

Вы представили новый сайт — и все в восторге. Ваш дизайн свеж, код безупречен, вы полностью готовы к запуску. Но тут кто-то интересуется: «А на японском работает?»
Вас бросает в холодный пот: вы понятия не имеете. Сайт работает на английском, а остальными языками вы планировали заняться попозже. Теперь вам придется переписывать весь движок для поддержки других языков. Дата запуска откладывается, и вы проводите следующие два месяца за исправлением ошибок, только чтобы убедиться, что вы пропустили добрую половину из них.
Локализация делает ваш движок готовым к работе на любом языке — и будет гораздо проще, если вы займетесь ею с самого начала. Компания-локализатор Alconost перевела для вас дюжину простых правил, благодаря которым можно спокойно запускаться в любой точке мира.
1. Вынесите все строки в ресурсы
Первый шаг в локализации — вынести все видимые для пользователей строки из кода в файлы ресурсов. Сюда входят заголовки, названия продуктов, сообщения об ошибках, надписи на изображениях и любой другой текст, который может быть виден пользователю.
В большинстве файлов ресурсов каждой строке присваивается имя, что позволяет вам указывать для нее разные варианты переводов. Многие языки используют файлы конфигурации вроде таких:
name = UsernameИли вот такие
.pot-файлы:msgid "Username"
msgstr "Nom d'utilisateur"Или вот такие XLIFF-файлы:
<trans-unit id="1"> source xml:lang="en">Username</source> <target xml:lang="fr">Nom d'utilisateur</target> </trans-unit>
Потом эти файлы подгружает библиотека, которая использует комбинацию языка и страны (локаль), чтобы определить правильную строку.
После того, как все строки будут вынесены во внешние файлы ресурсов, вы можете отправлять их переводчикам и получать от них переводы отдельными файлами для каждой локали, поддерживаемой вашим приложением.
2. Не допускайте конкатенации строк
Добавление одной строки к другой почти всегда приводит к ошибке локализации. Это хорошо видно на примере такого параметра, как
color.Допустим, в вашем канцелярском магазине есть такие товары, как карандаши, ручки и листы бумаги. Покупатели будут выбирать товар и затем его цвет. В корзине вы будете показывать им такие позиции, как «красный карандаш» или «синяя ручка» с помощью функции такого типа:
function getDescription() {
var color = getColor();
var item = getItem();
return color + " " + item;
}Этот код отлично работает для английского языка, в котором цвет идет первым — «red pencil», но совершенно не подходит для французского, на который «красный карандаш» переводится как «crayon rouge», а «синяя ручка» — как «stylo – encre bleue». Во французском языке определения идут после определяемых слов. Функция
getDescription никак не смогла бы поддерживать такие языки при простой конкатенации строк.Решение — указывать параметризованные строки, определяющие порядок названия и цвета товара для каждого языка. Определите строку ресурса, которая выглядит подобным образом:
itemDescription = {0} {1}Она может казаться незначительной, но именно она делает возможным перевод. Мы можем вот так использовать ее в новой функции
getDescription:function getDescription() {
var color = getColor();
var item = getItem();
return getLocalizedString('itemDescription', color, item);
}Теперь ваши переводчики могут легко менять порядок слов, например:
itemDescription = {1} {0}Так, функция
getLocalizedString берет имя строки ресурса (itemDescription) и несколько дополнительных параметров (цвет и товар), чтобы подставить их значения в строку ресурса. Большинство языков программирования содержат функцию, аналогичную getLocalizedString. (Единственное существенное исключение — JavaScript, но об этом мы поговорим позже.)Этот способ также работает для строк, содержащих текст, таких как эта:
invalidUser = The username {0} is already taken. Please choose another one.3. Внесите знаки препинания в строки ресурсов
Доработку пунктуации всегда хочется оставить на потом, чтобы сохранить возможность использовать одну и ту же строку, скажем, в названии поля, где после нее понадобится двоеточие, и в подсказке, где оно не понадобится. Но это — еще один плохой пример конкатенации строк.
Здесь, например, мы добавляем простую форму логина с использованием PHP в среде WordPress:
<form>
<p>Username: <input type="text" name="username"></p>
<p>Password: <input type="text" name="password"></p>
</form>
Нам нужно, чтобы форма работала и на других языках, поэтому давайте добавим строки для локализации. В WordPress это легко делается с помощью функции
__ (т. е. два нижних подчеркивания подряд):<form>
<p><?php echo(__('Username', 'my-plugin')) ?>: <input type="text" name="username"></p>
<p><?php echo(__('Password', 'my-plugin')) ?>: <input type="text" name="password"></p>
</form>
Видите ошибку? Это та самая конкатенация строк. Двоеточие после текста не локализовано. Ошибка проявится в таких языках, как французский, где двоеточие всегда должно отбиваться пробелами с обеих сторон. Пунктуация — часть строки и должна быть включена в файл ресурсов.
<form>
<p><?php echo(__('Username:', 'my-plugin')) ?> <input type="text" name="username"></p>
<p><?php echo(__('Password:', 'my-plugin')) ?> <input type="text" name="password"></p>
</form>
Теперь форма может использовать
Username: для английского языка и Nom d'utilisateur : — для французского.4. Иногда имя — это не имя
Меня зовут Зак Гроссбарт. Зак — мое имя, Гроссбарт — фамилия. У всех в моей семье фамилия Гроссбарт, но я — единственный Зак.
В англоговорящих странах первым принято называть имя, затем — фамилию. В большинстве азиатских стран — все наоборот, а в некоторых культурах пользуются одним только именем.
Виолончелист Йо-Йо Ма — представитель семьи Ма. На китайском он пишет первой свою фамилию: Ма Йо-Йо (???).
Но все еще интереснее, потому что многие люди, переезжая из азиатских стран в англоговорящие, меняют порядок упоминания имени и фамилии, чтобы не нарушать местные традиции. То есть вы не можете делать никаких предположений.
Вы должны обеспечить способ адаптировать отображение имен; вы не можете предположить, что имя всегда будет идти первым или фамилия — последней.
WordPress неплохо решает эту проблему, запрашивая у вас желаемый вариант отображения вашего имени (Имя / Фамилия / Псевдоним / Вариант отображения имени, который виден всем):

Было бы даже лучше, если бы WordPress поддерживал еще и второе имя, а также предоставлял возможность определить формат для конкретной локали, чтобы вы могли указать один вариант отображения для английского языка и другой — для китайского. Впрочем, совершенству нет предела.
5. Никогда не прописывайте в коде формат даты, времени или валюты
В мире нет согласия по поводу форматов отображения даты и времени. Кто-то пишет первым месяц (6/12/2012), а кто-то — день (21/6/2012). Одни люди указывают время в 24-часовом формате (14:00), другие — в 12-часовом (2:00 PM). Тайвань использует строки AM и PM в переводе и ставит их в начале (?? 2:00).
Ваш лучший вариант — хранить все даты и время в стандартном формате, таком как ISO 8601 или UNIX-время, и использовать библиотеки вроде Date.js или Moment.js, чтобы отображать все для конкретной локали. Эти библиотеки также справляются с отображением времени для конкретного часового пояса, так что вы можете хранить все даты и время на сервере в общем формате (таком, как UTC) и конвертировать в правильный для каждого часового пояса вариант в браузере.
Даты и время не менее сложны при отображении календарей и выбора дат. В США неделя начинается с воскресенья, в Великобритании — с понедельника, а на Мальдивах — с пятницы. Инструмент выбора дат jQuery UI содержит более 50 локализованных файлов для поддержки разных календарных форматов во всем мире.
То же справедливо и для валют и других числовых форматов. В одних странах в качестве разделителя в числах используют запятую, в других — точку. Всегда используйте библиотеку с локализованными файлами для каждой локали, которую вам нужно поддерживать.
Этот вопрос хорошо освещен в обсуждении лучших практик отображения летнего времени и часовых поясов на StackOverflow.
6. Почти всегда используйте UTF-8
История компьютерных кодировок длинна, но самое важное — помнить, что 99% времени ваш правильный выбор — это UTF-8. Единственный случай, когда UTF-8 не подходит, — когда вы работаете, в основном, с азиатскими языками и вам не обойтись без UTF-16.
Это часто случается с веб-приложениями. Если браузер и сервер используют разные кодировки, символы отображаются с искажением, и приложение наполняется квадратами и вопросительными знаками.
Много языков программирования хранят файлы в кодировке, которую система использует по умолчанию. Но англоязычность вашего сервера не будет иметь никакого значения, если все ваши пользователи просматривают сайт на китайском. UTF-8 решает эту проблему, стандартизируя кодировки для браузера и сервера.
Задавайте UTF-8 в начале всех ваших HTML-страниц:
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
И укажите UTF-8 в заголовке HTTP Content-Type:
Content-Type: text/html; charset=utf-8Спецификация JSON требует, чтобы все документы JSON использовали Unicode с UTF-8 по умолчанию, так что убедитесь, что вы используете UTF-8 при любом чтении или записи данных.
7. Предусмотрите сокращение и удлинение строк
При переводе меняется длина строк.

(210 пикселей на английском языке, 380 — на немецком)
«Повторите пароль» на немецком — почти вдвое длиннее, чем на английском. Если места будет недостаточно, ваш строки наползут на элементы управления. WordPress решает эту проблему, оставляя дополнительное место для каждой строки на случай ее удлинения.

Такой подход хорош для языков, в которых строки имеют примерно одинаковую длину, но в языках с длинными словами, — например, в немецком и финском, — строки наползут на элементы управления, если вы не оставите достаточно много места. Однако если вы добавите еще пространства, это приведет к тому, что в компактных языках, таких как китайский, названия будут расположены слишком далеко от соответствующих элементов управления, усложняя пользование формой.

Многие дизайнеры форм обеспечивают достаточное дополнительное место для строк, выравнивая их по правому краю или размещая над элементами управления.

Размещение текста над элементами управления решает проблему для коротких форм, но длинные — делает слишком длинными.
Идеального решения, как обеспечить работу вашего приложения на всех языках, нет; многие дизайнеры форм комбинируют эти подходы. Короткие подписи вроде «Имя пользователя» или «Роль» незначительно изменятся при переводе и потребуют совсем немного дополнительного места. Строки подлиннее изменятся серьезно и потребуют гораздо больше места в ширину или/и в высоту.

Здесь WordPress оставляет немного дополнительного места для строки «Биографическая информация», но размещает более длинное описание под полем, чтобы обеспечить запас для его увеличения при переводе.
8. Всегда используйте полную локаль
Полная локаль включает в себя язык и код страны, поддерживает альтернативные варианты написания, форматы дат и другие особенности, которые могут отличаться для двух стран, использующих один язык.
Всегда используйте при переводе полную локаль, а не только язык, чтобы было ясно, что подали на обед — деруны или драники, и можно было понять, 100 российских рублей для другой страны — это много или мало.
9. Никогда не доверяйте браузеру выбор локали
Локализация гораздо сложнее для браузеров и JavaScript, потому что они определяют локаль в зависимости от того, кто запрашивает.
В JavaScript есть свойство, сообщающее о текущем языке, которое называется
navigator.userLanguage. Его поддерживают все браузеры, но оно, как правило, бесполезно. Если я установлю Firefox на английском, для navigator.userLanguage будет отображаться значение English. Теперь я могу зайти в свои настройки и поменять предпочитаемые языки. Firefox позволяет мне выбрать несколько языков, так что я могу установить в порядке предпочтения: американский английский, любой другой английский и японский.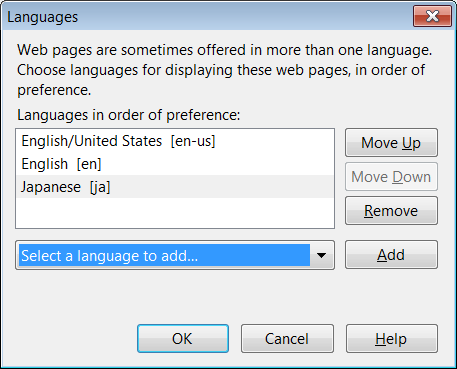
Выбор нескольких локалей позволяет серверам подобрать наилучшее соответствие между языками, которые я знаю и они поддерживают. Firefox берет эти локали и отправляет их серверу в заголовке HTTP следующим образом:
Accept en-us,en;q=0.7,ja;q=0.3Firefox даже использует качественный фактор (часть с
q=) для обозначения степени предпочтительности одной локали перед другой.Это означает, что сервер может предоставить контент на английском, японском или другом языке, если ни один из указанных он не поддерживает. Тем не менее, даже после установки желаемых языков в Firefox, в свойстве
navigator.userLanguage по-прежнему будет прописан английский и только он. С другими браузерами ситуация не намного лучше. И закончиться все может тем, что сервер решит, что я предпочитаю японский, а JavaScript — что я хочу читать по-английски.JavaScript никогда не имел решения этой проблемы, и вместо единой стандартной библиотеки локализации в нем — десятки стандартов. Лучшим выходом из ситуации будет интеграция в JavaScript-код страницы локали, выбранной сервером при обработке запроса. Тогда вы можете использовать локаль при форматировании любых строк, дат и чисел из JavaScript.
10. Учитывайте языки с прочтением слева направо и справа налево
Большинство языков пишутся слева направо, но арабский, иврит и немало других пишутся справа налево. В HTML есть свойство для
html-элемента под названием dir, которое определяет, читается ли страница ltr (слева направо) или rtl (справа налево).<html dir="rtl">Определяющее направление свойство есть и в CSS:
input {
direction: rtl;
}
После установки свойства
direction страница будет работать по стандартной HTML-разметке, но CSS-свойства float: не переключатся с left на right, и абсолютное позиционирование останется неизменным. Для более сложных макетов понадобится новая таблица стилей.Простой способ определить направление текущего языка — включить строку
direction в вынесенные в ресурсы строки.direction = rtlТеперь вы можете использовать эту строку для загрузки другой таблицы стилей, привязанной к текущей локали.
11. Никогда не сортируйте в браузере
JavaScript содержит функцию
sort, которая сортирует строки в алфавитном порядке. Она делает это, сравнивая каджый символ в каждой строке, чтобы определить, больше ли a, чем b, и меньше ли y, чем z. Поэтому она поставит 40 перед 5.Браузер определяет, что y идет перед z, используя большую таблицу соответствий для каждого символа. Впрочем, браузер включает эти таблицы только для текущей локали. Это значит, что браузер не сможет правильно отсортировать ваш список японских имен средствами английской локали; он отсортирует их по значениям Unicode, что неверно.
Эту проблему можно наблюдать в таких языках, как польский и вьетнамский, в которых часто используются диакритические знаки. Браузер может определить, что a идет перед b, но не знает, идет ли ? перед a.
Правильно отсортировать строки может только сервер. Убедитесь, что сервер располагает всеми картами кода для поддерживаемых языков, что вы отправляете браузеру отсортированные списки и что вы обращаетесь к серверу всякий раз, когда хотите их пересортировать. Убедитесь также, что при сортировке сервер принимает во внимание локаль (включая все с прочтением справа налево).
12. Тестируйте раньше и чаще
Большинство команд не беспокоится о локализации до тех пор, пока не станет слишком поздно. Крупный клиент в Азии пожалуется, что сайт не работает, — и все бросятся исправлять 100 мелких ошибок локализации, о которых никто и не думал. Если следовать приведенным в этой статье правилам, можно избежать многих проблем с локализацией, но тестировать все равно придется; а переводы, как правило, не будут готовы до конца проекта.
Раньше я переводил свои проекты на поросячью латынь, но так не проверялись азиатские символы, и ее не поддерживает большинство браузеров. Сейчас я тестирую переводы с помощью языка коса (
xh_ZA). Все браузеры поддерживают коса, а для Нельсона Манделы — это родной язык, но меня никто никогда не просил поддерживать его для продукта.Я не говорю на коса, потому создаю новый файл перевода и добавляю
xh в начало и конец каждой строки. Так легко заметить, не пропустил ли я строку в коде. Вставляю еще пару иероглифов японского кандзи для проверки кодировки и получаю беспорядочную строку, с помощью которой можно проверить все нюансы моих переводов.Создать файл для тестового перевода легко. Просто сохраните несколько файлов конфигураций с
xh_ZA в имени файла и замените…name = Username… на:
name = xh???Username???xhПолученная смесь позволяет проверить, перенес ли я все строки в ресурсы, использую ли правильную локаль, подходят ли мои формы для более длинных строк и правильную ли кодировку я использую. Потом я быстро сканирую приложение на все, где нет
xh, и исправляю ошибки до того, как они станут неотложными проблемами.Подойдите к локализации правильно заранее — и вы убережете себя от больших проблем в перспективе. А мы в Alconost готовы вам с этим помочь — от бесплатной консультации до собственно локализации.
Комментарии (11)
ua9msn
16.11.2016 12:55Браузер может определить, что a идет перед b, но не знает, идет ли ? перед a.
Неправда. Знает. Но с условием: нужно использовать INTL — Intl к нам приходит!
Надеюсь это не сильно нагло — вставлять ссылку на собственный пост?
Zibx
16.11.2016 13:36Можно сказать чётче — браузер вообще не умеет сортировать. Сортировкой занимается реализация метода sort в js, она в свою очередь написана на сях и очень хороша. Но эта функция требует опеределить операцию сравнения для любых двух элементов. И вот статья утверждает что сервер более тьюринг полный!

Neris
16.11.2016 12:56+3Периодически меня беспокоит один вопрос:
Например, имеем веб-приложение с локализацией через GNU/Gettext.
Есть фраза, в которой одно слово должно быть ссылкой, например:Я согласен с <a href="...длинная ссылка...">условиями использования продукта</a>.
1. Можно было бы разделить эту фразу на две: сам текст и текст ссылки, но тогда переводчик сойдет с ума, выискивать в файле перевода эти строки, они могут находится далеко друг от друга.
2. Можно сделать подстановку урла ссылки через какой-нить sprintf или, например, через замену ключевого слова "{url}" на ссылку, но в этом случае в переводы попадает HTML, и строки становятся не просто строками, а строками с разметкой. Плюс что делать если у нас там на ссылке должна быть куча атрибутов (класс, айди, таргет…).
3. Можно было бы изобрести свой DSL и выводить в перевод что-то типа «Я согласен с {link: условиями использования продукта}.», но это как-то слишком сложно для такой простой задачи.
Как бы лучше поступить в такой ситуации? Как такие проблемы решают на тех же десктопных гуях, где нет такого языка разметки, как HTML?
indestructable
16.11.2016 15:42Это вы зря, про простую задачу. DSL или строки с форматированием самое то.
mortimoro
16.11.2016 16:49Почти всегда имеет смысл обойтись первым вариантом. Просто потому, что переводчики чаще всего твой текст прогоняют через гугл-транслейт, исправляют явные ошибки и отдают заказчику, не вникая особо в смысл отдельных фраз — стоит ли упрощать переводчику работу, если он ее и так не выполняет как положено?
А если таки попадается качественный переводчик, который хочет не халтурить, а сделать вещь, то он все равно столкнется со множеством двусмысленных коротких фраз, которые вне контекста могут быть переведены по разному и иметь разный смысл. Потому после загрузки перевода в проект, качественный переводчик должен его пересмотреть и внести правки.

not_ice
16.11.2016 18:47+1Я делаю так: «Я согласен с {linkBegin}условиями использования продукта{linkEnd}.»
Где в {linkBegin} находится открывающий тег ссылки, в {linkEnd} — закрывающий.
Тогда переводчику понятен контекст, и он даже может изменить положение ссылки в тексте.
nerudo
Я бы добавил пункт 0: глубоко вдохните-выдохните 3 раза и хорошо подумайте — а нужна ли вам локализация. Я сейчас наблюдаю пример программы, которая падает (выдает ошибку) пытаясь открыть свои конфиги. Т.к. разработчики вместо printf/scanf решили выпендриться с локалями, но на шаг вперед не подумали: в их же текстовом конфиге идущем по-умолчанию для дробных чисел используется точка. А когда файл загружается с местной локалью — запятая. Самое смешное что где-то внутри все равно продолжает использоваться хранение данных в текстовом представлении и там уже захардкожено использование точки, поэтому ручная правка не помогает и впоследствии числа все равно искажаются.
Mercury13
Нечто подобное было на IT Happens: одной программе требуется английская системная локаль, другой — русская. А программам надо работать в связке. Сейчас у меня отвалилась часть интернета и ITH недоступен, так что дайте ссылку, у кого есть…
sand14
Это большая проблема при разработке многих продуктов, когда не уделяется внимание культуре строк при работе со сроками и их преобразовании в данные и обратно.
Очевидно, что в конфигах, файлах автоматизированного обмена и подобном, строчное представление данных всегда должно храниться в Invariant-культуре (которая должна использоваться и при обратном преобразовании).
Кстати, если говорить о .NET, то при разработке конфигов даже безобидный, на первый взгляд, оператор
string s = intVar.ToString()
может все сломать, т.к. в системе может быть не только переопределен знак минуса, но и даже сами цифры 0..9.
А вот .ToString(CultureInfo.InvariantCulture) мало то пишет в таких случаях
А то, что отображается на экране — как правило, с учетом текущей культуры системы (и преобразовывать введенные строки в данные с учетом нее).
musicriffstudio
вот старое обсуждение навязчивой локализации
https://habrahabr.ru/post/130003/