
По мотивам недавних обсуждений здесь захотелось более широко взглянуть на вопрос о том, кто больше кушает — новомодные хипстерские лямбды или старые проверенные анонимные классы. Давайте устроим словесную перепалку между ними и посмотрим, кто выиграет. Как с любым добротным холиваром, даже если не удастся выяснить победителя, можно узнать много нового для себя.
Первый раунд. Пространство на экране.
Лямбда-кун: хе. Хе-хе-хе. Нет, это несерьёзно. Ну как может сравниться вот это убожество:
Runnable r = new Runnable() {
@Override
public void run() {
System.out.println("Hello!");
}
};С вот этой красотой:
Runnable r = () -> System.out.println("Hello!");Анон-сан: ну-ну, молодой человек, незачем так выражаться. В наши дни никого не волнует, что там в файле на самом деле. Достаточно взять хорошую IDE и разница уже практически незаметна.
Вот как выглядит анонимный класс:
А вот лямбда: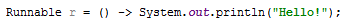
Анон-сан: при этом меня можно развернуть и посмотреть, что я такое на самом деле, а вот что вы такое на самом деле — большая загадка.
Второй раунд. Пространство на диске.
Лямбда-кун: кх-хм… Нет, это, конечно, нечестно. Ну ладно. Но на диске-то я занимаю меньше. Возьмём простой класс:
public class Test {
Runnable r = () -> {};
}А с тобой будет вот что:
public class Test {
Runnable r = new Runnable() {
@Override
public void run() {
}
};
}52 байта против 126! Каково, а?
Анон-сан: ну с байтами исходников я соглашусь, хотя кого они волнуют. А если скомпилировать?
Лямбда-кун: естественно, я выиграю! Из меня получится один файл, а из тебя вообще два! В двух файлах вдвое больше заголовков и всякой метаинформации.
Анон-сан: не спешите, молодой человек, давайте проверим. Запускаем javac Test.java для обоих версий. Что мы видим? Вариант с анонимным классом генерирует Test.class (308 байт) и Test$1.class (377 байт), всего 685 байт, а вариант с лямбдой генерирует только Test.class, зато он весит 783 байта. Почти сто байтов оверхед — не дороговато ли за синтаксический сахар?
Лямбда-кун: эээ, как это получилось? Не могло быть, я же легковеснее! Ну-ка, а с отладочной информацией сколько будет? Все же с ней компилируют.
Анон-сан: давайте попробуем: javac -g Test.java. Лямбда — 838 байт, анонимный класс — 825 байт. Так разница меньше, но всё же хвалёной легковесности не видно. Вы забываете, что на каждый вызов лямбды создаётся развесистая запись в Bootsrtap methods, которая анонимным классам не нужна.
Лямбда-кун: стой, стой. Я всё понял. Это не сама запись развесистая, а константы, которые попадают в пул констант. Всякие штуки вроде java/lang/invoke/LambdaMetafactory.metafactory:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;. Да, они длинные, но переиспользуются, если лямбд больше одной. Ну-ка, добавим вторую:
public class Test {
Runnable r = () -> {};
Runnable r2 = () -> {};
}Лямбда-кун: вооот, уже я выигрываю! С отладочной информацией 957 байт, а если заменить на анонимные классы, будет ажно 1351 байт в трёх файлах. Даже без отладочной информации я выигрываю. А ведь могут и другие константы эффективно переиспользоваться! Любые поля, методы, классы, используемые внутри лямбд. Если они используются в нескольких лямбдах или в лямбде и вокруг неё, то схлопнутся в одну константу. А с анонимными классами в каждом будет копия. То-то же!
Третий раунд. Классы в рантайме.
Анон-сан: видимо, тут мне придётся уступить. Если лямбд много, то вы действительно компактнее в скомпилированном виде. Однако более интересно, что происходит в рантайме, в памяти виртуальной машины. Пусть для тебя нету анонимного класса на диске, но точно такой же класс, а то и больший, будет сгенерирован при запуске и сожрёт все те же ресурсы.
Лямбда-кун: а вот и не те же! Я же легковеснее! Там наверняка сгенерируется маленький компактный классик, который не содержит всякой ненужной ерунды. Да и как ты это проверишь? Оно ж всё в рантайме в памяти!
Анон-сан: а вот этого вам стыдно не знать. Должны же вас как-то отлаживать разработчики. Есть недокументированное системное свойство jdk.internal.lambda.dumpProxyClasses, с помощью которого можно указать, в какой каталог скидывать сгенерированные рантайм-представления лямбд. Запускаем приложение с -Djdk.internal.lambda.dumpProxyClasses=. и всё видим.
Лямбда-кун: ага, только пока лямбду ни разу не используешь, рантайм-представление не будет сгенерировано вообще, а анонимные классы существуют всегда, даже если ни разу не пригодились!
Анон-сан: нет никакой разницы. Даже наоборот, разница не в вашу пользу. Анонимный класс существует всегда на диске, но он не будет загружен в память, пока не используется. Рантайм-представление лямбды, конечно, сгенерировано не будет, однако её тело в виде приватного синтетического метода загружается фактически вместе с классом, в котором она объявлена. Даже если тело ни разу не используется, оно память отъест. Впрочем, к этому вопросу вернёмся позднее. Посмотрим сперва, что происходит, если лямбда используется. Для этого нам потребуется немного модифицировать программу:
public class Test {
static Runnable r = () -> {};
public static void main(String[] args) { }
}Компилируем (хорошо, пусть с отладочной информацией), запускаем java -Djdk.internal.lambda.dumpProxyClasses=. Test и видим: лямбда создала класс Test$$Lambda$1.class, который весит 308 байт. Это помимо основного класса Test.class, который весит 1004 байта. Заменяем лямбду на аналогичный анонимный класс, имеем 508+399 байт в двух классах сразу, но в рантайме ничего не создаётся. Много вы всё-таки кушаете, молодой человек, на 405 байт больше меня.
Лямбда-кун: ну мы же договорились, что одной лямбдой меряться нечестно. Давай добавим вторую.
Анон-сан: да хоть десять. Дописываем static Runnable r1 = () -> {}; и так далее. Получается 11 классов, с лямбдами 5174 байта, а с анонимными — 5059 байт. Неспеша догоняю я вас, конечно, но, согласитесь, уж 10 лямбд не в каждом классе есть. Где-то после 14-го анонимного класса только вы начинаете кушать меньше.
Лямбда-кун: так-так. А давай-ка эти все лямбды поместим прямо в метод main(). Согласись, нечасто они в статических полях лежат, нэ?
public class Test {
public static void main(String[] args) {
Runnable r = new Runnable() {public void run() {}};
Runnable r1 = new Runnable() {public void run() {}};
Runnable r2 = new Runnable() {public void run() {}};
...
}
}Анон-сан: хм, а в чём разница?
Лямбда-кун: а скомпилируй, и увидишь. У меня-то как раз разницы нет, сгенерированные в рантайме классы весят столько же. А у тебя каждый байт на 40 потолстел. Теперь на десяти лямбдах я кушаю меньше (5290 байт против 4995). Уже даже на шести я тебя опережаю!
Анон-сан: ах, вон оно что. Для отладки в каждый анонимный класс теперь добавлена строчка EnclosingMethod: Test.main, что, конечно, съедает дополнительное место. Эх, зря я на отладочную информацию согласился.
Лямбда-кун: эта запись добавляется даже при полностью отключенной отладочной информации (javac -g:none). Этот атрибут обязан быть по спецификации вне зависимости от отладки. А моё рантайм-представление формально не является анонимным классом, и ему этот атрибут не нужен. Тебе ещё повезло, что имя метода main такое короткое. Если анонимные классы в методе с длинным названием, каждый будет отъедать дополнительно пропорционально его длине!
Анон-сан: по-моему, наша игра уже перетекает в нечестную плоскость. Так что вот, с вашего позволения, ответный удар: замыкание на переменных. Принимаю ваше условие и остаюсь внутри метода. Но захватим-ка переменную:
import java.util.function.IntSupplier;
public class Test {
public static void main(String[] args) {
int i = 0;
IntSupplier s = () -> i;
IntSupplier s1 = () -> i;
IntSupplier s2 = () -> i;
...
}
}Ну и для анонимных классов заменим на new IntSupplier() {public int getAsInt() {return i;}}. Как вы думаете, сколько теперь потребуется лямбд, чтобы победить анонимные классы?
Лямбда-кун: ну тут-то разницы быть не должно. У тебя компилятором генерируется синтетическое поле и конструктор с одним параметром, который это поле инициализирует. У меня примерно то же самое будет создано в рантайме. Какой-то примерно такой класс генерируется и для тебя, и для меня:
class Test$1 implements IntSupplier {
private final int val$i;
Test$1(int i) { val$i = i; }
@Override int getAsInt() { return val$i; }
}Анон-сан: такой, да не такой. Пробуем. Одна лямбда: 1493 байта, один анонимный класс: 1006 байт. Десять лямбд: 6803 байта, десять анонимных классов: 6039 байт. Двадцать лямбд: 12743 байта, двадцать анонимных классов: 11669 байт. Разрыв постоянно увеличивается! Тут хоть тысяча лямбд, а вам меня не догнать.
Лямбда-кун: ээ… Так. Ну-ка, декомпилируем. Это ещё что за ерунда? Какой-то фабричный метод? Глупость какая-то. Помимо конструктора мне ещё зачем-то добавляют метод вида static IntSupplier get$Lambda(int i) { return new Test$1(i);}. Бред какой-то, зачем?
Анон-сан: не бред, а производительность. Когда-то в незапамятные времена Walrus исправил скорость инстанциирования лямбд в интерпретаторе (JDK-8023984). Фабричный метод оказался быстрее, чем конструктор. Заметьте, молодой человек, со мной таких странных проблем не возникает, у меня всё быстро и так.
Лямбда-кун: вот же глупость-то! Нет чтобы допилить свои методхэндлы до ума, они костыли лепят… Интересно, может уже с тех пор допилили и этот метод не нужен стал?..
Анон-сан: как знать, как знать...
Лямбда-кун: однако мой ход! Принимаю твоё условие и захват переменной, но давай-ка не IntSupplier, а Supplier<Integer>:
import java.util.function.Supplier;
public class Test {
public static void main(String[] args) {
int i = 0;
Supplier<Integer> s = new Supplier<Integer>() {public Integer get() {return i;}};
Supplier<Integer> s1 = new Supplier<Integer>() {public Integer get() {return i;}};
...
}
}Ну а лямбда останется как раньше: Supplier<Integer> s = () -> i.
Анон-сан: хм… не вижу, где вы хотите меня околпачить… А, ну да, добавится запись типа Signature: Ljava/lang/Object;Ljava/util/function/Supplier<Ljava/lang/Integer;>; Это чтобы всякий reflection работал правильно и s.getClass().getGenericInterfaces() возвращал именно Supplier<Integer>, а не просто Supplier. А разве вам это не надо?
Лямбда-кун: выходит, что нет. Лямбде позволительно, чтобы для неё это не работало!
Анон-сан: однако хотя эта строчка отъест место, не верится мне, что сильно много против вашего фабричного метода.
Лямбда-кун: а ты не верь, а проверь. Теперь всего три лямбды кушают меньше, чем три анонимных класса (2963 против 3034 байта) и с каждой новой строчкой ты всё больше проигрываешь! Каждый анонимный класс кушает на 270 байт больше соответствующей лямбды. И это с учётом того, что у меня лишний фабричный метод!
Анон-сан: не может быть. Что же там ещё напихал-то компилятор? Ааа, как же я мог забыть. Бридж-метод. Так как в коде у нас Integer get() {}, а в интерфейсе после erasure — Object get(), нужен ещё мостик, который при вызове интерфейса перенаправит к Integer get(). А вам что ли мостик не нужен?
Лямбда-кун: нет, и мостик нам не нужен. Точнее наоборот, он нам нужен всегда, Object get() — это мостик, а реальная реализация в основном классе в синтетическом методе вида lambda$main$1. Но мостик всегда один, в случае с генериками второй мостик не нужен. А вот тебе потребовался и тут стало понятно, что мы всё-таки на самом деле легковеснее!
Анон-сан: вообще, конечно, наши тесты не сильно надёжные. Неизвестно, насколько на самом деле коррелирует размер класс-файлов и расход памяти в рантайме. Но на сегодня беседа и так затянулась, так что отложим этот вопрос на следующий раз.
Комментарии (35)


Regis
30.10.2016 16:16+4Спасибо за разбор, было довольно интересно. Правда сам предмет спора несколько сомнителен.
Во-первых обычно больше интересует производительность, а не размер вспомогательных объектов в байтах (хотя да, бывают кейсы, когда это важно).
Во-вторых все эти байтовые размеры в принципе могут поменяться с выходом новой версии компилятора.
В-третьих если говорить про расход памяти в рантайме, то нужно говорить про размер генерируемого native-кода — ведь совсем не обязательно, что больший по размеру байткод даст больший по по размеру native-код.
lany
30.10.2016 16:51+2Да, это всё важные вопросы, до них просто не успел дойти разговор :-) Если не поленюсь, будет продолжение спора. Ну и смысл не в том, чтобы понять, кто прав, а в том, чтобы поковыряться, как что внутри работает.

koeshiro
31.10.2016 09:40-2Я не ас. И не мастер. Но хотел бы напомнить про один важный момент по поводу первого «Но».
Многие программы в первую очередь передаются каким образом? Правильно «Интранетами». И есть не мало случаев при которых вес программы имеет значимую важность. К примеру вся мобильная разработка где получение программ 99.9% через интернет.
Сервера — история похожая. (спорный вопрос ибо бывает что сервера слабоваты)Regis
02.11.2016 12:35Доля размера которую вы сэкономите таким образом — самое большее десятые доли процента от общего размера.
koeshiro
02.11.2016 12:42Всё же — лучше чем ничего. Не так ли?
Тем более при этом получаем «Синтаксический сахар».
//-----------
Вообще. Я не утверждаю что это самый важный момент. Но мне он кажется важным.
Есть моменты в которых это может сыграть некоторую роль.
Не утверждаю что это нечто очень важное. (В вселенском масштабе)
Но говорю что учитывать это тоже может быть полезно.
Я вполне понимаю все те минусы что «злобные хатскеры поставили не верующему» (доля шутки),
но всё же считаю этот момент полезным.

akzhan
30.10.2016 21:16-5А смысл в этой статье?
Ведь понятно, что использование лямбд в любом языке в первую очередь обусловлено синтаксическим сахаром для производительности разработчика, а не для производительности кода.

PashaPash
31.10.2016 03:01+3Не в любом. В C# лямбда компилируется или в анонимный метод (не просто работает похожим образом, а реально в него компилируется), или в Expression Tree — композит, который в рантайме можно отобразить в SQL / OData filter / что угодно. Так что C# лямбды притащены ради уменьшения дырки между абстракциями repository / query object и обычными коллекциями объектов в памяти.
lany
31.10.2016 05:28+2Будете ли вы использовать синтаксический сахар, зная, что ваша программа от этого станет в 10 раз медленнее?
zhengxi
30.10.2016 21:34+3Скала 2.11 компиляет в анонимные классы, скала 2.12 в лямбды.
На реальных проектах у 2.12 jar'ы получаются в два-четыре раза меньше.
Но нагрузка CPU чуть больше (в пределах +10%).


sah4ez32
31.10.2016 03:22Спасибо за статью! Обязательно ждем продолжения, в такой же простой и легкой для восприятия форме!
ПС
Извините за бестактный вопрос, но как начинающему java разработчику, после ознакомления с вашим выступлением на java 8 puzzler на jPoint 2016, стало интересно применение стримов, можно будет увидеть статью про них такого же характера? Тем более, что в одной из недавних статей ссылались на тикет с YouTrack об «отказе» использования стримов в коде.lany
31.10.2016 05:26+2А что стримы? Стримы хорошие, надо их использовать, чем больше, тем лучше :D
Тем более, что в одной из недавних статей ссылались на тикет с YouTrack об «отказе» использования стримов в коде.
Больше верьте слухам!

TheKnight
31.10.2016 10:41lany: Видимо подразумевается ваш тикет о преобразовании stream-style кода в обычные циклы. На данный момент есть только преобразование из циклов в стримы.
sah4ez32: Стримы штука хорошая. Главное помнить правило отладки — отладка программы вдвое сложнее чем ее написание. Иногда стоит пожалеть своих коллег, которым придется смотреть код.lany
31.10.2016 10:57+1Ну если встать на цикл вида
for(Person person : people) {...}, IDEA предлагает превратить его в indexed loop. Это ж не означает, что надо отказываться от for-each циклов :-)
Jamefrus
31.10.2016 03:22Интересно, буду рад продолжению. Было бы неплохо оценить производительность кода со Stream API на анон. классах и лямбдах.
P.S. так как использую Kotlin, который в некоторых случаях использует анонимные классы.

leventov
31.10.2016 06:00+3Вот из-за таких авторов как lany, которые пишут только на русском, потом выясняется, что средняя компетентность среди русскоязычных Java-разработчиков выше, чем не русскоязычных.
avost
31.10.2016 09:32+4Ну, так пусть переводят себе. Чай не баре :).
Мы, вот, как-то не гнушаемся ни переводами, ни язык учить :)

foal
01.11.2016 05:01+2Спасибо! Полезненько… :)
Вот только не совсем корректно с местом на диске вышло, в общем случае 2 файла по 800 байт займут больше места чем один, но размером в 2000 байт.lany
01.11.2016 05:02Да, согласен. Логичнее было зажать в джарик и посмотреть его размер. Всё равно россыпь класс-файлов обычно никто не использует.

webkumo
02.11.2016 15:00NTFS же вроде умеет мелкие файлы в один кластер пихать? Или я что-то путаю?
foal
03.11.2016 00:48Ну я и написал — в общем случае. А NTFS может маленькие файлы в прямо в MFT держать, но, например, у меня это уже не работает для 800 байтового файла.
Да и про джарник — из двух файлов по 800 байт jar получается больший, чем из одного 2000 байтового.webkumo
03.11.2016 13:02Проверяли или умозрительное заключение? И при каком уровне сжатия?
foal
03.11.2016 13:58Какие мы строгие :) Скажем так, опыт и «умозрительное заключение» позволило мне это предположить, а эксперимент подтвердил это.
jar cvf a.jar AbstractManagerImpl.class InitializationException.class
a.jar — 1292
AbstractManagerImpl.class — 652
InitializationException.class — 609
jar cvf b.jar PlanetManager.class
b.jar — 1094
PlanetManager.class — 2652
Классы выбрал случайно, что бы по размеру подходили.webkumo
03.11.2016 18:51+1С одной стороны — интересный результат, с другой — это явно не чистый эксперимент — в данном случае класс PlanetManager явно отличается от классов AbstractManagerImpl и InitializationException.
Интересно было бы всё же, по аналогии со статьёй — один класс с лямбдой или два класса (с анонимным) реализующих один и тот же функционал сравнить — это было бы более показательно…foal
03.11.2016 21:13+1Угу, Но что-то мне подсказывает, что результат будет такой же — jar не использует solid сжатие, а расходы на служебную информацию будут примерно одинаковы.

slesar
01.11.2016 15:50А вот немного аналитики по теме от Джейка Вортона https://gist.github.com/JakeWharton/ea4982e491262639884e
Sirikid
Как показал «105 выпуск», объект анонимного класса лучше объект чем лямбда.
Спасибо вам за подробный разбор генерируемого байткода, осталось выяснить что будет быстрее :)
lany
Если не поленюсь, будет продолжение.
ukt
Может про компараторы расскажете в новой статье, если будет время, разумеется?
SirEdvin
Лямбды быстрее анонимных классов за счет того, что лямбды работают на invokedynamic, а анонимные классы через invokestatic, который несколько медленнее.
pjBooms
Во первых, лямбды не работают на invokedynamic, а создаются через invokedynamic, а объекты анонимных классов через new AClass$1(), то есть просто new и вызов конструктора. Первое создание лямбды много дороже, чем создание экземпляра анонимного класса, потому что нужно еще породить в рантайме анонимный класс завертку для лямбды, загрузить его, а только потом создать экземпляр этого порожденного класса. В случае анонимного класса, нужно только загрузить класс и создать экземпляр (тут кстати надо еще мерить, что быстрее прочитать готовый класс с диска или породить его на лету). Во второй же раз, если у лямбды не было контекста, то лямбда-объект автоматом закэшируется в объекте CallSite инструкции invokedynamic, то есть новых объектов создаваться не будет. В случае анонимного класса, каждый раз будет создаваться новый объект, если вы сами его руками не закэшируете. Если у лямбды есть контекст, то в обоих случаях нужно создавать новый объект, и создавать его через invokedynamic будет несколько дороже, чем в случае анонимного класса (хотя со временем, после оптимизаций, может оказаться один фиг).
Что касается invokestatic vs. invokedynamic, то invokestatic самая быстрая из всех invoke* инструкций байткода, потому что не требуется никого динамического диспатча (target всегда известен) и в отличии от invokespecial, который тоже не требует динамического диспатча, не требуется передавать параметр this. Invokedynamic же в общем случае самая медленная из всех invoke* инструкций байткода, хотя она сильно зависит от методхэндла колсайта, который возвращает бутстрэп метод. Если он вернет константный колсайт invokestatic методхэндла, то после некоторых приплясываний JVM, породится идентичный код тому, как если бы вы сразу позвали метод через invokestatic.