

К сожалению, у меня нет опыта работы с микросервисами, но около года назад я очень активно интересовался этой темой и изучил все источники информации, какие смог найти. Я просмотрел несколько выступлений на конференциях, прочитал несколько статей очень авторитетных и опытных специалистов вроде Мартина Фаулера, Фреда Джорджа, Эдриана Кокрофта и Криса Ричардсона, чтобы как можно больше узнать о микросервисах. Эта статья — результат моих изысканий.
Содержание
- SOA и микросервисы
- Когда следует использовать микросервисы?
- Предпосылки
- Характеристики
- Что такое микросервис?
- Насколько велик микросервис?
- Компонентное представление через сервисы
- Гетерогенность
- Организация человеческих ресурсов в соответствии с возможностями бизнеса
- Продукты, а не проекты
- Умные конечные точки и глупые каналы (Smart endpoints and dumb pipes)
- Децентрализованное управление
- Децентрализованное управление данными
- Автоматизация инфраструктуры
- Страховка от сбоев (Design for failure)
- Эволюционная архитектура
- Фронтенд/бэкенд
- Опасности
- Как декомпозировать единое приложение
- Заключение
Микросервисная архитектура — это подход к созданию приложения, подразумевающий отказ от единой, монолитной структуры. То есть вместо того чтобы исполнять все ограниченные контексты приложения на сервере с помощью внутрипроцессных взаимодействий, мы используем несколько небольших приложений, каждое из которых соответствует какому-то ограниченному контексту. Причём эти приложения работают на разных серверах и взаимодействуют друг с другом по сети, например посредством HTTP.
Иными словами, мы инкапсулируем определённые контексты приложения в микросервисы, по одному на каждый, а сами микросервисы крутим на разных серверах.
SOA и микросервисы
Согласно Мартину Фаулеру, термином SOA злоупотребляют все кому не лень, сегодня под ним подразумевают множество вещей. С точки зрения Мартина, микросервисы — это разновидность SOA.
Когда следует использовать микросервисы?
Как архитектор-теоретик, желающий стать практиком, я считаю следующее. Решая, использовать ли микросервисы, ни в коем случае нельзя руководствоваться мифами, или желанием «в следующий раз попробовать это», или стремлением быть на переднем крае технологий. К этому, в соответствии с выводами Рейчел Майерс, нужно подходить исключительно с прагматической точки зрения. Рейчел отмечает, что архитектура должна:
- делать продукт гибче и устойчивее к сбоям;
- облегчать понимание, отладку и изменение кода;
- помогать в командной работе.
Я согласен с Рейчел, но я также считаю, что этим критериям удовлетворяют и монолитные архитектурные схемы.
Мартин Фаулер выделяет несколько преимуществ монолитной и микросервисной архитектур, что поможет вам решить, какой подход выбрать:
| Преимущества | |
| Монолитная архитектура | Микросервисы |
| Простота Монолитная архитектура гораздо проще в реализации, управлении и развёртывании. Микросервисы требуют тщательного управления, поскольку они развёртываются на разных серверах и используют API. |
Частичное развёртывание Микросервисы позволяют по мере необходимости обновлять приложение по частям. При единой архитектуре нам приходится заново развёртывать приложение целиком, что влечёт за собой куда больше рисков. |
| Согласованность (Consistency) При монолитной архитектуре проще поддерживать согласованность кода, обрабатывать ошибки и т. д. Зато микросервисы могут полностью управляться разными командами с соблюдением разных стандартов. |
Доступность У микросервисов доступность выше: даже если один из них сбоит, это не приводит к сбою всего приложения. |
| Межмодульный рефакторинг Единая архитектура облегчает работу в ситуациях, когда несколько модулей должны взаимодействовать между собой или когда мы хотим переместить классы из одного модуля в другой. В случае с микросервисами мы должны очень чётко определять границы модулей! |
Сохранение модульности Сохранять модульность и инкапсуляцию может быть непросто, несмотря на правила SOLID. Однако микросервисы позволяют гарантировать отсутствие общих состояний (shared state) между модулями. |
| Мультиплатформенность/гетерогенность Микросервисы позволяют использовать разные технологии и языки, в соответствии с вашими задачами. |
|
Лично мне нравится прагматичный подход Эрика Эванса. Микросервисы с точки зрения аппаратных ресурсов имеют преимущества, которых лишены единые архитектуры, а также облегчают решение ряда задач с программной точки зрения:
| Микросервисы | |
| Аппаратные преимущества | Программные преимущества |
| Независимая масштабируемость При размещении модулей на отдельных серверных узлах мы можем масштабировать их независимо от других модулей. |
Сохранение модульности И единая, и микросервисная архитектуры позволяют сохранять модульность и инкапсуляцию. Однако это может быть довольно трудной задачей, на решение которой уйдут десятилетия, несмотря на правила SOLID. Зато микросервисы позволяют обеспечивать логическое разделение приложения на модули за счёт явного физического разделения по серверам. Физическая изолированность защищает от нарушения пределов ограниченных контекстов. |
| Независимый технический стек Благодаря распределению модулей по разным серверным узлам и независимому языку взаимодействия мы можем использовать совершенно разные языки программирования, инструменты взаимодействия, мониторинга и хранения данных. Это позволяет выбирать лучшие и наиболее удобные решения, а также экспериментировать с новыми технологиями. |
Независимая эволюция подсистем Микросервис может развиваться и ломать обратную совместимость, не обременяя себя поддержкой старых версий, так как всегда можно оставить старую версию микросервиса работающей необходимое время. |
Я считаю, что основные причины для использования микросервисов — аппаратные преимущества, недостижимые с помощью единой архитектуры. Так что если вам важны вышеописанные моменты, то микросервисы безальтернативны. Если же аппаратные преимущества для вас некритичны, то сложность микросервисной архитектуры может перевесить её достоинства. Также мне кажется, что с помощью единой архитектуры невозможно достичь частичного развёртывания и частичной доступности, характерных для микросервисов. Это не ключевые преимущества (хотя это в любом случае преимущества).
Вне зависимости от наших вкусов и пожеланий НЕЛЬЗЯ начинать новый проект сразу с использованием микросервисной архитектуры. Вначале нужно сосредоточиться на понимании задачи и на способе её достижения, не тратя ресурсы на преодоление огромной сложности создания экосистемы микросервисов (Ребекка Парсонс, Саймон Браун).
Предпосылки
Непрерывное развёртывание
Возможность и нацеленность на постоянное ускорение работы
Одна из причин использования микросервисов заключается в том, что мы хотим иметь возможность быстро что-то менять, чтобы реагировать на изменения бизнес-требований, опережать конкурентов. Или, выражаясь словами Эрика Эванса, нам нужно осознавать хаос в компаниях:
Реальность разработки ПО такова, что вначале мы никогда не имеем полного понимания задачи. Наше понимание углубляется по мере работ, и нам постоянно приходится рефакторить. Так что рефакторинг — это потребность, но в то же время и опасность, потому что код становится запутанней, особенно при несоблюдении ограниченности контекстов. Микросервисы заставляют соблюдать пределы ограниченных контекстов, что позволяет сохранять работоспособность, ясность, изолированность и инкапсулированность кода в отдельных связных модулях. Если модуль/микросервис становится запутанным, то эта запутанность только в нём и остаётся, а не распространяется за его пределы.
Нам нужно действовать быстрее на всех стадиях разработки! Это верно для любой архитектуры, но микросервисы в этом отношении удобнее. Мартин Фаулер говорит, что необходимо иметь возможность:
- Быстро вводить в эксплуатацию: быстро развёртывать новые машины для разработки, тестирования, приёмки и работы.
- Быстро развёртывать приложения: автоматически и быстро развёртывать наши сервисы.
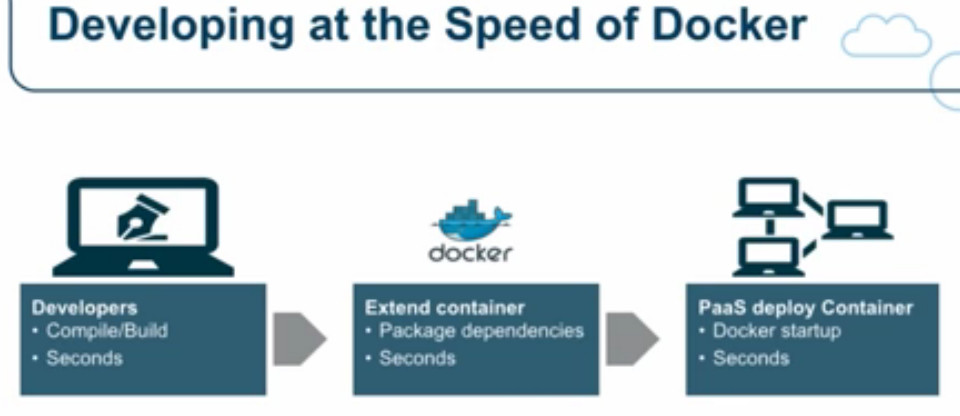
Фред Джордж утверждает то же самое: есть огромная потребность ускорить работу, чтобы выдержать конкуренцию! Он приводит ретроспективный анализ времени, необходимого на введение в эксплуатацию сервера, и отмечает, что в 1990-х требовалось 6 месяцев, в 2010-м благодаря облачным сервисам — 30 минут, а в 2015-м Docker позволял поднять и запустить новый сервер менее чем за минуту.
Эдриан Кокрофт, один из ключевых специалистов в Netflix Cloud и пионер в освоении микросервисов, отмечает, как важно находиться в первых рядах при освоении новых технологий, а также очень быстро вводить новые серверы и развёртывать новые версии своих приложений. Эдриан — большой поклонник Docker, поскольку этот сервис позволяет за секунды создавать сервер и развёртывать среды для разработки, тестирования и работы.
Усложнившийся мониторинг
Мониторинг крайне важен (Ребекка Парсонс), нам необходимо сразу узнавать о том, что сервер упал, что какой-то компонент перестал отвечать, что происходят сбои вызовов, причём по каждому из микросервисов (Фред Джордж). Также нам нужны инструменты для быстрой отладки (Мартин Фаулер).
Сильная devops-культура
Нам нужны devops’ы для мониторинга и управления, при этом между ними и разработчиками должны быть тесные отношения и хорошее взаимодействие (Мартин Фаулер). При работе с микросервисами нам приходится больше развёртывать, усложняется система мониторинга, сильно разрастается количество возможных сбоев. Поэтому в компании очень важна сильная devops-культура (Ребекка Парсонс).
Характеристики
Мартин Фаулер и Джеймс Льюис в своей широко известной статье и выступлениях (Фаулер, Льюис) приводят набор характеристик для определения микросервиса.
Что такое микросервис?
Лично я полностью согласен с определением Эдриана Кокрофта:
Архитектура на основе свободно сопряжённых сервисов с ограниченными контекстами. (Loosely coupled service oriented architecture with bounded contexts.)

Ограниченный контекст — это понятие явных границ вокруг какого-то бизнес-контекста. Например, в рамках электронной коммерции мы оперируем понятиями «темы» (themes), «поставщики платёжных услуг» (payment providers), «заказы», «отгрузка», «магазин приложений». Всё это ограниченные контексты, а значит — кандидаты в микросервисы.
Полезная общая информация о микросервисах приводится в книге Сэма Ньюмена «Building Microservices». По мнению Джеймса Льюиса, микросервисы должны:
- дёшево заменяться;
- быстро масштабироваться;
- быть устойчивыми к сбоям;
- никоим образом не замедлять нашу работу.
Насколько велик микросервис?
Джеймс Льюис утверждает, что сервис должен быть «настолько большим, чтобы умещаться в руке», то есть чтобы один человек мог полностью разобраться в его устройстве и работе.
Есть разные мнения о размерах микросервисов. Мартин Фаулер описывает случаи, когда соотношение количества сотрудников и сервисов колебалось от 60 к 20 до 4 к 200. К примеру, в Amazon используется подход с «командами на две пиццы» (two pizzas team): в команде микросервиса должно быть столько людей, чтобы их можно было накормить двумя пиццами.
Фред Джордж полагает, что микросервис должен быть «очень-очень маленьким», чтобы его создавал и сопровождал только один разработчик. То же самое говорит и Джеймс Льюис.
Я согласен с Джеймсом Льюисом, Фредом Джорджем и Эдрианом Кокрофтом. Мне кажется, микросервис должен соответствовать ограниченному контексту, который способен полностью понять один человек. То есть чем шире функциональность приложения, тем больше должно быть микросервисов. Например, в Netflix их около 800! (Фред Джордж)
Тем не менее как в самом начале жизненного цикла микросервиса, так и позднее ограниченный контекст может оказаться слишком велик для понимания одним человеком. Нужно выявлять такие ситуации и дробить подобные сервисы на более мелкие. Это соответствует концепциям архитектуры с эволюционным развитием и DDD, подразумевающим, что архитектура постоянно меняется/рефакторится по мере углубления в задачу и/или изменений бизнес-требований. Как говорит Ребекка Парсонс, «дробление крайне важно»: при разработке микросервисов труднее всего определять их границы. И при продвижении работы мы однозначно будем объединять или дробить сервисы.
Компонентное представление через сервисы
- Компонент — это элемент системы, который можно независимо заменить, усовершенствовать (Мартин Фаулер) и масштабировать (Ребекка Парсонс).
- При разработке ПО мы используем два типа компонентов:
А. Библиотеки: куски кода, применяемые в приложениях, которые могут дополняться или заменяться другими библиотеками, желательно без воздействия на остальную часть приложения. Взаимодействие происходит через языковые конструкты. Однако если интересующая нас библиотека написана на другом языке, мы не можем использовать этот компонент.
Б. Сервисы: части приложений, по факту представляющие собой маленькие приложения, выполняющиеся в собственных процессах. Взаимодействие выполняется за счёт межпроцессной связи, вызовов веб-сервисов, очереди сообщений и т. д. Мы можем использовать сервис, написанный на другом языке, поскольку он выполняется в собственном процессе (этот подход предпочитает Чед Фаулер). - Независимая масштабируемость — каждый сервис может быть масштабирован независимо от остального приложения.
Гетерогенность
Гетерогенность — это возможность построить систему с использованием разных языков программирования. У подхода есть ряд преимуществ (Мартин Фаулер), а Чед Фаулер считает, что системы обязаны быть гетерогенны по умолчанию, то есть разработчики должны стараться применять новые технологии.
Преимущества гетерогенной системы:
- Предотвращает возникновение тесных связей благодаря использованию разных языков.
- Разработчики могут экспериментировать с технологиями, что повышает их собственную ценность и позволяет не уходить в другие компании, чтобы попробовать новинки.
Правило. При экспериментах с новыми технологиями:
— нужно использовать маленькие элементы кода (code unit), модули/микросервисы, чтобы снизить риск;
— элементы кода должны быть одноразовыми (disposable).
Организация человеческих ресурсов в соответствии с возможностями бизнеса
Когда-то внутри команд разработчиков самоорганизовывались группы на основе используемых технологий. В результате проект создавали команда по DBA, команда разработки серверной части и команда разработки интерфейса, действовавшие независимо друг от друга. Такая схема сказывается на качестве продукта, потому что знания в конкретных областях и усилия по разработке рассеиваются по подгруппам.
При микросервисном подходе команды должны организовываться на основе бизнес-возможностей: например команда заказов, отгрузки, каталога и т. д. В каждой команде должны быть специалисты по всем необходимым технологиям (интерфейс, серверная часть, DBA, QA...). Это даст каждой команде достаточный объём знаний, чтобы сосредоточиться на создании конкретных частей приложения — микросервисов (Мартин Фаулер, Эрик Эванс).
Подход сочетается с законом Конвея, который гласит, что если нам нужны высокосвязные раздельные микросервисы, то структура организации должна отражать желаемую компонентную структуру.
Организации, разрабатывающие системы… создают архитектуры, которые копируют структуры взаимодействий внутри этих организаций.
Мелвин Конвей, 1967
Продукты, а не проекты
Раньше был такой подход: команда создаёт какую-то функциональность, а затем передаёт её на сопровождение другой команде.
В случае с микросервисами команда должна отвечать за свой продукт в течение всего его жизненного цикла, включая разработку, сопровождение и вывод из эксплуатации. Это формирует «продуктовое мышление», что означает сильную связь между техническим продуктом и его бизнес-возможностями. То есть создаётся прямая взаимосвязь: как приложение помогает своим пользователям расширить их бизнес-возможности.
Умные эндпойнты и глупые каналы (Smart endpoints and dumb pipes)
Опять же, в старые добрые времена компании использовали архитектуру Enterprise Service Bus (сервисная шина), при которой формируется канал коммуникаций между эндпойнтами и бизнес-логикой. Затем этот подход преобразился в spaghetti box.
Микросервисная архитектура переносит бизнес-логику в конечные точки и использует простые способы взаимодействия вроде HTTP.
Децентрализованное управление
Ключевые решения по микросервисам должны принимать люди, которые действительно разрабатывают микросервисы. Здесь под ключевыми решениями подразумевается выбор языков программирования, методологии развёртывания, контрактов публичных интерфейсов и т. д.
Децентрализованное управление данными
При традиционном подходе у приложения лишь одна база данных, и много разных компонентов бизнес-логики приложения «взаимодействуют» в рамках этой БД: напрямую читают из неё данные, принадлежащие другим компонентам. Это также означает, что для всех компонентов характерна одна и та же степень сохранности данных, даже если для каких-то из них это не самая лучшая ситуация (Мартин Фаулер).
При микросервисной архитектуре, когда каждый бизнес-компонент представляет собой микросервис, все компоненты обладают собственными базами данных, которые недоступны другим микросервисам. Данные компонента доступны (для чтения и записи) только через соответствующий интерфейс компонентов. Благодаря этому степень устойчивости данных варьируется в зависимости от компонента (Мартин Фаулер, Чед Фаулер).
С точки зрения Фреда Джорджа, это первый вызов на пути к микросервисной архитектуре.

Автоматизация инфраструктуры
Непрерывное развёртывание (Мартин Фаулер, Ребекка Парсонс, Чед Фаулер, Эрик Эванс):
- «Голубое» и «зелёное» развёртывание: нулевое время простоя.
- Автоматизация: нажатием одной кнопки можно развернуть несколько серверов.
- Серверы Phoenix: быстрый запуск и остановка.
- Мониторинг: можно заметить, когда что-то пошло не так, и отладить.
Страховка от сбоев (Design for failure)
Серверы, по которым распределено приложение, рано или поздно падают, особенно разные узлы. Поэтому архитектура приложений должна быть устойчива к таким сбоям (Мартин Фаулер).
Chaos monkey — это инструмент, созданный в Netflix. Он позволяет выключать серверы для проверки устойчивости системы к такому типу отказов (Мартин Фаулер).
Ребекка Парсонс считает очень важным, что мы больше не используем даже внутрипроцессное взаимодействие между сервисами, вместо этого для связи мы прибегаем к HTTP, который и близко не бывает столь же надёжен. В результате будут возникать сбои при общении сервисов друг с другом, и система должна быть к этому готова.
Архитектура с эволюционным развитием
Архитектура всего приложения не должна быть статичной, необходима возможность её простого развития в соответствии с потребностями бизнеса. Например, можно:
- Превратить (рефакторить) единое приложение в приложение микросервисное, изолировав и перенеся наборы бизнес-логики (ограниченные контексты) в отдельные микросервисы.
- Объединить существующие микросервисы, например когда часто приходится одновременно изменять разные микросервисы.
- Разделить существующие микросервисы, когда нужно и есть возможность развивать их по отдельности или когда мы понимаем, что разделение серьёзно повлияет на бизнес-логику.
- Временно добавить в приложение какую-то возможность, создав микросервис, который будет работать определённое время.
Фронтенд/бэкенд
Есть два подхода к структурированию фронтенда и бэкенда при микросервисной архитектуре:
- Раскидать все части пользовательского интерфейса по микросервисам и сохранять взаимосвязи между соответствующими микросервисами. Это позволяет наладить внутрипроцессное взаимодействие между фронтендом и бэкендом. Но тогда будет очень сложно, если вообще возможно, поддерживать связность UI. В случае перекрёстных изменений границ в UI нам придётся одновременно обновлять несколько микросервисов, создавая взаимосвязи и нарушая изолированность и независимость микросервисов, обеспечиваемые самой архитектурой. Получается практически антипаттерн!
- Раскидать кодовые базы фронтенда и бэкенда, оставив UI приложения одним целым, чтобы они потом взаимодействовали по HTTP. Микросервисы будут отделены друг от друга, что дополнительно разделит фронтенд и бэкенд. Зато UI можно поддерживать целиком, легко сохраняя его связность. Такую структуру рекомендует использовать Рейчел Майерс, и, насколько я понимаю, это единственный способ. В таком случае у нас есть два варианта взаимодействия между фронтендом и бэкендом:
- Много маленьких асинхронных HTTP-запросов вместо одного большого, что исключит возможность блокировки (этот подход предпочитает Чед Фаулер).
- Один большой запрос к специализированным сервисам (шлюзу/агрегатору/кешу), которые собирают данные со всей микросервисной экосистемы. Это уменьшает сложность UI.
Опасности
Нужно управлять гибкостью технологии
Одно из преимуществ микросервисов заключается в том, что мы можем применять разные технологии для решения одной и той же задачи. Например, в каждом микросервисе использовать разные библиотеки для XML-парсинга или разные инструменты сохранности данных. Но сама возможность не означает, что мы должны это делать. Не исключено, что обилие технологий и библиотек выйдет из-под контроля. Так что выберите базовый набор инструментов и обращайтесь к другим только тогда, когда это действительно нужно (Ребекка Парсонс).
Нужно управлять нестабильностью интерфейса
В начале разработки микросервиса его API особенно нестабилен. Но даже на более поздних стадиях, когда микросервис достаточно отработан, нам приходится менять API, его ввод и вывод. Осторожно вносите изменения, потому что другие приложения будут полагаться на стабильность API (Ребекка Парсонс).
Необходимо быть уверенными в согласованности данных
Микросервисы имеют собственные хранилища данных. И во многих случаях данные, принадлежащие одному микросервису, будут частично или целиком скопированы другим, клиентским микросервисом. Когда данные у поставщика меняются, он инициирует событие для запуска обновления данных, скопированных клиентским микросервисом. Событие попадает в очередь сообщений и ожидает, когда его получит клиентский микросервис.
Эта схема означает, что клиентский микросервис будет обладать устаревшими данными, пока не обнаружит нужное событие. Данные не согласованы.
Конечно, в итоге изменения будут применены ко всем копиям, а данные снова станут согласованными. Это называется eventual consistency — согласованность в конечном счёте. То есть мы знаем, что в течение короткого периода времени данные остаются несогласованными. Этот эффект имеет важное значение в ходе разработки приложений, от серверной части до UX-уровней (Ребекка Парсонс).
Как декомпозировать единое приложение
Приступая к созданию приложения, нужно изначально придерживаться единой архитектуры — по причине её простоты. В то же время нужно стараться создавать его как можно более модульным, чтобы каждый компонент легко переносился в отдельный микросервис (Ребекка Парсонс). Это сочетается с идеей Саймона Брауна о разработке приложения в виде набора раздельных компонентов в едином развёртываемом модуле.
При декомпозиции единой архитектуры в микросервисную, или в набор раздельных компонентов, необходимо думать о нескольких измерениях в поддержку нашего решения:
- Думайте об ограниченных контекстах, как это определено в DDD (Ребекка Парсонс, Рейчел Майерс)
- Каждый микросервис должен представлять собой ограниченный контекст, с точки зрения концепции бизнеса и с технической точки зрения. Обычно в рамках микросервиса должны быть соединения между элементами кода (между данными и/или бизнес-логикой), а также несколько соединений с внешними элементами кода.
- Думайте о бизнес-возможностях (Ребекка Парсонс: 1, 2)
- Какие потоки создания ценностей (value streams) существуют в организации? Бизнес-продукты? Какие доставляются бизнес-сервисы?
- Думайте о нуждах потребителей (Ребекка Парсонс: 1, 2, 3)
- Мы можем посмотреть на продукт не только как создатели, но и как потребители: что они хотят от нашего сервиса? Как они будут его использовать? Чего они ожидают?
- Думайте о шаблонах взаимодействия
- Какие части системы могут использовать одни и те же данные? Какие бизнес-логики будут взаимодействовать интенсивнее? (Ребекка Парсонс: 1, 2, 3)
- Есть ли в архитектуре единая точка отказа благодаря жёсткой зависимости одного микросервиса от многих других? (Рейчел Майерс)
- Думайте об архитектуре данных (Ребекка Парсонс: 1, 2, 3, Рейчел Майерс)
- Сервисы обладают собственными данными, у них свои базы данных, и нам нужно исходить из принципа согласованности в конечном счёте. Если две структуры данных очень сильно зависят друг от друга, то может быть целесообразнее держать их в одном микросервисе, чтобы не пришлось создавать механизм для работы с согласованностью в конечном счёте.
- Думайте о шаблонах взаимосвязанных изменений (Ребекка Парсонс: 1, 2, 3, Рейчел Майерс)
- Если можно предвидеть одновременное изменение двух элементов кода, то лучше хранить их в одном микросервисе, чтобы исключить лишние усилия по изменению API.
- Будьте готовы к слиянию и разделению сервисов (Ребекка Парсонс)
- Вероятно, вы не сможете всегда делать это вовремя. Но по мере получения опыта и углубления в задачу мы начинаем лучше понимать расположение ограниченных контекстов. Бизнес тоже будет меняться, и нам придётся к этому быстро приспосабливаться! Так что наша система должна позволять быстро разделять и объединять микросервисы.
- Шаблон Tolerant reader (Ребекка Парсонс)
- Всегда может возникнуть необходимость внести критическое изменение в обратную совместимость (backwards compatibility breaking change). Но мы можем постараться делать это лишь в крайнем случае. Чтобы не менять свой сервис постоянно, создайте его так, чтобы сервис приходилось менять только при изменении действительно важных данных.
- Без сохранения состояния и узлы Phoenix (Рейчел Майерс, Чед Фаулер, Эрик Эванс)
- Не дублируйте статичные файлы (HTML, CSS, JS, изображения) в приложениях и сервисах.
- Приложения с пользовательским интерфейсом должны быть полностью отделены от микросервисной экосистемы.
- Используйте однократные узлы.
- Используйте неизменяемое развёртывание (immutable deployments): никогда не обновляйте ПО на существующих узлах.
- Приоритет соглашения над конфигурацией (Convention over configuration) (Чед Фаулер)
- Принятые в вашей архитектуре структура и система наименований должны быть одинаковыми для всей экосистемы микросервисов.
- Создайте генератор микросервисной песочницы, чтобы у вас была начальная точка с уже заданной привычной структурой.
- Оптимизация взаимодействия между микросервисами (Чед Фаулер)
- Создайте базовую клиентскую библиотеку HTTP REST, оптимизированную для REST-вызовов, на основе которой можно строить конкретный микросервисный клиент, им будут пользоваться другие микросервисы. Этот оптимизированный клиент должен быть портирован на все языки, применяемые в вашей экосистеме.
- Обнаружение сервисов (Service discovery) (Чед Фаулер)
- Каждый микросервис должен знать, как контактировать с другими. Можно использовать локализованный (для каждого сервиса) конфиг, обновляемый сразу во всех местах при изменении расположения микросервиса.
- Мониторинг (Чед Фаулер)
- Измеряйте всё: сеть, машины, приложение.
- При создании нового микросервиса необходимо оснащать его всей необходимой функциональностью по мониторингу.
- Миграция от единой архитектуры к микросервисам (Чед Фаулер)
- Лучше использовать много маленьких запросов вместо нескольких больших (уберите соединения — joins).
- Разделяйте базы данных.
- Создавайте новые фичи в виде микросервисов, прототипов.
- Замените код в старой системе на API-вызовы новых микросервисов.
- Протестируйте в безумных условиях и под сумасшедшей нагрузкой.
- Долгосрочные цели (Чед Фаулер)
- Это должно работать.
- Это должно работать быстро.
- Это должно быть дешёвым => спотовые экземпляры (spot instances) AWS экономят от 85 до 95 % серверных узлов.
- Производительность (Чед Фаулер)
- Повышайте скорость разработки и развёртывания с помощью Docker.
Заключение
В большинстве проектов не требуется микросервисная архитектура, им нужна хорошая архитектура. Под этим я подразумеваю не только хорошую структуру, но также (может, это даже важнее) ясное определение этой структуры, чёткое и аккуратное отражение структуры в самом коде, чтобы это было очевидно для разработчиков и помогло им выделить ограниченные контексты и понять, когда стоит пересекать границы, а когда нет.
А дальше уже разработчикам решать, поддерживать или развивать архитектурную структуру. Это подразумевает строгое следование плану, структуре, архитектуре, что не всегда легко. Ведь мы всего лишь люди.
Полезные ссылки
Статьи
Werner Vogels • декабрь 2008 • Eventually Consistent – Revisited
Oracle • июнь 2012 • De-mystifying “eventual consistency” in distributed systems
Мартин Фаулер и Джеймс Льюис • март 2014 • Microservices
Конференции
Эдриан Кокрофт • январь 2015 • The State of the Art in Microservices
Чед Фаулер • июль 2015 • From Homogeneous Monolith to Radically Heterogeneous Microservices Architecture
Эрик Эванс • декабрь 2015 • DDD & Microservices: At Last, Some Boundaries!
Фред Джордж • август 2015 • Challenges in implementing Microservices
Джеймс Льюис • октябрь 2015 • Microservices and the Inverse Conway Manoeuvre
Джет Уэсли-Смит • октябрь 2014 • Real World Microservices
Мартин Фаулер • январь 2015 • Microservices
Рейчел Майерс • декабрь 2015 • Stop Building Services, Episode 1: The Phantom Menace
Ребекка Парсонс • июль 2015 • Evolutionary Architecture & Micro-Services
Комментарии (235)

sshikov
01.02.2017 19:17+17Ну почему все время за преимущества выдают какую-то, мягко выражаясь, хрень?
>У микросервисов доступность выше: даже если один из них сбоит, это не приводит к сбою всего приложения.
Да-а-а? Представим себе что это микросервис авторизации. Что, скажете нет, это не микросервис? Или его неработоспособность не отразится на работе всего приложения? Ха три раза.
Тщательнее надо формулировать, тщательнее.lega
01.02.2017 19:37+3И наоборот, если у меня один модуль (функция) сбоит, то это не значит, что оно приведет к сбою всего монолита. Тогда в каком месте у микросервисов тут выше доступность?
sshikov
01.02.2017 19:46+1Я бы на самом деле сформулировал бы как-то так — микросервисы должны позволять избавиться от single point of failure. Путем например легкого и быстрого параллельного развертывания нескольких копий. А сами по себе они точно также могут быть этой SPOF, как и модуль в монолитном приложении. Ни больше, ни меньше.
Т.е., не большая доступность, а простота обеспечения этой доступности, путем применения таких-то решений.
dimaaan
01.02.2017 20:03+7А что мешает развернуть несколько копий монолита?
sshikov
01.02.2017 20:10+1Ну, несколько копий монолита вероятно сожрут несколько больше ресурсов. А так ничего не мешает.
Имелось в виду, что в монолите не все является той самой точкой отказа, которую вообще стоит дублировать. Вынести эти части, сделать их автономными, и задублировать (заодно повысить производительность) — это вполне себе годная стратегия.dimaaan
01.02.2017 20:15+6Не очень понял вас.
- Допустим в микросервисах есть точка отказа. Мы дублируем микросервис с этой точкой — профит.
- Допустим в монолите есть точка отказа. Мы дублируем монолит — профит.
В чем разница?
sshikov
01.02.2017 20:19+5Что тут понимать? Монолит жрет 16Gb памяти. Микросервис, который точка отказа — 128Mb. Дублируем монолит — 32Gb потребности, дублируем микросервис — 16Gb + 128Mb*2. Все числа только как пример.
dimaaan
01.02.2017 20:27Теперь понятно.
Однако хочу заметить что это не повышение производительности (скорее наоборот из за накладных расходов на сетевое взаимодействие), а снижение потребления памяти.sshikov
01.02.2017 20:31А я разве обещал производительность?
Скорее это просто снижение накладных расходов на деплоймент (хотя если посчитать в сумме — то возможно окажется, что на развертывание сотни микросервисов уйдет намного больше ресурсов, чем на один монолит). Просто эти ресурсы — их можно будет проще горизонтально масштабировать.
Ну и да, сетевое взаимодействие вместо вызовов внутри процесса — это всегда минус микросервисам, без вопросов.VolCh
02.02.2017 08:46Ну и да, сетевое взаимодействие вместо вызовов внутри процесса — это всегда минус микросервисам, без вопросов.
Не сетевое, а межпроцессное. Микросервисы и сервисы вообще не обязаны общаться по сети, вполне могут использовать файловые сокеты, разделяемую память и т. п., хотя это накладывает ограничения на инфраструктуру.sshikov
02.02.2017 10:17Нет, не обязаны — но сплошь и рядом используется REST, JSON и т.п. — потому что это дает дополнительную гибкость, если угодно, особенно если вы хотите клиента на разных языках (а вы как правило хотите этого часто, почему нет?).
Так что насчет «всегда» — да, я выразился слишком сильно, но как правило взаимодействие все-таки требует дополнительных накладных расходов.VolCh
02.02.2017 10:26Требует, да, по определению сервиса как отдельного процесса или группы процессов. Но какое это будет взаимодействие сами принципы не диктуют.

Deosis
02.02.2017 11:24А могут использовать MQ и тогда почти не будет разницы, где расположены сервисы.
В одном процессе, в разных, или на разных серверах.
Это забота шины взаимодействия.

Source
03.02.2017 00:33+1Монолит жрет 16Gb памяти. Микросервис, который точка отказа — 128Mb.
Это что ж Вы такое делаете? Обычно 500 Mb под инстанс монолита более, чем хватает.
Хоть числа и только как пример, но их соотношение вызывает вопросы… На микросервис конечно меньше памяти приходится, но во-первых не в 100 с лишним раз, а раз в 5-10, да и сумма памяти, потребляемой всеми микросервисами скорее всего будет в пару раз больше, чем нужно монолиту.sshikov
03.02.2017 09:18>Это что ж Вы такое делаете?
То, что написано в ТЗ, а что?
>Обычно 500 Mb под инстанс монолита более, чем хватает.
Вот прямо так, без понимания того, какие задачи решаются? Хм.Source
03.02.2017 11:03-3У Вас, видимо, есть несколько примеров веб-приложений, которые могут по делу откушать 16 Gb оперативки?
sshikov
03.02.2017 11:18+2Web приложений? С чего вы взяли, что обсуждаемые микросервисы каким-то боком специфичны для веба? И тем более — что монолитные приложения ограничены им?
Source
03.02.2017 11:55-3В статье только аббревиатура HTTP встречается 6 раз, не считая множества других признаков… Так что уместнее вопрос, с чего Вы взяли, что тут обсуждается что-то кроме веб-приложений?
sshikov
03.02.2017 12:12+1Видите ли, я вот видел массу приложений, где http налево и направо — просто потому, что SOAP это обычно через http. Но они ни разу не являются веб-приложениями.
И мы тут, между прочим, corba обсуждали. Она видимо тоже веб.
А заодно, кстати, видел веб-приложения, которые совершенно по делу жрут 32 гигабайта и более — самый яркий пример это пожалуй IBM BPM. Всего-то на 50 пользователей, примерно.Source
03.02.2017 12:48-2В классических клиент-серверных приложениях все эти микросервисы 10 лет назад уже были, может ещё и раньше были… чего тут обсуждать то? Или Вы их теперь через Docker стали разворачивать? xD
видел веб-приложения, которые совершенно по делу жрут 32 гигабайта и более — самый яркий пример это пожалуй IBM BPM. Всего-то на 50 пользователей, примерно.
Судя по описанию, какая-то web-IDE для описания бизнес-процессов. Хз как она умудряется столько памяти жрать… Интерфейс весь (сохранение взаимного расположения, drag-n-drop, etc.) можно на клиенте отрабатывать, к серверу запросы только при явном сохранении или авто-сохранение раз в минуту, плюс подгрузка запрашиваемых данных в JSON.
Я даже демо-видео посмотрел ради интереса и в упор не вижу с чего бы воркеру этой штуки хотя бы 1 Gb по делу съесть, не то что 32. Просто это IBM и им наплевать сколько вам придётся памяти докупить xDSource
03.02.2017 12:58-2Кстати, посмотрел требования к IBM BPM Advanced 8.5.7
For 64-bit systems, the minimum system memory requirement to support a clustered configuration with a deployment manager, node agent, and single cluster member is 6 GB. However, for optimal performance the recommended configuration is 8 GB.
Даже исходя из этого, можно сделать вывод, что у вас скорее был какой-то баг с утечкой памяти...
sshikov
03.02.2017 13:17+2Не описания, а описания и выполнения. И да, процессы тоже жрут память.
Намекаю: если вы чего-то в жизни не видели, это не значит, что этого не бывает.
Если в рекомендациях у IBM что-то написано — это не значит, что этому нужно верить.
И нет, не было у нас утечки памяти — мы вполне способны это проверить, и проверяли. Не надо додумывать за других, особенно в областях, где вы соизволили посмотреть демо-видео…Source
03.02.2017 13:35-1Ох, как Вас бомбит, даже ссылку на официальные system requirements заминусовали… ну и ну.
Не описания, а описания и выполнения. И да, процессы тоже жрут память.
Ну, если у них бизнес-процессы выполняются в том же процессе, что и IDE, то это не монолит виноват, это уже фантасмагория какая-то.
Намекаю: если вы чего-то в жизни не видели, это не значит, что этого не бывает.
А я и не спорю, что бывает. Но когда такое бывает, всегда можно улучшить и привести систему в более адекватное состояние, было бы желание и ресурсы.
Если в рекомендациях у IBM что-то написано — это не значит, что этому нужно верить.
Вот как! То есть Вы считаете, что когда разработчик заявляет, что для оптимальной работы его системы требуется N памяти (где N — это дофига Gb), а по факту система потребляет 4*N, то это адекватная работа системы? IBM слишком высокомерна по отношению к своим пользователям, примерно как Вы — к собеседникам )
sshikov
03.02.2017 13:52+1Вы начали с самого начала делать выводы, исходя их взятых сугубо с потолка чисел, которые были просто примером. При этом я вам сразу сказал — вы пытаетесь что-то додумать, ничего не зная про требования. Т.е. вообще ничего.
И продолжаете это дальше — вы ничего не знаете про приведенную мной в пример систему, но при этом считаете, что она не может потреблять столько памяти. Продолжайте дальше — только без меня.
oxidmod
03.02.2017 11:30Есть еще одна проблема. Даже условно нелсложные веб-приложения со временем обрастают "инфраструктурой". Нужно поставить супервизор для воркеров. Нужно ставить всякие специфичные екстеншены/приложения для обработки юзерских аватаров, парсинга больших прайсов от поставщиков и 100500 прочих вещей которые нуны монолиту. И тут приходит час Ч, когда вы решили замасштабироваться горизонтально. Вы покупаете еще один сервер и начинаете на него сетапать все вот это добро, которым годами обрастало ваше монолитное приложение. Может у вас парсер прайса запускается раз в месяц, но его надо ставить. Может картинки у вас ресайзятя раз в год, но будь-добр ставь. Микросервисы за счет того что фокусируются на чемто одном требуют при масштабировании только необходимую инфраструктуру. И это безусловно плюс.
Source
03.02.2017 12:00Как правило, всё это добро сводится к запуску фоновых задач посредством того же монолита. Поэтому его сетап сводится к переносу crontab, если само приложение его не заполняет автоматически.
А если парсер прайса и ресайзер картинок — это отдельные приложения, то это уже и не монолит по сути.
VolCh
03.02.2017 16:38По мегабайту на пользователя нормально? А пользователей может быть 16 000.
Source
03.02.2017 17:14Нет, если потребляемое ОЗУ растёт линейно от кол-ва пользователей, то это нормально только для какого-нибудь кеша или in-memory БД, но там есть свои приёмы, чтобы ограничить потребляемую память сверху.
А для основного приложения — это совсем ненормально… Какой-нибудь reddit-эффект и у вас серваки вылетят с out of memory?oxidmod
03.02.2017 17:50ну если балансер всех 16к одновременных реквестов на одну ноду пустит, то так и будет))
Source
03.02.2017 18:06Под одновременными реквестами Вы имеете в виду в секунду или в минуту? Вообще, когда говорят про пользователей, обычно подразумевается, что в предыдущие N минут были какие-то запросы от 16 тыс. уников. Где N — время, исходя из которого границы визита определяются, для GA и Метрики — это 30 минут iirc. Напрямую rps из этого вывести сложно, не зная специфики приложения.
VolCh
04.02.2017 08:06Линейный рост потребляемого ОЗУ это норма, а часто идеал, которого не могут достигнуть. А под одновременными запросами имеются в виду не в секунду или в минуту, а именно одновременно обрабатываемые. Грубо, если запрос пользователя обрабатывается 100 мс, то 16000 одновременных пользователей означает 160000 запросов в секунду — в каждый момент времени обрабатывается 16 000 запросов.
А начнут серваки вылетать, ставить запросы в очередь или ещё как разумно реагировать зависит от архитектуры.Source
04.02.2017 12:23Линейный рост потребляемого ОЗУ это норма, а часто идеал, которого не могут достигнуть.
Т.е. у Вас по графику потребления ОЗУ на сервере можно сразу видеть, где были пиковые нагрузки? Ни CPU, ни Network I/O, а именно ОЗУ?
Грубо, если запрос пользователя обрабатывается 100 мс, то 16000 одновременных пользователей означает 160000 запросов в секунду — в каждый момент времени обрабатывается 16 000 запросов.
Такое количество запросов (популярность на уровне Twitter) никто в здравом уме не будет одним инстансом обрабатывать, т.е. как-то мимо начального вопроса получилось. На всю ферму серверов и 256 Gb нормально будет, а вот 16 Gb на один инстанс (а инстансов и на одном сервере может быть много) всё равно дичь получается.
VolCh
06.02.2017 13:15Т.е. у Вас по графику потребления ОЗУ на сервере можно сразу видеть, где были пиковые нагрузки? Ни CPU, ни Network I/O, а именно ОЗУ?
И по ОЗУ тоже, собственно обычно все эти графики хорошо коррелируют между собой. Обработка одного запроса требует и ОЗУ, и CPU, и I/O.
а вот 16 Gb на один инстанс (а инстансов и на одном сервере может быть много) всё равно дичь получается.
Пускай будет 1000 мс и 10 мегабайт на запрос — 16 гигов кончатся менее чем на 1600 пользователях по факту.Source
06.02.2017 14:57Я не понимаю, почему у Вас каждый запрос обязательно добавляет N мегабайт…
Возможно, у Вас какие-то очень специфичные задачи… У меня график занятого ОЗУ в течении дня обычно больше похож на горизонтальную линию, при том, что максимальная нагрузка в 20 с лишним раз больше минимальной.

indestructable
03.02.2017 19:10Пережатие видео и картинок, загружаемых пользователями, например.
Source
04.02.2017 00:17Да, я думал про такой вариант, но отбросил его, т.к. делать это на уровне своего приложения нелогично, когда уже есть ffmpeg, imagemagick и т.д.
Вопрос же был не в общем кол-ве занятой памяти на сервере, а исключительно про занятую под монолитное приложение.VolCh
04.02.2017 07:50когда уже есть ffmpeg, imagemagick
Которое ваше приложение будет использовать как микросервисы :)iCpu
04.02.2017 08:27Которые не выделываются и просто называются «библиотеками» и «приложениями».
Вы загоняете себя в ловушку терминологий.
Если динамическая библиотека или консольная тулза является микросервисом, то все стоны из монитора — пустая трата времени и сил. Все и так стараются делать модульные приложения там, где это даёт прирост, и ни один здравомыслящий человек не будет агитировать радикально против модульных систем.
В противном случае понятие «микросервисы» как самостоятельный термин обретает смысл. Но этот смысл — радикальная форма модульности, которая применима к узкому числу задач разработки высоконагруженных систем. За их пределами польза от радикалов очень сомнительна.VolCh
04.02.2017 08:35Динамическая библиотека не является — она действует в рамках одного процесса с приложением. (Микро)сервис является отдельным приложением, работающим в отдельном процессе, к которому основное приложение обращается средствами IPC. Традиционно в выражении «используем микросервис» имеется в виду «пользуемся средствами RPC для взаимодействия», то есть средствами удаленной коммуникацией, даже если приложение и сервис работают на одной логической машине, но это не обязательно.
iCpu
04.02.2017 08:53+1В этом случае ваш предыдущий комментарий. как и многие другие в этой теме, в общем случае не верен. Так как тот же самый ffmpeg не обязательно используется в качестве микросервиса, а может быть включён в приложение в качестве динамической библиотеки. Что выводит приложение из категории «монолит», не приводит в категорию «микросервисов» и позволяет максимально гибко контролировать соотношение скорость/масштабируемость и связность/распределённость.
И, кстати, выводит практически все программы из категории «монолит», ибо очень сложно найти приложение уровня пользователя, которое вообще не использует библиотеки операционной системы, на которой оно запущено.VolCh
06.02.2017 13:23Использование ffmpeg или системных библиотек как подключаемых не выводит приложение из монолитов. Вызовы API ОС в теории выводят, но всё же монолитом считают приложение, которое обращается только к ОС, но не к другим приложениям напрямую или через средства ОС. Есть приложения, которые ОС (или вообще биосом, а то и при страте процессора) только запускаются, а потом работают полностью автономно, но это уже какие-то супермонолиты. Считать их обычными монолитами, значит на большинстве практических задач исключить монолиты из рассмотрения вообще, подавляющее большинство систем не будут считаться монолитными.
iCpu
08.02.2017 06:03-1Выводит или не выводит — это очень дискуссионный вопрос. Взгляните на это не со стороны «единой программной памяти» (которой нет, у каждой библиотеки своя куча), а со стороны гибкости масштабирования приложения. Динамическая библиотека может быть загружена и выгружена на лету, средствами ОС (как и микросервисы), и может реализовывать как сам функционал, так и работу с микросервисами. То есть правильно построенный модульный проект может быть скомпанован в очень компактный альтруистичный дистрибутив, а может быть разделён на сеть микросервисов. И я бы не сказал, что это особо сложнее, чем просто микросервисная архитектура.
Конечно, тут же можно возразить, что это уже не монолитная архитектура, но, во-первых, вы уже написали «Использование ffmpeg или системных библиотек как подключаемых не выводит приложение из монолитов.», а во-вторых, динамические библиотеки с минимальными усилиями можно* превратить в статические (больше всего возни с глобальными объектами, которые не шарятся между модулями), а те собрать в единое неделимое приложение.
*Есть исключения.
Подытожу, я не говорю, что микросервисная архитектура — это плохо, она позволяет легко и быстро производить горизонтальное масштабирование. Но она НЕ серебряная пуля, и НЕ даёт преимуществ над правильно организованным модульным приложением в тех случаях, когда горизонтальное масштабирование не требуется. Напротив, оно вводит как ряд ограничений, вроде используемых протоколов взаимодействия и полного разнесения данных, так и ряд накладных расходов, в виде медленных внутренних сокетов (по сравнению с общей памятью и стеком).
Если мы говорим, что «монолит» — синоним «модульного», у меня для вас плохие вести.
Source
04.02.2017 11:21+1Которое ваше приложение будет использовать как микросервисы :)
Какая-то ложная дихотомия получается… Этак, если в проекте используется cron, то он уже микросервисным резко становится? xD
VolCh
06.02.2017 13:26Если приложение обращается к крону в качестве планировщика (обычно наоборот, крон обращается к приложению), то да. По сути крон есть микросервис планирования запуска задач. Впрочем как и большинство никсовых инструментов.
indestructable
06.02.2017 13:41"Резко" микросервисным не становится. Смотря что крон запускает. Если какую-то часть приложения, то приложение уже не монолит.

w4r_dr1v3r
01.02.2017 22:42Рискну: экономическая составляющая = рентабельность = стоимость?
VolCh
02.02.2017 08:43Да-а-а? Представим себе что это микросервис авторизации.
Будет работать публичная часть приложения. У вас это только форма аутентификации? Но ведь будет работать!sshikov
02.02.2017 10:18А почему она в монолитном приложении не будет работать? Форма будет открываться, точно также.
VolCh
02.02.2017 10:27Потому что приложение работать не будет.
rraderio
02.02.2017 10:29+6Почему это приложение работать не будет? все будет работать кроме формы аутентификации.
lpre
03.02.2017 14:24-1Наверное, имеются в виду отказы, приводящие к падению/недоступности приложения.
В одном случае упадет/недоступен только микросервис, в другом — весь монолит. Как то так.
rraderio
02.02.2017 10:19+2Так и с монолитом также, не будет работать авторизация, а все остальное будет.
VolCh
02.02.2017 10:29-4Монолит на то и монолит, что он или работает, или нет. Грубо, или слушает 80-й порт, или не слушает.
rraderio
02.02.2017 10:35+2Может один endpoint(controller/action) не работать, а все остальные вполне могут работать.
oxidmod
02.02.2017 10:41-2Скажем в случае PHP, так и будет. А в случае компилируемых приложений, один раз упав приложение уже само не поднимется и станет недоступно по всех ендпойнтах.

RPG18
02.02.2017 10:48+2Само не поднимется, но система может перезагрузить упавшее приложение.
oxidmod
02.02.2017 10:51-1Это все понятно, но это уже внешнее по отношению к приложению. Микросервисы же не тянут за собой подобной проблемы. Если микросервис упал, то остальные всеравно работают независимо от технологий, на которых они созданы.
зы. За что минус не пойму, аргументируйте чтолиRPG18
02.02.2017 11:06Начнем с того, что в зависимости от предметной области могут быть связи между микросервисами. И пока ключевой сервис не поднимется, то остальные сервисы будут ждать и ничего не делать. Независимо от монолит или мокросервисы, восстановление и отказоустойчивость это отдельная тема.
Так же в зависимости от предметной области, некоторые сервисы легко масштабировать, а другие почти невозможно.
oxidmod
02.02.2017 12:07Начнем с того, что в зависимости от предметной области могут быть связи между микросервисами.
Самое сложное в написании микросервисов — это определние границ этих микросервисов. Как уже писали в комментах, микросервис должен быть слабо связан с другими. Если этого достичь нельзя, то микросервисная архитектура не подходит для вашего приложения, вот и все. Не микросервисы плохие, просто они не подходят в данном конкретном случае.
malbaron
07.02.2017 17:15За что минус не пойму, аргументируйте чтоли
Не ставил минус, но, видимо за это:
Скажем в случае PHP, так и будет. А в случае компилируемых приложений, один раз упав приложение уже само не поднимется и станет недоступно по всех ендпойнтах.
Автоподъем сервисов реализуется нынче в любом продакшене. Хоть с микросервисами, хоть с крупносервисами.oxidmod
07.02.2017 17:31Средствами самого приложения?
mayorovp
07.02.2017 17:43Да, так тоже делают. Скажем, если в том же C# не использовать небезопасного кода, то довольно хорошо отрабатывает монитор в отдельном appdomain.
А можно эту задачу поручить и системе. Так, винда умеет перезапускать службы автоматически. В линуксе есть специальные обертки, которые занимаются перезапуском.
malbaron
07.02.2017 17:51Средствами самого приложения?
Иногда. Чаще внешними средствами.
Такое впечатление, что вы в глаза не видели микросервисы, если считаете, что оно там как-то само поднимается.
Отнюдь не сами микросервисы себя восстанавливают. Микросервисы роутятся на резервные в случае аварии и поднимаются внешними средствами по отношению к микросервисам.
С крупносервисами — также. Но иногда в них реализован и автоподъем. Для микросервисов такого не делается, так как микросервис — это управляемый извне маленький винтик большого механизма.
Если интересно — см. Kubernetes — это сейчас один из самых развитых инструментов для управления микросервисами.oxidmod
07.02.2017 18:44-1Такое впечетление что вы не читаете, но сразу бежите осуждать.
Речь шла о том, что если упадет монолит, то пока его не понимут (админы, системные утилиты, верховные силы) он будет лежать. И будет лежать весь полностью.
В случае монолита на пхп (как пример), это чуть менее критично, помтоу что каждый запрос стартует приложение по новому и лежать будет только то, что сломано, остальное вполне еще может работать.
В случае микросервисов (независимо от технологий), если падает микросервис, то остальное приложение будет функционировать (естественно зависит от степени критичности упавшего микросервиса)malbaron
07.02.2017 18:52+1В случае микросервисов (независимо от технологий), если падает микросервис, то остальное приложение будет функционировать (естественно зависит от степени критичности упавшего микросервиса)
Не все так просто.
1. Все до единого микросервисы поднимаются довольно долго. В сумме это заметно дольше, чем один монолит.
2. Монолит никто не мешает делать как минимум дублем — оригинал и реплика. Даже 2 реплики — сейчас сие стандарт для серьезных систем.oxidmod
07.02.2017 18:571. Ну это должен быть просто какойто колосальный косяк, чтобы все до единого микросервисы содержали ошибку и одновременно упали. Обычно падает один, растет очередь не обработанных событий, накрывается брокер, падает все. Но до момента падет все есть достаточно времени, чтобы откатиться на предыдущую стабильную версию и поднять один упавший микросервис, пока не упало все.
2. Конечно, можно запустить дубли монолита, если в релиз ветку пролез баг, то упадут все дубли монолита, а не все дубли одного из многих микрсоервисовmalbaron
07.02.2017 19:04А вы не пишите так, чтобы монолит падал целиком.
Современные языки программирования и инструменты тестирования облегчили вам задачу в последние годы более чем.
Когда монолит отказывается выполнять какую отдельную функцию и это вызывает возврат сообщения об ошибке — сие совершенно нормально и совершенно аналогично микросервисной архитектуре.
Вы не там ищете преимущества микросервисов.
Их преимущества в возможности горизонтального масштабирования, которая недоступна монолиту.
И за эти преимущества приходится платить менее оперативным перезапуском именно системы микросервисов и задержками в их связанностях. У монолитов все проще и быстрее.oxidmod
07.02.2017 19:18угу, проще и быстрей. Есть опыт деплоя монолита на продакшен ~ 3 часов.
malbaron
07.02.2017 19:53+1угу, проще и быстрей. Есть опыт деплоя монолита на продакшен ~ 3 часов.
Компилировали новую, предварительно опустив старую версию???malbaron
07.02.2017 19:59Или это был recover аварийно прерванных транзакций?
Уверяю вас, проблем при старте микросервисов, по причине более сложной их связанности — намного больше.
VolCh
02.02.2017 10:52-1Пока перезагружает всё приложение работать не будет :) Давайте только не углубляться, что у приложения несколько воркеров и запрос на конкретный ендпоинт будет ложить только один воркер, а остальные продолжат работать.

TerminusMKB
07.02.2017 10:25Откройте для себя, например, Java и Spring, прежде чем утверждать подобное.
VolCh
02.02.2017 10:49-1Вы не путаете «не работать» и «работать не корректно (на корректные запросы возвращать ошибку, например)»? Я говорю о ситуации «не работает» — API не доступен клиенту, отправляет запрос и или вообще не получает ответа, или получает ответ от инфраструктуры (сетевого стека ОС, например) «получатель не найден», «не могу установить соединение», «получатель разорвал соединение» и т. п. Не, может быть, конечно, несколько ендпоинтов, например основное приложение на 80 порту, а авторизация на 443 (защищаем только пароль/ключ клиента, а сессионный токен — нет) и 443 не работает (приложение при старте проигнорировало, что не смогло забиндить), но обычно всё же один делают.

dimaaan
01.02.2017 20:07+5Микросервисы позволяют по мере необходимости обновлять приложение по частям. При единой архитектуре нам приходится заново развёртывать приложение целиком, что влечёт за собой куда больше рисков.
А разве развертывание по частям не несет риски нарушения Согласованности (Consistency)?

DarkOrion
01.02.2017 20:10+13А почему никто не пишет, что при разделении монолита тотально падает время отклика системы? Вызов, который ранее случался через стек за несколько тактов теперь передается аж по сети, да еще с сериализацией в текст (http же).
Также возможность горизонтально масштабировать случается в ущерб возможности вертикально.
dimaaan
01.02.2017 20:18Согласен. Замолчали о важном факте.
Я считаю это необходимо добавить в минусы микросервисов.
VolCh
02.02.2017 08:49Это от архитектуры зависит. Время отклика может и уменьшаться при введении микросервисов. Грубо, раньше клиент делал один запрос к монолиту, который последовательно собирал данные из десятка слабосвязанных запросов по пятку таблиц в каждом, а теперь клиент делает десять запросов к сервисам одновременно, получая конечный результат раньше.

Diverclaim
02.02.2017 10:19+7Это означает только то что монолит был написан коряво. Если архитектура и бизнес-процесс позволяют из хранилища получать данные параллельно, то и монолит и микросервис могут их получать параллельно.
VolCh
02.02.2017 10:36-2У микросервисов у каждого свое хранилище, они не конкурируют, а у монолита одно хранилище как правило, а если их несколько и с каждым работает независимая часть монолита, то это уже не монолит получается :)
sshikov
02.02.2017 10:20+3Стоп, стоп. Вот не надо считать разработчиков монолита идиотами априори! )))
Если десять запросов можно сделать асинхронно — они и в монолите могут быть сделаны асинхронно — это не преимущество микросервисов.VolCh
02.02.2017 10:37-3Преимущество микросервисов — у каждого свое хранилище, запросы к ним не конкурируют.
rraderio
02.02.2017 10:42+7Точно также и в монолите, есть сервисы(не микро) и они делают запросы к разным хранилищам.
sshikov
02.02.2017 10:50-1Именно. Совершенно не понял, почему это я не могу сделать даже в рамках одной базы несколько файловых групп, размещенных на разных физических дисках, которые не конкурируют друг с другом за IOPs? Это делалось много лет назад, и делается.
А вот представить себе сто отдельных оракловых серверов вместо ста баз на одном физическом сервере мне как раз будет сложно — потому что это создаст лишние немалые расходы на их поддержку.VolCh
02.02.2017 10:55Конкурентность имелась в виду прежде всего транзакционная, а не за физические ресурсы.
sshikov
02.02.2017 11:19+3Параллельное выполнение транзакций вполне себе решается в рамках баз данных уже много лет как. Микросервисы тут ничего нового ровным счетом не дают. Еще раз — не надо представлять себе монолит как скажем один класс из 100000 строк. Такого не бывает. Даже в самом монолитном приложении есть модули, которые все равно независимы друг от друга. Иногда даже могут быть отдельно перезапущены. Это было возможно до того, как вообще появилось слово микросервис.
VolCh
02.02.2017 10:54-2Микросервис — разновидность сервисов. Если приложение разбито на сервисы, то оно уже не монолитно, а микро сервисы или «макро» — уже нюанс.
sshikov
02.02.2017 11:20+2Нюанс в том, что не разбитых на части приложений уже лет 30-40 как не делают вообще. Оно может быть монолитом в том смысле, что деплоится целиком — но при этом вполне состоять из частей. У него один общий файл конфигурации — но оно все равно состоит из ядра и плагинов.
mayorovp
02.02.2017 11:25Вот именно! Почему-то многие проводит дихотомию "микросервисы — монолит", забывая об остальных вариантах архитектуры. И выдают за достоинства микросервисов любые недостатки монолита.

jehy
02.02.2017 10:00Это только в том сферической случае, когда монолит был разнесён по микосервисам из точно того же кода, плюс у вас мгновенная скорость ответа от сервера клиенту.
По факту, микросервисная архитектура часто позволяет ускорить отдельные компоненты (этому мы дали больше ресурсов, для этого обновили окружение, этот выкинули и переписали на ассемблере), а оверхед на взаимодействие между микросервисами пренебрежимо мал по сравнению с общим временем работы и скоростью отдачи результата клиенту.
Насчёт сериализации в текст — вот вообще не понял. Если у вас были бинарные данные, они точно так же и останутся бинарными. Если нет, то там тот же незначительный оверхед.
lpwaterhouse
01.02.2017 20:13+1Все еще не понимаю почему SOA и микросервисы идут параллельно? Кто-то считает их чем-то отдельным, другие ближе к истине и считают микросервисы подмножеством SOA, но на самом-то деле это одно и то же ведь. Где грань находится?
sshikov
01.02.2017 20:26+3Да нет ее, этой грани. Знаете, мне как-то попался «рекламный» документ, о том, как мы будем внедрять микросервисы у себя в компании. Я его читаю, и вижу, что в нашем приложении, которое Java и OSGI, уже давно все микросервисы.
Вспоминаю, что было лет 10 назад — и понимаю, что EJB beans тоже были в значительной степени микросервисами. И те, и другие, не деплоятся сами по себе куда-то, а работают в контейнере — но это дает свои преимущества, скажем в плане мониторинга.
То есть, самой подобной архитектуре — ей сто лет в обед. Можно еще corba вспомнить, например. Скока это лет назад?
А дальше все зависит от того, где вы проведете границы между сервисами — может получиться хорошо, а может и не очень. Принципы — практически теже самые, что применяются «в малом» — сервис должен быть сильно связан внутри, и слабо снаружи. Так это верно для любого модуля, и это все знают.dimaaan
01.02.2017 20:30+1Вот именно.
Отсюда возникает логичный вопрос: откуда такая шумиха?sshikov
01.02.2017 20:35+3Сам бы хотел это знать :). Но вообще есть одно предположение — произошло некоторое развитие средств виртуализации, и стало очень просто задеплоить еще одну виртуалку с готовым к работе linux, или docker контейнер, где уже развернута база данных или apache, или что-то еще подобное. В мире Java это случилось лет 10 назад, в виде EJB или OSGI, и поэтому там микросервисы уже давно достарочно типичны. А щас стало возможно развернуть что угодно, одним пинком. Шумиха может и несколько излишняя, но какой-то смысл во всем этом несомненно есть.
indestructable
01.02.2017 20:37Появились средства контейнеризации, облака — и достали из закромов старый прием и назвали по-новому.
iCpu
02.02.2017 20:43+3Фигня. Это всё было и раньше, просто мы не знали, что оно называется именно так. Взгляните внимательно, это же агрессивный маркетинг, евангелистами которого являются говорящие головы крупных компаний. Не известные программисты со своим независимым мнением, а маркетологи компаний, продающих сервера. О чём это по вашему?
А по мне очевидно — о деньгах.Ребекка Парсонс считает очень важным, что мы больше не используем даже внутрипроцессное взаимодействие между сервисами, вместо этого для связи мы прибегаем к HTTP, который и близко не бывает столь же надёжен.
Спрашивается, ради чего необходимо отказываться от технологии, которая позволяет сэкономить время и ресурсы? Очевидно, деньги. И дело не столько в экономии самих тактов, сколько в создании новых квазипродуктов и захвате рынка у классических инструментов. Что мешает создать генератор API под все платформы и языки над MPI, к примеру? Почему нет? Видимо, потому, что рост рынка будет незначительным, а все деньги уйдут разработчикам MPI.
lpwaterhouse
01.02.2017 21:05Можно еще corba вспомнить, например. Скока это лет назад?
Трепыхается еще родненькая.
VolCh
02.02.2017 09:02Не одно, а подмножество. Грань, скорее всего, не в физическом размере, а в бизнес-отвественности. Микросервис имеет одну единственную собственную бизнес-ответственность, хранит данные только для неё, делегируя всё остальное, начиная с аутентификации, другим сервисам, если это вообще необходимо. Микросервисы хорошо ложаться на принципы DDD, на что указано в статье.
indestructable
01.02.2017 20:45О преимуществах микросервисов стоит судить не с точки зрения "модули, которые общаються по хттп вместо in-process call, зачем?", а с точки зрения облачного развертывания. Это скорее набор микро-приложений (а не модулей), которые друг с другом взаимодействуют мало и редко.
Представьте банковские сервисы: сервис курсов валют запрашивают миллион раз в день, сервис свифт-переводов — тысячу раз. В облаке дешевле отмасштабировать только нагруженный сервис — деплой и контейнер дешевые (бесплатные), плюс автомасштабирование от облачного вендора будет дешевле.
dimaaan
01.02.2017 20:52Т.е. содержание облака с двумя микросервисами, которые получают 1000000 и 1000 запросов за день будет дешевле содержания облака с двумя монолитами, которые получают 500000 и 500 запросов за день?
AFakeman
01.02.2017 23:41У васв облаке сколько угодно инствнсов микросервисов (пропорционально нагрузке), и у вас ровно ресурсов под каждый столько, сколько надо. Монолит же будет есть больше ресурсов, так как он будет готов как к миллиону переводов, так и к миллиону курсов валют, что оверхед.
dimaaan
02.02.2017 00:15+2Вы утверждаете, что он, при низкой нагрузке, будет жрать больше ресурсов, чем система микросервисов.
"Размазывая" работу монолита по микросервисам вы не уменьшаете общую нагрузку.
Монолит не будет есть больше ресурсов только потому что он монолит.
Монолит потребляет столько же ресурсов, как и микросервисы при одинаковой нагрузке. Просто некоторые части из которых он сложен буду простаивать.
Так что никакого оверхеда нет.AFakeman
02.02.2017 00:16Разве часть монолита которая простаивает не будет потреблять лишнего?
dimaaan
02.02.2017 00:20+1А что именно в простаивающем приложении может потреблять ресурсы?
Мне приходит на ум только "лишние" модули/библиотеки загруженные в память. Но это ничтожно мало.dimaaan
02.02.2017 00:25+1В случае, если облачный провайдер взимает плату за трафик внутри кластера микросервисов, получается наоборот: монолит жрет меньше
indestructable
02.02.2017 00:59Плюс (тут я не уверен, чисто как идея) — не будет ли проблем при запуске на одной машине нагрузки разных типов — множества быстрых запросов или маленького количества медленных, либо грузящих диск, или процессор.
indestructable
02.02.2017 00:55+2Если монолит — полный stateless и содержит в себе только обработчики запросов — то разницы нету.
Если монолит содержит в себе какое-то состояние — явное или неявное (кеши, сессии в памяти, восстановленные CQRS агрегаты ), или поведение — задачи по расписанию и т.п. — то разница есть, и значительная.dimaaan
02.02.2017 01:09А вот тут я с вами соглашусь.
Тем не менее, вы сами даете решения для монолита: stateless, липкие сессии, отдельный инстанс для задач по расписанию, распределенный кэш.
Хотя в этом случае задачи по расписанию можно выделить в отдельный микросервис, ибо ферма монолитов, будучи неправильно настроена, может конфликтовать пытаясь конкурентно выполнять эти задачи.
Получается, что микросервисы, в некоторых случаях, все же лучше чем монолит с состоянием.
Не если сравнивать с монолитом без состояния, увы, опять не вижу преимуществ.
VolCh
02.02.2017 09:28Считаем, что один инстанс может обработать по CPU/IO 500000 запросов первого типа и требует 100 метров памяти, или 1000 запросов второго типа и требует 500 метров памяти. В случае монолита вам нужно будет два инстанса с 600 метров, чтобы обрабатывать 1000000 и 1000 запросов, причем 500 метров на одном из них будут простаивать, а в случае микросервисов нужно два по 100 и один на 500 и простоев не будет.
DarkOrion
02.02.2017 09:50Считаем, что вам нужно не два инстанса по 100 и один 500 метров памяти, и не два по 600, а один на 700. Экономим на процессоре (и всем остальном кроме памяти), электричестве, аренде места в стойке.
VolCh
02.02.2017 10:59Это нарушение условий, это получается что один инстанс может обработать 1000000 запросов, не упираясь в CPU/IO, хотя и потребует 200 метров памяти. По условиям вертикальное масштабирование уже невозможно практически, только горизонтальное. Монолит мы будем вынуждены масштабировать весь, в сервисах — только узкие места.
sand14
01.02.2017 21:56-1Независимая эволюция подсистем
Микросервис может развиваться и ломать обратную совместимость, не обременяя себя поддержкой старых версий, так как всегда можно оставить старую версию микросервиса работающей необходимое время.Монолитное приложение делится на сборки (пакеты, динамические библиотеки).
Давно существуют технологии их параллельной (side-by-side) установки и выполнения.
При грамотном проектировании приложения оно и будет состоять из сборок (или групп сборок), являющихся по сути сервисами, к которым останется только добавить сетевой интерфейс для возможности масштабирования (в т.ч., как выше отметили, и каждого сервиса в отдельности) и взаимодействия по межплатформенным протоколам вместо интерфейсов объектной модели платформы, на которой разрабатывалось приложение.
Bsplesk
01.02.2017 22:40Пообщался, с народом, которые буржуинов обслуживают.
Так, вот есть вариант, одни жертвы пропаганды, и пытаются впихнуть Docker везде, что заканчивается печально(в основном по безопасности), ибо администрировать уникальных 100-500 сервисов black-box это еще то занятие, но зато у Google в наличии всегда бесплатные тестировщики.
Другие используют осознано.
Пример: ребята занимаются, глубоким анализом данных, им нужно быстро поднять супер кластер, выполнить анализ, и погасить кластер (дабы не переплачивать, за ресурсы) — они продают АНАЛИТИКУ, тем более все мы знаем, что производительность при использовании «контейнеров» в *nix близка к native. На безопасность, им грубо говоря «пофик», обновились раз в пол-года, год и норм. Вот это нормальный «case» для Docker.
Также, у них имеются, архаичные алгоритмы, использующие еще более архаичные библиотеки(libs), при этом утилизирующие процессор под 100%, кто их и как писал уже никто не знает, кроме того они работают, и не всегда есть время и ресурсы это перекомпилировать, и если архитектура чудным образом совпадает, то тут, Docker, аналогично рулит. Самое главное Docker позволяет, это делозасунуть в кластермасштабировать(но не все так гладко, как на бумаге).
Вообще Google, не дают покоя лавры java, если он добьется поддержки контейнеров для windows (по факту уже), и начнет перетягивать к себе в облака, завлекая сервисными «плюшками» + организуется инфраструктуру для Docker для домохозяек, где каждый условный расчет, можно будет запустить одной кнопкой на кластере, то вполне себе, конкурент java. Посмотрим, что из этого выйдет.

TigraSan
02.02.2017 02:34+1Пример монолита потребляющего больше ресурсов(как человеческих так и машинных) чем микросервисы:
Есть некий вебсервис, позволяет загружать и обрабатывать видео
Напиcан скажем на python, просмотров видео, комментариев и.т.д намного больше чем загрузок и обработки видео
backend можно разделить на две части — api для frontend-а и обработка видео
Обработка видео подразумевает, что система должна содержать в себе(а python, как правило. подразумевает и подгрузить) кучу библиотек, а в идеале иметь соответствующее железо
Фронтенду и бэкенду все это не нужно. Более того, они не должны страдать от бага в коде обработки видео и упасть при импортах.
При разделении на микросервисы отпадает необходимость оптимизаций и разделений на уровне кода, чтоб ни дай бог, бэкэнд api не попытался проимпортировать что-либо, что потянет за собой импорт, например opencv, которого и в помине нет на серверах api backend
Допустим баги это уже слишком, они должны выявляться раньше
Но в плане нагрузки — фронтенд и бэкэнд api нужно развернуть 100 раз, а сервис для обработки видео 10 раз
Монолит потребует загрузить тот же opencv все 110 раз. Либо быть аккуратней с импортами. А где нужно быть аккуратней — там опять таки баги
Докер же помогает поддерживать обе среды в постоянном состоянии, легко доступном как разработчикам, так и для деплоя. Отсюда и микросервис-бум. Раньше это было намного сложнее(не путать с невозможно)iCpu
04.02.2017 07:15Ответьте, с чего вы взяли, что «монолит» — это говнокод, в котором нет ни отлова ошибок, ни обработки исключительных ситуаций, ни, О УЖАС!, разделения на модули, которые можно обновлять по отдельности? Почему монолит — обязательно говнокод?
Вот вам контрпример, причём сильный. Никсовый bash обладает полным набором всех необходимых любому программисту функций. Большинство никсовых команд — приложения (читай — микросервисы). Иными словами, скрипты баша — одна из первых массовых микросервисных систем. Тем не менее, никто не программирует серьёзных приложений на bash. Все почему-то лезут то на плюсы, то на джаву, то на питон, то ещё куда. Вопрос: почему? И второй вслед: если эта логика справедлива на уровне построения модуля, то почему она перестаёт быть справедливой уровнем выше?
И под конец, хватит уже нахваливать докер. Это не панацея, а узко специализированная виртуальная машина под никсовые сервера. Которая за пределами своей задачи работает весьма херово.VolCh
04.02.2017 08:21ни, О УЖАС!, разделения на модули, которые можно обновлять по отдельности?
Если можно обновлять модули по отдельности без особых рисков — это уже не монолит.
Иными словами, скрипты баша — одна из первых массовых микросервисных систем.
Не верно. Скрипты баша — одна из первых массовых систем автоматической оркестрации микросервисов :)
узко специализированная виртуальная машина под никсовые сервера.
Не виртуальная машина, а удобный инструмент для управления изоляцией процессов средствами ОС. Докер не изолирует процессы больше чем может сама ОС, вся инфрастуктура докера по сути заточена на то, чтобы было удобно запустить стандартный процесс (ну и взаимодействовать с ним) стандартными средствами ОС, передав им нужные параметры изоляции в легко понятной человеку форме. Какие ещё задачи вы пытаетесь на докер возложить, что он с ними хреново справляется не в никсовом серверном окружении?iCpu
04.02.2017 08:42+1Если можно обновлять модули по отдельности без особых рисков — это уже не монолит.
Но ещё не микросервис.
Не верно. Скрипты баша — одна из первых массовых систем автоматической оркестрации микросервисов :)
Хоть груздём назови, только в печку не кидай.
Какие ещё задачи вы пытаетесь на докер возложить, что он с ними хреново справляется не в никсовом серверном окружении?
Работать под виндой?.. В целом, докер — вполне себе виртуальная машина. То, что он не эмулирует оборудование, а протаскивает его от хоста — не показатель. Куда интереснее, запустится ли он с отключёнными средствами аппаратной виртуализации аля Intel VT/AMD-V? Я не знаю.
Envek
04.02.2017 19:02+2Docker — не ВМ. Это всего лишь удобный консольный интерфейс для запуска программ в ограниченном окружении, используя уже имеющиеся в ядре Linux технологии: capabilities, namespaces, cgroups, veth, aufs, overlayfs, iptables. Плюс эффективное хранение контейнеров в виде «слоёных» ФС и удобство их создания, получения, распространения (Docker Hub). Ещё маркетинг и пиар. Всё.
запустится ли он с отключёнными средствами аппаратной виртуализации аля Intel VT/AMD-V
Если у вас запустится свежий Linux (на ядре 3.сколько-то там), то у вас запустится докер. Все эти побрякушки ему не нужны. Процессы в контейнере — это процессы вашей ОС. Просто у них подрезаны capabilities, они засунуты в namespace, на них навешана cgroup, у них свой виртуальный ethernet-адаптер и отдельный chroot на каждый контейнер. Если захотите, то сможете сделать это всё и ручками.
lega
04.02.2017 19:14для запуска программ в ограниченном окружении
Самое интересное что там можно запустить другой дистрибутив (ядро) отличное от хостовой ОС.malbaron
04.02.2017 20:37Самое интересное что там можно запустить другой дистрибутив (ядро) отличное от хостовой ОС.
Ключики в конфигурационном файле для другого ядра какие подскажите
Envek
04.02.2017 21:08Дистрибутив — да, ядро — нет. Процесс в контейнере будет загружать и использовать библиотеки из дистрибутива в контейнере (libc, например), но работать он будет на ядре вашей ОС. Потому что это будет процесс именно вашей ОС, и вы его увидите в списке процессов вашей ОС (
top,ps) и у него там будет PID и этот PID будет отличаться от того, что в контейнере (там он будет иметь PID 1, потому что в контейнере не запускается своей ОС).
Просто попробуйте выполнить
unameдля разных дистрибутивов:
? ~ docker run ubuntu:12.04 /bin/uname -a Linux 1c89ad5dc611 4.9.6-moby #1 SMP Sat Jan 28 17:18:18 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux ? ~ docker run ubuntu:16.04 /bin/uname -a Linux 4ec17fded22d 4.9.6-moby #1 SMP Sat Jan 28 17:18:18 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux ? ~ docker run centos:7 /bin/uname -a Linux efba65e848c1 4.9.6-moby #1 SMP Sat Jan 28 17:18:18 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
iCpu
04.02.2017 20:53На никсах — возможно. Я, как виндовый разработчик, могу говорить определённо только про виндовую ветвь. И что-то мне подсказывает, что в ней это всё сделано через виртуальную машину Hyper-V. Не знаю, быть может дело в том, что докер не ставится в отсутствии оной?
Envek
04.02.2017 21:24На других операционках да — ставится ВМ с Linux и на ней работает Docker. Про Windows не скажу — много лет уж не пользуюсь, но на макоси Docker безбожно тормозит и есть много геморроя с настройкой сети.
VolCh
06.02.2017 13:34В последних релизах виндовс «ядро» линукс реализовано (не до конца, правда) нативно, без виртуализации, просто ещё относительно высокоуровневое API над Kernel API наряду с Win API или как там оно называется. И под виндовс докер запускается, афаик, тремя основными способами: виндовс-докер для виндовс-приложений нативно над Win API, линукс-докер для линукс-приложений в виртуалке, линукс-докер для линукс-приложений нативно над Linuх API.
iCpu
06.02.2017 13:43Но зачем ему Hyper-V для нативных приложений Windows? Или это от лени, дабы не тратить время на отсталые оси и отсталых разработчиков?
VolCh
06.02.2017 13:47Есть Docker под Windows для Linux-приложений от команды докера — он через виртуалку работает, есть поддержка Linux от Microsoft — она нативная :)

VolCh
02.02.2017 10:17Создайте базовую клиентскую библиотеку HTTP REST, оптимизированную для REST-вызовов, на основе которой можно строить конкретный микросервисный клиент, им будут пользоваться другие микросервисы. Этот оптимизированный клиент должен быть портирован на все языки, применяемые в вашей экосистеме.
HTTP REST сомнительное решение для API микросервисов, бизнес-логика которых не состоит большей частью из CRUD операций над сущностями, а состоит из масштабных изменений (включая создание и удаление) состояний сущностей в ответ на какие-то события в другом ограниченном контексте или явные команды пользователей с небольшой полезной нагрузкой.
Какие-то варианты RPC и(или) MQ в случаях когда большинство сценариев использования выглядит примерно как (в скобках полезная нагрузка):
— зарегистрировать нового клиента (куча персональных данных)
— создать (список товаров и их количества) и предоставить ему договор со статусом «черновик»
— при подписании (просто событие) изменить статус договора на «подписан» и сформировать и предоставить счёт на оплату
— при оплате (сумма) и её достаточности изменить статус договора на «доставка» и сформировать бухгалтерские проводки и ордер службе доставки
— … куча событий службы доставки в другом контексте
— при получении подтверждения о доставке (просто событие) изменить статус договора и ордера на «исполнен», перенести договор их оперативного хранилища в архив, поставить «лайк» менеджеру для системы мотивации
И это только идеальный сценарий и без получения оперативной и глобальной аналитики
По сути у нас лишь две операции явно создающие какие-то сущности/ресурсы и куча неявных побочных созданий, изменений и т. п. других сущностей, о которых часто даже информировать инициатора запроса не нужно, просто сообщить ему «ваш запрос принят к обработке», а информировать надо кого-то другого.

velvetcat
02.02.2017 10:35+7OMG, опять «микросервисы — это масштабируемость». Масштабируемость сервиса зависит от того, создали его масштабируемым, или нет.
VolCh
02.02.2017 11:04-1Микросервисы гораздо легче (в том числе дешевле) масштабируются при прочих равных, если нагрузка на разные функции приложения в целом растёт непропорционально. Грубо, запросы к одной функции приложения стали делать в 10 раз чаще чем к остальным — в случае микросервисов мы отмасштабируем только эту функцию, в случае монолита или «макро»-сервиса будем вынуждены масштабировать и остальные, тратя зря ресурсы.
lega
02.02.2017 12:04При правильной архитектуре, можно выдернуть эту функцию из монолита (подменить на «прокси») и сделать микросервисом либо внешней либой (на c/с++, если нужна оптимизация), с минимальными изменениями в монолите. Преимущество в том, что это будет сделано когда будет реальная необходимость.
avost
03.02.2017 02:55+2А там в статье ровно это и написано — если у вас есть новый проект, не делайте его сразу на микросервисах. Но постарайтесь сделать его архитектуру такой, чтобы при необходимости, вы могли выдернуть из него компоненты и преобразовать их в микросервисы. "правильная архитектура" она же из нечего не появляется сама по себе. За ней должна какая-то идея стоять. Вот микросервисы и есть одна из таких идей. Примуществом этой идеи является то, что она достаточно внятно сформулирована.

ggo
02.02.2017 13:26Микросервисы, как и прочие технологии, не серебрянная пуля. Это все лишь инструмент для решения определенного класса задач.
Как и с любым инструментом, микросервисы нужно уметь правильно готовить. Не в смысле взял докер, разделил базы, выставил api в виде rest, etc. А в смысле, правильно оцениваешь риски и выгоды, и распределяешь их в оптимальном сочетании.
При «умелом подходе» на микросервисах запросто можно сваять известную коричневую органическую массу.
Точно так же как и при использовании монолита.
Верно и обратное, с головой можно качественно ваять и на микросервисах, и на монолите.
Главное преимущество микросервисов перед монолитами — собственно говоря почему про микросервисы говорят из каждой кофеварки — микросервисы лучше чувствуют себя в cloud.
indestructable
02.02.2017 17:53Если брать полный стейтлесс монолит, то он будет идентичен микросервисам в плане цены масштабирования только при условии, что хранилище данных масштабируется независимо.
Однако нагруженные микросервисы можно вынести на отдельные базы, если они допускают определенную несогласованность данных. Монолит так масштабировать обычно нельзя, т.к. некоторые части должны все-таки работать с согласованным хранилищем.
lega
02.02.2017 18:08Куски монолита тоже можно «вынести» на отдельные базы.
некоторые части должны все-таки работать с согласованным хранилищем.
Зависит от бизнес процессов.indestructable
02.02.2017 18:13Это должно быть заложено на этапе разработки. Просто запустить несколько инстансов, которые указывают на разные базы, не получится, т.к. запросы будут идти на случайный инстанс. Либо "умный" роутинг запросов на лоад балансере, но это, как мне кажется, крайняя и сложная мера.
malbaron
03.02.2017 10:24Единственные преимущество микросервисов — горизонтальное масштабирование. Если оно вообще на вашем проекте нужно, так как дает снижение производительности, если оно не нужно.
Все остальное прекрасно реализуется на монолите.

uniqm
03.02.2017 11:51+1Обсуждая микросервисы vs монолиты, нужно договориться, о каком монолите речь.
Просто у кого-то в голове возникает образ некого скомпилированного исполняемого файла, который при всем желании невозможно масштабировать количеством запущенных копий и балансировщиком перед ними.
А если представить RAILS-приложение(и подобные), которое вроде как монолит, то там прекрасно всё масштабируется. Тут единственный существенный минус — это выкатка новых версий подсистем монолита.VolCh
03.02.2017 16:45Масштабируется, но не прекрасно. Один только роутинг может занимать заметное время, если у вас тысячи роутов на регулярках. Да и сами обработчики займут место в памяти, даже если не вызываются. Прогретые кэши для всех них и т. п. А по факту реально используются юзерами с десяток, а все остальное раз в году для отчёта дергается или нового суперадмина назначить.
uniqm
03.02.2017 17:18Согласен, но быстродействие и потребление ресурсов (а я не думаю, что уж так много лишний «груз» кушает, конкретно в рельсах) это лишь пара критериев. Да, оба показатели будут хуже заточенных решений, вопрос насколько.
Зато, например, какая хорошая утилизация железа. Есть 10 серверов, раскатываем монолит на все сервера и гоним через балансировщик запросы. А в случае с микросервисами придется решать задачку — какой сервис на какую/какие машины раскинуть. В итоге часть железа простаивает, ибо заложили под пики нагрузки. Это можно победить, но ценою усложнения системы.VolCh
04.02.2017 07:48+1Утилизация как раз обычно с микросервисами лучше. Например, редко используемая функция (ежедневный отчёт какой-нибудь) требует несколько гигабайт оперативки и грузит процессор длительное время на 100%, а остальные вполне работают на сотне мегабайт и в основном ждут ответа от СУБД. Выносим её в микросервис и нам нужна только одна машина с гигабайтами, остальные по сотне мегабайт.
Source
04.02.2017 11:53Отчёты обычно формируются на основе сложных запросов к БД. Поэтому на порядок лучший профит получится, если формировать отчёт запросами к реплике БД, а не от того, что основная БД будет также загружена запросами из другого процесса.
VolCh
06.02.2017 13:37Реплика тут не причём, говорим о формировании самого отчёта средствами приложения, а не СУБД. Из СУБД данные пришли (из реплики или нет — приложению не важно), а мы на их основе формируем представление для пользователя.
Source
07.02.2017 20:37Так формирование отчёта по уже выбранным данным не требует гигабайтов оперативки, если это не отчёт на несколько тысяч листов. SQL для того и существует, чтобы из БД только нужные для отчёта цифры достать. Или Вы имеете в виду, что можно косячно формировать отчёт, но вынести это в микросервис и уже будет не так заметно, что отчёт формируется чёрти как?
Envek
04.02.2017 21:38+1Забыли про ещё один момент: цена добавления и последующего удаления временной функциональности из монолита.
Когда есть монолит и есть запрос «доделать существующее, но хитро» то есть большой соблазн это сделать именно в рамках монолита, хотя и известно, что это нужно временно (спустя год эта функциональность уже будет не нужна). Что же, добавляем функциональность, дорабатываем её, развиваем, а через некоторое время её нужно будет удалять и «выкорчевать» вросший в монолит код уже будет непросто. А если не выкорчёвывать, то будет мёртвый код, который будет постоянно мешать обновлять фреймворки и языки программирования и т.д. и т.п.
А если сделать под этот запрос отдельное приложение, то удалить его будет очень просто :-)
iCpu
08.02.2017 06:30Позвольте с вами не согласиться. Вам в любом случае нужно временную функциональность:
- Вызывать;
- Обрабатывать;
- Сохранять результат.
- Вызываться;
- Обрабатываться;
- Сохраняться.
- Вызова;
- Обработки;
- Сохранения.
Если вы считаете, что я в чём-то ошибаюсь — скажите, в чём?Envek
08.02.2017 09:06-1- Вызывать можно банальным редиректом или отдельным upstream'ом в Nginx.
- Обрабатываться оно будет в отдельном приложении-микросервисе
- Сохраняться будет в отдельную БД.
Сразу бонусом получаем лёгкость переноса этой функциональности (вместе с базой, которая в обычной архитектуре веб-приложений является «бутылочным горлышком») на отдельный сервер в случае резкого прилёта нагрузки на неё из-за которой начинает тормозить всё приложение.
Да, в монолите это всё тоже можно делать, но сложность монолита начинает расти, и разбираться в его коде тоже становится сложнее.
iCpu
08.02.2017 09:52+11) Его всё ещё нужно делать. Без разницы, как именно происходит вызов, данные для вызова должны быть подготовлены и упакованы. То есть код вызова в любом случае будет внедрён во все связанные модули. И должен будет удаляться оттуда. И если вы наивно полагаете, что код микросервисов не будет становиться сложнее, чем код монолита, (как минимум, столь же сложнее, как и) от того, что 20 микросервисов теперь будут дёргать нового временного друга, вы не очень умны.
2) Обработка не в смысле выполнение временной функциональности, а в смысле реакции остальной системы на возможные сценарии работы временной функциональности. Она в любом случае должна будет покрывать все стандартные ситуации работы Это я не про вылеты-перезапуски, а про вполне буднечные запросы-оповещения «я покушал» и «я покакал».
3) Данные подготавливаются не для повышения энтропии, а для вполне себе утилитарных нужд. Это значит, что они либо будут переводить систему в другое состояние (например, эмуляция оборудования), либо отображаться пользователю этой самой фичи (нужно будет создать запросы и, возможно, UIшки для отображения данных). То есть потребители данных должны получить унифицированный интерфейс, который возникнет не из воздуха, а будет внедрён в существующие модули соответствующей функциональности. А потом — удалён. И если вы думаете, что в микросервисах проще создавать эти самые связи внутри модулей, чем у монолита, опять же, вы либо не особо понимаете разницу, либо программировали монолиты в те времена, когда были говнокодером.
Иными словами, мантра «отдельное приложение» лично мне ничего не говорит. Да, есть лёгкость горизонтального масштабирования, а унифицированный API с удобным встраиванием есть? А отладка как, не хромает? Удобно ради какой-нибудь банальной мелочи целый микросервис городить и гонять тонны данных вместо внедрения пусть и неуместного в каком-нибудь контексте кода?
Да, сложность монолита растёт, но она растёт не быстрее, чем сложность взаимосвязей микросервисов.Envek
08.02.2017 10:21-1У вас какой-то переусложнённый пример в голове, как мне кажется.
Пример из жизни, который доставил мне боль и думая про который я писал комментарии: тупо веб-сайт.
Дано: веб-сайт с функциональностью создания опросов для пользователей (не основная функциональность, но есть).
Задача: сделать более хитрые опросы да ещё в разрезе подчинённых организаций (что-то типа, устроило ли вас обслуживание). Аутентификация-авторизация не нужна, UI отдельный, нужна выгрузка результатов в Excel. Взаимосвязи с остальным сайтом 0 (ноль).
Как сделали: добавили новые типы опросов (куча условной логики везде), новые шаблоны, справочник долбаных организаций в админке и ещё одна библиотека для работы с Excel (чем не устроила предыдущая, история не сохранила). А потом ещё некоторые из организаций начали активно себе накручивать голоса (вот тут приехала нагрузка, часть из которой была вызвана логикой отложенной обработки голосов, не нужной именно этой функциональности).
Как надо было сделать: скопировать всю базовую функциональность в отдельное приложение с отдельной базой, доработать её там, навернуть любых библиотек и наворотов по желанию, развернуть на отдельном домене и сервере и после того, как оно поработало и заказчик получил свои результаты — удалить нафиг сразу вместе с той виртуалкой, на которой оно было развёрнуто.iCpu
08.02.2017 10:43+1Сферический в вакууме.
А приведённая вами в пример задача в её текущей формулировке звучит скорее «нам дали протухшую задачу, мы наспех дерьмово спроектировали модули и не сделали бекапов, поэтому не проехали на Оке и пришлось вызывать говномесные тачки». Ваше решение «сделать всё то же самое, но на бекапе». Иными словами, у вас в любом случае были бы и новые шаблоны, и справочник долбаных организаций в админке, и ещё одна библиотека для работы с Excel, и куча условной логики везде. Ничего бы не изменилось. Ваша основная проблема в том, что никто не подумал изначально сделать опросы максимально изолированным модулем, чтобы его изменение не требовало такой боли. Проблема не в том, что opinion_poll.php был куском Monolith, а в том, что он не был ограничен opinion_poll.php и opinion_poll.html
Source
03.02.2017 17:51Кстати, роуты в Rails проверяются по порядку, так что если у Вас реально проблема с тысячами неиспользуемых роутов, то вынесите десяток реально используемых на самый верх routes.rb и остальные роуты будут отнимать ресурсы на проверку раз в году, или когда там до них дело дойдёт )
VolCh
04.02.2017 08:26В память всё равно загрузятся сразу :) И речь не конкретно о Rails, а подобных фреймворках в целом, в которых могут проверяться все роуты, а выбираться наиболее точно совпадающий. Например, если для роута get_user с путем /user не указан метод, а для post_user с тем же путем указан метод POST, то роутинг должен выбрать второй, если запрос на этот путь отправлен методом POST, независимо от того какой указан раньше.
Source
04.02.2017 12:00Естественно сопоставление роутов идёт с учётом метода. Это не значит, что из-за этого проверять придётся все. Но в память загрузятся все — это да… несколько десятков килобайт займут )))
VolCh
06.02.2017 13:40Я про то, что есть роуты без указания метода, а есть такой же но с методом. Запрос с этим методом должен отработать по этому роутеру, а со всеми остальными по первому, независимо от ого какой выше, какой ниже. Тут только всё проверять в общем случае без оптимизаций типа дерева роутов и т. п.
Source
06.02.2017 15:06А я понял, Вы про роуты, которые для всех методов подходят. В таком случае в Rails будут просто игнориться все последующие дубликаты этого роута с указанием конкретного HTTP-метода. Хотя допускаю, что где-то роутинг может искать best match до победного конца, но имхо это странный вариант… first match будет всегда работать быстрее.
Pilat
03.02.2017 12:47+1Пример: небольшая компания делает внутренний проект, пользователей несколько десятков по стране. Делает один человек. Естественно получается монолит в каком-то смысле. Потом добавляется второй проект, как-то связанный с первым — второй монолит. Потом ещё несколько. Все они взаимодействуют. Потом оказывается, что внутри первого есть малосвязанные компоненты, как-то друг с другом общающиеся все по разному — кто через базу, кто через CGI скрипт со странными форматами передачи данных, кто-то поставляет на соседний сервер обновления через rsync — зоопарк. Так как проект растянулся на десятилетия, есть архаичные версии систем, языков, технологий и библиотек. Проект работает сам собой годами, без серьёзного вмешательства. И тут надо что-то поменять. Небольшое. Например добавить 1000 пользователей. И оказывается что поменяв в одном месте — поменяется и в другом, а даже наличие описания не помогает потому что архитектура требует одного сервера в узком месте. Перенести на новую ОС не удаётся — там давно не поддерживаются старые библиотеки. Базы данных, которые обслуживают части монолита, не поддерживаются уже 10 лет но там где запущены — работают как часы и все забыли что они есть. Вот реальная проблема реальных систем не топовых компаний. На этапе разработки термина "микросервисы" не было. Теперь понятно, что надо было стандартизировать общение между компонентами и разделять на куски в расчёте на поддержку некоторых кусков 20 лет без изменений, а других править каждый день.
Сейчас огромный плюс разделения на микросервисы — возможность разделения задачи на разные языки и технологии и поддержка маленьких компонентов случайными людьми — по мере необходимости нанимаем специалиста по эрлангу или перлу или яве на текущую задачу на пару месяцев и всё хорошо. Сервис маленький, описание простое, протестировать можно. 20 лет назад были модны программисты-универсалы, сейчас больше одного-двух языков/технологий знают единицы. А выбор языка диктуется самыми разными причинами — например описание API на swagger довольно жёстко задаёт выбор одной из 20-ти технологий из которых половина Java.
А облака… это всё хорошо, но как-то облачно. Масса организаций в облако не отдаст ничего.
В общем, микросервисы — красивый термин, и статья как раз хорошо описывает что это такое на самом деле, без приукрашиваний.
uniqm
03.02.2017 14:52Все правильно, но сама задача «Разбить проект на слабосвязанные компоненты с жесткими контрактами на взаимодействие между ним» очень непростая, особенно если надо заглянуть в будущее. И по идее уже не так важно, внутри монолита дробить или между сервисами.
Мне кажется оптимальным начать с монолита, а походу смотреть и находить линии «разреза». Так не только я считаю, и другие видят в этом нормальную стратегию.
msts2017
03.02.2017 15:00-1чет не сказано чем микросервис отличается от сервиса, точнее почему понадобилось вводить новый термин.
oxidmod
03.02.2017 15:04+1Микросервис вовсе не значит что он будет микро в плане количества стрчоек кода. Он микро в плане количества решаемых задач. Микросервис делает всего одну вещь, но делает её хорошо, быстро и надежно. Unix-way короче
lega
03.02.2017 15:17+1А БД, вебсервер (mysql, redis, nginx...) относятся к микросервису? Отдельный процесс с коммуникацией «по сети», вроде подходит. Если да, то получается все изначально используют микросервисы.
oxidmod
03.02.2017 15:31не совсем)) эти вещи не решают бизнес-задач. Они решают технические вопросы хранения данных, общения с клиентом, еще чтото, но не решают бизнес-задач. Это инфраструктура для микросервиса)
lega
03.02.2017 22:05+1бизнес-задач
Это очень расплывчатое понятие, а модуль авторизации, модуль суммирования массива или другая арифметика, модуль поиска числа в массиве — бизнес задачи или нет? А если сервис (node.js) просто пересылает данные из nginx в mysql и обратно — бизнес логика/микросервис?
Я считаю проще, если я делаю какой-то (сетевой) вызов в другой самостоятельный процесс, то этот процесс — (микро)-сервис. Просто mysql/redis — это уже обыденность и не хочется признавать это микросервисами, т.к. микросервисы — это вроде как повышенная сложность. К тому же некоторые хранят часть логики в самой БД.oxidmod
04.02.2017 03:06Бизнес задачи это вполне конкретные понятия. Вы зачем собственно программу пишете? Вот сервис авторизации/аутентификации вполне решает бизнес-задачу по ограничению доступа к системе. Если бы он не решал, то его небыло бы в вашей системе, разве не так?
Bsplesk
04.02.2017 04:03+1Не так все просто, как сказали выше, «очень расплывчатое понятие»
Бизнес делает «бабки», на прямую этот сервис авторизации «бабки не делает», тоесть с точки зрения бизнеса это техническая поддержка/обслуга необходимая для выполнения бизнес процесса(ключевое — приносящий бабки), если только бизнес не продает услугу «авторизации/аутентификации», и вообще сейчас мода, что в бизнесе остаются только бизнес задачи, все остальное на «аутосорс», тоесть «авторизации/аутентификации» организовать через какой-нибудь «Центр авторизации TM ID» или Google или vk, выбрать из них лучшей по качеству услуги, тоже самое, как не держать уборщицу в штате, а вывести ее на «аутосорс», аналогично все то, что не требует менее «1 целой штатной единицы» по мнению менеджера.
Вот отсюда, и дует ветер всех этих «микро сервисов», чтобы в IT организовать тотже «ауторос», тоесть нужен для выполнения бизнес задачи (условно — продача чайников) — поиск, выбираем из поставщиков google/bing/yandex и.т.д., большие «дяди» вложились в cloud, теперь услуги продавать, окупать инвестиции.
Писал уже выше пример — кейс, для вашего бизнес процесса, нужны допустим какие-то вычисления, вот их то вы и заказываете (а docker просто обвязка, которая теоретически позволяет экономить бабло обеим сторонам, по идеи выгоднее виртуалок), и заказать эти вычисления вы, как у amazon, так и у google, и выбрать наиболее подходящий для себя вариант ---> по факту это загон в cloud, всем известно, как легко перевести часть процессов в cloud, и как сложно их оттуда порой выцара?пывать.
Прогноз: Как только «корпораты», переведут все часть процессов в cloud, так ловушка и захлопнется, и пойдет увеличение тарифов, ничего нового в общем. Но конкуренция среди cloud сервисов будет возрастать и это хорошо.
Вот по этому, ваши сервисы и назвали «микро», ибо они действуют в рамках большого сервиса, который предоставляет cloud провайдер.indestructable
06.02.2017 13:49Не совсем в тему микросервисов, но хочу заметить, что слово "бизнес" применительно к архитектуре приложения не имеет (в общем случае) отношения к коммерции, а обозначает ту "пользу", которую приносит конкретное приложение.
Поэтому сервис авторизации для конкретного приложения — это бизнес-функциональность, но в то же время используемая библиотека для OAuth2 — это уже не бизнес-часть, т.к. она универсальна и не привязана к предметной области.
Поэтому суммирование массива — не бизнес-функциональность, если у нас, конечно, не приложение по суммированию массивов (Excel).
VolCh
04.02.2017 07:39Все (почти) используют, но не все пишут :)
lega
04.02.2017 12:31Микро-сервис написанный не вами не перестает быть микро-сервисом.
VolCh
06.02.2017 13:43Команда пишет приложение, реализующие какие-то функции. От того, что это приложение используется сторонними приложениями как сервис или даже микросервис, от того, что это приложение использует сторонние приложения как сервисы или микросервис, никак не зависит является ли архитектура самого приложения монолитной или сервисно-ориентированной.

y90a19
07.02.2017 10:15+1Итак, отчего мы отказываемся в случае перехода на микросервисы
1) От транзакций. Главный минус
2) Получаем проблемы с версионной совместимостью этих микросервисов между собой
3) Вместо работы внутри процессора и системной шины мы гоняем данные по медленной сети и всему сетевому стеку. Сильное замедление работы. Получаем сильную зависимость от качества сети
4) Повышение надежности — миф. Приложение не может работать без какого-то компонента. Это будет некорректная работа.
5) Все эти микросервисы в сумме потребляют больше памяти и ресурсов, чем монолит
6) Вынужденное дублирование кода. Либо приходится делать какие-то отдельные проекты с общим кодом
7) Невозможность рефакторинга. Мы получаем кучу внешних интерфейсов, которые нельзя трогать. Либо придется править одновременно все микросервисы
8) Сложность при обновлении, если изменился внешний интерфес. Приходится обновлять одновременно несколько микросервисов. Если будет рассинхронизация — клиенты получат ошибки.
9) Сложность правки базы. Сложно понять, использует ли эту таблицу какой-то другой микросервис. Приходится пересматривать код всех микросервисов. И опять возникает проблема одновременного обновления.
Что получаем взамен? Мнимую красоту кода. И больше ничего. Очередная серебряная пуля
mayorovp
07.02.2017 10:33Про базу (п. 9) вы загнули. У каждого микросервиса должна быть своя база, или хотя бы своя схема в общей базе.
y90a19
07.02.2017 10:46кстати, что насчет ресурсов на работу кучи баз. Один только оракл кушает минимум 2 гига оперативной памяти
oxidmod
07.02.2017 11:03у вас вполне может быть один сервер-бд, но содержать несколько баз. В чем проблема? Вы явно не понимаете важности границ. Есть смысл выпиливать из монолита микросервис, когда вы четко определили его границы и данные, которыми он владеет.
y90a19
07.02.2017 11:13т.е. вы признаете необходимость и монолита, и нескольких сервисов вокруг. Евангелисты же выступают за полную ликвидацию монолита и замену его кучей сервисов с кучей межсервисных взаимодействий.
oxidmod
07.02.2017 11:24Я утверждаю, что микросервисы — это эволюция монолитного приложения, когда его сложность становится слишком большой.
oxidmod
07.02.2017 10:58+1- От каких транзакций вы отказываетесь?
- Никаких проблем нет. Вас никто не заставляет ломать обратную совместимость в минорных патчах. При необходимости таких изменений используется стандартное решение через /api/v1/… /api/v2/… при том вас никто не заставляет поддерживать 100500 версий. Пользователи этих апи — это все тоже ваше приложение и ваши коллеги, которых их саппортят. Приняли решение ломать совместимость, опубликовали соответсвующий раздел в доках, оповестили все команды и поставили дедлайн до которого они должны апнуться.
- Да, безусловно так, но никто не заставляет вас гонять данные через весь земной шар. Здажержки в локальной сети не такие уж и большие, особенно по сравнению с сетевыми задержками между вашим приложением и конечным пользователем. К томуже, шлюз, с которым общается конечный пользователь вполне может работать с остальными микросервисами асинхронно, что сведет сетевые задержки на общение микросервисов практически к константе, не зависящей от количества этих самых микросервисов.
- Не поверите, но может. Не случиться ничего страшного, если по какойто причине упадет рассылка писем. Да пользователи не получат писем некоторое время, но как только рассылка поднимется все задачи с очереди будут выполнены. Останется досутпной публичная часть системы, если вдруг упадет авторизация. Более того, залогиненые юзеры смогут продолжать работу. Да, когда падает критически важный микросервис, то работа встанет. Но даже в таком случае. На прошлой рабте у нас был здоровенный монолит, деплой которого на прод сервера в двух датацентрах занимал около 3 часов времени. Фикс в 5 минут времени деплоится 3 часа. Микросервисы меньше, проще, легче разворачиваются.
- Наоборот, микросервисы лучше утилизируют ресурсы. Их можно разворачивать на машинах оптимизированых на ту или иную нагрузку. Файлохранилищам нужны быстрые и надежные диски. кеши требовательны к объему озу и так дальше. Если ваш логин сервис не справляется с количеством жалеющих залогинится, то вам нужен просто еще один логин сервис, а не все огромное приложение.
- Отдельные проекты с общим кодом — плохой вариант. Да, нужно дублирование кода. Но это не так страшно. DDD отличо ложиться на идею микросервисов. Сервис владелец имеет код позволяющий создавать/менять/удалять некие сущности. Сервисы которым нужны эти сущности получают упрощенный код, рид-онли модели, на которые мапятся ответы апи сервиса-владельца. Да, лишний код, но он пишется один раз, да и пишется громко сказано. ИДЕ спокойно нагенерит класс с конструктором и пачкой геттеров.
- Это тоже что версионирование. Помогает с этим бороться во первых слоеная архитектура. Вы можете как угодно менять бизнес логику приложения, оставляя неизменный внешний интерфейс пока это возможно. Как только это становится невозможно, смотрите пункт 2. В монолите при таких изменениях вам точно также придется править все места, где модуль используется.
- Вы уже третий раз говорите одно и тоже. И я третий раз вам скажу, что эта проблема хоть и существует, но не такая страшная как вы её описываете.
- Вообще не проблема, ибо у каждого микросервиса есть своя бд для своих нужд и апи других сервисов для данных, которыми сервис не владеет.
Ну и как итог. Микросервисы далеко не серебрянная пуля. Более того, для большинства приложений они не нужны. Любой нормальный монолит вцелом пишеться как набор независимых модулей (читай микросервисов), работающих в пределах единого приложения. Сразу начинать писать приложение как микросервис — это глупая затея. На начальном этапе вы не установите границе микросервисов достаточно точно и как результат получите плохую масштабируемость и сильную связанность. Микросервисы — это следующий этап развития. Когда монолит становится слишком большим. Становится слишком большой команда, которая его поддерживает. Когда в монолите явно выделились группы независимых модулей которые решают бщую проблему и становится ясно, что их можно вынести в отдельное приложение. Когда видно какие компоненты зависят от каких данных и так дальше. Вот тогда приходят микросервисы.
y90a19
07.02.2017 11:04как делать одну транзакцию поверх нескольких микросервисов?
Например модуль складского учета и финансовый модуль. Произошла ошибка в финансовом модуле. Как откатить транзацию в модуле складского учета?mayorovp
07.02.2017 11:29Не надо откатывать. Надо повторять попытки достучаться до финансового модуля в фоне. Это и есть та самая устойчивость к отказам — складскому учету не нужен постоянно работающий финансовый модуль.
oxidmod
07.02.2017 11:36Если ваша бизнесс логика предпологает возможность отката зименений, то всеголишь нужно выставить соотвествующий апи ендпоинт и дернуть его в случае пробелм с финансовым модулем.
Как вариант можно сущностям добавить статус. И пока статус не станет подтвержденным их видно, но ими нельзя воспользоваться. Соотвественно можно мониторить зависшие в невесомости вещи и принимать какието решения/меры по их исправлению.y90a19
07.02.2017 11:44-1итого какие-то костыли и велосипеды вместо стандартных транзакций. Про это я и говорил в самом начале
mayorovp
07.02.2017 11:47У вас ошибка в комментарии:
вместо медленных транзакций
y90a19
07.02.2017 12:01Итого мы отказываемся от медленных транзакций чтобы использовать свои велосипеды. Верно?
mayorovp
07.02.2017 12:03Почему вы стандартные решения называете велосипедами?
y90a19
07.02.2017 12:20Как вариант можно сущностям добавить статус. И пока статус не станет подтвержденным их видно, но ими нельзя воспользоваться. Соотвественно можно мониторить зависшие в невесомости вещи и принимать какието решения/меры по их исправлению.
это явно не стандартное решение.
Ендпоинты — тоже довольно редко применяются и поддерживаются далеко не везде
lega
07.02.2017 12:08Произошла ошибка в финансовом модуле. Как откатить транзацию в модуле складского учета?
Вообще эти 2 могут быть в одном микросервисе, в разных «черных ящиках» (модулях). Но если все же они отдельно, вызов финансового модуля должен быть быстрый (0,1-1 сек), в итоге если фин. модуль возвращает ошибку, то откатываете незакрытую транзакцию в складском.
Если фин. модуль выполняет метод долго (1-10 мин), то у вас проблемы другого плана, т.к. такие долгие транзакции очень не желательны (особенно которые блокируют «пол базы»). И если нет возможности ускорить, например это внешний платежный сервис, который ждет когда пользователь кликнет кнопку, то вам нужно использовать 2-х фазный комит. И микросервисы в этом случае не осложняют ситуацию.
Но вообще, зачастую можно встретить когда микросервис осложняет транзакцию, это подразумевает использование одной БД, а значит имеет смысл держать эти части в одном микросервисе.
PS: Я за «монолит на старте»mayorovp
07.02.2017 13:38Вообще эти 2 могут быть в одном микросервисе, в разных «черных ящиках» (модулях).
Не могут. Это будет уже не микросервис.
PS Я за макросервисы и монолит на старте.
indestructable
07.02.2017 13:31Такое впечатление, что микросервисы, по-вашему, — это как dll, только доступные по сети.
vlad_zay
07.02.2017 10:47Самое большое преимущество микросервисов я вижу в их взаимозаменяемости. Если есть хороший стандартный интерфейс, можно легко поменять одну имплементацию/версию на другую (в т.ч. реализованную на другом ЯП/платформе), не трогая всю остальную систему. Жертвовать же производительностью (общение сервисов через сеть) за счёт небольшой экономии ОЗУ (создание новых экземпляров только нескольких сервисов на другом сервере вместо нового экземпляра целого монолита) не вижу никакого смысла.
y90a19
07.02.2017 10:54ну да, какой-то универсальный сервис. Например сервис адресов, которому не нужны ни транзакции, ни согласованность данных.
Но пытаться делить неразделимые вещи не стоит
rraderio
07.02.2017 10:52Допустим у нас есть приложение в котором пользователи могут регистрироваться, авторизоваться и что-то публиковать. Пользователи могут дружить. И каждый пользователь может видеть только публикации друзей.
А также пользователь может заблокировать любого другого пользователя, даже друга, и тогда заблокированный пользователь не сможет увидеть публикации.
Как в микросервисах хранить заблокированных пользователей? Ведь они нужны в 2 микросервисах: публикации и друзья.oxidmod
07.02.2017 11:18Это слишком простое приложение чтобы делать его микросервисным, но чисто теоретически. У вас есть некий юзер сервис, который которые хранит юзеров, хранит их связи с другими юзерами. Этот сервис предоставляет апи для получения инфы о юзере и о ег освязях.
У вас есть сервис публикаций, который предоставлеяет апи для создания постов и их просмотра.
При поытке просмотра поста этот сервис запрашивает список френдов юзера, который хочет смотреть пост и проверяет что это пост френда. Вот и все решение.
Иногда проверки прав на любые действия делегируют отдельному сервису.y90a19
07.02.2017 11:23-1Есть микросервис авторизации, и есть микросервис правки данных. При правке нужно сохранять id пользователя, совершившего эту правку.
Как это сделать, если базы разные?oxidmod
07.02.2017 11:29эм… ну какбы все запросы ходят с прикрепленным веб-токеном, который сожержит необходимый минимум инфы о юзере. На крайняк с сессионными куками содаржащими идентификатор юзера и по которому можно дернуть апи соотвествущео сервиса для получения более детальной информации
y90a19
07.02.2017 11:32т.е. отказываемся от форенкеев (целостности базы)
oxidmod
07.02.2017 11:44+2База самого микросервиса вполне целостная. Целосность расшаренных данных зависит от от логики приложения. Только и всего. Допустим ваш сервис постинга может удалять/помечать удаленными записи автора, по которому приходит 404 с сервиса пользователей.
Почему вас не возмущает, что если я зареган через соц сети, а потом взял и удалился из соцсети, то на вашем сайте я по прежнему есть? Смотрите на микросервисы как на независимые приложения. У приложения есть "свои данные", целостность которых контролируется базой этого приложения. Есть внешние, которые от этого приложения не зависят (Юзер удалился). Максимум что, сервис юзеров может бросить ивент об удалении юзера, а сервис постов подписатсья на него и както прорегаировать. Или не реагировать вовсе. Все зависит от бизнес-логика приложения.
ЗЫ. существуют монолиты исползьющие несколько хранилищ одновременно. При этом это не всегда даже РСУБД. Это может быть документоориентированная бд, может быть кей-велью хранилище, графовая бд, даже банальные файлы или удаленные сервисы всяких амазонов и иже с ними. Как же монолит поможет обеспечить целосность данных в этом случае? О каких венешних ключах может идти речь?
y90a19
07.02.2017 12:06База самого микросервиса вполне целостная.
только в пределах одного микросервиса.
Что делать, если id пользователей рассинхронизируются между базами?oxidmod
07.02.2017 12:18Каким образом? Всегда есть сервис владелец, который контролирует создание. И сервисы клиенты которые оперируют рид-онли данными полученными от сервиса-владельца. Рассинхрон может быть, если сервис-клиент напрямую удалит или изменит данные в чужой базе, но это противоречит всей идеологии микросервисной архитектуры
y90a19
07.02.2017 12:28Ну зачем-то же придумали форенкеи как метод обеспечения целостности
oxidmod
07.02.2017 12:42+2каждому инструменту свое применение. Внешние ключи отнюдь не панацея, к тому же довольно тяжелая штука при вставке/изменении/удалении записей.
mayorovp
07.02.2017 13:42Внешние ключи придуманы чтобы не оказалось, например, позиции на складе, которая принадлежит не пойми кому.
А ситуация, когда позиция на складе принадлежит клиенту, который больше не клиент — возможна и в жизни ("оставил и ушел"). А значит, должна иметь отражение в базе.
rraderio
08.02.2017 10:26Как это ушел, он вам об этом сказал? Если нет то откуда вы знаете что он ушел, может он после 5, 10 лет вернется.
iCpu
08.02.2017 10:21Любые распределённые данные без единого транзакционного центра всегда вероятностны. Всегда есть вероятность, что данные на одном сервере уже изменились с того момента, как мы получили последний ответ. И, что самое ужасное, у нас нет способа сказать «Всем ЦЫЦ! Батька думает.»
З.Ы. Монопольное владение.
y90a19
07.02.2017 11:39Ещё пример. И в финансовом, и в складском модуле нужно ФИО клиента при выводе списка.
Что вы предлагаете делать: дублировать их в разных базах или дергать отдельный запрос на каждую запись в списке?mayorovp
07.02.2017 11:53Дублировать.
Не смысла бороться за размер хранимых данных кроме как в самой большой таблице. В складском модуле самой большой таблицей будет журнал операций. Каждый клиент будет связан как минимум с двумя записями журнала, а скорее всего их будет еще больше.
y90a19
07.02.2017 11:55а что делать, если эти ФИО поменяются? Как их синхронизировать?
mayorovp
07.02.2017 12:01Тут три варианта.
Никак! ФИО в журнале операций должно быть таким же, что и документах (например, в накладной). А там данные измениться не могут.
При получении свежего токена от пользователя данные о нем в базе обновляются. Таким образом, ФИО в журнале будет старым пока пользователь не обратится (прямо либо опосредовано) к сервису.
- Изменения данных пользователей публикуются другим сервисом, а складской модуль на них подписан.
y90a19
07.02.2017 12:13-1итого стандартную целостность нужно обеспечивать руками и велосипедами
oxidmod
07.02.2017 12:23+1Обеспечьте целостность когда документы (накладные, квитанции и прочее) хранятся в документов монге, а юеры в mysql
iCpu
08.02.2017 06:52-1Вы ходите по кругу, mongo и mysql — уже отдельные (не микро) сервисы. Логично, что между ними уже нет взаимодействия, и любые попытки синхронизации ради обеспечения целостности — велосипеды.
Потому любые ваши наезды «обеспечьте», вообще-то не по адресу, так как речь идёт именно о том, что (микро-)сервисная архитектура этого сделать не может, на это способен только монолит. То есть распределённая база не может давать гарантии, в ней всё всегда вероятностное. В рамках одного единственного mysql же (или postgresql, который давно уже чавкает жсонами) такую целостность обеспечить очень просто и достаточно дёшево.
Ясное дело, что люди переходят на связки манги и мускула не от хорошей жизни, но не нужно, как веганы, верещать во все стороны «Я давлюсь этим сельдереем уже два месяца и отлично себя чувствую, а вы такие злые из-за мяса.» Вы НЕ можете обеспечить 100% целостности и синхронности в микросервисах, и никогда не сможете. Факт. Но вы можете повысить производительность и понизить вероятность ошибок так, что погрешности с лихвой покроются прибылью. Тоже факт. И не нужно городить что-то ещё.
rraderio
07.02.2017 11:28Т.е. то что в монолите можно было сделать в базе одним SELECT и где все проиндексировано, теперь надо делать 2 SELECT'a.
А что если между запрашиванием списка френдов юзера и SELECT'ом постов, меня заблокировали, я получу публикации которые не должен был получить.mayorovp
07.02.2017 11:35А что если между запрашиванием списка френдов юзера и SELECT'ом постов, меня заблокировали, я получу публикации которые не должен был получить.
Вы получите публикации которые вы могли бы получить если бы запросили их секундой раньше. Это не проблема.
Проблема будет, если запрашиванием списка френдов юзера и SELECT'ом постов другой пользователь сначала блокирует вас, а потом публикует что-нибудь. В таком случае вы можете получить публикацию, которой никогда бы не смогли получить при последовательном исполнении запросов.

thecoder
07.02.2017 11:52+1Народная мудрость: лучше 5 быстрых селектов, чем один с многоэтажными джойнами, который может внезапно стать медленным и сложно-отлаживаемым.
Потом эти же селекты раскидать на независимые сервисы, которые работают параллельно, отвечают асинхронно и склеить все в ноде.
Bsplesk
09.02.2017 16:55-1Все намного сложней, по факту при использовании сервисов получаем распределенную и возможно децентрализованную сеть со всеми плюсами и минусами — аля (torrent, blockchain), но без готового механизма синхронизации, на данный момент этот механизм нужно «костылить подпорками», причем этого решение может быть архисложным, но думаю не долго и возможно совсем скоро один из cloud провайдеров, предложит своё «незаменимое», универсальное решение (сервис «шин» в принципе уже есть, но это не совсем то).
И да, это скорей всего потребует или отказ от реляционных БД или их доработку, но думаю cloud провайдеры, предложат всем свою «суперудобную/масштабируемую» БД — по факту уже у них имеются, которая будет из себя предоставлять просто сервис.
Вот такой вот новый, дивный мир cloud, посмотрим получится ли у cloud провайдеров и их инвесторов реализовать данную идею. И главную идею, загнать «овец» в свои cloud сараи.
amaksr