
Антон Турецкий (Badoo)

Сегодня я приглашу вас на такую внутреннюю кухню Badoo расскажу о том, нужен ли Docker нам. Вы попробуете сделать выводы для себя, нужен ли он вам. Этой информации на просторах Интернета, соответственно, нет, потому что она вся вот такая – в нашем тесном узком кругу.

В течение доклада я расскажу про самую значимую вещь, которая касается того, с чего надо начинать выполнение любой задачи. Надо решить, зачем вы ее делаете, зачем вы за это беретесь?
Для себя мы на эти вопросы ответили, без проблем у нас не было бы никакого внедрения. Какую-то часть проблем мы решаем. Я выделил основные из них, я расскажу вам о них и о том, как мы с ними справились. В конце я порекламирую нас, какие мы замечательные, как мы любим всякие-разные новые велосипеды, как мы их делаем, смотрим, изобретаем. Я вам их покажу, про них расскажу, вы составите какое-то свое мнение. Итак, поехали!
То, зачем нужна служба эксплуатации, зачем, вообще, нужен какой-то бизнес, зачем нужны, в частности, админы.
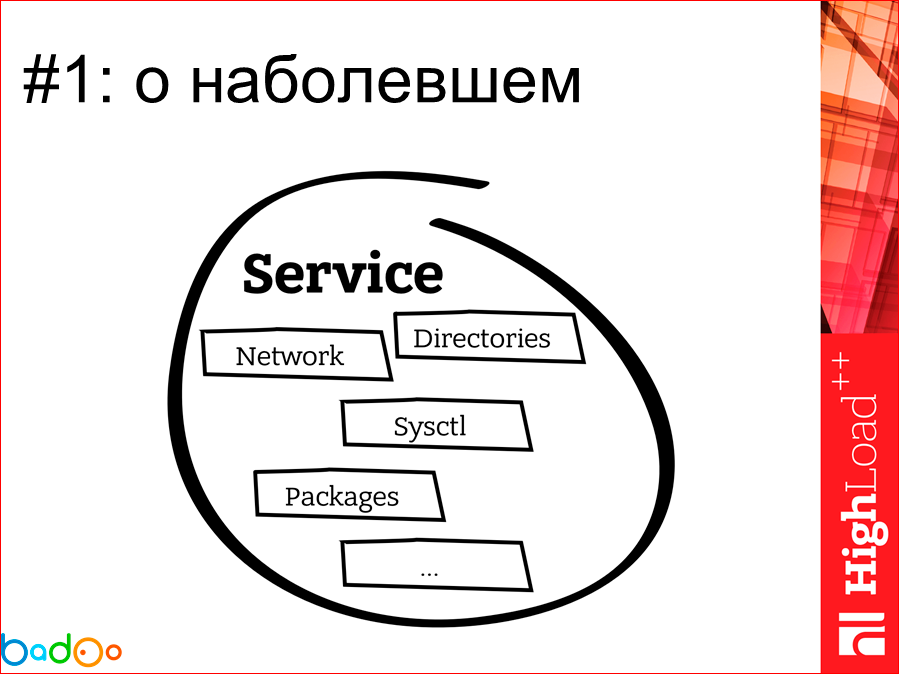
Основная наша ключевая единица – это сервис. Если не работает сервис, то, зачем мы все здесь собрались? В отдаленном представлении сервис выглядит примерно таким образом. Это кусок интеллектуальной собственности программиста, который пишет некую бизнес-логику и хочет что-то получить. Там слоями находятся какие-то сетевые настройки на машине, куча каких-то RPM-пакетов, связанные и не связанные с сервисом директории. В общем и целом, это представляет такой клубок, который служба эксплуатации получает к себе, и стикет системы, или как еще осуществляется передача сервиса от разработчика до продакшна. Наша основная задача заключается в том, что нам надо взять один большой и мощный сервер и напихать на него каких-то там сервисов.
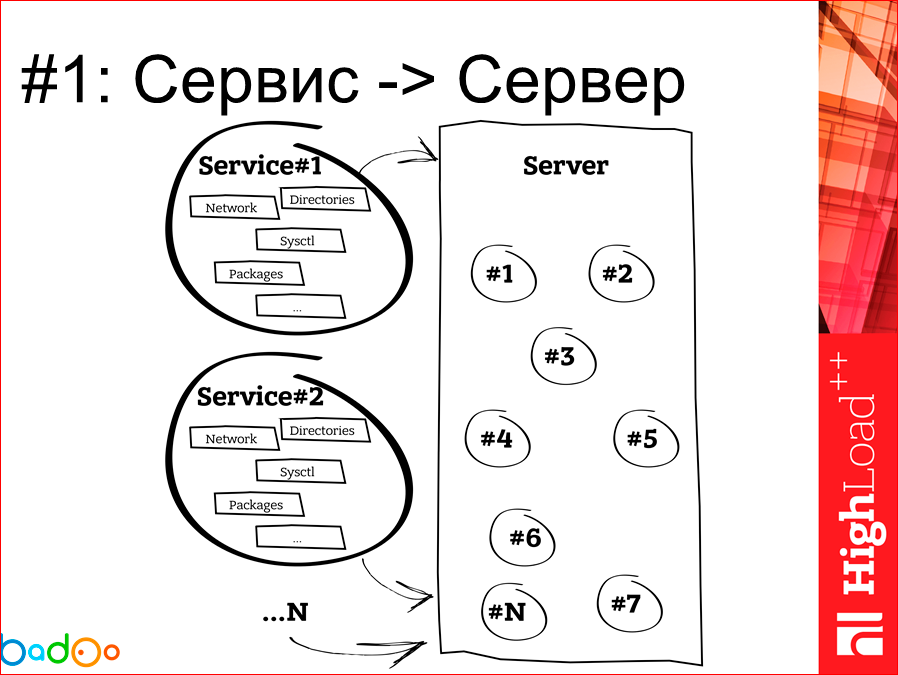
Все выглядит отлично. За последние несколько лет ситуация с этим не поменялась никак. Сервисы мы как выкатывали в формате клубка, так и выкатываем.
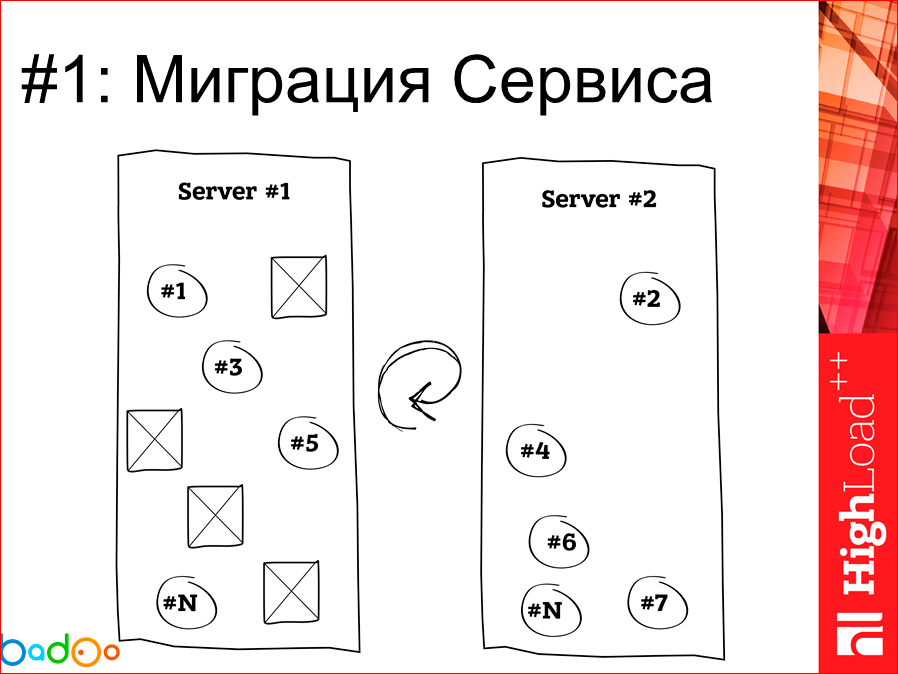
Проблема, которая у нас возникает – это когда нам нужно взять и по какой-то причине расселить наши сервисы, потому что машина не справляется, новое железо приехало, мы хотим просто взять его и смигрировать. И первое, что мы получаем при миграции, если мы не пользуемся, например, Docker’ом – это то, что мы сервис перетаскиваем на чистую машину, на чистой новой машине у нас все прекрасно, замечательно, директории подтянулись, но одна проблема… Кто использует систему управления конфигурациями типа Chef и Puppet, и кто выкатывается ими? А кто пишет, обратные манифесты по забиранию всего и вся? В зале – всего три человека. Соответственно, все, кто этого не пишет, я думаю, знают о том, что в вашем сервере в конечном итоге остаются какие-то дырки и куски наследия того, что там живет, и в зависимости от частоты этих миграций сервер рано или поздно растет и превращается в некую помойку. Если мы берем Docker и занимаемся той же самой миграцией, то мы как кирпичик вынули и положили в другое место, и ничего старого там не осталось. Замечательно.
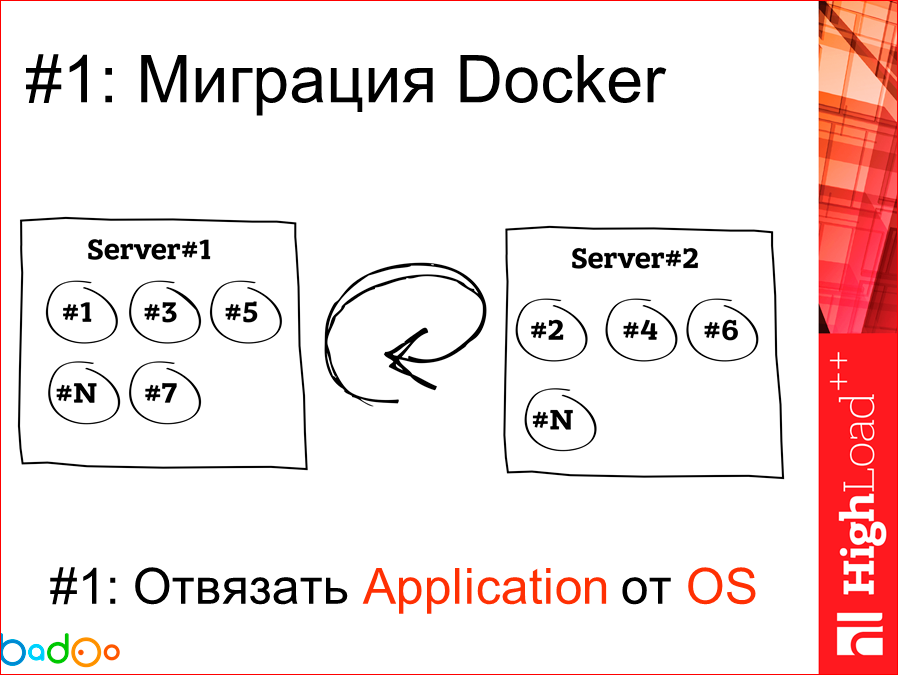
Таким образом, первая причина, по которой мы, вообще, начали смотреть на Docker со стороны эксплуатации – это задача по отвязыванию application, по сбору его в клубок, от операционной системы.
Следующий момент. Т.к. мы не программисты совсем, а все-таки инженеры и эксплуатационщики, то думая о наших ресурсах, мы всегда думаем о железе. Т.е. железо – это физические какие-то коробки, которые стоят в больших комнатах, там клевое охлаждение, надеемся, что уборщица туда не приходит.

И т.к. мы размещаем свое оборудование в выделенных дата-центрах, снимая какие-то кейджи, в определенный момент времени мы начинаем думать о том, что оборудование необходимо менять. По ряду причин – оборудование выходит более новое, оно больше выдает нам каких-то попугаев и единичек в производительности, рано или поздно нам нужно менять.

Соответственно, первая проблема, связанная с capacity planning, точнее, не проблема, а даже задача, заключается в том, что нам необходимо максимально рационально использовать место в наших стойках, потому что стойка – это какая-то отдача от нее, это аренда ящика, это стоимость электроэнергии и в первую очередь, это деньги.

Следующий вывод из первого момента заключается в том, что мы точно так же хотим максимально полезно использовать порты на сетевом оборудовании, потому что сетевое оборудование тоже юнитовое, оно тоже занимает место, тоже жрет электричество.

Мы плавно подходим к тому, что электроэнергию мы экономим, соответственно, денег сэкономили, сделали замечательно для окружающей среды, здорово. Это нас не сильно касается, но вот красивый и замечательный такой положительный бонус.

Но если мы говорим о том, что мы сервисы кучкуем на сервере более мощном, то мы получаем следующий пункт, который я обозначил «±» – мы приходим к ситуации, когда, вроде как, абстрагировано у нас появляется больше возможностей, больше единых точек отказа. Когда у вас один сервис живет на одной физической машине, как бы все хорошо, скорее всего, мы меньше теряем, если у нас сервер выйдет из строя. В данном случае, это слишком философский вопрос, потому что если мы тут говорим о замене старого оборудования на новое, новое, скорее всего, из строя выйдет с меньшей вероятностью, чем старое. И многие слышали, сколько проблем возникает в процессе деплоя. Т.е. по факту, по статистике можно сказать, что получение этого Single point of failure, оно гораздо меньше роялит на ваш продакшн, нежели кривая какая-то выкладка.

Третий момент, зачем и почему мы начали смотреть на Docker – это проблема волнующая и острая, это посадить ваше приложение от момента его написания программистом до выкатки в продакшн, не меняя ничего, на что приложение может завязываться. В случае использования Docker, т.к. мы изначально свои приложения подсаживаем в определенное окружение с какими-то либами, пакетами, еще с чем-то, оно у нас посажено с процессом сборки условно в team city. Дальше оно у нас в таком же первозданном виде едет в процесс Q&A тестирования, после этого у нас через staging, development наше готовое приложение в контейнере уже может ехать на продакшн. Т.е. мы на этом этапе откидываем в сторону какие-то изменения… Если у вас возникла проблема с приложением, и разное окружение этого приложения на development, на staging и на Q&A тестировании, то довольно тяжело понять, что же, вообще, влияет на наше приложение, что оно не работает, т.е. эту задачу мы здесь решили на 100%.

И последний пункт, который я отметил как пункт со звездочкой, потому что изначально, когда я увидел Dockerfile, мне показалось, что это какое-то возвращение лет на 10 назад. Непонятный бэш, ни бэш, чего-то надо писать, когда есть puppet, зачем писать эти txt файлики? Но на самом деле плюс этого заключается в том, что всегда, глядя на config соседа, ты можешь видеть, что и зачем человек делал, о чем он, возможно, думал, и зная о том, как работает Docker и глядя на такие Docker файлы, ты иногда можешь этот файлик менять, чтобы себе оптимизировать процесс накладывания слоев, выполнения чего-то, использование кэширования. Т.е. по факту, Dockerfile является хорошей постоянно поддерживаемой в актуальном виде документацией к вашему приложению.
Итак, мы ответили на вопрос для себя, зачем же мы хотели Docker и мы, внедряя это, всегда возвращаемся к этим буквам и смотрим: решили, не решили, относится, не относится?
Дальше интересный момент, который начался с процесса внедрения Docker у нас. Конечно, мы сталкивались с проблемами. Часть этих проблем обсуждалась на Github Docker и т.п. Часть решена, часть мы еще не поймали. Я думаю, что они придут к нам следом.

Первая интересная проблема заключалась в том, что мы хотим сбирать логи нашего приложения, хоть как-то централизованно. Перед нами встала задача: «сделайте нам некий syslog, программисты хотят писать в divlog, дальше мы его будем куда-то отсылать, обрабатывать и т.д.».

Мы посидели, подумали: как так взять в контейнер запихнуть второй сервис? Изначальная же идея: один контейнер – одна служба, работающая в нем. Неправильно. Дилемма возникает. Что делать?
Это получается +1 сервис, который надо пихать в каждый контейнер, гарантировать его работу, потому что с нас же спросят, если у нас там логи не доставились. Это подпункт, который оправдывает лень, что надо чего-то брать и делать. И задача, которая, как обычно, нам нужна вчера. Нам надо уже собирать логи со стороны программистов. Готова часть обработки этих логов, нам надо только взять и сделать. Соответственно, первое, что было придумано и что мы начали использовать – это мы взяли и смапили сокет dev/log внутрь контейнера и начали писать туда. Круто!

Решили, договорились, выкатили, отлично работает. Сообщения ходят. До первой проблемы, когда нам надо было на хостах поменять config’и syslog’а и сделать ему reload. Т.о. контейнеры продолжают держать старый сокет, писать что-то туда, сообщения никуда не уходят, они остаются там. Что делать?

Эта проблема – хороший кейс, который говорит о том, что вы не забывайте про первые набросы ваших решений, которые были на первом этапе. В данном случае нам пришлось вернуться назад, вернуться к идее о том, что «давайте сделаем syslog внутри контейнера, бог с ней, с этой идеей, что один сервис – один контейнер». И нам же никто не говорил физически про один сервис, т.е., может быть, там работает функционал одного сервиса, а процессов больше. Мы запихнули syslog в контейнер, config этого syslog’а не меняется, по факту поддерживать, кроме актуальной версии, нам ничего не нужно, потому как с syslog’а мы шлем на локальный хост той машины, где запускается, а дальше мы уже с syslog’а этой машины отправляем данные в некий наш центральный репозиторий с логами.

Следующая интересная проблема, которая касалась того, что в контейнер нам нужно какую-то директорию, условно говоря, добавить или какое-то блочное устройство. Вроде бы все просто, есть ключик -v, который ты прописываешь, добавляешь, у тебя все работает. И есть в нашей компании особенность такая, что мы используем некие loop-девайсы для раздачи своего кода, и потом его монтируем с -o loop. У нас появляется абстрактное блочное устройство, мы запускаем контейнером, мапим какое-то устройство там под директорию из этого loop-девайса. Все работает отлично и за счет особенности Docker’а, что каждую директорию, каждый файлик, которую он пытается замапить к себе внутрь, он идет по всей цепочке всех точек монтирования и тащит весь proc/mount, который нужен ему сейчас для запуска в том стейте, о котором вы ему говорите, весь proc/mount тащит за собой.
Дальше сама суть проблемы, я думаю, для всех становится понятной и очевидной, что мы хотим это loop-устройство отмонтировать, чтобы у нас там не было 12-20-50 на машине, нам старый код, недельный, не нужен. И что мы здесь получаем? Мы получаем ситуацию, когда у нас некий процесс держит блочное устройство, а отмонтировать мы его не можем. Для этого нам надо пойти, зайти в контейнер и попробовать отмонтировать там. Но т.к. контейнер мы запускаем в режиме «без привилегий», сделать umount с хост системы мы там не можем.

И у нас получается достаточно интересная проблема, которая говорит о том, что с контейнером мы можем сделать только рестарт. Это не решение, это действительно большая проблема, в принципе, решение которой может быть не техническое, а в виде каких-то договоренностей внутри организации.

Соответственно, первое решение, которое может подойти, оно в принципе работает – это взять и запустить контейнер в привилегированном режиме. Мы так не делаем.
Второе – сесть и подумать, разными отделами, с программистами, с релиз командой, еще с кем-то о том, что же и как мы можем сделать, чтобы нам не устраивать этих динамических точек монтирования, давайте от них как-нибудь отказываться.

Т.е. это один из тех кейсов, когда просто нужно сесть и подумать о том, что возможно сделать. Какие-то структурные внутренние договоренности и изменения, которые решат эту проблему. Т.е. биться о проблему с технической позиции в данном случае смысла не имело. Мы в случае Docker контейнеров просто перестали использовать такие динамические loop-девайсы.

Следующие интересные грабли связаны с iptables, с nf_conntrack. Что нам дает Docker, когда мы про него читаем? Он говорит о том, что мы можем запустить сколько угодно контейнеров, мы можем юзать огромное количество портов, мы можем устраивать связи между контейнерами внутри, у нас получается какая-то изоляция. Все говорят о том, что это будет, конечно, через iptables, есть такие правила, которые вы можете прописать, если вы забыли при запуске в контейнере их указать. Но никто не говорит явно об одном – о том, что в этом случае мы обязаны использовать линуксовый модуль nf_conntrack, который сам по себе я бы быстрым не назвал.

Есть два пути, по которым нам можно решать данную проблему.
Первый путь, если у вас приложение не очень нагруженное по сети – это жить, как есть. Все отлично, все работает, до того момента, пока вы не стукнулись с переполнением таблицы nf_conntrack. Что мы можем сделать, чтобы продлить себе жизнь? Увеличить таблицу nf_conntrack.
Дальше, это такая причинно-следственная связь – если мы увеличиваем саму таблицу conntrack, то мы должны увеличить хэш-таблицу соединений, чтобы их было больше, чем их есть по умолчанию в ядре линукса.
Стоит помнить про третий пункт, который у нас по умолчанию в линуксе хранит порядка 10-ти минут все соединения установленные, уже отработанные. По факту, для современного сервиса, я думаю, что больше 30 сек. после создания соединения, если что-то не произошло, то либо с сервисом плохо, либо коннекшн просто не нужен. Поэтому 10 мин – это реальный оверкил.

При данном подходе, как показала практика, мы можем сидеть и ждать. Но рано или поздно проблема возникнет, а она возникнет точно. И в какой-то момент уже эти увеличения просто не помогут в силу того, что за счет небыстрой работы conntrack сделать лучше уже ничего не получится.

Как мы решили для себя эту проблему? Первое, что хочу сказать, это то, что мы не используем conntrack, мы стараемся его не использовать на продакшн окружении, на наших сервисах. Мы его используем в части девела, мы его используем на стейжинге, потому что там количество сетевого обмена сильно меньше.
Из того, на что я предложил бы посмотреть – это замечательный проект Weave, который позволяет вам строить сетевое взаимодействие в обход сетевого оборудования, т.е. это более софтовое решение между вашими Docker-хостами. Самое простое решение – это использовать дефолотовые bridge, которые при запуске Docker может генерить. Также можно использовать встроенный линуксовый bridge-конфигуратор. И, если хочется красивости и чуть больше гибкости, есть замечательная шутка – Open vSwitch. На данный момент в списке плагинов для Docker никакой управлялки для Open vSwitch нет, что жаль, они обещали в прошлом году.

Как я сказал ранее, для себя мы решили это таким образом, что мы используем практически при запуске всех наших контейнеров опрокидывание сетевого устройства с хост-системы в контейнер и от conntrack мы избавляемся. Штампика, что problem solved я не поставил, потому что эта такая проблема, над которой стоит думать. Для себя мы ее решили так, кто-то, может быть, решит ее иначе.
Следующий интересный момент, с которым столкнулись большинство, кто с Docker имел хоть какое-то дело – это выбор Storage Driver, для того чтобы файлики хранить. Потому что у каждого есть плюсы, у каждого есть минусы. Есть AuFS, с которым они вышли на рынок и предложили, но который в mainline не вошел и не войдет никогда. Есть классное решение проблемы, когда вы берете логические устройства, занимаетесь их монтированием, т.е. это Device Mapper плюс какая-то встроенная файловая система, условно Х3. Вы занимаетесь этим монтированием – перемонтированием… Все это вырастает в такую, вообще, огромную цепочку этих слоев и логических устройств. Есть BTRFS, который половину функционала, нужного для Docker, поддерживает by default именно как заложенный функционал файловой системы. И есть еще несколько других штук, которые реализованы какими-то плагинами, некоторые клевые, некоторые не очень. Здесь я отметил те три вещи, с которыми приходилось работать, и среди которых приходилось выбирать.

И также смотрим на проблемы, которые может повлечь за собой BTRFS. BTRFS обязывает вас держать некое блочное устройство, которое будет являться rootdir’ом для Docker на BTRFS. Не в каждой таблице разделов разбиения на нашем сервере присутствовал BTRFS, соответственно, это нас обязывало заниматься ресетапом или попиливанием LWM и выделением этого раздела.
Второе – никто не скрывал того, что BTRFS никогда не делает ресинк сразу на диск, он никогда не пишет напрямую на блочное устройство, он сначала ведет какой-то свой журнал, пишет информацию в журнал, потом запускается ядерный процесс самого BTRFS, который смотрит на эту очередь, делает какие-то телодвижения и куда-то что-то записывает. На практике по нашим замерам performance от использования BTRFS получился. Где-то есть у нас блок девайс на 10-ом рейде, и мы получили от него где-то деленное пополам – это у нас выдавал BTRFS.
Очень актуальная проблема для службы мониторинга, отдела эксплуатации – это как, вообще, понять, сколько места занято на BTRFS, сколько свободно? И самая большая проблема, когда у тебя, вроде бы, место есть, а вроде его и нет – куда-то оно делось, и ты понимаешь, что у тебя мета-дата распухла, файлов занято, вроде, немного, и тебе нужно запустить ребаланс, а у тебя близко к пику и IO и так страдает, а еще ребаланс. Печаль.

Из плюсов BTRFS за последние год-два – это единственный storage driver, который нормально и, по крайней мере, ожидаемо работал с Docker. Вроде как, проблему решили, BTRFS – наш выбор. Докупим SSD, будем жить, бог с ним с перформансом, разберемся.

И тут не так давно посмотрели мы в сторону нового Storage Driver – OverlayFS. Забегая вперед, скажу, что мы занимаемся его внедрением, этап тестирования мы уже с ним прошли, какие-то тесты получили, тесты достаточно хорошие.
Почему я FS сереньким оставил, а Overlay красненьким закрасил? С версии 3.18 он вошел в ядро под другим названием, он вошел в ядро под названием модуля просто Overlay. Кто-нибудь знает, чем занимается встроенный уже давно в ядро модуль OverlayFS? Я тоже не знаю. Новых слайдов про Overlay не будет, я скажу информацию, которая была готова буквально на прошлой неделе. По нашим тестам скорость работы, время ответа с использованием OverlayFS на базе EX4, у нас в процентном соотношении такой overhead от Docker получился в пределах погрешности до 3-5%, не более, т.е. для себя мы рассматриваем его следующей точкой и следующим моментом, куда мы начнем мигрировать и делать. Единственный минус, который это на себя накладывает – это опять же ядро 3.18, минимум, т.е. надо обновляться, надо идти вперед.
Overlay FS работает относительно BTRFS для того, чтобы устраивать эти слои только для чтения, он использует хард-линки. Тут есть еще один плюс по сравнению с BTRFS, который заключается в том, что ваша операционная система в оперативный памяти может использовать файловый кэш. Но если вы используете BTRFS, т.к. там есть сабвольюмы и даже, если файлик, вроде как, дедуплицирован и, вроде как, ты понимаешь, что файлик – это один файлик, с точки зрения ОС Линукс файлик получается другой. И если с одного контейнера и с другого контейнера мы будем запрашивать, вроде как, один и тот же файл, то в кэше он, скорее всего, не останется или появится два разных кэша для этого файла. Overlay нас от этого избавляет. Как я сказал, performance получается на чтение/запись очень похожим на возможности родной файловой системы, почему нет? И для эксплуатации, и для мониторинга, и для всех продолжает работать старый DF. Мы знаем, сколько у нас там занято, сколько свободно. Круто. Т.е. нет этой загадки, не нужен ребаланс, отлично! Я считаю, что это наше будущее решение проблемы и те, кто не пробовал, призываю просто хотя бы посмотреть на этот драйвер.

Дальше обобщенные не выделенные проблемы, с которыми столкнулись. Заключаются они в том, что мы отошли от идеи того, что в одном контейнере может быть запущен только один сервис или одна служба. Но тут встал вопрос выбора того, как же нам запускать более одного, т.е. есть cmd, но какие рычаги у нас еще есть для того, чтобы что-нибудь еще запустить?
Первое, что мы решили – это написать костыль для Entrypoint, где мы запускаем какие-то кроны и т.п., подготавливаем наш контейнер перед запуском, запускаем фоновые какие-то службы и после этого передаем управление уже в инструкцию Docker cmd и запускаем наш основной сервис.

Т.к. это все было похоже на некий ну совсем костыль, и его страшно поддерживать, а еще entrypoint каждый человек из команды эксплуатации писал самостоятельно – они были сильно разными в зависимости от настроения. Нужно было искать какой-то более унифицированный подход. И из того, что посмотрели, выбор пал на S6, и мы сейчас его используем. Я оставил координаты проекта, это некий init-менеджер для работы внутри Docker-контейнеров. Он позволяет все базовые штуки, которые, как минимум, нам нужны, т.е. он позволяет сделать старт, сделать стоп. В зависимости от стопа ты можешь завершить контейнер или нет, ты можешь выполнить какой-то набор команд перед стартом контейнера и перед его остановом. Все достаточно неплохо. Тем, кого интересуют задачи и проблемы запуска более одной службы в контейнере, я рекомендую посмотреть на это.
Такая полу-проблема, полу-нет, и вопрос, тоже возникающий – можно ли использовать несколько From в Dockerfile. Ответ на этот вопрос в течение года менялся раза три. Причем, кардинально. Да-нет, нет-да – в зависимости от версии Docker. По нашему опыту я могу сказать, что можно использовать до первой проблемы, когда у вас иерархия слоев одного образа не пересечется с иерархией другого, и вы потеряете внезапно какой-нибудь файлик. Т.е. вы будете думать, что он там есть, а его там нет. И потеряете какое-то количество времени в поисках, почему его там нет, а он должен быть. Т.е. я бы порекомендовал не использовать.
Еще интересная проблема, с которой мы достаточно недавно столкнулись, недавно про нее узнали. Это такой клевый функционал в Docker с версии 1.6, по-моему. Они взяли и сделали команду docker.exec, где ты можешь взять и выполнить что-нибудь, выгружение контейнера с хост-системы, и посмотреть на результат. Все круто, но не так давно выяснилось, что этот exec сделан, вообще, для отладки, девелопмент-мода, т.е. он не предполагал, что ты можешь с хост-системы запускать какие-то мониторинговые штуки, которые там find отработал что-нибудь такое, поискал, cut сделал. И проблема заключалась в том, что в Docker inspect’е, если смотреть в name-space конкретного контейнера, все exec’и, всех их url’ы, по которым можно было посмотреть на их результат, они жили до тех пор, пока ты контейнер не перезагрузишь. Начиная то ли с 1.7, но скорее с версии 1.8, они сделали некий garbage collector, который смотрит по старинке, не осталось ли там мертвых ненужных exec’ов, и их чистит. Это было действительно большой проблемой, потому что если смотреть на потребление памяти, то с течением дней, недель память просто подрастала и подрастала, непонятно почему.

Общий совет, если у вас есть какая-то проблема, попробуйте спросить где-нибудь, и поискать решение этой проблемы, потому как Docker, сам по себе, очень быстро развивается, и там много чего меняется. Бывает такое, когда вы пытаетесь решить то, что уже решили другие неделю назад или в предыдущем релизе, или просто в мастер еще что-то не вошло.

Основной точкой у нас в компании является базовый образ, на фоне которого какими-то инструкциями мы выкатываем наше приложение. Соответственно, он является у нас не то чтобы проблемным участком, но это единственная точка во всей этой контейнеризации, за которой имеет смысл следить.

Как мы за ней следим сейчас у себя? Нам необходимо проверять, что все пакеты, нужные патч-сеты для нашего базового образа присутствуют, чтобы нам заранее известную дырку не выкатить, например, на продакшн. Как мы решаем эту проблему? Мы берем и по какому-то крону или в какое-то время запускаем в интерактивном режиме наш контейнер и, используя zypper или что еще можно придумать для какой-то другой ОС, мы просто чекаем по всем нашим репозиториям наличие каких-либо update’ов и, если они есть, мы передаем эту информацию в виде тикета на команду эксплуатационщиков, которые принимают решение о том, обновлять его дальше или не обновлять. Если обновлять, мы обновляем базовый образ и выкатываем его туда, где мы занимаемся сборкой. Если есть необходимость, и патч какой-то серьезный, нужен фикс, мы идем, обновляем нужный нам контейнер.

И перед тем, как нам, вообще, катить наш application на production, мы делаем сравнение нашего, скажем так, актуального RPM-списка пакетов и их версий, которые должны быть с тем, что присутствует в нашем вновь созданном контейнере. Если что-то не сходится, мы отправляемся обратно по ветке на момент сборки, тестирования и т.д. Т.е. пока мы не получим здесь соответствие того, что мы согласны с таким набором версий на продакшн, мы его принимаем.

Для того чтобы наши аппликухи как-то собирать, понятно, что мы руками не будем писать каждый раз и Dockerfile менять, версию нашего базового образа. Нам нужна некая автоматика. Автоматику мы эту сделали, прибегнув к использованию puppet. Назвали мы ее просто docker_build.

Какие требования мы накладывали на эту нашу автоматику? Мы хотели генерировать структуру директорий и конфигов для конкретного сервиса. Мы хотели научить и научили его делать инструкцию Dockerfile’а в автоматическом режиме. Мы хотели доставлять/вытаскивать из наших систем, сборок наших сервисов исполняемые файлы самого приложения и класть их рядом. Мы хотели, конечно же, чтобы он выполнял сборку. Отправлять результат в Registry, причем с возможностью либо отправлять, либо не отправлять, потому что там что-то может пойти не так, мы просто хотели локально посмотреть, что он там соберет. И необходимым функционалом являлось то, что мы хотели позволить тому, кто собирает контейнер, выполнять это руками.

Сервисы у нас выкатываются следующим образом. К нам в нашу тикет-систему в JIRA поступает задача о том, что наши разработчики решили, что собрали новую версию, и они хотят ее на продакшн. Они ставят нам задачу. Контейнер автоматически на тот момент собирается, он говорит, что статус «собран», все хорошо. В этом интерфейсе у нас есть функционал, если мы поменяли в puppet’е какие-то config’и, мы хотим сделать rebuild. Т.е. если нам нужен контейнер, не тот, что нам собрали, прислали, а с другими config’ами, мы можем это сделать здесь. Следующим, вторым шагом (на слайде) можем убедиться в том, что команда на пересборку направлена, и если все прошло хорошо, мы получаем некий success с адресом и ссылкой нашего нового контейнера в registry, откуда мы его можем забрать.
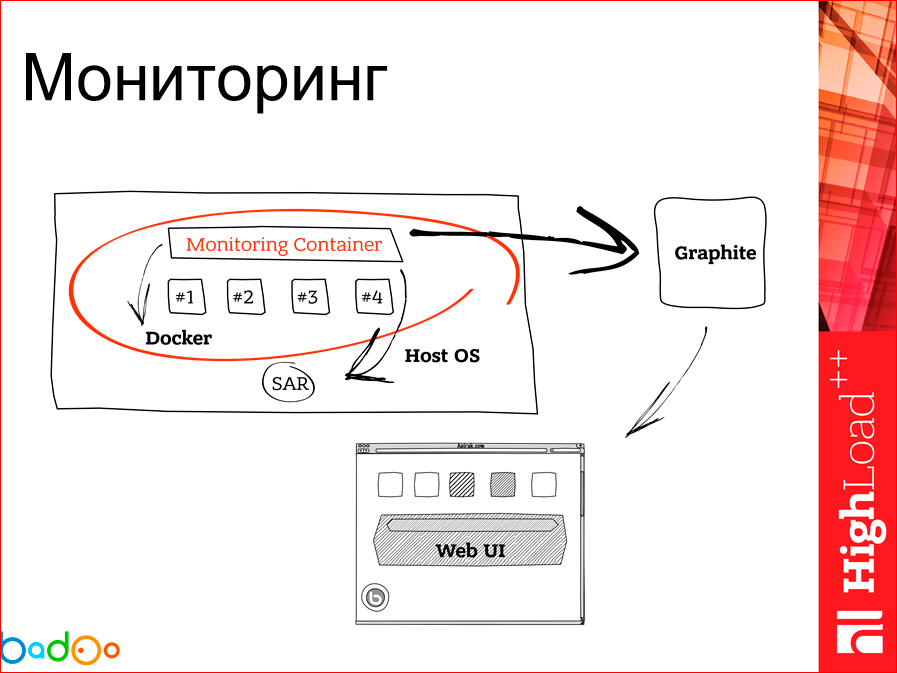
Docker хост и контейнер, работающий на нем, есть необходимость мониторить. Для решения этой проблемы мы в данном случае запилили первый велосипед, который является образом контейнера на каждом docker хосте, в котором мы коллектим какую-то информацию. Общая схема выглядит так, т.е. мы собираем на контейнере информацию, засылаем ее раз в какое-то время в Graphite, а уже там рисуем красивый интерфейс.

Как у нас выглядит этот мониторинговый контейнер? У нас есть Docker CLI внутри, потому что нам нужно собирать статистику через docker stats, по CPU и по памяти по каждому контейнеру. И мы по умолчанию используем на наших серверах SAR и запускаем наш мониторинговый контейнер. Мы диру SAR’ом подтягиваем. Раз в какое-то время наш docker контейнер мониторинговый запускает агрегатор статки, которого необходимо отправить в Graphite. Засылает ее туда. Не получилось отослать? Следующий проход. Он проверит, если остались какие-то слепки на FS, зашлет вторым прогоном. После чего мы это рисуем на Graphite. Сам контейнер, что он запущен, что он, вообще, есть на Docker хосте, мы мониторим Zabbix’ом.

В общем и целом, графики получаются приблизительно такие. Их много, они не очень читаемые, но, я думаю, графаны видели все. Вот так мы видим информацию по хосту памяти, мы можем смотреть по каждому контейнеру и информацию, в общем, о хосте по CPU.
Можем смотреть использование сети и т.д…
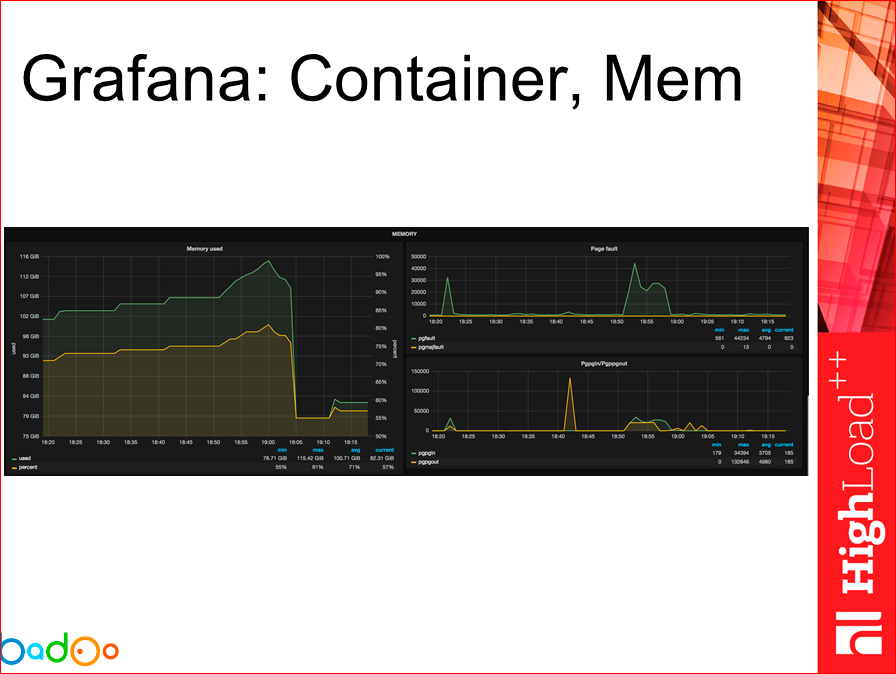
На данном слайде картинка уже о том, что происходит с самим контейнером, отвязываясь от самого хоста.
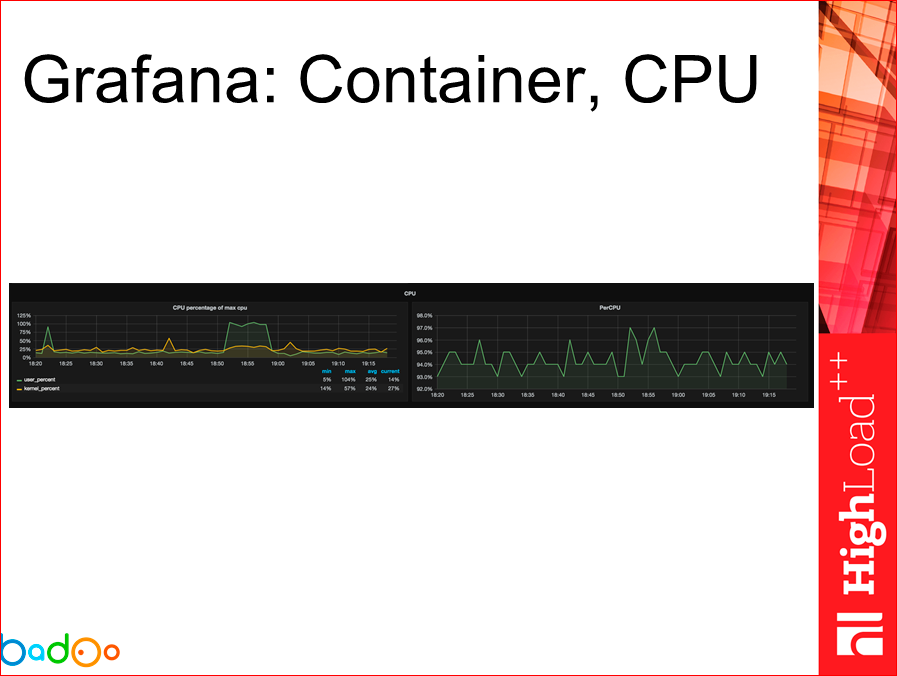
То же самое можно сказать про CPU.
И последний момент, которого я бы хотел коснуться – это изобретение еще одного велосипеда по оркестрации, по управлению нашими контейнерами, потому как мы, выбирая, не выбрали ничего из готовых решений. Я не буду останавливаться на тех решениях, которые мы рассмотрели, если кому-то будет интересно, позже это спросит. Я скажу, какой набор требований мы высказывали к нашему baDocker, чтобы его начать разрабатывать.

- Первое, что мне не понравилось, когда мы смотрели на готовые решения – это присутствие еще одного контейнера, который нужно запускать на каждом хосте,
который будет что-то там собирать и через него заниматься управлением. Первая фишка – это Clientless. Нам не нужен никакой клиент, у нас Docker API, зачем
нам еще что-то?
- Нам необходимо управление Registry двух версий – первой и второй. Потому что у нас есть старые наследия на версиях 1 и 2, и нам нужен старый Registry. И
у нас есть новые версии Docker, где мы используем Registry v2.
- Как обычно, мы хотим иметь всю-всю информацию о хостах, о контейнерах (я просто ее в кучу собрал). Всю информацию, которую можно было получить, хотим
иметь.
- Также хотим иметь некий планировщик задач, который будет получать какой-то набор инструкций о том, что «эти образы туда вылей, оттуда их забери, потому
что они не нужны, сервис уже уехал». Пока это такое кодовое название, пускай это будет Планировщик.
- И последнее, что хотелось бы видеть – это Dashboard, который скажет о том, что «хостов у тебя столько, там возможные проблемы, там невозможные, если
нужно, пойди, посмотри».
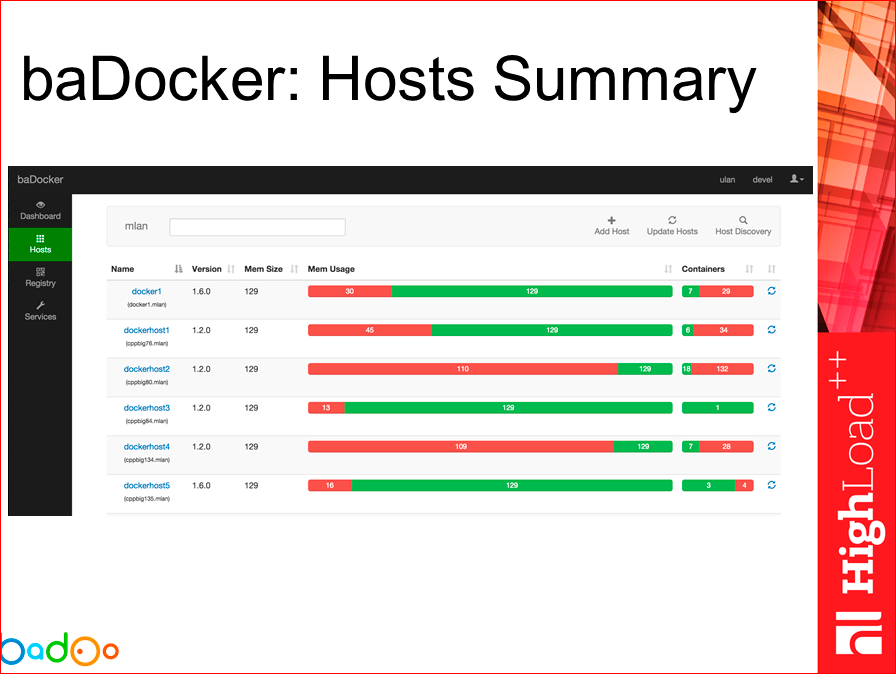
На текущий момент времени это выглядит приблизительно таким образом. Т.е. мы можем посмотреть Summary по нашим хостам, по каждой площадке, сколько памяти там всего, сколько занято, сколько контейнеров всего, сколько застопанно, сколько работает.

Мы можем зайти и детально посмотреть, какие контейнеры, из каких образов у нас запущены. Также мы можем клацнуть галочкой, посмотреть, какой версии конкретный сервис у нас работает.

Мы можем зайти с этого интерфейса на любой контейнер, чего-то там написать, получить какой-то вывод, например, «не коннектись через shell никуда»…

По нашим сервисам мы можем посмотреть, какие типы данного сервиса есть, какие есть версии, на каких серверах работают те или иные версии данного сервиса.

И можем использовать такие подсказки в виде темплейтов, как же нам запустить контейнер для этого сервиса, т.е. мы нажимаем на нужный нам тип и видим – вот подсказка: «пойди, запусти вот так, если тебе это нужно сделать руками».

В заключение хотелось бы сказать следующее – используя любой инструмент, в данном случае Docker, я бы рекомендовал использовать некий свой подход, смотреть нестандартно на некоторые вещи и, делая такое, принять во внимание проблемы других людей, которые эти проблемы решили или советуют, как их решить. И, конечно же, я хотел сказать о том, что изобретать велосипеды – это не стыдно, это клево и интересно, если только колеса не квадратные у вашего велосипеда.
Контакты
» a.turetsky@corp.badoo.com
» Блог компании Badoo
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. Сейчас мы активно готовим конференцию 2016 года — в этом году HighLoad++ пройдёт в Сколково, 7 и 8 ноября.
На HighLoad++ 2016 будет огромная секция по DevOps, вот некоторые из докладов по docker'у, вдруг вам будет интересно:
- 5 способов деплоя PHP-кода в условиях хайлоада / Юрий Насретдинов;
- Aviasales: миграция поискового движка в docker / Дмитрий Кузьменков;
- Собираем Docker-образы быстро и удобно / Дмитрий Столяров
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Комментарии (58)

p4s8x
06.10.2016 00:18+2Спасибо! Каждый раз смотрю\читаю ваши доклады и успеваю не наступить на какие-то грабли)
Планируете ли открыть baDocker сообществу?
banuchka
07.10.2016 12:54+3Хорошо, что Вам моя шапка не мешает воспринимать информацию. Да мы планируем это сделать, как только осознаем что это можно выкладывать, также как и часть других наработок, про которые в том числе я рассказывал ранее.


Fedcomp
06.10.2016 03:52+1Мне кажется самые первые грабли именно изза того что тащили часть хостовой системы в контейнер (не объяснили почему). Также непонятно зачем использовать блочное устройство в качестве ФС для хранения данных если можно просто засунуть код в докер.
И еще не увидел ни слова (в статье, видео не смотрел) про Docker volume.
Т.е по крайней мере первые грабли изза того что готовили докер не в концепции докера, а как то по своему.banuchka
07.10.2016 12:58+1«Концепция Docker» – это безусловно прекрасно. Вы не пробовали смотреть на инструмент, как на инструмент для достижения поставленных целей и решения конкретных задач? Иногда получается так, что для достижения решения нужно поскупиться концепцией и подойти к решению иначе…
Часть хостовой системы в контейнер – это вы про /dev/log или что-то еще? если будет более конкретный вопрос, то я попробую на него ответить.
Блочное устройство для docker root – это затем, что мы не хотели и не хотим получить BTRFS by default, именно поэтому был сделан отдельный том для docker root на BTRFS.
Код как таковой внутри контейнеров у нас не распространяется, т.к. большая часть сервисов, про которые я говорил — это binary.

shushu
06.10.2016 06:12+1Немного офтоп.
Как вообще разработчики живут со всем этим?
Нужно ставить весь стак компонентов и приложений локально?
Вы используете докер для девелопер среды тоже?
Насколько проблематично поддерживать контейнеры в актуальной версии?
спасибо
Kane
06.10.2016 08:49+1Нужно ставить весь стак компонентов и приложений локально?
Не обязательно. Разрабатывать можно как тебе удобно. Докер даёт возможность запустить приложение в конфигурации "как в продакшене". Для запуска нескольких связанных контейнеров используют Docker Compose
Насколько проблематично поддерживать контейнеры в актуальной версии?
Не проблематично, если деплой выглядит так:
- Собираем контенер.
- Тегируем его номером билда.
- На сервере загружаем контейнер нужной версии.
- Запускаем скачанную версию.
banuchka
07.10.2016 13:03+1Немного офтоп.
Как вообще разработчики живут со всем этим?
Вот и я задаю этот вопрос – как с этим жить?
Нужно ставить весь стак компонентов и приложений локально?
Нет, для этого у нас есть несколько devel площадок, которые представляют собой уменьшенную копию нашего production окружения. Именно там они занимаются разработкой, тестированием и прочими прелестями, которые им нравятся.
Вы используете докер для девелопер среды тоже?
на данный момент нет, но для среды тестирования используем.
Насколько проблематично поддерживать контейнеры в актуальной версии?
что именно вы имели ввиду? актуальность пакетов ОС и их обновления? Не могли бы вы уточнить вопрос, а я попробую дать более полный ответ.
Спасибо

Nengchak
06.10.2016 06:34Интересно, как сделали удаленный web терминал? Там ведь не поднят SSH Server в контейнере?
shushu
06.10.2016 06:42В любом контейнере можно запустить bash и без поднятого ssh
Nengchak
06.10.2016 06:51Не, я к тому, как туда инжектнуться удаленно? Насколько мне не изменяет память, в данный момент я могу сделать только — docker exec, который запущен в данный момент там же, где я нахожусь.

fuCtor
06.10.2016 07:41Думаю, что-то типа такого, https://docs.docker.com/engine/reference/api/docker_remote_api_v1.19/#/attach-to-a-container-websocket если почитать документацию есть эквивалент для docker exec, консольная утилита по сути своей лишь клиент к REST API.
Nengchak
06.10.2016 07:50Кажется оно, я его тыкал когда-то, но не помню почему не смог реализовать подобное. Если не изменяет мне память, я аттачился к процессу, запущенному внутри контейнера. увидеть бы живой пример данной реализации.
fuCtor
06.10.2016 08:03http://matthewvalimaki.com/docker/how-to-executing-commands-in-containers-using-docker-remote-api-v1-20/ в сети вот такое есть, можно попробовать на базе этого сделать.
banuchka
07.10.2016 13:07ssh внутри контейнеров у нас нет. Для web-терминала есть клиент-серверное приложение(я не помню название, но если очень нужно – могу вспомнить), которое у нас крутится на baDocker-сервере. По сути используется ssh соединение между baDocker сервером и docker хостом, где на последнем используется docker exec. Основная идея именно такая, если не лезть в дебри.

g_pavlovich
06.10.2016 08:36Я правильно понял что для service discovery используется что-то самописное? (Конец Видео) Интересно почему не тот же zookeeper/etcd/consul. Нет необходимости и слишком большой оверхэд по отношению к требуемым функциям?
banuchka
07.10.2016 13:11Да, все верно поняли. На данный момент это самописное к docker ecosystem не имеет никакого отношения. Одна из основных причин – сервисы у нас не подходят под определение микросервисов и мы не можем так просто взять и поднять N-инстансов одного сервиса(верно не для всех сервисов, но для большей их части), что хорошо подходит для того service discovery, про который вы спрашиваете.
Т.е. у нас скорее это выглядит так:
— ручное принятие решение о поднятии сервиса/инстанса
— подготовка инстанса
— поднятие
— проверка, что все хорошо
— добавление информации о том, что сервис есть и им можно пользоваться
На самом деле рассмотрение etcd/zookeeper у нас также идет, но я не могу сказать, что на данный момент есть готовое внедрение и полноценное использование, так что на данный момент вот так.lehha
08.10.2016 20:24В одном из докладов по биллингу в badoo слышал о дискавери на основе DNS. Такой подход сейчас используете или отошли от него? Например, выделенный поддомен со своими ns и низким ttl (10 секунд, например).
banuchka
10.10.2016 15:55+1Я не скажу на 100%, но скорее всего раз мои коллеги говорили о том, что это было, то скорее всего это так и осталось для каких-то специфичных сервисов/задач. Глобально такого нет.

vladar
06.10.2016 13:07Смотрели Kubernetes?
banuchka
07.10.2016 13:13+1Да, смотрели. Более того – продолжаю смотреть на него с разных сторон. До сих пор не могу понять как и с какой стороны это нам может подойти… к сожалению.
vladar
07.10.2016 15:46Ну вот логи ваши, например. В kubernetes основная единица не контейнер, а pod — это набор сгруппированных контейнеров, которые имеют доступ к одним и тем же ресурсам. Скажем, вы можете создать отдельный контейнер с syslog, который будет доступен в рамках pod по заданному порту на localhost.
Потом этот контейнер с syslog можете просто подключать к своим сервисным pod'ам. Деплоймент, обнаружение сервисов, балансировка нагрузки на сервисы, поддержка заданного количества инстансов — все делает сам. Сетевая модель — на выбор тот же WeaveNet, Flannel, Calico.
Докер отдельно для серьезных проектов всё равно нуждается в системе оркестрации. Без Swarm, Mesos или Kubernetes от него мало прока в продакшне. Можно, конечно, многое допиливать и додумывать (что и пришлось вам делать), а можно взять полноценную систему оркестрации и сильно упростить себе жизнь.
Собственно Docker сейчас делает собственную оркестрацию — Swarm mode (в 1.12 появился впервые), который только пытается делать часть из того, что уже умеет Kubernetes для продакшна.
Ну и не стоит забывать, что Kubernetes — это опыт Гугла в управлении своими сервисами (те же инженеры пишут, что рулят их production-серверами)

mkevac
07.10.2016 17:02Вы используете все эти новомодные слова или рассказываете теоретически? Просто все то что вы говорите выглядит красиво, но бьюсь об заклад что в реальности проблем 100500. Придется все свои существующие продукты переделывать так, чтобы они укладывались в видение Kubernetes как должно быть. А это примерно как «давайте перепишем все на Go».
vladar
07.10.2016 22:27Мы переходим на kubernetes в данный момент. Если собираетесь работать с docker'ом в продакшне, то рано или поздно — все эти 100500 проблем вы поимеете всё равно.
Собственно, изначально протестировали всё на Google Container Engine — это и есть kubernetes.
banuchka
08.10.2016 00:28Чудес не бывает: WeaveNet, Flannel, Calico – это мало того, что новые компоненты, так это еще и оверхед, от которого пострадает latency & throughput.
Что-то доступно по localhost в рамках pod – это также не чудо и имеет довольно простое объяснение. Данный бонус скорее относится к тем, кто приложение разрабатывает, чем к улучшению чего-то в production.
Балансировка – это прекрасно… RR, ну хорошо – есть еще healthcheck(не ох какой, но есть). То, куда приземляется трафик этого балансировщика… Вас все это устраивает?
Swarm mode не совместим с "--live-restore", как минимум. Swarm – это окончательно подсесть на Docker.
Stateful контейнеры – «не Docker way», но ничего не поделаешь – они есть и с этим как-то нужно жить. Мы приходим к тому, что желательно растянуть сторадж между хостами, на которых в случае чего pod/service может продолжить работу. Цепочку хотелок и зависимостей можно продолжать дальше долго.
К опыту Гугла я отношусь с большим уважением, также как и ко всем тем, кто занимается разработкой продуктов, которые в свою очередь оказывают неоценимую помощь остальным.
И как только я найду ответы хотябы на те сомнения и вопросы, что я написал – я непременно буду готов рассмотреть Kubernetes.
Если собираетесь работать с docker'ом в продакшне, то рано или поздно — все эти 100500 проблем вы поимеете всё равно.
Собираемся и спасибо за Ваши добрые пожелания :)vladar
08.10.2016 00:44Просто любопытно. Вы по сути делаете свой orchestration на докере. Интересно было узнать чем не устраивают существующие решения.
banuchka
08.10.2016 14:27+1Если вам не сложно – вы можете посмотреть видео с моими докладами, в том числе по Docker. Очень часто в самом их начале я рассказываю о причинах того, почему нам довольно не просто взять и начать использовать что-то готовое. Это все не от того, что нам очень просто брать и делать что-то самостоятельно, а часто от того, что в готовом нет минимума, без которого мы не можем «взлететь».
Давайте я попробую привести несколько пунктов:
— у нас мало сервисов, которые мажутся горизонтально просто включением новых инстансов
— на начальном этапе внедрения нам нужно было «оркестрировать» максимально одинаково то, что в Docker и то, что нет
— сетевой аспект меня тоже довольно сильно тревожит
Т.е. основных поинтов два — сеть и изначально отличная от нашей архитектура.vladar
08.10.2016 23:40Спасибо. В любом случае интересно было почитать топик и комментарии. Понимаю, что с вашим масштабом лучше быть консервативнее %)
banuchka
10.10.2016 15:53+1Тут дело не совсем в одном только консерватизме. Скорее я бы назвал это «разумная осторожность», которая должна гарантировать нам возможность сделать пару шагов назад, если что-то пойдет не так при том, чтобы ничего не поломать.

DarkTiger
06.10.2016 16:04Badoo лично мне интересна другой своей стороной — это единственный известный мне сайт, который на мобильной версии роняет Safari в iOS6, причем стабильно и регулярно. Все руки не дойдут поиссследовать, как ребятам это удалось.
mkevac
07.10.2016 12:13It was preceded by iOS 5 (final version was 5.1.1) and was succeeded by iOS 7 on September 18, 2013.
Закопайте уже ее…
A-Stahl
Посмотрел на головной убор докладчика и дальше читать не стал. Не смог.
Akuma
Зачем вообще ему шапка в помещении?
Kroid
Может, лысину скрывает. Или проспорил кому-то перед презой.
Alex_Crack
Думаю, имелись ввиду простые правила этикета: интеллигентному мужчине находится в помещении в головном уборе не красиво и не уважительно по отношению к другим.
Ghedeon
Всем плевать. Не нужно свой доморощенный семейный устав выдавать за правила этикета. Коль скоро он говорит по делу — пусть хоть маракасы на шею повесит.
Galangetan
Уважаемый, это не свой «доморощенный семейный устав», а общепринятое правило этикета, про которое вы можете прочитать в любой энциклопедии этикета.
Вот первая ссылка из гугла про это: http://www.dc-perekrestock.ru/use704.php
Ghedeon
Где вы все работаете, чистоплюи, которым нужна энциклопедия этикета, чтобы рассказать про контейнеры на технической конференции?
Я сам не маргинал, но у меня в команде парень с дредами, кто-то с татухами, другой любит ходить босым, а девчонка-тестер фанат тяжелой музыки и кожи. Выступают на конференциях, успешно контрибутят в open-source и вообще, ложили с прибором на тех, кого ебет их внешний вид. Все интересные личности, а с буквоедами энциклопедий я чувствую усну еще до того, как принесут меню на обеденном перерыве. Но это Берлин да, нам далеко до ваших арийских скреп и идеалов.
VenomBlood
Я не поленился и открыл ссылку, и знаете, такого бреда я давно не видел, причем он очень щедро приправлен сексизмом.
Чего только стоит: «Женщине шапку с большими полями нельзя носить после 5 вечера». А мужчине можно. А женщина значит должна всегда носить запасную шапку в кармане, а то вдруг 5 вечера а она еще не вернулась домой.
Или например то что мужчине предлагается снимать на улице шапку если он слышит гимн (кстати, гимн какой страны? Обязательно ли знать гимны всех стран?) или говорит с женщиной.
Даром что сжигать никого в этой статье не предлагают.
bohdan4ik
Буквоедствовал-буквоедствовал, да невыбуквоедствовал.
Не всякий головной убор является шляпой. Засим предлагаю спор считать завершённым.
Weageoo
Общепринятое… Странно, не помню, чтобы я или мои знакомые учавствовали в общественном обсуждении сего «достояния высших слоёв общества». Вам так хочется ограничиться в поведении длинным списком указаний, или же хочется ограничить других? Если первое — то пожалуйста, если второе — то не стоит. Пожалуйста, держите своих тараканов при себе.
Jesting
Прочитал как: макросы на шею.
VenomBlood
О, это вы наверное тот самый неадекватный HR, который требует дресс-код у программистов?
A-Stahl
Нет, я тот адекватный программист, который хоть и любит юмор, но не признаёт клоунаду на конференциях.
VenomBlood
Да, одному шорты — «клоунада», другому шапка, третьему крашеные волосы. А потом получаются вот такие истории, потому что вместо профессиональных качеств особо одаренные смотрят на то какая на ком футболка и шапка.
ToSHiC
(del) комментарий почему-то прилепился в этот тред.
Toledo
Не то, чтобы я не смог читать, но первое, что я подумал, когда увидел доклад — что это за хрень у него на голове, и зачем она ему нужна в помещении?! :)
olegbunin
Парни, завязывайте, такой стиль у человека. Какая разница, у кого какая шапка?
Двадцать первый век на дворе, конференция для гиков, а мы обсуждаем шапки.
fishca
правильно, нравится человеку быть чудиком, пусть будет им, но я бы не одел, т.к. тупо жарко голове
banuchka
Спасибо за ветку в комментариях – заставили с утра улыбнуться. Особенно мне понравились Ваши доводы про лысину, а также рассказы про нормы этикета.