
В первой части этого описания попытки решения интересной конкурсной задачи я рассказал о подготовке данных для анализа и о нескольких экспериментах. Напомню, условие задачи заключалось в том, чтобы с наибольшей вероятностью определить наличие слова в словаре, не имея доступа к этому словарю в момент выполнения программы и с ограничением на объем программы (включая данные) в 64K.
Как и в прошлый раз, под катом много SQL, JS, а также нейронные сети и фильтр Блума.
Напомню, последним описанным экспериментом была попытка решить задачу через построение дерева принятия решения. Следующей проверяемой технологией был алгоритм поиска взаимосвязей, входящий в пакет Microsoft Data Mining. Вот так выглядит результат его работы:
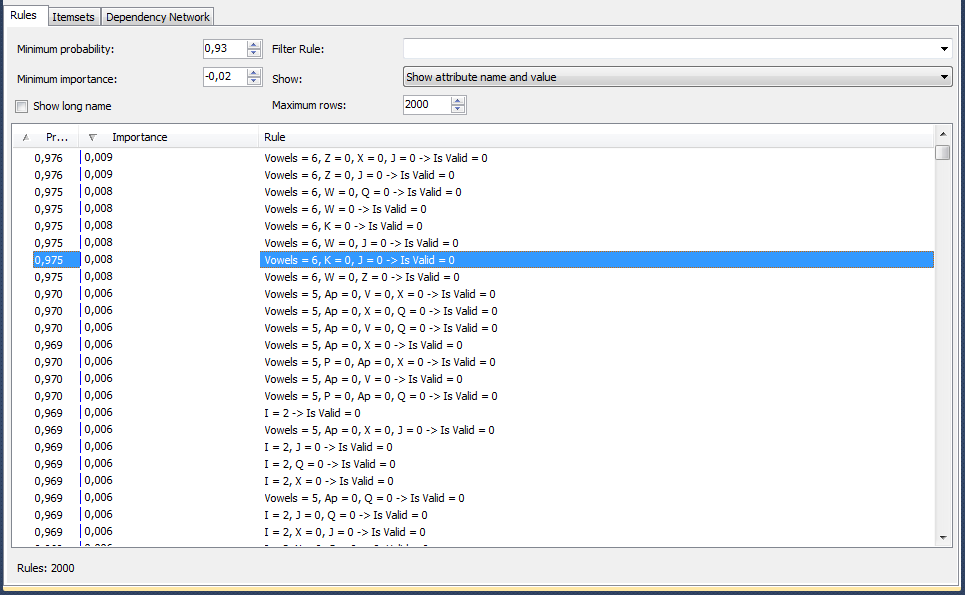
На картинке видно, что алгоритм нам показывает, что, по его мнению, если в слове 6 гласных и отсутствуют буквы "Z","X" и "J", то с вероятностью 97,5% слова нет в словаре. Проверяю, сколько тестовых данных покрывают все правила – оказывается, что большую часть. Радуюсь результату, беру правила, переключаюсь из DataGrip в WebStorm и пишу JS-код.
Код для проверки выглядит так:
var wordStat=getWordStat(word);
var wrongRules=0;
var trueRules=0;
function getWordStat (word)
{
//Считаем гласные и согласные
var result={vowels:0,consonants:0};
for (var i=0;i<word.length;i++)
{
result[word[i]]=result[word[i]]?(result[word[i]]+1):1;
if ('aeiouy'.indexOf(word[i])>-1)result.vowels++;
else if (word[i]!="'")result.consonants++;
}
return result;
}
for (i=0;i<rules.length;i++)
{
var passed=0;
var rulesCount=0;
for (var rule in rules[i]){
rulesCount++;
if((wordStat[rule.toLowerCase()]?wordStat[rule.toLowerCase()]:0)==rules[i][rule])passed++;
}
if (passed==rulesCount&&rulesCount!=0)
{
return false;
}
}
Об упаковке данных пока не думаю, просто строю в экселе json типа
var rules= [
{"Consonants":6,"H":0,"X":0,"J":0},
{"Consonants":6,"H":0,"V":0,"Q":0}
]Очередной "момент истины"… И очередное разочарование — 65%. Ни о каких 97.5% речь не идёт.
Проверяю, сколько данных и как отсеивается именно правилами – получаю много и ложноотрицательных и ложноположительных срабатываний. Начинаю понимать, в чём были два моих основных "прокола". Я не учёл повторы слов и пропорции массивов. Т.е.:
1) изначально предположил, что вероятность проверки на тестовых словах совпадёт с вероятностью в тестовых наборах. Но слова в тестовых наборах повторяются и эти повторы сильно снижают картину, если я на этих словах ошибаюсь. Кстати, сразу появляется мысль считать все повторяющиеся слова правильными.
2) алгоритмы майнинга сделали всё правильно: они увидели на миллион неправильных слов десять тысяч правильных и обрадовались вероятности в 99%. Неправильно сделал я, скормив алгоритму несоизмеримые объемы правильных и неправильных слов. Например, проверяем указанное выше правило {"Consonants":6,"H":0,"X":0,"J":0}:
select isvalid,count(*) from formining10 where Vowels=6 and Z=0 and X=0 and J=0
group by isvalid| isValid | count |
|---|---|
| 0 | 5117424 |
| 1 | 44319 |
Действительно, разница больше, чем в 100 раз, и алгоритм её распознал правильно. Но я-то не могу проигнорировать 44К правильных слов, т.к. при проверке пропорции будут примерно равны. Значит, и скармливать надо одинаковые по размеру массивы правильных и неправильных слов. Но ведь 600К неправильных слов будет мало… Беру другие 10М тестовых слов, но уже с повторами, т.е. не удаляя ни положительные, ни отрицательные дубликаты. Единственное, что делаю – убираю "мусор" через описанные в первой статье фильтры (несуществующие пары/тройки). Скармливаю майнингу… Увы, адекватных правил он при таком раскладе не находит, а при попытке построить дерево решений, говорит, что ничего хорошего не обнаружил. Напомню, все "очевидные" неправильные варианты я отрезал ещё до скармливания данных майнингу через неправильные пары/тройки.
Возвращаюсь к "описательному" методу.
Напомню, в первой части статьи для майнинга я создал на основании словаря таблицу, у которой строка соответствует слову, столбец – номеру символа в слове, а значениями ячеек является порядковый номер буквы в алфавите (27 для апострофа). Из этой таблицы я делаю "карту" для каждой длины, т.е. для какой длины на каком месте не может встречаться та или иная буква. Например, "7'4" означает, что в словах из семи букв апостроф не может быть четвёртым символом, а "15b14" означает, что в словах из 15 букв "b" ни разу не была замечена предпоследней.
Создаём таблицу с позициями букв для каждой длины слова
select length=len(word),'''' letter, charindex('''',word) number into #tmpl from words where charindex('''',word)>0
union
select length=len(word),'a' letter, charindex('a',word) number from words where charindex('a',word)>0
...
union
select length=len(word),'z' letter, charindex('z',word) number from words where charindex('z',word)>0Делаем декартово произведение букв, длин и позиций, а затем left join на существующие
select l.length,a.letter,l.length from allchars a
cross join (select 1 number union select 2 union select 3 union select 20 union select 21) n
cross join (select 1 length union select 2 union select 3 union select 20 union select 21) l
left join #tmpl t on a.letter=t.letter and t.number=n.number and t.length=l.length
where t.letter is not nullДальше дополняем номером позиции в слове "урезанную" полумеру из первой части для проверки несуществующих комбинаций из двух и трёх символов в слове.
Выбираем пары и тройки:
--Таблицы с результатом. cright и cwrong – количество правильных и неправильных слов.
create table stat2(letters char(2),pos int,cright int,cwrong int)
create table stat3(letters char(3),pos int,cright int,cwrong int)
create table #tmp2(l varchar(2),valid int,invalid int)
create table #tmp3(l varchar(3),valid int,invalid int)
--Пары
declare @i INT
set @i=0
while @i<20
begin
set @i=@i+1
truncate table #tmp2
truncate table #tmp3
--неправильные
insert into #tmp2
select substring(word,@i,2),0,count(*)
from wrongwords
where len(word)>@i
group by substring(word,@i,2)
--правильные
insert into #tmp3
select substring(word,@i,2),count(*),0
from words
where len(word)>@i
group by substring(word,@i,2)
insert into stat2
--результат
select e.letters2,@i,r.valid,l.invalid
from allchars2 e
left join #tmp2 l on l.l=e.letters2
left join #tmp3 r on r.l=e.letters2
end
declare @i INT
set @i=0
while @i<19
begin
set @i=@i+1
truncate table #tmp2
truncate table #tmp3
--неправильные
insert into #tmp2
select substring(word,@i,3),0,count(*)
from wrongwords
where len(word)>@i+1
group by substring(word,@i,3)
--правильные
insert into #tmp3
select substring(word,@i,3),count(*),0
from words
where len(word)>@i+1
group by substring(word,@i,3)
--результат
insert into stat3
select e.letters3,@i,r.valid,l.invalid
from allchars3 e
left join #tmp2 l on l.l=e.letters3
left join #tmp3 r on r.l=e.letters3
print @i
end
Копирую результат в эксель, играю с количеством в правильных и неправильных словах, оставляю только теоретически наиболее вероятные (встречается минимум у 5-10 слов) и наиболее полезные (соотношение правильно/неправильно минимум 1:300).
Делаю сводную таблицу. Результат выглядит так:
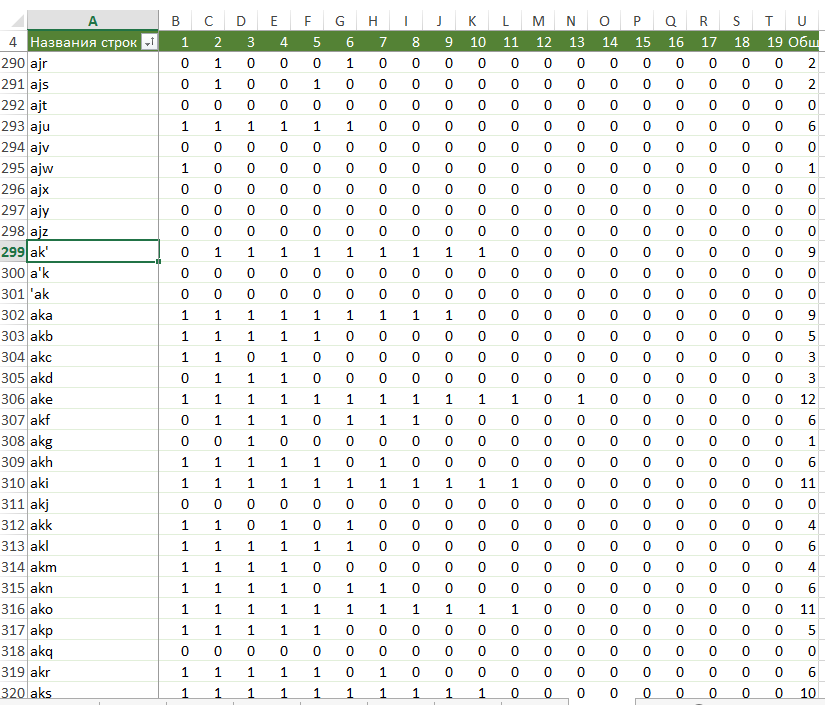
Делаю данные для программы: пара + битовая маска (см. формулу вверху картинки).
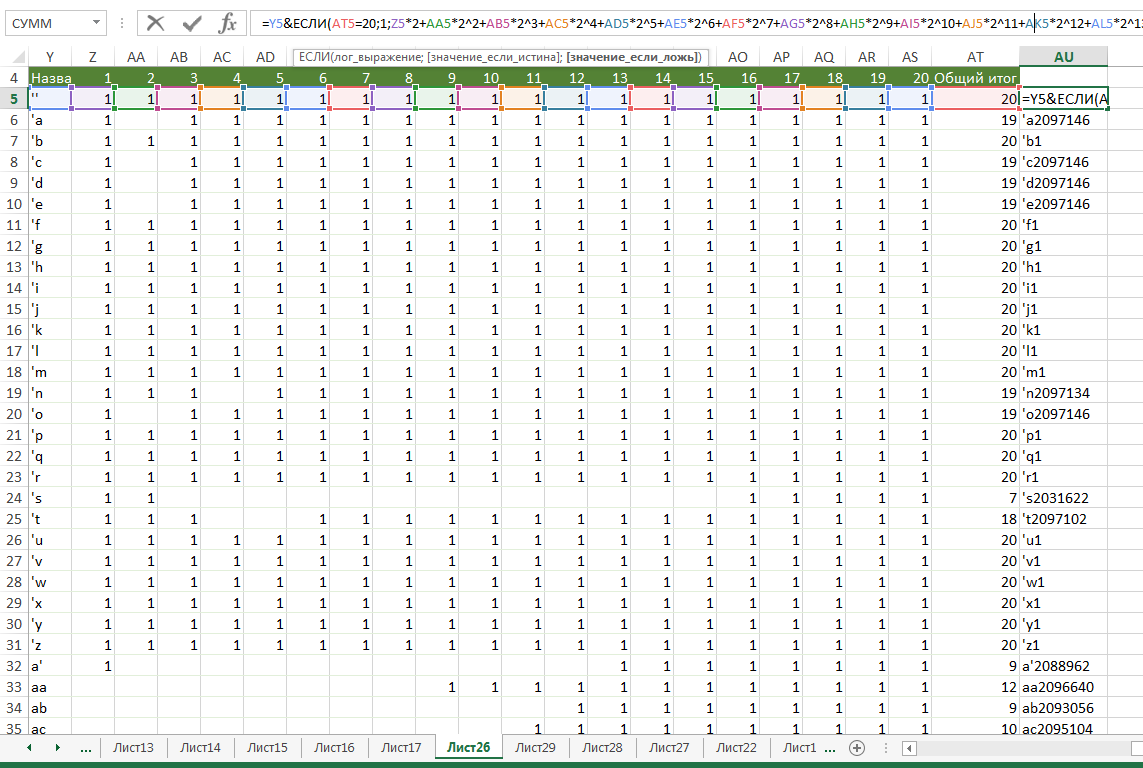
Код загрузки аналогичен описанному в первой части, а вот проверка меняется.
for (letters in letters2Map)
{
if (word.indexOf(letters)>=0) {
if ((letters2Map[letters] & 1) ==1)
{
result = return false;
}
for (var k=0;k<21;k++)
{
if (((letters2Map[letters] & Math.pow(2,k+1))==Math.pow(2,k+1))&& (letters[0] == word[k-1]) && (letters[1] == word[k]))
{
return false;
}
}
}
}
Проверяю: опять не больше 65%. Возникает желание немного "схитрить" и улучшить результат, опираясь на логику работы генератора:
- Считать все повторы правильными словами, т.к. неправильные повторяются намного реже. Есть какие-то странные явные лидеры по повторам среди неправильных, но их можно просто описать как исключения.
- Следить за пропорциями правильно/неправильно в пакетах из 100 слов и выравнивать их после перекоса 60/40.
Но оба этих варианта a) ненадёжные и б) "неспортивные", поэтому оставляю их на потом.
Хочу сделать последнюю проверку без ограничения на объем данных, чтобы убедиться в том, что "описательным" способом решить задачу невозможно. Для этого решаю к проверкам добавить все "соседствующие" пары и тройки символов. Начинаю с пар, наполняю таблицу:
declare @i INT
set @i=0
while @i<17
begin
set @i=@i+1
insert into stat2_1
select substring(word,@i,2),substring(word,@i+2,2),@i,count(*),0
from words
where len(word)>@i+3
group by substring(word,@i,2),substring(word,@i+2,2)
endСохраняю результат просто в текст, проверяю на данных – результат около 67%.
При этом нужно учитывать, что если слово не отсеивается как неправильное, то результат считается положительным. Это означает, что даже 67% достигается только благодаря тому, что примерно половина слов заведомо положительные, а это означает, что я отсеиваю чуть больше трети неправильных слов. Так как я перебрал практически все доступные варианты определения неправильности слова через комбинации букв прихожу к неутешительному выводу, что этот способ может работать только как дополнительный фильтр, и надо возвращаться к нейронным сетям. Ну не получится создать правила для опознания неправильных слов типа "numismatograph" и "troid".
Так как из-за слишком длительного обучения варианты с присутствием неправильных слов в наборе отпадают, решаю попробовать сеть Хопфилда. Нахожу готовую реализацию synaptic. Тестирую на небольшом наборе — результат на удивление неплохой. Проверяю массив на всех словах из 5 символов — результат превышает 80%. При этом библиотека даже умеет строить функцию, которая будет проверять данные без подключения самой библиотеки:
var run = function (input) {
F = {
0: 1,
1: 0,
...
370: -0.7308188776194796,
...
774: 8.232535948940295e-7
};
F[0] = input[0];
...
F[26] += F[0] * F[28];
F[26] += F[1] * F[29];
...
F[53] = (1 / (1 + Math.exp(-F[26])));
F[54] = F[53] * (1 - F[53]);
F[55] = F[56];
F[56] = F[57];
...
F[773] = (1 / (1 + Math.exp(-F[746])));
F[774] = F[773] * (1 - F[773]);
var output = [];
output[0] = F[53];
...
output[24] = F[773];
return output;
}Я наивно радуюсь (в очередной раз) и проверяю на всём массиве. Напомню, в прошлой части для обучения сетей я создал таблицу, в которой слова представлены последовательностью блоков по 5 бит, где каждый блок является двоичным представлением порядкового номера буквы в алфавите. Так как выгружаемые данные для 21*5 входных нейронов сильно превысят 64К, решаю разбивать длинные слова на две части и скармливать каждую из них.
Скрипт обучения:
var synaptic = require('synaptic');
var fs=require('fs');
var Neuron = synaptic.Neuron,
Layer = synaptic.Layer,
Network = synaptic.Network,
Trainer = synaptic.Trainer
function hopfield(size) {
var input = new synaptic.Layer(size);
var output = new synaptic.Layer(size);
this.set({
input: input,
hidden: [],
output: output
});
input.project(output, synaptic.Layer.connectionType.ALL_TO_ALL);
var trainer = new synaptic.Trainer(this);
this.learn = function(patterns) {
var set = [];
for (var p in patterns)
set.push({
input: patterns[p],
output: patterns[p]
});
return trainer.train(set, {
iterations: 50000,
error: .000000005,
rate: 1,
log:1
});
}
this.feed = function(pattern) {
var output = this.activate(pattern);
var pattern = [],
error = [];
for (var i in output) {
error[i] = output[i] > .5 ? 1 - output[i] : output[i];
pattern[i] = output[i] > .5 ? 1 : 0;
}
return {
pattern: pattern,
error: error
.reduce(function(a, b) {
return a + b;
})
};
}
}
hopfield.prototype = new synaptic.Network();
hopfield.prototype.constructor = hopfield;
var myPerceptron=new hopfield(11*5+2);
var array = fs.readFileSync('formining.csv').toString().split("\n");
var trainingSet=[];
for(i in array) {
if (!(i%10000)) console.log(i);
var testdata=array[i].split(",");
var newtestdata1=[]
var newtestdata2=[]
var length = parseInt(testdata[0]?1:0);
//Первый символ в наборе данных означает длину
testdata.splice(0, 1);
//На всякий случай дополнительный бит, означающий начало слова
newtestdata1.push(0);
for(var j=0;j<11*5;j++){
newtestdata1.push(parseInt(testdata[j]?1:0)?1:0);
}
if(length>11)
{
//Дополнительный бит, означающий окончание первой части слова
newtestdata1.push(1);
//Значение "1" дополнительного бита, означающее начало второй части слова
newtestdata2.push(1);
for(var j=11*5;j<22*5;j++){
newtestdata2.push(parseInt(testdata[j]?1:0)?1:0);
}
//Значение "0" дополнительного бита, означающее окончание второй части слова
newtestdata2.push(0);
}
else {
//Значение "0" дополнительного бита, означающее окончание полного слова
newtestdata1.push(0);
}
trainingSet.push(newtestdata1);
if(length>11){
trainingSet.push(newtestdata2);
}
}
myPerceptron.learn(trainingSet);Цикл для получения результата такой же, только вместо trainingSet.push будет получение прогноза через myPerceptron.activate(newtestdataX) и побитовое сравнение с последним элементом строки со словом, в котором я сохранил результат (файл с данными, конечно же, будет тоже другим – с добавлением неправильных слов).
Проверяю.
Катастрофа.
Ни одного правильного ответа. Точнее, на все вопросы получаю положительный ответ. Возвращаюсь к набору из пяти символов. Работает нормально. Убираю вторую часть слова – всё равно не работает как надо. Путём экспериментов натыкаюсь на странную особенность: массив на пяти символах работает нормально ровно до тех пор, пока я его не перемешаю. То есть алгоритм хорошо обучился исключительно благодаря удачному расположению звёзд. В любой другой ситуации на большом объеме данных независимо от настроек данный конкретный алгоритм подбирает множители таким образом, что они дают положительный ответ практически при любом наборе данных.
В очередной раз расстраиваюсь. До конца конкурса остался всего день, но решаю продолжить поиски. Натыкаюсь на фильтр Блума. Ставлю заведомо большой размер (10000000). Проверяю. 95%. Ура! Уменьшаю до миллиона – результат ухудшается до 81%. Решаю заменить слова их хэшем:
function bitwise(str){
var hash = 0;
if (str.length == 0) return hash;
for (var i = 0; i < str.length; i++) {
var ch = str.charCodeAt(i);
hash = ((hash<<5)-hash) + ch;
hash = hash & hash; // Convert to 32bit integer
}
return hash;
}
function binaryTransfer(integer, binary) {
binary = binary || 62;
var stack = [];
var num;
var result = '';
var sign = integer < 0 ? '-' : '';
function table (num) {
var t = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
return t[num];
}
integer = Math.abs(integer);
while (integer >= binary) {
num = integer % binary;
integer = Math.floor(integer / binary);
stack.push(table(num));
}
if (integer > 0) {
stack.push(table(integer));
}
for (var i = stack.length - 1; i >= 0; i--) {
result += stack[i];
}
return sign + result;
}
function unique (text) {
var id = binaryTransfer(bitwise(text), 61);
return id.replace('-', 'Z');
}Результат стал 88%. Выгружаю данные – много. Думаю, как уменьшить. Уменьшаю размер фильтра до 500000 – результат ухудшается до 80%. Предполагаю, что надо уменьшить количество слов.
Логичный первый шаг – убрать более, чем 100K дублей слов с "'s". Но хотелось бы ещё что-нибудь более существенное сделать. Все опробованные варианты уменьшения словаря перечислять не буду, остановлюсь на последнем, который я выбрал в качестве рабочего:
Основная идея в том, чтобы убрать из словаря слова, которые уже содержатся в других словах, но с приставками и окончаниями, а к словам-поглотителям добавить битовую маску, которая будет говорить о том, есть ли правильные слова такие же, как это, но без первых/последних 1/2/3/4 букв. Потом в момент проверки будем брать слово и пробовать его со всеми возможными приставками и окончаниями.
Например (вариант с "'s"), слово "sucralfate's4" означает, что ещё существует слово "sucralfate", а слово "suckstone16" означает, что есть ещё и слово "stone", а "suctorian's12" означает, что и "suctorian", и "suctoria" тоже будут правильными.
Осталась самая малость – придумать, как создать такой справочник. В итоге получается такой алгоритм:
Делаем таблицы с приставками и окончаниями
select word,p=substring(word,len(word),1),w=substring(word,1,len(word)-1) into #a1 from words where len(word)>2
select word,p=substring(word,1,1),w=substring(word,2,len(word)-1) into #b1 from words where len(word)>2
select word,p=substring(word,len(word)-1,2),w=substring(word,1,len(word)-2) into #a2 from words where len(word)>3
select word,p=substring(word,len(word)-2,3),w=substring(word,1,len(word)-3) into #a3 from words where len(word)>4
select word,p=substring(word,len(word)-3,4),w=substring(word,1,len(word)-4) into #a4 from words where len(word)>5
select word,p=substring(word,1,2),w=substring(word,3,len(word)-2) into #b2 from words where len(word)>3
select word,p=substring(word,1,3),w=substring(word,4,len(word)-3) into #b3 from words where len(word)>3
select word,p=substring(word,1,4),w=substring(word,5,len(word)-4) into #b4 from words where len(word)>4Общая таблица для результата
select word,
substring(word,len(word),1) s1, substring(word,1,len(word)-1) sw1,
substring(word,len(word)-1,2) s2, substring(word,1,len(word)-2) sw2,
substring(word,len(word)-2,3) s3, substring(word,1,len(word)-3) sw3,
IIF(len(word)>4,substring(word,len(word)-3,4),'') s4, IIF(len(word)>4,substring(word,1,len(word)-4),'') sw4,
substring(word,1,1) p1,substring(word,2,len(word)-1) pw1,
substring(word,1,2) p2,substring(word,3,len(word)-2) pw2,
substring(word,1,3) p3,substring(word,4,len(word)-3) pw3,
IIF(len(word)>4,substring(word,1,4),'') p4,IIF(len(word)>4,substring(word,5,len(word)-4),'') pw4,
se1=null,se2=null,se3=null,se4=null,pe1=null,pe2=null,pe3=null,pe4=null,excluded=0
into #tmpwords from words where len(word)>2Индексы, чтобы не ждать вечность
create index a1 on #tmpwords(word)
create index p0 on #tmpwords(s1)
create index p1 on #tmpwords(sw1)
create index p2 on #tmpwords(s2)
create index p3 on #tmpwords(sw2)
create index p4 on #tmpwords(s3)
create index p5 on #tmpwords(sw3)
create index p6 on #tmpwords(s4)
create index p7 on #tmpwords(sw4)
create index p20 on #tmpwords(p1)
create index p30 on #tmpwords(pw1)
create index p21 on #tmpwords(p2)
create index p31 on #tmpwords(pw2)
create index p41 on #tmpwords(p3)
create index p51 on #tmpwords(pw3)
create index p61 on #tmpwords(p4)
create index p71 on #tmpwords(pw4)Считаем и сохраняем количество слов с каждой приставкой и окончанием каждой длины:
select p into #a11 from #a1 a join words w on w.word=a.w and len(w.word)>2
group by p
having count(*)>1
select p into #a21 from #a2 a join words w on w.word=a.w and len(w.word)>2
group by p
having count(*)>1
select p into #a31 from #a3 a join words w on w.word=a.w and len(w.word)>2
group by p
having count(*)>1
select p into #a41 from #a4 a join words w on w.word=a.w and len(w.word)>2
group by p
having count(*)>1
select p into #b11 from #b1 a join words w on w.word=a.w and len(w.word)>2
group by p
having count(*)>1
select p into #b21 from #b2 a join words w on w.word=a.w and len(w.word)>2
group by p
having count(*)>1
select p into #b31 from #b3 a join words w on w.word=a.w and len(w.word)>2
group by p
having count(*)>1
select p into #b41 from #b4 a join words w on w.word=a.w and len(w.word)>2
group by p
having count(*)>1Помечаем слова-поглотители в таблице с результатом
update w set se1=1 from #tmpwords w join #a11 a on a.p=w.s1 join #tmpwords t on t.word=w.sw1
update w set se2=1 from #tmpwords w join #a21 a on a.p=w.s2 join #tmpwords t on t.word=w.sw2
update w set se3=1 from #tmpwords w join #a31 a on a.p=w.s3 join #tmpwords t on t.word=w.sw3
update w set se4=1 from #tmpwords w join #a41 a on a.p=w.s4 join #tmpwords t on t.word=w.sw4
update w set pe1=1 from #tmpwords w join #b11 a on a.p=w.p1 join #tmpwords t on t.word=w.pw1
update w set pe2=1 from #tmpwords w join #b21 a on a.p=w.p2 join #tmpwords t on t.word=w.pw2
update w set pe3=1 from #tmpwords w join #b31 a on a.p=w.p3 join #tmpwords t on t.word=w.pw3
update w set pe4=1 from #tmpwords w join #b41 a on a.p=w.p4 join #tmpwords t on t.word=w.pw4Создаём объединённый результат для того, чтобы выбрать наиболее частые варианты
select s1 p,count(*) cnt into #suffixes from #tmpwords where se1 is not NULL group by s1
union all
select s2,count(*) from #tmpwords where se2 is not NULL group by s2
union all
select s3,count(*) from #tmpwords where se3 is not NULL group by s3
union all
select s4,count(*) from #tmpwords where se4 is not NULL group by s4
select p1,count(*) cnt into #prefixes from #tmpwords where pe1 is not NULL group by p1
union all
select p2,count(*) from #tmpwords where pe2 is not NULL group by p2
union all
select p3,count(*) from #tmpwords where pe3 is not NULL group by p3
union all
select p4,count(*) from #tmpwords where pe4 is not NULL group by p4Оставляем только те, которые встречаются больше, чем в 100 словах.
select *,'s' type ,IIF(cnt>100,0,1) excluded into #result from #suffixes
union all
select *,'p' type, IIF(cnt>100,0,1) excluded from #prefixesОбнуляем статистику
update #tmpwords set se1=null,se2=null,se3=null,se4=null,pe1=null,pe2=null,pe3=null,pe4=nullУдаляем "лишние" приставки и окончания
delete a from #a11 a join #result r on r.p=a.p and r.type='s' and excluded=1
delete a from #a21 a join #result r on r.p=a.p and r.type='s' and excluded=1
delete a from #a31 a join #result r on r.p=a.p and r.type='s' and excluded=1
delete a from #a41 a join #result r on r.p=a.p and r.type='s' and excluded=1
delete a from #b11 a join #result r on r.p=a.p and r.type='p' and excluded=1
delete a from #b21 a join #result r on r.p=a.p and r.type='p' and excluded=1
delete a from #b31 a join #result r on r.p=a.p and r.type='p' and excluded=1
delete a from #b41 a join #result r on r.p=a.p and r.type='p' and excluded=1
Обновляем статистику для оставшихся наиболее часто встречаемых.
update w set se1=1 from #tmpwords w join #a11 a on a.p=w.s1 join #tmpwords t on t.word=w.sw1
update w set se2=1 from #tmpwords w join #a21 a on a.p=w.s2 join #tmpwords t on t.word=w.sw2
update w set se3=1 from #tmpwords w join #a31 a on a.p=w.s3 join #tmpwords t on t.word=w.sw3
update w set se4=1 from #tmpwords w join #a41 a on a.p=w.s4 join #tmpwords t on t.word=w.sw4
update w set pe1=1 from #tmpwords w join #b11 a on a.p=w.p1 join #tmpwords t on t.word=w.pw1
update w set pe2=1 from #tmpwords w join #b21 a on a.p=w.p2 join #tmpwords t on t.word=w.pw2
update w set pe3=1 from #tmpwords w join #b31 a on a.p=w.p3 join #tmpwords t on t.word=w.pw3
update w set pe4=1 from #tmpwords w join #b41 a on a.p=w.p4 join #tmpwords t on t.word=w.pw4Помечаем "поглощённые" слова
update t set excluded=1 from #tmpwords w join #a11 a on a.p=w.s1 join #tmpwords t on t.word=w.sw1
update t set excluded=1 from #tmpwords w join #a11 a on a.p=w.s1 join #tmpwords t on t.word=w.sw1
update t set excluded=1 from #tmpwords w join #a21 a on a.p=w.s2 join #tmpwords t on t.word=w.sw2
update t set excluded=1 from #tmpwords w join #a31 a on a.p=w.s3 join #tmpwords t on t.word=w.sw3
update t set excluded=1 from #tmpwords w join #a41 a on a.p=w.s4 join #tmpwords t on t.word=w.sw4
update t set excluded=1 from #tmpwords w join #b21 a on a.p=w.p2 join #tmpwords t on t.word=w.pw2
update t set excluded=1 from #tmpwords w join #b31 a on a.p=w.p3 join #tmpwords t on t.word=w.pw3
update t set excluded=1 from #tmpwords w join #b41 a on a.p=w.p4 join #tmpwords t on t.word=w.pw4
Профит :-)
select excluded,count(*) cnt from #tmpwords group by excluded| excluded | cnt |
|---|---|
| 0 | 397596 |
| 1 | 232505 |
Справочник сжался на 232505 записей "без потерь".
Теперь надо сделать проверку. Она сильно усложнилась и замедлилась из-за необходимости перебора всех возможных приставок и окончаний:
//Проверяем слово без изменений
result=bloom.test(unique(word))
if(result){
return true;
}
//Потом начинаем искать его модификации
for(var i=0;i<255;i++)
{
//Если слово само является словом-поглотителем
result=bloom.test(unique(word+i))
if(result){
return true;
}
//Проверяем с приставками и окончаниями
for (var part in parts ){
//1-окончание,2-приставка
var testword=(parts[part]==2?part:"")+word+(parts[part]==1?part:"");
//Количество символов является степенью двойки в битовой маске, приставки смещены на 4 бита
bitmask=Math.pow(2,(parts[part]-1)*4+part.length);
//Проверяем только допустимые варианты
if(i&bitmask==bitmask){
result=bloom.test(unique(testword+i))
if (result){
return true
}
}
}Запускаю. Результат ухудшился. Но ведь он должен был улучшиться! Времени не остаётся, отладчик в вебсторме жутко глючит, разобраться уже не успеваю. Отправлять то, что есть, смысла нет, но было интересно. Надеюсь, и вам тоже. "Отпуск" заканчивается, пора возвращаться к своим баранам своему проекту. Спасибо за внимание.
Комментарии (30)

rodgar
30.05.2016 10:38+2В отсутствие wtire-аккаунта, попытаюсь откомментировать тут, может примут…
За пару дней до окончания конкурса пришел к мысли об обучении на входящих данных.
Для эффективного обучения были нужны десятки миллионов слов, а у меня были только 6,5M, что бы не ждать выкачивания сделал генератор
if (rand(1) < 0.5) {return rand(0, 10000)} else {return rand(10000, 40000)}
Сначала понял что можно обучить базу до 99,98%. Не поверив в счастье несколько раз перечитал условия конкурса и решил рискнуть.
Основная проблема в проседании на старте, для нивелирования необученности поставил алгоритмы эвристика+обучение последовательно. Эвристика дает 75% (тут у меня был самый популярный вариант суффиксы + двойки\тройки), поэтому после обучения базы до этого процента она отключается что бы не мешать.
Результат: i.imgur.com/IK3LCZ6.png
На графике прогон имеющихся 6,5М слов 5 раз по кругу, поэтому мат.ожидание неправильных x5 от нормального и обучение прошло некорректно. Как результат асимптота в районе 91% На корректных данных к 20М получается 95%, 100М дают 99,9%.
Для эффективного использования памяти база очищается от слов с низким мат. ожиданием, потребление памяти растет до 1,2Gb к 10М и стабилизируется на этом уровне. Скорость работы порядка 1М слов в минуту.
Осталось дождаться решения организаторов по кол-ву запусков.
Per_Ardua
30.05.2016 11:59Я правильно понимаю, что ты запихал не результат сетки, а саму сетку, и она у тебя обучается в процессе работы программы? Если так, то это реально круто :)
u1d
30.05.2016 12:25+1«Сетка» скорее всего в виде массива с частотой, ключи в котором — хэши слов. Стат. метод работает только при истинности предпосылки о «редкости» неправильных слов. Если набор неправильных слов в тестовой выборке ограничить примерно тем же количеством, что и словарь правильных слов, то выигрыша от «дообучения» не будет.

Zavtramen
30.05.2016 12:28Тогда остальные алгоритмы тоже сольют, у большинства false positive в разы больше false negative.

Randl
30.05.2016 13:48Сольют, но не настолько. Если я правильно понимаю, если ограничить словарь не-слов размером словаря слов, то к 5-6М анализ частот сольётся до уровня
return true;Zavtramen
30.05.2016 13:59+1Все верно, результат будет в районе 50%. А насчет того что остальные сольют я уже не уверен. У них результаты по идее сильно измениться не должны.
rodgar
30.05.2016 14:07Если написано адекватно то при невозможности обучения алгоритм отвечает «я не знаю». Он может так ответить и после 10 объявлений и после 10М.
Zavtramen
30.05.2016 14:10Да, но к этому надо быть изначально готовым. Т.е. надо предположить, что тестовый генератор может изменится. А организаторы обещали его не менять. Вот только понять, что его дурят он сможет далеко не сразу.
Randl
30.05.2016 14:11Как достоверно определить невозможность обучения? Какой алгоритм использовать взамен?
Zavtramen
30.05.2016 14:13Процент выдачи правильных начнет расти слишком быстро, быстрее чем на нормальных данных, это несложно отследить. А взамен использовать те же алгоритмы что и остальные: блюм и пр.
Randl
30.05.2016 14:32Тогда на неравномерных данных будет отключаться, даже если они норм.
Допустим первые 1000 (10, 10000) слов правильные. Или из первых 40000 каждое повторяется минимум четырежды.
Короче, лучше, но не панацея.
Zavtramen
30.05.2016 14:34Надо определить для себя разумный порог при котором мы точно уверены что нас дурят. Я и говорю, что понять это заведомо можно далеко не сразу, но то что точно можно понять это без сомнения.
Randl
30.05.2016 14:37Да нет. Для любого алгоритма можно попасть на (или специально подобрать) плохие данные. И результативность в худшем случае — одна из метрик.
Zavtramen
30.05.2016 14:39Я обсуждал только тот вариант, когда генератор выдает не-слова из какого-то определенного набора.
Randl
30.05.2016 15:01Ну подобрать метод выдачи слов и не-слов так, чтобы частотный анализ именно в вашей реализации отключался или наоборот, безбожно врал но не отключался, можно практически к любой реализации "умного" анализатора.
rodgar
30.05.2016 14:58>Или из первых 40000 каждое повторяется минимум четырежды
Вы не поверите) Генератору слов в задаче далеко до идеального.
Например в первых 63к 'phy' встречается 10 раз. В 250к уже 32 раза. При среднем мат.ожидании 0,1 и 0,4 соот-но. Превышение на несколько порядков. И это не правильное слово.
С наскоку, как многие предлагают «словарик с каунтерами», получается ~80%.
Лечится подсчетом мат. ожидания топа выборки и его размера. Для правильных слов есть ограничение снизу\сверху. Снизу отсекаем неверные редкие, сверху отсекаем откровенные заскоки генератора. Пока топ слишком мал или слишком велик (но я заложил только снизу) никаких прогнозов не даем.
Если генератор переделать в режим 50\50 и установить ограничение на размер топа сверху то выборка никогда не обучится.Randl
30.05.2016 15:10В идеальном рандоме это как раз вполне норм.
Я говорю о том, что для любого алгоритма есть "плохие" и "хорошие" входные данные. Для анализа слов плохие входные — это всякие опечатки похожие на нормальные слова, или суффикс от одного слова, приставленный к другому. Для анализа частот — просто определенный порядок слов и не-слов.
ИМХО, в отрыве от ограничений на генератор, первое лучше чем второе. Хотя в реальной жизни данные первого типа встречаются скорее всего чаще.
Zavtramen
30.05.2016 15:12Дело не совсем в генераторе. Все дело в том, что на таких небольших длинах слов, кол-во не-слов крайне ограничено. Например для длины в 1 символ такое не-слово всего-то одно, это апостроф. Вот и получается, что генератор пытается генерировать не только одинаковое кол-во слов и не-слов, но и чтобы распределение по длинам слов было одинаковым. Т.е. выдали 20 однобуквенных слов, значит надо выдать и 20 однобуквенных не-слов, которое у нас всего одно. С двухбуквенными комбинациями такая же история, с трехбуквенными правда насколько я помню кол-во не-слов больше кол-ва слов, но генератор ведь тоже не все подряд генерит, а с разными степенями сходства с настоящими словами. Т.е. на маленьких длинах слов ему просто не хватает пространства для маневра.

n0isy
30.05.2016 12:40+1Неизвестен результат работы каждой конкретной функции, каким образом сеть учится?
Zavtramen
30.05.2016 13:24Словарь слов ограничен, а словарь не-слов — нет. Просто запоминает все входящие слова и те которые часто повторяются считает словами из словаря. И там нет никакой сети. Там десяток строк кода.
Randl
30.05.2016 13:52Жаль, что конкурс прошел мимо меня — узнал о нем только из первой части этой статьи.
Интересно, будут ли в ТОП10 действительно уникальные решения? Исходя из комментов под статьями о конкурсе, набор идей более-менее стандартен: суффиксы, блум-фильтр, нейросети, анализ частот.
Zavtramen
30.05.2016 14:15Нейросетей там скорее всего не будет.
Randl
30.05.2016 14:33Но идея эта приходила в голову многим.
Zavtramen
30.05.2016 14:35И не только эта ;) Don_Eric к примеру сыпал идеями как из рога изобилия, я про многие вещи даже не слышал.

FlashManiac
30.05.2016 17:27Интересно а никто не пробовал вытащить часть словаря из ПИ? )))
Zavtramen
30.05.2016 17:30+2И это тоже обсуждали. Но там очевидно что смещение каждого слова займет больше места чем сами слова.
FlashManiac
30.05.2016 17:41Ну а если разбить словарь на куски и каждому куску искать смещение? По идее кусок встречается чаще чем все вместе.
Zavtramen
30.05.2016 17:43Все равно выйдет дороже. В лучшем случае вы сконвертите словарь в смещения, которые в сумме займут столько же ), но попробуйте.
Per_Ardua
Я тоже сначала попался на эту удочку, но дело в том, что алгоритм после этого помимо правильных слов (которые он находит в 100% случаев), находит множество неправильных.
Да и ужать оставшиеся 300000 слов в 64KiB, даже с trie patricia и gzip'ом не получится. У меня получилось ужать только чуть больше 100000 слов в отведенные рамки памяти. Да и то, все слова не превышали определенную длину.
Но за статью Спасибо, было интересно узнать, как эту задачу решали другие.