

Одна из главных новостных сенсаций последних дней — подписание так называемого «пакета Яровой». Гвоздь программы — требование по хранению трафика до полугода и метаданных в течение трёх лет. Эта законодательная инициатива превратилась в полноценные законы, которые придётся соблюдать. По сути, речь идёт о повсеместном создании постоянно пополняемых архивов, что требует решения всевозможных вопросов, в том числе связанных с выбором подходящих систем хранения данных.
Архивирование трафика и метаданных не предполагает необходимости в быстром доступе. Эта информация никак не будет использоваться в повседневной деятельности компаний, она должна лишь складироваться на случай запроса властей. Это во многом облегчает задачу создания архивов, позволяя упростить их архитектуру.
В целом архив должен выполнять пять основных функций:
- Сохранение данных для будущего использования.
- Обеспечение постоянного доступа пользователей к хранимым данным.
- Обеспечение конфиденциальности доступа.
- Снижение нагрузки на рабочие системы за счёт переноса в архив статических данных.
- Использование политик хранения данных.
Передаваемый пользователями трафик и метаданные отличаются широким разнообразием и отсутствием структурированности. Добавьте к этому огромный объём и скорость прироста информации, особенно характерные для крупных компаний и сервисов, и получится классическое определение больших данных. Иными словами, изменения в законодательстве требуют массового решения проблемы хранения больших данных, постоянно и с большой скоростью поступающих в архивные системы. Поэтому архивы должны быть не только высокопроизводительны, но и иметь отличную горизонтальную масштабируемость, чтобы при необходимости можно было относительно просто увеличить мощности хранилища.
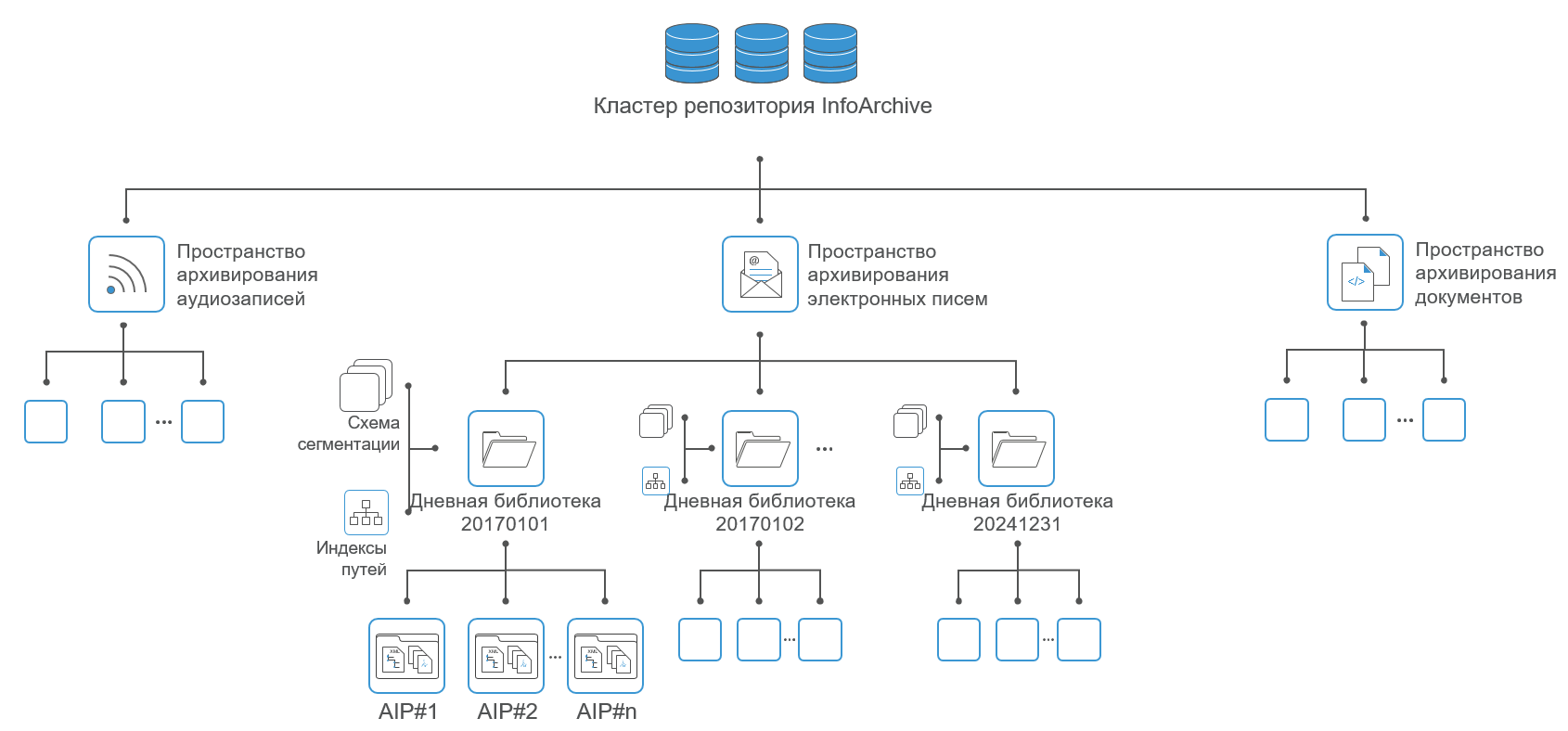
Архивирование больших данных
Для решения таких задач предназначена платформа EMC InfoArchive, о ней мы писали год назад. Это гибкая и мощная платформа архивирования корпоративного класса, представляющая собой комбинацию из СХД (NAS или SAN) и программной платформы архивирования.
К преимуществам InfoArchive можно отнести:
- Поддержка международных стандартов, в том числе открытые стандарты XML и OAIS (Open Archival Information System)
- высокую степени безопасности хранимых данных,
- удобство управления большими объёмами структурированных и неструктурированных данных,
- а также широкие возможности по конфигурированию и масштабированию.
InfoArchive состоит из следующих компонентов:
- Веб-приложение: основное приложение, обеспечивающее простой доступ к большинству настроек и функций системы.
- Сервер: сервисы архивирования для Web Server.
- XML-репозиторий (xDB): сервисы хранения данных для InfoArchive Server. База xDB включена в дистрибутив InfoArchive и автоматически устанавливается как часть ядра системы.
- Оболочка [опционально]: инструмент на основе командной строки для выполнения административных задач, добавления данных, управления и запроса объектов.
- Фреймворк для добавления данных [опционально].
Высокоуровневая архитектура InfoArchive:
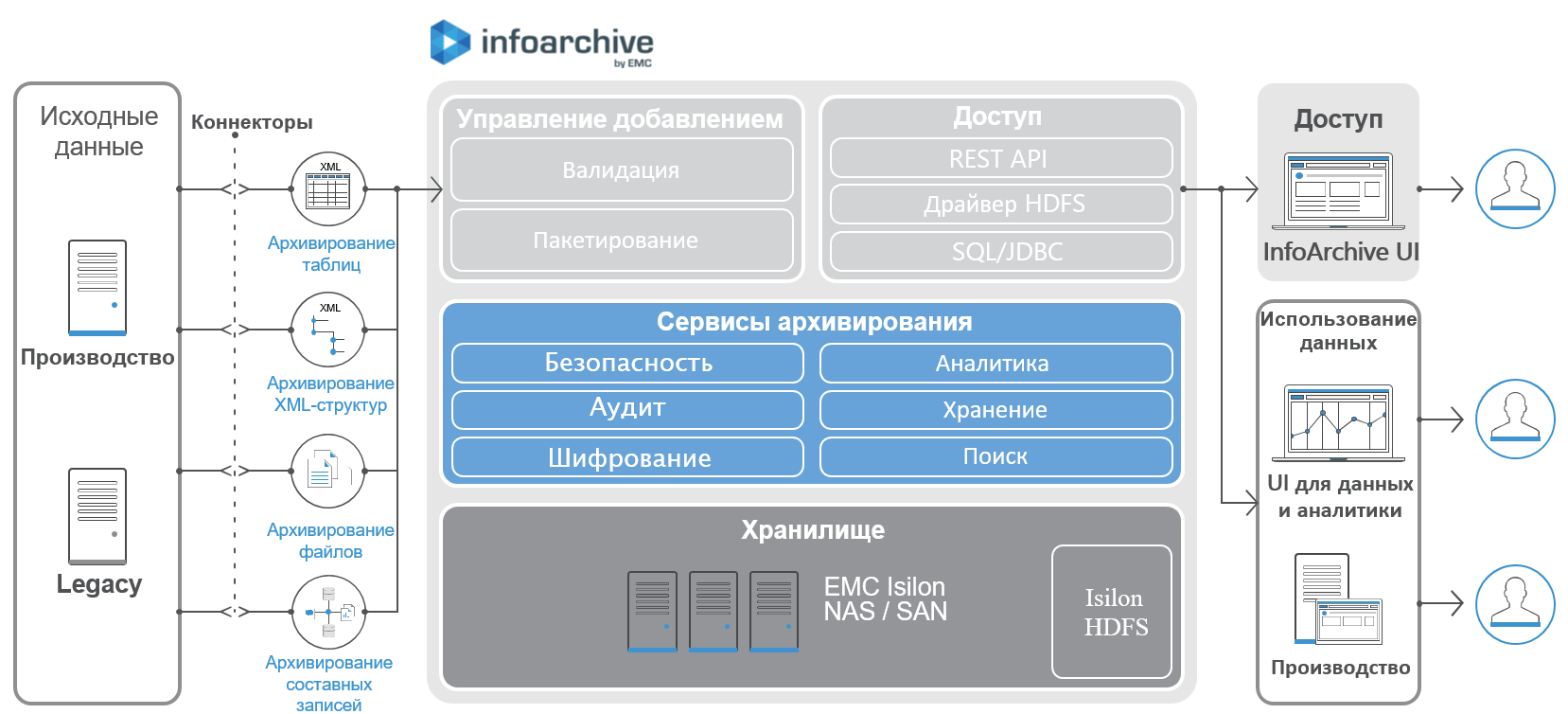
В зависимости от задач по обеспечению безопасности, лицензирования и прочих соображений InfoArchive может устанавливаться на одиночный хост, либо быть распределённым по нескольким хостам. Но в целом, при создании хранилища рекомендуется использовать наиболее простую архитектуру, это позволяет уменьшить задержку при передаче данных.
Логическая архитектура InfoArchive выглядит следующим образом:
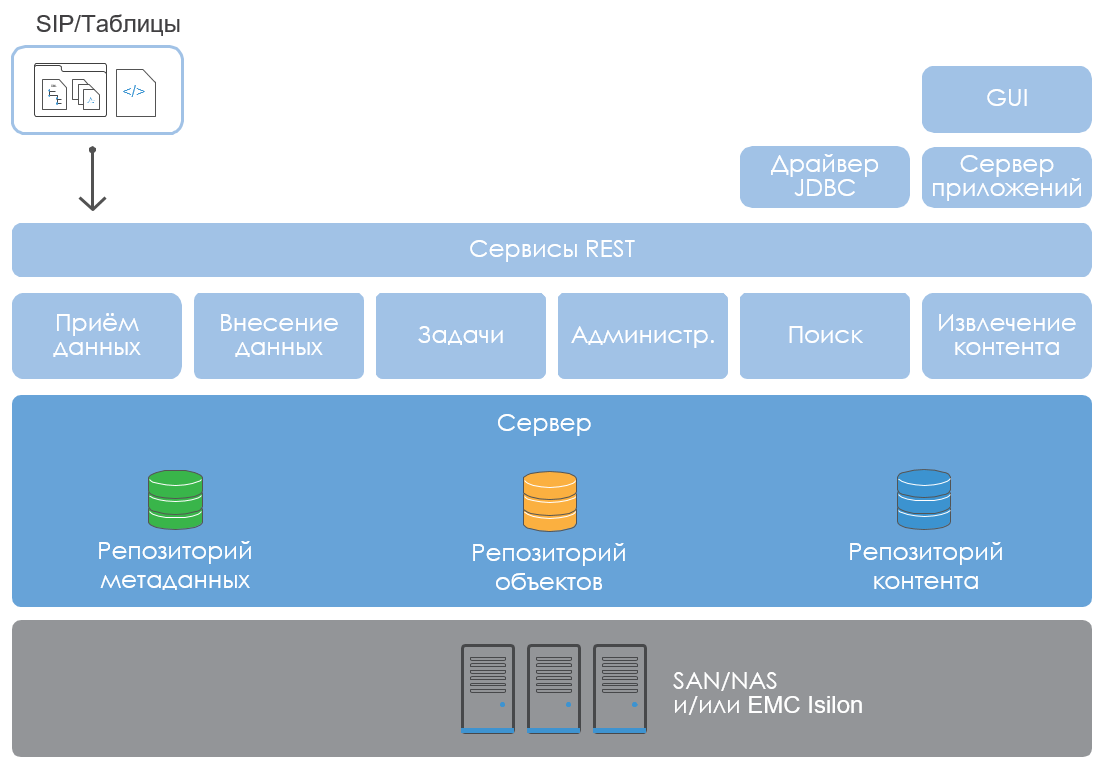
Серверы могут масштабироваться вертикально, либо «специализироваться» на разных функциях REST-сервисов — добавлении данных, поиске, администрировании и т.д. Это позволяет реализовать любую степень масштабируемости, увеличивая архив в соответствии с потребностями. А распределение нагрузки легко выполняется с помощью «классического» HTTP-балансировщика.
xDB
Одним из ключевых компонентов InfoArchive является автоматически развёртываемая СУБД xDB. Её свойства во многом определяют возможности всей системы, поэтому давайте подробнее рассмотрим этот компонент.
В xDB XML-документы и прочие данные хранятся в интегрированной, масштабируемой, высокопроизводительно объектно-ориентированной базе данных. Эта СУБД написана на Java и позволяет с высокой скоростью сохранять и манипулировать очень большими объёмами данных. Транзакционная система xDB удовлетворяет правилам ACID: атомарность, согласованность, изолированность и долговечность.
Физически каждая база данных состоит из одного или нескольких сегментов. Каждый сегмент распределён по одному или нескольким файлам, а каждый файл состоит из одной или нескольких страниц.
Связь между физической и логической структурами xDB:
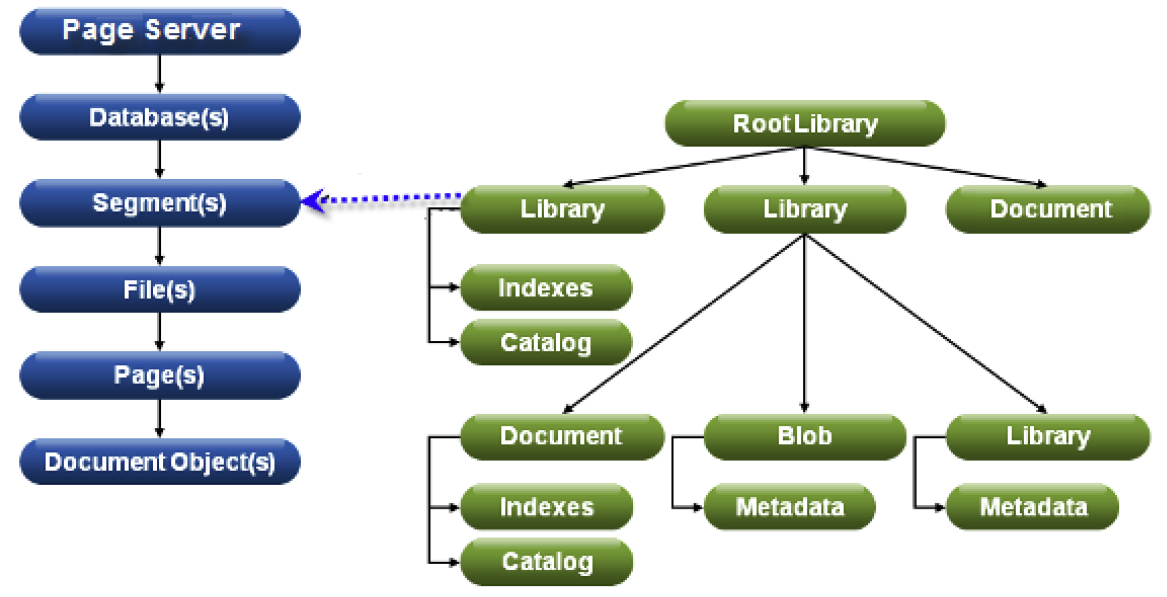
В качестве бэкенд-сервера приложений в xDB выступает так называемый страничный сервер (page server), передающий страницы данных фронтенд-приложениям (клиентским приложениям). В средах, где доступ к базе данных осуществляется от единственного сервера приложений, производительность обычно выше, если страничный сервер работает внутри одной JVM вместе с сервером приложений.
Если страничный сервер выполняет и другие задачи, то он называется внутренним сервером (internal server). А если на страничный сервер никаких дополнительных задач не возлагается, то он называется выделенным сервером (dedicated server). Выделенный сервер в сочетании с TCP/IP соединением между ним и клиентами обладает лучшей масштабируемостью по сравнению с сервером внутренним. Чем больше размеры архива, чем больше разных фронтенд-приложений обращаются к страничному серверу, тем больше аргументов за то, чтобы сделать его выделенным сервером.
Кластеризация xDB
xDB может быть развёрнута как на одном узле, так и на кластере — с использованием архитектуры без разделения ресурсов (shared-nothing architecture), задействующей Apache Cassandra. Вам не обязательно разбираться в Cassandra, хотя знание её основ облегчит настройку и управление кластером.
Кластеризация xDB осуществляется с помощью горизонтального масштабирования, при котором данные физически распределяются по нескольким серверам (узлам данных). Они не имеют общей файловой системы и взаимодействуют друг с другом по сети. Также в кластерах применяются конфигурационные узлы, содержащие полную информацию о строении кластера.
И одиночный узел, и кластер выступают в роли логического контейнера базы данных. Страничный сервер работает с папкой данных (data directory) узла — структурой, содержащей одну или несколько баз данных. Каждый узел содержит свой страничный сервер, и все эти серверы объединяются в кластер посредством конфигурационного узла.
Именно благодаря возможности кластеризации xDB пользователи InfoArchive могут работать с большими данными, поступающими с высокой скоростью. Это особенно актуально для постоянной записи пользовательского трафика крупных веб-сервисов и телеком-провайдеров: одиночный узел может упереться в возможности процессора и/или ёмкость дисковой подсистемы.
Пример кластера:
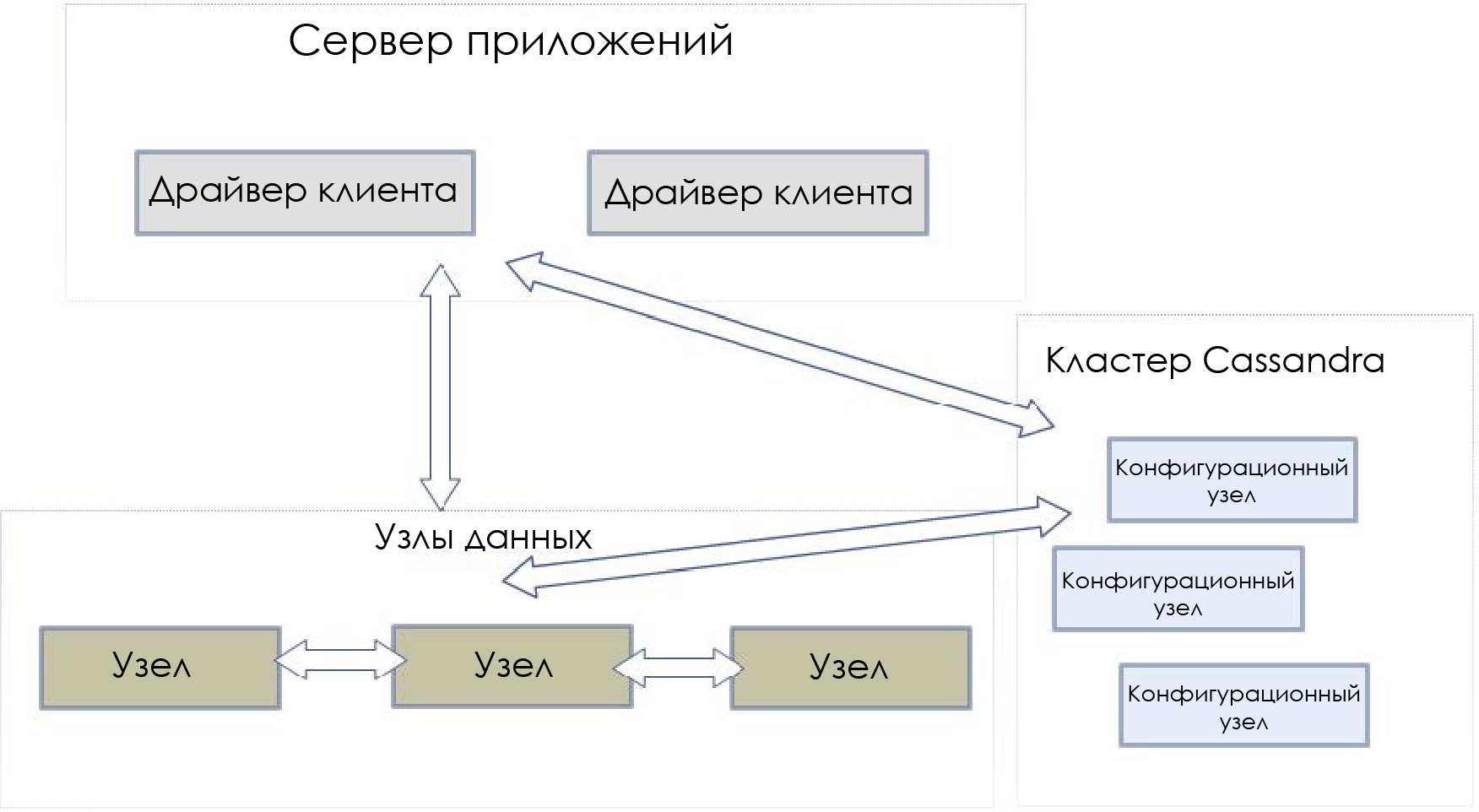
xDB-кластер состоит из компонентов трёх видов:
- Узлы данных. Хранилища информации. Каждый узел выступает в роли отдельного бэкенд-сервера, слушающего и способного принять запросы от других членов кластера. Драйвер(ы) клиента позволяет представить кластер так, словно он состоит из единственного узла. При этом драйвер не следует подключать напрямую к узлам данных, только через конфигурационные узлы.
- Конфигурационные узлы. Хранят метаданные, содержащие информацию обо всех узлах данных: базы данных, сегменты, файлы, пользователи, группы и распределение данных по узлу. Если конфигурационные узлы выходят из строя, кластер умирает. Поэтому содержимое этих узлов должно дублироваться.
- Драйверы клиентов. Удалённый xDB-драйверы, инициализируемые с помощью bootstrap URL одним из конфигурационных узлов. Приложения взаимодействуют с кластером через драйвер клиента, например, для создания новых баз данных, перемещения информации между узлами, добавления новых XML-документов и т.д. Драйвер клиента автоматически направляет запросы к данным на соответствующие узлы данных, ориентируясь на информацию с конфигурационных узлов.
Партиционирование данных
Распределение данных в xDB осуществляется на уровне отключаемых библиотек (detachable library). Отключаемая библиотека — это перемещаемый в рамках кластера блок данных. Обычно они используются для партиционирования. Каждая библиотека хранится или привязана всегда к какому-то одному узлу данных. При этом узел может хранить библиотеки, привязанные к другим узлам.
Также отключаемые библиотеки позволяют бороться с дисбалансом производительности кластера. Например, если какие-то узлы данных в кластере перегружены, то некоторые библиотеки могут переноситься на другие узлы.
Возможное применение партиционирования данных в InfoArchive:
Использование EMC Isilon для EMC InfoArchive
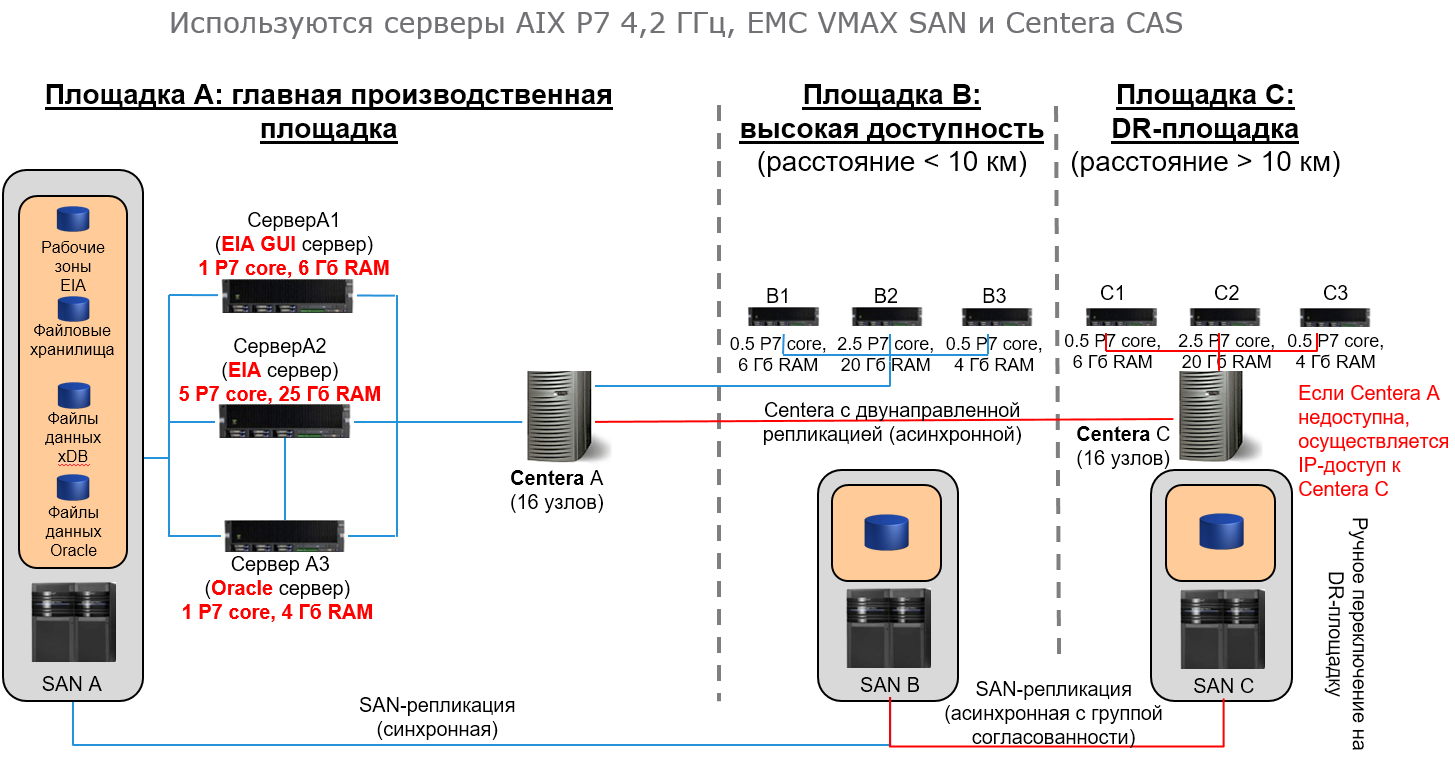
В качестве СХД для InfoArchive можно использовать EMC Isilon — горизонтально масштабируемая сетевая система хранения данных, которая обеспечивает функциональность всего предприятия и позволяет эффективно управлять растущими объемами архивных данных. Кластерная архитектура, лежащая в основе EMC Isilon, позволяет, как совместить в одной системе простоту использования и надёжность, так и обеспечить линейный рост объемов и производительность системы.
Изначально система может быть относительно небольшой, но с течением времени её размер может значительно увеличиться. Решение на основе EMC Isilon позволяет начать построение системы от 18 Тб и вырасти до 50 Пб в единой файловой системе. С ростом объёмов растёт лишь количество узлов в кластере. Сохраняется единая точка администрирования и единая файловая система. Таким образом, EMC Isilon можно эффективно использовать как единую консолидированную СХД и использовать её на протяжении всего жизненного цикла хранения информации. Такой подход позволяет избежать использования различных систем хранения, что упрощает внедрение, обслуживание, расширение и модернизацию системы. Как следствие, затраты на работу и обслуживание единого решения EMC Isilon значительно ниже, чем у решения, состоящего из нескольких традиционных систем.
Таким образом, СХД EMC Isilon эффективно дополняет архивную платформу InfoArchive.
Основные преимущества:
- Интеграция с ПО SmartLock обеспечивает совместимость со схемой «одна запись, многократное чтение» (WORM) на уровнях баз данных и хранения для предотвращения непреднамеренного, преждевременного или злонамеренного изменения, либо удаления данных.
- Сокращение затрат и оптимизация инфраструктуры. Горизонтально масштабируемая NAS-система Isilon обеспечивает коэффициент использования ресурсов системы хранения более 80%, а ПО Isilon SmartDedupeTM позволяет дополнительно на 35% снизить требования к ресурсам хранения.
- EMC Isilon, основанная на EMC Federated Business Data Lake, поддерживает протокол HDFS, поэтому все типы данных в InfoArchive можно предоставить для всех видов Hadoop.
- EMC Isilon позволяет быстро добавлять ресурсы хранения без простоев, ручной миграции данных или перенастройки логики приложений, что позволяет экономить ценные ИТ-ресурсы и сократить операционные издержки.
Примеры из жизни
В завершение статьи приведём пару примеров использования InfoArchive для создания ответственных систем архивирования.
Пример 1. Компания обрабатывает финансовые транзакции, данные поступают в архив в виде сжатых XML, в 12 одновременных потоков, около 20 млн. операций в день (порядка 320 Гб XML), 3,6 млн./56 Гб в час, 1017 операций/16 Мб в секунду.
Нагрузка при добавлении данных и поисковая производительность не зависят от количества уже архивированных объектов. Обработка дискриминантного запроса занимает около 1 секунды (1 результат), не дискриминантного — 4 секунды (200 результатов).
Пример 2. У другого заказчика данные поступают в архив в виде AFP-документов, структурированных и неструктурированных данных.
Средняя/пиковая нагрузка в день:
- 0,5 / 4 млн документов
- 20 / 60 млн записей
- 50 000 / 70 000 операций поиска
Производительность системы при добавлении данных в архив:
- 1,5 млн. документов в час в 12 одновременных потоков (около 60% времени тратится на конвертацию из AFP в PDF),
- либо 45 млн. структурированных записей в час в 10 одновременных потоков.
Это составляет менее 0,5% теоретической максимальной производительности СХД EMC Centera, которая используется в проекте.

- Среднее время поиска документа — 0,5 сек.
- Среднее время получения документа — 1,5 сек.
- Среднее время поиска структурированных данных среди 1 млрд. записей — 2,5 сек.
- До 15 000 операций поиска в час.
Заключение
Подписание «пакета Яровой» — это трудное испытание для всего IT- и телеком-сектора. Тем не менее, непростая задача создания многочисленных высокоскоростных и объёмных архивов может быть решена с помощью EMC InfoArchive — связки из СХД и программной платформы на базе СУБД xDB, имеющей широкие возможности по масштабированию и конфигурированию.
Комментарии (25)

nikitasius
20.07.2016 10:38+4Конечно круто, но блаблабла, импортозамена, блаблабла, «плитка с завода брата мэра», блаблабла, каким вы боком?
Решений и без вас хватает по другую сторону.

Ivan_83
20.07.2016 11:48+2Собственно netflow (метаданные) и раньше писали и хранили, тут особых проблем нет.
Лучше на РОИ проголосовать за отмену закона, чем страдать хернёй.
Кроме того, уже пообещали отечественную железку для исполнения закона, а вам не факт что сертификат на такое дадут.
Snowly
21.07.2016 03:50+2> Лучше на РОИ проголосовать за отмену закона, чем страдать хернёй.
Я думаю, что это оно то самое и есть :)

sergeysakirkin
20.07.2016 13:58+3Входные данные 1Гб/сек из них 40% шифрованных (не архивируемый поток с котиками)
Хотелось бы увидеть цифры:
Какая будет стоимость 1Гб при покупке?
Стоимость сервисного контракта на 1 год за 1Гб (винты не возвращаем)?
Необходимая мощность на 1Тб в ваттах?
Стоимость обучения персонала?
iAchilles
20.07.2016 13:59+8Бойкотирование — как ответ на «пакет Яровой».

maaGames
20.07.2016 17:21+4Бойкотируют провайдеры — лишаются лицензии.
Бойкотируют пользователи — пользователи сидят без интернета.
Т.е. в любом случае «государство» получает профит. Нет интернета — нет средства обмена информацией между террористами-педофилами.
Из законных способов есть только попытка достучаться до правительства путём петиций. Т.е. способов, по большому счёту, нет.
ZoomLS
20.07.2016 23:58Раньше было FIDO, может оно ещё вернётся ;)
Многие перейдут в децентрализованные анонимные сети и пусть архивируют чего хотят.
Kheus
20.07.2016 14:25+2Наверное, одна из главных задач ИТ это решить — нужно ли решать поставленную задачу в обозначенных условиях.
Alexey2005
20.07.2016 14:41+1А вот интересно, как с точки зрения закона Яровой рассматривается пожар в центре хранения данных? Или сбой оборудования с полной потерей данных? После этого такое хранилище должно платить штраф за нарушение закона?

EmmGold
20.07.2016 17:01Закон никак не касается хранилищ данных. Никто никого не заставляет хранить данные. Оператор связи должен предоставить данные по запросу, сделает он это или нет — выполнит он закон или нет.
maaGames
20.07.2016 17:23+4Вы случайно не политик?
Хотя, Ваше предложение может сработать для шифрованного трафика. Берём терабайт любого «шума», снабжаем его имеющимися реальными метаданными и делаем вид, что это и есть настоящий трафик. Расшифровать всё-равно не получилось бы.EmmGold
21.07.2016 20:06По поводу шума, уже встречал в сети программы по созданию трафика. Просто сеть постоянно загружена и изредка проскакивает полезный трафик.
По поводу расшифровки. Шум не особо отличается от зашифрованных данных. И расшифровывать эти «данные» будете вы, возможно с применением терморектального криптоанализа, любезно предоставленного весёлыми ребятами из органов.maaGames
21.07.2016 20:17Если к гипотетическому «мне» придут ребята из органов, то как бы они не имеют права прийти и что-то требовать без решения суда. Мы пока что в правовом государстве живём. А этот «яровой» пакет даёт органам право получать частную информацию без решения суда, но и без заглядывания ко мне в гости. Чувствуете разницу?
EmmGold
21.07.2016 20:47А разве подозрения в терроризме или экстремизме и т.п. не достаточно для основательной проверки? Для этого ведь всё и задумывается. Не думаю, что кто-то будет в реальном времени анализировать весь трафик для «предотвращения террористических атак», да и навряд ли это возможно…
maaGames
22.07.2016 15:08Сейчас, по закону, «маски шоу» могут прийти в гости в организацию. В произвольно взятую квартиру пока-что только по решению суда. Есть основания? Идут и получают разрешение суда.
Я не утверждаю, что они не могут вломиться в любой дом и получить решение суда завтра, со вчерашней датой. Но я говорю о законодательстве, а не о том, что его не соблюдают.old_bear
22.07.2016 19:35ЕМНИП по закону тоже могут. Например, если у них возникнет подозрение, что в вашей квартире совершается преступление (такое или что-то очень похожее по формулировке есть в законе о полиции). А основания для этого подозрения законом любезно не регламентируются.
Поправьте меня, если я не прав.

sumanai
21.07.2016 22:37Мы пока что в правовом государстве живём.
Я в России, правовым назвать его язык не поворачивается. А вы в каком?maaGames
22.07.2016 15:10От вращения вашего языка ни конституция, ни уголовный кодекс не меняются. Хотя, смотря где язык вращать… Я же не утверждаю, что закон всеми соблюдается. Я лишь говорю о том, как написано в законодательстве. Если выживешь, можно в Страсбургский суд или ещё где-нибудь в европе в суд подать. Имеете право. А вот сможете ли реализовать — это, так сказать, нюанс…
MaxAkaAltmer
Корпорация EMC — офис в Массачусетсе, США. Яровая случаем не на вас работает? А то смотрю — все уже продумали до мелочей.
Софт-то хоть открытый — в исходниках покопаться можно? А то доверять трафик страны не то что вероятному противнику, а даже его софту — это за гранью добра и зла.