
Определение 1. Однородный контейнер – это такой контейнер, в котором хранятся объекты строго одного типа.
Определение 2. Неоднородный контейнер — это такой контейнер, в котором могут храниться объекты разного типа.
Определение 3. Статический контейнер — это контейнер, состав которого полностью определяется на этапе компиляции.
Под составом в данном случае понимается количество элементов и их типы, но не сами значения этих элементов. Действительно, бывают контейнеры, у которых даже значения элементов определяются на этапе компиляции, но в данной модели такие контейнеры не рассматриваются.
Определение 4. Динамический контейнер — это контейнер, состав которого частично или полностью определяется на этапе выполнения.
По такой классификации, очевидно, существуют четыре вида контейнеров:
Статические однородные
Сможете придумать пример?Обычный массив —
int[n].
Статические неоднородные
Примеры?Наиболее яркий пример такого контейнера — это кортеж. В языке C++ он реализуется классом
std::tuple<...>.
Динамические однородные
Догадались?Правильно,
std::vector<int>.
Динамические неоднородные
Вот об этом виде контейнеров и пойдёт речь в данной статье.
Содержание
- Динамические неоднородные контейнеры
- Динамический кортеж
- Хранение данных
- Обработчики
- Доступ к данным
- Время жизни и безопасность исключений
- Прочие проблемы
- Замеры производительности
- Ссылки
Динамические неоднородные контейнеры
Существует несколько техник получения динамического неоднородного контейнера. Вот тройка, пожалуй, наиболее распространённых из них:
Массив указателей на полиморфный класс
Выбор
трусабалбесабывалого оопэшника.
struct base { virtual ~base() = default; ... }; struct derived: base { ... }; std::vector<std::unique_ptr<base>> v;
Массив объединений
Под объединением может пониматься как языковая возможность
union, так и библиотечный класс типаboost::variant(в C++17 появитсяstd::variant).
Массив произвольных объектов с использованием стирания типа
Например,
boost::any(В C++17 появитсяstd::any), в который можно положить что угодно.
У каждой из этих техник есть свои преимущества и недостатки, и мы их обязательно рассмотрим.
А сейчас пришло время осветить пункт, который до этого момента оставался в тени, несмотря на то, что он является частью названия (и сути) статьи.
Определение 5. Плотно упакованный контейнер — это такой контейнер, элементы которого лежат в непрерывной области памяти, и между ними нет пропусков (с точностью до выравнивания).
int[n], std::vector<int>, std::tuple<...>.
К сожалению, не всякий плотно упакованный контейнер является динамическим неоднородным. А нам нужен именно такой.
Но вернёмся к преимуществам и недостаткам вышеперечисленных техник получения динамических неоднородных контейнеров.
Массив указателей на полиморфный класс
Преимущества:
Относительная простота реализации
Наследование, полиморфизм, все дела. Эти вещи (к счастью или к сожалению?) знает даже новичок.
Лёгко вводить новые сущности
Не требуется никаких дополнительных действий для того, чтобы получить возможность вставлять новый объект в массив. Нужно только создать нового наследника базового класса.
И не нужно перекомпилировать код, зависящий от массива указателей.
Недостатки:
Зависимость от иерархии
В массив можно сложить только объекты, унаследованные от некоторого базового класса.
Избыточность кода
Для каждого нового элемента требуется создать новый класс в иерархии. То есть если я хочу складывать в контейнер два типа чисел — целые и плавучку, — то мне придётся завести базовый класс "число" и два его соответствующих наследника.
Неплотная упаковка
В массиве лежат только указатели, а сами объекты разбросаны по памяти. Это, в общем случае, будет негативно влиять на работу с кэшем.
Массив объединений
Преимущества:
Независимость от иерархии
В массив можно положить любой тип, указанный в объединении.
Объекты лежат в непрерывной области памяти
В массиве хранится не указатель, а сам объект.
Недостатки:
Зависимость от множества объектов, входящих в объединение
При добавлении нового объекта в объединение нужно перекомпилировать весь код, который явно зависит от нашего массива объединений.
Неплотная упаковка
Да, объекты лежат в непрерывной области памяти. Но нам хотелось бы получить плотную упаковку, а для этого необходимо, чтобы между объектами не было пустот. А пустоты могут быть.
Дело в том, что размер объединения равен размеру наибольшего типа этого объединения. Например, если в объединение входит два типа —
Xиchar, причёмsizeof(X) = 32, то каждыйcharбудет занимать 32 байта, хотя одного было бы вполне достаточно.
Массив произвольных объектов с использованием стирания типа
Преимущества:
Полная независимость
В любой момент в такой массив можно положить любой тип, и не придётся перекомпилировать ничего, что зависит от этого массива.
Недостатки:
Неплотная упаковка
Как и в случае с массивом указателей, объекты такого массива разбросаны по памяти (в общем случае это не так, потому что может использоваться оптимизация малых объектов, но для достаточно больших объектов это всегда верно).
Динамический кортеж
Итак, ни один из вышеперечисленных подходов не предполагает плотной упакови. Поэтому нужно разработать ещё один подход к созданию динамического неоднородного контейнера, который, ко всему прочему, обеспечит вожделенную плотную упаковку.
Для того, чтобы это сделать, сначала придётся получше разобраться с any. Работа с ним происходит примерно так:
int main ()
{
// Создание новой переменной из экземпляра произвольного типа.
auto a = any(1);
assert(any_cast<int>(a) == 1);
// Доступ к значению.
any_cast<int>(a) = 42;
assert(any_cast<int>(a) == 42);
// Присвоение значения нового типа в старую переменную.
a = std::string(u8"Привет!");
assert(any_cast<std::string>(a) == std::string(u8"Привет!"));
}Как это работает?
Не принимайте этот код слишком близко к сердцу, это схематичная реализация. За настоящей реализацией следует обратиться к более авторитетному источнику.
#include <cassert>
#include <utility>
enum struct operation_t
{
clone,
destroy
};
using manager_t = void (*) (operation_t, const void *, void *&);
// Для каждого типа в момент его укладки в `any` создаётся специальный обработчик, который затем
// будет использоваться для работы с этим типом.
template <typename T>
void manage (operation_t todo, const void * source, void *& destination)
{
switch (todo)
{
case operation_t::clone:
{
destination = new T(*static_cast<const T *>(source));
break;
}
case operation_t::destroy:
{
assert(source == nullptr);
static_cast<T *>(destination)->~T();
break;
}
}
}
class any
{
public:
any ():
m_data(nullptr),
m_manager(nullptr)
{
}
any (const any & that):
m_manager(that.m_manager)
{
m_manager(operation_t::clone, that.m_data, this->m_data);
}
any & operator = (const any & that)
{
any(that).swap(*this);
return *this;
}
any (any && that):
m_data(that.m_data),
m_manager(that.m_manager)
{
that.m_manager = nullptr;
}
any & operator = (any && that)
{
any(std::move(that)).swap(*this);
return *this;
}
~any ()
{
clear();
}
// Здесь происходит то самое "стирание" типа.
// Тип объекта в этом месте "забывается", и далее на этапе компиляции его узнать уже
// невозможно. Однако, благодаря сохранённому обработчику, на этапе исполнения будет
// известно, как управлять "жизнью" объекта: его копированием и разрушением.
template <typename T>
any (T object):
m_data(new T(std::move(object))),
m_manager(&manage<T>)
{
}
template <typename T>
any & operator = (T && object)
{
any(std::forward<T>(object)).swap(*this);
return *this;
}
template <typename T>
friend const T & any_cast (const any & a);
template <typename T>
friend T & any_cast (any & a);
void clear ()
{
if (not empty())
{
m_manager(operation_t::destroy, nullptr, m_data);
m_manager = nullptr;
}
}
void swap (any & that)
{
std::swap(this->m_data, that.m_data);
std::swap(this->m_manager, that.m_manager);
}
bool empty () const
{
return m_manager == nullptr;
}
private:
void * m_data;
manager_t m_manager;
};
// Для того, чтобы достать значение, нужно явно указать его тип.
// Использование:
//
// `any_cast<int>(a) = 4;`
//
template <typename T>
const T & any_cast (const any & a)
{
return *static_cast<const T *>(a.m_data);
}
template <typename T>
T & any_cast (any & a)
{
return *static_cast<T *>(a.m_data);
}Как вы уже поняли, динамический кортеж (ДК) будет развитием идеи с any. А именно:
- Как и в случае с
any, будет применена техника стирания типа: типы объектов будут "забываться", и для каждого объекта будет заведён "менеджер", который будет знать, как с этим объектом нужно работать. - Сами объекты будут уложены друг за другом (с учётом выравнивания) в непрерывную область памяти.
Работать он будет похожим на any образом:
// Создание первоначального кортежа из произвольного набора элементов.
auto t = dynamic_tuple(42, true, 'q');
// Индикация размера.
assert(t.size() == 3);
// Доступ к элементам по индексу.
assert(t.get<int>(0) == 42);
...
// Добавление новых произвольных элементов.
t.push_back(3.14);
t.push_back(std::string("qwe"));
...
// Модификация имеющихся элементов.
t.get<int>(0) = 17;Нужно больше кода
Ну что ж, приступим к самому интересному.
Хранение данных
Как следует из определения плотной упаковки, все объекты хранятся в едином непрерывном куске памяти. Это значит, что для каждого из них, помимо обработчиков, нужно хранить его отступ от начала этого куска памяти.
Отлично, заведём для этого специальную структурку:
struct object_info_t
{
std::size_t offset;
manager_t manage;
};Далее, нужно будет хранить сам кусок памяти, его размер, а также отдельно нужно будет помнить суммарный объём, занимаемый объектами.
Получаем:
class dynamic_tuple
{
private:
using object_info_container_type = std::vector<object_info_t>;
...
std::size_t m_capacity = 0;
std::unique_ptr<std::int8_t[]> m_data;
object_info_container_type m_objects;
std::size_t m_volume = 0;
};Обработчики
Пока что остаётся неопределённым тип обработчика manager_t.
Есть два основных варианта:
Структура с "методами"
Как мы уже знаем по
any, для управления объектом нужно несколько операций. В случае с ДК это, как минимум, копирование, перенос и разрушение. Для каждой из них нужно завести поле в структуре:
struct manager_t { using copier_type = void (*) (const void *, void *); using mover_type = void (*) (void *, void *); using destroyer_type = void (*) (void *); copier_type copy; mover_type move; destroyer_type destroy; };
Указатель на обобщённый обработчик
Можно хранить только один указатель на обобщённый обработчик. В этом случае нужно завести перечисление, отвечающее за выбор требуемой операции, а также привести к единому виду сигнатуры всех возмозных действий над объектом:
enum struct operation_t { copy, move, destroy }; using manager_t = void (*) (operation_t, const void *, void *);
Недостаток первого варианта в том, что для каждого действия требуется введение нового поля. Соответственно, память, занимаемая обработчиками будет раздуваться в случае добавления новых обработчиков.
Недостаток второго варианта в том, что сигнатуры разных обработчиков разные, поэтому приходится подгонять все обработчики под единую сигнатуру, при этом, в засисимости от запрошенной операции, некоторые аргументы могут оставаться ненужными, а иногда — о, боги — даже приходится вызывать const_cast.
На самом деле, есть и третий вариант: полиморфные обработчики-классы. Но этот вариант нещадно отметается как самый тормознутый.
Соответственно, недостатки одного из вариантов — это преимущества другого.
По итогам долгих размышлений и взвешиваний преимуществ и недостатков, недостатки первого варианта перевешивают, и выбор падает на меньшее зло — обобщённый обработчик.
template <typename T>
void copy (const void *, void *); // См. раздел "Время жизни и безопасность исключений".
template <typename T>
void move (void * source, void * destination)
{
new (destination) T(std::move(*static_cast<T *>(source)));
}
template <typename T>
void destroy (void * object)
{
static_cast<T *>(object)->~T();
}
template <typename T>
void manage (operation_t todo, const void * source, void * destination)
{
switch (todo)
{
case operation_t::copy:
{
copy<T>(source, destination);
break;
}
case operation_t::move:
{
move<T>(const_cast<void *>(source), destination);
break;
}
case operation_t::destroy:
{
assert(source == nullptr);
destroy<T>(destination);
break;
}
}
}Доступ к данным
Самое простое, что можно сказать про ДК.
Тип запрашиваемых данных известен на этапе компиляции, индекс известен на этапе исполнения, поэтому интерфейс доступа к объекту напрашивается сам собой:
template <typename T>
T & get (size_type index)
{
return *static_cast<T *>(static_cast<void *>(data() + offset_of(index)));
}
size_type offset_of (size_type index) const
{
return m_objects[index].offset;
}Также, для большей эффективности (см. графики производительности доступа в конце статьи) можно определить доступ к объекту по отступу:
template <typename T>
const T & get_by_offset (size_type offset) const
{
return *static_cast<const T *>(static_cast<const void *>(data() + offset));
}Ну и индикаторы по аналогии со стандартными контейнерами:
size_type size () const
{
return m_objects.size();
}
std::size_t capacity () const
{
return m_capacity;
}
bool empty () const
{
return m_objects.empty();
}Единственное, про что нужно сказать отдельно — это особый индикатор, сообщающий объём контейнера.
Под объёмом понимается суммарное количество памяти, занимаемое объектами, находящимися в ДК.
std::size_t volume () const
{
return m_volume;
}Время жизни и безопасность исключений
Крайне важные задачи — слежение за временем жизни объектов и обеспечение безопасности исключений.
Поскольку объекты конструируются "вручную" при помощи размещающего new, то они, естественно, и разрушаются "вручную" — явным вызовом деструктора.
Это создаёт определённые сложности с копированием и переносом объектов при переаллокации. Поэтому приходится реализовывать относительно сложные конструкции для копирования и переноса:
template <typename ForwardIterator>
void move (ForwardIterator first, ForwardIterator last, std::int8_t * source, std::int8_t * destination)
{
for (auto current = first; current != last; ++current)
{
try
{
// Пробуем перенести все объекты на новое место.
current->manage(operation_t::move,
source + current->offset, destination + current->offset);
}
catch (...)
{
// Если не получилось, то уничтожаем то, что уже было перенесено.
destroy(first, current, destination);
throw;
}
}
destroy(first, last, source);
}
template <typename ForwardIterator>
void copy (ForwardIterator first, ForwardIterator last, const std::int8_t * source, std::int8_t * destination)
{
for (auto current = first; current != last; ++current)
{
try
{
// Пробуем скопировать все объекты в новое место.
current->manage(operation_t::copy,
source + current->offset, destination + current->offset);
}
catch (...)
{
// Если что-то пошло не так, то уничтожаем всё, что уже было скопировано.
destroy(first, current, destination);
throw;
}
}
}Прочие проблемы
Одна из самых больших проблем была с копированием. И, хотя я с ней и разобрался, сомнения всё равно периодически возникают.
Поясню.
Допустим, мы кладём некопируемый объект (скажем, std::unique_ptr) в std::vector. Мы это можем сделать при помощи переноса. Но если мы попытаемся скопировать вектор, компилятор будет ругаться, потому что внутренние его элементы некопируемы.
В случае с ДК всё несколько иначе:
- В момент укладки элемента в ДК нужно создать обработчик копирования. Если объект некопируем, то обработчик не может быть создан (ошибка компиляции). При этом ещё неизвестно, собираемся ли мы вообще когда-нибудь копировать наш ДК.
- В момент собственно копирования ДК информация о копируемости типа — из-за стирания типа — уже недоступна.
В настоящее время выбрано следующее решение проблемы:
- Если объект копируем, то для него создаётся обычный копирующий обработчик.
- Если объект некопируем, то для него создаётся особый обработчик, который при попытке копирования бросает исключение.
template <typename T>
auto copy (const void * source, void * destination)
->
std::enable_if_t
<
std::is_copy_constructible<T>::value
>
{
new (destination) T(*static_cast<const T *>(source));
}
template <typename T>
auto copy (const void *, void *)
->
std::enable_if_t
<
not std::is_copy_constructible<T>::value
>
{
auto type_name = boost::typeindex::ctti_type_index::type_id<T>().pretty_name();
throw std::runtime_error(u8"Объект типа " + type_name + u8" некопируем");
}Ещё более сложная проблема возникает при сравнении двух ДК на равенство. Можно было бы обойтись тем же способом, но, помимо случая с ошибкой компилятора при попытке сравнить несравнимое, есть ещё случаи, когда компилятор генерирует не ошибку, а предупреждение — например, при вызове оператора равенства для чисел с плавающей точкой. Здесь, с одной стороны, нельзя бросать исключение, потому что пользователь мог осознавать свои действия и производить сравнение намеренно. С другой стороны, хотелось бы всё-таки как-то сообщить пользователю о небезопасной операции.
Эта проблема пока остаётся открытой.
Замеры производительности
Поскольку основной целью было создать именно плотно упакованный контейнер, чтобы иметь оптимальное время доступа к его элементам, в замерах производительности сравнивалась скорость доступа в ДК со скоростью доступа в массив указателей на "разбросанные" по памяти объекты.
Применялись две схемы "разбросанности":
Разреженность
Пусть
N— размер замеряемого массива,S— показатель разброса.
Тогда генерируется массив указателей размераN * S, а затем он прореживается так, что остаются только элементы под номерамиN * i,i = 0, 1, 2, ....
Перемешанность
Пусть
N— размер замеряемого массива,S— показатель разброса.
Тогда генерируется массив размераN * S, перемешивается случайным образом, а затем из него выбираются первыеNэлементов, а остальные выбрасываются.
А в качестве точки отсчёта времени доступа был взят std::vector.

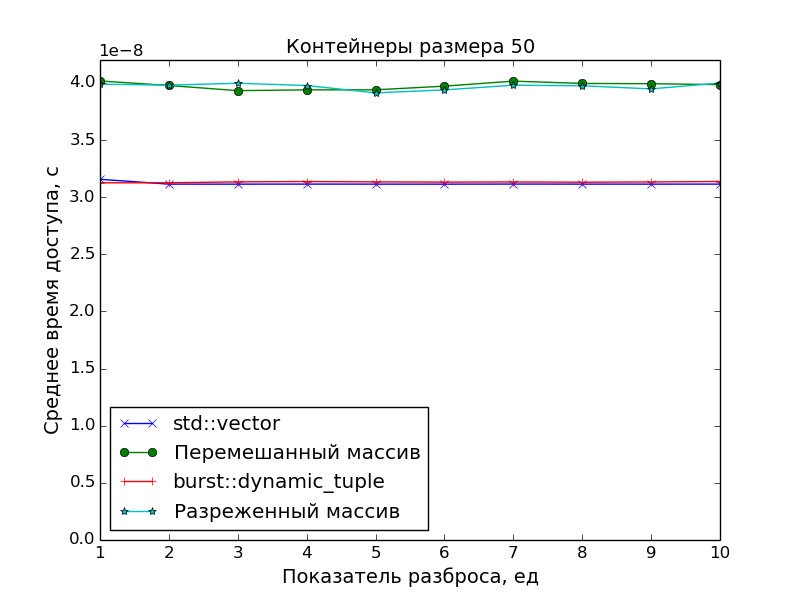
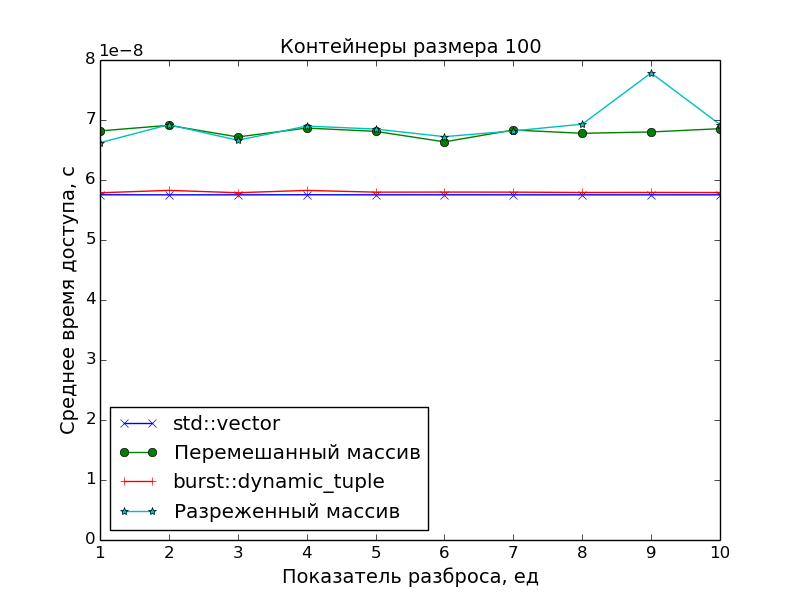
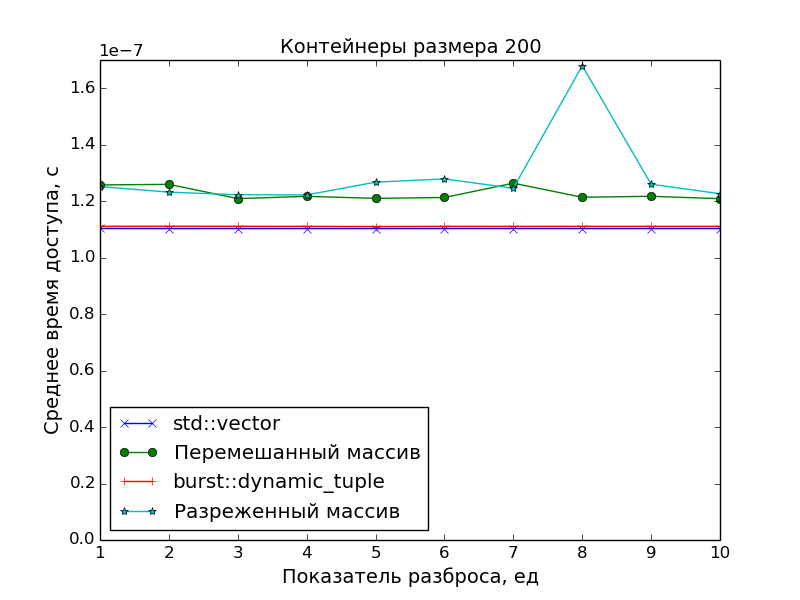
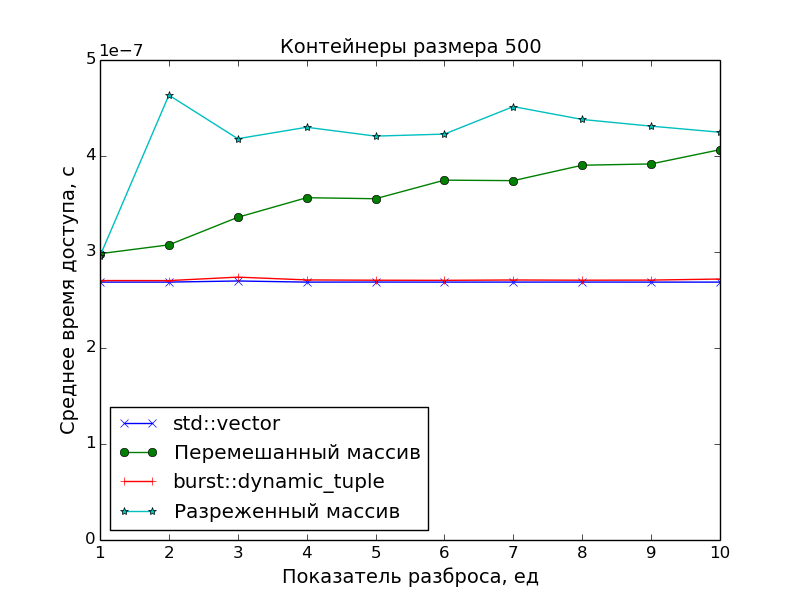
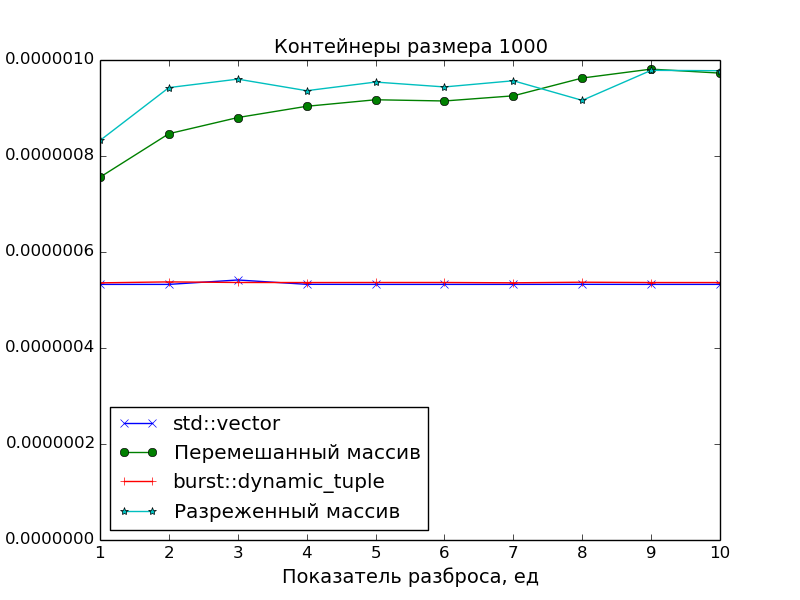
Графики подтверждают очевидное:
- Скорость доступа к элементам ДК идентична скорости доступа к элементам класса
std::vector(одно сложение указателей и одно разыменование). - Доступ к элементам массива указателей медленнее. Особенно это видно на больших массивах при показателе разброса
S > 1, когда данные перестают помещаться в кэш.
Все исходные коды доступны у меня на гитхабе.
Комментарии (62)

x512
02.06.2016 14:45+1Эх, где вы были пару лет назад?!!! Пришлось городить свои костыли. А так вещь нужная — мне потребовалсь для того чтобы сделать Entity-Component-System. вот для того чтобы в Entity хранить массив разнородных компонентов это решение в самый раз.
Xop
03.06.2016 06:38+2Кстати есть мнение, что компоненты лучше хранить отдельно, каждый тип в однородном контейнере, а из entity ссылаться на содержащиеся в ней компоненты по id/индексам.
tower120
02.06.2016 20:14А можно как то получить тип (
std::type_index) из вашего dynamic_tuple по индексу? Ну то-есть получить элемент по индексу, а потом в зависимости от его типа по своему обработать (как сstd::vector< std::variant<...> >).izvolov
02.06.2016 20:26+2А можно как то получить тип (std::type_index) из вашего dynamic_tuple по индексу?
Легко. Нужно только написать код :) .
На самом деле, это делается элементарно, просто у меня банально пока не было в этом интереса.
Поставил себе задачку.tower120
02.06.2016 20:42А можете привести участок кода где вы его используете как есть? Мне не понятно как можно получать 150 000й элемент массива и при этом наперёд знать его тип.
izvolov
02.06.2016 22:20-1К сожалению, не могу. Попробуйте представить его при реализации примера, описанного выше: https://habrahabr.ru/post/302372/#comment_9640418

qw1
05.06.2016 09:08Физически тип элемента в контейнере определяет только ф-ция manager.
можно предположить 2 сценария:
1. в operation_t добавить type (цена — виртуальный вызов, уже сделано)
2. сравнивать текущий manager с заданным. Например,
bool is_type<T>(int index) { return m_objects[index].manager == &management::manage<T>; }
второй вариант быстрый, но даёт только бинарный ответ.izvolov
05.06.2016 12:52+1Всё так.
Только я бы не стал называть первый сценарий виртуальным вызовом.
А второй сценарий у меня тоже используется, только не для индикации типа, а для проверки типа при доступе: https://github.com/izvolov/burst/commit/af23c847e63c0b4cc8119e6978728e245cfeaab2
izvolov
03.06.2016 10:34Сделал поддержку
std::type_index.
Оно?tower120
03.06.2016 14:48Возможно. Единственное но, std::type_index занимает 8 байт. Если набор хранимых типов заранее известен, то можно тип хранить в unsigned char. Разница становится ощутимой если хранить что то вроде std::optional (даже в обычном std::vector). Если же хранить как any — наверное подойдет как есть.
izvolov
03.06.2016 15:16Набор хранимых типов заранее неизвестен. Именно поэтому я и говорю, что ДК — это развитие идеи с
any.
OlegMax
03.06.2016 21:281. Не увидел упоминания memory alignment. Если этот аспект пропущен, то можно неожиданно получить серьезный удар по производительности.
2. Какие преимущества использования набора указателей на ф-ции (manager_t) перед виртуальными классами? На мой взгляд, именно для этого классы идеально и подходят.izvolov
03.06.2016 21:52Не увидел упоминания memory alignment
Очень странно. Я два раза упоминал про выравнивание.
А сам код есть в файле, на который я дал ссылку в конце статьи.
Какие преимущества использования набора указателей на ф-ции (manager_t) перед виртуальными классами?
Очевидно, отсутствие лишнего уровня косвенности. Вы же понимаете, как происходят виртуальные вызовы в языке C++?
- Отсутствие аллокаций.
Указатель на функцию глобален. А для класса нужно выделять память. Более того, это позволяет в процессе доступа проводить тривиальную проверку на то, что объект, который мы пытаемся достать, действительно имеет требуемый тип.
OlegMax
03.06.2016 22:22Выравнивание я просто сначала не заметил. Все ок.
Насчет уровня косвенности — спорно. В вашей реализации — вызов ф-ции по указателю (manage) + switch. Вызов виртуальной ф-ции = вызов ф-ции по указателю на указатель. Не думаю, что можно без замеров утверждать что будет быстрее в реальной жизни.
Не вижу, откуда взяться дополнительным аллокациям. Размер объекта без полей, реализующего виртуальный интерфейс, равен (surprise!) размеру manager_t. Размещающий new позволит отлично обойтись без доп. аллокаций.izvolov
03.06.2016 23:01Не думаю, что можно без замеров утверждать что будет быстрее в реальной жизни
Во-первых, разумеется, замеры я проводил.
Более того, первый вариант у меня был как раз на виртуальных вызовах. Потом я попробовал вариант со структурой с указателями, и всё стало "летать".
Вот уже между структурой и обобщённым обработчиком заметной разницы в скорости нет. Но структура, очевидно, занимает больше места. Поэтому окончательный выбор пал именно на обобщённый вариант.
Я не ставил своей целью рассказать про каждую мелочь, с которой я сталкивался в процессе разработки. И уж тем более не могу привести каждый замер, который я когда-либо производил.
Не вижу, откуда взяться дополнительным аллокациям
Нам нужно завести массив указателей на классы-обработчики. А сколько они занимают памяти — в данном случае не важно, потому что память под каждый из них будет выделяться в куче.
Размещающий new позволит отлично обойтись без доп. аллокаций
Вы предлагаете ещё и обработчиками вручную управлять?
И это только ради того, чтобы написать побольше кода, который ещё и работать будет медленнее?
Итак, имеющиеся варианты:
- Много кода и медленная программа.
- Мало кода и быстрая программа.
Нелёгкий выбор ждёт нас.
OlegMax
03.06.2016 23:34-1Совершенно бессмысленный shared_ptr в версии с виртуальными вызовами, конечно, подрывает доверие к вашей оценке.
izvolov
04.06.2016 00:15Механизм управления временем жизни указателя не влияет на доступ к элементу, на который он указывает.
Вообще, мне казалось очевидным, что виртуальный вызов дольше прямого.
Будет великолепно, если вы сделаете свои, хорошие, правильные замеры и покажете их обществу. Если я окажусь неправ, то я публично покаюсь.OlegMax
04.06.2016 09:39Вот исходник тестового примера (замеры времени Windows-only).
Я слишком спешу сейчас, чтобы проанализировать подробно, но на первый взгляд виртуальные ф-ции убедительно выигрывают на VS2015 x86 и x64.izvolov
04.06.2016 20:59Вы не то замерили.
Обработчиков много, а не один. Куча обращений к одному и тому же объекту замечательно кешируется. А вот когда их много и они разбросаны по памяти — это совершенно другая ситуация.
Но.
Вы меня натолкнули на интересную мысль как можно одновременно:
- Ещё сильнее всё ускорить.
- Сделать красивые вызовы без обобщённой сигнатуры.
Напишу попозже.
OlegMax
06.06.2016 09:39Мастер дискуссии уровня Бог:
А: Виртуальный вызов дольше прямого!
В: Вот замеры. В вашем случае (с switch) наоборот.
А: Так вы меряли на каком-то необычном процессоре с кэшами и предсказаниями переходов! На моей воображаемой системе без этих бесовских ухищрений все как я сказал. И вообще у меня голова разболелась.
izvolov
04.06.2016 22:14В общем, мысль моя не оправдалась, улучшить не удалось.
Тем не менее, я ради интереса померил производительность обработчиков на живом ДК размера от 10 до 1000 элементов.
Вывод: чем меньше элементов в контейнере, тем меньше разница между указателем на функцию (УФ) и полиморфными объектами (ПО).
10 элементов:
УФ: 2.9 попугаев.
ПО: 5.7 попугаев.
Разница в ~2 раза.
100 элементов:
УФ: 0.8 попугаев
ПО: 3.5 попугаев.
Разница в ~4 раза.
1000 элементов:
УФ: 0.29 попугаев.
ПО: 2.9 попугаев
Разница на порядок.
Структуру с указателями на функцию тоже мерил, результат практически идентичен УФ, но даже немного медленнее.
Дальнейшее обсуждение этой темы считаю нецелесообразным.
izvolov
04.06.2016 00:28И
shared_ptrтам, естественно, не бессмысленный.
Обработчик зависит только от типа объекта, ему не важно его значение. Поэтому для того, чтобы получить обработчик объекта при копировании, не нужно его пересоздавать (и опять лезть в кучу), а нужно только скопировать указатель на него.

Videoman
04.06.2016 00:03А правильно ли я понимаю, что ваш контейнер будет работать только на x86 архитектуре, где пофигу на выравнивание. Иначе, я не вижу где выравнивается адрес начала объекта? Попробую пояснить:
Допустим data_size() = 0. sizeof(uint8_t) = 1. Кладем в кортеж байт. sizeof(uint32_t)=4. При попытке положить целое его начало уже не будет выравнено, т.к. адрес будет data_size() + 1.izvolov
04.06.2016 00:04Послушайте, ну только что же обсуждали, что выравнивание есть.
https://github.com/izvolov/burst/blob/master/burst/container/dynamic_tuple.hpp#L335Videoman
05.06.2016 00:51Да, похоже выравнивание есть. Просто сбил с толку термин — «плотная» упаковка. Всегда думал что плотно можно упаковать только по-байтово, наподобие сериализации.

0xd34df00d
09.06.2016 04:08На x86 выравнивание важно только для SIMD уже весьма давно. А я сомневаюсь, что в таком коде компилятор все равно осилит векторизовать возможные циклы.
AndreySu
Пример use case-а из жизни, пожалуйста, т.е. для чего это необходимо в повседневной жизни. Иначе кажется что если необходимы такие конструкции это прежде всего говорит о плохой архитектуре приложения.
izvolov
Представьте, что у вас есть большое количество функций, которые друг от друга зависят. Зависимость заключается в том, что для каждой функции на этапе компиляции известно, результаты каких других функций требуются для вычисления этой функции. К примеру, для функций
известно, что функция
cвычисляется именно по тем данным, которые возвращают функцииaиb, а функцияdвычисляется по результатам функцийaиc(именно этих конкретных функций, а не любых функций, возвращающих нужный тип).Эти зависимости можно изобразить в виде графа:
Теперь представьте, что таких функций очень много и между ними куча зависимостей (но без циклов, разумеется), так что граф получается достаточно большим и сложным.
Далее, в динамике — во время исполнения программы — поступает информация о том, что нужно вычислить некоторое — заранее неизвестное — подмножество этих функций. При этом требуется избежать повторных вычислений. В примере выше функции
cиdобе зависят от результата функцииa, но функцияaдолжна быть вычислена только один раз.Допустим, нужно вычислить значение функции
d. Это значит, что нужно собрать весь граф, ведущий кd, произвести все промежуточные вычисления (а нашем примере для вычисления функцииdтребуется вычислить иa, иb, иc) в правильном порядке и без повторений, а затем передать полученные результаты в функциюd, чтобы получить искомый результат.А поскольку обращения на чтение и запись результатов промежуточных вычислений может быть очень много, желательно положить их радом, чтобы они почаще попадали в строчку кэша.
В свою очередь, прошу обосновать утверждение "если необходимы такие конструкции это прежде всего говорит о плохой архитектуре приложения".
А то получается, что и
boost::variant, иboost::any, и даже, простигосподи, полиморфные объекты в коде свидетельствуют о "плохой архитектуре".AndreySu
Не могу понять при чем здесь порядок вычисления в динамике функций без повторений и динамический неоднородный плотно упакованный контейнер? Вы пишете код, в котором присутствуют ветвления (if конструкция), возможно циклы возможно еще что то в динамике, после чего результат передаете в функцию d.
izvolov
Этих функций сотни. Какие именно будут выполняться — заранее неизвестно.
Предложите "хорошую" архитектуру.
Варианты "позвать пару ифчиков" по очевидным причинам не канают.
AndreySu
Тогда по каким критериям у вас вызываются сотни функций и без «ифчиков»? Вызов этих функций и вся бизнес логика которая их вызывает собственно похоже ни как не влияет на способ хранения информации как видно из коментария выше. И у вас контейнер компайл — тайм, это значит что и флоу бизнес логики тоже компайл тайм.
izvolov
У меня куча вычислений. Я знаю входные аргументы и выход каждого.
Во время исполнения мне приходит информация о том, что нужно посчитать. Промежуточные вычисления могут повторяться, поэтому нужно где-то запоминать результаты всех вычислений, чтобы не производить их заново каждый раз.
Для этого я топологически сортирую граф вычислений, в результате чего чётко определяется порядок вычислений. И в соответствии с этим порядком я и завожу динамический кортеж для хранения результатов. А поскольку обращений к результатам может быть очень много, я хочу положить их максимально близко друг к другу, чтобы было меньше промахов кэша.
Итак, получается, что я знаю типы, которые мне нужны, но не знаю места, где они лежат. В результате и получается контейнер, к которому можно обратиться по индексу в динамике, но взять оттуда заранее известный тип.
AndreySu
Вот по работе графа вычислений о котором вы говорите хотелось бы услышать, что это из себя представляет это тема интересна и тогда будет ясно как и для чего использовать такой контейнер.
izvolov
Я хотел начать статью с этого примера, но быстро выяснилось, что тогда статья будет о примере, а не о структуре данных.
AndreySu
И да, использование boost::any свидетельствует о плохой или не продуманной архитектуре. Необходимо использовать boost с умом, и в любых даже самых хороших фреймворках и библиотеках разработчики будут добавлять механизмы для того чтобы в плохо продуманную архитектуру можно было вставлять костыли и не рушить её совсем. До сих пор не могу придумать use case-а по использованиею так же boost::variant или boost::any.
izvolov
Пожалуйста, обоснуйте утверждение "использование boost::any свидетельствует о плохой или не продуманной архитектуре".
AndreySu
Да, вот интересен мне use case в продакшене, а не в каком либо тестовом или академическом коде.
izvolov
То, что лично вам что-либо не понадобилось, не значит, что это не нужно. Например, если пользоваться ассоциативными массивами размером не более 10 элементов, то даже
std::mapпрекрасно подойдёт. Но это не повод говорить, что использование хеш-таблицы свидетельствует о плохой архитектуре.Ещё раз.
Атеист не должен доказывать верующему отсутствие бога.
Вы выдвинули утверждение. Обойснуйте его, пожалуйста.
AndreySu
Я всего лишь хочу понять в какой архитектуре это может понадобится, то что вы предложили — это что то новое, и я хочу разобраться может это действительно то, чего мне в проектах не очень хватало. Но я никак не могу понять, если у вас контейнер с компайл тайм получением из него данных (как минимум) и при этом сотни функций значит тоже компайл тайм написаны (а, например, не грузятся из сотни дллок с сишным апи и слепливаются в динамике в бизнес логику). То тогда какой смысл использовать такой контейнер?
izvolov
На этапе компиляции известны только типы значений, которые я хочу туда класть или доставать. Но места, на которых лежат эти значения, выясняются только во время исполнения.
AndreySu
Теперь стало более ясно, но хотелось бы увидеть, возможно, в компайл тайм оптимизированный граф обработки который умеет класть данные в такой контейнер.
izvolov
Вернее, так: на этапе компиляции известно только всё множество
Fдоступных мне функций и, соответственно, множествоRтипов результатов этих функций.На этапе исполнения выясняется подмножество функций, которые мне нужно вычислить,
F0, и соответствующее подмножество их результатовR0, а также места, на которых будут лежать эти результаты в моём динамическом кортеже.RPG18
Например Variant активно используется в Qt. В том же самом Model-View программировании.
0xd34df00d
Там это на самом деле any.
jediserg
Нужно распарсить json. На выходе получаем древовидную структуру, где элемент может быть числом, строкой, массивом или объектом которые опять могут содержать массивы, объекты и тд. Вот этот самый элемент можно сделать boost variant
spice_harj
не надо далеко ходить, обработка и реконструкция экспериментальных данных. Когда необходимо работать с коллекциями и векторами совершенно разных типов с совершенно разными атрибутами (времена, размеры...) и т.д.
Мы, конечно, по старинке городим кучумалу по первому варианту, надо будет попробовать всё таки boost.
Yuuri
В общем-то любая одноуровневая объектная иерархия может быть заменена простым типом-суммой (см. про алгебраические типы), причём более эффективно и с меньшим количеством бойлерплейта. boost::variant – это наиболее точная их имитация-реализация, которую только можно изобразить на C++.
MaxQwerty
Делает ли то же самое модификатор constexpr из нового для многих стандарта c++0x?
izvolov
Не понял вопроса. Что — "то же самое"?
MaxQwerty
Вычисление возвращаемых значений из функций на этапе компиляции.
AndreySu
Этот модификатор всего лишь вычисляет то, что можно вычислить на уровне компиляции без динамически пришедших данных, т.е. константы.
DaylightIsBurning
Супер! У меня точно такая же задача возникла, но я решал через абстрактный тип
Result, а результаты вычислений храню вcuckoo_map<Key,unique_ptr>, получается, конечно не так производительно :(. Перешел бы на ваш контейнер, но мне нужен параллельный доступ, т.к. вычисления сильно многопоточные, потому пользуюсь libcuckoo.izvolov
Что вы понимаете под параллельным доступом?
DaylightIsBurning
Concurrent: операции вставки, чтения и удаления элементов из контейнера должны быть потокобезопасными, что бы результат вычислений мог быть прочитан/сохранён прямо из потока вычисления. Конечно, любой контейнер можно сделать concurrent, если добавить lock, но тогда производительность хуже, чем у однопоточного кода. Libcuckoo обеспечивает производительность на уровне
std::unordered_mapна каждый поток. Я когда-то сравнивалcuckoohash_mapс lock-free (libcds) контейнерами — libcuckoo выиграла с отрывом по производительности и удобству использования.izvolov
Посмотрел
libcuckoo.В общем-то, я совершенно иную задачу решал. Я хотел создать, в терминах статьи, динамический неоднородный плотный контейнер, причём последовательный.
А у них — ассоциативный контейнер (хеш-таблица), да ещё и оптимизированный для многопоточного доступа.
Наверное, можно сделать неоднородную хеш-таблицу. Возможно, можно даже сделать её плотной и многопоточной.
Но это будет уже совершенно другая структура данных.
А вообще, идея интересная...
DaylightIsBurning
Всё верно. Я имел ввиду, что, как Вы и отметили, любой контейнер можно превратить в неоднородный с помощью полиморфного
Resultиименно этот вариант я для себя и выбрал. Но, если контейнер при этом ещё и последовательный, — вообще отлично, производительность задаром не помешает.
Archy_Kld
«Пример use case-а из жизни»
Автонавигация VDO Dayton — именно таким образом хранятся данные карт и навигации.
AndreySu
Каким образом хранятся там? boost::variant? boost::any? Или все же структуры данных. Прошу не путать назначения типов.
Archy_Kld
Как реализовано в исходниках — сие мне не известно.
Формат закрытый, нигде не описываемый, инструментарий для работы с данными есть только у производителя.
Именно поэтому карты для этой навигации практически все только официальные, по платной ежегодной подписке.
Сами же данные карт и навигации — один сплошной файл, по структуре разбит на 2к блоки. Логический блок — несколько 2к блоков после первого, в заголовке которого явно указывается их число. Сами данные атомарно хранятся в невыровненном виде. Например, самые первые 3 байта в первом логическом 2к блоке — его адрес-смещение, следующий байт — размер логического блока. Далее насколько помню байт признака-ключа шифрования данных, байт типа блока и т.д.
00 00 02 03 — блок со смещением 2*2048, размером 3*2048 байт.
Структура данных 2к внутри зависит от типа блока, но сделана явно в полиморфных наследуемых структурах. Матрешки, в которых так же описывается размер содержимого.
Если ставить задачу чтения такого, без описываемых динамических неоднородных контейнеров обойтись можно и несложно.
Если поставить задачу компиляции таких данных, из OSM, например, то мне предлагаемый подход нравится настолько, что я статью себе в избранное занес.