

Недавно ZlodeiBaal писал о достижениях в сверточных нейронных сетях (CNN) (и, кстати, тут же успешно настроил и обучил сеть для поиска области автомобильного номера).
А я хочу рассказать про принципиально иную и, наверное, более сложную модель, которую сейчас развивает Алексей Редозубов ( AlexeyR), и про то, как мы, конечно проигнорировав некоторые важные элементы, и ее применили для распознавания автомобильных регистрационных знаков!
В статье несколько упрощенно напомню о некоторых моментах этой концепции и покажу, как оно сработало в нашей задаче.
Если потратить немного время на чтение последних новостей из нейробиологии, то любому, кто знаком с вычислительными нейросетями, станет несколько не по себе. Более того, может появиться пароноидальная мысль: «может зря вообще из нейронов пытаются собрать ИИ, может нейроны там не главные?» Нейроны проще было исследовать из-за их электрической активности. Например, глиальных клеток значительно больше, чем нейронов, а с их функцией не все понятно.
И не покидает общее впечатление, что те, кто занимается Deep learning, пользуются представлениями ученых 40х-60х годов, не спеша особенно разбираться в огромном массиве исследований нейробиологов.
AlexeyR замахнулся на концепцию работы мозга, согласующуюся с чуть более современными исследованиями нейрофизиологов.
Лично для меня важная проверка адекватности идеи — ее конструктивность. Можно ли вооружиться этой идеей и соорудить что-нибудь реально работающее?
Здесь постараюсь вас убедить, что концепт конструктивен и очень перспективен в том числе и с практической точки зрения.
Для начала приведу мои трактовки основных позиций идей Редозубова, которые мне кажутся важными:
Неклассический нейрон и волновые идентификаторы
Ученые давно заметили, что на теле нейрона вне синаптических щелей есть еще и метаботропные детекторы, которые не очевидно что делают. Вот на них можно возложить оригинальный механизм запоминания строго определенной окружающей этот детектор активности. При этом происходит одиночный спайк нейрона (его называют спонтанным), на котором располагается этот детектор. Такой не хитрый механизм позволяет запомнить и распространить уникальным узором информационную волну. В этой серии статей можно найти исходник этой модели. Вообще, это очень похоже на распространение слухов в социальной группе. Не обязательно всем жить рядом и собираться вместе, чтобы информация распространялась. Важно лишь чтобы связи с соседями были довольно плотные.
Честно говоря, я бесконечно далек от клеточной нейрофизиологии, но даже после прочтения статьи на вики, допустить существование иного способа передачи информации, отличного от синаптического, могу.
Второе, следующее из первого
Различные зоны мозга соединены не таким уж и большим количеством аксонов. Конечно, их там тьма, но точно не от каждого нейрона к каждому нейрону на следующем уровне, как принято в вычислительных нейронных сетях сейчас. А если мы научились распространять уникальные волны-идентификаторы, то вот и будем между зонами общаться с помощью таких дискретных идентификаторов. Вся информация, обрабатываемая мозгом, будет описываться дискретными волнами-идентификаторами (попросту — цифрами), например:
— позиция (скажем, позиция проекции объекта на сетчатке);
— время (субъективное ощущение времени человеком);
— масштаб;
— частоту звука;
— цвет
и т.д.
И будем пользоваться пакетным описанием, т.е. просто списком таких дискретных идентификаторов для описания того, что узнала зона.
Третье
Вот тут все с ног на голову относительно того, к чему все привыкли с Хьюбела и Визела
Небольшой экскурс в историю:
В 1959г. Хьюбел и Визел поставили интереснейший эксперимент. Они посмотрели, как в зрительной коре первого уровня нейроны откликаются на различные стимулы. И обнаружили некоторую организацию в ней. Одни нейроны реагировали на один наклон зрительного стимула, другие на другой. При этом внутри одной миниколонки (вертикальная структура из 100-300 нейронов в неокортексе) все нейроны реагировали на одинаковые стимулы. Потом появились сотни, если не тысячи, исследований уже с современным оборудованием, где селективность к чему только не обнаруживали в различных зонах. И к наклону, и к пространственной частоте, и к позиции, и скорости движения, и к частоте звука. Какой релевантный для заданного участка мозга параметр не задавали, обязательно находили некоторую селективность.
Визуальный кортекс зона V1
В зависимости от частоты звука А1
И вполне естественно сделать из этого вывод, что нейроны по мере обучения меняют синаптические веса так, чтобы узнавать линию или границу определенного наклона в своей рецептивной зоне. Следуя этим идеям, Лекун и построил сверточные сети.
Но будет куда эффективнее, говорит Алексей Редозубов, если эта миниколонка запомнит на себе совсем не конкретную фичу, а контекст. Контекст, например, — угол поворота. Второй контекст — позицию, третий — масштаб. А фичи будут вообще общие для некоторой окрестности на коре.
Таким образом, нужны самоорганизующиеся карты не для входной картинки (в визуальной коре), а самоорганизующиеся карты различных контекстов, релевантных зрительной коре. При этом близость этих контекстов можно оценить либо за счет их временной близости, либо за счет близости кодов идентификаторов.
И зачем нужна эта сложность с контекстом? А затем, что любая информация, с которой мы имеем дело, выглядит совершенно по-разному в зависимости от контекста. В отсутствии какой-либо априорной информации о текущем контексте, в котором находится наблюдаемая сущность, необходимо рассмотреть все возможные контексты. Чем в рамках предлагаемой модели и будут заниматься миниколонки неокортекса.
Такой подход — это лишь трактовка тех же сотен или тысяч экспериментов про самоорганизацию в коре мозга. Нельзя отличить в ходе эксперимента два результата:
1) я вижу наклоненную на 45 градусов границу относительно вертикали.
2) я вижу вертикальную границу, наклоненную на 45 градусов.
Кажется, что это одно и тоже. Но в случае второй трактовки можно обнаружить точно такую же активность в той же самой миниколонке, если мы покажем, скажем, лицо человека: «я вижу вертикальное лицо, наклоненное на 45 градусов». И зона не будет ограничена восприятием лишь одного типа объектов.
А с другой стороны, контекст и узнаваемое явление поменяются местами в другой зоне. Так, например, существуют два пути, по которому анализируется визуальная информация: dorsal и ventral. Для «dorsal stream» контекст — расположение в пространстве, направление движения и др. А для «ventral stream» контекстом могут являться характеристики наблюдаемого объекта, даже тип объекта. Если один из визуальных потоков обработки будет поврежден, то человек не станет слепым. Возникнут проблемы с восприятием сразу нескольких объектов одновременно, но со временем способность к восприятию нескольких объектов и взаимодействию с ними частично возвращается. Т.е. неплохое описание объекта получается и в «dorsal stream», и в «ventral stream». А лучше совсем не болеть и, с одной стороны, рассматривать различные гипотезы по положению, ориентации, а с другой, гипотезы вида «я вижу человека», «я вижу голову», «я вижу стул». Десятки миллионов и тех и других гипотез одновременно анализируются в зрительном тракте.
А теперь, собственно, об алгоритме распознавания автомобильных номеров, который основан на идеях AlexeyR.
Распознавание автомобильных номеров
Начну с примеров распознавания автомобильных номеров.

Кстати, тут не используются границы номера, т.е. этот метод распознавания вообще мало похож на классические алгоритмы. Благодаря этому не теряются драгоценные проценты из-за первичной ошибки определения границ номера. Хотя, именно с этим подходом, ничего не потерялось бы.
Архитектура
Чтобы распознать автомобильные номера, мы использовали 2 зоны:
1) Первая зона узнавала все, что похоже на буквы и цифры в автомобильном номере.
Входная информация — изображения.
При этом было 5 параметров, по которым была разбита вся зона:
— положение по X
— положеие по Y
— ориентация
— масштаб по оси X
— масштаб по Y
В итоге вышло около 700 000 гипотез. Что даже для видеокарты на ноутбуке не стало большой проблемой.
выход зоны — описание вида:
знак такой-то, положение, ориентация, масштаб.
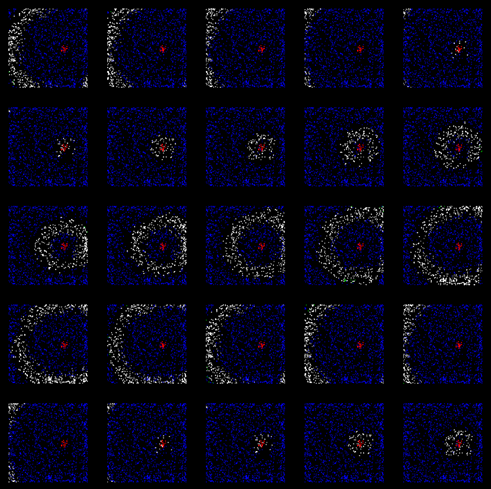
визуализация выхода:

Заметно то, что далеко не все знаки удавалось распознать на этом уровне, было полно ложных срабатываний, если номер был достаточно грязный.
2) Вторая зона
входная информация — выход первой зоны.
Занималась перспективными преобразованиями. Гипотез было около 6 млн. И единственный устойчивый паттерн, который узнавался тут — автомобильный номер в формате 6 знаков большего масштаба слева и 3 знака меньшего справа.
Проверялись все возможные перспективные преобразования. В одном из вариантов знаки из зоны 1 «складывались» наилучшим образом в известный нам паттерн автомобильного номера. Этот максимум и побеждал.

Но мы знаем, в каких контекстах должны быть знаки при заданном перспективном преобразовании, поэтому можем спроецировать их обратно на первую зону и найти уже корректные локальные максимумы в пространстве первой зоны.

Время на выполнение этого алгоритма составило около 15с на не самой быстрой NVIDIA GF GT 740M.
Еще примеры распознавания

Особенно показательны 3 и 4 столбцы автомобильных номеров.
Можно закрыть половину (и даже больше) знака, но все равно выберется единственная верная гипотеза о положении и ориентации автомобильного знака, т.к. нам известна его модель. Это фундаментальное свойство человеческого мозга — лишь по нескольким признакам (иногда ошибочно) узнавать объекты и явления.
А на четвертом примере из-за неидеальности работы первой зоны большинство цифр «потерялось». Но опять же, за счет представления о том, как выглядит автомобильный номер, была верно выбрана гипотеза о перспективном преобразовании. И уже за счет обратного проецирования на первую зону информации о том, где должны быть знаки, номер успешно распознается! Часть информации была потеряна, но восстановлена за счет того, что мы знаем — «именно там должны быть цифры и буквы».
Обучение
Непосредственно в приведенном примере обучение проводилось, с одной стороны, простейшее: «один раз показали и запомнили». А с другой стороны, чтобы получить сильный алгоритм распознавания, достаточно было просто предъявить 22 знака для первой зоны и один автомобильный номер для второй зоны. Это сверхбыстрое обучение. Не нужно было тысяч изображений.
Конечно, данные не были зашумлены помехами, все релевантные признаки были определены заранее, поэтому в данной реализации самообучение не развернулось в полной мере.
Но в концепции заложен необычный и мощный механизм самообучения. Точнее, тут необходимо обучать двум вещам:
1) Как одни и те же «фичи» преобразуются в различных контекстах. И ответить на не менее сложный вопрос: а что есть контекст для данной зоны? Интуитивно кажется, что для звука — частота и темп. Для движений — направление движения и темп. Для изображений — для какой зоны 2D преобразования, для какой-то уже 3D.
2) Найти устойчивые ситуации, т.е. набор фич, проявляющиеся часто в разных контекстах.
За последние несколько месяцев получилось кое-что сделать и в направлении самообучения. Так, например, при работе с визуальными образами объекту достаточно дважды появиться в кадре в различном контексте (масштаб, ориентация, положение) и удается получить его портрет, который затем пригоден для распознавания, несмотря на достаточно сложный фон и помехи. Все это выглядит, как сверхбыстрое самообучение.
К сожалению, подробное описание механизмов самообучения останется за рамками этой статьи.
А сверточные сети Яна Лекуна?
Сверточные сети (CNN) тоже прекрасно вписываются в эту модель. Свертка с ядрами производится для каждой позиции X,Y. Т.е. на каждом уровне в каждой позиции ищут одно из воспоминаний (ядер), таким образом позиция — тот самый контекст. И даже необходимо расположение рядом близких позиций, т.к. это используется на следующем уровне downsample, где выбирается локальный максимум из 4 точек. За счет этого получается обучать нейронную сеть сразу для всех позиций на изображении. Иными словами, если мы обучились узнавать кошечку в левом верхнем углу, то определенно узнаем ее и в центре. Стоит только заметить, что мы не сможем сразу узнать ее, повернутую на 45 градусов, или иного масштаба. Потребуется большая обучающая выборка для этого.
Сверточные сети за счет такого механизма устройства стали очень мощным инструментом в умелых руках. Но есть несколько недостатков, которые компенсируются различными методами, но являются принципиальными:
— уже зафиксирован только контекст положения, хотя даже при работе с изображениями важны ориентация, масштаб, перспектива, скорости движения при работе с видео и другие параметры;
— а значит нужно увеличивать обучающую выборку, т.к. у сверточной сети не заложен механизм преобразования, кроме перемещения, и надеяться, что остальные закономерности «всплывут» после длительного обучения;
— нет механизма «запоминания всего», только изменение весовых коэффициентов. Однажды увиденное уже не поможет при дальнейшем обучении, а значит обучающую выборку нужно правильно организовывать и в любом случае снова увеличивать. Иными словами: память отделена от архитектуры CNN.
— потеря информации при downsample и последующем upsample (в автоенкодерах на базе CNN), т.е. если строить обратную связь или обратную проекцию в CNN, то возникают проблемы с точностью воспроизведения;
— каждый следующий уровень так и продолжает оперировать пространственной инвариантностью «в плоскости», а на высших уровнях из-за отсутствия конструктивных идей снова приходят, например, к полносвязной архитектуре;
— достаточно сложно отслеживать и отлаживать те «модели», которые сформулировались в ходе обучения, да и не всегда они корректны.
Можно и усилить сверточные сети, например «зашить» еще несколько параметров, кроме X,Y. Но вообще-то надо развивать не самые простые алгоритмы самоорганизации карты контекстов, организовать «перетрактовку» воспоминаний, обобщение в разных контекстах и многое другое, что не совсем похоже на базовые идеи CNN.
Заключение
Одного примера с распознаванием номеров, реализованного весьма урезанным образом, конечно, недостаточно, чтобы говорить о том, что у нас в руках новая конструктивная модель устройства мозга. Лишь проба пера. Впереди еще очень много интересной работы. Сейчас AlexeyR готовит примеры с классическим MNIST на одной зоне, самообучением нескольких зон для распознавания речи. Кроме того, мы учимся работать с менее структурированной информацией — лицами людей. Тут уже не обойтись без мощного самообучения. И именно эти практические примеры заставляют буквально каждые 2 недели пересматривать некоторые детали концепции. Можно сколько угодно красиво рассказывать о стройной концепции и писать отличные книги, но куда важнее создать реально работающие программы.
В результате, шаг за шагом, должна получиться достаточно развитая модель, которая будет значительно универсальнее существующих CNN или, скажем, RNN по отношению к входной информации, порою обучающаяся буквально с нескольких примеров.
Приглашаем Вас следить за развитием модели в этот блог и блог AlexeyR!
Комментарии (104)

babylon
23.05.2016 01:35-202 недели пересматривать некоторые детали концепции.
Ха-ха! 2 недели… Когда занимался распознаванием рукописного текста, каждые 5 минут пересматривал детали концепции…
Считаю, что концепции распознавания любых объектов не должны различаться. Мне не нравятся нейронные сети. Мне нравятся таймлайны. Циклы мозга вам в помощь. Другие пути ведут в тупик.Время на выполнение этого алгоритма составило около 15с на не самой быстрой NVIDIA GF GT 740M.
. 15 сек — это трэш!
mynameisdaniil
23.05.2016 02:19+16Почему вы так агрессивны? Люди только начали, и видеокарта, судя по всему, у них макбучная. Работает ведь? Все будет хорошо.

MooNDeaR
23.05.2016 12:24+115 секунд — это на далеко не самой производительной видеокарте для ноутбуков. Да и я почти уверен, что автор статьи хотел рассказать идею, а не показать самую крутую реализацию в мире. Я полагаю, там еще оптимизировать и оптимизировать.

BelBES
23.05.2016 12:49Если честно, то и на уровне идеи не совсем понятно, что там на вход идет, что внутри происходит и что на выход...
Vasyutka
23.05.2016 13:36+1На вход картинка. Нашли 20ку самых лучших цифр/букв в первой зоне (варьируются позиция, масштаб, наклон, масштаб по X, масштаб по Y), передали на следующую — там все гипотезы по персп.преобразованиям, выбрали лучшую, спроецировали обратно на первую. И там уже в поле всех гипотез (миниколонок) с учетом обратного проецирования выбрали лучший резонанс с запомненными цифрами/буквами. на выход описание вида: 1 — буква 2 — цифра 3- цифра 4-… ну и так далее.
Все законы преобразований нам позволяет знать либо жизненный опыт, либо формула геом.преобразований 12 строках кодаBelBES
23.05.2016 13:43Возникает несколько вопросов:
- Гипотеза (судя по рисунку) — это некоторое ROI на изображении, имеющее заданные параметры положения, наклона и размера?
- Как именно происходит распознавание конкретных цифр/букв? Внутри каждого окна запускается классификатор?
- Что происходит в процессе обучения? Подстраиваются параметры для каждой из гипотез с целью, чтобы окна накидывались на картинку не рандомно а наиболее эффективным образом?
Пока оно мне видится как шаг назад относительно Deep Learning, больше смахивая на DPM.
Vasyutka
23.05.2016 13:50+1это точно не продолжение идей deep learning. Их и без нас продолжат.
некоторое ROI для зоны номер 1 — да. для зоны 2 — перспективное преобразование, описывание 4х угольником (ну тоже ROI, просто исковерканное).
да, каждая миниколонка-гипотеза решает а не припомнила она какую-то ситуацию. Не, там не SVM, попроще, но можно и ее в конкретной реализации.
в процессе обучения выбирается такой контекст (гипотеза, миниколонка), которая приводит видимую картинку к одному из воспоминаниний и формируется портрет. но не в этом примере. Скоро об этом напишет длиииную статью AlexeyR.BelBES
23.05.2016 14:05Тогда совсем не видно принципиальной разницы с DPM… просто AlexeyR тут как-то обещался похоронить Deep Learning, а на практике пока как-то на убийцу совсем не тянет этот подход...
Vasyutka
23.05.2016 14:08+1Сверточные сети на практике не тянули ни на что лет 15 :). все как-то контурные методы, ну Haar-detector и прочее правили бал.
BelBES
23.05.2016 14:10+2deformable part models (тотже автор позже перешел на DL и накреативил семейство RCNN детекторов объектов).
babylon
23.05.2016 15:25Неверно противопоставлять контурные методы, сверткам. Это как минимум неграмотно.
Vasyutka
23.05.2016 15:36Простите, а почему?
babylon
23.05.2016 16:35-1Эти методы используются для разных целей. Контурные методы строят деревья из сопряженных векторов, а свертки + словари их анализируют и в конечном счете анализируют кто есть и что. Естественно надо стремиться к эвристикам.

supersonic_snail
23.05.2016 16:39Какой-то набор слов.
> Естественно надо стремиться к эвристикам.
А вот это вообще успех. Давайте выкинем все наши наработки по Machine Learning за последние полвека, ага.babylon
23.05.2016 16:54-3То, что находится за пределами последних 10 лет несомненно в помойку. Я давно не занимаюсь ИИ или мне так кажется.
Самый лучший критерий эффективности программного продукта это прибыль. Мне не удалось довести свои алгоритмы до уровня продакшна. Может и хорошо. Зато потренировался. К сожалению, другие не довели свои даже до уровня моих. Но за то успешно ими торгуют.
Vasyutka
23.05.2016 14:18+2такую двухзонную модель именно в визуальном представлении можно притянуть к DPM и даже к навороченной CNN, а можно сказать «а это полным перебором вы задачу решили — лишь немного эвристики добавили, мы так в 93ьем только работали, когда Deep learning не придумали, — детский сад!». Кстати, как раз механика работы мозга: есть несколько запомненных моделей и одна из них, поиграв контекстами (вот эту деталь там она там градиентами, а тут яркость, другая деталь, если вот так подкрутить, сойдет соответственно за ту часть модели), была узнана. И вот родилась мысль «это ж DPM! если тут подкрутить и там подкрутить», а кто-то узнает другую модель. Но вообще согласен, конечно, внешне похожа эта реализация. Будем работать над тем, чтобы и Вас удивить!
ну и правильный ответ: «конечно, модель настолько крута, что включает в себя и DPM!» ))

buriy
23.05.2016 14:19+2Ну, тем, кто в теме, в целом понятно, что происходит.
Происходит фильтрация, что-то типа beam search, фильтра калмана или решета эратосфена:
Вместо того, чтобы сначала применить один фильтр (картинка -> границы номера), а потом второй (картинка->цифры) к наилучшему результату первого фильтра, составляются два списка наилучших результатов каждого фильтра, и оставляются те из них, которые максимально удовлетворяют взаимным ограничениям.
Это может с точки зрения полноты оказаться лучше, чем брать результаты одного фильтра, и потом для каждого результата применять другой фильтр.
Возможно, взят неудачный пример, потому как мне кажется, в данном случае по скорости получится не лучше, чем beam search для beam size = 10 (т.е. оставляем 10 лучших результатов первого фильтра, потом для каждого из них прогоняем второй фильтр).
Но есть задачи, где данный подход творит чудеса, например, для unsupervised-построения списка слов по темам для английского языка (например: актёры, президенты, бизнесмены, бренды телефонов, виды фруктов) из зашумлённых источников MS Research получили среднюю точность около 92.8%, в то время, как конкуренты — 70-85%:
http://research.microsoft.com/en-us/projects/probase/default.aspx
Или, например, для обучения при распознавании речи с помощью нейросетей используется метод вычисления ошибки CTC (Connectionist Temporal Classification), который по сути дела, накладывает на нейросеть функцию ошибки, которая зависит от ответа нейросети — по сути, глядя на положение других букв, предсказанное нейросетью, и выделяя диапазоны, где данная буква или звук может находиться, и поддерживая пропорциональную положительную обратную связь для этих мест (и отрицательную обратную связь для остальных диапазонов): https://i.gyazo.com/56ef8b991da9f2eebdfe17aaf3eff3d0.png
Метод, рассмотренный в посте, предлагает способ объединения нескольких уже натренированных нейросетей для получения более точного результата — в этом его ценность. Предполагается, что так же действует и мозг человека — учёные утверждают, что разные зоны коры обладают разной функциональностью, и намного более точный и полезный результат для многих задач может образовываться при взаимодействии этих зон.
Конечно, чем-то, конечно, эта мысль кажется банальной для тех, кто занимался оптимизацией запросов к базам данных, но, тем не менее, все методы фильтрации в наше время являются эвристическими, и кроме beam search, использованного метода и метода ансамбля экспертов больше методов-то особо и нет.
Ещё хочу добавить, что я уверен, без потери точности данный метод может быть заменён маленькой нейросетью, вычисляющей по результатам двух нейросетей итоговый результат — качество объединения этих фильтров. Фактически, авторы настроили параметры этой третьей нейросети вручную по своему набору данных.
(Соответственно, можно всё это заменить на одну большую нейросеть, объединяющую эти три...)Vasyutka
23.05.2016 14:46А окажется мозг — просто база данных :)
buriy
23.05.2016 15:01Мозг безусловно имеет много черт традиционных баз данных, AlexeyR именно про это и писал, вы же сами на его статью сослались: https://habrahabr.ru/post/217055/
Так что перечитайте: «Волна, описывающая текущее состояние мозга, может выступать аналогом запроса к базе данных. Так же, как результат операции над отношениями есть отношение, так и ответ мозга может быть совокупностью ассоциативно связанных описаний, совмещенных в одной волновой картине.» — чем это отличается от описания механизма работы оператора JOIN в RDBMS? :)
Ещё одну ссылку хочу дать. Те же идеи, но в другой обёртке, позволяющей применить их для слежения за объектами на смартфонах. Алгоритм Predator: https://habrahabr.ru/post/116824/

pehat
23.05.2016 13:39Результаты автора поста я вижу, вполне приемлемые. Если это треш — покажите Ваши сногсшибательные результаты, пожалуйста. Ну или хотя бы какие-нибудь.


TxN
23.05.2016 10:00+1Когда впервые наткнулся на цикл статей Алексея о его гипотезе работы мозга, читал запоем до глубокой ночи, пока не прочитал все. И было очень интересно, как эти принципы получится применить на практике.
С большим интересом прочитал вашу статью, несмотря на то, что специалистом в этой теме не являюсь.
Насколько я понял, данный метод позволяет обойтись без обучения нейросети на тысячах изображений, и достаточно совсем небольшой выборки? При этом, в отличие от классических нейронных сетей, эта позволяет искать нужную информацию на изображении вне зависимости от ее перспективного искажения, поворота и прочего? Какая при этом достигается точность? Выше, чем при использовании «классических» сетей?Vasyutka
23.05.2016 12:28конкретно для этих двух зон да. так, первичная аудио-кора может быть расчерчена по основному тону(частоте) и темпу произношения, может интонационным оттенкам. Это достаточно принципиально научиться обучаться этим закономерностям, какая зона бы ни была для разных типов информации.

sergeypid
23.05.2016 11:36+7Можно больше подробностей для специалистов? Какие входные для обучения (показали 22 автомобильных номера — это все цифры и буквы? Как насчет пространственных искажений?) Что такое гипотеза? Какие фичи использовались? В чем эффект обучения: если вы говорите о тысячах гипотез, то возможно речь идет о совместной оптимизации, но причем тут волновое распространение возбуждения? Пока статья выглядит как одно большое Вау.
Я два года назад познакомился с «Логикой мышления» Алексея, очень понравилось, но к сожалению, на практике не удалось поиграться.
myxo
23.05.2016 12:33Мне вот тоже совсем непонятно как именно была использованная сеть для обучения. А так тут по-сути «мы залили данные, получили такой результат». Я читал цикл статей Редозубова, но, к сожалению, не до конца. Описание обучения на реальных данных где-то там?
Vasyutka
23.05.2016 12:36+1обучение надо отдельно рассказывать. Тут оно было довольно слабым. Показал в одном контексте и запомнил. Гипотезы — это различные контексты, а если словами, то: а вот если бы это изображение было смещено по X,Y, повернуто так и вот так изменены масштабы, то… точно! точно цифра 2 была (или буква «В»), как мне ее однажды показали. Так и передадим на следующую зону: это цифра 2, смещена X,Y, повернута так и вот такой машстаб. И тоже самое для след.зоны: показал один ровный автомобильный номер, запомнил. теперь гипотеза — а какое перспективное преобразование приводит к тому одному автомобильному номеру.
пространственные искажения тут не обучались, а прямо запрограммированы. Что не отменяет того, что нужно уметь обучаться им. Только это можно делать с помощью любого визуального мусора, например, мотая головой.


Monnoroch
23.05.2016 12:31+3Talk is cheap, give me the code!
Серьезно, никакой информации в статье нет, только красивые картинки и оперирование эзотерическими (особенно для неспециалиста) терминами.
Область очень интересная, и если все честно, то результаты супер крутые, но пока есть ощущение, что это какая-то псевдонаука.
Напишите, пожалуйста, статью с подробным описанием технологии, с формулами и по возможности кодом.Vasyutka
23.05.2016 12:58+2да тут сразу весь расчет был написать мутненько, чтобы «журналиста изнасиловал ученый»! ))) И еще как код, как подробное описание, так сразу вся магия пропадет с формулировкой «а ну да… конечно это будет работать, очевидно же… скууукаа, какой же это ИИ!» Да, до ИИ еще как ложками грести через Атлантический океан.
Пишите в ЛС, если какие-то места кажутся совсем туманным именно Вам, — я поясню те моменты, с кусками кода, если потребуется. Можете сразу писать AlexeyR, он автор концепции.
ArtificialLife
23.05.2016 12:37Вот за такие посты я и люблю Хабр! Как приятно видеть, что не только ученые мирового уровня пытаются что-то изобрести в сфере ИИ. Даешь науку в массы!
supersonic_snail
23.05.2016 12:37+3> И не покидает общее впечатление, что те, кто занимается Deep learning, пользуются представлениями ученых 40х-60х годов, не спеша особенно разбираться в огромном массиве исследований нейробиологов.
Единственное общее, что современные нейронные сети имеют с мозгом — это изначальная мотивация и название. В остальном это набор перемножений матриц + крайне удачный алгоритм подбора элементов этих матриц. К тому же, все наработки нейрофизиологов скорее заключаются в том, как соединены нейроны внутри мозга (вот тут я могу быть неправ, поправьте, если не так). Гораздо более важная вещь — это как эти соединения формируются, о чем толком ничего неизвестно.
> Лично для меня важная проверка адекватности идеи — ее конструктивность. Можно ли вооружиться этой идеей и соорудить что-нибудь реально работающее?
Не согласен. Очень просто сделать алгоритм, который просто работает. Очень сложно сделать алгоритм, который работает лучше, чем все остальное в мире.
По делу — очень хочется увидеть количественное сравнение с теми же нейронными сетями. Несколько примеров показывают только качественный результат, вы могли их выбрать среди кучи неудачных срабатываний, и так далее. Если бы было — нейросети точность X%, ваше X+1%, тогда не было бы вопросов. Ну и да, 15 секунд на картинку это очень-очень долго.Vasyutka
23.05.2016 12:44+1Эксперимент тоже не был бы чистым. Ну научу я сетку так, как научу (например, плохо). Посоревноваться с кем-то — уже интереснее. Но мы года 2 назад выкладывали огромную базу номеров и предлагали попробовать распознать и мы напишем результат. Конечно, это утопия тратить чье-то время на «а давайте посоревнуемся».
«Очень сложно сделать алгоритм, который работает лучше, чем все остальное в мире.» А с другой стороны не так уж и сложно, если только мне надо решить эту задачу.
тут вопрос ресурсов: когда на другой стороне этот же алгоритм пишут несколько корпораций и в каждой сотни специалистов (каждый круче меня, например)… я лучше сделаю прототип, который мне подскажет куда двигаться дальше и двинусь дальше. И шанс дойти до серьезной модели, которую уже действительно можно в чем-то сделать лучше, повысится. Может окажется тупик, но мне кажется не рационально залипать на автомобильных номерах )).supersonic_snail
23.05.2016 12:55+1Для того, чтобы нормально друг с другом соревноваться, специально делаются открытые датасеты с фиксированными train-validation-test partitions. Вы могли бы взять вот этот — http://ufldl.stanford.edu/housenumbers/ — использовать препроцессинг, который описан тут — http://arxiv.org/abs/1312.6082 — и сразу получить результат против 11-слойной CNN. Задача очень похожа на автономера (номера домов с google street view), так что особой сложности не должно возникнуть. Конечно, это кому-то надо делать, что ресурсы, но тут уже ничего не поделать. Но если вы это сделаете, то сразу будет видно, что к чему.
Vasyutka
23.05.2016 13:07+1«специально делаются открытые датасеты с фиксированными train-validation-test partitions» ну еще мы заинтересованная сторона, так что не помогло бы :))).
«сразу будет видно, что к чему» — не уверен. Ну например, мы использовали «автомобильный номер выглядит так» (а это 8-9 знаков очень строго геометрически расположенные, если правильную перспективу подобрать). CNN такую штуку не соберет и всегда кто-то кто капнет скажет «аааа, а вы вот тут так мощно подсказали!», или «да и база у вас маленькая!». И вообще, совершенно не хочется в таких простых задачах бодаться с CNN, тем более что в этом случае можно чуть ли не математически показать эквивалентность в последствии полученных решений и по выч.результатам и по выделенным моделям в итоге внутри нейронной сетки. Что и разумно.Vasyutka
23.05.2016 13:11+1И да! очень хотелось бы независимой экспертизы, довести работу до идеального состояния, и чтобы узкий круг специалистов согласился с ней (или не согласились). Но ресурсы. Могу только предложить помочь! С вероятностью процентов несколько, что-то у нас с этой «сильно моделью» в итоге получится и усилия будут потрачены не зря :).

ZlodeiBaal
23.05.2016 13:14+2Это не корректное сравнение. Приведённый тут алгоритм служит для поиска известных шаблонов, которые можно заложить в качестве обучающего контекста. Для тех же номеров домов это невозможно. Слишком много вариантов.
Что касается «обучить сеть с 6-тью софтмаксами на выходе более-менее стандартной архитектуры, непредобученную, по датасету в 1000 неповёрнутых номеров», то такой подход даёт точность уровня 60%. Я это пробовал.
Нужно понимать, что у подхода, который тут представлен имеется кардинальное отличие от современных нейронных сетей. Процессы обучения и область применимости принципиально разные. Сравнить их на одном и том же датасете на сегодняшний день нельзя. Нейронные сети будут лучше работать когда задачу сложно сформулировать, но можно представить большим набором данных. Представленный тот подход — когда может существовать описательная модель данных, которую можно разложить и подсунуть.
Да, я не то что хорошо в подходе Редозубова разбираюсь, но Вася мне регулярно какие-то забавные идеи оттуда рассказывает.supersonic_snail
23.05.2016 15:51+1Хорошо, тогда можно использовать CNN+Spatial Transformer (http://arxiv.org/abs/1506.02025) Лично пользовался сетью, похожей на ST-based, оно очень хорошо работает, даже если обучающих данных немного. На тех же номерах домов ST на ура обходят ту 11-слойную CNN.
> Нужно понимать, что у подхода, который тут представлен имеется кардинальное отличие от современных нейронных сетей.
В статье подход то толком не описан, слишком мало деталей. Можете объяснить, в чем заключается кардинальное отличие?Vasyutka
23.05.2016 16:00да, Spatial Transformer — вот похоже очень на то, что сделано в этй реализации. И результаты может даже получше будут, т.к. данных тренировочных попихать побольше можно. А может похуже.
Кардинальное отличие в том, что Spartial Transformer не дает идей, как речь распознавать, как смысл текста и прочее-прочее. А тут нет ограничений. Обучить как идентификаторы (понятия) меняются в разных контекстах, выделить портреты часто встречающихся (с учетом контекста), передать на след. зоны и так дальше до удобно-интерпретируюемых понятий. Т.е. кажется, что значительно универсальнее + есть идеи про сверхбыстрое обучение (если за эталон брать deeplearning).supersonic_snail
23.05.2016 16:10Что-то я все еще не понял. Что мешает нам использовать фиксированное число ST+инициализировать их так, чтобы они примерно были в том месте, в котором должны быть символы+дать им перемещатся на не сильно большие расстояния и не сильно большие углы? Если так сделать, то мы успешно встраиваем prior о данных.
Deep Learning в сверхбыстрое обучение тоже умеет, но нужна предварительная фаза предобучения (я сейчас не про обучить на imagenet+дообучить там где надо, хотя это тоже чем-то похоже). В то, о чем вы писали про обучится с одного примера, Deep Learning толком не умеет, да. Но это дело времени, я уверен.
В общем реквестирую более детальную статью с алгоритмом обучения, иначе это будет бесконечный диалог :)
ZlodeiBaal
23.05.2016 16:12+2Можно. Можно вообще RCNN по каждой букве запилить. А можно ещё десятком других сетей. И это я пробовал. И находил варианты которые работают. Я лишь показал некорректность упомянутого.
Но я повторяю: сравнение некорректно. Как минимум потому что нужны большие датасеты для обучения сетей, а тут они не нужны.Тут — каждый пример значимый и референсный. Мне сложно объяснить концепцию, могу лишь предложить перечитать статьи Редозубова (вроде он даже продолжение обещает), а непонятные вопросы вытрясать из него и из Васи напрямую.

buriy
23.05.2016 15:14+1Кстати, напишите, пожалуйста, сколько данных вы брали для обучения модели, каким образом происходило обучение, и предложите какую-нибудь воспроизводимую меру качества вашей модели.
Преимущество модели — безусловно, взаимное обучение нейросетевых фильтров: когда из нескольких кандидатур, предложенных одним фильтром, можно выбрать наилучший результат с оглядкой на другой фильтр, и произвести дообучение фильтра. А потом наоборот.
P.S. А насчёт нейросети вы не совсем правы. Однослойная нейросеть обучается на полном MNIST с качеством 92%, а двухслойная на 1000 случайных изображений из MNIST должна показать результат около 90% по точности, если не ошибаюсь. Шестислойной сети (если я вас правильно понял) 1000 изображений конечно же не хватит, она существенно недообучится.
Поэтому мне бы хотелось попробовать повторить с помощью нейросетей ваш подход и посмотреть, получится ли результат лучше вашего.
Ваши базы номеров и машин у меня скачаны, может, пора их наконец-то использовать? :)Vasyutka
23.05.2016 15:47+1м… я не обучал в привычном для нейросетей смысле. показал 22 картинки цифр (по одной на каждую, с чистых номеров взятых). И после отправки результата с первой коры (в первую зону отправил чистый номер) во второй зоне запомнил как образец. просто концепция другая совсем. Сейчас такое чистое незамутненное обучение без подсказок делаем, но там прилично сложностей еще.
buriy
23.05.2016 15:58Ок, а второй фильтр?
Vasyutka
23.05.2016 16:12вторая «зона» приняла список «s, x y alpha sx sy» s — символ, x,y,alpha,sx,sy. символ намеренно похерила и запомнила список из 9 позиций: x,y,alpha,sx,sy. все. теперь, когда придет новый номер, каждая миниколонка за свою перспективу проверит, а не совпало ли с этим воспоминанием. такой второй фильтр. Потом спроецировала обратно какие x,y,alpha,sx,sy ожидала от первой зоны в рамках такой перспективы
buriy
23.05.2016 18:20ок, а «700 тыс кандидатов» — все равноценные? как избавляетесь от накопления ошибок со временем? тщательно подкрученными весами?
(я ведь весь этот путь прошёл в 2011 году с HTM — у меня были и проекции тоже! правда, там свои заморочки были)Vasyutka
23.05.2016 18:23что за накопления ошибок со временем?
buriy
23.05.2016 22:08Вы не могли бы представить верхнеуровневую модель происходящего, или лучше подождать поста Алексея?
Что меняется в модели со временем? Из чего состоит модель?
Без деталей, мне нужно только потоки данных, понять, что с чем и когда сравнивается и какие изменения с моделью данных происходят.
Если я правильно понял, модель цифр и знака загружается один раз и не изменяется. Но тогда каким образом она сравнивается с другими данными?
Вы перебираете все возможные позиции каждой цифры и смотрите коэффициент соответствия? Или что происходит?
«очно! точно цифра 2 была (или буква «В»), как мне ее однажды показали. Так и передадим на следующую зону: это цифра 2, смещена X,Y, повернута так и вот такой машстаб» — значит что, это бинаризация с вручную выбранным уровнем отсечки?Vasyutka
24.05.2016 00:19+1посты Алексея будут про другое. Для цифр да, там бинаризация по среднему из xor (или что-то очень похожее). Лучше было бы что посложней, но не заморачивался — и так почти всегда норм работало. на следующий уровень (втором) приходят дискретные описания где какая цифра расположена, как оринетирована и масштаб. Соответственно на втором уровне выбриается такое перспективное преобразовнаие, где модель лучшим образом соответсвует наблюдаемому в одном из контекстов (т.е. в одной из перспектив). Вот это как раз то место, где уже было интересно как реализовалось (лично мне), т.к. это не xor и не растровые картинки. Похоже на работу с «мешком признаком», по-моему так называется. Вот это будет у Алексея. Но и я сейчас передалал и первую зону на такое же дисректное описание — вообще поинтереснее работает.
BelBES
23.05.2016 16:37+1Хм… результаты из поста получены при тренировке на 22 картинках?
Vasyutka
23.05.2016 16:46+1тренировки не было. Просто показали «цифры, буквы выглядят так — 22 картинки», автомобилный номер — так — еще одна картинка. За счет богатого набора контекстов этого хватило. По нескольким картинкам получать можно классы и без явных подсказок как сейчас — об этом тоже скоро напишем. вот это точно магия в сравнении с нейросетями (deeplearning) современными ИМХО будет )
Vasyutka
23.05.2016 16:51+1с учителем и афинное преобразование задано ручками — не обучал. Но в перспективе для других зон нужно будет зависимость от контекста обучить. это тоже реально.
BelBES
23.05.2016 16:52Что значит "показали"? в смысле у вас было 22 размеченных картинки?
з.ы. было бы любопытно таки взглянуть на код...
ZlodeiBaal
23.05.2016 16:55+1Вася как-то путанно сказал. У него на вход подаётся:
- 22 картинки буков и цифр
- 1 картинка того как номер выглядит
- Явно прописанная модель как можно преобразовывать символы, по сути границы допустимости того, как можно описать номер
И это всё. Остальное обирается/строиться и додумывается самим алгоритмом.

rocknrollnerd
23.05.2016 22:12+5Двачну товарищей скептиков выше: это все очень мило, и я приятно удивлен, что из цикла довольно философских, как мне показалось, статей о том, как устроен мозг, получилось что-то практическое и ML-ное. Но действительно хотелось бы посмотреть вживую (и погонять у себя) эту штуку на чем-нибудь типа MNIST.
Более того, как бы это сказать… меня слегка удивляет, что авторы сами первым делом не занялись такой, казалось бы, довольно напрашивающейся и первоочередной проверкой своих идей на практике. А то «вы все застряли в сороковых годах, а у нас тут кардинально новая концепция мышления» — это звучит замечательно (хоть и несколько эзотерично), но наверное, надо первым делом хотя бы проверить, что она работает и обгоняет всех этих немодных Лекунов, Хинтонов и прочую публику?Vasyutka
24.05.2016 00:26+1Вот хотелось бы, чтбы было так. Но если взять конкретную задачу, то она в конце концов будет решена наилучшим образом при существующей на сегодня выч.мощности доступных средств. как правило, не хуже и не лучше. Применять эту мощную концепцию и потратить года два на разработку, отладку, сборк базы, внедрение. Или же не знать никакой концепции и сделать тоже самое за теже года два. В каком смысле да — философия. Но это лишь до той поры, пока не будет больше экспериментальных данных, или не станет ясна задача, где можно за счет каких-то крутых свойств этой модели можно быстрее выстрелить и вау показать.

Randl
24.05.2016 02:14+3Если получится решить какую-то задачу на уровне топовых современных решений и сделать публикацию на какой-нибудь конференции (желательно высокого уровня), то к исследованиям подключатся и другие люди.
А ждать вау-эффекта и делиться идеями с относительно небольшой аудиторией ИМХО значительно замедляет прогресс.
Другое дело, если практических результатов уровня других решений получить не получается ни на какой задаче. Тогда правда возникает вопрос, реально ли получить такие результаты вообще.
BelBES
24.05.2016 10:34+1Если получится решить какую-то задачу на уровне топовых современных решений и сделать публикацию на какой-нибудь конференции (желательно высокого уровня), то к исследованиям подключатся и другие люди.
Нынче модно выкладывать свои ML проекты на arxiv/gitxiv… там стоящую идею заметят и без конференций.
Randl
24.05.2016 12:11Не знал об этом. Но стоящую идею и на конференцию наверное возьмут? Хотя наверняка и не знаю, сам до публикаций еще не добрался.
Но идея одна и та же: стоит дать возможность другим людям, работающим в области, оценить, опробовать и развивать идею.
BelBES
24.05.2016 12:15+2В ML сейчас такая движуха, что новые проекты и статьи появляются на основе еще не опубликованных статей, поэтому для получения проще выложить в паблик препринты + код, чем ждать какого-нибудь CVPR/ICML. Ну и да, сейчас хорошим тоном считается выложить коды к статье на github.
Randl
24.05.2016 12:27Но ведь это значительно повышает объемы информации. Если я вижу статью с топовой конференции, или препринт принятой туда статьи — то я могу рассчитывать на определенное качество статьи. А читать все препринты от всех неизвестных исследователей — никакого времени не хватит.
BelBES
24.05.2016 12:32Да, это проблема) Немного помогает фильтрация по знакомым фамилиям авторов… но читать приходится много, чтобы ничего не упустить.
Даже если читать только статьи с конференций, то там все равно развесистые списки литературы, которые обычно тоже надо прочитать.Randl
24.05.2016 12:42Ну то есть публикация препринтов имеет смысл если уже есть имя. А так вполне возможно, что статью не заметят. С таким объемом информации читать препринты от любого ноунейма вряд ли кто-то будет мне кажется.
BelBES
24.05.2016 13:13Наличие кода и публикация его вместе со статьей на gitxiv повышают для проекта шансы быть замеченым.
Randl
24.05.2016 13:34Сойдемся на том, что конференция не обязательна, но с ней количество людей прочитавших статью будет больше. И в любом случае нужна публикация с подробным описанием методики и достойными результатами.
Vasyutka
24.05.2016 00:27+3mnist, кстати, надеюсь скоро покажем
supersonic_snail
24.05.2016 11:45+3Это хорошо, спасибо. Сразу просьба — сделайте еще cifar10/cifar100. Прошу, потому что хватает алгоритмов, которые достаточно хорошо работают на mnist-е, но при этом имеют проблемы с cifar-ами.
shabanovd
24.05.2016 12:12cifar10/cifar100 кажись не пригодные датасеты, потому что по одной картинки сложно отделить объект от фона. Нужно минимум от 3 до 5 последовательных кадров со смещением. Конечно можно получить результат и из 2 кадров от камер разнесенных на небольшое растояние, но «шум» еще будет довольно высоким.
Vasyutka
24.05.2016 18:10cifar10/cifar100 точно не близко — заведомо шаг не туда был. Такие изображения требуют очень много опыта и очень развитой структуры зон, обученных и грамотно взаимодействующих друг другом. Иначе получается диван-леопард и много других смешных эффектов

varagian
24.05.2016 01:55+1Более того, удивлён столь мягким тоном комментариев.
И можно было бы детально описать, что нужно исправлять, но мне кажется, что такой список уже когда-то составлялся. Поэтому просто оставлю здесь ссылку.Vasyutka
24.05.2016 18:24+1брать энергию из ниоткуда не предлагали, да и даже 1млн р не просим :). По-этому и комментарии, думаю, настолько мягкие.
Vasyutka
24.05.2016 18:31+2Хабр — не место для повышения некой «научной репутации». Когда будет обоснованная возможность обернуть все, что получается, в форму убедительную для большинства рационально мыслящих специалистов/экспертов — обязательно сделаем. Но в статье нет утверждения, что все сказанное — истина в последней инстанции. А чье-то внимание привлечет — супер!
shabanovd
24.05.2016 12:02MNIST никогда не проверялся на людях (покрайне мере мне это не известно). У меня получался процент корректного узнавания цифры менее 90%. Значил ли что «мои алгоритмы» далеки от ИИ?
BelBES
24.05.2016 12:18+1Еслить верить этой табличке, то люди решают задачу распознавания цифр с точностью ~98%
shabanovd
24.05.2016 12:28Там есть и другие цифры, например 82% и 100% («5 Evaluation of Human level performance») и разговор идет о house numbers, а не о MNIST
donec
28.05.2016 16:21Интересно всё же выходит, выдвигаются идеи, потом «научным» способом проверяются, и выдают результат, это похоже на ранние, первичные теории по теме физики, астрономии, химии, you name it, где есть предположения как оно устроено, потом они обрастают новыми предположениями, где-то опровергаются, и потом на их основе вырабатывается новый пласт, изменяющий первичные понятия.
Извините за такие сумбурные слова, но это действительно круто)

sim0nsays
24.05.2016 22:18+2Такой момент. Вы проводили только обучение или еще и валидацию на картинках, которые модель раньше не видела?
Вот те картинки выше — это на тренировочных или на валидационных?Vasyutka
25.05.2016 13:02не на тех, что обучался. Раньше не видела
sim0nsays
26.05.2016 21:06+1О, тогда можно разговаривать. Я перечитал все комментарии в после, но все равно не понял деталей, как оно работает.
Вот есть первый уровень, на вход прходят иозбражение, голые пиксели.
На выход он должен выдать X,Y, ориентацию и масштаб для каждого знака в номере.
Как он это делает конкретно и как обучается? «В итоге вышло 700000 гипотез» — как они формируются, как тренируются, и какие из них идут на следующий уровень во время собственно распознавания?
Далее есть второй уровень, куда приходит видимо картинка и некоторые гипотезы из прошлого уровня.
Она проверяет все возможные проективные преобразования и запоминает что в зависиости от чего?
pavel_kudinov
Очень интересно!
Если не секрет, код на видеокарте — CUDA или OpenCL?
Чистый C++ или из под какого-то другого языка и/или GPGPU фреймворка?
Vasyutka
CUDA C++, сейчас еще научился dll делать и вызывать в dotNET — уже почти удобно работать.
devzona
Этот момент, поподробнее можете описать, или посвятить коротенький пост
Vasyutka
да, с утра развернуто опишу в эту ветку — не заслуживает поста ИМХО )
Vasyutka
1) в VS создать проект CUDA, в его свойствах назначить собираться как dll
2) добавить .h файл, где описать функции нужные для внешнего использования:
#ifdef __cplusplus
extern «C» {
#endif
//sample function
int __declspec (dllimport) func(unsigned char* buf,int W,int H,int *output1);
}
не забыть включить этот хедр в cu файл и описать эти функции
еще удобно назначить сборку этой dll в папку сборки dotNET проекта
3) откыть вторую студию (и так и держать обе отрытых всегда), и в dotNET проекте в класс, где оперировать этими функциями планируете:
[DllImport(«cudaDll.dll», CallingConvention = CallingConvention.Cdecl)]
static extern int func(byte[] buf, int W, int H, ref int output1);
удобно достаточно сделано, указатель — это и массив передать можно из dotNET и ref-ом вернуть значение.
Ну а потом в студии, где CUDA проект, можно назначить для debug-а исполняемый файл, как для CUDA отладчика/профайлера, так и MVSC участков C++ кода. а dotNET проект просто вызывает нативные функции из dll.