем-то разберемся. Вот в первом предложении вы пишете: «вместо совершенных глупостей на фейсбуке про Нутаникс» и потом к этому возвращаетесь. Значит ли это, что вы считаете, что я про Нутаникс писал какие-то глупости и оскорбления? Можно ли ссылку? Может вы имеете в виду тот пост, из которого вы ретировались? Но там ни Нутаникса, ни оскорблений не было (насчет глупостей не могу судить, допускаю, что любое слово моё может быть глупым). Значит какой-то другой. Прошу пояснить.shapa
22.06.2017 22:47Коллега, коротко я веду к тому — что по моему мнению вы просто демагог, причем отсутствуют элементарные технические знания. Вот и все.
Смотрите выше ответ про «старые документы» и «мы не связаны с параллелс».vrubanov
22.06.2017 23:01Максим, вы переходите грань приличия в своих фантазиях о моей демагогии, ну и многое рассказываете о себе тем самым. Советую изучить такое ментальное искажение, как «психологические проекции». Можно начать с википедии.
Тем временем, не нужно приписывать мне утверждений, которых я не говорил. Росплатформа отдельная компания и не связана с Параллельс корпоративно. Но они наш важнейший партнер. Одно другому не мешает.shapa
22.06.2017 23:06Владимир, все понятно.
Конкретные факты:
1) доказана прямая связь и использование «прямо сейчас» ресурсов американских компаний Parallels и Virtuozzo.
2) Доказано что документация крайне свежая, исходя из чего заявление про «устаревшую документацию» — некорректно.
3) Ни одного конкретного опровержения ни одного из фактов из таблицы — не приведено.
Спасибо, было искренне забавно с вами общаться.vrubanov
22.06.2017 23:23Максим, похоже в вас погиб талант судьи басманного суда. По степени фантазий, псевдоразоблачений и следующих из них «выводов» вы бесподобны. Но попробуйте все же подумать, что истина может быть иной, чем вам, вполне допускаю, что искренно, кажется.
А опровержения фактов из вашей «объективной» таблицы лучше всего наблюдать на рабочем стенде. Приезжайте. Документацию же поправим, спасибо за QA. Кстати, можете прислать русскую документацию по Нутаниксу? Может тоже что полезное вам подскажем.
shapa
22.06.2017 22:05Владимир, пользуясь случаем.
Давно с интересом наблюдаю за вашей успешной карьерой — профессионалов рынка IT надо знать.
Это вы?
https://elibrary.ru/author_items.asp?authorid=17229&pubrole=100&show_refs=1&show_option=0
35 научных публикаций. Все верно? Или где-то ошибка?vrubanov
22.06.2017 22:36Максим, не совсем понимаю, какое это отношение к посту имеет. Такое впечатление, что вам очень хочется перейти на личности) Но я все же отвечу.
Классической наукой я уже давно не занимаюсь. К сожалению. Последний раз официальный список моих научных публикаций составлялся в ИСП РАН, где-то дома должна лежать заверенная копия. Там было что-то вроде 50. После этого было еще с десяток. На E-library в то время публикации не регистрировались. Я вообще удивлен, откуда e-library знает целых 35)
Но в любом случае, количество публикаций имеет значение только для ученых и официальных биографий. Больше толку от этого никакого нет. Почему вас это сейчас взволновало?shapa
22.06.2017 23:01Я близок к тому, чтобы (очень смягчая) назвать вас человеком не говорящим правду, всвязи с чем, с вами крайне сложно дискутировать.
По поводу отствутсвия связи с Parallels / Virtuozzo я выше уже все показал.
У вас в профиле, бездоказательно указано 50 научных публикаций. Библиотека показывает 35, начиная с 2001 года. Вы школьником тоже делали научные публикации?
РИНЦ работает с 2000-го года.vrubanov
22.06.2017 23:43Максим, не поверите, у меня были публикации и до 2000 года, будучи еще студентом Физтеха. Хотя в РИНЦ не учтены и многие после 2000. Или вы правда думаете, что все публикации регистрируются в РИНЦ? Если так, то учите матчасть, если претендуете на «экспертность» в вопросах подсчета публикаций)
Или вам нравится придумывать свою фантазийную реальность и в нее искренно верить? Только вот в настоящей реальности про 50 публикаций в моей официальной биографии — это меня обидели. Если отнестись к подсчету этих попугаев серьезно, то нужно добиваться исправления на «больше 60». Только вот беда, что даже если бы у меня их было даже 100, я не стал бы лучше.
kkx
24.06.2017 15:03автор явно не знаком с архитиктурой тех с кем сравнивается.
Отсутствие узких мест / точек отказа — должно быть «да» и для Virutozzo и для CEPH.
Интеллектуальный автоматический Data Tiering — у Virtuozzo есть. у CEPH насколько знаю не было.
Встроенный портал самообслуживания — речь об админке? тогда у Virtuozzo и это есть.
Локализация данных VM (data locality) — у Virtuozzo есть. Они это пиарили когда в россии про Nutanix еще никто не слышал даже…
Erasure Code — у Virtuozzo есть.
Поддержка All Flash — даже не написано о чем речь.
и далее по списку… стыдно должно быть за такие сравнения. Имхо за такое даже судить можно.AlexBin
26.06.2017 10:32Интеллектуальный автоматический Data Tiering — у Virtuozzo есть. у CEPH насколько знаю не было.
у Ceph есть
IT_pilot
24.06.2017 15:03А если сравнить с… Huawei FusionSphere, которая в том числе на Xen?
Там и гипервизор, и облачная платформа с порталом самообслуживания, и программная СХД. И все это гиперконвергентно, т.е. все живет на одних и тех же железках.
Dmitriy-Rosplatforma
24.06.2017 15:04+2Огромное количество пунктов в таблице не корректны или ложны, наши комментарии по пунктам:
1. Архитектура
В случае работы на уровне хоста / ядра ОС, проблемы безопасности и отказоустойчивости.
С точки зрения безопасности в большинстве случаев ни гипервизор, ни CVM не являются предметом для атаки. Если же будет взломан гипервизор, а AHV это тот же KVM, то ценности в CVM уже не будет. Сервисы работают в userspace, а ядро мы задействуем только с точки зрения оптимизации дискового IO.
2. «Заточенность» решения
Требования сервис-провайдеров к решению по виртуализации часто выше, чем требования корпоративного рынка, так как для сервис-провайдера каждая минута простоя это реальные легко подсчитываемые деньги, а каждый новый инженер — это снижение прибыли. На корпоративном рынке стоимость обслуживания часто важна лишь на бумаге, а посчитать стоимость простоя может далеко не каждая компания.
3. Отсутствие узких мест / точек отказа (централизованные сервисы, например cервера метаданных или сервера управления)
В Росплатформе нет единой точки отказа.
4. STIG политики (Security Technical Implementation Guide)
Есть команда, которая оперативно выпускает обновления безопасности. Ничего искать не нужно. Также, 95% клиентов используют изолированные от интернета сети, и обновления проходят внутренний стейджинг.
5. Расположение компании, разрабатывавшей основную часть ПО
Разработка находится полностью в России, весь девелопмент сидит в офисе в Москве.
Росплатформа полностью соответствует требованиям законодательства РФ к российскому ПО.
6. Встроенный полноценный мониторинг (все аппаратные и программные компоненты) и самодиагностика
Да, с точки зрения мониторинга нам еще есть над чем работать. В ближайшее время мы планируем интеграцию Расплатформы с наиболее распространенными OpenSource системами мониторинга.
7. Интеллектуальныи? автоматическии? Data Tiering — перемещение блоков данных между холодным и горячими уровнями в случае изменения частоты запросов к этим данным (“нагрев” или “охлаждение”)
Сейчас в решении поддерживаются уровни хранения данных и вы можете выбрать куда разместить свои сервисы — горячие или холодные данные, индивидуально для виртуальной машины. Поддержка Auto-tiering планируется, хотя применимость данной фичи довольно ограничена. В мире провайдеров она не нужна совсем, на корпоративном рынке она нужна для очень ограниченных кейсов.
8. Встроенныий портал самообслуживания
С точки зрения Virtual Datacenter мы интегрируемся с OpenStack, что закрывает все остальные кейсы.
А у Virtuozzo есть собственный портал самообслуживания для VPS — PowerPanel.
9. Локализация данных VM (data locality) — активные данные VM находятся на том-же сервере где работает виртуальная машина.
Кардинальное ускорение операций чтения и снижение нагрузки на сеть в разы.
Р-Хранилище использует Data Locality.
10. Репликация на уровне VM
Гео-репликация на уровне Object Storage выйдет в июле 2017 года.
Гео-репликация на уровне VM ожидается в конце 2017.
11. Восстановление целостности данных
В случае отказа хоста или диска восстановление происходит автоматически, даже в случае потери домена.
12. Дедупликация данных
Сейчас не реализовано, но дедупликация очень сильно влияет на производительность и при этом далеко не всегда эффективна,
TB данных сегодня значительно дешевле чем IOPS.
В будущем мы рассмотрим необходимость имплементации данной функциональности в нашем решении.
13. Компрессия данных
Будет реализовано к концу 2017.
14. Erasure Code (помехоустойчивое кодирование)
Реализовано, по умолчанию есть режимы 3+2,5+2,7+2,17+3
15. Поддержка All Flash
Поддерживается
16. Микс All Flash и Hybrid в едином кластере
Поддерживается
18. Обработка отказов SSD дисков с метаданными
Потеря MDS никак не влияет на работу кластера.
Метаданных у нас используется всего 1ГБ на почти 0.5PB данных в кластере, отреплицировать 1 ГБ ничего не стоит.
19. Поддержка VAAI и ODX (протоколы «разгрузки» операций ввода-вывода на систему хранения данных)
Зачем VAAI и ODX в гиперконвергентном решении, в котором предусмотрен только собственный гипервизор и собственный storage?
20. Поддержка Application Consistent Snapshots (провайдер VSS для Windows Server и имплементация для Linux)
Росплатформа использует VSS для онлайн резервного копирования. Для снапшотов действительно VSS не используется, так как мы делаем синхронную заморозку памяти и диска, поэтому все недописанные запросы к диску остаются в снимке памяти, и допишутся на диск при восстановлении. Также мы считаем что снапшоты это не серверный сценарий.
21. Неограниченное количество снапшотов VM, без влияния на производительность и возможностью манипуляций (в т.ч. удаления) снапшотов на любом уровне
В Росплатформе нет никаких ограничений на количество snapshots и связанную с этим производительность.
22. Встроенныий бэкап на Amazon / Azure
Нашим клиентам не требуется бекап в чужое облако, особенно в западные облака.
23. Распределенный отказоустойчивый cтек управления (management plane) без использования централизованных баз данных
Все сервисы управления отказоустойчивы.
24. Не требуются выделенные сервера управления
Никаких выделенных серверов не требуется.
25. Автоматические апгрейды аппаратных прошивок (биос, прошивки дисков и флеш, контроллеры и тд)
В отличии от Nutanix, Росплатформа работает поверх практически любого x86 железа и абсолютно абстрагирована от оборудования, пользователь волен делать с прошивками что хочет. И это более гибко для пользователя.
26. Прозрачное обновление без перезапуска клиентских сервисов при смене основной версии ПО
Не понятно, что имеется ввиду. Большинство обновлений происходит без перезагрузки. В случае необходимости перезагрузки пользовательские инстансы можно live мигрировать на другие ноды.
27. Поддержка гипервизоров
Наши коммиты постоянно идут в мейнстрим, и сообщество ими пользуется.
KVM тюнингованный для промышленного применения.
Отсутствие поддержки VAAI/ODX никак не влияет на «продуктивность» OpenStack.
28. Возможность запуска Microsoft Windows Server с полнои? поддержкои? от Microsoft (SVVP — Server Virtualization Validation Program)
Релиз новой версии состоялся недавно, и мы планируем получить сертификацию SVVP в ближайшее время.
29. Контейнерная виртуализация
Docker также поддержан
30. Встроенные бэкапы (без применения стороннего ПО) с пофайловым восстановлением и самообслуживанием
Есть встроенный бекап с расписанием в контрольной панели, с поддержкой технологии CBT для инкрементальных бекапов, без потери консистентности после миграции виртуальных машин. Восстановление на уровне блочных устройств.
31. Метро кластер (распределённый гео-кластер с синхронной репликацией данных)
Поддержано, кластер может быть растянут на несколько локаций с синхронным реплицированием
32. Поддержка кросс- гипервизорного DR
Росплатформе это не требуется, так как гипервизор только один.
33. Автоматическая конвертация гипервизора и всех VM на кластере (например, ESXi->AHV/KVM)
Конвертация возможна через открытые утилиты работы с KVM. Да, это не автоматически, но поддается простому скриптованию, а в случае миграции инстансов только такой вариант и работает, так как никакие автоматические миграции не учитывают многочисленные особенности инфраструктуры.
34. Встроенный SDN стек с интеграцией в аппаратное сетевое обеспечение
Росплатформа интегрируется с OpenStack и эта интеграция решает задачу SDN.
35. Поддержка Affinity / Anti- Affinity, для оптимизации лицензирования ПО
Не применимо, лицензии перманентны на физический процессор.
36. Поддержка RESTful API (стандарт индустрии)
Мы полностью поддерживаем Libvirt API, который также является стандартом индустрии. В случае интеграции с OpenStack — OpenStack API.
37. Бесплатный апгрейд ПО на новые версии (минорные и глобальные обновления версий) при наличии действующей базовой техподдержки
При наличии поддержки апгрейд бесплатен.
38. Ценообразование (для РФ) на готовые коммерческие решения (ПАК — программно аппаратныи? комплекс)
Очень интересный момент. Приведена стоимость за ПАК Скала-Р, который включает в себя помимо 4 серверов и ПО Росплатформа, также 56gbps коммутаторы, стойку, ПО мониторинга и все это вместе преднастроенное в сборе и может масштабироваться горизонтально с шагом в 1 сервер или вертикально за счет добавления дисков или JBOD полок.
Стоимость Nutanix, скорее всего, приведена за SMB комплект Nutanix Xpress на базе Supermicro BigTwin. Этот комплект не расширяется и имеет кучу ограничений приведенных здесь https://habrahabr.ru/company/nutanix/blog/301682/.
Так что сравнение совершенно не корректно.
Dmitriy-Rosplatforma
24.06.2017 15:15Комментарий выше висел в модерации 4 дня.
35. Поддержка Affinity / Anti- Affinity, для оптимизации лицензирования ПО
Можно привести ссылку, где указано, что вопросы лицензирования решаются с помощью affinity правил?
knutov
Пост у вас написан, простите, плохо, ибо что сказать хотели — не понятно, пока не посмотришь от какого юзера сделан пост.
Но раз уж за объективность и сравнение — хотелось бы добавить — сторадж у виртуоззо — это боль и ploop. Сам по себе ploop за последний год стал вполне неплох и перестал занимать в полтора+ раза больше места, чем должен, но по прежнему ломается, часто необратимо, если лежит на крутящихся дисках без батарейки (на SSD с повер лосс протекшн все норм). При этом три контейнера забивают намертво что гигабит, что десять и дальше всё.
Зайти с улицы и купить виртуоззо сложно (не знаю как в случае, если покупать импортозамещенную версию, может иначе), с суппортом у оригинального виртуоззо примерно никак, особенно у опенсурсной части.
С Ceph все в принципе и так понятно, а вот с raidix — неоднозначно. Да, оно больше заточено под операции с видеопотоками и большие потоковые линейные чтения, но — кому-то ведь по нагрузке этого достаточно. А в плане технологий у них сделано много интересного.
Учитывая, что виртуоззо и ceph — это то, что просто вообще не надо трогать (и это прекрасно понимает примерно каждый читатель хабра из вашей целевой аудитории), табличка сравнения из одного нутаникса выглядит как-то не очень. Уж лучше бы сравнили со ScaleIO. Которому, вероятно, нутаникс проиграл бы, но зато импортозамещение и можно выбирать по приоритетам.
Про стартовую стоимость — все же понимают, что комплект из трех серверов не имеет смысла, ибо когда сервера три, то можно сделать два одинаковых с каким-то рейдом внутри и дрбд поверх для HA. Что много дешевле и работает лучше, если нет задачи переложить ответственность за сломавшееся на вендора. А обычно таки (ну, в теории, должна) задача есть чтобы работало стабильней и быстрее, а не ответственность перекладывать.
Also, про нагрузку. Вот, например, я хостер. И сейчас мы не используем дисковые полки или гиперконвергентные штуки, но очень хотим. Гипер-в и квм. Знаем сколько иопсов на чтение и записи у нас на каждом сервере при использовании локальных дисков. Как посчитать сколько серверов, дисков и сети нужно в случае с нутаниксом и какая получится латенси?
pansa
sorry, что влезаю, а есть успешный опыт с drbd? А то вот пытались запустить, показалось сырым…
knutov
Сами сейчас не используем, но был и много раз видели у коллег.
Учитывая сколько ему лет — сырым оно быть вряд ли может. Так что если у вас наблюдаются какие-то проблемы — это повод спросить в каком-нибудь профильном телеграм чатике что вы сделали не так.
Но, в общем, "аппаратное" HA — это, я считаю, плохой путь, кроме очень узких задач.
shapa
Просаживает I/O где-то в два раза. Судя по отзывам из ceph community.
Я же писал — мы про бумажные «фичи» не говорим.
knutov
Все просаживают ио. Но требования то у вас какие? Сколько иопсов надо на чтение и запись?
И просаживает как? По иопсам, по мегабайтам, или по латенси?
shapa
IOPS, latency.
TaHKucT
есть положительный опыт на centos6 и соответственно drbd8+heartbeat+openvz6. Минус этого решения — при переключении роли с одного сервера на другой виртуалки «как бы перезагружаются», то есть HA есть, а FT нет (в терминалогии vmware) и большие накладные расходы (не в смысле производительности серверов, а в том смысле, что у меня 2 независимых кластера по 2 машины в каждом, то есть 2 сервера в работе и 2 в резерве. А хотелось бы конечно «два в работе, и один в резерве»). За те 3-4 года, что это работает пару раз происходило «нештатное» переключение (первый раз память начала сбоить, второй раз материнка) и все отработало нормально (правда загрузка 40 контейнеров разом — не самое простое испытание для дисковой подсистемы, процессор до половины времени в iowait проводил первые несколько минут после переключения).
Eдинственный вариант, которым у меня удалось поломать drbd и потребовалось руками чинить — это потеря связанности между хостами при нормальной работе обоих хостов (ha переводит drbd в UP и получаем split brain). Поэтому в работе оба узла связаны по 2 каналам, один через свич, он же для клиентского трафика, второй канал напрямую между сетевыми картами серверов.
AntonVirtual
> Поэтому в работе оба узла связаны по 2 каналам, один через свич, он же для клиентского трафика, второй канал напрямую между сетевыми картами серверов.
Отличное решение для 8+ узловых кластеров :)
TaHKucT
ага, можно брать откаты с производителей сетевых карт за продвижение этого подхода.
shapa
«ScaleIO Которому, вероятно, нутаникс проиграл бы, но зато импортозамещение»

Вы смеетесь? Нутаникс проиграл бы ScaleIO?
Даже сами Dell EMC его уже серьезно не рассматривают и не продвигают. Крупный банк в РФ тестировал и сравнивал — ScaleIO даже не запустился нормально. Все что реально продвигает сейчас DellEMC — это VSAN и Nutanix.
Свежая реклама приложена.
Про импортозамещение — это вы тоже серьезно? EMC ScaleIO стал импортозаместительным продуктом?
knutov
нутаникс вроде бы импортзамещен. scaleio — нет.
Что там как у крупного банка я не знаю, но видел несколько случаев другого опыта.
И уж если нутаникс лучше scaleio, то тем более логично сравнить их, я считаю.
shapa
Нет, не логично. Мы не делаем сравнений ради сравнений. В РФ со scaleio сталкивались примерно ноль раз, про то чтобы тестировали Nutanix vs ScaleIO — вообще один раз было. Так что искренне интересно про какие «обратные ситуации» речь. Надеюсь не «одна бабка на дворе сказала».
AntonVirtual
>нутаникс вроде бы импортзамещен. scaleio — нет.
Р.Хранилище же из Росплатформы и масса поделий на Ceph.
navion
Месяц назад анонсировали новую версию с кучей фичей и готовые железки.
AntonVirtual
Анонс — это хорошо, конечно. Но где продажи в России, где история успеха?
Где хотя бы внятное позиционирование ScaleIO vs VSAN vs XC?
navion
Куда им до таких мощных внедрений, а по позиционированию лучше спросите бывших коллег. Мне оно видится как классический
и бесплатныйSDS для кучи платформ и VMware идёт как приятный бонус, а не основная нагрузка.AntonVirtual
Ах, вам видится :)
Но вы сами того не замечая, привели прекрасный аргумент. Да, в Inchcape *часть* инфраструктуры сейчас переведена на NX1465, который может показаться смешным только если не задумываться о том, что этот кластер может с точки зрения производительности. Отзывы от заказчика на текущий момент прекрасные.
ВТБ вам достаточно крупный пример успеха Nutanix будет? В техническом сравнении с VSAN и в том числе со ScaleIO.
На ScaleIO есть публичные кейсы хотя бы размера Inchcape в России?
navion
Я не говорю, что Нутаникс плохой или ScaleIO хороший, но масштаб внедрений в пресс-релизах выглядит забавно.
Это уже интересней, могли бы ещё ПЛАТОНа вспомнить. А про ЕМЦ спрашивайте у ЕМЦ — мне оно близко условной бесплатностью и работой на всём подряд.
romxx
Поддержу позицию Антона. Если вы меряете эффективность, успех и «энтерпрайзность» количеством занятого места в стойке, то тогда, конечно, Nutanix — плохой выбор. А вот люди, зарабатывающие бизнесом и потом тратящие деньги на IT-инфраструктуру, уверен, думают иначе. И если задача, на которую раньше требовалось полстойки железного барахла, решается одной 4-нодовой 2U коробкой, за счет большей эффективности использования железа, то это же плюс, а не минус. Причем большой плюс.
Прошли времена, когда «богатство» и успешность компании измерялось числом занятых в датацентре стоек. Поэтому в числе занятых юнитов Nutanix конечно выглядит «забавно». Но «забавность» тут прежде всего в том, сколько раньше непроизводительно компания тратила, места, электричества, дорогущих энтерпрайзных дисковых шпинделей.
Так что спасибо за аргумент в пользу Nutanix ;)
navion
Просто из любопытства, где-то кроме подлодок с аваксами пара юнитов в стойке обходится в десятки килобаксов?
romxx
Я где-то пропустил какие-то промежуточные выкладки, поэтому затрудняюсь понять о чем вы спрашиваете. Если вам требуется ответ, то, пожалуйста, разверните мысль.
Для упрощения диалога: вы согласны, что когда бизнес-задача пользователя решается существенно меньшим объемом оборудования чем раньше и за меньшие деньги это — добро, или нет?
navion
Количество юнитов и энергоэффективность не является самоцелью за исключением очень редких случаев, вроде того датацентра в чемодане на NEXT.
А если половина стойки в итоге окажется дешевле по TCO, то бизнес выберет именно её, так как умение тратить деньги является показателем эффективности бизнеса.
shapa
Когда scaleio начнет поддерживать хотя-бы базовые вещи — мы можем вернуться к разговору, но пока вы реально очень-очень повеселили.
1) дедупликацию
2) компрессию
3) полноценный tiering
4) поддержку RF2 и RF3
5) Снапшоты на уровне VM
6) Локализация I/O
7) All Flash
И прочее-прочее — тогда можно будет говорить серьезно.
Фактически ScaelO ничем не лучше р-хранилища в общем-то.
knutov
1 и 2 — очень опциональные штуки. Причем онлайновая дедупликация на столько затратна по ресурсам, что часто вообще невыгодна.
5 — ну, тоже очень на любителя. Например, нам — не нужны. А какая кстати деградация производительности у нутаникса, когда много снапшотов?
3 — штука определенно приятная и нужная, но есть много задач, где она не играет критической роли и малосущественна.
про rf2/rf3 — вроде избыточное хранение у них есть. Какое и как — лень гуглить.
6 и 7 — не понял что вы имеете ввиду. Не вижу проблем с scaleio на только ссд.
AntonVirtual
Если 1 не всегда имеет смысл, и нишевое применение, то вот насчет 2 не соглашусь.
Только что вернулся от заказчика, где проходит тестирование. Средняя компрессия 2,5x на пачке баз данных. Что это означает? Это означает в том числе эффективное увеличение емкости SSD, а следовательно в 2.5x раз больше данных будут обслуживаться с SSD, и в том числе читаться на полной скорости с локальных дисков.
5 — нулевая деградация, в отличие, например, от снапшотов VMware.
knutov
Кому нужно увеличение емкости ради емкости?
Например, в силу требований по характеристикам нам в любом случае подходят ссд размером от 800/960 гб.
Сжатие в lz4 дает в среднем сжатие в 2-2.5 раза.
Реально данных на одном диске у нас 300-400 гигабайт.
Т.е. что есть сжатие, что нет — разницы никакой.
Вот если бы диски были не локальные, а дисковая полка или "гиперконвергентное" хранилище… Но что-то никто не хочет мне говорить какое будет латенси в этом случае и почему нужно купить нутаникс, если локальный топовый серверный ссд оказывается дешевле.
5 — ну, круто, не знал, что так вообще бывает. Но — например, нам — не нужно совсем.
AntonVirtual
Ну если у вас данных столько, что они влезают на один SSD, то тогда вообще непонятно о чем мы говорим в обсуждении многоузловых промышленных систем на сотни терабайт.
knutov
Потому что таких серверов много и в масштабах — можно было бы сэкономить. Но где спеки по латенси при использовании конкретной сети и олл флеш? В гугле не видно.
shapa
1-2) Тобишь вы считаете нормальным выкидывать массу денег на оборудование? Покупать в 3-4 раза больше дисков? Вы это серьезно вообще?
5) Вообще-то репликация LUN (то что делает ScaleIO) vs репликация per-VM — это те самые жигули vs BMW.
Просадка — ровно ноль, ибо снапшоты в Нутаникс ROW (redirect on write). Подавляющее большинство вендоров делает COW.
3) Да-да, конечно. Архивы хранить? И зачем там ScaleIO? Там ZFS хранилка на пару десятков петабайт легко справится.
6) Локализация блоков данных на те узлы где работает VM. Резкое снижение latency чтения, увеличение скорости и кардинальное снижение нагрузки на сеть.
ScaleIO это не умеет.
7) Да хоть все обвешать SSD — если платформа не рассчитана на All Flash — это будут выкинутые деньги.
Еще раз, я вообще не понимаю почему тут всплыл этот полуживой продукт. На него сам вендор уже внимания фактически не обращает.
К вам маркетологи EMC приходили?
knutov
Например, в нашем случае это пока оказывается очень сильно дешевле, чем покупать нутаникс и переходить на 10г+ сеть.
Нет, маркетологи к нам приходят только от нутаникса, но после озвучивания задач говорят, что нутаникс нам не нужен и уходят. А про EMC говорят люди, реально его использующие, но, это, конечно не банки и не энтерпрайз.
6 — кстати, как будет в этом случае житься с нутаниксом, если сеть — гигабит?
ps: А куда бы вам написать типа телеграма, чтобы вы рассказали какой нутаникс в каком виде нужен мне для конкретных двух задач и сколько это будет стоить?
AntonVirtual
https://t.me/nutanix_russia
shapa
«Про стартовую стоимость — все же понимают, что комплект из трех серверов не имеет смысла, ибо когда сервера три, то можно сделать два одинаковых с каким-то рейдом внутри и дрбд поверх для HA.»
Вы реально думаете что ДВА сервера будут работать? Арбитром / witnsess что будет выступать? Сисадмин вася на раскладушке в серверной?
Почитайте хотя бы paxos, и почему полноценный кластер / HA может работать минимум с трех узлов.
knutov
Т.е. слово drbd вы проигнорировали специально? Там еще pacemaker/heartbeat естественно.
o_serega
Кворум и актив/пассив (Dual-primary mode без gfs и ocfs2 не считается) — немного разные вещи.
knutov
Естественно с osfs )