
Хотя asyncio сам по себе и позволяет писать высоконагруженные веб-приложения, оптимизация производительности не была приоритетом при создании модуля.
Один из авторов упомянутого PEP-492 (async/await) Юрий Селиванов (на Хабре — 1st1, его твиттер) взялся за разработку альтернативной реализации цикла событий для asyncio — uvloop. Вчера вышла первая альфа-версия модуля, о чём автор написал развёрнутый пост.
Если вкратце, то uvloop работает примерно в 2 раза быстрее Node.js и практически не уступает программам на Go.
Использование
uvloop написан на Cython и построен на базе libuv.
Установить модуль можно стандартно (Windows в данный момент не поддерживается):
pip install uvloop
Использовать тоже не сложно:
import asyncio
import uvloop
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
Теперь любой вызов asyncio.get_event_loop() будет возвращать экземпляр uvloop.
Производительность
Подробнее про бенчмарки (методику проведения и выводы) можно почитать в оригинале, ниже только итоговые графики.
Результаты для простых TCP запросов разного размера:
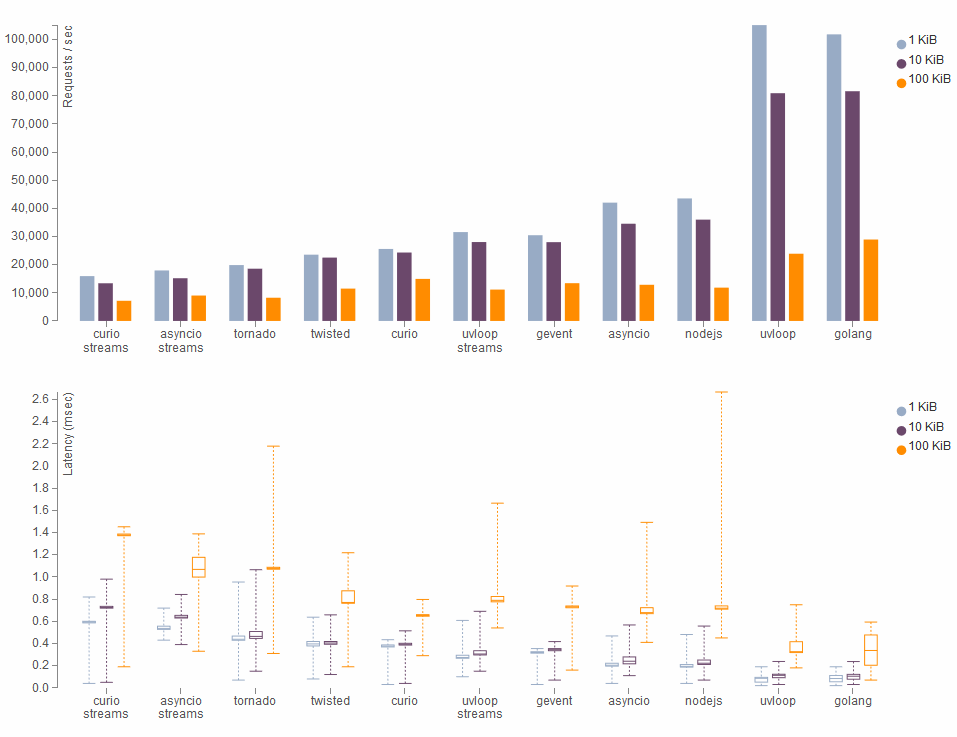
HTTP запросы:

Комментарии (48)

cy-ernado
04.05.2016 21:13-3Необходимо уточнить, что это на одном ядре, хоть результаты и впечатляют.
GIL никуда не девается, что печально.
veveve
04.05.2016 21:33+7При использовании нескольких процессов GIL'а нет. А треды, где GIL есть, использовать не особо и нужно: асинхронность во многом о том, чтобы уйти от расходов, с ними связанных. Разве нет?
cy-ernado
04.05.2016 22:04+3При использовании нескольких процессов GIL'а нет
Я и не говорил обратного.
А треды, где GIL есть, использовать не особо и нужно
И про треды я не говорил.
Можно бы было сделать пул из тредов и по ним распределять нагрузку, при этом используя ивентлуп.
Судя по реакции на мой коммент, позиция оппонентов заключается в том, что многоядерность не нужна, всем хорошо в одном треде, масштабирование через создание процессов всех устраивает, а GIL не является проблемой, я правильно понимаю?veveve
04.05.2016 22:31+1Можно бы было сделать пул из тредов и по ним распределять нагрузку, при этом используя ивентлуп.
А смысл? При классическом подходе, пул тредов создаётся как раз чтобы обрабатывать I/O операции. Асинхронность решает эту проблему гораздо эффективнее без тредов.
Гипотетические треды без GIL'а в асинхронном приложении помогли бы ускорить только не I/O операции, то есть там где мы упираемся в CPU. Но мы же на практике обычно упираемся не в CPU, а в скорость чтения-записи при I/O операциях.
То есть, я, честно говоря, не понимаю, как пул тредов мог бы дать дополнительный выигрыш в асинхронных веб-приложениях. За счёт чего?
P.S. Я в данной области не специалист, могу легко чего-то не понимать. Лично у меня реакция на ваш комментарий совершенно нормальная: мне самому интересно обсудить эту тему.cy-ernado
04.05.2016 23:51А смысл? При классическом подходе, пул тредов создаётся как раз чтобы обрабатывать I/O операции. Асинхронность решает эту проблему гораздо эффективнее без тредов.
Я плохо умею объяснять, более того, мои примеры могут показаться кому-то бредом фанатика другого языка, поэтому приведу в пример nginx:
Пулы потоков: ускоряем NGINX в 9 и более раз
Вроде бы там мотивация для пулов потоков описана.
1st1
05.05.2016 00:34threads pools в сочетании с IO малтиплексором в питоне не имеют особого смысла как раз из-за GIL.
veveve
05.05.2016 01:02+2Всё верно, гипотетический пул потоков без GIL'а может помочь в блокирующих операциях (там где долго работает CPU или при блокирующем I/O, например, чтении с диска).
Другое дело, как я понимаю, по хорошему, таких ситуаций не должно возникать. То есть, например, если у вас сервер при ответе клиенту читает большой файл с диска, потоки без GIL'а вам помогли бы, да, но не сказать, что корень проблемы здесь именно в GIL :)
Кстати, libuv (а, значит, потенциально и uvloop) поддерживает асинхронную работу с файлами, которая под капотом реализована как раз пулом тредов. Вот здесь обсуждение этой темы. Если я правильно понимаю, у этих тредов проблемы с GIL'ом нет.
VBart
06.05.2016 02:11+1AFAIK, при чтении большого файла с диска проблемы с GIL-ом в принципе нет, поскольку GIL используется только при работе с объектами внутри интерпретатора. Когда исполнение прерывается чтобы позвать какой-нибудь сискол (тот же
read()), то GIL отпускается.

roller
05.05.2016 00:29+4GIL просто есть, ничего лучше не придумали так что это не недостаток.
Масштабирование через создание процессов всех устраивает, так как в текущий исторический момент никто не будет тратить деньги на борьбу с GIL. В конце концов запускать по жирному процессу на ядро — вполне нормально. И haproxy вроде не вчера придумали.
ivlis
05.05.2016 03:01-2Смысл в том, что ускорение работает только когда у нас операции связанные с IO. Если бы будете что-то считать на CPU быстрее не будет. И это просто убивает в питоне. Единственная возможность это делать pickle, а это сильно ограничивает возможности. Уже сколько лет, а проблема никуда не делась.

itforge
05.05.2016 13:40+1Таки расчёты также будут быстрее. Если расчёты реализованы не в python-коде, а в бинарной либе, на работу которой ограничение GIL не распространяется. Самый простой пример, построение DOM дерева с помощью lxml.

FFiX
04.05.2016 21:50+1По описанию штука действительно крутая. Но интересует больше real world тестов. В жизни, все-таки, мы пишем что-то более сложное чем просто echo-сервер.
Даёт ли профит в связке с motor/другими асинхронными драйверами БД?veveve
04.05.2016 22:09+2> Но интересует больше real world тестов.
Вот тут есть сборник бенчмарков для asyncio. Например, по первой ссылке, на не тривиальной задаче «Load some data from DB using ORM, insert a new object, sort and render to template» aiohttp на базе asyncio прилично выигрывает у других питоновских фреймворков:
Результат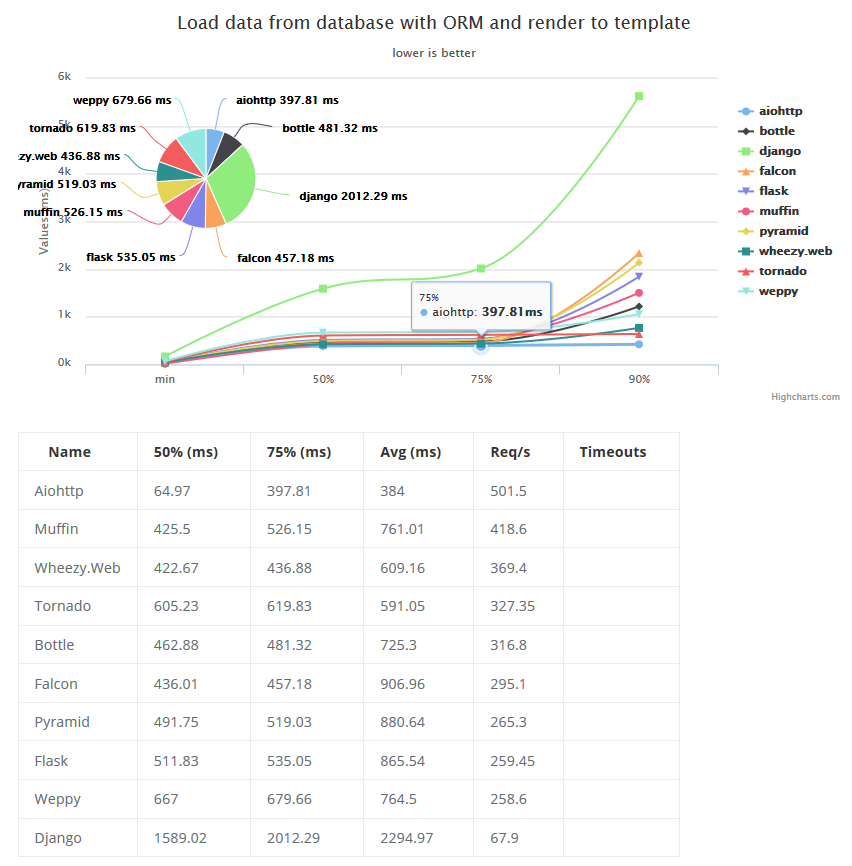
FFiX
05.05.2016 00:09+1Вопрос был именно в контексте uvloop.
С самим asyncio я достаточно давно знаком. Правда, в части клиентских приложений (в т.ч. в связке с aiohttp).
Правильно ли я понимаю, что:
1. Описанный в оригинальной статье httptools в клиентских приложениях поможет не сильно.
2. Вопрос с синхронным dns-резолвером в asyncio/aiohttp все еще открытый (я знаю про aiodns, но подружить их лично у меня не получилось).
Спасибо!1st1
05.05.2016 00:29> 1. Описанный в оригинальной статье httptools в клиентских приложениях поможет не сильно.
Да, httptools пока рано использовать. Я планирую его дописать, добавить нормальную имплементацию серверного протокола и т.п. Может быть Андрей Светлов начнет использовать его у себя в aiohttp, это был бы идеальный сценарий.
> 2. Вопрос с синхронным dns-резолвером в asyncio/aiohttp все еще открытый (я знаю про aiodns, но подружить их лично у меня не получилось).
В чем суть вопроса?FFiX
05.05.2016 00:35+1В чем суть вопроса?
DNS в asyncio синхронный.
Для DNS-запросов создается (автоматически) thread pool. При большом количестве запросов к разным хостам это здорово тормозит работу (по умолчанию их 5), а если увеличивать размер пула — производительность падает уже из-за большого количества переключений контекста. Да и смысл асинхронности теряется.1st1
05.05.2016 00:46+1Да, правильно. asyncio использует питоновый getaddrinfo, который использует системный getaddrinfo. В дополнение ко всему, под фрибсд и мак ос, питоновый getaddrinfo может использоваться только из одного треда (в 3.6 лок уберут).
uvloop использует libuv, которая использует системный getaddrinfo в тред пуле (так же как и asyncio). Тред пул в libuv без GIL, так что он будет чуть пошустрее.
Я думал для uvloop использовать c-ares. Его достаточно просто вкрутить. Один вопрос — действительно ли это нужно? Есть идеи как написать бенчмарк?FFiX
05.05.2016 01:03Один вопрос — действительно ли это нужно?
Мне сложно судить о реальной потребности в этом со стороны сообщества/разработчиков, я не изучал эту тему очень глубоко.
На трекере asyncio #160 уже достаточно давно открыта, но активности там мало. Еще, как я вижу из changelog еще не выпущенного релиза aiohttp, в будущей версии все же будет поддержка aiodns.
Есть идеи как написать бенчмарк?
М… можно попробовать поднять какой-нибудь hi-perf DNS-сервер вроде Knot DNS и подолбить его запросами.
veveve
05.05.2016 01:142. Вопрос с синхронным dns-резолвером в asyncio/aiohttp все еще открытый
Да, это прискорбно. У aiohttp есть и другие недостатки: например, нет и не будет поддержки SOCKS прокси. Лично я при написании своего краулера отказался от aiohttp в пользу asyncio + pycurl. У последнего (если скомпилирован с c-ares) асинхронный резолв dns из коробки. К тому же курл гораздо лучше проверен временем.itforge
05.05.2016 13:43А можете показать пример интеграции asyncio и pycurl?
veveve
05.05.2016 14:37+2Без проблем:
from contextlib import suppress from io import BytesIO import asyncio as aio import aiohttp import pycurl import atexit # Curl event loop: class CurlLoop: class Error(Exception): pass _multi = pycurl.CurlMulti() atexit.register(_multi.close) _futures = {} @classmethod async def handler_ready(cls, ch): cls._futures[ch] = aio.Future() cls._multi.add_handle(ch) try: return await cls._futures[ch] finally: cls._multi.remove_handle(ch) @classmethod def perform(cls): if cls._futures: while True: status, num_active = cls._multi.perform() if status != pycurl.E_CALL_MULTI_PERFORM: break while True: num_ready, success, fail = cls._multi.info_read() for ch in success: cls._futures.pop(ch).set_result('') for ch, err_num, err_msg in fail: cls._futures.pop(ch).set_exception(CurlLoop.Error(err_msg)) if num_ready == 0: break # Single curl request: async def request(url, timeout=5): ch = pycurl.Curl() try: ch.setopt(pycurl.URL, url.encode('utf-8')) ch.setopt(pycurl.FOLLOWLOCATION, 1) ch.setopt(pycurl.MAXREDIRS, 5) raw_text_buf = BytesIO() ch.setopt(pycurl.WRITEFUNCTION, raw_text_buf.write) with aiohttp.Timeout(timeout): await CurlLoop.handler_ready(ch) return raw_text_buf.getvalue().decode('utf-8', 'ignore') finally: ch.close() # Asyncio event loop + CurlLoop: def run_until_complete(coro): async def main_task(): pycurl_task = aio.ensure_future(_pycurl_loop()) try: await coro finally: pycurl_task.cancel() with suppress(aio.CancelledError): await pycurl_task # Run asyncio event loop: loop = aio.get_event_loop() loop.run_until_complete(main_task()) async def _pycurl_loop(): while True: await aio.sleep(0) CurlLoop.perform() # Test it: async def main(): url = 'http://httpbin.org/delay/3' res = await aio.gather( request(url), request(url), request(url), request(url), request(url), ) print(res[0]) # to see result if __name__ == "__main__": run_until_complete(main())
У меня отрабатывает за 3.7 секунды, как и aiohttp.
Идея тут какая: используем pycurl.CurlMulti. Готовность хендлеров — фактически колбеки. Чтобы сделать из них нормальную корутину, используем asyncio.Future.
Код сократил до предела, на практике надо добавить всяко-разно:
— Стараться использовать один хэндлер для одного хоста, чтобы выигрывать от keep-alive (тут подробнее).
— Семафор на одновременное кол-во запросов.
— Настройки хэндлера.
и т.п.
Из aiohttp используется только Timeout, который позже будет в самом asyncio. Пока можно просто скопировать код, чтобы не тащить весь aiohttp.
Как-то так.veveve
06.05.2016 18:10Важно!
Оказывается, в некоторых случаях цикл для perform может длиться долго, что «заморозит» главный цикл событий.
Чтобы этого не было, функцию perform надо поменять на такую:
@classmethod def perform(cls): if cls._futures: status, num_active = cls._multi.perform() _, success, fail = cls._multi.info_read() for ch in success: cls._futures.pop(ch).set_result('') for ch, err_num, err_msg in fail: cls._futures.pop(ch).set_exception(CurlLoop.Error(err_msg))

m0ody
09.05.2016 17:59+2Я вчера релизнул socks для asyncio/aiohttp: github.com/nibrag/aiosocks.
Либа пока сыровата, но уже что-то.
По поводу асинхронных днс запросов, то в мастер ветке уже есть решение с aiodns.

tumbler
05.05.2016 10:07+3Real-world счетчик статистики yast.rutube.ru: asyncio+aiohttp+asyncio_redis. По GET-запросу вытаскивается из редиса счетчик просмотров и возвращается в JSON. asyncio: 900-1000 RPS на локалхосте с одним воркером. uvloop: 1500-1600 RPS. Автору uvloop громадный респект, будем вкручивать в наши асинхронные сервисы.
ab -c 100 -n 10000.lega
05.05.2016 10:13Передавайте счетчик строкой (или хотя бы через msgpack) — поднимите производительность ещё больше.
tumbler
05.05.2016 10:16Хочется попробовать httptools еще вкрутить, посмотреть ускорение на парсинге запросов.
lega
05.05.2016 10:44Я бы на вашем месте ещё попробовал синхронный uwsgi, для такой задачи он может быть ещё быстрее (ну или как минимум для интереса).
tumbler
05.05.2016 10:58+1import redis import ujson as json client = redis.Redis() def application(env, start_response): start_response('200 OK', [('Content-Type', 'application/json')]) count = client.get("KEY") or 0 return [json.dumps({"result": count}).encode("utf-8")]
ab -c 100 -n 10000 http://127.0.0.1:8080/
7000 RPS.
Похоже мы не тот инструмент выбрали для такого плёвого дела :) Справедливости ради, еще нужен URL-роутер с получением идентификаторов из пути, но всё равно, разница будет огромной.lega
05.05.2016 12:57Ещё можете поиграться кол-вом потоков/процессов, наример если среднее время выполнения запроса ~1 мс, то можно поставить ~20 потоков, плюс передача строкой вместо json добавит произодительностьи
return b'{"result": %d}' % counttumbler
05.05.2016 13:20Да можно кучу мелких вещей сделать и в результате нехило поднять производительность. Но это никак не относится к тестам производительности uvloop.

arusakov
04.05.2016 22:52+5А откуда берется двукратное ускорение по сравнению в Node.js? Все асинхронное в ноде на том же самом libuv базируется.

dezconnect
04.05.2016 23:54+7JS внезапно не такой быстрый? :)
arusakov
05.05.2016 01:48+2V8 с учетом jit должен быть заметно шустрее CPython, который просто интерпретатор. Так что вопрос остается открытым.

Alex10
05.05.2016 02:00uvloop насколько я понял написан на Cython, а это по скорости фактически С
arusakov
05.05.2016 02:07+1А, ну, да. Бизнес логику только вряд ли кто захочет писать на Cython.
Hypnotoadhq
05.05.2016 11:32+1Вроде никто и не предлагает её писать на Cython. Речь идет о модуле.
arusakov
05.05.2016 12:48Как только вы начнете писать бизнес логику на обычном питоне, интерпретатор питона уничтожит весь выигрыш в скорости. Я это к тому, что на голом сетевом тесте возможно python + uvloop быстрее, чем node.js, но как только появится немного дополнительного код по обработке запроса и/или подготовке ответа, node.js (не говоря, кстати, уже о go lang) будут заметно превосходить питон.
Hypnotoadhq
05.05.2016 12:58+5Честно сказать выглядит довольно голословно. ВЕСЬ (на каких операциях?) выигрыш в скорости, добавив НЕМНОГО кода(какого?), ЗАМЕТНО (на глаз?).
Не в обиду, но все ваши комментарии разят глором за nodejs.arusakov
05.05.2016 13:20От вашего комментария разит капсом.
Если говорить в теории, то в общем случае интерпретатор медленнее, чем интерпретатор + JIT. С этим как бы ничего поделать нельзя. Хочется быстрый питон — берите PyPy, они с Node.js одного поля ягоды. А так по запросу «python vs node.js performance» в гугле можно найти множество сравнений. Хотя бы раз, два первые попавшиеся.
Но я не говорю, что нода идеальный инструмент — в ней свой набор проблем.
veveve
05.05.2016 13:21+2> интерпретатор питона уничтожит весь выигрыш в скорости
Может быть. Другое дело, что у Питона тоже есть реализация с JIT — PyPy. В данный момент там нет поддержки 3.5, поэтому с uvloop потестировать не получится. Но когда это случится, интересно будет посмотреть на Node vs. PyPy + uvloop :)

alaska332
10.05.2016 13:31-1Вот это новость.
Слушать неблокирующийся сокет и дергать коллбек, когда есть данные — надо постараться сделать это медленным. Надеюсь, эта либа работает не только с сокетами, а и с таймерами, сигналами, файловыми дескрипторами и т.д.
В Перле, на сколько я помню, все это было 10 лет назад.
Кризис over enegeneering?


Alex10
Очень приятная новость.