
Этот пост об архитектуре нашей системы, ее эволюционном развитии на протяжении уже почти 3-х лет и компромиссах между скоростью разработки, производительностью, стоимостью и простотой.
Упрощенно задача выглядела так — нужно соединить микроконтроллер с мобильным приложением через интернет. Пример — нажимаем кнопку в приложении зажигается светодиод на микроконтроллере. Тушим светодиод на микроконтроллере и кнопка в приложении соответственно меняет статус.
Так как мы стартовали проект на кикстартере, перед запуском сервера в продакшене у нас уже была довольно большая база первых пользователей — 5000 человек. Наверное многие из Вас слышали про известный хабра эффект, который положил в прошлом многие веб ресурсы. Мы, конечно же, не хотели повторять эту участь. Поэтому это отразилось на подборе технического стека и архитектуре приложения.
Сразу после запуска вся наша архитектура выглядела так:

Это была 1 виртуалка от Digital Ocean за 80$ в мес (4 CPU, 8 GB RAM, 80 GB SSD). Взяли с запасом. Так как “а вдруг лоад пойдет?”. Тогда мы действительно думали, что, вот, запустимся и тысячи пользователей ринут на нас. Как оказалось — привлечь и заманить пользователей та еще задача и нагрузка на сервер — последнее о чем стоит думать. Из технологий на тот момент была лишь Java 8 и Netty с нашим собственным бинарным протоколом на ssl/tcp сокетах (да да, без БД, spring, hibernate, tomcat, websphere и прочих прелестей кровавого энтерпрайза).
Все пользовательские данные хранились просто в памяти и периодически сбрасывались в файлы:
try (BufferedWriter writer = Files.newBufferedWriter(fileTo, UTF_8)) {
writer.write(user.toJson());
}Весь процесс поднятия сервера сводился к одной строке:
java -jar server.jar &Пиковая нагрузка сразу после запуска составила 40 рек-сек. Настоящего цунами так и не произошло.
Тем не менее мы много и упорно работали, постоянно добавляли новые фичи, слушали отзывы наших пользователей. Пользовательская база хоть и медленно, но стабильно и постоянно росла на 5-10% каждый мес. Так же росла и нагрузка на сервер.
Первой серьезной фичей стал репортинг. В момент когда мы начали его внедрять — нагрузка на систему уже составляла 1 млрд реквестов в месяц. Причем большинство запросов были реальные данные, такие как показания датчиков температуры. Было очевидно, что хранить каждый запрос — очень дорого. Поэтому мы пошли на хитрости. Вместо сохранения каждого реквеста — мы рассчитываем среднее значение в памяти с минутной гранулярностью. То есть, если вы послали в течении минуты числа 10 и 20, то на выходе получите значение 15 для этой минуты.
Сначала я поддался хайпу и реализовал данный подход на apache spark. Но когда дело дошло до деплоймента, понял что овчинка не стоит выделки. Так конечно было “правильно” и по “энтерпрайзному”. Но теперь мне предстояло деплоить и мониторить 2 системы вместо моего уютного монолитика. Кроме того добавлялся оверхед на сериализацию данных и их передачу. В общем я избавился от спарка и просто подсчитываю значения в памяти и раз в минуту сбрасываю на диск. На выходе выглядит это так:
Система с одним сервером монолитом отлично работала. Но были и вполне очевидные минусы:
- Так как сервер был в Нью-Йорке — в удаленных районах, например, Азии были визуально видны лаги при интерактивном использовании приложения. Например, когда вы меняли уровень яркости лампы с помощью слайдера. Ничего критического и ни один из пользователей на это не жаловался, но мы же изменяем мир, черт побери.
- Деплой требовал обрыва всех соединений и сервер был недоступен на ~5 сек при каждом перезапуске. В активную фазу разработки мы делали около 6 деплоев в мес. Что забавно — за все время таких вот рестартов — ни один пользователь не заметил недоступность серверов. То есть рестарты были настолько быстрыми (привет спринг и томкат), что пользователи вообще не замечали их.
- Отказ одного сервера, датацентра ложил всё.
Спустя 8 мес после запуска — поток новых фич немного спал и у меня появилось время, чтобы изменить эту ситуацию. Задача была проста — уменьшить задержку в разных регионах, снизить риск падения всей системы одновременно. Ну и сделать все это быстро, просто, дешево и минимальными усилиями. Стартап, все-таки.
Вторая версия получилась такой:
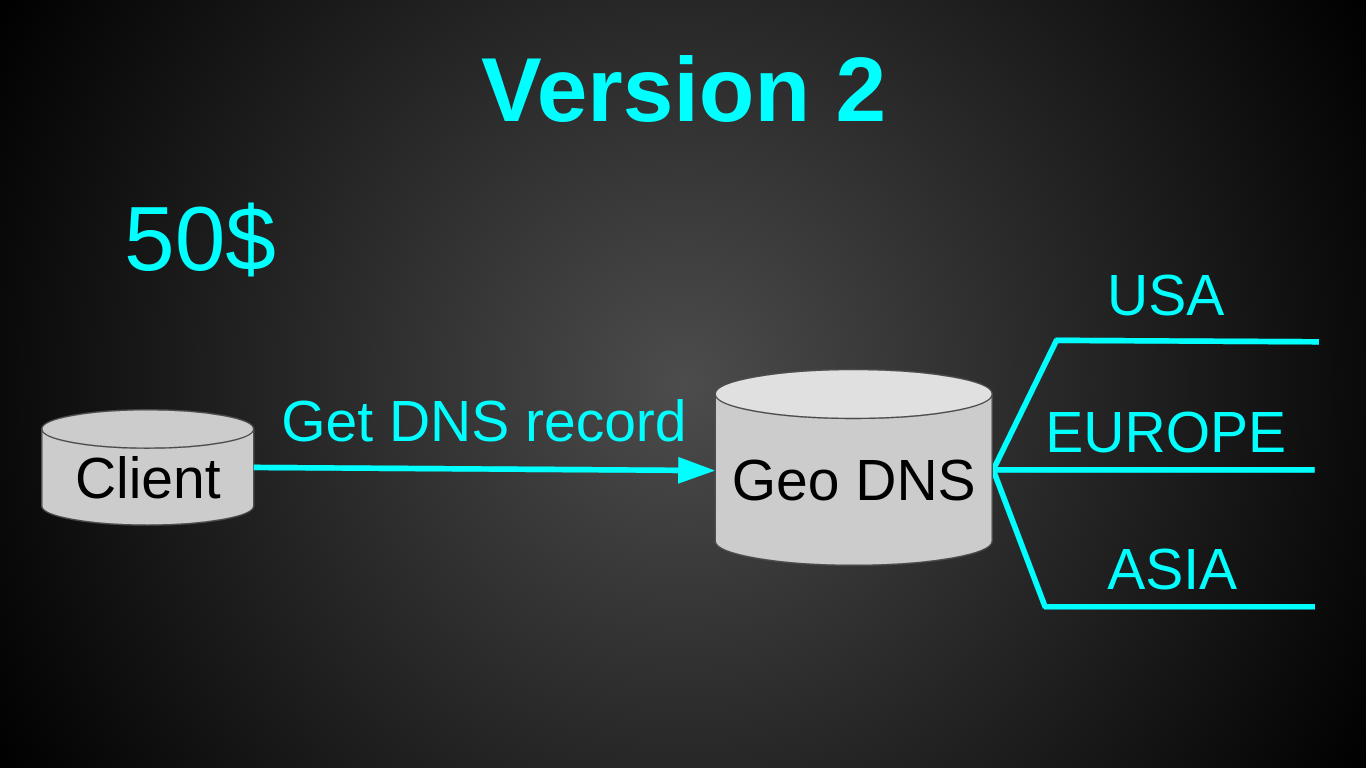
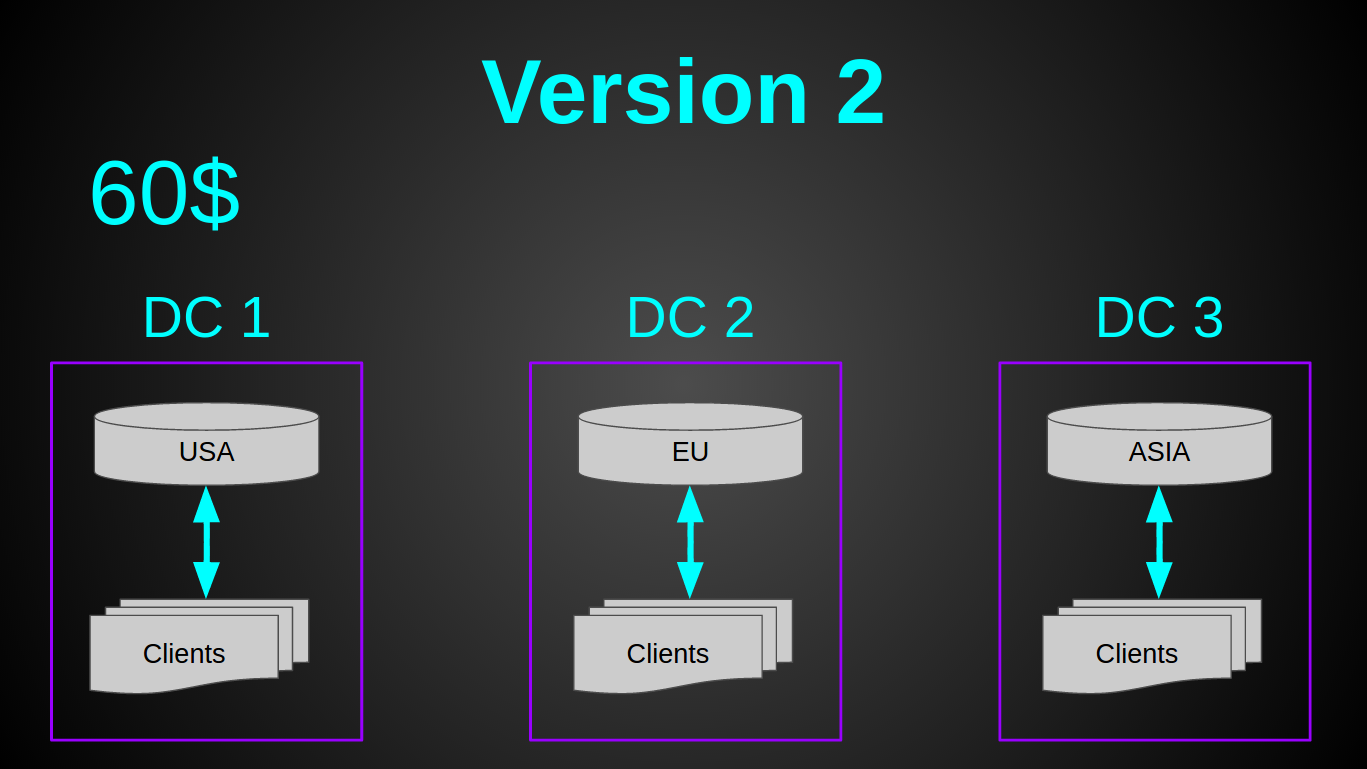
Как Вы, наверное, заметили — я остановил свой выбор на GeoDNS. Это было очень быстрое решение — вся настройка 30 мин в Amazon Route 53 на почитать и настроить. Довольно дешевое — Geo DNS роутинг у амазона стоит 50$ в мес (я искал альтернативы дешевле, но не нашел). Довольно простое — так как не нужен был лоад балансер. И требовало минимум усилий — пришлось лишь немного подготовить код (заняло меньше дня).
Теперь у нас было 3 монолитных сервера по 20$ (2 CPU, 2 GB RAM, 40 GB SSD) + 50$ за Geo DNS. Вся система стоила 110$ в мес, при этом она имела на 2 ядра больше за цену на 20$ дешевле. В момент перехода на новую архитектуру нагрузка составляла 2000 рек-сек. А прежняя виртуалка была загружена лишь на 6%.
Все проблемы монолита выше — решались, но появлялась новая — при перемещении человека в другую зону — он будет попадать на другой сервер и у него ничего не будет работать. Это был осознанный риск и мы на него пошли. Мотивация очень простая — юзеры не платят (на тот момент система была полностью бесплатной), так пусть терпят. Так же мы воспользовались статистикой, согласно которой — лишь 30% американцев хоть раз в жизни покидали свою страну, а регулярно перемещаются лишь 5%. Поэтому предположили, что данная проблема затронет лишь небольшой % наших пользователей. Предсказание оправдалось. В среднем мы получали около одного письма в 2-3 дня от пользователя у которого “Пропали проекты. Что делать? Спасите!”. Со временем такие письма начали очень сильно раздражать (несмотря на детальную инструкцию как быстро пользователю это пофиксить). Тем более такой подход врядли бы устроил бизнес, на который мы только начали переключатся. Нужно было что-то делать.
Вариантов решения проблемы было много. Я решил, что самым дешевым способом это сделать будет направлять микроконтроллеры и приложения на один сервер (чтобы избежать оверхед при передаче сообщений из одного сервера другому). В общем требования к новой системе вырисовывались такими — разные соединения одного пользователя должны попадать на один сервер и нужен shared state между такими серверами, чтобы знать куда конектить пользователя.
Я слышал очень много хороших отзывов о кассандре, которая отлично подходила под эту задачу. Поэтому решил попробовать ее. Мой план выглядел так:
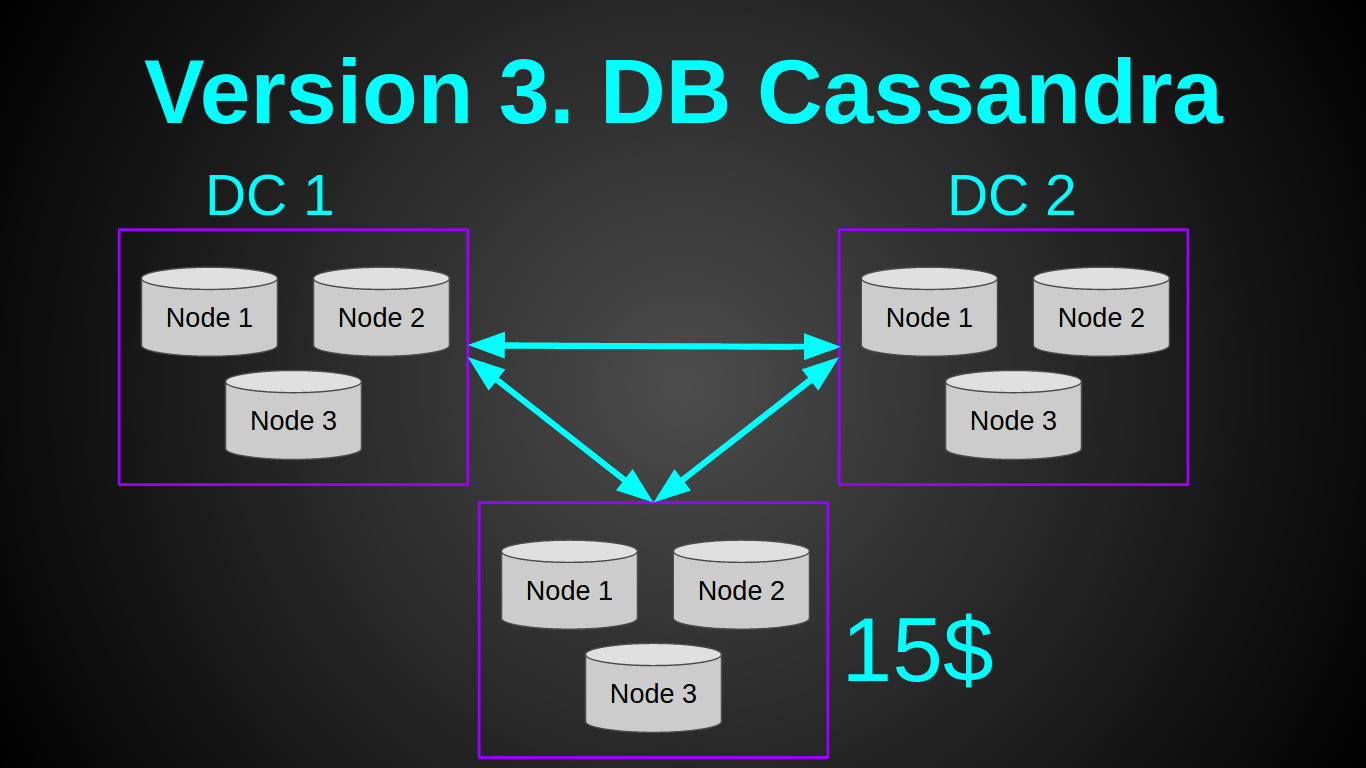
Да, я нищеброд и наивный чукотский юноша. Я думал что смогу поднять одну ноду кассандры на самой дешевой виртуалке у ДО за 5$ — 512 MB RAM, 1 CPU. И я даже прочитал статью счастливчика, который поднимал кластер на Rasp PI. К сожалению, мне не удалось повторить его подвиг. Хотя я убрал/урезал все буферы, как было описано в статье. Поднять одну ноду кассандры мне удалось лишь на 1Гб инстансе, при этом нода сразу же упала с OOM (OutOfMemory) при нагрузке в 10 рек-сек. Более-менее стабильно кассандра себя вела с 2ГБ. Нарастить нагрузку одной ноды касандры до 1000 рек-сек так и не удалось, опять OOМ. На этом этапе я отказался от касандры, так как даже если бы она показала достойный перформанс, минимальный кластер в одном датацентре обходился бы в 60уе. Для меня это было дорого, учитывая что наш доход тогда составлял 0$. Так как сделать надо было на вчера — я приступил к плану Б.
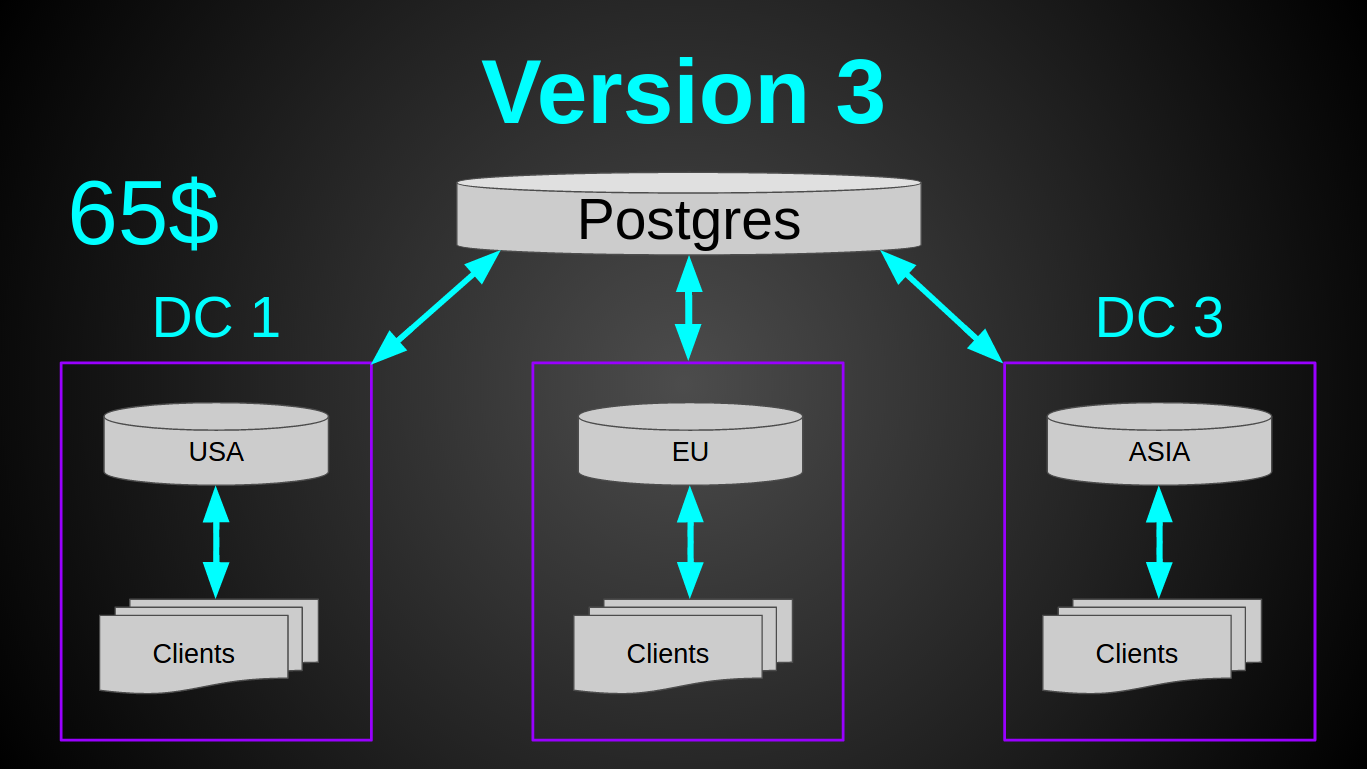
Старый, добрый постгрес. Он еще никогда меня не подводил (ну ладно, почти никогда, да, full vacuum?). Постгрес отлично запускался на самой дешевой виртуалке, абсолютно не кушал RAM, вставка 5000 строк батчем занимала 300мс и нагружала единственное ядро на 10%. То что надо! Я решил не разворачивать БД в каждом из датацентров, а сделать одно общее хранилище. Так как постгрес скейлить/шардить/мастер-слейвить труднее, чем ту же касандру. Да и запас прочности это позволял.
Теперь предстояло решить другую проблему — направлять клиента и его микроконтроллеры на один и тот же сервер. По сути, сделать sticky session для tcp/ssl соединений и своего бинарного протокола. Так как вносить кардинальные изменения в существующий кластер не хотелось, я решил переиспользовать Geo DNS. Идея была такая — когда мобильное приложение получает IP адрес от Geo DNS, приложение открывает соединение и шлет login по этому IP. Сервер в свою очередь или обрабатывает команду логина и продолжает работать с клиентом в случае если это “правильный” сервер или возвращает ему команду redirect с указанием IP куда он должен конектится. В худшем случае процесс соединения выглядит так:
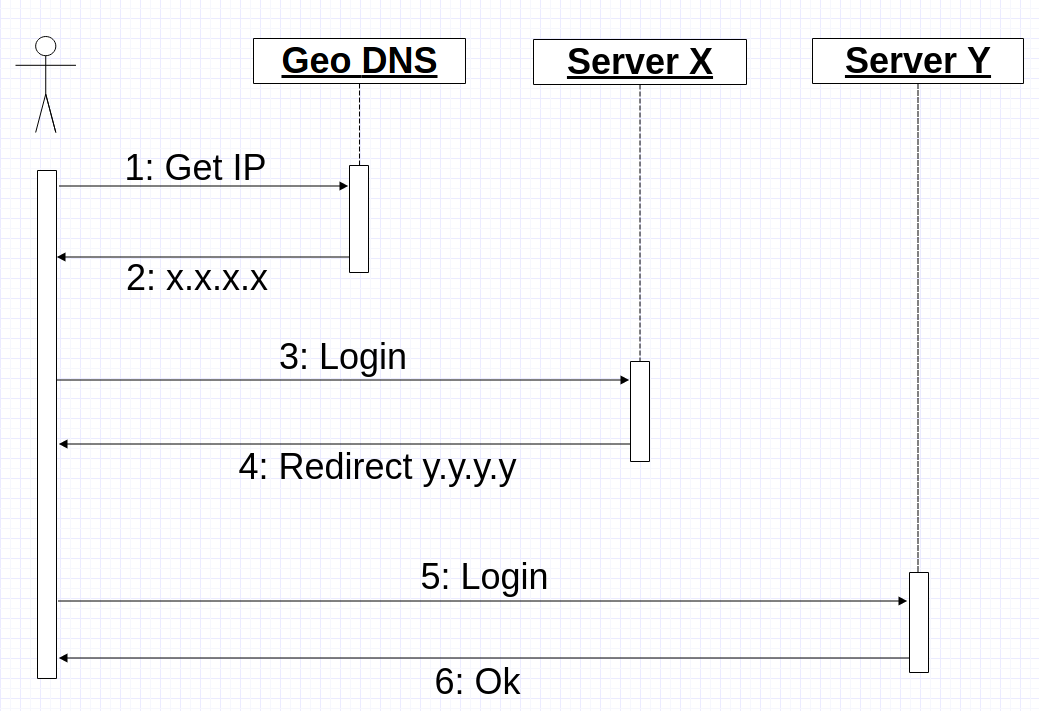
Но был один маленький ньюанс — нагрузка. Система на момент внедрения обрабатывала уже 4700 рек-сек. К кластеру постоянно были подключены ~3к устройств. Периодически конектилось ~10к. То есть при текущем темпе роста через год это уже будет 10к рек-сек. Теоретически могла возникнуть ситуация, когда много девайсов одновременно подключаются к одному серверу (например при рестарте, ramp up period) и если, вдруг, все они коннектились “не к тому” серверу, то могла возникнуть слишком большая нагрузка на БД, что может привести к ее отказу. Поэтому я решил подстраховаться и информацию о user-serverIP вынес в редис. Итоговая система получилась такой.
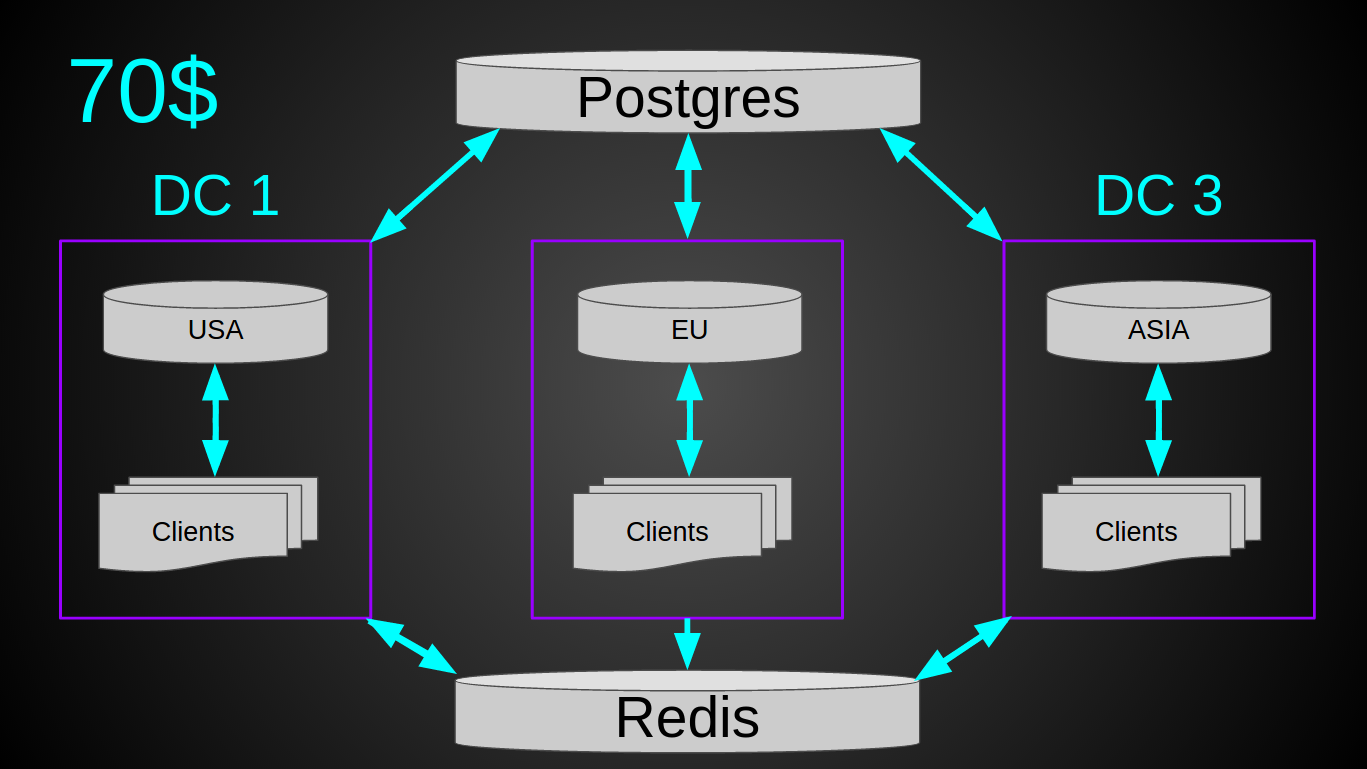
При текущей нагрузке в 12 млрд рек в месяц вся система нагружена в среднем на 10%. Сетевой трафик ~5 Mbps (in/out, благодаря нашему простому протоколу). То есть в теории такой кластер за 120$ может выдержать до 40к рек-сек. Из плюсов — не нужен лоад балансер, простой деплой, обслуживание и мониторинг довольно примитивные, есть возможность вертикального роста на 2 порядка (10х за счет утилизации текущего железа и 10х за счет более мощных виртуалок).
Проект опен-сорс. Исходники можно глянуть тут.
Вот, собственно, и все. Надеюсь статья Вам понравилась. Любая конструктивная критика, советы и вопросы — приветствуются.
Комментарии (63)

vjjvr
29.11.2016 13:16> Все пользовательские данные хранились просто в памяти и периодически сбрасывались в файлы
Кстати, вполне здравый подход.
У меня так разрабатываемый мною интернет-магазин года 3 работал.
Сейчас БД пихают где надо и не надо. А она во очень многих случаях вовсе не нужна.

grossws
29.11.2016 14:03Что вы так привязались к tomcat'у? Нормальный контейнер. У меня на ноуте стартует аж целых 55-60 ms, ужасно медленно.
Все пользовательские данные хранились просто в памяти и периодически сбрасывались в файлы
Дело хорошее, но предпочтительнее писать сначала во временный файл, а потом делать атомарный move. Тогда больше шансов не остаться без базы ,)
Сначала я поддался хайпу и реализовал данный подход на apache spark.
Как-то spark выглядит для такой задачи совсем странно. Не говоря уже про то, что он не относится к миру энтерпрайза.
Да, я нищеброд и наивный чукотский юноша. Я думал что смогу поднять одну ноду кассандры на самой дешевой виртуалке у ДО за 5$ — 512 MB RAM, 1 CPU. И я даже прочитал статью счастливчика, который поднимал кластер на Rasp PI. К сожалению, мне не удалось повторить его подвиг. Хотя я убрал/урезал все буферы, как было описано в статье. Поднять одну ноду кассандры мне удалось лишь на 1Гб инстансе, при этом нода сразу же упала с OOM (OutOfMemory) при нагрузке в 10 рек-сек. Более-менее стабильно кассандра себя вела с 2ГБ. Нарастить нагрузку одной ноды касандры до 1000 рек-сек так и не удалось, опять OOМ.
Вы хоть раз в её документацию-то заглядывали? "For both dedicated hardware and virtual environments: Production: 16GB to 64GB; the minimum is 8GB."

doom369
29.11.2016 14:10-1Что вы так привязались к tomcat'у? Нормальный контейнер.
Теперь уже да. Просто плохие воспоминания остались.
Дело хорошее, но предпочтительнее писать сначала во временный файл, а потом делать атомарный move. Тогда больше шансов не остаться без базы ,)
Согласен.
Как-то spark выглядит для такой задачи совсем странно.
Как по мне как раз идеально подходит под эту задачу.
Вы хоть раз в её документацию-то заглядывали?
Конечно. Та страничка из которой Вы это взяли появилась лишь в 2016 году.grossws
29.11.2016 17:15+2Как по мне как раз идеально подходит под эту задачу.
Конечно, на вкус и цвет, но у вас очень уж ограниченное по серверным ресурсам приложение, без минимально разумного количества памяти (напомню, что spark как раз и интересен возможностью выполнения стадий в памяти) и небольшой объем данных. Почему вы считаете, что он идеально подходит?
Конечно. Та страничка из которой Вы это взяли появилась лишь в 2016 году.
Они чуток реорганизовали документацию, но это не важно. Я помню аналогичные рекомендации ещё в районе C* 0.8. Вот, например, 2013 год из cassandra-user.
Abdgirk
29.11.2016 14:59забавно — коллега для своего pet-project делал примерно похожую вещь и для хранения данных с сенсора он запускал кассандру на raspberry pi)) Правда у него пиковая нагрузка была 200 запросов в секунду, и то для лоад теста…
doom369
29.11.2016 15:00+1Cудя по всему это было правдой для версии 0.х или 1.х. Сегодня минимальное требования для кассандры по RAM это 8 GB (по их доке).
Ну и распери тоже разные. Последние версии уже мощнее моих продакшн серверов.
DarkTiger
29.11.2016 15:21Не заметил никакого ускорения при переходе с Pi2 на Pi3. Вот ну совсем никакого.
Задача — фильтрация трафика, поступающего на комп старшего сына, через dansguardian. Ни на фильтрации, не на генерации отчетов.
SoloMidPlzD
29.11.2016 19:17чем DO лучше OVH?
vjjvr
29.11.2016 20:00Это далеко не одно и то же. Они разные.
У OVH лучше всего, с чем с ними мало кто сравним — это дешевые дедики.
Правда они на никаком железе (если другие вещи не особо критичны, то не ECC-память это существенный минус для серьезного проекта), что создает определенные риски.
Опытные люди знают, что если у вас серьезный проект — на 1 сервер в OVH полагаться нельзя. И рассчитывать на быстрое получение второго сервера в произвольный момент времени — тоже нельзя. На OVH нужно подстраховаться заранее.
Да, можно (и даже нужно если у вас серьезный проект) резервировать сервера. Современная традиция даже 3 сервера рекомендует, а не 2.
Но тут еще важный минус — при поддержании запасных серверов в актуальном состоянии вам их нужно синхронизировать. И тут в OVH вы можете запросто схлопатать бан из-за того, что пытаетесь синхронизироваться со своим же вторым сервером. Вас посчитают за хакера.
А DO — это прежде всего автоматизированные облачные технологии.
То облако, что делает OVH и в подметки не годится облаку DO.
Да и железо у DO совсем другого класса надежности.zapimir
29.11.2016 21:46Советую ещё Vultr глянуть, тарифы почти как в DO, но немного получше. Плюс есть такая фишка, как бесплатное хранение снэпшотов, т.е. можно настроить сервак, сделать снэпшот и удалить сервак, а потом когда нужно быстро поднять сервак из снэпшота (в том числе автоматизировано по API).
invite_ciel
29.11.2016 23:29Не могли бы Вы немного покритиковать Scaleway, если сталкивались с ними?
Субъективно — их маленькие ARM-сервера довольно неплохи, с ними не видно минусов виртуальных инстансов и удобный API для управления работающими инстансами. 4 ядра о двух гигабайтах, 50 гигабайт SSD выйдут в 3 евро.
Однако меня огорчает отсутствие того же ECC и IPv6, отсутствие ARM64 и не слишком большая адекватность накопителя — он подключен из СХД по NBD.doom369
29.11.2016 23:33Я могу покритиковать, так как рассматривал их для нашей платформы. В общем, если в пересчете на деньги, то CPU там получается где-то в 2 раза дороже чем у DO (по мощности). Так как разные архитектуры и у них разная произовдительность. Хотя если CPU не критичен, то вполне отличное решение для домашнего проекта. Правда, опять же, там полгода не было свободных серверов, что как бы намекает, на «серьезность».
vjjvr
29.11.2016 23:44У виртуальных инстансов нет минусов по сравнению с ARM.
Виртуальные инстансы в DO крутяться на Хеон-овом железе. И ресурсов DO выделяет по честному.
ARM же тянет только простую нагрузку.
За 4 евро можно взять небольшую VDS сопоставимых по памяти и намного лучших по процессору характеристик, построенную на базе системы с ECC и RAID и без страшного оверселлинга.

viru0
29.11.2016 19:27+1Дмитрий и Паша вы молодцы удачи вам.
А напишите статью о том как нашли первых пользователей, как проект начал «взлетать» и.т.п.
Очень интересно.doom369
29.11.2016 19:35+3Спасибо!
К сожалению, на хабре меня забанили за эти статьи. Поэтому я опубликовал их на украинском ресурсе:
Как мы запустили свой pet-проект: первый успех
Blynk: Как мы запустили свой pet-проект. 30 дней спустя
Blynk: Первые питчи, клиенты и деньги
dr_begemot
30.11.2016 14:23Спасибо за ссылки, хотел спросить такой же вопрос)
А почему забанили? Сам проект очень интересный!
viru0
01.12.2016 20:03+1Вот круто! Первые реальные деньги и почти 0 баксов на маркетинг.
У меня ж все наоборот, придумаешь что нить потратишь время и деньги, выясняется что людям не интересно.
Но читать такие статьи как ваша, очень заряжает! Значит идеи работают, люди интересуются. А значит и у меня есть шанс :-)

vittore
29.11.2016 21:36Мне вот любопытно, если бы это все строить с самого начала на GAE контейнерах, и использовать гугловый сторедж (https://cloud.google.com/storage/docs/storage-classes)- на сколько дешевле это бы получилоссь?
doom369
29.11.2016 22:59Мне вот любопытно, если бы это все строить с самого начала на GAE контейнерах,
Нашу задачу невозможно решить с помощью GAE контейнеров. Помимо того на GAE разрабатывать очень не удобно. Говорю как человек у которого там хостится несколько проектов :).vjjvr
29.11.2016 23:20Говорю как человек, у которого на GAE несколько проектов — как раз очень удобно.
Эт почему нельзя решить? Что там такого военного? Судя по вашему рассказу — все вполне типично.
По деньгами жестко вписать — это да, тут есть риски.
Все остальное — ничего особо невписывающегося нет.doom369
29.11.2016 23:27Эт почему нельзя решить?
Потому что у нас основа продукта это tcp/ssl соединения. А на GAE сокет поднять нельзя — «You cannot create a listen socket; you can only create outbound sockets».
vjjvr
29.11.2016 23:51Ага, согласен.
С учетом этой особенности вашего протокола тоже не стал бы заморачиваться с GAE.
vjjvr
29.11.2016 21:44-2Все проблемы монолита выше — решались, но появлялась новая — при перемещении человека в другую зону — он будет попадать на другой сервер и у него ничего не будет работать. Это был осознанный риск и мы на него пошли
Все гораздо хуже.
Человек, живущий в Европе просто устанавливал в качестве DNS-сервера модный 8.8.8.8 и после этого детектится как американец.
;)zapimir
29.11.2016 21:49+1vjjvr
29.11.2016 22:07Да, вы правы.
Он детектился как житель места, где находится ближайшая точка присутствия Google DNS.
zapimir
29.11.2016 22:55+1Подозреваю, что не всё так просто :) Я не думаю что у GoogleDNS есть серваки в Украине, пинг до 8.8.8.8 — 40 мс, из Италии — 22 мс, из Германии — 14 мс, из Нидерландов и Франции — 4,5 мс, у Великобритании — 2 мс. Подозреваю, что весь европейский трафик идет в любимую америкосовскими компаниями Ирландию. У Москвы ping 1.5 мс, т.е. есть серваки в России. Т.е. опять же по вашей теории, для всех из Великобритании, Германии, Нидерландов, Франции, Италии должен выдавать айпишник, как для Ирландии. А это не так, и выдаются разные айпишники, соответствующие стране запроса.

trix
29.11.2016 23:39Имхо, у вас яркий случай time-series data, и для отчетов и мониторинга отлично бы подошел Graphite+Grafana или что-то в этом духе. Kibana + Beats/Logstash тоже ниче так
doom369
29.11.2016 23:55Kibana
Платная, когда нужны фильтры по юзеру.
Graphite+Grafana
Вроде такая же проблема как у Кибаны.
Ну и эластиксерч очень прожорлив сам по себе.trix
30.11.2016 00:01Да, с относительной жручестью эластик-стэка согласен, что до графайта, то если вы делаете userId частью metric path, то нет проблем с фильтрацией. Хотя, конечно, надо точно знать ваш случай использования.
doom369
30.11.2016 00:04Хотя, конечно, надо точно знать ваш случай использования.
Нужно чтобы пользователь который лоигинится в приложение видел только свои данные.trix
30.11.2016 00:14Дело в том, что ни один из этих инструментов нельзя полностью отдавать на откуп случайному пользователю. Ни с какими платными плагинами. Эти интерфейсы изначально разрабатывались «для своих», умеючи очень легко можно сделать запрос, который сильно загрузит сервер. НО. если вы фильтруете некое безопасное подмножество функций, отсекая особенно тяжелые агрегирующие, и жестко контролируете time frame запроса, и, разумеется, metric path (чтобы изолировать только данные конкретного юзера) то особой проблемы нет.
doom369
30.11.2016 00:16Тогда я не совсем понял что Вы имели в виду под «у вас яркий случай time-series data». График с нагрузкой на сервер?
trix
30.11.2016 00:21любые данные от сенсоров с timestamp, вот тут примеры скриншотиков по теме http://homecircuits.eu/blog/platforms-for-iot-sensor-data/
doom369
30.11.2016 00:23Ну да. Только это все данные пользователя. То есть должно быть разделение. Для приватного сервера подойдет, но не для публичного облака. Мы кстати как раз вот ищем для веба решения. Пока выбор пал на graylog.
trix
30.11.2016 00:30у графайта есть http://graphite.readthedocs.io/en/latest/render_api.html
а для него есть некоторый выбор готовых скриптиков, типа https://github.com/prestontimmons/graphitejs
т.е. вы делаете свою страничку под юзера, с которой он может вызывать вышеназванный api, фильтруете его запросы на бэкенде, чтобы он из песочницы не вылез, и получается что-то вполне культурное.
собственно, с кибаной тот же подход применим.

renskiy
01.12.2016 10:25Я решил не разворачивать БД в каждом из датацентров, а сделать одно общее хранилище
А не быстрее/надежнее ли было чтобы каждый регион работал со своей БД? Ведь насколько я понял, данные пользователей никак не связаны между собой и можно хранить разных пользователей в разных БД, так?
Плюс, в каждом дата центре можно иметь свой локальный кэш с IP адресами юзеров (redis), которых GeoDNS периодически шлет в этот конкретный дата центр.doom369
01.12.2016 13:42А не быстрее/надежнее ли было чтобы каждый регион работал со своей БД?
Так и делаем. Сохранение в БД по сути лишь бекап данных.
Плюс, в каждом дата центре можно иметь свой локальный кэш с IP адресами юзеров (redis),
Частично так и есть. То есть кеш по сути есть для всех юзеров что принадлежат этому серваку и в редис запрос для них не делается. Кеш для всех пользователей не добавляю так как хочу иметь возможность мгновенно перенаправить траффик если понадобится.

Rulexec
01.12.2016 13:10Деплоитесь всё так же? kill, restart?
doom369
01.12.2016 13:44Да. Хотя пора бы уже написать какой-то автомейшн скрипт, что-то вроде:
app.sh start app.sh stopRulexec
01.12.2016 23:18Как запросов будет всё больше, кто-нибудь да заметит даунтайм.
Я бы подумал, как бы делать всё это дело бесшовно. На вскидку:
- Делаем так, чтобы могло работать два экземпляра сервера одновременно (проблемы в данном случае, как я понимаю, могут быть в основном из-за эксклюзивного доступа к файлам, в которые пишите)
- Запускаем приложение на каком-нибудь левом порту, например, 8001
- Настраиваем iptables на форвардинг 80 > 8001
- Когда хотим обновиться, поднимаем второй экземпляр, например, на порту 8002
- Перенастраиваем iptables на форвардинг 80 > 8002
- Посылаем первому экземпляру сигнал на завершение, на который оно должно дообработать текущие запросы, а больше и не придёт.
- Done.
Тут главное разобраться с iptables, чтобы оно случайно на половине TCP соединения не стало пакеты перебрасывать, а только новые. Если нельзя так — придётся свой роутер пилить.doom369
02.12.2016 00:06На самом деле, то что вы предложили легко решается с помощью Floating IPs. По простому — это айпи на которое можно вешать разные виртуалки. У меня пока не дошли руки до этого.
Ваш вариант тоже рабочий. Но он не подойдет если сам провайдер отключит виртуалку.

catanfa
01.12.2016 21:43Вы говорите, что используете одну-единственную ноду postgres. Но разве этот факт не означает, что в итоге всем клиентам, допустим, из Азии приходится всё равно ждать долгие пинги до постгреса? Или дело в том, что соединение с постгресом выполняется не на каждый запрос к вашему сервису?
doom369
01.12.2016 21:53+1Или дело в том, что соединение с постгресом выполняется не на каждый запрос к вашему сервису?
Именно. Каждый сервер вообще не делет никаких запросов по сети в момент когда получает реквест. Периодически (раз в 1 мин) все апдейты, которые накопил сервер скидываются в БД и на локальный диск. Локальный диск выступает по сути кешем, чтобы не ходить в БД (так как БД далеко и это увеличивает задержку).

IlyaSkriblovsky
05.12.2016 12:12Система на момент внедрения обрабатывала уже 4700 рек-сек. К кластеру постоянно были подключены ~3к устройств.
Я правильно понял, что устройства у вас посылают 1.5 запроса в секунду? Что-то как-то много.
Делаю очень похожий по сути сервис для сбора телеметрии с умных устройств, но на Python+MongoDB+Redis, поэтому ваш пост очень заинтересовал. И масштаб у меня примерно тот же — 10к устройств.doom369
05.12.2016 21:25+1Мы просто никак не ограничиваем пользователей в этом плане. Сколько хочешь столько и шли. Обычные IoT платформы берут деньги или за количество девайсов или за количество реквестов.
Я правильно понял, что устройства у вас посылают 1.5 запроса в секунду? Что-то как-то много.
Обычно на 1 устройство стараются повешать побольше сенсоров. 3 параметра телеметрии на 1 устройство классика, а если не ограничен батареей то можно постоянно быть онлайн и слать.
zapimir
У себя на Sypex Geo API тоже заморачивались с GeoDNS, и в итоге выбор пал на Zilore (очень понравился интерфейс, API хоть ещё и неофициальный, ну и конечно, то что он был бесплатный, а на начальном этапе, еще было непонятно насколько будет востребован наш сервис).
С архитектурой немного проще, для работы серверов достаточно простейших VPS (1 CPU + 512 МБ это даже с большим запасом). На серверах Nginx + PHP 7 (php-fpm) + Redis. Основной упор шел на общую отказоустойчивость и скорость получения данных.
Изначально база для учета запросов была на MySQL (точнее MariaDB), но потом от неё отказались в пользу Redis, а также схемы в которой есть пара контролирующих серверов (на них весит MySQL для общего учета, и синхронизации). Контролирующие сервера выполняют синхронизацию статистики между всеми рабочими серверами (сейчас их уже 11), она выполняется раз в минуту. Также если контролирующие сервера обнаруживают падение или неадекватное время ответа одного из рабочих серверов — с помощью API меняется DNS запись (TTL 60 секунд) и запросы идут на ближайший рабочий сервер.
doom369
Спасибо за ссылочку. Полезно.
Я решил Nginx не использовать, чтобы не заморачиватся с лишним деплойментом. У меня openSSL, epoll через яву.
zapimir
В Java же сама виртуальная машина много памяти жрёт, что повышает требования к железу. В моём случае, лучше эту память Redis'у отдать.
Насчёт Nginx, как-то в этом деле больше доверяю проверенному хайлоад решению, да и что там его деплоить. Добавить официальный репозиторий? Конфиг написан таким образом, что он подходит для любого сервера (отличие только в одном подключаемом файле, который добавляет в заголовки ответа реальное название и гео-расположение сервера).
В дальнейшем планируется перейти на Nginx + Go + Redis, пробовал Go + Redis, но пока как-то стремновато :)
doom369
На самом деле — нет. Жрут лишь библиотеки которые вы подключаете. Напимер hello world на java сам по себе будет потреблять лишь пару Мб памяти.
Джава тоже проверена временем и нагрузкой :). + я подключаю это через netty (готовый фреймворк). + по слухам netty быстрее Nginx (не проверял).
Думаю в Вашем случае должно взлететь.
vjjvr
GeoDNS работать не будет.
В принципе.
По той причине, что DNS кэшируется.
И кто второй с кэширующего сервера возьмет ваш IP-адрес — уже никак вы к географии не привяжите.
zapimir
Если бы GeoDNS не работал, то это было бы заметно по трафику. Так как TTL 60 секунд, то теоретически должны быть скачки трафика с одного сервера на другой (так как нагрузка по серверам не равномерна), в зависимости от того, кто первый зайдет и обновит данные в кэширующем сервере.
Так что не всё так плохо, тем более, что есть возможность указать на какой конкретно сервер вы хотите заходить для получения данных.
vjjvr
60 секунд TTL опять таки может сработать только для первого, кто запросит адрес спустя 60 секунд.
А все 1000 вторых, кто запросят адрес в промежутках между ними (если их провайдер кэширует с того же вторичного DNS) — получат именно кэш.
Кстати, вы знали, что многие дешевые домашние роутеры кэшируют DNS намертво и игнорируют TTL вплоть до своей перезагрузки?
Так как запрос к GeoDNS идет вовсе не с клиента — то Geo может сработать только относительно DNS-серверов, а не конечных клиентов.
А еще многие используют независимый от провайдера 8.8.8.8 и т.п. — тут ситуация еще хуже.
То есть если DNS провайдера хоть о чем то может сказать, то 8.8.8.8 не говорит вообще не об чем.
;)
GeoDNS, возможно, может как-то распределять (балансировать) запросы.
Но свою функцию Geo именно в смысле DNS он выполнить не сможет в принципе, — ибо таковы принципы устройства DNS.
Многоуровневость DNS мешает это сделать.
zapimir
Вы только забыли, что подобные DNS обычно работают по Anycast. Даже тот же 8.8.8.8 это не один сервак и соответственно кэширующие сервера на пути к DNS так же разные оказываются. Да и сам 8.8.8.8 из разных регионов будет выдавать разные IP серверов.
Так я об этом и говорил, вот есть к примеру у нас два сервера один в Нидерландах, другой в Германии, вроде как совсем рядом, но при этом в Германию трафик в 10 больше. Если бы GeoDNS не работал, то как вообще попадают на нидерландский сервак? И если бы работал именно так как Вы пишете, то трафик бы распределялся скачкообразно. Т.е. зашел чел из Германии весь трафик в течении минуты идет в Германию, в следующую минуту первым зашел из Нидерландов — минуту все идут в Нидерланды. Но такого поведения не наблюдается. Также весьма быстро в течении пары минут весь трафик перекидывается с одного сервера на другой, так что теории о том, что куча DNS игнорируют TTL также не подтверждаются на практике.
Понятное дело, что GeoDNS не идеальны, но в целом на практике показывают себя вполне неплохо. По крайней мере это справедливо для Anycast GeoDNS (возможно, если бы юзали свой сервак с патченым BINDом, было бы хуже). Да и в нашем случае, поскольку данные синхронизируются — не страшно, если человек попадет не на тот сервер.
Вот для примера выполнил с 6 серверов (Украина, Россия, Германия, Нидерланды, США, Франция).
nslookup api.sypexgeo.net 8.8.8.8
Запрос выполнялся одновременно (в Xshell, отправить команду во все сессии). Все 6 выдали разные IP, соответствующие настройкам GeoDNS, хотя все запросы идут к 8.8.8.8, и по вашей теории, все должны получить одинаковые IP.
Для нас сейчас единственная проблемка с GeoDNS — что нет разделения крупных стран на регионы. К примеру в России у нас 4 сервера раскиданных по стране, но нормально раскидать трафик по ним нельзя (чтобы люди из Владивостока не отправлялись в Москву). Хотя в Zilore и обещают добавить такой функционал.
vjjvr
1. Провайдеровские DNS — работают без каких либо Anycast. А вот у крупных хостеров — у тех да, бывают реализации с Anycast. Но только у крупных. Это отнюдь не общепринятая практика, а редкое, но приятное исключение.
2. Но это не имеет никакого значения. На самом деле с Anycast GeoDNS работает еще хуже. Из-за временного сбоя/аварии/просто задержке на каком-то маршруте клиент свяжется вовсе не с ближайшим сервером.
3. Строго говоря, Anycast реагируется не столько на географию, сколько на связанность в интернете.
4. В цепочке определения адреса IP по имени DNS может быть вовсе два сервера.
Вывод:
GeoDNS как-то там распределяет адреса.
Но нет никакой гарантии, что делает это географически корректно.
Ошибка может быть на внесена в десятке мест.
Отнюдь.
Пути в интернете не меняются каждые 60 секунд. Они не зависят от TTL DNS.
Поэтому при повторном обращении DNS-сервера хостеров стабильно перекидывают клиентов на все те же сервера (если за время предыдущего 60-ти секундного интервала не было аварий в интернете и пути не перестроились).
Они всего лишь хоть как-то балансируют трафик.
Но без гарантий, что будет выбран ближайший сервер.
Люди, имеющие тяжелый трафик, для которых это важно — разбирались с вопросом гораздо глубже, чем вы. И сделали неутешительный вывод: балансировка по DNS не работает. От слова совсем.
https://habrahabr.ru/company/ivi/blog/237349/
zapimir
Что-то Вы забыли прокомментировать, как одновременный запрос на 8.8.8.8 из 6 разных мест выдал 6 разных IP?
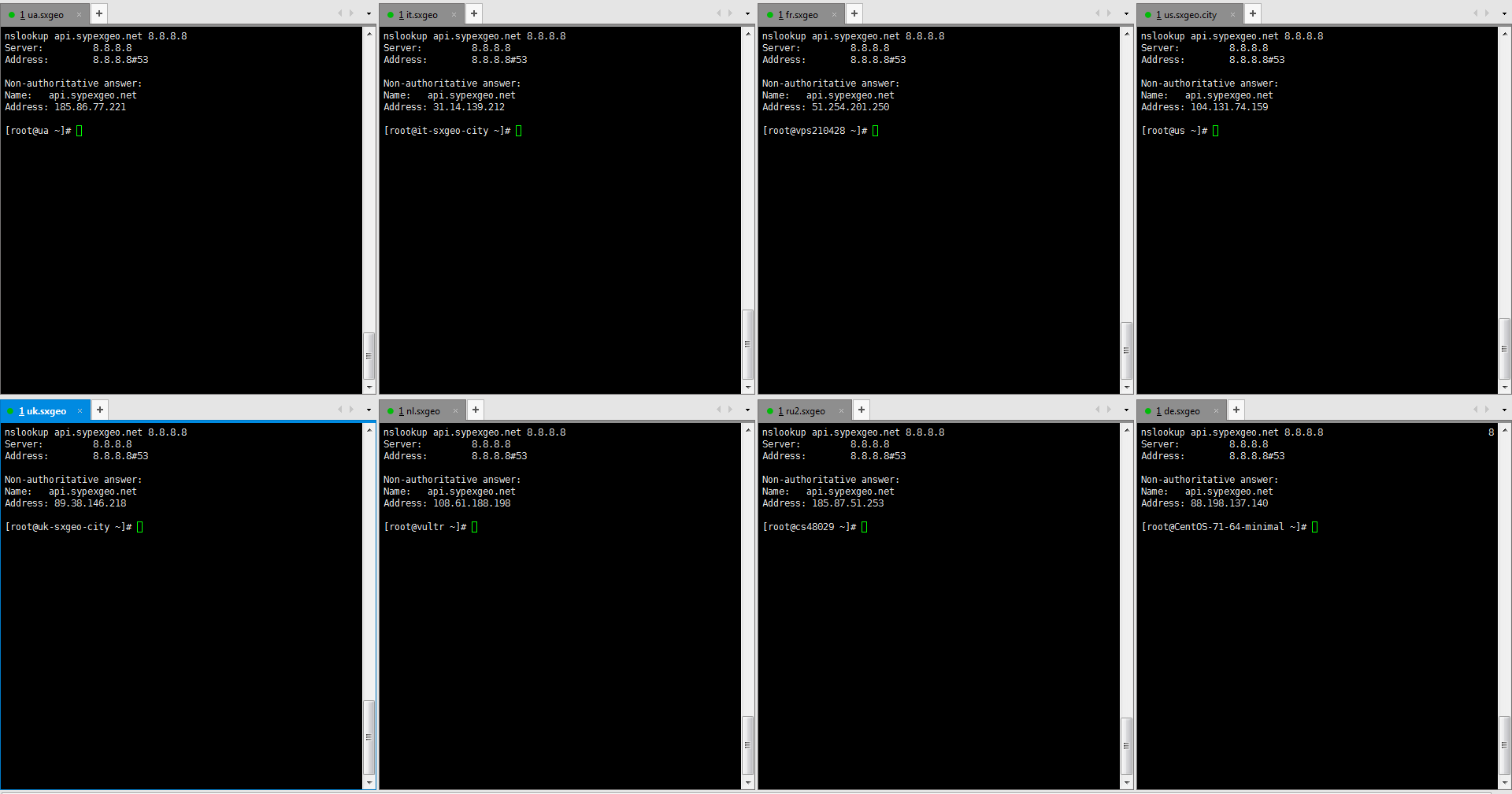
Что касается статьи Вы вообще читали её? Они рассматривали GeoDNS на собственном отдельном сервере. Понятное дело, что если пускать весь трафик на один DNS сервер в Москве, который будет раскидывать по другим серверам, то это далеко не то же самое, что использовать Anycast GeoDNS от того же Zilore. Опять же, что касается Google DNS у человека в статье сугубо теоретические заблуждения, которые опровергаются, тем же nslookup с разных серверов, вот скриншот.
Как GoogleDNS выдал 8 разных IP для одного адреса? Так, что говорить о том, что GeoDNS не работает совсем — это заблуждение. Да я согласен, что он не всегда оптимально работает (так как у некоторых провайдеров, может трафик весьма загадочно ходить), и лучше бы было Anycast решения, но это уже зависит от рентабельности. И то, что не подходит для CDN, вполне подходит для сервисов у которых множество легких запросов, а не раздача кучи видео-контента.
doom369
Небольшое уточнение. Мы используем Amazon сервера из Route 53.
zapimir
Пардон, это не Вас касалось, а статьи в предыдущем комменте, на основе которой делается вывод, что GeoDNS не работают принципиально.
doom369
А. Тогда продолжайте :). Много интересного узнал.