

Всем привет. Кто-то из вас, возможно, уже знаком с СУБД для данных в оперативной памяти, но на всякий случай — по ссылке можно найти их общее описание. Если вкратце, такие СУБД хранят данные целиком в оперативной памяти. Что это означает? Каждый раз, отправляя запрос на поиск или обновление данных, вы обращаетесь только к оперативной памяти в обход жесткого диска — на нем никакие операции не производятся. И это хорошо, потому что оперативная память работает намного быстрее любого диска. Примером такой СУБД является Memcached.
Секундочку, скажете вы, а как же восстановить данные после перезагрузки или поломки машины с такой СУБД? Если на машине установлена СУБД для хранения данных только в оперативной памяти, о них можно забыть: при отключении питания данные бесследно исчезнут.
Можно ли объединить достоинства хранения данных в оперативной памяти с надежностью проверенных временем СУБД вроде MySQL или Postgres? Конечно! Повлияет ли это на производительность? Вы удивитесь, но нет!
Встречайте СУБД для данных в оперативной памяти, обеспечивающие их сохранность: Redis, Aerospike, Tarantool.
Вы можете спросить, как же эти СУБД обеспечивают сохранность данных? Фокус в том, что все данные по-прежнему хранятся в оперативной памяти, но каждая операция вдобавок записывается в расположенный на диске журнал транзакций. Посмотрите на изображение ниже:
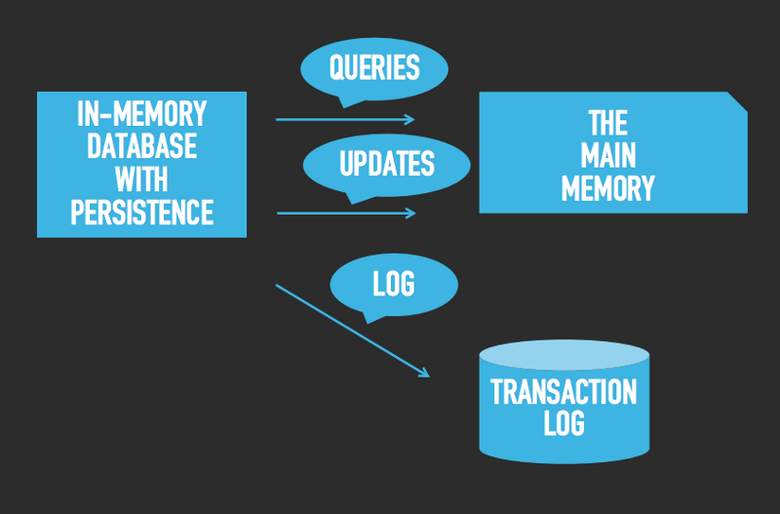
Первое, что вы, возможно, вынесете из этой схемы, — скорость исполнения запросов нисколько не страдает, несмотря на то что теперь СУБД постоянно создает записи в журнале. Производительность при этом не проседает, потому что все запросы по-прежнему обращаются напрямую к оперативной памяти. Отличные новости! :-) А как обстоят дела с обновлением данных? Каждое обновление (назовем его транзакцией) не только происходит в оперативной памяти, но и записывается на диск. На медленный диск. Такая ли это проблема? Давайте посмотрим на следующее изображение:

Транзакции всегда записываются в самый конец журнала. В чем плюс такого подхода? Диск работает довольно быстро. Если говорить о классическом жестком диске (HDD), он может записывать данные в конец файла со скоростью до 100 Мбайт/с. Не верите? Запустите этот тест из командной строки в Unix/Linux/macOS:
cat /dev/zero >some_fileИ посмотрите, как быстро увеличивается размер
some_file. Итак, жесткий диск весьма проворен при последовательной записи, однако его скорость резко падает при произвольной записи: обычно он способен выполнить около 100 таких операций. При побайтовой записи, когда каждый байт записывается в произвольное место на жестком диске, вы можете увидеть, что реальная максимальная производительность диска составляет 100 байтов/с. Еще раз, всего-навсего 100 байтов/с! Разница в шесть порядков между пессимистичной (100 байтов/с) и оптимистичной (100 000 000 байтов/с) оценками скорости доступа к диску столь велика потому, что для поиска по произвольному сектору на диске требуется физическое движение головки диска, тогда как при последовательном доступе можно считывать данные по мере вращения диска; головка при этом остается неподвижной.
Если говорить о твердотельном накопителе (SSD), здесь ситуация лучше из-за отсутствия движущихся частей. Однако соотношение пессимистичной (1—10 тысяч операций в секунду) и оптимистичной (200—300 Мбайт/с) оценок остается практически неизменным: четыре-пять порядков. Подробнее с этими показателями можно ознакомиться по ссылке.
Таким образом, наша СУБД для данных в оперативной памяти, по сути, наводняет журнал транзакциями со скоростью до 100 Мбайт/с. Достаточно ли это быстро? Очень быстро. Предположим, размер транзакции составляет 100 байтов, тогда скорость будет равняться миллиону транзакций в секунду! Это настолько хороший показатель, что вам абсолютно точно не придется волноваться о производительности диска при использовании подобной СУБД. По ссылке ниже находится подробный тест производительности одной СУБД в оперативной памяти при обработке миллиона транзакций в секунду, где проблемным элементом является не диск, а процессор:
> https://gist.github.com/danikin/a5ddc6fe0cedc6257853.
Подведем итог всему вышесказанному о дисках и СУБД в оперативной памяти:
- СУБД в оперативной памяти не обращаются к диску при обработке запросов, не изменяющих данные.
- СУБД в оперативной памяти все-таки обращаются к диску при обработке запросов, изменяющих данные, но работают с ним на максимальной скорости.
Почему же традиционные дисковые СУБД не берут на вооружение описанные техники? Во-первых, в отличие от СУБД в оперативной памяти, в традиционных СУБД необходимо считывать данные с диска при каждом запросе (давайте ненадолго забудем про кеширование, это тема для отдельной статьи). Заранее неизвестно, каков следующий запрос, поэтому можно считать, что каждый раз будет требоваться произвольный доступ к диску, а это, напомню, пессимистичный сценарий.
Во-вторых, дисковые СУБД должны сохранять данные таким образом, чтобы измененные данные можно было немедленно считать, в отличие от СУБД в оперативной памяти, которые не считывают с диска, за исключением случаев, когда при старте запускается восстановление. Именно поэтому для быстрого считывания дисковым СУБД нужны особые структуры данных, чтобы избежать полного сканирования журнала транзакций.
Одна из таких структур — B/B+-дерево, ускоряющее считывание данных. Недостатком этого дерева является необходимость изменять его при каждом меняющем данные запросе, что может привести к падению производительности из-за произвольного доступа к диску. Довольно много движков СУБД основано на B/B+-деревьях, из популярных можно назвать InnoDB от MySQL и движок Postgres.
Существует другая структура, которая лучше справляется с записью данных, — LSM-дерево. Это относительно новый тип деревьев, который не решает проблему произвольного считывания, но помогает избавиться от части проблем, связанных с произвольной записью. Примерами движков, использующих такие деревья, могут служить RocksDB, LevelDB или Vinyl. На изображении ниже приведена сводная информация о типах СУБД и используемых ими деревьях:

Резюмируем вышесказанное: СУБД в оперативной памяти, обеспечивающие сохранность данных, как при считывании, так и при записи могут работать очень быстро, а точнее — так же быстро, как и СУБД в оперативной памяти, которые не сохраняют данные на диске: первые используют диск настолько эффективно, что он никогда не становится проблемным местом.
P. S.
Последняя — по порядку, но не по значимости — тема, которую я хотел бы затронуть в статье, посвящена снимкам состояния. Снятие таких снимков необходимо для компактификации журналов транзакций. Снимок состояния базы данных — это копия всех имеющихся данных. Снимка и журналов с последними транзакциями достаточно для восстановления состояния вашей базы данных. Поэтому, имея свежий снимок состояния, можно удалять все старые журналы транзакций, предшествующие дате снимка.
Зачем компактифицировать журналы? Потому что чем больше журналов, тем дольше будет восстановление базы данных. И потом, вам ведь не хочется захламлять диск устаревшей и бесполезной информацией (ну хорошо, старые журналы иногда здорово выручают, но давайте поговорим об этом в отдельной статье).
По сути, периодически делая снимки состояния, вы целиком копируете базу данных из оперативной памяти на диск. Как только копирование закончилось, можно смело удалять все журналы, в которых нет транзакций, записанных позже последней транзакции в вашем снимке состояния. Довольно просто, не так ли? А все потому, что все транзакции начиная с самого первого дня попадают в снимок.
Вы могли задаться вопросом: как сохранить консистентное состояние базы данных на диск и как определить последнюю зафиксированную в снимке транзакцию при условии постоянного поступления новых транзакций? Об этом мы поговорим в следующей статье.
Комментарии (190)

outcoldman
01.12.2016 17:48+1Если кто-то действительно заинтересован разобраться в вопросе рекомендую:
- Lecture #02 — In-Memory Databases [CMU Database Systems Spring 2016] (весь курс хорош).
- OLTP Through the Looking Glass, and What We Found There (в лекции есть ссылка на эту статью о overhead, который существует в disk oriented DB, потому что они были реализованы под старую архитектуру).
В общем автор статьи делает упор на то, что БД в памяти просто быстрее работают, потому что пишут только в память, а она быстрее.
Так же делает упор, что в disk oriented DB, в плохом случае, при каждом чтении мы будет лезть на диск. Что подразумевает, что он сравнивает in-memory DB запущенную на PC при достаточным объемом памяти с disk oriented DB, у которой нет достаточно памяти, чтобы держать необходимые страницы в buffer pool.
vdmitriyev
01.12.2016 19:23+1Спасибо за ссылку на лекцию от CMU. В свою очередь могу порекомендовать материал аффилированный с SAP, но его стоит воспринимать только в качестве"концепта" в рамках БД в памяти — https://hpi.de/plattner/research/in-memory-data-management-for-enterprise-systems.html.

danzalux
07.12.2016 12:27И ещё один отличный курс, уже от open.hpi, на ту же тему. Ведёт «сам» дядько Платтнер (один из основателей SAP-а). Все видео и слайды доступны «безвоздмездно и без СМС», т.е. даром. Рассказывается и про историю идеи, и про концепт, и про внутреннее устройство.
In-Memory Data Management 2015
https://open.hpi.de/courses/imdb2015

danikin
01.12.2016 20:01Отчасти. В вопросе чтения — согласен с вами. И тут про сравнение с дисковой СУБД с buffer pool будет отдельная статья. В вопросе записи — не согласен. Запись в дисковой СУБД идет в B/B+ дерево как ни крути. И это медленней чем запись последовательно в файл.
outcoldman
01.12.2016 20:22+1Я не совсем понимаю о чем мы тут говорим.
Насколько я понимаю in-memory db vs disk oriented dbs. Дисковые БД в большинстве случаев будут медленнее, чем in-memory. Даже в случае чтения, потому что нет overhead на buffer pool, по другому организованы locking & latching, а так же используется другая схема организации данных в памяти, другой concurrency control. Это как раз и дает хороший прирост производительности, даже для чтения.
Есть огромное количество in-memory Db, которые даже и не задумываются о durability, то есть совсем не пишут на диск.
В всех мне известных нормальных disk oriented БД так же происходит запись сначала в transaction log, что подразумевает под собой последовательную запись.danikin
01.12.2016 21:04«Насколько я понимаю in-memory db vs disk oriented dbs. Дисковые БД в большинстве случаев будут медленнее, чем in-memory… » — на 100% согласен с этим абзацем!
«Есть огромное количество in-memory Db» — да! Но некоторые делают это и делают это правильно. Как делать это правильно — как раз написано в статье. Разумеется, по верхам, без деталей.
«В всех мне известных нормальных disk oriented БД так же происходит запись сначала в transaction log, что подразумевает под собой последовательную запись.» — Да. Но кроме этого запись происходит еще и в B/B+ дерево. И вот это есть рандомная запись на диск и это есть медленно.outcoldman
01.12.2016 21:23> Как делать это правильно — как раз написано в статье.
Правильно? Просто писать transaction log? А после restart ждать вечность, пока индексы опять построятся и данные загружаться в память?
> И вот это есть рандомная запись на диск и это есть медленно.
Ну она не влияет на саму запись в БД, это все делается отдельным working thread, притом все это может batching.
Чтобы меня правильно поняли — я за эту статью, просто хотелось дополнить, так как верно замечено «Разумеется, по верхам, без деталей.». :)danikin
01.12.2016 21:41-1«Правильно? Просто писать transaction log? А после restart ждать вечность, пока индексы опять построятся и данные загружаться в память? » — не совсем. Дочтите статью до конца. Там где про снимки состояния.
«Ну она не влияет на саму запись в БД, это все делается отдельным working thread, притом все это может batching.» — влияет, к сожалению. Потому что все что ушло в лог транзакций, но не записалось в дерево хранится в памяти. Рано или поздно эту память надо сбросить на диск в дерево. Механизма компактификации лога транзакций у дисковых СУБД нет (см. P.S. в моей статье про компактификацию лога транзакций), поэтому, чтобы восстановление не заняло вечности надо данные таки записать в дерево на диске, не дожидаясь даже пока кончится оперативная память. Упомянутый вами батчинг помогает лишь отчасти. Когда у вас идут случайные изменения строк в СУБД (это типичный workload), то батчи-не-батчи, все равно каждый батч надо распихать по разным частям дерева.
«Чтобы меня правильно поняли — я за эту статью, просто хотелось дополнить, так как верно замечено «Разумеется, по верхам, без деталей.». :)» Все верно :)
Breslavets
09.12.2016 10:57****************************************
Упомянутый вами батчинг помогает лишь отчасти. Когда у вас идут случайные изменения строк в СУБД (это типичный workload), то батчи-не-батчи, все равно каждый батч надо распихать по разным частям дерева.
********************************************
Это никак не влияет на время отклика.
По коммиту все не записанные данные из буфферного пула лога(память), пишутся ПОСЛЕДОВАТЕЛЬНО в лог-файл.
По завершению процесса клиенту сообщается о завершении commit(транзакции).
База НЕ ждет записи страниц памяти(измененных таблиц) в датафайлы.
Это может произойти довольно нескоро и делается это отдельным процессом-потоком.
И еще в дерево пишутся не кусочки информации, а страницы, по специальным алгоритмам, удерживающих в памяти часто используемую информацию.
Даже для отдельных таблиц можно указать приоритет удерживания их блоков в памяти.
Я к тому, что если в сервере есть много памяти, то при желании можно сделать из обычной базы почти In-memory…
danikin
09.12.2016 12:04-1«База НЕ ждет записи страниц памяти(измененных таблиц) в датафайлы. » — в общем случае это неверноу утверждение. Например, когда делается UPDATE, то надо подсчитать rows affected и вернуть это клиенту. Т.е. одной записи в лог транзакций мало, надо реально дождаться записи в табличное пространство, чтобы точно понять, сколько зааффектится row. Причем, это не только запись в индексы, но и чтение из индексов в перемешку. И все это с рандомным перемещением головки, потому что различные row и части индекса, которые изменяются, находятся в разных местах диска.
Если вся база целиком закэшированна в памяти, то это может дать гарантию, что вся информация, которая нужна, чтобы вернуть результат UPDATE (да и INSERT, кстати, тоже — ибо надо проверить на duplicate key), находится в кэше. Т.е. я частично с вами соглашусь — это закэшировать все целиком + иметь дополнительно ооочень много памяти, чтобы держать огромный write back буфер, то это будет чем-то похоже на in-memory.
Правда, будет все равно хуже чем in-memort:
1. Будет хуже по пропускной способности на запись, потому что рано или поздно надо записать данные в индексы рандомно. Страницы по специальным алгоритмам — это все равно рандомная запись страниц и это все равно не как у in-memory — полностью последовательный сброс снимка на диск, повторюсь еще раз, всегда при любых условиях, гарантрованно, последовательный.
2. Даже при наличие большого количества памяти нельзя хранить изменения в write back буферах вечно, потому что при старте тогда надо будет проиграть огромный накопившийся лог транзакций. И тут два варианта — или лог проигрывается всегда в память (забываем про табличное пространство и по сути держим всю базу в памяти, всегда проигрывая лог) или проигрывается при старте в табличное пространство. Оба варианта хуже чем in-memory. В первом варианте вам надо проигрывать огромный лог изменений vs снимок + небольшой лог изменений. Во втором варианте вам надо проиграть изменения не в память, а не диск и рандомно (изменения идут в случайном порядке, а не в таком, в каком бы вам хотелось и поэтому на диск в табличное пространство и индексы тоже применяется в случайном порядке).
3. Будет хуже по памяти, те понадобится больше памяти. Как минимум для write back буферов, которых у in-memory базы нет. И для кэша, потому что кэш — это структура данных оптимизированная под быстрое наполнение и освобождение, из-за чего жертвуется пространством. Например, если на диске страница с дырками, то и в кэше она с дыркам — чтобы быстрее читаться с диска без лишнего парсинга. Почитайте про устройства буферного пула в MySQL (InnoDB) тут: https://www.percona.com/files/percona-live/justin-innodb-internals.pdf и тут: https://michael.bouvy.net/blog/en/2015/01/18/understanding-mysql-innodb-buffer-pool-size/
GlukKazan
09.12.2016 12:23Например, когда делается UPDATE, то надо подсчитать rows affected и вернуть это клиенту. Т.е. одной записи в лог транзакций мало, надо реально дождаться записи в табличное пространство, чтобы точно понять, сколько зааффектится row
Это ещё зачем (исходим из того что все необходимые для запроса данные закешированы (повезло) и блокировка наложена успешно). Зачем ждать сброса грязных данных для ответа на update??? Строго говоря, тут и записи в REDO дожидаться не обязательно, транзакцию же не закрываем.danikin
09.12.2016 12:38-1Если мы исходим из того, что повезло, то да, ждать не надо. Все будет хорошо. За исключением пп.1,2,3 выше.
В вашем утверждении «База НЕ ждет записи страниц памяти(измененных таблиц) в датафайлы. „ не было сказано, что повезло. Оно было сделано безусловно.GlukKazan
09.12.2016 12:47Не в моём, но я всё равно не улавливаю логику. Если требуемых данных не оказалось в кэше, то их надо прочитать с диска. Зачем ждать запись на диск при выполнении update? И как это связано с подсчётом количества изменённых строк?
danikin
09.12.2016 15:56Записи ждать не надо, вы правы. Но чтение надо сделать, если данных нет в кэше (что вы сами и сказали) — и это рандомное обращение к диску, которое портит всю картину, что, в общем не сильно лучше, если даже дождаться записи.
Breslavets
09.12.2016 14:43+2+++++++++++++++++++++++++++++++
Т.е. одной записи в лог транзакций мало, надо реально дождаться записи в табличное пространство, чтобы точно понять, сколько зааффектится row.
++++++++++++++++++++++++++++++++++++++
Даже дальше читать не стал.
Я вам говорю как это есть в коммерческих СУБД, а не то, что вам представляется.
Изменения делаются только в буфере(в памяти) страниц(копии блоков таблиц и индексов в памяти).
Также делается запись в БУФЕР(память) лога.
По коммиту буфер лога сбрасывается в лог(redo write ahead).
ВСЁ — пользователю сообщается о успешном коммите.
Причем по коммиту сбрасываются данные не только своей транзакции, а всего что было до.
Если закешировать всю таблицу, то не потребуется и чтения блоков с диска при UPDATE.
А вот запись в датафайлы НИКАК не связана с временем отклика.
Это ассинхронный процесс для обеспечения чекпоинтов, которые будут использоваться при восстановлении и обеспечивают моменты времени в которые можно считать, что все блоки из памяти были записаны на диск(датафайлы).danikin
09.12.2016 15:53Если памяти хватает, чтобы хранить все грязные страницы всегда, тогда вы правы. Я придрался выше к тому, что в общем случае утверждение было неверно. Еще раз, если памяти хватает, то все хорошо. Но все равно будет работать медленнее чем in-memory и потреблять больше памяти, просто потому что in-memory заранее оптимизирована под работу, когда все всегда в памяти.
Breslavets
09.12.2016 18:32В каком общем случае?
Утверждение верно, почитайте про Write-ahead logging…
перед написанием следующей статьи, то что вы описали в статье всё точно также работает и в обычных базах. И запись в редо-лог и снапшоты(чекпоинты), нет только фазы загрузки базы в память на старте.
Вот этот ваш текст об обычных базах в корне не верен и заморочит не одну неокрепшую голову — «надо реально дождаться записи в табличное пространство»:
********************************************************
Breslavets
«База НЕ ждет записи страниц памяти(измененных таблиц) в датафайлы. »
danikin
— в общем случае это неверноу утверждение. Например, когда делается UPDATE, то надо подсчитать rows affected и вернуть это клиенту. Т.е. одной записи в лог транзакций мало, надо реально дождаться записи в табличное пространство, чтобы точно понять, сколько зааффектится row. Причем, это не только запись в индексы, но и чтение из индексов в перемешку. И все это с рандомным перемещением головки, потому что различные row и части индекса, которые изменяются, находятся в разных местах диска.
***********************************************************************danikin
09.12.2016 18:39Если есть труба, которая слева широкая, а справа — узкая и в нее втекает слева вода, заполняя все сечение трубы, то какая бы не была длинная эта труба, рано или поздно в нее будет втекать слева ровно столько воды сколько и вытекает справа. Т.е. узость трубы справа будет узким местом и будет влиять на количество воды, которое может втечь в нее в единицу времени слева.
Базе хошь-не-хошь придется дожидаться флаша грязных страниц на диск, потому что не будет хватать памяти, чтобы сохранять в ней грязные изменения. Если только, еще раз повторю, если только вся база целиком не закэширована в памяти. Т.е. в общем случае ваше утверждение остается неверным.Breslavets
09.12.2016 18:56+1типа выкрутились… :)
Этот текст уже правильный и сильно отличается от исходного, а то меня уже пугало,
что вы там собрались что-то писать про обычные базы.
Но огорчу, описанных проблем не возникает при как я писал адекватном железе, софте и админе. Чекпоинт плавненько идет не надрывая систему.
И тем не менее, то что вы написали можно отнести и к In-memory базам, когда им не хватит памяти…
Кроме того ждемс описания чудесато-шустрого процесса создания чекпоинта, т.е. снапшота.
Как это сделано в In-memory базе без рэндом записей?
Что весь кусок памяти(всю базу) на диск?
Но такое часто не поделаешь.Breslavets
09.12.2016 19:01+1Повторюсь, не пытаюсь доказать, что из обычной базы можно сделать полный эквивалент базы в памяти.
Можно сделать «почти» в каком-то варианте.
Но читать заблуждения о обычных базах тоже не хочется.
Вам не надо спешить, в том числе и со статьями.danikin
09.12.2016 19:06Я уже понял, что я кривовато сформулировал. И уважаемая бородатая общественность — любители старых добрых баз — тут же прицепилась к этому. Ну что ж, каждый получает удовольствие по своему.
danikin
09.12.2016 19:04Вы забыли добавить, что еще при адекватных пользователях, которые не создают нагрузку в 100K запросов в секунду :-)
Ибо, если пользователи не такие адекватные, то проблем не возникает только лишь при соответствующей настройке базы, чтобы она все грязные страница флашила путем последовательнорго обхода всей базы, чтобы не упираться в рандомную запись, а это значит, что пока она обходит должно быть место в памяти для хранения всех грязных страниц, что, в свою очередь, при равномерно распределенной нагрузке по всей базе почти неизбежно означает, что нужно в памяти хранить всю копию базы. Я этот тезив в том или ином виде повторяю уже Nый раз, и в ответ слышу лишь про магические хорошие настройки и тд без конкретнго объяснения физике процесса как узкая труба становится широкой.
in-memory базам хватает памяти. Они просто не работают, когда кончается память. Это не повод для гордости. Но это обратная строна медали, с которой надо мириться заранее при проектировании приложения. Ровно также как обычные базы перестают работать при нагрузке хотя бы 1/10 от in-memory баз, даже если все сидит в кэше. И с этим фактом тоже надо мириться заранее при проектировании приложения.
Вест кусок, да на диск. Описал тут в деталах в одном из коментов. И это можно делать часто, ибо это происходит линейно, диск не нагружая, оставляя много IOPS'ов для REDO.Breslavets
09.12.2016 19:39*************************************
Ровно также как обычные базы перестают работать при нагрузке хотя бы 1/10 от in-memory баз, даже если все сидит в кэше. И с этим фактом тоже надо мириться заранее при проектировании приложения.
***************************************************
Ну для того их и придумали, в памяти…
Oracle и Oracle TimesTen In-Memory Database :)
Кому не надо такой скорости хватит и обычных СУБД.
Про пользователей не совсем понятно, но по кэшу вам любой админ скажет, что в разогретой базе процент попадания в кэш идет под 100%.(тут могут быть тонкости с этими процентами, но в целом...).
Т.е. они практически ин-мемори. :)danikin
09.12.2016 20:36К утру сошлись на трех рублях :-)
В разогретой базе процент попадания в кэш высокий. Вопрос в том, как быстро работает это кэш версус ин-мемори база. Обычно хорошо, если в 10 раз медленнее, как я написал выше. Плюс его разгорев — это отдельная боль, я уже писал про это.
danikin
09.12.2016 20:36Не туда подцепил ответ )
К утру сошлись на трех рублях :-)
В разогретой базе процент попадания в кэш высокий. Вопрос в том, как быстро работает это кэш версус ин-мемори база. Обычно хорошо, если в 10 раз медленнее, как я написал выше. Плюс его разгорев — это отдельная боль, я уже писал про это.
Breslavets
09.12.2016 14:54--Правда, будет все равно хуже чем in-memort:
Я не вдаюсь в детали и не утверждаю обратного.
Но отмечаю, что конкретный момент увязки времени отклика и завершения процесса записи информации в базу освещен не верно.
Тут только добавляется время чтения блоков, если их нет в кэше.
Но я специально оговорил, что мы рассматриваем закешированную таблицу/индексы.
danikin
09.12.2016 15:53См. мой комент выше. Если закэшировать вообще все и вся, то да.
Breslavets
09.12.2016 16:00Да вы так и не поняли про запись.
Вам пытаются сказать, что коммерческие СУБД делают изменения таблиц-индексов ВСЕГДА в кэше(в памяти).
Запись по коммиту ведется только в редо-логи.
И запись в табличные пространства не влияет на время отклика в любом случае, так как она производится для измененных блоков во всей базе (любыми транзакциями) асинхронно от конкретной транзакции, а не как вы считаете, специально для конкретной транзакции что-то пишется в табличные пространства по коммиту.
Мы конечно говорим про нормально настроенную базу с адекватным железом и админом.
Breslavets
09.12.2016 17:14Кстати в статье запись тоже производится думаю примерно также и для тех же целей — то что в статье называется снимком(чистый чекпоинт в обычных базах).
Т.е. измененная информация даже в этих in-memory базах также пишется на диск в табличные пространства как и в обычных базах(независимо от комита в конкретной транзакции), иначе после перезагрузки не будет данных :).
В целом, по статье, я вижу отличие от обычных баз только в том, что при старте такой базы она полностью «восстанавливается» в память, ну и другие структуры — хотя это неправильный подход — на физическом уровне в обычных базах может быть что угодно.
В обычных базах мы можем указать таблицы, блоки которых хотим держать по возможности в памяти.danikin
09.12.2016 18:44Снимок можно делать реже или чаще — это никак не влияет на скорость работы IMDB. Это влияет только на скорость восстановления.
Насчет неправильного подхода — вопрос спорный. Вы можете настроить Oracle или вашу любимую классическую СУБД так, чтобы она заданные таблицы сразу на старте целиком загружала в память, вместе с индексами и с данными и никогда бы их из памяти не убирала и хранила бы их в памяти эффективно с точки зрения потребления памяти, а на также как эти данные представлены на диске? Если можете, то поделитесь, пожалуйста, настройками — я проведу бенчмарки на чтение таких таблиц. Если окажется, что они будут работать по скорости хотя бы рядом с IMDB, то я сниму перед ваши шляпу.Breslavets
09.12.2016 19:26*****************************************
Снимок можно делать реже или чаще — это никак не влияет на скорость работы IMDB. Это влияет только на скорость восстановления.
**************************************************
Вот, в обычных системах точно также, особенно если вспомнить, что в IMDB может памяти не хватить.
Ну и опять же при условии адекватности софта-железа-админа :)
Конечно почти также, иначе не придумывали бы IMDB.
Может получиться, что процесс записи нагружает хранилище и
это может сказаться скорости чтений блоков.
Но всё должно быть сбалансировано под задачу.
Не понял про «неправильный» подход…
Я говорил о неправильном вашем понимании шагов, которые выполняет СУБД при DML+commit.
И всегда подчеркивал, что полную IMDB из обычной не сделаешь.
Все же от задачи зависит.
Я, например знаю систему, в которой использовали Oracle In-Memory, а потом поняли, что хватит и обычного Oracle.
Если база редко перегружается и правильно настроена, то необходимые блоки будут всегда «разогреты»(почти :) ).
Breslavets
09.12.2016 20:31Перечитал про «неправильность» — ясно о чем…
Я там к тому, что выдвигать физические способы хранения-доступа на первый план не совсем корректно.
Есть обычные базы со своими запатентованными методами хранения-поиска…
Или, я например не уверен, что даже то же упомянутое LSM-дерево
не используется в каких-то обычных базах — почему нет?
В целом не эта рутина интересна и важна, если именно она конечно не решает проблемы, которые есть в обычных базах.
danikin
09.12.2016 20:39Еще раз повторюсь. Если вся база влезла в кэш, то тогда все хорошо. В противном случае аналог снимка (флаг грязных страниц) будет не успевать отрабатывать целиком, пока будут приезжать новые грязные страницы, и в этот момент придется задерживать клтиента пока не завершится флаш. Если вы считаете, что не придется, то куда тогда будут применяться изменения, если память кончилась? Только в REDO?
danikin
09.12.2016 18:40Если у вас достаточно памяти, то да. Если недостаточно памяти, то асинхронный процесс в какой-то момент превратится в синхронный, потому что не будет памяти, чтобы сохранять в ней грязные страницы.
Breslavets
09.12.2016 19:29Такого не бывает в коммерческих системах.
Если пЫонэр какой на коленках что-то наваял… да и продал… да еще и дали всё это «1C'нику админить…danikin
09.12.2016 20:41Это означает, что в вышеуказанных коммерческих системах размеры кэшей или буферных пулов задраны настолько высоко, что для данного паттерна нагрузки то, что я написал выше никогда не случается.
Breslavets
10.12.2016 17:12-1Перечитал еще раз, и увидел еще одно заблуждение по поводу обычных СУБД.
Даже не понял сначала с этой терминологией…
Снимки в IMDB — это аналоги чекпоинтов в обычных базах, ну и бакапы есть разных видов.
Память в адекватной системе не может кончится — специальный процесс постоянно следит за этим, выгружая наименее используемые блоки из кэша.
**************************************************************
Механизма компактификации лога транзакций у дисковых СУБД нет (см. P.S. в моей статье про компактификацию лога транзакций), поэтому, чтобы восстановление не заняло вечности надо данные таки записать в дерево на диске, не дожидаясь даже пока кончится оперативная память.
**********************************************************************
Не надо вам про обычные базы пока статью писать.
Лучше подробнее про IMDB рассказать.
Вот например, можно ли делать кластеры, что делать если потребуется увеличить размер базы.
Как это делается, растет и какие тут тонкости, чем платится и есть ли ограничения?
danikin
10.12.2016 21:55-1«выгружая наименее используемые блоки из кэша» — что приводит к рандомной записи на диск. Которой в IMDB нет.
«Механизма компактификации лога транзакций» — уже выше обсуждали, что тут неверно поняли друг друга, разное понимание терминалогии. Под компактификацией в IMDB понимается постоянный сброс полностью всего снимка всей базы данных, который снимает необходимость при восстановлении читать все логи, сделанные раньше снимка. Снимок всей базы у RDBMS не делается, потому что RDBMS не хранится вся в памяти.
«Не надо вам про обычные базы пока статью писать.» — это статья про IMDB. Но сравниваю с RDBMS. Чтобы было понятно тем кто сейчас на них сидит. Я понимаю, что тут сидят все профи по RDBMS. Вопрос только в том до каких нагрузок эти профи их разгоняли и во что эти профи упирались. Если вы на их нагрузках они ни во что не упирались, то не надо думать, что вы супер-профи и все про RDBMS знаете, все адекватно настроили и сидите на вершине мира, и не надо думать, что те, кто уже сидят на IMDB — полные мудаки и не пробовали различные варианты ускорить RDBMS прежде чем перейти на IMDB. Призываю вас сконцентрироваться на том, что для вас новое и познавать, вместо того, чтобы цепляться к каждой букве, строить неверные выводы и триумфировать на этом.
Теперь насчет кластеров. На моем опыте все делается на уровне приложения. Кластеризация на уровне СУБД (как это сделано в couchbase) приводит к излишним тормозам и головняку. Обыяно кластеризуем так, что разделяет разные независимые куски на разные базы и храним их на разных серверах. Рассказывать детали, чем платится и какие ограничения пока не хочу. Сначала все надо в более менее обоснованную статью выдать, сведя все факты, иначе вы выльете поток говна и троллинга, не разобравшись :-)
Lofer
10.12.2016 23:10-1«выгружая наименее используемые блоки из кэша» — что приводит к рандомной записи на диск. Которой в IMDB нет.
Как происходит «магия» «рандомной записи на диск. Которой в IMDB нет.» если по документации происходит работа с пачкой файлов ?!
Вы контролируете в какой сектор диска и что писать? Так вменяемые DB тоже это контролируют (в какое место внутри файла писать и когда)!
Согласно докам, все что Вы описали как «IMDB нет.» присутствует:
Tarantool’s disk-based storage engine is a fusion of ideas from modern filesystems, log-structured merge trees and classical B-trees. All data is organized into ranges. Each range is represented by a file on disk. Range size is a configuration option and normally is around 64MB. Each range is a collection of pages, serving different purposes. Pages in a fully merged range contain non-overlapping ranges of keys.
3.6.2. Vinyl features
- Separate storage formats: key-value (Default), or document (Keys are part of value)
- Versional database creation and asynchronous shutdown/drop
A scheduler assigns tasks to multiple background threads for transferring index data from memory to disk, and for reorganizing Runs. To support transactions, Set operations can be delayed until an explicit commit.
3.6.3.3. Inserting the next 200.000 keys
Several times, the in-memory index becomes too large and a Run Creation Thread transfers the keys to a Run. The Runs have been appended to the end of db file. The number of created Runs becomes large.
…
There is a user-settable maximum number of Runs per Range. When the number of Runs reaches this maximum, the vinyl scheduler wakes a Compaction Thread for the db file. The Compaction Thread merges the keys in all the Runs, and creates one or more new db files.
Now there are multiple pairs of in-memory indexes, and each pair has an associated db file. The combination of the in-memory indexes and the db file is called a Range, and the db file is called a Range File.
терзают смутные сомнения… :)danikin
10.12.2016 23:27У Tarantool есть два движка — memtx (движок по умолчанию — in-memory) и vinyl (дополнительный, не in-memory движок, т.е. он не хранит все данные в памяти и предназначен для use cases, когда все данные в память не влезают).
Вы считаете, что Vinyl — это in-memory движок? Ну ок, продолжайте считать дальше. И на основании этого заблуждения стройте какие-угодно теории. Стройте, не буду вам мешать. Если вам это доставляет удовольствие :-)Lofer
10.12.2016 23:56Так они же вроде как в связке работают и один дополняет другой, или еще и тут «магия»?
Если Вы говорите исключительно о «in-memory storage engine (memtx)» тогда и для других DB включайте магию (Oracle «Oracle Database In-Memory», Sql Server «In-Memory OLTP» т.д.) говорите и сравнивайте только с аналогичными фичами «данных в памяти».
danikin
11.12.2016 10:40«Так они же вроде как в связке работают и один дополняет другой, или еще и тут «магия»?» — не понял вашего вопроса, простите. Сформулируйте, плиз, по другому.
«Если Вы говорите исключительно о «in-memory storage engine (memtx)» тогда и для других DB включайте магию (Oracle «Oracle Database In-Memory», Sql Server «In-Memory OLTP» т.д.) » — какую магию, вы о чем?
«говорите и сравнивайте только с аналогичными фичами «данных в памяти».» — вы хотите, чтобы я в этой статье вместо того, что написал сравнил бы Tarantool с другими in-memory по их функциям? Мой ответ вам такой — менять эту статью на другую не буду. Эта статья конкретно про специфику IMDB в общем, а не про сравнение различных IMDB между собой. Сравнение Tarantool частично с Redis есть тут: https://habrahabr.ru/company/mailru/blog/317150/. Кроме того есть другое сравнение Tarantool с Redis вот тут https://hackernoon.com/tarantool-vs-redis-38a4041cc4bc#.yk5wxwdpx (написал внешний к Tarantool человек, там мой только перевод, ссылка на оригинал в тексте)Lofer
11.12.2016 15:29Можно ли заставить IMDB использовать только Vinyl или только Memtx в работе?
какую магию, вы о чем?
Когда вы приводите сравнение с «Обычной Базой Данных», то в этой «Обычной Базе Данных» слишком много проблем, по сравнению с IMDB. Основной акцент делается на «что приводит к рандомной записи на диск. Которой в IMDB нет.» и повторяется в разных вариантах.
Правда, будет все равно хуже чем in-memort:
1. Будет хуже по пропускной способности на запись, потому что рано или поздно надо записать данные в индексы рандомно.
Однако вам уже приводили примеры и ссылки, в которых «Обычные Базы Данных» отлично реализуют фунционал IMDB и это является одним из их штатных рабочих режимов. Да ладно… фиг с ним :)
Менять статью? зачем. Если не некоторые смущающие высказывания в ней и после нее, много людей бы не узнали бы любопытные подробности о этой теме:)
Так что спасибо :)danikin
11.12.2016 15:38В IMDB рандомной записи, действительно, нет (и в частности в Memtx в Tarantool). В конкретно Vinyl ее тоже нет. Поэтому она тянет нагрузку на запись больше чем InnoDB от MySQL, например. Бенчи скоро покажем. Сам по себе Vinyl основан на LSM и фейсбучном RocksDB. Бенчи RocksDB вот тут: http://smalldatum.blogspot.ru/2016/01/rocksdb-vs-innodb-via-linkbench.html
Другой акцент, который я дела, что даже если все сидит в кэшах, то IMDB все равно быстрее RDBMS, просто потому что она заточена под быть всегда in-memory.
Однако вам уже приводили примеры и ссылки, в которых «Обычные Базы Данных» отлично реализуют фунционал IMDB и это является одним из их штатных рабочих режимов. Да ладно… фиг с ним :)
Про функционал я вообще в статье ни разу не говорил. Функционала у RDBMS больше чем у IMDB. И это одно из преимуществ RDBMS. Я тут только про производительность.
Менять статью? зачем. Если не некоторые смущающие высказывания в ней и после нее, много людей бы не узнали бы любопытные подробности о этой теме:)
Так что спасибо :)
Вот именно. Я уж лучше переживу неадекватный троллинг, но дам людям новые знания.
Breslavets
11.12.2016 11:37danikin
Призываю вас сконцентрироваться на том, что для вас новое и познавать, вместо того, чтобы цепляться к каждой букве, строить неверные выводы и триумфировать на этом.
Дык в том то и дело, что большая часть того, что вы почему-то считаете новым в статье, таковым не является для обычных СУБД.
Начиная с последовательной записи в редо(Write-ahead logging — капитан очевидность)…
Из статьи я узнал нового только использовании LMS Дерева в одной из версий IMDB.
О том, что база перед стартом грузится в память — это итак понятно было.
Вы собирались писать о обычных СУБД — было бы интересно сравнить
производительность на одинаковых задачах IMDB vs usual RDBMS.
С использолванием кэша по умолчанию, с захешированными данными…
danikin
.
Я понимаю, что тут сидят все профи по RDBMS. Вопрос только в том до каких нагрузок эти профи их разгоняли и во что эти профи упирались. Если вы на их нагрузках они ни во что не упирались, то не надо думать, что вы супер-профи и все про RDBMS знаете, все адекватно настроили и сидите на вершине мира, и не надо думать, что те, кто уже сидят на IMDB — полные мудаки и не пробовали различные варианты ускорить RDBMS прежде чем перейти на IMDB. Призываю вас сконцентрироваться на том, что для вас новое и познавать, вместо того, чтобы цепляться к каждой букве, строить неверные выводы и триумфировать на этом
danikin
и не пробовали различные варианты ускорить RDBMS прежде чем перейти на IMDB.
Есть ощущение, что вы не особо пробовали обычные СУБД, ибо путаетесь в основах их устройства.
Тем не менее по-моему никто и не спорит о том, что IMDB имеет свою область применения.
Под вашу текущую задачу хорошо пошла IMDB — я так понял, что дешево и сердито. И пример хорош тем, что есть много таких задач(даже по объему если смотреть), где действительно нужно присмотреться к IMDB.
В то же время, на обычных СУБД работают очень высоко-нагруженные системы.
От биллинга в телекоммуникациях, до банковских и платежных систем с реально нешуточными нагрузками и объемами данных.
И поверьте, в этих системах денег особо не считают, надо было бы — использовали бы IMDB, если бы это было возможно(размеры баз, требования к downtime, надежности,...), и если бы это дало преимущества для бизнеса.
Вот этот ваш текст может быть истолкован неверно.
danikin
Механизма компактификации лога транзакций у дисковых СУБД нет
в терминологии IMDB — это чекпоинты в обычных базах.
После чекпоинта для горячего восстановления сбоя экземпляра
нужна только та часть лог-информации, что идет после этого чекпоинта.
Точно также как после снимка в IMDB не нужны старые журналы.
Тут их хранят(обычно на лентах) для возможного восстановления базы.
Сам процесс записи в табличные пространства не должен влиять на отклик в адекватной системе,
а процент попаданий при чтении(where ...) данных в кэш на горячих системах приближается к 100% — читай это IMDB.
danikin
Снимок всей базы у RDBMS не делается, потому что RDBMS не хранится вся в памяти.
Разные задачи, разные объемы,
Запись в датафайлы будет вестись даже при достаточном количестве памяти.
Старт базы будет быстрым.
danikin
11.12.2016 11:51Дык в том то и дело, что большая часть того, что вы почему-то считаете новым в статье, таковым не является для обычных СУБД.
Видимо, вы умеете читать мысли и знаете то, _что_я_считаю_новым_. Ок. Убеждать вас в обратном не вижу смысла, потому что вы лучше меня знаете, что я считаю, и что я не считаю :-)
Из статьи я узнал нового только использовании LMS Дерева в одной из версий IMDB.
Ну хотя бы в чем-то получили профит. Я рад.
Вы собирались писать о обычных СУБД — было бы интересно сравнить
производительность на одинаковых задачах IMDB vs usual RDBMS.
С использолванием кэша по умолчанию, с захешированными данными…
Уже писал выше, что напишу. И уже писал выше, что IMDB по моему опыту быстрее в десятки раз даже в этом случае. Не верите — проверьте, ну или ждите статьи.
Есть ощущение, что вы не особо пробовали обычные СУБД, ибо путаетесь в основах их устройства.
Не буду спорить с вашим ощущением. У меня тоже есть ощущение, что вы не пробовали обычные СУБД на нагрузках под 1000 транзакций в СЕКУНДУ и никогда не упирались в их потолок. Но я лучше оставлю его при себе.
От биллинга в телекоммуникациях, до банковских и платежных систем с реально нешуточными нагрузками и объемами данных.
Вы бы цифры привели. Я лично участвовал в разработке биллинга для МТС и других операторов задолго до работы в Mail.Ru. Там Oracle был окружен сапописной in-memory, чтобы справляться с нагрузкой. Beeline переходит уже на Tarantool (почитайте новости в Интернете). Сбербанк переводит свой процессинг на in-memory СУБД GridGain — почитайте тоже новости в Интернете. Я, вообще, предлагаю вылезли вам из ощущения мира, каким он был 20 лет назад. Он, не поверите, сильно поменялся с точки зрения нагрузок на СУБД и с точки зрения требованиям к latency.
И поверьте, в этих системах денег особо не считают, надо было бы — использовали бы IMDB, если бы это было возможно(размеры баз, требования к downtime, надежности,...), и если бы это дало преимущества для бизнеса.
Уже используют. См. выше. То, что вы не в курсе — не означает, что этого нет.
в терминологии IMDB — это чекпоинты в обычных базах.
После чекпоинта для горячего восстановления сбоя экземпляра
нужна только та часть лог-информации, что идет после этого чекпоинта.
Точно также как после снимка в IMDB не нужны старые журналы.
Тут их хранят(обычно на лентах) для возможного восстановления базы.
Сам процесс записи в табличные пространства не должен влиять на отклик в адекватной системе,
а процент попаданий при чтении(where ...) данных в кэш на горячих системах приближается к 100% — читай это IMDB.
Вот, пожалуй, единственное утверждение, с которым не хочется спорить. Все верно сказали :-)
Запись в датафайлы будет вестись даже при достаточном количестве памяти.
Старт базы будет быстрым.
Если бы вы использовали обычные СУБД на тех нагрузках, где IMDB вообще даже не начинают напрягаться (10К+ запросов в секунду), то вы бы поняли, что они начинают трещать по швам. И старт у них медленных, ибо нагрузка на холодную базу в 10K+ запросов в секунду убивает ее в щи.Breslavets
11.12.2016 16:24danikin
Я лично участвовал в разработке биллинга для МТС и других операторов задолго до работы в Mail.Ru. Там Oracle был окружен сапописной in-memory, чтобы справляться с нагрузкой.
Давным давно был СБОС, без всяких оберток.
Базы-обертки-кэши используют довольно часто, при этом ВСЯ информация всё равно хранится в обычных базах.
И основная часть кода работает с обычными базами.
Потому что этого достаточно и с обычными базами кодить привычнее.:)
Кроме того они имеют отлаженную систему резервирования, а этот рынок очень консервативен.
danikin
Beeline переходит уже на Tarantool (почитайте новости в Интернете).
Дык вот когда перейдут, тогда и поаплодируем уходу от «ораклов».
Интересно, как там «звонки» будут они хранить в IMDB и сколько такая база будет стартовать?
Так обычно не делают, и дальше обертки на входе системы IMDB не пускают.
Т.е. только критичный к производительности модуль заводят на эту промежуточную базу… например те же звонки можно, но только текущая обработка на входе, а потом перемещение в основную базу обработанной информации.
Ибо IMDB быстренько лопнет по памяти от такого потока.
Или есть секретный рецепт?
danikin
Сбербанк переводит свой процессинг на in-memory СУБД GridGain
Аналогично, переведет, посмотрим…
Всё переведут, или как вы писали выше — «Там Oracle был окружен сапописной in-memory»…
danikin
Уже используют. См. выше. То, что вы не в курсе — не означает, что этого нет.
Вы точнее формулируйте — уже хотят использовать…
Или используют на приеме, в какой-то части системы, в качестве быстрого буфера… — да это уже давно в работе, и скорее всего в этом виде и останется в большинстве критичных к хранению данных проектов.
Я бы подобные вопросы ставил не так, что какая-то контора(банк, билайн...) переводит систему на IMDB, а разработчик соответствующего софта переходит на IMDB.
Или еще точнее начинает дополнительно использовать IMDB в какой-то части системы.
Потому что сам банк или сотовая компания ничего не могут сами поменять.
Вот чей биллинг использует сейчас Билайн?
Как они могут просто базу поменять, если в Тарантуле, как я понял нет даже нормальной поддержки SQL.
Скорее всего поменяют ту «обертку» на критичной по нагрузке части.
Как это и есть сейчас в подобных проектах.
danikin
Я, вообще, предлагаю вылезли вам из ощущения мира, каким он был 20 лет назад. Он, не поверите, сильно поменялся с точки зрения нагрузок на СУБД и с точки зрения требованиям к latency.
Вылезти?
Пока везде основной объем информации хранят Oracle и прочие… «тарантулы» только в проектах или на критичной к performance части только на входе для текущей обработки…
Я вот помню также активно вылезали в объектно-ориентированные базы…
Преподнося их как что-то новое на фоне реляционных…
Да так активно пиарили, что казалось уже завтра Oracle нигде не будет. :)

Elsedar
01.12.2016 18:26Но ведь существует вероятность того, что БД ответит об успешном выполнении транзакции, в то время как сама транзакция еще не успеет записаться в файл, и в этот момент БД упадет/упадет сервер?

Karpion
01.12.2016 18:42Последовательность действий такая:
1) СУБД получила запрос;
2) СУБД прочитала данные из RAM, выставила в RAM нужные блокировки и записала транзакцию в журнал;
3а) СУБД сообщила о выполнении транзакции;
3б) СУБД изменила данные в RAM и сняла блокировки.
Пункты 3а и 3б можно выполнять параллельно.
В какой момент что-то там упадёт?Elsedar
01.12.2016 18:52Понял. Суть в том, что БД отвечает о выполнении транзакции только после фактический записи в журнал. В этом случае да, надежно, но время выполнения транзакции увеличивается до окончания записи на диск.
GlukKazan
01.12.2016 18:54Журнал пишется строго последовательно, желательно большими блоками. Это быстро, очень быстро.
Karpion
01.12.2016 21:02В тексте статьи было ясно сказано, что у СУБД есть две работы: это «запись транзакций в журнал» и «внесение изменений в БД».
Запись транзакций в журнал производится так: Сначала транзакции (от разных клиентов) накапливаются в памяти. Потом (или по ходу дела) для накопленных транзакций ставятся блокировки. Затем накопленные транзакции большим блоком пишутся в журнал. И это блок пишется непрерывным куском, поэтому пишется быстро.
Тут есть тонкость: нельзя накапливать транзакции, которые конфликтуют по блокировкам с более ранними ещё не выполненными транзакциями. Точнее, накапливать их можно, но в отдельной очереди. Тут всё сложно, я затрудняюсь точно сформулировать. Короче, у нас есть ограничение на размер единого блока, который мы пишем в журнал транзакций.
Но в любом случае, запись в журнал транзакций намного быстрее, чем внесение изменений в БД, расположенную на HDD.
rPman
06.12.2016 00:17запись транзакции в сотню байт на hdd проходит даже не на линейной скорости, а быстрее, на грани скорости шины sata, а точнее на скорости работы оперативной памяти кеша, пока он не будет заполнен, но при линейной записи он будет очищаться как раз на скорости линейной записи (т.е. если замерять время записи — оно будет минимальна, до тех пор, пока скорость очистки кеша будет быстрее или равна скорости его заполнения)
сама же запись в кеш на диске безопасна — при выключении она успеет записаться (за исключением ситуации с бедблоками)
GlukKazan
01.12.2016 18:49СУБД не отвечает пока не запишет данные в REDO. Если забыть о всяких новомодных async commit-ах.
GlukKazan
01.12.2016 18:48+2Начали за здравие, кончили за упокой.
давайте ненадолго забудем про кеширование, это тема для отдельной статьи
Как это «забудем»? Кэш — это главное, что есть в традиционных СУБД! Всё же сказанное относительно быстрой записи в REDO остаётся в силе. Именно поэтому его выносят на отдельный диск, а то и на SSD.
Недостатком этого дерева является необходимость изменять его при каждом меняющем данные запросе
Всё так, только не файл изменять а 1-2 страницы, опять же, скорее всего, закэшированные (не буду я про кэш забывать, что ещё за глупость?).
Ну и скромно обходится вниманием вопрос: как быть если данные в оперативную память не лезут? Да, да, можно разнести на разные хосты. А можно писать на диск. Всё от задачи зависит.
А так статья хорошая, годная.danikin
01.12.2016 20:06+1Кэш — это, на самом деле зло. Такое же зло как и наркотик. Хорошо, когда он есть и плохо, когда он кончается, но ты уже подсел. И про это тоже будет отдельная статья. Достаточно сказать вловосочетание «холодный старт», от которого у бывалых админов шевелятся седые волосы на всех местах.
«Всё так, только не файл изменять а 1-2 страницы» — да. И для этого надо сделать несколько рандомных чтений и записей на диск.
«Всё так, только не файл изменять а 1-2 страницы, опять же, скорее всего, закэшированные» — и? как закэшированность страниц ускоряет их запись?
«Ну и скромно обходится вниманием вопрос: как быть если данные в оперативную память не лезут? Да, да, можно разнести на разные хосты. А можно писать на диск. Всё от задачи зависит.» — и это тоже тема отдельной статьи. Хотите все в одну кучу? Сорри, я так не умею. Скажу тут лишь то, что если данные не лезут в RAM, то надо понять, а что мы от них хотим, от данных этих, быстрой обработки или медленной. Если быстрой, то хошь не хошь надо покупать RAM и разносить на разные сервера, тк диск медленный. Если не хотим быстрой, то унести эти данные в обычную СУБД. Зачем использовать микроспоп для заколачивания гвоздей?
«А так статья хорошая, годная.» — согласен на все 100! :-)Karpion
01.12.2016 21:42«БД в RAM» предполагает, что RAM достаточно велика, чтобы вместить всю БД. В этом случае вся БД будет закэширована.
Холодный старт для «БД в RAM» будет намного ужаснее, чем для обычной СУБД. Просто потому, что надо прочесть всю БД из последнего дампа и потом накатить на неё транзакции.
Кстати, дампы БД на диск — тоже не дешёвое удовольствие.GlukKazan
01.12.2016 22:02+1Да не слишком намного. TimesTen, например нормально стартует. За вполне приемлемое время.
danikin
01.12.2016 22:22+1Вот про это тоже надо делать отдельную статью :) Комментирую тезисно
1. Холодный старт для БД в RAM происходит гораздо быстрее чем для обычной СУБД, потому что БД в RAM все данные читает, необходимые для горячей работы читает последовательно с диска (логи и снэпшоты), а обычная СУБД этого не делает, она просто стартует сразу и далее прогревается пользовательскими запросами, которые бьют в случайные части файлов на диске. По нашему опыту прогрев, скажем, Tarantool идет со скоростью 60-100Mb/s, прогрев MySQL — 2Mb/s. Соответственно, 64Gb памяти будут залиты в случае Tarantool 6-10 минут, а в случае MySQL за 9 часов. Это адок для продакшн-системы.
2. Надо отдать должное обычным СУБД — они работают сразу после старта, без прогрева. In-memory СУБД пока не загрузят вся в память целиком, не работают. Это, кстати, не сложно пофиксить. Достаточно снэпшот хранить в виде B/B+ дерева,. В этом случае на старте зачитывается только кусок лога после последнего снжпшота и далее запросы на данные, которые не загружены еще в память отдаются с диска с примерно такой же скоростью, с которой они отдаются в случае не прогретой дисковой СУБД. Но так никто не делает ни в одной мне известной In-memory СУБД. Почему? Ответ кроется в п.3.
3. Если данные хорошо разделены на горячие и холодные, то горячие лежат в In-memory СУБД, а холодные в обычной СУБД. После рестарта In-memory СУБД заливает в себя быстро горячие данные. Да, во время заливки она недоступна. Но и обычная СУБД во время холодного старта недоступна на запросы к горячим данным (которых по определению ооочень много в секунду валится), потому что она упирается в диск. При этом обычная СУБД, в которой лежат лишь холодные данные, спокойно рестартует и начинает сразу отлично работать без всякого прогрева.
4. Дампы на диск в случае In-memory СУБД дешевы. Они используют диск линейно. Диск легко шедулится в этом случвае между логом транзакций и дампом. При этом чтению эти дампы не мешают. А на запись даже половина пропускной способности обычного магнитного диска (50Mb/s) более чем достаточна для любого обозримого потока транзакций, не говоря уж о пропускной способности SSD.
5. Коллега ниже привел его опыт с TimesTen. Соглашусь с ним. Ибо старт — это просто линейное чтение с диска.
imaimag
08.12.2016 11:54Холодный старт для «БД в RAM» будет намного ужаснее, чем для обычной СУБД.
Для этого существуют сервера-реплики.danikin
08.12.2016 13:28По моему опыту (да-да, мы криволапые админы, работающие на самом высоконагруженном сервисе в России и все такое) все наоборот.
Старт БД в RAM
1. Переключаем IP с мастера на реплику
2. Делаем мастер репликой
3. Новый мастер моментально обслуживает запросы
4. Предыдущий мастер в течении часа спокойно стартует
Старт БД НЕ В RAM
1. Прогреваем скриптиками кэш, плящем с бубном, молимся, что он хотя бы за сутки прогреется и начнет с нормальной скоростью сервить запросы
2. На реплику переключать бестолку. Почему? Потому что туда не идут запросы на чтение, поэтому кв кэше там нет тех данных, которые запрашиваются часто с клиентов, и поэтому реплика будет такой же холодной как и мастер.
GlukKazan
01.12.2016 22:13+1и? как закэшированность страниц ускоряет их запись?
Нормально ускоряет. Данные меняются в памяти (и пишутся в REDO), а потом не спеша выгружаются рандомным доступом на диск. Это пока кэша хватает, конечно. В остальном согласен почти полностью.
Я ведь чего вспылил? Показалось, что статья следует следующему плану:
- Рассказать всю удобную правду полностью (про скорость REDO), про неудобную (объём RAM) промолчать
- Как доходит до конкурентов (которые и не конкуренты вовсе, а просто про другие задачи), начать аккуратно передёргивать на тему «забудем про кэш» и «при любом изменении меняется всё B-дерево [целиком] [прямо на диске!]»
- Тут юные неокрепшие умы начинают воображать себе всяческие ужасы про традиционные СУБД — PROFIT!
Но если я не прав, то конечно извиняюсь. Я и сам IMDB очень даже люблю и уважаю. TimesTen тот же и MySQL Cluster.danikin
01.12.2016 22:32«Нормально ускоряет. Данные меняются в памяти (и пишутся в REDO), а потом не спеша выгружаются рандомным доступом на диск. Это пока кэша хватает, конечно. В остальном согласен почти полностью» — а толку-то? Если запись бьет рандомно, то кэшируй-не-кэшируй, все равно кэш надо сбросить на диск не одим бандлом, а кусочками, каждой транзакцией в отдельное место диска, заставляя его двигать головкой (если это HDD).
1. Я не сказал дополнительно, что база данных, у которой все данные лежат в памяти, ограничена объемом памяти. Согласен с вами. Скрыл горькую правду. Причем так скрыл, что без вашего зоркого ока-то не раскопали :-) Спасибо!
2а. "«забудем про кэш»" — забудем как про страшный сон, я бы сказал.
2б. "«при любом изменении меняется всё B-дерево [целиком] [прямо на диске!]»" — не нашел у себя эту цитату. Можете дать скриншот?
3. Поделитесь, какик ужасы эти самые умы вообразили? К сожалению, не могу влезть им в голову.
Ну вы, по своему правы. Особенно в пункте один :-)GlukKazan
01.12.2016 22:36+1Ну то что в квадратных скобках, «как бы между строк». Так будут воспринимать неокрепшие умы (по себе знаю). Про кэш — да, когда его нет (как в IMDB) это хорошо (когда нет как в RDBMS, ну типа нет на него памяти — это плохо). Я предлагаю закончить на этом пикировку, об одном ведь в общем-то говорим.
danikin
01.12.2016 22:41+1Я понял. Обвиняюсь в том, что оставил между строк текст, который ваш неокрепший ум воспринял неверно. Искренне сожалею об этом. На будущее буду внимательней читать между строк :-)
Давайте закончим. Миру мир. Каждый инструмент для своей работы.
danikin
01.12.2016 22:39+12. О, нашел: «Недостатком этого дерева является необходимость изменять его при каждом меняющем данные запросе» — изменять его — имеется в виду изменять какой-то из его элементов. Перестраивать все дерево, разумеется не надо. Ну а если мы бы в каком-то бреду решили перестроить все дерево, то следующего предложения не было бы «что может привести к падению производительности из-за произвольного доступа к диску», потому что при перестраивании всего дерева произвольного доступа нет, ибо этот процесс можно организовать последовательно. Но смысле в этом процессе я лично не вижу. Как раз смысл B-дерева в том, чтобы менять его элементы без изменнеия всей структуры.

imageman
07.12.2016 12:27Разве кэш на запись у вас отложенный? По нормальному (для надежности) его нельзя отложить даже на 1 мс, а это значит запись мелкими блоками 100 IOPS (на HDD).
danikin
08.12.2016 00:07+1Я так понимаю, что коллега имеет в виду кэш для table space (write back buffer). Т.е. в журнал транзакций пишем сразу, а в table space применяем отложено. Откладывать можно с точки зрения надежности насколько угодно долго — все равно все изменнеия сохраняются в логе и при рестарте считываются и накатываются в table space.
miksoft
01.12.2016 19:26А как «СУБД в оперативной памяти» выполняет запросы, требующие создания больших временных таблиц? Особенно, когда этих запросов много и на все сразу оперативки не хватит?
danikin
01.12.2016 20:14+1Разобью ваш вопрос на два:
1. Если цель создания временной таблицы — последовательная обработка данных, которые лежат в других таблицах не последовательно (СУБД так может делать иногда), то тогда для СУБД в оперативной памяти не нужны временные таблицы — она может обращаться к оригинальным таблицам рандомно, ибо память на рандомно работает даже быстрее чем диск последовательно.
2. Если цель создания временных таблиц — это что-то боле сложное, например, сортировка или просто промежуточные данные, которые созданы по некоему алгоритму из данных в СУБД, и они больше чем размер оперативной памяти, то… тогда, очевидно, никак. Для этих целей надо делать медленную реплику дисковой СУБД к быстрой in-memory СУБД и там спокойно и неспеша ворочать терабайтами.GlukKazan
01.12.2016 22:162 пункт немного мифический — если промежуточные данные настолько больше исходных, надо всерьёз думать об алгоритмах. По 1-му пункту согласен на 100%.
danikin
01.12.2016 22:34ЧТД, если пункт 2 мифический, то нам несказанно повезло и мы не будем создавать временные таблицы, расходуя драгоценную память :-)
Paskin
02.12.2016 10:36+1Временные таблицы в in-memory СУБД — суть индексы, содержащие ссылки на данные. А по поводу «памяти не хватит» — опять же, повторяющиеся значения заменяются ссылками на словарь (как при сжатии обычных файлов).
miksoft
02.12.2016 12:07Для этих целей надо делать медленную реплику дисковой СУБД к быстрой in-memory СУБД и там спокойно и неспеша ворочать терабайтами.
А если неспеша нельзя?
Реальный пример — у меня на сайте есть специфическая страница, на которой есть специфический SQL-запрос, при выполнении которого MySQL создает временный файл размер в 2 ГБ (в рамках примера считаем, что изменить это никак нельзя). Если туда зайдут одновременно 5 посетителей, то потребуется 10 ГБ дискового места. Запаса оперативки такого размера, разумеется, нет. А что в таком случае сделает «СУБД в оперативной памяти»? По идее, ей ничего не мешает иметь аналогичный механизм скидывания временных таблиц на диск. Но вот имеет ли в реальности — не знаю.
Собственно, я не прошу ответа прямо сейчас. Скорее, реквестирую статью на эту тему, если возможно. :)
Flip89
02.12.2016 08:35Статья конечно, отличная, как и другие из этой серии, danikin спасибо что делитесь этой интересной информацией! Правда не понятно почему статья не оформлена как перевод? https://medium.com/@denisanikin/what-an-in-memory-database-is-and-how-it-persists-data-efficiently-f43868cff4c1#.2af61ukjs Так же поделюсь ссылками на другие статьи по теме: https://medium.com/@denisanikin
danikin
02.12.2016 11:49Не за что! Вам спасибо за высокую оценку! :-)
Эта статья и есть перевод. А как надо было оформить?Flip89
02.12.2016 12:45+1Ну так на хабре вроде есть специальный тип статей «перевод» который отличается от обычных плашкой «Перевод», а самое главное ссылкой на оригинал. Чем это удобно — так это тем что можно дальше почитать статьи автора если тема интересна =)
danikin
06.12.2016 23:55Буду иметь в виду. Автор тут я, Денис Аникин, можете погуглить другие мои статьи (Dennis Anikin — если по английски решите почитать) :)
zhekappp
04.12.2016 22:24-5>cat /dev/zero >some_file
>И посмотрите, как быстро увеличивается размер some_file.
Мда, грустно и смешно такое читать.
Если человек ничего не знает про файловый кеш, то какие можно ожидать знания по работе реальных БД?danikin
05.12.2016 00:11+2Утверждается, что команда выше, если ее оставить на достаточно долгое время, будет демонстрировать максимальную скорость работы диска.
Конечно, если вам не важна сохранность изменений после перезагрузки компьютера, т.е. ваша операционная система настроена так, что вся доступная оперативная память используется для write back буферов, то придется подождать какое-то время, пока все эти буфера не наполнятся.
Хотя, в большинстве случаев, даже при таком аггресивном кэшировании записи, ждать придется недолго. Слава богу, память конечная и слава богу наполнится она быстро, потому что работает быстро (перегонка из буфера в памяти приложения в буфера Linux'а большими кусками через системный вызов происходит на моем опыте со скоростью полгига в секунду и выше). После чего пойдет уже реальная запись на диск, которая будет упираться в диск. И диск при такой нагрузке будет работать на максимальной скорости, ибо писать будет строго последовательно и большими кусками. Собственно, эту максимальную скорость вы и увидите по скорости роста файла.
Но хорошо, что есть такие профессионалы как вы, которые грустят, смеются, обличают других, ничего не знающих про файловый кэш, удивляются их знаниям по работе реальных БД и знают как минимум чуть больше чем ничего про файловый кэш. Они-то нам всем сейчас расскажут как все происходит на самом деле.zhekappp
05.12.2016 10:35Конечно расскажут ;) Сколько всего понаписано, а грамотно-то было всего-то немного поизучать, как правильно измерять производительность последовательной записи на диск и поменять команду cat на dd с правильными опциями. И работа такой команды будет гораздо ближе к тому, как работает запись в redo — синхронно, с ожиданием окончания каждой записи.
Ладно, пойдем дальше по статье…
>Во-вторых, дисковые СУБД должны сохранять данные таким образом, чтобы измененные данные можно было немедленно считать, в отличие от СУБД в оперативной памяти, которые не считывают с диска, за исключением случаев, когда при старте запускается восстановление. Именно поэтому для быстрого считывания дисковым СУБД нужны особые структуры данных, чтобы избежать полного сканирования журнала транзакций.
Можно какую-то ссылку на первоисточник такого утверждения? О какой хотя бы особо экзотичной БД идет речь? Речь об undo? Так оно точно также в памяти может хранится очень-очень долго. А если undo нет, то как же тогда ACID и как можно сравнивать нормальную RDBMS с чем-то таки типа ускоряющего кеша, который вообще не RDBMS ни разу.
>Одна из таких структур — B/B+-дерево, ускоряющее считывание данных.
По-простому, речь идет об индексах? Но какая разница, если у нас все в памяти, последовательное обращение или случайное?
Из комментариев:
>Потому что все что ушло в лог транзакций, но не записалось в дерево хранится в памяти. Рано или поздно эту память надо сбросить на диск в дерево. Механизма компактификации лога транзакций у дисковых СУБД нет (см. P.S. в моей статье про компактификацию лога транзакций), поэтому, чтобы восстановление не заняло вечности надо данные таки записать в дерево на диске, не дожидаясь даже пока кончится оперативная память.
Ух… это из какой-то параллельной вселенной знания? :)
Почитайте хоть какие-то основы что-ли https://habrahabr.ru/post/132107
>По нашему опыту прогрев, скажем, Tarantool идет со скоростью 60-100Mb/s, прогрев MySQL — 2Mb/s. Соответственно, 64Gb памяти будут залиты в случае Tarantool 6-10 минут, а в случае MySQL за 9 часов. Это адок для продакшн-системы.
А написать скриптик, который сразу после старта системы пробежится полным чтением и закинет в кэш данные по таблицам-индексам квалификация не позволяет? :)
>и? как закэшированность страниц ускоряет их запись?
даю подсказку — один блок может меняться миллионы-миллиарды раз, а записать его надо будет только 1 раз :)
— В целом статью можно было бы озаглавить «я не знаю как работают RDBMS, но in-mememory DB — это круто»
:)
По существу, мне, как человеку не знающему in-memory (и немного разбирающегося в обычных БД) гораздо интереснее было бы почитать, чем еще, кроме ограниченности размера БД, жертвуют in-memory ради производительности, т.е какие дополнительные ограничения накладывают на разработчика и архитектуру системы.
Да, и говорить про использование HDD, а не SSD для небольших баз при приличной нагрузке — это как-то странно тоже.danikin
05.12.2016 11:19+1Комментирую ваше сверху вниз
1. Существенное отличие dd от cat в данном контексте я вижу лишь в том, что в dd можно настроить fsync. Наверное, вы это имели в виду про правильные опции. Сразу возникает вопрос, какой размер записи выбирать перед каждым fsync? Производительность будет отличаться в зависимость от оного размера. Цель была замерить производительность диска в самом-самом лучшем кейсе.
Жду ваш пример команды, которую можно выполнить из консоли *nix системы, и которая более точно покажет максимальную производительность диска на запись чем моя команда. Пока лишь слова.
2. К сожалению, не могу залезть вам в голову и понять, что вы додумали и какие выводы сделали из того, что додумали. У меня мысль была простая — все, что изменено в дисковой СУБД (в любой), должно меняться не только в redo логе, но и в самом табличном пространстве. Да, пусть не сразу, да можно эти изменения кэшировать в памяти (в случае краша они все равно из redo лога восстановятся), но рано или поздно их надо применить в табличное пространство, просто потому что операции SELECT не парсят redo лог (это было бы слишком дорого и долго), они лезут в табличное пространство + смотрят в то, что в кэше. У in-memory баз данных изменения не надо применять в табличное пространство — только запись в redo лог (он же лог транзакций, как я называю его в статье).
3. Где у вас все в памяти? В дисковой СУБД? Вы статью читали вообще или по верхам? :) Я процитирую специально для тех кто в танке:
«поэтому для быстрого считывания дисковым СУБД нужны особые структуры данных, чтобы избежать полного сканирования журнала транзакций.
Одна из таких структур — B/B+-дерево, ускоряющее считывание данных»
4. Мы, наверное, по разному понимаем слово компактификация. То, что я понимаю под этим словом в своей статье я написал в P.S. Не поленитесь почитать.
5. Напишите, пожалуйста, скриптик, который закинет в кэш таблицы индексы, которые не влезают в память. Если они у вас всегда влезают, то это не означает, что у всех также. И если они у вас всегда влезают, то, возможно, вам надо рассмотреть in-memory СУБД. По крайней мере, скриптик писать не придется.
6. В вашем кейсе с миллионами и миллардами изменений одного блока — все так. Запись будет ускоряться. Не видел, правда, в продакшн нагрузке такое. Обычно у меня миллионы и десятки миллионов пользователей и они все пользуются сервисом, и их данные размазаны так или иначе по диску. Хотя, конечно, для системы, где один пользователель постоянно изменяет свои данные миллионы раз, согласен с вами, кэш на запись работает хорошо.
7. Обязательно изменю заголовок, если услышу от вас знание о работе RDBMS, которое бы противоречило тому, что написано в статье.
8. О, наконец-то по существу! :) Зависит от СУБД. В случае Tarantool мы постарались, чтобы таких ограничений было минимально. ACID-транзакции, хранимые процедуры, репликация — все в Tarantool есть. Нет, правда, SQL пока. Он на подходе. Планируем к концу этого года альфа-версия. Главная жертва — это то, что все в памяти. Остальные жертвы, если они есть, они не являются следствием того, что база в памяти, а скорее следствием сфокусированности той или иногй команды in-memory СУБД на тех или иных фичах.
9. Про HDD. В том то весь и фокус, что для in-memory базы вам не нужны SSD. У вас вся запись/чтение последовательное. Почитайте все-таки внимательно статью прежде чем осуждать. Ну или так сразу и напишите, не читал, но осуждаю :-)
babylon
05.12.2016 11:52Денис, дождёмся ли мы операционной системы на TNT? Проприетарный язык походу Вы делать не желаете. А зря.
danikin
05.12.2016 13:49Наc и так все бюьт за Lua, а вы говорите проприетарный :-)
Насчет операционки — на нас иногда находят мысли, что если унести какие-то вещи в kernel space для уменьшения переключения контекстов, но мы их гоним от себя и думаем как по другому еще можно уменьшить :-)
zhekappp
05.12.2016 12:16-11. Ох, беда, совсем же не fsync.
https://romanrm.net/dd-benchmark
ключевое — oflag=dsync
2. В in-memory изменения рано или поздно также применять в слепок. Разница в том, что для in-memory надо записать все данные, а в обычных надо записать только измененные. Т.е ничего нового тут не придумали — весь вопрос в правильных настройках этой записи и требуемого времени восстановления после краша.
3. Предлагаю Вам все-таки забыть мифическую теорию, что дисковым базам нужно зачем-то лазить за чтением на диски, если объем данных влезает в кэш. И, кстати, если in-memory поддерживают транзакционную целостность, то как же они обходятся без предыдущих версий данных в памяти? И как долго эти данные хранятся в памяти и какой объем занимают? Об этом было бы интересно почитать.
4. В обычных rdbms компактификация зовется checkpoint — момент времени в прошлом, про который мы знаем, что все данные измененные ранее уже сброшены на диск и redo ранее этого момента нам уже не потребуется в случае старта после краша. Можно еще здесь, например, почитать, для обретения ясности в голове:
https://habrahabr.ru/post/164447
5. Скриптик у меня есть, но он для Oracle. И преимущество обычных БД в том, что закинуть можно только те данные, которым нужно там быть сразу для быстрой работы критичных запросов — обычно это небольшая часть общего объема. А остальное пускай на дисках остается. А InMemory таки объемы вообще не под силу.
6. В обычных БД можно настраивать частоту сброса горячих блоков. И, например, для настроек 1 минута или 10 минут — количество IOPS по записи в файлики будет отличаться на порядки.
7. Ну так уже, выяснили, что 1) rdbms совсем не обязательно лезть за данными на диск, если он в кэше. 2) количество записи в файлы совсем не равно количеству изменений этих данных в памяти 3) какое отношение B+ деревья ко всему этому — вообще непонятно.
8. Термин ACID относится в целом к субд, а не к транзакциям. И как-то, опять же, сравнивать SQL и NoSQL… Разные задачи.
9. Ну, хорошо, я считают, что держать маленькую highload БД на HDD — это извращение ;)danikin
05.12.2016 15:25+21. Да, это флаг. А fsync — это системный вызов такой, который под капотом делает dd, когда вы ему флаг dsync задаете. Просил я вас трижды написать конкретную команду, так и не допросился. Можно мой cat заменить вот на такое: dd if=/dev/zero of=/root/testfile bs=1G count=1 oflag=dsync
2. Разница еще в том, что в in-memory записывается в слепок последовательно (раз в какое-то время во время снэпшоттинга), а в не in-memory записывается в слепок рандомно. У вас в не in-memory базе данных одно изменение стоит в среднем больше иопсов чем в in-memory, хотя и там и сям персистится.
3. Если не влезло в кэш, то, надо полагать, дисковая база данных при выполнении SELECT получает данные не рандомными обращениями в B+ деревья, а по воздуху из центрального зикурата на голубях.
Но, кажется, я начинаю понимать. Ваш вопрос такой — зачем ваще эти новомодные ин-мемори базы данных, когда есть дисковые базы данных, у которых можно задрать кэши и получить ту же инмемори. Да? Это тема отдельной статьи. У меня был доклад на хайлоуде про это. Я скоро опубликую. Если кратко, то in-memory в этом случае гораздо быстрее. Казалось бы и там все ин-мемори и здесь. Но когда база сразу заточена под in-memory, то она просто более эффективна, потому что какие-то вещи сразу по другому сделаны, без оглядки на то, что данные могут не влезть в память. В общем, расскажу.
Вторая половина вашего вопроса. База на базу не приходится. Кто-то хранит предыдущие версии (в памяти, разумеется). Кто-то блокирует все жестко. Про это тоже будут статьи обязательно.
4. Да, все веро.
5. Я придерживаюсь принципа — работает — не трож. Если Oracle работает хорошо, то не надо его менять на in-memory. Я не фанат священных войн между дисковыми и ин-мемори СУБД.
6. Да. Но, к сожалению, это не убирает рандомные обращения к диску, которые рано или поздно надо сделать, чтобы сохранить, скажем миллион изменений, которые прямо сейчас сидят в памяти и которым предстоит записаться в различные части диска.
7. 1) А, т.е. я этого факта не знал, пока вы не сказали? :) Цитирую сам себя тогда:
Во-первых, в отличие от СУБД в оперативной памяти, в традиционных СУБД необходимо считывать данные с диска при каждом запросе (давайте ненадолго забудем про кеширование, это тема для отдельной статьи).
7. 2) Не новость для меня
7. 3) Самое прямое. Это структура данных на диске для хранения индексов, которую используют традиционные дисковые СУБД. И эту структуру надо апдейтить. Пусть не на каждое изменение, но рано или поздно надо апдейтить, а значит рандомно читать от корня вниз, рандомно писать в листья, рандомно писать, чтобы сливать-разливать листья.
8. Вы задали вопрос (по существу). Я ответил. Если вам что-то не понятно, то уточните. Я не понимаю к чему этот пассаж.
9. Если маленькая highload БД помещается в память, то ей SSD не нужен. Перечитайте — статью — там популярно объяснено, почему не нужен :) Если она не помешается в память, то, возможно, она уже не такая маленькая.zhekappp
05.12.2016 16:161. ура
2. Это все же зависит объема измененных данных в отношении всего объема БД
3. Индексы точно также лежат в кеше. Oracle вообще пофиг, что там в блоках — данные, индексы или undo. Механизм работы с ними с точки зрения кэширования совершенно одинаков.
Я верю что in-memory быстрее для какого- набора операций — вопрос, чем при этом приходится жертвовать?
4. Тогда почему ранее Вы написали, что:
>Механизма компактификации лога транзакций у дисковых СУБД нет
5. Так я тоже не фанат, я просто не лезу в то, чего не знаю, но меня задевает, когда, вот, наоборот.
6. Все так, но это вопрос грамотного тюнинга системы. И, опять же, сохранить надо не миллион изменений, а только актуальную версию измененных данных. Вот, тот же undo, перетирается по кругу, например, в зависимости от выставленного retention.
7.3 Если это не NoSQL база и есть какие-то индексы, кроме первичных ключей, то никуда от этого не денешься в плане расположения данных. Но, еще раз напишу, что базам все равно, что там в блоках — индексы, данные — алгоритм работы с ними одинаков. Не надо никуда лезть на диски, если все помещается в память.
zhekappp
05.12.2016 16:24По 1 еще:
Надо только понимать, что реальная запись пойдет не одой операцией в 1g, а порциями, при этом не совсем понятно, какими
Т.е лучше явно написать что-то вида:
dd if=/dev/zero of=/root/testfile bs=1024k oflag=dsync
и наблюдать за ростом файла.

grossws
05.12.2016 17:11а в не in-memory записывается в слепок рандомно
Далеко не всегда верно. Если говорить, например, про Apache Cassandra (внутри LSM tree), то SSTable пишется и/или мержится на диск линейно.
danikin
06.12.2016 01:38Да. В контексте этого конкретного обсуждения, если вы читали его, «не in-memory» == «традиционная дисковая СУБД, основанная на B/B+ дереве»
LSM — это отличная структура данных! И я про это в статье упомянул и даже таблицу нарисовал, поищите выше по слову LSM.
Breslavets
09.12.2016 17:42*******************************************************************************
6. Да. Но, к сожалению, это не убирает рандомные обращения к диску, которые рано или поздно надо сделать, чтобы сохранить, скажем миллион изменений, которые прямо сейчас сидят в памяти и которым предстоит записаться в различные части диска.
**********************************************************************************
Расскажите как ЧАСТО и КАК делается снимок(на диск) в вашей терминологии и как он работает?
Вот база работает, в шустрой In-memory базе (в памяти) нашлепали изменения в блоках…
И… очень интересно послушать.danikin
09.12.2016 18:55+1Мой типичный кейс с Tarantool:
1. Размер базы данных 200-300Gb (чистые данные весят при этом где-то 80-90% от этого значения)
2. Размер REDO логов за сутки — 20-50Gb
3. Снимок делается раз в сутки. 200-300Gb сливаются на диск целиком. Это происходит последовательно, не сильно нагружая диск и почти никак не замедляя скорость работы REDO лога
4. Количество чтений у такой базы — обычно порядка 100 тыс в секунду — они сервятся из памяти, не нагружая на 100% даже одно ядро процессора. Количество записей 30-50 тыс в секунду, совсем почти не грузят процессор и грузят диск на единицы процентов (в пике это несколько мегабайт в секунду последовательной записи на диск). Грузят они диск лишь только записью в REDO
5. Все это работает на одном сервере supermicro ценой порядка $2700-3000
6. Есть еще несколько реплик для надежности. Они на ровно таком же железе. К ним запросы не идут, они вступают в бой только при проблемах с мастером, когда он отказывает
Если вы можете при таких же входных данных достигнуть такой же производительности любой классической СУБД, то вы — гений.Breslavets
09.12.2016 19:47Спасибо за пример, тут конечно хорошо, что запсь на диск снапшота не влияет на работу базы, т.к. чтения идут из памяти.
Гипотетически может замедлить запись в редо(т.е. commit'ы).
База конечно небольшая, но учитывая стоимость железа конечно отличный результат.GlukKazan
09.12.2016 20:30Гипотетически может замедлить запись в редо(т.е. commit'ы).
Не замедляет. Там версии в оперативной памяти создаются. То есть снимок не тормозит OLTP за счёт большего расхода оперативной памяти. Ну и плюс в том что пишется последовательно, в отличии от рандомной записи грязных блоков, конечно.danikin
09.12.2016 20:43Все верно говорите. По сути, есть два параллельных процесса записи на диск, каждый из которых пишет строго последовательно — запись в REDO и запись снимка. Запись снимка можно вести на «всех парах», потому что запись в REDO обычно редко потребляет больше нескольких % от максимальной производительности диска.
Breslavets
09.12.2016 20:44Это он OLTP при таком подходе не тормозит, а запись в редо может.
Но конечно на таком объеме это не критично.
Запустите копирование двух пусть последовательных файлов на чистом диске одновременно.
На активных системах редо выносят на отдельные диски, чтобы не рушить эту последовательную запись, ну и они могу быть сильно нагруженными.
Т.к. ВЕСЬ DML проходит через логи.
И если у вас они не нагружены, значит больше чтений в базе.danikin
09.12.2016 20:47Только лучше не копирование файлов, а копирование из /dev/zero, потому что копирование файла это чтение с диска и запись, а копирование из /dev/zero в файл — это только запись. Запускал. Один файл — 100Mb/s, два файла — по 50Mb/s. Это Linux. Там достаточно оптимально все устроено с точки зрения шаринга ресурсов диска.
Breslavets
09.12.2016 20:50Т.е. влияние есть, но в вашей задаче не проблема.
А можно разные диски задать для снапшота и редо?danikin
09.12.2016 21:12Можно. Но даже при моих нагрузках в 100K+ запросов в секунду одного HDD диска достаточно.
Breslavets
09.12.2016 21:02А как он снимок этот пишет на диск, если в базу запись идет постоянно?
Метки времени есть у страниц?
Не пишет те, у которых метки старше старта снятия снимка?
Или полную копию делает и пишет?danikin
09.12.2016 21:13А для этого я написал еще одну статью. Вот тут в деталях: https://habrahabr.ru/company/mailru/blog/317150/
imaimag
08.12.2016 12:11+1Ну, хорошо, я считают, что держать маленькую highload БД на HDD — это извращение ;)
Думаю, Mail.Ru с их нагрузками делают это вовсе не потому, что они представители ЛГБТ или у них денег нет на диски (тем более, что всего-то речь идет о каких-то 8-ми серверах).
А потому что провели замеры и убедились, что на линейном чтении/записи никакой необходимости в SSD нет, а места для множества журналов WAL на HDD все же побольше/подешевле.danikin
08.12.2016 13:30Все верно. Плюс, мы еще в Mail.Ru принимаем решения не на основе «извращние»/«православие», а на основе каких-то более понятных бизнес-терминов — быстрее/медленнее, дешевле/дороже и тд.
imaimag
08.12.2016 12:37А InMemory таки объемы вообще не под силу.
А RDBMS такие скорости не под силу.
И что?
Каждому инструменту — свое предназначение.
Гвозди отверткой забивать невозможно.
BoogerWooger
05.12.2016 11:45+1Появился образ эдакого «папы» по базам данных. С высоты своего огромного опыта работы может использовать фразочки типа «вам квалификация не позволяет?» или подлавливать на терминах типа «вы, наверное, индекс имели в виду?».
Под конец еще написать: «А вообще, я бы хотел почитать про другое».
При этом думать, что весь мир вокруг работает так же как у него, типа все по щелкчу пальцев побежали и поменяли HDD на SSD, или написали «скриптик, который пробежится полным чтением и закинет в кэш данные по таблицам-индексам» (это ваще огонь, я считаю). Про закешированность страниц тоже отличный коммент с подсказкой от «папы», вы правда считаете что сказали что-то умное?zhekappp
05.12.2016 13:11-1Да я не против, чтобы люди изобретали свое колесо, лучше прежних колес, особенно если за это платят.
Только хорошо бы для начала разобраться, и понимать, как работает то, что уже давно придумано.
>Про закешированность страниц тоже отличный коммент с подсказкой от «папы», вы правда считаете что сказали что-то умное?
Так кто-то же должен был это сказать, развеять, так сказать, заблуждения автора.
А какие претензии к скриптам разогрева кеша баз? Первый раз про такое слышите?
>типа все по щелкчу пальцев побежали и поменяли HDD на SSD
ну, сравните стоимость замены HDD небольшого объема на SSD и стоимость написания своей собственной RDMS, которая будет отличаться только в том, что скидывает данные на диски не случайным, а последовательным способом.
danikin
05.12.2016 15:29+1Вам никто и не предлагает писать собственную СУБД. Если вы ее напишите, то единственным ее пользователем будете вы сами, поэтому вам лично дешевле остаться на SSD.
imaimag
08.12.2016 12:17+1А какие претензии к скриптам разогрева кеша баз? Первый раз про такое слышите?
Зачем применять методики из одной (непохожей) СУБД, для СУБД другой?
Каждому инструменту — свой способ заточки.
В in-memory СУБД разогрев происходит автоматом при рестарте.
А чтобы не было простоев — просто используются сервера-реплики.
Один уже разогрет и работает, второй в этом момент рестартует.
Lofer
08.12.2016 12:40А как влияет скорость репликации между серверами на «гарантированно в памяти» и какая скорость синхронизации?
imaimag
08.12.2016 12:51А зачем там скорость в репликации-то в данном способе использования?
Рабочая разогретая реплика содержит 100% данных.
Вторая реплика может при этом стартовать весьма и весьма неспешно — этого никто и не заметит.Lofer
08.12.2016 13:08+1Вроде как очевидно.
Если сервер А упал, запросы должны на серевер Б. Сервер А обязан содержать данные, подтвержденные сервером Б (фактически двухфазный комит). Этот двухфазный комит стоит какие-то ресурсов.
В противном случае, если Сервер А подтвердил данные, а сервер Б еще не подтвердил их,
то после момента переключения Клиент будет пытаться оперировать данными, подтвержденными ТОЛЬКО сервером А о которых сервер Б еще не знает.imaimag
08.12.2016 13:18+1Если у вас есть PITR и WAL никуда не делись, то ничто никуда не теряется.
GlukKazan
08.12.2016 13:46Только вот изменения должны успеть записаться не только в локальный REDO, но и в REDO на всех репликах. То есть мы не имеем права завершать транзакцию пока реплики не отрапортуют о том, что успешно записали в REDO. То есть во время выполнения транзакции (при наличии синхронных реплик) включаются сетевые издержки на взаимодействие между репликами. Разумеется, можно делать часть реплик или даже все реплики асинхронными. Тогда сетевые издержки включаться не будут.
danikin
08.12.2016 13:35Согласен на 100%. Ну и потом, разгорев кэша идет вслепую, без информации, что именно надо греть. Греть-то надо данные, которые часто запрашиваются. А узнать кто запрашивается часто можно только после того как запросили. Логи предыдущих запросов (всех!) обычно не хранят и обычно разогрев на основании этих логов не делают. Но даже если уважаемый zhekap это делает, то он с высокой вероятностью получит при разогреве те же рандомные обращения к диску, что и при запросах от пользователя, потому что никто не гарантирует, что горячие данные сведены на диске в одну кучу. В IMDB как раз это гарантируется тем, что все данные в IMDB считаются горячими и все они одним линейным куском быстро зачитываются в память при старте.
Breslavets
09.12.2016 18:04+1*******************************************
Так кто-то же должен был это сказать, развеять, так сказать, заблуждения автора.
*****************************************************
Сверху вниз читаю,…
статья понравилась, но мне непонятно зачем автор начал сравнивать in-memory с обычными, в архитектуре которых у него ну явные пробелы.
Лучше бы больше рассказал про особенности — вот про те же снимки, которые как я понял аналог наших чекпоинтов, но каким-то чудными образом меньше нагружают I/O, избегая рэндом-записи.danikin
09.12.2016 18:58-1Про особенности я рассказал в коменте ниже. Сделаю еще одну статью, чтобы рассказать детали. Насчет обычных баз. Сравнение было приведено с целью, чтобы объяснить, что in-memory работают быстрее обычных и показать каким образом они быстрее. Но, похоже, я наступил на больные мозоли тех, кто всю жизнь работает с обычными СУБД, и кто сопротивляется наступлению новых технологий.
danikin
05.12.2016 15:27+1Согласен с вами! К сожалению, таких пап много. Когда достижений показать нельзя, то остается только сидеть на хабре папствовать :-)
BoogerWooger
05.12.2016 15:44+1Часто в таких дискуссиях много полезного узнаешь, по сути очень интересно читать, а авторы своими вопросами много полезной инфы открывают. Мне нравится и вопросы читать и ответы. Не нравится только переход на «вам квалификации не хватило?» — это реально обидно и хочеться ругаться. Для профессионалов это неприемлемо.
danikin
06.12.2016 01:40+1Согласен!
Самое любопытное, что извинений за оскорбления не следует.zhekappp
06.12.2016 09:34-3Странно извиняться перед автором безграмотной статьи, которому ни разу не стыдно.
И я не услышал, что именно, кроме отсутствия квалификации помешало грамотно построить работу с кешэм в MySQL? За что извиняться то?imaimag
08.12.2016 11:12Странно извиняться перед автором безграмотной статьи, которому ни разу не стыдно.
И я не услышал, что именно, кроме отсутствия квалификации помешало грамотно построить работу с кешэм в MySQL? За что извиняться то?
Использовать MySQL в данных случаях дороже на 1 миллионо долларов.
Вот здесь про это детально написано:
Как сэкономить миллион долларов с помощью Tarantool
danikin
08.12.2016 13:25Учитывая все коментарии выше, где безграмотность? Цитату в студию.
Далее, в какую сумму вы, уважаемый, квалифицированный знаток MySQL, оцениваете свои услуги по грамнотной настройке индексов MySQL, чтобы он работал быстрее Тарантула или хотя бы также? Назовите свою цену, я вас найму, срубите легкие деньги.
Скажу более, Percona вас оторвет с руками за любые деньги. Они с вашей помощью ускорят миллионы инстансов MySQL по всему миру до скорости in-memory баз данных и заработают на это миллиарды долларов.
И, наконец, Фейсбук тут же возьмем вас на работу — они выкинут все их кэши и прочие самописные штуки типа Tao или Dragon поверх MySQL и останутся с голым оптимизированным MySQL, работающим быстрее чем in-memory базы данных. Их специалисты, работающие в крупнейших технологических компаниях мира ждут вас с распростертыми объятиями. Странно6 что вы еще там не работаете.zhekappp
08.12.2016 13:58Спасибо, конечно, но я несколько другой области тружусь, где NoSQL до сих пор не особо применимы, а используются классические RDBMS.
Речь идет о финансовых данных, биллинг мобильных операторов, карточные процессинг и т.п.
Для FaceBook потерять пару комментов или отобразить их чуть позже — это фигня.
Для всего, что связано напрямую с деньгами такие вещи недопустимы.
Вот и вся разница.
Мне кажется, Вам отлично удаются маркетинговые статьи типа вот этой:
http://www.cnews.ru/news/top/2016-12-05_subd_mailru_tarantool_cherez_tri_nedeli_prevratitsya
И они вполне впечатлят каких-нибудь топ-менеджеров и принесут Вам доходы.
Но тут, по-большей части, технические специалисты и такого рода вещи, конечно, могут вызывать раздражение, так как админы и программисты в большинстве не очень любят маркетологов :)danikin
08.12.2016 14:07+11. «где NoSQL до сих пор не особо применимы, а используются классические RDBMS» — так примените RDBMS в той области, где безграмотные и криволапые админы, не умеющие написать скриптик прогрева применяют NoSQL. Не уходите от ответа!
2. Опять господин соврамши. Это статья не моя. Это журналисты из cnews. Они понабрались случайных фактов, вырванных из контекста, и сделали статью. Ее финальный вид с нами не согласовали. Оракл мы не собираемся убить через 3 недели альфа-версией SQL — это бред.
3. Хорошо, если это раздражение подкреплено какими-то фактами, а не слепой нелюбовью. Я тоже вас не люблю, вы неприятный человек, скажу прямо, но тем не менее спокойно с вами общаюсь, задаю вопросы по существу, до оскорблений не опускаюсь. И все, чтобы докопаться до истины, которая где-то сильно глубоко засела в вашей голове и не выходит наружу :-)
zhekappp
08.12.2016 14:33+11. Так я такого не предлагал. Это Вы считаете, что можно поставить две разные технологии в заведомо неравные условия и на основе этого делать какие-то выводы :) Я-то понимаю, что RDBMS — да, очень хреновенько масштабируется. Вот отсюда и надо расписывать преимущества NoSQL, не забывая и минусы. А не с точки зрения работы с дисками или тем, что LMS всегда лучше B-деревьев.
2. Фух, ура, у меня еще пока есть шанс не остаться безработным.
3. Т.е слова «папик, у которого нет достижений» не стоит расценивать, как наивную попытку менять задеть? :)danikin
08.12.2016 14:471. В какие неравные условия я поставил и какие выводы я сдалал. Цитату дадите?
2. Я бы не зарекался на вашем месте.
3. Вы даже цитировать не умеете. Я такого не говорил. Я говорил это: «Согласен с вами! К сожалению, таких пап много. Когда достижений показать нельзя, то остается только сидеть на хабре папствовать :-)»
imaimag
08.12.2016 16:24Спасибо, конечно, но я несколько другой области тружусь, где NoSQL до сих пор не особо применимы, а используются классические RDBMS.
Речь идет о финансовых данных, биллинг мобильных операторов, карточные процессинг и т.п.
Неужели все сырые данные сразу пишутся в РСУБД непосредственно?
А не используется никаких промежуточных специализированных более быстрых не РСУБД?
zhekappp
08.12.2016 16:35Я не очень понял термин «сырые данные».
По сути в силу необходимости ACID — да, когда вы расплатились в картой в магазине, то oracle выполнил 3-4 commit в redo.imaimag
08.12.2016 16:49Биллинг, например.
Он же изначально в форме не очень удобной для RDBMS.
К примеру, при звонке при тарификации по времени — разве не имеет разве смысла временно сохранить время начала звонка в другой более специализированной СУБД, чтобы записать в RDBMS просто весь звонок целиком как одну запись. Когда разговор закончится и будет известно и время начала и время конца.
Я имею ввиду нечто подобное под сырыми данными.Lofer
08.12.2016 16:54Ну почему?
Просто пишутся маркеры: начало звонка, конце звонка. двумя записями.
Потом проходит обработка ETL и приведение в более удобоваримую аналитическую форму/кубики.
zhekappp
08.12.2016 17:22С биллингом попроще в силу того, что если даже база недоступна, то коммутационное оборудование все равно генерит записи и они рано или поздно все равно доедут до базы. Небольшой уход в минус для абонентов вполне допустим.
В момент набора номера в базу вообще ничего не пишется, приложение по номеру примерно оценивает тариф (по закешированной в приложении информации об абоненте и тарифах) и выдает прикидку на коммутатор об оценочной максимальной продолжительности вызова. По окончании разговора, да — идет вставка записи в БД, и, чуть позже, обновление баланса.
Вот, платежи, должны быть закоммичены в момент, когда осуществляются. Но для этого можно использовать отдельную небольшую БД, а затем уже с небольшой задержкой обновлять баланс в биллинге — как это обычно и происходит.
imaimag
08.12.2016 12:08+1А если undo нет, то как же тогда ACID и как можно сравнивать нормальную RDBMS с чем-то таки типа ускоряющего кеша, который вообще не RDBMS ни разу.
Tarantool является однопоточным. С последовательной обработкой запросов.
Авторы утверждают, что отсутствие необходимости блокировок позволило серьезно поднять производительность.
Настолько серьезно, что Tarantool никогда не упирался на их задачах в процессор — раньше упирался в сеть.
Следовательно многоядерность и не нужна. Хотя, обсуждался вопрос реализовать многоядерность хотя бы для операций чтения.
Ну а если вам нужно задействовать все ядра сервера — запускаете несколько экземпляров Tarantool`а, между которыми шардите данные.
В такой же однопоточной системе последовательного исполнения запросов в пределах одного экземпляра Tarantool весь ACID зависит только от того, что вы там в хранимых процедурах намудрите. Даже напротив, напрограммировать в хранимых процедурах что, что нарушающее ACID довольно непросто.zhekappp
09.12.2016 19:05Все логично, но как только появляется больше одного экземпляра, то про ACID можно сразу забыть.
BoogerWooger
05.12.2016 14:01+21) про закешированность повторю Дениса — кейз с многократным обновлением одного блока означает что у вас странная нагрузка, что то типа ведения пяти счетчиков для миллионов событий. В этом случае вам вообще реляционные базы противопоказаны — для этих целей гораздо проще и дешевле использовать IMDB
2) слыхал. Даже видал как эти скрипты часами «прогревались», и наблюдал как они сосут в память данные одной таблицы, а юзера долбятся в другую. Но, наверное, я мало знаю о хороших скриптах прогревания баз.
3) Ну сравнил. Для тысячи серверов получил денег на зарплату для команды разработчиков, так что это не довод. Плюс чисто по личному опыту, хотя я, конечно, не мастак по части баз данных — с реляционной mysql и на SSD гиморы бывают, а тарантул на говнотазу со старыми HDD пашет как ракета.
Я бы с удовольствием во всех случаях работал бы с ораклом или sql сервером, люблю их за качество. Но поднимать эти самолёты ради микросервиса, который на тарантуле поднимается за 15 минут вместе с кодовой базой и держит при этом нагрузку в разы большую, уж проститеzhekappp
05.12.2016 14:201) есть существенная разница между блоком и записью. В одном блоке записей-то может быть немало
2) при правильном подходе работает
я согласен с 3 и дальше, но тут надо четко понимать круг решаемых задач и связанные с этим ограничения.
Т.е не пытаться сравнивать несравнимое и находить минусы там, где их нет при правильном подходе.
Можно и на grep и awr базы писать, но этот как-то не совсем же базы.danikin
05.12.2016 15:33Спасибо за ваше интересное мнение. Есть и другие мнения, когда просят сравнить дисковые СУБД и ин-мемори СУБД. Сравнение зачастую кому-то кажется поиском минусов.
Lofer
06.12.2016 13:23Я, в общем-то «старовер» в базах данных и руками пока не трогал «базы в памяти».
Насчет всех БД не скажу, но тот же SQL Server поддерживает несколько сценариев восстановления, в том числе и «последняя запись в лог». Так же не БД занимается сжатием лога, а отдельные сервисы. Так же управляет тем, в какую страницу БД и что писать.
Одна из таких структур — B/B+-дерево, ускоряющее считывание данных.
Задача дерева — ускорять поиск. к считыванию имеет отношение организация хранения страниц в БД.
Недостатком этого дерева является необходимость изменять его при каждом меняющем данные запросе, что может привести к падению производительности из-за произвольного доступа к диску.
Это не недостаток дерева, а любого индекса. Но для этого есть оптимизирующие механизмы.
Не могли бы прояснить несколько не понятных для меня нюансов.
1. Для каких сценариев применения предподчительны такие БД, или на каких сценариях вы приводите сравнения? Похоже идет разговор и различных сценариях применения.
2. Предположим, у нас есть две БД: disk & InMemory. Обе содержат одинаковый объем данных, одинаковые структуры (таблицы/индексы и т.д.), одинаковые сценарии работы и нагрузка. работают в одинаковом окружении, и памяти у обоих +25% к размеру данных, включая индексы. В чем по вашему ожидаются отличия в поведении этих двух БД?GlukKazan
06.12.2016 16:04IMDB применяются для минимизации времени отклика.
Есть предел, которому RDBMS не переступить (какой бы высокой не была пропускная способность).Lofer
06.12.2016 20:51А можно как-то в цифрах/попугаях выразить сравнительно? (можно эмпирически)
Например: Обращения к постоянной памяти — стоит Х попугаев, обращение к оперативной памяти — Y, перестройка индекса — ..., запуск и первые 100500 запросов с перебором случайных не повторяющихся значений —
Хотелось бы понять «за чей счет банкет» в IMDB? неужели «бесплатно» и нету никаких минусов-ограчений?
Как по мне, так в вырожденных случаях, я не вижу серьезных отличий.
Если зная характер нагрузки на мое приложение, я просто воткну какой-то Dictionary (Key-Value) массив в памяти с «капелькой мозгов» в бизнес логику — я получу результат по отклику не хуже (на 1000...10000 запросов).
Пока я вижу пояснение в виде: если ОС или БД закеширует в памяти ответы на запросы это будет хуже, чем наша IMDB которая их загрузит сразу.
Если наша IMDB будет писать лог это будет хуже, чем запись лога DiskDB и т.д.GlukKazan
06.12.2016 22:29Цифр под рукой нет (да и что бы вам дали абстрактные попугаи?), а «банкет» оплачивается из многих факторов.
- Из того что данные гарантированно находятся в ОП (в RDBMS этого гарантировать нельзя)
- Из того что исключается или минимизируется сетевое взаимодействие (если IMDB на том же хосте что и Application)
- Из того что полностью исключается SQL (парсинг и оптимизация)
- Из того что ослабляется или исключается журналирование (в большинстве RDBMS этого сделать нельзя)
- Из того что нет издержек по сбросу грязных данных на диск и не надо ждать завершения контрольных точек
- ...
Если очень надо, всё в ход идёт. Повторюсь, речь идёт о гарантированном времени обработки очень короткой и простой единичной транзакции. RDBMS можно хорошо тюнить на производительность, но по тюнингу времени отклика возможностей меньше. Особенно когда счёт идёт на микросекунды.
Минус, по большому счёту один — данные могут не поместиться в оперативку. Ну и всякая мелочь — например, что нет SQL, если мы от него отказались (кому-то критично, кому-то нет).
Если наша IMDB будет писать лог это будет хуже, чем запись лога DiskDB и т.д.
откуда это?Lofer
06.12.2016 23:34откуда это?
Пардон. Описка.
Это из вышележащих коментариев сторонников IMDB у меня сложилось мнение, что каким-то магическим образом работа с диском IMDB куда эффективнее DiskDB на сопоставимых операциях.
«Из того что полностью исключается SQL (парсинг и оптимизация)» — планы исполнения и предкомпиляция обычно отрабатывает один раз, а дальше от оптимизатора зависит. ну… тут допустим бонус у IMDB.
По прочим пунктам:
«Из того что данные гарантированно находятся в ОП (в RDBMS этого гарантировать нельзя)» — на 1000 одинаковых запросов точно будет. на 1...10 точно пофиг. пинг дольше будет идти :)
«Из того что исключается или минимизируется сетевое взаимодействие (если IMDB на том же хосте что» — межпроцессное общение не убирается в любом случае, а копирование через разделяемую память на одном хосте идет быстро, pipe или сокеты уже не важно. Опять же как будет сделана реализация. при одинаковом механизме разницы быть не должно.
«Из того что ослабляется или исключается журналирование (в большинстве RDBMS этого сделать нельзя)» — я приводил пример. не думаю что только МС такой «хитро-мудрый», а все остальные не догадались. при одинаковом механизме разницы быть не должно.
«Из того что нет издержек по сбросу грязных данных на диск и не надо ждать завершения контрольных точек» — тут точно будет паритет. Если вы пишете на диск свой журнал, то ОС будет управлять сбросом, или вы будете ее пинать, что бы сбросила данные или нет. Как напишет программер.
Из вашего пояснения я понял что IMDB это жутко оптимизированный кеш в памяти, поверх файловых кешей ОС, к которому прикрутили свой оптимизированный на одну задачу интерфейс.
Цена: Убрали уверсальность решаемых задач и ограничили объем обрабатываемых данных.GlukKazan
07.12.2016 09:53точно пофиг. пинг дольше будет идти
Если всё на одном хосте, никакого пинга вообще не будет. Кроме того, похоже вы не понимаете. Нам требуется гарантированное время, а при наличии кэша ничего гарантировать нельзя. Можно говорить только о производительности, в плане среднего количества транзакций за единицу времени, но никак не о времени обработки отдельной транзакции.
планы исполнения и предкомпиляция обычно отрабатывает один раз, а дальше от оптимизатора зависит
То есть, самый первый запрос будет выполняться дольше, а нам надо гарантированное время. И не надо говорить про «прогрев». Разобранный план запросто может уйти из Library Cache (терминология Oracle) и мы получим медленный запрос в произвольный момент времени. Можно конечно пытаться добиться того чтобы план не вытеснялся, но это та ещё магия.
межпроцессное общение не убирается в любом случае
Я об этом и говорю: IPC быстрее TCP через Loopback, который быстрее чем TCP через сеть. А TCP через сеть это очень весомые (и не всегда гарантированные) миллисекунды.
Как-то вот так всё выглядит
Lofer
07.12.2016 15:56Если требуется «гарантированный отклик» — тогда понятно. только спец решение.
Вопрос как этот отклик гарантируется, если «на одном хосте сидели ...»? жесткая привязка к ядрам процессора? к каналам ввода-вывода на «железо»?
Подозреваю, что под «прогрев» подразуевается помещение в оперативную память данных вообще до того, как БД станет доступна для других. Тут или залить snapshot IMDB или скриптами погонять — результат один.
Грязные данные это не журнал, а те изменения которые уже зафиксированы в журнале, но не сброшены на диск (рандомным доступом). В IMDB нет грязных данных, по определению, поскольку все данные в ОП.
Судя по коментариям, это могут быть или данные в журнале IMDB, еще не сброшенные на диск, или shapshot еще не сброшенный на диск. Эта операция тоже «не дешевая».
Тот же Windows 8...16 гб сливает в hybernate файл оперативную память пару десятков секунд в фактически монопольном доступе к жесткому диску.GlukKazan
07.12.2016 19:04Если требуется «гарантированный отклик»
Часто, но не только. Например Oracle Exalytics использует TimesTen для того чтобы поворочать аналитику в памяти (SQL у TimesTen, кстати, вполне полноценный). Летает как самолёт (стоит тоже).
жесткая привязка к ядрам процессора
Бывает.
Тут или залить snapshot IMDB или скриптами погонять — результат один.
Как я уже писал выше, снапшот заливается достаточно быстро. Это более дешёвая операция чем выполнение скриптов.
Судя по коментариям, это могут быть или данные в журнале
Не судите по комментариям. Грязные данные — в сегменте данных. То что не зафиксировано в журнале называется проще — незакомиченные транзакции. Ну и опять интересно, судя по каким комментариям? Я таких не помню.
Эта операция тоже «не дешевая».
Достаточно дешёвая.
danikin
08.12.2016 13:17Эта операция в большинстве моих кейсов — дешевая. Будет отдельная статья с деталями.
imaimag
08.12.2016 12:49Минус, по большому счёту один — данные могут не поместиться в оперативку
Разные инструменты — разный способ работы с ними.
Не нужно пытаться работать с in-memory ровно так же как и с RDBMS.
Наоборот — тоже не нужно.
Примеры использования очень разных СУБД в одном проекте для очень разных подзадач. Тут вам и in-memory и документарно-ориентированные и Cassandra-подобные с MapReduce…
https://habrahabr.ru/company/targetix/blog/266009/
https://habrahabr.ru/company/dca/blog/260845/
Способы обойти ограничения по памяти, если уж так прям край как надо именно in-memory СУБД, имеются.
Можно разделить данные по разным серверам — шардинг.
Можно использовать в Tarantool движок vinyl (в прежних версия sphia), а не движок memx, который включен в Tarantool по умолчанию — данные не обязаны помещаться в оперативную память. Правда vinyl/sphia это append only.
Сейчас Mail.ru проводит эксперименты по использованию vinyl в Tarantool для поиска по письмам. Речь идет о пентабайтах данных. Понятно, что это уже не чистая in-memory СУБД получается, но, возможно, для кого-то и такой способ использования окажется полезным.GlukKazan
08.12.2016 12:54Не нужно пытаться работать с in-memory ровно так же как и с RDBMS.
Это вы мне пишите? Я не пытаюсь.
danikin
08.12.2016 13:14Ускорять чтение данных — имеется в виду делать быстрее селекты. В это словосочетание входят и поиск по индексу и чтение данных. Простите, что я термин считывание понимаю не так как вы его понимаете. Хотя, это в практике вещей тут — взять слово, выдрать из контекста, понять его по другому и дальше научить аффтора прописным истинам, сделав вывод из своей фантазии, приписав автору того, чего нет на самом деле. Смысл? Поднять свою значимость?
«Это не недостаток дерева, а любого индекса» — ну а вы контекст расширьте. Фраза написана в контексте, что это дерево на диске. Каждое изменение (да и чтение тоже, кстати) — произвольный доступ к диску. В IMDB такого нет — там все в памяти. Недостаток это или нет? Вопрос филосовский. Кому-то нравится, когда помедленнее.
1,2. Я понял уже, что это тема для отельной статьи, даже двух. Так вот быстро и подробно не ответишь. Скоро опубликую. Вызову, наверное, опять шквал гнева у любителей старины, но что поделаешь :-)
babylon
06.12.2016 22:43Хотелось бы в остатке от обсуждения увидеть некоторый, если не научный, то хотя бы современный теоретический багаж. Я сомневаюсь, что такие сложенные вещи как СУБД в любой форме разрабатываются по наитию и в одиночестве.
LaRN
07.12.2016 12:27Хороший инструмент, но есть кейс, когда он не сработает.
Если размер таблиц(ы) больше объема ОЗУ выделенного для in-memory СУБД на сервере.
Тут все равно нужно будет обращаться к диску чтобы нужные данные подкачать в память.
arcman
07.12.2016 12:27Автор вначале приводит SQL базы данных и противопоставляет им NoSQL (key-value хранилища).
Это как бы не совсем адекватно и не всем подходит.
servekon
08.12.2016 00:29Для Postgres можно в памяти хранить индексы, что в некоторых случаях ускоряет процесс.
danikin
08.12.2016 13:18Ускоряет, но лишь частично. После обращения по индексу, нужно вытащить с диска с данные. А это обычно рандомное обращение к диску.
GlukKazan
08.12.2016 13:49+1Ну, справедливости ради, существуют планы выполнения запросов, на которых достаточно обращаться только к индексам.
Lofer
09.12.2016 22:48т.е по факту, как только латентность постоянной памяти, будет сопоставима с оперативной памятью, ваше решение перестанет быть «крутым».
если делать не на hdd а на ssd с pcie/NVMe то недостатки в виде «рандомное обращение к диску» перестануть быть весомым фактором.
судя по упоминаемому выше серверу супермикро.
Может у вас есть какие-то сравнительные тесты?danikin
10.12.2016 00:37Ну если вам от этого спать спокойней, то, да перестанет )))
А когда, сверх того, постоянная память будет адресоваться напрямую процессором и при этом каждое изменение (каждый байт) будет моментально и синхронно персистить с латентностью текущей RAM, то и ваши любимые дисковые СУБД полетят в помойку — достаточно будет взять любую библиотеку структур данных, например, плюсовую STL и использовать ее как персистентную базу данных.
Насчет SSD — там такая же проблема как с HDD, но не в тех масштабах. На 2 порядка быстрее HDD, но все еще на 4 порядка медленнее памяти.
Есть сравнительные тесты Tarantool с другими СУБД в памяти: http://highscalability.com/blog/2015/12/30/how-to-choose-an-in-memory-nosql-solution-performance-measur.html, https://medium.com/@rvncerr/tarantool-vs-competitors-racing-in-microsoft-azure-ebde9c5d619#.ispbmmius. С дисковыми СУБД сравнений нет — там и так понятно, что выигрышь на несколько порядков.Lofer
10.12.2016 02:57+1Насчет SSD — там такая же проблема как с HDD, но не в тех масштабах. На 2 порядка быстрее HDD, но все еще на 4 порядка медленнее памяти.
Как то вы слишком фривольно манипулируете цифрами.
Если протестировать RAM disk, для i7-5820K @ 4GHz, G.Skill 2133 DDR4
Sequential Read: 7407.388 MB/s
Sequential Write: 11478.855 MB/s
Random Read 512KB: 7218.039 MB/s
Random Write 512KB: 11622.896 MB/s
Для Samsung 950 Pro 512 Gb
Sequential Read: 2599 MB/s
Sequential Write: 1530 MB/s
Random Read 512KB: 1216 MB/s
Random Write 512KB: 1513 MB/s
Разницу на один порядок между оперативной памятью и SSD видно.
по IOPS разница: ~554 373 IOPS против ~44 9000 по чтению примерно в 10 раз
и
~468 428 IOPS против ~13 516 по записи примерно в 30 раз.
Можно, конечно заморочиться с ECC и размером кеша для серверов, но еще в 10 раз мы не натянем ну никак.
При интенсивной записи, станет колом что IMDB что DiskDB на записи журанала. Но это граничные условия, можем их опустить.
А вы утверждаете о разнице на 4 порядка (10 тыс раз!!!) между RAM и SSD!
Как то не аккуратно :)danikin
10.12.2016 10:43Я говорю об SSD дисках.
https://en.wikipedia.org/wiki/Solid-state_drive: Время случайного доступа 0.1ms (1e-4)
https://en.wikipedia.org/wiki/Dynamic_random-access_memory: Время случайного доступа 50ns (5e-9)
Разница даже 5 порядков.
Вы говорите от NVM https://en.wikipedia.org/wiki/NVM_Express. Они подороже чем SSD диски, но побыстрее. Там проблемы случайного доступа почти нет.
Правда, странно вы меряете случайный доступ — 512КБ блоками. Если мерять 4К блоками, то результат будет в несколько раз скромнее у конкретно Samsung 950 Pro: http://www.anandtech.com/show/9702/samsung-950-pro-ssd-review-256gb-512gb/7
Ну и давайте вспомним тот факт, что RDBMS медленнее IMDB, даже если все сидит в кэшах (т.е. тут уже не важно какой диск под базой, пусть это даже супербыстрый флеш).
В качестве иллюстрации могу привести пример теста MariaDB — одной из самых прогрессивных с точки зрения производительности RDBMS на текущий момент (это заоптимизированный форк MySQL, ее авторы — создатели MySQL, ушли оттуда и организовали свою компанию после того как Oracle купил MySQL), по крайней мере среди open source. Этот тест провели сами создатели этой СУБД, т.е. мы можем надеяться, что СУБД настроена на максимальную пиковую производительности. Вот подробности про тест: https://mariadb.org/10-1-mio-qps/. Он показывает миллион запросов в секунду на дорогущей машине IBM Power8 с 20 ядрами и 160 хардварными потоками (читай, на самом деле, как с 160 ядрами). А вот тест IMDB Tarantool, который показывает миллион запросов в секунду на одноядерном виртуальном амазоновском сервере за $5 в месяц: https://gist.github.com/danikin/a5ddc6fe0cedc6257853 (кстати, исходник открыт — можете повтоить своими руками, причем бесплатно — ибо этот сервер попадает под free tier у Амазона).
Отличие, грубо говоря, в 160 раз. Можно тут долго спорить о реальной параллельности ядер у Power8 (хотя 20 честных ядер там точно есть), а также о том, на каком железе работают сервисs Амазона, но, в целом, отличие очевидно. Заметьте, это достаточно честный бенч в том смысле, что в обоих случаях вендо выжал максимум из своего детища, максимально хорошо его настроив.Lofer
10.12.2016 13:28Давайте смотреть сопоставимые вещи, а не абстрактные «случайный доступ».
C учетом того, что у статьях упоминается своя версия fork и работы со страницами памяти, мы же оперируем большими наборами данных а не один… двумя байтами, соответсветнно и все «платежи», в виде промахов в кеш процессора, переупорядочиваяния станиц памяти при освобождении и будем пытаться включать. Так чуть корректнее будет.
Одинаковый тест, сопоставимые условия — сопоставимый итоговый результат. IOPS и передача данных.
По итогу и получатся, что при всех узкоспециализиованных преимуществах сумма всех факторов приводит к такому результату.
С этой точки зрения, сравнения количество полезной «работы» в итоге будет более корретно?Lofer
10.12.2016 14:41Спасибо за ссылки. Интересно.
Повторюсь, что я не спец по IMDB и возможно не корретно понял ваш тест.
Но я не заметил у вас:
How sysbench OLTP operates
During each iteration, a worker thread chooses a random table from the pool of defined OLTP tables. For the point selects it randomly chooses a row number between 1 and the number of rows per table (--oltp-table-size). The range queries, the update, and the delete / insert operations also use random row IDs.
Отличие, грубо говоря, в 160 раз
не понял на чем основано, если тестовые сценарии то разные.danikin
10.12.2016 22:04В одинаковых условиях мы сравнивали in-memory СУБД, например, вот тут http://highscalability.com/blog/2015/12/30/how-to-choose-an-in-memory-nosql-solution-performance-measur.html
Там многие популярные IMDB участвуют. Наш Tarantool самый быстрый. Ну и что скажете вы? Тест же провели вы сами, значит верить ему нельзя. Троль всегда найдет как затроллить.
Добавить к тем же условиям MySQL? Ну можно. Он будет минимум в 10 раз медленнее по моеиу опыту (даже если все-все-все будет сидеть в памяти, без единой операции к диску). Но мой опыт же для вас не авторитет и мое умение настраивать RDBMS для вас тоже не акторитет. Поэтому ссылаюсь на признанных профессионалов в этой области (MariaDB). Да, условия теста у нас и у них разные. Т.е. они в целом похожи — рандомно селектим и апдейдим в таблицу, но не вот тебя прям одно и тоже.
Далее еще нюанс. Делать бенчи, чтобы для вас лично показать, что IMDB сильно быстрее чем RDBMS на сходной нагрузки и далее долго и нудно убеждать вам, что условия разные и настроили мы RDBMS на максимальную производительность. Зачем? Чтобы что? Чтобы вы перешли на IMDB. Вы перейдете сами, если поймете, что ваше решение не справляется и вы никак не можете его ускорить. Однако, если на вашей нагрузке лошадь выгоднее автомобиля, то предлагаю ничего не менять, никуда не смотреть и быть довольным лошадью, пока она не перестанет справляться :-)
danikin
10.12.2016 21:57Не понял вашу глубокую мысль. Просите. Можете проще и популярнее сформулировать?
babylon
09.12.2016 01:48+1Если элементарные вопросы, вызывают столько комментариев, я представляю сколько их будет если начать обсуждать распараллеливание. Или допустим недостатки Lua. Хотя возможно всё обстоит наоборот и многим кажется, что уж в кешировании они точно эксперты. Та стратегия, что описал Денис применяется и намного меньших объемах данных. Потому как такая стратегия обусловлена логикой работы. А она примерно везде одинакова при грамотно выстроенной архитектуре.
imaimag
09.12.2016 08:57+1Или допустим недостатки Lua
Язык выбран за максимальную скорость, имхо.
Недостатки-недостатками, но решение на JavaScript, Python, Java, Ruby или кто другой внутри — было бы медленее существенно.danikin
09.12.2016 12:07Вот именно. Когда-нибудь мы про это напишем, покажем бенчи. Вызовем, разумеется, гнев любителей похапэ :-)
grossws
09.12.2016 13:54но решение на JavaScript, Python, Java, Ruby или кто другой внутри — было бы медленее существенно
Откуда такая уверенность про Java? У него JIT, который пилят уже как минимум десяток лет, очень неплох.
danikin
09.12.2016 15:57Java достаточно быстрый. Но его встроить внутрь СУБД достаточно сложно. Скорее надо СУБД внутрь Java встраивать :-)
babylon
10.12.2016 21:42Денис, напишите пожалуйста статью как встраивать Lua в ТNT, а то скучно.
danikin
10.12.2016 22:05-1Тут столько троллей, что я уже и не знаю, какие статьи писать. Лучше подожду, пока от нагрузки у уважаемых седовласых авторитетов RDBMS все встанет раком и они сами тихо под подушкой, никому не говоря, начнут юзать IMDB :-)
begemot_sun
Что делать когда место на диске кончится?
vma
fishca
4. Купить еще побольше дисков побольше
… и лучше заранее
eugenius_nsk
vma
а compress/vacuum по расписанию или запросу чем не подходит?
Indexator
convertor
патч Бармина…
Shrizt
Полагаю периодически делается снимок состояния базы в памяти на диск, и лог транзакций чистится.
vaniac
Место в памяти, нет?