

22 февраля 2017 года компания AMD официально представила семейство десктопных процессоров Ryzen. Те самые процессоры, которые должны наконец-то сделать AMD снова конкурентоспособной с Intel во всех рыночных сегментах, в том числе hi-end. Прошлое поколение процессоров Bulldozer во многом стало разочарованием и ограничилось преимущественно использованием в недорогих конфигурациях low-end. Технические характеристики новых чипов дают основания для осторожного оптимизма: AMD удалось добиться увеличения на 52% количества исполняемых машинных инструкций за такт (перевыполнена цель Zen в 40%). При этом восемь ядер и цена от $329 до $499. Это ставит Ryzen в один ряд с лучшими процессорами Intel.
Семейство Ryzen большое, но первыми появятся в продаже самые высокопроизводительные чипы Ryzen 7. Все они с восемью ядрами, 16 потоками и поддержкой одновременной многозадачности.
Линейка Ryzen 7 представлена тремя процессорами.
- Ryzen 7 1800X: 8C/16T, 3,6 ГГц базовая частота, 4,0 ГГц турбо, 95 Вт, $499
- Ryzen 7 1700X: 8C/16T, 3,4 ГГц базовая частота, 3,8 ГГц турбо, 95 Вт, $399
- Ryzen 7 1700: 8C/16T, 3,0 ГГц базовая частота, 3,7 ГГц турбо, до 65 Вт, $329
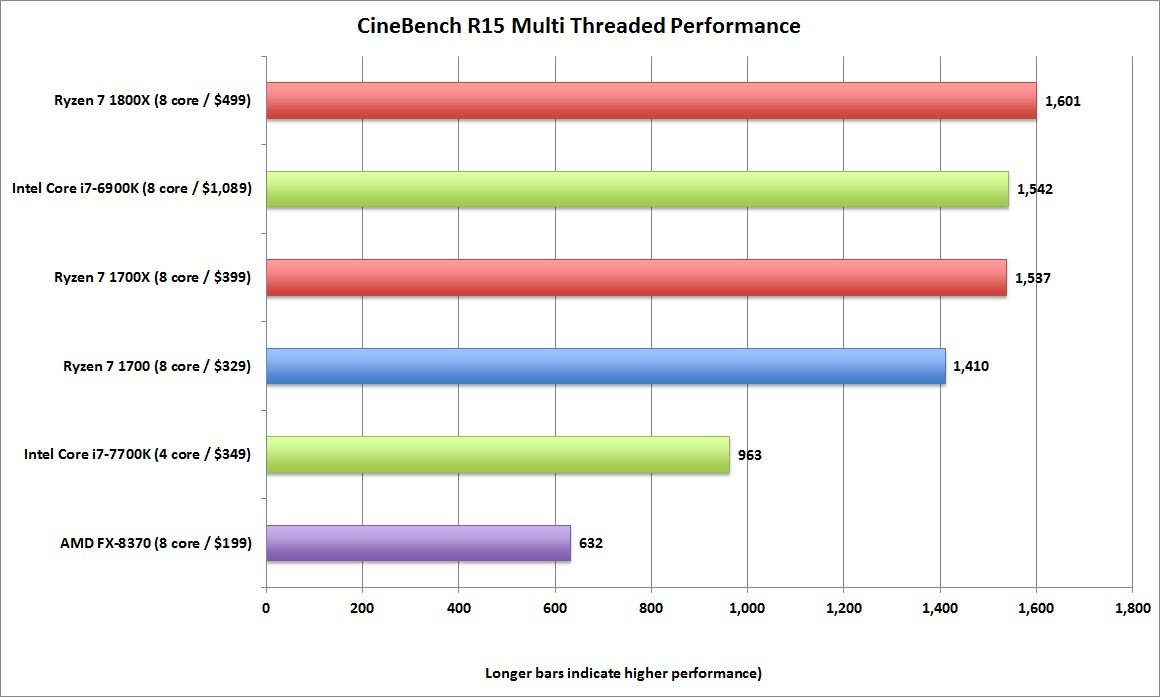
Топовая микросхема Ryzen 7 1800X стоимостью $499 должна конкурировать с процессором Intel Core i7-6900K стоимостью $1089-$1109. Согласно тестам производительности AMD, у этих процессоров примерно одинаковые результаты в однопоточных задачах. В многопоточных задачах Ryzen 7 1800X имеет преимущество.
Тесты проводились в бенчмарке Cinebench. В однопоточных задачах процессоры показали одинаковый результат 162. В многопоточных у Ryzen 7 1800X — результат 1601, что на 9% больше, чем у Core i7-6900K.

В сравнении наиболее мощных процессоров AMD и Intel первая имеет фору по частоте: базовая частота 3,6 ГГц против 3,2 ГГц у Core i7-6900K. В режиме турбо у них одинаковая частота 4,0 ГГц. Если тесты проводились на базовой частоте, то AMD может уступать Intel по показателю производительности на мегагерц. Но для большинства пользователей важен конечный результат, а не теоретические показатели. То есть реальная производительность и цена. По обоим этим показателям Ryzen 7 1800X превосходит Core i7-6900K, если верить AMD.
Ryzen 7 1800X сейчас является самым быстрым 8-ядерным процессором на рынке, заявляет AMD. Похожие, бенчмарки Ryzen из недавней утечки были близки к реальным цифрам.
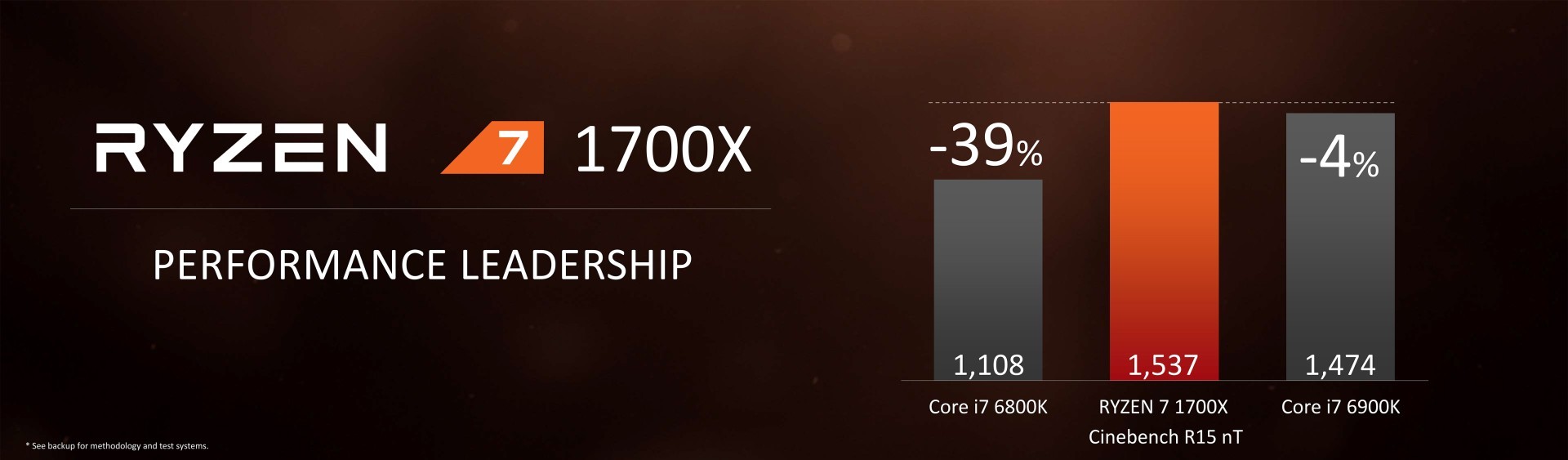
Второй процессор из представленной линейки Ryzen 7 1700X ($399) в многоядерном бенчмарке Cinebench показывает результат 1537, то есть на 4% больше, чем у Core i7-6900K ($1089).
В конце концов, третий процессор Ryzen 7 1700 с энергопотреблением до 65 Вт показывает в многоядерном тесте Cinebench результат 1410 баллов. AMD сравнивает его с результатом Core i7 7700K, который продаётся примерно по такой же цене $339, но Ryzen 7 1700 обходит его по производительности на 46%.
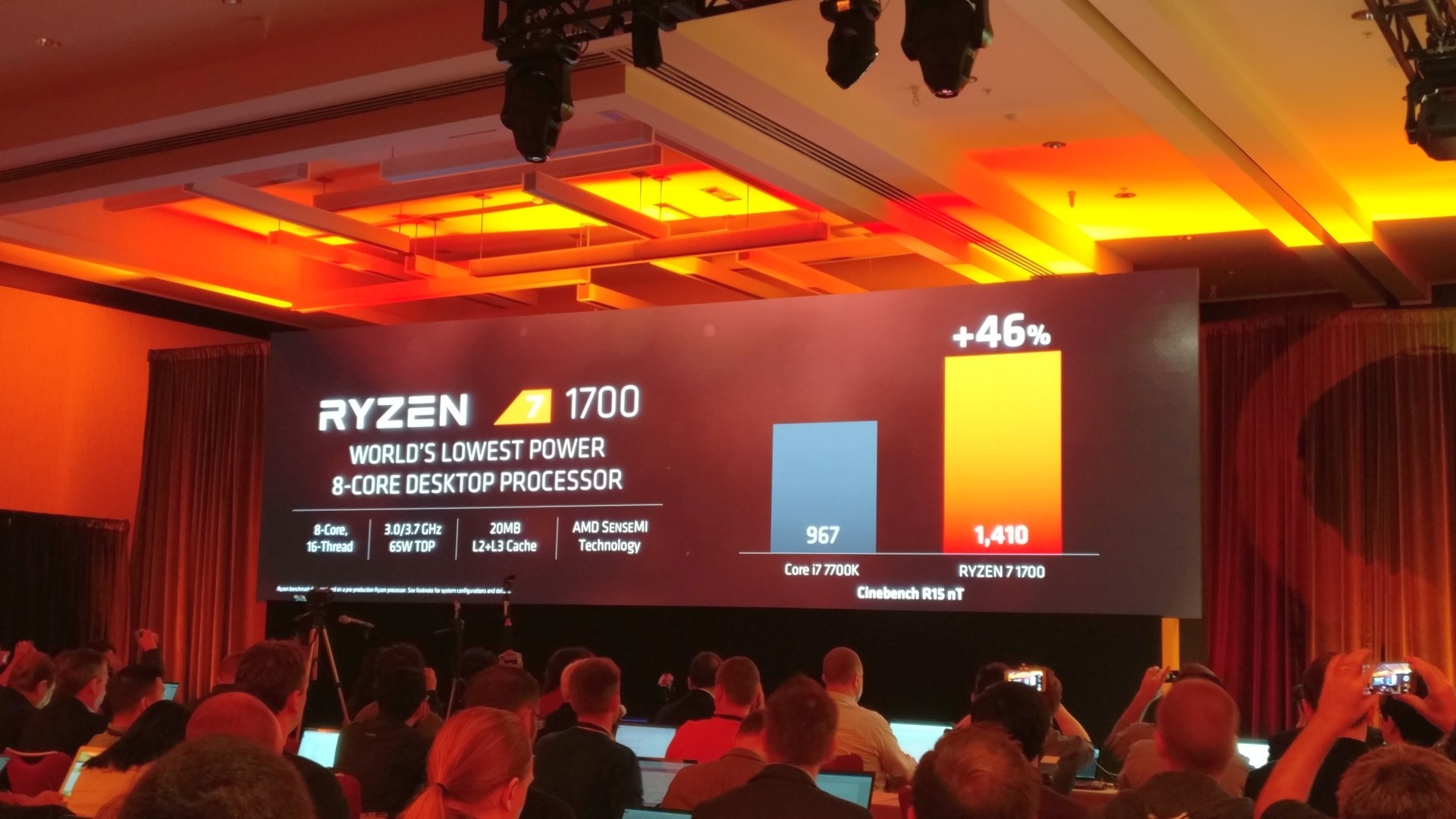
Ryzen 7 1700 позиционируется как самый экономичный 8-ядерный процессор на рынке, при этом значительно превосходящий по производительности процессоры Intel той же ценовой категории. Ryzen 7 1700 идёт в комплекте с тихим кулером Wraith Spire, который работает на 32 дБ. Так что он будет значительно тише, чем два более мощных брата по линейке.
В реальной задаче по кодированию видео в тесте Handbrake процессор Ryzen 7 1700 справился с задачей за 61,8 с, а Core i7 7700K — за 71,8 с.
В 2009 году Федеральная торговая комиссия признала, что тесты Cinebench дают нечестное преимущество Intel в сравнении с процессорами AMD, поскольку используют оптимизации компилятора Intel
Как и у Intel, в окончательном виде линейка Ryzen будет состоять из трёх семейств: премиальные процессоры Ryzen 7, среднеуровневые Ryzen 5 и самые дешёвые Ryzen 3. Сейчас представлены только самые производительные и дорогие, два остальных семейства выйдут позже в течение года, AMD не называет точные даты.

Ryzen 7
Новые процессоры уже доступны для предзаказа. Поставки начнутся 2 марта 2017 года. AMD планирует не допустить никакого дефицита: микросхем будет в избытке, также как обещают обильный выбор материнских плат на любой вкус. ASRock, Asus, Biostar, Gigabyte и MSI должны выпустить 82 разных модели материнских плат на платформе AM4 с чипсетами AMD X370 и B350. В самое ближайшее время в продаже появятся топовые геймерские десктопы, собраненые и оптимизированные для игр на платформе Ryzen (а во втором квартале выйдет ещё мощный видеоускоритель Radeon Vega, что только добавит всем счастья).
Radeon Vega
Если AMD сдержит все обещания, то на рынок десктопных процессоров может опять вернуться конкуренция AMD и Intel. Возможно, с ценовыми войнами, как в старые добрые времена. Это отличная новость для всех в мире, кроме сотрудников и акционеров компании Intel.
Сейчас предзаказы на микросхемы и компьютеры с процессорами Ryzen открыты у 180 розничных магазинов и интеграторов.
По мнению некоторых аналитиков, AMD специально растягивает анонсы во времени, чтобы оставить поле для тактического манёвра и нанести более сильный ущерб конкуренту. В то же время, у Intel тоже есть варианты для ответных действий. В первую очередь, это снижение цен на свои процессоры.
Комментарии (349)

stepmex
23.02.2017 11:33+3Хоть и сторонник AMD но всё время поражаюсь их логике, они постоянно сравнивают свою новую линейку с текущей линейкой Intel. И как обычно Intel выпускает новую линейку лучше. Почему не думать о перспективе и не сделать линейку с большим запасом мощности((

ruspartisan
23.02.2017 11:38+5Если бы они так могли сделать — с удовольствием бы выпустили. Но на самом деле в ближайших новых линейках Intel ожидаются только 6 ядер в десктопном сегменте на Coffee Lake и Skylake-X для High-end, и Skylake-X скорее всего будет процентов на 5-10 (и это оптимистичные оценки!) быстрее Broadwell-E на равной частоте.
Mad__Max
24.02.2017 02:45С учетом что за 4 предыдущих поколения они смогли из себя выдавить только около +20% (при одинаковом кол-ве ядер и частоте) скорости, то ничего кроме опускания цен на 6-ядерные камни до вменяемого уровня от них ожидать не стоит.
bzzz00
24.02.2017 15:06на самом деле неизвестно что интел может. у них просто стимула не было повышать производительность сильнее. так… слегка стимулировать граждан к покупкам. а вот теперь, если amd не сядет в лужу как в прошлый раз, мы и посмотрим что у intel есть в загашнике…

NetBUG
02.03.2017 01:55На мой взгляд, начиная с Ivy Bridge, Intel занималась оптимизацией энергопотребления (и неплохо в этом продвинулась) и улучшением GPU (вроде бы тоже, мне трудно судить).
Mad__Max
02.03.2017 02:35Можно и так сказать — для серверов и ноутбуков основной прогресс в энергоэффективность ушел (вычисления / 1 Вт мощности).
Для десктопов и ноутбуков — во строенную графику, которая сожрала большую часть прибавившихся за счет перехода на новые тех. процессы количества транзисторов.
В 6м поколении (skylake) даже в i7 графическая часть занимает уже больше площади кристалла и транзисторного бюджета, чем собственно сам процессор.
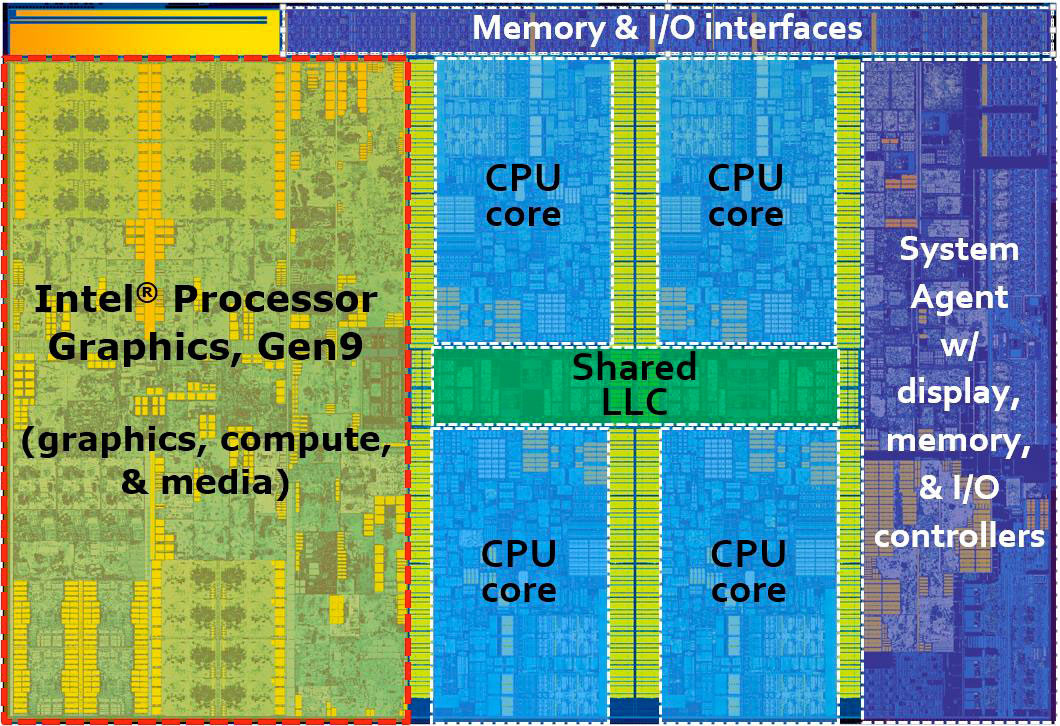
По графике прирост и правда очень солидный — от полной убогости в первых поколениях, до вполне приличного низкобюджетного решения.
Правда все-равно далеко до возможностей любых полноценных видеокарт. И даже все-еще отстают от встроенных графических модулей конкурента (гибридных APU от AMD)
Alexsey
04.03.2017 20:52-1В 6м поколении (skylake) даже в i7 графическая часть занимает уже больше площади кристалла и транзисторного бюджета, чем собственно сам процессор.
И лично мне это совсем не понятно. Абсолютное большинство людей вообще не пользуется встроенной графикой на i5/i7 какой бы хорошей она не была, лучше бы это место отдали под доп. ядра, а графику оставили в low-end и мобильных решениях. Надеюсь после пинка от амд до них эта мысль дойдет.w1nterfell
05.03.2017 00:14+1зачастую интегрированная графика используется в том случае, если компьютер собирается постепенно, когда денег нет на сборку всего и сразу, интеграшка дает возможность использовать компьютер хоть как-то, не дожидаясь покупки нормальной видеокарты

old_gamer
23.02.2017 11:50+1Ну а как сравнивать что-то с будущей линейкой, ее же нет. Да и запас, судя по всему, есть. Процессоры, похоже, очень быстрые будут, даже если Intel прилично улучшит следующее поколение, Рязань все равно должна остаться конкурентноспособной в текущем виде, а потом и ее улучшить можно будет дальше. Главное для AMD, имхо, начать продавать дорогие процессоры, чтобы было больше денег на R&D

Victor_Grigoryev
23.02.2017 11:50+4Вы не учли того, что красные безнадёжно остали на много лет со своими FX, ставшими в наши дни объектами поклонения у широких масс с бюджетом 100$ на всю сборку, включая стол, стул и периферию.
Чтобы смотреть в завтрашний день, надо хотя бы очутиться в сегодняшнем. Ryzen в кои-то веки даёт красным вернуть позиции хоть как-то. Первое поколение наконец поступает в продажу, а там и не за горами прямая дорога в будущее, всё в их руках.
DistortNeo
23.02.2017 18:09+2AMD серьзёно отстала от Intel с выпуском Sandy Bridge 6 лет назад. С тех пор рост производительности процессоров Intel сильно замедлился — 5-10% на поколение, а это очень медленно. Возможно, причиной было доминирующее положение.
Сейчас же AMD удалось догнать процессоры Intel по производительности. Производительность одного ядра Ryzen, конечно, не дотягивает до Skylake, но уже немного превышает Sandy Bridge. Очень надеюсь, что это приведёт к полноценной конкуренции и более быстрому росту производительности процессоров.lolipop
23.02.2017 18:28вы статью читали? на картинки смотрели? с чего вы взяли, что skylake быстрее ryzen?
DistortNeo
23.02.2017 18:49+1с чего вы взяли, что skylake быстрее ryzen?
Производительность одного ядра Ryzen, конечно, не дотягивает до Skylake, но уже немного превышает Sandy Bridge. Но AMD опять берёт верх числом ядер.
Я уже довольно много статей почитал, и доверия они у меня не вызвали — пока что всё вилами по воде писано, но в большинстве случаев i7 6900K оказывался быстрее. Нужно ждать официального релиза и честных тестов.lolipop
23.02.2017 19:12да, посчитал, действительно выходит 200 против 240 скайлейка, грустняво, но цена всё равно хороша.
Mad__Max
24.02.2017 03:08+1Делить результат на кол-во ядер в тесте, который далеко не идеально масштабируется с ростом кол-ва вычислительных потоков бестолковое занятие. Да еще на процессорах с весьма сильно отличающимися частотами работы (i7 7700k 4.2/4.5 ГГц, R7 1800X 3.6/4.0 ГГц).
Тут надо прогонять тесты на высокочастном варианте R3 или R5 с 4/6 ядрами, чтобы корректно сравнивать с 4х ядерными Skylake без экстраполяций.
А пока видно, что при одинаковом кол-ве ядер и частоте скорость получается примерно на уровне 5-6 поколений iCore, а до Skylake если и не дотягивает, то совсем немножко.
Даже если эти 200/240 взять, то это ~20% разницы по скорости на 1 ядро при ~15% разницы по рабочей частоте.

degorov
23.02.2017 13:01+2Лично мне даже более интересно то, что Intel теперь, вероятно, снизит цены на свою продукцию и/или наконец-то выпустит что-то новое и интересное, а не просто +10% и вуаля. Ну и кстати FXы тоже подешевеют, наверное, а они хоть и сильно отстали от Intel'ов, но за эти деньги очень даже сгодятся ещё довольно долго.
Sliptip
24.02.2017 11:00+2Согласен. Хоть и сам поклонник Intel, но пинка им дать давно как пора! Надеюсь, возрождение AMD, как производителя конкурентоспособных процессоров, этот пинок им обеспечит.
boblenin
23.02.2017 14:44+1Ну если следующее поколение процессоров intel даст прирост производительности такой же как два прошлых, то Ryzen все-равно в игре.
Structure
23.02.2017 15:05Без повышения частоты производительность на поток дешево расти не будет.
Сейчас есть только два варианта существенного роста — «идеальный кеш» и «идеальные предсказания». А для этого нужен большой объем памяти рядом с ядром, загрузка алгоритмов в кеш-контроллер и BPU, реализация суперспекулятивности, когда иногда обе ветки выполняются одновременно, но на разных ядрах.Mad__Max
24.02.2017 03:18+1Можно просто увеличить параллелизм внутри одного ядра — увеличить кол-во исполняющих блоков и пропускную способность декодера инструкций, вместо простого увеличения количества одинаковых ядер.
Но это потребует разработки ядра практически с нуля, а не умеренного тюнинга уже существующей архитектуры типа добавки кэша или подкручивания предсказателя переходов.
AMD на это решилась и практически в один прыжок ликвидировала отставание от лидера, который до этого 5 лет постепенно уходил в отрыв 6 раз подряд оптимизируя одну и ту же базовую архитектуру iCore вместо разработки новой.
Так же как когда-то сама Intel решиласьзакопать бабушкувыкинуть NetBurst на свалку и сделала огромный скачок с переходом на Core.
Забавно как компании в очередной раз поменялись ролями.Structure
24.02.2017 10:26Я уже думал про дополнительные исполнительные блоки. Рост может быть только в очень специфичных задачах. Так что не подходит.
Лучше уж сделать как в Power8. Его ядро можно представить как два, которые на однопоточной нагрузке объединяются. Тем самым увеличивается количество доступных ФУ.
Заголовок спойлераMost instructions (except for branches and condition register logical
instructions) are processed through the Unified Issue Queue (UniQueue),
which consists of two symmetric halves (UQ0 and UQ1).
There are also two copies of the general-purpose (GPR0 and
GPR1) and vector-scalar (VSR0 and VSR1) physical register files. One copy is
used by instructions processed through UQ0 while the other copy is for
instructions processed through UQ1.
The fixed-point, floating-point, vector, load and load-store pipelines are
similarly split into two sets (FX0, FP0, VSX0, VMX0, L0, LS0 in one set, and
FX1, FP1, VSX1, VMX1, L1, LS1 in the other set) and each set is associated
with one UniQueue half.
In ST mode, the two physical copies of the GPR and VSR have identical
contents. Instructions from the thread can be dispatched to either one of the
UniQueue halves (UQ0 or UQ1). Load balance across the two UniQueue
halves is maintained by dispatching alternate instructions of a given type to
alternating UniQueue halves.
In the SMT modes (SMT2, SMT4, SMT8), the two copies of the GPR and VSR
have different contents. The threads are split into two thread sets and each
thread set is restricted to using only one UniQueue half and associated
registers and execution pipelines.DistortNeo
24.02.2017 12:47-2Ещё немного и вы Hyper-Threading заново изобретёте.
Structure
24.02.2017 12:57+1HT увеличивает многопоточную производительность. А я про однопоточную.
DistortNeo
24.02.2017 13:03-3Его ядро можно представить как два, которые на однопоточной нагрузке объединяются.
Ну так вы только что описали HT.
Structure
24.02.2017 13:59Нет, это не HT.
При on/off HT количество доступных исполняющих устройств на поток не меняется.
Я же пишу про HT наоборот, когда поток может получить доступ к ресурсам второго ядра.DistortNeo
24.02.2017 15:30-1При on/off HT количество доступных исполняющих устройств на поток не меняется
Это почему же? При включённом HT два потока, выполняющиеся на одном ядре, вынуждены пользоваться общими ресурсами ядра. Поэтому при включении HT количество доступных ресурсов уменьшается пропорционально загрузке.
Structure
24.02.2017 16:02+3Мне нужно было написать "возможно доступных исполняющих устройств".
Так как HT не меняет их количество.
Еще раз. Я писал про производительность НА ПОТОК.
Человек предложил повысить количество ФУ. Но это мало что даст, т.к. очень мало задач требует большего числа ФУ, да и это редко является узкой частью из-за промахов кеша и ложных предсказаний. И раздувать ядро ради нескольких процентов в некоторых задачах как-то глупо.
Вот я и предложил сделать тесно связанные ядра, чтобы на ОДИН ПОТОК можно было использовать ресурсы второго ядра.
Это и есть «HT наоборот», когда два ядра обрабатывают один поток для увеличения ОДНОПОТОЧНОЙ производительности.
Когда как HT делит часть ресурсов одного ядра, чтобы загрузить их по максимуму для увеличения МНОГОПОТОЧНОЙ производительности.DistortNeo
24.02.2017 17:05Это и есть «HT наоборот», когда два ядра обрабатывают один поток для увеличения ОДНОПОТОЧНОЙ производительности.
Когда как HT делит часть ресурсов одного ядра, чтобы загрузить их по максимуму для увеличения МНОГОПОТОЧНОЙ производительности.Принципиальной разницы между этими решениями нет. В обоих случаях имеем логические ядра с разделяемыми ресурсами.
Structure
24.02.2017 17:49Разница в цене, так как она имеет нелинейную зависимость от сложности ядра.
И вот тут пара простых ядер намного дешевле, чем одно суперядро.
Да и для многих задач не нужны большие ядра.
Так что это только на бумаге 1+1 = 2 и 2/2 = 1Akela_wolf
24.02.2017 17:54Пара простых ядер будет медленнее чем одно сложное. Пример — Atom, в котором применили простые ядра (насколько я помню без поддержки суперскалярности). Как результат — значительная потеря производительности.
Mad__Max
25.02.2017 02:15В атомах главная проблема (по крайней мере в старых, за новыми не следил) был отказ от out-of-order execution (внеочередного исполнения команд)
Из-за чего ФУ часто по долгу простаивали — в ожидании подгрузки данных из памяти (или в лучшем случае кэша) или завершения предыдущего вычисления из которого нужно использовать результат как входные данные следующего.Akela_wolf
27.02.2017 05:22Так OoE (иначе называемая суперскалярность) и есть одна из главных сложностей в современном ядре. Отказ от OoE — цена за упрощение ядра.
u010602
24.02.2017 17:19+1Если можно ускорить обработку одного потока, то можно просто сделать более мощное ядро, а потом его разделить как HT. Возможно сейчас нет возможности улучшить производительность в однопоточном режиме, по-моему такой возможности давно особо нет, так мелкие улучшения но ни каких капитальных революций. Собственно потому и начали в свое время внедрять два ядра и стимулировать софт к многопоточности.

khajiit
24.02.2017 18:04+1А если ядер больше двух? И еще всякая дерготня через apic бегает? Опрашивать планировщиком, а не схлопнулись ли у нас ядра? А то некоторые процедуры бывают весьма time-critical, их нельзя вешать на "временно отсутствующее" ядро, чьи ФУ отданы другому.
Значит, надо сразу делать матрицы регистров, ИУ, декодеров, предсказателей, ВВ, программно конструировать цепочки ИУ и работать на архитектуре с условным выполнением инструкций. Итого вырисовывается какой-то arm-asic grid, причем сильно смахивающий на видеокарту.
Зато можно будет для множества нетребовательных задач расхлопнуться до decoders/2 логических процессоров, а для жесткой векторной арифметики хоть почти все узлы отдать одному логическому процу, оставив минимум под систему. Заработало ядро — затребовало из пула ресурсы, закончило обработку — отдало все ресурсы обратно в общий пул. Осталось еще beamVM портануть прямо на железо, и вот он — мега-SoC будущего, который захватит мир.
Правда, до того миру надо будет сильно упереться в пределы горизонтального масштабирования, которые пока что все еще удается отодвигать. Ну и схожего эффекта можно достичь и другими, не столь экстравагантными, способами.
Mad__Max
25.02.2017 02:07+1Какие несколько %? Самый кардинальные скачки в эффективности процессорных архитектур как раз и происходили только при увеличение кол-ва ФУ в ядре и увеличении пропускной способности декодера x86 в микроинструкции.
1й принципиальный скачок — переход к суперскалярной архитектуре в Pentium после 8086-486х. До этого в ядре было только по одному ФУ каждого типа и декодер способный выдавать по 1 инструкции/такт.
С Pentium декодер расширился до 2инструкций/такт и часть ФУ в удвоенном количестве.
2й скачок P6 с добавлением ФУ и расширением декодера до 3 инструкций/такт. Так же ввода SIMD (тоже больше ФУ в ядре)
Следующий скачок скорости — Core с еще большим количеством ФУ на ядро и декодером на 4 инструкции/такт. Который за счет этого превосходил как NetBurst так и конкутирующие K8 и K10 от AMD у которых декодер и ФУ были разработаны под 3 инструкции/такт.
У АМД ядра бульдозеров (FX серия) получились такими слабыми опять же из-за этого: часть ФУ разделена между 2мя ядрами, а производительность декодера только 2 инструкции/такт. В результате огромное отставание в однопоточной нагрузке от конкурента
AMD ZEN — отказ от узких 2/такт декодеров и разделяемых ФУ, полноценный декодер на 4 инструкции/такт как у iCore (+ до 2 иструкций из кэша уже декодированных). И сразу в один прыжок догнали Intel.u010602
25.02.2017 03:02-1Я правильно понимаю что от этого будет выигрышный только если эти 4 инструкции не зависят друг от друга? Тогда их можно распараллелить на несколько ФУ. Но фактически если сделать всех ФУ х2 и 2 инструкции за такт, то получаем 2 полноценных ядра + систему авто распараллеливания. Если же не все ФУ удвоены, а только самые востребованные то выходит экономия кремния. Если же отдавать эти дополнительные ФУ как виртуальное ядро, то даем возможность параллелить не только автоматически но и разработчикам.
И идея НТ наоборот заключается в том, чтоб взять 4 ядра с их 4 инструкции за такт и доп ФУ и эмулировать одно ядро на 16 инструкций за такт и кучей ФУ?
Если да, то мне кажется что это не сработает, наверное мало где бывает так чтоб по 16 независимых команды шли постоянно. Наверняка есть определенный предел мощности декодера, после которого идут или промахи предсказания ветвлений или просто ожидание результатов постоянное.
Может по этому они и стали делать реальные ядра, да еще и отдавать ресурсы по НТ, что уперлись в этот предел. И дальше нужно уже просить разработчиков нормально параллелить код, а не пробовать делать это автоматом налету.
А что если пробовать это все делать на уровне компилятора, находить такие не связанные инструкции и помечать их особым образом как те, что можно выполнять одновременно. Тогда можно отказаться от сложных декодеров, системы предсказания ветвлений. Правда хз как при этом сохранять контекст каждого микро потока…
Ладно, тема сложная, пускай специалисты лучше думают :)Mad__Max
25.02.2017 04:16+1Не обязательно не связанные. Сейчас все приличные ядра выполняют инструкции вообще не в том порядке в котором они записаны в программе (Внеочередное исполнение)
Поэтому когда попадаются инструкции зависящие по цепочке друг от друга, то все такие зависимые кроме первой «встают на паузу» и идут на исполнение по мере получения результата от предыдущей, а остальные ФУ в это время просто загружаются другими инструкциями — не зависящими друг от друга или для которых предыдущие от которых они зависели уже посчитаны.
Проблемы начинаются только когда таких взаимозависимых инструкций очень много — большая часть кода из таких состоит и из-за этого в пределах кэша инструкций уже не остается независимых, которые можно отправить на ФУ.
Смысл HT — прикинуться дополнительным ядром и взять 2й поток на тоже самое физическое ядро. Как раз чтобы загружать множественные ФУ внутри одного мощного ядра в моменты, когда они простаивают из-за того, что все ближайшие не связанные друг с другом инструкции уже обсчитаны и нужно ждать пока будут готовы данные предыдущих. Или в моменты когда дожидаемся подгрузки данных из памяти и ФУ простаивают по этой причине (например неправильное предсказание перехода — данные из памяти заранее не погрузились и инструкция будет десятки тактов ждать данных из основной памяти).
HT позволят подхватить инструкций из другого потока, которые почти гарантированно не будут зависеть от результатов инструкций в основном потоке. Т.к. либо относятся вообще к другом приложению, либо к другой задаче внутри одного приложения. Или же даже если это много потоков по обработке той же задачи в одном и том же приложении, но тогда программист должен был об распараллеливании сам подумать и как-то его реализовать.
Т.е. HT это источник независимых инструкций, позволяющий снизить простои ФУ.
В результате польза от него не очень большая и сильно варьирует от приложения от нескольких десятков % выигрыша и вплоть до отрицательных значений, когда итоговая скорость наоборот немного снижается. Если код и так хорошо на ФУ раскидывается и их загрузка близка к максимальной, то HT лишь увеличивает «накладные расходы» на работу с 2мя потоками вместо одного.
Идея свалить все на программистов — пусть у них голова об этом болит как расстреливать вычисления, совсем не новая. Примерно то что вы описали есть в архитектуре VLIW
Пробовали уже много раз, но как говорится «не взлетело».
Отказ от наращивания мощности ядра и вместо этого простое их тиражирование, которым занимались оба лидера последние годы — по сути другой подход к тому же. Пусть там программисты думают, как свое ПО на кучу независимых потоков разложить, а мы будем просто копировать одинаковые ядра вместо разработки новых более мощных/эффективных.
Но если используемый алгоритм и обрабатываемые данные позволяют их эффективно раскладывать на неограниченное количество независимых потоков, то с подобной работой намного лучше справятся вообще GPU, которые имеют просто гигантское преимущество на подобных задачах — скорость современных процессоров и близко не стояла.
А от CPU хочется все-таки как можно большей скорости выполнения последовательного кода.u010602
25.02.2017 19:24Ясно, подскажите, может знаете как на это реагирует график загрузки ядер в винде? Я замечаю что четные ядра загружены постоянно, а нечетные редко (вот примерно так http://c2n.me/3HSzsXK) Я думал что-это как раз связанно с тем, что нечетные ядра не настоящие, и их загрузить получается не всегда.
Но вот например компиляция проекта или запуск хрома с парой сотен вкладок загружают все ядра по полной. Можно это считать эффективным использованием НТ? Или нужно только делать вкл\выкл и замерять время?
В свое время я запускал одинаковые виртуалки с одинаковой нагрузкой на разном железе. На старых двуядерных системах я мог запустить только две. На 6 ядерном феноме — 6 виртуалок. А на 3770 10 штук. Я всегда считал это доказательством эффективности НТ в бытовых задачах. Я не прав?Mad__Max
25.02.2017 21:30+1Просто если ОС видит, что реально нагруженных потоков работой меньше чем логических ядер, то для максимальной скорости работы правильно и эффективно будет поместить по одному такому потоку на каждое физическое ядро, а виртуальные HT ядра оставить не используемыми или повесить на них какие-нибудь слабо нагруженные потоки.
Это оптимизация по скорости на уровне ОС. 2 потока на 2х разных физических ядрах разумеется будут работать намного быстрее, чем эти же 2 потока попавшие в одно физическое ядро через HT.
Внутреннюю загрузку ФУ внутри ядра ОС не видит, в обоих случаях будет отображаться 100% загрузка, только реальная скорость во 2м случае (2 потока попали в одно физ. ядро) будет намного ниже.
С виртуалками обычно вообще объем памяти критическое ограничение. Больше ядер конечно не помешает, но в плане увеличения скорости их работы, а не самой возможности их использовать.

0xd34df00d
27.02.2017 05:48+1Но если используемый алгоритм и обрабатываемые данные позволяют их эффективно раскладывать на неограниченное количество независимых потоков, то с подобной работой намного лучше справятся вообще GPU
Во-первых, GPU вроде как весьма проседают на бранчинге (хотя, может, уже и нет).
Во-вторых, писать под них существенно сложнее. Нельзя просто взять и собрать имеющийся код на плюсах, скажем, под GPU, тогда как параллелить грамотно написанный код куда проще.
DistortNeo
25.02.2017 03:11+1AMD ZEN — отказ от узких 2/такт декодеров и разделяемых ФУ, полноценный декодер на 4 инструкции/такт как у iCore (+ до 2 иструкций из кэша уже декодированных). И сразу в один прыжок догнали Intel.
Но, к сожалению, не перегнали. Скорее, только достигли уровня Sandy Bridge.
Например, FPU: у AMD был один FPU на 2 ядра, стало два 128-битных FPU на ядро. У Intel же уже с Haswell имеется по два 256-битных FPU на ядро. То есть могут оказаться задачи, в которых Zen в 8 потоков будет работать со скоростью 4-ядерника Intel.Mad__Max
25.02.2017 04:36Было 2 128 битных FMAC на модуль (при этом делимых между 2 ядрами) работающих с плавающей запятой, стало 2 256-битных FMAC в каждом ядре.
Все как у самых современных Intel

Там только какие-то сложности с реализацией AVX инструкций, из-за чего по 2 AVX 256 битных за такт по какой-то причине не может выполнять.DistortNeo
25.02.2017 05:09Было 2 128 битных FMAC на модуль (при этом делимых между 2 ядрами) работающих с плавающей запятой, стало 2 256-битных FMAC в каждом ядре.
Все как у самых современных IntelДанная диаграмма датируется весной 2015 года и не соответствует действительности. В обзорах последнего месяца указывается, что блоки AVX в Zen будут 128-битные. Возможно, в Zen+ они станут полноценным.
Mad__Max
25.02.2017 23:40Как-таковых блоков AVX там нет вовсе. AVX это набор инструкций, которые каким-то образом по усмотрению разработчика процессора транслируются на универсальные исполнительные устройства
На новых схемах архитектуры Zen 4 блока по работе с плавающей точкой + 4 блока с целочисленными данными в каждом ядре.
Видимо какие-то ограничения в трансляции, когда 2 AVX-256 инструкции нельзя одновременно исполнить на этих 4 блоках за 1 такт.
А вот до 4х других инструкций для данных с плавающей точкой за такт — можно.
Mad__Max
25.02.2017 04:53Не дописал. 2 256 бит AVX за такт оно не может, но судя по описаниям например может одну AVX + 2 других инструкции с плавающей запятой (SSE или х87) за один такт.
А целочисленных ФУ 4 штуки 128 битных на каждое ядро (против 2 на ядро в бульдозерах)
Structure
25.02.2017 13:05+1То есть могут оказаться задачи, в которых Zen в 8 потоков будет работать со скоростью 4-ядерника Intel.
1. Такой код нужно на ГПУ исполнять.
2. Иначе, скорей всего, производительность упрется в память, а еще и про другие инструкции не стоит забывать. Так что про разницу в 2 раза на реальных задачах для CPU я слабо верю.DistortNeo
26.02.2017 00:06+1- У кода на GPU есть недостаток: его ещё нужно написать. Не для каждой задачи это целесообразно делать.
- Да, текущие тесты показывают, что разницы нет. Может быть, в определённых синтетических сценариях она и будет — не знаю.
Я думаю, стоит дождаться выхода официальной документации на процессоры, а не гадать.
Structure
25.02.2017 11:12А вы на Интел гляньте с 2010 года. Ядро все сложнее, ROB раздули, планировщик раздули, а однопоточная производительность очень слабо растет.
Только сильно увеличили многопоточную.0xd34df00d
27.02.2017 05:51+1У меня в соседнем окне предельно тупая однопоточная задача на i7-3930K @ 4.2 ГГц считается в более чем два раза медленнее, чем та же задача на неразогнанном i7-6700 @ 3.4 ГГц.
Правда, в ещё одном окне есть ещё одна задача, в которой выигрыш — процентов 25 хорошо если.
boblenin
25.02.2017 04:34Ну так у Intel и число ядер не растет уже лет 7 не растет.

rub_ak
25.02.2017 07:48Ещё как растет. В 2012 было максимум 8 ядер, а в конце 2014 стало 18 ядер.
boblenin
25.02.2017 23:44+2На серверах — возможно. А на десктопах i7 заморозились.
rub_ak
26.02.2017 13:322011 сокет выпускают все кому не лень и во всех возможных форм-факторах можно хоть в тайваньский инвин ставить. А есть ещё Workstation где двухпроцессорные мамки стоят.
У нас на работе недавно только купили в КБ xeon 10 ядерный, до этого брали им 6 ядерные, для них это обычные компьютеры (и да корпуса inwin), на них cтоит windows 7 и solidwork
u010602
26.02.2017 13:02Правда там нюанс есть, было 8 ядер по 3.1 ггц, стало 18 по 2.3 ггц. Это рост в 1.6 раза.
Сейчас 24 по 2.4, это рост в 2.3 раза.
В начале 2011 было 6 по 3.47 ггц Тогда выходит что за 7 лет прирост 2.77 раза.
Конечно такие подсчеты не учитывают разных архитектурных улучшений, тем не менее «грубая производительность» выросла за 7 лет не так уж и сильно.
На десктопе за это время перешли от 4 по 3.33 к 10 по 3. Это прирост 2.25 раза.
Т.е. примерно одинаково с серверным сегментом.
И это логично, т.к. единственный сдерживающий фактор это охлаждение. 3770 на частоте 4 ггц уже очень сложно охлаждается мега двойным башенным куллером, а у него всего 95вт. Чем охлаждать 140-160 вт в режиме турбо я даже не знаю.rub_ak
26.02.2017 13:40Но самое главное desktop это всего лишь компьютер на столе на котором ты работаешь, а сервер это компьютер к которому подключаются клиенты. И эти понятия на прямую вообще не сравниваются в плане железа.

severgun
28.02.2017 14:42+1А чеще даже не работаешь, а скролишь вебстраничку которой конечно нужно 8 ядер по 3.2
Googlist
23.02.2017 16:12-4А смьісл? Они ж прежде всего коммерческая компания, их цель — заработать больше денег. Поєтому и вьіпускают в таком порядке для получения максимальной прибьіли, а не с целью абстрактной победьі над конкурентом.
Dmitry_4
24.02.2017 14:11Вот я тоже думаю у интела в загашнике еще много чего припасено. Как только амд выводит очередной «кипятильник», они ловко и непринужденно выводят совсем чуть более дорогого, но более быстрого в реальной жизни конкурента. И аэмдэшный «прорыв» оказывается отбит.
А вот о чем почему-то никто не говорит. На работе разработчики Android жаловались, что эмулятор андроида работает только на интеле, ибо амэдэ эту виртализацию аппаратно не поддеживает
Hanabishi
24.02.2017 19:58+1> кипятильник
А ничего, что амдшный проц 95 Вт и при этом обходит интеловский на 140 Вт?
> эмулятор андроида работает только на интеле, ибо амэдэ эту виртализацию аппаратно не поддеживает
Ложь и провокация, виртуализация поддерживается и прекрасно работает, самолично пользовался андроидом с виртуализацией на процессоре FX.
u010602
23.02.2017 18:47+2Мне кажется они специально взяли перерыв, в то время как линейки Интел показывают почти нулевой прирост производительности в реальных задачах. Сейчас если интел и выпустит что-то на 5-10% быстрее, или даже на 20% быстрее то все равно это не стоит +100% к цене. 8 ядер и 16 потоков на частоте 4 ГГЦ с поддержкой ECC памяти это просто нечем крыть кроме цены, я думаю мне такой системы хватит лет 5-7.
Сейчас у меня 3770К, 4 ядра на 4.1 ГГЦ и без ECC, аргументов купить комп на новой линейке интела нет ни каких.
Еще больше ядер — не нужно (пока), поддержку не существующих списков команд добавить нельзя, запас может быть только по частоте, а он зависит от тех процесса. Пока у них видимо нет сл тех процесса, а ждать его появления уже опасно.DistortNeo
23.02.2017 18:56+1Сейчас у меня 3770К, 4 ядра на 4.1 ГГЦ и без ECC, аргументов купить комп на новой линейке интела нет ни каких.
У меня 2600K @ 4.5 GHz, причём с отключенным HT (4 ядра/4 потока) — в моих задачах включение HT не только не приводит к росту, но даже снижает производительность.
Конечно, мне очень хочется 6900K — он бы дал прирост около ~3 раз для моих задач, но я, скорее всего, сделаю апгрейд на AMD в итоге.0xd34df00d
24.02.2017 03:21+1А это какие у вас задачи такие? А то у меня 3930k, и я оценивают потенциальный прирост процентов в 20-30.
DistortNeo
24.02.2017 04:11+1Обработка изображений, линейная алгебра. Задачи очень хорошо масштабируются по ядрам.
Поэтому ожидаю двукратный пророст от роста числа ядер + 20-25% прирост производительности на ядро, итого около 2.5 раз.Также появится возможность использования AVX2.
Ещё есть надежда, что SMT (аналог Hyper-Threading от AMD) даст небольшой прирост в производительности. Хотя здесь я настроен скептически: у Ryzen нет лишних блоков обработки FP, поэтому что в 8 потоков, что в 16 скорость вычислений будет, скорее всего, одинакова.0xd34df00d
24.02.2017 07:12Ух ё, я как-то пропустил, что у 6900k ажно восемь ядер. Тогда это имеет смысл, да.
А так у меня-то тоже линейная алгебра всякая, псевдообратные там считать, Левенберга-Марквардта прогонять, всякое такое. Опыт показывает, что оно всё в основном упирается в память.rub_ak
24.02.2017 07:37Так у вас и так 4 канала на память, а ели понадобятся ядра можно xeon недорогой на ebay взять. (Xeon E5-2695V2 12ядер, 30мб кэша HT, бу по 250$ продают)
Амд такого пока предложить не может.0xd34df00d
24.02.2017 07:39А смысла в этих 12 ядрах, если у него частота 2.4 ГГц, а мой 3930k стабильно работает на 4.2? Прирост получится несерьёзным.
Вот двухголовую систему из таких процов собрать было бы интересно, но сколько стоят соответствующие матери?rub_ak
24.02.2017 07:45Я гипотетически, вдруг они вам понадобятся.
0xd34df00d
24.02.2017 07:47Ну, представляется разумным оценивать суммарную производительность как произведение частоты ядра на количество ядер. С небольшим предпочтением пусть чуть менее суммарно производительных процессоров, но с более быстрыми ядрами (не все нагрузки параллелятся).
lolipop
24.02.2017 16:49двухголовые 1366 китайцы сливают дешевле 200 включая доставку.
0xd34df00d
24.02.2017 19:50А где посмотреть примеры того, что они продают? А то я в этом ничего не понимаю, только совсем базовые вещи слышал.
0xd34df00d
24.02.2017 07:43И, кроме того, я как-то понял, что никогда не задавался вопросом, как именно работают эти четыре канала?
Например, если у меня в памяти лежит кусок данных относительно подряд, с которым работает одно-единственное ядро, по идее, скорость обмена с памятью выше «одноканальной» не поднимется?DistortNeo
24.02.2017 13:01+1Многоканальный доступ означает, что процессор может одновременно работать с несколькими модулями памяти.
у меня в памяти лежит кусок данных относительно подряд
При многоканальном доступе данные размазаны по модулям (interleaving), так что при последовательном доступе будут задействованы все модули, и многоканальный доступ будет эффективен.0xd34df00d
24.02.2017 19:51В очевидно ограниченной по памяти задаче (и vtune говорит, что у меня всё упирается в шину памяти) я получаю на своём DDR3-1600 примерно 10 с небольшим гигабайт/с, что близко к теоретическому пределу для одноканального режима. Как можно проверить, собственно, многоканальный доступ у меня или нет?
DistortNeo
24.02.2017 20:09Да, ~10 Gb/s — это соответствует одноканальному режиму работы.
Окончательно в этом можно убедиться, посмотрев на данные, выдаваемые CPU-Z.0xd34df00d
24.02.2017 20:14Осталось вкорячить CPU-Z на эти мои линуксы :)
dmidecode про interleaved data depth говорит unknown.DistortNeo
24.02.2017 20:38dmidecode про interleaved data depth говорит unknown.
Странно. Впрочем, пока я его не обновил — мне он тоже ничего не выдавал.
rub_ak
24.02.2017 20:38cpu-z на вкладке memory показывает, а как установить правильно память смотрите руководство от материнки
Mad__Max
25.02.2017 02:21+1Серверные 12(на ядрах примерно как у Phemom II) и 16(примерно как у FX) ядерные камни у АМД уже очень давно были. И тоже на ебэй недорого за б/у встречаются.
Еще года 3-4 назад знакомые 4х сосетную машину на б.у. серверных камнях от AMD собирали с 48 рабочими ядрами в итоге.
Mad__Max
24.02.2017 03:41Да, тоже интересно как можно ожидать 3х кратный прирост, если основное преимущество это 8 ядер против 4, а масштабирование на количество ядер в самом лучшем случае линейное.
По частоте скорее всего это будет шаг назад (для 6900K 4.5 ГГц это почти нереально достичь без экстрима). Ну а обновленная архитектура даст только 10-30% прибавки в зависимости от задачи.
lolipop
23.02.2017 19:01+1к слову, разйзен умеет в ecc.
a5b
23.02.2017 21:38+3Все эти новости о поддержке ECC начались с того, что в спецификациях материнской платы нашли "совместимость" с модулем памяти ECC, про реальную реализацию ECC в процессоре данных нет. В обсуждении https://community.amd.com/thread/210870 заметили спецификации сходных плат, в которых честно указано, что модуль с 9 чипами памяти поставить можно (ECC и неECC DIMMы pin-совместимы), память заработает, но суммы ECC никто ни считать, ни исправлять не будет — http://www.gigabyte.us/Motherboard/GA-AX370-GAMING-5-rev-10#sp (AMD X370)
"Support for ECC Un-buffered DIMM 1Rx8/2Rx8 memory modules (operate in non-ECC mode)"
Работающий ECC увеличивает задержки примерно на такт (для каждого запроса требуется подсчитать код и, в случае чтения, может потребоваться инверсия одного из битов при получении признака ошибки), хотя и слабо влияет на реальную производительность.
Ранее корпорация AMD включала обычный SECDED ECC в некоторые десктопные продукты, но оставляла для серверных платформ более продвинутые варианты кодов, например:
Athlon 64, 2004 "2.4.2 Memory Controller… ECC checking with single-bit correction and double-bit detection • Chip Kill ECC allows single symbol correction and double symbol detection (Server/Workstation products only)";
16h G-Series SOC 2012, FT3 "Integrated Memory Controller… FT3 package… Supports ECC";
16h AMD Sempron, 2014 "FS1b package… Supports ECC"
16h A-Series Mobile "FT3 package… Supports ECC"
10h AMD Phenom II, 2010 "Integrated Memory Controller .."
В то же время ECC не включался в ряд встраиваемых APU, например 15h… Embedded R-Series, 2012 "Integrated Memory Controller", 15h A-Series APU 2012 "Integrated Memory Controller" — без ECC.
Точная информация будет через несколько недель с публикацией спецификаций на процессоры и чипсеты (поиск site:support.amd.com "family 17h"). Сейчас есть только предположения, хотя определенный код для F17 уже добавлен в ядро Linux: http://lxr.free-electrons.com/source/drivers/edac/amd64_edac.c?v=4.10#L2192, есть некоторая информация в истории этого файла: https://github.com/torvalds/linux/commits/master/drivers/edac/amd64_edac.c, например отказ включать ECC если он выключен (или не поддерживается) в BIOS "Forcing ECC on is not recommended on newer systems. Please enable ECC in BIOS".
a5b
23.02.2017 22:17+1Одно из изданий (STH) спросило на AMD Tech Day in San Francisco представителей AMD, ожидается ли анонс односокетных Zen/Ryzen с поддержкой ECC и получило ответ, что AMD не анонсирует таких продуктов при запуске Ryzen.
https://www.reddit.com/r/Amd/comments/5vpp40/no_ecc_support_in_any_of_the_currently_announced/ — https://www.servethehome.com/amd-ryzen-7-parts-available-for-pre-order-now/ "AMD RYZEN 7 PARTS AVAILABLE FOR PRE-ORDER NOW!" — PATRICK KENNEDY FEBRUARY 22, 2017
We did ask about a potential single socket Ryzen/ Zen part with ECC memory support and were told that AMD was not announcing such a product at this time alongside the Ryzen/ Zen launch.
u010602
24.02.2017 02:56+1Спасибо за это сообщение, хотя признаюсь честно, оно вызвали у меня негативные эмоции. :( А так хотелось ECC за вменяемые деньги… Буду надеяться АМД выпустит серверные версии за вменяемые деньги.
a5b
02.03.2017 20:03http://www.anandtech.com/print/11170/the-amd-zen-and-ryzen-7-review-a-deep-dive-on-1800x-1700x-and-1700 The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700 — March 2, 2017 9:00 AM EST
At this time AMD is not announcing any Pro parts, although it was confirmed to be that there are plans to continue the Pro line of CPUs with Ryzen to be launched at a later time.… A side note on ECC: given the design of Naples and the fact that it should be supporting ECC, this means that the base memory controller in the silicon should be able to support ECC. We know that it is disabled for the consumer parts, but nothing has been said regarding the Pro parts.… For our testing… 1800X, 1700X and 1700… At present, ECC is not supported.
a5b
24.02.2017 09:27Этот патч также несколько интересен своей историей. Принят патч с сообщением: http://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=044e7a414be9ba20826e5fd482214686193fe7b6
EDAC, amd64: Don't force-enable ECC checking on newer systems
It's not recommended for the OS to try and force-enable ECC checking.
This is considered a firmware task since it includes memory training,
etc, so don't change ECC settings on Fam17h or newer systems and inform
the user.
- amd64_warn("Forcing ECC on!\n"); + if (boot_cpu_data.x86 >= 0x17) { + amd64_warn("Forcing ECC on is not recommended on newer systems. Please enable ECC in BIOS."); + goto err_enable; + } else + amd64_warn("Forcing ECC on!\n");
В предыдущей версии патча https://www.spinics.net/lists/linux-edac/msg06912.html "[PATCH 07/17] EDAC/amd64: Don't try to force ECC settings on newer systems" просто не включали ECC даже по ecc_enable_override=1 и не выдавали каких-либо сообщений:
+ /* Don't try to enable DRAM ECC from Linux on newer systems. */ + if (boot_cpu_data.x86 >= 0x17) + return;
На что было указано: https://www.spinics.net/lists/linux-edac/msg06931.html "Add… along with a pr_info()
explaining to the user why we're not going to force-enable ECC."
Вся серия патчей AMD Fam17h EDAC — https://www.spinics.net/lists/linux-edac/msg06905.html
Поиск патчей в ядре по строке "17h" http://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/log/?qt=grep&q=17h (в частности, год назад там заметили раннее кодовое обозначение "AMD Zeppelin (Family 17h, Model 00h)")
ruspartisan
23.02.2017 11:36В реальной задаче по кодированию видео в тесте Handbrake процессор Ryzen 7 1700 справился с задачей за 61,8 с, а Core i7 7700K — за 71,8 с. И это несмотря на то, что скорость кодирования видео с аппаратной поддержкой всегда считалась сильной стороной процессоров Intel.
С вероятностью 95% кодирование осуществлялось программно, а не аппаратно.Laney1
23.02.2017 11:43типичная ализарщина. Аппаратное кодирование видео (QuickSync и т.п.) — сильная сторона интеловской интегрированной графики, собственно процессоры тут не при чем.

Alexsandr_SE
23.02.2017 12:28+1Так ведь процессора тестировали. Помнится по обзорам у «аппаратных» решений качество хуже, не на много, но хуже.
lolipop
23.02.2017 18:05+1да, только сравнивали топовые процессоры, которые ни у амд, ни у интел не имеют встройки.
Laney1
23.02.2017 11:38+4в процессорах Intel честный AVX2 (а в следующем поколении обещают AVX-512) плюс есть аппаратная поддержка транзакционной памяти (TSX). Учитываются ли в бенчмарках эти фичи, отсутствующие в Ryzen? Подозреваю что нет
oxidmod
23.02.2017 11:50+2Я думаю, что основной массе пользователей это не критично. С другой стороны осталось всего ничего и ютуб будет завалет реальными тестами/обзорами. Ну и цена. Вот то что может сыграть злую шутку с супер навороченными и технологичными процами интела
VaalKIA
23.02.2017 12:29+1Реальные тесты уже не за горами. А по поводу AVX2, насколько я понял, спаривание блоков для их выполнения, это всё равно быстрее, чем компиляция кода просто под AVX, так что спасибо АМД за то, что поддерживает AVX2 хотя бы так, чем никак.
Structure
23.02.2017 13:41А еще 4 канала памяти и больше линий PCI. И получаем проц+мать по космической цене.
Но многим ли это нужно?
DistortNeo
23.02.2017 18:46+1А какая разница, как реализован AVX? Для программиста важны характеристики latency и throughput. Но факт в том, что у Ryzen вычислительных блоков тупо меньше, чем у Skylake. Поэтому Skylake теоретически может за единицу времени выполнить больше команд AVX.
А вот что действительно плохо, так это 2-канальная память даже у 8-ядерника. У меня на Sandy Bridge часто бывает, что уже пары потоков достаточно, чтобы упереться в скорость памяти. Пример задачи: посчитать норму длинного вектора: 1 чтение, 1 умножение, 1 сложение на 8 элементов (32 байта). При скорости памяти 20 гбайт/сек получается всего 625 миллионов итераций в секунду на весь процессор, а между SSE и AVX-версиями алгоритма разницы нет никакой.
Приходится оптимизировать алгоритмы, добиваясь группировки данных в кэше и даже увеличивая вычисления за счёт уменьшения количества доступа к памяти. Так что я не удивлён тем, что инструкции AVX у AMD менее производительны, чем у Skylake: при двухканальной памяти при большом количестве ядер высокая производительность AVX просто не нужна. А AVX512 и подавно не нужен.
Varfalomey
23.02.2017 11:40CPU-Z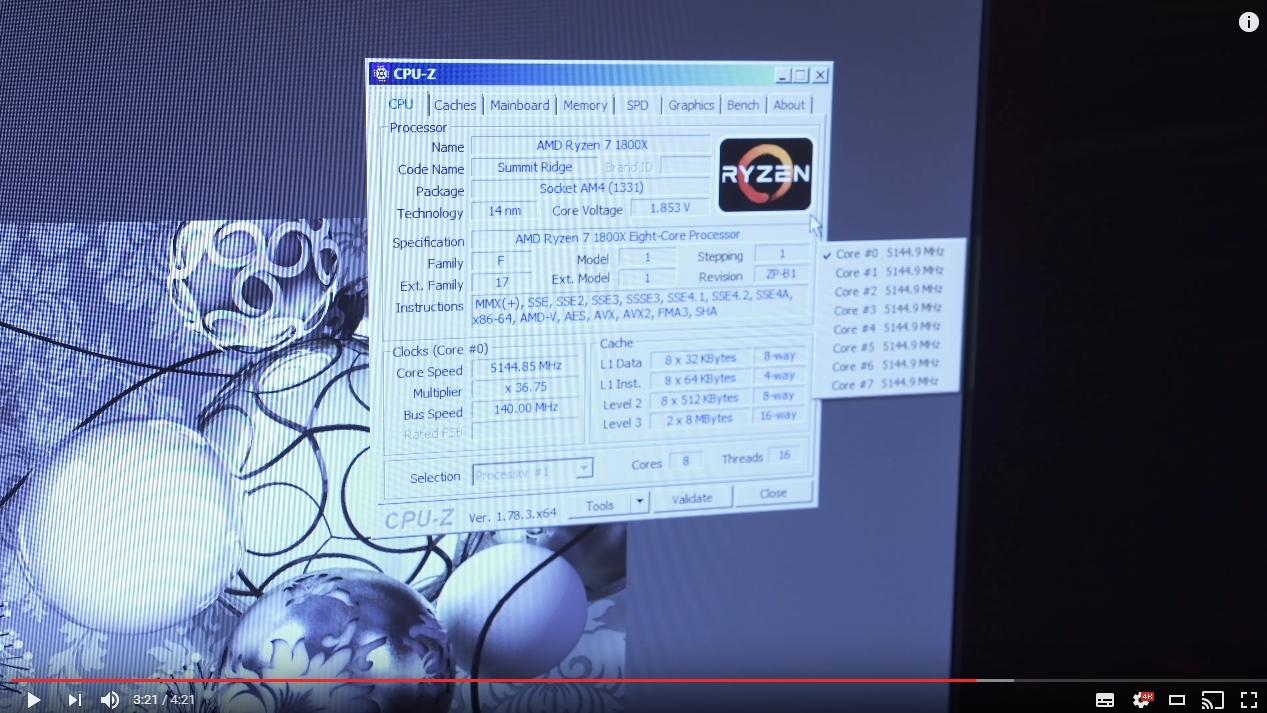

sleeply4cat
23.02.2017 18:33А почему вы округлили 5.1449 до 5.2?
nerudo
23.02.2017 18:49+9Очевидно же: 5.1449 => 5.145 => 5.15 => 5.2 ;) Вот 6, похоже, ника не получить…

Nick_Name
23.02.2017 20:41То, что вы сделали похоже на математический «развод» =), но так делать нельзя или точнее — так делать неверно. Округлять округлённое число — это увеличивать погрешность. Определитесь вначале до какого разряда хотите округлить, а потом округляйте, используя правила из школьного учебника. То есть решили округлить до десятых — отбрасываем цифры с сотых, учитывая что сотый разряд является 4, то округление происходит без усиления, то получаем 5,1 либо если до второго знака, то 5,14. Так будет правильно.
monster2106
23.02.2017 21:47+7По-моему очевидно, что у товарища выше это был сарказм. Там даже скобочка есть :-)
ghostinushanka
24.02.2017 01:28+1Вот 6, похоже, ника не получить…
Ну это смотря как округлять… опытный маркетолог и так может ;)
5.1449.ceil res0: Double = 6.0

ionicman
23.02.2017 12:01Я тоже ждал, когда-же анонсируют.
На русских оверклоках его ласково именуют «Рыжень» или «Рязань» :D
Я не очень люблю AMD еще с тех времен, когда были вечные проблемы с дровами и т.д., однако десктоп на AMDx2 у меня был — ничего плохого сказать не могу.
Однозначно было-бы отлично, если бы на рынок вернулась конкуренция, ибо Intel последнее время совсем обнаглел :)
Единственное, чего я опасаюсь — как бы не было того, что господа из AMD сравнивали мощность процов с текущей линейкой Intel, а ведь следующая уже вот-вот на подходе. И она может переплюнуть Рязань запросто — запас очень небольшой.
Но на самом деле тесты — это синтетика, она с реальностью далеко не всегда пересекается, поглядим, что геймеры напишут, а дальше уже будет понятно, что брать.
nafikovr
23.02.2017 12:14думаю запас по цене достаточно основательный.
ionicman
23.02.2017 12:28да, это реально конкурентное преимущество, согласен

xMushroom
23.02.2017 22:23+2Это первое, а второе — никаких оснований ожидать чего-либо большего стандартных 5-10% от следующей линейки Интела нет. То есть даже если и переплюнет, то очень ненамного.
Если же говорить о реальном прогрессе — 6-ядерники в массовом сегменте — то это не раньше 18 года. И все равно у AMD уже 8-ядерники там же.

stalinets
23.02.2017 12:19Замечательная новость. Это должно вызвать новый виток конкуренции, а значит — снижение цен, а значит — рост продаж, и этот рост всколыхнёт застой на рынке ПК.
Conscience
23.02.2017 12:21+2Меня не покидает стойкое ощущение какого-то подвоха. Ведь если все так прекрасно, как описывают сами АМД, то зачем продлевать обзорщикам NDA до второго марта (старт продаж)?

makaroff
23.02.2017 13:38+1Чтобы побольше шума создать.
Conscience
23.02.2017 14:44-2Т.е. у компании АМД задача создать побольше шума, а не продать побольше процессоров? Интересно.
Alexsey
23.02.2017 15:40После конференции они уже дали обзорщикам достаточно рассказать и показать чтобы большинство людей могли решить для себя надо оно им или нет. Единственное ограничение было в плане доступного софта, а так они дали обзорщикам делать с демо системами все что они хотят в пределах разумного.
Conscience
23.02.2017 15:44Так они им и процессоры для тестов раздали наверняка, но только NDA зачем-то продлили на два дня. Если с процессорами все так хорошо, то зачем скрывать это? Наоборот же надо рассказать и показать как все круто. Или не все так круто, и подвох где-то все же есть?
makaroff
23.02.2017 18:32+2Больше и дольше обсуждение и кипения повидла — возможность обхватить бОльшую аудиторию. Не все каждый день читают хай-тэк новости. Некоторые раз в месяц одним глазом.

Djeux
23.02.2017 12:43Если тесты честные, то как минимум монополии Интел придет конец и они перестанут ставить космические цены на процессоры серии extreme. Что есть хорошо при любом раскладе.
rub_ak
23.02.2017 13:06Серия extreme как стоила, так и будет стоить 1000$.
В давние времена у амд самих была своя серия десктопных процессоров с ценником 1000$rub_ak
23.02.2017 13:14+3UPD/ не знал что сейчас серия extreme выросла до 1,7к $
Djeux
23.02.2017 16:32+2Она не будет стоит 1.7к, в случае если АМДшные процессоры будут показывать приблизительную производительность за гораздо меньшие деньги.
Будет оно так или нет, поживем увидем.
Хотелось бы еще чтобы nvidia-у так же стали подпирать.
Конкуренция пойдет только на пользу покупателям.xMushroom
23.02.2017 22:30На nvidia вроде грех жаловаться — в отличие от интел, производительность растет исправно.
UJIb9I4AnJIbIrUH
23.02.2017 23:05+1Ну у nVidia (как и у AMD Radeon) это сделать проще простого. Даже если не улучшать архитектуру, то с переходом на новые техпроцессы просто наращивается число ядер в два раза и все дела. Помнится когда красные выпустили одночиповый HD5870 на 40 нм он работал на уровне двухчиповой GTX 295 поколения 55 нм. Ну и так далее…
А цпушникам надо придумывать способы увеличения производительности при том же числе ядер.
А по поводу реакции Intel: по-моему то, что они добавили Hyper-Threading в пентиумы на каби лэйк уже кое о чём говорит.
Djeux
24.02.2017 10:45Это если не смотреть в сторону титанов. Там соотношение цена-производительность выходит за разумные рамки.
История получается прям как с extreme серией.
Когда +20% производительности дает +80% к цене. В такой ситуации они просто стригут деньги с людей для кого фактор денег отсутствует. Потом через пол года выпускают промежуточный вариант аля 980Ti, который убивает напрочь весь смысл в покупке Titan-а.

Oplkill
23.02.2017 13:19Само по себе наличие дешевых и хорошо работающих процессоров АМД(покрывающие 85% всех нужд на оценку Хорошо) уже наносит «урон» интел. (но это в стране единорогов, где нет такого понятия как кортелей и подобных этому понятий)

betrachtung
23.02.2017 13:39+2Шикарно. Такое ощущение, что возвращаются времена Athlon, Athlon XP, Athlon 64 — красные снова на коне.
Возможно, впервые за много лет я куплю их процессор. Тем более, я люблю холодные процессоры, а у них даже на лютом топе TDP 65 Вт, что же будет в среднем сегменте?Googlist
23.02.2017 16:21-1На скрине вьіше цпу-з под разгоном до несчастньіх 5 ГГц кор вольтаж 1,853, сомневаюсь в его «холодности».
oxidmod
23.02.2017 16:29В процах с «X» на конце есть тезнология авторазгона. Она гонит проц пока позволяет охлаждение

olgerdovich
23.02.2017 16:34-2как вы точку над «ы» поставили? и зачем? чтобы читатели начали яростно скрести экраны и в итоге повысили оборот производителей и продавцов мониторов?

Alex_ME
23.02.2017 16:37+5Мягкий знак и латинская i. Возможно, у человека просто нет "ы" в раскладке.
olgerdovich
23.02.2017 16:44Спасибо, оказывается, все просто. Да, дурака свалял, надо было поводить курсором по экрану с зажатой ЛКМ, тогда бы сразу стало ясно.
Тогда стоит посоветовать Googlist'у завести себе букву «ы» тем или иным образом, а то так много мониторов могут несколько преждевременно исчерпать ресурс.

heaver
23.02.2017 17:36U+0456 — Белорусская либо Украинская. Но, поскольку в Белорусской раскладке клавы есть буква «ы», скорее Украинская.
sleeply4cat
23.02.2017 18:38+2
perfect_genius
23.02.2017 21:22+1Скопируйте «глючный» текст выше, вставьте его куда-нибудь и пробуйте удалять Backspace'ом =)
Mad__Max
24.02.2017 04:32Сразу вспомнились времена ZX Spectrum когда подобная фигня(только позабористей) использовалась как «защита» от копирования/взлома, прятать код на бейсике.
DistortNeo
24.02.2017 04:55-1?ьтатичоп отэ орп онсеретни ыб олыБ?
(кстати, не пытайтесь копировать, а потом вставлять эту строчку)Mad__Max
24.02.2017 05:22+2Ну вот типа того, что у вас в примере выше. С разных помощью спец. символов (включая управляющие) забитых в текст программы при выводе ее на экран вместо кода отображалась какая-нибудь надпись или рисунок из символьной псевдографики.
Типа программа такая-то (с) Вася Пупкин.
Не влезать объет!
От загрузки в нормальный внешний редактор это не спасет, но от просмотра штатными встроенными в ПЗУ средствами спрятать можно было.
OutOfMemory
26.02.2017 12:49+3Для упрощения интерпретации в Спектруме текст программы на Бейсике записывался в файлах и в ОЗУ в виде байткода. Байткод вместо привычного исходного кода содержал сложный набор данных — номер строки, длину, ключевые слова (исполняемые команды), пятибайтовые числа, печатные символы, управляющие символы, разделители и т.д.
Для отображения текста программы на экране выполнялась команда LIST, которая распарсивала байткод.Также распарсивание происходило при вызове строки программы в область редактирования.
Защита заключалась в обфускации байткода так, чтобы при отображении и редактировании стандартными средствами происходило искажение исходного кода, вплоть до его полной нечитаемости или невозможности отредактировать.Обычно такой текст выглядел как бессмысленный набор команд. Иногда основная часть текста не отображалась вообще, потому что затиралась вызовом удаления, при этом выдавался текст из комментариев или набор печатных псевдографических символов.
Способов манипуляций с байт-кодом Бейсика было множество, вот тут есть очень краткое описание нескольких:
https://geektimes.ru/post/103127/
Если интересно, можно почитать вот эти книги:
ZX-Spectrum изнутри. Защита и взлом программ
Как работать с защищёнными программами (тайники спектрума)
Тайники ZX Spectrum и вечная жизнь в 600 играх
Тайники ZX Spectrum и как установить вечную жизньDistortNeo
26.02.2017 17:05Спасибо, теперь стало понятно. Про байт-код помню — застал такое время, но тогда даже и не думал, с ним можно проделывать такие хаки.
DrGluck
28.02.2017 17:51Туда ещё можно было вставлять куски на ассемблере. Собственно, так и работали почти все «Cracked by Bill Gilbert» загрузчики игр. Код на Бейсике был примерно такой: 10 RANDOMIZE USR 25820 и дальше нечитаемая фигня.
UJIb9I4AnJIbIrUH
23.02.2017 21:26+4Заметил точку в букве «ьі» и подумал «опять чем-то запачкал экран».

SotaSill74
24.02.2017 09:18+2Сорри за оффтоп.
Заголовок спойлераИнтересно, а что Вы подумаете, увидев букву Ї ї?
Давайте усложним — вот буква Ґ ґ.
Вам ещё мало? — тогда представляю Вам: Є є!
Не согласны с поворотом?, Ну тогда встречайте азбуку Кирилла и Мефодия, а с ними ещё + 20 букв:

mort1s
24.02.2017 09:18+1За это говорим спасибо Джиму Келлеру(снова) и его команде, жаль его не было на презентации.

zookko
23.02.2017 15:01Интел тоже сделала один интересный ход — на всех новых пентиумах включен НТ, нижний сегмент теперь полностью за ними, если АМД быстро не выкатит что-то сравнимое.
Akela_wolf
23.02.2017 15:29Спорно. Заглянул на сайт DNS — нашел там только Pentium G4600 с конфигурацией 2c/4t цена порядка 5000 рублей (в моем регионе).
Идем и смотрим что за эти деньги предлагает AMD уже сейчас: A8-7600 (4c/4t + video), FX-6100 (6c/6t без видео), FX-4350 (4c/4t без видео). Конечно в данном случае ядро AMD < ядро Intel т.к. речь идет об архитектуре Steamroller, но говорить что «нижний сегмент полностью за Intel» я бы не стал даже сейчас. А в перспективе выйдут APU на основе ZEN (я так подозреваю в конфигурациях 4/8, 4/4 и, возможно, 2/4), что позволит ответить Intel и в этом сегменте.UJIb9I4AnJIbIrUH
23.02.2017 23:49+1Если верить тестам, то Pentium G4560 имеет производительность уровня i5 2500K и обходит FX-6300 по производительности и особенно по соотношению производительность/цена. А 2500K хоть и ветеран, но, судя по тестам, может дать A8-7600 фору.
Alexsey
23.02.2017 15:41+2если АМД быстро не выкатит что-то сравнимое
АМД пока еще не показали ryzen 5 и ryzen 3, так что все еще впереди.stalinets
23.02.2017 16:12Вот кстати интересно, будут ли 5 и 3 существенно отличаться от нынешнего топа, или это будет просто топ с бракованными и потому отключёнными ядрами и кэшем? Насколько я слышал, Интел из бракованных i7 делает весь спектр от i5 до пентиумов.
zookko
23.02.2017 16:18Западные специалисты, знакомые с производством, говорят, что доля «отбраковки» <10%, остальное — кристаллы изначально созданные как i5\i3 и т.д.
сейчас не проблема получить изображение кристалла, если бы все i3 были урезанными i7 — это было бы давно уже обнаружено.
Akela_wolf
23.02.2017 17:08+1ZEN состоит из модулей по 4 ядра (разделяемые ресурсы модуля — только L3 кэш, в отличие от Бульдозеров). То есть R7 — 2 модуля, R5 — те же 2 модуля, по одному ядру в каждом отключено, R3 — 1 модуль. То есть R7 и R5 — скорее всего один и тот же кристалл (в т.ч. отбраковка), R3 — отдельный кристалл.

alexk24
23.02.2017 19:45Т.е. велика вероятность что в R5 из 2-х отключенных ядер реально бракованным будет только одно и будет шанс включить доп ядро?
Akela_wolf
24.02.2017 07:32-1Не думаю. По тем статьям, которые я читал — количество ядер в модулях должно быть обязательно равным. То есть возможна конфигурация 3+3, но невозможны конфигурации 4+2 и 4+3

slafniy
24.02.2017 09:17Не так. Разделяемых ресурсов вообще нет между модулями, на каждый модуль по 8 мб л3 кеша. Новые восьмиядерники это склейки из двух 4хядерных модулей. Да даже на картинку с кристаллом гляньте…
Akela_wolf
24.02.2017 14:10Я так и написал — разделяемые ресурсы (между ядрами) модуля — L3 кэш. То есть у ядер одного модуля все свое, кроме L3 кэша, который общий для всех ядер модуля. Разделяемых между модулями ресурсов нет, модули полностью независимы.
Максимально, насколько я понимаю, будет 4 модуля в кристалле. Серверные процессоры (Naples) по имеющейся на данный момент информации будут представлять из себя 2 шестнадцатиядерных кристалла.
Dum_spiro_spero
23.02.2017 15:20Крайне любопытно.
Если процессор действительно хорош — то как он получился?
На R&D нужны средства и хорошие сотрудники. А из АМД все разбегались и они набирали кого попало (информация от наших изнутри, но уже устаревшая). Видимо что-то поменялось, интересно что?
По наблюдениям стагнация уже давно. К тому же десктопы нужны мало кому, домой народ берет ноуты экономя место, на работу — моноблоки.
Единственно мы покупаем десктопы — но мы лаборатория и нам надо считать круглосуточно. Дома у меня ноут подключенный к большому монитору+клава+мышка. На i5 вполне можно что-то считать, но предпочитаю по тимвьюверу зайти на рабочий комп. Т.е. идея тонких клиентов проникла сама собой.
В общем искренне желаю успеха красным.
Alexufo
23.02.2017 15:34+3К тому же десктопы нужны мало кому,
единственная возможность купить цена/производительность/минимизация стоимости ремонта — это десктоп.
Моноблоки и ноуты это дикие цены по сравнению с железом десктопа.immaculate
23.02.2017 17:21+3Ноут дает свободу. Я, например, никогда не сижу на одном месте дольше 1-2 недель. Десктоп с собой не возьмешь даже на дачу. Поэтому уже лет 7-8 пользуюсь исключительно ноутбуками.
Надеюсь, AMD и для ноутов выпустит что-то реально конкурирующее с Intel. А то такое ощущение, что они серьезных процессоров для ноутбуков не делали никогда. А еще очень печальные воспоминания о видеокарте Radeon в прошлом ноутбуке (грелась адски, ноутбук на колени не положить было).Alexufo
23.02.2017 17:34+1иногда вопроса выбора не стоит — а стоит вопрос будет комп или нет. И тогда и десктоп постаскать приходится если приспичит.

hzs
23.02.2017 20:56+1У меня ноутбук был MSI S271, на AMD, на первом 64 разрядном двухядерном процессоре, который был использован в ноутбуках, так что не стоит считать, что красные всегда были лузерами.
Ноуту уже лет 8, семёрка, на случай необходимости винды, спокойно себе на этом ноуте работает.
Но да, греется, писец как.
FlarGargoyl
23.02.2017 20:57Для ноутов у них текущая серия интересная, APU, особенно А10. Деньги за «камень» открвоенно смешные, в камне — в добавок ко всему — видло, звуковуха, и вроде сетёвка (ну кроме распайки разъёмов, конечно).
Серия и задумывалась под невысокое потребление и ТДП, и миниатюризацию, ноуты, моноблоки, микропк, SoC итд
На ноуте с предпоследним топом А10 — споконо шпилил себе в Баттылфылд 3\4 в т.ч. в мультиплеер, не имея внешней видяхи.
Для «дома\работы» хватит уж тем более.immaculate
24.02.2017 00:13Меня интересует совокупность параметров. Например, для меня еще важно разрешение экрана и длительность автономной работы. Например, этот комментарий пишу сидя в аэропорту. Между рейсами 13 часов, розеток в зале ожидания почти нет. Несколько розеток для зарядки телефонов, и все уже заняты. В общем, считаю, что ноутбук должен работать без зарядки хотя бы 6-7 часов.
Когда покупал свой нынешний ноут пару лет назад, ноуты на AMD сливали по всем параметрам. У всех ноутов на процессорах AMD были никакие экраны (с разрешением типа 1366x768) и никакое время автономной работы. И вообще, было похоже, что это ноуты сляпанные кое-как, для самых непридирчивых покупателей, типа «ребенку для учебы». Сбалансированной конфигурации с хорошим экраном, временем работы, расширяемостью (чтобы установить более 4 Гб RAM) просто не было.
Meklon
24.02.2017 01:29Я часто решаю проблему розеток в аэропортах тройником и выдергиванием вендинговых автоматов из розетки.
FlarGargoyl
24.02.2017 17:11ну тут стоит учитывать, что мануфактуреры (ох и слово) железа енд-юзерского — и разработчики их составляющих — слегка разная штука. Не все серии всего железа удачно «обыгрываются» производителем, ориентирующимся на рынок потребительский.
По поводу расширяемости — я лично пердпочитаю ПроБук серию НР, ДЕЛЛЫй ентерпрайзных моделей, и верхний сегмент Лениво.
С остальным так или иначе имел серьезные проблемы с обслуживанием и расширяемостью.
1080р довольно давно идущий в ногу стандарт, хотя именно ноуты я предпочитаю небольшие, а с моим зрением вглядываться в 1080р на 12\14", даже при масштабирования текста — не айс, но это детали личные уже.DistortNeo
24.02.2017 17:46+2По поводу расширяемости — я лично пердпочитаю ПроБук серию НР, ДЕЛЛЫй ентерпрайзных моделей, и верхний сегмент Лениво.
Обоснуйте, что понимаете под обслуживаемостью и расширяемостью. Конкретно в HP и Lenovo меня дико раздражает BIOS Whitelist — не могу ни проапгрейдить Wi-Fi карточку, ни поставить Mini PCI-E SSD. В отличие от десктопов, идеальных ноутбуков нет — приходится либо мириться с недостатками, либо сильно переплачивать.
FlarGargoyl
24.02.2017 17:58ну manufacturer ACL-листы еще никто не отменял, увы. Никто в Лениво не хочет, чтоб вы купили ссд у Самсуя и вайфлю от ЛГ :)
Обслуживаемость и расширяемость в моём понимании — легко открыть, достать до нужного компонента не снимая материнку, легко заменить комплектующую типа кулера\клавиатуры\тачпада\памяти итд.DistortNeo
24.02.2017 18:38+1ну manufacturer ACL-листы еще никто не отменял, увы. Никто в Лениво не хочет, чтоб вы купили ссд у Самсуя и вайфлю от ЛГ :)
Даже ещё хуже: я не могу в старый ноут HP воткнуть карточку от более нового ноутбука HP. Никто не хочет, чтобы вы сделали небольшой апгрейд вместо покупки нового ноутбука.
Обслуживаемость и расширяемость в моём понимании — легко открыть, достать до нужного компонента не снимая материнку, легко заменить комплектующую типа кулера\клавиатуры\тачпада\памяти итд.
Я бы тогда назвал надёжностью и ремонтопригодностью.
А расширяемостью в современных ноутбуках, увы, не пахнет: со времем становится только хуже.
boblenin
26.02.2017 00:20+1HP уж точно в этом не образец.
1) Для прочистки радиатора — надо всю железяку разбирать, а тема плохих систем охлаждения — это любимая болячка HP.
2) Смена диска еще туда-сюда, а вот оперативка в нескольких моделях, попадавшихся мне располагалась по обе стороны материнки — опять разбор всей машинки.
Lenovo соглашусь, Dell похуже, но тоже хорошо. HP — ужос.

Warlock_9000
24.02.2017 09:48+2Обслуживаю несколько организаций — у них удаленка, работа с документами и интернет. Амд А4 с частотой повыше, 4гб памяти, ssd 120гб, нормальный блок питания и любой корпус — выходит в 13 тыс. + винда, если кому нужна еще 7 тыс. Ноуты за 20 тыс явно плачевные по производительности. Мониторы как правило не меняются, живут 2-3 смены системника.
Alexufo
24.02.2017 15:48+1про то и речь. SSD, блок питания, корпус — при апгрейде не требуют замены.Дешевые ноуты просто издевательство.
u010602
24.02.2017 17:30+4Для офисных работников апгрейд можно свести к наращиванию ОЗУ и замене процессора на более быстрый, тогда вообще все остается, а цена апгрейда меньше 100 баксов на место. У многих кому 8-9 лет назад собирал компы на АМ2+ они все еще трудятся после апгрейда, даже в современные игры можно сносно играть. А офисные задачи так подавно.
Собственно потому рынок десктопов и падает, т.к. они сильно медленно ломаются, в итоге даже те кто делает апгрейд, сбрасывают старье на вторичный рынок, который отнимает продажи у современного лоу-энда.
Мне иногда кажется что мы(человечество) в один момент произведем столько компов и комплектующих, что просто отпадет необходимость в производстве новых, и пока избыток будет потребляться забудем как это делать, а гиганты обанкротятся.
oxidmod
23.02.2017 15:46+4К тому же десктопы нужны мало кому,
гейминг и еше раз геймингDrako_Staarn
23.02.2017 15:54-2Ну, гейм-ноуты тоже есть. Да, дорого, но есть, и видимо спрос тоже имеет место, иначе бы не штамповали их как бешеные.
oxidmod
23.02.2017 16:10Их и не штампуют как бешенные) Сравните количество предложени геймерских ноутов и всех сотальных.
Потом просмотрите их спецификации и отсейте «геймерские» с мобильным видео и прочими несуразицами.
Ну и главная пробелма геймерского ноута в батарейке)) а на привязи зарядки он теряет главный козырь — мобильность)Drako_Staarn
23.02.2017 16:12Ну сравните количество год назад и сейчас, после выхода мобильных «Паскалей». И да, для такого ноута автономность — не приоритет. А при желании можно найти даже машинку с 7700K (да, десктопным, да с заменой).
oxidmod
23.02.2017 16:20+2Да, новые зеленые карты сделали возможным поставить нормальную карту в ноут, но всеже но. Если я беру игровой ноут без цели носить его с собой, то зачем мне платить за дисплей в ноуте, если я могу взять нормальный монитор? Зачем мне платить за клаву и тачпад, если я всеравно буду брать полноразмерную клаву и мышу с кучей кнопок и макросами? Геймеры отнюдь не глупы и считать умеют.
зы. Если такие ноуты делают, значит комуто это надо, но всеже это скорей из разряда выпендрежа, а не реальной пользы
zomby
23.02.2017 16:50Носить игровой ноут с собой ежедневно — зачем? На работе в обед поиграть? Гейм-ноут это такой себе полустационарный аппарат, удобный для частых переездов, командировок, жизни «на два дома» и т.п. Батарейка-то там не главное. Я вот не представляю себе места, где можно играть и при этом нет розетки. Туповремяубивалку лучше на телефоне запустить, а для серьёзных игр нужна спокойная обстановка, много времени и стол для мышки.

B0MJE
23.02.2017 20:36а для серьёзных игр нужна спокойная обстановка, много времени и стол для мышки.
Миллионы консольщиков по всему миру пустили слезу.
zomby
23.02.2017 16:11Десктопы некому пиарить. А на топовые игровые ноуты всегда куча обзоров, которые скорее служат имиджевой рекламой производителя. Собс-но для этого и штампуют эти гейм-ноуты, похоже.
DistortNeo
23.02.2017 21:16+1Отличие десктопа от ноутбука заключается в том, что десктоп вы можете собрать из отдельных компонент, а ноутбук — нет. Поэтому десктопы как единое целое нет смысла пиарить.
aliev
23.02.2017 16:40+4Гейм ноуты нужны ради одного, чтобы можно было в любом месте пожарить яичницу или воспользоваться в качестве фена с горячим воздухом.
DmitryMry
23.02.2017 18:04+1Несколько раз встречал информацию от людей, занимающихся ремонтами ноутбуков, что половина всех ноутбуков, находящихся в ремонте в сервис-центрах — это как раз позиционирующиеся как игровые, и причина поломки у них — перегрев.

ns3230
24.02.2017 05:35Истину глаголят. Если использовать постоянно, регулярно играть и давать другие большие нагрузки, делая это во всех возможных местах и позах (за столом, в кресле, на кровати, в самолете, автобусе, электричке) — даже у моделей с вроде как чепуховым (по меркам игровых ноутов) ТДП видяхи 20-30 Вт — она года через три может «отвалиться». Лично у меня в двух ноутах отваливался чип, хотя в одном был Rdeon HD5470, во втором — GeForce GT610. А еще помню, во времена вапа была такая мобильная соцсеть спейсес. И посиживал я там в форуме, по компам и железу людей консультировал иногда. Так ко мне неоднократно обращались люди старшего школьного возраста с просьбами подсказать нормальный игровой ноут. Не раз объяснял про нагрев, про все то, что крайне не рекомендуется с ними делать, чтобы не кипели. Кто-то решал, что при таком раскладе лучше уже стационар+нетбук, несколько человек купили таки ноуты. Из них двое потом очень долго (год может) меня постоянными вопросами доставали, как уменьшить нагрев, как убрать тротлинг, как сделать, чтобы вертушки не так шумели, и т.д.
PendalFF
23.02.2017 22:01+1Ключевое слово ТОЖЕ.
Хоть я и не геймер, но напуркуа бы мне отдавать 100+ тысяч рублей за то что я получу за 25-30 максимум.
Днесь вот пробегали dell t3500 по 8тр за платформу без озу и хдд. Докидываем 64 гуга рамы, ссд и видяху покруче и получаем в пределах 30к тазик на котором ведьмак на ультра графике бегает на фпс не ниже 60.UJIb9I4AnJIbIrUH
23.02.2017 22:17Вы ведь это несерьёзно пишете? Потому как 64 Гб оперативки это уже как минимум 22000 рублей
Conscience
23.02.2017 23:10Я думаю человек опечатался, там по спекам максимум 24гб (6х4гб ЕСС ддр3), на али это тысяч 5 рублей.
UJIb9I4AnJIbIrUH
23.02.2017 23:14+2Крутая цена, не знал про такой аттракцион невиданной щедрости. А почему так дёшево?
0xd34df00d
24.02.2017 03:32Эх… Покупал в 2013 году по 700 рублей плашка на 8 гигов.
DistortNeo
24.02.2017 04:14+2Да, хорошее время было из-за перепроизводства оперативной памяти. И в ноут, и в десктоп по 16 гигов воткнул. Зато харды из-за потопа были дорогие.
Warlock_9000
24.02.2017 09:51По моему на них больше обзоров просто делается, слюнями покапать, вокруг попрыгать.
Dum_spiro_spero
24.02.2017 00:14+2Все же хабр это некая ниша. У меня закрылась (точнее существенно перепрофилировалась) дружественная компьютерная фирма которая существовала лет 20. Почему? Директор сказал, а все — компьютеры никто не покупает. Можно конечно сказать, что не смогли трансформироваться в торговлю всем подряд — когда и процессоры и кофеварки и телефоны. В основном фирма поставляла компы организациям и редким физическим лицам типа меня.
Несколько лет назад ко мне регулярно обращались друзья чтобы я им собрал комп. Все прекратилось. Теперь я иногда помогаю купить друзьям ноуты и сразу их проапгрейдить — поставить больше памяти+SSD.
navion
24.02.2017 19:52Организации стали больше покупать компьютеры от большой тройки, так как разница в цене минимальная, а качество и сервис не сравнить с локальными сборщиками.
Dum_spiro_spero
26.02.2017 22:16А кто у нас большая тройка в этом сезоне/веке? В качестве думаю разницы нет вообще, насчет сервиса — вопрос спорный — как угодно может быть, у маленьких фирм преимущество в мобильности и возможности нетривиальных решений. Но это конечно отчаянно холиварно. )))
Мы все компы (включая многопроцессорные серверы) сами собираем и немного допиливаем, но мы лаборатория.rub_ak
26.02.2017 23:18HP, DELL, Lonovo?
navion: Сервис, а в России им кто-то пользуется? Какой может вообще быть сервис от сборщиков PC? Заметить модуль можно и самому, все в открытой продаже. Качество да тут могут быть нюансы, но только в сборке, все остальное (может кроме мат плат, но брак он везде брак, у нас HP мамки также умирали, как и все остальные ) все самое обычное. А вот на счет цены я бы поспорил.DistortNeo
26.02.2017 23:35+1Сервис, а в России им кто-то пользуется?
Да, крупные корпорации пользуются, особенно бюджетные.
navion
27.02.2017 11:02+1Сервис, а в России им кто-то пользуется?
Я пользуюсь, причем не только в заржранске, но и в филиалах за сотни километров, где хелпдеска нет вообще. Очень удобно когда запчасть присылают (иногда с инженером для её установки) через пару дней после обращения.
По качеству у брендов лучше корпуса (толще сталь, меньше размер, удобный дизайн и разбираются без отвёртки) с БП, регулярно обновляют UEFI, есть готовые пакеты драйверов для деплоя и серийник сохраняется при замене материнки. Из минусов: нельзя поставить мощную видеокарту из-за БП (справедливо и для младших WS) и сейчас Dell стал использовать нестандартный форм-фактор даже в MT (лучше сразу брать SFF).
А у сборщиков SLA с ремонтом на месте либо нет вообще, либо просят за него неприличных денег, да и с запчастями вечно проблемы — сегодня нет одного, завтра другого, послезавтра третьего и потом это напоминает о себе, если замена оказалась косячная.
С серверами другое дело: цену делают опции и у tier 1 они в 2-4 раза дороже, так что даже с услугами «местных вендоров» платформы от Intel или Supermicro выходят в разы дешевле.
Alexufo
24.02.2017 12:50+1гейминг и еше раз гейминг
нищебродинг и еще раз нищебродинг. Самый популярный вариант.
slafniy
24.02.2017 14:53+2Если процессор действительно хорош — то как он получился?
Да очень просто — Интел сидели на месте, развлекались с термопастой, с блокированием разгона, добавляли одну самую важную ножку на сокет… вот и дождались когда АМД догонит.
KoToSveen
27.02.2017 12:31+1У Intel`а вообще в природе заложено то отломать, то добавить
одну самую важную ножку на сокет
Erenzil
23.02.2017 16:53ИМХО неудивительно. AMD на своих FX процах смогли уложить 8 ядер 4.0 ГГц в 125 ватт, при том что техпроцесс был 32нм. При всем при этом Intel Xeon e5 2680 (32нм) на 2.7 ГГц был 130 ватт. Теперь добавим сюда тот факт что ФХ серия стоила как грязь. А сейчас у AMD есть доступ к 14нм.
Надеюсь что райзен взлетит.
(Я понимаю что интел хеон был ГОРАЗДО круче для рендера и что де-факто у амд 4 ядра всегда простаивали из-за использования двухьядерных модулей вместо полноценных ядер. Я рассматриваю райзен как проц для игр и редкого создания видосов для тубика, буду ждать процы с 4 и 6 ядрами)
vrmzar
23.02.2017 20:28-2У FX никогда не было полноценных восьми ядер, потому и уложились.
Ну и что бы два раза не вставать пожелаю, что бы после релиза не вылезло никаких непредвиденных разработчиками косяков. Вроде кривых термоинтерфейсов, багов в микрокоде и тому подобного.Erenzil
23.02.2017 23:47ядра как раз были полноценные, там какой-то блок (целочисленный или с плавающй запятой) был один на два ядра и поэтому де-факто получалось 4 модуля вместо 8 ядер
P.S. насчет веги — радеон 7970 все еще советуют, спасибо новым драйверам и GCN. вега в любом случае сможет.Mad__Max
25.02.2017 02:41+1С плавающей запятой. И декодер всего на 2 инструкции/такт (у интел 4/такт). В результате даже если 2е ядро этими разделяемыми блоками в данный момент не пользуется, то их не получалось по полной загрузить работой из одного потока.
В результате при однопоточной нагрузке сильное отставание от Intel. А вот если ПО все 8 потоков более-менее равномерно загружает получалось вполне на уровне с младшими i7 работающими в те же 8 потоков.Erenzil
25.02.2017 18:55-1насколько я понял, программы считали двухъядерный блок одним ядром как раз из-за одного плавающего блока и поэтому они не работали на полную

Greendq
23.02.2017 16:58+1Они бы ещё и дрова для последней убунты допилили нормально — вообще была бы сказка. А то при обновлении с 15 до 16 убунты пользователи получают дикое разочарование.
Nuke
23.02.2017 18:20третий процессор Ryzen 7 1700 с энергопотреблением до 65 Вт
У ализара потребление = tdp.xforce
23.02.2017 18:44В случае с процессором оно в целом так и есть. Ему больше некуда энергию девать.

Labunsky
23.02.2017 19:53+1Таки нет, tdp почти никак не связана с потреблением и даже выделением тепла, так как определение для него придумывает производитель
Для примера - вот так его понимает интелThe upper point of the thermal profile consists of the Thermal Design Power (TDP) and the associated Tcase value. Thermal Design Power (TDP) should be used for processor thermal solution design targets. TDP is not the maximum power that the processor can dissipate.
NiTr0_ua
23.02.2017 20:44+1tdp != тепловыделение в общем-то, это абстрактное «требование к системе охлаждения». у амд было довольно честным раньше (как с райзенами — тесты покажут), у интелов порой случались казусы, когда i3 мобильный с tdp 17W кушал более 30Вт под нагрузкой… вроде ivy bridge какой-то.

kt368
23.02.2017 20:44Всегда считал, что 99% энергии, потреблённой процессором идёт в тепло (из-за паразитных ёмкостей/сопротивлений), разве это не так?
PendalFF
23.02.2017 22:08В общем и целом 100% любой энергии рано или поздно становятся теплом.
Вопрос только в том когда, где и в каких количествах именно.

Ivan_83
23.02.2017 19:33+2Если попытаться смотреть объективно то:
Плюсы:
1. хороший КПД на Ватт, похоже в некоторых задачах лучше интелового
2. SHA инструкции
3. гуманный ценник
4. никаких ограничений с разгоном и вроде как память до 3600
5. нормальный термоинтерфейс а не майонез
Минусы:
1. нет HBM памяти
2. нет AVX512, впрочем у интела тоже не очень
Смущает:
1. не на всех скриншотах CPU-Z есть SHA в наборах инструкций
2. мало тестов
3. вероятно к концу года или в течении года появятся процы на зен повкуснее…
Если не вылезет никаких косяков в тестах и пр то возьму себе Ryzen 7 1700X, ибо доплачивать 100 баксов за 200 МГц того не стоит а на коредуо иногда напрягает время сборки…slafniy
24.02.2017 14:45+1В плюсах вы сравниваете с Интел, а в минусах сравниваете с чем?
Ivan_83
25.02.2017 00:12-2С тем что могло быть/ожидается.
Про HBM память амд само жужжало что в апу как минимум её напихает и будет счастье.
(возможно что апу на зен с hbm памятью будут много лучше таких же но с большим количеством ядер, ибо она как огромный л4 кеш в некоторых задачах даст дофига приросту)
авх512 вполне могло быть, хотя бы в каком то виде и это был бы просто праздник :)
2 DistortNeo
А вот и нет.
AVX512 и пропускная способность памяти коррелируют слабо, если только мы не занимаемся копированием или поиском или какой то очень простой обработкой.
К тому же префечтем никто не запрещает пользоваться.
И есть просто алгоритмы которые берут вот этот самый один блок в 128/256/512 бит и долго жуют его в регистрах, например тот же стрибог (отечественный хэш), и уже после они результат сохраняют или опять же в регистры или в память и читают следующий кусок памяти.
2 clawham
Я бы уже давно купил себе инел если бы не их жлобство:
— авх512 пообещали и зажали
— пихают хреновый термоинтерфейс — а это значит что 5 лет проц не отходит, скорее всего года через 3-4 начнёт сваливаться в тротлинг и нужно будет или обновляться или скальпировать
— всякие intel ME и прочий бред который они пихают в процы анб и копирастов ради
Те кому нужно качество сжатия — жмут на процах через х264, в желез жмут как правило всякие экодеры которым нужен реалтайм а зрители всё равно не заметят.
Загрузить 4/8/16/128 ядер мне не трудно — постоянно что то компеляю, в основном оно хорошо масштабируется на любое количество ядер.
Говорить о том что i7-7700 быстрее 1800х пока рано.
2 h31
Тут штука вот в чём.
Когда есть аппаратное шифрование AES-NI то результат его 100% такой же как и софтварного.
А вот в случае кодирования всё совсем иначе: одна и также картинка может получатся сотней разных способов. Многое зависит от алгоритма, хороший алгоритм простым не получается, поэтому всё что в железе — это сильно упрощённые варианты.
Если хочешь увидеть разницу то в ffmpeg есть режим с отображением motion vectors (один из каких то фильтров), можно включить через ffplay. Вот там очень сильно видно разницу между аппаратными кодеками и софтварными: у сотфварных стрелочки всегда параллельны и их много, а у аппаратных стрелки в разные стороны а иногда их и нет вовсе. Это говорит о том, что аппаратные кодеки меньше ищут/находят перемещённых блоков. В итоге аппаратным кодекам нужно больше битрейта для сохранения того же качества.
2 navion
Странная претензия к AMD.
Взять тот же гигабайт с интелами, там тоже трудно мать найти без PCI. Видимо маркетологи считают что лучше поставить один-два через специальный мост PCI<->PCI-E чем не сделать этого.
У меня у самого двоякое отношение к этому: с одной стороны у меня куча PCI железок с другой я понимаю что вероятность что они мне понадобятся не большая, а вот вероятность что лет через 5 мне нужно будет воткнуть какой нибудь USB4.0 контроллер или сетевку на 10G (в ближайшие год-два) намного выше.
Когда я слезал с пень3 в начале 2008 то там все 5-6 PCI слотов были заняты + агп видюха.
Касательно VGA — у меня есть два ещё живых и использующихся моника у которых только VGA. Покупать переходник из HDMI в VGA мало кто захочет да и редкие они: 3 года назад в мск было в паре магазинов на заказ, нынче чуть лучше.
Клав и мышей с PS/2 ещё полно. В том числе и тех что никак не сломаются.
Да что там, вот COM — вообще как таракан, всех переживёт и ничего его не выведет из техники.
Даже LPT зачем то до сих пор живо.
nlykl
27.02.2017 13:44+2— всякие intel ME и прочий бред который они пихают в процы анб и копирастов ради
У AMD есть свой ME, называется Platform Security Processor.
DistortNeo
23.02.2017 19:36+3Я бы минусы объединил. При текущей пропускной способности памяти смысла в AVX512 попросту нет.
Ну то, что смущает, что мало тестов, так процессоры ещё не начали продаваться. Ждите, осталась неделя.
tot418
23.02.2017 20:34Это отличная новость для всех в мире, кроме сотрудников и акционеров компании Intel.
Думаю не совсем так, так как что то мне подсказывает, что антимонопольный комитет уже придерживает Intel за причинное место, по x86.
gkvert
23.02.2017 21:14За последний год стоимость акций AMD выросла с 2 $ до 14$. Похоже уже и инвесторы поверили в камбек AMD на рынок декстопных процессоров.
maniacscientist
23.02.2017 23:01Чего то подозрительная разница между 1700 и 1800Х. 170 енотов за 600 МГц при разблокированном множителе — это как понимать? В 1700 кристалл настолько отбракованный что только 3.0/3.7 и может? Больше мне как бы не надо, а вот если он у меня через 4-5 лет крякнет — будет обидно
Al_Azif
24.02.2017 03:19Многопроцессорность есть?
DistortNeo
24.02.2017 04:15+1Информации о серверных процессорах AMD пока нет. Сейчас они выкатывают только флагманские десктопные процессоры.
UJIb9I4AnJIbIrUH
24.02.2017 04:49+1Al_Azif
25.02.2017 09:1016 ядер — серьёзная подножка серверному интелу. Узнать бы ценник.
Mad__Max
26.02.2017 00:1232 же ядра(64 потока), а не 16.
А 12 и 16 ядерные давно уже были. На 12 ядерных от AMD (примерно как 2 Phenom II X6 в одном кристалле со сниженными частотами) не только сервера делали, даже по суперкомпьютерам одно время существенный кусок рынка откусили.
Slonyxia
24.02.2017 09:19+1Надеюсь, что амд взлетят, ибо интел откровенно обнаглели без конкуренции, начиная после санди бриджа показывать 3-5? прироста.
Интересно, что там по разгону и производительности у 4с/8тsevergun
01.03.2017 13:15Может потому что уже не получается получить прирост больше чем 3-5? Легко показывать 40% прирост после 10 лет простоя еще и в единственном тесте на который ты изначально точил инструкции.
DistortNeo
01.03.2017 13:34Интересно, какова причина остановки роста тактовой частоты? Почему уменьшение техпроцесса на порядок не дало возможности создавать процессоры с частотой 20 ГГц?
u010602
01.03.2017 15:24Если детально: https://habrahabr.ru/company/intel/blog/194836/
Если коротко — как минимум тепловыделение будет от 500вт до небес.DistortNeo
01.03.2017 16:30+1Как раз эта статья вызывает только ещё больше вопросов:
Один из таких способов – переход к более совершенному технологическому процессу.… Тем не менее, производители микропроцессоров постоянно совершенствуют технологический процесс, и частота за счет этого постепенно ползет вверх.
До 32 нм всё так и было: 45 нм — предел 3600 МГц (максимальное повышение частоты без значительного повышения напряжения), 32 нм — предел 4500 МГц, а затем всё встало. Сейчас уже 14 нм — предел всё те же 4500 МГц.
u010602
02.03.2017 02:42+1Сложно сказать, т.к. я не специалист. Можно лишь порассуждать. Например AMD FX-8370 удалось разогнать до рекордных 8722 МГц, он на 32нм, по моим прикидкам он выделял около 530вт тепла в таком режиме и охлаждался азотом. Если же посмотреть табличку с рекордами тут https://valid.x86.fr/records.html То видно что с переходом на новых техпроцесс макс частота падает, потом они улучшают архитектуру и разгон снова повышается до 8 с копейками ГГЦ, причем эта граница держится еще со времен Пентиумов 4, напряжения на которых берутся рекорды тоже подозрительно похожие (около 2 или около 4 вольт). Т.е. фактически тех процесс вообще ни как не влияет на предельную скорость работы уже давно. А влияет он только на то, сколько транзисторов можно впихнуть в полу киловатный кипятильник размером с брошку.
Самый быстрый П4 был 3.8ггц, самый быстрый и7 на 14нм, барабанная дрожь тоже 3.8 ггц в турбо. С умеренным разгонов 99% камней возьмут 4.1-4.3 ггц, т.е. половину от рекорда, в свое время то-же было у П4.
Лично я делаю вывод что 9ггц это на данный момент предел частоты кремневых процессоров, а половина от предела это серийный результат. И т.к. про это проблему молчат уже много лет, скорее всего она принципиальная, роста частоты ждать не стоит, все что сделано из кремния понемногу подтянется к частоте в 4-4.5 ггц и на этом остановится. А маркетинг создаст искусственную градацию вниз.Mad__Max
02.03.2017 03:44Самый быстрый i7 в плане штатных частот это 4,2/4,5 ГГц: i7-7700K
Как раз поэтому его для «битья» AMD взяла в тесты которые тут обсуждали — быстрейший из существующих 4х ядерных при штатной работе.
Так же были FX от самой AMD штатно работающие на 4.5 и 4.7 Ггц, хоть и очень прожорливые.
Так что прогресс по частоте в зависимости от техпроцесса есть, хоть и очень медленный. Тем более у P4 была совсем другая архитектура — специально оптимизированная на достижение больших частот в ущерб многому другому. Настолько в ущерб, что эти высокие частоты его не спасли.
И современные i7 это дальние потомки/глубокая модернизация Pentium III и Pentium M, а не P4 с которым сравнивать не особо корректно. От них частоты выросли в 3-4 раза уже.
Что же до того почему не растет. Где-то читал, что уже вообще постепенно упираемся в барьер задаваемый скоростью света.
Хоть и кажется что она почти бесконечно большая и задержки из-за нее ощутимо сказываются только в космических масштабах или хотя бы при скоростной связи с другим континентом, но это только кажется. Даже если на пальцах прикинуть — для штатной частоты работы последнего i7 в 4.5 ГГц электрический сигнал распространяясь со скоростью света за один такт успевает пройти всего 300000000/4500000000 = 0.067, т.е. всего 67 миллиметров.
Причем это в идеальном случае — за 1 такт на 67мм расстояния реальный сигнал не передать — через 1 такт «на другом конце» значения какого-то показателя (напряжения, силы тока и т.д.) только начнет меняться. Само изменение тоже занимает время.
67мм это конечно больше размера кристалла процессора или тем более размера 1 ядра в нем (а между ядрами и другими модулями в кристалле передача идет на меньших частотах).
Но уже вполне сравнимо. Тем более что в реальных схемах сигналы передаются далеко не по прямой дающей кратчайшее расстояние. И это далеко не единственный вид и причина задержек, но зато фундаментальный и неустранимый.
Поэтому создать и показать работу(переключение) единичного транзистора на частоте скажем в даже 100 ГГц — довольно легко. А вот даже имея такие транзисторы, создать из них очень сложную схему (типа процессорного ядра) разные части которой удалены друг от друга в пространстве, но при этом должны работать синхронно друг с другом — уже скорее всего принципиально невозможно.u010602
02.03.2017 04:48Я не совсем понимаю при чем тут архитектура и наследие между процессорами. Я лишь сравниваю частоты одних из самых сложных интегральных схем из разных эпох с разрывом в 10 лет.
Насчет 7700К да проморгал, спасибо, очень он свежий. Я смотрел на 6920HQ http://ark.intel.com/products/88972
Но даже с учетом этого, моя теория в целом верна. За счет третей или четвертой оптимизации тех процесса 14нм они смогли повысить качество и поднять частоту еще немного. Но если посмотреть на рекорды разгона, то там все те-же 7.3 ГГЦ (думаю потому что он свежий, и через год будет около 8ГГЦ) и все те-же 2 вольта напряжения.
Даже если все процессоры будут по качеству как самые идеальные образцы и будут работать под 2В напряжением, выделять 600вт, то частота все равно будет фиксированная, и менее чем в 2 раза больше чем сейчас. Это идеальный сценарий. А в реальном сценарии ни какого роста частоты «в разы» и уж тем более «на порядок» не будет. Я даже не уверен что 5 ГГц возьмем в ближайшем будущем в серийных образцах.
Меня другой вопрос интересует, если взять процессор по тех процессу 65нм и сделать его с точностью 14нм процесса, можно ли будет повысить процент способных к 7ГГц до значительного? И не получится ли что i7 2го поколения на 7ггц будет быстрее чем i7-7700K на 4.5 ггц.
И вот еще момент, если верить википедии то транзистор по технологии 65нм на порядки превосходит по частоте процессоры, т.е. частотные пределы транзистора давно перестали быть сдерживающим фактором, и от меньших тех процессов роста частоты ждать не стоит. Очевидно проблемы в чем-то другом, возможно в скорости света, возможно в наводках, возможно в перегреве, возможно в чем-то другом. Но не похоже чтоб их пытались решить.
Сейчас просто выжимают оптимизацию из существующей технологии, софт и железо притираются, вводят новые команды, новые подходы к написанию кода. А вот гонка гигагерцов уже лет 10 как завершилась.Mad__Max
03.03.2017 21:01Притом, что в плане работы основных вычислительных блоков P-3 и P M это были даже более сложные и совершенный схемы чем P-4, основу которого упростили специально для достижения высоких частот. Потом в последующих от этого отказались и вернулись к предыдущим вариантам.
Так что если бы современные процессоры были наследниками P4, а не P3, то сейчас мы бы видели серийные процессоры работающие в штатном режиме на частотах 5-6 ГГц, 6-7 ГГц при стандартном разгоне и штурмовали отметку 10 ГГц при экстремальном. Правда по реальной полезной скорости (вычислений) они были бы наоборот хуже современных.
Я даже не уверен что 5 ГГц возьмем в ближайшем будущем в серийных образцах.
Я же упомянул AMD с 4,5 и 4,7 ГГц базовой частоты: AMD FX-9590, вышел больше 3х лет назад, 4.7 Ггц базовая, 5 ГГц турбо, до 5.2 ГГц турбо если только 1-2 ядра загружены.
До сих пор самый высокочастотный (но не самый быстрый) серийный x86 процессор.
Все еще свободно можно купить и относительнонедорого
Хотя врядли стоит — соотношение цена/качество не ахти. Лучше либо FX-83xx, которые почти в 2 раза дешевле, но только на ~20 % медленнее. Или если денег много то Intel i7.
И не получится ли что i7 2го поколения на 7ггц будет быстрее чем i7-7700K на 4.5 ггц.
i7 2го и поколения переделанный по 14нм по частотам скорее всего практически не отличался — никаких значимых изменений в архитектуру за все эти 5 поколений так и не внесли — увеличивали объемы разных буферов, улучшали точность предсказания ветвлений, сильно нарастили мощность встроенного GPU и т.д. Но само х86 ядро практически тем же осталось.
А вот если взять какой-нибудь из последних P4 и просто конвертировать его схему на 14нм, то частотные рекорды будут.u010602
04.03.2017 12:41Насчет архитектуры Р-4 версия интересная, спасибо. Жаль нельзя ее проверить на практике.
Насчет турбо скорости в 5ггц у единственного процессора с тепловыделением выше 220вт, да вы правы оказывается он есть (я не знал), и формально он серийный, но фактически очень большая редкость, которую довольно сложно иметь дома. Не уверен что его вообще можно охладить воздухом если честно… Так что для меня это выглядит скорее как промышленно разогнанный экземпляр для энтузиастов. Можно отобрать чипы которые способны брать и большие частоты, собственно оверклокеры это и делают. Но какой процент выхода годных чипов будет? А какое охлаждение нужно будет? Ну т.е. это все еще не массовый продукт. Возможно я не правильно подобрал слово «серийный».
Насчет 14нм возможно вы не совсем поняли мою идею. Я предлагал не уменьшить размер транзисторов, а повысить точность создания крупных транзисторов. Т.е. трафарет от 32нм, а точность изготовления от 14нм. Возможно повышенная точность даст больший % процессоров способных разгонятся до 7+ ггц. Т.е. если сейчас на это способен один из 1000, то с таким трюком будет каждый 10ый. Мне просто кажется что способность к разгону конкретного экземпляра зависит напрямую от погрешностей изготовления, чем их меньше — тем выше предельная частота.
a5b
02.03.2017 05:36+2"единичного транзистора на частоте скажем в даже 100 ГГц… А вот даже имея такие транзисторы, создать из них очень сложную схему"
Частоты транзисторов уже выше 100 ГГц (хоть это и немного другие транзисторы, но порядок примерно такой) — Samsung 28nm "Ft (maximum unity gain frequency) of 280GHz and Fmax of 400GHz" — http://electronics360.globalspec.com/article/4078/samsung-foundry-adds-rf-to-28-nm-cmos
Собранная из транзисторов схема (любая — т.е. даже локальная типа сумматора или стадии ALU/FPU блока) для повышения своей полезности за такт переключает целые цепочки транзисторов. Традиционно задержку схемы (critical path) считали в т.н. Logical Effort в нормализованных (не зависящих от техпроцесса) единицах, например в ?, где одна ? = 3RC ("delay of an inverter driving an identical inverter with no parasitic capacitance") или в "FO4" (Fan-out of 4 — "one FO4 is the delay of an inverter, driven by an inverter 4x smaller than itself, and driving an inverter 4x larger than itself.… 5·? = FO4"). В http://en.wikipedia.org/wiki/FO4 есть некоторые оценки длины такта в единицах FO4 для разных процессоров: "IBM Power6 has design with cycle delay of 13 FO4;3 clock period of Intel's Pentium 4 at 3.4 GHz is estimated as 16.3 FO4.4"; Еще примеры из http://www.realworldtech.com/fo4-metric/ — Revisiting the FO4 Metric, 2002:
- Horowitz, Page 38[1]: “Current” SOA is approximately 16 FO4.
- Hrishikesh et al. [5]: Current Intel Processors are ~12 FO4.
- Chinnery et al. [3]: Alpha 21264 has 15 FO4.
- Chinnery et al. [3]: Custom IBM PPC test chip, 1 GHz @ 0.25um, FO4 of 13.
- “in a standard 0.18um process, a typical flop equates to about 3 FO4 delays, with the FO4 delay being about 25ps”
- POWER6 FPU — http://www.eetimes.com/document.asp?doc_id=1159233 — 65-nm SOI 4-GHz — 13-FO4 pipeline
Примеры схем и их FO4 http://www.realworldtech.com/fo4-metric/3/ — быстрый 64-битный однотактный сумматор — 7-5 FO4, разные варианты сдвига — http://www.realworldtech.com/fo4-metric/4/; часть FO4 требуется затратить на skew синхросигнала и slack/guard тригерров вокруг комбинационной логики.
К сожалению в оценках схем через FO4 не учитываются задержки проводов, а сейчас именно провода в большей степени ограничивают скорости (и кроме того, в длинных проводах частенько ставят усилители, которые также имеют задержку). Рекомендую материалы с https://inst.eecs.berkeley.edu/~cs250/sp16/ (осторожно, соавторы Risc-V) —
- https://inst.eecs.berkeley.edu/~cs250/sp16/lectures/lec04-sp16.pdf Physical Realities: Beneath the Digital Abstraction, Part 1: Timing. (провода с 15 слайда) 24: Flip-Flop delays eat into "time budget", Clock skew also eats into "time budget", "Components of Path Delay"; 36 — retiming of Power 4; 42 — предлагают подход GALS: Globally Asynchronous, Locally Synchronous с синхронными блоками в 0.05-1 млн транзисторов (т.е. глобально процессор как раз асинхронен — каждое ядро или пара ядер работают на своем дереве синхросигнала — http://images.anandtech.com/doci/10127/OC%20Diagram.png — SKL-S — Skylake on LGA 1151 — 3 входных напряжения: uncore, gpu, ядра+кэш; 4-5 коэффициентов от BCLK: GPU, core, ring, memory. Haswell, LLC. В многоядерных у Интел уже в 2014 году было 3 clock domain по 5 ядер в каждом)
- https://inst.eecs.berkeley.edu/~cs250/sp16/lectures/lec05-sp16.pdf Physical Realities: Beneath
the Digital Abstraction, Part 2: Power & Energy: "Computations per W-h doubles every 1.6 years", Switching Energy, Leakage Currents, Device engineers trade speed and power, Six low-power design techniques - https://inst.eecs.berkeley.edu/~cs250/sp16/lectures/lec07-sp16.pdf Memory Technology and Patterns (там от длин проводов могут увеличиваться задержки доступа к большим массивам)
Существуют проекты технологий с пониженными задержками логического элемента (и резко пониженными температурами, жидкий азот для них слишком горяч; 4-7 K) и огромными проблемами каскадирования более 3-4 элементов друг за другом. Авторы вынуждены строить "процессоры" и "алу" с очень короткими (в единицах FO4) стадиями
https://pdfs.semanticscholar.org/015c/52e3ee213ae1d0eefe8815a0023bd48a4d99.pdf#page=4
"eight bit-stream arithmetic logic units (ALUs) interleaved with eight 8-bit general-purpose integer registers (R0-R7)" (АЛУ работает побитно, каждый однобитный кусочек АЛУ находится рядом с "битовой колонкой" регистрового файла), "A single-bit ALU (bALU) has a 3-stage execution pipeline" — один бит в АЛУ обрабатывается в 3-тактовом конвейере и это bit-sequential processor, т.е. для одной операции над 8 битным регистром требуется 12 тактов. Зато тактовая частота 17-20 ГГц.Mad__Max
03.03.2017 21:30+1Спасибо за пачку интересного чтива.
Ну в общем как и думал от всех этих «нано» технологий на базе графена или нанотрубок, где демонстрируют одиночные экспериментальные транзисторы работающие на частотах до порядка Террагерца можно ничего особо не ждать.
Т.к. и обычные кремниевые транзисторы уже давно и в серийном исполнении могут работать на сотнях ГГц частоты. И все уже ограничивается в первую очередь схемотехникой, а не базовыми элементами.

unwrecker
24.02.2017 10:25При всей любви к АМД, меня всё же настораживает наименование линейки ровно как у Интела: 3, 5, 7. Когда внедрили аналогичный по смыслу p-рейтинг, с производительностью у АМД было не очень…
Akela_wolf
24.02.2017 14:15+1Да ну? Athlon 3200+ уверенно бил по производительности Pentium 4 3.2 Ghz (которому равен по рейтингу) и шел на равных при разгоне «пня» до 3.4-3.5 ГГц. Собственно AMD примерно на 10% занижала рейтинг процессоров (видимо подстраховывались)
А вот с выходом Core/Core Duo — да, дела AMD стали печальнее.
mazahakajay
24.02.2017 12:23Отличные новости. Неужели вернутся времена, когда можно было взять нормальный компьютер за вменяемые деньги? И не важно на интеле или на АМД.
Отличная новость!
clawham
24.02.2017 12:23Самый интересный вопрос о кодировании видео — использовали ли они ускорение встроенного видеоядра. 630 графика интела дает в 264 кодере х10 производительность. никакому процессору этот прирост и не снился — если нет то сравнение некоректно. Даже видео паскаль с кудой не достигает такой скорости как то что сделали в видеоядре интел!
Так то меня интел бесит. Начиная с термопасты под крышкой и заканчивая архитекторными нюансами. Но увы альтернатив по перегонке видео нет. Ежели интел работал с видеоядром то это нереально круто что райзен смог такое.
Alexufo
24.02.2017 13:05фанаты x264 говорят хардварщина отстой. Только софтварные кодаки если нужно качество.
clawham
24.02.2017 14:40Мне глубоко пофигу какой кодек. у меня с каждой поездки по 180 гиг несжатого видео с фотиков с потоком в 70к я его пересжимаю иногда в 10 где хочу оставить качество а иногда и в 3к когда надо оставить абы було.
Кроме того сильнейше выручает скорость одного потока ведь когда надо стабилизировать картинку то работает максимум полтора потока — один стабилизирует а второй распаковывает/запаковывает назад. и вот тут то амд сразу в пролете ибо даже в топе на один поток они слабее i7 а i7-7700 на один поток слабее i5-7600 который я и приобрел недавно. Вот таки дела малята. я свой проц не могу загрузить на 100% — максимум 75. Нет смысла в 16 потоках когда у тебя одна задача!Alexufo
24.02.2017 14:45А нету в фотике выбора битрейта?
DistortNeo
24.02.2017 15:34Вы правда считаете, что фотик будет жать лучше? Задача фотика — сохранить видео в реальном времени, а не максимально сильно сжать видео.
clawham
24.02.2017 18:34+1core i5-7600k есть встроенная графика hd630
легко конвертирует 4к в 5 раз быстрее чем реальное воспроизведение при этом загрузка проца 30%.
я говорю о том что мне всеравно чем они этого добились но если с фотика моего 1 час видео конвертируется 2 минуты то я офигеваю от скорости а если пол часа то я офигеваю от тупости. для примера могу привести время конвертации с использованием видеокарты hd630 — 2 минуты. и без видеокарты — только проц 4 ядра 4 потока — 20 минут. тот же ш7-7700 этот же видик конвертирует 13 минут без видеокарты и 8 минут в паре с 1080 нвидиевской. апаратное nvenc естественно задействовано. Мне побоку внешней или внутренней. кстати если вставить ко мне внешнюю видео в систему — внутренний кодек остается работать! тоесть как видеокарта она гуано может быть но как апаратный ускоритель h264 — отличная штука! и зачем мне 16 ядер если распаковка архива — один поток, проведение документов в 1с — один поток, 99% игр — 2 потока, фотошоп — 3 потока, лайтрум 4 потока. Даже 4 ядра я нереально редко вижу занятыми на 100%. зато регулярно вижу 25% загшрузку — тоесть уперлось в одно ядро и все… тупим…
Фотик может писать 20кбит но это такое порно что лучше писать в 80 а потом компом перегонять. тем более есть моменты которые надо покачественнее сохранить а есть такие что и удаляются до перегонки.
DistortNeo
24.02.2017 19:1213 минут без видеокарты и 8 минут в паре с 1080 нвидиевской
Что-то здесь нечисто. Хотя, если почитать поподробнее, то окажется, что:
Видеокарты не очень подходят для кодирования видео из-за особенности их архитектуры. Терафлопсы у 1080 просто не получается эффективно использовать в конкретной задаче.
- Intel добавила в интегрированное видеоядро отдельный участок, который занимается только видео.
Тогда не удивительно, что полноценный аппаратный кодер будет выигрывать по скорости у неспециализированного инструмента. И это хорошо. Надеюсь, следующим этапом развития процессоров будет аппаратный FRC (frame rate conversion).
А основной недостаток встроенного кодера у Intel, судя по отзывам — это жертва качеством ради скорости и меньшая гибкость в настройке кодера. Но для большинства пользователей это не критично — ну будет файл больше размером в итоге, ну и ладно.

h31
24.02.2017 20:33+1Видеокарты не очень подходят для кодирования видео из-за особенности их архитектуры.
У всех современных видеокарт есть аппаратные блоки кодирования видео. Если говорить конкретнее — AMD VCE, NVENC (aka PureVideo).
Я не видел сравнения кодировщиков Intel vs AMD/Nvidia, но, думаю, качество и скорость там явно не хуже.
Dum_spiro_spero
28.02.2017 22:50clawham
Отличный пример, что многоядерность нужна не всем. А мне наоборот — нашим расчетам чем больше ядер, тем лучше. Причем многоядерность важнее чем частота в некоторых диапазонах того и другого.
Больше процессоров хороших и разных!clawham
01.03.2017 10:19Раз так то вам путь к серсверным ксеонам с 12 ядрами. Или к платам с 2-3 такими процами на борту. Или уже освойте Куду — там полторы тысячи процев +-.
Извольте мы говорим не о зионах серверных, которые и разрабатывались для 100500 потоковости а о обычных консьюмери процах где максимум что в 99.9999% задач это 1-2 потока игры видео и иногда — какие-то Click-to-convert приложения "уменьшить размер видео с фотика" и все. Не думаю что каждый пользователь дома брутфорсит хеши или майнит коины — для этого процы безнадежны — видеокарты намного лучше но тоже увы полный шлак уже — электричество не отрабатывают. Революции не будет… не произошло… увы. ЗА последние 6 лет скорость одного потока реально возросла всего лишь в два раза.0xd34df00d
02.03.2017 00:32+1Или уже освойте Куду — там полторы тысячи процев +-.
Освойте куду, освойте куду… Предположим, у меня есть задача, где мне надо параллельно оптимизировать параметры кучи мелких функций (ну, математически, как в методах оптимизации) по методу наименьших квадратов, скажем. В C++ под обычные x86 у меня есть, скажем, dlib, куда я просто запихиваю искомую функцию, её производные и точки, а она дальше сама всё делает. Как мне быть под кудой? Писать всё это руками и благодарить nvidia, что хотя бы базовые матричные операции уже реализованы?clawham
02.03.2017 12:04-1Если я знаю как и что считать то мне всеравно как и на чем это реализовывать. а если доверять всяким длибам неизвестно под что оптимизированным и под что писанным то конечно начинаются поиски того камня который и был у разработчика этого длиба когда он её писал.
Потому многие свои расчеты я по раз 20 переделываю в программе через разные функции разные способы выделения амяти и т.д. пока не получу наилучший по скорости результат с наименьшими затратами памяти. И зачастую готовые универсальные библиотеки проигрывают конечному результату сделанному под конкретное имеющееся железо(на котором оно и будет крутиться) и под конкретную задачу. Яркий тому пример — printf и вся его братия из STDLIB которая вместе с ним едет. в условиях микроконтролеров это иногда выливается в занятие половины флеша ненужными универсальными функциями которые на отображение примитивного 4значного числа могут зажрать под 8000 тактов. в то время как руками написанная функция -аналог без ничего лишнего укладывается в 2% флеши и 400 тактов. Что называется почувствуй разницу.
Потому возражение не защитано. Я могу привести ещё 100500 примеров когда стандарнтые либы не подошли а немного допиленные руками — взлетели/загудели. У каждого камня есть свои слабые и сильные стороны. Сила программистов ресурсоёмких приложений — эксплуатировать сильные стороны и обходить слабые.
0xd34df00d
02.03.2017 21:41+1Я бы не стал сравнивать printf с библиотеками для линейной алгебры, например.
Mad__Max
03.03.2017 21:37Я сейчас вообще не программирую, так что так мимопроходил. Но в том же в послених его версиях dlib есть поддержка GPU и CUDA в частности.
Правда там вроде бы это относится только к нейронным сетям и обработке изображений. Линейная алгебра скорее всего не портирована на GPU0xd34df00d
04.03.2017 01:15Да, оно там для cuDNN или как там правильно называется. Взять и произвольный
dlib::solve_least_squares_lmтуда запихнуть вряд ли получится.
lolipop
24.02.2017 16:59+1еще раз, что у интела, что у амд в топовых многоядерных процессорах нет встроенной видеокарты.

ksenobayt
24.02.2017 17:41Что является абсолютно логичным решением: человек, который покупает топ, явно берёт его не для того, чтоб сидеть на встроенном граф-ядре и раскладывать Солитер.
clawham
24.02.2017 19:01+1нелогично — кроме встроенного видео это же ядро дает просто термоядерное ускорение h264 как енкодинг так и декодинг. сидеть на нем понятное дело нет смысла но в некоторых задачах оно нереально полезное дело!
ksenobayt
24.02.2017 19:03Чуть выше там уже говорили, что аппаратный энкод 264-го у Интела так себе. Я вынужден присоединиться, и выразить аналогичное мнение.
DistortNeo
24.02.2017 19:15Зато аппаратный декодер очень полезен в мобильных устройствах. Десктопу пофигу: декодирование — процесс не очень затратный, а вот в случае ноутбука даже небольшая нагрузка может сильно повлиять на время автономной работы.
ksenobayt
24.02.2017 19:20+1Энкодить на мобильных устройствах h264 — очень такой странный кейс. Для меня, по крайней мере. В любом случае, не нужно путать десктопные камни с предназначенными для работы в переносных устройствах. Это совершенно разные разницы, которые никакого отношения не имеют к изначальному недовольству lolipop тем, что встроенного видео нет в топовых десктопных камнях.
lolipop
24.02.2017 20:02эм, вообще-то я недовольства не высказывал, я так-то просто констатировал. но вообще грустняво, когда снимаешь на задохлый айфончик видео в 4К, а потом не можешь на 6ядерном компьютере с топовой видеокартой проиграть.
ksenobayt
24.02.2017 20:08Откровенно говоря, не понимаю увлечённости по 4K.
У меня до сих пор 1920х1200, и мне хватает на 27 дюймах выше крыши.lolipop
24.02.2017 20:11шрифты не говно, 32", 4K.
ksenobayt
24.02.2017 20:43+1Ну, у меня Linux, мне проблемы виндошрифтов попросту неизвестны.
Уже скоро пару лет будет, как не загружался.DistortNeo
24.02.2017 21:15+1А причём здесь виндошрифты? Любой шрифт будет выглядеть лучше, если его рендерить с высоким DPI.
А проблема в том, что Linux до сих не умеет нормально работать с HighDPI: в нём это делается на уровне приложений. Если приложение не поддерживает переменный DPI, то оно будет отрисовываться очень мелко.
В Windows же приложение, не умеющее в HighDPI, система просто обманывает. Таким образом, в Windows масштабируется всё (ну кроме случаев, когда приложение заявляет, что оно DPI-aware, а на самом деле нет).
ksenobayt
24.02.2017 21:20А мне HighDPI и ни к чему: на 1920х1200 сглаживание на 96 ppi вполне нормально справляется, и глаза ничто не режет.

LynXzp
27.02.2017 00:58Извините, на 27 дюймовом мониторе? Меня на 23-х дюймовом артефакты сглаживания бесят (на расстоянии вытянутой руки). Я про цветовые шлейфы слева и справа. На мой взгляд четкая попиксельная лесенка лучше трехцветной линии.
u010602
27.02.2017 16:44Вообще даже не представляю о чем вы говорите, какая еще цветная лесенка? Пользуюсь 27" на 2560х1440 на расстоянии метр, до этого были кучи разных экранов на разных расстояниях, ни когда не замечал ни каких проблем с шрифтами в винде. А сглаживание шрифтов добавляет полу темные пиксели, а не цветные.
LynXzp
27.02.2017 17:18+2
Чуть дальше сядешь — не заметно, чуть ближе — становится едва заметным, глаза напрягаются и только через несколько часов понимаешь в чем дело. Windows/Linux — кажется одинаково (но не уверен, Windows не запускал года три, а на ноутбуках незаметно — dpi выше). Возможно зависит от монитора.u010602
27.02.2017 18:05Да, действительно есть, проверил «лупой», ни когда этого не замечал. Даже с 10см смотрю на экран, вижу каждый отдельный пиксель, и меж-пиксельную сетку, но не вижу этих оттенков. вот только у буквы М смог разглядеть две цветные точки с 5 см. А так оно для меня выглядит как номер 2 на вашем фото.
П.С. Дальтонизма нет, тесты на цветовое восприятие проходил, результаты очень высокие.
Mad__Max
27.02.2017 21:23Где-то есть настройка меняющая вид сглаживания — более грубый но только оттенками серого целыми пикселями и более точное субпиксельное сглаживание, но дающее цветные разводы из-за того, что индивидуальные субпиксели отвечающие за 3 базовых цвета используются.
Мне 1й вариант больше всего нравится. Без сглаживания плохо, но и цветные разводы тоже напрягают.
lolipop
24.02.2017 22:33default OS? у меня, например, хакинтош в качестве OS. и как раз там и исторически, и сейчас в том числе, самые не ШГ.
ksenobayt
24.02.2017 22:34Да, я 90% времени на никсах. Винда у меня осталась только под пятую GTA, в которую играть уже некогда и не с кем :)
0xd34df00d
26.02.2017 02:21Не знаю насчёт хакинтоша, но от шрифтов на имеющемся у меня макбуке мне хочется плакать почти в прямом смысле.
DistortNeo
24.02.2017 20:11Всё просто: если устройство может снимать в 4К, то пусть снимает. Иногда лучше потом на этапе обработки пережать или убрать лишнее, чем потом сокрушаться, что качество исходника было низким.
Sioln
02.03.2017 10:54Вот да!
Первое время снимал в 4К, а потом подумал, чего жрать память зазря. Часто нет там ничего такого, что в 4К показывать надо.
И вот, жизнь научила, что снимать надо всегда в 4К, потому что переключиться тупо можешь не успеть.
https://youtu.be/q9m_m62YPKk?t=38Meklon
02.03.2017 21:240xd34df00d
24.02.2017 20:14Был 27" на 2560х1440, сменил на 4k, теперь на 2560x1440 смотреть не могу. Пишу код, поэтому, по факту, важны только шрифты, да.
navion
24.02.2017 20:41+1Спасибо MS за сглаживание шрифтов от которого вытекают глаза через 5 минут работы за монитором со стандартным разрешением.
navion
24.02.2017 19:40-1С материнками у AMD по-прежнему всё печально — ни одной модели без устаревших портов (PS/2, VGA, PCI) и свистоперделок, как делал Intel.
Вся надежда на Zotac, если они решат сделать ZBOX на Ryzen с Vega.lolipop
24.02.2017 20:06+1честно говоря, не понял ваших претензий, вы недовольны тем, что нет PCI-портов?
может еще флоппик попросите?navion
24.02.2017 20:34Наоборот, раздражает их наличие. Уж VGA давно пора закопать или хотя бы заменить на DVI-I, но тайваньцы всё равно их лепят даже в mATX.

Chamie
24.02.2017 21:07Всё равно непонятно. Место занимают, или что?
ksenobayt
24.02.2017 21:17+1Поддерживаю, на самом деле. У меня в PCI воткнута Audigy 2 ZS Platinum — вполне нормальная по характеристикам карточка что тогда, что сейчаc, да и под Linux драйверы есть вполне съедобные. То, что карте почти 15 лет, совершенно не мешает ей выполнять свои задачи. И идти и покупать что-то из современного барахла только из-за того, по какому интерфейсу она подключается, у меня нет ни малейшего желания, пока эта не сдохнет.
kdekaluga
04.03.2017 14:29Согласен! Была Audigy2 и прекрасно работала, пока не перешел под Win 7 64. Тут у нее проблема с драйверами, которые давали BSOD в совершенно непредсказуемых местах. А так была отличная карта и функции свои выполняла тоже прекрасно. Если бы не винда, так на ней бы и сидел (=> нужен PCI слот). (проблему пришлось решить покупкой SB-Z, который на удивление оказался годным продуктом, но вот лучше ли он Audigy — сказать сложно).
Также на предыдущей плате была ситуация, когда грозой (через Ethernet-кабель интернет-провайдера Б) выбило встроенную сетевуху. Пришлось вставлять имеющуюся сетевуху (а это PCI) в первый попавшийся слот. Поэтому, лучше иметь такой слот свободным, чем не иметь его. Тем более, что сейчас у людей чаще всего занят вообще только один слот (реже — два, еще реже — больше).
Alexufo
24.02.2017 21:22+4ни в коем случае. Куча мониторов рабочих с одним VGA интерфейсом. VGA прекрасно работает до fullHD.
А DVI-I — только людей путать очередными переходниками и на бабки разводить.DistortNeo
24.02.2017 21:40+1Стоит заметить, что в процессорах Skylake поддержки аналогового сигнала встроенным видеоядром больше нет. Так что ни VGA, ни DVI-I там больше нет — Intel уже сделала шаг.
navion
24.02.2017 23:39+2Даже на 1600x1200 кабель ловил помехи и появлялся муар, а мониторы с DVI у меня с 2005 года.

stAndrew
25.02.2017 10:19+2Скорее всего дело было в некачественном VGA-кабеле без ферритовых колец. У меня fullHD монитор подключен по VGA, никаких помех нет. Но на некоторых кабелях я их видел.
Википедия пишет, что даже выше FullHD можно получить.
Today, the VGA analog interface is used for high definition video, including resolutions of 1080p and higher.
https://en.wikipedia.org/wiki/Video_Graphics_Arrayu010602
25.02.2017 18:07Поддержу вас, у меня тоже 1080p через VGA кабель длинной 8 метров, да еще и проложен в кабель канале с USB, HDMI и Ethernet. Муара нет. Кабель толщиной с женский мизинец + феррит на обоих концах, толщиной с мужской большой палец.
Mad__Max
26.02.2017 00:22А еще были такие кабели как VGA ==> 5 BNC, которыми крупные профессиональные ЭЛТ мониторы к видеокартам подключаются.
У меня такой был (собственно и сейчас есть), там 1600х1200 @ 100 Гц без проблем передавалось. С которыми обычный DVI в принципе не справляется (нужен минимум Dual-Link DVI ну или DisplayPort)
clawham
24.02.2017 23:26+1убил бы всех кто не ставит копеешные включенные в проц и чипсет интерфейсы на плату — нереально напрягает.
DjOnline
26.02.2017 00:07Знаете в чём жесть? За несчастные 4% между 1700x и 1800x хотят $100, +20% к цене.
VaalKIA
26.02.2017 00:13+3Верхняя строчка топа в линейке любой продукции всегда взлетает по цене, вы как вчера родились.

chieftain_yu
27.02.2017 11:09+2Реактив квалификации «чистый» по составу отличается от квалификации «особо чистый» меньше, чем на 2%. А вот по стоимости — может на несколько порядков…
Mad__Max
27.02.2017 21:27+2Это просто не так считаете. Чистый и особо чистый отличаются количеством примесей — примерно на порядок. Потому и в цене не меньше чем на порядок.

Lennonenko
03.03.2017 00:42просто вы не в таргете
сэкономьте 20% и разгоните
а чувак, имеющий лишние 100 баксов возьмёт топ
кто-то вон и титаны покупает
dmitry_ch
01.03.2017 13:38Только вот покупая комп или сервер, многие, слишком многие, будут думать — возьму-ка я лучше Intel. У AMD, может, удельная цена и неплоха, но беру-то надолго, так что сэкономлю раз, а переживать, что у меня не Intel, буду постоянно.
Именно потому, что много раз было уже, когда AMD предлагал убийцу Intel, а по факту оказывалось, как в начале поста написано,
Прошлое поколение процессоров… во многом стало разочарованием и ограничилось преимущественно использованием в недорогих конфигурациях…
Akela_wolf
01.03.2017 18:00+3Не знаю — не знаю… Я в конце 2015-го брал себе рабочий комп (под разработку, в том числе под несколько одновременно работающих виртуалок). Приоритетом было именно количество ядер/потоков, пусть отдельная задача будет работать несколько медленнее, зато не будет конкурировать с другими за ресурсы ЦП. Выбрал восьмиядерник FX-8320 т.к. по цене он находился в районе Core i3 (2c/4t), но для моих задач 8 ядер подходят лучше. И до сих пор не жалуюсь и совершенно не переживаю что у меня не интел. Буду смотреть на Ryzen, может быть буду обновляться на R7 1700/1700X, если он действительно превзойдет мою вишеру раза в 2-2,5 по общей многопоточной производительности.
Lennonenko
03.03.2017 00:45+1эээ, шашечки или ехать?
пройдёт немного времени, появятся реальные тесты, народ подсчитает попугаев на доллар и выберет
плюс есть идейные в обоих лагерях, я, например, принципиально беру амд, просто так, религия
kdekaluga
04.03.2017 14:46Времена, когда люди жалели, что взяли Амд, а не Интел ушли вместе с атлонами хр :) Я сам, в целом, поклонник Интел (сейчас i5-3570K), но когда (в свое время) заметил, что у соседа, только что купившего атлон 64 на 2ГГц Half-life2 идет раза в два быстрее, чем у меня на Р4 2.8ГГц, пошел и купил себе атлон 64 :) даже не просто «пошел», а съездил в Москву за ним (сам из другого города). Еще потом разогнал его с 2 до 2.5 ГГц и ни разу не жалел, что выбрал именно его. Он отлично отработал положенные себе 3 или 4 года и был сменен на Core 2 duo 3.4GHz. Так что если AMD выпустит удачный процессор по хорошей цене, не надо руководствоваться предрассудками.
DistortNeo
02.03.2017 18:47Спасибо. Очень неплохие результаты. Из этих тестов как раз и вылезает преимущество Intel при выполнении операций AVX за счёт большего числа блоков FPU (Intel: два 256-битных блока, AMD: два 128-битных). Причём это преимущество раскрывается только при использовании HT — один поток не способен загрузить все FPU-блоки одновременно.
Интересно, будет ли в Zen+ четырёхканальная память?
DistortNeo
02.03.2017 19:12Update
Спасибо. Очень неплохие результаты. ...
Это относилось вот к этому:
Через гугл уже можно выковырять обзоры :)
https://3dnews.ru/948466
oxidmod
03.03.2017 09:11Ну что же, если верить обзорам на ютубчике, то AMD таки смогла. С нетерпением жду 5-ую серию, шестиядерник скорей всего.
зы. надеюсь во втором поколении они улучшат работу с вещественными числами и недоразумения с памятью)
Mad__Max
03.03.2017 21:51+1Еще свежий обзор с тестами в куче реальных приложений:
Процессор AMD Ryzen 7 1800X — Прорыв, о необходимости которого так долго говорили большевикиMad__Max
03.03.2017 22:07Тест больше показывает насколько все еще плохо оптимизирована под многопоточность большая часть софта — во многих тестах лидирует вообще высокочастотный 4х ядерник i7-6700K, обгоняя не только Zen но и 6 и 8 ядерные камни самой Intel.
В ПО где 6-8 ядерные Intel имеют преимущество над i7-6700K (= софт умеет большое кол-во потоков использовать) Zen крут.













{kind=link}
{kind=link}
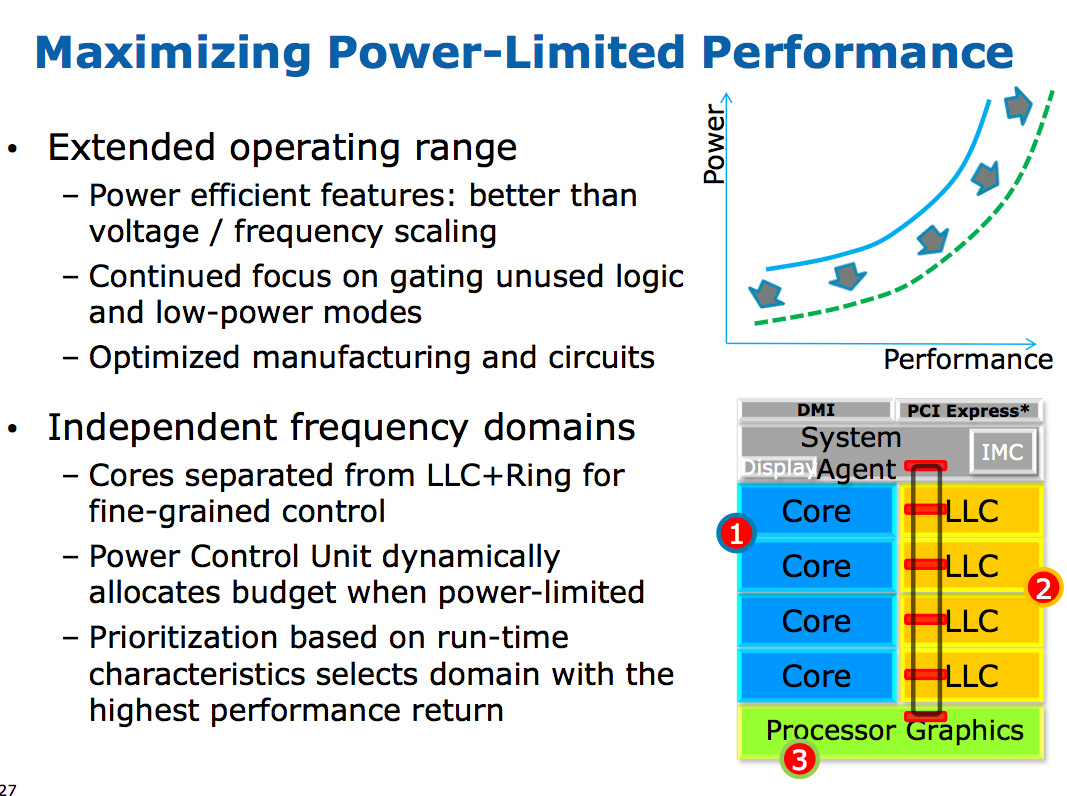{kind=link}
melchermax
Я уже ощущаю зуд в районе кошелька, очень уж хочется воплотить наконец-то одну давнюю задумку. С Интел выходило бы дороговато, а с АМД жаба может и ослабить железную хватку на горле.
olgerdovich
я уже поощущал жжение в другом районе, я недавно воплотил наконец-то одну давнюю задумку как раз с Интел.
melchermax
Сразу видно, что жаба у вас более слабая, сильно не душит. Моя — как Карелин :)
Structure
Компьютер по цене процессора Интел
qwertyqwerty
А гроб белый сколько стоит?
Prame
это Eclipse – P400 или P400S (Silent Edition)
гугл говорит что в районе $80