

Мы продолжаем цикл публикаций о внедрении инструментов и практик DevOps в нашей компании. Недавно мы рассказывали о том, как анализируем уязвимости с помощью нейронных сетей и нечеткой логики, а сегодня поговорим о внедрении системы мониторинга Zabbix в процессы разработки и тестирования.
Типичные проблемы тестирования
Одной из серьезных проблем, которую мы хотели решить с помощью внедрения практик DevOps была организация мониторинга ИТ-систем. До этого он осуществлялся недостаточно активно. Это приводило к целому ряду сложностей. Например, мы могли поздно заметить, что на диске нужной машины кончилось место, о проблемах сигнализировали перебои в работе сервисов и приложений. Все это острые проблемы для процесса разработки и тестирования, поскольку из-за таких ошибок продукт может быть нестабильным, а отловить в нем баги становится сложнее.
При тестировании продукта необходимо анализировать множество показателей: логи, загруженность сервера, доступность внутренних и внешних сервисов и т.д. Кроме того, от версии к версии список наблюдаемых параметров может изменяться.
Для решениях всех этих проблем мы решили интегрировать в процессы разработки и тестирования систему мониторинга Zabbix. Вот, как мы это сделали, и что получилось в итоге.
Как мы внедряли Zabbix
Вообще, системы мониторинга делятся по функциям и по типам. Разделение по функциям можно описать так:
- Мониторинг ситуации — оповещение о критических событиях и ошибках (классическая ситуация «SMS в 2 ночи»).
- Мониторинг трендов — информация собирается для дальнейшего анализа.
- Performance-мониторинг — отслеживание быстродействия системы.
Мониторинг по типам делится на:
- Системный мониторинг — анализируется состояние ОС и системных служб.
- Мониторинг приложений — реализуется внутри приложения.
- Бизнес-метрики — реализуется внутри приложения.
Применяемый нами механизм позволяет «закрывать» все эти функции и осуществлять системный мониторинг полностью, а мониторинг приложений — частично.
Для оптимизации процесса тестирования мы решили разграничить зоны ответственности между командой DevOps, разработчиками и тестировщиками, написали собственные инструменты для взаимодействия с Zabbix (zabbixtools) и перешли к использованию подхода “monitoring as code”.
Разграничение ответственности выглядит так — если у нас есть хост, который нужно мониторить, то тестировщик назначает ему определенную роль. У каждого хоста может быть только одна роль, в которой может быть несколько профилей — их предоставляет команда DevOps. Профили могут быть разные — для мониторинга процессов, служб, API и т.д.
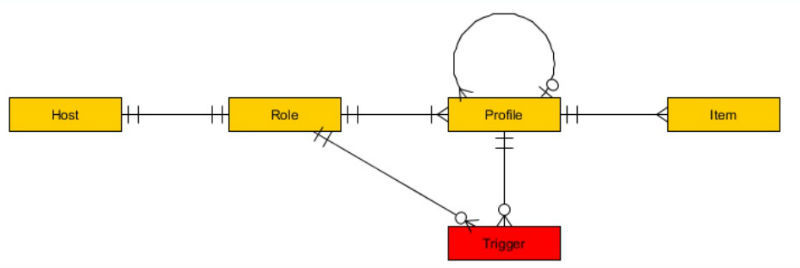
В пакет zabbixtools входят скрипты Python и Powershell (репозиторий проекта на GitHub), которые расширяют функциональность системы Zabbix в части:
- кастомных проверок на Zabbix-агентах и внешних проверок на сервере;
- кастомизации оповещений — интеграции с различными сервисами и workflow;
- работы через API — например, массовое редактирование хостов и других сущностей;
- Конфигурировании мониторинга при развертывании продукта или тестов.
Система мониторинга должна быть гибкой и легко конфигурируемой, чего не скажешь о веб-интерфейсе Zabbix. Поэтому для упрощения конфигурирования решено было реализовать систему, при которой как можно больше данных о наблюдаемых показателях Zabbix должен был забирать с целевого сервера. Для упрощения настройки, в zabbixtools используется функциональность Low Level Discovery (LLD).
Это позволяет вносить любые настройки мониторинга на самом отслеживаемом сервере, а не в «админке» Zabbix.
Примерная схема реализации данной функции представлена на схеме:
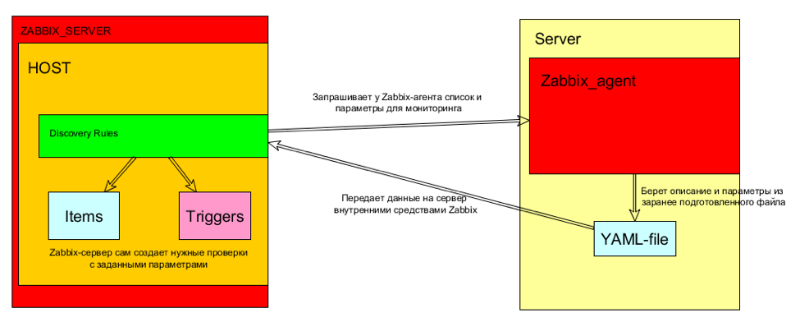
Вот как это работает:
- LLD запрашивает у Zabbix-агента конфигурацию мониторинга (с требуемыми параметрами). Например, списки служб, доступных сайтов или дисков с необходимым количеством места
- Zabbix-агент предоставляет параметры, фактически, берет их из файла yaml-формата.
- LLD создает необходимые Item и Trigger на хосте. При этом условия срабатывания триггера тоже могут задаваться на стороне агента.
Таким образом, для настройки нового хоста с определенными правилами командам нет необходимости изучать административный интерфейс, достаточно лишь добавить нужный набор профилей в роль, которая будет привязана к данному серверу. Веб-интерфейс будет использоваться только для просмотра текущего состояния/исторической информации.
Пример встраивания системы мониторинга в процессы разработки/тестирования
Проблема мониторинга при разработке и тестировании продукта — меняющийся от версии к версии список наблюдаемых параметров.
Например, возможна ситуация, когда для двух релизова нам необходимо мониторить следующие показатели:
1. Release N.0- Мониторим доступность ресурса А по протоколу HTTP
- Мониторим сервис В
- Мониторим сервис С
- Для ресурса X выставляем критическое значение Y
2. Release N+1.0- Мониторим доступность ресурса А по протоколу HTTPS
- Мониторим сервис С (но его имя изменилось)
- Мониторим сервис D
- Для ресурса Х выставляем критическое значение Z
Причем сегодня на стенде SERVER-1 будет развернута одна версия продукта, а завтра — нужно разворачивать другую. В системах мониторинга любые изменения делаются вручную в веб-интерфейсе со статическими заданными параметрами.
zabbixtools вместе с LLD позволяет решить эту проблему, двумя возможными способами:
1. Конфигурация мониторинга (yaml-файлы) разворачиваются при деплое продукта (файлы берутся из того же репозитория, что и исходный код продукта).
- Поддержка актуальности конфигурации мониторинга остается задачей разработчиков.
- Конфигурация мониторинга различается от ветке к ветке/от фиче к фиче.
- Проводится SMOKE-тестирование уже при деплое продукта, даже если нет нужды запускать тесты.
2. Конфигурация мониторинга (yaml-файлы) разворачиваются при тестировании продукта (файлы берутся из того же репозитория, что и код для теста).
- Поддержка актуальности конфигурации мониторинга — задача тестировщиков.
- SMOKE-тесты могут быть выполнены системой мониторинга.
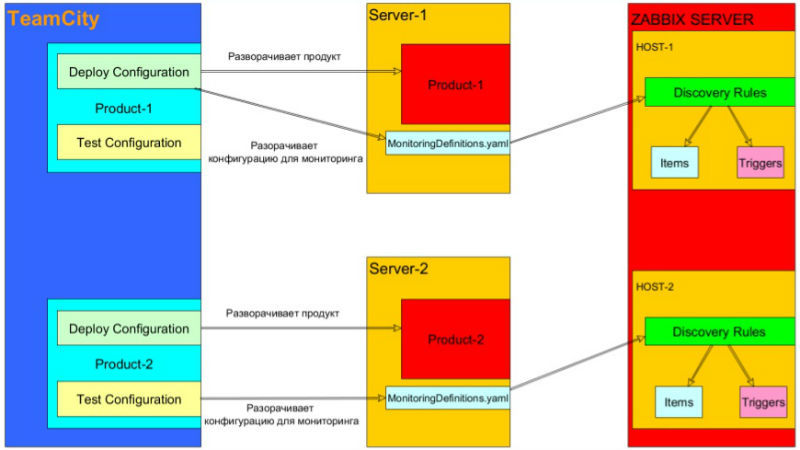
Эта схема позволяет настраивать мониторинг в зависимости от релиза продукта и держать его под версионным контролем. Также мы можем реализовывать SMOKE-тестирование средствами самой системы мониторинга. Кроме того, такая конфигурация позволяет разграничить ответственность между командами DevOps, разработки и тестирования — в частности, программистам и тестировщикам не нужно разбираться с работой Zabbix и его API.
В итоге участие разных команд требуется лишь в определенные промежутки времени. Например, при развертывании продукта разработчики отвечают за поддержку актуальности конфигурации мониторинга, конфигурация мониторинга различается от ветки к ветке и от фичи к фиче, а SMOKE-тестирование осуществляется при деплое даже без запуска тестов.
При тестировании продукта за поддержку актуальности конфигурации мониторинга отвечают тестировщики, SMOKE-тесты могут быть выполнены системой мониторинга.
Примеры работы
Ниже представлены примеры конфигураций для мониторинга сайтов, служб, процессов и размера папок.
Рассмотрим ситуацию, в которой нам нужно мониторить доступность внутренних и внешних сайтов — от них мы должны получать ответ HTTP 200 OK. Для этого надо просто добавить строки в файл
websites.yaml. Если же требуется осуществлять мониторинг работы служб (службы должны быть включены), то их следует добавить в services.yaml.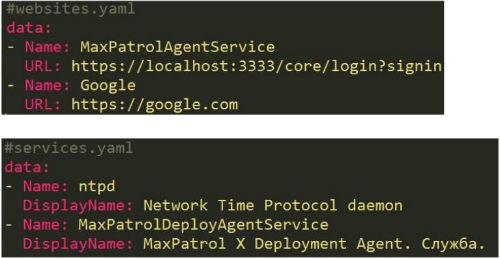
В том случае, если необходимо наблюдать за потреблениями памяти определенных процессов, сделать это можно с помощью нескольких строк в process.yaml.
Еще одно полезное свойство этого инструмента — возможность установки разных пороговых значений для метрик. Если, к примеру, нам важно, чтобы размер папки Cache был небольшим, а логи могут разрастаться в размере, то можно просто добавить разные
CriticalSize у папок в foldersize.yaml.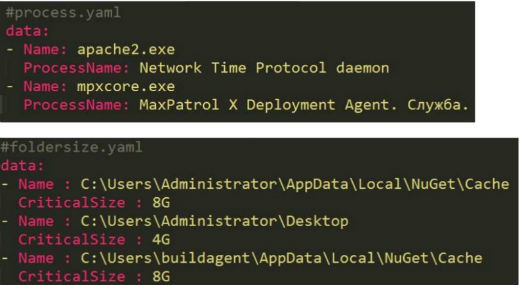
P.S. Рассказ о нашем опыте интеграции мониторинга с помощью Zabbix в процессы разработки и тестирования был представлен в рамках DevOps-митапа, который состоялся осенью 2016 года в Москве.
Видео:
Слайды:
По ссылке представлены презентации 16 докладов, представленных в ходе мероприятия. Все презентации и видео выступлений добавлены в таблицу в конце этого топика.
Автор: Алексей Буров
Поделиться с друзьями
Комментарии (5)


kozzztik
31.03.2017 12:49Есть еще такая штука как «прогнозирующий мониторинг». Это, грубо говоря, если места на диске вполне достаточно на данный момент, но если оно продолжит убывать текущими темпами, то оно очень быстро закончится. Позволяет отлавливать сбои до того, как они станут проблемой. Кстати, Zabbix это тоже умеет начиная, если память не изменяет, с 3.0.

athacker
07.04.2017 17:54Система мониторинга должна быть гибкой и легко конфигурируемой, чего не скажешь о веб-интерфейсе Zabbix.
В системах мониторинга любые изменения делаются вручную в веб-интерфейсе со статическими заданными параметрами.
«Чего только не придумают люди, лишь бы документацию не читать» (с) :-)
Вообще-то у заббикса есть API, который позволяет все эти прекрасные вещи делать совсем не руками. Так что можно было бы навешивать шаблоны для мониторинга различных версий/приложений на конкретные хосты, и менять их при смене версии/приложения. Это можно делать через API.
SchmeL
Собственно поэтому отказались от Заббикса в пользу Icinga2+Graphite