

На мастер-классах будут рассмотрены самые различные темы по базам MySQL: создание и использование тестового сервера, тонкости отладки медленных запросов, особенности систем блокировок, влияние оборудования и конфигурации на производительность, сбор данных с минимальной нагрузкой на сервер.
Сегодня предлагаем вашему вниманию перевод небольшого обзора, в котором Света Смирнова ? старший инженер службы технической поддержки Percona и Анастасия Распопина, специалист по маркетингу, сравнивают как PostgreSQL и MySQL справляются с миллионами запросов в секунду.
5-го июля для участников PG Day’17 Светлана более подробно расскажет про архитектуру MySQL сервера и специфику работы с разными его частями, такими как оптимизатор, табличные движки, системы блокировок.
Анастасия: Могут ли базы данных с открытым исходным кодом справиться с миллионом запросов в секунду? Многие защитники открытого исходного кода ответят «да». Однако утверждений недостаточно для обоснованных доказательств. Именно поэтому в этой статье мы делимся результатами тестов от Александра Короткова (CEO of Development, Postgres Professional) и Светы Смирновой (главный инженер по техническому обслуживанию, Percona). Сравнительное исследование производительности PostgreSQL 9.6 и MySQL 5.7 будет особенно полезно для окружений с несколькими базами данных.
Идея этого исследования состоит в том, чтобы обеспечить честное сравнение двух популярных СУБД. Света и Александр хотели протестировать самые последние версии MySQL и PostgreSQL с помощью одного и того же инструмента при одних и тех же сложных рабочих нагрузках и с использованием одинаковых параметров конфигурации (где это возможно). Однако, поскольку экосистемы PostgreSQL и MySQL эволюционировали независимо друг от друга, со стандартными инструментами тестирования (pgbench and SysBench), используемыми для каждой базы данных, это было непростое путешествие.
Задача легла на экспертов по базам данных с многолетним практическим опытом. Света работала в качестве старшего главного инженера по технической поддержке в группе проверки ошибок службы поддержки MySQL в Oracle на протяжении восьми с лишним лет, а с 2015 года работала главным инженером по техническому обслуживанию в компании Percona. Александр Коротков является одним из основных разработчиков PostgreSQL и разработчиком ряда функций PostgreSQL, включая команду CREATE ACCESS METHOD, общий интерфейс WAL, неблокирующий Pin/UnpinBuffer, индексный поиск для регулярных выражений и многого другого. Итак, у нас подобрался довольно приличный актерский состав для этой пьесы!
Света: Дмитрий Кравчук регулярно публикует подробные результаты тестов для MySQL, так что основной задачей было подтвердить, что MySQL может выполнить миллионы запросов в секунду. Как показывают наши графики, мы уже прошли эту отметку. Как инженер поддержки я часто работаю с клиентами, у которых есть гетерогенные базы данных в их окружениях, и мне хотелось знать о влиянии переноса задач из одной базы данных в другую. Поэтому я была рада возможности поработать с компанией Postgres Professional и выявить сильные и слабые стороны этих двух баз данных.
Мы хотели протестировать обе базы данных на одном оборудовании, используя одинаковые инструменты и тесты. Мы собирались проверить базовую функциональность, а затем работать над более детальными сравнениями. Таким образом, мы могли бы сравнить различные сценарии использования из реальной жизни и популярные функции.
Спойлер: Мы пока далеки от окончательных результатов. Это начало серии статей.
Базы данных с открытым исходным кодом на больших машинах, серия 1: «Это было близко…»
Postgres Professional вместе с Freematiq предоставили для тестов две мощные современные машины.
Конфигурация оборудования:
Процессоры: физические = 4, ядра = 72, виртуальные = 144, hyperthreading = да
Память: 3.0T
Скорость диска: около 3K IOPS
ОС: CentOS 7.1.1503
Файловая система: XFS
Также я использовала менее производительную машину Percona.
Конфигурация оборудования:
Процессоры: физические = 2, ядра = 12, виртуальные = 24, hyperthreading = да
Память: 251.9G
Скорость диска: около 33K IOPS
ОС: Ubuntu 14.04.5 LTS
Файловая система: EXT4
Обратите внимание, что машины с меньшим количеством процессорных ядер и более быстрыми дисками чаще используются для инсталляций MySQL, чем машины с большим количеством ядер.
Первое, что нам нужно было согласовать, — это какой инструмент использовать. Справедливое сравнение имеет смысл только в том случае, если рабочие нагрузки максимально приближены.
Стандартный инструмент PostgreSQL для тестирования производительности — pgbench, а для MySQL — SysBench. SysBench поддерживает несколько драйверов баз данных и скриптовые тесты на языке программирования Lua, поэтому мы решили использовать этот инструмент для обеих баз данных.
Первоначальный план состоял в том, чтобы преобразовать тесты pgbench в синтаксис SysBench на Lua, а затем запустить стандартные тесты для обеих баз данных. Получив первые результаты, мы изменили наши тесты, чтобы лучше изучить специфические возможности MySQL и PostgreSQL.
Я сконвертировала тесты pgbench в синтаксис SysBench и поместила тесты в open-database-bench репозиторий GitHub.
И тогда мы оба столкнулись с трудностями.
Как я уже писала, я также прогоняла тесты на машине Percona. Для этого сконвертированного теста результаты были почти идентичными:
Машина Percona:
OLTP test statistics:
transactions: 1000000 (28727.81 per sec.)
read/write requests: 5000000 (143639.05 per sec.)
other operations: 2000000 (57455.62 per sec.)
Машина Freematiq:
OLTP test statistics:
transactions: 1000000 (29784.74 per sec.)
read/write requests: 5000000 (148923.71 per sec.)
other operations: 2000000 (59569.49 per sec.)
Я начала расследование. Единственным, в чём машина Percona превосходила Freematiq, была скорость диска. Поэтому я начала прогонять read-only тест pgbench, который был идентичен point select тесту SysBench с полным набором данных в памяти. Но на этот раз SysBench использовал 50% доступных ресурсов CPU:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4585 smirnova 20 0 0,157t 0,041t 9596 S 7226 1,4 12:27.16 mysqld
8745 smirnova 20 0 1266212 629148 1824 S 7126 0,0 9:22.78 sysbench
У Александра, в свою очередь, были проблемы с SysBench, который не мог создать высокую нагрузку на PostgreSQL при использовании prepared statements:
93087 korotkov 20 0 9289440 3,718g 2964 S 242,6 0,1 0:32.82 sysbench
93161 korotkov 20 0 32,904g 81612 80208 S 4,0 0,0 0:00.47 postgres
93116 korotkov 20 0 32,904g 80828 79424 S 3,6 0,0 0:00.46 postgres
93118 korotkov 20 0 32,904g 80424 79020 S 3,6 0,0 0:00.47 postgres
93121 korotkov 20 0 32,904g 80720 79312 S 3,6 0,0 0:00.47 postgres
93128 korotkov 20 0 32,904g 77936 76536 S 3,6 0,0 0:00.46 postgres
93130 korotkov 20 0 32,904g 81604 80204 S 3,6 0,0 0:00.47 postgres
93146 korotkov 20 0 32,904g 81112 79704 S 3,6 0,0 0:00.46 postgres
Мы связались с автором SysBench Алексеем Копытовым, и он исправил проблему MySQL. Решение следующее:
• используйте SysBench с параметрами --percentile = 0 --max-requests = 0 (разумное использование CPU);
• используйте ветвь concurrency_kit (лучший параллелизм и обработка Lua);
• перепишите скрипты Lua для поддержки prepared statements (pull request: github.com/akopytov/sysbench/pull/94);
• запускайте как SysBench, так и mysqld с предварительно загруженной библиотекой jemalloc или tmalloc.
Исправление для PostgreSQL уже на подходе. На данный момент Александр преобразовал стандартный тест SysBench в формат pgbench, и на этом мы застопорились. Не так много нового для MySQL, но, по крайней мере, у нас была исходная точка для сравнения.
Следующая трудность, с которой я столкнулась, — это параметры операционной системы по умолчанию. Если коротко, то я изменила их на рекомендуемые (описано ниже):
vm.swappiness=1
cpupower frequency-set --governor performance
kernel.sched_autogroup_enabled=0
kernel.sched_migration_cost_ns= 5000000
vm.dirty_background_bytes=67108864
vm.dirty_bytes=536870912
IO scheduler [deadline]
Те же параметры были лучше и для производительности PostgreSQL. Александр настроил свою машину аналогично.
После решения этих проблем мы узнали и реализовали следующее:
• мы не можем использовать один инструмент (пока);
• Александр написал тест для pgbench, имитируя стандартные тесты SysBench;
• мы все еще не можем писать кастомные тесты, поскольку используем разные инструменты.
Но мы могли бы использовать эти тесты в качестве исходной точки. После работы, выполненной Александром, мы застряли в стандартных тестах SysBench. Я преобразовала их для использования prepared statements, а Александр преобразовал их в формат pgbench.
Стоит упомянуть, что я не смогла получить такие же результаты, как у Дмитрия, для тестов Read Only и Point Select. Они похожи, но немного медленнее. Нам нужно исследовать, является ли это результатом использования разных аппаратных средств или недостатком возможностей тестирования производительности с моей стороны. Результаты тестов Read-Write совпадают.
Между тестами PostgreSQL и MySQL было еще одно различие. У пользователей MySQL обычно много соединений. Установка значения переменной max_connections и ограничение общего числа параллельных подключений до тысяч не редкость в наши дни. Хотя это и не рекомендуется, люди используют данную функцию даже без плагина thread pool. В реальной жизни большинство этих соединений «спят». Но всегда есть шанс, что все они будут использованы в случае увеличения активности веб-сайта.
Для MySQL я проводила тесты до 1024 соединений. Я использовала степени двойки и множители количества ядер: 1, 2, 4, 8, 16, 32, 36, 64, 72, 128, 144, 256, 512 и 1024 потока.
Для Александра было важнее провести тест меньшими шагами. Он начал с одного потока и увеличивал на 10 потоков, пока не достиг 250 параллельных потоков. Таким образом, вы увидите более подробный график для PostgreSQL, но результатов после 250 потоков нет.
Вот результаты сравнения.
Point SELECT
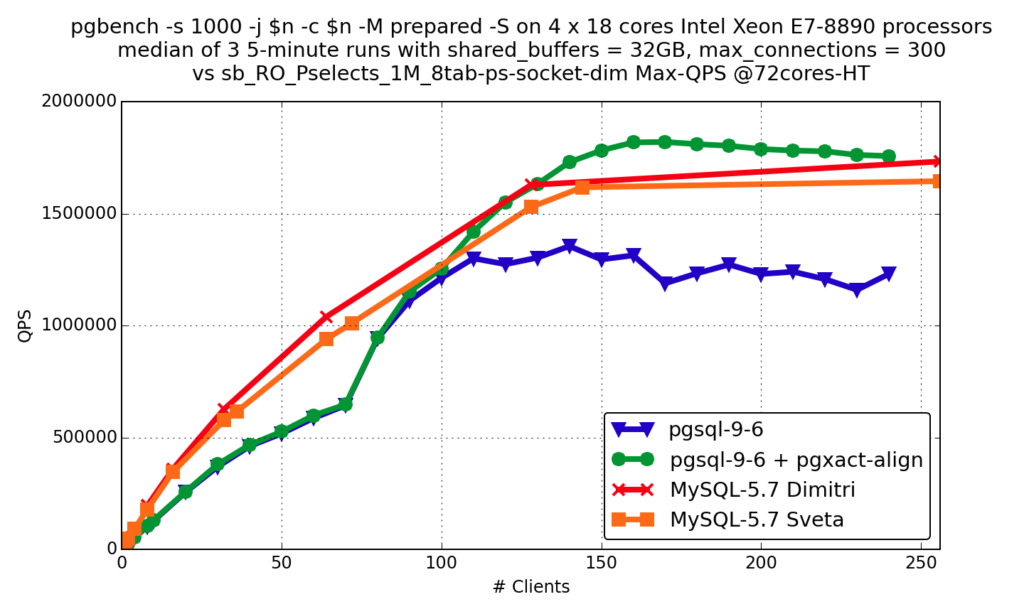
pgsql-9.6 — стандартный PostgreSQL
pgsql-9.6 + pgxact-align — PostgreSQL с этим патчем (подробнее можно почитать в этой статье)
MySQL-5.7 Dimitri — сервер Oracle MySQL
MySQL-5.7 Sveta — сервер Percona 5.7.15
OLTP RO

OLTP RW
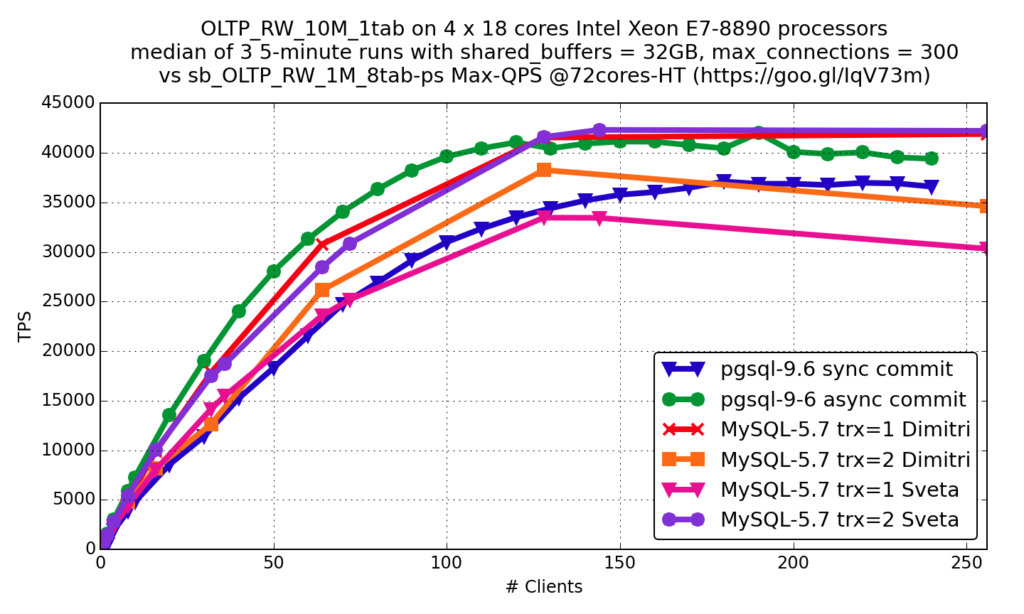
Синхронизация при commit в PostgreSQL является функцией, аналогичной innodb_flush_log_at_trx_commit = 1 в InnoDB, а асинхронный коммит аналогичен innodb_flush_log_at_trx_commit = 2.
Вы видите, что результаты очень похожи: обе базы данных развиваются очень быстро и хорошо работают с современным оборудованием.
Результаты MySQL, которые показывают 1024 потока для справки.
Point SELECT и OLTP RO
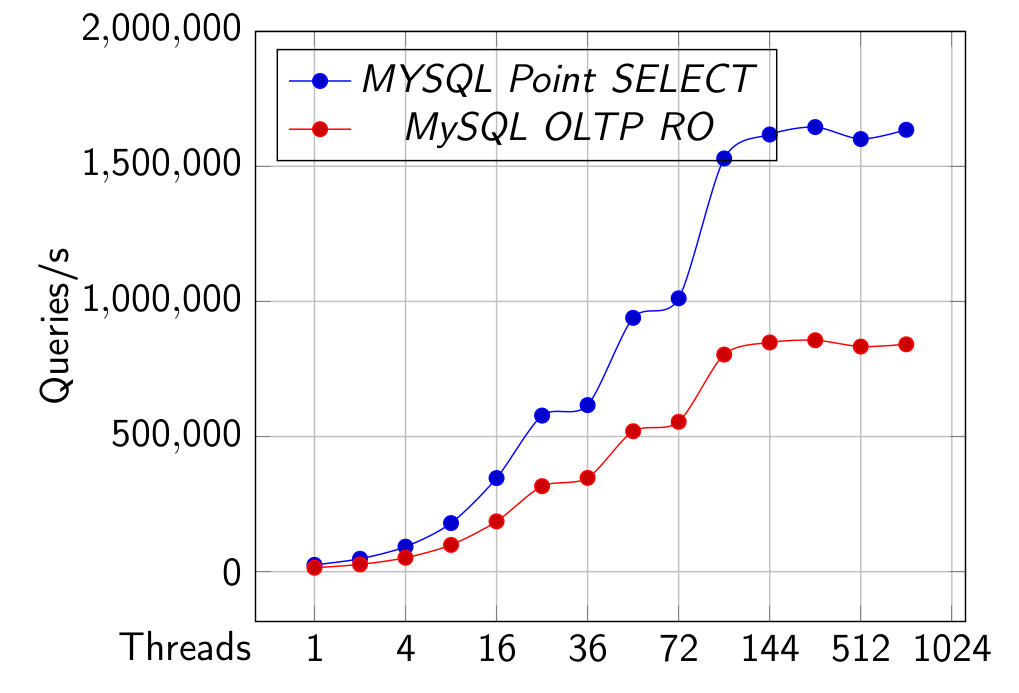
OLTP RW с innodb_flush_log_at_trx_commit, установленным на 1 и 2

Получив эти результаты, мы провели несколько специальных тестов, которые будут рассмотрены в отдельных статьях.
Дополнительная информация
Опции MySQL для тестов OLTP RO и Point SELECT:
# general
table_open_cache = 8000
table_open_cache_instances=16
back_log=1500
query_cache_type=0
max_connections=4000
# files
innodb_file_per_table
innodb_log_file_size=1024M
innodb_log_files_in_group=3
innodb_open_files=4000
# Monitoring
innodb_monitor_enable = '%'
performance_schema=OFF #cpu-bound, matters for performance
#Percona Server specific
userstat=0
thread-statistics=0
# buffers
innodb_buffer_pool_size=128000M
innodb_buffer_pool_instances=128 #to avoid wait on InnoDB Buffer Pool mutex
innodb_log_buffer_size=64M
# InnoDB-specific
innodb_checksums=1 #Default is CRC32 in 5.7, very fast
innodb_use_native_aio=1
innodb_doublewrite= 1 #https://www.percona.com/blog/2016/05/09/percona-server-5-7-parallel-doublewrite/
innodb_stats_persistent = 1
innodb_support_xa=0 #(We are read-only, but this option is deprecated)
innodb_spin_wait_delay=6 #(Processor and OS-dependent)
innodb_thread_concurrency=0
join_buffer_size=32K
innodb_flush_log_at_trx_commit=2
sort_buffer_size=32K
innodb_flush_method=O_DIRECT_NO_FSYNC
innodb_max_dirty_pages_pct=90
innodb_max_dirty_pages_pct_lwm=10
innodb_lru_scan_depth=4000
innodb_page_cleaners=4
# perf special
innodb_adaptive_flushing = 1
innodb_flush_neighbors = 0
innodb_read_io_threads = 4
innodb_write_io_threads = 4
innodb_io_capacity=2000
innodb_io_capacity_max=4000
innodb_purge_threads=4
innodb_max_purge_lag_delay=30000000
innodb_max_purge_lag=0
innodb_adaptive_hash_index=0 (depends on workload, always check)
Опции MySQL для OLTP RW:
#Open files
table_open_cache = 8000
table_open_cache_instances = 16
query_cache_type = 0
join_buffer_size=32k
sort_buffer_size=32k
max_connections=16000
back_log=5000
innodb_open_files=4000
#Monitoring
performance-schema=0
#Percona Server specific
userstat=0
thread-statistics=0
#InnoDB General
innodb_buffer_pool_load_at_startup=1
innodb_buffer_pool_dump_at_shutdown=1
innodb_numa_interleave=1
innodb_file_per_table=1
innodb_file_format=barracuda
innodb_flush_method=O_DIRECT_NO_FSYNC
innodb_doublewrite=1
innodb_support_xa=1
innodb_checksums=1
#Concurrency
innodb_thread_concurrency=144
innodb_page_cleaners=8
innodb_purge_threads=4
innodb_spin_wait_delay=12 Good value for RO is 6, for RW and RC is 192
innodb_log_file_size=8G
innodb_log_files_in_group=16
innodb_buffer_pool_size=128G
innodb_buffer_pool_instances=128 #to avoid wait on InnoDB Buffer Pool mutex
innodb_io_capacity=18000
innodb_io_capacity_max=36000
innodb_flush_log_at_timeout=0
innodb_flush_log_at_trx_commit=2
innodb_flush_sync=1
innodb_adaptive_flushing=1
innodb_flush_neighbors = 0
innodb_max_dirty_pages_pct=90
innodb_max_dirty_pages_pct_lwm=10
innodb_lru_scan_depth=4000
innodb_adaptive_hash_index=0
innodb_change_buffering=none #can be inserts, workload-specific
optimizer_switch="index_condition_pushdown=off" #workload-specific
Параметры MySQL SysBench:
LD_PRELOAD=/data/sveta/5.7.14/lib/mysql/libjemalloc.so
/data/sveta/sbkk/bin/sysbench
[ --test=/data/sveta/sysbench/sysbench/tests/db/oltp_prepared.lua | --test=/data/sveta/sysbench/sysbench/tests/db/oltp_simple_prepared.lua ]
--db-driver=mysql --oltp-tables-count=8 --oltp-table-size=10000000
--mysql-table-engine=innodb --mysql-user=msandbox --mysql-password=msandbox
--mysql-socket=/tmp/mysql_sandbox5715.sock
--num-threads=$i --max-requests=0 --max-time=300
--percentile=0 [--oltp-read-only=on --oltp-skip-trx=on]
Параметры PostgreSQL pgbench:
$ git clone https://github.com/postgrespro/pg_oltp_bench.git
$ cd pg_oltp_bench
$ make USE_PGXS=1
$ sudo make USE_PGXS=1 install
$ psql DB -f oltp_init.sql
$ psql DB -c "CREATE EXTENSION pg_oltp_bench;"
$ pgbench -c 100 -j 100 -M prepared -f oltp_ro.sql -T 300 -P 1 DB
$ pgbench -c 100 -j 100 -M prepared -f oltp_rw.sql -T 300 -P 1 DB
Функции в MySQL 5.7, которые существенно улучшили производительность:
- InnoDB: оптимизация списка транзакций:
- InnoDB: уменьшение contention для lock_sys_t::mutex:
- InnoDB: исправление contention index->lock:
- InnoDB: ускоренный и параллельный сброс страниц на диск:
- масштабируемость MDL (Meta-Data Lock):
- удаление THR_LOCK::mutex для InnoDB: Wl #6671;
- партицированный LOCK_grant;
- число партиций постоянно;
- ID потока, используемый для назначения партиции:
- неблокирующий захват MDL lock для DML:
Анастасия: Первоначальные результаты этого исследования были анонсированы на Percona Live Amsterdam 2016. Новые интересные результаты были добавлены во вторую версию той же речи, которая была представлена на Moscow HighLoad++ 2016.
Дальнейшие версии исследования будут доступны для всех участников мастер-класса Светы на PG Day'17. Если у вас есть вопросы и пожелания по тому, о каких аспектах производительности PostgreSQL и MySQL вы бы хотели узнать подробнее, оставляйте комментарии, мы обязательно учтем ваши пожелания!
Комментарии (21)

svetasmirnova
12.04.2017 06:01+4Ребят, вы, конечно, молодцы. Но где указание, что это перевод? Где ссылка на блог компании Percona, где пост был изначально опубликован? Где прямое явное указание в начале текста на то, что PostgreSQL тестировали специалисты именно по нему, а именно компания PostgreSQL Professional?

rdruzyagin
12.04.2017 09:39Света, информация о том, что это перевод, и его авторстве указана согласно гайдлайнам хабра с момента публикации статьи. Ссылку плейнтекстом добавил в начало, что ни у кого никаких сомнений не возникало. Перевод мы обсуждали и согласовывали с Настей еще задолго до начала работ по нему.
Информация о том, что тестирование PG проводил Александр, указана в первом же абзаце перевода вашей статьи, мы здесь ни на грам ничего не изменили. Авторство блогпоста на сайте перконы принадлежит тебе и Насте, что мы и указываем во вступлении. Александр автором статьи на сайте Percona не значится.svetasmirnova
12.04.2017 14:18Ну вот сейчас понятнее, спасибо! А то в начале получалось, что это мы с Настей вдвоём тестировали, а не статью писали. А суть проекта именно в том, что специалист по PostgreSQL тестирует PostgreSQL, специалист по MySQL тестирует MySQL.
Zoomerman
12.04.2017 09:31+1Спасибо за статью! Позвольте мне изложить свой вывод, а вы по возможности исправьте, если где-то заблуждаюсь.
— максимальная производительность БД достигается при равенстве логических ядер количеству параллельных потоков запросов;
— разница производительности MySQL и PostgreSQL в «тюнингованных» системах порядка 2%;
— PostgreSQL тюнинговать технически сложнее (нужно добавлять патч), для MySQL достаточно поколдовать с настройками;
— В разгоне БД первостепенное значение имеет скорость дисковой системы, а не количество ядер;
— Наибольший эффект при оптимизации скорости БД даёт рефакторинг структуры базы и оптимизация запросов, нежели смена СУБД с одной на другую.
P.S. Немного завис в начале статьи, когда увидел, что 12 ядер выдали такой же результат, как мои 4 на дефолтных настройках. Замерил IOPS — у меня чтение/запись 43k/40k в отличие от авторских 33k. Списал на то, что я измерял на реальном проекте, а не на авторских скриптах.
P.P.S. Я, конечно понимаю, мастеркласс и всё такое… Реально не вижу разницы, кроме как технической между этими двумя СУБД (из статьи). Интересно было бы увидеть эти же графики в этих же режимах на более слабой машине. А так информации мало на мой взгляд.Ivan22
12.04.2017 12:26разницы нет, т.к. думаю тесты простые. Стоит взять более сложные и специализированные кейсы — и сразу же начнется проявлятся разница, причем в зависимости от узконаправленности теста будет впереди как одна так и другая система. (См. кейс убера )
svetasmirnova
12.04.2017 14:012% — это погрешность всё-таки. Насчёт патча — это конкретный ворклод. Наверняка и для MySQL можно найти такой даже сейчас, что только патчить. PS — у да, там и ворклод, и скорость диска имеют значение.

saterenko
12.04.2017 10:02+1Две хорошо оптимизированные базы, работающие по одной схеме и на одном железе будут показывать сравнимые результаты. На чтении скорость будет зависеть от того, сколько данных помещается в кеш и какова скорость чтения диска, на записи какова скорость записи на диск. Ни чего удивительного, что результаты похожи.
Сейчас гораздо важнее простота администрирования и разворачивание кластера на множестве серверов, а не скорость работы одного мега-сервера. Если у перконы, без опыта, я развернул кластер за час и он работал из коробки, без танцев с бубнами, то с постгрёй у меня уже 3 девопса, не меньше двух недель каждый, пытались построить кластер и результат я могу оценить на три с минусом.
Это мой опыт, может у кого-то он другой. Я лишь хочу сказать, что все эти тесты в статье оторваны от жизни, протестируйте скорость разворачивания, скорость работы и стабильность кластеров из баз данных.DRDOS
12.04.2017 13:08Вы совершенно правы поддерживаю!
Вечно придумывают искусственные тесты, что бы показать свою крутость.
А реальное, большинство интересуют другие проблемы.Diaskhan
12.04.2017 13:34У МарияДБ кластера есть проблема (Галера). При двух нодовом кластере возникают проблемы репликаций,
Низкоуровневый Деадлок. resource deadlock avoided
То что postgre нужно 3 девопса, Это больше проблема наследия Линуха. Где каждый параметр должен прописываться в conf файле.
Поддержка Firebird такая же сложная если не хуже! Но на то и нужен Opensource, Когда Вам не гарантируют сервис Enteprise баз данных. На то он и Opensource, за удобство нужно платить конторе которая создает это удобство!
svetasmirnova
12.04.2017 14:03В принципе были планы к ним и перейти. Просто с чего-то начинать же нужно. В статье именно поэтому подробно описываются трудности, с которыми мы столкнулись

SyCraft
12.04.2017 13:18innodb_buffer_pool_size=128000M
innodb_buffer_pool_instances=128 #to avoid wait on InnoDB Buffer Pool mutex
innodb_buffer_pool_instances: Multiple innodb buffer pools introduced in InnoDB 1.1 and MySQL 5.5. In MySQL 5.5 the default value for it was 1 which is changed to 8 as new default value in MySQL 5.6. Minimum innodb_buffer_pool_instances should be lie between 1 (minimum) & 64 (maximum). Enabling innodb_buffer_pool_instances is useful in highly concurrent workload as it may reduce contention of the global mutexes.
Те это значение, согласно документации, не может быть более 64
Да и согласно этой статьи http://dimitrik.free.fr/blog/archives/2012/10/mysql-performance-innodb-buffer-pool-instances-in-56.html
Больше, не всегда значит лучше
svetasmirnova
12.04.2017 14:12Кстати good point. Их по факту 64, конечно. Вообще я не очень понимаю в каких случаях лучше меньше да лучше сейчас, на 5.7+. Конкретно в этом тесте я видела Buffer pool mutex contention при меньших значениях. Но было бы интересно попробовать с данными, где result set большой.
dmitry_ch
Картинка интересна: слон и сам мокрый (хотя сухопутный зверь), и дельфин менее покрыт водой (хотя водоплавающий). Душевная картинка: «бесполезная забота».
kozzztik
старший инженер службы технической поддержки и специалист по маркетингу сравнивают как PostgreSQL и MySQL справляются с миллионами запросов в секунду.
Специалист по маркетингу тоже крайне важен в оценке производительности систем )
svetasmirnova
Это перевод статьи из блока компании где я работаю. Вот оригинал:
svetasmirnova
Сорри, планшет отправил комментарий неоконченный. Это перевод статьи из блога компании где я работаю. Вот оригинал: https://www.percona.com/blog/2017/01/06/millions-queries-per-second-postgresql-and-mysql-peaceful-battle-at-modern-demanding-workloads/ Настя там в роли ведущего, она ничего не тестировали. Тестировала я и Александр Коротков из PostgreSQL Professional. То есть идея была в том, что специалист по PostgreSQL и MySQL совместно работают на одинаковом железе. Чтобы не было такого: «Света взяла постгрес из коробки и у неё он какой-то тормозной» и аналогично с другой стороны.
Fortop
Так а где одинаковое железо?
Или я был невнимателен или в статье оно сильно разное
svetasmirnova
Пропустили. Я перевод не вычитывала. В оригинале где я про более слабую машину говорю — это тест MySQL- я. А результаты PostgreSQL и MySQL сравнивались на идентичных машинах. (На которых 144 ядра)
svetasmirnova
Ну и, кстати, я видела очень крутые исследования сейлзов (продавцов), которые потом тру девелоперы в своих презентациях показывали. Так что не вижу ничего плохого или странного в том, что специалист по маркетингу что-то тестирует. Хоть в данном случае у Насти была другая роль.
ser_rostr2
Специалист по СЕО по твоему не может быть в прошлом хорошим инженером?)