

Если программист хорошо знаком только с высокоуровневыми языками, например PHP, то ему не так просто освоить некоторые идеи, свойственные низкоуровневым языкам и критичные для понимания возможностей информационно-вычислительных процессов. По большей части причина в том, что в низко- и высокоуровневых языках мы решаем разные проблемы.
Но как можно считать себя профессионалом в каком-либо (высокоуровневом) языке, если даже не знаешь, как именно работает процессор, как он выполняет вычисления, эффективным ли способом? Сегодня автоматическое управление памятью становится главной проблемой в большинстве высокоуровневых языков, и многие программисты подходят к её решению без достаточной теоретической базы. Я уверен, что знание низкоуровневых процессов сильно помогает в разработке эффективных высокоуровневых программ.
Программы многих школьных курсов по программированию до сих пор начинаются с освоения азов ассемблера и С. Это крайне важно для будущих программистов, которым подобные знания очень пригодятся в будущей карьере. Высокоуровневые языки постоянно и сильно меняются, а интенсивность и частота изменений в низкоуровневых языках на порядок ниже.
Я считаю, что в будущем появится куча применений для низкоуровневого программирования. Поскольку всё начинается с основ, то не пропадёт потребность и в людях, создающих эти основы, чтобы другие могли возводить на них новые уровни, в результате создавая цельные, полезные и эффективные продукты.
Вы действительно думаете, что интернет вещей будет разрабатываться на высокоуровневых языках? А будущие видеокодеки? VR-приложения? Сети? Операционные системы? Игры? Автомобильные системы, например автопилоты, системы предупреждения о столкновении? Всё это, как и многие другие продукты, пишется на низкоуровневых языках вроде С или сразу на ассемблере.
Вы можете наблюдать развитие «новых» архитектур, например очень интересных ARM-процессоров, которые стоят в 98 % смартфонов. Если сегодня вы используете Java для создания Android-приложений, то лишь потому, что сам Android написан на Java и С++. А язык Java — как и 80 % современных высокоуровневых языков — написан на С (или С++).
Язык С пересекается с некоторыми родственными языками. Но они используют императивную парадигму, а потому мало распространены или не столь развиты. Например, Fortran, относящийся к той же «возрастной группе», что и С, в некоторых специфических задачах более производителен. Ряд специализированных языков могут быть быстрее С при решении чисто математических задач. Но всё же С остаётся одним из наиболее популярных, универсальных и эффективных низкоуровневых языков в мире.
Приступим
Для этой статьи я воспользуюсь машиной с процессором X86_64, работающей под управлением Linux. Мы рассмотрим очень простую программу на С, которая суммирует 1 миллиард байтов из файла менее чем за 0,5 секунды. Попробуйте проделать это на любом из высокоуровневых языков — вы и не приблизитесь по производительности к С. Даже на Java, с помощью JIT, с параллельными вычислениями и хорошей моделью использования памяти в пространстве пользователя. Если языки программирования не обращаются напрямую к машинным инструкциям, а являются некой промежуточной формой (определение высокоуровневых языков), то они не сравнятся по производительности с С (даже с помощью JIT). В некоторых областях разрыв можно уменьшить, но в целом С оставляет соперников далеко позади.
Сначала мы подробно разберём задачу с помощью С, затем рассмотрим инструкции X86_64 и оптимизируем программу с помощью SIMD — разновидности инструкций в современных процессорах, позволяющей обрабатывать большие объёмы данных одной инструкцией в несколько циклов (несколько наносекунд).
Простая программа на С
Чтобы продемонстрировать возможности языка, я приведу простой пример: открываем файл, считываем из него все байты, суммируем их, а полученную сумму сжимаем в один байт без знака (unsigned byte) (то есть несколько раз будет переполнение). И всё. Ах да, и всё это мы постараемся выполнить как можно эффективнее — быстрее.
Поехали:
#include <stdio.h>
#include <stdint.h>
#include <string.h>
#include <fcntl.h>
#include <unistd.h>
#define BUF_SIZE 1024
int main(int argc, char **argv)
{
int f, i;
ssize_t readed;
unsigned char result = 0;
unsigned char buf[BUF_SIZE] = {0};
if (argc != 2) {
fprintf(stderr, "Использование: %s \n", argv[0]);
exit(-1);
}
f = open(argv[1], O_RDONLY);
if (f == -1) {
perror("Не могу открыть файл");
}
while ((readed = read(f, buf, sizeof(buf))) > 0) {
for (i=0; i < readed; i++) {
result += buf[i];
}
}
close(f);
printf("Чтение завершено, сумма равна %u \n", result);
return 0;
}Для нашего примера возьмём файл на 1 Гб. Чтобы создать такой файл со случайными данными, просто воспользуемся
dd:> dd if=/dev/urandom of=/tmp/test count=1 bs=1G iflag=fullblockТеперь передадим файл в нашу программу (назовём её file_sum) в качестве аргумента:
> file_sum /tmp/file
Read finished, sum is 186Можно просуммировать байты самыми разными способами. Но для эффективности нужно понимать:
- Как работает CPU и что он умеет (какие вычисления может производить).
- Как работает ядро ОС (kernel).
Вкратце: необходимы некоторые знания по электронике и низкому уровню ОС, на которых выполняется наша программа.
Помните о ядре
Здесь мы не будем углубляться в работу ядра. Но помните, что мы не станем просить процессор взаимодействовать с диском, на котором хранится наш файл. Дело в том, что на дворе 2016 год, и мы создаём так называемые программы пользовательского пространства (ППП). Одно из определений гласит, что такие программы НЕ МОГУТ напрямую обращаться к оборудованию. Когда возникает необходимость воспользоваться оборудованием (обратиться к памяти, диску, сети, картридеру и так далее), программа с помощью системных вызовов просит операционную систему сделать это для неё. Системные вызовы — это функции ОС, доступные для ППП. Мы не будем спрашивать диск, готов ли он обработать наш запрос, просить его переместить головку, считать сектор, перенести данные из кеша в основную память и так далее. Всё это делает ядро ОС вместе с драйверами. Если бы нам нужно было заняться такими низкоуровневыми вещами, то мы писали бы программу «пространства ядра» — по сути, модуль ядра.
Почему так? Почитайте мою статью про распределение памяти. Там объясняется, что ядро управляет одновременным выполнением нескольких программ, не позволяя им обрушить систему или перейти в необратимое состояние. При любых инструкциях. Для этого ядро переводит процессор в режим третьего кольца защиты. А в третьем кольце программа не может обращаться к аппаратно отображаемой памяти (hardware mapped memory). Любые подобные инструкции будут генерировать в процессоре исключения, как и все попытки доступа к памяти за пределами совершенно конкретных границ. На исключение в процессоре ядро отвечает запуском кода исключения (Exception code). Он возвращает процессор в стабильное состояние и завершает нашу программу с помощью какого-то сигнала (возможно, SIGBUS).
Третье кольцо защиты — режим с самыми низкими привилегиями. Все ППП выполняются в этом режиме. Можете его опробовать, считав первые два бита CS-регистра в своём X86-процессоре:
gdb my_file
(gdb) p /t $cs
$1 = 110011Первые два бита (младшие) обозначают текущий уровень кольца защиты. В данном случае — третий.
Пользовательские процессы работают в строго ограниченной изолированной среде, настраиваемой ядром, которое само выполняется в нулевом кольце (полные привилегии). Поэтому после уничтожения пользовательского процесса утечка памяти невозможна. Все структуры данных, имеющие к этому отношение, недоступны для пользовательского кода напрямую. Ядро само заботится о них при завершении пользовательского процесса.
Вернёмся к нашему коду. Мы не можем управлять производительностью чтения с диска, поскольку за это отвечают ядро, низкоуровневая файловая система и аппаратные драйверы. Мы воспользуемся вызовами
open()/read() и close(). Я не стал брать функции из libC (fopen(), fread(), fclose()), в основном потому, что они являются обёртками для системных вызовов. Эти обёртки могут как улучшать, так и ухудшать общую производительность: всё зависит от того, какой код прячется за этими инструкциями и как они используются самой программой. LibC — это прекрасно спроектированная и высокопроизводительная библиотека (ряд её ключевых функций написан на ассемблере), но всем этим функциям «ввода-вывода» нужен буфер, которым вы не управляете, и они по своему усмотрению вызывают read(). А нам надо полностью контролировать программу, так что обратимся напрямую к системным вызовам.На системный вызов ядро чаще всего отвечает вызовом
read() файловой системы, давая аппаратному драйверу команду ввода/вывода. Все эти вызовы можно отследить с помощью Linux-трассировщиков, например perf. Для программ системные вызовы затратны, потому что приводят к переключению контекста — переходу из пользовательского пространства в пространство ядра. Стоит этого избегать, поскольку переходы требуют от ядра значительного объёма работ. Но нам нужны системные вызовы! Самый медленный из них — read(). Когда он делается, процесс наверняка будет выведен из очереди выполнения в CPU и переведён в режим ожидания ввода/вывода. Когда операция завершится, ядро вернёт процесс в очередь выполнения. Эту процедуру можно контролировать с помощью флагов, передаваемых вызову open().Как вы можете знать, ядро реализует буферный кеш, в котором сохраняются недавно считанные с диска чанки данных из файлов. Это означает, что если вы несколько раз запустите одну программу, то в первый раз она может работать медленнее всего, особенно если подразумевается активное выполнение операций ввода/вывода, как в нашем примере. Так что для измерения затраченного времени мы будем брать данные, например, начиная с третьего или четвёртого запуска. Либо можно усреднить результаты нескольких запусков.
Получше узнайте своё железо и компилятор
Итак, мы знаем, что не в силах целиком управлять производительностью трёх системных вызовов:
open(), read() и close(). Но давайте здесь доверимся разработчикам пространства ядра. Кроме того, сегодня многие используют SSD-накопители, так что можно с определённой долей уверенности предположить, что наш одногигабайтный файл считается достаточно быстро.Что ещё замедляет код?
Способ сложения байтов. Может показаться, что для этого достаточно простого цикла суммирования. Но хочу ответить: узнайте получше, как работают ваш компилятор и процессор.
Давайте скомпилируем код в лоб, без оптимизаций, и запустим его:
> gcc -Wall -g -O0 -o file_sum file_sum.cЗатем отпрофилируем с помощью команды
time:> time ./file_sum /tmp/big_1Gb_file
Read finished, sum is 186
real 0m3.191s
user 0m2.924s
sys 0m0.264sНе забудьте запустить несколько раз, чтобы прогреть кеш страницы ядра. У меня после нескольких прогонов суммирование одного гигабайта с SSD заняло 3,1 секунды. Процессор ноутбука — Intel Core i5-3337U @ 1,80 ГГц, ОС — Linux 3.16.0-4-amd64. Как видите, самая обычная X86_64-архитектура. Для компилирования я использовал GCC 4.9.2.
Согласно данным
time, большую часть времени (90 %) мы провели в пользовательском пространстве. Время, когда ядро что-то делает от нашего имени, — это время выполнения системных вызовов. В нашем примере: открывание файла, чтение и закрывание. Довольно быстро, верно?Обратите внимание: размер буфера чтения равен одному килобайту. Это означает, что для одногигабайтного файла приходится вызывать
read() 1024*1024 = 1 048 576 раз. А если увеличить буфер, чтобы уменьшить количество вызовов? Возьмём 1 Мб, тогда у нас останется только 1024 вызова. Внесём изменения, перекомпилируем, запустим несколько раз, отпрофилируем:#define BUF_SIZE 1024*1024
.
> gcc -Wall -g -O0 -o file_sum file_sum.c
> time ./file_sum /tmp/big_1Gb_file
Read finished, sum is 186
real 0m3.340s
user 0m3.156s
sys 0m0.180sОтлично, удалось снизить с 264 до 180 мс. Но не увлекайтесь увеличением кеша: у скорости
read() есть определённый предел, а буфер находится в стеке. Не забывайте, что максимальный размер стека в современных Linux-системах по умолчанию 8 Мб (можно изменять).Старайтесь вызывать ядро как можно реже. Программы, интенсивно использующие системные вызовы, обычно делегируют вызовы ввода/вывода выделенному треду и/или программному вводу/выводу для асинхронности работы.
Быстрее, сильнее (и не настолько уж труднее)
Почему сложение байтов выполняется так долго? Проблема в том, что мы просим процессор выполнять его очень неэффективным способом. Давайте дизассемблируем программу и посмотрим, как процессор это делает.
Язык С — ничто без компилятора. Это лишь приемлемый для человека язык программирования компьютера. А чтобы преобразовать С-код в низкоуровневые машинные инструкции, требуется компилятор. Сегодня мы по большей части используем С для создания систем и решения низкоуровневых задач, потому что хотим иметь возможность без переписывания портировать код с одной процессорной архитектуры на другую. Именно поэтому в 1972 году был разработан С.
Так вот, без компилятора язык С — пустое место. Плохой компилятор или его неверное использование может привести к низкой производительности. То же самое справедливо и для других языков, компилируемых в машинный код, например для Fortran’а.
Процессор выполняет машинный код, который можно представить в виде инструкций языка ассемблера. С помощью компилятора или отладчика инструкции ассемблера легко извлекаются из С-программы.
Ассемблер несложно освоить. Всё зависит от архитектуры, и здесь мы рассмотрим только наиболее распространённый вариант с X86 (для 2016 года — X86_64).
В архитектуре X86_64 также нет ничего сложного. Просто в ней ОГРОМНОЕ количество инструкций. Когда я делал первые шаги в ассемблере (под Freescale 68HC11), то использовал несколько десятков инструкций. А в X86_64 их уже тысячи. Мануалы в то время были такими же, как сегодня: непонятными и многословными. А поскольку PDF тогда не было, то приходилось таскать с собой огромные книги.
Вот, к примеру, мануалы Intel по X86_64. Тысячи страниц. Это первичный источник знаний для разработчиков ядра и самых низкоуровневых разработчиков. А вы думали, что можно было бы улучшить ваши онлайн-мануалы по PHP?
К счастью, для нашей маленькой программы нет нужды читать все эти цифровые фолианты. Здесь применяется правило 80/20 — 80 % программы будет сделано с помощью 20 % общего количества инструкций.
Вот С-код и дизассемблированная часть, которая нас интересует (начиная с цикла while()), скомпилированная без оптимизаций с помощью GCC 4.9.2:
#define BUF_SIZE 1024
int main(int argc, char **argv)
{
int f, i;
ssize_t readed;
unsigned char result = 0;
unsigned char buf[BUF_SIZE] = {0};
if (argc != 2) {
fprintf(stderr, "Использование: %s \n", argv[0]);
exit(-1);
}
f = open(argv[1], O_RDONLY);
if (f == -1) {
perror("Не могу открыть файл");
}
while ((readed = read(f, buf, sizeof(buf))) > 0) {
for (i=0; i < readed; i++) {
result += buf[i];
}
}
close(f);
printf("Чтение закончено, сумма равна %u \n", result);
return 0;
}
00400afc: jmp 0x400b26 < main+198>
00400afe: movl $0x0,-0x4(%rbp)
00400b05: jmp 0x400b1b < main+187>
00400b07: mov -0x4(%rbp),%eax
00400b0a: cltq
00400b0c: movzbl -0x420(%rbp,%rax,1),%eax
00400b14: add %al,-0x5(%rbp)
00400b17: addl $0x1,-0x4(%rbp)
00400b1b: mov -0x4(%rbp),%eax
00400b1e: cltq
00400b20: cmp -0x18(%rbp),%rax
00400b24: jl 0x400b07 < main+167>
00400b26: lea -0x420(%rbp),%rcx
00400b2d: mov -0xc(%rbp),%eax
00400b30: mov $0x400,%edx
00400b35: mov %rcx,%rsi
00400b38: mov %eax,%edi
00400b3a: callq 0x4005d0 < read@plt>
00400b3f: mov %rax,-0x18(%rbp)
00400b43: cmpq $0x0,-0x18(%rbp)
00400b48: jg 0x400afe < main+158>
00400b4a: mov -0xc(%rbp),%eax
00400b4d: mov %eax,%edi
00400b4f: callq 0x4005c0 < close@plt>Видите, насколько неэффективный код? Если нет, то позвольте мне кратко рассказать вам об ассемблере под X86_64 с комментариями к вышеприведённому дампу.
Основы ассемблера под X86_64
Здесь мы пробежимся по верхам, а за подробностями обратитесь к материалам один, два и три.
Мы будем оперировать байтами и степенями 2 и 16.
- Каждая инструкция хранится в памяти по определённому адресу, указанному в левой колонке.
- Каждая инструкция уникальна и имеет имя (мнемоническое): LEA — MOV — JMP и так далее. В современной архитектуре X86_64 существует несколько тысяч инструкций.
- X86_64 — это CISC-архитектура. Одна инструкция может преобразовываться в конвейере в несколько более низкоуровневых инструкций, для выполнения каждой из которых иногда требуется несколько процессорных циклов (clock cycles) (1 инструкция != 1 цикл).
- Каждая инструкция может принимать максимум 0, 1, 2 или 3 операнда. Чаще всего 1 или 2.
- Существует две основные модели ассемблера: AT&T (также называется GAS) и Intel.
- В AT&T вы читаете INSTR SRC DEST.
- В Intel вы читаете INSTR DEST SRC.
- Есть и ряд других отличий. Если ваш мозг натренирован, то можно без особого труда переключаться с одной модели на другую. Это всего лишь синтаксис, ничего более.
- Чаще используется AT&T, кто-то предпочитает Intel. Применительно к X86 в модели AT&T по умолчанию используется GDB. Подробнее о модели AT&T.
- В X86_64 применяется порядок следования байтов от младшего к старшему (little-endian), так что готовьтесь преобразовывать адреса по мере чтения. Всегда группируйте побайтно.
- В X86_64 не разрешены операции «память-память». Для обработки данных нужно использовать какой-нибудь регистр.
- $ означает статичное непосредственное значение (например, $1 — это значение '1').
- % означает доступ к регистру (%eax — доступ к регистру EAX).
- Круглые скобки — доступ к памяти, звёздочка в С разыменовывает указатель (запись (%eax) означает доступ к области памяти, адрес которой хранится в регистре EAX).
Регистры
Регистры — это области памяти фиксированного размера в чипе процессора. Это не оперативная память! Регистры работают гораздо быстрее RAM. Если доступ к оперативке выполняется примерно за 100 нс (в обход всех уровней кеша), то доступ к регистру — за 0 нс. Самое главное в программировании процессора — это понимать сценарий, который повторяется раз за разом:
- Из оперативной памяти в регистр грузятся данные: теперь процессор «обладает» значением.
- С регистром выполняется что-нибудь (например, его значение умножается на 3).
- Содержимое регистра отправляется обратно в оперативную память.
- Если хотите, то можно перемещать данные из регистра в другой регистр того же размера.
Напоминаю, что в X86_64 нельзя выполнять обращения «память-память»: сначала нужно передать данные в регистр.
Существуют десятки регистров. Чаще всего используются регистры «общего назначения» — для вычислений. В архитектуре X86_64 доступны следующие «универсальные» регистры: a, b, c, d, di, si, 8, 9, 10, 11, 12, 13, 14 и 15 (в 32-битной X86 набор другой).
Все они 64-битные (8 байтов), НО к ним можно обращаться в четырёх режимах: 64-, 32-, 16- и 8-битном. Всё зависит от ваших потребностей.
Регистр A — 64-битный доступ. RAX — 64-битный. EAX — 32-битный. AX — 16-битный. Младшая часть: AL, старшая часть: AH.
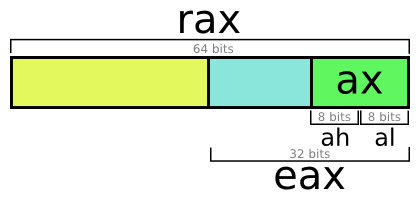
Всё очень просто. Процессор — это глупый кусок кремния, он выполняет только простейшие операции с крохотными порциями байтов. В регистрах общего назначения можно обращаться минимум к байту, а не биту. Краткий словарь:
- Один байт = 8 битов, это наименьшее доступное количество информации. Обозначается как BYTE.
- Двойной байт = 16 битов, обозначается как WORD.
- Двойной двойной байт = 32 бита, обозначается как DWORD (двойной WORD).
- 8 смежных байтов = 64 бита, обозначается как QWORD (четверной WORD).
- 16 смежных байтов = 128 битов, обозначается как DQWORD (двойной четверной WORD).
Больше информации об архитектуре X86 можно найти на http://sandpile.org/ и сайтах Intel/AMD/Microsoft. Напоминаю: X86_64 работает несколько иначе, чем X86 (32-битный режим). Также почитайте выборочные материалы из мануалов Intel.
Анализ кода X86_64
00400afc: jmp 0x400b26 JMP — это безусловный переход (unconditional jump). Перейдём по адресу 0x400b26:
00400b26: lea -0x420(%rbp),%rcx
00400b2d: mov -0xc(%rbp),%eax
00400b30: mov $0x400,%edx
00400b35: mov %rcx,%rsi
00400b38: mov %eax,%edi
00400b3a: callq 0x4005d0 < read@plt>В этом коде делается системный вызов
read(). Если вы почитаете конвенцию вызовов в X86_64, то увидите, что большинство параметров передаются не стеком, а регистрами. Это повышает производительность вызова каждой функции в X86_64 Linux по сравнению с 32-битным режимом, когда для каждого вызова используется стек.Согласно таблице системных вызовов ядра, в
read(int fd, char *buf, size_t buf_size) первый параметр (дескриптор файла) должен быть передан в RDI, второй (буфер для заполнения) — в RSI, а третий (размер буфера для заполнения) — в RDX.Рассмотрим вышеприведённый код. Здесь используется RBP (Register Base Pointer, указатель базового регистра). RBP запоминает самое начала пространства текущего стека, в то время как RSP (Register Stack Pointer, указатель стека регистра) запоминает вершину текущего стека, на случай, если нам понадобится с этим стеком что-то сделать. Стек — это просто большой кусок памяти, выделенный для нас. Он содержит локальные переменные функции, переменные
alloca(), адрес возврата, может содержать аргументы функций, если их несколько штук.В стеке хранятся локальные переменные функции
main(), в которой мы сейчас находимся:00400b26: lea -0x420(%rbp),%rcxLEA (Load Effective Address) хранится в RBP минус 0x420, вплоть до RCX. Это наша переменная буфера —
buf. Обратите внимание, что LEA не считывает значение после адреса, только сам адрес. Под GDB вы можете напечатать любое значение и произвести вычисления:> (gdb) p $rbp - 0x420
$2 = (void *) 0x7fffffffddc0С помощью
info registers можно отобразить любой регистр:> (gdb) info registers
rax 0x400a60 4196960
rbx 0x0 0
rcx 0x0 0
rdx 0x7fffffffe2e0 140737488347872
rsi 0x7fffffffe2c8 140737488347848
... ...Продолжаем:
00400b2d: mov -0xc(%rbp),%eaxПоместим значение по адресу, указанному в RBP минус 0xc — в EAX. Скорее всего, это наша переменная
f . Это можно легко подтвердить:> (gdb) p $rbp - 0xc
$1 = (void *) 0x7fffffffe854
> (gdb) p &f
$3 = (int *) 0x7fffffffe854Идём дальше:
00400b30: mov $0x400,%edxПоместим в EDX значение 0x400 (1024 в десятичном выражении). Это
sizeof(buf): 1024, третий параметр read().00400b35: mov %rcx,%rsi
00400b38: mov %eax,%edi
00400b3a: callq 0x4005d0 < read@plt>Запишем содержимое RCX в RSI, второй параметр
read(). Запишем содержимое EAX в EDI, третий параметр read(). Затем вызовем функцию read().При каждом системном вызове его значение возвращается в регистр A (иногда ещё и в D).
read() возвращает значение ssize_t, которое весит 64 бита. Следовательно, для чтения возвращаемого значения нам нужно проанализировать весь регистр A. Для этого воспользуемся RAX (64-битное чтение регистра A):00400b3f: mov %rax,-0x18(%rbp)
00400b43: cmpq $0x0,-0x18(%rbp)
00400b48: jg 0x400afe < main+158>Запишем возвращаемое значение
read() из RAX по адресу, указанному в RBP минус 0x18. Быстрая проверка подтверждает, что это наша переменная readed из С-кода.CMPQ (Compare Quad-Word, сравнение четверного WORD). Сравниваем значение
readed со значением 0.JG (Jump if greater, переход по условию «больше»). Переходим по адресу 0x400AFE. Это всего лишь сравнение в цикле
while() из нашего С-кода. Продолжаем читать буфер и переходим по адресу 0x400AFE, это должно быть начало цикла
for().00400afe: movl $0x0,-0x4(%rbp)
00400b05: jmp 0x400b1b < main+187>MOVL (Move a Long, копирование длинного целого). Записываем LONG (32 бита) значения 0 по адресу, указанному в RBP минус 4. Это
i — целочисленная переменная в C-коде, 32 бита, то есть 4 байта. Потом она будет сохранена как самая первая переменная в стековом фрейме main() (представленном RBP).Переходим по адресу 0x400B1B, здесь должно быть продолжение цикла
for().00400b1b: mov -0x4(%rbp),%eax
00400b1e: cltq
00400b20: cmp -0x18(%rbp),%rax
00400b24: jl 0x400b07 Записываем в EAX значение, указанное в RBP минус 4 (вероятно, целое число).
CLTQ (Convert Long To Quad). CLTQ работает с регистром A. Он расширяет EAX до 64-битного целочисленного значения, получаемого RAX.
CMP (Compare value, сравнение значения). Сравниваем значение в RAX со значением, на которое указывается по адресу в RBP минус 0x18. То есть сравниваем переменную
i из цикла for() с переменной readed.JL (Jump if Lower, переход по условию «меньше»). Переходим по адресу 0x400B07. Мы на первом этапе цикла
for(), так что да, переходим.00400b07: mov -0x4(%rbp),%eax
00400b0a: cltq
00400b0c: movzbl -0x420(%rbp,%rax,1),%eax
00400b14: add %al,-0x5(%rbp)
00400b17: addl $0x1,-0x4(%rbp)
00400b1b: mov -0x4(%rbp),%eax
00400b1e: cltq
00400b20: cmp -0x18(%rbp),%rax
00400b24: jl 0x400b07 < main+167>А теперь самое интересное.
Записываем (MOV)
i в EAX (как говорилось выше, i — это –0x4(%rbp)). Затем делаем CLTQ: расширяем до 64 бит.MOVZBL (MOV Zero-extend Byte to Long). Добавляем нулевой байт к длинному целому, хранящемуся по адресу (1*RAX+RBP) минус 0x420, и записываем в EAX. Звучит сложно, но это просто математика ;-) Выходит вычисление
buf[i] с помощью одной инструкции. Так мы проиллюстрировали возможности указателей в языке C: buf[i] — это buf + i*sizeof(buf[0]) байтов. Получившийся адрес легко вычисляется на ассемблере, а компиляторы выполняют кучу математических вычислений, чтобы сгенерировать такую инструкцию.Загрузив значение в EAX, мы добавляем его в
result:00400b14: add %al,-0x5(%rbp)Помните: AL — младший байт 8-байтного RAX (RAX и AL представляют собой регистр A) — это
buf[i], поскольку buf относится к типу char и весит один байт. result находится по адресу –0x5(%rbp): один байт после i, расположенного на расстоянии 0x4 от RBP. Это подтверждает, что result — это char, весящий один байт.00400b17: addl $0x1,-0x4(%rbp)ADDL (Add a long, добавление длинного целого — 32 бита). Добавляем 1 к
iИ снова возвращаемся к инструкции 00400b1b: циклу
for().Краткий итог
Устали? Это потому, что у вас нет опыта в ассемблере. Как вы могли убедиться, расшифровка ассемблера — это всего лишь арифметика на уровне начальной школы: сложить, извлечь, умножить, разделить. Да, ассемблер прост, но очень многословен. Чувствуете разницу между «труден» и «многословен»?
Если вы хотите, чтобы ваш ребёнок стал хорошим программистом, то не делайте ошибки и не ограничивайте его изучением математики только с основанием 10. Тренируйте его переключаться с одного основания на другое. Фундаментальную алгебру можно полностью понять только тогда, когда вы можете представить любые величины с любым основанием, особенно 2, 8 и 16. Для обучения детей рекомендую использовать соробан.
Если вы чувствуете себя в математике не слишком уверенно, то лишь потому, что ваш мозг всегда натаскивали только на операции с основанием 10. Переключаться с 10 на 2 трудно, потому что эти степени не кратны. А переключаться между 2 и 16 или 8 легко. Потренировавшись, вы сможете вычислять большинство адресов в уме.
Итак, нашему циклу
for() нужно шесть адресов памяти. Он был преобразован как есть из исходного C-кода: цикл выполняется для каждого байта с побайтным суммированием. Для одногигабайтного файла цикл приходится выполнять 0x40000000 раз, то есть 1 073 741 824.Даже на 2 ГГц (в CISC одна инструкция != один цикл) прогон цикла 1 073 741 824 раза отнимает достаточно времени. В результате код выполняется около 3 секунд, потому что побайтное суммирование в считанном файле крайне неэффективно.
Давайте всё векторизуем с помощью SIMD
SIMD — Single Instruction Multiple Data, одна инструкция, множественный поток данных. Этим всё сказано. SIMD представляет собой специальные инструкции, позволяющие процессору работать не с одним байтом, одним WORD, одним DWORD, а с несколькими из них в рамках одной инструкции.
Встречайте SSE — Streaming SIMD Extensions, потоковое SIMD-расширение. Вам наверняка знакомы такие аббревиатуры, как SSE, SSE2, SSE4, SSE4.2, MMX или 3DNow. Так вот, SSE — это SIMD-инструкции. Если процессор может единовременно работать с многочисленными данными, то это существенно уменьшает общую продолжительность вычислений.

При покупке процессора обращайте внимание не только на количество ядер, размер кешей и тактовую частоту. Важен ещё набор поддерживаемых инструкций. Что вы предпочтёте: складывать каждую наносекунду один байт за другим или прибавлять 8 байтов к 8 каждые две наносекунды?
SIMD-инструкции позволяют очень сильно ускорять вычисления в процессоре. Они используются везде, где допускается параллельная обработка информации. Некоторые из сфер применения:
- Матричные вычисления, лежащие в основе графики (но GPU делает это на порядок быстрее).
- Сжатие данных, когда за раз обрабатывается по несколько байтов (форматы LZ, GZ, MP3, Divx, H264/5, JPEG FFT и многие другие).
- Криптография.
- Распознавание речи и музыки.
Возьмём, к примеру, оценку параметров движения (Motion Estimation) с помощью Intel SSE 4. Этот критически важный алгоритм используется в каждом современном видеокодеке. Он позволяет на основе векторов движения, вычисленных по базовому кадру F, предсказать кадр F+1. Благодаря этому можно программировать только перемещение пикселей от одной картинки к другой, а не кодировать картинки целиком. Яркий пример — замечательные кодеки H264 и H265, у них открытый исходный код, можете его изучить (только сначала прочитайте про MPEG).
Проведём тест:
> cat /proc/cpuinfo
processor : 2
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i5-3337U CPU @ 1.80GHz
(...)
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm ida arat epb xsaveopt pln pts dtherm tpr_shadow vnmi flexpriority ept vpid fsgsbase smep ermsВсе эти флаги — по большей части поддерживаемые моим процессором инструкции и наборы инструкций.
Тут можно увидеть sse, sse2, sse4_1, sse4_2, aes, avx.
AES лежит в основе AES-шифрования! Прямо в CPU, с помощью кучи специализированных инструкций.
SSE4.2 позволяет одной инструкцией вычислять контрольную сумму CRC32, а с помощью нескольких инструкций — сравнивать строковые значения. Свежайшие функции
str() в библиотеке libC основаны на SSE4.2, поэтому вы можете так быстро грепать слово из гигантского текста.SIMD нам поможет
Пришло время улучшить нашу С-программу с помощью SIMD и посмотреть, станет ли она быстрее.
Всё началось с технологии MMX, которая добавляла 8 новых 64-битных регистров, от MM0 до MM7. MMX появилась в конце 1990-х, и отчасти из-за неё Pentium 2 и Pentium 3 стоили очень дорого. Теперь эта технология совершенно неактуальна.
Разные версии SSE, вплоть до последней SSE4.2, появлялись в процессорах примерно с 2000-го по 2010-й. Каждая последующая версия совместима с предыдущими.

Сегодня самая распространённая версия — SSE4.2. В ней добавлено 16 новых 128-битных регистров (в X86_64): с XMM0 по XMM15. 128 битов = 16 байтов. То есть, заполнив SSE-регистр и выполнив с ним какое-то вычисление, вы обработаете сразу 16 байтов.
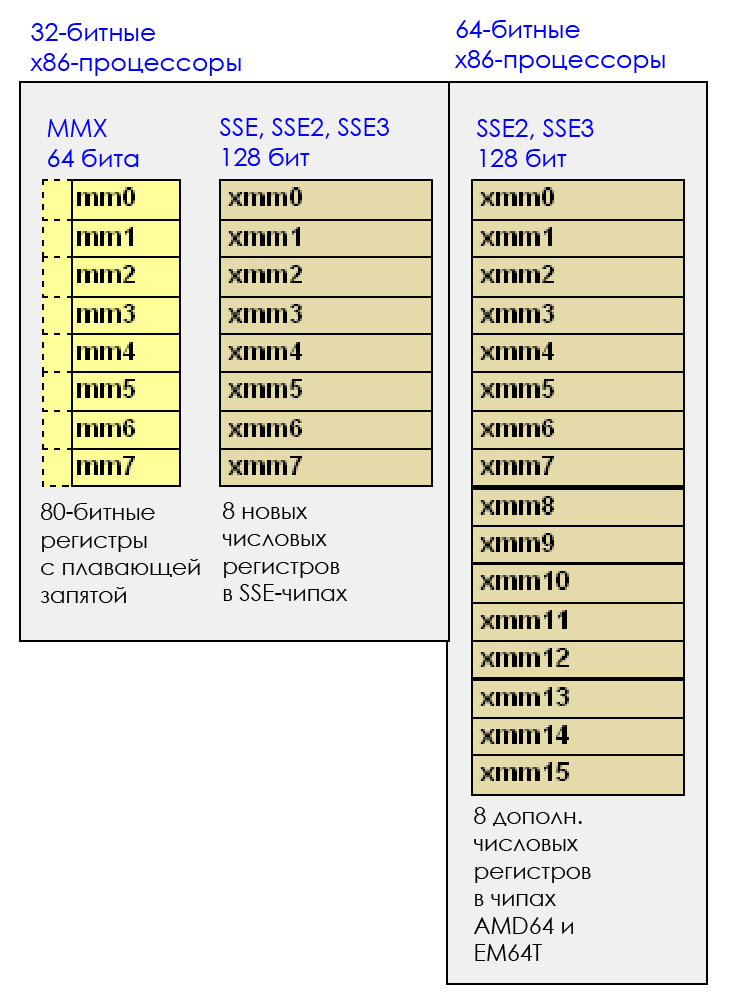
А если обработать два SSE-регистра, то это уже 32 байта за раз. Становится интересно.
С 16 байтами на регистр мы можем хранить (размеры LP64):
- 16 байтов: шестнадцать C-символов.
- Два 8-байтных значения: два длинных значения из С или два числа с двойной точностью (double precision float).
- Четыре 4-байтных значения: четыре целочисленных или четыре числа с одинарной точностью (single precision float).
- Восемь 2-байтных значения: восемь коротких значений из C.
Например:
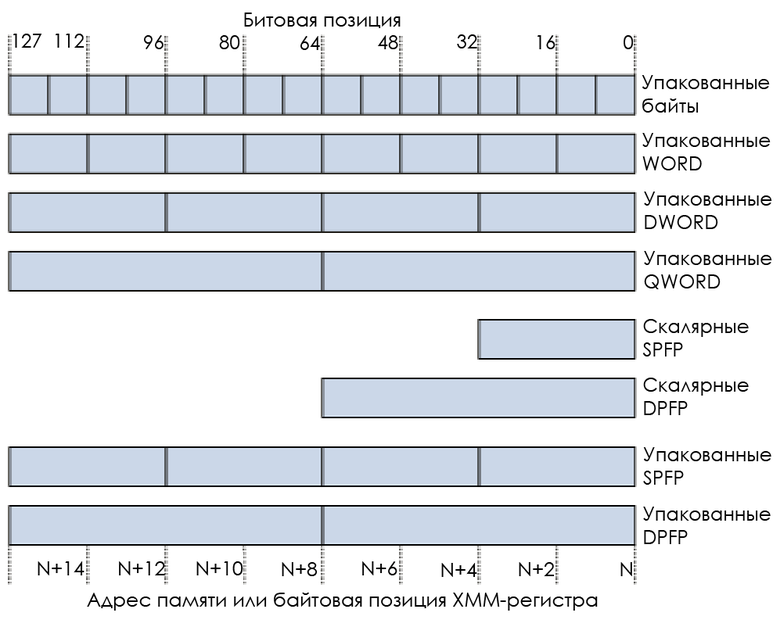
SIMD также называют «векторными» инструкциями, потому что они работают с «вектором» — областью, заполненной разными мельчайшими объектами. Векторная инструкция одновременно обрабатывает разные данные, в то время как скалярная инструкция — только одну порцию данных.
В нашей программе можно реализовать SIMD двумя способами:
- Написать на ассемблере код, работающий с этими регистрами.
- Использовать Intel Intrinsics — API, позволяющий писать C-код, который при компилировании преобразуется в SSE-инструкции.
Я покажу вам второй вариант, а первый сделаете сами в качестве упражнения.
Пропатчим наш код:
#include <stdio.h>
#include <stdint.h>
#include <string.h>
#include <fcntl.h>
#include <unistd.h>
#include <tmmintrin.h>
#define BUF_SIZE 1024
int main(int argc, char **argv)
{
int f, i;
ssize_t readed;
__m128i r = _mm_set1_epi8(0);
unsigned char result = 0;
unsigned char buf[BUF_SIZE] __attribute__ ((aligned (16))) = {0};
if (argc != 2) {
fprintf(stderr, "Использование: %s \n", argv[0]);
exit(-1);
}
f = open(argv[1], O_RDONLY);
if (f == -1) {
perror("Не могу открыть файл");
}
while ((readed = read(f, buf, sizeof(buf))) > 0) {
for (i=0; i < readed; i+=16) {
__m128i a = _mm_load_si128((const __m128i *)(buf+i));
r = _mm_add_epi8(a, r);
}
memset(buf, 0, sizeof(buf));
}
for (i=0; i<16; i++) {
result += ((unsigned char *)&r)[i];
}
close(f);
printf("Чтение завершено, сумма равна %u \n", result);
return 0;
}
Видите новый заголовок tmmintrin.h? Это интеловский API. Для него есть прекрасная документация.
Для хранения результата суммирования (накопительного) я решил использовать только один SSE-регистр и заполнять его строкой из памяти. Вы можете поступить иначе. Например, взять сразу 4 регистра (или вообще все), и тогда вы будете суммировать 256 байтов в 16 операциях :D
Помните размеры SSE-регистров? Наша цель — суммировать байты. Это значит, что мы будем использовать в регистре 16 отдельных байтов. Если почитаете документацию, то узнаете, что существует много функций для «упаковки» и «распаковки» значений в регистрах. Нам они не пригодятся. В нашем примере не нужно превращать 16 байтов в 8 WORD или 4 DWORD. Нам нужно просто посчитать сумму. И в целом SIMD даёт гораздо больше возможностей, чем описано в этой статье.
Итак, теперь вместо побайтового сложения мы будем складывать по 16 байтов.
В одной инструкции мы обработаем гораздо больше данных.
__m128i r = _mm_set1_epi8(0);Предыдущее выражение подготавливает XMM-регитр (16 байтов) и заполняет его нулями.
for (i=0; i < readed; i+=16) {
__m128i a = _mm_load_si128((const __m128i *)(buf+i));
r = _mm_add_epi8(a, r);
}Каждый цикл
for() теперь должен увеличивать буфер не на 1 байт, а на 16. То есть i+=16.Теперь обращаемся к буферу памяти
buf+i и наводим его на указатель __m128i*. Таким образом мы берём из памяти порции по 16 байтов. С помощью _mm_load_si128() записываем эти 16 байтов в переменную a. Байты будут записываться в XMM-регистр как «16*один байт».Теперь с помощью
_mm_add_epi8() добавляем 16-байтный вектор к нашему аккумулятору r. И начинаем прогонять в циклах по 16 байтов.В конце цикла последние байты остаются в регистре. К сожалению, нет простого способа добавить их горизонтально. Это можно делать для WORD, DWORD и так далее, но не для байтов! К примеру, взгляните на
_mm_hadd_epi16().Так что будем работать вручную:
for (i=0; i<16; i++) {
result += ((unsigned char *)&r)[i];
}Готово.
Компилируем и профилируем:
> gcc -Wall -g -O0 -o file_sum file_sum.c
> time ./file_sum /tmp/test
Read finished, sum is 186
real 0m0.693s
user 0m0.360s
sys 0m0.328sОколо 700 мс. C 3000 мс при классическом побайтовом суммировании мы упали до 700 при суммировании по 16 байтов.
Давайте дизассемблируем код цикла
while(), ведь остальной код не изменился:00400957: mov -0x34(%rbp),%eax
0040095a: cltq
0040095c: lea -0x4d0(%rbp),%rdx
00400963: add %rdx,%rax
00400966: mov %rax,-0x98(%rbp)
0040096d: mov -0x98(%rbp),%rax
00400974: movdqa (%rax),%xmm0
00400978: movaps %xmm0,-0x60(%rbp)
0040097c: movdqa -0xd0(%rbp),%xmm0
00400984: movdqa -0x60(%rbp),%xmm1
00400989: movaps %xmm1,-0xb0(%rbp)
00400990: movaps %xmm0,-0xc0(%rbp)
00400997: movdqa -0xc0(%rbp),%xmm0
0040099f: movdqa -0xb0(%rbp),%xmm1
004009a7: paddb %xmm1,%xmm0
004009ab: movaps %xmm0,-0xd0(%rbp)
004009b2: addl $0x10,-0x34(%rbp)
004009b6: mov -0x34(%rbp),%eax
004009b9: cltq
004009bb: cmp -0x48(%rbp),%rax
004009bf: jl 0x400957Нужно пояснять? Заметили
%xmm0 и %xmm1? Это используемые SSE-регистры. Как мы с ними поступим?Мы выполняем MOVDQA (MOV Double Quad-word Aligned) и MOVAPS (MOV Aligned Packed Single-Precision). Эти инструкции делают одно и то же: перемещают 128 битов (16 байтов). А зачем тогда две инструкции? Я не могу этого объяснить без подробного рассмотрения архитектуры CISC, суперскалярного движка и внутреннего конвейера.
Далее мы выполняем PADDB (Packed Add Bytes): складываем друг с другом два 128-битных регистра в одной инструкции!
Цель достигнута.
Об AVX
AVX (Advanced Vector eXtension) — это будущее SSE. Можно считать AVX чем-то вроде SSE++, вроде SSE5 или SSE6.
Технология появилась в 2011-м вместе с архитектурой Intel Sandy Bridge. И как SSE вытеснила MMX, так теперь AVX вытесняет SSE, которая превращается в «старую» технологию, присущую процессорам, из десятилетия 2000—2010.
AVX увеличивает возможности SIMD, расширяя XMM-регистры до 256 битов, то есть 32 байтов. Например, к регистру XMM0 можно обращаться как к YMM0. То есть регистры остались те же, просто были расширены.

AVX-инструкции можно использовать с XMM-регистрами из SSE, но тогда будут работать только младшие 128 битов соответствующих YMM-регистров. Это позволяет комфортно переносить код из SSE в AVX.
Также в AVX появился новый синтаксис: для одного места назначения опкоды могут брать до трёх исходных аргументов. Место назначения может отличаться от источника, в то время как в SSE оно являлось одним из источников, что приводило к «деструктивным» вычислениям (если регистр позднее должен был стать местом назначения для опкода, то приходилось сохранять содержимое регистра, прежде чем выполнять над ним вычисление). Например:
VADDPD %ymm0 %ymm1 %ymm2 : Прибавляет числа с плавающей запятой с двойной точностью из ymm1 в ymm2 и кладёт результат в ymm0Также AVX позволяет в формуле MNEMONIC DST SRC1 SRC2 SRC3 иметь в качестве адреса памяти один SRC или DST (но не больше). Следовательно, многие AVX-инструкции (не все) могут работать прямо из памяти, без промежуточной загрузки данных в регистр, а многие способны работать с тремя источниками, не только с двумя.
Наконец, в AVX есть замечательные FMA-инструкции. FMA (Fused Multiply Add) позволяет одной инструкцией выполнять такие вычисления: A = (B * C) + D.
Об AVX2
В 2013 году вместе с архитектурой Haswell появилась технология AVX2. Она позволяет добавлять байты в 256-битные регистры. Как раз то, что нужно для нашей программы. К сожалению, в AVX1 этого нет. При работе с 256-битными регистрами AVX может выполнять операции только с числами с плавающей запятой (с половинной, одинарной или двойной точностью) и с целочисленными. Но не с одиночными байтами!
Пропатчим нашу программу, чтобы использовать AVX2 и новую инструкцию VPADDB, добавляющую байты из YMM-регистров (чтобы складывать по 32 байта). Сделайте это самостоятельно, потому что мой процессор слишком старый и не поддерживает AVX2.
Мануалы по AVX и AVX2 можно скачать тут.
Об AVX-512
По состоянию на конец 2016 года технология AVX-512 предназначена для «профессиональных» процессоров Xeon-Phi. Есть вероятность, что к 2018 году она попадёт и на потребительский рынок.
AVX-512 снова расширяет AVX-регистры, с 256 до 512 битов, то есть 64 байтов. Также добавляется 15 новых SIMD-регистров, так что становится доступно в сумме 32 512-битных регистра. Обращаться к старшим 256 битам можно через новые ZMM-регистры, половина объёма которых доступна YMM-регистрам из AVX, а половина объёма YMM-регистров доступна XMM-регистрам из SSE.
Информация от Intel.
Сегодня мы можем предсказывать погоду на 15 дней вперёд благодаря вычислениям на супервекторных процессорах.
SIMD везде?
У SIMD есть недостатки:
- Необходимо идеально выравнивать данные в области памяти.
- Не каждый код допускает такое распараллеливание.
Сначала про выравнивание. Как процессор может обращаться к области памяти для загрузки 16 байтов, если адрес не делится на 16? Да никак (в одной инструкции вроде MOV).
Конструктор Lego позволяет хорошо проиллюстрировать концепцию выравнивания данных в памяти компьютера.
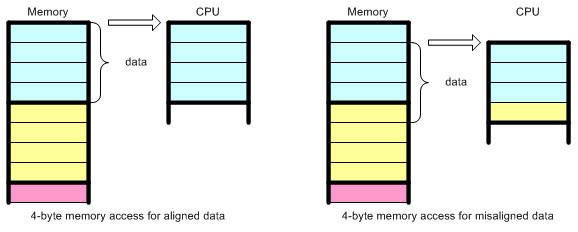
Видите проблему? Поэтому я использую в С-коде:
unsigned char buf[BUF_SIZE] __attribute__ ((aligned (16))) = {0};чтобы компьютер хранил
buf в стеке по адресу, который делится на 16.SIMD можно использовать и с невыравненными данными, но за это придётся расплачиваться так дорого, что лучше вообще не прибегать к SIMD. Вы просите процессор загрузить данные по адресу Х, затем по адресу Y, затем удалить байты из Х, затем из Y, затем вставить рядом две области памяти. Ни в какие ворота не лезет.
Подробнее о выравнивании:
Обратите внимание, что выравнивать данные в памяти рекомендуется и при работе с «классическим» С. Эту методику мы используем и в PHP. Любой автор серьёзной С-программы обращает внимание на выравнивание и помогает компилятору генерировать более качественный код. Иногда компилятор может «предполагать» и выравнивать буферы, но при этом часто задействуется динамическая память (куча), и потом приходится наводить порядок, если вас волнует падение производительности при каждом обращении к памяти. Это особенно характерно для разработки С-структур.
Другая проблема, связанная с SIMD, — ваши данные должны быть пригодны для распараллеливания. Приложение должно передавать данные в процессор в параллельных потоках. В противном случае компилятор сгенерирует классические регистры и инструкции, без использования SIMD. Однако не каждый алгоритм можно так распараллелить.
В общем, за SIMD придётся заплатить некую цену, но она не слишком велика.
Боремся с компилятором: включаем оптимизацию и автовекторизацию
В начале статьи я говорил о половине секунды на суммирование байтов. Но у нас сейчас 700 мс, это никак не 500!
Есть один трюк.
Вспомните, как мы компилировали наш С-код. Мы отключили оптимизации. Не буду вдаваться в подробности о них, но в имеющей отношение к PHP статье я рассказывал, как расширение OPCache может цепляться к PHP-компилятору и выполнять оптимизационные проходы в сгенерированном коде.
Здесь всё то же самое, но объяснять слишком сложно. Оптимизировать код непросто, это огромная тема. Погуглите некоторые термины и получите примерное представление.
Упрощённо: если приказать компилятору сгенерировать оптимизированный код, то он наверняка оптимизирует его лучше вас. Поэтому мы используем более высокоуровневый язык (в данном случае — С) и компилятор.
С-компиляторы существуют с 1970-х годов. Их оттачивали около 50 лет. В каких-то очень редких и специфических случаях вы сможете оптимизировать лучше, но и только. При этом вам придётся идеально разбираться в ассемблере.
Однако нужно знать, как компилятор работает, чтобы понимать, можно ли оптимизировать ваш код. Есть много рекомендаций, которые помогают компилятору генерировать более качественный код. Начните изучать вопрос отсюда.
Скомпилируем первую версию нашей программы — побайтное сложение без использования Intrinsics — с полной оптимизацией:
> gcc -Wall -g -O3 -o file_sum file_sum.c
> time ./file_sum /tmp/test
Read finished, sum is 186
real 0m0.416s
user 0m0.084s
sys 0m0.316sОбщее время всего 416 мс, а суммирование байтов заняло только 84 мс, тогда как на системные вызовы и доступ к диску потрачено аж 316 мс.
Мда.
Дизассемблируем. Полный код можно посмотреть здесь.
Интересный кусок:
00400688: mov %rcx,%rdi
0040068b: add $0x1,%rcx
0040068f: shl $0x4,%rdi
00400693: cmp %rcx,%rdx
00400696: paddb 0x0(%rbp,%rdi,1),%xmm0
0040069c: ja 0x400688
0040069e: movdqa %xmm0,%xmm1
004006a2: psrldq $0x8,%xmm1
004006a7: paddb %xmm1,%xmm0
004006ab: movdqa %xmm0,%xmm1
004006af: psrldq $0x4,%xmm1
004006b4: paddb %xmm1,%xmm0
004006b8: movdqa %xmm0,%xmm1
004006bc: psrldq $0x2,%xmm1
004006c1: paddb %xmm1,%xmm0
004006c5: movdqa %xmm0,%xmm1
004006c9: psrldq $0x1,%xmm1
004006ce: paddb %xmm1,%xmm0
004006d2: movaps %xmm0,(%rsp)
004006d6: movzbl (%rsp),%edx
(...) (...) (...) (...)Проанализируйте его сами. Здесь компилятор использует много трюков, чтобы повысить эффективность программы. Например, разворачивает обратно (unroll) циклы, определённым образом распределяет байты по регистрам, передавая побайтно одни и сдвигая другие.
Но здесь точно сгенерированы SIMD-инструкции, поскольку наш цикл можно «векторизовать» — превратить в векторные инструкции SIMD.
Попробуйте проанализировать весь код целиком, и вы увидите, насколько умно компилятор подошёл к решению задачи. Он знает цену каждой инструкции. Он может организовать их так, чтобы получился наилучший код. Здесь можно почитать о каждой оптимизации, выполняемой GCC на каждом уровне.
Самый трудный уровень — O3, он включает «векторизацию дерево — цикл», «векторизацию дерево — slp», а также размыкает циклы.
По умолчанию используется только O2, потому что из-за очень слишком агрессивной оптимизации O3 программы могут демонстрировать неожиданное поведение. Также в компиляторах бывают баги, как и в процессорах. Это может привести к багам в генерируемом коде или к неожиданному поведению, даже в 2016 году. Я с таким не сталкивался, но недавно нашёл баг в GCC 4.9.2, влияющий на PHP с -O2. Также вспоминается баг в управлении FPU.
Возьмём в качестве примера PHP. Скомпилируем его без оптимизации (-O0) и запустим бенчмарк. Затем сравним с -O2 и -O3. Бенчмарк должен просто перегреться из-за агрессивных оптимизаций.
Однако -O2 не активирует автовекторизацию. Теоретически при использовании -O2 GCC не должен генерировать SIMD. Раздражает факт, что каждая программа в виде Linux-пакета по умолчанию скомпилирована с -O2. Это как иметь очень мощное оборудование, но не использовать его возможности целиком. Но мы же профессионалы. Вы знаете, что коммерческие Linux-дистрибутивы могут распространяться с программами, которые при компилировании сильно оптимизируются под оборудование, с которым распространяются? Так делают многие компании, в том числе IBM и Oracle.
Вы тоже можете самостоятельно компилировать их из исходных кодов, используя -O3 или -O2 с нужными флагами. Я использую -march=native для создания ещё более специализированного кода, более производительного, но менее портируемого. Но он иногда работает нестабильно, так что тщательно тестируйте и готовьтесь к сюрпризам.
Кроме GCC, есть и другие компиляторы, например LLVM или ICC (от Intel). На gcc.godbolt.org можно в онлайне протестировать все три. Компилятор Intel генерирует лучший код для процессоров Intel. Но GCC и LLVM быстро догоняют, к тому же у вас могут быть свои идеи относительно методики тестирования компиляторов, разных сценариев и кодовых баз.
Работая со свободным ПО, вы свободны. Не забывайте: вас никто не будет подбадривать.
Вы же не покупаете коммерческую суперпрограмму, которая неизвестно как скомпилирована, и если её дизассемблировать, то можно попасть в тюрьму, поскольку это запрещено во многих странах. Или вы всё же это сделали? Ой.
PHP?
А при чём тут вообще PHP? Мы не кодим PHP на ассемблере. При генерировании кода мы полностью полагаемся на компилятор, потому что хотим, чтобы код был портируем на разные архитектуры и ОС, как и любая С-программа.
Однако мы стараемся использовать хорошо проверенные хитрости, чтобы компилятор генерировал более эффективный код:
- Многие структуры данных в PHP выравнены. Диспетчер памяти, выполняющий размещения куч, всегда выравняет по вашей просьбе буфер. Подробности.
- Мы используем alloca() только там, где она работает лучше кучи. Для старых систем, не поддерживающих alloca(), у нас есть собственный эмулятор.
- Мы используем встроенные команды GCC. Например, __builtin_alloca(), __builtin_expect() и __builtin_clz().
- Мы подсказываем компилятору, как использовать регистры для основных обработчиков виртуальной машины Zend Virtual. Подробности.
В PHP мы не используем JIT (ещё не разработали). Хотя планируем. JIT — это способ генерирования ассемблерного кода «на лету», по мере выполнения некоторых машинных инструкций. JIT улучшает производительность виртуальных машин, таких как в PHP (Zend), но при этом улучшения касаются только повторяющихся вычислительных паттернов. Чем больше вы повторяете низкоуровневые паттерны, тем полезнее JIT. Поскольку сегодня PHP-программы состоят из большого количества разнообразных PHP-инструкций, JIT оптимизирует только тяжёлые процессы, обрабатывающие большие объёмы данных в секунду в течение долгого времени. Но для PHP такое поведение нехарактерно, потому что он старается обрабатывать запросы как можно скорее и делегировать «тяжёлые» задачи другим процессам (асинхронным). Так что PHP может выиграть от внедрения JIT, но не настолько, как та же Java. По крайней мере, не как веб-технология, а при использовании в качестве CLI. CLI-скрипты сильно улучшатся, в отличие от Web PHP.
При разработке PHP мы редко обращаем внимание на сгенерированный ассемблерный код. Но иногда мы это делаем, особенно столкнувшись с «неожиданным поведением», не относящимся к С. Это может говорить о баге компилятора.
Чуть не забыл про SIMD-расширение Джо для PHP. Не спешите осуждать: это проверка концепции, но зато хорошая проверка.
У меня есть много идей относительно PHP-расширений, связанных с SIMD. Например, я хочу портировать на С часть проекта math-php и внедрить SIMD. Можно сделать расширение с публичными структурами, позволяющими PHP-пользователям применять SIMD для линейных алгебраических вычислений. Возможно, это поможет кому-то создать полноценную видеоигру на PHP.
Заключение
Итак, мы начали с создания простенькой программы на С. Увидели, что компилирование без оптимизаций привело к генерированию очень понятного и дружественного к GDB ассемблерного кода, при этом крайне неэффективного. Второй уровень оптимизации по умолчанию в GCC не подразумевает включения автовекторизации, а следовательно, не генерирует SIMD-инструкции. С использованием -O3 GCC по производительности превзошёл результаты от нашей реализации SIMD.
Также мы увидели, что наша реализация SIMD — всего лишь проверка концепции. Для дальнейшего улучшения производительности мы могли бы прибегнуть к AVX и ряду других регистров. Также при доступе к файлу можно было бы использовать mmap(), но в современных ядрах это не дало бы эффекта.
Создавая код на С, вы возлагаете работу на компилятор, потому что он её сделает лучше вас. Смиритесь с этим. В каких-то случаях вы можете взять бразды правления в свои руки и написать ассемблерный код напрямую или с помощью API Intel Intrinsics. Также каждый компилятор принимает «расширения» из языка С, которые помогают сгенерировать желаемый код. Список GCC-расширений.
Кто-то предпочитает использовать Intel Intrinsics, кто-то сам пишет ассемблерный код и считает, что так проще. Действительно несложно вставлять ассемблерные инструкции в С-программу, это позволяет делать каждый компилятор. Либо можно написать один файл проекта на ассемблере, другие на С.
Вообще С — действительно классный язык. Он стар и мало изменился за 45 лет, что доказывает его устойчивость, а значит, наше железо работает на твёрдом фундаменте. У С есть конкуренты, но он справедливо занимает львиную долю рынка. На нём написаны все низкоуровневые системы, которые мы сегодня используем. Да, теперь у нас больше потоков, несколько ядер и ряд других проблем вроде NUMA. Но процессоры по-прежнему обрабатывают так же, как и раньше, и только невероятно талантливые инженеры Intel и AMD умудряются следовать закону Мура: теперь мы можем использовать очень специализированные инструкции, одновременно обрабатывая много данных.
Я написал эту статью, потому что недавно встретил талантливых специалистов, которые полностью игнорируют всё, что здесь написано. Я подумал, что они многое упускают и даже не понимают этого. Вот и решил поделиться своими знаниями о том, как выполняются низкоуровневые вычисления.
Будучи пользователями высокоуровневых языков, не забывайте, что вы создаёте свои продукты на фундаменте из миллионов строк С-кода и миллиардов процессорных инструкций. Проблема, которую вы встретите на высоком уровне, может решаться на более низких. Процессор не умеет врать, он очень глуп и выполняет простейшие операции с крохотными объёмами данных, но зато с огромной скоростью и совсем не так, как это делает наш мозг.
Полезные ссылки:
- Intel: The significance of SIMD, SSE and AVX
- NASM
- GCC SIMD switches
- Online JS based X86 compilers
- ARM Processor Architecture
- Modern X86 Assembly Language Programming: 32-bit, 64-bit, SSE, and AVX
- X86 Opcode and Instruction Reference
- Dragon Book
- X264 Assembly with SIMD
- LAME MP3 quantizer SIMD
- Mandelbrot Set with SIMD Intrinsics
- ASM.js
- Joe's PHP SIMD
Комментарии (266)

fishca
08.12.2016 22:04+2Он стар и мало изменился за 45 лет
Я бы сказал что он Super Star!
Много технических низкоуровневых знаний в статье, но она от этого только лучше. Надо почаще возвращаться к истокам.

Varim
08.12.2016 22:07+5Регистр A — 64-битный доступ. RAX — 32-битный. EAX — 16-битный. AX — 8-битный. Младшая часть: AL, старшая часть: AH.
кажися правильно — RAX — 64-битный. EAX — 32-битный. AX — 16-битный. Младшая часть: AL — 8, старшая часть: AH — 8.
AloneCoder
08.12.2016 23:57Да, верное замечание — на иллюстрации это видно наглядно, упустил сей момент и поправил
ilmarin77
08.12.2016 22:08+3Видимо не все jit компиляторы равноценны:
модифицировал код — заменил тип result на double, поправил printf скомпилировал с -О0:
$ time ./a.out /tmp/test Чтение завершено, сумма равна 136901097048.000000 real 0m2.910s user 0m2.728s sys 0m0.180s
Написал аналогичную программу на lua:
local block = 1024 if #arg < 1 then print(string.format("Usage:%s <input>",arg[0],#arg)) return 1 end local f = io.open(arg[1], "rb") local result=0.0 while true do local bytes = f:read(block) if not bytes then break end local i for i=1,#bytes do result=result+string.byte(bytes,i) end end print(string.format("Result:%f",result))
Запустил через luajit ( в установке torch):
time th test.lua /tmp/test Result:136901097048.000000 real 0m2.063s user 0m1.956s sys 0m0.136silmarin77
08.12.2016 23:09+1Ещё один эксперимент:
делаем#define BUF_SIZE 1024*1024
и компилируем с -O3:
time ./std /tmp/test Чтение завершено, сумма равна 136901097048.000000 real 0m0.987s user 0m0.884s sys 0m0.100s
Теперь сравниваем с этой программой на lua + torch:
local block = 1024*1024 if #arg < 1 then print(string.format("Usage:%s <input>",arg[0])) return 1 end local f = torch.DiskFile(arg[1], 'r') f:binary() f:quiet() -- disable error reporting local result=0.0 while true do local bytes = f:readByte(block) if bytes:size()==0 then break end local tensor=torch.ByteTensor(bytes) result=result+torch.sum(tensor) end print(string.format("Result:%f",result))
time th test_torch.lua /tmp/test Result:136901097048.000000 real 0m1.101s user 0m0.828s sys 0m0.284s
kafeman
09.12.2016 05:57Мне кажется, что некорректно измерять JIT через time. Вы же для Си время компиляции не считаете?
ilmarin77
09.12.2016 07:12+1Можно посчитать:
$ time gcc -O3 test.c real 0m0.089s user 0m0.076s sys 0m0.004s

aso
09.12.2016 08:14+2Мне кажется, что некорректно измерять JIT через time.
Э-ээ, правда?
Вы же для Си время компиляции не считаете?
Вы ещё время разработки предложите учитывать…
Программа на Си компилируется один раз — а запускается многократно, время компиляции «размазывается» по всем запускам.
Fesor
09.12.2016 19:48+2Речь идет о том, что для jit надо прогревать код, что бы оптимизирующий компилятор начал оптимизировать горячие участки кода. Об этом к слову в статье упоминается.
aso
12.12.2016 08:37А какая разница конечному пользователю, к примеру?
Он будет получать билды с «прогретым» кодом?Fesor
12.12.2016 11:11+2обычно программисты сами вставляют кусочки кода, которые "прогревают" какой-то код при инициализации приложения, чтобы намекнуть JIT что мол "эта штука будет выполняться часто, оптимизируй ее".
Так что да, для конечного пользователя все будет хорошо, ибо часто вызываемый код будет работать быстро, а редко вызываемый код… не сильно будет влиять на общую картину.

Akon32
09.12.2016 12:39Лет 6 назад сравнивал подобным образом C (gcc -O3) и Java (hotspot). Какая технология выигрывала — зависело от модели процессора.

apangin
08.12.2016 22:39+6Попробуйте проделать это на любом из высокоуровневых языков — вы и не приблизитесь по производительности к С. Даже на Java, с помощью JIT, с параллельными вычислениями и хорошей моделью использования памяти в пространстве пользователя.
В своём недавнем выступлении на конференции Joker я как раз сравнивал Java и C на похожем примере. И там Java на малюсенькую долю секунды даже опередила C. Я заметил, что если число итераций цикла не константное, то GCC не делает loop unrolling даже с -O3. А JVM делает. И векторизировать по умолчанию умеет. А статистика, собранная в run-time, позволяет JVM выполнять спекулятивные оптимизации, на которые статические компиляторы не способны в принципе.kmu1990
08.12.2016 22:59статические компиляторы не способны в принципе
это слишком сильное утверждение, статические компиляторы способны делать спекулятивные оптимизации, но это не супер удобно, ну и не получится в runtime пересмотреть принятые на этапе компиляции решения.
PsyHaSTe
15.12.2016 17:54Это значит «не может»
kmu1990
15.12.2016 17:57Вообще-то могут, более того они это делают, поэтому неправильно говорить, что они «не способны в принципе».
PsyHaSTe
15.12.2016 18:31Просто если подумать, кому нужно решение которое в рантайме нельзя пересмотреть? Это как branch prediction, который неправильно наспекулировал, но не останавливает конвеер и не пытается пойти по нужной ветке, а говорит «да забей и так норм» и идет дальше по накатаной.
kmu1990
15.12.2016 18:42+1Код сгенерированный статическим компилятором так и JIT-ом должен быть корректным независимо ни от чего, просто он может быть неэффективным для тех веток/участков кода, которые согласно профайлу/собранной статиситике являются редкими. Так что я не понял ваше сравнение с некорректным branch prediction-ом — если мы не угадали нужную ветку и пошли по неправильной, даже когда поняли это — это некорректный код, т. е. совсем другая история.
То что не может статический компилятор по сравнению с JIT-ом, это понять, что какой-то код в процессе работы из редко используемого превратился в часто используемый. Но спекулятивные оптимизации, о которых говорилось в оригинальном комментарии, статические компиляторы все еще могут выполнять и более того они это делают…PsyHaSTe
15.12.2016 18:55Если вы про «собрать профиль выполнения на макете и использовать его для оптимизации» — это конечно возможно, но на практике а) этим мало кто заморачивается и б) на результирующей машине все может быть совсем иначе (и оптимизация становится ДЕоптимизацией), а профилировать на боевом стенде под рабочей нагрузкой я думаю вряд ли кто-то может себе позволить.
kmu1990
15.12.2016 19:01Во-первых, оно может стать деоптимизацией, а может и не стать — так что рассуждать не конкретно, о том на сколько хорошо/плохо работает профилирование для статических компиляторов не имеет смысла.
Во-вторых, мое замечание касалось ровно того момента, что статические компиляторы «не способны впринципе» на спекулятивные оптимизации — это утверждение просто не корректно.
В-третьих, у вас есть какая-то разумная статистика того кто этим заморачивается, а кто нет? Если есть поделитесь. Если же ваше утверждение базируется на том, что вы никогда не встречали тех, кто этим заморачивается, то об этом тоже стоит упомянуть ради объективности.PsyHaSTe
15.12.2016 19:18Ну прям по всем подобным утилитам в мире у меня информации нет, но вот по дотнету сказать можно, что NGEN с профилем используется чуть реже, чем никогда.
kmu1990
15.12.2016 19:37Во-первых, к контексте обсуждения опять же не понятно на чем основано ваше утверждение — у вас есть какая-то статистика или вы просто не встречали тех, кто так делал.
Во-вторых, элементарный поиск по документации выдал мне следующую ссылку:
https://msdn.microsoft.com/ru-ru/library/6t9t5wcf(v=vs.110).aspx
Из которой я понял, что NGEN используется в дополнение к JIT, а не вместо (если я понял не правильно поправьте меня), так что не очень понятно, на сколько это показательный пример того, что статическая компиляция с профайлом это редкая вещь.PsyHaSTe
15.12.2016 19:45На сегодняшний день JIT это единственный способ скомпилировать программу, единственная разница, что NGEN позволяет прогнать джит заранее по приложению, используя хостовую машину в качестве «донора». Профиль соответственно позволяет улучшить некоторые предположения компилятора (см. ссылку).
Из более-менее распространенного ПО, где используется NGEN я могу назвать разве что Paint.Net, правда я не уверен, что они используют профиль.
То есть возможность-то есть, только ей почему-то никто не пользуется.kmu1990
15.12.2016 19:57Во-первых, JIT в моем комментарии это не название компилятора/утилиты/еще чего-то, имелось ввиду что NGEN используется не вместо Just-In-Time компиляции, а в дополнение к ней. Откуда и возник вопрос, является ли NGEN репрезентативным примером.
Во-вторых, как я понял, ваш комментарий можно интерпретировать так: «у меня нет никакой статистики об использовании, но я (почти) не знаю тех кто пользуется этой фичей» (серьезно, почему люди так тяжело указывать этот не мало важный момент)?
В-третьих, у меня есть догадка почему — NGEN позволяет ускорить запуск, а после запуска JIT уже сам разберется со сбором статистики и оптимизациями, которые на ней основаны. Другими словами профилирование на самом деле происходит, просто отложенно.PsyHaSTe
15.12.2016 22:29Отвечаю на во-первых, т.к. в C# нет AOT-компилятора отдельного, то есть только джиты (JIT86, JIT64 и RyuJIT), которые можно запустить на экзешнике заранее (получается как бы AOT, но компилятор тот же, что и будет компилить байт-код в случае джита).
Отвечаю на во-вторых, так можно интепретировать любой ответ, например «у меня нет никакой статистики о вращении чайника по эллиптической орбите между Солнцем и Землей, и я (почти) не знаю тех, кто в него верит»,
Отвечая на в-третьих, NGEN полностью генерирует готовый код (как кстати следует из названия), после его работы JIT вообще не запускается на целевой машине.kmu1990
15.12.2016 22:59так можно интепретировать любой ответ
Это не правда. Можно подкреплять ответ объективными фактами — туда-то туда-то был встроен такой-то такой-то счетчик и за такое-то время набралось столько-то, там-то и там был проведен опрос и из стольких-то ответивших столько-то ответили так-то и тд и тп — это объективные факты, про которые известно каким образом они получены.
А можно просто сказать, я никогда не видел то-то и то-то и поэтому я считаю, что того-то и того-то не существует. Это субъективное мнение, подкрепленное личным опытом одного конкретного человека.
И то и другое имеет право на существование, но полезно понимать чем мнение подкрплено/не подкреплено.
как кстати следует из названия
Вообще-то не следует, NGEN (Native Image Generator) — генерирует нативный код, но из этого не следует, что в процессе работы этот код нельзя заменить новым, сгенерированным на лету. Но впрочем ответ на свой вопрос я получил, спасибо.PsyHaSTe
15.12.2016 23:29Объективные факты — статьи/посты (на том же хабре) и прочие success story, по количеству которых можно об этом судить.

lieff
15.12.2016 19:26+1Я заморачивался. И jit и статически wpo\pgo, и «вручную» динамически на сях.
Могу сказать что продолжать собирать статистику в иннер лупах в рантайме уже после свершенных оптимизиций (т.е. менять свой выбор) достаточно дорогостоящая операция и эффект от нее не очевиден, нужно инкрементировать счетчики на бранчах, что может сильно все замедлить. Тут все очень тонко.
Так же, когда есть ожидание смены нужного выбора — можно делать такие оптимизации и без JIT. Нужно завести 2 ветки кода с разными __builtin_expect и вести статистику вручную. Можно оборвать ведение статистики и передать управление веткам с отключенной статистикой.
Так же иногда можно собирать статистику отдельно и переключать разные преднастроенные __builtin_expect ветки, а статистику собирать или прекращать на основе каких-то факторов.

orcy
09.12.2016 11:51> а которые статические компиляторы не способны в принципе.
Ну я бы не сказал. Chrome под Windows собирается с PGO, например.
il--ya
09.12.2016 15:54Кстати да, у меня первый же вопрос при взгляде на эту программу был «а почему число итераций не константное, если мы претендуем на скорость»? Добавляется элементарно, после чтения делаем проверку
while ((read = read(f, buf, sizeof(buf))) > 0) { if (read == sizeof(buf)) { for (i=0; i < sizeof(buf); i++) { result += buf[i]; } } else { for (i=0; i < read; i++) { result += buf[i]; } } }Gryphon88
09.12.2016 16:45Ветки if/else полностью синонимичны. Какой выигрыш такая проверка что даёт?
il--ya
09.12.2016 16:51Константное число итераций в цикле. См. коммент apangin выше (на который я и отвечал):
если число итераций цикла не константное, то GCC не делает loop unrolling даже с -O3
И это касается не только gcc, да и не может компилятор в принципе эффективно развернуть, не зная число итераций.Gryphon88
09.12.2016 17:23Мы читаем наш файл кусками по BUF_SIZE или меньше: последний считанный кусок будет меньше, если размер файла не кратен BUF_SIZE. В любом случае else ветка будет исполнена максимум единожды. Я не понимаю, как тут разворачивание циклов уживется с дополнительным ветвление, чтобы дать выигрыш по скорости. Разве обе ветки не начнут исполняться одновременно до результата проверки равенства со сбросом невалидных результатов после, таким образом украв часть регистров? Всегда путался во всей этой магии «под капотом».
il--ya
09.12.2016 17:37+2Всё правильно, цикл в else исполнится один раз, он не критичен, его не надо оптимизировать.
Цикл в if исполнится миллион раз (автор заявляет 1млрд байт). Компилятор сгенерирует разный код для того, что в if и того, что в else. Цикл с фиксированным числом итераций (sizeof(buf) это константа — 1024) компилятор развернёт на несколько циклов, т.е. например заменит на 128 итераций по 8 шагов в каждой, и развёрнутый код ещё дополнительно оптимизирует.
conterouz
09.12.2016 18:27-1Конкретно в этом примере Java (1.05 сек) у меня медленнее C (0.2 сек) в 5 раз, при использовании буфера в мегабайт.
import java.io.*; public class Main { public static void main(String[] args) throws Exception { if (args.length < 1) { System.out.println("Usage main <filename>"); System.exit(1); } byte[] buf = new byte[1024*1024]; FileInputStream is = new FileInputStream(args[0]); int readed; byte total = 0; while ((readed = is.read(buf, 0, buf.length)) > 0) { for (int i = 0; i < readed; i++) { total += buf[i]; } } System.out.println("Result is:" + total); } }
и даже версия для JMH выдает аналогичные результаты
import org.openjdk.jmh.annotations.*; import java.io.*; public class MyBenchmark { @Benchmark @BenchmarkMode({Mode.AverageTime}) public byte testMethod() throws Exception{ // This is a demo/sample template for building your JMH benchmarks. Edit as needed. // Put your benchmark code here. byte[] buf = new byte[1024*1024]; FileInputStream is = new FileInputStream("/tmp/test"); int readed; byte total = 0; while ((readed = is.read(buf, 0, buf.length)) > 0) { total += sumBuf(buf, readed); } return total; } public byte sumBuf(byte[] buf, int readed) { byte total=0; for (int i = 0; i < readed; i++) { total += buf[i]; } return total; } }
при этом для в C нет ручных оптимизаций, а только -O2

kloppspb
08.12.2016 23:07-1BTW, мелочь, но в данном примере — работает :-)
[23:01:12] $ time ./test-read /tmp/test Чтение завершено, сумма равна 197 real 0m0.573s user 0m0.159s sys 0m0.405s [23:03:44] $ time ./test-fread /tmp/test Чтение завершено, сумма равна 197 real 0m0.459s user 0m0.253s sys 0m0.208s

leotsarev
08.12.2016 23:46+14Это прям истинный пост настоящего адепта С.
Долго оптимизировал на низком уровне, потом выяснил, что компилятор все равно выигрывает. Это первый закон оптимизации — в простых случаях компилятор обыгрывает человека. Атаковать низкий уровень надо в самую последнюю очередь.
А в первую очередь надо атаковать высокий уровень.
Теперь вернемся в реальность и представим, что перед нами стоит именно такая, искусственная задача (а не реальное приложение, где низкоуровневная производительность не так важна).
Формулировка:
Прочитать файл размером гигабайт, посчитать его сумму.
Закон иерархии памяти утверждает, что доступ к каждому следующему уровню иерархии дороже на порядок (читать с диска в память примерно на столько дороже чтения с памяти в регистры процессора). Пока мы запускаем программу честно (в первый раз, не на кешированном файле), это подтверждается.
Таким образом, для максимальной оптимизации программы необходимо и достаточно, чтобы суммирование исполнялось одновременно с чтением с диска. Если это сделать, то скорость суммирования не важна (она всегда будет быстрее чтения). И тут выигрывает любой язык, в котором есть встроенные удобные потоки и асинхронность. Подсказка: это многие языки верхнего уровня, но не С :-)
Единственное, языки с JIT будут проигрывать бенчмарки мини-программ за счет времени на компиляцию, но достаточно обработать AOT-компилятором, чтобы это преимущество исчезло.
kloppspb
09.12.2016 00:22+2Ну, распараллелить сишный код, да под линуксом — не вопрос вообще.
А вот как замена чтения на буферизированный ввод (без изысков, просто на уровне выбора других функций стандартной библиотеки) ускоряет программу в полтора раза сходу, показал чуть выше. Странно, что эта [элементарная] сторона оптимизации проскакала мимо.
MacIn
09.12.2016 21:22Подсказка: это многие языки верхнего уровня, но не С :-)
Для данной синтетической задачи надо всего лишь два системных вызова: создание потока и захват мьютекса (создание-удаление тоже, но это мелочь). Что вовсе не требует высоких абстракций, тут хоть на машинном языке пиши.
ilmarin77
09.12.2016 01:21+2Эксперимент с Питоном и numpy:
import sys import numpy as np block=1024 result=0 with open(sys.argv[1], "rb") as f: while True: bytes = np.fromfile(f, dtype='uint8', count=block) if bytes.shape[0]==0 : break result+=np.sum(bytes) print("Result:{:f}".format(result))
$ time python test_numpy.py /tmp/test Result:136901097048.000000 real 0m4.539s user 0m4.384s sys 0m0.232s
Если увеличить размер буфера до 1024*1024, то будет:
$ time python test_numpy.py /tmp/test Result:136901097048.000000 real 0m1.007s user 0m0.948s sys 0m0.304s
kx13
09.12.2016 09:50+4От питона здесь только чтение данных в память.
Все равно код, выполняющий расчеты, написан на С.
Хотя это как раз показывает, на сколько удобнее питон для такого рода задач. И то, что каждому языку свое место.
vlade11115
09.12.2016 19:11Тут ещё бонусом получаем честную сумму, из за использования длинной арифметики, тогда как у автора будут множественные переполнения переменной, что вообще то неопределённое поведение.
А вообще вам нужно запускать все примеры на своей машине, тогда время из статьи можно сравнивать такой реализацией (это конечно если вы не запускали тест на такой же машине как у автора).ZyXI
09.12.2016 19:15+2Переполнения являются неопределённым поведением только если вы используете знаковые целые. Для беззнаковых целых переполнение по стандарту, вообще?то, невозможно (C99, 6.2.5, параграф 9):
A computation involving unsigned operands can never overflow, because a result that cannot be represented by the resulting unsigned integer type is reduced modulo the number that is one greater than the largest value that can be represented by the resulting type.
ZyXI
09.12.2016 19:23Правда, я, как и многие другие программисты, кого я видел, предпочитаю говорить, что для беззнаковых переполнение определено. Но в стандарте написано — нет, текущее поведение не является переполнением. Определения «overflow» я как?то не нашёл, а всё зависит от него.
vlade11115
10.12.2016 14:04Я опирался на статью, а конкретнее:
Чтобы продемонстрировать возможности языка, я приведу простой пример: открываем файл, считываем из него все байты, суммируем их, а полученную сумму сжимаем в один байт без знака (unsigned byte) (то есть несколько раз будет переполнение). И всё. Ах да, и всё это мы постараемся выполнить как можно эффективнее — быстрее.
(Выделение моё).ZyXI
10.12.2016 21:13+1Очевидно, автор тоже считает, что текущее поведение беззнаковых целых описывается термином «переполнение». Но факт в том, что текущее поведение, во?первых, определено, во?вторых, не считается переполнением по стандарту. О том, переполнение это или нет, ещё можно спорить, но никакого неопределённого поведения там нет в принципе ни по стандарту, ни на практике. По стандарту есть только определяемое реализацией поведение:
unsigned charвовсе не обязан быть восьмибитным.

agmt
09.12.2016 01:28+9Внутренний перфекционист огорчается, что теперь основное время тратится не на суммирование, а на бесполезное копирование данных (это я про read()).
Замена чтения на:
readed = lseek(f, 0, SEEK_END); buf = (unsigned char*)mmap(0, readed, PROT_READ, MAP_SHARED, f, 0);
ускорило у меня в 3 раза (при условии, что файл уже в кешах).
Вопрос: каков предел информации для статьи, ориентированной на знакомство, а и так затронуло уже множество аспектов?

saboteur_kiev
09.12.2016 02:35+9«Вы действительно думаете, что интернет вещей будет разрабатываться на высокоуровневых языках?»
Простите, но он уже разрабатывается на них. Скетчи для ардуино и других подобных платформах пишутся на высокоуровневых скриптовых языках. На низкоуровневых пишутся разве что драйвера и ядро.geher
09.12.2016 11:59+1Скетчи для ардуино обычно пишутся как раз на старом добром С++.

vlreshet
09.12.2016 12:36Обычно — да. Но бывают исключения
geher
09.12.2016 19:30+1Iskra JS, строго говоря, ардуиной не является. Но это так, придирки к вопросу о товарном знаке.
Кстати, исключение не единственное. Есть еще ряд микроконтроллеров, которые программируются на js, lua (при наличии соответствующей прошивки), C#. Что, впрочем, не отменяет факта существенно большей популярности более других плат.
saboteur_kiev
09.12.2016 18:30С++ как-то изменился немного:
https://www.arduino.cc/en/Reference/HomePage
https://www.arduino.cc/en/Reference/WiFiServergeher
09.12.2016 19:21+1Это всего лишь дополнительная библиотека для работы с ардуиной, которая не исключает возможности пользоваться всяким сиплюсплюсным богатством (если памяти микроконтроллера хватит).
А в недрах их IDE еще находится файлик с функцией main, который перед сборкой присобачивается к проекту. И в этом main находится вызов того самого setup и тот самый цикл, который дергает loop

Suvitruf
09.12.2016 05:50+2Программы многих школьных курсов по программированию до сих пор начинаются с освоения азов ассемблера и С.
C и ассемблер в школе? О_оFGV
09.12.2016 09:18+1а что? 8080 вполне осваивается школьником
Suvitruf
09.12.2016 10:03-2Я учился в техническом лицее, где упор был на матан, информатику и т.п. Но даже мы изучали всё на Pascal'е. Да даже на первых 2 курсах университета всё изучалось на нём. Это уже потом в ход пошли C++ и C#.
Varim
09.12.2016 10:06+3А что значит «даже»?
Си легче с++ и с#, а 8ми битный ассемблер очень простой, проще тригонометрии.
Я вообще не понимаю почему в школе не учат двоичной системе, логике и комбинаторике.Suvitruf
09.12.2016 10:11Учат всему этому, но алгоритмы до сих пор на Pascal преподают.
zica
09.12.2016 12:23+1А вот и нет. Язык выбирается учителем. На ЕГЭ задания написаны на алг. языке, паскале, питоне, и си (раньше бейсик вместо питона был). Я например С преподаю.

Sirikid
10.12.2016 17:29+1Почему Си? Я не преподаю (сам не так давно окончил школу), но после прочтения этой PDF (http://www.stolyarov.info/pvt/anti_c) все претензии вида «ууу, устаревший паскаль», как-то испарились.

s-kozlov
11.12.2016 07:29+1Есть ответ: http://info.fenster.name/misc/teaching_c.pdf. Но, как пишет автор, проблема в том, что на ФИТ НГУ не выделяют время для изучения паскаля.
zica
12.12.2016 10:561. Да я с половиной статьи не согласен… чтобы ответить по существ, то придётся не меньшую написать.
2. А вообще, по хорошему, надо начинать не с си или паскаля, а классе в 5, с какого-нибудь скретча или ему подобного.
3. Есть у меня такая мысль, что в школе учить надо не языку, а программированию. (Тут ещё одна проблема, не забывайте, что школы общеобразовательные и 90% детей всё равно что вы там преподаёте).
4. У нас линукс на всех машинах, сам Бог велел не на паскале писать, а на си.
5. Спор между си и питоном был бы более актуален, а паскаль имхо, точно надо на свалку истории отправлять.
safinaskar
10.12.2016 03:06+1Да потому что для обычного человека (таковыми являются большинство) высокоуровневые вещи проще низкоуровневых. Как в математике, так и в программировании. В математике под низкоуровневыми вещами я понимаю логику (на ней всё держится), а высокоуровневыми — все остальные разделы (они понятнее для большинства, так как, взять ту же геометрию, более наглядны). Ну а в программировании, понятное дело, низкий уровень — это всякий ассемблер, а высокий — всякие скриптовые языки. Вторые понятнее для большинства. В том числе потому, что на них можно быстренько сделать что-нибудь наглядное. Сайт. Программу, рисующую график или какую-нибудь анимацию. Игру. И так далее.
Даже у нас на мехмате МГУ математическая логика далась студентам хуже всего.
А один вузовский преподаватель-математик (!), правда, не из МГУ, сказал мне, что не лезет в основания математики глубже некоторого уровня. "Вот здесь вот я для себя поставил черту, глубже я не лезу" — сказал он в ответ на мои многочисленные вопросы о математической логике.
Так что делаю вывод, что, наверное, из миллиона людей только несколько штук имеют до такой степени аналитический склад ума, что им математическая логика проще всего остального
yaeuge
12.12.2016 15:38Вы говорите о разной простоте. Идейная простота ассемблера вовсе не подразумевает простоту использования его в качестве языка программирования. А простота тех же скриптовых языков, напротив, скрывает под собой сложнейшие механизмы и тонны кода (сравните функционал каких-нибудь регулярных выражений с кодом на си).
Думаю, в плане трудозатрат для обучения, как высокоуровневые, так и низкоуровневые технологии примерно одинаковы. Просто у них совершенно разные ниши.
grossws
12.12.2016 16:04-1сравните функционал каких-нибудь регулярных выражений с кодом на си
Особенно забавно, что интерпретатор этих регулярок в случае большинства скриптовых языков будет на Си. И никто не мешает на Си взять какую-нибудь классическую pcre.
yaeuge
12.12.2016 16:48Это конечно же :)
Функциональность языка почти всегда можно расширить библиотеками, а если и их недостаёт по каким-то причинам, то и вовсе писать на языке более высокого уровня, который в свою очередь будет так же написан на языке более низкого.
Я лишь привёл регэкспы как некоторый пример высокоуровневого инструмента. Код с их использованием получается максимально лаконичным (и простым), что делает их мощным средством разработки, однако это совершенно не означает прозрачность (то есть, простоту) их реализации.
MacIn
13.12.2016 01:56+4Идейная простота ассемблера вовсе не подразумевает простоту использования его в качестве языка программирования
Обычная путаница между «сложно» и «тяжело». Сложно научиться управлять экскаватором, а копать — легко. Копать лопатой — просто и тяжело.
lexofein
09.12.2016 09:18+2Автор определенно из не нашей реальности =) Я в 2009 году из школы свалил там был pascal, сейчас занимаюсь с племянником 8 классником — pascalabc.net(ну хоть за это спасибо). Я читал тут статью про деда который в лицеях с 7 класса кажись на С учит писать и его ученики к окончанию школы серьезные штуки делают, но это скорее исключения чем многие школы.
Varim
09.12.2016 10:03+18ми классник спокойно понимает «Язык программирования C Керниган Ритчи»

monah_tuk
10.12.2016 11:08Мне вот трудно далось. Но я сам мыкался. Попробовал Паскаль (Бейсик в базе уже был), как-то легче пошло. Через год снова попробовал C… и не понял, чего я сразу не понял :) Но это уже было классу к 9-10.
Dimonkov
09.12.2016 09:18А у нас только c++. И то, на уровне говнокода, с массивами на тысячу элементов в глобальной переменной.
NecroKot
09.12.2016 15:35+1Выпустился в 2013. Ассемблера не было, но программа была сильная:
8 класс — языки Си и Паскаль, основные структуры данных.
9 класс — только Си, более сложные структуры и алгоритмы
10, 11 классы — С++, рисовали всякие интересности с использованием OpenGL.
При этом за говнокод можно было и по ушам получить и пойти переписывать. И ещё кружок этот же преподаватель ведёт, там гораздо сложнее программа. Так что школы разные бывают.

beeruser
10.12.2016 09:5510-12 летний может спокойно писать на асме. Было бы желание.
К тому же школьник-школьнику рознь. Вот, например ~8 класс.
https://github.com/intelfx/Homework_2011Suvitruf
10.12.2016 10:08Школьная программа рассчитана на среднестатистического ученика. Приятно, что в 8 классе человек такие вещи делает, но не строить же программу только под него?
Varim
10.12.2016 10:12я бы не смешивал школьную программу и школьников, всегда можно сходить в библиотеку или попросить купить книгу, за что я благодарен как библиотекам так и родителям.
zica
12.12.2016 11:14Да, ассемблер, а что такого, очень помогает в объяснении, например, темы «Хранение целых/вещественных чисел в памяти компьютера». Правда инструменты далеко вперёд шагнули, вот например прекрасная статья, что и как давать детям: http://kpolyakov.narod.ru/download/inf-2012-07.pdf.
s-kozlov
09.12.2016 06:20+4А язык Java — как и 80 % современных высокоуровневых языков — написан на С (или С++).
Есть мнение, что язык Java написан на английском (т.к. это спецификация и не более), у JVM есть несколько реализаций, некоторые из которых (Maxin) написаны на Java, а стандартная библиотека практически полностью написана на Java.
aso
09.12.2016 08:12+4Например, Fortran, относящийся к той же «возрастной группе», что и С, в некоторых специфических задачах более производителен.
Щито?
Фортран лет на двадцать старше Си — от чего не имеет ряда полезных фич.
Плюс «моделей ассемблера» существует множество, не сводимое к AT&T и Интел, GAS — это GNU assembler.
Для ассемблера Вы используете AT&T синтаксис — что довольно специфично, fasm и masm юзают Интел.
Последний в x86 вообще более распространён, для которого характерны заметно другие подходы в синтаксисе: — т.е. «доллары» и «проценты» там не используются.
Ну и вообще, в других ассемблерах в качестве маркера «непосредственного значения» может использоваться '#', регистры пишутся непосредственно, без «процента», а «разыменовывание указателя» (косвенное обращение к памяти) может так же обозначаться знаком '@'.
P.S. Да, когда-то регистры общего назначение так же именовались «свероперативным запоминающим устройством».safinaskar
10.12.2016 05:39+1На меня что-то нашло и я ответил вам статьёй: https://habrahabr.ru/post/317300

johnfound
09.12.2016 10:25-4Все оптимизации в языках высокого уровня (C это ЯВУ) сводятся до "давайте сделаем это на ассемблере и придумаем как обмануть компилятора, чтобы генерировал наш код".
А почему? Компилятор, он не священная корова. Зачем нам посредник в общением с
богомпроцессором? Написать все на ассемблере и все дела. Я именно так и делаю. Код получается не хуже чем на C, а иногда даже лучше. Вот отзыв одного удивленного программиста после просмотра моего ассемблерного кода (кстати веб приложение):
Just had a cursory peek at the source code. What struck me most strongly is that the number of LOC that are not direct calls to Sqlite is quite low, the overall size of the project is very small, and that it's remarkably easy to work out what the code actually does.
khim
09.12.2016 18:19+4Что будете делать когда приложение придётся на ARM'овском сервере пускать? Или когда хотя бы какой-нибудь AVX1024 выйдет?
Написать на ассемблере программу, которая будет сегодня работать, чем программа на C — не проблема. Написать её так, чтобы она нормально работала на процессоре, который ещё не разработали… лет так через 10… нереально.
А программы «на выброс» можно на чём угодно писать — хоть на Brainfuck'е.johnfound
09.12.2016 19:11-3А я на ассемблере пишу уже около 30 лет. И программы написаны примерно в 1987-ом, все еще работают нормально. Правда, они под ДОС, но что поделать, ни Линукс ни Windows тогда не было.
А вообще, каждая программа нуждается в поддержке. И на C/C++ и на ассемблере. Компиляторы меняются, стандарты языка меняются. И заметьте, они меняются намного быстрее, чем процессоры. Так что, через 10 лет, программа на C/C++ тоже вполне вероятно не скомпилируется сразу, а понадобиться пошаманить над исходниками.
MacIn
09.12.2016 21:29+3Правда, они под ДОС, но что поделать, ни Линукс ни Windows тогда не было.
Вот. А программы написанные на Си (без вставок на асме) — будут работать, только перекомпилировать надо. И что самое забавное — даже если программа была бы написана на какой-нибудь ЕС ЭВМ, она тоже бы перекомпилировалась и заработала. С огооврками, конечно, но с ассемблером не сравнить.
П.С. сам — фанат Ассемблера, но надо и меру знать.johnfound
09.12.2016 21:39А программы написанные на Си (без вставок на асме) — будут работать, только перекомпилировать надо
Ну, это вряд ли. Работать будут только очень, очень простые программы. И те, которые изначально писались чтобы были 100% переносимые. А это наверное 3% от всех сишних программ. И даже те, вряд ли можно перекомпилировать просто так на современных компиляторов.
MacIn
09.12.2016 21:44Ок. Проблема только в том, что программа на ассемблере под ДОС не будет работать вовсе. Никакая — ни простая, ни сложная.
johnfound
09.12.2016 22:11Ну, почему сразу "вовсе"? Конечно, немножко придется подкоректировать исходники, но общая канва программы будет та же самая и вполне заработает например в Линукс.
khim
09.12.2016 23:19Конечно, немножко придется подкоректировать исходники, но общая канва программы будет та же самая и вполне заработает например в Линукс.
Не будет. Операционка использующая Long Mode не совместима с 16-битными режимами. В принципе. Ни Windows x64, ни Linux.
Представить себе кусок кода, который можно выдрать из 16-битной программы и всунуть в 32-битную программу можно — но вряд ли такое можно было написать 30 лет назад, до появления 32-битных процессоров.
Да, можно поставить VMWare, можно DoxBox — но после того, как вы начинаете вкручивать в вистему всё это хозяйство разговоры о том, что всё «просто и понятно» можно уже всёрьёз не воспринимать.
MacIn
09.12.2016 23:46Потому что код под 8086 не пойдет на Itanium как ни танцуй с бубном. И под Win32 на x86 без 8086VM тоже
johnfound
10.12.2016 00:01Так он и на ARM не пойдет. Просто надо написать ту самую программу для ARM. И будут нам всем две отличные программы, наместо одну посредственную.
MacIn
10.12.2016 00:38+3Люди не будут ждать, пока напишут «такую же, но без пуговиц». Надо здесь и сейчас. Поэтому переносимая программа — отличная. А привязанная к железу — посредственная. Критерий другой.
johnfound
10.12.2016 11:15-7А вот и нет. Это вообще-то устарелое мышление. В нулевых годах так и было, когда прогресс в железе шел быстрым ходом и софт не успевал за ним, а новые процессоры исправляли медленный софт очень быстро.
Те времена прошли. Были, да сплыли. Теперь процессоры уже не станут быстрее. А потребители хотят чтобы софт становился лучше. Чтобы не ждать все время и чтобы программы не висли и результат давали, ну вот сейчас.
Параллельные алгоритмы и многоядерные процессоры дадут некоторое время на перегруппировку, но далеко не все алгоритмы работают параллельно.
Так что учите ассемблер. Пригодится.
MacIn
10.12.2016 17:08+2А вот и да. Это верно и при неменяющейся производительности, просто в силу наличия разных платформ.
Так что учите ассемблер. Пригодится.
Сбавьте тон, не красит. Не уверен, что вы знаете его лучше меня.johnfound
10.12.2016 19:04-1Не уверен, что вы знаете его лучше меня.
Я тоже не уверен. Давайте разберемся… В конце концов, я программы на ассемблере пишу постоянно и публикую в сети:
Вот — IDE для FASM на ассемблере. Сам сайт сделан на CMS на ассемблере. А еще есть у меня высокопроизводительный форум на ассемблере.
А можно чего нибудь вашего посмотреть, чтобы было на ассемблере?
saboteur_kiev
10.12.2016 22:35+3Процессоры становятся быстрее. Просто гонка пошла не в частоту, а в новые инстркуции, в количество ядер. Насколько быстро и гибко вы можете поддерживать софт на ассемблере, чтобы он мог быстрее выполнять задачи, учитывая новые тенденции?
Где применяется сайт и форум на ассемблере? Какие задачи он решает?
Вы же должны понимать, что удобство разработки, скорость разработки, и вовремя исправленная уязвимость — это тоже высокая производительность, которую нужно принимать в расчет, а не только мерять скорость отлика на форуме с 100 уников в день, с чем легко справляется даже юкоз?johnfound
11.12.2016 00:47-3Процессоры становятся быстрее. Просто гонка пошла не в частоту, а в новые инстркуции, в количество ядер.
Все это, просто судороги умирающего закона Мура. Недолго продлятся.
Вы же должны понимать, что удобство разработки, скорость разработки, и вовремя исправленная уязвимость — это тоже высокая производительность,
Так, да не так. Потому что суммарное время выполнения программы намного выше чем время разработки (а если наоборот, то такую программу и обсуждать не стоит). Поэтому стоит поработать немножко больше, экономя время потребителей.
Да, понятно что время разработки, оно ближе к телу разработчика, а время выполнения — оно там, при потребителей случается. Куда они денутся? Подождут немножко. А программа загружается 30 секунд? Ничего, пусть не закрывают. А ждать приходится сто раз, пока откроется окно — ерунда, вот у меня стоит супер-пупер-зверь машина и у меня не тормозит. Пусть они купят еще 32GB RAM и все будет ОК.
А вот, возьмут и уйдут там, где их время не разбрасывают и ценят.
А между прочем, время разработки на ассемблере не так и большое. Посмотрите на мой проект форума (ссылка наверх) — зайдите в хранилище кода и посмотрите сколько время оно мне заняло. Оно не так уж и большое.
Время исправления багов и уязвимостей также намного ниже ожидаемого. (кстати, уязвимости в ассемблерном коде почти и нет, потому что он проще и чище)
Поглядите немножко на исходниках — там все читается просто и понятно.
Не так страшен черт как его малюют. :)
johnfound
11.12.2016 00:55-1Где применяется сайт и форум на ассемблере? Какие задачи он решает?
А жрет он ресурсов очень и очень немного. И CPU и памяти. А на хостинге, они оплачиваются и недешево.
По моим прикидкам, при всех равных условиях, форум на ассемблере может обслуживать от 5 до 10-ти раз больше посетителей, чем такой же, но на PHP.
saboteur_kiev
11.12.2016 19:47+6Вы не ответили на вопрос, где именно применяется ваш сайт и форум на ассемблере, кроме как на нем висит лично ваш блог?
Вы смогли договориться с каким-нибудь из хостеров, чтобы именно ваш движок был насильно установлен у всех клиентов?
Вы смогли придумать, как быстро вы сможете исправлять уязвимости на вашем сайте и хостинге, написанные на ассемблере?
Вы смогли прицепить апи и документацию, чтобы к вашему сайту и форуму на ассемблере люди могли легко добавлять плагины?
Вы никак не хотите понять, что вы меряете попугаев, а не реальный прирост?
«Все это, просто судороги умирающего закона Мура. Недолго продлятся.»
Вы никогда не пробовали потестировать с какой скоростью пережимается видео на процессоре 5-летней давности и на шестом поколении от интела, которое по частоте в полтора раза ниже? И сколько при этом тратится энергии?
Очень Вас прошу, научитесь адекватно воспринимать тот факт, что метрики измерения разные нужны, и разные важны. А пересчет исключительно тактов процессоров — это всего лишь один, и не такой важный на сегодняшний день.Varim
11.12.2016 20:17-2с какой скоростью пережимается видео на процессоре 5-летней давности и на шестом поколении от интела
А что это типичная задача?
Был у меня процессор
Амд 4400+ 2гб озу, C# проект билдился 30 сек,
Купил i5-3570k + 16гб озу, более быстрая память, диск ssd — проект билдится 25 сек. БД работают так же. Браузеры так же, IDE так же.
Ранзица в 7 лет, прироста скорости повседневных задач = 0.
Апгрейд сделал только ради памяти, так как просто нужно было запускать кучу виртуальных машин для теста, кроме памяти, на 100% хватало древнего атлона.
С учетом наличия конвеера и кеша во всех процессорах, на мой взгляд, на производительность влияет только частота проца и памяти, которая уже давно практически не растет. Растет только маркетинговый булшит.
Я согласен что некоторые специализированные команды в процессорах появляются, которые что то ускоряют, но это что то — малый процент от задач.
johnfound
11.12.2016 21:04Вы не ответили на вопрос, где именно применяется ваш сайт и форум на ассемблере, кроме как на нем висит лично ваш блог?
Мне это достаточно. Стоит мне копейки (ну 2.50€ в месяц). Всякие Слэшдот-эффекты не грозят (а были). А монетизировать все это мне совершенно недосуг. Скачивайте и пользуйтесь на здоровье.
Вы никогда не пробовали потестировать с какой скоростью пережимается видео на процессоре 5-летней давности и на шестом поколении от интела, которое по частоте в полтора раза ниже? И сколько при этом тратится энергии?
Крохи, все это! Крохи! Ну сделают еще в 5 раз быстрее, ну и что? Экспоненциальный прогресс уже не будет! Вы разницу между экспоненциальной и линейной функцией знаете?
MacIn
11.12.2016 22:22Нет, нельзя.
Забавно, что не уточнялось, о каком именно мнемокоде идет речь.
Я не пишу Open Source ПО, уж извините. Все, что пишется по работе, включая куски на ассемблере, закрыто. В моем любительском активе — любительская ОС на ассемблере, а также отдельный язык ассемблера, реализованный в моем микрокоде для моей модели процессора своей архитектуры.
В конце концов, я программы на ассемблере пишу постоянно и публикую в сети
Это не показатель хорошего знания. Можно уметь играть в шахматы, но не уметь выигрывать. Надеюсь, аналогия ясна? Закодировать в мнемокоде простыней какой-либо алгоритм, даже большой, уровня CMS-IDE по шаблонам могут многие (например, самый примитивный кодогенератор самого примитивного компилятора ЯВУ), это не то, что называется «знать ассемблер».
Я могу посмотреть ваши исходные тексты, проблема лишь в том, что критика с моей стороны будет наверняка заведомо воспринята как «а ты кто?», а это скучно.johnfound
11.12.2016 22:42Я могу посмотреть ваши исходные тексты, проблема лишь в том, что критика с моей стороны будет наверняка заведомо воспринята как «а ты кто?», а это скучно.
А я, вообще то, критики не боюсь. И не потому что мой код совершен, а потому что это один из путей сделать его лучше. Но конечно, это возможно только если критика конструктивная.
MacIn
13.12.2016 02:02+2Похвальный подход, вызывает уважение. Ради интереса посмотрел несколько файлов вашей CMS — это именно шаблонные вещи, вида «обнулим этот блок, скопируем отсюда указатель на стек, конкатенируем в буфер вот эти строки». Это по сути ничем от кода, сгенерированного компилятором, не отличается, разве что старый теплый ламповый трюк с флагом переноса радует. Есть ли куски кода, критичные по скорости или размеру, которыми вы гордитесь в силу применения нестандартных решений, до которых не может дойти компилятор, для расширения моего кругозора?
johnfound
13.12.2016 02:12-2Дело в том, что все так, а результат в целом, все таки нельзя сделать на ЯВУ. Никак не получится. Ну, не считая, если переводить от ассемблер на C 1 в 1. Да и тогда результат будет ужасен как читаемость кода, больше и несколько медленнее.
MacIn
13.12.2016 02:14+3а результат в целом, все таки нельзя сделать на ЯВУ
Почему?
Есть ли куски кода, критичные по скорости или размеру, которыми вы гордитесь в силу применения нестандартных решений, до которых не может дойти компилятор, для расширения моего кругозора?
johnfound
13.12.2016 02:43-2Почему?
Сложно объяснить. Главное, потому что на ассемблере, человек программирует не так как на ЯВУ. Кстати, поэтому ни в коем случае ассемблер нельзя учить изучая результаты компиляции.
Есть ли куски кода, критичные по скорости или размеру, которыми вы гордитесь в силу применения нестандартных решений, до которых не может дойти компилятор, для расширения моего кругозора?
Есть такие куски.
Fesor
11.12.2016 23:53ваш форум написан на ассамблере и пишет штуки вроде "Script run time: 6.598 ms".
мои проекты на php, который рестартует после каждого запроса, написан на Symfony, использует жирную ORM и т.д. и время обработки запросов всего-то 30ms.
А если я возьму какой-нибудь nodejs для сравнения? Ему не нужно "умирать" после каждого запроса, все будет крутиться в памяти. По сути мы тут упремся скорее в работу с базой данных нежели в nodejs.
Да и тот же php, можно взять php-pm или uwsgi и разогнать это добро до уровня 10ms, что уже сравнительно одинаково.
А теперь самое интересное. Итоговое время загрузки страницы вашего форума на ассемблере составляют 300ms. То есть обрабатывается запрос за 10ms или за 30ms — это уже не столь важно, поскольку по итогу для конечного пользователя запросы обрабатываются одинаково быстро/медленно.
Ну и еще штука… попробуйте подсчитать сколько стоит поддержка кода на ассемблере и на каком-нибудь javascript/php. А теперь прикиньте сколько часов нужно на разработку форума? А теперь прикинем разницу в часах и попробуем посчитать, насколько серверов у нас хватит сэкономленных денег.
johnfound
12.12.2016 00:08-1А теперь самое интересное. Итоговое время загрузки страницы вашего форума на ассемблере составляют 300ms. То есть обрабатывается запрос за 10ms или за 30ms — это уже не столь важно, поскольку по итогу для конечного пользователя запросы обрабатываются одинаково быстро/медленно.
Это имеет значение для моего кармана, когда оплачиваю хостинг.
Ну и еще штука… попробуйте подсчитать сколько стоит поддержка кода на ассемблере и на каком-нибудь javascript/php.
А мне на ассемблере дешевле, потому что я ассемблер знаю, а js/php нет.
Да и никакая особая поддержка не приходится делать. Не знаю как там на php, может они все время ковыряют в коде, исправляют баги и уязвимости затыкают.
На ассемблере такие страсти не бывают. Были некоторые баги, которые исправил во время альфа и бета тестов и все. Теперь, программировать придется только когда понадобится новую функциональность добавлять.
MacIn
13.12.2016 02:04Теперь, программировать придется только когда понадобится новую функциональность добавлять.
Здесь «собака и порылась». Расширять/править php дешевле.
А мне на ассемблере дешевле, потому что я ассемблер знаю, а js/php нет
В данный момент — да, но если изучить php, то вы быстро отобьете время, на это потраченное, и улетите вперед по сравнению с собой же старым.johnfound
13.12.2016 02:18В данный момент — да, но если изучить php, то вы быстро отобьете время, на это потраченное, и улетите вперед по сравнению с собой же старым.
Нет не улечу вперед. Я оттуда возвращаюсь.
MacIn
13.12.2016 02:31Иметь более широкий спектр инструментов для решения задачи = быть более эффективным, быть впереди. Изучение php с каким-либо фреймворком на начальном уровне потребует недели вашего времени, а написание программ на нем будет идти быстрее просто в силу большей выразительности языка.
johnfound
13.12.2016 02:37Изучение php с каким-либо фреймворком на начальном уровне потребует недели вашего времени, а написание программ на нем будет идти быстрее просто в силу большей выразительности языка.
Я оттуда возвращаюсь.
MacIn
13.12.2016 03:04Вы не можете возвращаться оттуда, если, как сами заявили, «потому что я ассемблер знаю, а js/php нет»
johnfound
13.12.2016 03:22Ну, php немножко. Первая версия MiniMag была на php, потом переписал на ассемблере и получилась MiniMagAsm.
А вот в Delphi и Perl вообще то эксперт. Этим на хлеб-соль зарабатывал долгие годы.

vintage
10.12.2016 11:21+4johnfound
10.12.2016 11:37Это что? Argumentum ad verecundiam?
У него интерес. Он же компиляторы на C++ и D разрабатывает. Конечно что так говорит будет.
Но кстати, если разработка ведется на C или C++, то наверное проблема несколько легче. Но когда такое начинают говорить программисты на всякие Питоны, тогда звучит и правда смешно.
vintage
10.12.2016 11:59+2Это информация к размышлению. Можете представить, что это говорит Санта Клаус, если вам так проще воспринимать информацию. ;-)
Я в основном на JS разрабатываю и вижу, как былые оптимизации превращаются в деоптимизации с развитием jit-компиляторов.
Zapped
09.12.2016 10:34-1[зануда mode on]
if (argc != 2) { fprintf(stderr, "Использование: %s \n", argv[0]); exit(-1); }
вероятно, должно быть
if (argc != 2) { fprintf(stderr, "Использование: %s FILE\n", argv[0]); exit(-1); }
;)


renskiy
09.12.2016 11:01+6Вы действительно думаете, что интернет вещей будет разрабатываться на высокоуровневых языках? А будущие видеокодеки? VR-приложения? Сети? Операционные системы? Игры? Автомобильные системы, например автопилоты, системы предупреждения о столкновении?
Все это если не уже пишут на высокоуровневых языках, то точно в будущем будут это делать (как минимум бОльшую часть таких решений). Эффективность требует выносить низкоуровневые часто используемые вещи в высокоуровневые абстракции. В этом случае КПД может быть и не будет равен единице, но высокоуровневые решения всегда будут к этому значению стремиться. И в какой момент плюсы от высокоуровневого подхода начнут значительно перевешивать минусы пониженного КПД.
Хотя конечно всегда будет существовать класс задач, где необходимо выжимать максимум из железа. Но их будет исчезающе мало относительно всех остальных задач.johnfound
09.12.2016 11:22+1Все это может быть только если быстродействие компьютеров повышается быстрее, чем сложность программ, которые на них выполняются.
А закон Мура уже не действует. Откуда лишней производительности взяться?
Некоторые даже считают что In 9 years Assembler will return to mainstream.
MacIn
09.12.2016 21:43+1Некоторые даже считают что In 9 years Assembler will return to mainstream.
Это просто тупо мнение гражданина в его блоге. Без каких-либо доводов. Не считать же доводом «ассемблер будет нужен, потому что нужна высокая производительность». И так понятно, что есть места, где он нужен.khim
09.12.2016 23:20Ассемблер вернётся когда Закон Мура прекратит своё действие. Сейчас всё упирается в то, что выигрыш на качестве кода не компенсируется тем, что на написание этого кода нужно на порядок больше времени.
Но с чего этот товаристч решил, что именно через 9 лет мы дойдём до передела — мне не очень ясно.johnfound
10.12.2016 00:02Ассемблер вернётся когда Закон Мура прекратит своё действие
Уже.
khim
11.12.2016 01:20Даже и близко нет. Третье измерение только-только начали осваивать. Да, там выигрыш будет поменьше (уменьшение техпроцесса вдвое даёт возможность разместить на чипе вчетверо больше транзисторов, а уменьшение толщины вафли даёт выигрыш вдвое), но с учётом того, что начинаем мы с макропараметров (толщина «пирога» сегодня — это ощутимые доли миллиметра), то ещё лет 20 нам обеспечено.
ZyXI
11.12.2016 04:14Насколько я понимаю, там проблемы с теплоотводом. Напихать вдвое больше транзисторов в ту же ширину можно, заставить одновременно работать вдвое больше транзисторов — нет. Причём это проблема уже с одним слоем: https://habrahabr.ru/company/intel/blog/158223/. Т.е. третье измерение получается нужным только для того, чтобы отправить слабоиспользуемые (отвод тепла с одной стороны эффективнее, чем с другой) блоки поглубже и немного повысить энергоэффективность — как за счёт увеличения числа транзисторов (тот же принцип, что обуславливает существование «тёмного кремния»), так и за счёт уменьшения длины проводников. Или сделать систему компактнее для какой?либо специфической задачи (скорее всего, не относящейся к потребительскому сегменту). Но никак не ускорить что?либо. Перед освоением третьего измерения для ускорения процессоров нужно что?то сделать с тепловыделением, а прорыва здесь пока не видно, хотя он возможен.
khim
12.12.2016 18:52Перед освоением третьего измерения для ускорения процессоров нужно что?то сделать с тепловыделением, а прорыва здесь пока не видно, хотя он возможен.
Ничего не нужно делать. Нужно просто вспомнить что повышение частоты вдвое увеличивает тепловыделение в восемь раз. Так что — да, по мере увеличения числа слоёв частоты процессоров будут падать. А головная боль разработчиков — будет расти.
Но тут как бы мы уже по проторенной дорожке идём: с тех пор, как производительность одного ядра упёрлась в потолок и стали наращивать количество ядер. Топовые Xeon'ы с десятками ядер работают на более низкой частоте, чем многие более дешевые ЦПУ.
Akon32
12.12.2016 16:18+3Ассемблер вернётся когда Закон Мура прекратит своё действие.
Вряд ли. В глобальном плане эффективнее по трудозатратам вкладываться в продвинутые оптимизаторы.
В наш век интернетаОдин раз реализуется некоторая оптимизация в компиляторе — и её могут использовать все.
А продвинутых программистов, знающих все тонкости (или достаточно тонкостей, чтобы выиграть у оптимизатора), из-за увеличения сложности систем очень мало, и работают они медленнее компилятора.

kulikovDenis
09.12.2016 11:59-1«Автомобильные системы, например автопилоты, системы предупреждения о столкновении»
Эти системы будут писать в первую очередь на надежных языках, именно поэтому на языках высокого уровня.
Ada, Java, C#.geher
09.12.2016 12:05+3Будут писать, как всегда, на всех языках.
В том числе и на С, и на ассемблере, и на новомодных языках, которые пока еще не придумали.
RomanArzumanyan
09.12.2016 14:44+2Наверняка, в 80% случаев, разработкой таких систем будут руководить менеджеры-разгильдяи, а писать код будут серийные программисты. Язык вторичен.
Иначе это так и не станет дёшево и не появится в каждой кредитной малолитражке.
geher
09.12.2016 12:22Дожили. Язык С уже низкоуровневый. Разжаловали.

1Nexus0
09.12.2016 13:56-3Поддерживаю.
Cогласно классификации: С — высокоуровневый, процедурный. Таки не Ассемблер же.s-kozlov
09.12.2016 17:07+7Согласно чьей классификации? «Высокоуровневость» — понятие относительное. Я понимаю, что есть некая академическая классификация (у самого в универе курс по Си назывался «Программирование на языке высокого уровня»), но называть высокоуровневым язык, в котором, например, вместо массивов и строк — адреса в виртуальной памяти (!), можно только забыв про 90% существующих языков программирования.
geher
09.12.2016 19:46Есть разделение на языки машинозависимые, сиречь ассемблеры и иже с ними, и машинонезависимые, сиречь языки высокого уровня.
На основании этого привык считать язык С языком высокого уровня.
Хотя, конечно, согласен, высокоуровневость — понятие относительное. И вполне допускаю возможность введения новой классификации. Но в этом случае принцип разделения языков стоит обозначить явно, ибо принятую классификацию вроде как не отменяли (по крайней мере я такого не помню).
1Nexus0
12.12.2016 13:57Согласно официальной, академической, по которой учат студентов.
Разница в этой классификации в том, как именно человек пишет код (ну во всяком случае, как я это вижу).
Вы при работе с массивами в C напрямую взаимодействуете с адресами в памяти, с регистрами? В машинном представлении?
Подозреваю, что вы обращаетесь к элементам массива по индексу, да еще и через приятного вида синтаксис, и работа с ними не особо отличается от той же Java, кроме того, что С нужно следить за выделенной памятью.
В ассемблере (символьное обозначение машинных команд) же само понятие массива весьма эфемерно и его еще нужно, так сказать, смоделировать. Т.е. вам нужно через низкоуровневые операции с памятью, реализовать то, что есть в С «из коробки»
s-kozlov
12.12.2016 17:08+3и работа с ними не особо отличается от той же Java
Ну да, ну да, только вот у сишных массивов нет контроля границ, длину надо таскать явно вместе с указателем — в общем, в Си нет массивов. То, что некий адрес и целое число являются массивом — плод воображения разработчика, не более. Так что говорить, что Си поддерживает массивы, — то же самое, что «Си поддерживает ООП».1Nexus0
13.12.2016 11:321. Вырывать строку из контекста, это не есть признак хорошей аргументации.
2.Ну да, ну да, только вот у сишных массивов нет контроля границ, длину надо таскать явно вместе с указателем — в общем, в Си нет массивов.
— из этой фразы вообще непонятно как сделан вывод ов Си нет массивов
Расскажите пожалуйста, чем же являются эти пресловутые массивы в других ЯП?
Если у языка «опасная» архитектура и повышенное требование к внимательности и рукам разработчика, это автоматически делает его более низкоуровневым и трушным?
3.То, что некий адрес и целое число являются массивом — плод воображения разработчика, не более
Все эти ваши дататайпы, структуры и объекты + синтаксический сахар — плод воображения разработчика, так сказать — human interface. Есть только 1 и 0, да и то это человеческая абстракция. На самом деле есть сигналы и физическое состояние транзисторов — вот это прямо таки самый «низкий» уровень (но не конечный), <irony> когда научитесь менять вручную и контролировать состояние каждого транзистора, тогда будете гуру «низкоуровневости» </irony>s-kozlov
13.12.2016 14:42Расскажите пожалуйста, чем же являются эти пресловутые массивы в других ЯП?
int[] arr = new int[10];
int* arr = (int*) malloc(10 * sizeof(int));
В первом случае тип переменной — массив целых чисел. Во втором — указатель. Первый я могу передать в другой метод или вернуть из другого метода без хаков и костылей, второй — нет. «Массив» в Си — это паттерн, а не элемент языка.
Все эти ваши дататайпы, структуры и объекты + синтаксический сахар — плод воображения разработчика, так сказать — human interface. Есть только 1 и 0, да и то это человеческая абстракция. На самом деле есть сигналы и физическое состояние транзисторов — вот это прямо таки самый «низкий» уровень (но не конечный), когда научитесь менять вручную и контролировать состояние каждого транзистора, тогда будете гуру «низкоуровневости»
Передергиваете. Меня не особо волнует, что происходит, когда я пишу
. Главное — как с этим работать на выбранном мной уровне. Это называется абстракцией.case class Person(firstName: String, lastName: String)
Если у языка «опасная» архитектура и повышенное требование к внимательности и рукам разработчика, это автоматически делает его более низкоуровневым и трушным?
Кто говорил об «опасной архитектуре» или «повышенном требованим к внимательности и рукам разработчика»? Не я.1Nexus0
15.12.2016 14:12+1Давайте разбираться.
но называть высокоуровневым язык, в котором, например, вместо массивов и строк — адреса в виртуальной памяти (!), можно только забыв про 90% существующих языков программирования.
На этом основании вы говорите о том, что С не является высокоуровневым.
Потом мы цепляемся за реализацию массивов.
Ну да, ну да, только вот у сишных массивов нет контроля границ, длину надо таскать явно вместе с указателем — в общем, в Си нет массивов.
По прежнему не понятно, почему заявляется о том, что в С отсутствует этот сложный тип данных.
Комментарий про «опасную» архитектуру так же относится именно к этой фразе.
int[] arr = new int[10];
int* arr = (int*) malloc(10 * sizeof(int));
Видимо вас очень беспокоят динамические массивы в С.
В первом случае тип переменной — массив целых чисел. Во втором — указатель
Первый случай.
Ваш пример — это статический массив:
int[] arr = new int[10];
Оператор new указывает на то, что каждый элемент массива получает значение по умолчанию. Каким оно будет определяется на основании типа данных (0 для int). Динамические массивы в Java реализованы через классы Vector и ArrayList и для управления элементами эти классы используют методы интерфейсов Collection и List.
ArrayList <Integer> i = new ArrayList<Integer>(); i.add(3); i.add(new Integer(34)); System.out.println("i size: "+i.size()); System.out.println("i elements:" +i.get(0).intValue()+", "+i.get(1));
Статический массив С:
int arr[3] = {0, 1, 2};
Статический массив Java:
int arr[] = {10,20,30};
Как видите, разница даже в синтаксисе невелика
Ну, напомню, что в Java все сложные типы данных ссылочные, в Java массивы являются объектами. Это значит, что имя, которое даётся каждому массиву, лишь указывает на адрес какого-то фрагмента данных в памяти. Кроме адреса в этой переменной ничего не хранится. Индекс массива, фактически, указывает на то, насколько надо отступить от начального элемента массива в памяти, чтоб добраться до нужного элемента. Просто в Java нет явных указателей, и в нормальных условиях, ручного управления памятью.
Второй случай.
int* arr = (int*) malloc(10 * sizeof(int));
Выделяется 10 блоков по sizeof(int) байт каждый, к элементам массива можно обращаться как через индекс так и через разыменование arr[i] и *(arr+i).
Здесь речь идет только о динамическом массиве, который вы пытаетесь сравнивать со статическим Java. В C динамические массивы реализованы через явные указатели, за которыми действительно сложно следить.
Первый я могу передать в другой метод или вернуть из другого метода без хаков и костылей, второй — нет. «Массив» в Си — это паттерн, а не элемент языка.
Жалуетесь на архитектуру языка.
Передергиваете. Меня не особо волнует, что происходит, когда я пишу
Главное — как с этим работать на выбранном мной уровне. Это называется абстракцией.case class Person(firstName: String, lastName: String)
Не передергиваю. Вспомните, изначально речь шла о «низкоуровневости».
И это ваша фраза раскрывает просто все.
Только один ответ может быть на такое — очень жаль.
Как можно называть язык низкоуровневым, когда за вас все делает компилятор, выдавая оптимизированный по своему алгоритму машинный код, производительность которого может довольно сильно варьироваться в зависимости от компилятора и его настроек. Так же напоминаю, что для действительно низкоуровневых операций в С делают ассемблерные вставки.
PS
Просьба не делать выводов типа таких:
«но называть высокоуровневым язык, в котором, например, вместо массивов и строк — адреса в виртуальной памяти (!), можно только забыв про 90% существующих языков программирования.»
не имея достаточных оснований. Еще больше поражает, что такие заявления еще и «плюсуют»
ZyXI
15.12.2016 19:14Статический массив С:
int arr[3] = {0, 1, 2};
Статический массив Java:
int arr[] = {10,20,30};
Как видите, разница даже в синтаксисе невеликаC99 вполне себе позволяет написать
int arr[] = {0, 1, 2}. И дажеint arr[] = { [1]=1, [2]=2 }. Указывать длину было обязательно только в предыдущих версиях стандарта (ну, или при отсутствии начального значения).
s-kozlov
15.12.2016 20:14По прежнему не понятно, почему заявляется о том, что в С отсутствует этот сложный тип данных.
Пока вы не покажете мне место в стандарте Си, где специфицирован тип данных «массив», у которого есть атрибут «длина», обсуждать эту тему нет смысла. Указатель — это не массив. То, что на основе указателей можно делать «как бы массивы», — это паттерн, а не элемент языка, точно так же, как возможность реализовать виртуальный полиморфизм через самодельную таблицу виртуальных методов не делает Си объектно-ориентированным.
Комментарий про «опасную» архитектуру так же относится именно к этой фразе.
Зачем вы настойчиво пихаете «опасную архитектуру» в это обсуждение?
Как можно называть язык низкоуровневым, когда за вас все делает компилятор, выдавая оптимизированный по своему алгоритму машинный код, производительность которого может довольно сильно варьироваться в зависимости от компилятора и его настроек.
А вы Си хотя бы с джавой сравните и подумайте себе на досуге, как можно называть Си высокоуровневым.
Жалуетесь на архитектуру языка.
Во-первых, не жалуюсь, а говорю очевидные вещи. Во-вторых, если не «жаловаться», появится волшебная возможность не использовать хаки и костыли при передаче массивов между методами?
Просьба не делать выводов типа таких… не имея достаточных оснований.
Основания я привел. Просьба прочитать.kmu1990
15.12.2016 20:49+1Пока вы не покажете мне место в стандарте Си, где специфицирован тип данных «массив», у которого есть атрибут «длина», обсуждать эту тему нет смысла.
1. Почему длина совершенно обязательно должна быть аттрибутом объекта, а не частью типа например?
2. Если оставить этот вопрос в стороне то вот вам:
An array type describes a contiguously allocated nonempty set of objects with a
particular member object type, called the element type. 36) Array types are
characterized by their element type and by the number of elements in the array. An
array type is said to be derived from its element type, and if its element type is T, the
array type is sometimes called ‘‘array of T ’’. The construction of an array type from
an element type is called ‘‘array type derivation’’.
An array type of unknown size is an incomplete type. It is completed, for an identifier of
that type, by specifying the size in a later declaration (with internal or external linkage).
Другими словами даже для языка C масив и указатель — это разные типы. Разница в типах скрывается из-за неявного приведения, но в языке C масив это явно выделяемый стандратом тип. Хотя, конечно, он не такой же как массив в Java.s-kozlov
16.12.2016 06:17Почему длина совершенно обязательно должна быть аттрибутом объекта, а не частью типа например?
А тип — это, по вашему, что? Когда я храню указатель на область памяти в одной переменной, а длину — в другой, — с каких пор это считается типом данных, поддерживаемым языком?ZyXI
16.12.2016 06:43А с какой стати длина массива является его частью? Wiki говорит просто, что массив — это «тип или структура данных в виде набора компонентов (элементов массива), расположенных в памяти непосредственно друг за другом». О том, где и в каком виде (есть ведь варианты массивов без длины в явном виде — заканчивающиеся специальным элементом) хранится длина, и хранится ли она где?либо вообще ни слова.
s-kozlov
16.12.2016 07:25-2А с какой стати длина массива является его частью?
Ну мало ли что там говорит самый большой труд дилетантов. Как работать с массивом, не зная его длину? А если длина хранится в отдельной переменной, то можно, конечно, завернуть ее вместе с указателем в одну структуру и назвать это типом данных, но это уже пользовательский тип данных.ZyXI
16.12.2016 07:37+3Нормально с ним работать, вы пропустили моё замечание, что вместо длины может быть терминатор. Ещё, возможно, вы передаёте массивы фиксированной длины (и она хранится в каком?то
#define). Или знаете какое?то свойство массива, позволяющее в конкретном случае обойтись без длины и без терминаторов. Или решили в качестве эксперимента отлавливать SEGV при выходе за границы, таким образом определяя длину на месте. Ещё можно вспомнить, что аллокатор длину где?то таки хранит и можно достать её оттуда, если вас не пугает привязка к аллокатору и конкретному диапозону его версий.s-kozlov
16.12.2016 16:47Вы что, издеваетесь? Где тут поддержка длины на уровне языка? Всё, надоело одно и то же говорить про паттерны и прочее.
ZyXI
16.12.2016 17:30Я не издеваюсь. Я говорю, что поддержка массивов на уровне языка не предполагает поддержку длины массива. Эта часть ветки началась с утверждения «в Си нет массивов», основанного на «у сишных массивов нет контроля границ, длину надо таскать явно вместе с указателем». Сейчас идёт дискуссия «что считать массивом» — вы всё время утверждаете, что вам нужно таскать длину и указатель раздельно, вам отвечают, что
- В случае с массивами вида
Type array[LEN], длина известна на этапе компиляции в области видимости и таскать её не нужно. - Длина вообще не является частью массива, поэтому обосновывать отсутствие поддержки массивов в C отсутствием у массивов атрибута длины в том или ином виде некорректно.
khim
16.12.2016 17:42Сколько можно переливать из пустого в порожнее? Рассмотрите лучше такой вопрос: можно ли считать что-то языком высокого уровня если часть этого языка точно является языком высокого уровня?
Как видим и массивы есть и длина отлично передаётся куда нужно. Чего вам ещё для «щастя» нужно?#include <iostream.h> template<typename T, size_t N> void print_array(T(&array)[N]) { for (auto& element : array) { std::cout << element << std::endl; } } int main() { int array[] = {1, 2, 3}; print_array(array); } --- $ g++ test.cc -o test $ ./test 1 2 3ZyXI
16.12.2016 17:54Это C++. Дискуссия о C, здесь длина просто так никуда не передаётся. И C не является частью C++, равно как и наоборот. Когда?то C++ можно было рассматривать как надстройку над C, но это уже давно не так.
khim
16.12.2016 18:05Дискуссия о C, здесь длина просто так никуда не передаётся.
Вот прямо даже так? Отлично она передаётся до тех пор, пока вы «голый» массив не попытаетесь передать в функцию. Заверните в структуру — и сможете передавать ваш массив куда угодно.
Дизайнерское решение, возможно, не самое удачное, но говорить на этом основании, что «в C нет массивов» глупо.ZyXI
16.12.2016 18:12О том, что в C «нет массивов» говорю не я. Но с тем, что «у массивов C в большинстве случаев (исключая статические массивы) нет поддержки длины на уровне языка» я согласен — такой «завёрнутый» массив потребует от вас самому писать код для поддержки актуальности длины, это не поддержка на уровне языка.
khim
16.12.2016 18:25Но с тем, что «у массивов C в большинстве случаев (исключая статические массивы) нет поддержки длины на уровне языка» я согласен — такой «завёрнутый» массив потребует от вас самому писать код для поддержки актуальности длины, это не поддержка на уровне языка.
Не потребует. Все операции, которые имеются в таком высокоуровневом языке программирования как Pascal (ISO 7185:1990, не путать с Extended Pascal ISO/IEC 10206) в C имеются тоже и отлично работают для «завёрнутых в структуру» массивов. Включая передачу параметров и прочее.
Pascal, как бы, считается фактически «эталоном» языка высокого уровня, так что неясно о чём вы тут спорите. О том, что C содержит низкоуровневые операции, которые не очень «к лицу» высокоуровневому языку? Да, разумеется, кому-то это нравится, кому-то — нет. О том, что в нём нет поддержи массивов? Нет — поддержка есть и ничуть не худшая чем во многих других языках, которые родились тогда же, когда и C.ZyXI
16.12.2016 23:25Какие операции вы имеете ввиду? Просто покажите код, в котором создаётся массив с сохранённой где?то длиной, а потом его длина изменяется и это передаётся в функцию. Я не вижу, как вы могли бы это сделать, не реализовав либо небольшую библиотеку для работы с массивами и спрятав нужные манипуляции там, либо не трогая в явном виде переменую/атрибут структуры с длиной.
khim
17.12.2016 03:47+2Какие операции вы имеете ввиду?
Все, поддерживаемые «эталонным» языком программирования высокого уровня под названием Pascal (ISO 7185:1990), как я уже сказал. За исключением автоматической проверки выхода за границы массивов, возможно (хотя и в Паскале с ней всё непросто: на практике очень много компиляторов её не поддерживают по умолчанию… некоторые не поддерживают вообще).
Просто покажите код, в котором создаётся массив с сохранённой где?то длиной, а потом его длина изменяется и это передаётся в функцию.
Для начала вы покажите мне такой код на языке Pascal (ISO 7185:1990), а потом уж будем говорить.
Я не вижу, как вы могли бы это сделать, не реализовав либо небольшую библиотеку для работы с массивами и спрятав нужные манипуляции там, либо не трогая в явном виде переменую/атрибут структуры с длиной.
А откуда такие хотелки? Вы и в Java так не сделаете!
Есть, правда, другая задача: написать одну функцию, работающую с разными массивами — ну так этого мало где было в те времена, когда C разрабатывался. Никакие распространённые языки «родом из 80х» так не умеют! Ни Pascal (ISO 7185:1990), ни Ада 83, ни, как мы уже убедились, C…
Для решения этой задачи, собственно, и появились такие языки как Extended Pascal (ISO/IEC 10206), Ada95 и C++.
Так были в языках, существовавших ранее массивы или нет? Была ли у них поддержка длины? Я думаю Вирт очень сильно удивится если вы начнёте ему объяснять, что в Pascal «нет поддержки длины массива на уровне языка» — он как бы этим и славился с момента своего создания (хотя многие коммерческие компиляторы, появившиеся позднее на эту поддержку «забили»). Но вот исполнить ваши хотелки — да, он не мог. Никак. Не было там таких механизмов.
- В случае с массивами вида
kmu1990
16.12.2016 11:18Вы чего-то явно не поняли, вы храните длину, потому что она не является частью типа и вам приходится ее хранить, но если она часть типа, то хранить ее не нужно — она просто является константой известной компилятору.
ZyXI
16.12.2016 13:05То, что считает массивом спецификация C99 и то, что считается массивом по той же wiki — разные вещи. Я, wiki, и, наверняка, многие программисты, считают
int *array = malloc(len * sizeof(*array));массивом, но константой в этом случае длина не является. Это уже не первый пример наличия собственных терминов в спецификации: по C99 в результате операции(uint8_t)255 + (uint8_t)1не произойдёт переполнения — полученный 0 можно скорее описать как «сложение по модулюsizeof(uint8_t)*CHAR_BITS + 1», но спецификация в явном виде говорит, что это не переполнение. Тем не менее, большинство известных мне программистов назовут это переполнением беззнакового целого.kmu1990
16.12.2016 13:11Во-первых, не нужно говорить за всех, вы можете считать как угодно, но это ваше мнение, остальные могут говорить за себя сами.
Во-вторых, вопрос был показать в стандарте языка тип массив, про который известна его длина — я его показал, что не так?
В-третьих, я лично считаю массивом любую непрерывную в памяти последовательность элементов одного типа, и массивы из стандарта языка C прекрасно согласуются с этим.ZyXI
16.12.2016 13:37Массивы в выделенной
mallocпамяти тоже «непрерывные в памяти последовательности элементов одного типа» (в wiki примерно такое же определение, и я исходил именно из него — но это более широкое определение, чем то, что спецификация называет массивом), но никакой длины к ним C не прилагает. Я выше отвечал вашему оппоненту, что длина не является неотъемлемой частью массива, и существование массивов в C следует рассматривать именно исходя из этого: массивы в C есть, но длина к массиву не прилагается и не должна.
Кроме того, те массивы с известной на этапе компиляции длиной, о которых вы говорите, существуют только в определённой области видимости. Хотите передать их за пределы (даже в соседнюю функцию, при условии, что массив объявлен внутри данной) — организуйте передачу длины отдельно. Нормально они передаются, только будучи частью составного типа, причём если в составном типе массив постоянной длины. Это не делает их не массивами, но это заставляет программистов использовать в качестве массивов именно указатели на область памяти, не допуская выхода за границы массива различными способами, включая передачу длины отдельно от массива.
kmu1990
16.12.2016 13:42Массивы в выделенной malloc памяти тоже «непрерывные в памяти последовательности элементов одного типа»
Я хоть где-нибудь утверждал обратное?
Это не делает их не массивами, но это заставляет программистов использовать в качестве массивов именно указатели на область памяти
Я не понимаю, что вы пытаетесь мне доказать? Давайте начнем с того, что вы укажите с каким из моих утверждений вы не согласны, и может быть тогда ваши аргументы будут иметь для меня хоть какой-то смысл?ZyXI
16.12.2016 15:22С «даже для языка C масив и указатель — это разные типы»: по спецификации массивом называется конкретный класс типов, тогда как с точки зрения программиста
int *— часто тоже массив, но тем не менее это указатель. И массив видаType *пасуют между функциями (в моей практике) чаще, чем что?то ещё.
Или, скорее, с тем, что следует рассматривать «массивы» (в терминах спецификации) C как поддержку языком массивов (соответствующих более общему определению), а не показывать вместо этого, что язык поддерживает использование
Type *как массивов — и того, что есть здесь достаточно для того, чтобы утверждать, что массивы поддерживаются.kmu1990
16.12.2016 16:25С «даже для языка C масив и указатель — это разные типы»: по спецификации массивом называется конкретный класс типов, тогда как с точки зрения программиста int * — часто тоже массив
Во-первых, язык C определяется стандратом. В стандарте есть разделение между типом массив и указатель. Это разделение есть не случайно, а потому что это разные типы с точки зрения языка и ведут они себя по-разному. Вы хотите оспорить, что стандарт языка проводит такое разделение?
Во-вторых, я где-то утверждал, что указатель нельзя интерпретировать как массив и использовать его вместо встроенных язык массивов?
Или, скорее, с тем, что следует рассматривать «массивы» (в терминах спецификации) C как поддержку языком массивов (соответствующих более общему определению)
Такое ощущение, что вы не со мной спорите, а со своим воображением. Был задан конкретный вопрос, про тип «массив» с аттрибутом «длина» в стандарте языка, я дал конкретный ответ — типа с аттрибутом «длина» нет, но тип «массив», для которого длина это параметр типа есть. Вы оспариваете корректность ответа?ZyXI
16.12.2016 17:48Такое ощущение, что вы не со мной спорите, а со своим воображением. Был задан конкретный вопрос, про тип «массив» с аттрибутом «длина» в стандарте языка, я дал конкретный ответ — типа с аттрибутом «длина» нет, но тип «массив», для которого длина это параметр типа есть. Вы оспариваете корректность ответа?
Возможно. Корректность ответа на этот вопрос я не оспариваю, но дискуссия началась с того, что «C низкоуровневый» и, потом, «в C нет массивов». На второе утверждение, мне кажется, мы решили ответить по?разному, вокруг этого и спор.
khim
16.12.2016 17:53+1Типичный спор о тривиальностях.
Причём правильный ответ, как бы, знают обе стороны: да, массивы в C, конечно же, есть. Нет, передать их в функцию нельзя. Ограничение странное, но делает ли оно, само по себе, язык C языком низкого уровня? Можно спорить до бесконечности.
kmu1990
16.12.2016 18:27что «C низкоуровневый» и, потом, «в C нет массивов».
Так вы бы тогда и адресовали свои аргументы, тому кто высказывает такие мнения, а не мне.
На второе утверждение, мне кажется, мы решили ответить по?разному, вокруг этого и спор.
Вам может только казаться, потому как я на такой вопрос вообще не отвечал.
terryP
09.12.2016 13:38+1Мы рассмотрим очень простую программу на С, которая суммирует 1 миллиард байтов из файла менее чем за 0,5 секунды. Попробуйте проделать это на любом из высокоуровневых языков — вы и не приблизитесь по производительности к С. Даже на Java, с помощью JIT, с параллельными вычислениями и хорошей моделью использования памяти в пространстве пользователя
Эээ, чтение из файла всегда намного медленнее, чем сложение байтов, то есть при параллельных вычислениях все будет определяется скоростью чтения из файла, а оно во всех языках сделано как правило системными вызовами ОС или низкоуровневым кодом (считай тем же C), то есть производительность будет везде одинаковая (плюс/минус незначительные расходы на обертки системных функций) и если не считать прогрев JVM (а есть способы компильнуть код Java или C# в чистый машинный код, ну и в реальном приложении запуск окружения редко имеет значение), то производительность будет одна и та же. Отсюда вся статья не имеет никакого смысла.khim
09.12.2016 18:23Эээ, чтение из файла всегда намного медленнее, чем сложение байтов
Это только если ваш файл живёт на диске. Ваш КО.

mxms
09.12.2016 13:48C не является низкоуровневым языком программирования. К таковым относится Ассемблер и, возможно, Форт.
kmu1990
09.12.2016 17:50Форт простите? Каким образом он более низкоуровневый чем C?
mxms
09.12.2016 22:27-1А тем, мон ами, что существуют хардварные Форт-процессоры. Кстати, именно поэтому я и написал слово «возможно». А вот С-процессоров в природе, отчего-то, не встречается.
kmu1990
09.12.2016 23:00+2Во-первых, не ами, и уж тем более не ваш.
Во-вторых, Лисп-машины тоже существовали (и из того что я знаю были несколько более коммерчески успешными, чем аппаратные реализаций Forth-а), но назвать функциональный язык с динамической типизацией и сборкой мусора низкоуровневым у меня язык не повернется. Я бы сказал, что высокоуровневость языка определяется его возможностями, а не способом их реализации.mxms
09.12.2016 23:07Однако же у Форта стэковая архитектура. Что ещё один плюс в сторону его, повторюсь, возможного отнесения у низкоуровневым языкам.
kmu1990
09.12.2016 23:14А у ассемблеров зачастую нет, но они тем не менее зачастую считаются низкоуровневыми, т. е. стековая архитектура, чтобы вы в это понятие не вкладывали не показатель ничего.
mxms
09.12.2016 23:19В процессорах стэк вызовов отменили теперь? Вот так новость…
kmu1990
09.12.2016 23:29+2В C тоже есть стек вызовов, хотя стандарт языка и не формализует такого понятия, но вы почему-то не отнесли его к низкоуровневым языкам по наличию этого самого стека вызовов. И вообще многие языки, в которых есть функции, которые можно вызывать и из которых можно возвращаться, полагаются на наличие этого стека вызовов.
mxms
10.12.2016 14:34-1Работа процессора непосредственно завязана на понятие стека. Соответственно, на него завязан и Ассемблер как (за исключением деталей) не более чем мнемоническое обозначение машинного кода. Так на него в ещё большей степени завязан и Форт.
kmu1990
10.12.2016 14:55+4Работа процессора завязана на память, регистры и на операции работы с ними. Более того есть популярные процессоры, в которых, например, инструкция вызова функции сохраняет адрес возврата в регистр, а не в память. Что теперь ассемблер для этой архитектуры не низкоуровневый? Только потому что он не сохраняет адрес возврата в память и не называет эту память стеком?
То что вы называете стеком — это просто значение некоторого регистра и операции, которые пользуются этим регистром как указателем и изменяют его. Например, в x86 есть инструкции push и pop, которые оперируют регистром rsp и памятью, на которую он указывет — их называют инструкциями работы со стеком. Но есть в x86 и инструкии stos/lods, которые делают практически то же самое, только используют регистр rdi как укзатель, но их почему-то не называют инструкциями работы со стеком.
Другими словами, работа процессора не завязана на понятие стека — на понятие стека завязана голова инженера, который пишет ПО под этот процессор. И в этом смысле стек вызовов в языке С (или любом другом императивном языке) ничем ни хуже.mxms
11.12.2016 16:41-1Если бы работа процессора не была бы завязана на стек, отсутствовали бы команды по работе с ним, равно как и специальный регистр для хранения указателя.
Далее, в Форт вообще всё построено на работе со стеком (стеками точнее). И С в этом отношении имеет мало общего со стековой архитектурой.kmu1990
11.12.2016 17:05Не люблю повторяться, но для вас сделаю исключение, то что вы называете инструкциями для работы со стеком мало чем отличается от инструкций, которые называются инструкциями работы со строками — это просто название, и название появилось не потому что процессору нужен стек, а потому что инженеру он нужен. Процессору абсолютно без разницы как эти инструкции называются.
Но если вы так хотие наставивать на своем аргументе, то давайте его применять до конца — в процессорах так же не редко встречаются инструкции для поддержки AES или CRC, это значит, что процессор завязан на понятия AES и CRC? Или то, что кто-то назвал инструкции stos/lods инструкциями работы со строками, делает процессор завязанным на понятие строки?mxms
12.12.2016 21:55Это всё понятно. Точно так же JMP, CALL и RET можно представить как MOV. Мне, как писавшему и на различных Ассемблерах и Фортах (и сам Форт), это говорить излишне.
Вообще, я настаиваю на одном аргументе, а именно С — язык высокого уровня. Языками низкого уровня я считаю Ассемблер и, возможно, Форт. Почему возможно мы, полагаю, уже обсудили.kmu1990
12.12.2016 22:02+1До сих пор вы, похоже, обсуждали это сами с собой, потому как я до сих пор не увидел ни одного критерия по которому Forth более низкоуровневый чем C. Все что вы сказали про Forth в той же степени относится и к C.
mxms
12.12.2016 22:15-1Тогда продемонстрируйте С-процессор.
kmu1990
12.12.2016 22:23+2Диалог пошел по кругу. Налицие процессора ничего не доказывает, и как пример вам я уже приводил Lisp-машины. По вашей логике, если наличие процессора показатель, то Lisp (опять же повторюсь, язык с динамической типизацией и сборкой мусора) более низкоуровневый чем C.
mxms
14.12.2016 16:40-1Я не в курсе насчёт Лисп-машин и Лиспа как такового (не было интереса, равно как и нужды), но считаю, что если язык представляет собой мнемонические обозначения машинных кодов, то это язык низкого уровня. Т.е. Форт будет таковым для Форт-процессора, а Лисп — для, соответстветственно, Лисп-процессора. Более того, сама возможность создать процессор под язык будет говорить о его возможной низкоуровневости.
Кстати, говоря о типизации данных как признаке языка высокого уровня, то в стандартном Форте её нет. В отличие от С.kmu1990
14.12.2016 17:25+1Более того, сама возможность создать процессор под язык будет говорить о его возможной низкоуровневости.
Существование Lisp-машины показывает, что создать железяку, которая реализует даже довольно высокоуровневый язык, гипотетически, возможно. Так что по вашей логике любой язык будет низкоуровневым.
Кстати, говоря о типизации данных как признаке языка высокого уровня, то в стандартном Форте её нет. В отличие от С.
Да, наконец-то вы привели хоть одно реальное отличие. Это правда, что многие ассемблеры безтиповые, но с другой стороны посмотрим на Java байткод, непосредственно стек и локальные переменные типа не имеют, но инструкции, которые ими оперируют разделены на типы (разные целые числа, floating point и отдельный тип для ссылок) так, чтобы перед загрузкой байткода его можно было верифицровать на корректность работы с типами — это довольно слабая, но типизация.Varim
14.12.2016 17:29многие ассемблеры безтиповые
float, int8, int32 за типы не считают?
Есть еще вроде когда в указателях доп инфу суют, например в младшие биты при выравнивании памяти.kmu1990
14.12.2016 17:41А в каких ассемблерах вы видели типы float, int8 и int32? Там может быть регистр в N бит, в который можно записать N бит целого числа или N бит floating point числа, а потом, например, сложить это значение со значением в другом регистре, причем при сложении интерпретация этих значений как целых/floating point зависит от операции, которую вы вполняете, а не от того, что вы реально туда положили.
В известных мне ассемблерах я не знаю способа указать, что значение, которое я хочу загрузить из памяти в регистр или сохранить из регистра в память имеет какой-то тип, могу указать только размер (скорее должен) этого значения.
С другой стороны, я когда-то слышал о типизированных ассемблерах, но никогда их в глаза не видел.
Есть еще вроде когда в указателях доп инфу суют, например в младшие биты при выравнивании памяти.
Это довольно простой и понятный прием, когда в младшие биты указателя вставляют какие-то флаги (например, цвет для красно-черного дерева или признак «удаленности» узла связаного списка в каких-нибудь lock-free списках), но какое это имеет отношение к типизации?
mxms
14.12.2016 17:33-1Да, такова логика. И я не вижу в чём её ошибочность.
Касаемо байткода, то я вообще не стал бы его считать языком программирования. В противном случае любой шитый код (а байткод это его новое имя применительно к Java) нужно считать таковым. Пример неудачный.kmu1990
14.12.2016 17:47+2В противном случае любой шитый код (а байткод это его новое имя применительно к Java) нужно считать таковым.
Во-первых, байткод это не название шитого кода применительно к Java, еще до Java байткода был байткод для Pascal виртаульной машины (p-code), а до этого был байткод для BCPL виртуальной машины (O-code), причем оба появились до появления языка Forth (откуда, как я понимаю вы и позаимствовали термин «шитый код») — не нужно все сводить к Forth;
Во-вторых, с чего бы это байткод не язык программирования? На нем точно так же можно писать программы (как и на ассемблере). Пример очень удачный, просто он вам не нравится.mxms
14.12.2016 17:54-4Вероятно, прежде чем рассуждать об отличиях байткода от шитого кода, вам неплохо было бы разобраться о том, что из себя представляет последний да и попросту разобраться с процессом компиляции как таковым.
kmu1990
14.12.2016 18:00+1Во-первых, я не рассуждал про отличия байткода от шитого кода — это вы сказали, что байткод — это новое имя для шитого кода применительно к Java, я вам просто объяснил, что идеи использованые в JVM не новы и существовали до появления языка Forth.
Во-вторых, я вполне достаточно знаком с процесом компиляции и идеей байткода. Тем более что не нужно быть гением чтобы разобраться в этих концепциях — этому прекрасно могут научить в универе, причем не только теорию, но и практику. А так же в этом можно разобраться самостоятельно, например, LLVM неплохое место чтобы начать. Но переход на личности, вместо разумных аргументов я трактую как отсуствие последних с вашей стороны и на этом я свами закончил.mxms
15.12.2016 15:00-1Вашу фразу «откуда, как я понимаю вы и позаимствовали термин «шитый код»» иначе как некомпетентность в этих вопросах я не могу трактовать.
Байткод Java это разновидность шитого кода («свёрнутый шитый код»).
MacIn
14.12.2016 21:26+1Касаемо байткода, то я вообще не стал бы его считать языком программирования. В противном случае любой шитый код (а байткод это его новое имя применительно к Java) нужно считать таковым. Пример неудачный.
Это уже терминологический спор. Если посмотреть на гостовские определения, можно обнаружить такие понятия, как «программа на машинном языке» — это то, что мы кратко называем бинарником. Т.е. сам исполняемый файл — это программа на языке программирования «машинный код».mxms
15.12.2016 15:13Согласен, что вопрос в терминологии. Я выше уже упоминал, что байткод это разновидность шитого кода. Последний термин имеет более давнюю историю, поэтому разумно придерживаться его.
Также, повторюсь, я считаю, что языком низкого уровня может считаться тот язык, который является мнемоническим обозначением команд процессора — машинного когда. Это, безусловно, Ассемблеры и Форт для форт-процессоров. Выше привели ещё примеры для Лиспа и лисп-процессора (ничего конкретного про него не знаю).
Далее, сама возможность реализации конструкций языка программирования в железе (машинных кодах), возможно может означать что этот язык — язык низкого уровня. А наличие таковой будет однозначным свидетельством того что данный язык программирования — язык программирования низкого уровня.terryP
15.12.2016 17:48+3Форт для форт-процессоров
А чем Java процессоры отличаются от форт-процессоров тогда? В отличие от форт процессоров они вполне существуют и используются.
mxms
15.12.2016 18:22Не сталкивался с ними «in the wild», но коли так, то байткод Java (но не сам Java) можно считать языком низкого уровня. Возражений нет.
mxms
15.12.2016 18:38Вот тут ниже написали касаемо т.н. Java-процессоров
ARMv8 требует от всех процессоров поддержку режима Jazelle, но при этом требует чтобы количество аппараратно исполняемых инструкций было равно нулю.
.
В этом свете дезавуирую своё предыдущее заявление.
MacIn
15.12.2016 19:02В таком случае, байт-код той же JVM — это программа на машинном языке виртуальной машины. Никакой разницы между интерпретацией байт-кода виртуальной машиной и мнемокода микропрограммным автоматом ЦП нет кмк.
Varim
11.12.2016 17:37Если бы работа процессора не была бы завязана на стек, отсутствовали бы команды по работе с ним, равно как и специальный регистр для хранения указателя.
Ложное утверждение.
Команды работы со стеком в процессорах присутствуют исключительно для быстроты работы со стеком, их можно было бы заменить на несколько команд, просто ради оптимизации добавили команду для работы со стеком. Грубо говоря вместо 8х команд загрузки регистров в память и 2х команд сложения/вычитания, есть одна команда загрузки в стек.
«Специальный регистр» можно было бы заменить на не специальный регистр, просто есть команды которые сделаны что бы автоматом с ним работать, для быстроты и удобства, то есть сделана абстракция. А абстракции нужны не процессору, а исключительно мыслящим приматам- людям.
В одноадрессных ЭВМ что нельзя было использовать стек? Просто не было одной команды.
Про форт ничего не скажу, не в курсе.
MacIn
10.12.2016 17:10Работа процессора непосредственно завязана на понятие стека.
Нет. Стек — это абстракция. Есть кристаллы с аппаратным стеком, но это не нечто сущее.
mxms
10.12.2016 14:41-2И не надо передёргивать. Я написал «возможно». Вы понимаете разницу?
При этом С это язык высокого уровня безо всяких оговорок.
MacIn
09.12.2016 23:48Это опять же абстракция уровня микропрограммы, а не железа. Так-то можно микропрограммную ЛИСП машину написать.
Varim
10.12.2016 09:39в x86 серии вплоть до x486 не было стека в процессорах, в более поздних не знаю, не учил (стек мат сопроцессора не считаю), и думаю до сих пор в 86-процессорах стека нет.
Есть всего лишь несколько регистров для работы со стеком, сам стек же хранится в оперативной памяти (или может в теневой памяти).
Команды для сохранения/извлечения состояния ЦП можно назвать стеком?mxms
10.12.2016 14:29Место хранения стека дело двадцать пятое. Важно что сама архитектура предполагает его наличие.
Varim
10.12.2016 15:18В процессорах стэк вызовов отменили теперь? Вот так новость
в мат сопроцессоре есть стек, в x86 — отсутствует стек.
Стек вызовов служит для ускорения поддержки стека вызовов языков программирования.
Важно что сама архитектура предполагает его наличие.
если у процессора нет команд для работы со стеком, приходится сохранять стек другими командами, такой «ручной» стек это стек или нет?
MacIn
10.12.2016 17:14+1Архитектура комманд или архитектура процессора? Архитектура комманд — предполагает, процессора — нет. Это может быть микропрограмма вида
Пересылка из регистра S в регистр адреса Пересылка из регистра Х в регистр данных Строб записи Пересылка константы 4 в регистр-защелку Пересылка регистра S в регистр-защелку Сложение Пересылка результата АЛУ в регистр S
aso
12.12.2016 08:11в x86 серии вплоть до x486 не было стека в процессорах
Ой.Varim
12.12.2016 12:50регистры для работы с отдельной областью памяти и несколько команд для работы с памятью как со стеком, это на мой взгляд не значит что в процессоре есть стек, а просто команды для работы со стеком. В мат сопроцессоре, есть стек, на регистрах сопроцессора.
aso
12.12.2016 13:15А что, по-Вашему, значит, что у «процессора есть стек»?
Основное назначение стека — хранение адресов возврата из процедур и прерываний, т.е. аппаратная поддержка рекурсивности вызовов, call, ret и iret (или их аналоги).
pop / push — оне чиста «вкусняшки».
Оддельный аппаратный стек мог быть организован, как минимум — ещё на древнем 580ИК80 ака i8080.Varim
12.12.2016 13:33В процессорах стэк вызовов отменили теперь? Вот так новость…
просто мне показалась эта фраза не совсем корректной, и тут понеслось.
что значит у «процессора есть стек»?
в самом процессоре, как у мат процессора. И возможно как у Форт (про форт ничего не знаю)
call, ret и iret
можно эмулировать, mov add sub jump. Переключение таблиц дескрипторов, страниц памяти или таблицу прерываний в зашщищеном режиме так эмулировать не стоит.
ветку стоит прекращать, всё все поняли.aso
12.12.2016 13:43+1в самом процессоре, как у мат процессора.
Нонафига, сэр?
И возможно как у Форт (про форт ничего не знаю)
Форт by default исходит из модели стек-машины с 64кбайт общей памяти, стеком, размещённым в ней (что естествественно) и растущим «от верхней границы вниз».
call, ret и iret
можно эмулировать,
Слово «атомарность» благородному сэру незнакомо.
И прерывание, бодренько вклинившееся в эмулируемую очередь инсрукций — распишет авторский продукт по всем испостясям.
Либо потребует кажный разик enable/disable int.
ветку стоит прекращать, всё все поняли.
Зарадибога.kmu1990
12.12.2016 16:33А можно подробнее, при каких обстоятельствах вам понадобится атомарность инструкции call или инструкции ret? Допустим инструкцию прервали в середине, произошло прерывание, если обработчик прерывания корректный, то он все вернет в состояние «как было», если нет то атомарный у вас ret/call или нет, то все и так плохо.
aso
13.12.2016 07:46А можно подробнее, при каких обстоятельствах вам понадобится атомарность инструкции call или инструкции ret?
Ой.
Допустим инструкцию прервали в середине
Инструкции не прерываются, они — атомарны by design.
произошло прерывание, если обработчик прерывания корректный, то он все вернет в состояние «как было»
фкакое «какбыло»?
Эмуляция инструкции call может выглядеть примерно так:
inc SP
mov (SP),IP
add (SP),offset __next
jmp <my_func>
__next:
(Ассемблер условный, скобочки — косвенная адресация, offset — смещение до метки.)
Прерывание между первой и второй командой — даёт нам мусор в стеке, между третьей и четвёртой — пропуск вызова функции.
Возврат из функции или прерывания — при не-атомарности тоже нарисуют цену на дрова.kmu1990
13.12.2016 12:24Инструкции не прерываются, они — атомарны by design.
Во-первых, я написал «допустим», что бы разобраться в гипотетических проблемах ситуации, когда инструкция ret или call будет прервана.
Во-вторых, то, что инструкции не прерываются не значит, что они атомарны — это разные свойства, более того инструкции не атомарны, как вы говорите, «by design» и тому есть некоторое количество примеров.
фкакое «какбыло»?
Очевидно, имеется ввиду состояние (в основном, подразумевается состояние регистров), в котором находилось ядро процессора до вызова обработчика прерывания.
Прерывание между первой и второй командой — даёт нам мусор в стеке
и в чем проблема то? По возвращению из обработчика прерывания мы запишем на стек вместо мусора правильное значение и никаких проблем.
между третьей и четвёртой — пропуск вызова функции.
с чего бы это? Опять же когда обработчик прерывания вернет управление
мы продолжим с того места, где мы остановились, т. е. c jmp, который вызовет функцию как и требовалось.
MacIn
13.12.2016 02:12И прерывание, бодренько вклинившееся в эмулируемую очередь инсрукций — распишет авторский продукт по всем испостясям.
Либо потребует кажный разик enable/disable int.
Строго говоря, прерывание тоже может быть реализовано по-разному, например, как регистр, проверяемый перед выборкой очередной команды.
MacIn
13.12.2016 02:10А что, по-Вашему, значит, что у «процессора есть стек»?
В контексте разговора выше — аппаратная реализация.
Основное назначение стека — хранение адресов возврата из процедур и прерываний, т.е. аппаратная поддержка рекурсивности вызовов, call, ret и iret (или их аналоги).
Это может быть микропрограммная реализация, а не аппаратная. Со стороны машинного языка будет выглядеть идентично.aso
13.12.2016 07:53В контексте разговора выше — аппаратная реализация.
Нокак, сэр?
Сама концерция [микро]процессора предполагает некую шнягу, которая умеет вычислять и «делать программу» — но не имеет памяти.
Если внутри системы будет много памяти (несколько К, к примеру) — то с чего это всё будет называться «процессором», а не микроконтроллером (однокристалльной микро-ЭВМ на старые деньги)?
Это может быть микропрограммная реализация, а не аппаратная.
Ифчом разница при программировании процессора?MacIn
13.12.2016 08:38Сама концепция [микро]процессора предполагает некую шнягу, которая умеет вычислять и «делать программу» — но не имеет памяти.
Это некорректное заявление.
Если внутри системы будет много памяти (несколько К, к примеру) — то с чего это всё будет называться «процессором», а не микроконтроллером (однокристалльной микро-ЭВМ на старые деньги)?
У Itanium'а 2К только регистровой памяти. Это раз, аппаратный стек может быть микроскопическим (см. Intel 4004), это два.
Ифчом разница при программировании процессора?
При программировании в машинных кодах — нифчом. Вопрос стоял в виде «есть ли в процессоре стек» и трактовке того, что такое «в процессоре есть».
aso
13.12.2016 10:51-1Это некорректное заявление.
Прафтаа?
Ну, ежели у Вас своё собственное определение понятия «процессор»…
У Itanium'а 2К только регистровой памяти.
У последнего?
И сколько VLIW команд исполняет одновременно?
Это раз, аппаратный стек может быть микроскопическим (см. Intel 4004), это два.
И толку от трёх уровней стека?
При программировании в машинных кодах — нифчом.
А в чём ещё может программироваться процессор? — В итоге всё всегда сводится к «машинным кодам» в той или иной форме.
А Вы часто программируете микрокод процессора?
Вопрос стоял в виде «есть ли в процессоре стек» и трактовке того, что такое «в процессоре есть».
Всю жезнь эта трактовка была одинаковой — «архитектура процессора/ЭВМ предполагает реализацию стека». Различие промежду «в памяти» или «в процессоре» — никогда не делалось.
Вот в ЕС ЭВМ, как и у её прородителя — IBM System/360 стека действительно не было.MacIn
14.12.2016 02:06Прафтаа?
Ну, ежели у Вас своё собственное определение понятия «процессор»…
Не паясничайте. То, что вы под «памятью» понимаете исключительно внешнее ОЗУ — ваше дело. Память, если выражаться вашим языком, это такая шняга, где хранятся данные. Регистр — это память.
У последнего?
И сколько VLIW команд исполняет одновременно?
У навскидку нагугленного. 6 или 8, не помню.
И толку от трёх уровней стека?
Ну, спросите у создателей Intel 4004, расскажете.
А в чём ещё может программироваться процессор? — В итоге всё всегда сводится к «машинным кодам» в той или иной форме.
А Вы часто программируете микрокод процессора?
Мы же рассуждаем об аппаратной/микропрограммной реализации, поэтому, соответственно, надо уточнять и этот момент.
Всю жезнь эта трактовка была одинаковой — «архитектура процессора/ЭВМ предполагает реализацию стека». Различие промежду «в памяти» или «в процессоре» — никогда не делалось.
Вопрос привычки, эпохи и так далее. Вот тут выше как раз этот вопрос и поднялся.
Вот в ЕС ЭВМ, как и у её прородителя — IBM System/360 стека действительно не было.
Смотря у какой модели.
monah_tuk
10.12.2016 11:22Гм… а как быть с семейством расширений Jazelle для ARM (ЕМНИП, технологию дропнули)? Получается и Java низкоуровневая :)
khim
11.12.2016 01:27+2Гм… а как быть с семейством расширений Jazelle для ARM
Одни поддерживали не язык Java, а байткод Java. Он низкоуровневый, тут и спорить не о чем. Но если считать что все языки, которые в принципе могут компилироваться в низкоуровневое представление — низкоуровневые, то у нас вообще высокоуровневых языков не останется.
ЕМНИП, технологию дропнули
Нет, там смешнее. Во всех современных процессорах она «поддерживается» — и во всех через одно место. Jazelle предполагает исполнение байткода частью процессором, частью — интерпретатором в операционке. ARMv8 требует от всех процессоров поддержку режима Jazelle, но при этом требует чтобы количество аппараратно исполняемых инструкций было равно нулю. Вот такой шедевр научно-технической мысли.

ndv79
09.12.2016 15:35+3Автор, берите сразу быка за рога! Мы итак знаем, что космические корабли бороздят пространство.
Везде, где я встречался с ассемблером (в последнее время — это видео-кодэки), делается так: берется программа на Си, компилируется в ассемблер с -O3, после чего руками делается множество научных тыков: там заменили память на регистр, сям поменяли ветки при ветвлении. Так и рождается чуть-более-оптимальный ассемблерный код.
il--ya
09.12.2016 15:40while ((readed = read(f, buf, sizeof(buf))) > 0) { for (i=0; i < readed; i+=16) { __m128i a = _mm_load_si128((const __m128i *)(buf+i)); r = _mm_add_epi8(a, r); } memset(buf, 0, sizeof(buf)); }
А зачем мемсетить весь буфер, если можно обнулять только то, что реально нужно (а в 99.9999% и вовсе не нужно, поскольку read вернёт 1024 байта)?
while ((read = read(f, buf, sizeof(buf))) > 0) { int tail = (sizeof(buf) - read) % 16; if (tail) memset(buf + read, 0, tail); for (i=0; i < read; i+=16) { __m128i a = _mm_load_si128((const __m128i *)(buf+i)); r = _mm_add_epi8(a, r); } }
alsii
09.12.2016 15:49Мелко! Даешь микропрограммирование, коневейеры и сверхпараллельный перенос. Как можно писать на ассемблере, если не знаешь, как работают сумматоры, когда выполняется
lea -0x420(%rbp),%rcx?
/sarсasm
Все это становится полезно не раньше, чем когда оно становится необходимо. Подобные оптимизации всегда аппаратно-зависимы, поэтому пока вы не уверены твердо на какокой аппаратуре будет запускаться ваш код, смысла в подобной оптимизации чуть менее, чем никакого. А это, наверно 90% случаев. Так что лучше отдать эти вещи [JIT-]компилятору. Уж он то точно знает, что у него под ногами.
Psychopompe
09.12.2016 16:13+1Например, Fortran, относящийся к той же «возрастной группе», что и С, в некоторых специфических задачах более производителен. Ряд специализированных языков могут быть быстрее С при решении чисто математических задач.
Можно привести примеры?khim
09.12.2016 18:26+1Всё тот же Fortran и всякие реализации BLAS. Но на самом деле это обман. Любой код на C можно довести до того уровня, что и Fortran'овский путём тщательного добавления restrict в нужные места. Только одна беда — если не очень хорошо понимать что там происходит в коде, то можно сделать очень быструю, но неправильно работающую программу.
Psychopompe
10.12.2016 08:13А можете поподробнее рассказать? Я не сильно разбираюсь в деталях оптимизации, но работа порой требует.
khim
11.12.2016 01:30Вообще-то Wikipedia про всё подробно рассказывает — ссылку я давал выше. И как
restrictможет ускорять программу и как он может вести к беде. В Fortran передаваемые параметры всегдаrestrict, отсюда получается что типичную программу на фортране компилятору легче «переваривать», чем программу на C.
ilmarin77
09.12.2016 19:14Все эти примеры (и очевидность преимущества C над ассемлером) интересней запускать на маленьких слабых процессорах.
Например, на Raspberry Pi Model B+, общая память 512мб, Raspbian 8:
Компиляция пример:
$ time gcc -O3 test.c real 0m8.620s user 0m1.150s sys 0m0.210s
Тесты (файл test перенёс с декстопа, SD Sandisk Ultra), buffer=1024*1024:
$ time ./a.out test Чтение завершено, сумма равна 136901097048.000000 real 1m15.829s user 0m30.600s sys 0m6.430s $ time luajit test.lua test Result:136901097048.000000 real 1m26.749s user 0m45.850s sys 0m9.780s $ time python test_numpy.py test Result:136901097048.000000 real 1m19.225s user 0m31.570s sys 0m10.950s
Кто-нибудь может сравнить с чем-нибудь на MIPS.
burjui
10.12.2016 00:31То, что процессоры «маленькие и слабые», не имеет значения. Результаты ваших тестов объясняются тем, что JIT в Lua и Python не оптимизирован для MIPS, что неудивительно, учитывая сравнительно низкую популярность MIPS.
ilmarin77
10.12.2016 00:35+1Raspberry PI — это ARM v7, и разница в скорости выполнения C и luaJIT там опять небольшая:
1m15.829s против 1m26.749s, большую часть времени программа ждёт данных с SD карты.
ilmarin77
10.12.2016 05:16Для интереса попробовал с torch на Raspberry PI:
$ time th test_torch.lua test Result:136901097048.000000 real 1m4.043s user 0m12.100s sys 0m10.850s
Получается лидер.

impwx
Особый респект за перевод текстов на картинках!