
Егор: Здравствуйте, фрилансеров ищите?)
Я: А вы что умеете?
Егор: А мы, собственно, толком ничего не умеем и хотим работать за опыт.)
Егор оказался неплохо подкованным пареньком и я предложил ему потестировать нашу либу cjCore.
Надо пояснить, что это такое. На гитхабе у нас есть репозиторий, куда мы сваливаем свои наработки, а cjCore — это одна из наших библиотек на C++.
Егор клонировал себе либу и попытался её скомпилировать, но не тут-то было. У него возникли проблемы с компиляцией нашей юникодной String.
Как известно, в стандартном С++ нет нормальных юникодных строк и поэтому многие пишут для этого свои классы. Например, в Qt написана своя QString на базе библиотеки ICU. И мы тоже решили написать свою строчку, но стали использовать не ICU, а библиотеку Boost или C++11 на выбор, кому что нравится больше.
У Егора последняя версия Ubuntu, но по какой-то причине, у него строка из C++11 компилироваться не захотела, а тянуть Boost только ради какой-то строчки он посчитал делом слишком накладным (попутно пожаловавшись на слабенький интернет) и решил использовать свободную библиотеку, в конце концов он остановился на utfcpp.sourceforge.net.
Нахрапом взять эту библиотеку Егору не удалось. Он постоянно мне скидывал возникающие ошибки, я что-то подсказывал, но постоянно что-то у него не получалось…
Тем временем я зашёл в Википедию: ru.wikipedia.org/wiki/UTF-8 и нашел там интересную табличку «Конвертирование в UTF-8»:

И тут ко мне приходит безумная мысль: написать функции преобразования UTF-8 -> UTF-32 и обратно чистым кодом, без всяких библиотек!
Я: Сейчас я кое-что скину, если у меня получится
Егор: Ок
Никаких тяжёлых операций, только проверка условий, сложение и операции с битами, 40 минут и готово!
Я: Для чего нужны либы? Чтобы быстренько своё сваял и всё работает: github.com/sitev/cjCore/blob/master/src/test_utf32to8.cpp
Егор: А обратно?
Я: Помню, сколько времени потребовалось, чтобы разобраться с кодировками в с++11 и бусте, наверное, неделя
Ещё минут 30-40 и заработала обратная конвертация.
Егор взялся за тестирование и через какое-то время скинул скриншот:
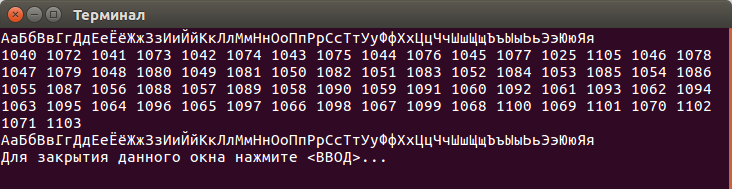
Я: Типа пашет?
Егор: Не типа, а пашет: 1 строчка — исходная, 2 строчка — UTF-32, 3 строчка — из UTF-32 в UTF-8.
Спасибо Егору, он оптимизировал получившийся код, а я его обернул в виде класса Utf: github.com/sitev/cjCore/blob/master/src/utf.cpp и попросил Егора протестировать быстродействие.
Результат не заставил себя ждать, скорость в 2-2.5 раза быстрее, чем utfcpp.sourceforge.net! К сожалению, сравнить по скорости с другими библиотеками, у нас не нашлось времени, а попробуйте сами и выложите результаты в комментариях.
Как оказалось, процесс программирования перекодировки Юникода туда-обратно очень увлекательный, заставляет с горящими глазами и учащенным сердцем быстро-быстро стучать по клавишам…
Комментарии (16)

Tujh
16.01.2017 11:58Почему только UTF-32 <-> UTF-8? Целевая платформа — только Linux?

sitev_ru
18.01.2017 09:41Нам для задач достаточно UTF-8 и UTF-32… Для доступа или замены i-ого символа для скорости лучше применять UTF-32, для остальных случаях, видимо UTF-8 подходит… UTF-16 что-то промежуточное и непонятно зачем нужное…
Tujh
18.01.2017 10:10+1UTF-16 что-то промежуточное и непонятно зачем нужное
Ну как сказать, для Windows sizeof( wchar_t ) == 2, и в ней нативно используется UCS-2 (ранний вариант стандарта UTF-16, не допускающий последовательностей если правильно помню), в Linux sizeof( wchar_t ) == 4 и применяется UTF-32.
Если работать с современными системами, основанными на коде WinNT, то основными вызовами там будут вызовы функций с постфиксом W, например OpenFileW(...), ожидающие на входе именно «двубайтные» символы, а если вызывать OpenFileA(...) с обычными «однобайтными», то система выполнит преобразование символов и всё равно вызовет OpenFileW(...). При этом UTF-8 не поддерживается.
Поэтому я и спросил про целевую платформу. При использовании Windows с подходом «достаточно UTF-8 и UTF-32» возникнут огромные накладные расходы дополнительных преобразований. QChar, кстати, тоже 16-ти битный, что чревато опять же, накладными расходами, если его использовать (ведь не просто так же вы о нём в статье упоминали?).


DeXPeriX
16.01.2017 12:03+6А с решением Bjorn Hohrmann не сравнивали? Его код выглядит гениально коротким и быстрым.

mefrill
16.01.2017 13:59UNICODE это не только преобразование из utf-8 в utf-32 и обратно, там главное — классификация символов. В библиотеке Strutext https://github.com/merfill/strutext реализован UTF-8 итератор по байтовому потоку, а также в symbols.h определены классы символов и функция определения класса по его коду. Код итератора — это адаптация библитеки разбора utf-8 от unicode.org, там сделано хорошо и быстро. Классы символов лежат в файле UnicdeData.txt, это родная база классов символов от unicode.org, которая при сборке проекта парсится в сишные структуры.
sitev_ru
18.01.2017 09:49Написать свою реализацию преобразований юникода пришло спонтанно:
И тут ко мне приходит безумная мысль: написать функции преобразования UTF-8 -> UTF-32 и обратно чистым кодом, без всяких библиотек!
, на изучения всего просто не хватает времени…

Akon32
16.01.2017 16:24Никаких тяжёлых операций, только проверка условий, ...
Сброс конвейера, все дела, не? Всё-таки интересно было бы увидеть сравнение с решением Bjorn Hohrmann (ссылка выше). Не берусь сказать, что будет быстрее.
Ещё можно "поиграться" со std::string::reserve(). В вашем коде оно будет вызываться явно больше одного раза (на больших строках), при желании можно сократить до одного вызова вначале.
Это следует учитывать и при сравнительных тестах.

DrSmile
16.01.2017 19:53+2Нету проверок на Overlong Sequence и прочий испорченный UTF8 — потенциальная дыра в безопасности.
mwambanatanga
Егору не грех бы и заплатить…
3aicheg
Что за греховная мысль…