
Уже больше года, как у меня есть свой хобби-проект, в котором я разрабатываю движок базы данных для хранения временных рядов — dariadb. Задача довольно интересная — тут есть и сложные алгоритмы да и область для меня совершенно новая. За год был сделан сам движок, небольшой сервер для него и клиент. Написано все это на С++. И если клиент-сервер находится пока в достаточно сыром состоянии, то движок уже обрел некоторую стабильность.Задача хранения временных рядов достаточно распространена там, где есть хоть какие-то измерения (от SCADA-систем до мониторинга состояния серверов).
Для решения этой задачи есть некоторое количество решений разной степени навороченности:
В качестве вводной статьи могу посоветовать широко известную в определенных кругах статью от FaceBook “Gorilla: A Fast, Scalable, In-Memory Time Series Database”.
Основной задачей же dariadb было создание встраиваемого решения, которое можно было бы (подобно SQLite) встроить в свое приложение и переложить на него хранение, обработку и анализ временных рядов. Из поставленных задач на данный момент выполнено приём, хранение и обработка измерений. Проект пока носит исследовательский характер, поэтому сейчас для использования в продакшене он не годится. Во всяком случае пока :)
Временной ряд измерений
Временной ряд измерений представляет из себя последовательность четверок {Time, Value, Id, Flag}, где
- Time, время измерения (8 байт)
- Value, сам замер (8 байт)
- Id, идентификатор временного ряда (4 байта)
- Flag, флаг замера (4 байта)
Флаг используется только при чтении. Есть специальный флаг “нет данных” (_NO_DATA = 0xffffffff), который проставляется для значений, которых или нет совсем или они не удовлетворяют фильтру. Если в запросе поле флаг указано не 0 (ноль), то для каждого измерения, которое подходит по времени для запроса, к его полю flag применяется операция "логическое И", если ответ равен фильтру, то измерение проходит. Значение поступают в порядке возрастания метки времени (но это не обязательно, иногда нужно записать значение “в прошлое”), по ним надо уметь делать срез и запрашивать интервалы.
Читаем срез
Срез значения для временного ряда на метку времени T, это значение, которые существует в момент времени T или “левее” этого времени.Мы всегда возвращаем левое ближайшее, но только если устраивает флаг. Если значения нет или флаг не подходит, то “нет данных”.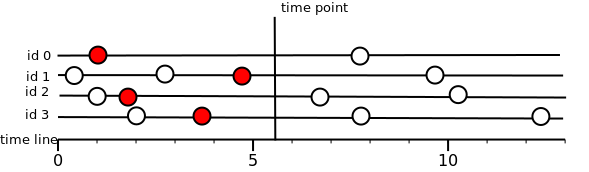
Тут важно понять, почему именно возвращается “нет данных” для значений, не попавших под флаг. Может так случиться, что ни одно из хранимых значений не попадает под флаг, тогда это приведет к чтению всего хранилища. Поэтому было принято решение, что если значение на момент среза есть, но флаг не совпал, то считаем, что значения нет.
Читаем интервал.
Тут все значительно проще: возвращаются все значения, которые попали во временной интервал. Т.е. должно выполняться условие from<=T<=to, где T — время замера.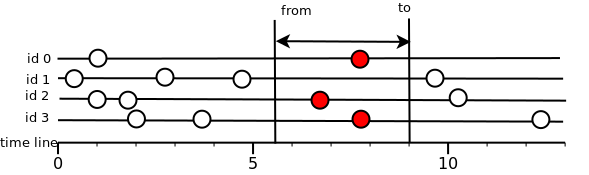
Если измерение попадает в интервал, но не удовлетворяет флагу, то оно отбраковывается. Данные всегда отдаются пользователю в порядке возрастания метки времени.
МинМаксы, последние значения, статистика.
Также есть возможность получить для каждого временного ряда его минимальное и максимальное время, которое записано в хранилище; последнее записанное значение; разную статистику на интервале.
Базовое устройство хранилища
Получился проект со следующими характеристиками:
- Поддержка неотсортированных значений
- Значения, которые записаны в хранилище поменять уже нельзя.
- Различные стратегии записи.
- Хранение на диске в виде LSM-дерева (https://ru.wikipedia.org/wiki/LSM-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE).
- Высокая скорость записи:2.5 — 3.5 миллиона записей в секунду, при записи на диск; 7-9 миллионов записей в секунду при записи в память.
- Восстановление после сбоев.
- CRC32 для всех сжатых значений.
- Два варианта запроса данных: Functor API (async) — для запроса передается колбек-функция, которая будет применяться для каждого значения, попавшего в запрос. Standard API — значения вернуться в виде списка или словаря.
Статистика на интервале: время min/max; значения min/max количество измерений; сумма значений
Реализованы следующие слои: хранение в оперативной памяти, хранение на диске в лог файлах, хранение в сжатом виде.
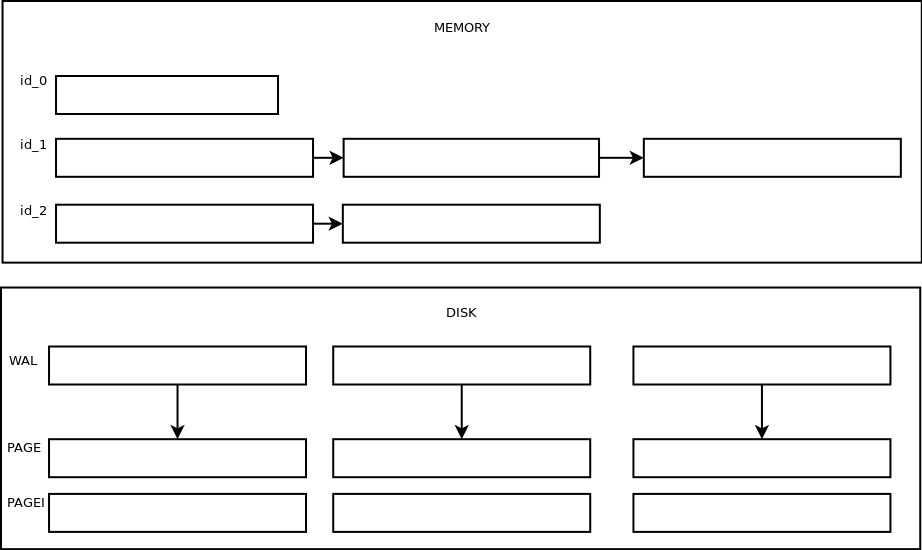
Лог-файлы (*.wal)
Это просто лог-файлы. В памяти держится небольшой буфер, при заполнении которого он сортируется и сбрасывается на диск. Максимальный размер буфера и файла регламентируется настройкам (см. ниже). При запросах весь файл вычитывается и значения попавшие в запрос отдаются пользователю. Никаких индексов и маркеров для ускорения поиска, просто лог-файл. Имя файла формируется из времени создания этого файла в микросекундах + расширение (wal).
Сжатые страницы (*.page)
Страницы получают путем сжатия лог-файлов и их имя совпадает с лог-файлом из которого страница была получена. Если при старте у нас оказывается, что есть страницы с таким же именем (без учета расширения), что и лог файл, то мы делаем вывод, что хранилище не было остановлено нормальным способом, страница удаляется и сжатие повторяется вновь.Эти файлы уже лучше оптимизированы для чтения. Они состоят из наборов чанков, каждый чанк хранит отсортированные и сжатые значения для одного временного ряда, максимальный размер чанка ограничен настройками. В конце файла находится футер, который хранит минмаксы времени, фильтр блума для id попавших в файл временных рядов, статистику для хранимого временного ряда.

Для каждой страницы создается индексный файл. Индексный файл содержит набор минмаксов времени для каждого чанка в странице, id временного ряда, позицию в странице. Таким образом, при запросах за интервал или среза нам просто необходимо в индексном файле найти нужные чанки и вычитать их из страницы.В каждом чанке значения хранятся в сжатом виде. Для каждого поля измерения используется свой алгоритм (вдохновлялся знаменитой статьей “Gorilla: A Fast, Scalable, In-Memory Time Series Database”):
DeltaDelta — для времени
Xor — для самих значений
LEB128 — для флагов
В результате на разных данных сжатие достигает до 3-х раз.
Футеры индексных файлов всегда лежат в кеше и используются для быстрого поиска нужных страниц, для выдачи результатов.
Хранение в памяти
В памяти каждый временной ряд хранится в списке (простой std::list из stl) чанков, а для быстрого поиска над всем этим построено B+ дерево, построенное по максимальному времени каждого чанка. Таким образом, при запросах интервала или среза, мы просто находим чанки, которые содержат нужные нам данным, распаковываем их и отдаем. Хранилище в памяти ограничено по максимальному размеру, т.е. если мы слишком энергично будем писать в него, то лимит быстро кончится и дальше все пойдет по сценарию, который определяется стратегией хранения
Cтратегии хранения
WAL — данные пишутся только в лог файлы, пережатие в страницы автоматически не запускается, но есть возможность запустить сжатие всех лог-файлов вручную.
COMPRESSED — данные пишутся в лог файлы, но как только файл достигает предела (см настройки), рядом создается новый файл, а старый ставится в очередь на сжатие.
MEMORY — все пишется в память, как только достигаем лимит, самые старые чанки начинаем сбрасывать на диск.
- CACHE — пишем и в память и на диск. данная стратегия дает скорость записи как у COMPRESSED, зато быстрый поиск для свежих недавно записанных данных. Для данной также актуален лимит по памяти, если мы его достигнем, то старые чанки просто удаляются.
Переупаковка и запись в прошлое.
Возможна запись данных в любом порядке. Если стратегия MEMORY и мы пишем в прошлое, которое хранится еще в памяти, то мы просто добавим в существующий чанк новые данные. Если же мы пишем так далеко в прошлое, что это время уже не находится в памяти, или стратегия хранения у нас не MEMORY, то данные запишутся в текущий чанк, но при чтении данных будет использован алгоритм k-merge, что немного замедляет чтение, если таких чанков очень много. Чтобы такого не было, есть вызов repack, который переупаковывает страницы, убирая дубликаты и сортируя данные в порядке возрастания метки времени. При этом страницы схлопываются так, чтобы на каждом уровне было страниц не больше, чем задано настройками (LSM — дерево).
Создание временного ряда
Выбор идентификатора для временного ряда можно реализовать самостоятельно, а можно возложить на dariadb — реализована возможность создания именованных временных рядов, затем по имени можно получить идентификатор, а его уже прописать в нужное измерение. Это проще чем кажется. В любом случае, если вы запишите измерение, но оно не описано в файле с временными рядами (создается автоматически при инициализации хранилища), то измерение будет записано без каких либо проблем.
Настройки
Настройки можно задать через класс Settings(см пример ниже). доступны следующие настройки:
- wal_file_size — максимальный размер лог файла в измерениях (не в байтах!).
- wal_cache_size — размер буфера в памяти, в который пишутся измерения, перед тем как попасть в лог-файл.
- chunk_size — размер чанка в байтах strategy — стратегия хранения.
- memory_limit максимальный размер занимаемой памяти хранилищем в ОЗУ.
- percent_when_start_droping — процент заполнения памяти ОЗУ хранилищем, когда начнется сброс чанков.
- percent_to_drop — сколько процентов памяти надо очистить, когда мы достигли предела по памяти.
- max_pages_in_level — максимальное количество страниц (.page) на каждом уровне.
Итоговые бенчмарки
Приведу скоростные характеристики на типичных задачах.
Условия:
2 потока пишут по 50 временных рядов, в каждом ряде измерения за 2-е суток. Частота замера — 2 измерения в сек. В итоге получаем 2000000 измерений. Машина Intel core i5 2.8 760 @ GHz, 8 Gb озу, жесткий диск WDC WD5000AAKS, Windows 7
Средняя скорость записи в секунду:
| WAL, зап/сек | Compressed, зап/сек | MEMORY, зап/сек | CACHE, зап/сек |
|---|---|---|---|
| 2.600.000 | 420.000 | 5.000.000 | 420.000 |
Чтение среза.
Выбирается N случайных временных рядов, для каждого находится время, на котором точно есть значения и запрашивается среза на случайный момент времени в этом интервале.
| WAL, сек | Compressed, сек | MEMORY, сек | CACHE, сек |
|---|---|---|---|
| 0.03 | 0.02 | 0.005 | 0.04 |
Время чтение интервала за 2-е суток для всех значений:
| WAL, сек | Compressed, сек | MEMORY, сек | CACHE, сек |
|---|---|---|---|
| 13 | 13 | 0.5 | 5 |
Чтение интервала за случайный промежуток времени
| WAL, зап/с | Compressed, зап/с | MEMORY, зап/с | CACHE, зап/с |
|---|---|---|---|
| 2.043.925 | 2.187.507 | 27.469.500 | 20.321.500 |
Как все собрать и попробовать.
Проект сразу задумывался как кроссплатформенный, разработка его идет на windows и ubuntu/linux. Поддерживаются компиляторы gcc-6 и msvc-14. Сборка через clang пока не поддерживается.
Зависимости
В Ubuntu 14.04 надо подключить ppa ubuntu-toolchain-r-test:
$ sudo add-apt-repository -y ppa:ubuntu-toolchain-r/test
$ sudo apt-get update
$ sudo apt-get install -y libboost-dev libboost-coroutine-dev libboost-context-dev libboost-filesystem-dev libboost-test-dev libboost-program-options-dev libasio-dev libboost-log-dev libboost-regex-dev libboost-date-time-dev cmake g++-6 gcc-6 cpp-6
$ export CC="gcc-6"
$ export CXX="g++-6"Пример использование в качестве встраиваемого проекта (https://github.com/lysevi/dariadb-example)
$ git clone https://github.com/lysevi/dariadb-example
$ cd dariadb-example
$ git submodule update --init --recursive
$ cmake .Сборка проекта у разработчика
$ git clone https://github.com/lysevi/dariadb.git
$ cd dariadb
$ git submodules init
$ git submodules update
$ cmake .Запуск тестов
$ ctest --verbose .Пример
Создание хранилища и наполнение значениями
#include <iostream>
#include <libdariadb/dariadb.h>
#include <libdariadb/utils/fs.h>
int main(int, char **) {
const std::string storage_path = "exampledb";
// удалим старое хранилище, если оно есть
if (dariadb::utils::fs::path_exists(storage_path)) {
dariadb::utils::fs::rm(storage_path);
}
// инициализируем настройки. ничего менять не будем
auto settings = dariadb::storage::Settings::create(storage_path);
settings->save();
//создадим два временных ряда. p1 и p2 содержат идентификаторы временных
//новых рядов
auto scheme = dariadb::scheme::Scheme::create(settings);
auto p1 = scheme->addParam("group.param1");
auto p2 = scheme->addParam("group.subgroup.param2");
scheme->save();
//создаем сам движок.
auto storage = std::make_unique<dariadb::Engine>(settings);
auto m = dariadb::Meas();
auto start_time = dariadb::timeutil::current_time(); //текущее время в милисекундах
// пишем значения в оба временных ряда по очереди за интервал
// [currentTime:currentTime+10]
m.time = start_time;
for (size_t i = 0; i < 10; ++i) {
if (i % 2) {
m.id = p1;
} else {
m.id = p2;
}
m.time++;
m.value++;
m.flag = 100 + i % 2;
auto status = storage->append(m);
if (status.writed != 1) {
std::cerr << "Error: " << status.error_message << std::endl;
}
}
}Открытие хранилища и чтение интервала.
#include <libdariadb/dariadb.h>
#include <iostream>
// функции для вывода измерения на экран
void print_measurement(dariadb::Meas&measurement){
std::cout << " id: " << measurement.id
<< " timepoint: " << dariadb::timeutil::to_string(measurement.time)
<< " value:" << measurement.value << std::endl;
}
void print_measurement(dariadb::Meas&measurement, dariadb::scheme::DescriptionMap&dmap) {
std::cout << " param: " << dmap[measurement.id]
<< " timepoint: " << dariadb::timeutil::to_string(measurement.time)
<< " value:" << measurement.value << std::endl;
}
class QuietLogger : public dariadb::utils::ILogger {
public:
void message(dariadb::utils::LOG_MESSAGE_KIND kind, const std::string &msg) override {}
};
class Callback : public dariadb::IReadCallback {
public:
Callback() {}
void apply(const dariadb::Meas &measurement) override {
std::cout << " id: " << measurement.id
<< " timepoint: " << dariadb::timeutil::to_string(measurement.time)
<< " value:" << measurement.value << std::endl;
}
void is_end() override {
std::cout << "calback end." << std::endl;
dariadb::IReadCallback::is_end();
}
};
int main(int, char **) {
const std::string storage_path = "exampledb";
// заменяем стандартный логер. это нужно, чтобы не захламлять
// вывод консоли
dariadb::utils::ILogger_ptr log_ptr{new QuietLogger()};
dariadb::utils::LogManager::start(log_ptr);
auto storage = dariadb::open_storage(storage_path);
auto scheme = dariadb::scheme::Scheme::create(storage->settings());
// получаем идентификаторы временных рядов.
auto all_params = scheme->ls();
dariadb::IdArray all_id;
all_id.reserve(all_params.size());
all_id.push_back(all_params.idByParam("group.param1"));
all_id.push_back(all_params.idByParam("group.subgroup.param2"));
dariadb::Time start_time = dariadb::MIN_TIME;
dariadb::Time cur_time = dariadb::timeutil::current_time();
// запрашиваем интервал
dariadb::QueryInterval qi(all_id, dariadb::Flag(), start_time, cur_time);
dariadb::MeasList readed_values = storage->readInterval(qi);
std::cout << "Readed: " << readed_values.size() << std::endl;
for (auto measurement : readed_values) {
print_measurement(measurement, all_params);
}
// применяем колбек к значениям в интервале
std::cout << "Callback in interval: " << std::endl;
std::unique_ptr<Callback> callback_ptr{new Callback()};
storage->foreach (qi, callback_ptr.get());
callback_ptr->wait();
{ // статистика
auto stat = storage->stat(dariadb::Id(0), start_time, cur_time);
std::cout << "count: " << stat.count << std::endl;
std::cout << "time: [" << dariadb::timeutil::to_string(stat.minTime) << " "
<< dariadb::timeutil::to_string(stat.maxTime) << "]" << std::endl;
std::cout << "val: [" << stat.minValue << " " << stat.maxValue << "]" << std::endl;
std::cout << "sum: " << stat.sum << std::endl;
}
}Чтение среза данных
Тут открытие хранилища и получения идентификаторов ничем не отличается от предыдущего примера, поэтому приведу только пример получения среза
dariadb::Time cur_time = dariadb::timeutil::current_time();
// запрашиваем срез;
dariadb::QueryTimePoint qp(all_id, dariadb::Flag(), cur_time);
dariadb::Id2Meas timepoint = storage->readTimePoint(qp);
std::cout << "Timepoint: " << std::endl;
for (auto kv : timepoint) {
auto measurement = kv.second;
print_measurement(measurement, all_params);
}
// последние значения
dariadb::Id2Meas cur_values = storage->currentValue(all_id, dariadb::Flag());
std::cout << "Current: " << std::endl;
for (auto kv : timepoint) {
auto measurement = kv.second;
print_measurement(measurement, all_params);
}
// применяем функцию к каждому значению в срезе.
std::cout << "Callback in timepoint: " << std::endl;
std::unique_ptr<Callback> callback_ptr{new Callback()};
storage->foreach (qp, callback_ptr.get());
callback_ptr->wait();Ссылки
Комментарии (49)
ik62
05.03.2017 21:01+1В таких базах есть еще интересный вопрос поддержания retentions разного разрешения (типа аггрегация ежеминутных данных за час в одно среднее значение за час). Это делается автоматом в хранилищах типа RRD или whisper, не знаю насчет InfluxDB.
И еще, возможно пропустил — как удаляются старые данные?
Wolverine
05.03.2017 23:57У InfluxDB есть CONTINUOUS QUERY с помощью, которых можно делать downsampling

lysevi
06.03.2017 07:40- Я считаю, что такие вещи, как запись статистических данных (среднее за час/минуту) не задача самого движка хранения. Да, в dariadb реализован метод stat, который выдаст вам для определенного измерения среднее значение, мин/максы. Но вот ведение параллельного временного ряда, со статистикой, это не задача движка. Я бы это вынес в серверную часть. Что я и сделаю в будущих версиях.
- Что касается удаления. Сейчас есть два способа удалить:
- метод erase — который просто удалит страницы из интервала.
- метод compact (в ветке dev) — с его помощью можно не только удалить выборочно измерения, но и заменить группу замеров на 1.
Да, можно сделать сейчас и более элегантное удаление, как в leveldb (запись специального значения в базу, которое говорит, что у нас удалена какая то часть), но этого пока у меня нет в планах. Если найдется гурппа желающих, то сделаю.
Roman_Kh
05.03.2017 21:07-1feather-файлы можно писать со скоростью 800 Мбайт/с (и даже быстрее, если ваше хранилище обеспечит нужную производительность)
blosc'ом можно сжимать данные очень быстро и просто одновременно, причем это может быть даже быстрее чем mem-to-mem копирование.
Зачем нужна ваша DariaDB?

elusiveavenger
06.03.2017 08:59Осмелюсь предположить, что бы впечатлить девушку. Даже осмелюсь угадать имя… Впрочем, вы сами всё понимаете.
slavaZim
06.03.2017 09:00Уточните, пожалуйста, свое понимание слова «хобби» в выражении «хобби проект».
Зачем нужен ваш комментарий?
ELazin
07.03.2017 13:46+1Feather это exchange формат данных для R датафреймов (чтобы их можно было передавать между R и Pandas), у датафрейма совсем другая модель данных (ряды должны быть выровнены, количество рядов доложно быть известно заранее и тд), использование отдельного feather файла на каждый временной ряд totally defeats the purpose этого формата, к тому же у них в README жирным шрифтом выделено — «Do not use Feather for long-term data storage».
Blosc — компрессор, который не подходит для TSDB, которая держит открытыми очень много рядов (например миллион), каждый ряд нужно уметь читать независимо, поэтому ему нужен свой отдельный контекст компрессора, а этот контекст обычно занимает десятки килобайт. Ну и еще он медленный.
eao197
05.03.2017 21:55+2Вопрос по коду примеров. А почему вы создаете объект Callback через new:
std::unique_ptr<Callback> callback_ptr{new Callback()}; storage->foreach (qp, callback_ptr.get()); callback_ptr->wait();
В этом есть какой-то тайный смысл? Или это можно переписать так:
Callback callback; storage->foreach(qp, &callback); callback.wait();

Dehumanizer
05.03.2017 23:47А почему вы используете 4 байта для флага? Простите если читал невнимательно.
lysevi
06.03.2017 07:29+1А это эмпирически. дело в том, что я работаю с одной такой большой SCADA системой, так по опыту могу сказать, что 2 байт уже слишком мало, а 64 слишком много.
namwen
06.03.2017 05:59Все хорошо, полезно в любом случае, но почему не выбрали LMDB изначально для своих задач, к примеру? Он ведь уделывает вас по производительности в разы, да и функциональность значительно выше.
lysevi
06.03.2017 07:331. как я понял, LMDB — key-value база, а это совсем не то, что база данных для timeseries. Я сильно не вчитывался, но если в lmdb можно сделать запрос интервала и среза, то ее можно использовать как timeseries.
2. Dariadb — хобби проект. Он не рассчитан (во всяком случае пока) на продакшн. Делался для себя, чтобы понять как оно там внутри.namwen
06.03.2017 10:44LMDB действительно KVS, оно действительно не предоставляет из коробки того высокоуровневного интерфейса, который ждешь от timeseries dbs (кстати, InfluxDB может использовать под капотом LMDB), но сама задача работы с timeseries абсолютно спокойно укладываются в парадигму KV (а тут не только LMDB, но и родственники LevelDB идеально впишутся), все сведется к простейшей обертке и range scans.
ELazin
07.03.2017 08:06Эта задача не ложится на обычные KV-stores, предоставляющие oredered map inteface (LMDB, LevelDB). Чтобы понять почему, подумайте, что у вас будет ключем.

alexeibs
07.03.2017 12:04Да хотя бы конкатенация время + имя ряда
ELazin
07.03.2017 13:37ОК, допустим вы хотите выбрать конкретный временной ряд чтобы нарисовать график, делаете full scan между двумя метками времени, на один байт полезных данных LevelDB читает несколько KB мусора, значение read amplification просто неприличное, пользователь ждет суточный график несколько минут.
alexeibs
07.03.2017 15:10«хотя бы» означает один возможных вариантов решения. Безусловно выбор ключа зависит от того, какие у вас данные, как вы по ним будете искать. Если рядов очень много и между 2 метками времени ожидается «неприличное» количество мусора, то имена рядов и метку времени можно просто поменять местами в ключе.
ELazin
07.03.2017 16:10Можно поменять, тогда вы будете писать ключи в случайном порядке и получите кучу других проблем (долгие compaction паузы, например). Проблема в том, что данные приходят упорядоченными по метке времени, а читаются в совершенно другом порядке. Помимо обычных point запросов есть еще aggregations, joins, group by запросы, в каждом из которых разные ключи будут давать разные результаты. Я уже промолчу о том что KV-stores не могут делать join-ы и агрегировать данные, т.е. вам как-то вручную придется написать свою БД. Чуваки из influxdb попытались, в итоге отказались от LevelDB, а потом и от BoltDB (который является клоном LMBD), т.к. на типичный KV это все не ложится вообще. Более или менее нормально это ложится на колумнарные БД.
alexeibs
07.03.2017 17:51Ветка обсуждения наша началась с комментария о том, можно ли применить один из существующих KV стораджей, для реализации DariaDB. Внутри DariaDB — LSM c блум-фильтрами. Что похоже к примеру на RocksDB или LevelDB. Соответственно, вопрос «почему нельзя было взять готовый LSM в виде существующего KV-store» вполне резонный. Ну а вопросы про «read amplification», aggregations, joins, group by запросы в KV-стораджах здесь не совсем уместны, т.к. сравнивать нужно не KV-стораджи и аналитические колумнарные БД, а KV-стораджи и DariaDB. Как в DariaDB обстоят дела со всем этим?
lysevi
07.03.2017 19:41Если брать готовое решение (абстрактный KV-сторадж или leveldb для конкретности), то их можно использовать, если они дают построить в памяти (ну или на диске) индекс таким образом, чтобы мы знали какие временные ряды имеются в хранилище, где они лежат на диске, чтобы не заниматься сканированием всего файла, а сразу сделать seek к нужным данным, а также уметь эффективно упаковывать значения временного ряда, потому что самое поле Value может почти не меняться для рядом стоящих замеров. Если абстрактный kv-сторадж это умеет, то его можно использовать вместо dariadb.
В dariadb заголовки индексных файлов лежат в памяти, по этим заголовкам мы определяем нужные нам файлы (индексные), проходим по ним и находим смещения нужных нам чанков, которые попали в запрос. Сами индексные файлы небольшие, для страницы в 1 мегабайт размером, индексный файл будет примерно 30 килобайт, при желании их вообще можно полностью держать в памяти. Причем сами индексы содержат статистику, поэтому для запроса среднего на интервале, или минимума за период, читать и распаковывать страницу не надо.
Что касается джоинов, то это вполне себе реализуемая вещь. Единственная проблема, что сейчас реализовано так, что упакованные данные для каждого временного ряда полностью вычитываются с диска в память, что в случае большого запроса скушает всё, что есть. Такой подход выбран, как самый простой в реализации. Позже это можно сделать "по правильному".
А вот с group by хотелось бы пример реального использования. Мне оно не встречалось, поэтому интересно зачем оно и как использовать.
alexeibs
07.03.2017 23:02Как в DariaDB обстоят дела со всем этим?
Мой вопрос был скорее адресован автору комента выше :)
Если абстрактный kv-сторадж это умеет, то его можно использовать вместо dariadb.
Я думаю, что хороший kv-сторадж умеет эффективно искать по ключу, а также умеет сжимать данные. Можно почитать, к примеру, как устроена RocksDB.
Причем сами индексы содержат статистику
Вот этого в kv-сторадже вероятно нет. Но до определенных пределов это может компенсироваться быстрым чтением или каким-нибудь кэшем сбоку.ELazin
08.03.2017 13:44А может специализированный движок будет лучше работать? Вы же предлагаете написать часть БД вприложении, кэш сбоку, потом окажется что нужен обработчик запросов свой и тд. Путем, который вы предлагаете многие уже пошли, может кому-нибудь стоит попробовать специализированное решение?
ik62
07.03.2017 16:58«почти» ложится на «почти» KV. Напрмер, на кассандре, с некоторыми приседаниями, получается.
namwen
07.03.2017 23:16-1При этом тот же InfluxDB (который в плане производительности TS держится в топе) в качестве storage использует LMDB / LevelDB и его наследников, да? Ключом timestamp'а будет достаточно. Я действительно могу чего-то не улавливать, буду признателен за объяснение.
ik62
07.03.2017 23:26ключем может быть, к примеру, и час суток, а значением — отсортированные минутные замеры (с таймстампами).
namwen
07.03.2017 23:27-1Да без вопросов, я к тому, что нет проблем в реализации TS на KV, более того, все так и делают, по сути, оно абсолютно спокойно укладывается в идеологию, а как организовывать это все — уже индивидуально.
ELazin
08.03.2017 13:48+1InfluxDB не держится в топе, КМК (что это за топ такой вообще?). Он на очень толстой машине может выдать чуть больше 0.5М операций записи в секунду. И они начали это делать только после того, как выкинули LevelDB, RocksDB и LMDB (там были plugable движки когда-то) из проекта и начали использовать TSM-tree — специализированный движок для хранения временных рядов (это еще в v0.9 было, года два назад).

basp
09.03.2017 08:48+1Есть хорошее объяснение того, почему KV не годится для временных баз данных — это та статья, которую вы, собственно, комментируете :)
Ну, и мне кажется, что реальный «топ» таких баз данных — это закрытые энтерпрайз-решения

WVitek
06.03.2017 10:42Мне довелось работать с базами замерных данных по объектам (суть те же временные ряды).
Наиболее актуальными видами запросов были следующие (как для одного ряда, так и для группы рядов):
- выборка последнего значения по состоянию на момент времени, но не ранее заданного момента времени (фактически, выборка последнего значения в интервале);
- выборка значений за временной период + последнего значения по состоянию на начало периода, но не ранее заданной даты.
У автора есть размышления не сей счёт или таких нюансов пока не касались?lysevi
06.03.2017 13:03"выборка последнего значения по состоянию на момент времени, но не ранее заданного момента времени (фактически, выборка последнего значения в интервале);"
А это чем отличается от среза на момент времени? Вам фактически возвращается значение, которое не позднее заданного времени.
WVitek
06.03.2017 16:48При обычном срезе давность последних значений ничем не ограничена, а часто нужны последние, но не слишком старые данные.
Например, значения телеметрического замера тока электродвигателя, работающего с изменяющейся загрузкой, быстро теряют актуальность (замер суточной давности имеет мало смысла).
Я к тому, что обычно востребовано последнее значение, находящееся между двух заданных дат, а не просто по состоянию на одну дату.
ELazin
07.03.2017 13:56+1Это все специфические запросы, которые нужны только в вашем проекте. Это все решается через запрос данных за интервал. БД не должна делать предположений о данных, а вы, фактически, хотите чтобы БД знала о том, что измерение является актуальным N секунд, поэтому последнее значение нужно искать не дальше N секунд в прошлом. У всех разные предпосылки.

Siemargl
06.03.2017 11:25По опыту согласен с комментарием, кроме того по опыту, обработка параметров происходит поочередно.
Два следствия для производительности для последовательного чтения записи:
- хранить лучше каждый параметр отдельным хранилищем/файлом
- это даст возможность предсоздавать файлы определенного размера, в том числе циклические
Ну и еще по закрытию периода (месяц, год) данные становятся менее актуальными и востребованными и можно думать об их перемещении на более дешевое хранение. Возможно, актуальными останутся агрегаты.
Перечень time-series dbms, возможно из них можно найти еще идеи для реализацииlysevi
06.03.2017 13:04"хранить лучше каждый параметр отдельным хранилищем/файлом"
это смотря сколько значений. Знаю "скаду", где 100к временных рядов с разным шагом записи.
ik62
06.03.2017 14:14у нас в три сервера graphite собирается порядка 800к метрик с разрешением 1 минута(хрянятся 2 суток), из которых делаются ряды с разрешением пол-часа, два часа и т.д. Хранилище — carbon/whisper. Каждая метрика там хранится в отдельном файле вместе со всеми ретеншнами.
Есть тестовый стенд со сбором порядка 40к метрик в кассандру с time window compaction strategy.
Такие данные в любом случае нужно хранить на нескольких сервреах с прицелом на автоматический файловер и избыточность — на случай выходя из строя, апгрейда и т.д. Кассандра в этом смысле идеальна — все механизмы у неё встроенные. Графит с карборонм — хуже.
Siemargl
06.03.2017 14:39Как уже заметили, это не так уж и много. Кроме того, можно при желании иерархически разложить по каталогам, или при нехватке мощностей, по серверам.
Мой пойнт был в том, чтобы при необходимости например, построить 15 графиков из 100к по архивным данным, не пришлось 15 раз перечитать данные с диска от всех 100к параметров.lysevi
06.03.2017 15:00а в dariadb эти данные считаются за один проход с диска, потом уже в памяти будут выдаваться последовательно для каждого временного ряда.
Siemargl
06.03.2017 17:29Не годится. Сначала вы в пример ставите систему со 100к параметров, а теперь утверждаете, что всё поместится в память?
Не поместится, возьмем суточный график.
Даже без накладных данных это ~400 Тб, если параметр пишется с 500мс интервалом и если попытаться прочитать 100к параметров нахрапом.

banzayats
06.03.2017 14:56+2Может кому будет интересен сравнительный анализ Timeseries DB: Open Source Time Series DB Comparison
banzayats
06.03.2017 15:01И описание: Top10 Time Series Databases
ELazin
07.03.2017 13:58+4Рейтинг составлен разработчиками DalmatinerDB на основе данных из интернета (сами они ничего не тестировали). Это все что нужно знать.
click0
Осталось привести список мониторингов, где подобная база будет быстрее.