

Помните мою недавнюю статью «Что такое СУБД в оперативной памяти и как она эффективно сохраняет данные»? В ней я привел краткий обзор механизмов, используемых в СУБД в оперативной памяти для обеспечения сохранности данных. Речь шла о двух основных механизмах: запись транзакций в журнал и снятие снимков состояния. Я дал общее описание принципов работы с журналом транзакций и лишь затронул тему снимков. Поэтому в этой статье о снимках я расскажу более обстоятельно: начну с простейшего способа делать снимки состояния в СУБД в оперативной памяти, выделю несколько связанных с этим способом проблем и подробно остановлюсь на том, как данный механизм реализован в Tarantool.
Итак, у нас есть СУБД, хранящая все данные в оперативной памяти. Как я уже упоминал в моей предыдущей статье, для снятия снимка состояния необходимо все эти данные записать на диск. Это означает, что нам нужно пройтись по всем таблицам и по всем строкам в каждой таблице и записать все это на диск одним файлом через системный вызов write. Довольно просто на первый взгляд. Однако проблема в том, что данные в базе постоянно изменяются. Даже если замораживать структуры данных при снятии снимка, в итоге на диске можно получить неконсистентное состояние базы данных.
Как же добиться состояния консистентного? Самый простой (и грубый) способ — предварительно заморозить всю базу данных, сделать снимок состояния и снова разморозить ее. И это сработает. База данных может пребывать в заморозке довольно продолжительное время. К примеру, при размере данных 256 Гбайт и максимальной производительности жесткого диска 100 Мбайт/с снятие снимка займет 256 Гбайт/(100 Мбайт/с) — приблизительно 2560 секунд, или (опять же приблизительно) 40 минут. СУБД по-прежнему сможет обрабатывать запросы на чтение, но не сможет выполнять запросы на изменение данных. «Что, серьезно?» — воскликнете вы. Давайте посчитаем: при 40 минутах простоя, скажем, в день СУБД находится в полностью рабочем состоянии 97% времени в самом лучшем случае (на деле, конечно, процент этот будет ниже, потому что на длительность простоя будет влиять множество других факторов).
Какие тут могут быть варианты? Давайте приглядимся к тому, что происходит. Мы заморозили все данные лишь потому, что необходимо было скопировать их на медленное устройство. А что если пожертвовать памятью для увеличения скорости? Суть в следующем: мы копируем все данные в отдельную область оперативной памяти, а затем записываем копию на медленный диск. Кажется, этот способ получше, но он влечет за собой как минимум три проблемы разной степени серьезности:
- Нам по-прежнему необходимо замораживать все данные. Допустим, мы копируем данные в область памяти со скоростью 1 Гбайт/с (что опять же слишком оптимистично, потому что на деле скорость может составлять 200-500 Мбайт/с для более-менее продвинутых структур данных). 256 Гбайт/(1 Гбайт/с) — это 256 секунд, или около 4 минут. Получаем 4 минуты простоя в день, или 99.7% времени доступности системы. Это, конечно, лучше, чем 97%, но ненамного.
- Как только мы скопировали данные в отдельный буфер в оперативной памяти, нужно записать их на диск. Пока идет запись копии, исходные данные в памяти продолжают меняться. Эти изменения как-то нужно отслеживать, например, сохранять идентификатор транзакции вместе со снимком, чтобы было понятно, какая транзакция попала в снимок последней. В этом нет ничего сложного, но тем не менее делать это необходимо.
- Удваиваются требования к объему оперативной памяти. На самом деле нам постоянно нужно памяти вдвое больше, чем размер данных; подчеркну: не только для снятия снимков состояния, а постоянно, потому что нельзя просто увеличить объем памяти в сервере, сделать снимок, а потом снова вытащить планку памяти.
Один из способов решить эту проблему — использовать механизм копирования при записи (далее для краткости я буду использовать английскую аббревиатуру COW, от copy-on-write), предоставляемый системным вызовом fork. В результате выполнения данного вызова создается отдельный процесс со своим виртуальным адресным пространством и используемой только для чтения копией всех данных. Только для чтения копия используется потому, что все изменения происходят в родительском процессе. Итак, мы создаем копию процесса и не спеша записываем данные на диск. Остается вопрос: а в чем тут отличие от предыдущего алгоритма копирования? Ответ лежит в самом механизме COW, который используется в Linux. Как упоминалось немного выше, COW — это аббревиатура, означающая copy-on-write, т.е. копирование при записи. Суть механизма в том, что дочерний процесс изначально использует страничную память совместно с родительским процессом. Как только один из процессов изменяет какие-либо данные в оперативной памяти, создается копия соответствующей страницы.
Естественно, копирование страницы приводит к увеличению времени отклика, потому что, помимо собственно операции копирования, происходит еще несколько вещей. Обычно размер страницы равен 4 Кбайт. Предположим, вы изменили небольшое значение в базе данных. Сперва происходит прерывание по отсутствию страницы, т.к. после выполнения вызова fork все страницы родительского и дочернего процессов доступны только для чтения. После этого система переключается в режим ядра, выделяет новую страницу, копирует 4 Кбайт из старой страницы и снова возвращается в пользовательский режим. Это сильно упрощенное описание, подробней о том, что происходит на самом деле, можно почитать по ссылке.
Если внесенное изменение затрагивает не одну, а несколько страниц (что весьма вероятно при использовании таких структур данных, как деревья), вышеописанная последовательность событий будет повторяться снова и снова, что может значительно ухудшить производительность СУБД. При высоких нагрузках это может привести к резкому увеличению времени отклика и даже непродолжительному простою; к тому же в родительском процессе будет произвольно обновляться большое количество страниц, в результате чего может быть скопирована почти вся база данных, что, в свою очередь, может привести к удвоению необходимого объема оперативной памяти. В общем, если вам повезет, обойдется без скачков во времени отклика и простоя базы данных, если же нет — готовьтесь и к тому, и к другому; ах да, и про удвоенное потребление оперативной памяти тоже не забудьте.
Еще одна проблема с fork в том, что этот системный вызов копирует таблицу дескрипторов страниц. Скажем, при использовании 256 Гбайт памяти размер этой таблицы может достигать сотен мегабайтов, поэтому ваш процесс может зависнуть на секунду-другую, что опять же увеличит время отклика.
Использование fork, конечно, не панацея, но это пока лучшее, что у нас есть. На самом деле некоторые популярные СУБД в оперативной памяти до сих пор применяют fork для снятия снимков состояния — например, Redis.
Можно ли тут что-то улучшить? Давайте присмотримся к механизму COW. Копирование там происходит по 4 Кбайт. Если изменяется всего один байт, копируется все равно вся страница целиком (в случае с деревьями — много страниц, даже если перебалансировка не требуется). А что если нам реализовать собственный механизм COW, который будет копировать лишь фактически измененные участки памяти, точнее — измененные значения? Естественно, такая реализация не послужит полноценной заменой системного механизма, а будет использоваться лишь для снятия снимков состояния.
Суть улучшения в следующем: сделать так, чтобы все наши структуры данных (деревья, хеш-таблицы, табличные пространства) могли хранить много версий каждого элемента. Идея близка к многоверсионному управлению параллельным доступом. Разница же в том, что здесь это улучшение используется не для собственно управления параллельным доступом, а лишь для снятия снимков состояния. Как только мы начали делать снимок, все операции по изменению данных создают новую версию изменяемых элементов, тогда как все старые версии остаются активными и используются для создания снимка. Посмотрите на изображения ниже. Данная логика справедлива для деревьев, хеш-таблиц и табличных пространств:
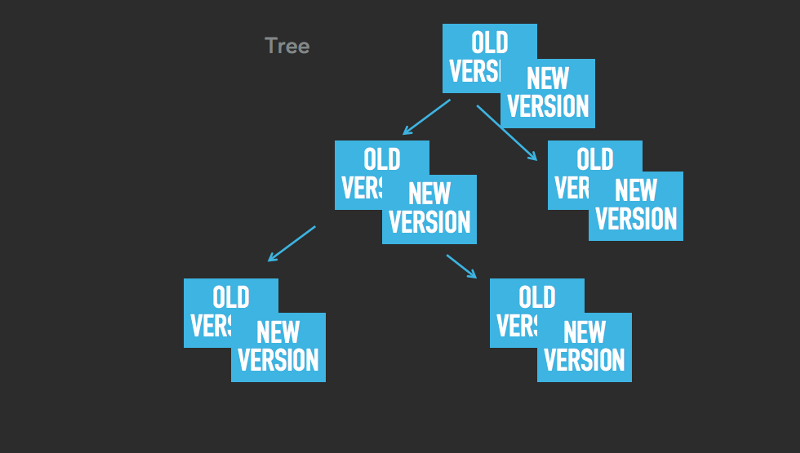
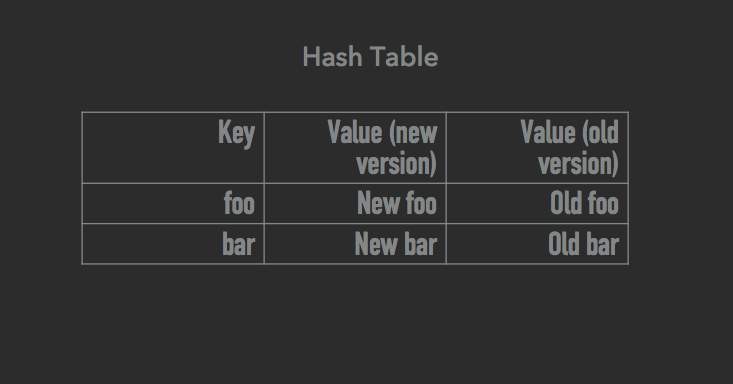

Как вы можете видеть, у элементов могут быть как старые, так и новые версии. К примеру, на последнем изображении в табличном пространстве у значений 3, 4, 5 и 8 по две версии (старая и соответствующая ей новая), у остальных же (1, 2, 6, 7, 9) по одной.
Изменения происходят только в более новых версиях. Версии же постарее используются для операций чтения при снятии снимка состояния. Основное отличие нашей реализации механизма COW от механизма системного в том, что мы не копируем всю страницу размером 4 Кбайт, а лишь небольшую часть действительно измененных данных. Скажем, если вы обновите целое четырехбайтное число, наш механизм создаст копию этого числа, и скопированы будут только эти 4 байта (плюс еще несколько байтов как плата за поддержание двух версий одного элемента). А теперь для сравнения посмотрите на то, как ведет себя системный COW: копируется 4096 байтов, происходит прерывание по отсутствию страницы, переключение контекста (каждое такое переключение эквивалентно копированию приблизительно 1 Кбайт памяти) — и все это повторяется несколько раз. Не слишком ли много хлопот для обновления всего-навсего одно целого четырехбайтного числа при снятии снимка состояния?
Мы применяем собственную реализацию механизма COW для снятия снимков в Tarantool начиная с версии 1.6.6 (до этого мы использовали fork).
На подходе новые статьи по этой теме с интересными подробностями и графиками с рабочих серверов Mail.Ru Group. Следите за новостями.
Все вопросы, связанные с содержанием статьи, можно адресовать автору оригинала danikin, техническому директору почтовых и облачных сервисов Mail.Ru Group.
Комментарии (24)

robert_ayrapetyan
08.12.2016 22:56-1danikin, вот тут — http://nadeausoftware.com/articles/2012/05/c_c_tip_how_copy_memory_quickly получают 40Гбайт\сек (т.е. около 6.5 секунд на всю вашу базу). Не очень понятна фраза:
>скорость может составлять 200-500 Мбайт/с для более-менее продвинутых структур данных
т.е. вы получается копируете не непрерывный блок памяти, а дерево (обходом по нодам?)
Почему так?
danikin
09.12.2016 12:19Потому что так устроены деревья. Они не непрерывно лежат в памяти. Почитайте тут: https://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B0%D1%81%D0%BD%D0%BE-%D1%87%D1%91%D1%80%D0%BD%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE.
В Тарантуле используются структуры, которые лучше локализованы в памяти чем красно-черные деревья. Можно про них почитать тут: https://habrahabr.ru/company/oleg-bunin/blog/310560/. Но и они не непрерывно лежат в памяти.
Вы, очевидно, знаете о структуре данных, в которой можно хранить деревянный индекс и которая непрерывно лежит в памяти. Можете дать ссылку на описание? Наверное, мы что-то упустили из виду.
Сразу скажу, что дерево, разложенное в массив (по сути, отсортированный массив) — плохая структура. Она, конечно, копируется линейно, но в ней можно за LogN делать поиски, но вставка в нее будет за N.
Ваша ссылка, простите, неактуальна. Там 40Гб/сек они получают при копировании массива в 2 килобайта, потому что он сразу целиком помещается в кэш процессора. Посмотрите внимательней на графики — чем больше размер массива, тем меньше Гб/сек.robert_ayrapetyan
10.12.2016 00:43-1Верно, с размера массива, превышающего кеш процессора, скорость порядка 5Гб\сек, т.е. около минуты на 256Гб, тут я ошибся, простите. По поводу расположения в памяти — поясните, какая разница как локализована структура, если использовать placement new или shared memory (задействуя всю мощь аллокаторов), и копировать потом непрерывным блоком весь этот кусок памяти?
danikin
10.12.2016 00:55Вот именно.
Вы, Роберт, простите, теоретик. Давайте перейдем в область практики. Я у вас попросил вариант структуры в студию. Его все еще нет.
Насчет placement new и т.д., вы, очевидно, забыли, что структура изменяется. Из нее удаляются куски, добавляются новые, изменяются старые. Что делать с дырками? Оставлять как есть и просто выделять память в конец? Вариант структуры, которая не меняется, я привел выше — отсортированный вектор.
P.S.
Если вы сделаете в Тарантул pull-request, который мы примем и который бы поменял там все структуры таким образом, чтобы они копировались в среднем со скоростью 5Gb/s для баз данных в 256Gb, и которые при этом не занимали бы больше памяти, чем имеющиеся, то я вам тут же заплачу 3 миллиона рублей.
P.P.S.
Даже если допустить, что сделать структуры данных применимые для Тарантула, которые можно копировать со скоростью 5Gb/сек, то минута простоя и удвоенное потребление памяти — это все равно не вариант.robert_ayrapetyan
10.12.2016 02:40-1В своем проекте я использую key-value хранилище, целиком находящееся в гигантском куске shared memory. В частности, используется std::map и ее реализация берет на себя всю рутину по выделению\освобождению памяти в этом куске памяти (она сама знает как переиспользовать освобожденную память и не добавлять узлы только в конец, например).
Вы поймите: не нужно думать о стуктуре данных вообще: есть выделенный непрерывный кусок памяти, в нем расположена структура с вашими данными (std::map или самописное дерево, массив, неважно, оно какой угодно сложности и формы). Вы знаете где она начинается и где заканчивается. Поэтому вы его копируете непрерывным куском в другой участок памяти, и потом на диск сбрасываете уже сколько угодно долго.
Тут вообще хорошо бы уточнить — какова цель получения этого дампа данных?danikin
10.12.2016 10:48Вопрос: что происходит с освобожденной памятью внутри этого дерева? Как она переиспользуется? С какой стоимостью происходит выделение в ней? (линейный поиск?). Если она никак не переиспользуется, то память в конечном итоге при интенсивной работы базы данных кончится, причем не поможет даже перезагрузка, потому что на диске в вашем случае дамп будет выглядеть также как в памяти. Если она переиспользуется, то это линейный поиск и медленная работа базы данных. И то и другое — плохо.
Цель дампа (снимка) в том, чтобы быстрее стратовать после перезагрузки. Если у вас есть только логи, то они могут проигрываться долго, потому что в них, скажем, обновления одного и того же элемента данных могут присутствовать много раз, а в снимке — только один раз — финальное значение.robert_ayrapetyan
10.12.2016 19:43-1Отвечаю вопросами на ваш вопрос:
1. Вы не выделяете под свою структуру всю доступную память (линейный непрерывный кусок памяти) заранее, а только по мере добавления узлов (запрашивая новый адрес для очередного узла структуры у ОС каждый раз), таким образом вся структура оказывается размазанной и не расположена в непрерывном участке виртуального адресного пространства?
2. Ваша структура — это всего лишь данные и указатели на узлы структуры?
3. Если внутри вашей структуры где-либо используются абсолютные адреса, что стоит переделать ее на использование только относительных (смещений от начала структуры)?danikin
10.12.2016 22:07Что происходит при апдейте и удалении? Например, удаляется строка из БД. Или, например, обновляется поле и увеличивается его размер. Я уже как минимум третий раз в различных видах задаю этот вопрос. Ответа нет.
robert_ayrapetyan
10.12.2016 23:23-1Я вам в третий раз говорю о том, как можно быстро скопировать ВАШУ структуру, вы мне задаете упорно в третий раз вопрос о МОЕЙ структуре из моего проекта
Забудьте, у нас диалог глухого со слепым очевидно…danikin
10.12.2016 23:31А я в третий раз спрашиваю — КАК? Наша конкретная структура не линейно лежит в памяти. У вас есть более умная структура? Расскажите, как она устроена. Мой скайп danikin2. Если у вас цель не самопиариться на хабре, а получить ответы на ваши вопросы, то стучитесь мне в скайп — все расскажу, ну или свой скайп оставьте — я вам постучусь.
robert_ayrapetyan
10.12.2016 23:44-1Любую структуру можно расположить в непрерывно выделенном участке памяти. Это вам должно быть интересно, как (возможно) улучшить ваш проект, мне на него глубоко пофиг… Скайп я вам свой давать не собираюсь, если хотите — стучите в джаббер ara1307@jabber.org.
danikin
11.12.2016 10:45Постучался вам с гмейла, danikin1@gmail.com
Надеюсь, у вас хватит уверенности в себе пообщаться со мной и вы не будете скрываться :-)
«Любую структуру можно расположить в непрерывно выделенном участке памяти» — ответа на вопрос как это сделать так и не поступило. Возможно, если выйдете на связь, расскажите. Пока звучит голословненько.

onyxmaster
09.12.2016 10:56Huge pages?
danikin
09.12.2016 12:22Давайте я постараюсь угадать, что вы имели в виду в своем комментарии. Вы имели в виду, что почему бы не включить huge pages (2Mb по дефолту, или еще больше) и это бы ускорило радикально fork, и убрало бы описываемую в этой статье проблему. Да?
onyxmaster
10.12.2016 13:31-1Да, это один из вариантов. Я согласен, что структуры данных, которые поддерживают версионирование более эффективны, но именно проблему с копированием таблиц страниц можно обойти таким способом. Конечно, у больших страниц есть минусы при случайном доступе, возможно для вашего сценария они неприменимы.
danikin
10.12.2016 22:09Отличный способ. Меняется одно значение в базе данных и копируется минимум 2Мб (или какой размер страницы вы выбрали?). А на практике — еще больше. Допустим, если у вас дерево и надо его перебалансировать и сделать несколько записей в рандомные куски памяти, то, глядишь, и десяток мегабайт скопируйте. И так на каждое обновление значения в базе (а их может быть и сто тысяч в секунду). Отличное решение.
onyxmaster
10.12.2016 14:41И да, я прошу прощения за недостаточно развёрнутый комментарий, сказывается низкий навык публичного общения. Slack низводит до уровня чат-бота :)
danikin
10.12.2016 22:10Ну все ок, я научился уже угадывать, что люди спрашивают. Просто иногда лучше явно спросить, что имели в виду, чтобы человек после уже ответа на вопрос не сказал бы, что «а я имел в виду совсем другое».

ggo
09.12.2016 13:50А можете поделиться реальным кейсом с цифрами? Размер БД, скорость изменений (как много изменений в БД), за сколько скидывается снимок на диск, сколько при этом накапливается изменений в диффах (соответственно сколько нужно дополнительной памяти), скорость диска, каков прирост вычислительной нагрузки во время сброса снимка на диск и т.д.

darkmind
16.12.2016 17:28Как только мы скопировали данные в отдельный буфер в оперативной памяти, нужно записать их на диск. Пока идет запись копии, исходные данные в памяти продолжают меняться. Эти изменения как-то нужно отслеживать
Вот этот кусок не понял. Да, данные меняются, но в оригинальной же памяти, зачем за ними следить? При заморозке считали айди последней транзакции из commit log'а и записали рядом. Все, у вас есть полная, консистентная копия, на момент транзакции N.danikin
16.12.2016 21:01Я, возможно, криво сформулировал. Но имелось в виду ровно то, что вы написали :-)
interrupt
danikin
Да, ссылка не туда вообще. Спасибо! Сейчас поправим. Речь про таблицу страниц: https://en.wikipedia.org/wiki/Page_table