
Набор задач для обучения с подкреплением сильного ИИ в рамках универсальной платформы OpenAI
Основанная Илоном Маском и соратниками некоммерческая организация OpenAI, которая ставит целью создание безопасного (то есть общедоступного и открытого) искусственного интеллекта, сделала очередной шаг для осуществления своих планов. OpenAI представила связующее программное обеспечение Universe для тренировки и обучения сильного ИИ. Теоретически, обучение может происходить на всей информации человечества, доступной через интернет. Это игры, веб-сайты и прочие приложения.
Всего девять строчек кода — и вашему ИИ доступны тысячи окружений для тренировки.
С помощью программной платформы Universe интеллектуальный агент будет использовать компьютер в точности так же, как это делает человек: он будет смотреть на пиксели компьютерного экрана и взаимодействовать при помощи клавиатуры и мыши (пока виртуальных).
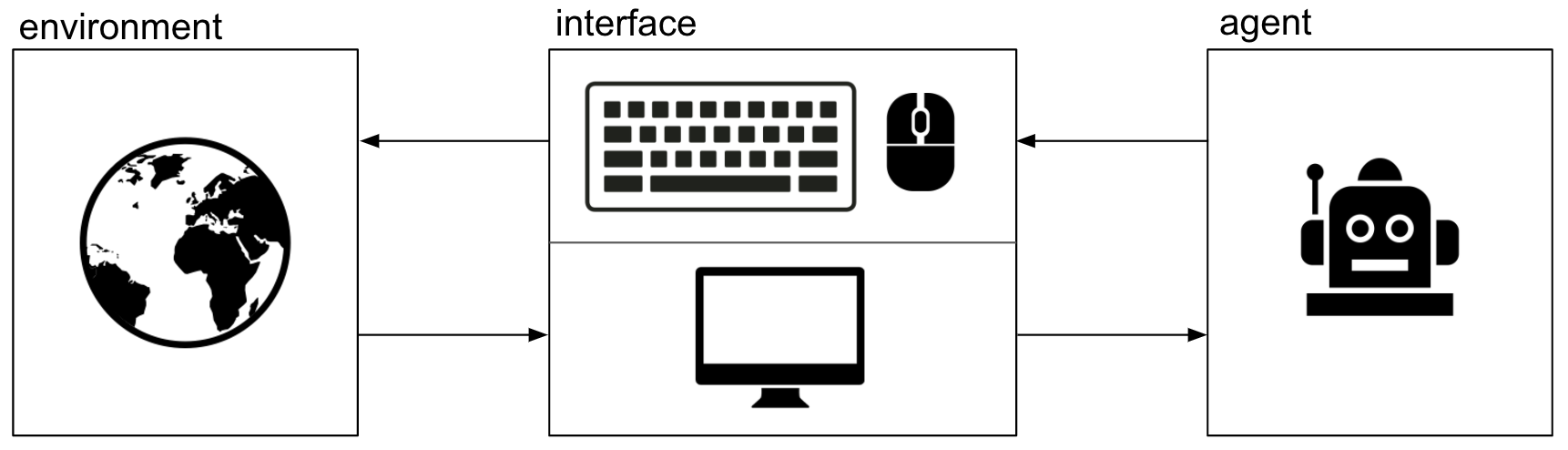
Искусственный интеллект познает мир через интерфейс программы VNC для удалённого доступа к рабочему столу
Предполагается тренировать интеллектуального агента на полном наборе задач. Платформа Universe открывает для ИИ любые задания, которые человек способен решать за компьютером.
Окружения OpenAI Gym
Открытие всеобщей универсальной платформы — продолжение планомерных действий OpenAI по созданию всемирного открытого универсального ИИ. В апреле текущего года организация выпустила публичную бета-версию инструментария OpenAI Gym для разработки и сравнения алгоритмов обучения с подкреплением. «Спортзал» OpenAI Gym состоит из большого количества окружений (от симулятора гуманоидного робота до игр Atari). Есть сайт для сравнения и воспроизведения результатов.
OpenAI Gym совместим с алгоритмами, написанными в любом фреймворке, в том числе Tensorflow и Theano. Изначально окружения создаются на Питоне, но в будущем разработчики планируют сделать возможность реализовать их на любом языке программирования.
OpenAI считает, что обучение с подкреплением — важный способ машинного обучения, который позволит в значительной степени усовершенствовать ИИ. В процессе обучения таким методом испытуемая система (агент) обучается, взаимодействуя с некоторой средой. В отличие от традиционного обучения с учителем, откликом на принятые решения ИИ являются сигналы подкрепления, при этом некоторые правила подкрепления формируются динамически и труднодоступны пониманию человека, то есть базируются на одновременной активности формальных нейронов.

Сигнал подкрепления распознаётся модулем оптического распознавания текста на скорости 60 fps: видео
Связующий софт OpenAI Universe
Представленная сегодня Universe — это связующее программное обеспечение, которое полностью поддерживает среду набор инструментов и среду выполнения окружений OpenAI Gym. Благодаря этому связующему ПО планируется кардинально увеличить количество окружений для тренировки ИИ.
Если раньше крупнейший каталог приложений для обучения с подкреплением включал в себя только 55 игр Atari (Atari Learning Environment), то на платформе Universe ожидается появление игр от многих других разработчиков, в том числе Valve, EA и Microsoft.
С самого начала через «миддлварь» Universe доступны тысячи игр (флэш-игры, многопользовательские змейки Slither, Starcraft, GTA V ми другие), разнообразные браузерные задачи (вроде заполнения форм) и приложения (такие как головоломки fold.it). Практически любую игру можно свободно запустить с помощью питоновской библиотеки universe, которая опубликована в открытом доступе на Github.
import gym
import universe # register Universe environments into Gym
env = gym.make('flashgames.DuskDrive-v0') # any Universe environment ID here
observation_n = env.reset()
while True:
# agent which presses the Up arrow 60 times per second
action_n = [[('KeyEvent', 'ArrowUp', True)] for _ in observation_n]
observation_n, reward_n, done_n, info = env.step(action_n)
env.render()Вышеприведённый код запускает агента искусственного интеллекта играть в игру Dusk Drive.
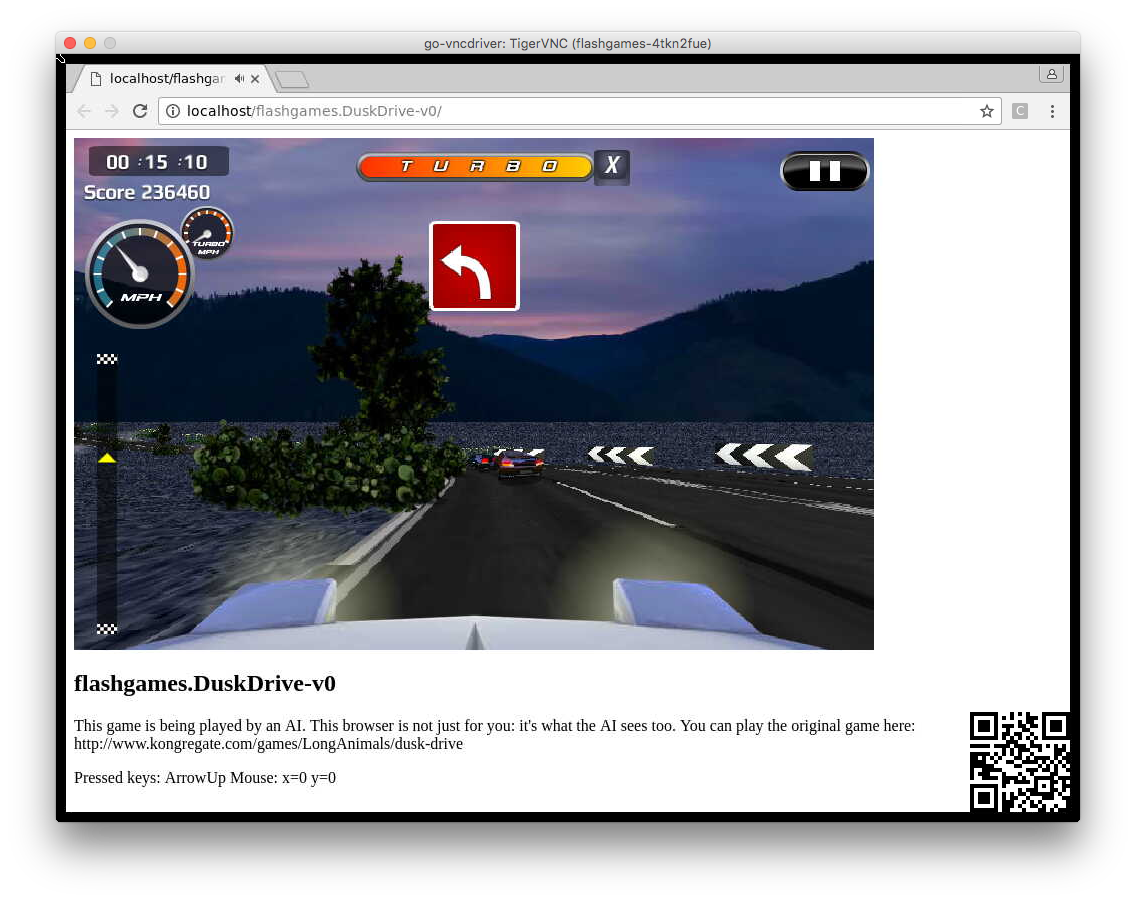
Игра Dusk Drive
«Наша конечная цель состоит в разработке единого интеллектуального агента, который способен гибко применять опыт, накопленный в Universe, для решения новых задач и быстрого получения нового опыта, что станет важным шагом на пути к сильному ИИ», — сказано в заявлении OpenAI.
Программные окружения Universe устанавливаются в контейнерах Docker. Как уже было сказано, они общаются с интеллектуальным агентом посредством визуального интерфейса — через «экран», «клавиатуру» и «мышь», как с человеком. Интерфейс реализован с помощью программы VNC для удалённого доступа к рабочему столу.
По идее, постоянное повышение мастерства ИИ с накоплением опыта в различных мелких задачах поможет ему всё быстрее осваивать каждую новую задачу, применяя уже имеющиеся знания. Платформа и набор окружений Universe может стать для интеллектуальных агентов такой же стандартной единой площадкой для тренировки и обучения с подкреплением, какой является набор данных ImageNet — база изображений для обучения классификаторов нейросетей при обучении с учителем.
Обучение с подкреплением действительно может быть весьма эффективным. Например, интеллектуальный агент Universe примерно шесть суток тренировался играть в многопользовательскую веб-игру Slither. После шести дней ИИ набирает в игровых сессиях в среднем 1000 очков с максимальным результатом 1400 очков. Для сравнения, сотрудник из организации OpenAI с пятичасовым опытом игры набирает в среднем 1400 очков с максимальным результатом 7050.
В данный момент агентам через связующее программное обеспечение Universe доступны следующие игры и приложения от партнёров OpenAI: Portal, Fable Anniversary, World of Goo, RimWorld, Slime Rancher, Shovel Knight, SpaceChem, Wing Commander III, Command & Conquer: Red Alert 2, Syndicate, Magic Carpet, Mirror's Edge, Sid Meier's Alpha Centauri и Wolfram Mathematica. Список будет увеличиваться.
Поделиться с друзьями
Комментарии (13)

Shultc
07.12.2016 12:36Я так и не понял, эта штука может работать только с вшитыми в неё играми, или я, как программист, могу подогнать под неё любую игру найденную в интернете?
DarCKoder
Как же хочется начать понимать подобные статьи(((
Belking
Десять лет уже родителям настраиваем компьютеры, роутеры и смартфоны. Ничего удивительного, что на их месте мы оказались куда моложе — мир меняется ускоренными темпами) Умение работать с искусственным интеллектом через 10 лет станет жизненно необходимым
ooptimum
Это довольно обширная тема и начать ее действительно глубоко понимать довольно непросто. Что еще осложняется тем, что практически все теоретические работы в данной области сделаны и делаются на Западе, поэтому и вся литература тоже не на русском.
Если вкратце, то существуют 3 парадигмы в машинном обучении: обучение с учителем (supervised learning), обучение без учителя (unsupervised learning) и обучение с подкреплением (reinforcement learning). Последнее используется в случаях, когда обучение ИИ по тем или иным причинам должно идти методом, во многом подобным методу проб и ошибок, когда за каждое выполненное действие агент (тот, кто выполняет действия и обучается) получает определенное вознаграждение. Например, у людей на разных полюсах шкалы вознаграждений находятся боль (низкий уровень вознаграждения) и наслаждение (высокий уровень). Конечная цель агента — максимизация суммарно полученного вознаграждения. В данной статье речь идет как раз о таком методе. Он же используется в Alpha GO, Giraffe и многих других приложениях, где агент познает «мир вокруг себя» самостоятельно и так же самостоятельно учится взаимодействовать с ним с максимальной выгодой для себя.
Belking
Спасибо за разъяснения, не могли бы вы объяснить еще пару моментов?
А эта Universe от open.ai — она сама рисует для агента шкалу вознаграждений, или надо изначально предусмотреть?
В играх помимо основной цели есть еще и различного рода вторичные, есть пасхальные яйца. Как понять, какой ИИ получил больше вознаграждения, тот который прошел Witcher 3 за 8 часов, или тот который выполнил все побочные концовки и открыл все карты за 80?
Опять же, за что вознаграждают машину? За приобретаемый опыт (хорошие выстрелы, минимум столкновений машин), или за достижение заложенных в нее целей?
BelBES
Судя по тому, что фреймворк является оберткой над кучей разных игр, то скорей всего reward для каждой из игр нужно задавать руками.
RL — он скорее о тренировке "рефлексов", необходимых для победы в игре, а не о глубоком понимании самой игры. Т.е. агент скорей обучится совершать какие-то регулярные действия для повышения reward, чем "искать пасхалки".
За то-же, за что и игрока. Reward функция, как правило, используется игровая (т.е. очки, жизни и тд и тп), т.е. сделал какое-то действие — получил очков и сеть запомнила такую последовательность действий и тд и тп.
Belking
Интересно, если задавать reward руками, то универсальность сразу теряется. У них вроде как смысл в том, чтобы агенты играли во множество игр сразу. Писать для каждой игры в ручную мне кажется большой затратой сил и времени для. Может быть, сейчас — ручками, а потом для игр будут шаблоны, основанные на предпочтениях ИИ-шников, проект же open-source.
А что мешает сделать наградой — собранный объем информации с игры? Создаем хранилище, наполняемое по определенным правилам, чтобы агент изучал окружающий его мир. При чем делаем множество разделов: это и изучение механики действий в игре (например, собрать инструкцию о том, как быть самым добрым в Масс Эффекте*), игровых мест (изучение биомов игры). Эдакий реверс-инженер. Идеальный бета-тестер, кстати.
* очень интересно, как поступит добрый натренированный бот в выборе между убийстве людей или сената
BelBES
Я вероятно не корректно выразился, у них есть не конкретное рапсределение этой функции, а только его значения в некоторых точках пространства. И суть RL как раз в том, чтобы восстановить это распределение. Ну а как эта обратная связь реализована — это все таки часть специфичная для конкретной игры. Без обратной связи Q-Learning не работает.
А как считать эту меру информации?
Belking
Да, наверное я романтизирую. У меня в голове рисуется картинка, как некий бот буквально оживает в игре и начинает учиться.
Оценить обстановку — повертел мышкой — ага, вид от первого лица. Диалог? — водит мышкой, ага, можно выбирать, попробуем это. И параллельно те же самые действия совершает множество агентов. Ага, 90% агентов пошли этим путем, но зачем пошли остальные? Надо изучить. Ага, наш средний результат в этом заезде три минуты на круг, но лидеры рейтинга почему-то используют совсем отличную стратегию от среднячков, давайте изучим
Но это наверное относится уже к сильному ИИ и просто не реализуемо на такого рода платформах?
ooptimum
Грубо говоря, именно так и происходит, как у вас рисуется в голове, если абстрагироваться от вопросов взаимодействия с игровым интерфейсом. :) Боты, в основе которых лежат алгоритмы reinforced learning, учатся на своих ошибках, точно так же, как это делают высшие животные.
Belking
Спасибо, прочитал оба комментария, книгу взял на заметку — тема очень интересная и по мере получения ответов на одни вопросы, появляется несколько других) например, что будет, если параллельно с тем, как агент играет сам, он будет смотреть Lets play записи и сравнивать свои поступки с поступками ведущих, либо достигая чекпоинта — сравнивать свои достижения с массивом облачных сохранений на этом месте других игроков.
Представляя миллион таких агентов, удаляющих те или иные свои «копии» за недостаточность награды, не посчитают ли они, что люди вообще к этой награде не стремятся и мешают?)))
ooptimum
В случае Let's play — такой вариант обучения возможен, например, если функция оценки — тоже нейросеть, обученная на реплеях (это будет уже supervised learning), а в случае массива облачных сохранений — скорее нет, чем да, т.к. бот не знает, какие действия привели к какому-то конкретному результату в таблице.
Про миллион агентов — вы сами того не ведая примерно описали генетические методы обучения. Что касается морали ботов — если вы ее не заложите, то ее и не будет, т.е. если бот посчитает, что ему выгоднее заниматься тимкиллом и это разрешено правилами, то он будет заниматься тимкиллом. Если я правильно понял ваш вопрос.
ooptimum
Честно говоря, я лишь вкратце почитал про эту OpenAI Universe и не знаю как она функционирует. Как я понял, это унифицированный интерфейс к различным играм, выступающим в роли тестовых сред. Т.е. это нечто вроде тестовых наборов MNIST, CIFAR10, NISTP и т.д., но для другого класса алгоритмов. OpenAI Universe предназначена в первую очередь для разработчиков алгоритмов и снимает с них заботу о разработке интерфейса взаимодействия с какой-то конкретной игрой из их набора, т.е. позволяет сосредоточиться именно на алгоритме AI, а не на важных, но все же второстепенных вопросах с т.з. разработчика AI.
Вознаграждение — это не какая-то абстракция, а конкретная скалярная величина. Т.е. у кого больше это число, тот и получил большее суммарное вознаграждение, выраженное данным числом.
За что вознаграждают — зависит от использованного алгоритма. В некоторых играх, чаще всего аркадных, это число набранных очков в каждый определенный момент времени. Соответственно, мы можем посчитать разность очков в разные моменты времени. В других играх используются функции-оценщики, оценивающие текущий расклад в некоторых попугаях. Например, если взять шахматы, в каждый момент игры вы как игрок находитесь в определенном состоянии, которое можно оценить по куче разных критериев: есть ли у вас ферзь, скольким фигурам вы угрожаете, объявили ли вы шах и т.д. (у хороших функций оценки это сотни параметров), вы делаете ход и ваше состояние меняется — вознаграждением за ход будет разность между оценками состояний до хода и после. Есть алгоритмы, которые не пользуются такими функциями вообще. Если для оценки хода вы пользуетесь какой-то вариацией алгоритма minimax, то обязательно будут состояния, в которые вы никогда не будете попадать, особенно если вы не можете просчитать все возможные варианты развития событий, т.к. это слишком дорого по времени, и ограничиваете minimax по глубине или каким-то другим способом, но в них попадать все же желательно, т.к. это может дать вам преимущество в будущем, которое вы не просчитали. Т.е. существует проблема баланса между исследованием и использованием того, в чем вы уверены точно: синица в руках или журавль в небе. Т.е. может быть когда-нибудь бот узнает о том, что открывать все локации и проходить все добавочные задания в итоге выгоднее. Но для этого он должен делать исследовательские ходы, которые имеют более низкую предсказанную оценку, нежели уже какие-то известные.
В общем, это обширная тема. И если она вас интересует, я рекомендую для начала почитать книгу «Reinforcement Learning: An Introduction», Richard S. Sutton and Andrew G. Barto — она есть в свободном доступе.