
В первой статье мы рассмотрели механизм индексирования PostgreSQL, во второй — интерфейс методов доступа, и теперь готовы к разговору о конкретных типах индексов. Начнем с хеш-индекса.
Hash
Устройство
Общая теория
Многие современные языки программирования включают хеш-таблицы в качестве базового типа данных. Внешне это выглядит, как обычный массив, но в качестве индекса используется не целое число, а любой тип данных (например, строка). Хеш-индекс в PostgreSQL устроен похожим образом. Как это работает?
Как правило, типы данных имеют очень большие диапазоны допустимых значений: сколько различных строк можно теоретически представить в столбце типа text? В то же время, сколько разных значений реально хранится в текстовом столбце какой-нибудь таблицы? Обычно не так много.
Идея хеширования состоит в том, чтобы значению любого типа данных сопоставить некоторое небольшое число (от 0 до N?1, всего N значений). Такое сопоставление называют хеш-функцией. Полученное число можно использовать как индекс обычного массива, куда и складывать ссылки на строки таблицы (TID). Элементы такого массива называют корзинами хеш-таблицы — в одной корзине могут лежать несколько TID-ов, если одно и то же проиндексированное значение встречается в разных строках.
Хеш-функция тем лучше, чем равномернее она распределяет исходные значения по корзинам. Но даже хорошая функция будет иногда давать одинаковый результат для разных входных значений — это называется коллизией. Так что в одной корзине могут оказаться TID-ы, соответствующие разным ключам, и поэтому полученные из индекса TID-ы необходимо перепроверять.
Просто в качестве примера: какую хеш-функцию можно придумать для строк? Пусть число корзин равно 256. Тогда в качестве номера корзины можно взять код первого символа (допустим, у нас однобайтовая кодировка). Хорошая ли это хеш-функция? Очевидно, нет: если все строки начинаются с одного и того же символа, все они попадут в одну корзину; о равномерности тут нет и речи, придется перепроверять все значения и весь смысл хеширования потеряется. Что, если просуммировать коды всех символов по модулю 256? Будет гораздо лучше, хотя тоже далеко не идеально. Если интересно, как на самом деле устроена такая хеш-функция в PostgreSQL, посмотрите определение hash_any() в hashfunc.c.
Устройство индекса
Вернемся к хеш-индексу. Наша задача состоит в том, чтобы по значению некоторого типа данных (ключ индексирования) быстро найти соответствующий TID.
При вставке в индекс вычислим хеш-функцию для ключа. Хеш-функции в PostgreSQL всегда возвращают тип integer, что соответствует диапазону 232 ? 4 миллиарда значений. Число корзин изначально равно двум и увеличивается динамически, подстраиваясь под объем данных; номер корзины можно вычислить по хеш-коду с помощью битовой арифметики. В эту корзину и положим наш TID.
Но этого недостаточно, ведь в одну корзину могут попасть TID-ы, соответствующие разным ключам. Как быть? Можно было бы записывать в корзину вместе с TID-ом еще и исходное значение ключа, но это очень сильно увеличило бы размер индекса. Так что для экономии места в корзине сохраняется не сам ключ, а его хеш-код.
При поиске в индексе мы вычисляем хеш-функцию для ключа и получаем номер корзины. Остается перебрать все содержимое корзины и вернуть только подходящие TID-ы с нужными хеш-кодами. Это делается эффективно, поскольку пары «хеш-код — TID» хранятся упорядоченно.
Но может так получиться, что два разных ключа не просто попадут в одну корзину, но и будут иметь одинаковые 4-байтовые хеш-коды — коллизии никто не отменял. Поэтому метод доступа просит общий механизм индексирования контролировать каждый TID, перепроверяя условие по табличной строке (механизм умеет это делать заодно с проверкой видимости).
Страничная организация
Если посмотреть на индекс не с точки зрения планирования и выполнения запроса, а глазами менеджера буферного кеша, то окажется, что вся информация, все индексные записи должны быть упакованы в страницы. Такие индексные страницы помещаются в буферный кеш и вытесняются оттуда точно так же, как и табличные страницы.
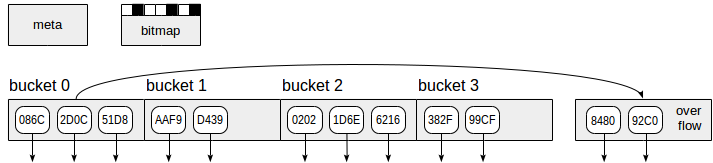
Хеш-индекс, как видно на картинке, использует страницы (серые прямоугольники) четырех видов:
- Метастраница (meta page) — нулевая страница, содержит информацию о том, что находится внутри индекса;
- Страницы корзин (bucket page) — основные страницы индекса, хранят данные в виде пар «хеш-код — TID»;
- Страницы переполнения (overflow page) — устроены так же, как страницы корзин, и используются в случае, когда одной страницы для корзины не хватает;
- Страницы битовой карты (bitmap page) — в них отмечаются освободившиеся страницы переполнения, которые можно использовать для других корзин.
Стрелочки вниз, идущие от элементов индексных страниц, символизируют TID-ы — ссылки на табличные строки.
При очередном увеличении индекса одномоментно создается в два раза больше корзин (и, соответственно, страниц), чем в прошлый раз. Чтобы не выделять сразу такое, потенциально большое, количество страниц, в версии 10 сделали более плавное увеличение размера. Ну а страницы переполнения выделяются просто по мере необходимости и отслеживаются в страницах битовой карты, которые также выделяются по мере надобности.
Заметим, что хеш-индекс не умеет уменьшаться в размере. Если удалить часть проиндексированных строк, однажды выделенные страницы уже не возвращаются операционной системе, а только переиспользуются для новых данных после очистки (VACUUM). Единственный вариант уменьшить физический размер индекса — перестроить его с нуля командой REINDEX или VACUUM FULL.
Пример
Приведем пример создания хеш-индекса. Чтобы не изобретать свои таблицы, здесь и дальше мы будем пользоваться демонстрационной базой данных по авиаперевозкам, и на этот раз возьмем таблицу рейсов.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Неприятной особенностью текущей реализации хеш-индекса является то, что действия с ним не попадают в журнал упреждающей записи (о чем нас и предупреждает PostgreSQL при создании индекса). Как следствие, хеш-индексы не могут быть восстановлены после сбоя и не участвуют в репликации. Кроме того, хеш-индекс значительно уступает B-дереву по универсальности применения, и его эффективность тоже вызывает вопросы. То есть сейчас применять такие индексы не имеет практического смысла.
Впрочем, ситуация изменится уже этой осенью с выходом десятой версии PostgreSQL. В ней хеш-индекс снабдили наконец поддержкой журнала и дополнительно оптимизировали выделение памяти и эффективность одновременной работы.
Семантика хеширования
Почему же хеш-индекс просуществовал чуть не от самого рождения PostgreSQL до наших дней в состоянии, в котором им нельзя воспользоваться? Дело в том, что алгоритм хеширования используется в СУБД очень широко (в частности, для хеш-соединений и группировок), и системе надо знать, какую хеш-функцию применять к каким типам данных. Но это соответствие не статично, его нельзя задать раз и навсегда — PostgreSQL позволяет добавлять новые типы на лету. Вот в методе доступа по хешу такое соответствие и содержится, а представлено оно в виде привязки вспомогательных функций к семействам операторов:
demo=# select opf.opfname as opfamily_name,
amproc.amproc::regproc AS opfamily_procedure
from pg_am am,
pg_opfamily opf,
pg_amproc amproc
where opf.opfmethod = am.oid
and amproc.amprocfamily = opf.oid
and am.amname = 'hash'
order by opfamily_name,
opfamily_procedure;
opfamily_name | opfamily_procedure
--------------------+--------------------
abstime_ops | hashint4
aclitem_ops | hash_aclitem
array_ops | hash_array
bool_ops | hashchar
...
Хотя эти функции и не документированы, ими можно воспользоваться для вычисления хеш-кода значения соответствующего типа. Например, для семейства text_ops используется функция hashtext:
demo=# select hashtext('раз');
hashtext
-----------
127722028
(1 row)
demo=# select hashtext('два');
hashtext
-----------
345620034
(1 row)
Свойства
Посмотрим свойства хеш-индекса, которые этот метод доступа сообщает о себе системе. Запросы мы приводили в прошлый раз; сейчас ограничимся только результатами:
name | pg_indexam_has_property
---------------+-------------------------
can_order | f
can_unique | f
can_multi_col | f
can_exclude | t
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t
bitmap_scan | t
backward_scan | t
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | f
search_array | f
search_nulls | f
Хеш-функция не сохраняет отношение порядка: из того, что значение хеш-функции одного ключа меньше значения функции другого ключа, нельзя сделать никаких выводов о том, как упорядочены сами ключи. Поэтому хеш-индекс в принципе может поддерживать единственную операцию «равно»:
demo=# select opf.opfname AS opfamily_name,
amop.amopopr::regoperator AS opfamily_operator
from pg_am am,
pg_opfamily opf,
pg_amop amop
where opf.opfmethod = am.oid
and amop.amopfamily = opf.oid
and am.amname = 'hash'
order by opfamily_name,
opfamily_operator;
opfamily_name | opfamily_operator
---------------+----------------------
abstime_ops | =(abstime,abstime)
aclitem_ops | =(aclitem,aclitem)
array_ops | =(anyarray,anyarray)
bool_ops | =(boolean,boolean)
...
Соответственно хеш-индекс не может выдавать упорядоченные данные (can_order, orderable). По той же причине хеш-индекс не работает с неопределенными значениями: операция «равно» не имеет смысла для null (search_nulls).
Поскольку в хеш-индексе не сохраняются ключи (а только хеш-коды ключей), он не может использоваться для исключительно индексного доступа (returnable).
Многоколоночные индексы (can_multi_col) этот метод доступа не поддерживает.
Внутренности
Начиная с версии 10, во внутреннюю структуру хеш-индекса можно будет заглянуть с помощью расширения pageinspect. Вот как это будет выглядеть:
demo=# create extension pageinspect;
CREATE EXTENSION
Метастраница (получаем число строк в индексе и максимальный задействованный номер корзины):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
Страница корзины (получаем число актуальных строк и строк, которые могут быть очищены):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
И так далее. Но понять смысл всех доступных полей вряд ли получится без изучения исходного кода. При наличии такого желания начать стоит с README.
Продолжение следует.
Поделиться с друзьями
x-wao
Хеш-индексы мало кто пробовал, из-за того, что они работают без WAL. С 10-ки, в которой оно наконец появятся, ситуация, возможно, изменится. Кто-нибудь из читателей использует Hash-индексы, и зачем?
afiskon
Amit Kapila не так давно показал, что хэш-индексы иногда могут быть быстрее B-деревьев. Следовательно, если вы ищите только по равенству, имеет смысл сравнить оба варианта и выбрать тот, который на ваших данных и объемах будет быстрее.
erwins22
Я пытался, раз в 10 медленнее обычных.
Кто то тут на habre пытался (я предложил попробовать) с аналогичным результатом, там задача была — связка двух таблиц по ключевому полю.
насколько я вижу по описанию и отсутствия тестов производительности совсем все плохо…
Ivan22
тем не менее при джоина почему-то только хэш-таблицы строяться.
erwins22
тут небольшая разница, я говорю о хешиндексах(постоянно хранимых), а вы о хештаблицах.(динамически создаваемых)
erwins22
https://habrahabr.ru/post/317980
Ivan22
а суть таже. Построить хешиндекс в памяти и потом по нему быстро искать.
erogov
Они, конечно, похожи на уровне общей идеи, но на этом сходство и заканчивается.
Starche
Пробовал с полгода назад. На таблице 250М записей для запросов «IN (1000 значений)» при поиске по 64-символьному текстовому ключу (sha1-хэш) скорость чтения по hash-индексу была в три раза лучше чем по btree.
Плюс хорошее влияние на скорость записи (обновление hash-индекса очень быстрое в сравнении с btree). Ну и размер индекса тоже сильно меньше.
В общем, я бы их с удовольствием использовал в проекте, если бы не отсутствие репликации.