

Время на месте не стоит, и у горячо любимого всеми Docker от версии к версии появляется новый функционал. Случается так, что когда читаешь Changelog для новой версии, видишь там то, что может пригодиться и сделать какие-то вещи лучше, чем есть на данный момент.
Так дело обстояло и в моем случае. Хочу заметить, что многие задачи, которые приходится делать, я делаю по принципу keep it simple. То есть почти всегда, если для решения задачи можно использовать простые инструменты и шаги, я выберу этот путь. Я понимаю, что простой или сложный шаг или инструмент — оценка субъективная, но т.к. работаем мы в команде, то вот такие критерии могут подходить при выборе инструментов:
- используется ли инструмент в инфраструктуре?
- если требуется что-то новое, то нельзя ли использовать то, что уже есть?
- насколько сильно обслуживание (обновление, перезапуск) сервиса будет отличаться от остальных сервисов?
- <...>
В этой статье речь пойдет о сетевом аспекте Docker. Расскажу обо всем по порядку, но хочу заметить, что на этот раз я не буду говорить «мы используем сеть хоста, всячески избегая применения NAT».
О том, как Docker работает с сетью, можно ознакомиться по ссылке. Выделим основные моменты:
- default bridge network;
- host network;
- user defined network.
Как я говорил ранее в некоторых своих публичных выступлениях, нам нужна максимальная производительность сети для наших контейнеров. Если говорить о production, то NAT для контейнеров мы не используем.
Долгое время (да чего уж скрывать — и по сей день) для запуска контейнеров мы используем параметр --net=host, получая тем самым «нативный» eth внутри контейнера. Да, в этом случае одного бенефита — изоляции — мы, конечно, лишаемся… Но посмотрев на плюсы и минусы в нашем конкретном случае, мы намеренно пришли к такому решению, т.к. задачи изолировать сеть между запущенными приложениями в рамках одного хоста не стояло. Хочу напомнить, что пишу я о конкретном месте применения Docker — в Badoo.
Что мы знаем про наши сервисы:
- у нас есть карта размещения сервисов на серверах;
- у нас есть карта портов для каждого сервиса и его типа (или типов, если их много);
- у нас есть договоренность о том, что порты должны быть уникальными.
Исходя из вышесказанного, мы гарантируем следующее:
- если мы запускаем несколько сервисов на одной машине с --net=host, то пересечения портов мы не получим: все запустится и будет работать;
- если нам станет мало одного eth-интерфейса, то мы физически подключим еще один и посредством, например, DNS, раскидаем нагрузку между ними.
Все хорошо, тогда зачем мне пришлось что-то менять?
Дело было вечером, делать было нечего… Ранее говорилось о том, что мы продолжаем переносить наши сервисы в контейнеры. При следовании такому сценарию, как это обычно бывает, самые сложные остаются на потом. Причин для этого может быть масса:
- сервис критичен;
- отсутствие достаточного опыта, чтобы предложить максимально прозрачный и быстрый переезд сервиса в контейнер;
- можно «добавить что-то еще по вкусу».
Ну так вот. Был (и есть) у нас один такой сервис, который давно написан. Он и по сей день отлично работает, но есть у него несколько минусов:
- работает он на одном ядре (да, такое бывает);
- восполняя первый пробел, стоит отметить, что можно запустить несколько инстансов сервиса и использовать taskset/--cpuset-cpus;
- сервис «сильно» использует сеть, а также ему требуется большое количество портов для исходящих соединений.
Вот так сервис запускался ДО:
- на машине, где планировалось поднятие сервиса, нужно было добавить дополнительный IP-адрес (или даже несколько) — ip a add (тут можно сразу указать на много минусов данного подхода, о которых мы знаем);
- про вышесказанное стоит помнить, чтобы не получить, к примеру, 2 одинаковых адреса на разных машинах;
- в конфигурации демона стоило указать, на каком адресе он работает, как раз чтобы не «съесть» все порты соседа или хост-системы.
Как можно было решить задачу, если бы было лень изобретать новые методы:
- оставить все как есть, но обернуть в контейнер;
- поднимать на dockerhost все те же дополнительные IP-адреса;
- «биндить» приложение на конкретный адрес.
Как к задаче решил подойти я? Изначально, конечно, это все выглядело как эксперимент, да чего скрывать — это и было экспериментом. Мне показалось, что для этого сервиса как нельзя кстати подойдет MACVLAN-технология, которая на тот момент была отмечена в Docker как Experimental (версия 1.11.2), а вот в версии 1.12 всё уже доступно в основном функционале.
MACVLAN — это, по сути, Linux switch, который основан на статичном соответствии MAC и VLAN. Здесь используется unicast-фильтрация, не promiscuous-режим. MACVLAN может работать в режиме private, VEPA, bridge, passthru. MACVLAN — это reverse VLAN в Linux. Данная технология позволяет взять один реальный интерфейс и сделать на его основе несколько виртуальных с разными MAC-адресами.
Также сравнительно недавно появилась технология IPVLAN(https://www.kernel.org/doc/Documentation/networking/ipvlan.txt). Основное отличие от MACVLAN заключается в том, что IPVLAN может работать в L3 mode. В данной статье я буду рассматривать вариант использования MACVLAN (в режиме bridge), потому что:
- не стоит ограничение в 1 MAC-адрес с одного линка на активном сетевом оборудовании;
- количество контейнеров на хосте не будет таким большим, что может привести к превышению mac capacity. С течением времени этот момент у нас может, конечно, измениться;
- на данном этапе L3 не нужен.
Чуть подробнее про MACVLAN vs IPVLAN можно ознакомиться по ссылке http://hicu.be/macvlan-vs-ipvlan.
Вот здесь можно почитать теорию и как это работает в Docker: https://github.com/docker/docker/blob/master/experimental/vlan-networks.md.
Теория — это отлично, но даже там мы видим, что overhead имеет место быть. Можно и нужно посмотреть на сравнительные тесты пропускной способности MACVLAN в интернете (например, http://comp.photo777.org/docker-network-performance/ и http://delaat.net/rp/2014-2015/p92/report.pdf), но также неотъемлемой частью эксперимента является проведение теста в своих лабораторных условиях. Поверить на слово — хорошо, но «потрогать руками» и сделать выводы самому — интересно и необходимо.
Итак, поехали!
Для того чтобы проверить, работает ли MACVLAN в Docker, нам нужно включить в последнем поддержку экспериментальных функций.
Если данный функционал при сборке не включен, то в логах можно будет видеть вот такие сообщения об ошибках:
# docker network create -d macvlan --subnet=1.1.1.0/24 --gateway=1.1.1.1 -o parent=eth0 cppbig_vlan
Error response from daemon: plugin not found
А в логах процесса будет следующее:
docker[2012]: time="2016-08-04T11:44:44.095241242Z" level=warning msg="Unable to locate plugin: macvlan, retrying in 1s"
docker[2012]: time="2016-08-04T11:44:45.095489283Z" level=warning msg="Unable to locate plugin: macvlan, retrying in 2s"
docker[2012]: time="2016-08-04T11:44:47.095750785Z" level=warning msg="Unable to locate plugin: macvlan, retrying in 4s"
docker[2012]: time="2016-08-04T11:44:51.095970433Z" level=warning msg="Unable to locate plugin: macvlan, retrying in 8s"
docker[2012]: time="2016-08-04T11:44:59.096197565Z" level=error msg="Handler for POST /v1.23/networks/create returned error: plugin not found"Если вы видите такие сообщения — значит, поддержка MACVLAN в Docker не включена.
Тест был символическим, с использованием iperf. Для каждого варианта я запускал сначала 1 клиента, потом 8 в параллель. Вариантов было 2:
- --net=host;
- --net=macvlan.
# docker run -it --net=host --name=iperf_w_host_net --entrypoint=/bin/bash dockerio.badoo.com/itops/sle_12_base:latest
# iperf3 -s -p 12345
-----------------------------------------------------------
Server listening on 12345
-----------------------------------------------------------
Запускаем клиента:
# iperf3 -c 1.1.1.2 -p 12345 -t 30
На сервере получаем результат:
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth
[ 5] 0.00-30.04 sec 0.00 Bytes 0.00 bits/sec sender
[ 5] 0.00-30.04 sec 2.45 GBytes 702 Mbits/sec receiver
На клиенте:
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-30.00 sec 2.46 GBytes 703 Mbits/sec 0 sender
[ 4] 0.00-30.00 sec 2.45 GBytes 703 Mbits/sec receiver
Запускаем в параллель 8 клиентов:
# iperf3 -c 1.1.1.2 -p 12345 -t 30 -P 8
На сервере получаем результат:
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth
[ 5] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 5] 0.00-30.03 sec 314 MBytes 87.7 Mbits/sec receiver
[ 7] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 7] 0.00-30.03 sec 328 MBytes 91.5 Mbits/sec receiver
[ 9] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 9] 0.00-30.03 sec 305 MBytes 85.2 Mbits/sec receiver
[ 11] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 11] 0.00-30.03 sec 312 MBytes 87.3 Mbits/sec receiver
[ 13] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 13] 0.00-30.03 sec 316 MBytes 88.3 Mbits/sec receiver
[ 15] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 15] 0.00-30.03 sec 310 MBytes 86.7 Mbits/sec receiver
[ 17] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 17] 0.00-30.03 sec 313 MBytes 87.5 Mbits/sec receiver
[ 19] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 19] 0.00-30.03 sec 321 MBytes 89.7 Mbits/sec receiver
[SUM] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[SUM] 0.00-30.03 sec 2.46 GBytes 704 Mbits/sec receiver
На клиенте:
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-30.00 sec 315 MBytes 88.1 Mbits/sec 0 sender
[ 4] 0.00-30.00 sec 314 MBytes 87.8 Mbits/sec receiver
[ 6] 0.00-30.00 sec 330 MBytes 92.3 Mbits/sec 0 sender
[ 6] 0.00-30.00 sec 328 MBytes 91.6 Mbits/sec receiver
[ 8] 0.00-30.00 sec 306 MBytes 85.6 Mbits/sec 0 sender
[ 8] 0.00-30.00 sec 305 MBytes 85.3 Mbits/sec receiver
[ 10] 0.00-30.00 sec 313 MBytes 87.5 Mbits/sec 0 sender
[ 10] 0.00-30.00 sec 312 MBytes 87.4 Mbits/sec receiver
[ 12] 0.00-30.00 sec 317 MBytes 88.8 Mbits/sec 0 sender
[ 12] 0.00-30.00 sec 316 MBytes 88.4 Mbits/sec receiver
[ 14] 0.00-30.00 sec 312 MBytes 87.1 Mbits/sec 0 sender
[ 14] 0.00-30.00 sec 310 MBytes 86.8 Mbits/sec receiver
[ 16] 0.00-30.00 sec 314 MBytes 87.9 Mbits/sec 0 sender
[ 16] 0.00-30.00 sec 313 MBytes 87.6 Mbits/sec receiver
[ 18] 0.00-30.00 sec 322 MBytes 90.2 Mbits/sec 0 sender
[ 18] 0.00-30.00 sec 321 MBytes 89.8 Mbits/sec receiver
[SUM] 0.00-30.00 sec 2.47 GBytes 707 Mbits/sec 0 sender
[SUM] 0.00-30.00 sec 2.46 GBytes 705 Mbits/sec receiver
2. Запускам сервер, используя MACVLAN:
# docker run -it --net=cppbig_vlan --name=iperf_w_macvlan_net --ip=1.1.1.202 --entrypoint=/bin/bash dockerio.badoo.com/itops/sle_12_base:latest
# iperf3 -s -p 12345
-----------------------------------------------------------
Server listening on 12345
-----------------------------------------------------------
Запускаем клиента:
# iperf3 -c 1.1.1.202 -p 12345 -t 30
На сервере получаем результат:
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth
[ 5] 0.00-30.04 sec 0.00 Bytes 0.00 bits/sec sender
[ 5] 0.00-30.04 sec 2.45 GBytes 701 Mbits/sec receiver
На клиенте:
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-30.00 sec 2.46 GBytes 703 Mbits/sec 0 sender
[ 4] 0.00-30.00 sec 2.45 GBytes 702 Mbits/sec receiver
Запускаем в параллель 8 клиентов:
# iperf3 -c 1.1.1.202 -p 12345 -t 30 -P 8
На сервере получаем результат:
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth
[ 5] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 5] 0.00-30.03 sec 306 MBytes 85.4 Mbits/sec receiver
[ 7] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 7] 0.00-30.03 sec 319 MBytes 89.1 Mbits/sec receiver
[ 9] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 9] 0.00-30.03 sec 307 MBytes 85.8 Mbits/sec receiver
[ 11] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 11] 0.00-30.03 sec 311 MBytes 87.0 Mbits/sec receiver
[ 13] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 13] 0.00-30.03 sec 317 MBytes 88.6 Mbits/sec receiver
[ 15] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 15] 0.00-30.03 sec 322 MBytes 90.1 Mbits/sec receiver
[ 17] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 17] 0.00-30.03 sec 313 MBytes 87.5 Mbits/sec receiver
[ 19] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 19] 0.00-30.03 sec 310 MBytes 86.7 Mbits/sec receiver
[SUM] 0.00-30.03 sec 0.00 Bytes 0.00 bits/sec sender
[SUM] 0.00-30.03 sec 2.45 GBytes 700 Mbits/sec receiver
На клиенте:
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-30.00 sec 307 MBytes 85.8 Mbits/sec 0 sender
[ 4] 0.00-30.00 sec 306 MBytes 85.5 Mbits/sec receiver
[ 6] 0.00-30.00 sec 320 MBytes 89.6 Mbits/sec 0 sender
[ 6] 0.00-30.00 sec 319 MBytes 89.2 Mbits/sec receiver
[ 8] 0.00-30.00 sec 308 MBytes 86.2 Mbits/sec 0 sender
[ 8] 0.00-30.00 sec 307 MBytes 85.9 Mbits/sec receiver
[ 10] 0.00-30.00 sec 313 MBytes 87.5 Mbits/sec 0 sender
[ 10] 0.00-30.00 sec 311 MBytes 87.1 Mbits/sec receiver
[ 12] 0.00-30.00 sec 318 MBytes 89.0 Mbits/sec 0 sender
[ 12] 0.00-30.00 sec 317 MBytes 88.6 Mbits/sec receiver
[ 14] 0.00-30.00 sec 324 MBytes 90.5 Mbits/sec 0 sender
[ 14] 0.00-30.00 sec 322 MBytes 90.2 Mbits/sec receiver
[ 16] 0.00-30.00 sec 314 MBytes 87.9 Mbits/sec 0 sender
[ 16] 0.00-30.00 sec 313 MBytes 87.6 Mbits/sec receiver
[ 18] 0.00-30.00 sec 311 MBytes 87.1 Mbits/sec 0 sender
[ 18] 0.00-30.00 sec 310 MBytes 86.8 Mbits/sec receiver
[SUM] 0.00-30.00 sec 2.46 GBytes 704 Mbits/sec 0 sender
[SUM] 0.00-30.00 sec 2.45 GBytes 701 Mbits/sec receiver
Как видно из результатов, overhead есть, но в данном случае можно считать его не критичным.
Ограничения технологии by design: доступность контейнера с хоста и доступность хоста из контейнера отсутствует. Нам такой функционал необходим, потому что:
- часть проверок доступности сервиса проверяется «хелперами» Zabbix, которые выполняются на том хосте, где работает сервис;
- есть необходимость использовать кеширующий DNS, который расположен на хост-системе. В нашем случае это Unbound;
- бывает необходимость использовать доступ к еще каким-то сервисам, запущенным на хост-системе.
- Это лишь часть причин, по которым доступ «хост <==> контейнер» нам необходим. Взять и переделать архитектуру подобных узлов в одночасье невозможно.
Варианты преодоления данного ограничения:
- Использовать два и более физических линка на машине. Это дает возможность взаимодействия через соседний интерфейс. Например, взять eth1 и отдать его специально для MACVLAN, а на хост-системе продолжать использовать eth0. Вариант, безусловно, неплохой, но это влечет за собой необходимость держать одинаковое количество линков на всех машинах, где мы планируем запускать подобные сервисы. Реализовать это дорого, не быстро и не всегда возможно.
- Использовать еще один дополнительный IP-адрес на хост-системе, повесить его на виртуальный MACVLAN-интерфейс, который нужно поднять на хост-системе. Это приблизительно так же сложно с точки зрения поддержки («не забыть/не забывать»), как предыдущее предложение — это раз. А, так как ранее я говорил о том, что наш сервис сам по себе требует дополнительного адреса, то в итоге для запуска такого сервиса нам потребуется:
- адрес для основного интерфейса хост-системы (1);
- адрес для сервиса (2);
- адрес для виртуального интерфейса, через который мы будем взаимодействовать с сервисом (3).
В данном случае получается, что нам нужно слишком много IP-адресов, которые, по большому счету, использоваться будут мало. Помимо излишнего расходования IP-адресов стоит также помнить, что нам нужно будет поддерживать статичные маршруты через этот самый виртуальный интерфейс до контейнера. Это не непреодолимая сложность, но усложнение системы в целом — факт.
Внимательный читатель задаст вопрос: «А зачем адрес на основной интерфейс и на MACVLAN-интерфейс, если можно адрес основного интерфейса отдать виртуальному?» В таком случае мы оставим нашу систему без адресов на реальных интерфейсах, а на такой шаг я пойти пока не готов.
В предыдущих двух вариантах предполагалось, что адреса всех интерфейсов принадлежат одной сети. Как несложно представить, даже при 100 серверах в такой подсети, если завести по три адреса, то в /24 мы уже не попадаем.
- Сервисный IP. Суть идеи заключается в том, что мы делаем отдельную подсеть для сервисов. Как это выглядит:
- на сервер начинаем подавать «тегированный» траффик;
- native VLAN оставляем в виде основной сети для dockerhost (eth0);
- поднимаем виртуальный интерфейс с 802q, без IP-адреса на хост системе;
- используем для сервиса IP-адрес из сервисной сети.
Рассматривать, как уже стало понятно, будем пункт три. Чтобы все у нас заработало, нужно проделать несколько действий:
- для того чтобы подать «тегированный» трафик на интерфейс, кто нам нужен? Правильно, сетевики! Просим их выполнить переключение access-порта в порт, на который подаем 2 VLAN;
- поднять дополнительный интерфейс на хосте:
# cat /etc/sysconfig/network/ifcfg-vlan8 BOOTPROTO='static' STARTMODE='auto' VLAN='yes' ETHERDEVICE='eth0' # ip -d link show vlan8 31: vlan8@eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether e4:11:5b:ea:b6:30 brd ff:ff:ff:ff:ff:ff promiscuity 1 vlan protocol 802.1Q id 8 <REORDER_HDR>
- завести MACVLAN-сеть в Docker
# docker network create -d macvlan --subnet=1.1.2.0/24 --gateway=1.1.2.1 -o parent=vlan8 c_services
- убедиться, что сеть в Docker появилась:
# docker network ls | grep c_services a791089219e0 c_services macvlan
Все сделал, все хорошо. Тут я решил посмотреть на общие графики по хосту (а если быть точнее, то на это обратил мое внимание коллега). Вот такую картину мы там увидели:
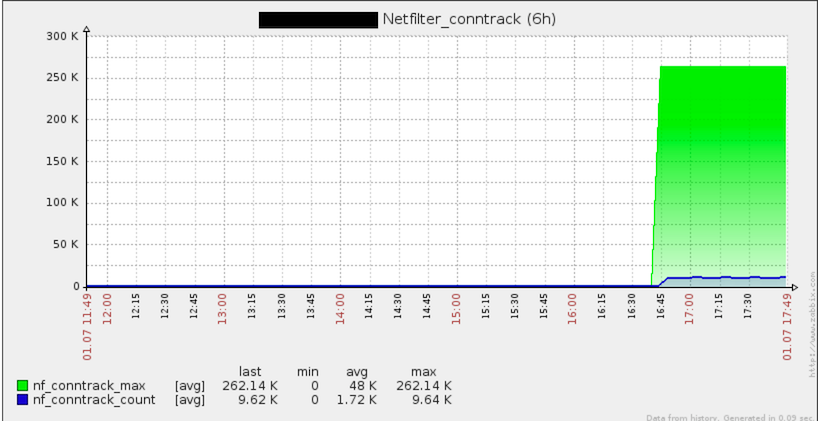
Да, здесь видно использование conntrack на хосте.
Как так? Ну не нужен же conntrack для МACVLAN?! Так как дело было уже вечером, я решил проверить даже самые невероятные теории. В подтверждение моих теоретических знаний, connection tracking был на самом деле не нужен. Без него все продолжало работать. Выгрузка модулей, так или иначе завязанных на conntrack, была невозможной только в момент запуска моего контейнера. Идеи меня покинули, и пошел я домой, решив, что утро вечера мудренее.
На следующий день я в очередной раз убедился в точности данного высказывания. Итак, я решил «топорным» методом сделать так, чтобы Docker не мог подгружать nf_conntrack. Сначала я его просто переименовал (т.к. blacklist игнорируется при загрузке модуля через modprobe), после чего запустил свой контейнер снова. Контейнер, как и ожидалось, поднимался и отлично себя чувствовал, но в логе я увидел сообщения о том, что четыре правила не могут быть добавлены в iptables. Получается, что conntrack нужен? Вот правила, которые не хотели добавляться:
-t nat -A OUTPUT -d 127.0.0.11 -p udp --dport 53 -j DNAT --to-destination 127.0.0.11:35373
-t nat -A POSTROUTING -s 127.0.0.11 -p udp --sport 35373 -j SNAT --to-source :53
-t nat -A OUTPUT -d 127.0.0.11 -p tcp --dport 53 -j DNAT --to-destination 127.0.0.11:41214
-t nat -A POSTROUTING -s 127.0.0.11 -p tcp --sport 41214 -j SNAT --to-source :53
53 порт? Налицо работа, связанная с «резолвером». И тут я, к своему удивлению, узнаю про embedded DNS server. Ну хорошо, пусть и встроенный, но можно же как-то опциями выключить его? Нет, нельзя :)
Далее я попробовал вернуть модуль, запустить сервис, поправить правила из iptables и выгрузить модули… Но не тут то было. Путем ковыряния modinfo я выяснил, какой там модуль от какого зависит, и какой из них кого тянет за собой. При создании сети Docker принудительно делает modprobe xt_nat, который, в свою очередь, зависит от nf_conntrack, вот тому подтверждение:
# modinfo xt_nat
filename: /lib/modules/4.4.0-3.1-default/kernel/net/netfilter/xt_nat.ko
alias: ip6t_DNAT
alias: ip6t_SNAT
alias: ipt_DNAT
alias: ipt_SNAT
author: Patrick McHardy <kaber@trash.net>
license: GPL
srcversion: 9982FF46CE7467C8F2361B5
depends: x_tables,nf_nat
intree: Y
vermagic: 4.4.0-3.1-default SMP preempt mod_unload modversions
Как я уже говорил, все работает и без этих модулей. Соответственно, мы можем сделать вывод, что в нашем случае они не нужны. Остается вопрос: зачем, все же, они нужны? Я не поленился и заглянул в 2 места:
- на Docker issues;
- в исходный код.
И что я там нашел? Верно: для любого user defined network Docker делает modprobe. Смотрим код и видим 2 интересных для нас пункта:
if out, err := exec.Command("modprobe", "-va", "nf_nat").CombinedOutput(); err != nil {
logrus.Warnf("Running modprobe nf_nat failed with message: `%s`, error: %v", strings.TrimSpace(string(out)), err)
}
if out, err := exec.Command("modprobe", "-va", "xt_conntrack").CombinedOutput(); err != nil {
logrus.Warnf("Running modprobe xt_conntrack failed with message: `%s`, error: %v", strings.TrimSpace(string(out)), err)
}
И вот такое еще:
if err := r.setupIPTable(); err != nil {
return fmt.Errorf("setting up IP table rules failed: %v", err)
}
Делаем патч, а точнее — выкидываем все ненужное :) Делаем новую сборку Docker.
Смотрим. Все ок, все работает.
На этом этапе можно считать, что вся наша схема в лабораторных условиях работает, осталось сделать самую малость — прицепить ее к нашему сервису. Хорошо, возвращаемся к сервису и смотрим на его общую архитектуру:
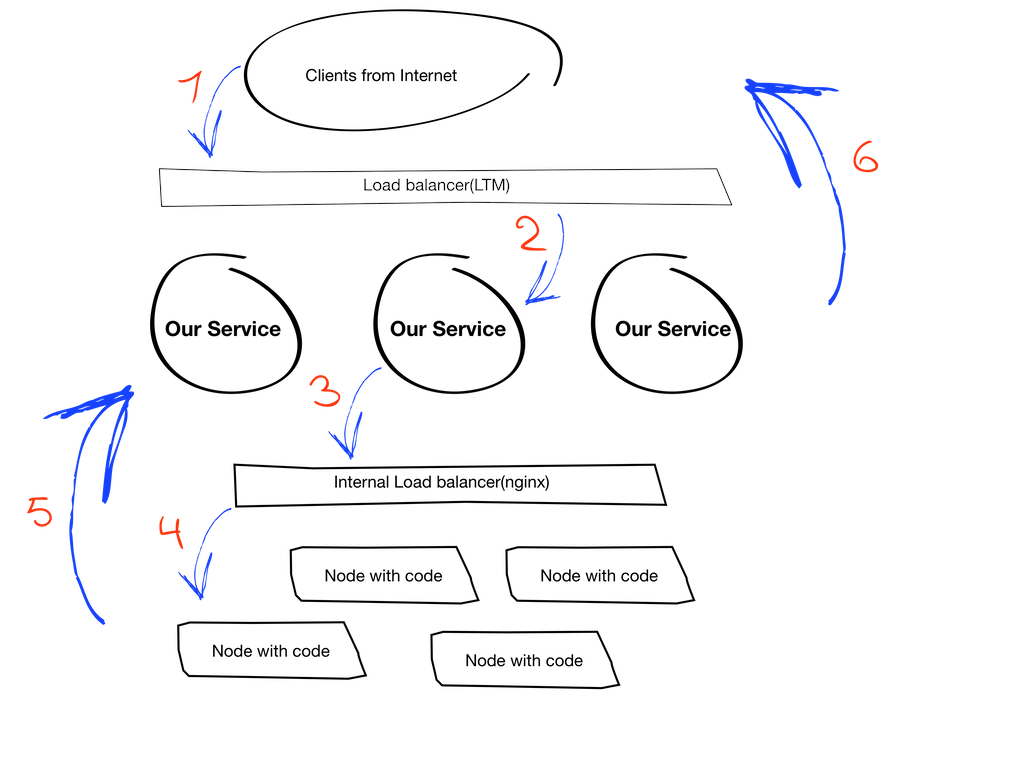
Пояснения о том, как оно работает:
- (1 и 6) мобильный клиент устанавливает соединение с неким урлом, за которым стоит балансировщик;
- (2) балансировщик выбирает нужный инстанс нашего сервиса и позволяет установить соединение клиент-сервис;
- (3 и 4) далее наш сервис проксирует запросы от клиента на кластер с кодом, но тоже через балансировщик в виде nginx. Вот тут мы и вернулись к нашему требованию о том, что nginx должен быть на той же машине, что и сервис. На данный момент также есть ограничение в том, что он должен быть именно на хосте, а не в контейнере (это, кстати, решило бы проблему сразу). Мы не будем в данной статье рассуждать о причинах этого требования, а примем это как условие.
- (5) у каждого инстанса нашего сервиса есть определенный id, который нужен коду, чтобы понимать, через какой именно инстанс отвечать клиенту.
В первом приближении нам ничто не мешает собрать образ с нашим сервисом и запустить его уже в контейнере, но есть одно НО. Так уж сложилось, что для тех сервисов, которым нужно взаимодействие с внешним балансировщиком, у нас присутствует определенный набор статических маршрутов, например, вот такой:
# ip r
default via 1.1.2.254 dev eth0
10.0.0.0/8 via 1.1.2.1 dev eth0
1.1.2.0/24 dev eth0 proto kernel scope link src 1.1.2.14
192.168.0.0/16 via 1.1.2.1 dev eth0
Т.е. все, что должно идти в или из наших внутренних сетей, идет через .1, а остальное — через .254.
Почему это проблема в нашем случае? Потому что при запуске контейнера в его маршрутах мы видим следующее:
# ip r
default via 1.1.2.1 dev eth0
1.1.2.0/24 dev eth0 proto kernel scope link src 1.1.2.14
Попытка поменять маршруты внутри контейнера ни к чему не приведет, т.к. он у нас не привилегированный (--priveleged). Остается менять маршруты руками после старта контейнера с хоста (тут кроется большое заблуждение, но про это — дальше). Здесь варианта два:
- делать это руками, используя namespace контейнера;
- взять pipework https://github.com/jpetazzo/pipework и сделать все то же самое, но с его помощью.
Скажу сразу, что с этим можно жить, но существуют опасности, как у студента: «можно забыть, забить или запить» :)
Стремясь к идеалу, мы сделали для этой сервисной сети все маршруты через default gw, а всю сложность маршрутизации переложили на сетевой отдел. Всё. Точнее, я думал, что всё…
Как мне показалось на тот момент — решение отличное. Если бы все работало именно так, как я рассчитывал, так бы оно и было, но на этом ничего не закончилось. Чуть позже стало понятно, что при такой схеме мы получаем асимметричный роутинг для тех сетей, в которых есть маршрут через наш LTM. Чтобы стало чуть более понятно, я попробую показать, какие подсети у нас могут быть.
- Сеть, у которой есть только 1 default gw и нет внешнего балансировщика.

- Сеть, у которой более одного GW: например, балансировщик внешних запросов. Сложность в том, что внутренний трафик мы через него не гоняем.
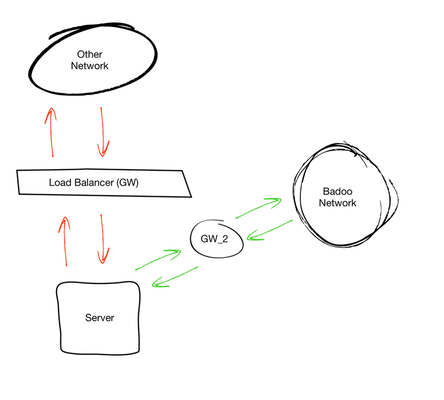
Поговорив с сетевиками, мы сделали следующие выводы:
- они не готовы брать на себя ответственность и следить за всеми сетями, в которых роутинг будет именно таким;
- мы, со своей стороны, не готовы поддерживать статичные маршруты для всех таких сетей на серверах
Получилось так, что при желании сделать что-то простое, мы получили проблему на ровном месте, и если бы не подумали сразу о возможных сложностях, это привело бы к довольно грустным последствиям.
Я всегда говорю, что не стоит забывать про идеи, которые приходили в голову раньше, но были отвергнуты. Мы вернулись к мысли использовать статические маршруты внутри контейнера.
Итак, вот те условия, которые гарантируют нам работу нашего сервиса в контейнере:
- сам сервис;
- выделенный IP для сервиса;
- доступность сервиса и адреса со всех наших подсетей;
- возможность использовать и менять маршруты при запуске контейнера (самое важное, потому что именно это можно забыть).
Запускать контейнеры в привилегированном режиме (--privileged) не хотелось и не хочется. Я изначально не подумал про Linux capabilities, которые можно добавлять и убирать при запуске контейнера. Подробнее про них можно почитать вот тут. Для нашей задачи было достаточно добавить NET_ADMIN.
Вот теперь картинка сложилась, и мы можем добавить все нужные нам штуки, связанные с маршрутизацией, в автозапуск.
Давайте посмотрим, как выглядит наш Dockerfile в близком к финальному результату.
Dockerfile:
FROM dockerio.badoo.com/itops/sle_12_base:latest
MAINTAINER #MAINTEINER#
RUN /usr/bin/zypper -q -n in iproute2
RUN groupadd -g 1001 wwwaccess
RUN mkdir -p /local/SERVICE/{var,conf}
COPY get_configs.sh /local/SERVICE/
COPY config.cfg /local/SERVICE/
ADD SERVICE-CERTS/ /local/SERVICE-CERTS/
ADD SERVICE/bin/SERVICE-BINARY-${DVERSION} /local/SERVICE/bin/
ADD SERVICE/conf/ /local/SERVICE/conf/
COPY routes.sh /etc/cont-init.d/00-routes.sh
COPY env.sh /etc/cont-init.d/01-env.sh
COPY finish.sh /etc/cont-finish.d/00-finish.sh
COPY run /etc/services.d/SERVICE/
COPY finish /etc/services.d/SERVICE/
RUN touch /tmp/fresh_container
ENTRYPOINT ["/init"]
На что тут стоит обратить внимание:
- мы используем s6 overlay как supervisor внутри контейнера;
- мы добавляем пакет iproute, чтобы можно было править маршруты;
- мы добавляем запуск нескольких скриптов, которые выполняются ДО старта нашего сервиса (директория /etc/cont-init.d/), а также добавляем скрипты, которые будут выполнены ПОСЛЕ завершения работы сервиса, но ДО того, как опустится контейнер (/etc/cont-finish.d/);
- мы добавляем файл /tmp/fresh_container для того, чтобы понимать, первый ли раз стартует наш контейнер или нет. Чуть яснее про это будет, когда я покажу содержимое остальных скриптов;
Используемые скрипты:
- get_configs.sh — это скрипт, который смотрит, есть ли конфиг для сервиса в нашей системе хранения и генерации конфигов, доставляет их в контейнер, проверяет на валидность, и если все в порядке, то с ним и запускает. Подробнее про это мы рассказывали на Docker Meetup;
- routes.sh — скрипт, который подготавливает маршруты внутри контейнера:
#!/usr/bin/with-contenv sh if [ ! -x /usr/sbin/ip ];then echo -e "\e[31mCan't execute /usr/sbin/ip\e[0m"; [ $(pgrep s6-svscan) ] && s6-svscanctl -t /var/run/s6/services exit 1; else LTMGW=$(/usr/sbin/ip r show | /usr/bin/grep default | /usr/bin/awk {'print $3'} | /usr/bin/awk -F \. {'print $1"."$2"."$3".254"'}) DEFGW=$(/usr/sbin/ip r show | /usr/bin/grep default | /usr/bin/awk {'print $3'} | /usr/bin/awk -F \. {'print $1"."$2"."$3".1"'}) /usr/sbin/ip r replace default via ${LTMGW} /usr/sbin/ip r add 192.168.0.0/16 via 10.10.8.1 dev eth0 /usr/sbin/ip r add 10.0.0.0/8 via 10.10.8.1 dev eth0 echo -e "\e[32mAll job with routes done:\e[0m\n$(/usr/sbin/ip r show)" fi
- env.sh — скрипт, который готовит окружение для нашего сервиса; зачастую именно он выполняется только 1 раз при первом старте контейнера:
#!/usr/bin/with-contenv sh if [ ! -z "${ISTEST}" ];then exit 0;fi if [ ! -n "${SERVICETYPE}" ];then echo -e "\e[31mPlease set SERVICE type\e[0m"; [ $(pgrep s6-svscan) ] && s6-svscanctl -t /var/run/s6/services exit 1; fi bash /local/SERVICE/get_configs.sh || exit 1 echo -e "\e[32mSERVICE ${SERVICETYPE} is running\e[0m"
- finish.sh — скрипт, который просто чистит pid-файлы от нашего сервиса. Конкретный сервис настолько крут (как Чак Норрис), что сам этого не делает, но он не запустится, если обнаружит старые pid-файлы :)
- run — это скрипт, который запускает наше приложение:
#!/usr/bin/with-contenv bash exec /local/SERVICE/bin/SERVICE-${DVERSION} -l /local/SERVICE/var/mobile-${SERVICETYPE}.log -P /local/SERVICE/var/mobile-${SERVICETYPE}.pid -c /local/SERVICE/conf/SERVICE.conf -v ${VERBOSITY}
- finish — скрипт, который тушит контейнер в случае, если сервис завершил свою работу:
#!/bin/sh [ $(pgrep s6-svscan) ] && s6-svscanctl -t /var/run/s6/services
Строка для запуска нашего сервиса будет выглядеть так:
docker run -d --net=c_services --ip=1.1.2.17 --name=SERVICE-INSTANCE16 -h SERVICE-INSTANCE16.local --cap-add=NET_ADMIN --add-host='nginx.localhost:1.1.1.17' -e SERVICETYPE=INSTANCE16_eu1 -e HOST_IP=1.1.1.17 --volumes-from=badoo_loop dockerio.badoo.com/cteam/SERVICE:2.30.0_994
На этом перенос нашего сервиса в контейнер можно считать успешным. Забегая вперед, хочу заметить, что MACVLAN/IPVLAN мы используем в других наших сервисах, но примером послужил именно этот эксперимент.
Антон banuchka Турецкий
Site Reliability Engineer, Badoo
Комментарии (30)

AlexGluck
25.08.2016 00:48+1А почему вы не рассмотрели получение маршрутов от DHCP в зависимости от хостнейма? И огород городить бы не пришлось с Linux capabilities. Да и логика микросервисов ломается, хотя все её ломают кроме меня. За то что я идейный меня уже пожурили на работе.

banuchka
25.08.2016 12:47Исторически у нас всё несколько иначе – hostname в зависимости от адреса. Для данной задачи изначально делали VLAN, в котором даже нет DHCP хелпера. Если посмотреть под другим углом, то может быть и предложенная вами реализация оказалась бы уместна.
По поводу идей и логики микросервисов это все, конечно, хорошо, но не под все условия подходит. С моей точки зрения очень часто получается так, что идею микросервисов предлагают, а о том, будет ли с таким подходом хорошо и удобно – забывают.
В данном случае мы можем рассматривать Docker как и любой другой инструмент для выполнения тех или иных задач, а решение о том, как выполнять эти задачи остается за нами. Такой подход мне ближе.
Также в данном случае, я не считаю, что получился «огород», так как данная схема для нас вполне привычная.AlexGluck
25.08.2016 17:29В любом случае по моему проще добавить DHCP в этот отдельный VLAN, а условие отдачи маршрутов натянуть через типовой ключ(hostname или ip адрес, да любой который подходит). Ну а про докеры я просто поплакался.

o_serega
25.08.2016 16:45В начале поста, вы заявляете про простоту решений, а в итоге получили далеко не самую простую систему. Да и маршруты внутри докер контейнера, на мое скромное мнение, не самое лучшее решение. Да и вообще в вашем использовании докер контейнеров, теряются все его фишки, тут больше уже напоминает, натянуть технологию на свои реалии
banuchka
25.08.2016 17:17О том, почему маршруты внутри контейнера я попытался объяснить в теле статьи. Если это не до конца понятно – могу попробовать еще раз.
Простота решения – это мера сильно субъективная. Если вы хотите, то давайте я по каждому пункту, который кажется не простым, отвечу почему я считаю его простым. Осталось только обозначить пункты.
Как я сказал в комментарии выше – есть технология, а то как ее применять и использовать – это уже дело личное. Можно рассматривать предложенное решение не в формате «так нужно делать», а в формате «можно сделать вот так вот».
А какие фишки docker'а являются важными для вас и какие из них я потерял?o_serega
25.08.2016 17:24+1Простота самого докер имеджа, по факту это сугубо приложение, плюс минимум окружения, необходимое только для запуска самого приложения. В идеале что бы было достаточно сделать docker pull, а потом docker run, ну порт узакать для биндинга — все, мне кажется, что в вашем случаи, докер просто не та технология. Но это все мое имхо и Вы вообще можете на меня не обращать внимания)
banuchka
25.08.2016 17:44Не обращать внимания – неправильно, дискуссия – всегда отлично!
Давайте попробуем посмотреть на «docker run» с той точки зрения, что вы готовы указать порт для приложения:
docker run -d \ // здесь мы выбираем тип сети для контейнера, выдаем ему ip-адрес: --net=c_services --ip=1.1.2.17 \ // указываем имя, т.к. просто удобнее смотреть потом на docker ps. Можно не указывать. --name=SERVICE-INSTANCE16 \ // это опять же приятнее рандомайза, т.е. дело эстетики. Можно не указывать. -h SERVICE-INSTANCE16.local \ // да, тут чуть сложнее и мне это нужно: --cap-add=NET_ADMIN \ // добавить запись в /etc/hosts. Можно сделать иначе, но так оно прозрачнее. --add-host='nginx.localhost:1.1.1.17' \ // переменные окружения. То, что вы говорили про порт для приложения: -e SERVICETYPE=INSTANCE16_eu1 -e HOST_IP=1.1.1.17 \ // чтобы не указывать вереницу служебных директорий, которые нам нужны в определенных контейнерах. --volumes-from=badoo_loop \ // имя образа: dockerio.badoo.com/cteam/SERVICE:2.30.0_994
docker pull также можно не делать, run сделает его за вас :)
Итого в сухом остатке мы получаем, что сложность команды заключается в:
- --cap-add
- --add-host
А если учитывать то, что руками мы это не выполняем, то вывод напрашивается сам собой.o_serega
25.08.2016 18:02НУ соркестрировать можно и самый клинический случай — это никто не оспаривает, но я имел ввиду docker run -d -p 8888:9999 blalala/hahha:latest
Если у вас такие особенностью с сетью (я про маршруты), Вы не смотрели opencontrail или calico, может оно вам реально жизнь упростит.
лично у нас с сетью тоже не все гладко, для балансинга там свой влан и тп, я вообще апаю контейнер без сети и через pipework добавляю контейнер на нужный бридж от нужного влана, таблица контракта для хост системы не юзается.banuchka
25.08.2016 18:09вот от pipework и ручных телодвижений в случае поднятия контейнера я стараюсь держаться дальше, т.к. есть вероятность, что кто-то из коллег или, например, службы мониторинга не осилит определенные действия без понимая картины в целом.
«opencontrail или calico» – не смотрели. Особенности у нас только такие, о которых я написал в статье: есть всего 2 варианта :)
o_serega
25.08.2016 18:13Ну у нас не руками, это жело все автоматизируется легко) Но плюс, что образ один и тот же, что для разработчиков, что для прода, специально что-то модифицировать внутри имеджа не надо. Может стоит все же глянуть на выше описанные решения, может они смогут вам помочь с маршрутами и не надо будет сие дело притаскивать в сам имедж
banuchka
25.08.2016 18:16спасибо, я обязательно посмотрю на вышеназванные решения.
o_serega
25.08.2016 18:18Я не говорю, что оно панацея и может я все же не до конца понял особенности ваши (точнее я уверен что не понял), но стоит глянуть, во всяком случаи тот же калико обменивается маршрутами о сетях используемых на докер хостах, но это стоит все поизучать, лично я смотрю в сторону этих двух решений в качестве альтернативы fleet в кубернетес.
banuchka
25.08.2016 18:26мне если честно, то совсем не хочется зарываться в сторону софтовой маршрутизации. Как минимум на данный момент у нас есть отдел сетевых инженеров, которым по вопросам сети я доверяю больше, чем себе.
В данном примере я делаю какие-то телодвижения в рамках одного хоста, а гейтвеи и условия балансировки, а также маршруты до них я не меняю/не нарушаю. Это важно как минимум и потому, что не все сервисы в контейнерах. Т.е. решения так или иначе связанные с маршрутами и завязанные на docker и его экосистему на данный момент для внедрения сильно не рассматриваются.o_serega
25.08.2016 18:28ну вот не получившись поиметь от сетевого отдела большего чем влан, пришлось изощеряться, но это даже и к лучшему, многое стало более настраиваемо и гибче, а под капотом там все равно проверенные временем протоколы маршрутизации, но мне проще, я немало в телекоме поработал.
Ну а вообще да: работает — не трож)
AlexGluck
25.08.2016 18:52Вот такое
docker run -d \
// здесь мы выбираем тип сети для контейнера, выдаем ему ip-адрес:
// Этого можно было бы не делать будь у вас DHCP
--net=c_services --ip=1.1.2.17 \
// указываем имя, т.к. просто удобнее смотреть потом на docker ps. Можно не указывать.
// Это необходимо для создания фильтрации в централизованном лог сервере
--name=$VARIABLE \
// это опять же приятнее рандомайза, т.е. дело эстетики. Можно не указывать.
// Это необходимо для системы мониторинга, но можно через dhcp проставлять
-h $VARIABLE.local \
// да, тут чуть сложнее и мне это нужно:
// это так же решается dhcp сервером
--cap-add=NET_ADMIN \
// добавить запись в /etc/hosts. Можно сделать иначе, но так оно прозрачнее.
// если у нас есть dhcp значит и dns можно поставить и управлять этим можно будет централизованно
--add-host='nginx.localhost:1.1.1.17' \
// переменные окружения. То, что вы говорили про порт для приложения:
// этого тоже можно избежать забирая $VARIABLE из хостнейма и присвоенный адрес из системы
-e SERVICETYPE=INSTANCE16_eu1 -e HOST_IP=1.1.1.17 \
// чтобы не указывать вереницу служебных директорий, которые нам нужны в определенных контейнерах.
// Это сугубо специфичное и должно указываться в dockerfile
--volumes-from=badoo_loop \
// имя образа:
dockerio.badoo.com/cteam/$VARIABLE:2.30.0_994
Можно с лёгкостью уменьшить до
VARIABLE=SERVICE;docker run -d \
// Это необходимо для создания фильтрации в централизованном лог сервере, можно наверно не указывать
--name=$VARIABLE \
// имя образа:
cteam/$VARIABLE:2.30.0_994
Итого наш контейнер запускается и работает независимо от ключей, требуется только указать имя образа в registry. Разве не это есть упрощение?
banuchka
25.08.2016 19:36Можно с лёгкостью уменьшить до
VARIABLE=SERVICE;docker run -d \
// Это необходимо для создания фильтрации в централизованном лог сервере, можно наверно не указывать
--name=$VARIABLE \
// имя образа:
cteam/$VARIABLE:2.30.0_994
если SERVICE == 'ubuntu', а версия == 'latest'(кстате, почему вы ее в переменную не вынесли?), то конструкция:
VARIABLE=ubuntu;docker run -d --name=$VARIABLE cteam/$VARIABLE:latest
работать не будет.
Если говорить серьезно, то все, что вы сочли лишним и решили не указывать – нам важно и нужно. Например через --volumes-from мы добавим или не добавим интерпретатор php, если он по какой-то причине нужен внутри контейнера. Мы также прокинем в контейнер служебные директории, откуда потом будем собирать статистику – да это все про работу одного сервиса.
В данном случае мы не рассматриваем один сервис, как один *nix сервис. Сервис в данном случае – это некоторое приложение, которое должно выдавать ожидаемый нами результат. Да, часто получается так, что для работы данного сервиса может потребоваться более одного *nix сервиса.
Через -e мы передаем параметры, на основании которых мы должны сделать вывод о том, какой тип данного сервиса мы хотим запускать… Опять же – это не указывать нельзя.AlexGluck
25.08.2016 20:03Я каждый убранный пункт прокомментировал, всё что мы не указали подтягивается либо из дефолтных настроек докера, либо из dhcp, либо из dns. Так как у вас в любом случае есть свои dns и dhcp сервера и выносить с них этот функционал не было никакого смысла. Что же касается дефолтных настроек докера то у вас физические машины и сами контейнеры управляются через оркестрацию вашу. Так что я просто использовал то что у вас есть для упрощения нового.
banuchka
25.08.2016 20:30Хорошо, вот ваш самый первый комментарий:
docker run -d \
// здесь мы выбираем тип сети для контейнера, выдаем ему ip-адрес:
// Этого можно было бы не делать будь у вас DHCP
--net=c_services --ip=1.1.2.17 \
Неважно есть у нас dhcp или нет, но указать тип сети для контейнера мы должны, а иначе мы используем default bridge, так? Изначально я говорю о том, что нам нужен и мы используем MACVLAN.
Идем дальше. Можно не указывать --ip=. Можно, но тогда нам либо pool адресов при создании macvlan сети для docker нужно как-то обозначить, либо как-то блеклистить те адреса, которые мы не хотим получить в своем контейнере, так?
// это опять же приятнее рандомайза, т.е. дело эстетики. Можно не указывать.
// Это необходимо для системы мониторинга, но можно через dhcp проставлять
-h $VARIABLE.local \
Для какой системы мониторинга?
// да, тут чуть сложнее и мне это нужно:
// это так же решается dhcp сервером
--cap-add=NET_ADMIN \
мы меняем default gw, который мы проставляли при создании MACVLAN сети на .254, что сделать без NET_ADMIN не получится(да, можно через pipework, но мне не нравится такой вариант)
// добавить запись в /etc/hosts. Можно сделать иначе, но так оно прозрачнее.
// если у нас есть dhcp значит и dns можно поставить и управлять этим можно будет централизованно
--add-host='nginx.localhost:1.1.1.17' \
эта запись будет разной, в зависимости от хоста, на котором запускам контейнер. Да, тоже самое значение я передаю позже в -e HOST_IP=1.1.1.17, его можно использовать. Но т.к. сущности разные, то и указываю отдельно там и там.
// этого тоже можно избежать забирая $VARIABLE из хостнейма и присвоенный адрес из системы
-e SERVICETYPE=INSTANCE16_eu1 -e HOST_IP=1.1.1.17 \
можно завязаться на hostname, но т.к. мы обеспечиваем работу сервиса, то сущностью «сервис» оперировать логичнее.
// Это сугубо специфичное и должно указываться в dockerfile
--volumes-from=badoo_loop \
нет, нельзя это указывать в Dockerfile, т.к. там мы можем указать какие директории будем экспортировать, а нам нужен еще и импорт.
AlexGluck
25.08.2016 21:04а иначе мы используем default bridge, так?
Нет, мы через оркестрацию задаём всем физическим машинам настройки докера. А именно удаляем все имеющиеся сети и добавляем macvlan. И к контейнеру привязывается единственная наша сеть через macvlan.
Для какой системы мониторинга?
Вы в badoo используете заббикс с LLD на основе хостнеймов. Читал с митапа заббикса ваш доклад.
мы меняем default gw, который мы проставляли при создании MACVLAN сети на .254, что сделать без NET_ADMIN не получится
Через dhcp вы так же можете получить маршруты, в том числе и default gw.
эта запись будет разной, в зависимости от хоста, на котором запускам контейнер. Да, тоже самое значение я передаю позже в -e HOST_IP=1.1.1.17, его можно использовать. Но т.к. сущности разные, то и указываю отдельно там и там.
это я не совсем понимаю, плодить сущности конечно не хорошо, но если это обход Ограничения технологии by design: доступность контейнера с хоста и доступность хоста из контейнера отсутствует. То думаю это самое простое решение.нет, нельзя это указывать в Dockerfile, т.к. там мы можем указать какие директории будем экспортировать, а нам нужен еще и импорт.
Здесь я наверно не прав.banuchka
25.08.2016 21:14Вы можете показать практически работающее решение, на основании того, как вы его описываете? А именно:
- задать docker демону работу через macvlan сеть by default
- чтобы контейнеры(пусть все, хотя не всегда это нужно) использовали именно эту сеть
- чтобы контейнер, mac которого мы не знаем получал заранее известный ip (тут спорно, т.к. можно обыграть иначе, но пусть так)
- чтобы контейнер по dhcp(центральному, а не тому, что предоставляет macvlan) получал default gw, а также 2-3 кастомных маршрута
AlexGluck
25.08.2016 21:32Вы можете показать практически работающее решение, на основании того, как вы его описываете?
Нет, я выдвинул предположение о том что правильней для такого функционала было бы использовать. Все последующие комментарии были только для более полного и подробного описания идеи. Надеюсь вы не серчаете на меня.banuchka
25.08.2016 23:04Конечно не серчаю, мы же просто обсуждали предложенную вами идею. Обсуждать, предлагать, да и вообще думать – очень полезно.
Изначально, когда вы абстрактно предложили свою идею, без подробностей – она казалась вполне себе состоятельной, я воспринял некоторые моменты по-своему. Далее, когда вы начали более подробно раскрывать её – стало понятно, что не всё можно сделать так просто и прозрачно, а значит это скорее всего приведет к некоторым дополнительным костылям/сервисам и т.д. (не обязательно, но на основании написанного – приведет).
Где-то в середине дискуссии мы говорили о том, что можно упростить предложенную мной строку запуска(про linux capabilities продолжать не будем) – я согласен, можно. Но приведенная строка запуска не дает до конца расслабиться инженеру в те моменты, когда он запускает сервис или диагностирует его, т.е. глядя на строку запуска он уже имеет некоторое понимание о том, с чем ему придется иметь дело. Можем упростить команду и скрыть детали? Да! Проблема лишь в том, что это мы уберем в дебри инита нашего контейнера, тем самым осложним диагностику, если это потребуется. А самое главное – человеку придется меньше думать и работать со «сферическим конем в вакууме» =)
p.s.: самое главное и хорошее – это то, что у вам есть мысли и идеи, а также и то, что вы не боитесь и не стесняетесь ими делиться. Так держать!
ToSHiC
А почему вы не рассматривали вариант с macvlan интерфейсом в качестве основного на хост-системе? А на eth0 даже адрес не навешивать. Заодно и пакеты перестанут ходить через свитч.
banuchka
В статье я сделал оговорку по этому поводу, также в ней содержится и ответ:
Для того, чтобы пакеты перестали ходить через свитч мы также высадили nginx в контейнер, который использует нужную нам сеть.
ToSHiC
Видите, читатель оказался недостаточно внимательным :)
Опасаетесь остаться без control flow? Тогда, как вариант — отдельные запасные адреса на eth0 интерфейсе, чтобы было куда придти, если совсем всё плохо стало. в целом же macvlan не выглядит менее надёжным, чем бридж, а его активно используют и навешивают адреса именно на него.
banuchka
Вариант с таким или подобным развитием мы вполне рассматриваем, но внедрять пока не стали. Скорее всего мы ждем момента, когда накопится достаточный эксплуатационный опыт с тем, что есть, а уж если он будет положительным…