
Реляционные БД хранят структурированные данные, которые обычно представляют объекты реального мира. Скажем, это могут быть сведения о человеке, или о содержимом корзины для товаров в магазине, сгруппированные в таблицах, формат которых задан на этапе проектирования хранилища.
Нереляционные БД устроены иначе. Например, документо-ориентированные базы хранят информацию в виде иерархических структур данных. Речь может идти об объектах с произвольным набором атрибутов. То, что в реляционной БД будет разбито на несколько взаимосвязанных таблиц, в нереляционной может храниться в виде целостной сущности.
Внутреннее устройство различных систем управления базами данных влияет на особенности работы с ними. Например, нереляционные базы лучше поддаются масштабированию.

Какую технологию выбрать? Ответ на этот вопрос зависит от особенностей проекта, о котором идёт речь.
О выборе SQL-баз данных
Не существует баз данных, которые подойдут абсолютно всем. Именно поэтому многие компании используют и реляционные, и нереляционные БД для решения различных задач. Хотя NoSQL-базы стали популярными благодаря быстродействию и хорошей масштабируемости, в некоторых ситуациях предпочтительными могут оказаться структурированные SQL-хранилища. Вот две причины, которые могут послужить поводом для выбора SQL-базы:
- Необходимость соответствия базы данных требованиям ACID (Atomicity, Consistency, Isolation, Durability — атомарность, непротиворечивость, изолированность, долговечность). Это позволяет уменьшить вероятность неожиданного поведения системы и обеспечить целостность базы данных. Достигается подобное путём жёсткого определения того, как именно транзакции взаимодействуют с базой данных. Это отличается от подхода, используемого в NoSQL-базах, которые ставят во главу угла гибкость и скорость, а не 100% целостность данных.
- Данные, с которыми вы работаете, структурированы, при этом структура не подвержена частым изменением. Если ваша организация не находится в стадии экспоненциального роста, вероятно, не найдётся убедительных причин использовать БД, которая позволяет достаточно вольно обращаться с типами данных и нацелена на обработку огромных объёмов информации.
О выборе NoSQL-баз данных
Если есть подозрения, что база данных может стать узким местом некоего проекта, основанного на работе с большими объёмами информации, стоит посмотреть в сторону NoSQL-баз, которые позволяют то, чего не умеют реляционные БД.
Вот возможности, которые стали причиной популярности таких NoSQL баз данных, как MongoDB, CouchDB, Cassandra, HBase:
- Хранение больших объёмов неструктурированной информации. База данных NoSQL не накладывает ограничений на типы хранимых данных. Более того, при необходимости в процессе работы можно добавлять новые типы данных.
- Использование облачных вычислений и хранилищ. Облачные хранилища — отличное решение, но они требуют, чтобы данные можно было легко распределить между несколькими серверами для обеспечения масштабирования. Использование, для тестирования и разработки, локального оборудования, а затем перенос системы в облако, где она и работает — это именно то, для чего созданы NoSQL базы данных.
- Быстрая разработка. Если вы разрабатываете систему, используя agile-методы, применение реляционной БД способно замедлить работу. NoSQL базы данных не нуждаются в том же объёме подготовительных действий, которые обычно нужны для реляционных баз.
В следующем разделе рассмотрим некоторые различия между технологиями SQL и NoSQL. А именно, сначала взглянем на простой пример, показывающий фундаментальное различие двух подходов к организации баз данных, потом поговорим о масштабируемости и индексации данных. А в итоге остановимся на примере большой CRM-системы, нуждающейся в высокой производительности хранилища данных.
SQL и NoSQL
Начнём с некоторых ключевых концепций реляционных и нереляционных баз данных. Ниже показана база данных, содержащая сведения о взаимоотношениях людей. Вариант a — это бессхемная структура, построенная в виде графа, характерная для NoSQL-решений. Вариант b показывает, как те же данные можно представить в структурированном виде, типичном для SQL.
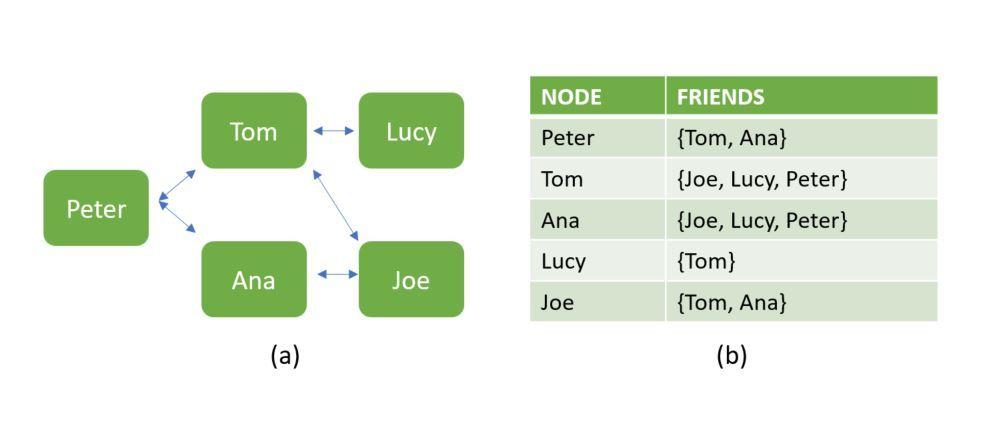
Два варианта представления данных
Бессхемность означает, что два документа в структуре данных NoSQL не должны иметь одинаковые поля и могут хранить данные разных типов. Вот, например, массив объектов, набор полей которых не совпадает.
var cars = [
{ Model: "BMW", Color: "Red", Manufactured: 2016 },
{ Model: "Mercedes", Type: "Coupe", Color: "Black", Manufactured: "1-1-2017" }
];При реляционном подходе данные надо хранить в заранее спроектированной структуре, из которой эти данные потом можно извлекать. Например, используя оператор
JOINпри выборке из двух таблиц:SELECT Orders.OrderID, Customers.Name, Orders.Date
FROM Orders
INNER JOIN Customers
ON Orders.CustID = Customers.CustIDКак более продвинутый пример, для демонстрации того, когда SQL предпочтительнее NoSQL, рассмотрим особенности применения в NoSQL-базах алгоритмов уплотнения. Проблема заключается в том, что в некоторых NoSQL-базах (например, в CouchDB и HBase) постоянно приходится формировать так называемые
sstables — строковые таблицы в формате ключ-значение, отсортированные по ключу. В такие таблицы, которые сохраняются на диск, данные попадают из таблиц, хранящихся в памяти, при их переполнении и в других ситуациях. При интенсивной работе с базой создание таблиц, со временем, приводит к тому, что подсистема ввода-вывода устройства хранения данных становится узким местом для операций чтения данных. Как результат, чтение в NoSQL-базе происходит медленнее, чем запись, что сводит на нет одно из главных преимуществ нереляционных баз данных. Именно для того, чтобы уменьшить этот эффект, системы NoSQL используют, в фоновом режиме, алгоритмы уплотнения данных, пытаясь объединить множество таблиц в одну. Но и сама по себе эта операция весьма ресурсоёмка, система работает под повышенной нагрузкой.Масштабируемость
Одно из основных различий рассматриваемых технологий заключается в том, что NoSQL-базы лучше поддаются масштабированию. Например, в MongoDB имеется встроенная поддержка репликации и шардинга (горизонтального разделения данных) для обеспечения масштабируемости. Хотя масштабирование поддерживается и в SQL-базах, это требует гораздо больших затрат человеческих и аппаратных ресурсов.
| Тип хранилища данных |
Сценарий использования |
Пример |
Рекомендации |
| Хранилище типа ключ-значение |
Подходит для простых приложений, с одним типом объектов, в ситуациях, когда поиск объектов выполняют лишь по одному атрибуту. |
Интерактивное обновление домашней страницы пользователя в Facebook. |
Рекомендовано знакомство с технологией memcached. Если приходится искать объекты по нескольким атрибутам, рассмотрите вариант перехода к хранилищу, ориентированному на документы. |
| Хранилище, ориентированное на документы |
Подходит для хранения объектов различных типов. |
Транспортное приложение, оперирующее данными о водителях и автомобилях, работая с которым надо искать объекты по разным полям, например — имя или дата рождения водителя, номер прав, транспортное средство, которым он владеет. |
Подходит для приложений, в ходе работы с которыми допускается реализация принципа «согласованность в конечном счёте» с ограниченными атомарностью и изоляцией. Рекомендуется применять механизм кворумного чтения для обеспечения своевременной атомарной непротиворечивости. |
| Система хранения данных с расширяемыми записями |
Более высокая пропускная способность и лучшие возможности параллельной обработки данных ценой слегка более высокой сложности, нежели у хранилищ, ориентированных на документы. |
Приложения, похожие на eBay. Вертикальное и горизонтальное разделение данных для хранения информации клиентов. |
Для упрощения разделения данных используются HBase или Hypertable. |
| Масштабируемая RDBMS |
Использование семантики ACID освобождает программистов от необходимости работать на достаточно низком уровне, а именно, отвечать за блокировки и непротиворечивость данных, обрабатывать устаревшие данные, коллизии. |
Приложения, которым не требуются обновления или слияния данных, охватывающие множество узлов. |
Стоит обратить внимание на такие системы, как MySQL Cluster, VoltDB, Clustrix, ориентированные на улучшенное масштабирование. |
Более подробное сравнение SQL и NoSQL можно найти в этом материале. Вот его основные положения. А именно, были проведены испытания трёх основных характеристик систем: параллельная обработка данных, работа с хранилищами информации, репликация данных. Возможности параллельной обработки оценивались путём анализа механизмов блокировки, управления параллельным доступом на основе многоверсионности, и ACID. Тестирование хранилищ охватывало и физические носители, и хранилища использующие оперативную память. Репликацию испытывали в синхронном и асинхронном режимах.
Используя данные, полученные в ходе испытаний, авторы делают выводы о том, что SQL-базы с возможностью кластеризации показали многообещающие результаты производительности в расчёте на один узел, и, кроме того, обладают способностью масштабируемости, что даёт системам RDBMS преимущество перед NoSQL за счёт полного соответствия принципам ACID.
Индексация
В системах RDBMS индексация используется для ускорения операций извлечения данных из баз. Отсутствие индекса означает, что таблица должна быть просмотрена целиком для того, чтобы выполнить запрос на чтение.
И в SQL, и в NoSQL-базах индексы служат одной и той же цели — ускорить и оптимизировать извлечение данных. Но то, как именно они работают — различается из-за разных архитектур баз данных и особенностей хранения информации в базе. В то время, как SQL-индексы представлены в виде B-деревьев, которые отражают иерархическую структуру реляционных данных, в NoSQL базах данных они указывают на документы, или на части документов, между которыми, в основном, нет никаких отношений. Вот подробный материал на эту тему.
CRM-системы
CRM-приложения — это один из лучших примеров систем, для которых характерны огромные объёмы ежедневно обрабатываемых данных и очень большое количество транзакций. Все разработчики таких приложений используют и SQL, и NoSQL базы данных. И, хотя большая часть данных транзакций всё ещё хранится в SQL-базах, применение находят общедоступные системы класса DBaaS (data-base-as-a-service, база данных как сервис), наподобие AWS DynamoDB и Azure DocumentDB, в результате, серьёзная нагрузка по обработке данных может быть перенесена в облачные NoSQL-базы.
В то время, как использование подобных служб освобождает разработчика от решения задач по обслуживанию хранилищ, это, кроме того, область, где NoSQL базы применяются для того, для чего они, в основном, и были созданы, например, для глубинного анализа данных. Объёмы информации, хранимой в огромных CRM-системах финансовых и телекоммуникационных компаний, было бы практически невозможно проанализировать, используя инструменты вроде SAS или R. Это потребовало бы огромных аппаратных ресурсов.
Главное преимущество таких систем — использование неструктурированных данных, похожих на документы. Такие данные могут подаваться на вход статистических моделей, которые дают компаниям возможность выполнять различные виды анализа. CRM-приложения, кроме того, являются весьма удачным примером, в котором две системы баз данных выступают не конкурентами, а существуют в гармонии, играя каждая свою роль в большой архитектуре управления данными.
Итоги
Занимаясь поиском системы управления базами данных, можно выбрать одну технологию, а позже, уточнив требования, переключиться на что-то другое. Однако, разумное планирование позволит сэкономить немало времени и средств.
Вот признаки проектов, для которых идеально подойдут SQL-базы:
- Имеются логические требования к данным, которые могут быть определены заранее.
- Очень важна целостность данных.
- Нужна основанная на устоявшихся стандартах, хорошо зарекомендовавшая себя технология, используя которую можно рассчитывать на большой опыт разработчиков и техническую поддержку.
А вот свойства проектов, для которых подойдёт что-то из сферы NoSQL:
- Требования к данным нечёткие, неопределённые, или развивающиеся с развитием проекта.
- Цель проекта может корректироваться со временем, при этом важна возможность немедленного начала разработки.
- Одни из основных требований к базе данных — скорость обработки данных и масштабируемость.
В итоге хочется сказать, что в современном мире нет противостояния между реляционными и нереляционными базами данных. Вместо этого стоит говорить об их совместном использовании для решения задач, на которых та или иная технология показывает себя лучше всего. Кроме того, всё сильнее наблюдается интеграция этих технологий друг в друга. Например, Microsoft, Oracle и Teradata сейчас предлагают некоторые формы интеграции с Hadoop для подключения аналитических инструментов, основанных на SQL, к миру неструктурированных больших данных.
Уважаемые читатели, а вам приходилось выбирать системы управления базами данных для собственных проектов? Если да — поделитесь пожалуйста опытом, расскажите, что и почему вы в итоге выбрали.
Комментарии (23)


ZurgInq
27.03.2017 16:09+1Вопрос поставлен неверно изначально. Как и под итог:
Вот признаки проектов, для которых идеально подойдут SQL-базы:
БД должна выбираться не под проект, а под задачи. Так или иначе, в одном проекте могут использоваться как реляционные БД, так и так называемые NoSQL.
max1gu
27.03.2017 17:27+7Вроде как не маленькая статья, а ни о чем.
При выборе базы данных первый вопрос не что и как хранить, вы на него потом найдете ответ, а что вам надо с данными делать.
Если вам ничего с ними делать не надо, то и хранить их не надо. База данных не нужна.
Если вам надо посмотреть на них справа, потом сверху, потом посчитать вхождение «этого» в «то», средние, промежуточные итоги — то без SQL это очень затруднительно. Как минимум закончится изобретением миниSQL на коленке.
Если вам надо записать много данных, а потом их просто показать, целиком или кусками — то можно пробовать NoSQL. Но как только у вас появятся дополнительные требования к фильтрованию и связям — то вы постепенно начнете смотреть в сторону SQL — там уже есть ответы на многие ваши ещё не заданные вопросы.
Характерно, что сам вопрос о NoSQL встал на повестку дня когда память стала доступна гигабайтами и не надо заморачиваться быстродействием — положил базу в память и все.
Истина посредине. Для хранилища котиков подойдет NoSQL, т.к. зачастую записей будет больше, чем чтения. При этом взаимосвязи авторов котиков будут храниться в SQL, а сам SQL ещё разделится на горячие и холодные данные.
Кроме этого, NoSQL, как и другие не типизированные средства разработки, выполняет социальную функцию — легкий вход в программирование широких масс населения, оставляя вопросы типов и структур данных для тех, кто прошел идиотентест простых ответов на простейшие вопросы.
Иначе нельзя объяснить «преимущество» NoSQL — «отсутствие жесткой структуры данных». Это как же вы с данными работать будете если не знаете что там? По сути, под каждый кейс данных писать парсер и распознавать содержимое.
ZOXEXIVO
27.03.2017 22:30-2Я, скорее, склюняюсь к тому, что ваш комментарий ни о чем.
сам вопрос о NoSQL встал на повестку дня когда память стала доступна гигабайтами
Вы что-то путаете…
взаимосвязи авторов котиков будут храниться в SQL
…
как же вы с данными работать будете если не знаете что там
по вашему, работа с NoSQL базой на уровне приложения это отправка и получение строки?
легкий вход в программирование широких масс населения
все-таки, основной поток это как раз те, кого перестали устраивать текущие решения
VolCh
27.03.2017 22:54Иначе нельзя объяснить «преимущество» NoSQL — «отсутствие жесткой структуры данных». Это как же вы с данными работать будете если не знаете что там?
А зачем хранилищу данных работать с данными? Его дело их получать, хранить и отдавать. Для этого схема не нужна особо, разве что для оптимизаций.
NumLock
27.03.2017 18:29В тытруба есть хорошая лекция о «больших данных».
www.youtube.com/watch?v=SzNr5LXvAv0
Там очень хорошо объясняется для чего и где используется SQL и NoSQL БД.

freeg0r
27.03.2017 18:29| Необходимость соответствия базы данных требованиям ACID (Atomicity, Consistency, Isolation, Durability — атомарность, непротиворечивость, изолированность, долговечность)
Вообще то под Durability в ACID обычно понимается «надежность».
BorisDT
28.03.2017 07:44+1Я к недостаткам SQL в быстро развивающейся системе еще добавил бы непредсказумость нагрузки на сервер БД. Любой разработчик кастомного отчета, веб-сервиса и т.п. начинает писать SQL запросы в меру своего опыта и разумения. Следствие — падение производительности. Как уже отмечено в статье, отмаштабировать это в случае SQL практически невозможно.

erop
28.03.2017 09:04А почему бы не сделать отчет с реплики? Или вообще получать отчеты с OLAP модели? И не с помощью «SQL запросов в меру своего опыта», а с помощью специальных инструментов генерации отчетов.
VolCh
28.03.2017 09:36Как минимум это дополнительные ресурсы (и финансовые, и человеческие), которые средней руки разработчик и оценить-то толком не может (кроме реплики разве что), не говоря о убедительной демонстрации преимуществ бизнесу, чтобы он согласился эти ресурсы тратить.
erop
28.03.2017 11:57Честно говоря, буквально недавно столкнулся когда администраторы достаточно серьезной бизнес-системы, столкнувшись с продолжительной и ресурсно-затратной генерацией отчетов, на мое предложение использовать реплику, спросили «а что это такое». Это я к тому, что таки да, не все даже знают, что СУБД могут самостоятельно «копировать» данные с одного сервера на другой. С другой стороны, смотреть как в настоящее время люди мучаются с SQL запросами вместо того, чтобы использовать современные и доступные инструменты, основанные на in-memory и прочих Tabular model, тоже как-то грустно. Да, требуются определенные скилы. Но это точно, не rocket science и гораздо проще в плане «интеллекто-емкости» работы разработчика по проектированию.
VolCh
28.03.2017 13:46Мучаются, скорее всего, не из-за информированности (поищите, например, по Хабру OLAP). Либо, как вариант, из-за отсутствия нормальных FOSS инструментов для отчётов по данным из FOSS СУБД, прежде всего MySQL и PostgreSQL. Беглый гуглеж говорит только о теории, либо продуктах Microsoft и Oracle.
В ваших силах, кстати, повысить информированность, написав посто или серию о подобных инструментах :)
nApoBo3
28.03.2017 11:47Т.е. если любой разработчик начнет писать запросы в силу своего опыта и разумения к NOSQL это не приведет к деградации производительности?
ИМХО при идентичных требованиях к данным масштабирование SQL и NOSQL может быть выполнено в равной мере( ограничением станут только блокировки, с ними тоже можно работать, но это значительно повышает требования к квалификации ). Если мы можем расшарить данные по нескольким узлам, мы можем это сделать и там и там. Просто в NOSQL в силу парадигмы данные низкосвязные, а использование SQL как правило приводит к высокой связности данных, но это лишь практика использования не более того( если не считать требования нормализации непреложным законом вселенной ).
Никто не мешает развязать данные и в SQL, но при этом многие плюшки SQL станут вам недоступны( которых собственно говоря в NOSQL просто нет ).BorisDT
03.04.2017 09:38Насколько я понимаю, в NOSQL разработчику прсото не сможет написать слишком сложный запрос (например с кучей join и встроенных функций), и ему придется писать несколько простых, после чего агрегировать данные на уровне приложения. Простые же запросы с некотрой вероятностью еще и будут кэшироваться, не доходя до СУБД.

vintage
03.04.2017 09:54Даже в монге есть агрегированные запросы, на которых можно такого намутить, что плакать хочется.
VolCh
03.04.2017 10:09Некоторые NoSQL базы позволяют исполнять на стороне СУБД полноценные функции на ЯП общего назначения типа JavaScript или Erlang, выдавая в приложение ровно то, что ему нужно без дополнительных агрегаций, соединений и т. п.
nApoBo3
03.04.2017 22:27По своему опыту могу сказать, очень сложно, если вообще возможно реализовать систему которая будет быстрее современных СУБД при оперировании множествами. Да, для каждого отдельного очень узкого случая как правило можно придумать велосипед, но не для общего случая.
grigorym
28.03.2017 09:20+2Большая статья, полная воды и фактических ошибок. «Вариант b показывает, как те же данные можно представить в структурированном виде, типичном для SQL» — автор вообще знаком с принципами декомпозиции данных, «типичными для SQL»? Или «SQL-индексы представлены в виде B-деревьев, которые отражают иерархическую структуру реляционных данных» — что-что? Иерархическую структуру реляционных данных? А если я свой линейный массив ключей-чисел сложил в B-дерево, то оно тоже будет отражать иерархическую структуру, которой отродясь не было в моем линейном массиве чисел?
lega
28.03.2017 22:46О выборе SQL-баз данных
Ну в некоторых NoSQL тоже есть и транзакции и структра и джойны с псевдо-SQL, и где тут преимущество у SQL базы? Или называть такие БД как реляционная NoSQL? А вот например в OrientDB есть ссылки, данные могут ссылаться друг на друга, это как раз то что «доктор прописал» для построения реляций, а в SQL БД этого нет. Т.е. OrientDB более реляционен?
Пора уже выбирать базы по фичам, а не делить на 2 лагеря. Да и вообще, хранить таблицами не эффективно для 80% случаев в которых используется SQL субд.
А про индексы, как уже отметили выше, автор бред написал.
sbnur
Исходно вопрос о противостоянии схем баз данных никогда не ставился — в теории рассматривались три базовых вида; сетевые, иерархические и реляционные.
Последние приобрели большую популярность в силу создания программных продуктов, использующих реляционную модель вместе с языком SQL запросов.
Но другие модели также использовались с меньшей популярностью в обычной пользовательской среде.
В настоящее время развитость информационных технологий, расширение областей применения этих технологий и возросший массовый уровень профессионализма специалистов по информационным технологиям естественно расширили области применения всех моделей данных.
Поэтому, как и указано, решать надо по месту какую модель использовать.