
 Продолжим изучать общие принципы работы со стандартными коллекциями (модуль collections в ней не рассматривается) Python. Будут рассматриваться способы объединения и обновления коллекций с формированием новой или изменением исходной, а также способы добавлять и удалять элементы в изменяемые коллекции.
Продолжим изучать общие принципы работы со стандартными коллекциями (модуль collections в ней не рассматривается) Python. Будут рассматриваться способы объединения и обновления коллекций с формированием новой или изменением исходной, а также способы добавлять и удалять элементы в изменяемые коллекции.Данная статья является продолжением моей статьи "Python: коллекции, часть 2: индексирование, срезы, сортировка".
Для кого: для изучающих Python и уже имеющих начальное представление о коллекциях и работе с ними, желающих систематизировать и углубить свои знания, сложить их в целостную картину.
Оглавление:
- Объединение строк, кортежей, списков, словарей без изменения исходных.
- Объединение множеств без изменения исходных.
- Объединение списка, словаря и изменяемого множества с изменением исходной коллекции.
- Добавление и удаление элементов изменяемых коллекций.
- Особенности работы с изменяемой и не изменяемой коллекцией.
1. Объединение строк, кортежей, списков, словарей без изменения исходных
Рассмотрим способы объединения строк, кортежей, списков, словарей без изменения исходных коллекций — когда из нескольких коллекций создаётся новая коллекция того же тип без изменения изначальных.
- Объединение строк (string) и кортежей (tuple) возможна с использованием оператора сложения «+»
str1 = 'abc' str2 = 'de' str3 = str1 + str2 print(str3) # abcde tuple1 = (1, 2, 3) tuple2 = (4, 5) tuple3 = tuple1 + tuple2 print(tuple3) # (1, 2, 3, 4, 5)
- Для объединения списков (list) возможны три варианта без изменения исходного списка:
- Добавляем все элементы второго списка к элементам первого, (аналог метод .extend() но без изменения исходного списка):
a = [1, 2, 3] b = [4, 5] c = a + b print(a, b, c) # [1, 2, 3] [4, 5] [1, 2, 3, 4, 5]
- Добавляем второй список как один элемент без изменения исходного списка (аналог метода.append() но без изменения исходного списка):
a = [1, 2, 3] b = [4, 5] c = a + [b] print(a, b, c) # [1, 2, 3] [4, 5] [1, 2, 3, [4, 5]]
- Добавляем все элементы второго списка к элементам первого, (аналог метод .extend() но без изменения исходного списка):
- UPD: Способ добавленный longclaps в комментариях:
a, b = [1, 2, 3], [4, 5] c = [*a, *b] # работает на версии питона 3.5 и выше print(c) # [1, 2, 3, 4, 5]
- Со словарем (dict) все не совсем просто.
Сложить два словаря чтобы получить третий оператором + Питон не позволяет «TypeError: unsupported operand type(s) for +: 'dict' and 'dict'».
Это можно сделать по-другому комбинируя методы .copy() и .update():
dict1 = {'a': 1, 'b': 2} dict2 = {'c': 3, 'd': 4} dict3 = dict1.copy() dict3.update(dict2) print(dict3) # {'a': 1, 'c': 3, 'b': 2, 'd': 4}
В Питоне 3.5 появился новый более изящный способ:
dict1 = {'a': 1, 'b': 2} dict2 = {'c': 3, 'd': 4} dict3 = {**dict1, **dict2} print(dict3) # {'a': 1, 'c': 3, 'b': 2, 'd': 4}
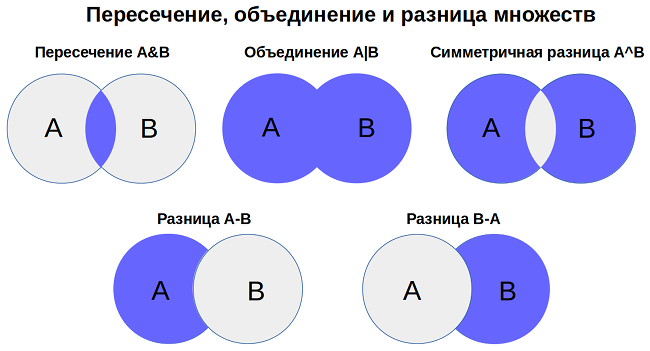
2. Объединение множеств без изменения исходных
Для обоих типов множеств (set, frozenset) возможны различные варианты комбинации множеств (исходные множества при этом не меняются — возвращается новое множество).
# Зададим исходно два множества (скопировать перед каждым примером ниже)
a = {'a', 'b'}
b = { 'b', 'c'} # отступ перед b для наглядности
- Объединение (union):
c = a.union(b) # c = b.union(a) даст такой же результат # c = a + b # Обычное объединение оператором + не работает # TypeError: unsupported operand type(s) for +: 'set' and 'set' print(c) # {'a', 'c', 'b'}
- Пересечение (intersection):
c = a.intersection(b) # c = b.intersection(a) даст такой же результат print(c) # {'b'} Пересечение более 2-х множеств сразу: a = {'a', 'b'} b = { 'b', 'c'} c = { 'b', 'd'} d = a.intersection(b, c) # Первый вариант записи d = set.intersection(a, b, c) # Второй вариант записи (более наглядный) print(d) # {'b'}
- Разница (difference) — результат зависит от того, какое множество из какого вычитаем:
c = a.difference(b) # c = a - b другой способ записи дающий тот же результат print(c) # {'a'} c = b.difference(a) # c = b - a другой способ записи дающий тот же результат print(c) # {'c'}
- Симметричная разница (symmetric_difference) Это своего рода операция противоположная пересечению — выбирает элементы из обеих множеств которые не пересекаются, то есть все кроме совпадающих:
c = b.symmetric_difference(a) # c = a.symmetric_difference(b) # даст такой же результат print(c) # {'a', 'c'}
3. Объединение списка, словаря и изменяемого множества с изменением исходной коллекции
- Для списка
- Добавляем все элементы второго списка к элементам первого с измением первого списка методом .extend():
a.extend(b) # a += b эквивалентно a.extend(b) print(a, b) # [1, 2, 3, 4, 5] [4, 5]
- Добавляем второй список как один элемент с изменением первого списка методом .append():
a.append(b) # a += [b] эквивалентно a.append(b) print(a, b) # [1, 2, 3, [4, 5]] [4, 5]
- Добавляем все элементы второго списка к элементам первого с измением первого списка методом .extend():
- Для изменения словаря с добавления элементов другого словаря используется метод .update().
Обратите внимание: для совпадающих ключей словаря при этом обновляются значения:
dict1 = {'a': 1, 'b': 2} dict2 = {'a': 100, 'c': 3, 'd': 4} dict1.update(dict2) print(dict1) # {'a': 100, 'c': 3, 'b': 2, 'd': 4}
- Для изменяемого множества (set) кроме операций, описанных в предыдущем разделе, также возможны их аналоги, но уже с изменением исходного множества — эти методы заканчиваются на _update. Результат зависит от того, какое множество каким обновляем.
- .difference_update()
a = {'a', 'b'} b = { 'b', 'c'} a.difference_update(b) print(a, b) # {'a'} {'b', 'c'} a = {'a', 'b'} b = { 'b', 'c'} b.difference_update(a) print(a, b) # {'a', 'b'} {'c'}
- .intersection_update()
a = {'a', 'b'} b = { 'b', 'c'} a.intersection_update(b) print(a, b) # {'b'} {'b', 'c'} a = {'a', 'b'} b = { 'b', 'c'} b.intersection_update(a) print(a, b) # {'b', 'a'} {'b'}
- .symmetric_difference_update()
a = {'a', 'b'} b = { 'b', 'c'} a.symmetric_difference_update(b) print(a, b) # {'c', 'a'} {'c', 'b'} a = {'a', 'b'} b = { 'b', 'c'} b.symmetric_difference_update(a) print(a, b) # {'a', 'b'} {'c', 'a'}
4 Добавление и удаление элементов изменяемых коллекций
Добавление и удаление элементов в коллекцию возможно только для изменяемых коллекций: списка (list), множества (только set, не frozenset), словаря (dict). Причём для списка, который является индексированной коллекцией, также важно на какую позицию мы добавляем элемент.

Примечания:
- Примеры использования метода .insert(index, element)
my_list = [1, 2, 3] my_list.insert(0, 0) # index = 0 - вставляем в начало print(my_list) # [0, 1, 2, 3] my_list.insert(10, 4) # Индекс выходит за границы списка - просто добавим в конец print(my_list) # [0, 1, 2, 3, 4] my_list.insert(-10, -1) # Индекс выходит за границы в минус - добавим в начало print(my_list) # [-1, 0, 1, 2, 3, 4] my_list = [1, 2, 3] my_list.insert(1, 1.5) # Вставим между 1 и 2 (индексация с нуля!) # То есть вставляется на позицию с указанным индексом, а то значение что на ней было # и те что правее - сдвигаются на 1 индекс вправо print(my_list) # [1, 1.5, 2, 3]
- Примеры использования оператора del
# Работает со списком my_list = [1, 2, 3, 4, 5, 6, 7] del my_list[1] # Удаление элемента по индексу print(my_list) # [1, 3, 4, 5, 6, 7] del my_list[-3:-1] # Удаление элементов выбранных срезом print(my_list) # [1, 3, 4, 7] # del my_list[10] # IndexError: list assignment index out of range # Работает со словарем my_dict = {'a': 1, 'b': 2, 'c': 3} del my_dict['b'] print(my_dict) # {'a': 1, 'c': 3} # del my_dict['z'] # KeyError при попытке удалить не сушествующий
- Удаление и добавление элементов списка срезом рассматривается во второй статье.
- Пример работы .append() и .extend() рассматривается в третьей главе этой статьи.
5 Особенности работы с изменяемой и не изменяемой коллекцией
- Строка неизменяемая коллекция — если мы ее меняем — мы создаем новый объект!
str1 = 'abc' print(str1, id(str1)) # abc 140234080454000 str1 += 'de' print(str1, id(str1)) # abcde 140234079974992 - Это НОВЫЙ объект, с другим id!
Пример кода с двумя исходно идентичными строками.
str1 = 'abc' str2 = str1 print(str1 is str2) # True - это две ссылки на один и тот же объект! str1 += 'de' # Теперь переменная str1 ссылается на другой объект! print(str1 is str2) # False - теперь это два разных объекта! print(str1, str2) # abcde abc - разные значения
- Список изменяем и тут надо быть очень внимательным, чтобы не допустить серьезную ошибку! Сравните данный пример с примером со строками выше:
list1 = [1, 2, 3] list2 = list1 print(list1 is list2) # True - это две ссылки на один и тот же объект! # А дальше убеждаемся, насколько это важно: list1 += [4] print(list1, list2) # [1, 2, 3, 4] [1, 2, 3, 4] # изменилось значение ОБЕИХ переменных, так как обе переменные ссылаются на один объект!
А если нужна независимая копия, с которой можно работать отдельно?
list1 = [1, 2, 3] list2 = list(list1) # Первый способ копирования list3 = list1[:] # Второй способ копирования list4 = list1.copy() # Третий способ копировани - только в Python 3.3+ print(id(list1), id(list2), id(list3), id(list4)) # все 4 id разные, что значит что мы создали 4 разных объекта list1 += [4] # меняем исходный список print(list1, list2, list3, list4) # [1, 2, 3, 4] [1, 2, 3] [1, 2, 3] [1, 2, 3] # как мы и хотели - изменив исходный объект, его копии остались не тронутыми
В следующих статьях планируется продолжение:
- (скоро) Тонкости генерации коллекций.
- (возможно в будущем) Модуль collections.
Приглашаю к обсуждению:
- Если я где-то допустил неточность или не учёл что-то важное — пишите в комментариях, важные комментарии будут позже добавлены в статью с указанием вашего авторства.
- Если какие-то моменты не понятны и требуется уточнение — пишите ваши вопросы в комментариях — или я или другие читатели дадут ответ, а дельные вопросы с ответами будут позже добавлены в статью.
- .difference_update()
Комментарии (24)

longclaps
19.01.2017 02:50+1a.append(b) print(a, b) # [1, 2, 3, [4, 5]] [4, 5]
Это — не конкатенация, уберите.
Чтоб два раза не вставать:
>>> a, b = [1, 2, 3], [4, 5] >>> a + b # вот это - конкатенация [1, 2, 3, 4, 5] >>> [*a, *b] # работает на версии питона 3.5 и выше [1, 2, 3, 4, 5] >>>
и, наконец,>>> a += b # эквивалентно a.extend(b) >>> a [1, 2, 3, 4, 5]
DaneSoul
19.01.2017 09:40Большое спасибо за Ваши дельные замечания и дополнения!
Убрал термин конкатенация везде, поставил вместо него объединение, так как четкого однозначного определения не нашел, а суть указанных мной способов — объединение коллекций или добавление в нее нового элемента.
[*a, *b] - добавил этот способ с указанием Вашего авторства
Добавил комментарии
a += b # эквивалентно a.extend(b) a += [b] # эквивалентно a.append(b)

ShashkovS
19.01.2017 11:02+1Я бы ещё добавил, что все приведённые варианты копирования списков «наивные»:
>>> a = [1, [2, 3], 4] # В списке ссылка на объект 1, на объект (список), на объект 4 >>> b = a.copy() # Новый объект список, в котором ровно те же ссылки, в частности ссылка на тот же список >>> a[1].append(3.5) # Так как ссылка на список общая, то и список общий >>> print(b) [1, [2, 3, 3.5], 4]
Визуализатор 1;
Если нужно копировать рекурсивно по полной:
>>> from copy import deepcopy >>> c = deepcopy(a) >>> a[1].append(3.75) >>> print(c) [1, [2, 3, 3.5], 4] >>> print(a) [1, [2, 3, 3.5, 3.75], 4]
Причём копирует всё достаточно аккуратно:
from copy import deepcopy a = [1, 2] b = [3, [[5, [a, 4], a], a, 6], a] c = deepcopy(b) a[1] = 9 print(b) print(c) c[2][1] = 3 print(c) print(id(c[2]), id(c[1][1]), id(c[1][0][2]), id(c[1][0][1][0])) [3, [[5, [[1, 9], 4], [1, 9]], [1, 9], 6], [1, 9]] [3, [[5, [[1, 2], 4], [1, 2]], [1, 2], 6], [1, 2]] [3, [[5, [[1, 3], 4], [1, 3]], [1, 3], 6], [1, 3]] 15864976 15864976 15864976 15864976
(аккуратно, но абсолютно всё. Функции и всё, что в них замкнуто, скажем, просто дублируются)
Визуализатор 2.DaneSoul
19.01.2017 12:49Большое спасибо за дельный детальный комментарий!
Добавил ссылку на него в конце статьи.

zitryss
19.01.2017 11:16+2Для операций над множествами intersection и symmetric_difference имеется короткая форма записи:
a = {'a', 'b'} b = { 'b', 'c'} c = a & b # c = a.intersection(b) print(c) # {'b'} c = a ^ b # c = a.symmetric_difference(b) print(c) # {'c', 'a'}DaneSoul
19.01.2017 12:49Большое спасибо за дополнение!
Добавил в соответствующие места в статье, с указанием Вашего авторства.

Johan
19.01.2017 15:50А так же, и для остальных двух:
>>> {'a', 'b'} - {'b', 'c'} # difference {'a'} >>> {'a', 'b'} | {'b', 'c'} # union {'b', 'c', 'a'}

renskiy
19.01.2017 11:19+1В Питоне 3.5 появился новый более изящный способ
На самом деле ещё во втором питоне можно было получать третий словарь путём слияния двух других:
dict3 = dict(dict1, **dict2)DaneSoul
19.01.2017 12:50Большое спасибо за дополнение!
Добавил в соответствующее место в статье, с указанием Вашего авторства.

worldmind
19.01.2017 11:44> В Питоне 3.5 появился новый более изящный способ
чем это они изящный? Вот если бы + перегрузили это было бы изящноDaneSoul
19.01.2017 11:48Перегрузить + конечно было бы еще изящней, но это явно четче и понятней, чем комбинация .copy() и .update()
Собственно способ указанный renskiy выше тоже очень хорош, добавлю его чуть позже в статью.
ShashkovS
19.01.2017 12:53+1Перегружать немного опасно, так как операция слияния словарей разрушительна.
Что должна делать
{1: 'one'} + {1: 'zero'}
?
Всевозможные варианты вида dict(dict1, **dict2) и dict(**dict1, **dict2) вернут {1: 'zero'}.Norraxx
19.01.2017 13:32Операцию + над словарями можно заменить такой штукой.
>>> x = {"a": 1} >>> y = {"b": 2} >>> dict(x.items(), **y) {'a': 1, 'b': 2}
worldmind
19.01.2017 15:56Ну и + должен делать также, только при этом быть значительно читаемее
Johan
19.01.2017 16:08Согласен с ShashkovS, операция с потерей данных не должна проходить незаметно. Кроме того, для сложения свойственна коммутативность, которой при сложении словарей и не пахнет. Конкатенация списков, конечно, тоже не коммутативна, но там, хотя бы, интуитивно ясен порядок в результате.
worldmind
19.01.2017 16:11согласен, значит не сложение, а какой-нибудь метод я-ля union или merge, но без магических символов в стиле си, не так
dict3 = dict(dict1, **dict2)
а так
dict3 = merge(dict1, dict2)Johan
19.01.2017 16:52В целом, такая функция в 5 строк пишется. Но, как-то, это unpythonic, нет единственного способа сделать это правильно.
DaneSoul
19.01.2017 18:31Вот по поводу магических символов согласился бы в том случае, если бы это было введено специально для объединения словарей, но это стандартный синтаксис передачи переменного числа параметров в функцию. Это гибкий и удобный способ, вполне в духе Питона.
Почему это не должно работать в функции создания словаря dict() — это ведь по сути такая же функция как и остальные?
Более того, при создании словаря не функцией dict(), а задав пары ключ: значение в фигурных скобках {} мы по сути имеем дело с коротким синтаксисом вызова той самой функции, так что вполне логично применять синтаксис по передаче переменного числа аргументов и тут.worldmind
19.01.2017 18:47Ну да, вариант который в 3.5 появился в эту логику вписывается, а вот вышеупомянутый вариант который был в ранних версиях чуток кривоват.
Один косяк — насколько понимаю и вариант добавленный в 3.5 не рекурсивный (сам не тестил, может ошибаюсь)
worldmind
19.01.2017 16:00Кстати, важный момент это мерджинг вложенных словарей, то что в перле выглядит как merge($hash1, %hash2) в питоне какими-то замороченными способами делается
sergnosov1
В качестве предложения. Было бы замечательно сопровождать рассказ об операциях с коллекциями информацией о сложности операций в О-нотации. Это полезная информация при выборе коллекций для использования.
DaneSoul
В конце первой статьи приведены ссылки на информацию по алгоритмической сложности операций с коллекциями.