

Привет! В двух моих последних статьях я говорил о том, как СУБД в оперативной памяти обеспечивают сохранность данных. Найти их можно здесь и здесь.
В этой статье я хотел бы затронуть проблему производительности СУБД в оперативной памяти. Давайте начнем обсуждение производительности с простейшего случая использования, когда просто изменяется значение по заданному ключу. Для еще большей простоты предположим, что серверная часть отсутствует, т.е. не происходит никакого клиент-серверного взаимодействия по сети (дальше будет понятно, зачем мы это сделали). Итак, СУБД (если ее можно так назвать) находится полностью в оперативной памяти вашего приложения.
За неимением сервера базы данных вы, возможно, хранили бы пары «ключ-значение» в хеш-таблице в памяти вашего приложения. В C/C++ эта структура данных выглядела бы так:
std::unordered_mapЧтобы проверить скорость работы этой структуры, я создал файл
1.cpp со следующим содержимым:#include <map>
#include <unordered_map>
#include <iostream>
const int SIZE = 1000000;
int main()
{
std::unordered_map<int,int> m;
m.reserve(1000000);
long long c = 0;
for (int i = 0; i < SIZE;++i)
c += m[i*i] += i;
std::cout << c << std::endl;
}Затем я его скомпилировал и запустил:
g++ -std=c++11 -O3 1.cpp -o 1
MacBook-Air-anikin:Downloads anikin$ time ./1и получил следующий результат:
real 0m0.465s
user 0m0.422s
sys 0m0.032sЧто из этого можно вынести? Мои выводы такие:
- Я люблю C/C++.
- Я люблю свой старый добрый MacBook Air (вообще-то, нет, потому что он работает все медленней и медленней, но это отдельная история).
- Я люблю использовать флаг оптимизации
-O3. Некоторые боятся его применять, но напрасно, потому что, в противном случае, производительность будет плохой. Чтобы продемонстрировать это, давайте запустим такую команду:
MacBook-Air-anikin:Downloads anikin$ g++ -std=c++11 1.cpp -o 1 MacBook-Air-anikin:Downloads anikin$ time ./1
И убедимся, что результат без-O3вдвое хуже:
real 0m0.883s user 0m0.835s sys 0m0.033s - Приложение большей частью проработало в пользовательском режиме. Непродолжительное же время, проведенное в режиме ядра, было потрачено скорее всего на предварительное выделение страниц для хеш-таблицы (и
-O3, кстати, это время не оптимизировал), выполнение системного вызова mmap и загрузку исполняемого файла. - Это приложение вставляет приблизительно миллион ключей в хеш-таблицу. Здесь слово приблизительно означает, что на самом деле в хеш-таблице может оказаться меньше миллиона ключей из-за повторов, вызванных переполнением при перемножении i*i. Таким образом, вставка новых данных может превратиться в обновление данных уже существующих. Однако операций с хеш-таблицей производится ровно миллион.
- Приложение вставляет миллион ключей и завершает работу примерно за полсекунды, т.е. оно производит около двух миллионов вставок пар «ключ-значение» в секунду.
Последнее наблюдение представляет особый интерес. Можно считать, что у вас уже есть движок хранилища пар «ключ-значение» в оперативной памяти в лице
std::unordered_map, способный выполнить два миллиона операций в секунду на одном ядре вот такого старого доброго MacBook Air:MacBook-Air-anikin:Downloads anikin$ uname -a
Darwin MacBook-Air-anikin.local 13.4.0 Darwin Kernel Version 13.4.0: Mon Jan 11 18:17:34 PST 2016; root:xnu-2422.115.15~1/RELEASE_X86_64 x86_64Обратите внимание, что я использовал целочисленные ключи и значения. Я мог бы использовать строки, но не сделал этого просто потому, что не хотел, чтобы выделение памяти и копирование повлияли на результаты теста. Еще один аргумент против строк: при использовании
std::unordered_map<std::string, …> больше вероятность возникновения коллизий, снижающих производительность.Можно видеть, что хеш-таблица в оперативной памяти способна выполнить два миллиона операций в секунду на одном ядре, однако, напомню, я собирался говорить о СУБД в оперативной памяти. В чем же отличие СУБД в оперативной памяти от хеш-таблицы в оперативной памяти? СУБД — это серверное приложение, тогда как хеш-таблица является библиотекой, т.е. СУБД — это хеш-таблица плюс кое-что еще. И это кое-что еще включает в себя как минимум саму по себе серверную обвязку.
Давайте создадим серверное приложение на базе
std::unordered_map<int, int>. Наивный подход мог бы выглядеть примерно так:- Принимаем соединения в основном потоке.
- Создаем новый поток для каждого принятого соединения (или заводим пул заранее созданных потоков).
- Защищаем
std::unordered_mapс помощью какого-нибудь примитива синхронизации (например, мьютекса). - Не забываем о сохранности данных — записываем каждую операцию обновления в журнал транзакций.
Не хотелось бы утомлять вас написанием кода приложения, поэтому давайте представим, что мы это уже сделали. Возьмите любой сервер базы данных, устроенный по принципу «отдельный поток для каждого соединения» (MySQL, MariaDB, Postgres и т.д.): он может выполнять в лучшем случае десятки тысяч запросов в секунду на одном ядре (на 16- или 32-ядерном сервере это может быть и под миллион операций в секунду). Это хорошо известно из различных бенчмарков. Лучший показатель производительности среди традиционных СУБД, что мне удалось найти в сети, составляет около миллиона запросов в секунду и принадлежит MariaDB, работающей на компьютере с 20-ю ядрами. Подробные выкладки можно найти здесь. Путем несложных вычислений получаем 50 тысяч запросов в секунду на одно ядро. Одна из лучших СУБД на рынке, которую оптимизируют, возможно, лучшие специалисты в мире, обрабатывает всего лишь 50 тысяч простейших запросов (по сути, поиск по ключу) в секунду на одном ядре.
50 тысяч и два миллиона — сорокакратная разница, если сравнивать с
std::unordered_map. Как вам это нравится? Мы всего лишь добавили к структуре данных сервер, чтобы предоставить другим приложениям удаленный доступ к ней, — и наша производительность упала в 40 раз! (Еще раз повторюсь, это бенчмарк с простейшими операциями, все лежит в кэше, СУБД настроена лучшими специалистами в мире — и настроена на максимальную пропускную способность, минимизируя все накладные расходы, которые могут быть в СУБД.) Это настолько обескураживает, что, кажется, лучше забыть о многоуровневой архитектуре и писать всю бизнес-логику и логику СУБД в одном приложении внутри одного процесса. Это, конечно же, была шутка. Лучше попробовать оптимизировать работу сервера базы данных.Давайте посмотрим через призму системных вызовов на то, что происходит, когда сервер с вышеупомянутой архитектурой обрабатывает транзакцию:
- Чтение запроса из сети.
- Блокировка хеш-таблицы.
- Разблокирование хеш-таблицы.
- Запись в журнал транзакций.
- Запись в сеть.
Получаем по крайней мере пять системных вызовов к СУБД на один запрос. Выполнение каждого вызова требует входа в режим ядра и выхода из него.
При входе в режим ядра и выходе из него происходит переключение режимов, что влечет за собой некоторый объем работы. Детали можно почитать, например, здесь. К тому же переключение режимов может вызвать переключение контекста и привести к еще большим копированию и задержкам. Подробней об этом можно узнать по ссылке.
Чтобы показать вам все зло системных вызовов (поймите меня правильно, я люблю системные вызовы, но они медленные, поэтому я стараюсь не злоупотреблять ими), я написал еще одну программу (на C):
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
int fd = open(“/dev/zero”, O_RDONLY);
for (int i = 0; i < 1000000; ++i)
{
unsigned char c;
if (read(fd, &c, 1) == -1)
{
fprintf(stderr, “error on read\n”);
break;
}
}
close(fd);
return 0;
}Эта программа всего-навсего производит миллион побайтовых чтений из файла
/dev/zero. Результаты теста следующие:MacBook-Air-anikin:Downloads anikin$ time ./2
real 0m0.639s
user 0m0.099s
sys 0m0.495sВо-первых, программа проводит практически все время в режиме ядра. Во-вторых, она производит около полутора миллионов системных вызовов в секунду. Напомню, что производительность хеш-таблицы составляла примерно два миллиона операций в секунду. Любопытно, что системный вызов read на 30% медленнее поиска в хеш-таблице. И это при всей простоте данного вызова: он не обращался к диску или сети, а просто возвращал нули.
Как я писал выше, при использовании сервера базы данных на одну операцию поиска в хеш-таблице приходится как минимум пять системных вызовов. Это означает, что нам требуется как минимум в (5 * 1.3 = ) 6.5 раз больше времени только на системные вызовы! Если перевести ситуацию в налоговую плоскость, то системные вызовы — это как 85%-ный налог. Были бы вы рады 85%-ному налогу на зарплату, т.е. если бы получали всего 15 из 100 заработанных вами рублей? Поразмыслив над этим, давайте вернемся к read, write и прочим системным вызовам. Они выполняют широкий спектр задач: чтение из сетевого буфера, выделение блоков памяти в ядре Linux, поиск и изменение внутренних ядерных структур и т.д. Поэтому более чем 85%-ный налог выглядит на самом деле очень даже небольшим. Для проверки того, сколько системных вызовов производит MySQL или любая другая традиционная СУБД при обработке запроса, в Linux можно использовать утилиту strace.
Итак, системные вызовы — это зло. Можно ли от них отказаться совсем и перенести всю логику СУБД в ядро? Звучит неплохо, но сложно. Возможно, есть более практичное решение. Посмотрите на пример ниже:
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
int fd = open(“/dev/zero”, O_RDONLY);
for (int i = 0; i < 1000; ++i)
{
unsigned char c[1000];
if (read(fd, &c, 1000) == -1)
{
fprintf(stderr, “error on read\n”);
break;
}
}
close(fd);
return 0;
}Результат следующий:
MacBook-Air-anikin:Downloads anikin$ time ./2
real 0m0.007s
user 0m0.001s
sys 0m0.002sЭта программа делает ровно то же, что и предыдущая, — копирует миллион байтов из файла
/dev/zero — однако время выполнения у нее — всего 7 мс, что почти в 100 раз быстрее предыдущего результата в 639 мс! Как такое возможно? Трюк в том, что мы уменьшаем количество системных вызовов и увеличиваем объем работы, который каждый из них выполняет. Оказывается, системные вызовы не такое уж и зло, если хорошенько нагружать их работой. Платишь фиксированную цену за вызов — и потом можешь использовать их практически бесплатно. Это похоже на заграничные парки развлечений: заплатил один раз за входной билет — и пользуйся весь день любыми аттракционами. Ну или чуть меньше, чем весь день: стоимость билета останется неизменной, хотя в пересчете на отдельный аттракцион выйдет немного дороже.Итак, чтобы ускорить работу сервера базы данных, нам нужно производить меньше системных вызовов и выполнять больше операций внутри каждого такого вызова. Как же этого добиться? Давайте просто объединим запросы и их обработку:
- Считываем 1000 запросов из сети с помощью одного вызова read.
- Блокируем хеш-таблицу.
- Обрабатываем 1000 запросов.
- Разблокируем хеш-таблицу.
- Записываем 1000 транзакций в журнал с помощью одного вызова write/writev.
- Записываем 1000 ответов в сеть с помощью одного вызова write.
Замечательно! Но подождите-ка секундочку, СУБД обычно не обрабатывает запросы пачками (по крайней мере, если ее не просят об этом явно), она работает в режиме онлайн: как только поступает запрос, СУБД тут же его обрабатывает с минимально возможной задержкой. Она не может ждать поступления пачки в 1000 запросов, потому что этого может и никогда не произойти.
Как решить эту проблему?
Посмотрим на общественный транспорт. Там эта проблема была решена еще в прошлом веке (если не в позапрошлом). Билет на автобус дешевле поездки на такси, потому что у автобуса выше пропускная способность — а значит, и цена поездки на одного пассажира ниже. Однако задержка (время ожидания) автобуса (или поезда метро, в зависимости от конкретного города) примерно такая же, как у такси в оживленном центре (я наблюдал эту закономерность как минимум в Нью-Йорке, Москве, Париже, Берлине и Токио). Как это работает?
Суть в том, что автобус никогда не дожидается, пока на остановке окажется сотня человек. Пассажиров на остановке обычно всегда достаточно, потому что центр — это оживленная часть города (читай: рабочая нагрузка высокая). Таким образом, один автобус останавливается, забирает пассажиров (до наполнения салона или пока на остановке никого не останется) и уезжает. Затем подходит следующий автобус и снова забирает достаточное количество пассажиров, потому что за время, прошедшее между отъездом первого автобуса и приездом второго, на остановке появились новые люди. Автобус никогда не ждет наполнения. Он работает с минимальной задержкой: люди есть — забрал, поехал дальше.
Чтобы СУБД работала так же, необходимо рассматривать сетевую подсистему, обработчик транзакций и дисковую подсистему как независимые автобусы (или, если хотите, поезда метро). Каждый из этих автобусов работает асинхронно по отношению к двум другим. И каждый из этих автобусов забирает столько пассажиров, сколько есть на остановке. Если пассажиров недостаточно — что ж, да, процессор используется неэффективно, потому что автобусы с высокой фиксированной стоимостью проезда остаются практически пустыми. С другой стороны, а что в этом такого? Мы прекрасно справляемся с имеющейся нагрузкой. Процессор может быть загружен на 99% как при 10 тысячах запросов в секунду, так и при миллионе запросов в секунду, но время отклика будет одинаково хорошим, потому что количество системных вызовов в обоих случаях одно и то же. И этот показатель важнее количества переданных за один системный вызов байтов. Процессор всегда загружен, но он удивительным образом масштабируется под нагрузкой, оставаясь равно загруженным как при больших, так и при малых объемах выполняемой работы. Напомню: время отклика практически не изменится, даже если количество выполняемых в системном вызове операций будет различаться в 100 раз. Причиной этому является очень высокая фиксированная цена одного системного вызова.
Как все это реализовать наилучшим образом? Асинхронно. Рассмотрим на примере СУБД Tarantool:
- Tarantool имеет три потока: поток для работы с сетью, поток для обработки транзакций (мы пользуемся сокращением TX, от transaction processing, но не спрашивайте, почему там X, а не P!) и поток для работы с диском.
- Поток для работы с сетью читает запросы из сети (сколько сможет прочитать из сетевого буфера без блокировки ввода/вывода, будь то один запрос, тысяча или больше) и затем передает их в TX. Он также получает ответы от TX и пишет их в сеть, и делает он это в одном сетевом пакете вне зависимости от того, сколько ответов содержит пакет.
- Поток TX группами обрабатывает в оперативной памяти транзакции, полученные из потока для работы с сетью. Обработав одну группу транзакций в памяти, он передает ее в поток для работы с диском; при этом группы передаются одна за другой, без учета того, сколько транзакций находится в той или иной группе. Это как толпа людей, сошедших с поезда и направляющихся к автобусной остановке. Подъезжающий автобус заберет с остановки всех пассажиров до единого. Если кто-то не успел дойти до остановки до отправления автобуса, ему придется дожидаться следующего. Автобус не ждет ни одной лишней миллисекунды: если за последним пассажиром никого больше нет, он отправляется в путь. Обработав группу, поток для работы с диском возвращает ее потоку TX, чтобы тот закоммитил транзакции и вернул все содержащиеся в данной группе запросы в поток для работы с сетью.
Именно таким способом мы существенно сократили количество системных вызовов в Tarantool. По ссылке можно подробней прочитать о том, как наша система работает и справляется с миллионом транзакций в секунду на одном ядре.
На изображении ниже схематично приведен весь рабочий процесс:
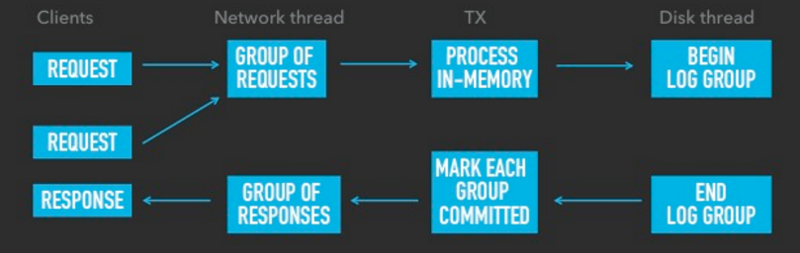
Главное, на что здесь стоит обратить внимание, — это то, что каждый поток выполняется параллельно и не мешает работе оставшихся двух. Чем параллельней и выше нагрузка, тем меньше системных вызовов приходится на запрос и тем больше запросов система может обработать в секунду.
При этом мы имеем хорошее время отклика, потому что потоки не простаивают в ожидании других потоков, а просто выполняют имеющуюся у них на текущий момент работу, и пока это происходит, для них параллельно подготавливается новая порция работы.
Будут еще статьи про СУБД в оперативной памяти. Следите за обновлениями!
Все вопросы, связанные с содержанием статьи, можно адресовать автору оригинала danikin, техническому директору почтовых и облачных сервисов Mail.Ru Group.
Комментарии (30)

shadowjack
09.12.2016 21:38+8… как наша система работает и справляется с миллионом транзакций в секунду на одном ядре.
Можно уточнить, эти транзакции (которых миллион на одном ядре) состоят из нескольких атомарных операций? Их можно в процессе выполнения откатить? Изолированы ли они как-то друг от друга (блокировки, вот это вот всё)?


TimsTims
10.12.2016 01:34> мы пользуемся сокращением TX
Наверное пошло от:
Tx Rx
T — Trancieve (отправление)
R — Recieve (получение)

Lofer
10.12.2016 01:35+2Мда…
По сути документации:
This model makes all programmatic locks unnecessary: cooperative multitasking ensures that there will be no concurrency around a resource, no race conditions, and no memory consistency issues
и
box.begin() Begin the transaction. Disable implicit yields until the transaction ends. Signal that writes to the write-ahead log will be deferred until the transaction ends. In effect the fiber which executes box.begin() is starting an “active multi-request transaction”, blocking all other fibers.
box.commit() End the transaction, and make all its data-change operations permanent.
box.rollback() The requests in a transaction must be sent to the server as a single block. It is not enough to enclose them between begin and commit or rollback. To ensure they are sent as a single block: put them in a function, or put them all on one line, or use a delimiter so that multi-line requests are handled together.
И судя по тому, что в документации написано, что все попадает в один исполнительный поток на сервере, ждет! асинхронного подтверждения на запись на диск, а в случае проблемы откатывает все, что было изменено после операции вызвашей проблему.
До полноценной RDMS ей как до границы раком.
Безусловно, много там интересных вещей и ребята проделали большую работу, но это по факту Key-Value массив «на стероидах» в памяти, с обвязкой для репликации и самовосстановления из сохранных на диске данных.
zzzcpan
12.12.2016 10:58+1Ждет подтверждения от диска наверное же при коммите, что вполне обычно в таких случаях. Коммит должен гарантировать ту D из ACID. Все так делают.
А вот на счет полноценности не стоит ругать. Их транзакции довольно просты и понятны, изолированы друг от друга и не оставляют много пространства для ошибок, в отличии от того ада, который вы увидите в базах данных с MVCC, типа InnoDB или PostgreSQL, где среднестатистический программист даже и не знает о разных уровнях изоляции и отсутствии 100% гарантий на consistency (по ACID).Lofer
12.12.2016 13:23С самим ACID то нет вопросов. Вопрос с несколькими ACID, даже если они меняют не перекрывающиеся данные :) Нашел на сайте описание детальное, а потом потерял.
All database operations in a transaction should use the same storage engine. It is not safe to access tuple sets that are defined with {engine='vinyl'} and also access tuple sets that are defined with {engine='memtx'}, in the same transaction.
Then the only safe atomic functions for memtx databases would be functions which contain only one database request, or functions which contain a select request followed by a data-change request.
maxzhurkin
10.12.2016 11:09+2Автор некорректно хвалит опцию -O3, сравнивая её с -O0; разумеется, сравнение с гораздо более безопасной и менее спорной так же в некоторых других отношениях -O2 не дало бы такого выигрыша в производительности.

danikin
12.12.2016 13:49Справедливое замечание. Принимаю. Проверили конкретную программу с -O2 и даже с -O1 — примерно также как с -O3. Однако, все равно остаюсь фанатом -O3. На моей практике всегда, если падало с -O3, то после даже нескольких дней копаний, чертыханий и ругани про себя на кривую реализацию gcc, всегда находил конкретный баг. Хотя, честно скажу, руки постоянно тянулись вернуть все в -O2. Возможно, я не натыкался на реальные баги в gcc, связанные с -O3.

phprus
12.12.2016 16:19Я в своей практике общения с g++ сталкивался с двумя глобальными проблемами из-за -O3.
Первая — gcc 4.4.4 на некотором коде с некоторым набором параметров компилятора просто падал с core dump. Тогда оптимизация была просто понижена до -O0 (чтобы вообще не разбираться), благо не компилировался код вспомогательного приложения и разбираться, что не нравится компилятору особого смысла не было — и так все работало быстро.
Вторая проблема была с gcc 4.3.4. В приложении использовался Boost и его контейнеры из Boost.Container. Наиболее яркое и запомнившееся проявление проблемы было, когда был boost::container::vector с данными, если у него посмотреть size(), то там одно значение (неправильное или 0), если посчитать end()-begin() — другое значение (почти всегда правильное), если отладчиком посмотреть в структуру, где оно хранит данные, то в памяти значения всегда верные.
Ни в одной другой версии компилятора (новее) воспроизвести не удалось. В gcc 4.3.4 Нормально работало только с оптимизацией -O1. Я бы еще понял, если бы код был многопоточный, но код был однопоточным и по сути логически один и тот же код давал то правильные данные, то неправильные.
Если у Вас есть идея, как можно подебажить второй случай, то я с радостью ее выслушаю, так как мне было бы интересно попытаться докопаться до причины такого поведения компилятора.danikin
13.12.2016 11:46Обычно в таких случаях я локализовывал проблему до минимальной программы, на которой она воспроизводится, т.е. откусывал от нее куски «методом половинного деления», пока не оставалась минимальная по размеру программа, в которой устойчиво воспроизводилась проблема. Далее я превращал все в ассемблер и разбирался, как на самом деле выглядит код. В вашем случае — во что конкретно развернулось end()-begin().
Другой способ поиска проблемы, если программа точно однопоточная (надо в этом убедиться, ибо потоки могут юзаться где-то в либах глубоко внутри), то надо искать в выходы за границы массива и аккуратно проверить, что арифметика указателей везде корректная + надо посмотреть на const_cast, static_cast и reinterpret_cast (а также C-style cast) — нет ли там опасного.
k_simakov
10.12.2016 19:141. Подскажите, почему для тестов взят unordered_map, вместо обычного map? В индексах СУБД часто используются деревья, поэтому пример с map-ом был бы более репрезентативным.
2. Подскажите, почему был выбран именно такой тест? Какое поведение СУБД он моделирует?
for (int i = 0; i < SIZE;++i) c += m[i*i] += i;
3. Не до конца понятно, как технически реализуется групповое чтение запросов из сокета. Ведь в традиционной схеме сервер устанавливает с клиентом соединение, для чего на стороне сервера создается индивидуальный для конкретного клиента сокет, из которого сервер читает запрос и куда сервер пишет ответ. В такой схеме не получится организовать групповое чтение. Можете подсказать, какая техника работы с сокетом в данном случае предлагается.
alekciy
11.12.2016 13:32Предположу, что какой нибудь epoll.
k_simakov
11.12.2016 13:46epoll возвращает список сокетов, в которых готовы данные для чтения. Вопрос в том, каким образом одним системным вызовом можно выполнить чтение из нескольких готовых сокетов? Традиционный recv позволяет прочитать данные только из одного сокета.
danikin
12.12.2016 13:10+1Клиент внутри себя параллельно (паралллельно, потому что у клиента много потоков внутри) формирует запросы и далее запихивает их в один сокет одним пакетом. Они приезжают на сервер. Сервер считывает пакет за один сискол.
danikin
12.12.2016 13:55Забыл на 1 и 2 ответить. Ответ на 3 ниже.
1. Потому что хэш быстрее дерева на точечных лукапах и тест у нас точечного лукапа (на range лукапах, разумеется, надо брать дерево, ибо хэш их не умеет). В IMDB Tarantool есть хэш индекс (https://tarantool.org/doc/singlehtml.html). В RDBMS Postgres тоже есть хэш индекс (https://www.postgresql.org/docs/9.1/static/indexes-types.html).
2. Внешние сложения — чтобы оптимизатор прошел цикл, без свертки всего сразу. Умножение внутри — чтобы обеспечить какой-никакой рандом. Реальный рандом сам бы вносил в вычисления большую погрешность, т.к. выполняется не быстро.

apachik
12.12.2016 10:58-2а что за история с замедлением макбука? в эпле тоже заговор, да? или вы винду на нем катаете?
masterspline2
12.12.2016 10:58Вы описали пакетную обработку информации (batch processing), но, почему-то, ни разу не упомянули этот термин.
danikin
12.12.2016 13:11+1Я этот термин специально не ввожу, чтобы тролли как мухи не налетели. Это онлайн обработка. Автобус не ждет пока пакет (салон) наполнится.

Kealon
12.12.2016 10:58Хорошая статья, терминология тут особо не важна
Важно то, что она очень доступно доводит читателя до нужных мыслей
maxtm
12.12.2016 10:58+1Миллион? На одном ядре? Это очень круто!
Не могли бы Вы дать конфигурацию сервера, который позволит повторить такой результат?
С большим удовольствием поставлю Tarantool на самый мощный сервер DO для эксперимента.
Сообщите, пожалуйста, какой сервер использовали Вы, для сравнения результатов.danikin
12.12.2016 13:12В статье все написано. Если кликните на эту ссылку, то все увидите. Это Amazon t2.micro.
Именно таким способом мы существенно сократили количество системных вызовов в Tarantool. По ссылке можно подробней прочитать о том, как наша система работает и справляется с миллионом транзакций в секунду на одном ядре.
amarao
Мне кажется, называть хеш-таблицу СУБД — это сильно большая натяжка. Очень сильно.
kir_vesp
Мне кажется вы что-то не так прочитали.
amarao
СУБД не имеет никакого отношения к серверам. Можно иметь sqlite, работающий с локальной базой, и всё равно иметь СУБД. Ключевое в СУБД — это предоставление механизмов для работы с базами данных. Произвольная выборка, правила запросов, etc.
То, что вы описываете, мало отличается от обычного жёсткого диска. Записали по ключу (номеру сектора), прочитали по ключу. Чтобы жёский диск превратился в СУБД, оно должно быть способно делать хоть что-то полезное. Например, WHERE. Или ORDER BY. Или LEFT INNER JOIN. Ну хотя бы WHERE LIMIT и SORT, как самый минимум.