
Часть 2
Продолжение статьи о написании UI тестов на Cucumber с помощью Selenide. В первой части был разобран простейший пример smoke-теста для riskmarket.ru. В этой части апгрейдим тест до полноценного проекта с отчетами, поговорим о скриншотах, кастомных Condition, проаннотируем элементы, введем PageObject.
Получившийся проект вполне можно использовать как фундамент для ваших UI тестов.
Видео исполнения теста на youtube
Структура проекта:
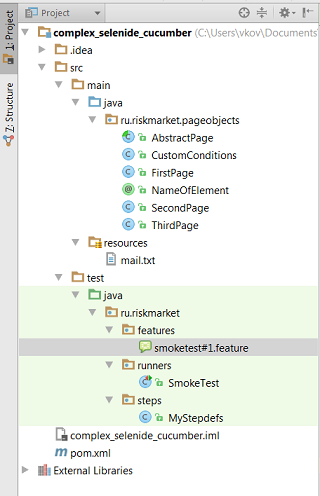
Используем Intellij IDEA, Maven и Junit.
В mail.txt записаны логины, пароли аккаунтов для работы с тестом. ВНИМАНИЕ: если будете запускать у себя, имейте ввиду, что система выкинет одного из юзеров, которые будут логиниться под одним логином/паролем. Поменяйте мейл
Dependency в pom.xml:
<dependencies>
<dependency>
<groupId>com.codeborne</groupId>
<artifactId>selenide</artifactId>
<version>3.5</version>
</dependency>
<dependency>
<groupId>info.cukes</groupId>
<artifactId>cucumber-java8</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>info.cukes</groupId>
<artifactId>cucumber-junit</artifactId>
<version>1.2.4</version>
</dependency>
</dependencies>По сравнению с первой частью, добавлен cucumber-junit – библиотека для запуска Junit тестов с Cucumber. Есть такая же, как минимум, для TestNG
Добавлен пакет runners. В нем лежит класс SmokeTest, который воспринимается Junit-ом как тест, который будет запускаться по команде mvn test. Рассмотрим этот класс подробнее
@RunWith(Cucumber.class)
@CucumberOptions(
plugin = {"html:target/cucumber-report/smoketest", "json:target/cucumber.json"},
features = "src/test/java/ru/riskmarket/features",
glue = "ru/riskmarket/steps",
tags = "@smoketest")
public class SmokeTest
{
@BeforeClass
static public void setupTimeout()
{
Configuration.timeout = 10000;
}
}@RunWith – аннотация, отвечающая за запуск данного JUnit теста вместе с Cucumber
@CucumberOptions – здесь настраиваем наш Cucumber тест
plugin – отвечает за создание отчетов о тесте (раньше назывался format). Об отчетах позже
features – путь до фич
glue – путь до степов
tags – фичам и даже отдельным сценариям можно присваивать тэги; данный параметр указывает какие именно тесты будут запущены.
Тэги записываются в строчку через запятую: “@smoketest, @alltests, @special”. Например, у вас есть несколько фич, вы можете во все добавить @alltests и тогда раннер с параметром tags = “@alltests” запустить все тесты.
Тэги добавляются в фичи перед ключевым словом Features: через пробел или с новой строки
Само тело класса можно оставить пустым, но так как я запускаю тесты с медленным инетом, настрою здесь селенидовский таймаут – делаю это через JUnit’овский @BeforeClass, указываю 10с против дефолтовых 4с. Также в конфигурации вы можете указать, например, под каким браузером запускать тесты
System.setProperty("webdriver.chrome.driver", "src/main/resources/chromedriver.exe");
Configuration.browser = "chrome";Если решили поменять браузер, то не забудьте скачать нужный вам драйвер с сайта Selenium и указать его местоположение. Сейчас в качестве примера оставляю закомменчеными строки в раннере.
Степы в фиче smoketest повторяют действия из фичи из первой части, но написаны немного по-другому, т.к. теперь используем PageObject.
PageObject – это паттерн, который подразумевает, что существуют классы отдельных страниц, которые содержат определения необходимых для тестов элементов, с указанными селекторами. Тогда в логике степов используются не селекторы, а определенные ранее элементы. Это нужно на случай изменения html-структуры проекта. Если изменение происходит, то меняются только селекторы в PageObject, и не приходиться искать по всем StepDefinition, какие селекторы теперь рабочие, а какие нет.
В нашем тесте есть три страницы, которые указаны в пакете ru.riskmarket.pageobjects. Принято писать pageobjects в main/java (в сорцах), потому что pages – это не сами тесты. В каждой странице указаны принадлежащие ей элементы, с которыми взаимодействует тест.
Добавление своей аннотации
Теперь представим, что у нас огромный проект с несколькими страницами, на которых сотня элементов, динамические таблицы, что-то еще, в общем, сложный проект. В таком случае появляются элементы такого типа – «первая ячейка третьей колонки в таблице согласования». С учетом желания переиспользовать степы, необходимо каким-то образом передавать название элемента в метод, определяющий логику степа. Наш сложный элемент в PageObject будет определен так
@FindBy(xpath = "селектор")
public SelenideElement firstCellAtThirdRowAtAssessmentTable;И тогда степ, записывающий что-то в эту ячейку, мог бы выглядеть так:
And type to firstCellAtThirdRowAtAssessmentTable text: "Hello, Cucumber!"Как видите, теряется преимущество понятности степов. Хотелось бы, чтобы степ выглядел так:
And type to “First Cell At Third Row At Assessment Table” text: "Hello, Cucumber!"Тогда нужно каким-то образом в методе степа из StepDef сопоставить элемент с его именем из самого степа.
Мое решение – добавление аннотации @NameOfElement.
Разбирать аннотацию не буду, это отдельная тема. Главное, что писать их достаточно просто.
В итоге, после добавления аннотации, получается двойная работа: вместо того, чтобы напрямую обратиться к элементу, тем более что его наименование известно, это делается через рефлексию и аннотацию. Но это жертва ради красивых, читаемых фич.
В итоге наш элемент будет определен так:
@NameOfElement("First Cell At Third Row At Assessment Table")
@FindBy(xpath = "селектор")
public SelenideElement firstCellAtThirdRowAtAssessmentTable;А в StepDef:
@And("^type to input \"([^\"]*)\" text: \"([^\"]*)\"$")
public void typeToInputText(String nameOfElement, String text)
{
somePage.get(nameOfElement).sendKeys(text);
}Метод get(nameOfElement) с помощью рефлексии находит по имени поле в классе страницы, а дальше срабатывает @FindBy от Selenium и возвращается элемент на странице.
Метод get(nameOfElement) определен в классе AbstractPage.java, который наследуется всеми страницами.
Поговорим про изменения в MyStepDef.
Добавлены поля
FirstPage firstPage = page(FirstPage.class);
SecondPage secondPage = page(SecondPage.class);
ThirdPage thirdPage = page(ThirdPage.class);page(PageObject.class) – это метод Selenide, который инкапсулирует селениумовский PageFactory. Опять же значительное сокращение кода. Это необходимо для того, чтобы отрабатывали @FindBy при поиске элемента на странице.
В методах степов, в отличие от первого варианта проекта, селенидовские $(селектор) заменены на поиск элемента в нужной странице по его имени. В степах, общих для всех страниц, элемент ищется по всем страницам.
Подробнее про should(Condition)
По своей сути селенидовская проверка условий should/shouldBe/shoudHave/…. (методы делают одно и то же, но называются по-разному, чтобы легче читалось), являются аналогами assert’ов, с той разницей, что если используются assertы, то необходимо позаботиться о создании скриншотов по падению assertов. Опять же дополнительный код, который придется разбирать тестеру, который придет на ваше место. А в случае с Cucumber еще придется изрядно повозиться.
should(Condition) автоматически делает скриншот при падении и в отчете будет указана ссылка на скриншот. По умолчанию они сохраняются в папке проекта build.
Вырезка из лога:
Element not found {By.xpath: //button[.='Вход в кабинет']}
Expected: visible
Screenshot: file:/C:/Users/vkov/Documents/GitHub/RiskMarket/complex_selenide_cucumber/build/reports/tests/1460907962193.0.png Как видите, логирование происходит по аналогии с assertThat – пишется что должно было быть и что было по факту.
Для большинства случаев уже написан нужный вам Condition, поищите, прежде чем использовать assertThat. В крайнем случае, если нужного Condition нет, а скриншот делать надо, можно создать свой собственный. Простой пример такого лежит в классе CustomCondition. Он повторяет действия, который выполняет Condition.appear.
Для should() можно добавить свое описание, которое залогируется:
somePage.get("Имя элемента").shouldBe(Condition.visible.because("Потому что..."))В случае Cucumber, считаю, что это лишнее, поскольку вы точно повторите текст, которым у вас описан степ, где происходит эта проверка.
Для коллекций элементов также написаны should(). Пример из проекта:
Вид в фиче:
Then collection of "Результаты поиска" should not be emptyВид в MyStepdefs:
@Then("^collection of \"([^\"]*)\" should not be empty$")
public void collectionOfShouldNotBeEmpty(String collection)
{
ElementsCollection selenideElements = secondPage.getCollection(collection);
selenideElements.shouldHave(CollectionCondition.sizeGreaterThan(0));
}Объяснения излишни, все ясно из кода.
Поговорим об отчетах
Вернемся к классу-раннеру `SmokeTest.java'
@RunWith(Cucumber.class)
@CucumberOptions(
plugin = {"html:target/cucumber-report/smoketest", "json:target/cucumber.json"},
features = "src/test/java/ru/riskmarket/features",
glue = "ru/riskmarket/steps",
tags = "@smoketest")
public class SmokeTest
{
@BeforeClass
static public void setupTimeout()
{
Configuration.timeout = 10000;
}
}Если не указать в @CucumberOptions plugin, то не будет создан никакой отчет.
plugin = {“ html:target/cucumber-report/smoketest”} создает отчеты в таком виде:

Зеленым обозначены степы, которые прошли успешно, красным – свалились, бирюзовым – не начались выполняться. Еще бывает желтый – это значит, что степ не определен, напоминание для вас. На красном фоне можно найти линк на скриншот и весь остальной StackTrace.
Эти отчеты хороши, удобно читаемы, из них можно копипастить в steps-to-reproduce при заведении баги.
Но есть еще лучше.
Отсюда: https://github.com/damianszczepanik/maven-cucumber-reporting
Добавьте в pom.xml
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<testFailureIgnore>true</testFailureIgnore>
</configuration>
</plugin>
<plugin>
<groupId>net.masterthought</groupId>
<artifactId>maven-cucumber-reporting</artifactId>
<version>2.0.0</version>
<executions>
<execution>
<id>execution</id>
<phase>verify</phase>
<goals>
<goal>generate</goal>
</goals>
<configuration>
<projectName>cucumber-selenide-example</projectName>
<outputDirectory>target/cucumber-html-reports</outputDirectory>
<cucumberOutput>target/cucumber.json</cucumberOutput>
<parallelTesting>false</parallelTesting>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>В @CucumberOptions укажите plugin = {"json:target/cucumber.json"}. Данный модуль собирает отчет именно из .json – отчета.
Строка <cucumberOutput>target/cucumber.json</cucumberOutput> — настраивает место откуда брать .json-отчет
Строка <outputDirectory>target/cucumber-html-reports</outputDirectory> — настраивает куда будет складываться отчет.
Модуль работает только через mvn clean install. После исполнения в target/cucumber-html-reports откройте feature-overview.html и получите такие штуки:
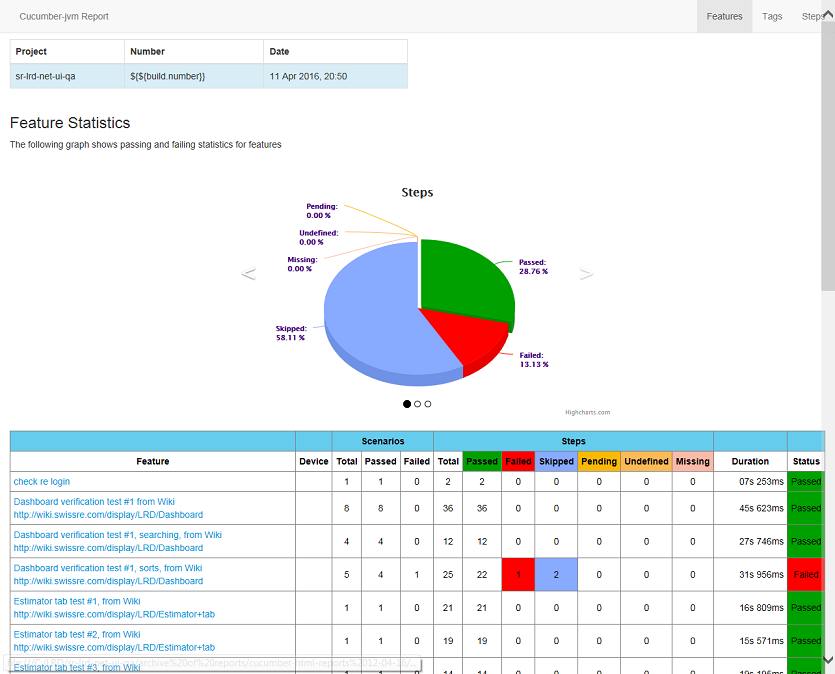
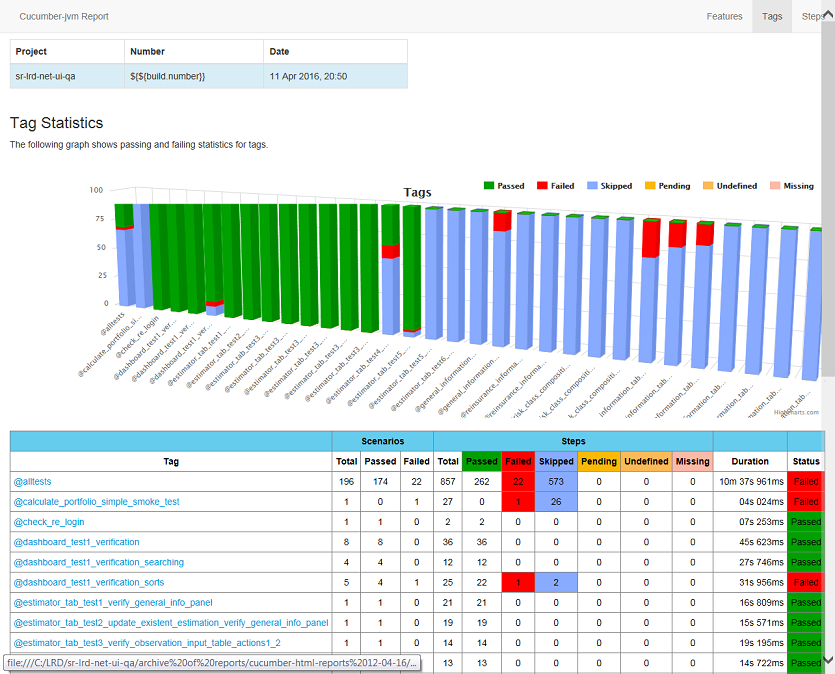
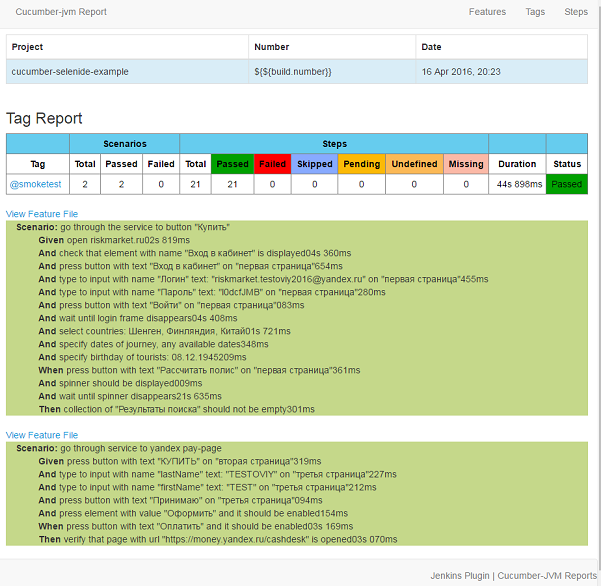
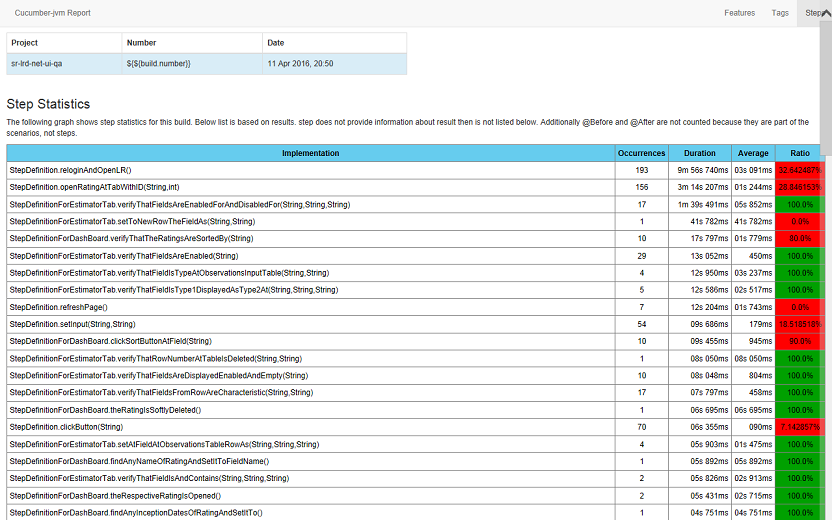
Во вкладке Steps (последний скриншот) оценки по времени для анализа степов на предмет рефакторинга.
Вообще модуль был написан для CI Jenkins. Как получить такие отчеты в Jenkins смотрите тут: https://github.com/damianszczepanik/cucumber-reporting
Для Bamboo он не настроен, поэтому можно использовать модуль, описанный в этой статье, и просто указать место положение отчета как артифакт.
На этом всё. Понятных, не падающих тестов вам!
P.S. В статью не влезло использование параметризованных степов (Scenario Outline:, Examples: ) Если надумали использовать Cucumber у себя, почитайте про это здесь.
grebivan
А почему выбор пал на java+cucumber, а не, например, python+behave?
vasidzius
Пока только в джаву умею. На собрании старших товарищей из BDD выбор пал на Cucumber. Другие фреймворки пока не смотрел