
Исходное состояние – я руководил службой внедрения и сопровождения в частной медицинской компании. Филиальная сеть отделений в регионах, которая работает под управлением единой системы. Так же используется схожее оборудование на всех объектах. Фактически все оборудование подключено в систему и отдает данные (диализные аппараты, лабораторные анализаторы, аппараты УЗИ и кардиографы, измерители веса и давления, водоподготовка, система вентиляции, датчики температуры и влажности).
Сеть отделений постоянно расширяется. В каждом отделении есть ИТ-специалист. Далеко не всегда этот специалист компетентен в различных областях. Задача стояла достаточно масштабная по обеспечению работоспособности довольно сложной с точки реализации системы.
Проблема
Описание инцидентов специалистами 1-го уровня поддержки. Имеется в виду то, что одну и ту же ошибку каждый описывал как мог, как хотел, как хватало фантазии… Тяжело перечислить все вариации. Так же хотелось сократить время на решение инцидентов. Особенно тех, которые уже однажды происходили и были описаны. То есть нужно было обеспечить максимальное закрытие инцидентов на 1-м уровне поддержки с достаточно высокой скоростью и качеством.
Мне не нравится существующий способ описания Базы знаний. Потому что одна и та же ошибка может быть вызвана различными причинами. Соответственно и описание решений должно быть множественным. Чего на самом деле нет. И сам поиск решения – достаточно долгий с точки зрения необходимого количество шагов. По большому счету обычно База знаний – это набор файлов.
Не маловажно еще и аккуратность описания решения. Важно учесть понятие «Лучшая практика». Просто приведу пример. Когда на утро предварительно настроенный пост самообслуживания частично перестал работать – перестал работать тач-скрин, ИТ специалист потратил 2 часа и 5 минут на устранение инцидента. Я специально не стал вмешиваться чтобы пронаблюдать действия и увидеть результат. Причина была в том, что санитарка шваброй чуть выдернула USB-шнур тач-скрина. С помощью алгоритмов эта проблема устранялась в течении максимум 5-ти минут.
Поэтому мне захотелось использовать преимущество автоматизированного решения на основе СППР, которое бы позволило решать мне конкретную масштабную задачу. При этом расширить практику на все отделения. Особенно актуально для вновь открываемых отделений и новых ИТ-специалистов. Потому что со временем система становилась сложнее и в нее подключалось все больше и больше различного оборудования.
Хотелось воспользоваться преимуществом системы – формированием протокола, который описывает шаги прохождения по алгоритму. То есть решить проблему того как единообразно описывать инциденты – копипастить протокол в заявку.
Реализация
В Алгоритм-Дизайнере была создана первичная структура алгоритма, где были созданы разделы для описания:
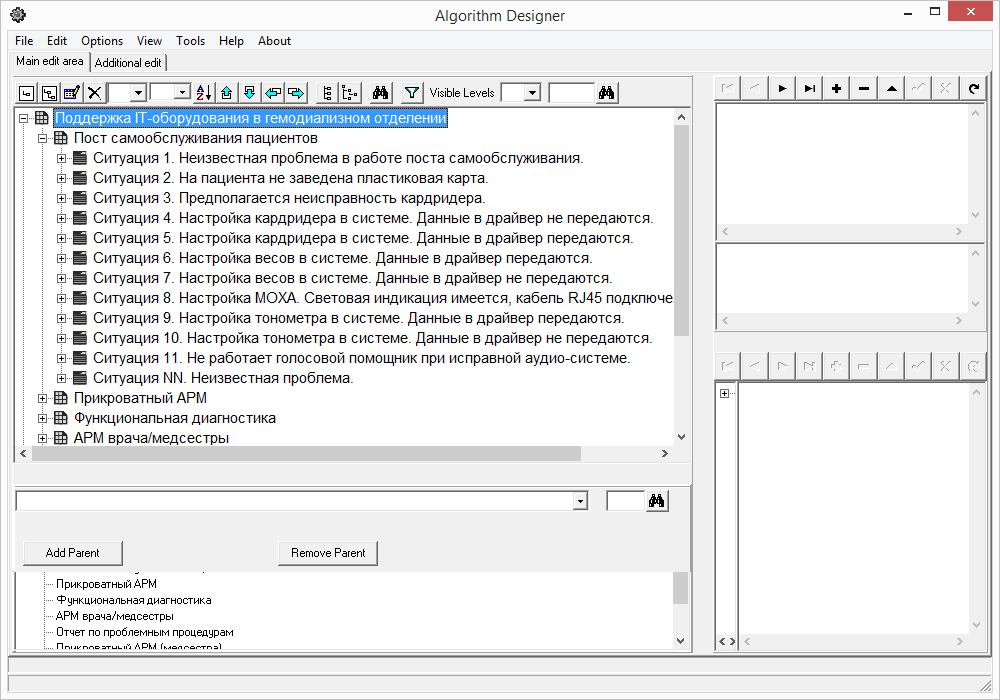
Для начала был выбран пост самообслуживания пациентов. Потому что пациенты в начале и в конце каждой смены проходили через этот пост. И сбой в работе поста самообслуживания мог привести к задержке каждой смены.
Пост самообслуживания пациентов:
• Системный блок
• Монитор с тач-скрином
• Колонки (используются для голосового помощника)
• Кард-ридер (используется для идентификации пациента)
• Весы
• Измеритель давления
• Принтер
• Синтезатор речи
• Программа MaximusDriver, которая отвечает за все подключенное оборудование
• Программа Maximus, запущенная в режиме поста самообслуживания
Поскольку Весы и Измеритель артериального давления передают данные через COM порт, то существовали вариации подключения:
• Через COM-порт
• С использованием MOXA
• Через переходник USB-COM
Соответственно, нужно было учесть эти вариации. Как и то что модели Весов и Измерителей артериального давления так же могли меняться.
Алгоритм наполнялся по мере наличия свободного времени и осознания того как он должен работать. Так же несколько решений были внесены сразу после возникших и решенных инцидентов.
Первично разрабатывалась 1-я ситуация, которая позволяла локализовать проблему.
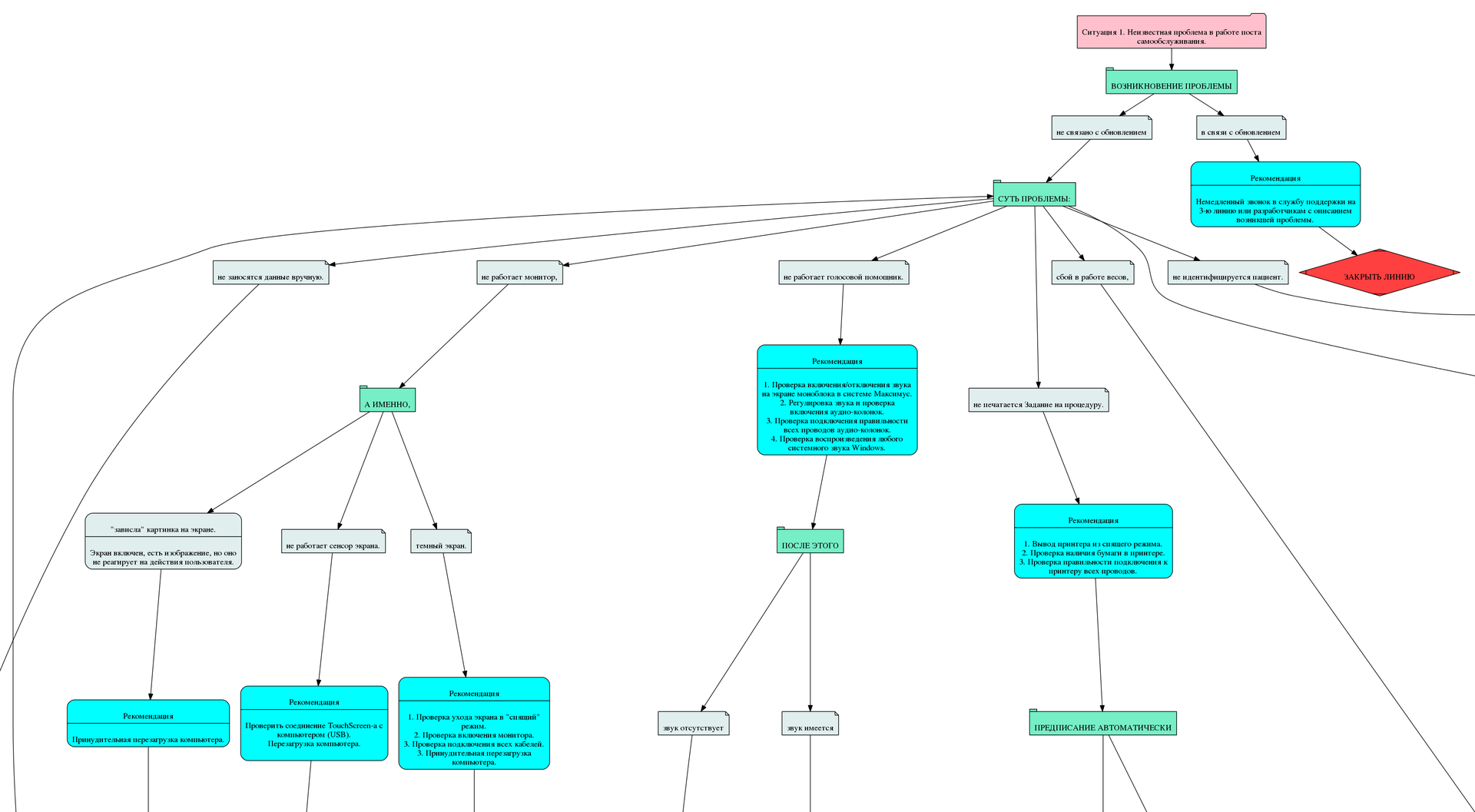
Остальные ситуации уже позволяли решать конкретную локализованную проблему.
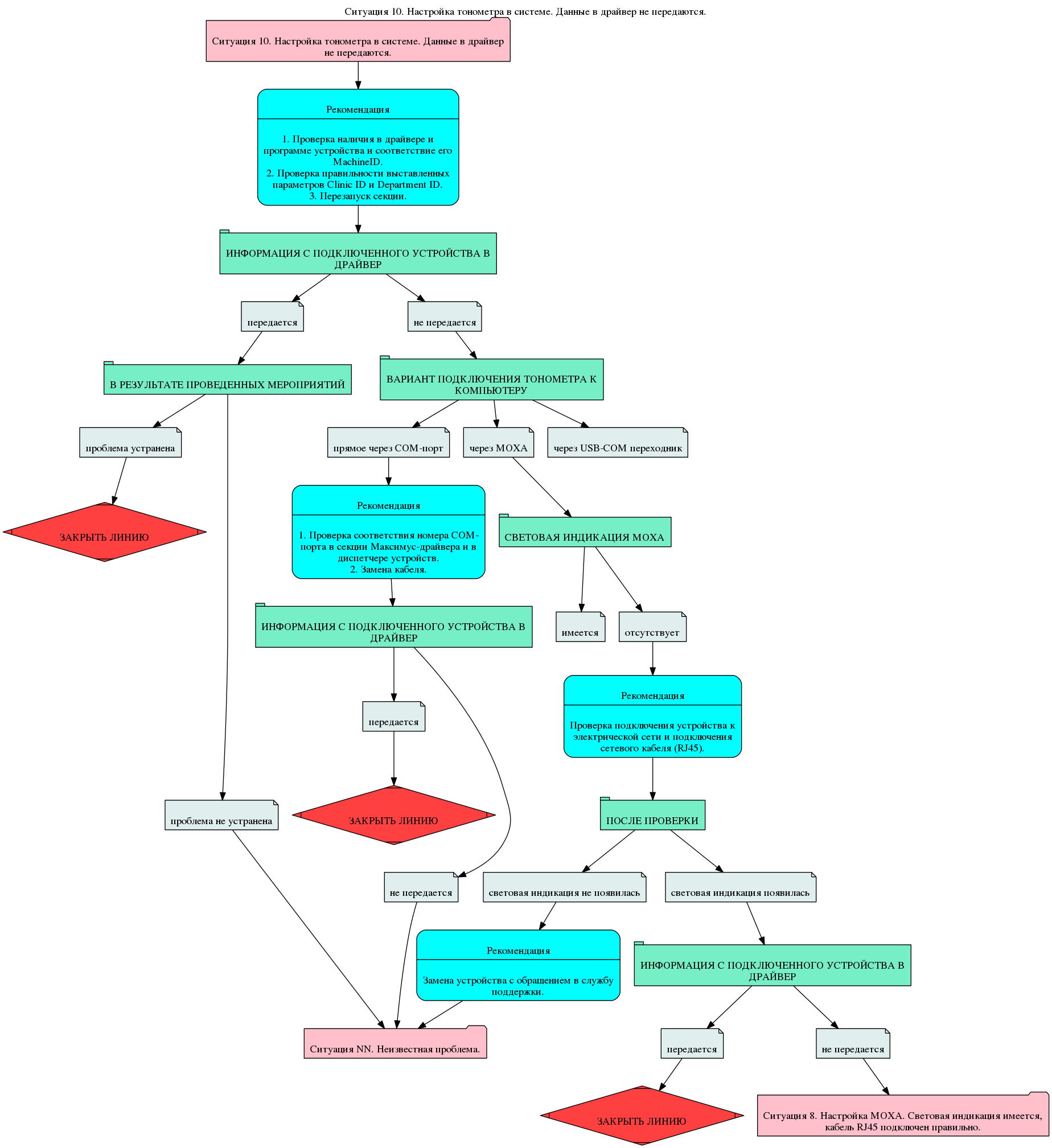
Принцип работы.
При диагностике в самом начале устанавливается факт того, возникла ли ошибка в следствии обновления системы. Объясню почему. Дело в том, что обновление системы проходило одновременно во всех отделениях. Соответственно все использовали одну и ту же версию Базы данных и одну и ту же версию бинарных файлов. То есть ошибки в системе были так же общими. Обнаруженная и исправленная ошибка для одного отделения автоматически ретранслировалась на все отделения.
Ситуация локализации проблемы получилась более масштабной. Сами же ситуации по решению более краткие.
Так же была предусмотрена ситуация-заглушка. То есть, если все описанные способы диагностики и решений не помогли, система адресует на эту ситуацию-заглушку. Там содержится рекомендация передать на следующий уровень поддержки.
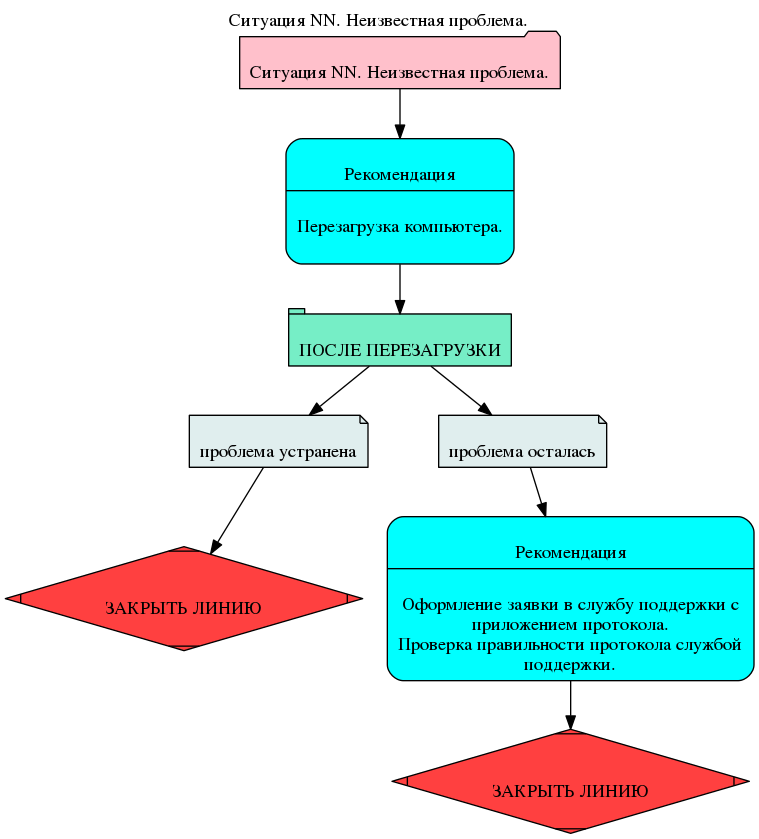
Вообще методика создания СППР позволяет создавать заглушки на еще не описанные случаи. Что позволяет фактически сразу использовать систему без риска того, что возникнет ошибка в случае отсутствия описания какого-то раздела.
Функция печати диаграмм алгоритма позволяла визуально оценивать цепочку действий и рекомендаций.
Было еще желание реализовать возможность управления по отклонениям. Что это означает? Обычно анализ сбоев, простоев и т.п. Проводится по итогам месяца или недели. Что дает чисто статистическую информацию. По ней, конечно же, и можно и нужно принимать управленческие решения. Но объективно это малоэффективно.
Назовите меня идеалистом. Но тут речь идет о вполне нормальном способе контроля и управления. То есть возможность выявления инцидента и возможность вмешаться или подключиться для его устранения. То ест недопущение простоя. Для этого планировался интерфейс, в котором бы отображались текущие прохождения локальными ИТ-специалистами по алгоритмам. То есть можно было бы видеть и в виде протокола что за инцидент, и на каком этапе его решения находится специалист. Соответственно отреагировать и подключить дополнительные силы из центрального офиса.На сегодня такая панель разработана.
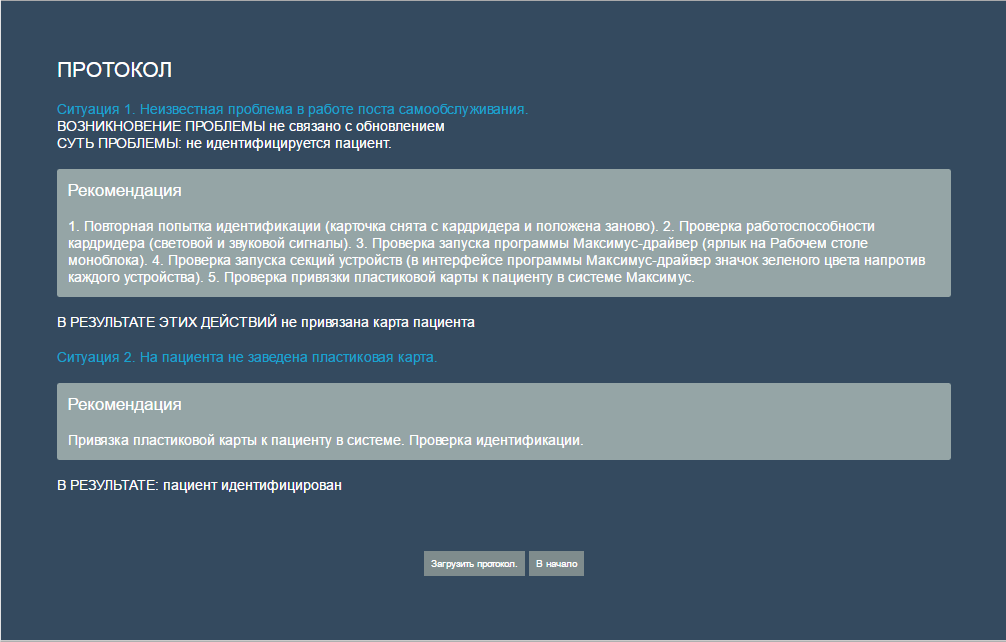
Пример полученного протокола после прохождения по алгоритму:
Пример чат-бота Telegram, который работает на ядре СППР из Часть 3. Чат-бот Telegram на ядре логики СППР : @DSSUABot
Комментарии (6)

netmans
28.07.2016 12:25Здравствуйте, коллега :) Скажите, на чём построено ядро системы?

AlexVist
28.07.2016 12:36Здравствуйте, коллега! :) На чем построено ядро — это предмет 3-й статьи, которая является Частью 1-й. :) Должен извиниться за такую обратную очередность изложения материала. Но она продиктована именно тем, что так понятнее. Переходом от более простого к более сложному. Статья готова и скоро я ее опубликую.
Забегая чуть вперед скажу, что использовалась платформа СППР Универсальные алгоритмы. На скриншоте в этой статье есть Алгоритм-Дизайнер. Собственно, это и есть инструмент, в котором создается логическая модель алгоритма СППР. Для использования модели был разработан Алгоритм-Навигатор — web-приложение, которое работает на всех устройствах. И в дополнение был разработан чат-бот Telegram, который просто использует уже созданную модель.
Причем, сама платформа позволяет создавать экспертные системы для любой проф. области. При этом обладает открытой логической моделью (всегда можно печатать диаграммы) и может создаваться уже без участия программистов. То есть экспертом или группой из своей проф. области.
Подробно я опишу платформу в 1-й части. Надеюсь Вам будет интересно. :)
centrin0
Где исходники бота для телеграмма? Без этого не интересно.
AlexVist
Приветствую! Мне жаль, что без исходника чат-бота Вам не интересно. Потому что статья посвящена конкретной прикладной проблеме — поддержке оборудования, выход из строя которого приводил к серьезным проблемам и задержкам в работе. Так же сложности многоуровневой поддержки в распределенной филиальной сети. И способу решения этой задачи путем применения методики и платформы для создания экспертных систем. В данном случае экспертная система строилась для службы поддержки. Решалась задача по быстрому и эффективному решению возникающих проблем.
Если внимательно посмотреть на скриншот Алгоритм-Дизайнера, то видно. что задумка была охватить гораздо больше оборудования в отделениях. Позволить часть проблем решать персоналу самостоятельно дав им в руки инструмент, который проведет их шаг за шагом к локализации проблемы и ее решению.
Уверяю, что чат-бот не содержит в себе ничего особенного. Там просто вывод сообщений с кнопками и функция редактирования сообщений. Он писался как надстройка над уже существующим логическим ядром экспертной системы. Частично логику Вы можете увидеть в скриншотах диаграмм. Ну, и сам чат бот при вводе команды /listsit выдает ситуации и ссылки на функцию генерации диаграммы для выбранной ситуации. То есть Вы можете просмотреть всю логику, потому что при движении по алгоритму Вы делаете всего лишь несколько шагов.
Но и функция генерации диаграмм не есть часть чат-бота. Она была уже реализована в рамках ядра экспертной системы. Потому что оно строится по принципу «Открытого исходного кода» логической модели. Если интересно, то диаграммы строятся средствами Graphviz.