
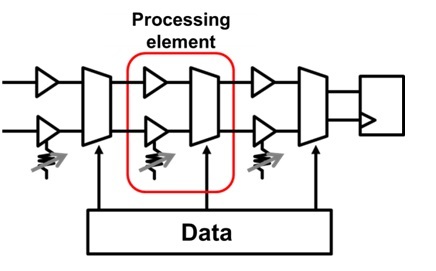
Японская компания Toshiba заявила о своем вкладе в развитие Интернета вещей и анализа больших данных. На этот раз она разработала нейроморфный процессор с очень низким энергопотреблением для нейронных сетей с временной задержкой (TDNN). Эта сеть состоит из большого количества модулей, в которых используется не цифровая, а аналоговая обработка данных.
Алгоритмы глубинного обучения требуют огромного числа вычислений. Их выполняют на процессорах с высокой производительностью, которые потребляют много энергии. Однако если мы хотим, чтобы эти алгоритмы работали в Интернете вещей, различных датчиках и смартфонах, нужны энергоэффективные микросхемы, которые могут выполнять большое число операций, потребляя при этом крайне мало энергии.
В чипе Toshiba применяется аналог временного интервала и методы смешанной обработки сигналов (TDAMS). Они позволяют уменьшить размеры нейроморфного процессора. Арифметические операции вроде сложения эффективно выполняются в TDAMS при помощи задержки времени цифрового сигнала, передающего логический элемент как аналоговый сигнал. Используя эту технику, процессор для глубинного изучения конструируется всего из трех логических элементов и одноразрядной памяти с полностью пространственно развернутой архитектурой. Японская компания создала прототип микросхемы с ячейками статической памяти (SRAM), успешно распознавший рукописный текст. Расход энергии на одну операцию составил 20,6 фемтоджоулей, что эквивалентно 46 триллионам операций в секунду с 1Вт потребляемой мощности. Результат оказался в 1/6 раз лучше, чем последнее достижение, продемонстрированное на International Solid-State Circuits Conference 2016.
В компьютерной архитектуре фон Неймана большая часть энергии потребляется при перемещении данных между памятью и процессором. Наиболее эффективный альтернативный способ сокращения «пути» передачи данных заключается в том, чтобы поместить огромное количество процессоров, каждый из которых будет обрабатывать только один элемент набора данных, который находится рядом. Когда входной сигнал преобразуется в выходной, точкам хранения данных присваивается определенный вес. Именно вес является тем параметром, который будет в автоматическом режиме управлять глубинным процессом обучения. Чем ближе точка будет к выходному сигналу, тем больше вес.
Архитектура имеет сходство с мозгом человека: сила связи между нейронами – весовой коэффициент, который встроен в синапсы (процессоры). Синаптические связи между нейронами имеют различную силу. Эта сила связи определяется выходной сигнал. Таким образом, синапс выполняет своего рода обработку. Эта архитектура привлекательна для разработчиков, но у нее есть один существенный недостаток: ее массовое производство требует большого количества арифметических схем, которые быстро становятся слишком большими.
Разумеется, это не первый нейроморфный процессор, который можно использовать в работе с искусственными нейросетями. Компании Qualcomm, IBM, Human Brain Project, KnuEdge Inc. и другие активно занимаются разработкой чипов, имитирующих работу человеческого мозга. В 2014 году компания IBM Research представила чип TrueNorth из миллиона цифровых нейронов и 256 миллионов синапсов, которые входят в состав 4096 синапсных ядер. Над этой разработкой шесть лет трудились сотрудники компании по заказу DARPA. Они не прошли даром: в 2011 году прототип состоял всего из 256 нейронов, а уже через три года насчитывал миллион. На демонстрации возможностей чип распознавал на видео с перекрестка автомобили, велосипедистов и пешеходов. Обычный ноутбук справился с этой задачей, обработав кадры в 100 раз медленнее и потребляя в 1000 раз больше энергии, чем микросхема IBM. C 2016 года чипы тестируются в Ливерморской национальной лаборатории. Исследователи пытаются выяснить, в какой области они окажутся наиболее эффективными.
Компания Qualcomm представила свой прототип процессора, имитирующего свойства человеческого мозга, на год раньше IBM – в 2013. Проект получил название Zeroth (“нулевой”). Создатели заявляли, что их процессор, размещенный в смартфонах, компьютерах, роботах и других устройствах, позволит им самообучаться в процессе работы. Первые чипы должны были появиться в 2014 году, однако этого не произошло. Вместо этого компания выпустила в 2015 году одноименную распознавательно-вычислительную платформу.
Другой пример – процессор KnuPath Hermosa от KnuEdge Inc.: 256 процессорных ядер, 64 программируемых модуля DMA, 72Мбайт встроенной памяти, 34 Ватта потребляемой мощности. В составе процессора 16 двунаправленных каналов ввода-вывода, что позволяет обеспечить пропускную способность подсистемы оперативной памяти до 320Гбит/с. Сейчас компания активно работает над созданием программного обеспечения, совместимого с нейроморфным процессором. Она уже выпустила программу KnuVerse, которая умеет распознавать и идентифицировать голос. В отличие от других голосовых помощников, KnuVerse может работать в шумной обстановке. Кроме того, разработчики программы решили многие проблемы, связанные с безопасностью. Разработка увидела свет еще пять лет назад, но использовалась только военными.
Что касается практического применения нейроморфных технологий, Samsung в своих смартфонах Galaxy S7 и S7 Edge использует чип FinFET Exynos 8890. Главная его особенность заключается в ядре М1, в который встроена нейросеть.
Комментарии (20)
napa3um
08.11.2016 17:45+3> Результат оказался в 1/6 раз лучше.
http://img0.joyreactor.cc/pics/post/full/Чилик-Комиксы-3134922.jpeg


Wedoslaw
08.11.2016 17:45USB ускоритель для нейросетей на aliexpress есть, называется CM1K.
rPman
09.11.2016 18:31не могу найти сравнения работы этих устройств с решениями на основе x86 процессоров и opencl gpu
судя по спецификации чипа они не содержат огромного количества нейронов (1к штук и 30к категорий классификатора, я так понял они програмируемые), единственный бонус — низкое энергопотребление, но при высокой цене оно нивелируется.
Khort
08.11.2016 19:16Есть еще другая недавняя разработка — в Манчестере сделали чип SPINNAKER, на базе которого собрали 6 шкафов двухметровой высоты с 500тыс цифровых нейронов. Каждый нейрон — ядро ARM996, на кристалле их уместилось 16 или 18, не помню.
Интересно, что все эти нейросети как известный М-драйв — вроде бы работают, но никто не понимает как :) нет законченной теории нейросетей, все строится на экспериментах.
Вот к примеру, этот аналоговый нейровычислитель явно экономнее и быстрее шкафа на ядрах АРМ, на много-много порядков. Тогда почему в Манчестере построили шкаф, а китацы сделали аналоговую схему??
Нейросетями занимаются уже лет 50, и до сих пор четко не доказана ни их эффективность, ни способ реализации. Все это очень занимательно, но околонаучно, имхо.napa3um
08.11.2016 20:21+2Нейросети — это не то, что собрал, и оно начинает работать. Под каждую архитектуру нейросети (архитектура определяет и устройство нейрона, и топологию самой сети) подбирается задача, её представление в виде входных сигналов и способ «обучения» (способ настройки весов синапсов и других параметров, если они есть, по набору эталонных данных задачи). Потому нельзя сказать, что чип круче шкафа, там различия не только в железе, но и в самой задаче (и в команде специалистов, занимающихся проектированием решения). И вы правы, нейросети сейчас переживают второе рождение, и куча энтузиастов ищут «философский камень» сразу во всех направлениях, и даже в тех, в которых надёжных научных теорий ещё нет. Экономическая выгода первенства в решении практических задач в большинстве случаев важнее, чем «научная чистота».
Khort
08.11.2016 22:49В этом и проблема, что «подбирается». Напридумано множество реализаций казалось бы одного и того же — аналога живого нейрона, причем эти реализации настолько разные, что просто диву даешься. В аналоговых реализациях все притянуто за уши к схематехнике, в цифровых — к возможностям аппаратуры, топология сети — разнится от задачи к задаче, а в основе что, теория? Но теории ведь нет, все рекомендации получены экспериментально, методом проб и ошибок. Я вовсе не против нейросетей, но с очень большим подозрением отношусь к разработкам со столь сырым бэкграундом. Будет готова теория, тогда другое дело.
Рождение отнюдь не второе, первый раз я столкнулся с нейросетями больше 20 лет назад, и тогда волна их популярности была уже далеко не первая. Насколько я знаю, нейросетями занимались и в СССР, и в РФ в 90е даже что то на ПЛИС делали. Но поскольку военные не ведутся на популизм — им подавай факты и доказательства, то так все и заглохло.napa3um
08.11.2016 22:52+2Вы, наверное, поседеете, когда узнаете о вычислительной математике и о невозможности аналитического решения широчайшего класса практических математических задач людей. Нейросеть в этом смысле вовсе не «ужаснее» метода Ньютона для нахождения корней сложных функций.
Khort
08.11.2016 23:22О математике, использующейся в нейросетях? Это и есть корень проблемы. Нет теории — нет математики, и каждый в результате творит что хочет, в меру своей фантазии.
По большому счету, нейросеть — это всего лишь обучаемый фаззи контроллер, задачи его понятны и с помощью нечеткой логики решаемы. Проблема только только в обучении.napa3um
08.11.2016 23:23О математике, в которой нейросети — лишь капля в море: https://ru.wikipedia.org/wiki/Вычислительная_математика
uSasha
09.11.2016 11:47Toshiba — не китайцы.
Ядро ARM996 было выпущено 10 лет назад не является оптимизированным по энергоэффективности, возможно его выбрали потому, что лицензия была дешевой/бесплатной.
Аналоговый вычислитель сделать всегда сложнее цифрового.
Важным моментом будет скорость шины, возможно у старого дохлого ядра есть серьезные ограничения.Khort
09.11.2016 12:16Разработку возглавлял человек, стоящий у истоков ARM — Steve Furber, так что вопросов с лицензией, думаю, не стояло. Ядро очень древнее, и без FPU, но зато частоту 200 МГц вытянули (130нм тех. процесс).
Шина использовалась двупроводная — асинхронный последовательный канал. Таким образом они эмулировали связи между нейронами. В результате, эти шкафы иначе как в качестве нейросети использовать нельзя. Видимо, сэкономили на корпусе — меньше выводов делать надо было.
Что проще делать — аналоговый вычислитель, или цифру, не скажу, не знаю. Процессоры проектировал, а вот нейросети не приходилось. Но чисто из общих соображений: в аналоговом вычислителе один кондесатор заменяет целый сегмент памяти, а куча логики логики заменяется RC-цепочками. Учитывая, что проектируют такие вещи с использованием шаблонов — должно по идее быть и быстро, и не сложно, и итоговое количество транзисторов снижается на несколько порядков по сравнению с цифрой.
Mad__Max
17.11.2016 06:44Так этот специализированный чип изначально начинали проектировать тоже немногим меньше 10 лет назад. На момент начала работы это было относительно современное ядро.
Там еще и старый 130нм техпроцесс используется.
Все дело не в лицензии а в строимости проектирования и запуска производства партии чипов. Для старых технологий разовые (не зависящие от объема тиража) расходы низкие. Всего порядка нескольких десятков тысяч долларов + плата за каждую изготовленную пластину с чипами. Тогда как для самых современных счет может идти на несколько миллионов долларов + плата за каждую пластину.
Это оправдано, когда речь идет о производстве какого-нибудь массового ширпотреба — эта стоимость размажется тонким и почти незаметным слоем по десяткам миллионов произведенных одинаковых чипов.
Но если нужно выпустить какой-то сильно специфический чип под конкретный проект, которых нужно всего несколько тысяч, максимум десятков тысяч штук — это неприемлемо. Чипы «золотые» получатся.
Ну а энергоэффективности они добились простыми методами — понижением тактовой частоты и рабочего напряжения. В результате чип с 18 ARM ядрами, кэш памятью в каждом ядре(32+64 КБ) и 128 МБ обшей памяти потребляет всего около 1 Вт. Суперкомпьютер на миллион таких ядер, способный моделировать сеть из более миллиарда нейронов в реальном времени потреблял бы около 50 кВт — примерно на 2 порядка меньше чем универсальный суперкомпьютер построенный на современных процессорах и моделирующий такую сеть чисто программно (без оптимизации своей архитектуры под нейронные сети)
Если бы финансирование проекта не срезали, то после периода испытаний и подтверждения эффективности такого подхода были планы переделать под более современное ARM ядро (правда сильно упростив его/повыкидав все «лишнее» их него) и перевести на более менее современный тех-процесс (28-32 нм) запихнув в один чип уже больше 100 ядер и еще больше встроенной памяти. Ну и с большей серией чипов, которых хватило бы для постройки машины разумных размеров и энергопотребления способной в реальном времени крутить ИНС уровня сложности примерно соответствующей человеческому мозгу.
Mad__Max
17.11.2016 06:12+1Эм, вы путаете. Там не 500 тыс. нейронов, а именно 500 тыс. ярм-ядер (+32 кб SRAM памяти интегрированных в каждое ядро, + 128 МБ общей DRAM памяти на каждый кристалл из 18 ядер).
Одно такое ядро с интергрированной памятью по стандартным алгоритмам способно эмулировать работу сразу 1000 нейронов и около 100 тысяч синапсов в реальном времени и потребляет всего около 0,06 Вт электроэнергии (около 1 Вт на весь кристалл из 16+2 ядер и встроенной памяти).
Так что этот «шкаф» несмотря на то что он производен по устаревшим технологиям способен моделировать нейронную сеть из 500 миллионов нейронов. Полная версия машины, когда ее доделают будет больше миллиарда нейронов в реальном времени моделировать.
Причем алгоритмы можно менять на ходу — ядра то универсальные, просто меняй исходный код, перекомпилируй и запускай заново. То что нужно для научно-исследовательских проектов.
Тогда как на таких «аналоговых нейровычислителях» редко когда больше 1 миллиона нейронов реализовано — на 3 порядка меньше. Причем реализовано аппаратно с жестко фиксированными свойствами (моделью работы нейрона) — надо что-то изменить в модели? Проектируй и запускай в производство новую серию чипов, а старую можешь выкинуть.Khort
17.11.2016 08:30+1Ошибся, прошу прощения, даже на википедии написано про эмуляцию 1000 нейронов. И ядро ARM там другое — 968.
Любопытно, что они полностью самосинхронный NoC сделали. Видимо очень быстрый интерфейс получился, поскольку накладные расходы у такого решения — 2 такта на пересинхронизацию на каждой стороне. Надо будет почитать еще про этот чип, много интересных решений. Спасибо за наводку!
rPman
09.11.2016 18:52Подскажите, при создании нейрочипа речь идет только о реализации в железе быстрой нейросети (на вход подаем входы, на выходе — выходы), соответственно масштабируемой количественно (подаем 100500 входов, получаем сразу 100500 выходов) или каждый чип еще и самообучение умеет проводить каким-нибудь методом, т.е. мы подаем чипу еще и обучающую выборку?
Robotex
А можно где-то купить себе нейроморфный чип для опытов?
QuaziKing
+1. Очень интересует этот вопрос
andybelo
И шо, вы нашли этот магазин с микросхемами, или из под полы?