
Эта статья представляет собой формализованный ответ на публикацию на форуме IDZ. Проблема, которую описывал автор исходной публикации, заключалась в том, что производительность работы кода не увеличивалась в достаточной степени при использовании OpenMP на 8-ядерном процессоре E5-2650 V2 с 16 аппаратными потоками. Потребовалось некоторое время на форуме, чтобы помочь автору публикации и предоставить ему необходимые подсказки, однако времени для оптимизации кода было недостаточно. В этой статье описываются дальнейшие методики оптимизации в дополнение к описанным на форуме IDZ.

Должен сказать, что не знаю уровня квалификации автора первоначальной публикации. Буду исходить из того, что автор недавно окончил учебное заведение, в котором могли преподавать параллельное программирование с упором на масштабирование. На практике же чаще бывает, что системы располагают ограниченным количеством вычислительных ресурсов (потоков), поэтому следует помнить не только о масштабировании, но и об эффективности. В исходном примере кода, опубликованном на форуме, содержится базовая информация, помогающая понять, как решать проблемы эффективности (в большей степени) и масштабирования (в меньшей степени).
При подготовке кода для этой статьи я взял на себя смелость переработать образец кода, сохранив его общее устройство и компоновку. Я сохранил основной алгоритм без изменений, поскольку пример кода был взят из приложения, в котором могли быть и другие функции в дополнение к описываемому алгоритму. В предоставленном образце кода использовался массив LOGICAL (маска) для управления потоком. Образец кода мог быть написан и без логических массивов, но этот код мог представлять собой фрагмент более крупного приложения, в котором эти массивы масок могли быть необходимы в силу каких-либо причин, не столь очевидных в образце кода. Поэтому я оставил маски на месте.
Изучив код и первую попытку распараллеливания, я определил, что было выбрано не самое оптимальное место для создания параллельной области (параллельный DO). Исходный код выглядит примерно так.
При первой попытке распараллеливания пользователь применил её к циклу do j =. Это наиболее интенсивный уровень цикла, но для решения этой проблемы на этой платформе нужно работать на другом уровне.
При этом использовалось 16 потоков. Два внутренних цикла вместе выполняют 8100 итераций, что дает примерно по 506 итераций на поток (если у нас 16 потоков). Тем не менее вхождение в параллельную область осуществляется 120 раз (60*2). Работа, выполненная в самом внутреннем цикле, не имела большого значения, но потребовала ресурсов. Из-за этого параллельная область охватила значительную часть приложения. При наличии 16 потоков и 60 итераций счетчика внешних циклов (120 при использовании циклов) эффективнее создавать параллельную область в цикле do k.
Код был изменен так, чтобы выполнять цикл do k много раз и вычислить среднее время выполнения всего цикла do k. При применении методик оптимизации можно использовать разницу между средним временем работы исходного кода и переработанного кода для измерения достигнутых улучшений. У меня нет 8-ядерного процессора E5-2650 v2 для тестирования, но нашелся 6-ядерный процессор E5-2620 v2. Слегка переработанный код выдал следующие результаты:
На 6-ядерном процессоре E5-2620 v2 повышение производительности должно быть где-то в диапазоне между шестикратным и двенадцатикратным (если учесть дополнительные 15 % на гиперпоточность, то скорость должна вырасти в 7 раз). Повышение производительности в 4,74 раза. Значительно меньше, чем предполагалось: мы рассчитывали на семикратное ускорение.
В дальнейших разделах этой статьи мы рассмотрим другие методики оптимизации.
Обратите внимание, что отчет ParallelAtInnerTwoLoops указывает, что во втором запуске множитель отличался от множителя первого запуска. Причина такого поведения в удачном размещении кода (либо в неудачном). Сам по себе код не изменялся, он полностью одинаковый в обоих запусках. Разница состоит лишь в добавлении дополнительного кода и во вставке операторов вызова в эти подпрограммы. Важно помнить, что размещение тесных циклов может в значительной степени повлиять на производительность этих циклов. В некоторых случаях производительность кода может существенно измениться даже при добавлении единственного оператора.
Для упрощения чтения изменений кода текст трех внутренних циклов был заключен в подпрограмму. За счет этого становится проще изучать код и проводить диагностику с помощью профилировщика VTune. Пример из подпрограммы ParallelAtkmLoop:
Первый этап оптимизации включает два изменения.
В результате этих двух изменений производительность выросла в 2,46 раза по сравнению с первоначальной попыткой распараллеливания. Это неплохой результат, но стоит ли останавливаться на достигнутом?
В самом внутреннем цикле мы видим следующее:
Получается, что на каждую итерацию приходится неодинаковый объем работы. В таком случае лучше использовать динамическое планирование. Следующий этап оптимизации применяется к ParallelAtkmLoopDynamic. Это тот же самый код, что и ParallelAtkmLoop, но с добавлением schedule(dynamic) к !$omp do.
Одно лишь это простое изменение привело к повышению скорости в 1,25 раза. Обратите внимание, что динамическое планирование не единственный возможный способ планирования. Есть и другие типы, достойные изучения. Также помните, что для этого типа планирования часто добавляется модификатор (размера фрагмента).
Следующий уровень оптимизации, обеспечивающий ускорение еще в 1,52 раза, можно назвать агрессивной оптимизацией. Для достижения этого добавочного прироста скорости на 52 % требуются ощутимые усилия по программированию (впрочем, ничего запредельно сложного). Возможность этой оптимизации определена путем анализа ассемблерного кода в VTune.
Следует особо подчеркнуть, что нет необходимости понимать ассемблерный код для его анализа. Как правило, можно исходить из следующего:
чем больше ассемблерного кода, тем ниже производительность.
Можно провести прямую параллель: чем сложнее (объемнее) ассемблерный код, тем больше вероятность, что компилятор упустит возможности оптимизации. При обнаружении упущенных возможностей можно использовать простую методику, чтобы помочь компилятору оптимизировать код.
В коде основного алгоритма мы видим.
Запустим Intel Amplifier (VTune) и в качестве примера рассмотрим строку 540.

Это часть инструкции, осуществляющей умножение двух чисел. Для этой частичной информации можно ожидать:
Если нажать кнопку Assembly в Amplifier.
Затем сортируем по номеру строки кода.
В строке кода 540 мы видим следующее.
Для умножения двух чисел используется в общей сложности 46 ассемблерных инструкций.
Теперь перейдем к взаимному влиянию.
Эти два числа — ячейки двух массивов. У массива SLX шесть подписок, у другого массива — одна. Две последние ассемблерные инструкции: vmovss из памяти и vmulss из памяти. Мы надеялись получить полностью оптимизированный код, соответствующий нашим ожиданиям. В приведенном выше коде 44 из 46 ассемблерных функций связаны с вычислением индексов массивов для этих двух переменных. Естественно, для получения индексов в массивах может потребоваться несколько инструкций, но 44 — явно слишком много. Можно ли каким-либо образом снизить сложность?
При просмотре исходного кода (наиболее поздней версии, показанной выше) видно, что два последних подчиненных сценария SLX и один подчиненный сценарий dz являются инвариантными для двух наиболее внутренних циклов. В случае с SLX левый из двух индексов (две переменные управления наиболее внутренними циклами) представляет собой непрерывный фрагмент массива. Компилятор не распознал неизменные (находящиеся справа) индексы массива в качестве кандидатов для инвариантного кода цикла, который можно вывести из цикла. Кроме того, компилятору не удалось распознать два индекса, расположенные левее всего, для сворачивания в один индекс.
Это хороший пример возможной оптимизации, которая может быть осуществлена компилятором. В этом случае следующая процедура оптимизации, при которой инвариантные подчиненные сценарии выводятся из цикла, обеспечивает повышение производительности в 1,52 раза.
Теперь мы знаем, что значительная часть кода do включает непрерывные фрагменты массивов с несколькими подчиненными сценариями. Можно ли сократить количество подчиненных сценариев, не переписывая все приложение?
Ответ: да, можно, если инкапсулировать более мелкие срезы массивов, представленные меньшим количеством подчиненных сценариев. Как сделать это в нашем примере кода?
Я решил применить этот подход к двум уровням вложенности.
Самый внешний уровень передает фрагменты массива уровня bid.
Обратите внимание, что для массивов без указателей (распределяемых или с фиксированными размерами) массивы являются непрерывными. Это дает возможность «срезать» самые правые индексы для передачи фрагмента непрерывного массива, для чего нужно просто вычислить смещение в подмножестве более крупного массива. При этом для попытки «срезать» любые другие индексы, кроме самых правых, потребуется создать временный массив, чего следует избегать. Впрочем, в некоторых случаях даже это может быть целесообразно.
На втором вложенном уровне мы раскрыли дополнительный индекс массива цикла do k, а также сжали два первых индекса в один.
Обратите внимание, что в точке вызова передается фрагмент непрерывного массива (ссылка). Пустые аргументы вызванной процедуры указывают непрерывный фрагмент памяти такого же размера с другим набором индексов. Если вы соблюдаете осторожность при работе в Фортране, это вполне осуществимо.
Все действия по созданию кода сводятся к операциям копирования и вставке, а затем к поиску и замене. За исключением этого, поток кода не изменяется. Это мог бы сделать и внимательный начинающий программист, располагающий необходимыми инструкциями.
В будущих версиях компилятора встроенные средства оптимизации могут сделать все эти действия ненужными, но сейчас «ненужное» программирование может в некоторых случаях привести к существенному повышению производительности (в данном случае на 52 %).
Равноценная инструкция теперь такова.

Ассемблерный код теперь выглядит так.

Вместо 46 инструкций осталось 6, то есть в 7,66 раза меньше. Таким образом, снижение количества подчиненных сценариев в массиве позволяет снизить количество инструкций.
Внедрение двухуровневого вложения со «срезанием» привело к повышению производительности в 1,52 раза. Стоит ли повышение производительности на 52 % дополнительных усилий? Решайте сами, здесь все субъективно. Можно предполагать, что алгоритмы оптимизации, заложенные в будущие версии компиляторов, будут сами проводить извлечение подчиненных сценариев инвариантных массивов, что было сделано вручную выше. Но пока можно использовать описанную методику «срезания» и сжатия индексов.
Надеюсь, мои рекомендации окажутся полезными.
» Исходный код примера
Должен сказать, что не знаю уровня квалификации автора первоначальной публикации. Буду исходить из того, что автор недавно окончил учебное заведение, в котором могли преподавать параллельное программирование с упором на масштабирование. На практике же чаще бывает, что системы располагают ограниченным количеством вычислительных ресурсов (потоков), поэтому следует помнить не только о масштабировании, но и об эффективности. В исходном примере кода, опубликованном на форуме, содержится базовая информация, помогающая понять, как решать проблемы эффективности (в большей степени) и масштабирования (в меньшей степени).
При подготовке кода для этой статьи я взял на себя смелость переработать образец кода, сохранив его общее устройство и компоновку. Я сохранил основной алгоритм без изменений, поскольку пример кода был взят из приложения, в котором могли быть и другие функции в дополнение к описываемому алгоритму. В предоставленном образце кода использовался массив LOGICAL (маска) для управления потоком. Образец кода мог быть написан и без логических массивов, но этот код мог представлять собой фрагмент более крупного приложения, в котором эти массивы масок могли быть необходимы в силу каких-либо причин, не столь очевидных в образце кода. Поэтому я оставил маски на месте.
Изучив код и первую попытку распараллеливания, я определил, что было выбрано не самое оптимальное место для создания параллельной области (параллельный DO). Исходный код выглядит примерно так.
bid = 1 ! { not stated in original posting, but would appeared to be in a DO bid=1,65 }
do k=1,km-1 ! km = 60
do kk=1,2
!$OMP PARALLEL PRIVATE(I) DEFAULT(SHARED)
!$omp do
do j=1,ny_block ! ny_block = 100
do i=1,nx_block ! nx_block = 81
... {code}
enddo
enddo
!$omp end do
!$OMP END PARALLEL
enddo
enddoПри первой попытке распараллеливания пользователь применил её к циклу do j =. Это наиболее интенсивный уровень цикла, но для решения этой проблемы на этой платформе нужно работать на другом уровне.
При этом использовалось 16 потоков. Два внутренних цикла вместе выполняют 8100 итераций, что дает примерно по 506 итераций на поток (если у нас 16 потоков). Тем не менее вхождение в параллельную область осуществляется 120 раз (60*2). Работа, выполненная в самом внутреннем цикле, не имела большого значения, но потребовала ресурсов. Из-за этого параллельная область охватила значительную часть приложения. При наличии 16 потоков и 60 итераций счетчика внешних циклов (120 при использовании циклов) эффективнее создавать параллельную область в цикле do k.
Код был изменен так, чтобы выполнять цикл do k много раз и вычислить среднее время выполнения всего цикла do k. При применении методик оптимизации можно использовать разницу между средним временем работы исходного кода и переработанного кода для измерения достигнутых улучшений. У меня нет 8-ядерного процессора E5-2650 v2 для тестирования, но нашелся 6-ядерный процессор E5-2620 v2. Слегка переработанный код выдал следующие результаты:
OriginalSerialCode
Average time 0.8267E-02
Version1_ParallelAtInnerTwoLoops
Average time 0.1746E-02, x Serial 4.74На 6-ядерном процессоре E5-2620 v2 повышение производительности должно быть где-то в диапазоне между шестикратным и двенадцатикратным (если учесть дополнительные 15 % на гиперпоточность, то скорость должна вырасти в 7 раз). Повышение производительности в 4,74 раза. Значительно меньше, чем предполагалось: мы рассчитывали на семикратное ускорение.
В дальнейших разделах этой статьи мы рассмотрим другие методики оптимизации.
OriginalSerialCode
Average time 0.8395E-02
ParallelAtInnerTwoLoops
Average time 0.1699E-02, x Serial 4.94
ParallelAtkmLoop
Average time 0.6905E-03, x Serial 12.16, x Prior 2.46
ParallelAtkmLoopDynamic
Average time 0.5509E-03, x Serial 15.24, x Prior 1.25
ParallelNestedRank1
Average time 0.3630E-03, x Serial 23.13, x Prior 1.52Обратите внимание, что отчет ParallelAtInnerTwoLoops указывает, что во втором запуске множитель отличался от множителя первого запуска. Причина такого поведения в удачном размещении кода (либо в неудачном). Сам по себе код не изменялся, он полностью одинаковый в обоих запусках. Разница состоит лишь в добавлении дополнительного кода и во вставке операторов вызова в эти подпрограммы. Важно помнить, что размещение тесных циклов может в значительной степени повлиять на производительность этих циклов. В некоторых случаях производительность кода может существенно измениться даже при добавлении единственного оператора.
Для упрощения чтения изменений кода текст трех внутренних циклов был заключен в подпрограмму. За счет этого становится проще изучать код и проводить диагностику с помощью профилировщика VTune. Пример из подпрограммы ParallelAtkmLoop:
bid = 1
!$OMP PARALLEL DEFAULT(SHARED)
!$omp do
do k=1,km-1 ! km = 60
call ParallelAtkmLoop_sub(bid, k)
end do
!$omp end do
!$OMP END PARALLEL
endtime = omp_get_wtime()
...
subroutine ParallelAtkmLoop_sub(bid, k)
...
do kk=1,2
do j=1,ny_block ! ny_block = 100
do i=1,nx_block ! nx_block = 81
...
enddo
enddo
enddo
end subroutine ParallelAtkmLoop_subПервый этап оптимизации включает два изменения.
- Перемещение распараллеливания на два уровня циклов выше, на уровень цикла do k. За счет этого количество вхождений в параллельной области уменьшилось в 120 раз.
- В приложении использовался массив LOGICAL в качестве маски для выбора кода. Я переделал код, использующийся для формирования значений, чтобы избавиться от ненужных манипуляций с массивом маски.
В результате этих двух изменений производительность выросла в 2,46 раза по сравнению с первоначальной попыткой распараллеливания. Это неплохой результат, но стоит ли останавливаться на достигнутом?
В самом внутреннем цикле мы видим следующее:
... {construct masks}
if ( LMASK1(i,j) ) then
... {code}
endif
if ( LMASK2(i,j) ) then
... {code}
endif
if( LMASK3(i,j) ) then
... {code}
endifПолучается, что на каждую итерацию приходится неодинаковый объем работы. В таком случае лучше использовать динамическое планирование. Следующий этап оптимизации применяется к ParallelAtkmLoopDynamic. Это тот же самый код, что и ParallelAtkmLoop, но с добавлением schedule(dynamic) к !$omp do.
Одно лишь это простое изменение привело к повышению скорости в 1,25 раза. Обратите внимание, что динамическое планирование не единственный возможный способ планирования. Есть и другие типы, достойные изучения. Также помните, что для этого типа планирования часто добавляется модификатор (размера фрагмента).
Следующий уровень оптимизации, обеспечивающий ускорение еще в 1,52 раза, можно назвать агрессивной оптимизацией. Для достижения этого добавочного прироста скорости на 52 % требуются ощутимые усилия по программированию (впрочем, ничего запредельно сложного). Возможность этой оптимизации определена путем анализа ассемблерного кода в VTune.
Следует особо подчеркнуть, что нет необходимости понимать ассемблерный код для его анализа. Как правило, можно исходить из следующего:
чем больше ассемблерного кода, тем ниже производительность.
Можно провести прямую параллель: чем сложнее (объемнее) ассемблерный код, тем больше вероятность, что компилятор упустит возможности оптимизации. При обнаружении упущенных возможностей можно использовать простую методику, чтобы помочь компилятору оптимизировать код.
В коде основного алгоритма мы видим.
Код
subroutine ParallelAtkmLoopDynamic_sub(bid, k)
use omp_lib
use mod_globals
implicit none
!-----------------------------------------------------------------------
!
! dummy variables
!
!-----------------------------------------------------------------------
integer :: bid,k
!-----------------------------------------------------------------------
!
! local variables
!
!-----------------------------------------------------------------------
real , dimension(nx_block,ny_block,2) :: &
WORK1, WORK2, WORK3, WORK4 ! work arrays
real , dimension(nx_block,ny_block) :: &
WORK2_NEXT, WORK4_NEXT ! WORK2 or WORK4 at next level
logical , dimension(nx_block,ny_block) :: &
LMASK1, LMASK2, LMASK3 ! flags
integer :: kk, j, i ! loop indices
!-----------------------------------------------------------------------
!
! code
!
!-----------------------------------------------------------------------
do kk=1,2
do j=1,ny_block
do i=1,nx_block
if(TLT%K_LEVEL(i,j,bid) == k) then
if(TLT%K_LEVEL(i,j,bid) < KMT(i,j,bid)) then
LMASK1(i,j) = TLT%ZTW(i,j,bid) == 1
LMASK2(i,j) = TLT%ZTW(i,j,bid) == 2
if(LMASK2(i,j)) then
LMASK3(i,j) = TLT%K_LEVEL(i,j,bid) + 1 < KMT(i,j,bid)
else
LMASK3(i,j) = .false.
endif
else
LMASK1(i,j) = .false.
LMASK2(i,j) = .false.
LMASK3(i,j) = .false.
endif
else
LMASK1(i,j) = .false.
LMASK2(i,j) = .false.
LMASK3(i,j) = .false.
endif
if ( LMASK1(i,j) ) then
WORK1(i,j,kk) = KAPPA_THIC(i,j,kbt,k,bid) &
* SLX(i,j,kk,kbt,k,bid) * dz(k)
WORK2(i,j,kk) = c2 * dzwr(k) * ( WORK1(i,j,kk) &
- KAPPA_THIC(i,j,ktp,k+1,bid) * SLX(i,j,kk,ktp,k+1,bid) &
* dz(k+1) )
WORK2_NEXT(i,j) = c2 * ( &
KAPPA_THIC(i,j,ktp,k+1,bid) * SLX(i,j,kk,ktp,k+1,bid) - &
KAPPA_THIC(i,j,kbt,k+1,bid) * SLX(i,j,kk,kbt,k+1,bid) )
WORK3(i,j,kk) = KAPPA_THIC(i,j,kbt,k,bid) &
* SLY(i,j,kk,kbt,k,bid) * dz(k)
WORK4(i,j,kk) = c2 * dzwr(k) * ( WORK3(i,j,kk) &
- KAPPA_THIC(i,j,ktp,k+1,bid) * SLY(i,j,kk,ktp,k+1,bid) &
* dz(k+1) )
WORK4_NEXT(i,j) = c2 * ( &
KAPPA_THIC(i,j,ktp,k+1,bid) * SLY(i,j,kk,ktp,k+1,bid) - &
KAPPA_THIC(i,j,kbt,k+1,bid) * SLY(i,j,kk,kbt,k+1,bid) )
if( abs( WORK2_NEXT(i,j) ) < abs( WORK2(i,j,kk) ) ) then
WORK2(i,j,kk) = WORK2_NEXT(i,j)
endif
if ( abs( WORK4_NEXT(i,j) ) < abs( WORK4(i,j,kk ) ) ) then
WORK4(i,j,kk) = WORK4_NEXT(i,j)
endif
endif
if ( LMASK2(i,j) ) then
WORK1(i,j,kk) = KAPPA_THIC(i,j,ktp,k+1,bid) &
* SLX(i,j,kk,ktp,k+1,bid)
WORK2(i,j,kk) = c2 * ( WORK1(i,j,kk) &
- ( KAPPA_THIC(i,j,kbt,k+1,bid) &
* SLX(i,j,kk,kbt,k+1,bid) ) )
WORK1(i,j,kk) = WORK1(i,j,kk) * dz(k+1)
WORK3(i,j,kk) = KAPPA_THIC(i,j,ktp,k+1,bid) &
* SLY(i,j,kk,ktp,k+1,bid)
WORK4(i,j,kk) = c2 * ( WORK3(i,j,kk) &
- ( KAPPA_THIC(i,j,kbt,k+1,bid) &
* SLY(i,j,kk,kbt,k+1,bid) ) )
WORK3(i,j,kk) = WORK3(i,j,kk) * dz(k+1)
endif
if( LMASK3(i,j) ) then
if (k.lt.km-1) then ! added to avoid out of bounds access
WORK2_NEXT(i,j) = c2 * dzwr(k+1) * ( &
KAPPA_THIC(i,j,kbt,k+1,bid) * SLX(i,j,kk,kbt,k+1,bid) * dz(k+1) - &
KAPPA_THIC(i,j,ktp,k+2,bid) * SLX(i,j,kk,ktp,k+2,bid) * dz(k+2))
WORK4_NEXT(i,j) = c2 * dzwr(k+1) * ( &
KAPPA_THIC(i,j,kbt,k+1,bid) * SLY(i,j,kk,kbt,k+1,bid) * dz(k+1) - &
KAPPA_THIC(i,j,ktp,k+2,bid) * SLY(i,j,kk,ktp,k+2,bid) * dz(k+2))
end if
if( abs( WORK2_NEXT(i,j) ) < abs( WORK2(i,j,kk) ) ) &
WORK2(i,j,kk) = WORK2_NEXT(i,j)
if( abs(WORK4_NEXT(i,j)) < abs(WORK4(i,j,kk)) ) &
WORK4(i,j,kk) = WORK4_NEXT(i,j)
endif
enddo
enddo
enddo
end subroutine Version2_ParallelAtkmLoop_subЗапустим Intel Amplifier (VTune) и в качестве примера рассмотрим строку 540.
Это часть инструкции, осуществляющей умножение двух чисел. Для этой частичной информации можно ожидать:
- загрузку значения по какому-либо индексу SLX;
- умножение на значение какого-либо индекса dz.
Если нажать кнопку Assembly в Amplifier.
Затем сортируем по номеру строки кода.
В строке кода 540 мы видим следующее.
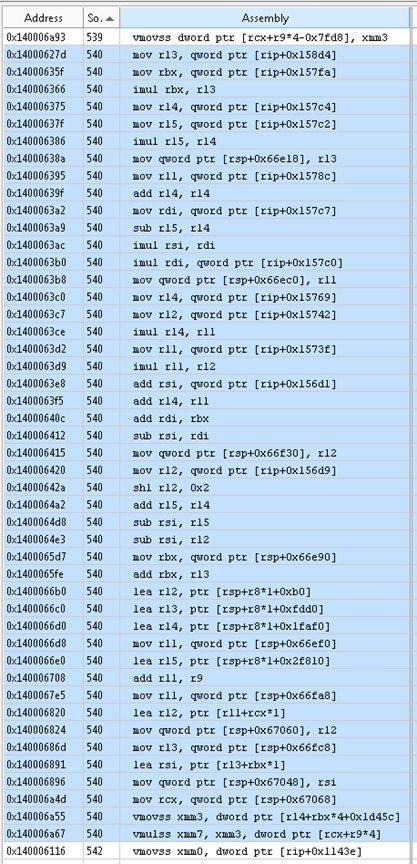
Для умножения двух чисел используется в общей сложности 46 ассемблерных инструкций.
Теперь перейдем к взаимному влиянию.
Эти два числа — ячейки двух массивов. У массива SLX шесть подписок, у другого массива — одна. Две последние ассемблерные инструкции: vmovss из памяти и vmulss из памяти. Мы надеялись получить полностью оптимизированный код, соответствующий нашим ожиданиям. В приведенном выше коде 44 из 46 ассемблерных функций связаны с вычислением индексов массивов для этих двух переменных. Естественно, для получения индексов в массивах может потребоваться несколько инструкций, но 44 — явно слишком много. Можно ли каким-либо образом снизить сложность?
При просмотре исходного кода (наиболее поздней версии, показанной выше) видно, что два последних подчиненных сценария SLX и один подчиненный сценарий dz являются инвариантными для двух наиболее внутренних циклов. В случае с SLX левый из двух индексов (две переменные управления наиболее внутренними циклами) представляет собой непрерывный фрагмент массива. Компилятор не распознал неизменные (находящиеся справа) индексы массива в качестве кандидатов для инвариантного кода цикла, который можно вывести из цикла. Кроме того, компилятору не удалось распознать два индекса, расположенные левее всего, для сворачивания в один индекс.
Это хороший пример возможной оптимизации, которая может быть осуществлена компилятором. В этом случае следующая процедура оптимизации, при которой инвариантные подчиненные сценарии выводятся из цикла, обеспечивает повышение производительности в 1,52 раза.
Теперь мы знаем, что значительная часть кода do включает непрерывные фрагменты массивов с несколькими подчиненными сценариями. Можно ли сократить количество подчиненных сценариев, не переписывая все приложение?
Ответ: да, можно, если инкапсулировать более мелкие срезы массивов, представленные меньшим количеством подчиненных сценариев. Как сделать это в нашем примере кода?
Я решил применить этот подход к двум уровням вложенности.
- На самом внешнем уровне bid (данные модуля указывают, что в фактическом коде используется 65 значений bid).
- На следующем уровне — на уровне цикла do k. Кроме того, мы объединяем два первых индекса в один.
Самый внешний уровень передает фрагменты массива уровня bid.
bid = 1 ! in real application bid may iterate
! peel off the bid
call ParallelNestedRank1_bid( &
TLT%K_LEVEL(:,:,bid), &
KMT(:,:,bid), &
TLT%ZTW(:,:,bid), &
KAPPA_THIC(:,:,:,:,bid), &
SLX(:,:,:,:,:,bid), &
SLY(:,:,:,:,:,bid))
…
subroutine ParallelNestedRank1_bid(K_LEVEL_bid, KMT_bid, ZTW_bid, KAPPA_THIC_bid, SLX_bid, SLY_bid)
use omp_lib
use mod_globals
implicit none
integer, dimension(nx_block , ny_block) :: K_LEVEL_bid, KMT_bid, ZTW_bid
real, dimension(nx_block,ny_block,2,km) :: KAPPA_THIC_bid
real, dimension(nx_block,ny_block,2,2,km) :: SLX_bid, SLY_bid
…Обратите внимание, что для массивов без указателей (распределяемых или с фиксированными размерами) массивы являются непрерывными. Это дает возможность «срезать» самые правые индексы для передачи фрагмента непрерывного массива, для чего нужно просто вычислить смещение в подмножестве более крупного массива. При этом для попытки «срезать» любые другие индексы, кроме самых правых, потребуется создать временный массив, чего следует избегать. Впрочем, в некоторых случаях даже это может быть целесообразно.
На втором вложенном уровне мы раскрыли дополнительный индекс массива цикла do k, а также сжали два первых индекса в один.
!$OMP PARALLEL DEFAULT(SHARED)
!$omp do
do k=1,km-1
call ParallelNestedRank1_bid_k( &
K_LEVEL_bid, KMT_bid, ZTW_bid, &
KAPPA_THIC_bid(:,:,:,k), &
KAPPA_THIC_bid(:,:,:,k+1), KAPPA_THIC_bid(:,:,:,k+2),&
SLX_bid(:,:,:,:,k), SLY_bid(:,:,:,:,k), &
SLX_bid(:,:,:,:,k+1), SLY_bid(:,:,:,:,k+1), &
SLX_bid(:,:,:,:,k+2), SLY_bid(:,:,:,:,k+2), &
dz(k),dz(k+1),dz(k+2),dzwr(k),dzwr(k+1))
end do
!$omp end do
!$OMP END PARALLEL
end subroutine ParallelNestedRank1_bid
subroutine ParallelNestedRank11_bid_k( &
k, K_LEVEL_bid, KMT_bid, ZTW_bid, &
KAPPA_THIC_bid_k, KAPPA_THIC_bid_kp1, KAPPA_THIC_bid_kp2, &
SLX_bid_k, SLY_bid_k, &
SLX_bid_kp1, SLY_bid_kp1, &
SLX_bid_kp2, SLY_bid_kp2, &
dz_k,dz_kp1,dz_kp2,dzwr_k,dzwr_kp1)
use mod_globals
implicit none
!-----------------------------------------------------------------------
!
! dummy variables
!
!-----------------------------------------------------------------------
integer :: k
integer, dimension(nx_block*ny_block) :: K_LEVEL_bid, KMT_bid, ZTW_bid
real, dimension(nx_block*ny_block,2) :: KAPPA_THIC_bid_k, KAPPA_THIC_bid_kp1
real, dimension(nx_block*ny_block,2) :: KAPPA_THIC_bid_kp2
real, dimension(nx_block*ny_block,2,2) :: SLX_bid_k, SLY_bid_k
real, dimension(nx_block*ny_block,2,2) :: SLX_bid_kp1, SLY_bid_kp1
real, dimension(nx_block*ny_block,2,2) :: SLX_bid_kp2, SLY_bid_kp2
real :: dz_k,dz_kp1,dz_kp2,dzwr_k,dzwr_kp1
... ! next note index (i,j) compression to (ij)
do kk=1,2
do ij=1,ny_block*nx_block
if ( LMASK1(ij) ) then Обратите внимание, что в точке вызова передается фрагмент непрерывного массива (ссылка). Пустые аргументы вызванной процедуры указывают непрерывный фрагмент памяти такого же размера с другим набором индексов. Если вы соблюдаете осторожность при работе в Фортране, это вполне осуществимо.
Все действия по созданию кода сводятся к операциям копирования и вставке, а затем к поиску и замене. За исключением этого, поток кода не изменяется. Это мог бы сделать и внимательный начинающий программист, располагающий необходимыми инструкциями.
В будущих версиях компилятора встроенные средства оптимизации могут сделать все эти действия ненужными, но сейчас «ненужное» программирование может в некоторых случаях привести к существенному повышению производительности (в данном случае на 52 %).
Равноценная инструкция теперь такова.
Ассемблерный код теперь выглядит так.
Вместо 46 инструкций осталось 6, то есть в 7,66 раза меньше. Таким образом, снижение количества подчиненных сценариев в массиве позволяет снизить количество инструкций.
Внедрение двухуровневого вложения со «срезанием» привело к повышению производительности в 1,52 раза. Стоит ли повышение производительности на 52 % дополнительных усилий? Решайте сами, здесь все субъективно. Можно предполагать, что алгоритмы оптимизации, заложенные в будущие версии компиляторов, будут сами проводить извлечение подчиненных сценариев инвариантных массивов, что было сделано вручную выше. Но пока можно использовать описанную методику «срезания» и сжатия индексов.
Надеюсь, мои рекомендации окажутся полезными.
» Исходный код примера
Поделиться с друзьями

slonopotamus
Почему нельзя просто так взять и дать статье название отражающее ее содержимое?
GlukKazan
Видимо, это как-то связано с названием оригинальной статьи?
Или это был вопрос автору (ну, или там, риторический)?
slonopotamus
1. Как это отменяет факт неинформативности ее названия?
2. «Мопед не мой, я просто разместил объяву»? Слабая отмазка, это переводящий принимает решение какой именно текст переводить и публиковать.
3. И оригинал и перевод опубликованы в корпоративных блогах интел
GlukKazan
Критика должна быть конструктивной.
Какие ваши предложения по названию статьи?
slonopotamus
Что за стереотипы, никому она ничего не должна.
Контрпример: некто опубликовал доказательство теоремы. Другой прочитал его, нашел ошибку в рассуждениях и объявил что доказательство таковым не является. Все, конец, никаких дальнейших «ну тогда сам докажи» от нашедшего ошибку не требуется.
Мы же тут не про воспитание детей говорим (в котором я всецело за воспитание через утверждения, а не отрицания).
GlukKazan
Ну вот и автор статьи ничего никому не должен. Вы имеете право на своё мнение — он на своё.
Уж простите мне моё капитанство.
GlukKazan
Да, кстати. А статья хорошая!
И останется такой (почти) под любым названием.