
Отчасти это дело вкуса, поэтому, кому интересно как это делаю я, добро пожаловать под кат.
Несмотря на то, что «вся правда» о h-файлах содержится в соответствующем разделе описания препроцессора gcc, позволю себе некоторые пояснения и иллюстрации.
Итак, если дословно, заголовочный файл (h-файл) — файл содержащий Си декларации и макро определения, предназначенные для использования в нескольких исходных файлах (с-файлах). Проиллюстрируем это.
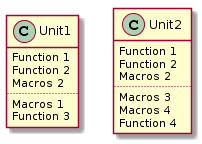
Легко заметить, что функции 1 и 2, а так же макрос 2, упомянуты в обоих файлах. И, поскольку, включение заголовочных файлов приводит к таким же результатам, как и копирование содержимого в каждый си-файл, мы можем сделать следующее:
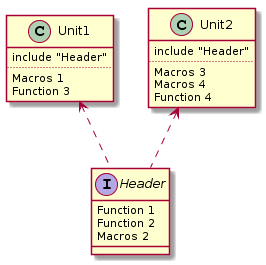
Таким образом мы просто выделили общую часть из двух файлов и поместили ее в заголовочный файл.
Но является ли заголовочный файл интерфейсом в данном случае?
- Если нам нужно использовать функциональность, которую реализуют функции 1 и 2 где то еще, то Да
- Если макрос 2, предназначен только для использования в файлах Unit1.c и Unit2.c, то ему не место в интерфейсном файле
Более того, действительно ли нам необходимо иметь два си-файла для реализации интерфейса, определенного в заголовочном файле? Или достаточно одного?
Ответ на этот вопрос зависит от деталей реализации интерфейсных функций и от их места реализации. Например, если сделать диаграммы более подробными, можно представить вариант, когда интерфейсные функции реализованы в разных файлах:

Такой вариант реализации приводит к высокой связности кода, низкой тестируемости и к сложности повторного использования таких модулей.
Для того, что бы не иметь таких трудностей, я всегда рассматриваю си-файл и заголовочный файл как один модуль. В котором,
- заголовочный файл содержит только те декларации функций, типов, макросов, которые являются частью интерфейса данного модуля.
- Си-файл, в свою очередь, должен содержать реализацию всех функций, декларированных в h- файле, а также приватные типы, макросы и функции, которые нужны для реализации интерфейса.
Таким образом, если бы мне довелось реализовывать код, которому соответствует диаграмма приведенная выше, я бы постарался, добиться следующего (окончания _с и _h в именах файлов добавлены по причине невозможности использовать точку в инструменте, которым я пользовался для создания диаграмм):

Из диаграммы видно, что на самом деле мы имеем дело с двумя независимыми модулями, у каждого из которых имеется свой интерфейс в виде заголовочного файла. Это дает возможность использовать только тот интерфейс, который действительно необходим в данном конкретном случае.Более того, эти модули могут быть протестированы независимо друг от друга.
Читатель, наверное, заметил, что макрос 2 из заголовочного файла снова вернулся в виде копии в оба си-файла. Конечно, это не очень удобно поддерживать. Но и делать данный макрос частью интерфейса не правильно.
В таких случаях, я предпочитаю делать отдельный заголовочный файл содержащий типы и макросы, необходимые нескольким си-файлам.
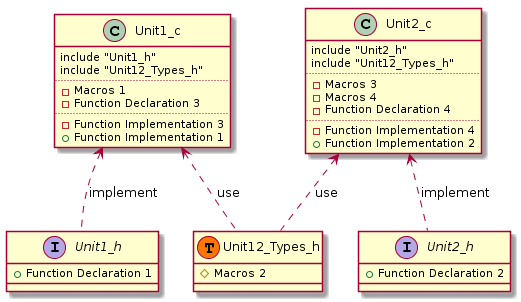
Надеюсь, мне удалось обозначить те сущности, которые нуждаются в том, что бы быть помещенными в заголовочные файлы. А так же, показать разницу между интерфейсам и файлами, содержащими декларации и макросы, необходимые нескольким си-файлам.
Спасибо за внимание к материалу.
Комментарии (25)

Cromathaar
04.04.2016 10:43+1Если думать о заголовочных файлах как об интерфейсах, то интерфейс в первую очередь должен представлять из себя согласованную абстракцию, а не быть местом, куда попросту выносятся пересекающиеся декларации.

MacIn
04.04.2016 17:08Пересекающиеся декларации — это тоже вид абстракции, правда, самый примитивный.

ffs
04.04.2016 10:50-3Стыдно в таком признаться в 2016, но сколько раз я не начинал «изучать с++ за N дней», всегда запинался на подобной мелочи и потом меня «отпускало».
Самое первое — беру книгу, читаю, хочу начать писать код. Скачиваю вижуал студию, создаю проект, компилю-запускаю, бдыщ — не хватает всяких std**** итд. Гуглю, подключаю, их не находит. Позже оказывается что они есть только в про- или какой-то ещё крутой версии, а чего стоит структура пустого проекта из десятка файлов, в назначении которых без бутылки не разобраться, а толком описания всего хозяйства я нигде так и не нашел.
В результате самого большого прогресса достиг пользуясь убунтой и gcc, но там далеко продолжить не смог, т.к. по непонятным для меня причинам видеокарта перестала что-либо показывать после загрузки иксов в любом линуксе с драйвером nvidia.
Вот прочитал вашу статью и опять загорелся, тем более что друг зазывает делать игру на unreal 4. Можете (не только автор, все) посоветовать какую-то книгу/цикл_статей/еще_что-то, что поможет в моём случае?Alexx999
04.04.2016 12:24+3По поводу студии — нынешний Community Edition является прошкой без полутора фич, так что в этом плане стало попроще.
GCC можно поднять и на винде, вместе со всеми прочими никсовыми утилитами (MinGW либо Cygwin).
Shifty_Fox
04.04.2016 12:24+2Можно скачать mingw, использовать с Eclipse CDT или %YOUR_FAVOR_IDE%. Eclipse умеет сам составлять makefile для сборки. Сам по себе C\C++ достаточно прост, в нем просто много возможностей, которые можно использовать, а можно и не использовать, самый минимум же языка требует только auto main() -> int, пары системных заголовков и того что вы сами в него вставите.
По поводу литературы, возможно книга Герберта Шилдта вам поможет. Но помните, под каждый движок, включая unreal 4, архитектура и паттерны с код стайлом сильно разнятся, язык очень универсальный, общий знаменатель там фактически функции и классы, а способов выразить один и тот же паттерн по 3-4 варианта. Изучайте основы, и углубляйтесь в программирование конкретно под Unreal 4, сэкономите время.Gryphon88
04.04.2016 13:40+3Добавлю, что помимо справочников Шилдта, которые можно использовать для быстрого старта, хорошо бы почитать Страуструпа. Вообще, хорошо взять книгу автора языка, просто чтобы понять, зачем и почему сделано именно так, а потом прочесть уважаемую книгу со словом «effective» в названии, чтобы понять, во что оно выродилось.
Плюс надо помнить, что многие хорошие практики в С являются нежелательными в плюсах, например (осторожно, умеренный холивар!) сишные перечисления и макросы рекомендуется в плюсах не использовать, а упирать на инлайновые функции и шаблоны.
akalend
04.04.2016 14:32+3Книги с «effective» в названии явно не для новичков, пусть сперва Шилдта освоит.
Foreglance
07.04.2016 00:22Из вступления к курсу «DEV210x Introduction to C++» на edx.org:
So if you have a book that, I don't know, one of your
parents used in college to learn C++ from, please do not look
at that book. Like don't even open it. Because it's going to
be full of old-school, we don't do it like that anymore, that's
harder than it needs to be ways of coming at C++. And what James
and I want to show you today is that C++ is not a scary language.
It's a very powerful and expressive language with elegance and expressivity.Gryphon88
07.04.2016 14:45+1Очень грамотное вступление. Я примерно так же открыл для себя «21st Century C» by Klemens. Книга начинается с настройки окружения, в т.ч. гита, рассматривается жизненный цикл приложения, есть ряд оговорок типа «так сделали в 70е и это было разумно, а потом лепили костыли. Теперь все пользуются этой штукой и нам остаётся только изучать её и лепить свои костыли» (про automake и поведение линковщика вроде) и «Если Ваш компьютер имеет больше 512 Мб оперативки. Вы можете игнорировать эту „best practice“»
MacIn
07.04.2016 16:08Это самый начальный курс? У них в аннотации написано, что освоенное пригодится при прохождении следующих курсов, но я не нашел курса для более продвинутых. Вы не смотрели следующие?
Foreglance
08.04.2016 08:54Этот курс для начинающих — базовый синтаксис с интересными деталями. Другие пока не встречал и не искал.

moveax3
05.04.2016 00:24+2вот поэтому изучать надо начинать с запусков gcc в консольке, простого текстового редактора и понимания сути того, что ты делаешь и что происходит, а не с создания проектов в визуалстудиях
Xitsa
04.04.2016 11:55А я, наверное, не устану рекомендовать классическую книгу, посвящённую в том числе и планированию размещения кода по заголовочным, исходным файлам и модулям: John S. Lakos — Large-Scale C++ Software Design.
Она, конечно, скучная и уже старая, но общие идеи не устарели до сих пор.

olegy
04.04.2016 12:05+3Нужно разделять интерфейсные и внутренние описания, аля в C++ public vs private & protected описания. В больших С проектах, мы пользуемся такими соглашениями в именовании файлов:
<module_name>-<submodule1>.c
<module_name>-<submodule2>.c
<module_name>.h — интерфейс модуля (public)
<module_name>_int.h — внутренние определения модуля (protected)
Это в общем то предмет соглашения разработчиков (стиль программирование, так же сюда входят именование переменных и т.п.)
orcy
04.04.2016 13:21+1Инструмент для рисования диаграмм выглядит очень интересным, спасибо за ссылку!

a-ilin
05.04.2016 00:51+1В некоторых случаях используемые фреймворки накладывают свои условия. Например, в Qt, если класс использует сигналы/слоты или другую метаинформацию, такой класс должен располагаться в заголовочном файле. Так как moc-компилятор (один из инструментов Qt) по умолчанию обрабатывает только заголовочные файлы. Для сокрытия «приватных» классов от пользователя используются «приватные» заголовочные файлы, имеющие формат имени {classname}_p.h
Wilk
Здравствуйте.
В ряде случаев вопрос с необходимостью использования макроса в нескольких независимых файлах я решаю созданием отдельного заголовочного файла, содержащего только этот макрос. Решение не самое элегантное, однако избавляет от решения сложнейшей задачи — придумывания имения для файла, в котором хранятся различные утилитарные макросы.
В случае, если необходимо объявить какой-либо тип, который будет входить в интерфейс модуля, я стараюсь сделать так, чтобы пользователю описание типа было не видно. Конечно, это маразм и попахивает плюсами головного мозга, однако у меня есть оправдание — я хочу максимально сохранить совместимость между версиями библиотек и избавить себя от необходимости изменять зависимое ПО в случае изменения структуры данных в новой версии библиотеки. Поясню идею: я вижу пользователя библиотеки неплохим парнем, но желающим решить какую-либо задачу попроще либо хитро. Это означает, что пользователь может использовать для работы с объектами типов данных, объявленных в библиотеке, не библиотечные функции. Например, выделять память для объекта самостоятельно, либо использовать напрямую какое-либо поле. Всё бы ничего, но в случае, если структура данных изменится, весь код надо будет исправлять для поддержки работы с новой версией библиотеки.
Кроме того, при использовании такого подхода появляется возможность экспериментировать с типами данных, подменяя их на различные варианты при сборке. Хотя до полноценного решения, аналогичного применяемому в том же ядре Linux и других проектах, использующих объектно-ориентированные техники в C, всё ещё далеко.
0xFE
Доброго времени суток.
Я не совсем понял как Вы это делаете.
Если интерфейсная функция принимает указатель на структуру в качестве параметра, Вы просто декларируете это как foo( void * )? Я просто не сталкивался с такой потребностью.
Спасибо.
Wilk
Здравствуйте.
Я использую предварительное объявление:
AliceInWonderland.h:
private/AliceInWonderland.h:
AliceInWonderland.c:
Таким образом, определение типа видно только там, где это необходимо. Пользователям же библиотеки известно только о том, что существует такой тип, как Alice_t. Более ничего. Естественно, в случае необходимости доступа к полям возникает необходимость в создании соответствующих функций доступа.
Конечно, решение не идеальное и может создавать лишнюю головную боль, но на данный момент код, в котором я использую такой подход, имеет малый объём, поддерживается только мной и работает.
P.S. Да, я ошибся термином: правильно было сказать не "описание типа" (declaraion), а "определение типа" (definition).
0xFE
Да, это интересно. Буду иметь ввиду такой способ.
Большое спасибо.