
Нахождение экстремума (минимума или максимума) целевой функции является важной задачей в математике и её приложениях (в частности, в машинном обучении есть задача curve-fitting). Наверняка каждый слышал о методе наискорейшего спуска (МНС) и методе Ньютона (МН). К сожалению, эти методы имеют ряд существенных недостатков, в частности — метод наискорейшего спуска может очень долго сходиться в конце оптимизации, а метод Ньютона требует вычисления вторых производных, для чего требуется очень много вычислений.
Для устранения недостатков, как это часто бывает, нужно глубже погрузиться в предметную область и добавить ограничения на входные данные. В частности: МНС и МН имеют дело с произвольными функциями. В статистике и машинном обучении часто приходится иметь дело с методом наименьших квадратов(МНК). Этот метод минимизирует сумму квадрата ошибок, т.е. целевая функция представляется в виде:
Алгоритм Левенберга — Марквардта используется для решения нелинейного метода наименьших квадратов. Статья содержит:
- объяснение алгоритма
- объяснение методов: наискорейшего спуска, Ньтона, Гаусса-Ньютона
- приведена реализация на Python с исходниками на github
- сравнение методов
В коде использованы дополнительные библиотеки, такие как numpy, matplotlib. Если у вас их нет — очень рекомендую установить их из пакета Anaconda for Python
Зависимости
Алгоритм Левенберга — Марквардта опирается на методы, приведённые в блок-схеме
Поэтому, сначала, необходимо изучить их. Этим и займёмся
Определения
— наша целевая функция. Мы будем минимизировать
. В этом случае,
— градиент функции
в точке
—
, при котором
является локальным минимумом, т.е. если существует проколотая окрестность
, такая что
— глобальный минимум, если
, т.е.
— матрица Якоби для функции
в точке
, так как в этом случае мы имеем дело с отображением из
-мерного вектора в
-мерный, поэтому нельзя просто посчитать первые производные по одному измерению, как это происходит в градиенте. Подробнее
— матрица Гессе (матрица вторых производных). Необходима для квадратичной аппроксимации
Выбор функции
В математической оптимизации есть функции, на которых тестируются новые методы. Одна из таких функция — Функция Розенброка. В случае функции двух переменных она определяется как
Я принял
Будем рассматривать поведение функции на интервале
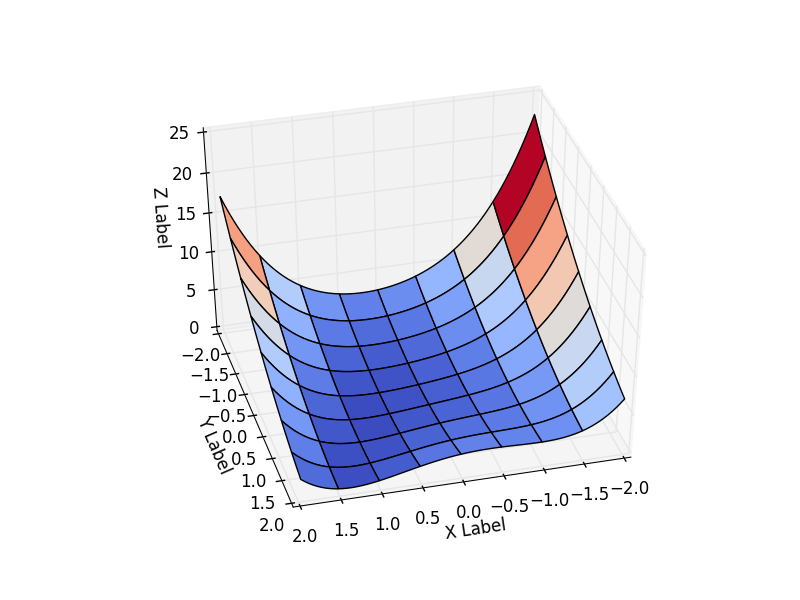
Эта функция определена неотрицательно, имеет минимум
В коде проще инкапсулировать все данные о функции в один класс и брать класс той функции, которая потребуется. Результат зависит от начальной точки оптимизации. Выберем её как
functions.py
class Rosenbrock:
initialPoint = (-2, -2)
camera = (41, 75)
interval = [(-2, 2), (-2, 2)]
"""
Целевая функция
"""
@staticmethod
def function(x):
return 0.5*(1-x[0])**2 + 0.5*(x[1]-x[0]**2)**2
"""
Для нелинейного МНК - возвращает вектор-функцию r
"""
@staticmethod
def function_array(x):
return np.array([1 - x[0] , x[1] - x[0] ** 2]).reshape((2,1))
@staticmethod
def gradient(x):
return np.array([-(1-x[0]) - (x[1]-x[0]**2)*2*x[0], (x[1] - x[0]**2)])
@staticmethod
def hesse(x):
return np.array(((1 -2*x[1] + 6*x[0]**2, -2*x[0]), (-2 * x[0], 1)))
@staticmethod
def jacobi(x):
return np.array([ [-1, 0], [-2*x[0], 1]])
"""
Векторизация для отрисовки поверхности
Детали: http://www.mathworks.com/help/matlab/matlab_prog/vectorization.html
"""
@staticmethod
def getZMeshGrid(X, Y):
return 0.5*(1-X)**2 + 0.5*(Y - X**2)**2
Метод наискорейшего спуска (Steepest Descent)
Сам метод крайне прост. Принимаем
Нужно найти
где
Так как мы минимизируем
Направление у нас верное, но делая шаг длиной
Теоретически, чем меньше шаг, тем лучше. Но тогда пострадает скорость сходимости. Рекомендуемое значение
В коде это выглядит так: сначала базовый класс-оптимизатор. Передаём всё, что понадобится в дальнейшем (матрицы Гессе, Якоби, сейчас не нужны, но понадобятся для других методов)
class Optimizer:
def _init_(self, function, initialPoint, gradient=None, jacobi=None, hesse=None,
interval=None, epsilon=1e-7, function_array=None, metaclass=ABCMeta):
self.function_array = function_array
self.epsilon = epsilon
self.interval = interval
self.function = function
self.gradient = gradient
self.hesse = hesse
self.jacobi = jacobi
self.name = self.<strong>class</strong>.<strong>name</strong>.replace('Optimizer', '')
self.x = initialPoint
self.y = self.function(initialPoint)
"Возвращает следующую координату по ходу оптимизационного процесса"
@abstractmethod
def next_point(self):
pass
"""
Движемся к следующей точке
"""
def move_next(self, nextX):
nextY = self.function(nextX)
self.y = nextY
self.x = nextX
return self.x, self.y
Код самого оптимизатора:
class SteepestDescentOptimizer(Optimizer):
...
def next_point(self):
nextX = self.x - self.learningRate * self.gradient(self.x)
return self.move_next(nextX)
Результат оптимизации:
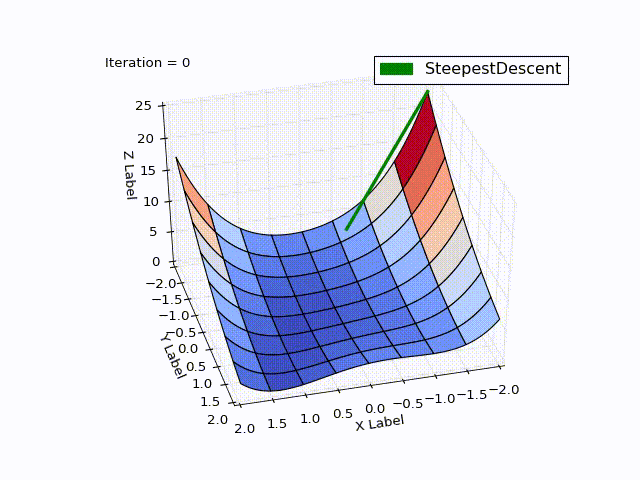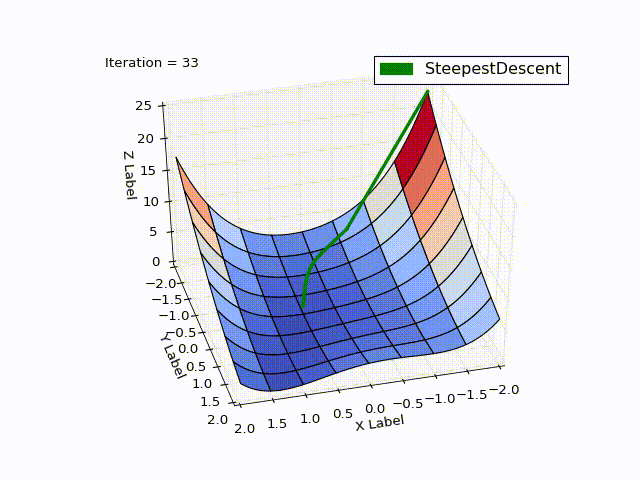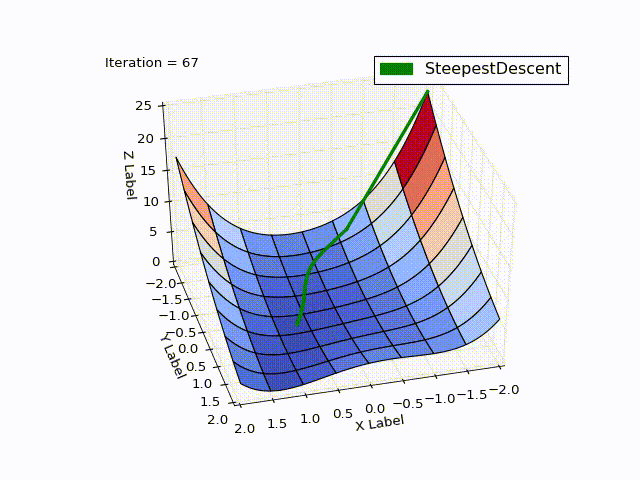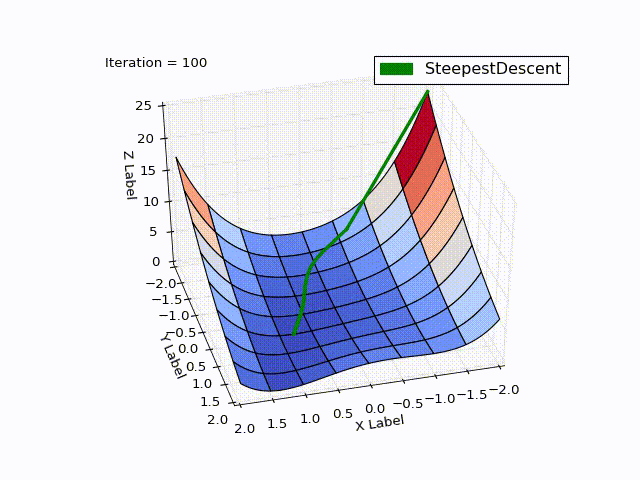
| Итерация | X | Y | Z |
|---|---|---|---|
| 25 | 0.383 | -0.409 | 0.334 |
| 75 | 0.693 | 0.32 | 0.058 |
| 532 | 0.996 | 0.990 |
Бросается в глаза: как быстро шла оптимизация в 0-25 итерациях, в 25-75 уже медленне, а в конце потребовалось 457 итераций, чтобы приблизиться к нулю вплотную. Такое поведение очень свойственно для МНС: очень хорошая скорость сходимости вначале, плохая в конце.
Метод Ньютона
Сам Метод Ньютона ищет корень уравнения, т.е. такой
А есть ещё Метод Ньютона для оптимизации. Когда говорят о МН в контексте оптимизации — имеют в виду его. Я сам, учась в институте, спутал по глупости эти методы и не мог понять фразу «Метод Ньютона имеет недостаток — необходимость считать вторые производные».
Рассмотрим для
Принимаем
Разлагаем
Несложно показать, что если
Продифференцируем обе части по
В многомерном случае первая производная заменяется на градиент, вторая — на матрицу Гессе. Делить матрицы нельзя, вместо этого умножают на обратную (соблюдая сторону, т.к. коммутативность отсутствует):
Аналогично одномерному случаю — нужно проверить, правильно ли мы идём? Если матрица Гессе положительно определена, значит направление верное, иначе используем МНС.
В коде:
def is_pos_def(x):
return np.all(np.linalg.eigvals(x) > 0)
class NewtonOptimizer(Optimizer):
def next_point(self):
hesse = self.hesse(self.x)
# Если H - положительно определённая - Ок, иначе мы идём не в том направлении, используем МНС
if is_pos_def(hesse):
hesseInverse = np.linalg.inv(hesse)
nextX = self.x - self.learningRate * np.dot(hesseInverse, self.gradient(self.x))
else:
nextX = self.x - self.learningRate * self.gradient(self.x)
return self.move_next(nextX)
Результат:

| Итерация | X | Y | Z |
|---|---|---|---|
| 25 | -1.49 | 0.63 | 4.36 |
| 75 | 0.31 | -0.04 | 0.244 |
| 179 | 0.995 | -0.991 |
Сравните с МНС. Там был очень сильный спуск до 25 итерации (практически упали с горы), но потом сходимость сильно замедлилась. В МН, напротив, мы сначала медленно спускаемся с горы, но затем движемся быстрее. У МНС ушло с 25 по 532 итерацию, чтобы дойти до нуля с
Это частое поведение: МН обладает квадратичной скоростью сходимости, если начинать с точки, близкой к локальному экстремуму. МНС же хорошо работает далеко от экстремума.
МН использует информацию кривизны, что было видно на рисунке выше (плавный спуск с горки). Ещё пример, демонстрирующий эту идею: на рисунке ниже красный вектор — это направление МНС, а зелёный — МН
[Нелинейный vs линейный] метод наименьших квадратов
В МНК у нас есть модель
В линейном МНК у нас есть
Для линейного МНК решение единственно. Существуют мощные методы, такие как QR декомпозиция, SVD декомпозиция, способные найти решение для линейного МНК за 1 приближённое решение матричного уравнения
В нелинейном МНК параметр
Здесь же приходится находить решение итеративно, причём решение зависит от выбора начальной точки.
Методы ниже имеют дело как раз с нелинейным случаем. Но, сперва, рассмотрим нелиненый МНК в контексте нашей задачи — минимизации функции
Ничего не напоминает? Это как раз форма МНК! Введём вектор-функцию
и будем подбирать
Тогда нам нужна мера — насколько хороша наша аппроксимация. Вот она:
Я применил обратную операцию: подстроил вектор-функцию
Напоследок, один очень важдный момент. Должно выполняться условие
Метод Гаусса-Ньютона
Метод основан на всё той же линейной аппроксимации, только теперь имеем дело с двумя функциями:
Далее делаем то же, что и в методе Ньютона — решаем уравнение (только для
Несложно показать, что вблизи
Код оптимизатора:
class NewtonGaussOptimizer(Optimizer):
def next_point(self):
# Решаем (J_t * J)d_ng = -J*f
jacobi = self.jacobi(self.x)
jacobisLeft = np.dot(jacobi.T, jacobi)
jacobiLeftInverse = np.linalg.inv(jacobisLeft)
jjj = np.dot(jacobiLeftInverse, jacobi.T) # (J_t * J)^-1 * J_t
nextX = self.x - self.learningRate * np.dot(jjj, self.function_array(self.x)).reshape((-1))
return self.move_next(nextX)
Результат превысил мои ожидания. Всего за 3 итерации мы пришли в точку
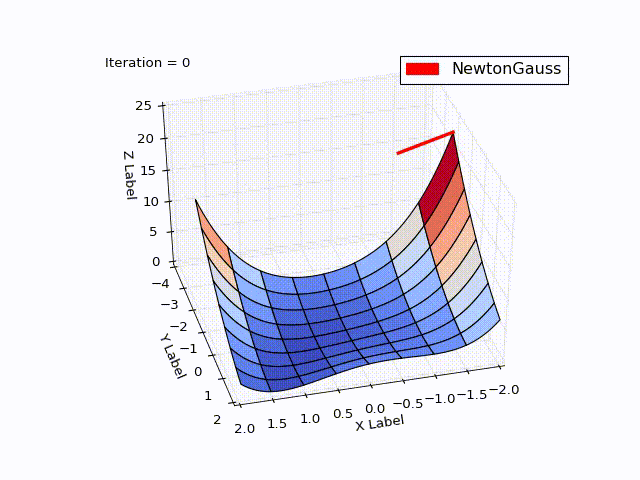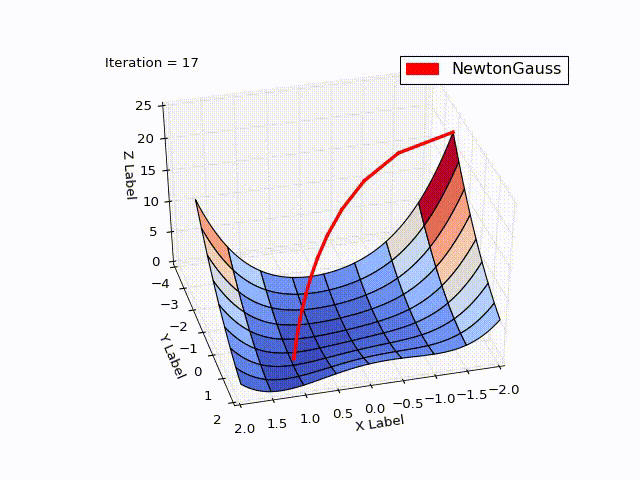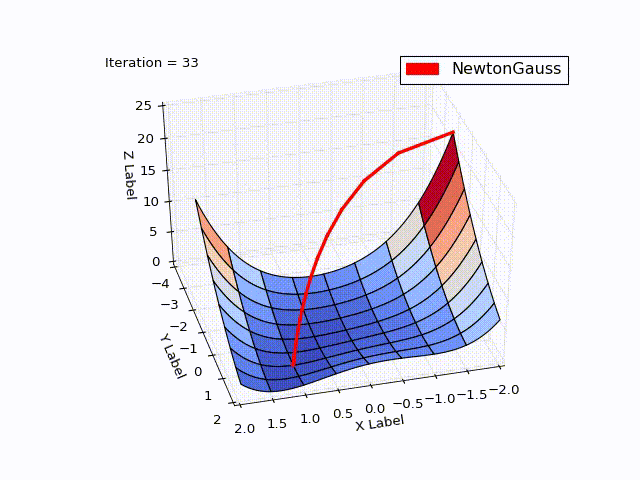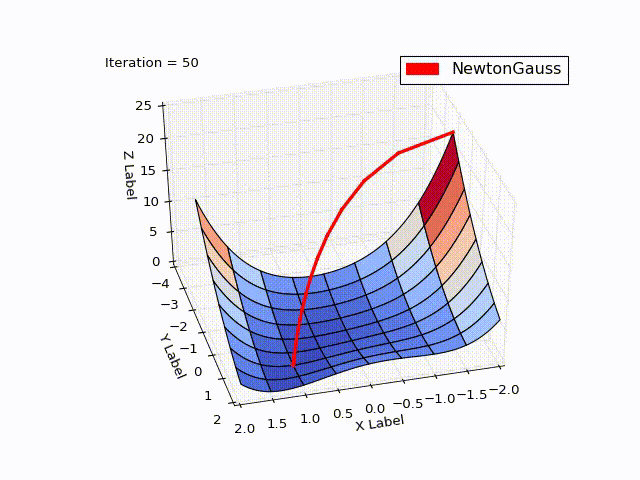
Алгоритм Левенберга — Марквардта
Он основан на одной из версий Методе Гаусса-Ньютона ("damped version" ):
Диагональные элементы
Для больших
Сам алгоритм в процессе оптимизации подбирает нужный
Если
Начальное значение

В оптимизаторах я не реализовывал критерий остановки — за это отвечает пользователь. Мне нужно было только движение к следующей точке.
class LevenbergMarquardtOptimizer(Optimizer):
def __init__(self, function, initialPoint, gradient=None, jacobi=None, hesse=None,
interval=None, function_array=None, learningRate=1):
self.learningRate = learningRate
functionNew = lambda x: np.array([function(x)])
super().__init__(functionNew, initialPoint, gradient, jacobi, hesse, interval, function_array=function_array)
self.v = 2
self.alpha = 1e-3
self.m = self.alpha * np.max(self.getA(jacobi(initialPoint)))
def getA(self, jacobi):
return np.dot(jacobi.T, jacobi)
def getF(self, d):
function = self.function_array(d)
return 0.5 * np.dot(function.T, function)
def next_point(self):
if self.y==0: # Закончено. Y не может быть меньше нуля
return self.x, self.y
jacobi = self.jacobi(self.x)
A = self.getA(jacobi)
g = np.dot(jacobi.T, self.function_array(self.x)).reshape((-1, 1))
leftPartInverse = np.linalg.inv(A + self.m * np.eye(A.shape[0], A.shape[1]))
d_lm = - np.dot(leftPartInverse, g) # moving direction
x_new = self.x + self.learningRate * d_lm.reshape((-1)) # линейный поиск
grain_numerator = (self.getF(self.x) - self.getF(x_new))
gain_divisor = 0.5* np.dot(d_lm.T, self.m*d_lm-g) + 1e-10
gain = grain_numerator / gain_divisor
if gain > 0: # Ок, хорошая оптимизация
self.move_next(x_new) # ok, шаг принят
self.m = self.m * max(1 / 3, 1 - (2 * gain - 1) ** 3)
self.v = 2
else:
self.m *= self.v
self.v *= 2
return self.x, self.y
Результат получился тоже хороший:
| Итерация | X | Y | Z |
|---|---|---|---|
| 0 | -2 | -2 | 22.5 |
| 4 | 0.999 | 0.998 | |
| 11 | 1 | 1 | 0 |
При learningrate =0.2:
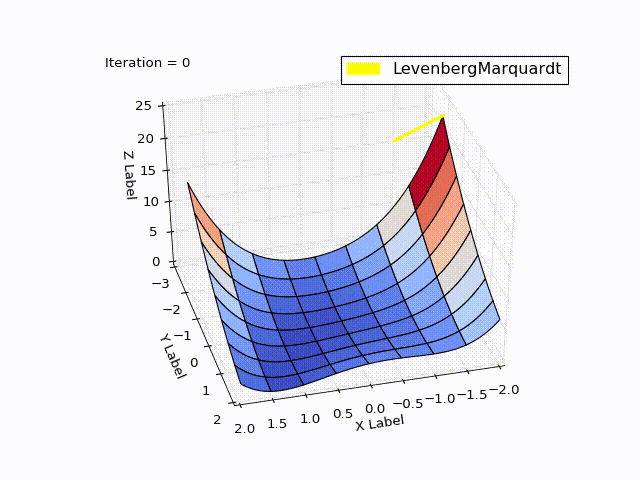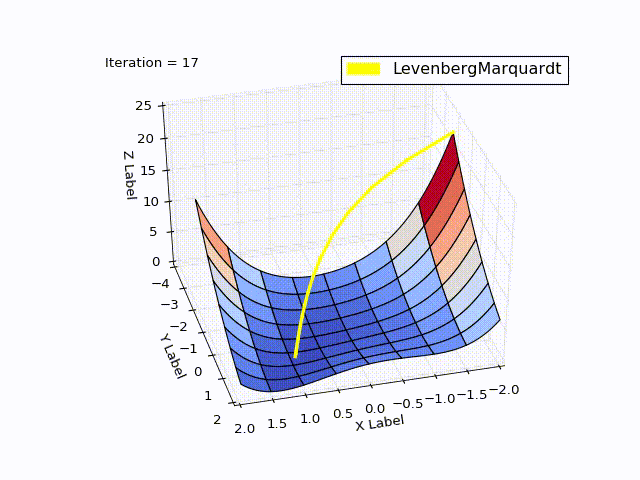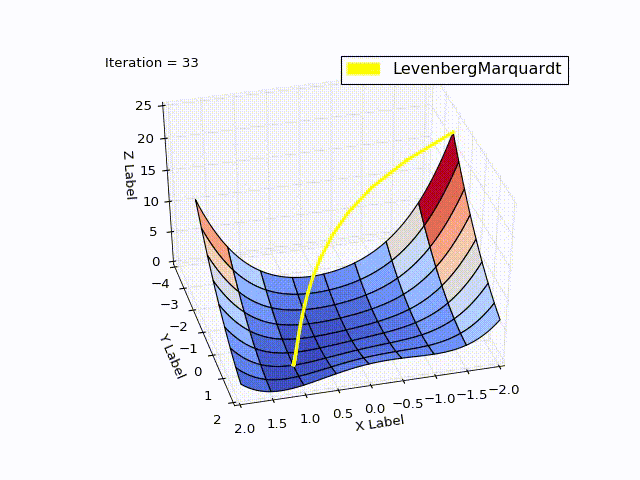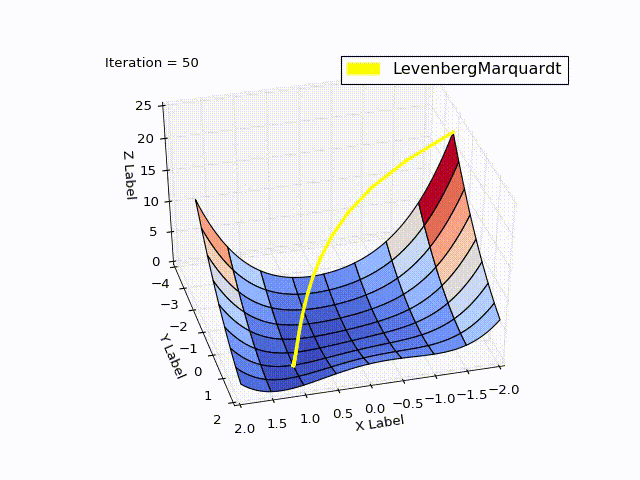
Сравнение методов
| Название метода | Целевая функция | Достоинства | Недостатки | Сходимость |
|---|---|---|---|---|
| Метод наискорейший спуск | дифференцируемая | -широкий круг применения -простая реализация -низкая цена одной итерации |
-глобальный минимум ищется хуже, чем в остальных методах -низкая скорость сходимости вблизи экстремума |
локальная |
| Метод Нютона | дважды дифференцируемая | -высокая скорость сходимости вблизи экстремума -использует информацию о кривизне |
-функция должны быть дважды дифференцируема -вернёт ошибку, если матрица Гессе вырождена (не имеет обратной) -есть шанс уйти не туда, если находится далеко от экстремума |
локальная |
| Метод Гаусса-Нютона | нелинейный МНК | -очень высокая скорость сходимости -хорошо работает с задачей curve-fitting |
-колонки матрицы J должны быть линейно-независимы -налагает ограничения на вид целевой функции |
локальная |
| Алгоритм Левенберга — Марквардта | нелинейный МНК | -наибольная устойчивость среди рассмотренных методов -наибольшие шансы найти глобальный экстремум -очень высокая скорость сходимости (адаптивная) -хорошо работает с задачей curve-fitting |
-колонки матрицы J должны быть линейно-независимы -налагает ограничения на вид целевой функции -сложность в реализации |
локальная |
Несмотря на хорошие результаты в конкретном примере рассмотренные методы не гарантируют глобальную сходимость (найти которую — крайне трудная задача). Примером из немногих методов, позволяющих всё же достичь этого, является алгоритм basin-hopping
Совмещённый результат (специально понижена скорость последних двух методов):
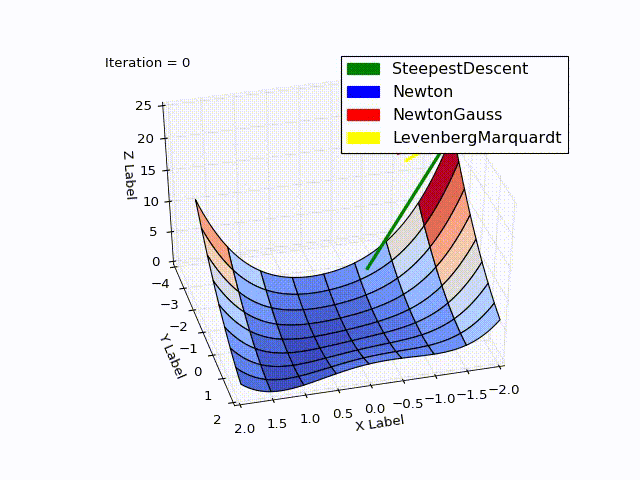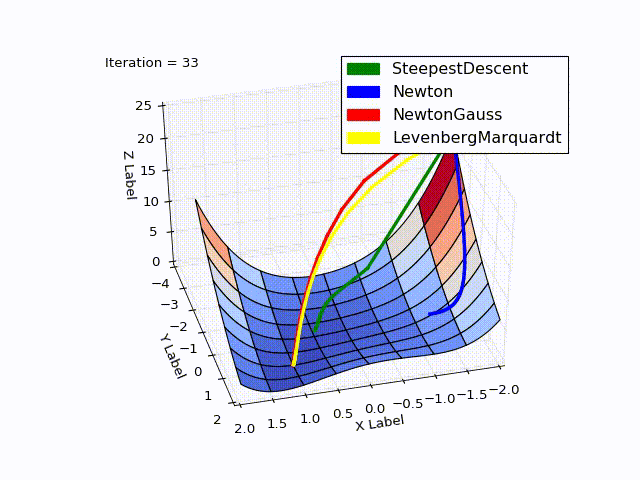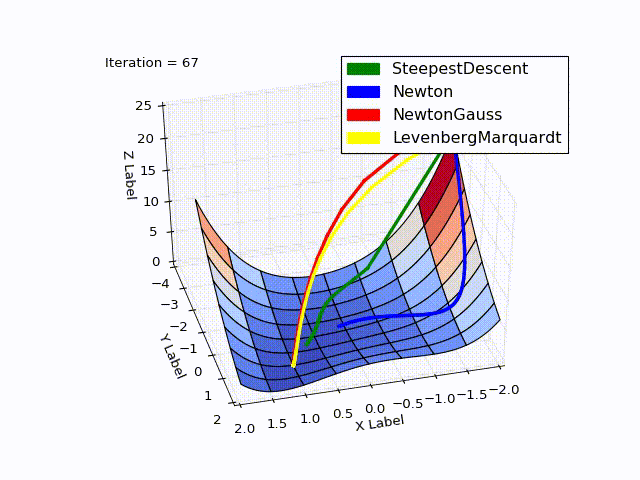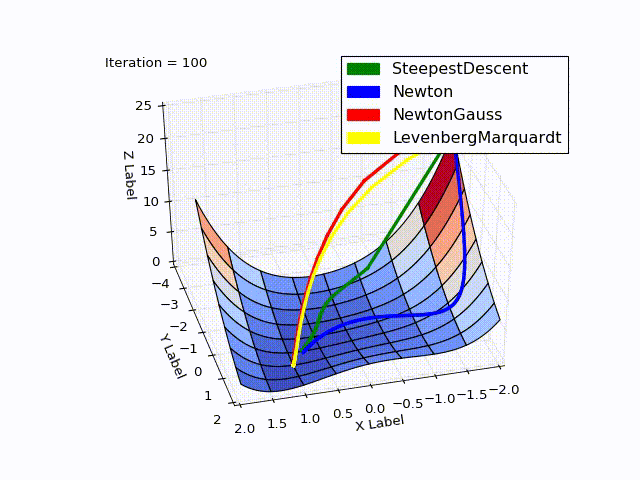
» Исходники можно скачать с github
» Источники
- K. Madsen, H.B. Nielsen, O. Tingleff (2004): Methods for non-linear least square
- Florent Brunet (2011): Basics on Continuous Optimization
- Least Squares Problems
Комментарии (27)
kxx
26.08.2016 21:56+4Хорошая статья. Помню, в университете при написании дипломной работы использовал этот алгоритм для обучения многослойных сетей — при ограниченных ресурсах LMA является хорошей альтернативой другим методам. Еще можно добавить, что ? можно рассматривать как параметр регуляризации, и иногда его сомножитель I заменяют на diag(JTJ) для улучшения сходимости.

AndreyDmitriev
26.08.2016 22:29Спасибо, прочитал с удовольствием, словно в университет обратно вернулся.
У меня такой вопрос — а почему Python? Есть же куча средств, где всё это реализовано библиотеками.
Ну вот, скажем, на LabVIEV Levenberg-Marquardt прямо из коробки.
Смотрите, как симпатично получается:
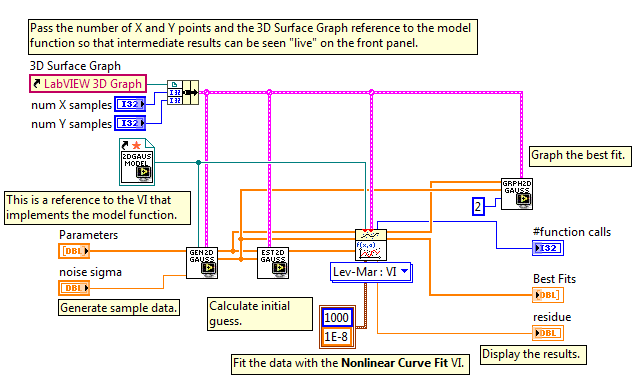

Я вовсе не холивара ради, просто это экономит огромную кучу времени. Даже с применением Anaconda (спасибо за наводку) вам пришлось написать некоторое количество обвязки плюс код для рисования графиков… Ну или Matlab как-то больше ожидаешь увидеть для решения подобных задач.kxx
27.08.2016 00:00+1Matlab, например, платный. В Python есть замечательный пакет SciPy, в котором как раз реализовано множество оптимизационных алгоритмов — глобальных/локальных, условных/безусловных…

lightforever2
27.08.2016 12:44+2- Целью статьи было собрать всё в 1 месте. Разъяснить теорию, предоставить работающий код, показать на графике. На мой взгяд, так материал воспринимается гораздо проще и эффектнее. Если бы я просто вызывал методы готовой библиотеки, то согласитесь, что это было бы не так интересно(и понятно)
- Как отметил kxx, в Python есть пакет SciPy (который кстати входит в Anaconda), в котором есть всё для наших целей

mgodzi
27.08.2016 12:47Спасибо большое автору за интересную статью! Давно пользуюсь этим методом.
Важное отличие Левенберга — Марквардта, из-за которого я перешел на него с квазиньютоновского Limited-memory BFGS, это возможность Л-М корректно работать в пространстве переменных разного масштаба. LBFGS очень удобен тем, что экономит итерации и ограниченно потребляет память на задачах локальной оптимизации в пространствах большой размерности. Мы удачного использовали его в задачах размерности 30 000, 100 000 и более, например в оптимизации атомных структур больших молекул — там все координаты и их изменения одинакового масштаба, например ангстремы.
Однако, в иных задачах, таких как фиттинг модели под экспериментальные данные, варьируемые параметры модели могут оказаться сильно разных масштабов. Варианты вроде искать оптимум в пространстве логарифмов параметров не всегда разумны. А при введении скалирующих коэффициентов Левенберг — Марквардт по моему опыту оказывается более толерантен к ошибкам скалирования, чем LBFGS, который начинает давать разные оптимумы в зависимости от конкретного выбора скалирования.
Насколько я понял в SciPy сейчас отсутствует реализация Левенберга — Марквардта, мне кажется автор этой статьи вполне дозрел добавить этот метод в SciPy, это был бы очень серьезный вклад.
Однажды столкнулся с необходимостью проводить глобальный фиттинг, пришлось писать собственную реализацию на С++ с использованием оптимизатора Л-М из библиотеки ALGLIB, так как в SciPy этот метод отсутствовал, в Mathematica он формально есть, но заставить его работать в моей задаче мне не удалось — в Mathematica несколько оптимизаторов, метод оптимизации L-M задается как параметр и поддерживается только одним из оптимизаторов, как раз тем, в который нельзя передать в качестве функции свой код. В Matlab тоже оптимизация хромает.lightforever2
27.08.2016 12:52Здравствуйте. Как отметил Andy_U, Scipy уже содержит алгоритм Левенберга — Марквардта. Вот ссылка. А вот для задачи curve_fitting
chersanya
27.08.2016 15:58+1В случае, если требуется Левенберг — Марквардт не для минимизации «в общем», а для подгона модели к данным (метод наименьших квадратов), то можно взять «обёртку» над scipy — lmfit, которая значительно удобнее для такого применения (хотя и не идеальна), а также содержит дополнительные функции.

JamaGava
28.08.2016 16:53Статья оказалась полезной для меня, спасибо.
Хотелось бы узнать Ваше мнение о методе Нелдера-Мида.
lightforever2
29.08.2016 11:55+1Главное преимущество в методе Нелдера-Мида, на мой взягляд, является отсутствие ограничения на гладкость функции(т.е. существования производных в каждой точке функции). Ещё он даёт высокую хорошую оптимизацию на первых итерациях, хотя на это способны и рассмотренные методы.
Минусом является плохая сходимость в конце оптимизации, а то и вообще отсутствие сходимости.
Я читал, что его используют, когда не нужна хорошая точность результатов, например для оценки параметров в методе опорных векторов
Alexey_mosc
29.08.2016 12:02Отличная статья! Отличная анимация!
Вопрос. Такой метод будет нормально работать в условиях многочисленных локальных минимумов, гребней, оврагов и т.д.? То есть на очень сложной поверхности?lightforever2
29.08.2016 16:27Я так понял, что вас интересует вероятность нахождения глобального минимума. Она выше, чем у многих известных мне методов. Так что да, работать должна хорошо, но глобальной сходимости никто не гарантирует.
Если имеется ввиду просто сходимость, то сойдётся к локальному минимуму.
victor1234
30.08.2016 04:02Посоветуйте либу на С++ реализующую этот алгоритм. Начать изучать (и использовать в простых задачах) ceres-solver. Что скажите о ней?

Unrul
01.09.2016 16:52+1Было дело использовал библиотеку CppNumericalSolvers Только заголовочные файлы, небольшая и хорошо расширяема. Автор быстро отвечает на тикеты :)


alexkolzov
30.08.2016 20:31Спасибо за статью, вынудила залезть в книжки.
У Вас в предисловии к методу Ньютона разделяется (возможно, ненамеренно) метод решения нелинейных уравнений и метод одноименный оптимизации. Фактически это один и тот же метод, если свести задачу поиска минимума функции к решению уравнения «градиент равен нулю».
Зачем в алгоритме Ньютона делать проверку на положительную определенность гауссиана, ведь она требуется только в точке минимума и совершенно не обязательно присутствует в окрестности этой точки?
Откуда взята рекомендованное значение 0.05 на шаг в МНС?
Вопросы вызвал метод Гаусса-Ньютона (ранее не встречал), формулировка мне показалась странноватой. Фактически оптимизирующей последовательностью в данном случае (при \alpha = 1) является последовательность минимумов тейлоровых приближений первого порядка целевой функции. Это кажется странным, ведь остаточный член формулы Тейлора может считаться пренебрежимо малым лишь в достаточно малой окрестности точки разложения, а в данном случае искомый минимум может быть от нее сколь угодно далеко. Такую быструю сходимость для функции Розенброка, по-видимому, можно связать с достаточно «хорошим» поведением ее производных. В литературе, на кторую Вы ссылаетесь, утверждается, что если такая последовательность сходится, то она сходится к стационарной точке. Но я не нашел никаких упоминаний того, при каких условиях гарантируется, либо хотя-бы имеет смысл надеяться, что последовательность сойдется. Встречали ли Вы упоминания чего-либо подобного? Также в данном случае не очень понятен смысл и критерий выбора значения параметра «шага» алгоритма.lightforever2
31.08.2016 12:17- «У Вас в предисловии к методу Ньютона разделяется (возможно, ненамеренно) метод решения нелинейных уравнений и метод одноименный оптимизации. Фактически это один и тот же метод, если свести задачу поиска минимума функции к решению уравнения «градиент равен нулю» „
Я не отрицаю общей идеи методов, но решения уравнений будут разные. В методе для поиска корня предполагается дополнительно, что f(x*)=0 и используется только линейная аппроксимация - “Зачем в алгоритме Ньютона делать проверку на положительную определенность гауссиана, ведь она требуется только в точке минимума»
Вы думаете в верном направлении, только смотрите в чём фокус: мы на каждом шаге аппроксимируем квадратичной функцией в окресности. А далее — ищем минимум этой аппроксимации. И это на Каждой итерации. - «Откуда взята рекомендованное значение 0.05 на шаг в МНС», например отсюда 14 стр. Вообще рекомендуют использовать шаги 0.005, 0.01, 0.05, и 0.10
- «Вопросы вызвал метод Гаусса-Ньютона (ранее не встречал), формулировка мне показалась странноватой. Фактически оптимизирующей последовательностью в данном случае (при \alpha = 1) является последовательность минимумов тейлоровых приближений первого порядка целевой функции. Это кажется странным, ведь остаточный член формулы Тейлора может считаться пренебрежимо малым лишь в достаточно малой окрестности точки разложения, а в данном случае искомый минимум может быть от нее сколь угодно далеко»
Согласен, однако это рекомендованное значение. Тут можно принять во внимание, что целевая функция неотрицательна, на практике я читал метод работает хорошо с таким коэффициентом.
- " Но я не нашел никаких упоминаний того, при каких условиях гарантируется, либо хотя-бы имеет смысл надеяться, что последовательность сойдется"
Стр. 21 «The method with line search can be shown to have guaranteed
convergence» при выполнении условий. Про полный ранг J я писал в статье. Про ограничение F(x)<=F(x_0) можно было добавить
alexkolzov
01.09.2016 01:06+11. Ну правильно, решается уравнение F(x) = 0 с нелинейной функцией F. Для этого оно приводится к форме задачи о поиске неподвижной точки путем умножения слева на несигнулярную матрицу (-A) (выбираемую в принципе произвольно и в общем отличающуюся на каждой итерации) и прибавления к обеим частям x, из чего имеем:
x — A*F(x) = x.
В классическом методе Ньютона в качестве A берется обратная к F'(x) = J(x) и вводится итерационная последовательность
А чтобы исключить необходимость обращения якобиана, можно это привести в неявной формуле относительно приращения:
Теперь для задачи оптимизации функции F имеем уравнениеего якобиан = гессиан целевой функции. Итого имеем
.
Сравните это с написанным у Вас.
2. Вы не ответили на вопрос зачем в Вашем случае требовать положительность гессиана. Вы действительно движетесь на каждой итерации в направлении наивысшей кривизны, но делать трудоемкую проверку на положительную определенность-то зачем? Это, конечно, не криминал, и даже объяснимо, поскольку в случае положительной определенности матрицы A поправка (x_{k+1} — x{k}) определяет т.н. «направления спуска» и оказываются применимы классические теоремы сходимости методов прямого поиска. Но в таком случае нужно накладывать ограничения на выбор последовательности значений «шага» — иначе это требование бессмысленно. А в приведенной формулировке об этом не упоминается. Я, честно сказать, не видел применения к реальным задачам модифицированных методов Ньютона с проверкой и коррекцией определенности гессиана. Возможно, Вы видели?
3. На странице 14 приведены результаты вычислительных экспериментов при минимизации конкретной функции, с чего Вы решили, что это рекомендуемые значения? Меня смутило вот что. Из теории градиентных методов известно, что при выборе постоянного на протяжении всего оптимизирующего процесса «шага» есть порог значения, при котором процесс теряет устойчивость. Этот порог сильно зависит от вида целевой функции. Откуда могут взяться такие рекомендации? Единственное, что мне приходилось видеть, это замечания вроде: «попробуйте значение на-вскидку, разошлось — уменьшите, сходится но медленно — прервите и уменьшите шаг». А так, чтоб конкретные значения…
4 и 5. Действительно, не слишком внимательно изучил материал. При более подробном изучении увидел, что определяемое поправкой направление оказывается направлением спуска, а значит есть классы функций, для которых гарантированно существует последовательность «шагов», приводящая к стационарной точке. Но, например, здесь подтверждают мое предположение о том, что для сходимости с произвольным шагом функция должна быть достаточно гладкой и достаточно пологой. А здесьше доказательно показывается, что применяемых обыкновенно условий Гольдштейна и Вульфа для шага итерации не достаточно для сходимости.
- «У Вас в предисловии к методу Ньютона разделяется (возможно, ненамеренно) метод решения нелинейных уравнений и метод одноименный оптимизации. Фактически это один и тот же метод, если свести задачу поиска минимума функции к решению уравнения «градиент равен нулю» „
antoxin
02.09.2016 16:35Подскажите почему траектория поиска в трех методах из четырех летит в начале поиска в воздухе, а не ползет по поверхности функции.
lightforever2
05.09.2016 11:26Координаты выходят за пределы нарисованного интервала, поэтому так кажется. На самом деле она тоже ползёт по функции
MichaelBorisov
Наконец-то серьезная статья, спасибо! Отличный метод. Использую его в работе. Работает действительно надежно.
lightforever2
Спасибо! Рад стараться