

Я волком бы выгрыз бюрократизм!
Владимир Маяковский
Рассмотрим в этой статье проблему стандартизации записей. Стандартизация, прежде всего, нужна при импорте миллионов записей, накопившихся за десятилетия. Данные, имеющие разную кодировку страниц из разных автоматизированных систем, собираются в единую базу информационной системы. В таком случае, обращение к функциям чтения строк по ascii, типа QRchar себя не оправдывает, поскольку формат Юникода от записи к записи отличается. К тому же кириллица в словах часто бывает перемешана с цифрами и латиницей (например, когда вместо 'ч' пишется '4'). При этом прямая циклическая замена цифр и латиницы на кириллицу в строке невозможна, так как цифры с латиницей встречаются в и обозначениях.
Пользовательские справочники позволяют отслеживать и фиксировать закономерности неправильного написания тех или иных фрагментов, указывая, на что их менять в общем цикле. По справочнику окончаний можно распознать часть речи, а по части речи определить алгоритм передвижения слова в строке для приведения к шаблонному виду.

С подобной проблемой мне часто приходится сталкиваться при систематизации тысяч записей, которые я получаю после сканирования.

Если не избавиться от недоработанного формата записей, неполноценная сортировка замедлит работу в несколько раз.
Если данные должны оставаться в нетронутом виде, предлагаю использовать утилиту, меняющую только отображение записей.

В промежуточные таблицы на базе MS Access, как вариант, с применением технологии ADO помещаем одни и те же данные двух видов. Записи перемещаем из полученного в работу отчета ApEx в резервную промежуточную предварительно очищенную таблицу ADOTableReserve при выполнении запроса или циклическим перебором, который описан ниже. Резервируем в одной таблице ADOTableReserve данные в нетронутом виде. Определяем количество строк i_RecordCount и столбцов i_ColumnCount, а так же и номер столбца i_String, который содержит подлежащие стандартизации записи отчета ApEx:
openDialog := TOpenDialog.Create(self);
openDialog.Filter := '*.xls;*.xlsx|*.xls;*.xlsx';
if openDialog.Execute then
begin
ApEx := CreateOleObject ('Excel.Application');
try
ApEx.Workbooks.Open(openDialog.FileName,0,true);
ApEx.DisplayAlerts := false;
openDialog.Free;
except
showmessage ('Файл для обработки данных не определен!');
end;
ApEx.Workbooks.Close;
ApEx.Application.quit;
ApEx := Unassigned;
openDialog.Free;
end;
for i := 1 to i_ RecordCount do
begin
begin ADOTableReserve.Append;
for c:=1 to i_ColumnCount do
begin
ADOTableReserve.FieldByName('a'+inttostr(ColumnCount)).AsString:=
Ap.ActiveSheet.Cells[i, ColumnCount];
end;
ADOTableReserve.Post;
end;
NB: FieldByName передает информацию о номере столбца в отчете MS Excel.
В другой таблице ADOTableDebug приводим эти записи к шаблонному написанию. Данные из ADOTableReserve перемещаются в предварительно очищенную отладочную таблицу ADOTableDebug по тому же принципу, но уже с обращением к функции Pattern():
ADOTableDebug.FieldByName('a'+inttostr(ColumnCount)).AsString:= Trim(AnsiUpperCase(ADOTableReserve.FieldByName('a'+inttostr(ColumnCount)).AsString));
if ColumnCount = i_String then Pattern ();
NB: функция Pattern () обращается к ряду пользовательских справочников и приводит записи к шаблонному виду.
Если ситуация требует сравнивать записи с их шаблонным написанием, то утилита снабжается соответствующей промежуточной таблицей перечень шаблонов в утилите, хранящей эти шаблоны:
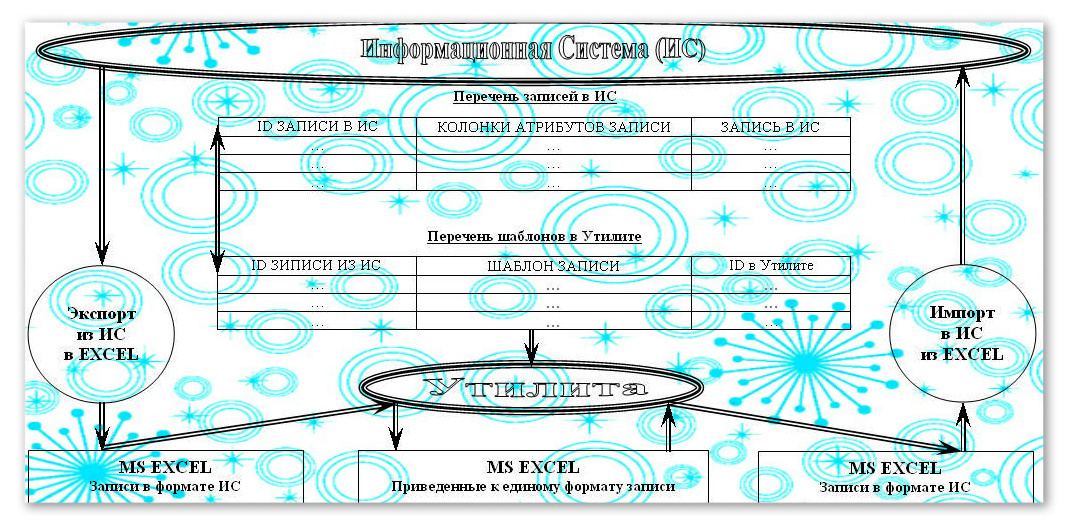
В противном случае определяем существительные по справочнику окончаний и ставим их вперед. Меняем в существительных цифры и латиницу на кириллицу. Остальные слова в записях приводим к верхнему регистру. Отображаем в экранной форме обе таблицы. Осуществляем возможность сортировки записей в гриде по нажатию на заголовок столбца. Используем функцию индексного поиска активной записи в одной таблице для быстрого перехода к той же записи в другой. Анализируем данные, формируем для дальнейшей работы с данными отчет формата MS Excel, отдаем отчет в работу с записями шаблонного вида. Отчет дополняется комментариями в рабочих столбцах. При необходимости внести комментарии в базу Информационной системы по описанному выше алгоритму в таблице ADOTableDebug находим строки, соответствующие записям отчета формата MS Excel. Идентификаторы строк промежуточных таблиц ADOTableReserve и ADOTableDebug совпадают. Обновляем таблицу ADOTableReserve комментариями из таблицы ADOTableDebug. Вернувшись к первоначальному виду записей, формируем отчет формата MS Excel для импорта комментариев в базу Информационной системы. Если дополненный комментариями в рабочих столбцах отчет формата MS Excel может содержать идентификаторы строк Информационной Системы, то записи к первоначальному виду не приводим. Тогда для импорта комментариев в базу Информационной системы передаем отчет с шаблонным написанием слов.

Когда удается достичь согласования на замену всех записей в единой для всех базе данных, обновляемой в режиме клиент-сервер одновременно, тогда и начинается самое интересное – коллективная доработка пользовательских справочников, используемых функцией Pattern (), позволяющей стандартизировать записи.
Комментарии (9)

pavlyuts
19.07.2016 17:24Я, конечно, дико извиняюсь, но у меня вопрос:
А использовать нормальные системы класса ETL/MDM/DQ принципиально нельзя? Ну, собственно, которые специально предназначены для решения задач сведения данных и делают это с гораздо меньшим геморроем и более высоким качеством?
А тут получился прекрасный костыль красного дерева с инкрустацией и лакировкой :)
Beetle_ru
20.07.2016 19:16Вы про абсурдность функции Pattern ()? Мы про необходимость сохранения целостности записей на этапе обработки соответствующих этим записям данных. Заметим, что функция Pattern () упоминается вскользь. Если кому-то проще обращение к тому, что называется 'нормальные системы класса ETL/MDM/DQ', то это ничего не меняет. Смотрите нашу новую статью в продолжение темы конвертации — 'Адаптация SQL' о совместимости СУБД, где в PostgreSQL создается БД из скрипта MySQL
pavlyuts
25.07.2016 11:45Объясняю. Вы здесь сосредоточены на технических деталях, а не на бизнес-результате, раз. Второе, если у вас действительно задача обработать в полезный результат миллионы исторических записей, то вы с ними делаете где-то 10% от того, что с ними СЛЕДОВАЛО бы делать. Естественно, не самодельными костылями, а специально для этого предназначенными средствами. А там используются и нечеткая логика, и подобие, и предварительная валидация/актуализация/нормализация отдельных полей, ну и вишенкой на торте — дедубликация массивов и построение мастер-массива.
То есть как самопальное, простое, и доступное решение проблемы оно, наверное, весьма даже хорошо, хотя, еще раз, бизнес-проблему оно решает на тройку с минусом. Особенно если Вам приходится сливать данные из трех-пяти унаследованных систем с целью получить нормальную, к примеру, клиентскую базу где таки одна запись-один клиент, и эта запись содержит всю совокупность информации из всех исходных источников. То есть те самые пресловутые мастер-данные, aka Customer Data Integration.
Естественно, вся эта история стоит денег, и немалых. «Но можно и не платить! Если Вас не интересует результат...» (с) Жванецкий
ice2heart
Шикарные схемы.
Nekto_Habr
У Тинькофф всегда передовой дизайн :)