
- В какой день недели и время суток лучше всего публиковаться?
- Есть ли зависимость между числом подписчиков и популярностью постов?
- Каких постов больше: обучающих материалов, переводов или прочих?
И многое другое…

Что мы сделали?
24 апреля 2017 года была собрана статистика по всем последним публикациям на Хабрахабре. Оказалось, что в период с 20 сентября 2016 года по 22 апреля 2017 года:
- Создано 6550 публикаций, исключая «Мегапосты» с анонсом в верхнем меню и посты, опубликованные компаниями, прекратившими активность на Хабре.
- В среднем в день публиковалось 30 постов, а в месяц более 900.
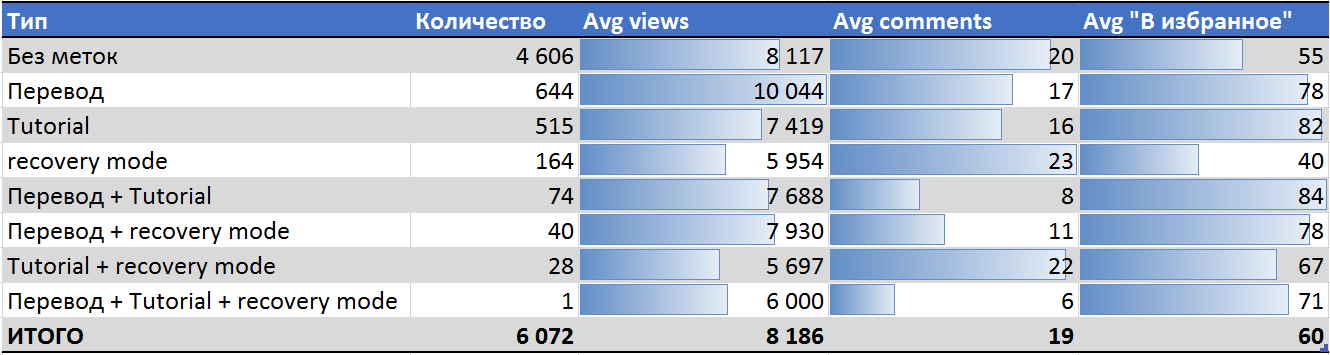
- Около 12,5% было помечено тегом «Перевод», 10% с пометкой «Tutorial» и 4% с «recovery mode». Около 76% постов не имело таких отметок, при этом некоторые записи обозначены двумя и более тегами.
Для достоверности статистики из более 6,5к публикаций мы удалили публикации, количество просмотров которых не попадает в 99,7% область нормального распределения просмотров. Такие посты могут испортить статистику, сильно повлияв на средние значения и стандартные отклонения в дальнейших расчетах. Публикации мы удаляли до тех пор, пока все они не укладывались в . Всего было удалено 7,4% супер-публикаций.
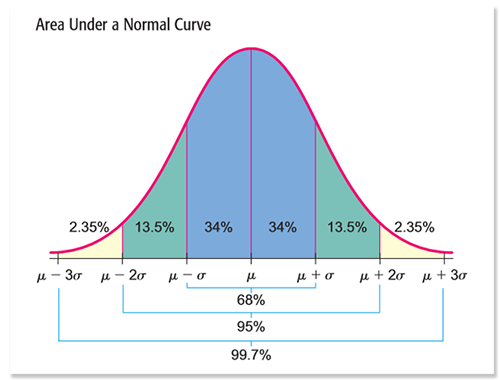
Плотность нормального распределения
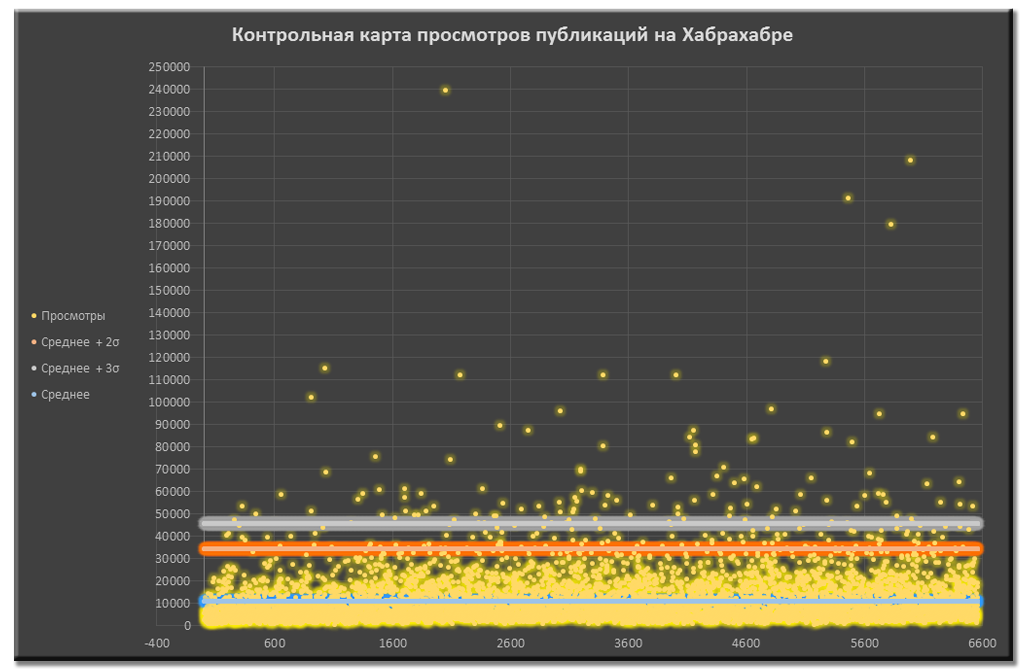 Контрольная карта просмотров публикаций до чистки данных
Контрольная карта просмотров публикаций до чистки данных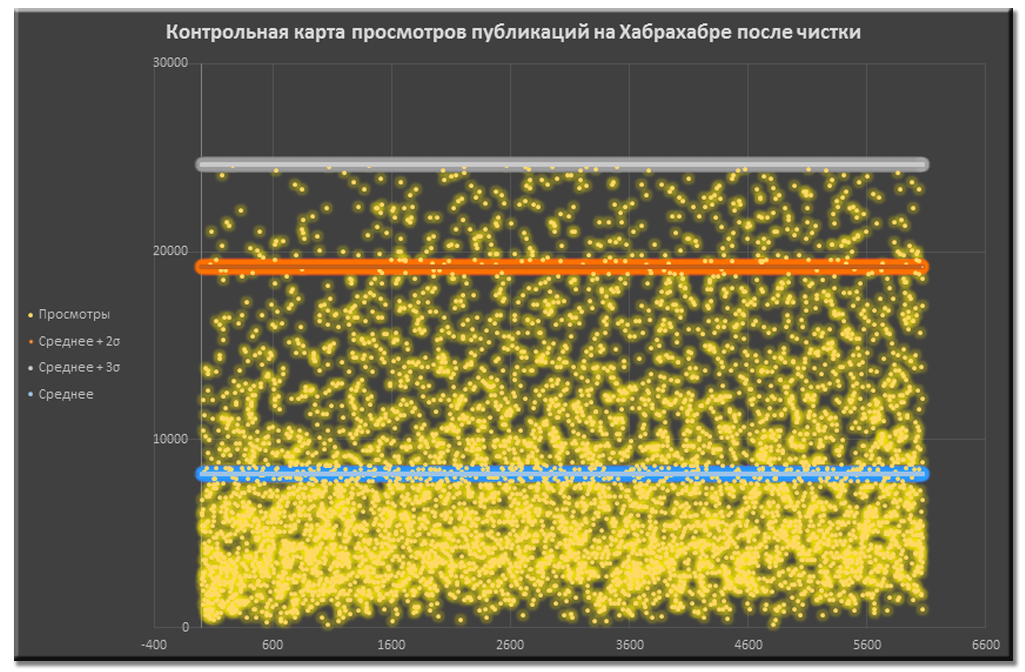 Контрольная карта просмотров публикаций после чистки данных
Контрольная карта просмотров публикаций после чистки данныхПолезная находка #1
Среди почищенного набора данных
- Переводы набирают наибольшее число просмотров и лучше среднего поста добавляются в избранное, вызывая при этом меньше среднего число комментариев.
- Обучающие материалы просматриваются меньшее количество раз, чем средняя статья, но лучше всех добавляются в избранное, особенно в случае с переводным Tutorial.
- Для реабилитационного поста пользователю с отрицательной кармой лучше всего сделать перевод годного материала.
Полезная находка #2
- Количество подписчиков не влияет на количество просмотров публикации. Например, google с 14000 подписчиками на момент публикации набрал 570 просмотров одного из своих постов за 40 дней.
- Чтобы хуже всего сконвертировать количество подписчиков в количество просмотров, необходимо публиковать статьи частями и добавлять номера частей в заголовок. К 3 или 4 части публикации количество просмотров, как правило, падает до минимума. Срабатывает принцип «воронки». Те, кто не читал первую часть, редко берутся за вторую. Среди читавших 1 статью серии лишь часть пользователей будет читать вторую. Возможно, выходом будет расположить информацию о прочих статьях серии внутри публикации.
- Приглашения и объявления, конечно, соберут малое число просмотров. Статистика рекомендует интегрировать приглашения и объявления внутрь статей.
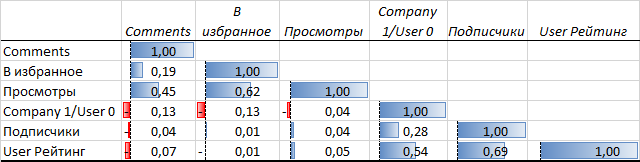
Попарная корреляция основных показателей
Полезная находка #3
Лучшие дни недели
- по количеству просмотров Суббота и Воскресенье (худший Среда).
- по количеству добавлений в избранное Понедельник и Воскресенье.
- по количеству комментариев Вторник и Суббота.
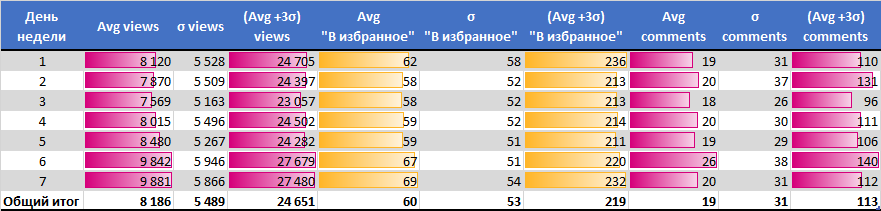
Лучшее время
- по количеству просмотров с 23:30 до 00:00
- по количеству добавлений в избранное с 6:30 до 8:30
- по количеству комментариев с 5:30 до 7:30

Лучшее время публикации при учете дня недели — ночь с пятницы на субботу или вечер воскресенья.
 Картинка может быть увеличена по клику (открывается в текущем окне)
Картинка может быть увеличена по клику (открывается в текущем окне)О выводах
Согласно смыслу закона больших чисел, всегда найдётся такое конечное число испытаний, при котором с любой заданной наперёд вероятностью меньше 1 относительная частота появления некоторого события будет сколь угодно мало отличаться от его вероятности. На этом свойстве основаны методы оценки вероятности на основе анализа конечной выборки. Наша выборка для каждого разреза имела более 30 результатов эмпирических испытаний — фактических показателей публикаций.
При публикации одной конкретной статьи приведенные выше закономерности могут не оказать значительного влияния или будут нивелированы другими факторами. Если же планируется опубликовывать серию постов, использование этих закономерностей может принести пользу. В каждом отдельном случае наибольшее влияние на показатели популярности статьи имеет её содержание.
Рейтинги
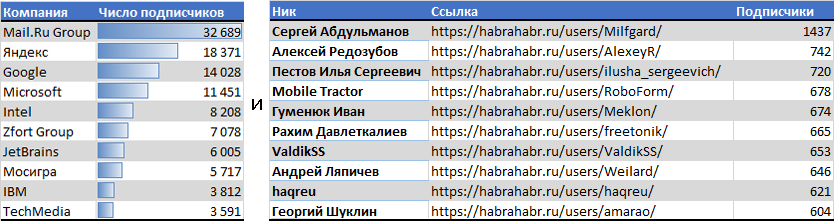
ТОП10 Компаний и Пользователей с наибольшим числом подписчиков
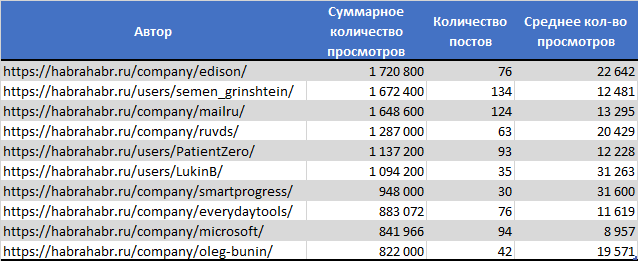
ТОП10 с наибольшим числом просмотров
ТОП10 с наибольшим числом комментариев

ТОП10 с наибольшим числом добавлений в избранное
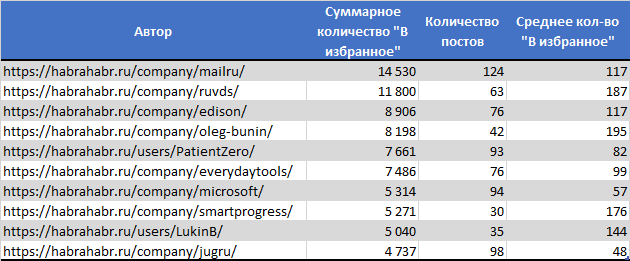
- Наибольшее число комментариев собрала статья «Почему мы злые?»
- Самой просматриваемой статьей, обладающей также наибольшим количеством добавлением в избранное, стала «Как «пробить» человека в Интернет: используем операторы Google и логику»
- 2 место по количеству добавлений в избранное заняла публикация «Самые полезные приёмы работы в командной строке Linux»
P.S.
Если Вас интересует какая-либо зависимость показателей, оставьте комментарий, по возможности постараемся рассчитать и опубликовать. Напишите нам и мы отправим вам ссылку на файл Excel c данным о публикациях, которые мы собрали.
Комментарии (35)

Pointman
27.04.2017 09:56+1спасибо большое, все таки статистика дело наглядное.

Cloud4Y
27.04.2017 10:00Мы делали акцент именно на распределении показателей, чтобы не показывать только среднюю «температуру по больнице». Математическое ожидание и среднеквадратическое отклонение позволяют понять с какой вероятностью в том или ином случае может быть получен тот или иной результат.

shybovycha
27.04.2017 10:10А вот мне было бы интересно увидеть, сколько постов написаны, так сказать, "от чистого сердца", то бишь без тега "Блог компании X"
Cloud4Y
27.04.2017 10:16+453,9% за период написано в личных блогах, 46,1% в блогах компаний. Мы не склонны утверждать, что это отражает зависимость создания поста «от чистого сердца»

den_golub
27.04.2017 10:15Было бы неплохо провести подобное исследование с некоторыми оговорками:
- Брать только хабраюзеров, выкинув блоги компаний
- При этом провести выборку по юзерам пришедшим на хабр, за последний год — два
Чтоб посмотреть не столько крутость показателей, сколько то благодарю чему удаются прорваться новичкам.Cloud4Y
27.04.2017 10:18+1Отличная идея! Если вы не против, мы опубликуем аналитику на эту тему в скором времени. Это потребует сбора дополнительных данных.


DavidKakaladze
27.04.2017 10:23Около 12,5% было помечено тегом «Перевод», 10% с пометкой «Tutorial» и 4% с «recovery mode». Около 76% постов не имело таких отметок, при этом некоторые записи обозначены двумя и более тегами
Всего 102,5% постов?Cloud4Y
27.04.2017 10:23+5«при этом некоторые записи обозначены двумя и более тегами» — пересечение множеств

OsipovRoman
27.04.2017 10:36+1Спасибо за отличный пост!
В 2015-м году написал пост под названием "Детальный анализ Хабрахабра с помощью языка Wolfram Language (Mathematica)", в котором были проанализированы все доступные на тот момент посты (за исключением тех, у которых отрицательная карма (не учел, так как не попали в тот момент в поле зрения, на что указали в комментариях) и мегапостов (не помню, были ли они тогда, если честно)). Рад, что результаты перекликаются с вашим исследованием.

Cloud4Y
27.04.2017 10:42Спасибо! У вас тоже отличный анализ проведен. Возник вопрос, проводилась ли чистка данных на «выбросы из распределения» перед анализом?
OsipovRoman
27.04.2017 12:44+1Там, где я работал со статистикой и теорией вероятности, использовал SKD (Kernel density estimation), что устраняет выбросы, однако тесты вроде хи-квадрат не проводились, так как вообще говоря практически все они работают исходя из гипотезы о нормальности распределения, а тут видно, что они не все нормальные, а некоторые являются скорее смесью распределений.
Эти вопросы крайне интересные. Возможно у меня будет когда-то время продолжить начатый анализ.
Dmitry_4
27.04.2017 13:52А почему у меня в мобильной версии стало всего несколько тем показывать? Это что за нововведение?
Nekto_Habr
27.04.2017 16:11по количеству комментариев с 5:30 до 7:30
Хмм. Понятно, что перед выходом из дома на работу. Но неужели у большинства есть силы соображать и что-то комментить в это время? То ли дело обед. В общем, неожиданно.OsipovRoman
27.04.2017 17:00+4Важно тут также учитывать аудиторию и часовые пояса.
Скажем, вот распределение населения РФ по часовым поясам:

Ясно, что если в статье использовали время МСК (скорее всего), то когда в Москве 6 утра, условно, в РФ уже на Дальнем Востоке день к концу идет.
Учитывая это, не так удивительно, что ранние посты читаются активно.
Код на языке Wolfram Language для получения инфографики:
Подробнее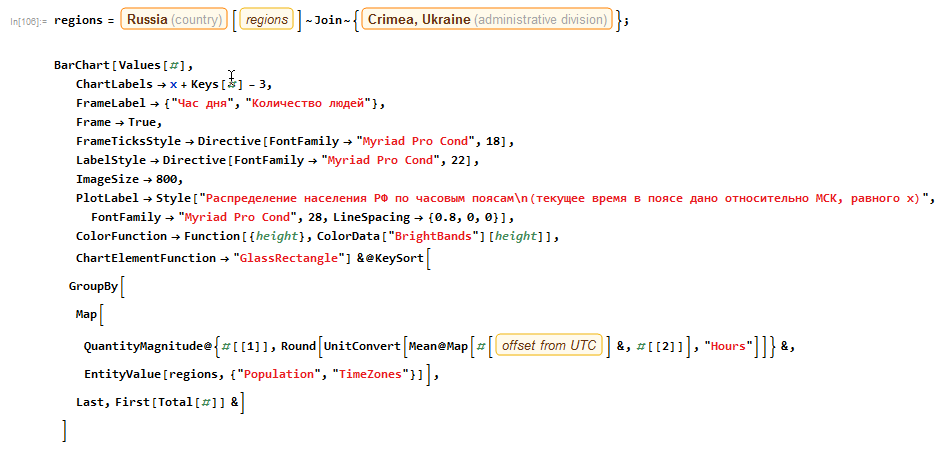
Для копирования:
regions =
Entity["Country", "Russia"][
EntityProperty["Country", "AdministrativeDivisions"]]~
Join~{Entity["AdministrativeDivision", {"Crimea", "Ukraine"}]};
BarChart[Values[#],
ChartLabels -> x + Keys[#] - 3,
FrameLabel -> {"Час дня", "Количество людей"},
Frame -> True,
FrameTicksStyle -> Directive[FontFamily -> "Myriad Pro Cond", 18],
LabelStyle -> Directive[FontFamily -> "Myriad Pro Cond", 22],
ImageSize -> 800,
PlotLabel ->
Style["Распределение населения РФ по часовым поясам\n(текущее \
время в поясе дано относительно МСК, равного x)",
FontFamily -> "Myriad Pro Cond", 28, LineSpacing -> {0.8, 0, 0}],
ColorFunction ->
Function[{height}, ColorData["BrightBands"][height]],
ChartElementFunction -> "GlassRectangle"] &@KeySort[
GroupBy[
Map[
QuantityMagnitude@{#[[1]],
Round[UnitConvert[
Mean@Map[#[
EntityProperty["TimeZone", "OffsetFromUTC"]] &, #[[2]]],
"Hours"]]} &,
EntityValue[regions, {"Population", "TimeZones"}]],
Last, First[Total[#]] &]
]
mgcv
27.04.2017 20:51+1коллеги, весь ваш анализ на основе нормального распределения никуда не годится. У вас по определению Пуассон (и около него), поскольку все значения положительные. Распределение явно асимметричное (что видно даже по картинке), поэтому никакие границы от нормального распределения тут не работают — используйте хоть гамму, что ли…
Cloud4Y
27.04.2017 20:51Верно тут смесь распределений. Критерий удаления публикаций с очень малым количеством просмотров сформулировать сложно. Есть не только «супер-статьи», но и те, которые не привлекают никакого внимания и уходят в небытиё, спустившись в ленте «все подряд». Более правильным подходом будет анализировать статьи группами, но встает вопрос правил разделения. Для статьи «средней интересности» распределение будет стремиться к нормальному. Попадание в «лучшие» меняет распределение, нужна метка «был в ТОПе»
Как Вы считаете применима центральная предельная теорема в этом случае? Мы пришли к выводу о доминирующем влиянии фактора содержания статей (фактора их интересности) и фактора попадания в ТОП. В этих условиях одного распределения может быть недостаточно. Его мы использовали для демонстрации вариабельности показателей статей, чтобы читающие думали о доверительном интервале, а не о математическом ожидании.
Ко всем данным были применены одни и те же правила, потом показатели групп данных сравнили между собой и сделали выводы. Скорее суть статьи в сравнении показателей, а не в абсолютных значениях.
Cloud4Y
27.04.2017 21:13+1Вот графическая интерпретация мысли
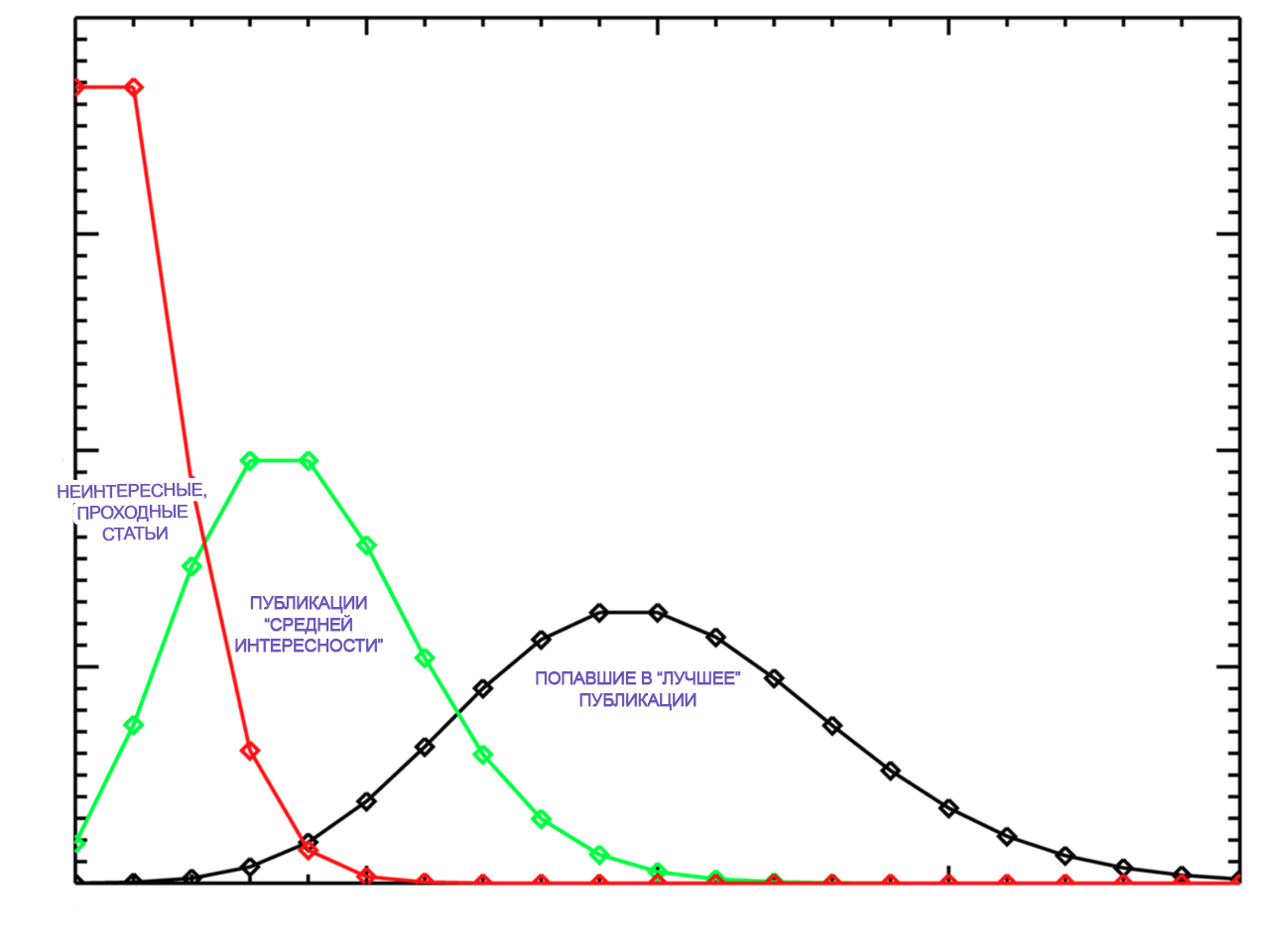
mgcv
28.04.2017 21:03Ваша картинка лишний раз подтверждает, что имеет место Пуассон, который с ростом среднего сходится к нормальному. Чем меньше среднее, тем более несимметричное распределение имеет место (графики визуально похожи на чистое распределение Пуассона, но нужно считать модель, и проверять адекватность). Похоже, ничего выкидывать не нужно, нужно строить обычную модель GLMM, из которой и получать ответы на все вопросы — что от чего и как зависит, где разница/влияние значимо, где нет, и т.д., и т.п… Можно потом динамику привинтить, оценку взаимодействия факторов, и т.д. Данные вообще открытые?
Cloud4Y
29.04.2017 06:56Число наступлений определённого случайного события за единицу времени, когда факт наступления этого события в данном эксперименте не зависят от того, сколько раз и в какие моменты времени оно осуществлялось в прошлом, и не влияет на будущее. А испытания производятся в стационарных условиях, то для описания распределения такой случайной величины обычно используют закон Пуассона.
Как вы считаете, зависит число просмотров публикации от уже набранного числа просмотров, при условии что на Хабре поведение показателей статьи сильно изменяется после выхода статьи в «лучшее»?
Можно использовать распределение, предназначенное, например, для расчета количества проезжающих машин по участку дороги за единицу времени, в данном случае?
Приход одного читателя в течение любого интервала не зависит от прихода любого другого читателя в течение любого другого интервала? Зависит, а чтобы использовать распределение Пуассона, не должно зависеть.
Метод подбора распределения для явления с комплексной структурой внутри по внешнему виду распределения неверный.
В статье есть ссылка для получения таблицы Excel с данными, которые мы собрали для публикации.
Cloud4Y
29.04.2017 08:55Схожим является распределение высоты деревьев, оно нормальное. Это распределение получено в результате того, что деревья росли, как росли показатели статей. Статьи как три типа деревьев:
1) неинтересные статьи — деревья, которые засохли (норм. расп. более вероятно, чем расп. Пуассона)
2) средней интересности статьи — деревья, которые росли в нормальных условиях (норм. расп.)
3) попавшие в лучшее статьи — деревья, которым давали удобрения или растущие в очень благоприятных условиях (норм. расп.)
Cloud4Y
29.04.2017 09:01кратко: это не распределение Пуассона
Cloud4Y
29.04.2017 13:16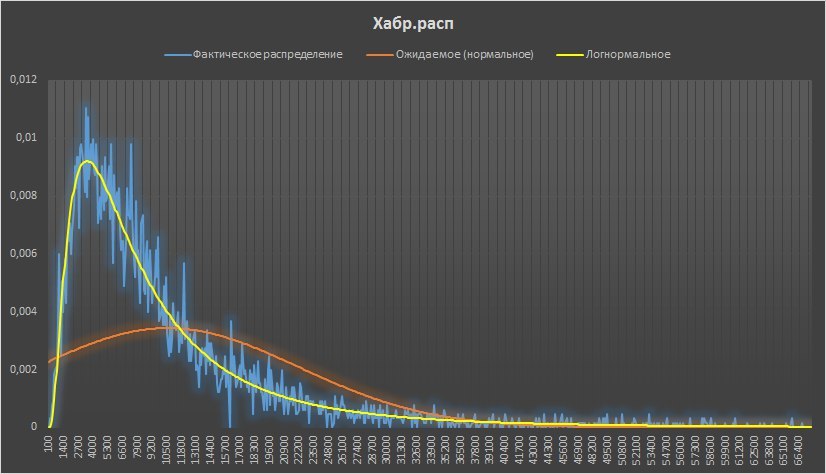
Распределение подобрать можно, оно логнормальное, для этого распределения получается, что мы работали не с 99,7% распределения, а с 92% публикаций.
Меняются ли от этого выводы — нет (только абсолютные значения доверительных интервалов, но не их соотношения (больше или меньше) между друг другом)…

xjukebox
28.04.2017 14:51Нужно было не просто учитывать количество просмотров, а количество просмотров на единицу времени. Так данные были бы точнее и не включали бы в себя «супер-статьи» которые за короткий промежуток времени набирают много просмотров и те статьи, которые за большое количество времени не собрали просмотров вообще.

shybovycha
То, что ссылки в таблицах представлены полным URL и при этом не кликабельны — вызывает несколько меньшее количество удовольствия.
Cloud4Y
Для получения полного удовольствия мы оставили ссылку на нас, по которой можно, оставив сообщение, получить весь файл Excel. Дублируем вот
shybovycha
Или можно сделать таблицы с кликальными ссылками =) User experience же!
ragequit
Задача уровня «садомазохизм» с текущими инструментами верстки таблиц на ХХ и ГТ. Инфа 146%, уж лучше отдельный док.