
Обзор парка Twitter
Twitter пришёл из эпохи, когда в дата-центрах было принято устанавливать оборудование от специализированных производителей. С тех пор мы непрерывно разрабатывали и обновляли серверный парк, стремясь извлечь пользу из последних открытых технологических стандартов, а также повысить эффективность работы оборудования, чтобы обеспечить наилучший опыт для пользователей.
Наше текущее распределение оборудования показано ниже:
Сетевой трафик
Мы начали уходить со стороннего хостинга в начале 2010 года. Это означает, что нам пришлось изучить, как строить и обслуживать свою инфраструктуру самостоятельно. Имея смутные представления о нуждах базовой инфраструктуры, мы начали пробовать разные варианты архитектуры сети, оборудования и производителей.
К концу 2010 года мы закончили первый проект архитектуры сети. Она должна была решить проблемы с масштабированием и обслуживанием, которые мы испытывали у хостера. У нас стояли коммутаторы ToR с глубокими буферами для обработки всплесков служебного трафика, а также коммутаторы ядра и операторского класса без переподписки на этом уровне. Они поддерживали раннюю версию Twitter, которая установила несколько заметных инженерных достижений, таких как рекорды TPS (твитов в секунду) после выхода японского фильма «Замок в небе» и во время Чемпионата мира по футболу 2014.
Если быстро перенестись на пару лет, то у нас уже работала сеть с точками присутствия на пяти континентах и дата-центры с сотнями тысяч серверов. В начале 2015 года мы начали испытывать некоторые проблемы роста из-за изменения сервисной архитектуры и увеличенных потребностей по мощности и в конечном счёте достигли физических ограничений масштабируемости в дата-центре, когда mesh-топология не могла выдержать добавление дополнительного оборудования в новых стойках. Вдобавок, IGP в существующем дата-центре начал вести себя непредсказуемо из-за увеличившегося масштаба маршрутизации и сложности топологии.
Чтобы справиться с этим, мы начали переводить существующие дата-центры на топологию Clos + BGP — преобразование, которое пришлось делать на живой сети. Несмотря на сложность, его завершили с минимальным влиянием на сервисы за относительно короткое время. Сейчас сеть выглядит так:
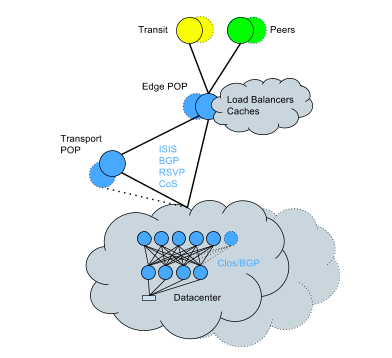
Ключевые моменты нового подхода:
- Меньший радиус воздействия от сбоя одного устройства.
- Возможности горизонтального масштабирования пропускной способности.
- Меньший оверхед движка маршрутизации на CPU; намного более эффективная обработка изменений маршрутизации.
- Бoльшая ёмкость маршрутизации из-за сниженного оверхеда CPU.
- Более подробный контроль правил маршрутизации по каждому устройству и каждому соединению.
- Больше нет вероятности столкнуться с корневыми причинами самых серьёзных инцидентов, которые случались в прошлом: увеличенное время реконвергенции протокола, проблемы сбитых маршрутов и неожиданные проблемы из-за врождённой сложности OSPF.
- Возможность перемещения стоек без последствий.
Посмотрим подробнее на нашу сетевую инфраструктуру.
Трафик дата-центра
Задачи
Наш первый дата-центр был построен по образцу ёмкости и профилей трафика известной системы, установленной у нашего хостинг-провайдера. Прошло всего несколько лет, и наши дата-центры были на 400% больше, чем в оригинальном дизайне. И сейчас, когда наш стек приложений эволюционировал, а Twitter стал более распределённым, профили трафика тоже изменились. Изначальные предположения, на которых разрабатывался дизайн сети в начале, более не актуальны.
Трафик растёт быстрее, чем мы успеваем переделывать целый дата-центр, поэтому важно создавать высоко масштабируемую архитектуру, которая позволит последовательно добавлять ёмкость вместо резких миграций.
Разветвлённая система микросервисов требует высоконадёжной сети, которая способна выдержать разнообразный трафик. Наш трафик варьируется от долгоживующих TCP-соединений до специальных задач MapReduce и невероятно коротких микровсплесков. Изначально для работы с этим разнообразием видов трафика мы развернули сетевое оборудование с глубокими пакетными буферами, но из-за этого там возникли собственные проблемы: более высокая стоимость и возросшая аппаратная сложность. В поздних проектах использовались более стандартные размеры буфера и сквозные функции коммутации вместе с лучше настроенным TCP-стеком на стороне сервера для более изящной обработки микровсплесков.
Полученные уроки
Спустя годы и после сделанных улучшений мы поняли несколько вещей, которые стоит упомянуть:
- Проектируйте за рамками изначальных спецификаций и требований, делайте смелые и быстрые изменения, если трафик приближается к верхней границе ёмкости, заложенной в сеть.
- Полагайтесь на данные и показатели, чтобы принимать корректные решения технического дизайна, и удостоверьтесь, что эти метрики понятны сетевым операторам — это особенно важно на хостинге или в облаке.
- Нет такой вещи как временное изменение или обходной путь: в большинстве случаев обходные пути — это технический долг.
Трафик бэкбона
Задачи
У нас трафик бэкбона кардинально нарастал каждый год — и мы до сих пор видим всплески в 3-4 раза от нормального трафика, когда перемещаем трафик между дата-центрами. Это ставит уникальные задачи для исторических протоколов, которые не были рассчитаны на такое. Например, протокол RSVP в MPLS предполагает в некоторой степени постепенное наращивание трафика, а не внезапные всплески. Нам пришлось потратить немало времени на настройку этих протоколов, чтобы получить максимально быстрое время отклика. Вдобавок, для обработки скачков трафика (особенно при репликации в системах хранения данных) мы реализовали систему приоритетов. Хотя нам всегда требуется гарантировать доставку пользовательского трафика, но мы можем допустить задержку низкоприоритетного трафика репликации из систем хранения с суточными SLA. Таким образом, наша сеть задействует всю доступную пропускную способность и максимально эффективно использует ресурсы. Пользовательский трафик всегда важнее, чем низкоприоритетный трафик бэкенда. Кроме того, для решения проблем упаковки в контейнеры (bin-packing), связанных с автоматической пропускной способностью RSVP, мы внедрили систему TE++, которая при увеличении трафика создаёт дополнительные LSP и удаляет их при уменьшении трафика. Это позволяет нам эффективно управлять трафиком между соединениями, одновременно снижая нагрузку на CPU, необходимую для поддержки большого количества LSP.
Хотя изначально никто не занимался проектированием трафика для бэкбона, позже его добавили, чтобы помочь нам масштабироваться в соответствии с нашим ростом. Для этого мы произвели разделение ролей с отдельными маршрутизаторами для маршрутизации трафика ядра и граничного трафика, соответственно. Это также позволило нам масштабироваться в бюджетном режиме, поскольку не понадобилось покупать маршрутизаторы со сложной граничной функциональностью.
На границе это означает, что здесь у нас ядро подключено ко всему и можно масштабироваться очень горизонтальным образом (например, устанавливать много, много маршрутизаторов на одном месте, а не только парочку, поскольку межсоединения ядра связывают всё насквозь).
Чтобы масштабировать RIB в наших маршрутизаторах для удовлетворения требований к масштабированию, пришлось внедрить отражение маршрутов, но сделав это и перейдя на иерархическую структуру, мы также реализовали клиентов отражателей маршрутов для их собственных отражателей маршрутов!
Полученные уроки
За последний год мы перенесли конфигурации устройств в шаблоны, и теперь регулярно проверяем их.
Граничный трафик
Всемирная сеть Twitter имеет прямые межсоединения с более чем 3000 уникальными сетями во многих дата-центрах по всему миру. Прямая доставка трафика — главный приоритет. Мы перемещаем 60% нашего трафика через наш глобальный сетевой бэкбон на точки межсоединения и точки присутствия (POP), где у нас работают локальные серверы фронтенда, замыкающие клиентские сессии, — всё чтобы быть как можно ближе к пользователям.
Задачи
Непредсказуемость мировых событий ведёт к таким же непредсказуемым всплескам трафика. Эти всплески во время крупных событий вроде спортивных состязаний, выборов, стихийных бедствий и других значительных событий подвергают напряжению нашу сетевую инфраструктуру (особенно фото и видео). Они трудно предсказуемы либо наступают вовсе без предупреждения. Мы обеспечиваем ёмкость для таких событий и готовимся к большим скачкам — часто в 3-10 раз выше нормальных пиковых уровней, если в регионе намечается значительное событие. Из-за нашего ежегодного значительного роста наращивать ёмкость в требуемом объёме представляется важной задачей.
Хотя мы по возможности устанавливаем пиринговые соединения со всеми клиентскими сетями, здесь не обходится без проблем. На удивление часто сети или провайдеры предпочитают устанавливать межсоединения вдалеке от домашнего рынка или из-за своих правил маршрутизации направляют трафик на точку присутствия за пределами рынка. И хотя Twitter открыто устанавливает пиринговые соединения со всеми крупнейшими (по количеству пользователей) сетями, где мы видим трафик, не все интернет-провайдеры делают так же. Мы тратим значительное время на оптимизацию наших правил маршрутизации, чтобы направить трафик настолько близко к нашим пользователям, насколько это возможно.
Полученные уроки
Исторически, когда кто-то отправлял запрос к
www.twitter.com, основываясь на местоположении нашего DNS-сервера, мы отдавали им разные региональные IP-адреса, чтобы направить на конкретный кластер серверов. Такая методология (GeoDNS) частично неточная, потому что нельзя полагаться на пользователей в вопросе выбора корректных DNS-серверов или на нашу способность точно определить, где в мире физически располагается DNS-сервер. Вдобавок, топология интернета не всегда соответствует географии.Для решения проблемы мы перешли на модель BGP Anycast, в которой мы заявили одинаковый маршрут со всех локаций и оптимизировали нашу маршрутизацию, чтобы прокладывать наилучший путь от пользователей к нашим точкам присутствия. Поступая таким образом, мы получаем максимально возможную производительность с учётом ограничений топологии интернета и не зависим от непредсказуемых предположений о том, где располагаются DNS-серверы.
Хранение
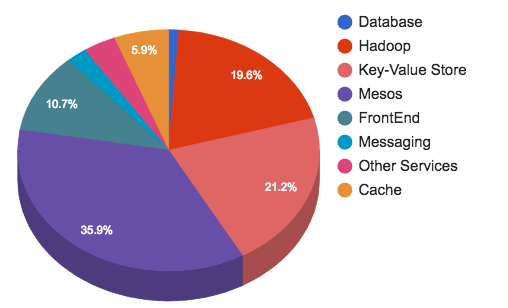
Ежедневно публикуются сотни миллионов твитов. Они обрабатываются, хранятся, кэшируются, поставляются и анализируются. Для такого объёма контента нам нужна соответствующая инфраструктура. Хранение и обмен сообщениями представляют 45% всего объёма инфраструктуры Twitter.
Группы хранения и обмена сообщениями обеспечивают следующие сервисы:
- Кластеры Hadoop для вычислений и HDFS.
- Кластеры Manhattan для всех хранилищ key-value с малой задержкой.
- Хранилища Graph для шардированных кластеров MySQL.
- Кластеры Blobstore для всех крупных объектов (видео, изображения, бинарные файлы...).
- Кластеры кэширования.
- Кластеры обмена сообщениями.
- Реляционные хранилища (MySQL, PostgreSQL и Vertica).

Задачи
Хотя на этом уровне есть ряд различных проблем, одной из самых заметных, которые пришлось преодолеть, стало множественное владение (multi-tenancy). Часто у пользователей возникают граничные ситуации, которые влияют на существующие владения и заставляют нас строить выделенные кластеры. Чем больше выделенных кластеров — тем больше операционная нагрузка, чтобы поддерживать их.
В нашей инфраструктуре нет ничего удивительного, но вот несколько интересных фактов:
- Hadoop: наши многочисленные кластеры хранят более 500 ПБ, разделённые по четырём группам (реальное время, обработка, хранилище данных и холодное хранилище). В самом большом кластере более 10 тыс. нод. У нас работает 150 тыс. приложений и запускается 130 млн контейнеров в день.
- Manhattan (бэкенд для твитов, личных сообщений, твиттер-аккаунтов и др.): у нас работает несколько кластеров для разных задач, это большие кластеры с множественным владением, меньшие для необычных задач, кластеры read only и read/write для трафика с большой нагрузкой на чтение и запись. Кластер read only обрабатывает десятки миллионов запросов в секунду (QPS), а кластер read/write — миллионы QPS. В каждом дата-центре есть кластер с самой большой производительностью — кластер наблюдаемости, который обрабатывает десятки миллионов записей.
- Graph: наш исторический шардированный кластер на основе Gizzard/MySQL для хранения графов. Наш социальный граф Flock способен справляться с пиковой нагрузкой в десятки миллионов QPS, распределяя её на серверы MySQL в среднем с 30-45 тыс. QPS.
- Blobstore: хранилище для изображений, видео и больших файлов, которое содержит сотни миллиардов объектов.
- Cache: кластеры Redis и Memcache кэшируют пользователей, таймлайны, твиты и др.
- SQL: включает в себя MySQL, PostgreSQL и Vertica. MySQL/PosgreSQL используются там, где нужна строгая целостность, в управлении рекламными кампаниями, обменом рекламы, а также для внутренних инструментов. Vertica — колоночное хранилище, которое часто используется как бэкенд для продаж с поддержкой Tableau и организации пользователей.
Hadoop/HDFS также является бэкендом для системы логгирования на базе Scribe, но сейчас завершаются последние этапы тестирования перехода на Apache Flume. Он должен помочь в преодолении ограничений, таких как отстутствие лимитов/сужения полосы для трафика отдельных клиентов в агрегаторы, отсутствие гарантии доставки по категориям. Также поможет решить проблемы с повреждением памяти. Мы обрабатываем более триллиона сообщений в день, все они обрабатываются и распределяются в более 500 категорий, объединяются, а затем выборочно копируются по нашим кластерам.
Хронологическая эволюция
Twitter был построен на MySQL и изначально все данные хранились в нём. Мы перешли от маленькой базы данных к большому инстансу, а затем к большому количеству больших кластеров БД. Ручное перемещение данных между инстансами MySQL отнимало много времени, так что в апреле 2010 года мы представили Gizzard — фреймворк для создания распределённых хранилищ данных.
В то время экосистема выглядела так:
- Реплицированные кластеры MySQL.
- Шардированные кластеры MySQL на основе Gizzard.
После релиза Gizzard в мае 2010 года мы представили FlockDB, решение для хранения графов поверх Gizzard и MySQL, а в июне 2010 года — Snowflake, наш уникальный сервис присовоения идентификаторов. 2010-й стал годом, когда мы вложились в Hadoop. Изначально предназначенный для хранения бэкапов MySQL, теперь он интенсивно используется для аналитики.
Около 2010 года мы также внедрили Cassandra в качестве решения для хранения данных, и хотя она не заменила полностью MySQL из-за отсутствия функции автоматического постепенного увеличения, но стала применятся для хранения показателей. Поскольку трафик увеличивался в геометрической прогрессии, нам нужно было увеличивать кластер, так что в апреле 2014 года мы запустили Manhattan: нашу распределённую базу данных в реальном времени с множественным владением. С тех пор Manhattan стал одним из наших основных уровней хранения, а Cassandra была выведена из строя.
В декабре 2012 года Twitter разрешил закачку фотографий. За фасадом это стало возможным благодаря новому решению для хранения данных Blobstore.
Полученные уроки
С годами, по мере миграции данных из MySQL в Manhattan для улучшения доступности, снижения задержек и более простой разработки, мы также внедрили дополнительные движки для хранения данных (LSM, b+tree…) для лучшего обслуживания наших шаблонов трафика. Вдобавок, мы извлекли уроки из инцидентов и начали защищать наши уровни хранения данных от злоупотреблений, отправляя назад сигнал давления и активировав фильтрацию запросов.
Мы продолжаем концентрироваться на том, чтобы обеспечить правильный инструмент для работы, но для этого нужно понимать все сценарии использования. Универсальное решение типа «один размер подходит всем» редко работает — следует избегать срезать углы в граничных ситуациях, потому что нет ничего более постоянного, чем временное решение. И последнее, не переоценивайте своё решение. У всего есть преимущества и недостатки, и всё нужно адаптировать, не теряя связи с реальностью.
Кэш
Хотя кэш занимает всего около 3% нашей инфраструктуры, он является критически важным для Twitter, поскольку защищает наши хранилища бэкенда от тяжёлого трафика на чтение, а также позволяет хранить объекты с высокой ценой разбухания. Мы используем несколько технологий кэширования, вроде Redis и Twemcache, в огромном масштабе. Более конкретно, у нас работает смесь кластеров Twitter memcached (twemcache), выделенных или с множественным владением, а также кластеры Nighthawk (шардированный Redis). Мы перевели почти всё наше основное кэширование с голого металла на Mesos для снижения эксплуатационных расходов.
Задачи
Масштабирование и производительность — основные задачи для системы кэширования. У нас работают сотни кластеров с совокупной скоростью передачи пакетов 320 млн пакетов в секунду, доставляя 120 ГБ/с нашим клиентам, и мы ставим цель обеспечить каждый отклик с задержкой в пределах 99,9% и 99,99% даже во время пиковых скачков трафика во время значительных событий.
Чтобы соответствовать нашим целям по уровню обслуживания (service level objectives, SLO) в части высокой пропускной способности и низких задержек, требуется непрерывно измерять производительность наших систем и искать варианты для оптимизации эффективности. С этой целью мы написали программу rpc-perf, она помогает лучше понять, как ведут себя наши системы кэширования. Это критически важно для планирования ёмкости, поскольку мы перешли с выделенных серверов на текущую инфраструктуру Mesos. В результате такой оптимизации удалось более чем удвоить пропускную способность на один сервер без ущерба для задержек. Мы всё ещё думаем, что здесь возможны большие оптимизации.
Полученные уроки
Переход на Mesos стал огромной эксплуатационной победой. Мы кодифицировали наши конфигурации и можем постепенно разворачивать их, сохраняя коэффициент попадания в кэш и избегая проблем для постоянных хранилищ данных. Рост и масштабирование этого уровня происходит с большей уверенностью.
С тысячами соединений на каждый инстанс twemcache, любой перезапуск процесса, всплеск сетевого трафика или другая проблема может вызвать DDoS-подобный наплыв соединений на уровень кэша. По мере масштабирования это стало более чем серьёзной проблемой. Мы внедрили бенчмарки, которые помогают в случае DDoS сужать полосу для соединений к каждому отдельному кэшу при большом уровне реконнектов, иначе мы бы отступили от своих заявленных целей по уровню обслуживания.
Мы логически разбиваем наши кэши по пользователям, твитам, таймлайнам, и т. д., так что в целом каждый кэширующий кластер настроен на конкретное использование. В зависимости от типа кластера, он может обрабатывать от 10 млн до 50 млн QPS, и работает на количестве инстансов от сотен до тысяч.
Haplo
Позвольте нам представить Haplo. Это основной кэш для таймлайнов Twitter и он работает на кастомизированной версии Redis (с использованием HybridList). Операции чтения из Haplo осуществляет Timeline Service, а операции записи — Timeline Service и Fanout Service. Это также один из наших кэшей, которые ещё не мигрировали на Mesos.
- Совокупное количество команд от 40 млн до 100 млн в секунду.
- Сетевой ввод-вывод 100 Мбит/с на хост.
- Совокупное число запросов на обслуживание 800 тыс. в секунду.
Для дальнейшего чтения
Яо Юэ (@thinkingfish) за годы провёл несколько отличных лекций и опубликовал ряд статей о кэшировании, в том числе о нашем использовании Redis, а также о нашей более новой кодовой базе Pelikan. Можете посмотреть эти видео и почитать недавний пост в блоге.
Работа Puppet в большом масштабе
У нас работает большой массив инфраструктурных сервисов ядра, такие как Kerberos, Puppet, Postfix, Bastions, Repositories и Egress Proxies. Мы концентрируемся на масштабировании, создании инструментария и управлении этими сервисами, а также на поддержке расширения дата-центров и точек присутствия. Только за прошлый год мы значительно расширили географию наших точек присутствия, что потребовало полной переделки архитектуры того, как мы планируем, готовим и запускаем новые локации.
Для управления всеми конфигурациями мы используем Puppet и ставим на наших системах начальную пакетную установку. Этот раздел описывает некоторые задачи, которые пришлось решить и что мы планируем делать с нашей инфраструктурой для управления конфигурациями.
Задачи
По мере роста для удовлетворения запросов пользователей мы быстро переросли стандартные инструменты и практики. У нас более 100 авторов коммитов в месяц, более 500 модулей и более 1000 ролей. В конечном счёте, нам удалось уменьшить количество ролей, модулей и строк кода, в то же время улучшив качество нашей кодовой базы.
Ветки
У нас есть три ветки, на которым Puppet ссылается как на окружения. Это позволяет как полагается тестировать, обкатывать и в итоге выпускать изменения для рабочего окружения. Мы допускаем и отдельные специализированные окружения для более изолированного тестирования.
Перенесение изменений из тестового в рабочее окружение в данный момент требует некоторого человеческого участия, но мы двигаемся к более автоматизированной системе CI с автоматизированным процессом интеграции/отката.
Кодовая база
Наш репозиторий Puppet содержит более 1 млн строк кода, где только код Puppet составляет более 100 тыс. строк в каждой ветке. Мы недавно провели массивную чистку кодовой базы, удалив ненужный и повторяющийся код.
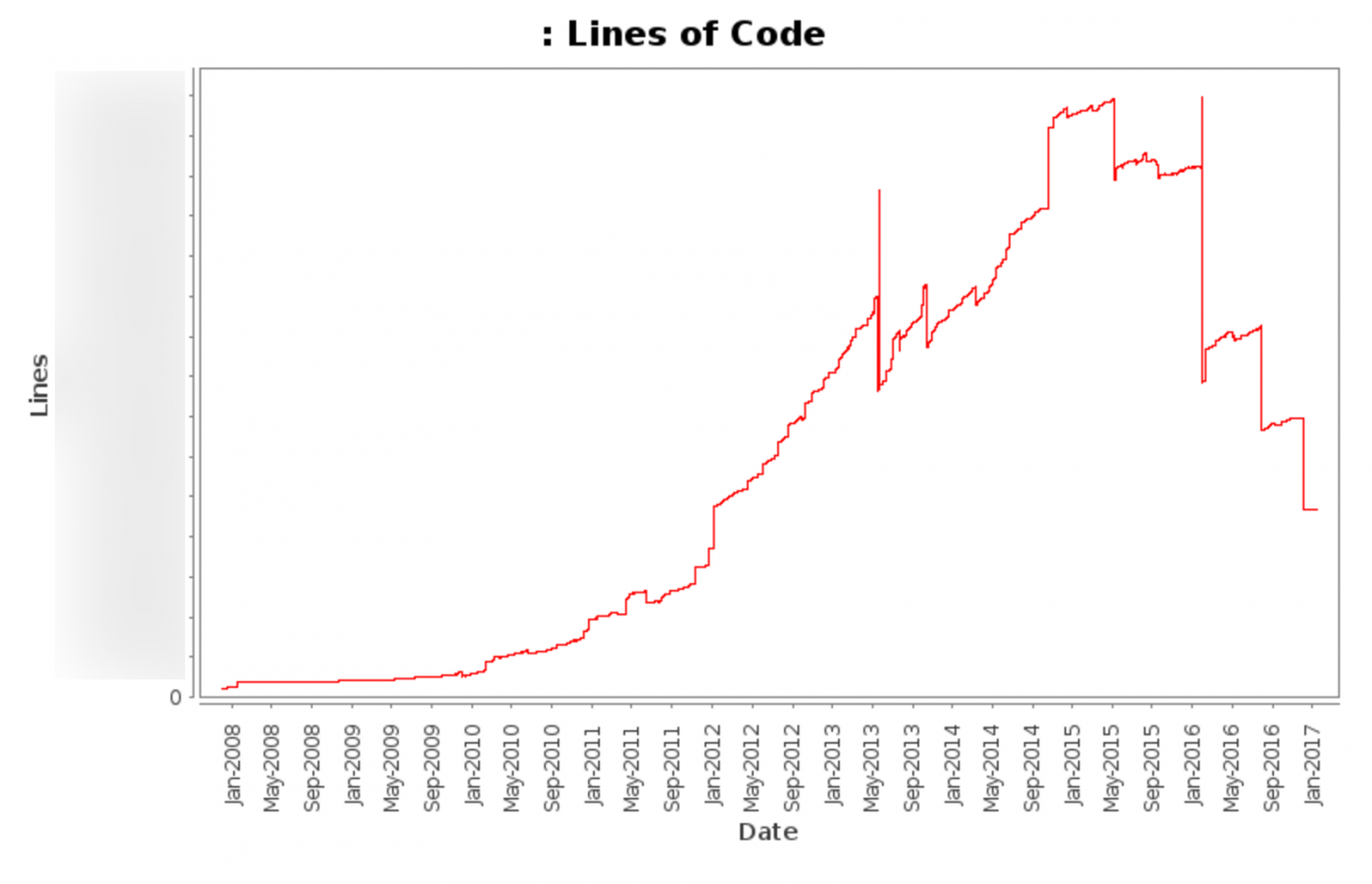
Этот график показывает общее количество строк кода (без учёта различных автоматически обновляющихся файлов) с 2008 года до сегодняшнего дня.

Этот график показывает общее количество файлов (без учёта различных автоматически обновляющихся файлов) с 2008 года до сегодняшнего дня.
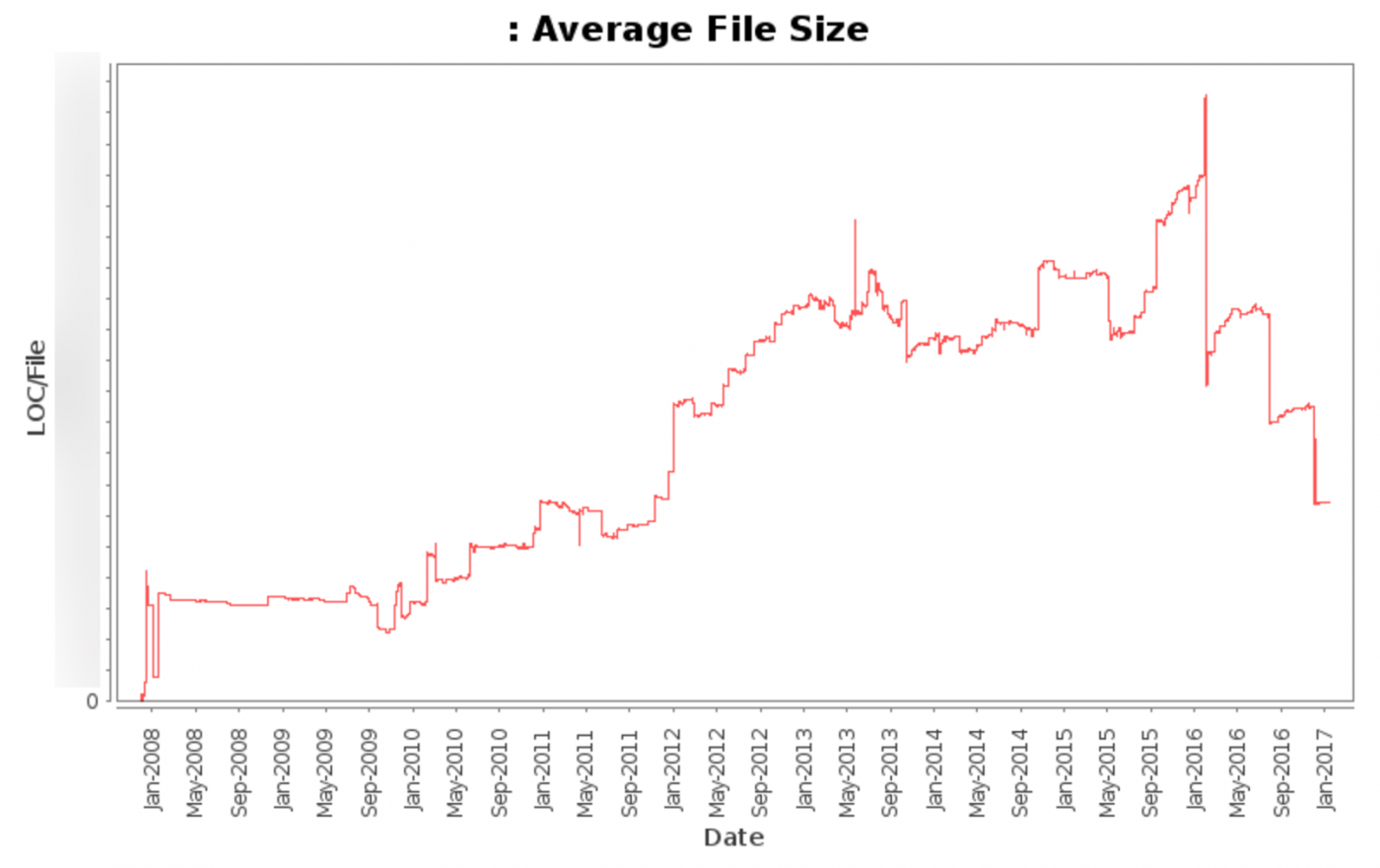
Этот график показывает средний размер файла (без учёта различных автоматически обновляющихся файлов) с 2008 года до сегодняшнего дня.
Большие победы
Самыми большими победами для нашей кодовой базы стали статический анализ кода (линтинг), хуки для проверки стиля, документация лучших практик и проведение регулярных рабочих совещаний.
С инструментами для линтинга (puppet-lint) мы смогли соответствовать общепринятым стандартам для линтинга. Мы уменьшили количество ошибок линтинга и предупреждений в нашей кодовой базе на десятки тысяч строк, а преобразования затронули 20% кодовой базы.
После первоначальной чистки теперь стало легче делать более мелкие изменения в кодовой базе, а внедрение автоматизированной проверки стиля как хука для контроля версий драматически сократило количество ошибок стиля в нашей кодовой базе.
С более чем сотней авторов коммитов в Puppet во всей организации, намного возрастает важность документирования практик оптимальной работы, как внутренних практик, так и стандартов сообщества. Наличие единого справочного документа улучшило качество кода и скорость его внедрения.
Проведение регулярных вспомогательных совещаний (иногда по приглашениям) помогает оказывать помощь один на один, когда тикеты и канале в чате не обеспечивают достаточной плотности коммуникации или не могут отобразить полную картину того, чего требуется достичь. В результате, после совещаний многие авторы коммитов улучшили качество кода и скорость работы, поняв требования сообщества, лучшие практики и как лучше применять изменения.
Мониторинг
Системные показатели не всегда полезны (см. лекцию Кейтлин МакКэфри на конференции Monitorama 2016), но они обеспечивают дополнительный контекст для тех показателей, которое мы считаем полезными.
Некоторые из самых полезных показателей, по которым создаются оповещения и составляются графики:
- Сбои работы: количество неуспешных запусков Puppet.
- Продолжительность работы: время, которое требуется клиенту Puppet для выполнения работы.
- Отсутствие работы: количество запусков Puppet, которые не состоялись в ожидаемом интервале.
- Размеры каталогов: размер каталогов в мегабайтах.
- Время компиляции каталогов: время в секундах, которое требуется каталогу для компиляции.
- Количество скомпилированных каталогов: количество каталогов, которые скомпилировал каждый Master.
- Файловые ресурсы: количество обработанных файлов.
Все эти показатели собираются для каждого хоста и суммируются по ролям. Это позволяет мгновенно выдавать оповещения и определять наличие проблемы для конкретных ролей, наборов ролей или проблем более широкого действия.
Эффект
После перехода с Puppet 2 на Puppet 3 и обновления Passenger (позже опубликуем посты по обеим темам) мы смогли уменьшить среднее время работы процессов Puppet в кластерах Mesos с более чем 30 минут до менее 5 минут.

Этот график показывает среднее время работы процесса Puppet в секундах в наших кластерах Mesos.
Если хотите помочь с нашей инфраструктурой Puppet, приглашаем на работу!
Поделиться с друзьями
http3
А пользователей сотни миллионов.
Один сервер обслуживает 1000 пользователей? :)
Ну такое.
Та какой там трафик.
При 140 символах то. :)
Зачем? :)
Что такое прямое межсоединение?
Оптика с ДЦ Твиттера в другой ДЦ?
Второе утверждение спорно.
С таким же успехом вы не определите и новым способом.
А первое утверждение тоже не совсем правильно.
Что значит «некорректный ДНС»?
Правильно было бы нельзя по расположению ДНС судить о расположении пользователя.
Возьмем тот же 8.8.8.8
Расскажите лучше, как реализуется выборка для ленты.
Разные пользователи могут быть подписаны на разные каналы.
Какой-то бред написан.
Может 99,9% и 99,99% запросов с нормальной задержкой? :)
Ну и раньше твиттер тупил у меня.
kgnk
Не самое интересное, что можно спросить. На формирование лент пользователей уже очень много материала. Набросать свою систему подписок и лент — это максимум часа два.
Суть в том, что у каждого пользователя имеется своя собственная лента (множество идентификаторов записей); когда кто-то публикует запись, то его подписчикам в ленты «вставляется» идентификатор.
Судя по тому, что у Twitter частенько бывают задержки появления твитов в ленте, алгоритм у них примерно такой.
http3
Ну вставился ИД куда-то.
Хоть это как-то сомнительно выглядит.
Как выбирать потом записи?
Как храняться элементы ленты?
На разных серверах?
То есть для формирования ленты нужно сходить на N серверов? :)
kgnk
Если есть ID записи, в чём проблема его получить?
Вот пост про то, как делают быстрые ленты.
http3
Та получить можно при любой архитектуре.
Интересно было, как это сделать грамотней. :)
Может какое-то геораспределение того, на что подписаны и т.д. и т.п.
Или у твиттера все по тупому сваливается в одну кучу? :)