
Bash-скрипты: начало
Bash-скрипты, часть 2: циклы
Bash-скрипты, часть 3: параметры и ключи командной строки
Bash-скрипты, часть 4: ввод и вывод
Bash-скрипты, часть 5: сигналы, фоновые задачи, управление сценариями
Bash-скрипты, часть 6: функции и разработка библиотек
Bash-скрипты, часть 7: sed и обработка текстов
Bash-скрипты, часть 8: язык обработки данных awk
Bash-скрипты, часть 9: регулярные выражения
Bash-скрипты, часть 10: практические примеры
Bash-скрипты, часть 11: expect и автоматизация интерактивных утилит
Для того, чтобы полноценно обрабатывать тексты в bash-скриптах с помощью sed и awk, просто необходимо разобраться с регулярными выражениями. Реализации этого полезнейшего инструмента можно найти буквально повсюду, и хотя устроены все регулярные выражения схожим образом, основаны на одних и тех же идеях, в разных средах работа с ними имеет определённые особенности. Тут мы поговорим о регулярных выражениях, которые подходят для использования в сценариях командной строки Linux.

Этот материал задуман как введение в регулярные выражения, рассчитанное на тех, кто может совершенно не знать о том, что это такое. Поэтому начнём с самого начала.

Что такое регулярные выражения
У многих, когда они впервые видят регулярные выражения, сразу же возникает мысль, что перед ними бессмысленное нагромождение символов. Но это, конечно, далеко не так. Взгляните, например, на это регулярное выражение
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$На наш взгляд даже абсолютный новичок сходу поймёт, как оно устроено и зачем нужно :) Если же вам не вполне понятно — просто читайте дальше и всё встанет на свои места.
Регулярное выражение — это шаблон, пользуясь которым программы вроде sed или awk фильтруют тексты. В шаблонах используются обычные ASCII-символы, представляющие сами себя, и так называемые метасимволы, которые играют особую роль, например, позволяя ссылаться на некие группы символов.
Типы регулярных выражений
Реализации регулярных выражений в различных средах, например, в языках программирования вроде Java, Perl и Python, в инструментах Linux вроде sed, awk и grep, имеют определённые особенности. Эти особенности зависят от так называемых движков обработки регулярных выражений, которые занимаются интерпретацией шаблонов.
В Linux имеется два движка регулярных выражений:
- Движок, поддерживающий стандарт POSIX Basic Regular Expression (BRE).
- Движок, поддерживающий стандарт POSIX Extended Regular Expression (ERE).
Большинство утилит Linux соответствуют, как минимум, стандарту POSIX BRE, но некоторые утилиты (в их числе — sed) понимают лишь некое подмножество стандарта BRE. Одна из причин такого ограничения — стремление сделать такие утилиты как можно более быстрыми в деле обработки текстов.
Стандарт POSIX ERE часто реализуют в языках программирования. Он позволяет пользоваться большим количеством средств при разработке регулярных выражений. Например, это могут быть специальные последовательности символов для часто используемых шаблонов, вроде поиска в тексте отдельных слов или наборов цифр. Awk поддерживает стандарт ERE.
Существует много способов разработки регулярных выражений, зависящих и от мнения программиста, и от особенностей движка, под который их создают. Непросто писать универсальные регулярные выражения, которые сможет понять любой движок. Поэтому мы сосредоточимся на наиболее часто используемых регулярных выражениях и рассмотрим особенности их реализации для sed и awk.
Регулярные выражения POSIX BRE
Пожалуй, самый простой шаблон BRE представляет собой регулярное выражение для поиска точного вхождения последовательности символов в тексте. Вот как выглядит поиск строки в sed и awk:
$ echo "This is a test" | sed -n '/test/p'
$ echo "This is a test" | awk '/test/{print $0}'
Поиск текста по шаблону в sed

Поиск текста по шаблону в awk
Можно заметить, что поиск заданного шаблона выполняется без учёта точного места нахождения текста в строке. Кроме того, не имеет значение и количество вхождений. После того, как регулярное выражение найдёт заданный текст в любом месте строки, строка считается подходящей и передаётся для дальнейшей обработки.
Работая с регулярными выражениями нужно учитывать то, что они чувствительны к регистру символов:
$ echo "This is a test" | awk '/Test/{print $0}'
$ echo "This is a test" | awk '/test/{print $0}'
Регулярные выражения чувствительны к регистру
Первое регулярное выражение совпадений не нашло, так как слово «test», начинающееся с заглавной буквы, в тексте не встречается. Второе же, настроенное на поиск слова, написанного прописными буквами, обнаружило в потоке подходящую строку.
В регулярных выражениях можно использовать не только буквы, но и пробелы, и цифры:
$ echo "This is a test 2 again" | awk '/test 2/{print $0}'
Поиск фрагмента текста, содержащего пробелы и цифры
Пробелы воспринимаются движком регулярных выражений как обычные символы.
Специальные символы
При использовании различных символов в регулярных выражениях надо учитывать некоторые особенности. Так, существуют некоторые специальные символы, или метасимволы, использование которых в шаблоне требует особого подхода. Вот они:
.*[]^${}\+?|()Если один из них нужен в шаблоне, его нужно будет экранировать с помощью обратной косой черты (обратного слэша) —
\.Например, если в тексте нужно найти знак доллара, его надо включить в шаблон, предварив символом экранирования. Скажем, имеется файл
myfile с таким текстом:There is 10$ on my pocketЗнак доллара можно обнаружить с помощью такого шаблона:
$ awk '/\$/{print $0}' myfile
Использование в шаблоне специального символа
Кроме того, обратная косая черта — это тоже специальный символ, поэтому, если нужно использовать его в шаблоне, его тоже надо будет экранировать. Выглядит это как два слэша, идущих друг за другом:
$ echo "\ is a special character" | awk '/\\/{print $0}'
Экранирование обратного слэша
Хотя прямой слэш и не входит в приведённый выше список специальных символов, попытка воспользоваться им в регулярном выражении, написанном для sed или awk, приведёт к ошибке:
$ echo "3 / 2" | awk '///{print $0}'
Неправильное использование прямого слэша в шаблоне
Если он нужен, его тоже надо экранировать:
$ echo "3 / 2" | awk '/\//{print $0}'
Экранирование прямого слэша
Якорные символы
Существуют два специальных символа для привязки шаблона к началу или к концу текстовой строки. Символ «крышка» —
^ позволяет описывать последовательности символов, которые находятся в начале текстовых строк. Если искомый шаблон окажется в другом месте строки, регулярное выражение на него не отреагирует. Выглядит использование этого символа так:$ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}'
$ echo "likegeeks website" | awk '/^likegeeks/{print $0}'
Поиск шаблона в начале строки
Символ
^ предназначен для поиска шаблона в начале строки, при этом регистр символов так же учитывается. Посмотрим, как это отразится на обработке текстового файла:$ awk '/^this/{print $0}' myfile
Поиск шаблона в начале строки в тексте из файла
При использовании sed, если поместить крышку где-нибудь внутри шаблона, она будет восприниматься как любой другой обычный символ:
$ echo "This ^ is a test" | sed -n '/s ^/p'
Крышка, находящаяся не в начале шаблона в sed
В awk, при использовании такого же шаблона, данный символ надо экранировать:
$ echo "This ^ is a test" | awk '/s \^/{print $0}'
Крышка, находящаяся не в начале шаблона в awk
С поиском фрагментов текста, находящихся в начале строки мы разобрались. Что, если надо найти нечто, расположенное в конце строки?
В этом нам поможет знак доллара —
$, являющийся якорным символом конца строки:$ echo "This is a test" | awk '/test$/{print $0}'
Поиск текста, находящегося в конце строки
В одном и том же шаблоне можно использовать оба якорных символа. Выполним обработку файла
myfile, содержимое которого показано на рисунке ниже, с помощью такого регулярного выражения:$ awk '/^this is a test$/{print $0}' myfile
Шаблон, в котором использованы специальные символы начала и конца строки
Как видно, шаблон среагировал лишь на строку, полностью соответствующую заданной последовательности символов и их расположению.
Вот как, пользуясь якорными символами, отфильтровать пустые строки:
$ awk '!/^$/{print $0}' myfileВ данном шаблоне использовал символ отрицания, восклицательный знак —
!. Благодаря использованию такого шаблона выполняется поиск строк, не содержащих ничего между началом и концом строки, а благодаря восклицательному знаку на печать выводятся лишь строки, которые не соответствуют этому шаблону.Символ «точка»
Точка используется для поиска любого одиночного символа, за исключением символа перевода строки. Передадим такому регулярному выражению файл
myfile, содержимое которого приведено ниже:$ awk '/.st/{print $0}' myfile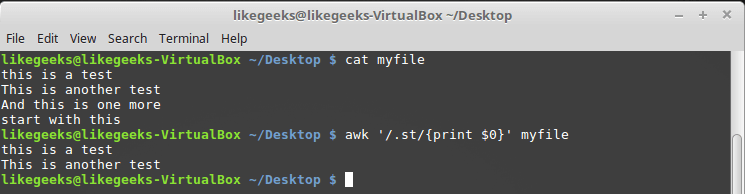
Использование точки в регулярных выражениях
Как видно по выведенным данным, шаблону соответствуют лишь первые две строки из файла, так как они содержат последовательность символов «st», предварённую ещё одним символом, в то время как третья строка подходящей последовательности не содержит, а в четвёртой она есть, но находится в самом начале строки.
Классы символов
Точка соответствует любому одиночному символу, но что если нужно более гибко ограничить набор искомых символов? В подобной ситуации можно воспользоваться классами символов.
Благодаря такому подходу можно организовать поиск любого символа из заданного набора. Для описания класса символов используются квадратные скобки —
[]:$ awk '/[oi]th/{print $0}' myfile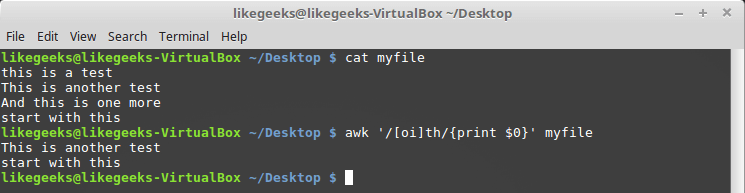
Описание класса символов в регулярном выражении
Тут мы ищем последовательность символов «th», перед которой есть символ «o» или символ «i».
Классы оказываются очень кстати, если выполняется поиск слов, которые могут начинаться как с прописной, так и со строчной буквы:
$ echo "this is a test" | awk '/[Tt]his is a test/{print $0}'
$ echo "This is a test" | awk '/[Tt]his is a test/{print $0}'
Поиск слов, которые могут начинаться со строчной или прописной буквы
Классы символов не ограничены буквами. Тут можно использовать и другие символы. Нельзя заранее сказать, в какой ситуации понадобятся классы — всё зависит от решаемой задачи.
Отрицание классов символов
Классы символов можно использовать и для решения задачи, обратной описанной выше. А именно, вместо поиска символов, входящих в класс, можно организовать поиск всего, что в класс не входит. Для того, чтобы добиться такого поведения регулярного выражения, перед списком символов класса нужно поместить знак
^. Выглядит это так:$ awk '/[^oi]th/{print $0}' myfile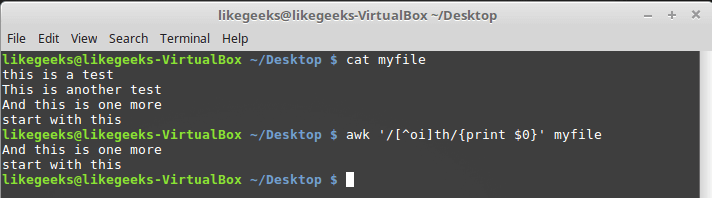
Поиск символов, не входящих в класс
В данном случае будут найдены последовательности символов «th», перед которыми нет ни «o», ни «i».
Диапазоны символов
В символьных классах можно описывать диапазоны символов, используя тире:
$ awk '/[e-p]st/{print $0}' myfile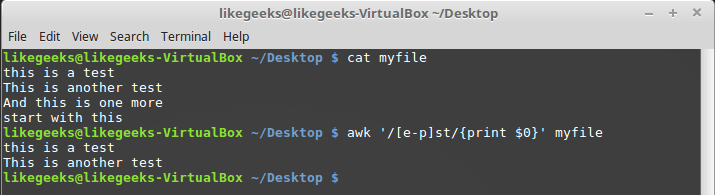
Описание диапазона символов в символьном классе
В данном примере регулярное выражение реагирует на последовательность символов «st», перед которой находится любой символ, расположенный, в алфавитном порядке, между символами «e» и «p».
Диапазоны можно создавать и из чисел:
$ echo "123" | awk '/[0-9][0-9][0-9]/'
$ echo "12a" | awk '/[0-9][0-9][0-9]/'
Регулярное выражение для поиска трёх любых чисел
В класс символов могут входить несколько диапазонов:
$ awk '/[a-fm-z]st/{print $0}' myfile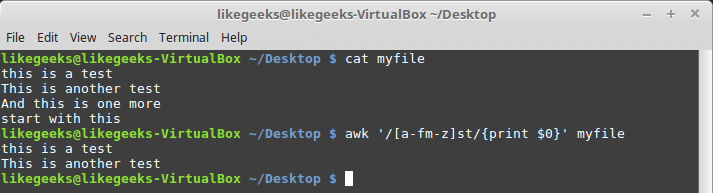
Класс символов, состоящий из нескольких диапазонов
Данное регулярное выражение найдёт все последовательности «st», перед которыми есть символы из диапазонов
a-f и m-z.Специальные классы символов
В BRE имеются специальные классы символов, которые можно использовать при написании регулярных выражений:
[[:alpha:]]— соответствует любому алфавитному символу, записанному в верхнем или нижнем регистре.[[:alnum:]]— соответствует любому алфавитно-цифровому символу, а именно — символам в диапазонах0-9,A-Z,a-z.[[:blank:]]— соответствует пробелу и знаку табуляции.[[:digit:]]— любой цифровой символ от0до9.[[:upper:]]— алфавитные символы в верхнем регистре —A-Z.[[:lower:]]— алфавитные символы в нижнем регистре —a-z.
[[:print:]]— соответствует любому печатаемому символу.[[:punct:]]— соответствует знакам препинания.[[:space:]]— пробельные символы, в частности — пробел, знак табуляции, символыNL,FF,VT,CR.
Использовать специальные классы в шаблонах можно так:
$ echo "abc" | awk '/[[:alpha:]]/{print $0}'
$ echo "abc" | awk '/[[:digit:]]/{print $0}'
$ echo "abc123" | awk '/[[:digit:]]/{print $0}'
Специальные классы символов в регулярных выражениях
Символ «звёздочка»
Если в шаблоне после символа поместить звёздочку, это будет означать, что регулярное выражение сработает, если символ появляется в строке любое количество раз — включая и ситуацию, когда символ в строке отсутствует.
$ echo "test" | awk '/tes*t/{print $0}'
$ echo "tessst" | awk '/tes*t/{print $0}'
Использование символа * в регулярных выражениях
Этот шаблонный символ обычно используют для работы со словами, в которых постоянно встречаются опечатки, или для слов, допускающих разные варианты корректного написания:
$ echo "I like green color" | awk '/colou*r/{print $0}'
$ echo "I like green colour " | awk '/colou*r/{print $0}'
Поиск слова, имеющего разные варианты написания
В этом примере одно и то же регулярное выражение реагирует и на слово «color», и на слово «colour». Это так благодаря тому, что символ «u», после которого стоит звёздочка, может либо отсутствовать, либо встречаться несколько раз подряд.
Ещё одна полезная возможность, вытекающая из особенностей символа звёздочки, заключается в комбинировании его с точкой. Такая комбинация позволяет регулярному выражению реагировать на любое количество любых символов:
$ awk '/this.*test/{print $0}' myfile
Шаблон, реагирующий на любое количество любых символов
В данном случае неважно сколько и каких символов находится между словами «this» и «test».
Звёздочку можно использовать и с классами символов:
$ echo "st" | awk '/s[ae]*t/{print $0}'
$ echo "sat" | awk '/s[ae]*t/{print $0}'
$ echo "set" | awk '/s[ae]*t/{print $0}'
Использование звёздочки с классами символов
Во всех трёх примерах регулярное выражение срабатывает, так как звёздочка после класса символов означает, что если будет найдено любое количество символов «a» или «e», а также если их найти не удастся, строка будет соответствовать заданному шаблону.
Регулярные выражения POSIX ERE
Шаблоны стандарта POSIX ERE, которые поддерживают некоторые утилиты Linux, могут содержать дополнительные символы. Как уже было сказано, awk поддерживает этот стандарт, а вот sed — нет.
Тут мы рассмотрим наиболее часто используемые в ERE-шаблонах символы, которые пригодятся вам при создании собственных регулярных выражений.
?Вопросительный знак
Вопросительный знак указывает на то, что предшествующий символ может встретиться в тексте один раз или не встретиться вовсе. Этот символ — один из метасимволов повторений. Вот несколько примеров:
$ echo "tet" | awk '/tes?t/{print $0}'
$ echo "test" | awk '/tes?t/{print $0}'
$ echo "tesst" | awk '/tes?t/{print $0}'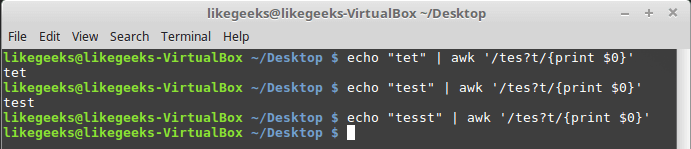
Вопросительный знак в регулярных выражениях
Как видно, в третьем случае буква «s» встречается дважды, поэтому на слово «tesst» регулярное выражение не реагирует.
Вопросительный знак можно использовать и с классами символов:
$ echo "tst" | awk '/t[ae]?st/{print $0}'
$ echo "test" | awk '/t[ae]?st/{print $0}'
$ echo "tast" | awk '/t[ae]?st/{print $0}'
$ echo "taest" | awk '/t[ae]?st/{print $0}'
$ echo "teest" | awk '/t[ae]?st/{print $0}'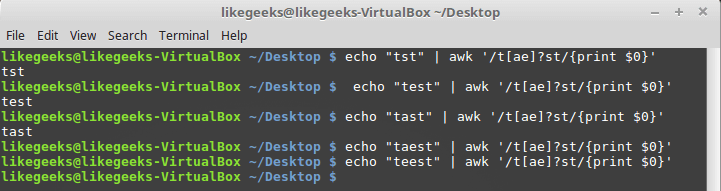
Вопросительный знак и классы символов
Если символов из класса в строке нет, или один из них встречается один раз, регулярное выражение срабатывает, однако стоит в слове появиться двум символам и система уже не находит в тексте соответствия шаблону.
?Символ «плюс»
Символ «плюс» в шаблоне указывает на то, что регулярное выражение обнаружит искомое в том случае, если предшествующий символ встретится в тексте один или более раз. При этом на отсутствие символа такая конструкция реагировать не будет:
$ echo "test" | awk '/te+st/{print $0}'
$ echo "teest" | awk '/te+st/{print $0}'
$ echo "tst" | awk '/te+st/{print $0}'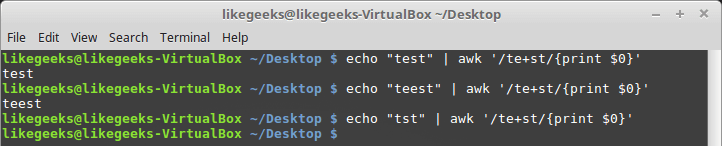
Символ «плюс» в регулярных выражениях
В данном примере, если символа «e» в слове нет, движок регулярных выражений не найдёт в тексте соответствий шаблону. Символ «плюс» работает и с классами символов — этим он похож на звёздочку и вопросительный знак:
$ echo "tst" | awk '/t[ae]+st/{print $0}'
$ echo "test" | awk '/t[ae]+st/{print $0}'
$ echo "teast" | awk '/t[ae]+st/{print $0}'
$ echo "teeast" | awk '/t[ae]+st/{print $0}'
Знак «плюс» и классы символов
В данном случае если в строке имеется любой символ из класса, текст будет сочтён соответствующим шаблону.
?Фигурные скобки
Фигурные скобки, которыми можно пользоваться в ERE-шаблонах, похожи на символы, рассмотренные выше, но они позволяют точнее задавать необходимое число вхождений предшествующего им символа. Указывать ограничение можно в двух форматах:
n —число, задающее точное число искомых вхождений
n, m —два числа, которые трактуются так: «как минимум n раз, но не больше чем m».
Вот примеры первого варианта:
$ echo "tst" | awk '/te{1}st/{print $0}'
$ echo "test" | awk '/te{1}st/{print $0}'
Фигурные скобки в шаблонах, поиск точного числа вхождений
В старых версиях awk нужно было использовать ключ командной строки
--re-interval для того, чтобы программа распознавала интервалы в регулярных выражениях, но в новых версиях этого делать не нужно.$ echo "tst" | awk '/te{1,2}st/{print $0}'
$ echo "test" | awk '/te{1,2}st/{print $0}'
$ echo "teest" | awk '/te{1,2}st/{print $0}'
$ echo "teeest" | awk '/te{1,2}st/{print $0}'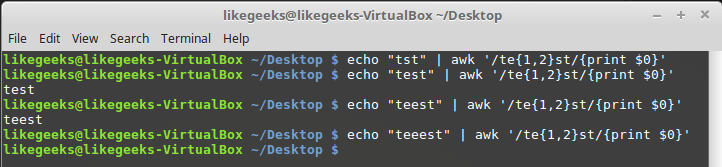
Интервал, заданный в фигурных скобках
В данном примере символ «e» должен встретиться в строке 1 или 2 раза, тогда регулярное выражение отреагирует на текст.
Фигурные скобки можно применять и с классами символов. Тут действуют уже знакомые вам принципы:
$ echo "tst" | awk '/t[ae]{1,2}st/{print $0}'
$ echo "test" | awk '/t[ae]{1,2}st/{print $0}'
$ echo "teest" | awk '/t[ae]{1,2}st/{print $0}'
$ echo "teeast" | awk '/t[ae]{1,2}st/{print $0}'
Фигурные скобки и классы символов
Шаблон отреагирует на текст в том случае, если в нём один или два раза встретится символ «a» или символ «e».
?Символ логического «или»
Символ
| — вертикальная черта, означает в регулярных выражениях логическое «или». Обрабатывая регулярное выражение, содержащее несколько фрагментов, разделённых таким знаком, движок сочтёт анализируемый текст подходящим в том случае, если он будет соответствовать любому из фрагментов. Вот пример:$ echo "This is a test" | awk '/test|exam/{print $0}'
$ echo "This is an exam" | awk '/test|exam/{print $0}'
$ echo "This is something else" | awk '/test|exam/{print $0}'
Логическое «или» в регулярных выражениях
В данном примере регулярное выражение настроено на поиск в тексте слов «test» или «exam». Обратите внимание на то, что между фрагментами шаблона и разделяющим их символом
| не должно быть пробелов.Группировка фрагментов регулярных выражений
Фрагменты регулярных выражений можно группировать, пользуясь круглыми скобками. Если сгруппировать некую последовательность символов, она будет восприниматься системой как обычный символ. То есть, например, к ней можно будет применить метасимволы повторений. Вот как это выглядит:
$ echo "Like" | awk '/Like(Geeks)?/{print $0}'
$ echo "LikeGeeks" | awk '/Like(Geeks)?/{print $0}'
Группировка фрагментов регулярных выражений
В данных примерах слово «Geeks» заключено в круглые скобки, после этой конструкции идёт знак вопроса. Напомним, что вопросительный знак означает «0 или 1 повторение», в результате регулярное выражение отреагирует и на строку «Like», и на строку «LikeGeeks».
Практические примеры
После того, как мы разобрали основы регулярных выражений, пришло время сделать с их помощью что-нибудь полезное.
?Подсчёт количества файлов
Напишем bash-скрипт, который подсчитывает файлы, находящиеся в директориях, которые записаны в переменную окружения
PATH. Для того, чтобы это сделать, понадобится, для начала, сформировать список путей к директориям. Сделаем это с помощью sed, заменив двоеточия на пробелы:$ echo $PATH | sed 's/:/ /g'Команда замены поддерживает регулярные выражения в качестве шаблонов для поиска текста. В данном случае всё предельно просто, ищем мы символ двоеточия, но никто не мешает использовать здесь и что-нибудь другое — всё зависит от конкретной задачи.
Теперь надо пройтись по полученному списку в цикле и выполнить там необходимые для подсчёта количества файлов действия. Общая схема скрипта будет такой:
mypath=$(echo $PATH | sed 's/:/ /g')
for directory in $mypath
do
doneТеперь напишем полный текст скрипта, воспользовавшись командой
ls для получения сведений о количестве файлов в каждой из директорий:#!/bin/bash
mypath=$(echo $PATH | sed 's/:/ /g')
count=0
for directory in $mypath
do
check=$(ls $directory)
for item in $check
do
count=$[ $count + 1 ]
done
echo "$directory - $count"
count=0
doneПри запуске скрипта может оказаться, что некоторых директорий из
PATH не существует, однако, это не помешает ему посчитать файлы в существующих директориях.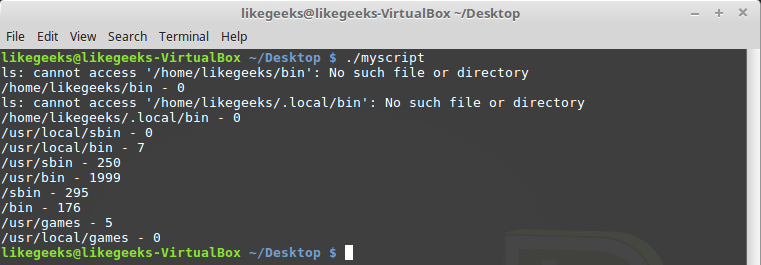
Подсчёт файлов
Главная ценность этого примера заключается в том, что пользуясь тем же подходом, можно решать и куда более сложные задачи. Какие именно — зависит от ваших потребностей.
?Проверка адресов электронной почты
Существуют веб-сайты с огромными коллекциями регулярных выражений, которые позволяют проверять адреса электронной почты, телефонные номера, и так далее. Однако, одно дело — взять готовое, и совсем другое — создать что-то самому. Поэтому напишем регулярное выражение для проверки адресов электронной почты. Начнём с анализа исходных данных. Вот, например, некий адрес:
username@hostname.comИмя пользователя,
username, может состоять из алфавитно-цифровых и некоторых других символов. А именно, это точка, тире, символ подчёркивания, знак «плюс». За именем пользователя следует знак @.Вооружившись этими знаниями, начнём сборку регулярного выражения с его левой части, которая служит для проверки имени пользователя. Вот что у нас получилось:
^([a-zA-Z0-9_\-\.\+]+)@Это регулярное выражение можно прочитать так: «В начале строки должен быть как минимум один символ из тех, которые имеются в группе, заданной в квадратных скобках, а после этого должен идти знак @».
Теперь — очередь имени хоста —
hostname. Тут применимы те же правила, что и для имени пользователя, поэтому шаблон для него будет выглядеть так:([a-zA-Z0-9_\-\.]+)Имя домена верхнего уровня подчиняется особым правилам. Тут могут быть лишь алфавитные символы, которых должно быть не меньше двух (например, такие домены обычно содержат код страны), и не больше пяти. Всё это значит, что шаблон для проверки последней части адреса будет таким:
\.([a-zA-Z]{2,5})$Прочесть его можно так: «Сначала должна быть точка, потом — от 2 до 5 алфавитных символов, а после этого строка заканчивается».
Подготовив шаблоны для отдельных частей регулярного выражения, соберём их вместе:
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$Теперь осталось лишь протестировать то, что получилось:
$ echo "name@host.com" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}'
$ echo "name@host.com.us" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}'
Проверка адреса электронной почты с помощью регулярных выражений
То, что переданный awk текст выводится на экран, означает, что система распознала в нём адрес электронной почты.
Итоги
Если регулярное выражение для проверки адресов электронной почты, которое встретилось вам в самом начале статьи, казалось тогда совершенно непонятным, надеемся, сейчас оно уже не выглядит бессмысленным набором символов. Если это действительно так — значит данный материал выполнил своё предназначение. На самом деле, регулярные выражения — это тема, которой можно заниматься всю жизнь, но даже то немногое, что мы разобрали, уже способно помочь вам в написании скриптов, которые довольно продвинуто обрабатывают тексты.
В этой серии материалов мы обычно показывали очень простые примеры bash-скриптов, которые состояли буквально из нескольких строк. В следующий раз рассмотрим кое-что более масштабное.
Уважаемые читатели! А вы пользуетесь регулярными выражениями при обработке текстов в сценариях командной строки?
Комментарии (44)

ghostinushanka
03.05.2017 15:16+1Для того, чтобы это сделать, понадобится, для начала, сформировать список путей к директориям. Сделаем это с помощью sed, заменив двоеточия на пробелы
$ echo $PATH | sed 's/:/ /g'
Я чуть не расплакался со смеху, сабшел, да ещё и sed для этого… Не удержался, простите. Невероятно что себе некоторые люди позволяют публиковать.
echo ${PATH//:/ } #всёZyXI
03.05.2017 15:30Они тут ещё пути по пробелам делят. Вспомнил сколько в моём $PATH из cygwin пробелов… По?хорошему нужно устраивать
whileцикл с${PATH%%:*}, раз уж доtypeset -Tbash не доросла (возможность zsh, позволяет связать скалярный (читай строковый) параметр, содержащий разделённый некоторым символом список, с параметром?списком).ZyXI
03.05.2017 15:35Хотя нет, тут должно быть что?то с временной установкой IFS=: и созданием спискового параметра:
saved_ifs="$IFS" IFS=: path=( $PATH ) IFS=$saved_ifs for p in "${path[@]}" ; do … done
И никаких регулярных выражений вообще.
ghostinushanka
03.05.2017 22:08Я интереса ради прикинул несколько вариантов решений на которые меня натолкнуло ваше предложение использовать while, вот так безопаснее всего для данного конкретного случая (и заодно работает на Linux/BSD), но читаемость — ад… это мне и самому понятно:
while IFS= read -r -d: path; do i=0; while read -d $'\0' ; do let i=i+1; done < <(find "${path/#\~/$HOME}" -maxdepth 1 -type f -print0 2>/dev/null); printf "%5d - %s\n" $i "${path}"; done < <(echo "${PATH}")
Неплохой квест для начинающих получился в итоге — понять что вообще тут происходит.ZyXI
03.05.2017 22:46Если хотите на чистом POSIX shell, то лучше именно вариант с
${PATH%}:
list_paths() { local paths="$PATH" while test -n "$paths" ; do local next_path="${paths%%:*}" printf '%s\0' "$next_path" paths="${paths#*:}" if test "$next_path" = "$paths" ; then break fi done } list_paths | xargs -0 printf 'path item: %s\n'
Если вы знаете, что такое
${var#},${var%%}и что такое*внутри, то всё просто и понятно. Единственное но: мне долгое время не удавалось запомнить, что из#и%делает что, пока я не додумался до мнемоники: «авторы стандарта обманывают:#комментирует до конца строки, но удаляет с начала» (короткий вариант: «#противоположно комментарию»).ghostinushanka
03.05.2017 23:03+1Моя мнемоника # и % связана с положением на клавиатуре при стандартной английской раскладке.
Шарп на тройке (раньше), процент на пятёрке (позже) => Шарп трёт с начала, процент с конца.ZyXI
03.05.2017 23:05У меня dvorak, а на клавиатуру я не смотрю. Так что такая мнемоника мне в голову придти не могла.
ZyXI
03.05.2017 23:24Точнее, у меня programming dvorak. Тут процент на единице, а решётка на
=, до максимального удаления друг от друга не хватает одной клавиши, а относительный порядок обратный. Можно было бы запомнить как «процент оставляет начало, решётка оставляет конец» также привязав к клавиатуре, но эти символы на разных руках, это не воспринимается как что?то находящееся в одной последовательности. Ну и «оставляет» сложно использовать как мнемонику, если после решётки/процента у вас написано не что оставить, а что удалить.
ZyXI
03.05.2017 23:01Кстати, вы куда?то потеряли
-e, еслиPATH=-e. И новую строку, еслиPATH=$'/bin:/hacky/path\n'.
Если строка может содержать любые данные, то
echoиспользовать нельзя. А куда делась новая строка изPATH=$'/hacky/path\n'я сам не знаю; если засунуть её внутрь, то всё нормально.
Хотя я сейчас заметил: если $PATH состоит только из одного каталога, то ничего у вас не печатается, не только если этот каталог
-e. А, в отличие от$'/hacky/path\n'в конце$PATHиPATH=-eданный сценарий вполне реален: я себе так в тестах powerline относительно чистую среду для тестирования организую: создаю свой каталог, пихаю туда символические ссылки на нужные программы и делаю его единственным каталогом в$PATH.ZyXI
03.05.2017 23:04Уточнение: вы теряете не единственный каталог в $PATH, когда он единственный. Вы всегда теряете последний каталог. Хотя этот вариант просто поправить: просто используйте
"$PATH:"вместо"$PATH".ZyXI
03.05.2017 23:16Т.е. поправленный ваш вариант будет просто
while IFS= read -r -d: path; do i=0; while read -d $'\0' ; do let i=i+1; done < <(find "$path" -maxdepth 1 -type f -print0 2>/dev/null); printf "%5d - %s\n" $i "${path}"; done < <(printf '%s' "${PATH}:")
Тут ещё одно отличие:
~/в $PATH раскрывает bash. Другие оболочки (проверено в zsh, posh, dash, busybox ash, ksh, mksh) этим не отличаются. Libc (execlp, execvp, execvpe) этим не отличается также. Поэтому я раскрытие~удалил, если у вас есть такие пути, то вы оказываете себе медвежью услугу: только bash будет понимать, что там $HOME, остальные же будут понимать такое как./~/….ghostinushanka
03.05.2017 23:34"${PATH}:" — не досмотрел, вы правы, поскольку -d флаг у read является «data-end».
С echo -e я вас не понял. По дефолту применяется -E «disable interpretation of backslash escapes», чего я и добивался чтобы табы, переносы строк, нульбайты и так далее не интерпретировались, соответственно while IFS= read -r -d: будет резать исключительно по двоеточиям.
А вот про "${path/#\~/$HOME}" сдаётся мне не поняли вы. Это замена тильды в начале на $HOME (parameter expansion — search and replace) как раз на тот случай, если кто-то умудрился себе в PATH тильду засунуть. Проверьте ваш вариант убрав 2>/dev/null — словите ошибку в find на тильде потому что она не раскроется.ZyXI
03.05.2017 23:47С echo -e я вас не понял. По дефолту применяется -E «disable interpretation of backslash escapes», чего я и добивался чтобы табы, переносы строк, нульбайты и так далее не интерпретировались, соответственно while IFS= read -r -d: будет резать исключительно по двоеточиям.
Во?первых, не везде. К примеру, создаёте вы «кроссплатформенный» bash/zsh скрипт. А в zsh по?умолчанию
-e, но есть настройка BSD_ECHO. Во?вторых, я имел ввиду, когдаPATHравен-eу вас будетecho -e, что не выведет ничего.
Проверьте ваш вариант убрав 2>/dev/null — словите ошибку в find на тильде потому что она не раскроется.
Словлю, но не ошибку. Только bash раскрывает тильду там. Для остальных это
./~. Так что «ошибка» — полностью корректное и ожидаемое поведение. И, кстати, вы написали${path/#\~/$HOME}. А что если в$PATHне~/, а~foo/? В любом случае, не копируйте ошибки bash.ZyXI
04.05.2017 00:10Чтобы было понятнее: напишите скрипт
dir="$(mktemp -d)" cd "$dir" mkdir -p home/bin mkdir -p \~/bin HOME="$dir/home" printf '#!/bin/sh\necho script' > home/bin/script printf '#!/bin/sh\necho script2' > home/bin/script2 printf '#!/bin/sh\necho vulnerable' > \~/bin/script chmod a+x home/bin/script chmod a+x home/bin/script2 chmod a+x \~/bin/script PATH='~/bin' if test $# -gt 0 ; then "$@" else script fi cd / /bin/rm -r "$dir"
Теперь запустите его (далее он зовётся
script.sh) в bash и в другой оболочке (если нужно что?то вроде fish, то можно писатьsh script.sh =fish -c script, а так просто{shell} script.sh). Результаты будут такие:
% bash script.sh script % dash script.sh vulnerable % posh script.sh vulnerable % sh script.sh =fish -c script vulnerable % zsh script.sh vulnerable % mksh script.sh vulnerable % ksh script.sh vulnerable % echo 'main() { execlp("script", "script", "script"); }' > prog.c % sh script.sh =tcc -run $PWD/prog.c vulnerable % sh script.sh =vim --cmd 'echo executable("script2")' --cmd qa 0 % sh script.sh =nvim --cmd 'echo system(["script"])' --cmd qa vulnerable % sh script.sh =python -c 'from subprocess import check_call ; check_call(["script"])' vulnerable
В вашем примере find найдёт скрипт с
echo script. Но с какой радости, если все остальные запустят не его, а скрипт сecho vulnerable?ZyXI
04.05.2017 00:21Уточнение:
=fish— это возможность zsh. В остальных оболочках нужно писать"$(which fish)".
ghostinushanka
04.05.2017 00:12Только bash раскрывает тильду там.
bash-4.4$ export PATH="~/Desktop" bash-4.4$ /usr/bin/find "${PATH}" -maxdepth 1 -type f find: ~/Desktop: No such file or directory
Даже баш не раскроет (кавычки виноваты), вот что я имел ввиду. Поэтому тильда заменяется на $HOME
А что если в $PATH не ~/, а ~foo/?
Из ~foo/ после замены получится /home/usernamefoo (что вполне ожидаемо) и при раскрытии башем — получится тожесамое всёравно.
Я, если вы не поняли, не утверждаю что тильду в PATH иметь нормально, как раз наоборот. Этот пример замены — полученные на практике синяки поскольку тильду мне туда подсовывали.
К примеру, создаёте вы «кроссплатформенный» bash/zsh скрипт.
Я всё же ограничился на комментариях к Башу, цикл статей ведь о нём :)
Формально вы правы конечно.ZyXI
04.05.2017 00:19Пока писали комментарий, я написал свой. Я к тому, что вариант без замены работает корректно, в моём примере он найдёт
"$dir/~/bin/script", а не"$dir/home/bin/script", хотя bash запустит"$dir/home/bin/script". Нельзя там писать раскрытие~, вы найдёте не то.
И ещё вы забыли одну вещь: на случай, если в
$PATHвстретится пустой каталог (к примеру,/bin::/sbin), то вам нужно написать: ${path:=.}. Потому что пустое значение — это текущий каталог, ноfind ''пишетfind: ‘’: Нет такого файла или каталога.ghostinushanka
04.05.2017 00:46Меня сбивает с толку слово «раскрытие». Нету там никакого раскрытия, происходит замена знака «тильда» содержимым определённой переменной. Почему вы это раскрытием называете?
bash-4.4$ homedir="/home/username" bash-4.4$ var1="dir/~/bin/script" bash-4.4$ echo ${var1/#\~/$homedir} dir/~/bin/script bash-4.4$ var2="~/bin/script" bash-4.4$ echo ${var2/#\~/$homedir} /home/username/bin/script
Возвращаясь к тому что можно создать директорию с названием "~". Да можно. Да вы правы что из-за того что другие шелы не делают то самое раскрытие (tilde -> $HOME -> actual value) — поведение будет разное. Я с самого начала с этим не спорю.
Как я уже писал выше — цикл статей о баше, я ограничился им. Если мы ещё и про шелл-кроссплатформенность будем комментировать… собственно пример тому — сегодняшние полотнища.
то вам нужно написать: ${path:=.}
Категорически не согласен, в моей версии :: выдаст ошибку и будет отловлен редиректом:
bash-4.4$ cat pathfinder.bash p="/bin::/sbin" while IFS= read -r -d: path; do i=0; while read -d $'\0' ; do let i=i+1; done < <(find "${path/#\~/$HOME}" -maxdepth 1 -type f -print0 2>/dev/null); printf "%5d - %s\n" $i "${path}"; done < <(echo "${p}:") bash-4.4$ bash pathfinder.bash 37 - /bin 0 - 40 - /sbin
Единственная некрасивость — ноль у директории без имени.
Вами предложенный default value добавит дополнительную строку с кол-вом файлов в ".", что противоречит исходной задаче извлечения кол-ва файлов в директориях из PATHZyXI
04.05.2017 01:36Вами предложенный default value добавит дополнительную строку с кол-вом файлов в ".", что противоречит исходной задаче извлечения кол-ва файлов в директориях из PATH
Не противоречит:
% (cd /bin ; PATH='/xxx:' /bin/bash -c 'sh --version') GNU bash, version 4.3.48(1)-release (x86_64-pc-linux-gnu) Copyright (C) 2013 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software; you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law.
Вопрос на засыпку: откуда bash внезапно взял исполняемый файл
sh? Каталога/xxxу меня нет. Кстати, работает и с пустым$PATH.ghostinushanka
04.05.2017 09:49А если сделать так, то не сработает:
(cd / ; PATH= /bin/bash -c 'sh --version') /bin/bash: sh: No such file or directory
И ответ очевиден, вы в вашем примере сначала перешли в директорию /bin, откуда баш прочитал sh напрямую. Честно говоря вообще не понял к чему именно этот пример.
Я говорил о том, что вами предложенная замена на default value выпишет так же кол-во файлов в той директории, где вы находитесь на момент запуска скрипта — это противоречит условиям исходной задачи.ZyXI
04.05.2017 19:35Bash не берёт файлы из текущего каталога, если текущего каталога в $PATH нет. Уберите из моего примера единственное находящееся там двоеточие, получите ту же ошибку. С пустым $PATH то же самое: не хотите читать бинарники из текущего каталога, не допускайте пустых путей в $PATH. Задача не решена, замена пустой строки на default value нужно.
Я не понимаю, зачем вы настаиваете на откровенно некорректном ответе. Когда в $PATH есть пустой путь, bash ищет исполняемые файлы и скрипты (я про команду
.) в текущем каталоге. Задача — искать файлы в $PATH. Если они ищутся в текущем каталоге, то задача — искать их в том числе в текущем каталоге. Вы не ищете — задача не решена.ZyXI
04.05.2017 19:52Снимаю «некорректность» до ответа на https://habrahabr.ru/company/ruvds/blog/327896/#comment_10203768.
ZyXI
04.05.2017 01:43Меня сбивает с толку слово «раскрытие». Нету там никакого раскрытия, происходит замена знака «тильда» содержимым определённой переменной. Почему вы это раскрытием называете?
Потому что это называется «tilde expansion». К примеру, из CHANGES самого bash:
Bash no longer expands tildes in $PATH elements while in Posix mode.
«Expands» часто переводится как «раскрывает». Так что это раскрытие и есть.
ZyXI
04.05.2017 01:50И, кстати, говорите про bash? Где код, который предотвращает раскрытие
~в$PATH, если bash 4.4 и выше и находится в POSIX режиме? Я его у вас не видел. И про~foo/сейчас проверил:bash -c 'PATH='~zyx/bin' ; srun'вполне себе вызывает мой скрипт из$HOME/bin, а ваш код этот скрипт в этом случае не найдёт. Так что не нужно писать там${path/#\~/$HOME}, это не полностью соответствует даже самому bash, не то что не совместимо с остальными оболочками.
ghostinushanka
04.05.2017 09:43Вы сами и ответили, именно так и есть, я это прекрасно знаю, поэтому, именно по этому ваша формулировка меня и сбивает с толку. В мной приведённом примере раскрытия не происходит, происходит контролируемая замена знака «тильда» на содержимое переменной $HOME и лишь только в том случае, если тильда является первым знаком в данной секции, потому что ожидается (предполагается) что кто-то умудрился себе домашнюю директорию обозначить тильдой в PATH.
В моём конкретном примере, где используется find, так как $path внутри цикла обёрнут двойными кавычками во избежание проблем с пробелами и другими белыми знаками, внимание, раскрытия тильды НЕ произойдёт (я уже вам предлагал это попробовать), поэтому и конструкция которая это раскрытие заменяет.
Я уже несколько раз повторил что мы говорим об одном и том же, вы просто сфокусировались на конкретной вещи, так и не вникнув в суть мной предложенного решения. Я не спорю с вами что тильду класть себе в PATH не следует.ZyXI
04.05.2017 19:45Задача буквально звучит как «Напишем bash-скрипт, который подсчитывает файлы, находящиеся в директориях, которые записаны в переменную окружения PATH». Я интерпретирую её как «Написать bash?скрипт, который подсчитывает файлы, находящиеся в каталогах, в которых POSIX?совместимая оболочка будет искать исполняемый файлы и скрипты», потому что это то, что первое приходит на ум (если бы был пользователем bash, писал бы про то, где будет искать сам bash). Хотелось бы услышать вашу точную интерпретацию, а то я могу сказать, что если в $PATH находится
/usr/local/bin, то там записаны следующие каталоги:
- /
- /usr
- /usr/local
- /usr/local/bin
- /bin
Они же ведь там действительно записаны!
ghostinushanka
04.05.2017 20:03Вы просто на ровном месте взяли и от себя добавили про POSIX-совместимую оболочку в вашей интерпретации.
Я не против, это отличное решение.
Мы находимся в цикле статей про bash и задача «bash-скрипт» а не «POSIX-compatible-скрипт». Почему же вас тогда не устраивает решение для баша на баше?ZyXI
04.05.2017 20:06Потому что оно некорректно. Во?первых, пустой каталог. Во?вторых,
~user. В?третьих, режим POSIX?совместимости и определённая версия bash (в нём, кстати, не запустится process substitution). Если вы настаиваете, что ваш скрипт должен «подсчитывать файлы, находящиеся в каталогах, в которых bash будет искать исполняемые файлы и скрипты», то исправьте все три проблемы.ZyXI
04.05.2017 20:45Кстати, моё решение именно этой задачи с bash:
set -e set -u path_iter() { local paths="$PATH" while true ; do local next_path="${paths%%:*}" local real_next_path="${next_path:-.}" "${@:-echo}" "$real_next_path" paths="${paths#*:}" if test "$next_path" = "$paths" ; then break fi done } count_files() { local path="$1" ; shift test -d "$path" || return local filenum="$(find "$path" -maxdepth 1 -type f -exec echo \; | wc -c)" printf '%5u - %s\n' "$filenum" "$path" } if ( ( test ${BASH_VERSION%%.*} -gt 4 || ( test ${BASH_VERSION%%.*} -eq 4 && eval '(( ${BASH_VERSINFO[1]} >= 4 ))' ) ) && ( set +o | grep -q -x 'set -o posix' ) ) then bash_count_files() { count_files "$@" } else bash_count_files() { local path="$1" ; shift # Warning: assumes specific kind of escaping bash does. /usr/bin/printf # uses another way. path="$(printf "%qx" "$path")" path="${path%x}" path="${path/#\\~/\~}" eval "path=$path" count_files "$path" } fi path_iter bash_count_files
Если убрать ветвление с
bash_count_files, то оно запустится даже в posh.
ghostinushanka
04.05.2017 21:21UPDATE: пока писал ответ, вижу вы обновлённый скрипт с «точкой» добавили.
Во?первых, пустой каталог.
Я наконец-таки понял что вы имели ввиду вот этой фразой:
И ещё вы забыли одну вещь: на случай, если в $PATH встретится пустой каталог (к примеру, /bin::/sbin), то вам нужно написать: ${path:=.}. Потому что пустое значение — это текущий каталог, но find '' пишет find: ‘’: Нет такого файла или каталога.
Я думал, что вас не устроило, что если в PATH встретится «пустышка» то find выдаст ошибку (из-за наличия кавычек)
cd /bin && find "" -maxdepth 1 -type f find: cannot search `': No such file or directory
вместо того, чтобы использовать текущий каталог, как он это делает по дефолту в линуксе:
cd /bin && find -maxdepth 1 -type f # here be files
Вы же говорили об этом (из man bash):
A zero-length (null) directory name in the value of PATH indicates the current directory. A null directory name may appear as two adjacent colons, or as an initial or trailing colon.
Но чёрт возьми, исправьте тогда и ваш собственный скрипт, поскольку на «adjanced colons» и «initial colon» он выдаст пустой путь (а не вами предложенную точку), а «trailing colon» не распознает вообще.
Я сидел и в упор не мог понять, что же вас так сильно в этом конкретном случае не устраивало, особенно с учётом того, что поведение вашего скрипта аналогично.
Смеюсь в голос (с себя). Да конечно, добавляем туда точку.
Во?вторых, ~user.
Вот мой пример:
bash-4.4$ mkdir ~/bin && ln -s /bin/sh ~/bin/sh bash-4.4$ ls bin/ sh bash-4.4$ PATH=~bin bash-4.4$ /usr/bin/which sh bash-4.4$ PATH=~/bin bash-4.4$ /usr/bin/which sh /home/tester/bin/sh
Мной предложенный вариант замены тильды приведёт к аналогичному результату.
P.S. Предлагаю перевести диалог в личные сообщения чтобы дальше не плодить полотнища в комментариях.ZyXI
04.05.2017 21:30Нет, когда я начал писать свою альтернативу в список тестируемых $PATH попал в том числе
:/bin:/usr/bin::~zyx/bin. Это полностью эквивалентно:/bin:/usr/bin::~/bin, т.к. в системе яzyx. Под~userя имею ввиду именно это.
И, кстати:
V=~xxx_nonexistent_user/bin echo $V # echoes `~xxx_nonexistent_user/bin` mkdir -p $V ln -s /bin/sh $V/s (PATH=$V:$PATH ; s --version) # Prints bash version
В моём варианте это обрабатывается также правильно. А если вы просто берёте и заменяете тильду — то нет.
ghostinushanka
03.05.2017 15:39Да понятное дело что пути с пробелами в указаном примере тут же сломаются и что вообще весь этот пример можно переписать в однострочник через find. Я просто выдернул из статьи уже просто режущее глаза выражение.
Подумайте чего только стоит упоминание о регексах, если читателей заранее не проинформировали что в баше есть понятие glob. Скольким кол-вом отстреленых конечностей закончится попытка применения регексов в баше напрямую — я думать просто не хочу.
P.S. Если кому-то не понравился тон предыдущего сообщения, прошу понять что я (и не только) уже неоднократно критиковал неточности и неверную информацию в статьях этого цикла. Но вот это, ровно как и регекс для мейла на который обратил внимание redfs, уже настоящий антипаттерн учащий читателей плохому. Такое на хабре, ИМХО, вообще появляться не должно.
ZyXI
03.05.2017 16:11Кстати, в linux используют два основных движка регулярных выражений — glibc и libpcre. ERE и BRE — это диалекты, предоставляемые одним движком glibc, если только авторы утилиты не решили реализовать регулярные выражения сами. Многие программы (тот же grep) могут использовать, на выбор, ERE, BRE и PCRE (хотя последнее обычно можно отключить при компиляции).

pmcode
03.05.2017 20:01-1Было бы очень круто если бы вы нашли возможность сверстать весь этот цикл статей в один документ, html или pdf без разницы. Для человека, который на шелле пишет раз в полгода, и каждый раз задается вопросом «Как же там этот долбаный getopts работает...» отличная шпора.
ZyXI
03.05.2017 20:09+1С таким количеством ошибок и неточностей что в коде, что в тексте, использовать эту «отличную шпору» будет попросту опасно.
pmcode
03.05.2017 20:59+2Когда пишешь скрипт, и делаешь это нечасто, не куда-то продакшен, а для себя, чтобы где-то заткнуть дырку, быстро решить какую-то задачу на коленке и приступить к следующей, то такие гайды нужны. Когда нужно быстро врубиться в тему или вспомнить начатое — тоже.
Представьте на минуту, что люди обычно вполне отдают себе отчет какой код, где и когда стоит оптимизировать, и к каким пособиям для этого обращаться. Ошибки всплывут в процессе отладки, а для уточнений по конкретным параметрам есть man.
Так что да, эта статья, мне лично полезна. Она простая, последовательная и годно оформлена. Отличный кандидат для шпоры. Минусуйте дальше.ZyXI
03.05.2017 21:20Значительную часть неточностей можно было бы исправить, чтобы статья была действительно нормальной. С такой статьёй вы будете «затыкать дырку», не видя проблема, привыкните, а потом выйдете из «зоны комфорта» и напишете тот же код с итерацией по $PATH в cygwin. И получите странные ошибки, некорректно работающий код, а если не повезёт ещё и какой?нибудь
rm -rf /. А если это было вашим «введением» в программирование на bash, то проблемы вам ещё будет трудно исправить.
ghostinushanka
03.05.2017 21:23+4Блин, ну хоть к другим частям прочтите комментарии.
В четвёртый раз: Advanced Bash-Scripting Guide [single-page, html, 2.3Mb]
Во второй раз: Bash Hackers Wiki [вагон и маленькая тележка примеров, описания, ссылки на кучу других полезных ресурсов вроде bash pitfalls]
Проблема в том что оно не на русском? Тогда лучше поддержите меня в том что я уже предлагал переводчикам из ruvds направить своё время и силы на перевод указанных вещей, вместо этого материала.


iig
03.05.2017 23:07Регулярные выражения странный предмет… Во первых, в bash их нет. Во вторых, очень не часто встречаются задачи, которые хорошо решаются этими самыми выражениями. Примером тому оба примера из статьи: для проверки email указанное заклинание не годится (и достаточно сложно проверить почему; наглядности в регэкспах 0). А второй пример — классическая сова, натянутая на глобус. Без регэкспов решается гораздо проще.

dgluhov
04.05.2017 13:07Символ точка в регулярном выражении это не любой символ, это любой единичный символ за исключением перевода строки т.е. [^\n], а для единичного необязательного символа есть оператор?.. Например colou?r. В приведенном примере регулярного выражения для email адресов допустимым будет адрес состоящий из одних точек .....@.....ru, что неверно, такой адрес недопустим.
Интересны были бы практические примеры с командой grep для разбора файлов логов веб сервера на предмет поиска попыток эксплойтов и т.п., например.
mike_y_k
04.05.2017 13:07А стоит ли так упираться в обработку текста в shell скрипте? Несколько проще сделать это на том же perl к примеру.
Тут стоит таки наверное сделать в статьях упор не на конкретный shell, а на способы решения задачи с вариантами и их оценкой. Конечно в очень узкой сфере работы с пакетами ограниченность средств полезна, но нельзя таки делать из bash универсального монстра.
redfs
Не используйте регулярку для проверки email из этой статьи. Она неправильная