
В этой статье мы разберем, как получить и использовать API сайта, если по нему нет документации или оно еще не открыто официально. Руководство написано для новичков, которые еще не пробовали зареверсить простой API. Для тех же кто сам занимался подобным ничего нового здесь нет.
Разбор проведем на примере API сервиса https://www.captionbot.ai/ который недавно открыл Microsoft (спасибо им за это). Многие могли прочитать о нем в статье на Geektimes. Сайт использует ajax запросы в формате JSON, поэтому скопировать их будет легко и приятно. Поехали!
Анализируем запросы
В первую очередь открываем инструменты разработчика и анализируем запросы, которые сайт посылает на сервер.
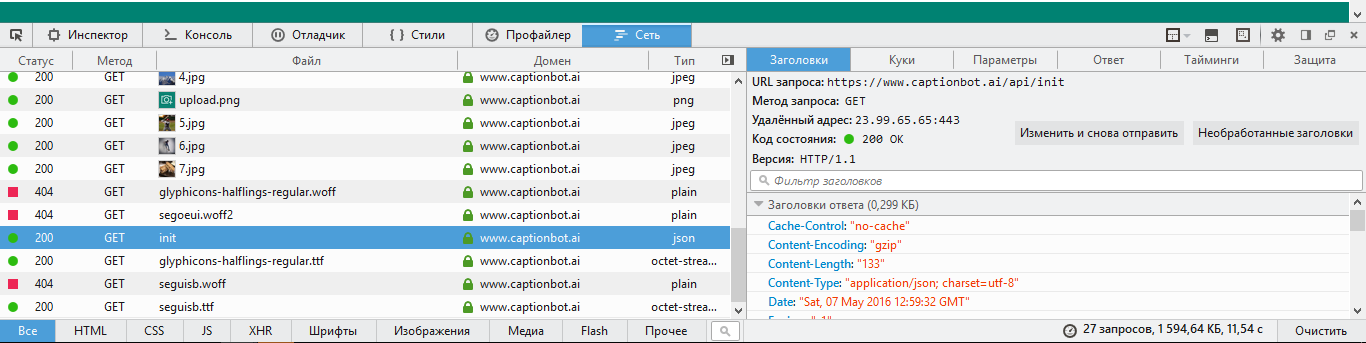
В нашем случае все интересующие нас запросы имеют базовый URL https://www.captionbot.ai/api
Инициализация
При первом открытии сайта идет GET запрос на /api/init без параметров.
Ответ имеет Content-Type: application/json, при этом в теле ответа нам приходит просто строка вида:
"54cER5HILuE"Запомним это и идем дальше.
Отправка URL
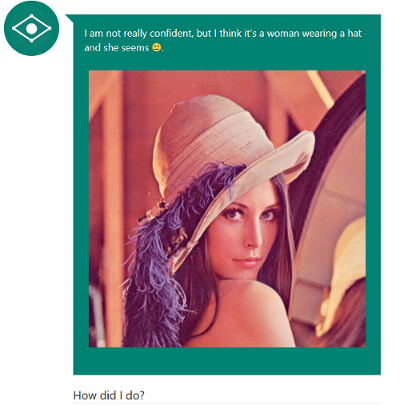
У нас есть два способа загрузить изображение: через URL и через загрузку файла. Для теста берем URL изображения Лены с вики и отсылаем. В сетевой активности появляется POST запрос на /api/message со следующими параметрами:
{
"conversationId": "54cER5HILuE",
"waterMark": "",
"userMessage": "https://upload.wikimedia.org/wikipedia/ru/2/24/Lenna.png"
}Ага, говорим себе мы, значит метод init вернул нам строку для conversationId, а в userMessage попала наша ссылка. Что такое waterMark пока непонятно. Смотрим на данные ответа:
"{\"ConversationId\":null,\"WaterMark\":\"131071012038902294\",\"UserMessage\":\"I am not really confident, but I think it's a woman wearing a hat\\nand she seems . \",\"Status\":null}"Зачем-то закодировали JSON дважды, ну да ладно. В человеческом виде это выглядит так:
{
"ConversationId": null,
"WaterMark": "131071012038902294",
"UserMessage": "I am not really confident, but I think it's a woman wearing a hat\\nand she seems .",
"Status": null
}Все параметры по пути поменяли манеру написания, но это мелочи жизни. Итак, нам вернули некоторое значение WaterMark, почему-то пустой ConversationId, собственно подпись к фото в поле UserMessage и некий пустой статус.
Загрузка изображения
Далее, не закрывая вкладку, пробуем ту же операцию с загрузкой фото из локального файла. Видим POST запрос на /api/upload в формате multipart/form-data с названием поля file:
-----------------------------50022246920687
Content-Disposition: form-data; name="file"; filename="Lenna.png"
Content-Type: image/pngВ ответ получаем строку URL нашего загруженного файла, можем перейти по нему и убедиться в этом:
"https://captionbot.blob.core.windows.net/images-container/2ogw3q4m.png"Затем отсылается уже знакомый нам запрос на /api/message:
{
"conversationId": "54cER5HILuE",
"waterMark": "131071012038902294",
"userMessage": "https://captionbot.blob.core.windows.net/images-container/2ogw3q4m.png"
}Вот и пригодился waterMark из предыдущего ответа, а URL тот, что нам вернул метод upload. Данные ответа аналогичны предыдущим.
Пишем обертку
Чтобы использовать полученные знания с удобством, делаем простую обертку на вашем любимом языке программирования. Я сделаю это на Python. Для запросов к сайту использую requests, так как он удобный и в нем есть сессии, которые хранят cookie за меня. Сайт использует SSL, но по дефолту requests будет ругаться на сертификат:
hostname 'www.captionbot.ai' doesn't match either of '*.azurewebsites.net', '*.scm.azurewebsites.net', '*.azure-mobile.net', '*.scm.azure-mobile.net'Решается это установкой флага verify=False при каждом запросе.
import json
import mimetypes
import os
import requests
import logging
logger = logging.getLogger("captionbot")
class CaptionBot:
BASE_URL = "https://www.captionbot.ai/api/"
def __init__(self):
self.session = requests.Session()
url = self.BASE_URL + "init"
resp = self.session.get(url, verify=False)
logger.debug("init: {}".format(resp))
self.conversation_id = json.loads(resp.text)
self.watermark = ''
def _upload(self, filename):
url = self.BASE_URL + "upload"
mime = mimetypes.guess_type(filename)[0]
name = os.path.basename(filename)
files = {'file': (name, open(filename, 'rb'), mime)}
resp = self.session.post(url, files=files, verify=False)
logger.debug("upload: {}".format(resp))
return json.loads(resp.text)
def url_caption(self, image_url):
data = json.dumps({
"userMessage": image_url,
"conversationId": self.conversation_id,
"waterMark": self.watermark
})
headers = {
"Content-Type": "application/json"
}
url = self.BASE_URL + "message"
resp = self.session.post(url, data=data, headers=headers, verify=False)
logger.debug("url_caption: {}".format(resp))
if not resp.ok:
return None
res = json.loads(json.loads(resp.text))
self.watermark = res.get("WaterMark")
return res.get("UserMessage")
def file_caption(self, filename):
upload_filename = self._upload(filename)
return self.url_caption(upload_filename)Комментарии (15)

Mayflower
08.05.2016 13:08Товарищи минусующие, реквестирую ваш фидбек: что не так? Это моя первая статья, поэтому хочу узнать, что можно улучшить.
lizarge
08.05.2016 16:46+2Все например, статья описывает то что известно и делается любым разработчиком с минимальным знаем основ http запросов. Ничего нового кроме того что Microsoft не позаботился о защите она не несет. Лучше бы вы написали статю как поднять тот же captionbot на своем сервере используя Сaffe, но это уже совсем другой уровень.
summerwind
09.05.2016 00:48О защите чего именно не заботится Microsoft? Вы ведь в любом SPA можете увидеть в консоли, какие запросы отправляются на сервер.

icoz
09.05.2016 10:01Что хоть за сервис?
Чем нам может помочь знание этого api?
Имея красивую обертку над api на Питоне, мы теперь можем… (продолжите фразу).Mayflower
09.05.2016 11:04У меня например на нем работает Телеграм бот, который присылает подпись на любое присланное фото или URL. Можно сделать фото и получить к нему подпись за несколько секунд.
icoz
09.05.2016 11:57Думаю, что это стоило указать в статье. А то какой-то сферический конь в вакууме получается… Особенно для тех, кто в этой теме не варится.
Типа такого:

Mayflower
09.05.2016 11:19Целью всего этого занятия было посмотреть на сервис, насколько хорошо подписи подходят к изображениям. Можно взять базу потеганных изображений, скормить captionbot'у через API и посмотреть на процент вхождения тега в подпись. Но это пока что в планах на будущее.
icoz
09.05.2016 10:10А минусуют, скорее всего, за то, что здесь реверс-инжиниринга почти и нет. Ценности api конкретного сервиса тоже не видно.
В результате хабр пополнился статьёй, которая не несёт никакой ценности, но будет вылезать в поисковых запросах и затруднять поиск действительно полезной информации.
icoz
09.05.2016 10:21+1А минусуют, скорее всего, за то, что хабр пополнился почти никому ненужной статьей.
Реверс-инжиниринга здесь почти нет, а тот что есть — очевиден. Ценности данный конкретный API также не несет. Но эта статья теперь есть на хабре. Она будет вылезать в поисковой выдаче и затруднять поиск действительно ценной информации.
ИМХО, конечно.
kursorik2
А я думал что судя по заголовку в статье, автор расскажет как правильно парсить контент с сайта без API.
Mayflower
Да, наверное заголовок вышел не самый удачный. Есть ли совет как сделать лучше?
evnuh
«Пользуемся недокументированным API сайта captionbot.ai»
Mayflower
Спасибо. Меняю, чтобы не вводить людей в заблуждение