

Привет, Хабр! Меня зовут Евгений Гугучкин, я – разработчик Badoo в команде «Платформа».
Наша команда работает над интересными и нужными задачами. Одна из них – разработка распределённого хранилища временных рядов, в решении которой я принимал непосредственное участие.
Недавно мы завершили большой и сложный этап, и нам захотелось поделится с вами нашими успехами, рассказать, почему мы занимались этой задачей и каких достигли результатов.
Зачем нам вообще хранилище временных рядов
Представьте систему со сложным поведением, состоящую из множества компонентов и связей между ними. Оценить состояние этой системы, отклонение от нормы, причину этого отклонения – это нетривиальная задача. Badoo – это один из примеров такой системы. Мы собираем и храним значения огромного числа метрик, счёт идёт на сотни миллионов. И это жизненно важно для компании, поскольку позволяет обнаруживать проблемы на ранних этапах и оперативно находить источники этих проблем.
Чтобы иметь как можно более полную картину, мы собираем довольно много различных метрик, начиная от сугубо технических, связанных с профилированием кода и компонентов нашей архитектуры, и заканчивая множеством «продуктовых» метрик.
Этот большой поток данных мы должны сохранить. Куда? Правильно! В хранилище временных рядов.
На данный момент мы храним более 300 миллионов метрик, обновляя их со скоростью около 200 000 значений в секунду. Эти данные занимают 16 Тб на 24 серверах.
Какое хранилище мы использовали до сих пор
Уже в течение многих лет мы используем RRDtool – набор утилит для работы с временными рядами. Несмотря на то, что он был создан 18 лет назад и уже длительное время не развивается, он имеет свои плюсы:
- «из коробки» умеет рисовать графики;
- может на лету производить вычисления с временными рядами;
- объём, занимаемый одной метрикой, не меняется независимо от того, сколько данных туда записано.
Последнее свойство для нас особенно важно, и я расскажу о нём подробнее. Каждая метрика хранится в отдельном файле в формате RRD. Файл содержит специальные структуры: кольцевые архивы.
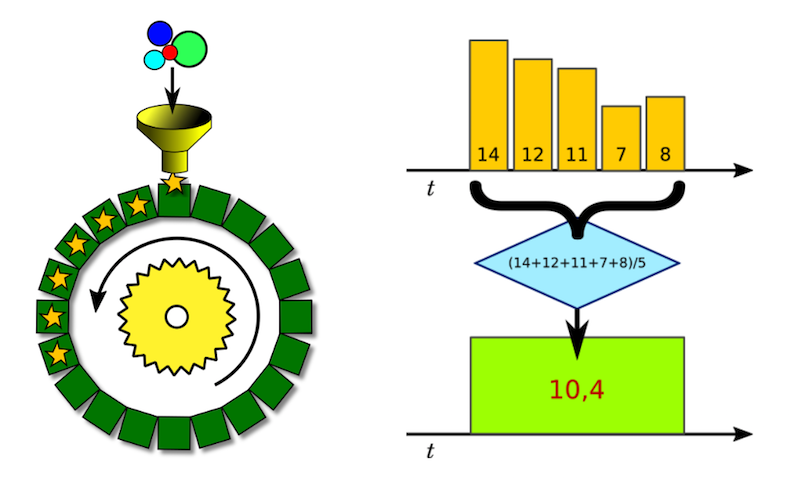
Мы можем представить себе кольцевой архив как фиксированный набор ячеек, в каждой из которых хранится одно значение за определённый интервал времени.
Допустим, интервал времени, покрываемый ячейкой, равен пяти минутам, а наша агрегирующая функция – вычисление среднего арифметического. Значит, в ячейку попадёт сумма всех измерений, попадающих в нашу пятиминутку, поделённая на количество этих измерений.
Схематично этот процесс изображён на рисунке выше. Назовём его даунсемплинг, поскольку с его помощью мы понижаем уровень детализации данных.
Поскольку недавние измерения нам хочется видеть с хорошей детализацией, мы храним несколько кольцевых архивов для каждой метрики. И даже в этом случае снижение уровня детализации даёт нам существенную экономию места на диске.
В общем, за годы использования RRDtool мы оценили:
- высокую скорость чтения: RRDtool написан на C, считывает данные с локального диска, производит все вычисления и отдаёт сразу готовую картинку в формате PNG; вряд ли какое-то другое решение превзойдёт его по скорости выполнения запроса;
- отсутствие необходимости думать обо всех нюансах, связанных с закольцованностью и агрегацией: RRDtool делает всё сам, мы просто отправляем туда данные;
- контролируемый размер датасета: нам достаточно знать количество метрик и не нужно учитывать частоту измерений.
Почему же мы задумались о новом хранилище? Самое время рассказать о недостатках и проблемах, с которыми мы столкнулись.
Почему нам понадобилось новое хранилище
Неэффективное использование дисков
Судя по всему, разработчики RRDtool не рассчитывали на запись больших объёмов данных, потому что уже при обновлении 300 метрик в секунду мы начинаем упираться в диск.
Причина, во-первых, в том, что используется read before write, то есть при каждом обновлении необходимо прочитать файл метрики с диска и записать новую его версию или часть.
Во-вторых, такая операция производится с каждой метрикой. Это значит, что для трёх сотен метрик мы имеем соответственно несколько сотен дисковых операций с произвольным доступом в секунду.
Для решения этой проблемы мы используем специальный демон rrdcached, который буферизует несколько поступающих значений одной метрики в памяти, скажем, за десять минут и записывает их потом за одну итерацию. Так мы смогли на порядок уменьшить количество дисковых операций и, следовательно, увеличить пропускную способность.
Следующим шагом стало использование SSD, что также дало десятикратное увеличение пропускной способности на запись.
В итоге мы добились показателя в 30 тысяч записей в секунду. И тем не менее в силу вышеперечисленных особенностей RRDtool на наших rrd-серверах мы имеем:
- тысячи дисковых операций в секунду со случайным доступом и, как следствие, высокий iowait: 15–20%;
- высокую интенсивность записи, что в итоге приводит к износу SSD;
- расход оперативной памяти: в нашей конфигурации это более 30 Гб на буферизацию, и более 16 Гб ОС выделяет под inode cache (у нас десятки миллионов файлов-метрик в файловой системе).
Проблемы с резервным копированием
C RRDtool не работает подход инкрементальных бэкапов: отправляя одно значение в метрику, мы изменяем весь файл с метрикой, и при следующем бэкапе нам надо сохранить целиком новую версию. И так для каждой из десятков миллионов метрик на сервере. Это занимает так много времени, что от регулярных бэкапов нам пришлось отказаться.
Локальный доступ к файлам
 Эта особенность сама по себе не является проблемой, пока мы помещаемся на одном сервере и не планируем горизонтально масштабироваться.
Эта особенность сама по себе не является проблемой, пока мы помещаемся на одном сервере и не планируем горизонтально масштабироваться.
Когда же мы шагнули за пределы одного сервера, мы решили эту проблему консервативным способом: каждое приложение, работающее с временными рядами, прописано на определённом сервере и запускается только там, где хранятся его данные.
 Это работает, хотя и доставляет неудобства:
Это работает, хотя и доставляет неудобства:
- каждый раз при создании нового приложения приходится думать, куда его лучше «подселить»;
- если вдруг твой коллега одновременно с тобой выбрал тот же сервер, может возникнуть ситуация «перенаселения»;
- нередко приходится переносить приложения со всеми его данными вручную с сервера на сервер.
В конце концов, и этот подход себя исчерпал: рано или поздно должно появиться приложение, данные которого не помещаются на один сервер. И этот момент настал – появилось приложение, под которое мы выделили отдельный сервер, однако свободное место стремительно заканчивалось. Счёт шёл на дни. Тогда мы оперативно сделали относительно простую реализацию для распределения записи и чтения через единую точку входа в виде REST API.
Это решение с самого начала рассматривалось нами как временное. Однако мы решили тактическую задачу: устранили препятствия для роста. Это сработало, и в таком виде датасет нашего приложения вырос до шести серверов.
Но это добавило и новых трудностей: мало того, что временное решение было неудобным в эксплуатации и требовало доработок, добавилась критичная для нас проблема – низкая отказоустойчивость: при остановке одной ноды останавливалась вся запись. К тому же это хранилище унаследовало все проблемы RRDtool, которые я описывал выше.
В общем, на этом этапе стало очевидно, что надо искать более подходящее решение, лишённое этих недостатков.
А раз уж мы решили искать замену, было бы неплохо заодно учесть и ещё несколько проблемных моментов, чуть менее критичных для нас.
- Хотелось бы иметь возможность переписывать или дописывать данные задним числом. RRDtool, например, требует, чтобы каждое новое значение метрики было за время, большее предыдущего. Это вынуждает собирать все данные в одном месте, упорядочивать их по времени и отправлять в хранилище по очереди. К тому же мы вынуждены резервировать какой-то временной интервал, в течение которого ждём, чтобы по возможности все данные добрались до нашей центральной очереди.
- Проблема с длинными именами метрик. Поскольку в RRDtool мы отображаем имя метрики на имя файла, то упираемся в ограничения файловой системы, где полный путь файла не должен превышать 255 символов.
- Компактность. В случае хранения разреженных временных рядов в формате RRD фиксированный размер файла поворачивается к нам своей… тёмной стороной: даже одно записанное значение резервирует на диске место как для полноценной метрики.
Помимо этого, мы добавили такое требование, как долговечность, поскольку, как оказалось, некоторые из рассматриваемых решений при определённых условиях теряют сохранённые в них данные.
Какие альтернативы мы рассматривали
Итак, мы составили список требований и оценили наиболее популярные open-source-решения в данной предметной области. Вот что у нас получилось:
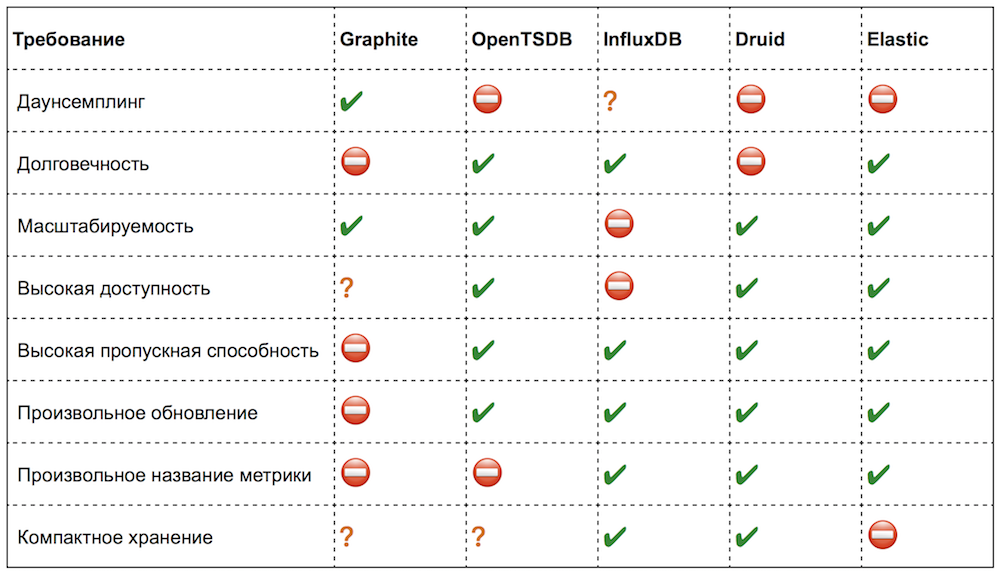
На самом деле, не всегда возможно чётко определить соответствие тому или иному требованию (там, где ситуация неоднозначна, я поставил знак вопроса).
Лично мне очень понравились решения, которые мы рассматривали. Во всех есть интересные идеи и просто удобные функции. Но сейчас я не буду останавливаться на них подробно, а постараюсь обозначить только важные для нас моменты и критичные недостатки.
Graphite
Обладает большинством недостатков RRDtool, к тому же потребляет очень много CPU. Но главная претензия – Graphite «молча» теряет данные, когда ему не хватает ресурсов, если, например, не успевает обрабатывать или записывать.
OpenTSDB
При всех достоинствах этого решения оно обладает и рядом досадных ограничений:
- отсутствие даунсемплинга при записи и хранении;
- невозможность понять, какие метрики (и сколько) в него записаны;
- ограничения на названия метрик;
- отсутствие простого способа удалить метрику (а мы регулярно удаляем устаревшие);
- запрос на получение последнего значения метрики приводит к сканированию данных на диске и очень неэффективен;
- ограничения в API массового чтения и, как следствие, затруднения при реализации даунсемплинга.
Причём все эти проблемы – не следствие архитектурных ограничений, а просто недоделанный функционал.
InfluxDB
Это решение казалось идеальным. Не хватало только одного, самого важного, пункта – оно не масштабировалось «из коробки». Впрочем, его open-source-версия не масштабируется и сейчас: авторы работали над кластеризацией больше года и в итоге решили закрыть этот функционал. А жаль, мы очень рассчитывали…
Druid
Когда мы знакомились с ним, это был не столько сервис, сколько фреймворк. К тому же почти без документации. Чтобы получить от него то, что мы хотели, пожалуй, пришлось бы дописывать или переписывать какие-то его части.
Elasticsearch
Elasticsearch – вообще-то продукт немного из другой области. Но в последнее время в нём появились функции для аналитических запросов. В целом, он доказал, что справляется с задачей хранения «сырых» данных, но при этом требовал в четыре раза больше места на диске и потреблял в пять раз больше CPU, чем OpenTSDB. И ещё мы столкнулись со странной особенностью: чем больше шардов в индексе, тем медленнее он работает на запись (хотя здравый смысл подсказывает, что должно быть наоборот).
В итоге ни одно из этих решений из коробки не удовлетворило наши требования. Нужно было либо продолжать поиски, либо «взяться за напильник», чтобы добиться желаемого.
Cassandra. Почему мы выбрали её
Надо сказать, что два решения из таблицы нас особенно заинтересовали, так что мы интегрировали эти хранилища на уровне proof of concept в наш фреймворк для испытания в реальных приложениях на реальной нагрузке.
Речь про InfluxDB и OpenTSDB. К сожалению, InfluxDB отпал после того, как разработчики отказались от поддержки кластеризации в открытой версии, а OpenTSDB не поддерживал даунсемплинг и ещё некоторые нужные нам функции, о которых я уже упоминал (удаление метрик, получение последнего значения и пр.).
Однако OpenTSDB показал очень хорошую производительность, масштабируемость, отказоустойчивость. В общем, самые важные пункты в нашей таблице.
Если разобраться, OpenTSDB – это «обёртка» над распределённой СУБД Apache HBase, добавляющая REST API-доступ и умеющая упаковывать данные для СУБД соответствующим образом. Все понравившиеся нам качества обеспечиваются именно распределённой СУБД, а все недостающие функции – легко реализуются поверх неё.
Когда мы, наконец, осознали, что подходящего хранилища не существует, мы решили сделать его сами по аналогии с OpenTSDB на основе распределённой СУБД, добавив туда кольцевые архивы, как в RRDtool.
Но теперь перед нами встал выбор распределённой СУБД. На этот раз мы не стали проводить масштабное исследование, а ограничились сравнением уже упомянутого Apache HBase и ещё одной распределённой СУБД – Apache Cassandra. Обе СУБД основаны на модели данных Google Bigtable. Apache Cassandra к тому же позаимствовала некоторые идеи у Amazon DynamoDB, что пошло ей только на пользу.
Как водится, у каждого варианта есть как плюсы, так и минусы. Тем не менее они оба способны справиться с поставленной нами задачей. Как же мы выбирали между этими СУБД?
На мой взгляд, каждая история выбора – это всегда немного субъективная история. И тем не менее я попробую обосновать наш выбор. Ниже в таблице – список различий, которые повлияли на наше решение. Было бы неправильно говорить, что это недостатки HBase – нет, просто особенности, которые надо иметь в виду при разработке.
| Cassandra | HBase |
|---|---|
| Отсутствие зависимостей | Требуются ZooKeeper и Hadoop |
| Простота настройки | Нужно настраивать все компоненты |
| Язык запросов CQL | Громоздкий API |
| Децентрализованная | Есть мастер нода – SPOF |
| Равномерное распределение нагрузки | Проблема hotspot |
| Материализованные представления | Реализация на стороне приложения |
| Вторичные индексы | Реализация на стороне приложения |
| Logged Batches | Реализация на стороне приложения |
| Производительный драйвер для PHP 7 | Thrift-клиент для PHP |
Как видно из таблицы, работать с Cassandra проще и удобнее по многим пунктам. Это и более простая установка, и настройка, и свой язык запросов, и хорошая документация. В отличие от HBase, в Cassandra нет мастер-ноды и, соответственно, не требуется её дублирование для обеспечения высокой отказоустойчивости. C Cassandra не надо следить за тем, чтобы данные распределялись равномерно между узлами, в то время как в HBase возможны перекосы в нагрузке, и приложение само должно следить за тем, как распределяются данные. Не последнюю роль сыграло и наличие драйвера для PHP 7, на который мы тогда перешли.
Как мы храним временные ряды в Cassandra
Подробное описание Apache Cassandra не уместилось бы в целую статью. К тому же в интернете есть достаточное количество хороших материалов на эту тему, в том числе и на Хабре. Однако некоторые общие моменты стоит упомянуть.
- Данные в Cassandra распределяются в кластере таким образом, что каждая запись имеет копии на соседних узлах. Количество копий записи (фактор репликации) – конфигурируемый параметр.
- В случае если одна из нод становится недоступной, запросы как на чтение, так и на запись продолжают обслуживаться соседними узлами, содержащими реплики недоступной ноды.
- Добавление новых узлов происходит без простоя. Данные автоматически перераспределяются по кластеру.
- Производительность увеличивается линейно с ростом размера кластера.
- Для хранения данных используется LSM-дерево – структура, обеспечивающая очень эффективное обновление данных и вставку новых записей.

- Для доступа к данным Cassandra предлагает табличную модель данных и язык запросов CQL, однако это всё синтаксический сахар, а в реальности «под капотом» лежит модель key-value. Но в отличие от простой key-value-модели, где и ключ и значения имеют тип BLOB, в Cassandra value является структурой, а именно – ассоциативным массивом, упорядоченным по значению ключа. При этом:
• можно изменять и добавлять за раз по одному или более элементу такого массива;
• элементы каждого такого ассоциативного массива хранятся на диске по возможности последовательно;
• это позволяет очень эффективно одним обращением к диску получать как один элемент массива, так и диапазон значений, и, разумеется, весь массив целиком.
Вот именно на уровне этой key-value-модели я и попробую на пальцах объяснить, как мы реализовали хранение временных рядов.
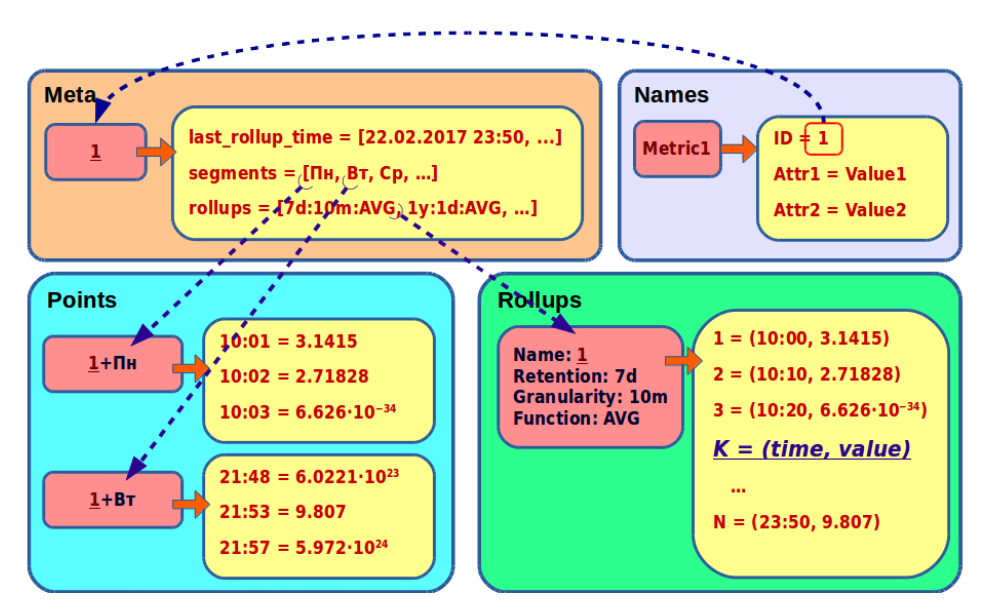
 Для начала давайте рассмотрим хранение первичных, неагрегированных, данных. Они состоят из имени метрики и её значений. Каждое значение – это пара timestamp: double. Поместим эти данные в таблицу Points.
Для начала давайте рассмотрим хранение первичных, неагрегированных, данных. Они состоят из имени метрики и её значений. Каждое значение – это пара timestamp: double. Поместим эти данные в таблицу Points.
Как видно, такая структура очень хорошо ложится на внутреннее представление данных в Cassandra. Но есть один нюанс: так мы можем легко превысить ограничение Cassandra на размер ассоциативного массива. Формально это 2 миллиарда, но на практике лучше не превышать 100 тысяч.
 Это ограничение легко обойти, если шардировать данные одной метрики по суткам. В названии ключа к имени метрики добавляется дата. Теперь значения метрики будут хранится в нескольких ассоциативных массивах – по одному на каждые сутки. Назовём эти шарды с первичными данными суточными сегментами, или просто сегментами. Если записывать значения в метрику каждую секунду, то размер сегмента не превысит 86 400 значений.
Это ограничение легко обойти, если шардировать данные одной метрики по суткам. В названии ключа к имени метрики добавляется дата. Теперь значения метрики будут хранится в нескольких ассоциативных массивах – по одному на каждые сутки. Назовём эти шарды с первичными данными суточными сегментами, или просто сегментами. Если записывать значения в метрику каждую секунду, то размер сегмента не превысит 86 400 значений.
 С первичными данными, кажется, всё ясно. Но напомню, мы хотели хранить исторические данные в виде агрегированных кольцевых архивов. Эти данные будем хранить в новой таблице Rollups.
С первичными данными, кажется, всё ясно. Но напомню, мы хотели хранить исторические данные в виде агрегированных кольцевых архивов. Эти данные будем хранить в новой таблице Rollups.
Здесь у нас будет сложный ключ. Он будет определять и метрику, и свойства архива. В принципе, всё, как в RRDtool: архив определяется периодом архива, ценой ячейки и агрегирующей функцией.
А в ассоциативном массиве храним:
- ключ – номер ячейки К, вычисляемый по формуле
K = floor(time % retention / granularity); - значение – кортеж, состоящий из пары: время, соответствующее ячейке, и собственно значение ячейки.
В итоге данные одной метрики оказались разбросаны по разным таблицам и ключам. У метрики есть первичные данные в нескольких сегментах и несколько архивов с разной детализацией.
Чтобы прочитать все данные метрики, нужно знать её ключи – какие у неё сегменты и архивы. Такую информацию мы соберём в отдельную таблицу Meta.

Тут по имени метрики мы храним:
- список её сегментов;
- список её архивов;
- самую старшую ячейку среди всех архивов метрики (на временной шкале это можно представить как правую границу заархивированных данных; с её помощью мы всегда можем и вычислить левую границу, и выбрать самый подходящий архив, соответствующий запросу).
Можно заметить, что название метрики входит в состав всех ключей. Это усложняет операцию её переименования и увеличивает расход места на диске, потому что метрики у нас действительно длинные, в среднем не менее 100 символов. Мы приняли решение вместо названия использовать идентификатор и хранить его в отдельной таблице Names.
Теперь нам достаточно создать новую запись в таблице Names – и мы переименовали метрику. Кроме того, в будущем метрикам можно будет назначать атрибуты и делать сложные выборки метрик по значениям этих атрибутов.
Перезапись данных и даунсемплинг
Мы решили хранить как первичные данные, так и агрегированные. Первичные, в таблице Points, хранятся несколько дней, после чего целыми сегментами агрегируются и отправляются в архив. Это позволяет нам с одной стороны перезаписывать данные задним числом (правда, только в пределах последних семи дней), а с другой – хранить данные в компактном архиве.
У нас высокие требования к производительности даунсемплинга. Чтобы успевать, надо обрабатывать 700 метрик в секунду, или более 60 миллионов в сутки. Именно столько сегментов у нас создаётся за сутки в данный момент. Как обеспечить это и не нагрузить диски? Cassandra позволяет последовательно сканировать всю таблицу или какую-то её часть. И за счёт этого удаётся избегать неэффективного рандомного обращения к диску. При текущих объёмах мы можем вычитать все первичные данные за шесть–восемь часов в несколько потоков. Благодаря этому максимальная производительность нашего даунсемплинга – 170 миллионов суточных сегментов в сутки.
Чтение данных
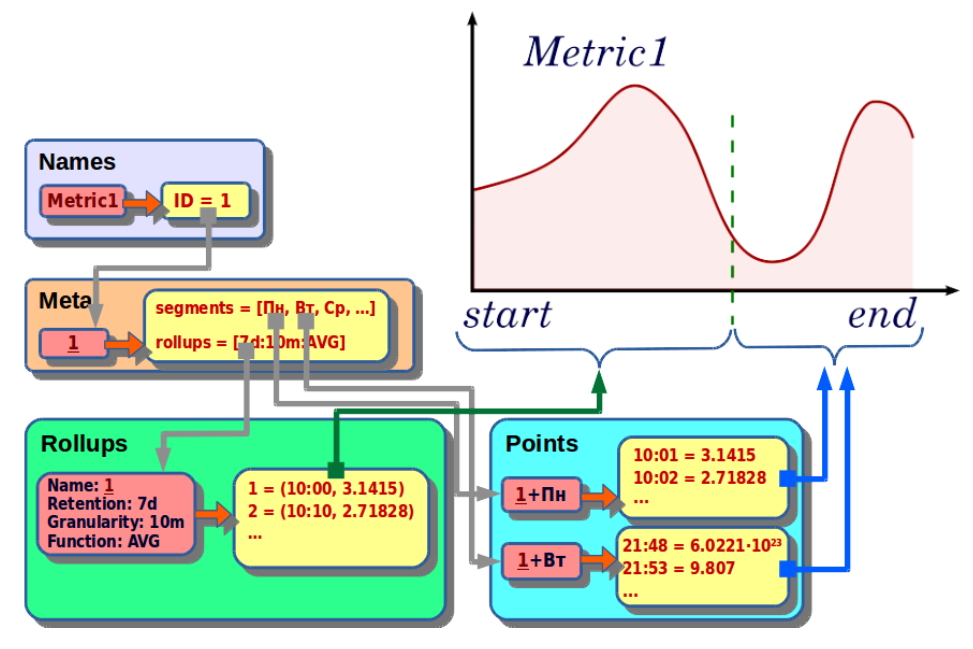
Запрос на чтение содержит следующие параметры:
- metric_name – имя метрики;
- start – начало запрашиваемого интервала;
- end – конец запрашиваемого интервала;
- func – агрегирующая функция;
- step – шаг детализации.
Выполняется такой запрос по следующему алгоритму:
- По имени метрики находим идентификатор.
- По идентификатору получаем метаинформацию о метрике: список сегментов, список архивов и максимальное время архивов.
- Выбираем подходящий архив таким образом, чтобы он соответствовал агрегирующей функции, покрывал запрашиваемый интервал времени и имел подходящую детализацию.
- Выбираем сегменты, входящие в искомый интервал.
- Архивы и «сырые» данные объединяем и ресемплим с нужным нам шагом детализации.
- На выходе получаем набор значений метрики от start до end с шагом step.
REST API
Чтобы иметь возможность писать в наше хранилище не только из PHP, мы реализовали доступ к нему через REST API. И реализовали его, конечно, на любимом нами nginx и PHP.
Важным моментом является использование кэша, куда мы сохраняем идентификаторы метрик по их именам. Нам нужен быстрый кэш, откуда мы планируем читать более 200 тысяч раз в секунду. Мы используем APCu cache.
Чтобы REST API не стал «бутылочным горлышком», мы сделали его распределённым. А чтобы повысить hit rate и сделать использование кэша метрик эффективным, мы закрепляем метрику за конкретным сервером по ее хешу.
Для клиента все узлы одинаковые, и ему необязательно знать о привязке метрики к серверу. Как в этом случае обрабатываются запросы? Давайте рассмотрим на примере пяти узлов.
Клиент выбирает один из пяти узлов кластера REST API случайным образом. Допустим, на узел №3 приходит пакетный запрос на запись 100 метрик. На сервере эти 100 метрик группируются в пять подзапросов. Так что в каждой группе оказывается приблизительно по 20 метрик, закреплённых за одним сервером. Впоследствии эти подзапросы отправляются на соответствующие им соседние узлы.
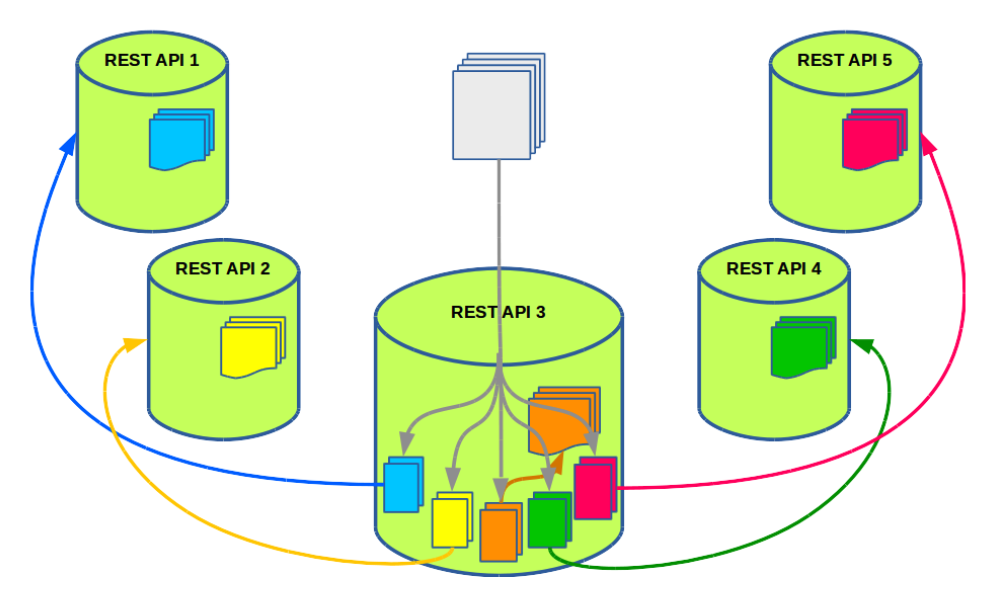
В такой схеме, когда метрика должна обрабатываться только на конкретном узле, мы получаем проблему в случае падения узла. То есть нам недостаточно иметь отказоустойчивое хранилище – нам нужен отказоустойчивый кластер REST API-узлов.

В нашем случае это не представляет труда. Мы реализовали простой failover.
Представим, что нода №4 оказывается недоступной. В этом случае один из подзапросов остаётся необработанным. А нам нельзя останавливать обработку и ждать, пока узел №4 поднимется.
Решение очевидно: мы незаметно для клиента повторяем процедуру с группировкой метрик, но теперь только для одного необработанного подзапроса, и распределяем подзапросы только между живыми узлами.
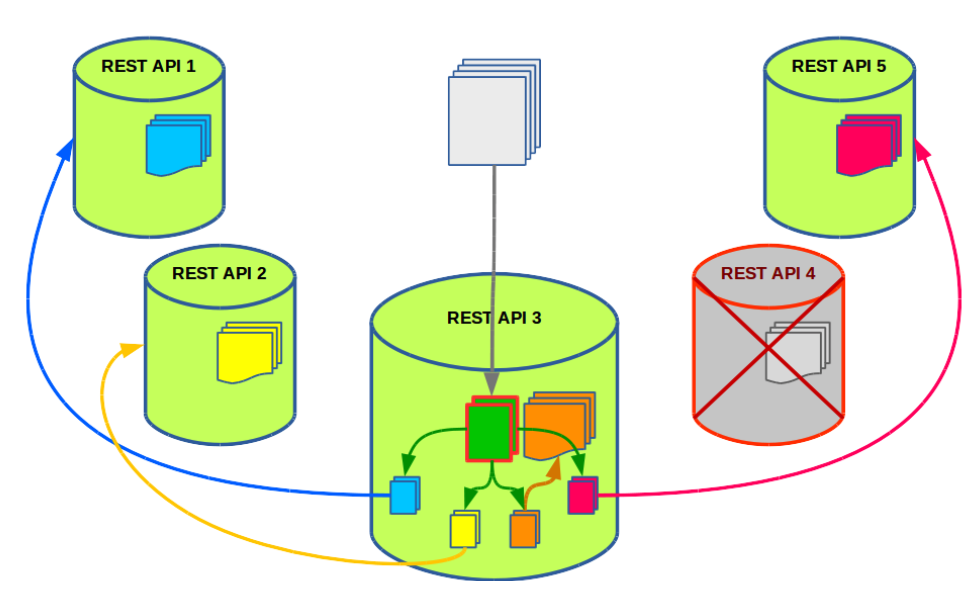
Данные о родных метриках кэшируются узлами на сутки, а данные о чужих – только на один час. Таким образом, падение одной ноды не особенно сказывается на hit rate: большинство метрик по-прежнему обслуживаются своими узлами, а чужие метрики не занимают кэш надолго.
Каких результатов нам удалось добиться
К настоящему моменту мы перенесли часть данных в новое хранилище. Это метрики того самого приложения, датасет которого не помещался на одном сервере и для которого мы сделали импровизированный кластер из шести серверов.
Вот что у нас в итоге получилось:
- новый кластер состоит из девяти серверов;
- в данный момент там хранится 180 миллионов метрик;
- максимальная пропускная способность на запись – 250 тысяч в секунду;
- максимальная скорость даунсемплинга –170 миллионов сегментов в сутки;
- для самих временных рядов мы используем фактор репликации, равный двум;
- объём данных – приблизительно 9 Тб;
- REST API-кластер у нас размещается на тех же серверах, что и кластер Cassandra.
Сравнивая новое хранилище с нашим RRD-кластером, стоит отдельно упомянуть о таком показателе, как средний размер метрики. Формально при прочих равных условиях средний размер метрики в Cassandra на 30% меньше, чем в RRD-хранилище. Но используемые для хранения в Cassandra LSM-деревья требуют резервирования свободного места на диске под временные файлы (для процесса, называемого compaction).
В нашем случае приходится резервировать около 60% от размера датасета. В итоге средний размер метрики с учётом этого получился на 20% больше, чем в старом хранилище. Это можно рассматривать как цену за производительность и отказоустойчивость.
Подводя итоги, можно сказать, что наше новое решение для хранения временных рядов предоставляет нам отказоустойчивость и масштабируемость, превосходя при этом старое хранилище по производительности. И главное – пусть с некоторыми оговорками, но мы достигли практически всех целей, которые ставили перед собой.
К сожалению, в рамках одной статьи невозможно рассмотреть все вопросы реализации. Так, мы не затронули такие вопросы, как уровни консистентности при чтении и записи; как мы обходимся без транзакций, полноценная поддержка которых в Cassandra отсутствует; как мы используем материализованные представления; какие оптимизации мы планируем сделать; и многие другие. Возможно, этому будет посвящён один из наших следующих постов.
Комментарии (32)
ik62
22.03.2017 13:59+1Добрый день!
Вы не упомянули или я пропустил
1) вы используете TTL для записи метрик и TWCS? Или как вы чистите устаревшие данные?
2) Как происходит аггрегация в следующий роллап — вычитываете все данные в нужном диапазоне и аггрегируете? Как организован и распараллелен этот процесс?
Заранее спасибо за ответы. Может еще возникнут вопросы.
che
22.03.2017 14:40+5TTL решили не использовать что бы избежать ситуации когда данные удалились по TTL, но по какой-то причине не переложились в rollups. Сейчас же мы можем приостанавливать даунсемплинг (на время обслуживания, например, поскольку дайнсемплинг работает с CL=ALL) не опасаясь потери сырых данных. Можем увеличивать временное окно в котором данные хранятся сырыми. В общем, процесс под контролем.
А раз не используем TTL то и TWCS отпадает как не эффетивный при явно удаляемых данных.
Данные в points у нас удаляются целыми сегментами (партициями) при перекладывании в rollups в агрегированном виде. А в rollups как таковой нет операции удаления, есть перезапись.
Предвосхищая следующие вопросы:
— мы используем LCS для индекса имен и STCS для всех остальных данных.
— да, для points мы имеем лаг между удалением данных и реальным пуржингом с диска: ~ 1.5 недели
— для rollups трудно точно оценить какую часть данных составляют устаревшие версии переписанных значений (по грубой оценке это 30-40% от всего объема rollups), но мы следим за «средним размером метрики» и она нас устраивает.
Использование TTL возможно и имело бы смысл, но при этом всплывут новые проблемы которые потребуют решения.
В общем, мы пока не получили негативный опыт с нашей моделью данных что бы реально задумываться над использованием TTL.

Grigor60
22.03.2017 15:16+1А вы расматривали kairosDB, есди да? то почему не подошел.
Мyе кажеться что проект имплеметирует именно вашу задачу.che
22.03.2017 15:17+4Больше года назад, когда мы рассматривали готовые решения, мы смотрели и на KairosDB. Некоторые наши претензии к OpenTSDB относились и к KairosDB. Но самое главное, KairosDB как минимум не соответствовал требованию «долговечность» — т.е. терял данные из буфера в памяти, когда не мог сбросить его в Cassandra. Кстати, разработчики, как я сейчас вижу, уже исправили эту проблему пару месяцев назад.

tru_pablo
22.03.2017 18:10-4Опять вы везде путаетесь в числах.
Вы в декабре говорили
девять серверов;
10 Тб данных;
100 000 значений в секунду;
140 миллионов метрик.
А теперь в одном месте
300 миллионов метрик
200 000 значений в секунду.
16 Тб на 24 серверах
и тут же рядом
180 миллионов метрик;
объём данных – приблизительно 9 Тб;
Как-то уж определитеськакой у вас большойчем хвастаетесь.
Оставшиеся 15 серверов и 120млн метрик где? На старом кластере в rrd?che
22.03.2017 18:47+4Rrd: 100к/сек, 15 серверов, 120кк метрик
Cassandra: 100к/сек, 9 серверов, 180кк метрик.
Вернее уже 190 миллионов в Cassandra
Оставшиеся 15 серверов и 120млн метрик где? На старом кластере в rrd?
— совершенно верно
alogicman
22.03.2017 21:43+2элементы каждого такого ассоциативного массива хранятся на диске по возможности последовательно
почему «по возможности»? И в sstable, и в memtable данные лежат упорядоченно по колонкам.
А как обрабатываете ситуацию, когда данные записались только в часть таблиц, например, в Points данные записались, а при записи в Meta допустим сервис помер…che
22.03.2017 21:43+2почему «по возможности»? И в sstable, и в memtable данные лежат упорядоченно по колонкам.
Потому что в случае нескольких sstable часть партиции может оказаться в одном файле, а часть в другом.
che
22.03.2017 21:45+3А как обрабатываете ситуацию, когда данные записались только в часть таблиц, например, в Points данные записались, а при записи в Meta допустим сервис помер…
Конкретно в этом сценарии: допустим клиент отправляет одно значение. Мы сперва делаем вставку в meta — запись о том что у нас появился новый сегмент у метрики, потом запись в points. Если сервис упал перед вставкой в points, мы имеем только запись о том что у метрики есть сегмент но он пустой.
Дальше все зависит от клиентского приложения — как он обрабатывает ошибку при отправке в удаленный сервис, ведь ответ об успешной вставке он не получил. В нашем случае мы делаем несколько попыток отправить данные снова. Если лимит попыток исчерпан, то данные остаются в локальном журнале приложения. Для таких случаев у нас есть скрипт который периодически делает replay по таким журналам.
В случае, если по каким-то причинам приложение забивает на ошибку, и не продолжает обновлять метрику, эта метрика остается с пустым сегментом. В нашей модели данных это валидная ситуация, которая не приводит к ошибкам при чтении.
Для метрик, которые давно не обновлялись у нас есть скрипт который периодически сканирует все записи в таблице meta и «подчищает мусор»:
— Во-первых, удаляет все записи из всех таблиц для устаревшей метрики. При этом из таблицы meta данные удаляются в последнюю очередь, так что при падении этого скрипта он в следующий раз все равно дойдет до этой записи и завершит свое дело.
— Во-вторых, проверяются сегменты которые должны были быть давно задаунсеплены, и, в случае пустых сегментов они просто удаляются.

Wolverine
23.03.2017 00:08+2InfluxDB
Это решение казалось идеальным. Не хватало только одного, самого важного, пункта – оно не масштабировалось «из коробки». Впрочем, его open-source-версия не масштабируется и сейчас: авторы работали над кластеризацией больше года и в итоге решили закрыть этот функционал. А жаль, мы очень рассчитывали…
Функционал перенесли в платную Enteprise версию, там есть кластеризация.
Как вариант еще можно нарезать single-instance и балансировать запись в зависимости в зависимости от метрик (метрики Х пишем в этот инстанс, метрики У в другой), а сам интсанс резервировать через Influx Relay, но это конечно не так красиво, как кластеризация из коробки.
alexkrash
23.03.2017 12:39+4Такой вариант уже существовал в виде rrd-кластера (за вычетом резервирования), и менять шило на мыло выглядит не вполне целесообразно.
darkmind
23.03.2017 20:07+1В сторону kairosdb не смотрели? Это как раз time-series сервис хранящий данные в Кассандре. По сути это дб схема + апи.
che
23.03.2017 20:08+1В сторону KairosDB смотрели. Я описывал в комментарии выше. Тогда она работала не стабильно. Могла потерять данные, в случае потери коннекта к Cassandra, причем без оповещения клиента. Более подробно мы ее не изучали, так что, подходит ли она нам — это открытый вопрос. В частности, по производительности даунсемплинга. Это надо бы протестировать. Например, в нашей реализации мы не сразу добились приемлемой скорости архивирования.
Civil
24.03.2017 09:17+2Справедливости ради, вы сделали некорректную оценку Graphite'а. Конкретнее:
1. У него изначально во всех доступных реализациях есть перезапись точек в прошлом (у вас стоит галочка что нету).
2. У него множество совместимых реализаций с немного отличающимися характеристиками, вы видимо посмотрели бегло на то что в гитхабе graphite-project, без попыток найти решения проблем. Например есть альтернативная реализация демона, осуществляющего запись — go-carbon, которая на одном среднем сервере не напрягаясь выдает 350 тысяч точек в секунду на запись. Кстати проект существует несколько лет уже.
3. Опять же альтернативные реализации стека реализуют и HA и позволяют масштабироваться (см carbonzipper). Проект в OpenSource'е и активно развивается года так с 2013-2014.
В целом интересно не только, сколько вы смогли записать, но и как вы читаете? Я имею в виду какого характера запросы, как много метрик и точек вы выбираете и т.п.che
24.03.2017 15:31+11. У него изначально во всех доступных реализациях есть перезапись точек в прошлом (у вас стоит галочка что нету).
Так действительно заявляют авторы Graphite. Я если честно, засомневался в этом, зная что в whisper-формате хранятся только агрегированные данные. И действительно, когда приходит запрос на запись уже существующей точки, то переписывается вся ячейка архива.
Представьте, что у нас какой-то результат измерения дошел до хранилища с запозданием, когда значение ячейки, в которую он попадает, уже сформировано как AVG от других измерений.
Хорошо, если перезаписываемое значение попадет в самый детальный архив, с минутными ячейками, например. Мы можем даже не заметить каких то искажений в данных, а если «уйти» далеко в прошлое, то мы перезапишем, скажем, часовую ячейку полностью. Т.е. мы потеряем часть данных, а именно вклад всех предыдущих значений, которые составили результирующее значение часовой ячейки.
Так что, как перезапись — это действительно сработает. Но пользы от этого нет: что бы корректно это использовать надо где-то (где?) хранить еще и все сырые данные из которых при необходимости мы будем вычислять новый агрегат.
Я бы сказал что это не то что нам хотелось, а именно, «дописывать данные задним числом», как и сказано в статье.
2. У него множество совместимых реализаций с немного отличающимися характеристиками, вы видимо посмотрели бегло на то что в гитхабе graphite-project, без попыток найти решения проблем. Например есть альтернативная реализация демона, осуществляющего запись — go-carbon, которая на одном среднем сервере не напрягаясь выдает 350 тысяч точек в секунду на запись. Кстати проект существует несколько лет уже.
Вы правы, мы не рассматривали все альтернативные реализации. Основная причина почему мы восприняли graphite без энтузиазма — это проблема в его протоколе: вы отправляете данные в сокет и у вас нет информации обработаны ли они как вы ожидали или пропали по какой-то причине. Эту же проблему, судя по всему, унаследовал и go-carbon.
Признаю, 350к в секунду (или 21 миллионов в минуту) на одном севере — выглядит очень интересно! Но возникают вопросы:
Обновляется 350к разных метрик? Или это интенсивное обновление нескольких метрик? Интересно сколько обновляется уникальных метрик, скажем, за 10 минут?
Держит ли go-carbon такую скорость постоянно в течении длительного времени или это пиковая скорость пока данные копятся в кэше?
На сколько мне известно whisper-формат очень похож на формат rrdtool. Т.е. это тоже огромное число файлов и как следствие большое число рандомных IOPs. Вы не могли бы рассказать подробнее за счет чего достигается такая высокая скорость записи в go-carbon?
Обычный carbon на питоне выдал мне 20к в секунду и уперся в CPU (на настольном компьютере). Если бы на настольном комьютере были HDD вместо SSD, я, уверен, в первую очередь узким местом были бы диски. С go-carbon CPU по-идее используется на порядок эффективнее, но проблему с IO он вряд ли решает.
3. Опять же альтернативные реализации стека реализуют и HA и позволяют масштабироваться (см carbonzipper). Проект в OpenSource'е и активно развивается года так с 2013-2014.
Вообще, когда мы рассматривали вариант с развитием распределенного rrdtool-кластера, у нас вырисовывалось что то похожее по архитектуре на graphite. Но, как я говорил, от родовых проблем rrdtool это не избавляло. А проблемы частично похожие на проблемы graphite. Интересно, как авторы carbonzipper решают некоторые из них.
Например, как я понял, carbonzipper позволяет на лету объединять результат одной метрики с разных серверов, где лежат ее реплики. Как решаются конфликты при объединении разных значений одной и той же ячейки?
Автоматизирован ли процесс синхронизации данных между репликами, что бы в итоге привести их к одному виду, что бы можно было безболезненно вывести ноду из кластера, и быть уверенным что все ее данные уже хранятся на соседней ноде? По моему мнению, формат whisper не подходит для таких задач.Civil
24.03.2017 16:36+1Так что, как перезапись — это действительно сработает. Но пользы от этого нет: что бы корректно это использовать надо где-то (где?) хранить еще и все сырые данные из которых при необходимости мы будем вычислять новый агрегат.
Да, такая проблема есть если у вас есть тенденция переписывать очень старые данные. В случаи с графитом стараются все таки иметь детальный архив размеров от 1 дня, отчасти чтобы позволить данным приходить с некоторой разумной задержкой. Я честно говоря слабо представляю себе use-case когда данные приходят с задержкой на 2-3 дня.
Обновляется 350к разных метрик? Или это интенсивное обновление нескольких метрик? Интересно сколько обновляется уникальных метрик, скажем, за 10 минут?
go-carbon естественно имеет некоторый in-memory кэш, в котором для каждой метрики копятся данные (с целью в том числе снизить рандомность записи). То есть в таком тесте это некоторое разумное количество записей в файл в секунду (мы у себя ограничиваем например 30к, что примерно соответствует 25% загрузке дисков наших). В целом 350к точек в секунду может быть и 350к разных метрик и это стабильная скорость при наличии достаточного количества памяти чтобы иметь кэш (я бы сказал 350к при наличии средненьких ССДшек можно получить при 16-32ГБ оперативной памяти под кэш, вероятно даже меньше). Естественно в жертву приносится некоторая надежность данных в случаи смерти железки (все что в кэше, но не на диске будет потеряно). Ноиз плюсов — при 128-256ГБ оперативной памяти оно может довольно спокойно жить на чем-то типа SAN на обычных дисках.
В случаи чтения, данные выбираются как с диска, так и из кэша.
Например, как я понял, carbonzipper позволяет на лету объединять результат одной метрики с разных серверов, где лежат ее реплики. Как решаются конфликты при объединении разных значений одной и той же ячейки?
На текущий момент считается что первая вернувшаяся и есть правильная.
Процесс «лечения» данных идет в фоне фактически набором скриптов — периодически процесс пробегает и сравнивает файлы.
Для миграции можно использовать buckytools, там проблема переноса данных на новую ноду довольно неплохо решена.
che
24.03.2017 16:13+1В целом интересно не только, сколько вы смогли записать, но и как вы читаете? Я имею в виду какого характера запросы, как много метрик и точек вы выбираете и т.п.
Это хороший вопрос! Вернее здесь два вопроса: 1. Какая производительность чтения? и 2. Как мы пользуемся этими данными?
Я начну с последнего вопроса:
У нас есть аномали-детекшн для нескольких тысяч метрик. Причем написанный еще для старого хранилища. Остальные данные мы отображаем в виде графиков. Причем практически все метрики тщательно классифицированы и сгруппированы так что добраться до любой из них можно за несколько кликов. Процесс примерно такой: в случае проблемы срабатывает аномали-детекшн и дальше проблема диагностируется визуальным изучением метрик из проблемной области.
Что касается производительности чтения. При попытке выбрать какую то показательную метрику для измерения скорости чтения всплывает много нюансов от которых зависит результат:
— на сколько много у нас читателей и как интенсивно они читают;
— на сколько часто мы перечитываем одни и те же метрики;
— включают ли запрашиваемые периоды роллапы или состоят только из сырых данных;
— вычитываем ли мы последовательно (для даунсемплинга) или рандомно, и т.д.
Если пропускная способность на запись у нас измерилась естественным образом на реальной нагрузке, то с чтением так не получилось. Реальная нагрузка на чтение — это периодические загрузки дашбордов с графиками. Дашборды разные, в которых задействованы 10 метрик, в некоторых до 5 тысяч. Иногда требуются данные за пол года, но чаще за последние сутки. Так что показателем эффективности для нас является время, которое пользователь проводит в ожидании загрузки.
Проводить специальные объективные эксперименты мы не стали. Для себя мы удовлетворились простым тестом: загрузка дашборда с 100 метриками из старого хранилища и из нового. Получили 700 миллисекунд против 400. При этом, в это значение входит и логика по генерации дашборда. Если приблизительно убрать этот вклад, то получится 600 vs 300, т.е. в два раза лучше чем rrd. Если измерять в точках в секунду, то получается ~ 480000 точек в секунду.
Но, повторюсь, этот показатель полученный на коленке и не учитывающий многие факторы.Civil
24.03.2017 19:02Интересно, спасибо.
Еще хотелось бы уточнить про характер нагрузки. Насколько принято у вас держать dashboard'ы постоянно открытыми с автообновлением, например? Или мониторы в офисе и т.п.
То есть насколько сильный постоянная составляющая для запросов, а насколько часто приходят живые люди с их задачами?
Еще не сравнивали ли вы как меняется скорость запросов в случаи вашей базы и rrd в зависимости от разных time frame'ов и количества метрик и от количества одновременных пользователей? Например довольно частая проблема систем что у них разная зависимость времени выполнения работы от этих параметров. На 1 запросе по 100 метрик может победить одна система, а на 50 запросах в секунду по 1000 метрик в среднем — уже другая (а та которая победила в первом случаи вообще сложиться и откинуть копыта).Civil
24.03.2017 19:22О, прошу прощения что еще отдельным комментарием, но интересно еще примерно какое железо вы использовали под backend/frontend.
che
27.03.2017 17:04Сейчас у нас уже 2 кластера.
Первый, как я говорил, состоит из 9 серверов.
Диски:
— Под систему и commitlog HDD
— Под данные JBOD 4 x HDD
ОЗУ: 128гб. Большая часть используется под Page Cache.
CPU: Intel Xeon. По 32 логическиз ядра на ноду
Второй, новый кластер, на который мы переводим оставшиеся метрики, состоит из 5 серверов:
Диски:
— Под систему и commitlog HDD
— Под данные JBOD 5xSSD
ОЗУ: 64гб
CPU: Intel Xeon. По 24 логическиз ядра на ноду
REST API как я говорил работает на тех же серверах.
che
27.03.2017 17:03К сожалению, я не смогу дать вам детальное описание паттерна чтения. Мы пытались «в лоб» собирать такую статистику, но она слишком «прыгала» и была не показательной. Хотя, если уделить этой задаче должное внимание, мы бы конечно вывели какую-то показательную метрику, для оценки производительности. Можно, например попробовать анализировать, количество прочитанных точек в час.
В данный момент, мы исходим из того что чтения на несколько порядков меньше чем записи, акцентируя таким образом внимание на производительность записи.
Открытые дашборды с авто обновлением — у нас привычная практика, но какая это доля от живых обращений никто не считал, как и зависимость лэтенси от нагрузки.Civil
28.03.2017 13:27Хорошо, спасибо.
Жаль конечно что не изучали детально чтение.
И наверное последний вопрос который пришел в голову — а вы считали сколько у вас байт занимает 1 точка сейчас и сколько было раньше? Тоже интересный показатель как по мне.
xhumanoid
27.03.2017 13:00пару замечаний:
1) HBase — Есть мастер нода – SPOF. мастеров в кластере несколько, выбираются кворумом, выпадение даже текущего не влияет на работу кластера (сам делал rolling restart всего кластера под нагрузкой, вышестоящие приложения лишь замечали небольшой скачек latency, драйвер сам детектил поведение и повторял запрос в новую ноду)
2) Druid — Долгове?чность — немного не понял, так как:
а) данные поступают в систему из kafka, пока блок не окажется в deepstorage то offset в kafka не комитится, данные всегда в очереди доступны
б) так как данные по большему immutable (сегменты полностью immutable, метаданные в реляционке лежат), то гарантии сохранности лежат или на deepstorage (это s3/hdfs зачастую) или как у вас резервирования sql базы сделано.
если я что-то неправильно понял, то уточнитеche
27.03.2017 19:19Я не в коей мере не принижаю достоинств HBase. Возможно вы пропустили это при чтении, но я написал примерно то же что и вы:
В отличие от HBase, в Cassandra нет мастер-ноды и, соответственно, не требуется её дублирование для обеспечения высокой отказоустойчивости
а) данные поступают в систему из kafka, пока блок не окажется в deepstorage то offset в kafka не комитится, данные всегда в очереди доступны
б) так как данные по большему immutable (сегменты полностью immutable, метаданные в реляционке лежат), то гарантии сохранности лежат или на deepstorage (это s3/hdfs зачастую) или как у вас резервирования sql базы сделано.
Но в самом Druid нет (или не было на тот момент?) встроенного механизма позволяющего избежать потери данных при падении реалтайм ноды до того как сегмент сохранился в дип сторадж. Таким образом это должно решаться на уровне приложения, использующего Druid. В частности, при помощи kafka.xhumanoid
27.03.2017 21:14ну дублирование не совсем корректное название, особенно что она очень легковесная, но хорошо.
по поводу друида: вы данные в него предполагали напрямую заливать?
просто везде где сталкивался с метриками мы гнали их через очередь, мало ли как индексатор себя поведет
независимо это cassandra/hbase/druid



eigrad
30.03.2017 02:13+1> Elasticsearch
> И ещё мы столкнулись со странной особенностью: чем больше шардов в индексе, тем медленнее он работает на запись (хотя здравый смысл подсказывает, что должно быть наоборот).
Есть такое. Лечится группировкой данных в bulk запросах по шардам. То есть в одном bulk запросе все документы должны отправляться в один шард. Этого поидее должно быть достаточно, чтобы избавиться от горлышка на синхронизации запросов в шардах. Но в идеале — смотрим в исходниках elasticsearch алгоритм вычисления номера шарда по routing (https://gist.github.com/ei-grad/c6794b151f6df49b6b6d94befff877e6), получаем через allocation explain API на какой ноде сейчас находится primary-реплика этого шарда, и шлём этот bulk запрос напрямую в неё, а не через Client-ноду (и уж тем более не через произвольную data-ноду).
У меня при такой схеме количество шардов влияет на скорость индексации линейно (на самом деле нет, я просто стал в питонячий клиент упираться на подготовке данных :(, увеличивать число шардов дальше не хочется, и так уже по 10 шардов на 4-ядерную ноду с учетом реплик, а текущих 100к записей в секунду, до которых успевает разогнаться импорт на получасовых батчах вполне хватает).
sergeypid
Вы как-то специально говорите Кассандре, что нужно последовательно сканировать таблицу, или это автоматически получается?
che
Да, это специальный тип запросов. Внешне в CQL он почти не отличается о обычных, кроме того что в WHERE секции используется функция token(), которая возвращает хэш от ключа, по которому (по хешу) в реальности и упорядочены данные на диске:
SELECT * FROM Table WHERE token(pk) >= :start_token limit 10
SELECT * FROM Table WHERE token(pk) > token('prev_value_pk') limit 10
Это так же дает возможность разбить все данные таблицы на относительно равные сегменты выбрав правильный start_token и end_token из всего возможного диапазона токенов и вычитывать данные параллельно.