
В предыдущих статьях я рассказал об этапах выполнения запросов и о статистике.
Теперь пришла пора рассмотреть самые важные узлы, из которых может состоять план. Я начну со способов доступа к данным, и в этой статье расскажу о последовательном сканировании.
В прошлый раз я показывал, как на основе статистики вычисляется кардинальность, а в этой и следующих буду демонстрировать, как рассчитывается стоимость узлов плана. Не то, чтобы конкретные формулы оценки имели большое значение для понимания деталей работы планировщика, но мне хочется показать, что все цифры выводятся из статистики без привлечения черной магии.
Подключаемые движки хранения
Способ организации данных на диске, принятый в PostgreSQL, не является ни единственно возможным, ни наилучшим для всех типов нагрузки. Следуя идее расширяемости, начиная с версии 12 PostgreSQL позволяет создавать и подключать различные табличные методы доступа (движки хранения данных), хотя в настоящее время «из коробки» доступен только один:
SELECT amname, amhandler FROM pg_am WHERE amtype = 't'; amname | amhandler
−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−
heap | heap_tableam_handler
(1 row) Имя движка может указываться при создании таблицы (CREATE TABLE ... USING); по умолчанию используется движок, определяемый значением параметра default_table_access_method.
Чтобы ядро могло однотипно работать с разными движками, табличные методы доступа должны реализовывать специальный интерфейс. Функция, указанная в столбце amhandler, возвращает интерфейсную структуру, содержащую всю необходимую для ядра информацию.
Бóльшая часть компонентов ядра остается общей для любых табличных методов доступа:
менеджер транзакций, включая поддержку ACID и изоляции на основе снимков;
буферный менеджер;
подсистема ввода-вывода;
TOAST;
оптимизатор и исполнитель запросов;
индексная поддержка.
Не все эти компоненты могут быть нужны движку, но возможность их использования остается.
В свою очередь, движок определяет:
формат версии строки и структуру данных;
реализацию сканирования таблицы;
реализацию вставок,удалений, обновлений и блокировок;
правила видимости версий строк;
процедуры очистки и анализа;
оценку стоимости последовательного сканирования.
Исторически PostgreSQL использовал единственную систему хранения данных, встроенную в ядро без какого-либо определенного программного интерфейса. Поэтому сейчас крайне сложно создать удачный интерфейс, который учитывал бы все сложившиеся особенности стандартного движка и при этом не мешал бы другим методам.
Например, до сих пор остается нерешенным вопрос с журналом. Новые методы доступа требуют журналирования специфичных операций, о которых ядро ничего не знает. Существующий механизм унифицированных журнальных записей как правило не подходит из-за слишком больших накладных расходов. Можно ввести еще один интерфейс для подключения новых типов журнальных записей, но в этом случае от внешнего кода будет зависеть надежность восстановления после сбоя, что крайне нежелательно. Пока остается только изменять ядро специально под каждый движок.
В настоящее время ведется работа над несколькими движками, среди которых:
-
Zheap призван справиться с проблемой разрастания таблиц. Для этого он реализует обновление версий строк на месте и выносит исторические данные, необходимые для построения снимка, в отдельное undo-хранилище. Такой движок будет полезен при нагрузке, включающей активное обновление данных.
Устройство движка покажется знакомым пользователям Oracle, хотя есть и нюансы (например, интерфейс индексных методов не позволяет создавать индексы с собственной версионностью).
-
Zedstore реализует колоночное хранение и должен быть эффективен для OLAP-запросов.
Данные организованы в основное B-дерево идентификаторов версий строк, а каждый столбец хранится в собственном B-дереве, связанном с основным. В перспективе движок может сохранять в одном дереве сразу несколько столбцов, получая гибридное хранилище.
Последовательное сканирование
Движок хранения отвечает за физическую организацию табличных данных и предоставляет метод доступа к ним — последовательное сканирование, — при котором полностью читается файл (или файлы) основного слоя таблицы. На каждой прочитанной странице проверяется видимость каждой версии строки; версии, не удовлетворяющие условиям запроса, отбрасываются.
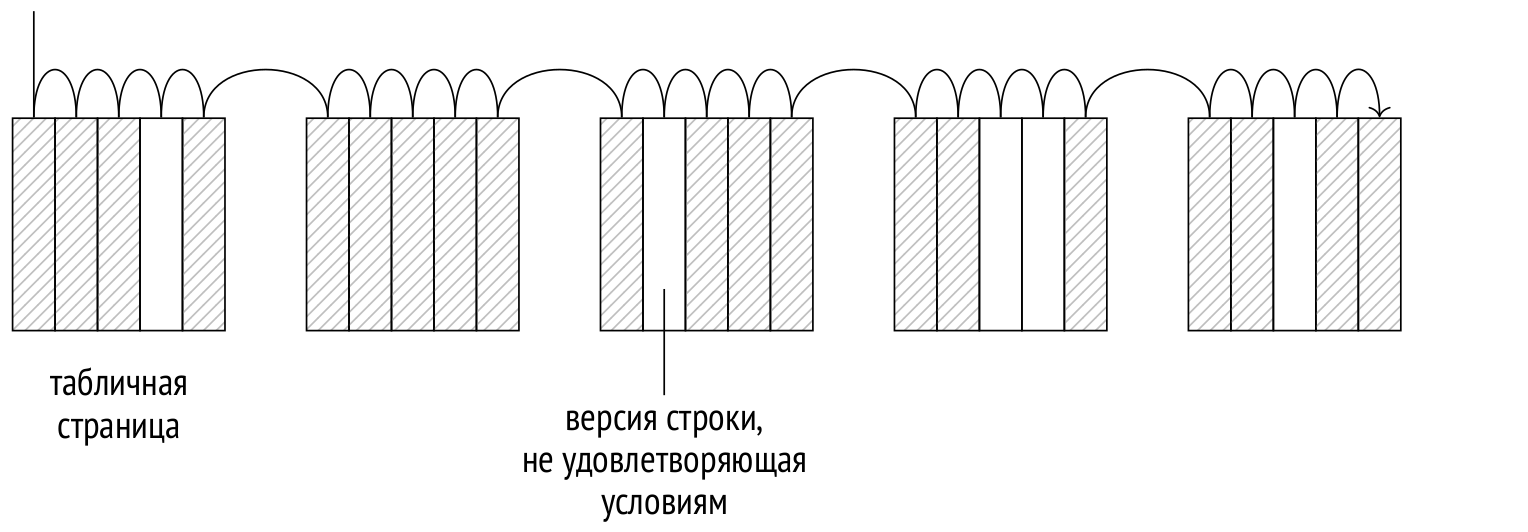
Чтение происходит через буферный кеш; чтобы большие таблицы не вытесняли полезные данные, для последовательного сканирования используется буферное кольцо небольшого размера. При этом другие процессы, одновременно сканирующие ту же таблицу, присоединяются к кольцу и тем самым экономят дисковые чтения. Поэтому в общем случае сканирование может начаться не с начала файла.
Последовательное сканирование — самый эффективный способ прочитать всю таблицу или значительную ее часть. Иными словами, последовательное сканирование хорошо работает при низкой селективности. (При высокой селективности, когда из всей таблицы нужна только небольшая часть строк, более предпочтительным будет использование индекса.)
Пример плана
В плане выполнения последовательное сканирование представляется узлом Seq Scan:
EXPLAIN SELECT * FROM flights; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on flights (cost=0.00..4772.67 rows=214867 width=63)
(1 row)Оценка количества строк (rows) является базовой статистикой:
SELECT reltuples FROM pg_class WHERE relname = 'flights'; reltuples
−−−−−−−−−−−
214867
(1 row)В оценке стоимости оптимизатор учитывает две составляющие: дисковый ввод-вывод и ресурсы процессора.
Стоимость ввода-вывода рассчитывается как произведение числа страниц в таблице на стоимость чтения одной страницы, при условии, что страницы читаются последовательно. Когда буферный менеджер запрашивает у операционной системы страницу данных, физически с диска за один раз читается больший объем данных, так что с высокой вероятностью несколько следующих страниц уже окажутся в кеше ОС. За счет этого стоимость последовательного чтения одной страницы (которая для планировщика определяется значением параметра seq_page_cost, по умолчанию 1) получается меньше, чем стоимость при случайном доступе (определяемая значением параметра random_page_cost, по умолчанию 4).
Соотношение по умолчанию характерно для HDD-дисков; для накопителей SSD имеет смысл существенно уменьшить значение random_page_cost (значение seq_page_cost как правило не трогают, оставляя в качестве опорного единичного значения). Поскольку стоимости зависят от характеристик оборудования, параметры обычно задают на уровне табличных пространств (ALTER TABLESPACE ... SET).
SELECT relpages, current_setting('seq_page_cost') AS seq_page_cost,
relpages * current_setting('seq_page_cost')::real AS total
FROM pg_class WHERE relname='flights'; relpages | seq_page_cost | total
−−−−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−−
2624 | 1 | 2624
(1 row)Приведенная формула отчетливо показывает последствия разрастания таблиц из-за несвоевременной очистки: чем больший объем занимает основной слой таблицы, тем больше страниц придется сканировать, независимо от количества актуальных версий строк в них.
Оценка ресурсов процессора складывается из стоимости обработки каждой версии строк (которая определяется для планировщика значением параметра cpu_tuple_cost, по умолчанию 0.01):
SELECT reltuples,
current_setting('cpu_tuple_cost') AS cpu_tuple_cost,
reltuples * current_setting('cpu_tuple_cost')::real AS total
FROM pg_class WHERE relname='flights'; reltuples | cpu_tuple_cost | total
−−−−−−−−−−−+−−−−−−−−−−−−−−−−+−−−−−−−−−
214867 | 0.01 | 2148.67
(1 row)Сумма двух приведенных оценок и составляет полную стоимость плана. Начальная стоимость равна нулю, поскольку последовательное сканирование не требует выполнения подготовительных действий.
Если на сканируемую таблицу наложены условия, они отображаются в плане запроса под узлом Seq Scan. Оценка числа строк будет учитывать селективность условий, а оценка стоимости — затраты на их вычисления. Команда EXPLAIN ANALYZE выведет и реально полученное количество строк, и количество строк, отфильтрованных условиями:
EXPLAIN (analyze, timing off, summary off)
SELECT * FROM flights WHERE status = 'Scheduled'; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on flights
(cost=0.00..5309.84 rows=15383 width=63)
(actual rows=15383 loops=1)
Filter: ((status)::text = 'Scheduled'::text)
Rows Removed by Filter: 199484
(5 rows)Пример плана с агрегацией
Рассмотрим чуть более сложный пример плана выполнения запроса с агрегацией:
EXPLAIN SELECT count(*) FROM seats; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Aggregate (cost=24.74..24.75 rows=1 width=8)
−> Seq Scan on seats (cost=0.00..21.39 rows=1339 width=0)
(2 rows)План состоит из двух узлов: верхний узел Aggregate, в котором происходит вычисление функции count, получает данные от нижнего узла Seq Scan, выполняющего сканирование таблицы.
Подготовительные работы узла Aggregate — собственно агрегация, которая невозможна без получения всех строк от нижестоящего узла. Оценка вычисляется исходя из оценки выполнения условной операции cpu_operator_cost над каждой входной строкой (значение по умолчанию 0.0025):
SELECT
reltuples,
current_setting('cpu_operator_cost') AS cpu_operator_cost,
round((
reltuples * current_setting('cpu_operator_cost')::real
)::numeric, 2) AS cpu_cost
FROM pg_class WHERE relname='seats'; reltuples | cpu_operator_cost | cpu_cost
−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−+−−−−−−−−−−
1339 | 0.0025 | 3.35
(1 row)Полученная оценка добавляется к полной стоимости нижележащего узла Seq Scan.
Полная стоимость узла Aggregate увеличивается на стоимость обработки одной строки результата cpu_tuple_cost:
WITH t(cpu_cost) AS (
SELECT round((
reltuples * current_setting('cpu_operator_cost')::real
)::numeric, 2)
FROM pg_class WHERE relname = 'seats'
)
SELECT 21.39 + t.cpu_cost AS startup_cost,
round((
21.39 + t.cpu_cost +
1 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost
FROM t; startup_cost | total_cost
−−−−−−−−−−−−−−+−−−−−−−−−−−−
24.74 | 24.75
(1 row)Параллельные планы выполнения
Начиная с версии 9.6 PostgreSQL поддерживает параллельное выполнение запросов. Идея состоит в том, что ведущий процесс, выполняющий запрос, порождает (с помощью postmaster) несколько рабочих процессов, которые одновременно выполняют одну и ту же параллельную часть плана. Результаты этого выполнения передаются ведущему процессу, который собирает их в узле Gather. В свободное от приема данных время ведущий процесс также может выполнять параллельную часть плана.
При необходимости можно отключить ведущий процесс от выполнения параллельной части плана с помощью параметра parallel_leader_participation, который появился в версии 11.

Разумеется, запуск процессов и пересылка данных требуют определенных ресурсов, поэтому далеко не каждый запрос имеет смысл выполнять параллельно.
Кроме того, даже при параллельном выполнении не все шаги плана запроса могут быть распараллелены. Часть операций может выполняться ведущим процессом в одиночку, последовательно.
Параллельное последовательное сканирование
Примером узла, предназначенного для параллельного выполнения, является Parallel Seq Scan — «параллельное последовательное сканирование».
Название звучит противоречиво (все-таки, параллельное или последовательное?), но, тем не менее, отражает суть операции. С точки зрения обращений к файлу, страницы таблицы читаются последовательно, в том же порядке, в котором они читались бы при обычном последовательном сканировании. Однако чтение выполняется несколькими параллельно работающими процессами. Процессы синхронизируются между собой с помощью специально отведенного участка общей памяти, чтобы не прочитать одну и ту же страницу дважды.
Тонкий момент состоит в том, что вместо общей картины последовательного сканирования операционная система видит несколько процессов, выполняющих случайное чтение. Из-за этого предвыборка данных, обычно ускоряющая последовательное чтение, работает плохо. Поэтому, начиная с версии PostgreSQL 14, каждому процессу выделяется для чтения не одна, а набор подряд идущих страниц.
Сама по себе операция параллельного сканирования не имеет большого смысла, поскольку к обычным затратам на чтение страниц добавляются накладные расходы на пересылку данных от процесса к процессу. Но если рабочие процессы выполняют какую-то обработку прочитанных строк (например, агрегацию), то суммарное время выполнения запроса может оказаться существенно меньшим.
Пример параллельного плана с агрегацией
План выполнения простого запроса с агрегацией над большой таблицей будет использовать параллелизм:
EXPLAIN SELECT count(*) FROM bookings; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize Aggregate (cost=25442.58..25442.59 rows=1 width=8)
−> Gather (cost=25442.36..25442.57 rows=2 width=8)
Workers Planned: 2
−> Partial Aggregate
(cost=24442.36..24442.37 rows=1 width=8)
−> Parallel Seq Scan on bookings
(cost=0.00..22243.29 rows=879629 width=0)
(7 rows)Узлы ниже узла Gather составляют параллельную часть плана. Она выполняется в каждом из рабочих процессов (которых в данном случае запланировано 2 штуки) и, возможно, в ведущем процессе (если это не отключено параметром parallel_leader_participation). Сам узел Gather и узлы выше него составляют последовательную часть плана и выполняются только в ведущем процессе.
Узел Parallel Seq Scan представляет сканирование таблицы в параллельном режиме. В поле rows показана оценка числа строк, которые обработает один процесс. Всего запланировано два рабочих процесса, и еще часть работы выполнит ведущий, поэтому общее число строк в таблице делится на 2,4 (а не на 3, поскольку доля ведущего процесса уменьшается с ростом числа рабочих процессов).
SELECT reltuples::numeric, round(reltuples / 2.4) AS per_process
FROM pg_class WHERE relname = 'bookings'; reltuples | per_process
−−−−−−−−−−−+−−−−−−−−−−−−−
2111110 | 879629
(1 row)Стоимость узла Parallel Seq Scan оценивается почти так же, как и для последовательного сканирования. Выигрыш получается за счет того, что каждый из процессов обрабатывает меньшее количество строк, но составляющая ввода-вывода учитывается полностью, поскольку таблицу все равно придется прочитать целиком страница за страницей:
SELECT round((
relpages * current_setting('seq_page_cost')::real +
reltuples / 2.4 * current_setting('cpu_tuple_cost')::real
)::numeric, 2)
FROM pg_class WHERE relname = 'bookings'; round
−−−−−−−−−−
22243.29
(1 row)Следующий узел — Partial Aggregate — выполняет агрегацию данных, полученных рабочим процессом, то есть в данном случае подсчитывает количество строк.
Оценка стоимости агрегации выполняется уже известным образом и добавляется к оценке сканирования таблицы:
WITH t(startup_cost) AS (
SELECT 22243.29 + round((
reltuples / 2.4 * current_setting('cpu_operator_cost')::real
)::numeric, 2)
FROM pg_class WHERE relname='bookings'
)
SELECT startup_cost,
startup_cost + round((
1 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost
FROM t; startup_cost | total_cost
−−−−−−−−−−−−−−+−−−−−−−−−−−−
24442.36 | 24442.37
(1 row)Следующий узел — Gather — выполняется ведущим процессом. Этот узел отвечает за запуск рабочих процессов и получение от них данных.
Оценка стоимости запуска процессов (независимо от их количества) определяется для планировщика значением параметра parallel_setup_cost (по умолчанию 1000), а стоимость пересылки каждой строки данных между процессами — parallel_tuple_cost (по умолчанию 0.1). В данном случае преобладает начальная стоимость (запуск процессов), и это значение добавляется к начальной стоимости узла Partial Aggregate. Полная стоимость учитывает пересылку двух строк, и это значение складывается с полной стоимостью узла Partial Aggregate:
SELECT
24442.36 + round(
current_setting('parallel_setup_cost')::numeric,
2) AS setup_cost,
24442.37 + round(
current_setting('parallel_setup_cost')::numeric +
2 * current_setting('parallel_tuple_cost')::numeric,
2) AS total_cost; setup_cost | total_cost
−−−−−−−−−−−−+−−−−−−−−−−−−
25442.36 | 25442.57
(1 row)Последний узел — Finalize Aggregate — агрегирует полученные узлом Gather от параллельных процессов частичные агрегаты. Он оценивается так же, как и обычная агрегация. Начальная стоимость учитывает агрегацию трех строк; это значение складывается с полной стоимостью узла Gather (поскольку для вычисления результата нужны все строки). К полной стоимости добавляется стоимость выдачи одной строки результата.
WITH t(startup_cost) AS (
SELECT 25442.57 + round((
3 * current_setting('cpu_operator_cost')::real
)::numeric, 2)
FROM pg_class WHERE relname = 'bookings'
)
SELECT startup_cost,
startup_cost + round((
1 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost
FROM t; startup_cost | total_cost
−−−−−−−−−−−−−−+−−−−−−−−−−−−
25442.58 | 25442.59
(1 row)Ограничения параллельного выполнения
Количество рабочих процессов
Вообще механизм фоновых рабочих процессов используется не только для параллельного выполнения запросов. Например, рабочие процессы задействованы в логической репликации, ими могут пользоваться расширения. Общее число одновременно выполняющихся рабочих процессов ограничено значением параметра max_worker_processes (по умолчанию 8).
Количество одновременно выполняющихся фоновых рабочих процессов, занимающихся параллельными планами, ограничено значением параметра max_parallel_workers (по умолчанию также 8).
Количество рабочих процессов, обслуживающих один ведущий процесс, ограничено значением параметра max_parallel_workers_per_gather (по умолчанию 2).
Значения этих параметров следует изменить в зависимости от:
возможностей аппаратуры — система должна располагать свободными ядрами, не занятыми другими задачами;
наличия в базе данных больших таблиц;
нагрузки — должны выполняться запросы, потенциально выигрывающие от параллельного выполнения.
В большинстве случаев таким критериям удовлетворяют OLAP-, а не OLTP-системы.
Планировщик вообще не будет рассматривать параллельное сканирование, если по его оценке из таблицы будет прочитано меньше, чем min_parallel_table_scan_size данных (по умолчанию 8MB).
Обычно число процессов вычисляется по формуле
Она означает, что каждое увеличение таблицы в три раза будет добавлять еще один параллельный процесс. Например, при значениях параметров по умолчанию:
таблица, |
количество |
8 |
1 |
24 |
2 |
72 |
3 |
216 |
4 |
648 |
5 |
1944 |
6 |
Число процессов можно и явно указать в параметре хранения parallel_workers таблицы.
В любом случае число процессов не будет превышать значения параметра max_parallel_workers_per_gather.
Если запросить информацию из небольшой таблицы размером 19 Мбайт, будет запланирован и запущен один рабочий процесс (Workers Planned и Workers Launched):
EXPLAIN (analyze, costs off, timing off)
SELECT count(*) FROM flights; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize Aggregate (actual rows=1 loops=1)
−> Gather (actual rows=2 loops=1)
Workers Planned: 1
Workers Launched: 1
−> Partial Aggregate (actual rows=1 loops=2)
−> Parallel Seq Scan on flights (actual rows=107434 lo...
(6 rows)При запросе данных из таблицы размером 105 Мбайт, будет запланировано только два процесса из-за ограничения max_parallel_workers_per_gather:
EXPLAIN (analyze, costs off, timing off)
SELECT count(*) FROM bookings; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize Aggregate (actual rows=1 loops=1)
−> Gather (actual rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
−> Partial Aggregate (actual rows=1 loops=3)
−> Parallel Seq Scan on bookings (actual rows=703703 l...
(6 rows)Сняв ограничение, получим расчетные три процесса:
ALTER SYSTEM SET max_parallel_workers_per_gather = 4;
SELECT pg_reload_conf();
EXPLAIN (analyze, costs off, timing off)
SELECT count(*) FROM bookings; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize Aggregate (actual rows=1 loops=1)
−> Gather (actual rows=4 loops=1)
Workers Planned: 3
Workers Launched: 3
−> Partial Aggregate (actual rows=1 loops=4)
−> Parallel Seq Scan on bookings (actual rows=527778 l...
(6 rows)Если при выполнении запроса число свободных слотов окажется меньше запланированного количества процессов, будут запущено только доступное количество рабочих процессов.
Не распараллеливаемые запросы
Не каждый запрос может выполняться в параллельном режиме. Не могут распараллеливаться:
-
Запросы, изменяющие или блокирующие данные (
UPDATE,DELETE,SELECT FOR UPDATEи т. п.).Начиная с версии PostgreSQL 11 ограничение не касается запросов, которые используются в командах
CREATE TABLE AS,SELECT INTOиCREATE MATERIALIZED VIEW, а в версии 14 к этому списку добавилась командаREFRESH MATERIALIZED VIEW.Но вставка строк во всех этих случаях выполняется последовательно.
Запросы, выполнение которых может быть приостановлено. Это относится к запросам в курсорах, в том числе в циклах FOR PL/pgSQL.
-
Запросы, содержащие вызовы небезопасных функций, помеченных как PARALLEL UNSAFE. К таковым по умолчанию относятся все пользовательские функции и небольшая часть стандартных. Список небезопасных функций можно получить из системного каталога:
SELECT * FROM pg_proc WHERE proparallel = 'u'; Запросы, находящиеся в функциях, которые вызываются из распараллеленного запроса (чтобы не допустить рекурсивного разрастания количества рабочих процессов).
Часть из этих ограничений может быть снята в следующих версиях PostgreSQL. Так, например, в версии 12 появилась возможность распараллеливания запросов на уровне изоляции Serializable.
Запрос может не выполняться в параллельном режиме по нескольким причинам:
данный запрос в принципе не может быть распараллелен ни при каких обстоятельствах;
параллельный план запрещен значениями конфигурационных параметров (в том числе из-за ограничения на размер таблиц);
параллельный план имеет более высокую стоимость по сравнению с последовательным.
Чтобы проверить, может ли запрос быть распараллелен в принципе, можно на время включить параметр force_parallel_mode. При этом планировщик будет строить параллельные планы во всех случаях, когда это возможно:
EXPLAIN SELECT * FROM flights; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on flights (cost=0.00..4772.67 rows=214867 width=63)
(1 row)SET force_parallel_mode = on;
EXPLAIN SELECT * FROM flights;QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Gather (cost=1000.00..27259.37 rows=214867 width=63)
Workers Planned: 1
Single Copy: true
−> Seq Scan on flights (cost=0.00..4772.67 rows=214867 width=63)
(4 rows)Ограниченно распараллеливаемые запросы
В целом, чем большую часть плана удается выполнить параллельно, тем больший возможен эффект. Однако есть ряд операций, которые в целом не препятствуют распараллеливанию, но сами могут выполняться только последовательно в ведущем процессе. Иными словами, они не могут появиться в дереве плана ниже узла Gather.
Нераскрываемые подзапросы. Наиболее очевидный пример такой операции, связанной с нераскрываемыми подзапросами, — чтение результата общего табличного выражения (узел плана CTE Scan):
EXPLAIN (costs off)
WITH t AS MATERIALIZED (
SELECT * FROM flights
)
SELECT count(*) FROM t; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Aggregate
CTE t
−> Seq Scan on flights
−> CTE Scan on t
(4 rows)Если общее табличное выражение не материализуется (что стало возможным в версии PostgreSQL 12), то план не содержит узла CTE Scan и это ограничение не действует.
При этом само общее табличное выражение вполне может вычисляться в параллельном режиме, если это выгодно:
EXPLAIN (costs off)
WITH t AS MATERIALIZED (
SELECT count(*) FROM flights
)
SELECT * FROM t; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
CTE Scan on t
CTE t
−> Finalize Aggregate
−> Gather
Workers Planned: 1
−> Partial Aggregate
−> Parallel Seq Scan on flights
(7 rows)Вторая операция — использование нераскрываемого подзапроса, представленного в плане узлом SubPlan:
EXPLAIN (costs off)
SELECT *
FROM flights f
WHERE f.scheduled_departure > ( -- SubPlan
SELECT min(f2.scheduled_departure)
FROM flights f2
WHERE f2.aircraft_code = f.aircraft_code
); QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on flights f
Filter: (scheduled_departure > (SubPlan 1))
SubPlan 1
−> Aggregate
−> Seq Scan on flights f2
Filter: (aircraft_code = f.aircraft_code)
(6 rows)Первые две строки показывают план основного запроса: выполняется последовательное сканирование таблицы flights и каждая строка проверяется на соответствие фильтру. Условие фильтрации включает в себя подзапрос, план которого приведен, начиная с третьей строки. То есть узел SubPlan выполняется несколько раз, в данном случае — для каждой строки последовательного сканирования.
Верхний узел Seq Scan в этом плане не может участвовать в параллельном выполнении, поскольку пользуется результатами узла SubPlan.
И, наконец, третья операция — вычисление нераскрываемого подзапроса, представленного в плане узлом InitPlan:
EXPLAIN (costs off)
SELECT *
FROM flights f
WHERE f.scheduled_departure > ( -- SubPlan
SELECT min(f2.scheduled_departure) FROM flights f2
WHERE EXISTS ( -- InitPlan
SELECT *
FROM ticket_flights tf
WHERE tf.flight_id = f.flight_id
)
); QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on flights f
Filter: (scheduled_departure > (SubPlan 2))
SubPlan 2
−> Finalize Aggregate
InitPlan 1 (returns $1)
−> Seq Scan on ticket_flights tf
Filter: (flight_id = f.flight_id)
−> Gather
Workers Planned: 1
Params Evaluated: $1
−> Partial Aggregate
−> Result
One−Time Filter: $1
−> Parallel Seq Scan on flights f2
(14 rows)В отличие от SubPlan, узел InitPlan вычисляется только один раз (в данном примере — один раз при каждом выполнении узла SubPlan 2).
Родительский для InitPlan узел не может участвовать в параллельном выполнении (но узлы, пользующиеся результатом вычисления InitPlan — могут, как в этом примере).
Временные таблицы. Временные таблицы сканируются только последовательно, так как доступны исключительно ведущему процессу:
CREATE TEMPORARY TABLE flights_tmp AS SELECT * FROM flights;
EXPLAIN (costs off)
SELECT count(*) FROM flights_tmp; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Aggregate
−> Seq Scan on flights_tmp
(2 rows)Ограниченно распараллеливаемые функции. Вызовы функций, помеченных как PARALLEL RESTRICTED, могут выполняться только в последовательной части плана. Список таких функций можно получить из системного каталога запросом
SELECT * FROM pg_proc WHERE proparallel = 'r';
Помечать собственные функции как PARALLEL RESTRICTED (и тем более как PARALLEL SAFE) нужно с большой осторожностью, внимательно изучив имеющиеся ограничения.
mzinal
Параллельное чтение разных участков одной таблицы само по себе может оказаться быстрее строго последовательного чтения, если подсистема ввода-вывода действительно способна выполнять запрошенные операции параллельно.
erogov Автор
Честно говоря, не думаю. Процессам все время приходится синхронизироваться между собой, так что особого параллелизма при чтении не получится. Да и в модели стоимости считается, что чтение будет последовательным.
edo1h
ну это если считать, что запрос выбирает много данных.
а если он выбирает одну запись из многих миллионов? в большинстве случаев поделить запрос на несколько подзапросов, каждый из которых читает из своей части таблицы, будет явно выгоднее, дисковая подсистема просто не способна показать максимальную скорость в один поток.
erogov Автор
А если выбирает мало данных, то параллельное выполнение вообще не будет использоваться. Сейчас перечитал - у меня неточность: параллельное сканирование не рассматривается, если мы собираемся прочитать из таблицы меньше, чем min_parallel_table_scan_size (а не если полный размер таблицы меньше этого значения).
В целом-то вы правы, но реализация parallel seq scan вряд ли даст такой выигрыш. Другое дело - сканирование секционированных таблиц начиная с версии 11: https://commitfest.postgresql.org/16/987/ Вот там параллельно читаются целые секции и никакая синхронизация в процессе чтения не нужна.