
Стандартная библиотека языка C++ очень неплоха. Долгие годы стандартные алгоритмы верой и правдой служат простому плюсовику!
Но вся отрасль бурно развивается, и язык C++ вместе с ней. Уже давно люди стали понимать, что как бы хороши ни были стандартные алгоритмы, у них есть большой недостаток: нулевая компонуемость. Иначе говоря, невозможно без дополнительных сложностей объединить в цепочку несколько алгоритмов преобразования, фильтрации, свёртки и т.д. и т.п.
Существует несколько вариантов решения данной проблемы. Один из них — ленивые вычисления и диапазоны — уже на подходе к стандартной библиотеке.
Однако, и старые добрые алгоритмы пока рано списывать со счетов.
В этой статье я хочу рассмотреть один из приёмов, который хоть и не является полноценным решением проблемы компонуемости алгоритмов, но вполне способен и упростить работу со старыми стандартными алгоритмами, и обязательно пригодится для работы с грядущими версиями стандарта языка C++.
Содержание
- Техника функциональных объектов
- Простая композиция
- Многопозиционная композиция
- Дополнение
- Заключение
Техника функциональных объектов
Прежде, чем приступить непосредственно к сути, хочу затронуть технику, которая пока что не очень широко представлена в текущей стандартной библиотеке, но, судя по всему, будет достаточно распространена в STL2, по крайней мере, в той её части, где будут повелевать ленивые вычисления и диапазоны.
Если вы опытный плюсовик, то можете смело пропускать эту часть.
Вы всё ещё здесь? Тогда представьте, что у нас есть набор контейнеров, и перед нами стоит трудная задача: записать размеры всех этих контейнеров в другой контейнер.
Напишем функцию, которая возвращает размер контейнера:
template <typename Container>
constexpr decltype(auto) size (Container & container)
{
return container.size();
}Теперь, казалось бы, ничто не мешает вызвать стандартный алгоритм std::transform.
std::vector<std::vector<int>> containers{...};
std::vector<std::size_t> sizes;
std::transform(containers.begin(), containers.end(), std::back_inserter(sizes), size);Но не тут-то было:
// Ошибка компиляции:
//
// couldn't deduce template parameter '_UnaryOperation'
// std::transform(containers.begin(), containers.end(), std::back_inserter(sizes), size);
// ^~~~size — это шаблонная функция. Конкретизируется шаблонная функция либо явно (в нашем случае это будет size<std::vector<int>>), либо в момент вызова. А просто запись size не позволяет компилятору понять, с какими аргументами данная функция будет вызываться.
Эту проблему можно обойти, если объявить size не функцией, а функциональным объектом:
struct size_fn
{
template <typename Container>
constexpr decltype(auto) operator () (Container & container)
{
return container.size();
}
};
constexpr auto size = size_fn{};Теперь больше никаких ошибок компиляции:
std::transform(containers.begin(), containers.end(), std::back_inserter(sizes), size);Конечно же, умудрённый опытом плюсовик скажет, что у функциональных объектов есть и определённые недостатки по сравнению с функциями. Но заострять на этом внимание мы сейчас не будем.
Простая композиция
Итак, техника освоена, рассмотрим более сложный жизненный пример.
Представьте, что нам нужно достать из ассоциативного массива все связанные значения. Для этого можно применить уже знакомый нам алгоритм std::transform:
std::map<std::string, double> m{...};
std::vector<double> r;
std::transform(m.begin(), m.end(), std::back_inserter(r), [] (const auto & p) {return p.second;});Пока что всё достаточно просто. Короткая и понятная лямбда-функция, всё хорошо. Но если логика отображения усложнится, то ситуация резко ухудшится.
Например, нужно взять не просто второй элемент пары, а вычислить квадратный корень из него, и результат округлить до ближайшего целого. Лямбда становится слишком длинной, придётся форматировать:
std::transform(m.begin(), m.end(), std::back_inserter(r),
[] (const auto & p)
{
return std::lround(std::sqrt(p.second));
});С другой стороны, наше намерение можно было бы выразить короче и нагляднее:
std::transform(m.begin(), m.end(), std::back_inserter(r), get<1> | sqrt | lround);Внимание привлекает запись get<1> | sqrt | lround. Данный синтаксис следует понимать так: взять элемент кортежа с индексом 1, взять квадратный корень из него и округлить до ближайшего целого. В точности то, что и требовалось.
Схематично это можно изобразить так:
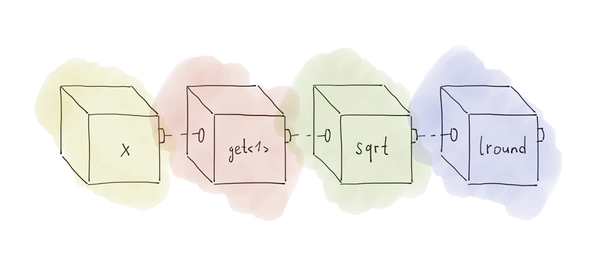
Реализовать функциональный объект get можно следующим образом:
template <std::size_t Index>
struct get_fn
{
template <typename Tuple>
constexpr decltype(auto) operator () (Tuple && t) const
{
using std::get;
return get<Index>(std::forward<Tuple>(t));
}
};
template <std::size_t Index>
constexpr auto get = get_fn<Index>{};Функциональные объекты sqrt и lround предлагаю реализовать в качестве упражнения всем заинтересовавшимся.
Сам же механизм композиции реализуется посредством соответствующего функционального объекта:
template <typename L, typename R>
struct compose_fn
{
template <typename ... Ts>
constexpr decltype(auto) operator () (Ts && ... ts) const &
{
return l(r(std::forward<Ts>(ts)...));
}
template <typename ... Ts>
constexpr decltype(auto) operator () (Ts && ... ts) &
{
return l(r(std::forward<Ts>(ts)...));
}
template <typename ... Ts>
constexpr decltype(auto) operator () (Ts && ... ts) &&
{
return std::move(l)(std::move(r)(std::forward<Ts>(ts)...));
}
L l;
R r;
};
template <typename L, typename R>
constexpr auto compose (L && l, R && r)
-> compose_fn<std::decay_t<L>, std::decay_t<R>>
{
return {std::forward<L>(l), std::forward<R>(r)};
}
template <typename ... Ts, typename R>
constexpr auto operator | (compose_fn<Ts...> l, R && r)
{
return compose(std::forward<R>(r), std::move(l));
}Важно отметить, что в данной реализации функция compose применяет композицию справа налево, как принято в математике. Иначе говоря, compose(f, g)(x) эквивалентно f(g(x)).
Оператор же меняет порядок композиции. То есть (f | g)(x) эквивалентно g(f(x)).
Это сделано для того, чтобы не вводить в заблуждение программиста, знакомого с такими решениями, как Boost Range Adaptors, range-v3, а также с консольным конвеером.
Многопозиционная композиция
Пока что всё было легко и понятно. Но на этом мы не остановимся.
Допустим, мы хотим отсортировать массив пар:
std::vector<std::pair<int, type_with_no_ordering>> v{...};Для второго элемента пары не задано отношение порядка (что понятно из его названия), поэтому сравнивать по нему не имеет смысла, более того, такое сравнение просто не скомпилируется. Поэтому сортировку запишем так:
std::sort(v.begin(), v.end(), [] (const auto & l, const auto & r) {return l.first < r.first;});Выглядит длинновато. Можно для красоты отформатировать.
std::sort(v.begin(), v.end(),
[] (const auto & l, const auto & r)
{
return l.first < r.first;
});На мой взгляд, это более удобно для чтения, но всё равно достаточно многословно.
Можно ли упростить это выражение? Попробуем написать псевдокод, в котором словами выразим то, что мы хотим сделать:
std::sort(v.begin(), v.end(), меньше_по_первому_элементу);Нужное нам действие — сравнение по первому элементу — можно разделить на два логических этапа: взятие первого элемента от каждой пары и собственно сравнение.
Для взятия первого элемента создадим функциональный объект на основе уже имеющегося get:
constexpr auto first = get<0>;Для собственно сравнения в СБШ уже есть подходящий инструмент: std::less.
Но как скомпоновать эти функции вместе? Попробую наглядно проиллюстрировать проблему.
Сравниватель алгоритма std::sort ожидает на вход два объекта.
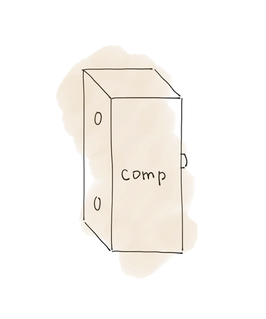
И сам по себе std::less удовлетворяет этому условию.
В то же время, first — одноместная функция. Он принимает только один аргумент. Не стыкуется:
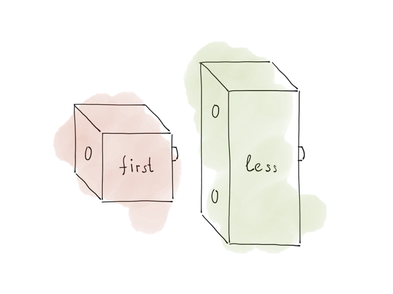
Значит, мы не можем просто написать first | std::less{}.
При этом результат, который мы хотим получить, должен выглядеть как-то так:
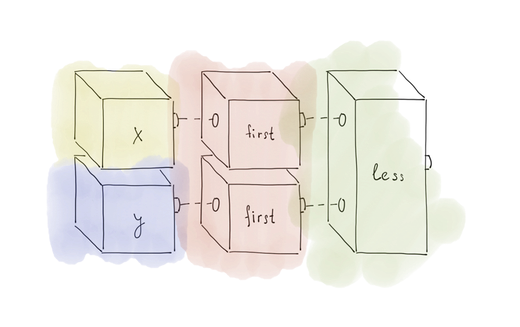
То есть компоновать с функцией std::less мы должны весь этот блок:
Если переводить мысли в код, то мы хотим получить следующую запись:
std::sort(v.begin(), v.end(), each(first) | std::less<>{});Но получается, что функция, порождённая записью each(first) должна не только принимать, но и возвращать сразу два значения, чтобы подать их на вход std::less. А в языке C++ функция не может вернуть более одного значения!
Однако, решение есть. Нужно реализовать особую схему композиции для функционального объекта each.
Сам функциональный объект each тривиален:
template <typename UnaryFunction>
struct each_fn
{
UnaryFunction f;
};
template <typename UnaryFunction>
constexpr auto each (UnaryFunction && f)
-> each_fn<std::decay_t<UnaryFunction>>
{
return {std::forward<UnaryFunction>(f)};
}Это даже не совсем функциональный объект. Скорее, это специальный контейнер-тег, который при композиции будет сообщать механизму композиции о том, что композицию сохранённой внутри контейнера функции нужно провести не так, как обычно.
А вот и сами механизмы композиции:
template <typename L, typename R>
struct each_compose_fn
{
template <typename ... Ts>
constexpr decltype(auto) operator () (Ts && ... ts) const &
{
return l(r(std::forward<Ts>(ts))...);
}
template <typename ... Ts>
constexpr decltype(auto) operator () (Ts && ... ts) &
{
return l(r(std::forward<Ts>(ts))...);
}
template <typename ... Ts>
constexpr decltype(auto) operator () (Ts && ... ts) &&
{
return std::move(l)(r(std::forward<Ts>(ts))...);
}
L l;
R r;
};
template <typename UnaryFunction1, typename UnaryFunction2>
constexpr auto compose (each_fn<UnaryFunction1> l, each_fn<UnaryFunction2> r)
-> each_fn<decltype(compose(l.f, r.f))>
{
return {compose(std::move(l.f), std::move(r.f))};
}
template <typename L, typename UnaryFunction>
constexpr auto compose (L && l, each_fn<UnaryFunction> r)
-> each_compose_fn<std::decay_t<L>, UnaryFunction>
{
return {std::forward<L>(l), std::move(r.f)};
}
template <typename UnaryFunction, typename R>
constexpr auto operator | (each_fn<UnaryFunction> l, R && r)
{
return compose(std::forward<R>(r), std::move(l));
}Главное отличие от обычной композиции — в раскрытии списка аргументов.
В функции compose раскрытие происходит так: l(r(args...)), а в each_compose — иначе: l(r(args)...).
Другими словами, в первом случае применяется одноместная функция к результату многоместной функции, а во втором случае — многоместная функция к результатам применения одноместной функции к каждому из входных параметров.
Теперь мы можем компоновать многоместные функции с одноместными:
std::sort(v.begin(), v.end(), each(first) | std::less<>{});
std::lower_bound(v.begin(), v.end(), x, each(second) | std::greater<>{});
// и т.п.Это победа.
Дополнение
Многие отметят, что слишком накладно реализовывать для каждой функции, каждого свойства объекта и т.п. отдельный функциональный объект. И с этим невозможно не согласиться. Например, в одном из примеров выше было бы удобнее не реализовывать новые функциональные объекты для функций lround и sqrt, а использовать имеющиеся библиотечные.
Существует пусть и неидеальное, но рабочее решение данной проблемы — барабанная дробь — макросы.
Например, для вызова функции-члена класса макрос можно реализовать так:
#define MEM_FN(f) [] (auto && x, auto && ... args) -> decltype(auto) { return std::forward<decltype(x)>(x).f(std::forward<decltype(args)>(args)...); }Использоваться он будет следующим образом:
std::vector<std::vector<int>> containers{...};
std::none_of(containers.begin(), containers.end(), MEM_FN(empty));Аналогичные макросы можно реализовать и для вызова свободных функций:
#define FN(f) [] (auto && ... args) -> decltype(auto) { return f(std::forward<decltype(args)>(args)...); }И даже для доступа к членам класса:
#define MEMBER(m) [] (auto && x) -> decltype(auto) { /* Тот самый случай, когда скобки вокруг возвращаемого выражения */ /* действительно нужны */ return (std::forward<decltype(x)>(x).m); }
struct Class
{
int x;
};
std::vector<Class> v{...};
std::remove_if(v.begin(), v.end(), MEMBER(x) | equal_to(5));Код местами упрошён, чтобы не вводить слишком много новых сущностей.
Заключение
Для чего всё это нужно? Почему нельзя просто пользоваться лямбдами?
Лябдами пользоваться можно и нужно. Но, к сожалению, лямбды зачастую порождают очень много дублирющегося кода. Бывает, что лямбды полностью повторяют друг друга. Бывает, что несколько лямбд отличаются совсем немного, но декомпозиции при этом они не поддаются.
Описанный в данной статье подход позволяет собирать простые лямбды из "кубиков", снижая количество написанного вручную кода и, вследствие этого, уменьшая вероятность совершить ошибку при написании очередной лямбды.
Этот подход хотя и может работать самостоятельно, но предназначен он в первую очередь для упрощения работы с алгоритмами и диапазонами.
Полный код со всеми подробностями.
Ссылки
Комментарии (5)

nikitablack
23.05.2017 14:55+1Интересная статья, спасибо за труд. Объясните пожалуйста, зачем вы здесь вызываете
std::move?
template <typename ... Ts> constexpr decltype(auto) operator () (Ts && ... ts) && { return std::move(l)(std::move(r)(std::forward<Ts>(ts)...)); }izvolov
23.05.2017 17:02+2С удовольствием.
Факт №1
Методы классов в языке C++ могут перегружаться по категории экземпляра класса:
struct Class { void f () const &; // Вызывается, когда экземпляр является ссылкой на константу. void f () &; // Вызывается, когда экземпляр является ссылкой. void f () &&; // Вызывается, когда экземпляр является ссылкой на rvalue. };
https://wandbox.org/permlink/Og3kWTDeZFMj0ncP
Факт №2
Функциональный объект может быть классом, обладающим нетривиальным состоянием и имеющим перегрузки оператора "скобки", описанные выше.
Суть
Теперь реализуем такой функциональный объект с состоянием и перегрузками оператора вызова.
Пусть это будет функциональный объект, который хранит некоторую строчку, в оператор вызова принимает контейнер, в который он эту строчку записывает:
template <typename T> struct push_back_fn { T value; template <typename Container> void operator () (Container & c) const & { c.push_back(value); } template <typename Container> void operator () (Container & c) & { c.push_back(value); } template <typename Container> void operator () (Container & c) && { // Наш объект является `rvalue`, а значит, скоро закочит своё // существование. Следовательно, строчка ему больше не понадобится, // так что владение строчкой можно отдать контейнеру. c.push_back(std::move(value)); // <-- } }; template <typename T> auto push_back (T && t) -> push_back_fn<std::decay_t<T>> { return {std::forward<T>(t)}; }
Теперь использование:
int main () { // Сохранили экземпляр нашего функционального объекта. Он `lvalue`. auto pb = push_back(std::string("qwerty")); // Записали копию строки в конец контейнера. std::vector<std::string> v; pb(v); // Записали ещё одну копию той же строки в коней другого контейнера. std::vector<std::string> w; pb(w); // А здесь наш `push_back_fn` вызывается как `rvalue`, // поэтому ни одного копирования не произошло. push_back(std::string("asdfgh"))(v); }
https://wandbox.org/permlink/MK2gIPzT3TOWBlw5
Исходя из всего вышеперечисленного, при композиции нужно обеспечить правильные вызовы каждого функционального объекта, чтобы не производить лишние действия в том случае, когда этого можно избежать.
nikitablack
23.05.2017 17:43Спасибо, теперь понял. Смутило, что в примерах в статье отсутствуют эти перегрузки.
bfDeveloper
Спасибо за статью. Интересно.
Не совсем понятен вопрос, в чём преимущество перед диапазонами? Вы сами про них упоминаете, но в чём их минусы? Почему бы не пользоваться ими?
Там компонуемость лучше, написание функций проще и без макросов. Тот же пример из документации:
Ничто не мешает пользоваться ими уже сейчас. Да, не в std, но ranges-v3 уже работающая header-only имплементация. Принести её в проект ничего не стоит.
izvolov
Спасибо за вопрос. Во вступлении я об этом упоминал, но не слишком подробно.
Я ни в коем случае не утверждаю, что есть какие-то преимущества перед диапазонами. Наоборот, всё, что здесь описано, как раз и родилось из активного использования диапазонов и адаптеров.
В данной публикации я хотел описать именно технику. А поскольку техника сама по себе не требует работы именно с диапазонам, то, чтобы не вводить новых сущностей, я пользовался исключительно стандартной библиотекой.