

Подготовка
Традиционно, если вы еще не работали с ASP.NET Core, то здесь есть ссылки на все, что для этого понадобится.
Запускаем Visual Studio, создаем новое веб-приложение:
Веб-приложение готово. При желании его можно запустить.
Приступаем
Модели
Начнем с моделей. Вынесем их классы в отдельный проект — библиотеку классов AspNetCoreStorage.Data.Models:
Добавим класс нашей единственной модели Item:
public class Item
{
public int Id { get; set; }
public string Name { get; set; }
}
Для нашего примера этого хватит.
Абстракции взаимодействия с хранилищем
Теперь перейдем непосредственно к взаимодействию с хранилищем, которое в нашем веб-приложении будет реализовано с применением двух шаблонов проектирования — Единица работы и Репозиторий. Имплементация этих шаблонов упрощенно означает, что взаимодействие с хранилищем в рамках одного запроса будет гарантированно производиться в едином контексте хранилища, а для каждой модели будет создан отдельный репозиторий, содержащий все необходимые методы для манипуляций с ней.
Для обеспечения возможности простого переключения между различными реализациями взаимодействия с хранилищем, наше веб-приложение не должно использовать какую-то конкретную реализацию напрямую. Вместо этого все взаимодействие с хранилищем должно производиться через слой абстракций. Опишем его в библиотеке классов AspNetCoreStorage.Data.Abstractions (создадим соответствующий проект).
Для начала добавим интерфейс IStorageContext без каких-либо свойств или методов:
public interface IStorageContext
{
}
Классы, реализующие этот интерфейс, будут непосредственно описывать хранилище (например, базу данных со строкой подключения к ней).
Далее, добавим интерфейс IStorage. Он содержит два метода — GetRepository и Save:
public interface IStorage
{
T GetRepository<T>() where T : IRepository;
void Save();
}
Этот интерфейс описывает реализацию шаблона проектирования Единица работы. Объект класса, реализующего этот интерфейс, будет единственной точкой доступа к хранилищу и должен существовать в единственном экземпляре в рамках одного запроса к веб-приложению. За создание этого объекта у нас будет отвечать встроенный в ASP.NET Core DI.
Метод GetRepository будет находить и возвращать репозиторий соответствующего типа (для соответствующей модели), а метод Save — фиксировать изменения, произведенные всеми репозиториями.
Наконец, добавим интерфейс IRepository с единственным методом SetStorageContext:
public interface IRepository
{
void SetStorageContext(IStorageContext storageContext);
}
Очевидно, что этот интерфейс описывает классы репозиториев. В момент запроса репозитория объект класса, реализующего интерфейс IStorage, будет передавать единый контекст хранилища в возвращаемый репозиторий с помощью метода SetStorageContext, чтобы все обращения к репозиторию производились в рамках этого единого контекста, как мы говорили выше.
На этом общие интерфейсы описаны. Теперь добавим интерфейс репозитория нашей единственной модели Item — IItemRepository. Этот интерфейс содержит лишь один метод — All:
public interface IItemRepository : IRepository
{
IEnumerable<Item> All();
}
В реальном веб-приложении здесь также могли бы быть описаны методы Create, Edit, Delete, какие-то методы для извлечения объектов по различным параметрам и так далее, но в нашем упрощенном примере в них необходимости нет.
Конкретные реализации взаимодействия с хранилищем: перечисление в памяти
Как мы уже договорились выше, у нас будет две реализации взаимодействия с хранилищем: на основе базы данных SQLite и на основе перечисления в памяти. Начнем со второй, так как она проще. Опишем ее в библиотеке классов AspNetCoreStorage.Data.Mock (создадим соответствующий проект).
Нам понадобится реализовать 3 интерфейса из нашего слоя абстракций: IStorageContext, IStorage и IItemRepository (т. к. IItemRepository расширяет IRepository).
Реализация интерфейса IStorageContext в случае с перечислением в памяти не будет содержать никакого кода, это просто пустой класс, поэтому перейдем сразу к IStorage. Класс небольшой, поэтому приведем его здесь целиком:
public class Storage : IStorage
{
public StorageContext StorageContext { get; private set; }
public Storage()
{
this.StorageContext = new StorageContext();
}
public T GetRepository<T>() where T : IRepository
{
foreach (Type type in this.GetType().GetTypeInfo().Assembly.GetTypes())
{
if (typeof(T).GetTypeInfo().IsAssignableFrom(type) && type.GetTypeInfo().IsClass)
{
T repository = (T)Activator.CreateInstance(type);
repository.SetStorageContext(this.StorageContext);
return repository;
}
}
return default(T);
}
public void Save()
{
// Do nothing
}
}
Как видим, класс содержит свойство StorageContext, которое инициализируется в конструкторе. Метод GetRepository перебирает все типы текущей сборки в поисках реализации заданного параметром T интерфейса репозитория. В случае, если подходящий тип обнаружен, создается соответствующий объект репозитория, вызывается его метод SetStorageContext и затем этот объект возвращается. Метод Save не делает ничего. (На самом деле, мы могли бы вообще не использовать StorageContext в этой реализации, передавая null в SetStorageContext, но оставим его для единообразия.)
Теперь посмотрим на реализацию интерфейса IItemRepository:
public class ItemRepository : IItemRepository
{
public readonly IList<Item> items;
public ItemRepository()
{
this.items = new List<Item>();
this.items.Add(new Item() { Id = 1, Name = "Mock item 1" });
this.items.Add(new Item() { Id = 2, Name = "Mock item 2" });
this.items.Add(new Item() { Id = 3, Name = "Mock item 3" });
}
public void SetStorageContext(IStorageContext storageContext)
{
// Do nothing
}
public IEnumerable<Item> All()
{
return this.items.OrderBy(i => i.Name);
}
}
Все очень просто. Метод All возвращает набор элементов из переменной items, которая инициализируется в конструкторе. Метод SetStorageContext не делает ничего, так как никакого контекста в этом случае нам не нужно.
Конкретные реализации взаимодействия с хранилищем: база данных SQLite
Теперь реализуем те же самые интерфейсы, но уже для работы с базой данных SQLite. На этот раз реализация IStorageContext потребует написания некоторого кода:
public class StorageContext : DbContext, IStorageContext
{
private string connectionString;
public StorageContext(string connectionString)
{
this.connectionString = connectionString;
}
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
base.OnConfiguring(optionsBuilder);
optionsBuilder.UseSqlite(this.connectionString);
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
modelBuilder.Entity<Item>(etb =>
{
etb.HasKey(e => e.Id);
etb.Property(e => e.Id);
etb.ForSqliteToTable("Items");
}
);
}
}
Как видим, кроме реализации интерфейса IStorageContext этот класс еще и наследует DbContext, представляющий контекст базы данных в Entity Framework Core, чьи методы OnConfiguring и OnModelCreating он и переопределяет (не будем на них останавливаться). Также обратите внимание на переменную connectionString.
Реализация интерфейса IStorage идентична приведенной выше, за исключением того, что в конструктор класса StorageContext необходимо передать строку подключения (конечно, в реальном приложении указывать строку подключения таким образом неправильно, ее следовало бы взять из параметров конфигурации):
this.StorageContext = new StorageContext("Data Source=..\\..\\..\\db.sqlite");
А также, метод Save должен теперь вызывать метод SaveChanges контекста хранилища, унаследованный от DbContext:
public void Save()
{
this.StorageContext.SaveChanges();
}
Реализация интерфейса IItemRepository выглядит теперь таким образом:
public class ItemRepository : IItemRepository
{
private StorageContext storageContext;
private DbSet<Item> dbSet;
public void SetStorageContext(IStorageContext storageContext)
{
this.storageContext = storageContext as StorageContext;
this.dbSet = this.storageContext.Set<Item>();
}
public IEnumerable<Item> All()
{
return this.dbSet.OrderBy(i => i.Name);
}
}
Метод SetStorageContext принимает объект класса, реализующего интерфейс IStorageContext, и приводит его к StorageContext (то есть к конкретной реализации, о которой этот репозиторий осведомлен, так как сам является ее частью), затем с помощью метода Set инициализирует переменную dbSet, которая представляет таблицу в базе данных SQLite. Метод All на этот раз возвращает реальные данные из таблицы базы данных, используя переменную dbSet.
Конечно, если бы у нас было более одного репозитория, было бы логично вынести общую реализацию в какой-нибудь RepositoryBase, где параметр T описывал бы тип модели, параметризировал dbSet и передавался затем в метод Set контекста хранилища.
Взаимодействие веб-приложения с хранилищем
Теперь мы готовы немного модифицировать наше веб-приложение, чтобы заставить его выводить список объектов нашего класса Item на главной странице.
Для начала, добавим ссылки на обе конкретные реализации взаимодействия с хранилищем в раздел dependencies файла project.json основного проекта веб-приложения. В итоге получится как-то так:
"dependencies": {
"AspNetCoreStorage.Data.Mock": "1.0.0",
"AspNetCoreStorage.Data.Sqlite": "1.0.0",
"Microsoft.AspNetCore.Diagnostics": "1.0.0",
"Microsoft.AspNetCore.Mvc": "1.0.1",
"Microsoft.AspNetCore.Server.IISIntegration": "1.0.0",
"Microsoft.AspNetCore.Server.Kestrel": "1.0.1",
"Microsoft.Extensions.Logging.Console": "1.0.0",
"Microsoft.NETCore.App": {
"version": "1.0.1",
"type": "platform"
}
}
Теперь перейдем к методу ConfigureServices класса Startup и добавим туда регистрацию сервиса IStorage для двух разных реализаций (одну из них закомментируем, обратите внимание, что реализации регистрируются с помощью метода AddScoped, что означает, что временем жизни объекта является один запрос):
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
// Uncomment to use mock storage
services.AddScoped(typeof(IStorage), typeof(AspNetCoreStorage.Data.Mock.Storage));
// Uncomment to use SQLite storage
//services.AddScoped(typeof(IStorage), typeof(AspNetCoreStorage.Data.Sqlite.Storage));
}
Теперь перейдем к контроллеру HomeController:
public class HomeController : Controller
{
private IStorage storage;
public HomeController(IStorage storage)
{
this.storage = storage;
}
public ActionResult Index()
{
return this.View(this.storage.GetRepository<IItemRepository>().All());
}
}
Мы добавили переменную storage типа IStorage и инициализируем ее в конструкторе. Встроенный в ASP.NET Core DI сам передаст зарегистрированную реализацию интерфейса IStorage в конструктор контроллера во время его создания.
Далее, в методе Index мы получаем доступный репозиторий, реализующий интерфейс IItemRepository (напоминаем, все получаемые таким образом репозитории будут иметь единый контекст хранилища благодаря применению шаблона проектирования Единица работы) и передаем в представление набор объектов класса Item, получив их с помощью метода All репозитория.
Теперь выведем полученный список объектов в представлении. Для этого укажем перечисление объектов класса Item в качестве модели вида для представления, а затем в цикле выведем значения свойства Name каждого из объектов:
@model IEnumerable<AspNetCoreStorage.Data.Models.Item>
<h1>Items from the storage:</h1>
<ul>
@foreach (var item in this.Model)
{
<li>@item.Name</li>
}
</ul>
Если сейчас запустить наше веб-приложение мы должны получить следующий результат:
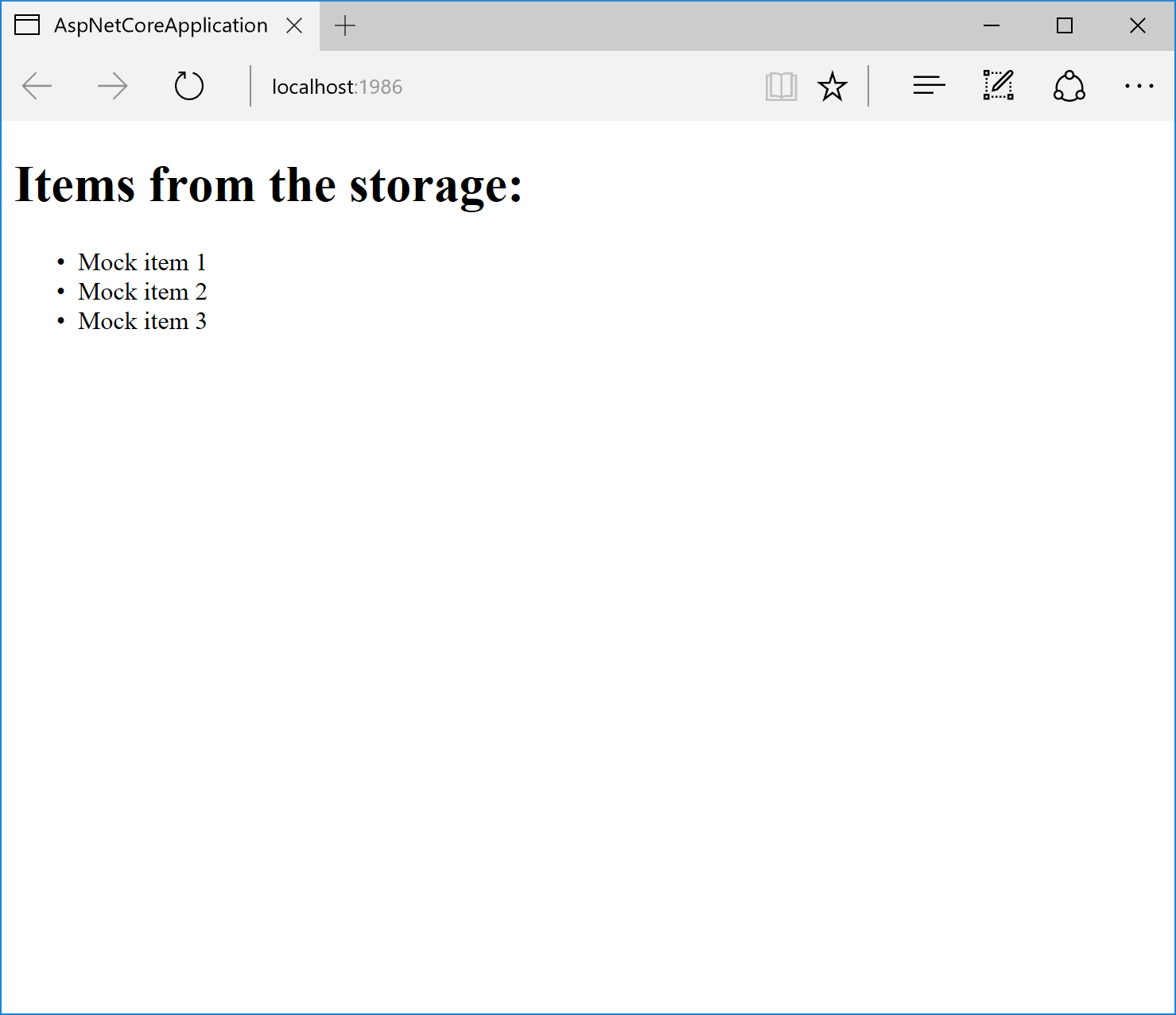
Если же мы поменяем регистрацию реализации интерфейса IStorage на другую, то и результат изменится:

Как видим, все работает!
Заключение
Встроенный в ASP.NET Core механизм внедрения зависимостей (DI) очень упрощает реализацию подобных нашей задач и делает ее более близкой, простой и понятной новичкам. Что касается непосредственно Единицы работы и Репозитория — для типичных веб-приложений это наиболее удачное решение взаимодействия с данными, упрощающее командную разработку и тестирование.
Тестовый проект выложен на GitHub.
Об авторе

Дмитрий Сикорский — владелец и руководитель компании-разработчика программного обеспечения «Юбрейнианс», а также, совладелец киевской службы доставки пиццы «Пиццариум».
Последние статьи по ASP.NET Core
1. Создание внешнего интерфейса веб-службы для приложения.
2. В ногу со временем: Используем JWT в ASP.NET Core.
3. ASP.NET Core на Nano Server.
Комментарии (58)

SilverFerrum
12.10.2016 17:52Абстракция на абстракции и абстракцией погоняет.
Какой смысл создавать Storage и IStorage, если с таким же успехом можно просто запросить StorageContext в контроллере?
Я пойму еще создать ItemManager со специфическими функциями для этой сущности, но зачем дублировать готовый функционал ef core?
DmitrySikorsky
12.10.2016 19:26+1Storage является реализацией Единицы работы, поэтому именно его мы и инжектим в контроллер. Это ведь удобно — иметь единую точку доступа ко всем репозиториям с единым контекстом и возможностью фиксации всех изменений. Инжектить StorageContext в контексте приведенной архитектуры не имеет смысла.
Насчет дублирования готового функционала EF. Вы правы, DbContext также является реализацией Unit of work и можно использовать его напрямую. В простых приложениях это вполне применимо. Но что если на каком-то этапе потребуется, как в примере, использовать другой источник данных, вообще не основанный на EF. Например, JSON HTTP API или же, снова-таки случай из примера, перечисление в памяти для тестирования. Что тогда? Тогда придется либо признать, что сделать этого уже нельзя (без переписывания всего, что связано с механизмом взаимодействия с данными), либо сесть и все-таки внедрить слой абстракций, например, с помощью описанного в статье подхода, но все-равно с переписыванием всего. А ведь в реальных долгоиграющих проектах задачи и условия меняются постоянно.
Смотрите, предположим, у вас есть необходимость выбрать всех людей со средней зарплатой больше Х. Вы получаете соответствующий репозиторий из единицы работы и затем выполняете 1 метод, который просто принимает параметр Х. Вам не нужно заботиться о том, как именно реализован этот метод с точки зрения предметной области или с точки зрения базы данных или другого хранилища. Вы просто его используете. Он вполне может быть написан кем-то другим и его логика может 10 раз измениться в процессе, но остальной код менять не потребуется. Также если вам нужен конкретный человек, вы получаете его по идентификатору также из репозитория. Часто для решения первой задачи вводится еще слой сервисов, но он практически всегда избыточен и попросту дублирует наборы методов из репозиториев, поэтому почти всегда я размещаю ВСЕ методы для манипуляции объектами определенного типа в репозиторий. Представьте, что вы используете в контроллерах DbContext и DataSet напрямую. Вы будете везде писать один и тот же Linq-запрос, чтобы выбрать необходимые объекты? Или как вы сказали, создадите просто висящий в воздухе ItemManager? Тогда наверняка часть методов будут выполняться на DbSet, а часть — на ItemManager, что приведет к путанице и сделает еще более сложными описанные выше сценарии.

DenomikoN
12.10.2016 17:52-1Мне данная реализация Repository показалась странной. А где UnitOfWork?
Хотелось бы видеть более качественные технические статьи в профильном блоге.DmitrySikorsky
12.10.2016 18:02+1Storage является реализацией Unit of work. Т. к. этот класс представляет собой хранилище (базу данных или нечто другое), удобнее его так и называть.
Ice2burn
12.10.2016 20:16+1Когда пару лет назад ковырял MVC 3,4,5 почти не встречал в статьях данных паттернов.
А с выходом ASP.NET CORE — повсеместно. Меня будто вновь воспитывают.DmitrySikorsky
12.10.2016 23:09Для «старого» ASP.NET есть отличная статья по реализации этих шаблонов из 10 шагов.
В этой статье я не пытался заново рассказать о самих шаблонах (по сути, здесь вообще нет их детального описания). Лишь показать простой пример реализации на новой технологии со встроенным DI. Сейчас я думаю, что стоило бы более детально рассказать о том, когда их следует применять, а когда — нет.
musuk
12.10.2016 21:17+1Как я понимаю, у вас Repository.All возвращает DbQuery. И данные вы, фактически, вытаскиваете на View в for. И получается, у вас всё завязано на глобальный (per Request) DbContext, который, кстати, ещё и не thread safe…
Я, честно, говоря, думал что глобальный DbContext уже вышел из моды. Мне больше такая штука нравится Аmbient DbContext
Вот бы такой же пример, но не с select, а с update, и чтобы были связанные сущности, транзакции, как в реальной жизни.
DmitrySikorsky
12.10.2016 23:13Боюсь, я чрезмерно упростил пример, вы правы. Я сконцентрировался на решении понятной для меня задачи имплементации знакомого шаблона на новой технологии и не стал углубляться в саму суть этих паттернов и в их сценарии использования. Могу привести несколько примеров применения практически идентичного подхода в реальных проектах, если это поможет.

Splo1ter
13.10.2016 09:14+1Владельцы и руководители не умеют писать код, за IEnumerable по пальцам надавал бы.
NIKOSV
13.10.2016 09:14Как правильно выше пишут, EntityFramework сам по себе уже и UnitOfWork и репозиторий и всякие абстракции над ним не несут ничего кроме избыточности и связывания рук. Достаточно добавить парочку интерфейсов над DbContext чтобы можно было его пропихивать через DI контейнер и все.
Абстракции можно оправдать только одним аргументом — возможность в будущем заменить EntityFramework на что-то другое, или вообще избавится от реляционной базы данных в пользу чего то другого. Но,
1. На практике это происходит очень редко;
2. Если это происходит, обычно простым написанием новых IBlaBlaRepository не обойтись — все-равно придется пол проекта перелапачивать чтобы эффективно использовать новый DAL и базу.DmitrySikorsky
13.10.2016 10:04Слой абстракций необходим именно для этого, верно, для ослабления связывания. Но я не могу сказать, что он несет какую-то лишнюю нагрузку или усложнение даже в простых проектах, в которых, возможно, никогда не потребуется что-то еще, кроме EF. Такой подход просто разделяет приложение на отдельные части, которые легко и удобно сопровождать и понимать. Чем вы за это платите? Парочкой «дополнительных» интерфейсов. Я считаю, что положительный эффект несравнимо больше.
NIKOSV
13.10.2016 10:31Тем, чтобы по каждому пчиху типа:
var names = dbContext.Employee.Where(e => e.Salary > 5000).Select(e => e.Name).ToArray();
не пришлось на интерфейс и реализацию вешать это:
IEnumerable<string> GetEmployeeNamesWithSalaryGreaterThan(decimal salary);
Если есть часто используемые запросы в базу которые хочется переиспользовать, можно в extension методы вынести.
EntityFreamwork сам по себе уже абстракция которая отделяет данные от всего приложения. Хоть убейте не понимаю как набор IBlaBlaRepository с кучей методов в каждом из них, лучше «разделяет приложение» чем одна IDbContextFactory которая создает DbContext с набором IQueryable.DmitrySikorsky
13.10.2016 11:30+1Уверяю вас,
IEnumerable<string> GetEmployeeNamesWithSalaryGreaterThan(decimal salary);
значительно лучше, чем
var names = dbContext.Employee.Where(e => e.Salary > 5000).Select(e => e.Name).ToArray();
Можно, конечно, писать эти условия Where прямо в контроллере, но это примерно то же самое, что и писать там непосредственно SQL-запросы. Посмотрите сами на этот код. А если там будет больше условий и если вы не писали этот запрос, как вам понять, что он делает, быстро? И сравните его с понятным названием метода, и тогда вы, возможно, поймете, зачем используются репозитории (или сервисы, кто как любит).
Также представьте, что вы написали несколько таких конструкций по проекту, а затем вам поступает задача изменить условие с БОЛЬШЕ на БОЛЬШЕ ИЛИ РАВНО. И что тогда? Будете везде лазить и изменять. И так делают, к сожалению, большинство.
По поводу EF уже абстракция повторюсь, существует не только EF. Посмотрите хотя бы на пример. Если вы на 100% уверены, что вашему проекту не потребуется что-то другое и знаете, что его ждет дальше — прекрасно, можно все упростить и использовать напрямую DbContext и linq-запросы в контроллерах.Bonart
13.10.2016 11:48Посмотрите сами на этот код. А если там будет больше условий и если вы не писали этот запрос, как вам понять, что он делает, быстро? И сравните его с понятным названием метода, и тогда вы, возможно, поймете, зачем используются репозитории (или сервисы, кто как любит).
Не пойму, зачем городить абсолютно некомпозабельный сервис там, где достаточно метода расширения.
DmitrySikorsky
13.10.2016 12:02Так а где достаточно? У нас статья о примере реализации 2х шаблонов, а не «Лучший способ доступа к данным в простом приложении». Т. е. суть статьи — посмотреть, как реализовать эти два шаблона на ASP.NET Core. Я не утверждаю, что это единственно правильный подход во всех ситуациях.
Bonart
13.10.2016 17:20Эти шаблоны в EF уже реализованы, причем в форме, допускающей и композицию, и проекции и много что еще.
NIKOSV
13.10.2016 12:19Можно, конечно, писать эти условия Where прямо в контроллере, но это примерно то же самое, что и писать там непосредственно SQL-запросы.
Большая разница, linq типизированное а SQL запросы нет
Посмотрите сами на этот код. А если там будет больше условий и если вы не писали этот запрос, как вам понять, что он делает, быстро? И сравните его с понятным названием метода, и тогда вы, возможно, поймете, зачем используются репозитории (или сервисы, кто как любит).
Ну выносите запрос в приватный метод класса где он реально используется, делов то. Есть же полно способов навести красоту )
Также представьте, что вы написали несколько таких конструкций по проекту, а затем вам поступает задача изменить условие с БОЛЬШЕ на БОЛЬШЕ ИЛИ РАВНО. И что тогда? Будете везде лазить и изменять. И так делают, к сожалению, большинство.
Опять же, есть куча способов такие ситуации разрулить, например те же экстеншн методы о которых я упоминал. В этом то и вся суть, у вас полно пространства для маневров, вы не связываете себе руки и к каждой конкретной ситуации подходите отдельно. Если же вы решили связаться со своим репозиторием над EntityFramework, у вас выбора особого не остается — чуть что или новый репозиторий или новый метод в репозитории, потом к нему тесты, документация, и т.д.
По поводу EF уже абстракция повторюсь, существует не только EF. Посмотрите хотя бы на пример. Если вы на 100% уверены, что вашему проекту не потребуется что-то другое и знаете, что его ждет дальше — прекрасно, можно все упростить и использовать напрямую DbContext и linq-запросы в контроллерах.
Я на 100% уверен что если что-то такое произойдет, что потребует отказаться от EF, то это не обойдется простым написанием новых репозиториев. Можно конечно написать совершенную изоляцию слоя данных, но а) правильную изоляцию сделать сложно и довольно затратно; б) эффективность и производительность будет хуже. Так что это компромисс, кому что лучше ).DmitrySikorsky
13.10.2016 13:27Нет, большой разницы между выполнением SQL-запросов и Linq-запросов прямо в контроллере нет. Конечно, это не так жестко, но это все-равно усложняет командную разработку, сопровождение, поиск и исправление ошибок, изменение логики (т.к. обычно куски кода просто копируют а уже потом выделяют в отдельные методы, «если заработает»).
Насчет выноса в приватные методы класса (контроллера, например) чего-то для загрузки данных из бд — даже не будут комментировать.
В целом, вы правы. Есть «куча способов разрулить такие ситуации» и тут как раз описан один из них.
Bonart
13.10.2016 09:42Service Locator, Protocol, Method Injection — просто сборник антипаттернов какой-то.
В качестве вишенки на торте — протекающая абстракция в виде наследования от DbContext.
И чего только люди ни придумают, лишь бы IQueryable не реализовывать.DmitrySikorsky
13.10.2016 10:22Выше уже ответил на ваш комментарий. Сейчас не понимаю до конца, что вы имеете в виду. Будет здорово, если сможете более детально описать, в чем именно состоит недостаток подхода по-вашему и как избежать этих недостатков, сохранив слабую связанность системы.

myx
13.10.2016 18:00Как минимум, создав IStorage вы реализовали паттерн Service Locator. Который является анти паттерном, потому что теперь любой контроллер будет получать доступ ко всем репозиториям, а не только к выбранным. Это отличный способ создать контроллеры, которые будут делать слишком много работы.
Еще и реализовали как-то странно. Зачем там рефлексия с активатором, когда можно просто сделать new T()?DmitrySikorsky
13.10.2016 18:13Я сделал так для упрощения. Можно было бы иметь свойства для получения каждого репозитория, но чтобы не добавлять их вручную можно просто запрашивать по интерфейсу, т. к. в сборке все-равно не будет неподходящих реализаций, к которым не должно быть доступа.
myx
13.10.2016 18:17да, с new T я ступил. Но все это конечно нужно было делать через DI. И без IStorage и всего того, о чем справедливо написал Bonart ниже.
Bonart
13.10.2016 18:01Давайте подробно по всему примеру:
- Класс модели таковым не является — это не модель, а DTO, чье главное свойство — автоматическая (де-) сериализация. Для ORM удобно, для бизнес-логики — ужасно.
- IStorageContext — маркерный интерфейс, никому на самом деле не нужен. Вся реальная работа все равно идет с его наследниками.
- IStorage — большой привет от антипаттерна ServiceLocator. До рантайма никак не понять, к каким же именно репозиториям есть доступ. С методом Save непонятно, сколько раз его можно вызывать и неясно, что происходит после неудачной попытки записи.
- IRepository — маркерный интерфейс, да еще и с Metod Injection. Непонятно, что будет делать реализация до первого вызова SetStorage, что прозойдет после второго и последующего вызовов, как понять, что вызов SetStorage уже выполнен и т.п. Протокол во всей красе.
- IItemRepository — интерфейс не обобщенный. Это что же, для каждой простой модели свой интерфейс репозитория определять?
- Storage — ручной перебор типов через отражение, плюс антипаттерн Constrained Construction — конструктор репозитория не должен иметь параметров. Вместо одной реализации на оба варианта предлагается почти полная копипаста.
Нормально спроектированных классов и интерфейсов нет ни одного. И это учебный пример в блоге компании Микрософт.

ZOXEXIVO
13.10.2016 09:54IQueryable решит ваши проблемы?
Наверное, круто, его везде прокидывать не задумываясь, открыт ли ваш контекст или нет, да?DmitrySikorsky
13.10.2016 10:07+1Не понимаю, при чем тут IQueryable. Если вы о методе All, то это просто пример, суть ведь не в этом методе. Я написал там, что в реальности там бы были методы Create, Edit, Delete и так далее. Методы для выборки одного и многих элементов по различным параметрам.
indestructable
Не претендую на абсолютную истину, но выглядит, как по мне, немного избыточно.
IStorage, и почему бы не внедрить его через конструктор.В чем вообще цель выделения
IStorage, если все гвоздями прибито к Entity Framework?Тут недавно был по большей части терминологический спор о том, в чем состоят обязанности репозитория. Не хочется его начинать снова, но я считаю, что в "стандартном" трехзвенном приложении нужны минимально следующие абстракции:
DenomikoN
Если посмотреть на EF со стороны, то DbContext — это и есть UnitOfWork, а DataSet — репозитории. В проекте «три страницы» их более чем достаточно.
SilverFerrum
Согласен. Когда-то EF таким не являлся и был разработан этот шаблон. Сейчас он устаревший, статья вводит в заблуждение начинающих разработчиков.
DmitrySikorsky
Дело в том, что такой подход дает универсальность. Не всегда в качестве хранилища используется база данных и не всегда в качестве ORM используется EF. А использование дополнительного слоя репозиториев позволят скрыть за ними реализацию тех или иных методов. Например, если есть метод фильтрации объектов, то гораздо удобнее использовать метод вроде GetFiltered(query), чем в каждом месте, где это необходимо, писать Linq-выражения. Кроме того, с точки зрения командной разработки такой подход позволяет разработчику, например, какого-то контроллера вообще не знать, как именно производится фильтрация объектов, просто вызывая один метод, который написан кем-то другим. Это важно и удобно.
Bonart
… и на очередном добавляемом методе (хорошо если третьем, хуже если двадцатом) разработчика начинает брать сомнение. Ибо типовые LINQ-выражения легко поместить в метод расширения, а с традиционным репозитарием этот номер не пройдет.
DmitrySikorsky
Уточните, пожалуйста, в метод расширения чего именно? Вы имеете в виду расширить перечисление методом для выборки, например, популярных товаров?
Bonart
В том числе и так.
Главная проблема репозиториев — они очень плохо ложатся на реляционную модель.
LINQ — вариант принципиально более гибкий.
DmitrySikorsky
Если мы будем расширять общие интерфейсы методами, которые относятся к различным сущностям, получим в итоге мусорку, которую невозможно будет сопровождать и использовать. Представьте, что у вас будет 100 методов расширения, понадобится вставлять название сущности в их имена и так далее. Короче, это не вариант. Если честно, я пытаюсь понять, в чем недостаток, например, репозиториев, чтобы изменить свой подход, если он действительно не оптимален. Но пока что я к этому не пришел. Во множестве проектов не было проблем с реляционной моделью, даже наоборот. Сложные вещи, действительно, необходимо решать отдельными решениями, но так в любом случае будет, мне кажется. Приведите, пожалуйста, если можно, какой-то пример удачной реализации, чтобы понят вашу идею.
chumakov-ilya
Представьте, что у вас большой проект и в репозитории 100 методов вида: All, AllActive, AllActivePerCustomer, AllActivePerCustomerByDate… это не мусорка? Один из вариантов убрать дублирование кода из полученного репозитория — построить запросы через методы-расширения вида IQueryable Active(this IQueryable queriable), о которых, внезапно — упоминал Bonart. Следующий шаг — выкинуть методы репозитория за ненадобностью и строить запросы в сервисном слое из типовых методов-расширений.
Вы, конечно же, можете возразить — вместо 100 методов в репозитории будет один метод GetFiltered(query). Что есть query? Если IQueryable — то см. выше. А если писать запросы на самодельном DSL, то есть вероятность, что для большого проекта в итоге получится дорогая и ограниченная… надстройка над LINQ.
DmitrySikorsky
В репозитории находятся только те методы, которые относятся к конкретной сущности, поэтому вряд ли их будет часто слишком много. Обычно около 5-10 в моих проектах в среднем. Но даже если их будет 100 в этом нет ничего страшного, если это действительно необходимые и полезные методы. Если вы будете строить ваши запросы как методы расширения на IQueryable то придется при необходимости реализовывать этот интерфейс для различных источников данных, т.к. не всегда можно обойтись EF, как я уже писал не раз. В общем, не вижу смысла и особой разницы. Просто нужно выбирать подход исходя из задачи.
Что касается GetFiltered, то это пример, просто подразумевается функция, которая отбирает отфильтрованные объекты по одному или нескольким параметрам.
Bonart
Это та самая неподдерживаемая мусорка. А потом будет внезапный сюрприз в виде произвольных отчетов и все равно придется делать IQueryable.
DmitrySikorsky
Нет, это не мусорка, а понятный класс с большим количеством методов. Они все сосредоточены в одном месте, поэтому их легко поддерживать, сопровождать и документировать. Если у вас реально возникнет необходимость в 100 методах в репозитории, думаю, это будет не самая сложная часть приложения. И все-равно правильнее иметь 100 методов в одном месте, чем размазанную логику взаимодействия с БД.
В реальности бывают разные ситуации. Например, «отчеты» вообще часто генерируются на стороне сервера и затем представляются в виде «фейковых» сущностей из вьюх баз данных или как-то еще. Суть не в этом.
Bonart
кратко именуемый "неподдерживаемая мусорка".
вместо единственной реализации IQueryable
DmitrySikorsky
согласитесь, отсутствие 100 методов в одном классе не означает, что нигде не будет кода, который должен был бы там размещаться, раз уж у нас есть эти 100 сценариев. правильно? т. е. этот код все-равно будет. либо это будет 100 методов расширения, либо это будет непосредственное использование конструкций Where прямо в коде где-то минимум 100 раз, но скорее всего это будет запутанная и неподдерживаемая смесь этих двух подходов. словом, плохо. но я не навязываю вам свое мнение.
Bonart
Какая еще мусорка?
Методы расширения не меняют контракт расширяемого интерфейса, поэтому их может быть ровно столько сколько нужно.
DmitrySikorsky
Для меня важно, чтобы интерфейс доступа к данным предоставлял ровно тот набор возможностей, который необходим, и ничего больше. Если над реализацией взаимодействия с БД работает один человек, а использует его другой человек, то у другого человека не будет возможности и соблазна вместо метода расширения (не зная, что он существует или же что он подходит в данном случае) писать непосредственно запросы на Linq либо добавлять свои методы расширения. Также важно иметь все взаимодействие на одном уровне. Имею в виду, чтобы не было такого, что часть метода напрямую вызывается на DbSet, часть — расширения Linq, а еще часть — ваши расширения. По сути, я использовал бы ваш подход только для чего-то простого.
Bonart
Это ничего, что ваш вариант на каждый чих требует дергать разработчика, реализующего взаимодействие с БД?
Ничего, что комбинировать результат двух методов репозитория снаружи нереально?
Ничего, что любая дополнительная фильтрация, требуемая клиентом, будет не в базе, а в памяти?
DmitrySikorsky
В смысле «дергать» разработчика? Есть класс, есть описанные методы. Если нужно что-то добавить уже не в процессе планирования задача на команду, то да, дергать разработчика, но это уже из другой области.
Тут смысл как раз в том, чтобы избежать фильтрации в памяти. Чтобы все было за кулисами, за репозиториями. В этом и суть шаблона. Нужны отфильтрованные, разбитые на страницы данные? Пожалуйста. Нужен объект по идентификатору? Пожалуйста. Нужно создать, удалить объект? Пожалуйста. А с целью оптимизации для каждой реализации репозитория будет собственный подход к каждому методу. Где-то достаточно Where-запроса, а где-то нужно выполнит хранимую процедуру или же обратиться ко вьюхе в базе или еще миллион моментов, но все это вас, как разраотчика, например, контроллера, не волнует и не касается.
Bonart
Их очень легко оказывается недостаточно для какой-нибудь очередной задачи. С IQueryable таких проблем практически нет.
В том-то и проблема, что для реляционной модели характерны весьма разнообразные запросы с кучей фильтраций и соединений. А в традиционном репозитории шаг влево-шаг вправо от голого CRUD — и привет.
DmitrySikorsky
Приведите пример, пожалуйста. Пока что выглядит неубедительно.
indestructable
Таких проблем нет, есть другие — размазанный и дублированный код доступа к данным, который расположен в не предназначенном для него слое, который невозможно протестировать и инкапсулировать, например, в базе, при необходимости.
Ну, в общем-то, в этом и смысл репозитория, так-то можно и SQL писать в коде, что, в определенном приближении, равноценно LINQ запросам в бизнес-логике.
Bonart
С чего вдруг размазанный и дублированный? Методы расширения помогут, инкапсулировать в базе это не нужно.
Гораздо серьезнее другая проблема — использование ORM DTO в качестве объектов бизнес-логики, и реальная граница пролегает не по IQueryable, а там где DTO приходится мапить на бизнес, нередко вручную.
Что и делает данный паттерн сильно специфичным. Я иногда к нему прибегаю (в тех случаях, когда набор соединений и фильтраций заведомо ограничен, а требования по производительности велики), но реализую с полной изоляцией — никаких DTO в интерфейсах, чтение и модификация раздельно.
Неравноценно от слова совсем. "Определенное приближение" не сработало ни разу за всю мою карьеру. Конечно, IQueryable требует иного обращения чем IEnumerable, но это справедливо и для IObservable, а уж про Sprache вообще молчу.
И, разумеется, никакого LINQ over IQueryable в бизнес-логике нет по очень простой причине — IQueryable работает с DTO, а не с бизнес-объектами.
RouR
Вы точно в курсе что связка из IQueryable и linq может конвертироваться напрямую в sql запрос со всеми необходимыми where, order by, group by?? И никакой фильтрации в памяти приложения не будет, т.к. эти займётся сама БД.
Using IQueryable with Linq
DenomikoN
Скажите пожалуйста, как бы вы решили такую проблему: у вас есть несколько типов сущностей — допустим разработчики и таски. Вам для главной страницы нужно выбрать всех разработчиков и их активные таски.
DmitrySikorsky
2 варианта:
1. Выбрать всех разработчиков с помощью репозитория разработчиков и затем выгружать их таски отдельными запросами с помощью репозитория тасок, но это неэффективно.
2. Выбрать всех разработчиков вместе с их тасками одним запросом, если это поддерживается хранилищем (если не поддерживается (например, мы работаем с JSON API) — первый вариант). Т. е. мы обращаемся к репозиторию разработчиков и он возвращает разработчиков + некий граф объектов при необходимости в виде свойств разработчиков (в контексте EF — свойств навигации).
DmitrySikorsky
Забыл ответить. По моему мнению репозиторий должен возвращать IEnumerable, т. к. подразумевается, что это финальный запрос, т. к. в этом состоит суть репозитория. Хотя для упрощения можно вернуть IQueryable и где-то в контроллерах использовать Where-запросы как лазейку для лени, но это плохо и усложняет код.
DmitrySikorsky
Совершенно верно, я согласен. Но было бы неправильным делать в качестве примера огромный проект только для того, чтобы продемонстрировать, что подход вряд ли стоит использовать в проектах на 3 страницы. Эти шаблоны очень удобно применять когда есть вероятность использования различных хранилищ, для тестирования и так далее, когда даже наперед неизвестно, как требования будут изменяться дальше и хочется достигнуть минимальной связанности системы, чтобы можно было сопровождать ее максимально просто.
DmitrySikorsky
Попробую ответить по порядку.
1. Т. к. мы реализуем шаблон Единица работы, точкой входа у нас все-таки должен быть соответствующий объект, который существует в единственном экземпляре в контексте одного запроса. Теоретически можно инжектить репозитории и вообще все что угодно, но какой смысл? Инжектить десятки различных типов, затем по отдельности их все запрашивать. А где выполнять сохранение? А как иметь единый контекст? Это все решает UoW.
2. Интерфейс репозитория не знает об IStorage. Он знает только о контексте хранилища (о самом «представлении» базы данных, например, что бы это ни было в конкретном случае), т. к. в противном случае ему просто не с чем было бы работать.
Насчет выделения IStorage и EF. Я не согласен, что все прибито к EF. В простых случаях, где просто нужно сохранить немного объектов где-нибудь, можно всегда обходиться EF. Но в чем-то побольше источниками данных вполне могут выступать и HTTP-сервисы, и файловая система и так далее. Если мы завяжем реализацию на EF, придется потом все переписывать, если возникнет необходимость в чем-то еще. Вот и все.
Насчет обязанности репозиториев. Обязанностью репозитория является агрегация всех методов для манипуляции с данными определенного типа (одной сущностью) и сокрытие особенностей реализации этих манипуляций. Иногда есть смысл разделять CRUD-операции и операции предметной области на репозитории и сервисы, но чаще последние являются избыточными и я помещаю все на один уровень — уровень репозиториев. Т.е. необходимо вам получить объект по идентификатору или же набор объектов по определенным признакам (например, 10 самых популярных товаров в интернет-магазине за вчера) — все это делается одним методом одного репозитория. Т.е. запросы одного уровня.
Насчет абстракций в трехзвенном приложении. В общем-то я с вами согласен. За исключением того, что часто нет смысла в разделении репозиториев и сервисов.
indestructable
Разделение на репозитории и сервисы нужно только в случае, если есть бизнес-логика.
Я идею теперь понял, забыл, что в названии статьи упоминался unit of work.
А где метод Save вызывается?
Вообще я считаю, что юнит ов ворк не самый удобный паттерн для приложений с бизнес логикой. Очень легко получить неконсистентность данных в памяти и в хранилище. Часто приходится вызывать сохранение несколько раз, транзакционность тоже через отдельные сохранения. После сбоя сохранения контекст может быть непригоден для использования.
DmitrySikorsky
В нашем примере, к сожалению, нигде. А вообще — я делаю примерно так.
Согласен, что в каждом случае необходимо исходить из задачи.
RouR
Считаю дурным тоном в mvc-контроллере работать напрямую с репозиторием. Нужен промежуточный слой, внутри которого будет бизнесс-логика, логика кеэширования и инвалидации кэша и т.п.