
Типичный день в нейрокурятнике — куры часто еще и крутятся в гнезде
Чтобы довести, наконец, проект нейрокурятника до своего логического завершения, нужно произвести на свет работающую модель и задеплоить ее на продакшен, да еще и так, чтобы соблюдался ряд условий:
- Точность предсказаний не менее 70-90%;
- Raspberry pi в самом курятнике в идеале мог бы определять принадлежности фотографий к классам;
- Нужно как минимум научиться отличать всех кур друг от друга. Программа максимум — также научиться считать яйца;
В данной статье мы расскажем что же в итоге у нас получилось, какие модели мы попробовали и какие занятные вещи нам попались на дороге.
Статьи про нейрокурятник
Заголовок спойлера
- Вступление про обучение себя нейросетям
- Железо, софт и конфиг для наблюдения за курами
- Бот, который постит события из жизни кур — без нейросети
- Разметка датасетов
- Работающая модель для распознавания кур в курятнике
- Итог — работающий бот, распознающий кур в курятнике
0. TL;DR
Для самых нетерпеливых:
- Точность получилась в итоге порядка 80%;
- Датасет можно скачать тут;
- ipynb jupyter notebook'а со всеми выкладками и boiler-plate код с пояснениями можно скачать тут, html версию тут;
- Скрипты для демонизации и деплоя на прод — тут (ipynb);
1. Прелюдии
Получилось также весьма кстати, потому что буквально несколько дней назад вышло это видео, под которым есть весьма полезная копипаста.
Из современных инструментов, которые адекватно подходят этой цели в голову приходят только сверточные нейросети. Поковырявшись (по ссылке рекурсивная статья про нейросети, если вы хотите научиться) весьма основательное время в нейросетях, поучаствовав в нескольких соревнованиях (к сожалению уже закрытых) на Kaggle (из открытых заинтересовали морские котики, но там сложновато) и тем самым по большей части пройдя курс от fast.ai, я обрисовал для себя примерно такой план:
- Разметить небольшой датасет (а сегодня реально не нужно много данных, чтобы построить классификатор);
- Использовать keras для тестирования максимально большого числа архитектур в течение максимум 1 дня;
- Если получится использовать неразмеченные фотографии, чтобы увеличить точность (semi-supervised подход);
- Попытаться сделать визуализацию активаций внутренних слоев нейросети;
2. Посмотрим, что получилось!
Layer (type) Output Shape Param #
=================================================================
batch_normalization_1 (Batch (None, 700, 400, 3) 2800
_________________________________________________________________
conv2d_1 (Conv2D) (None, 698, 398, 32) 896
_________________________________________________________________
batch_normalization_2 (Batch (None, 698, 398, 32) 2792
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 232, 132, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 230, 130, 64) 18496
_________________________________________________________________
batch_normalization_3 (Batch (None, 230, 130, 64) 920
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 76, 43, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 209152) 0
_________________________________________________________________
dense_1 (Dense) (None, 200) 41830600
_________________________________________________________________
batch_normalization_4 (Batch (None, 200) 800
_________________________________________________________________
dense_2 (Dense) (None, 8) 1608
=================================================================
Total params: 41,858,912
Trainable params: 41,855,256
Non-trainable params: 3,656
_________________________________________________________________
Итоговая архитектура модели in a nutshell, которая дала порядка 80% точности
Для начала давайте разберемся, что же творится в курятнике. Чтобы успешно сделать прикладной проект, всегда нужно пытаться контролировать максимальную часть технологической цепочки. Вряд ли получится сделать проект, если данные поступают в виде «вот вам 10 терабайт видео в ужасном качестве, сделайте нам модель распознавания видео в режиме реального времени за 10,000 рублей » или «вот вам 50 фото этикеток от пива» (юмор, но это примеры, основанные на реальных… проектах, слава богу не моих).
- Куры постоянно залазят в гнездо, чтобы просто посидеть или из любопытства, особенно молодые;
- Молодые куры (белые на фото выше) — до определенного момента не откладывали яйца в гнездо, а просто ковыряли чужие яйца;
- У кур бывают стычки, но в 95% случаев соблюдаются правила: i) в гнезде 1 курица ii) за время пребывания курицы в гнезде делается 10-20 уникальных фоток iii) курица как правило польностью закрывает яйца собой iv) текущий вид на куриц является продуктом нескольких итераций поиска оптимального расположения камеры;
- В день делается порядка 300-400 фото, откладывается 5-8 яиц (молодые куры по глупости и боязни неслись в прямом смысле слова под пол, потом после того как было найдено скопище из 22 яиц под полом, они стали нестись в гнездо);
- На ночь курам выключают свет — они ложатся спать;
- Было размечено порядка 900 фото;
Давайте посмотрим сколько фото получилось для каждого класса:
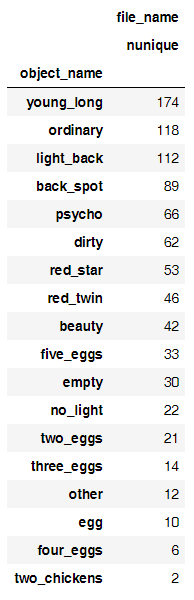
Изначально увидев такой расклад, я подумал, что получится даже отличать фотографии с количеством яиц, но нет. Чтобы максимизировать точность на такой небольшой выборке, надо постараться сделать несколько вещей:
- Правильно выбрать алгоритмы предобработки данных (логично, что куры крутятся в гнезде, поэтому можно вращать фотографии хоть на 180 градусов!);
- Выбрать адекватную по размеру и сложности модель;
С предобработкой просто — нужно просто взять простейшую линейную модель и попробовать 5-10 сочетаний параметров — при достаточном количестве прогрммного сахара в Keras это делается подстановкой параметров для такого небольшого датасета в течение часа (тренировка 10 эпох модели занимает по 50-100 секунд на 1 эпоху). Не в последнюю очередь это также делается с целью регуляризации. Вот пример одной из оптимальных методик:
genImage = imageGeneratorSugar(
featurewise_center = False,
samplewise_center = False,
featurewise_std_normalization = False,
samplewise_std_normalization = False,
rotation_range = 90,
width_shift_range = 0.05,
height_shift_range = 0.05,
shear_range = 0.2,
zoom_range = 0.2,
fill_mode='constant',
cval=0.,
horizontal_flip=False,
vertical_flip=False)
Вы можете посмотреть почти полный лог экспериментов тут:
- ipynb jupyter notebook'а со всеми выкладками и boiler-plate код с пояснениями можно скачать тут, html версию тут;
Что касается выбора самой модели, то опробовав разные архитектуры на ряде датасетов, остановился примерно на такой модели (забыл Dropout — но тесты с ним не дали прироста точности):
def getTestModelNormalize(inputShapeTuple, classNumber):
model = Sequential([
BatchNormalization(axis=1, input_shape = inputShapeTuple),
Convolution2D(32, (3,3), activation='relu'),
BatchNormalization(axis=1),
MaxPooling2D((3,3)),
Convolution2D(64, (3,3), activation='relu'),
BatchNormalization(axis=1),
MaxPooling2D((3,3)),
Flatten(),
Dense(200, activation='relu'),
BatchNormalization(),
Dense(classNumber, activation='softmax')
])
model.compile(Adam(lr=1e-4), loss='categorical_crossentropy', metrics=['accuracy'])
return model
Вот ее графическое представление:
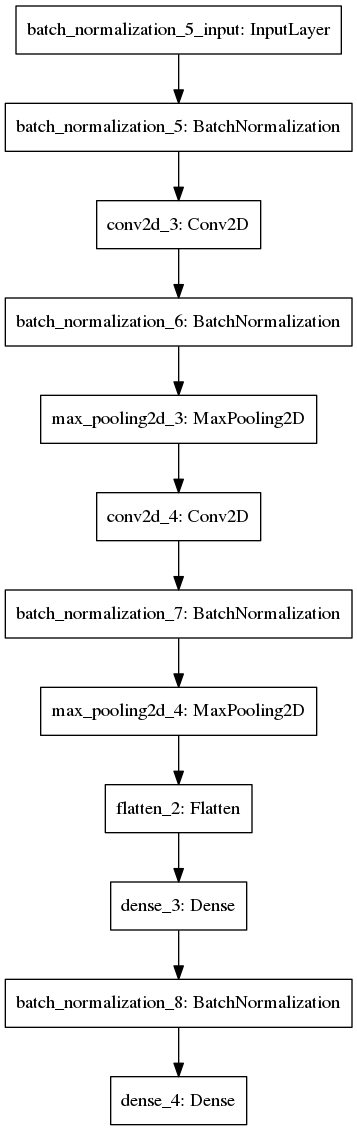
Поясню состав слоев и почему в принципе почти любая современная CNN выглядит очень похоже:
- BatchNormalization — усредняет входящие данные (вычитает среднее и делит на стандартное отклонение), что ускоряет тренировку нейросети в десятки раз. Если интересно почему — то уходите в рекурсию тут или тут. Обязателен к применению;
- Convolution2D — сверточные слои. По сути представляют собой фильтры, чтобы нейросеть смогла научиться распознавать абстрактные образы. По идее визуализация должна была быть включена в эту статью, но у я не осилил в итоге (если вы не знаете как выглядят изнутри нейросети, то вот ссылки для вас 1 2 3;
- MaxPooling2D — усреднение значений фильтров. Обязателен после сверточных слоев;
- Dropout — по сути нужен для регуляризации. В эту спецификацию модели не включил его, потому что брал код из другого своего проекта и просто забыл из-за высокой точности модели;
- Flatten — чтобы потом вставить dense слой, иначе не получится;
Спецификация модели с dropout выглядит вот так (но почему-то он не дал прироста точности на первый взгляд как я потом не извращался, вероятно регуляризация и так была достигнута предобработкой фото + фотки большие).
# let's try a model w dropout!
def getTestModelNormalizeDropout(inputShapeTuple, classNumber):
model = Sequential([
BatchNormalization(axis=1, input_shape = inputShapeTuple),
Convolution2D(32, (3,3), activation='relu'),
BatchNormalization(axis=1),
Dropout(rate=0.3),
MaxPooling2D((3,3)),
Convolution2D(64, (3,3), activation='relu'),
BatchNormalization(axis=1),
Dropout(rate=0.1),
MaxPooling2D((3,3)),
Flatten(),
Dense(200, activation='relu'),
BatchNormalization(),
Dense(classNumber, activation='softmax')
])
model.compile(Adam(lr=1e-4), loss='categorical_crossentropy', metrics=['accuracy'])
return model
Обратите внимание, что используется categorical_crossentropy вместе с softmax. В качестве оптимизатора используется adam. Не буду останавливаться почему я выбрал именно их (такое сочетание по сути стандарт), но вы можете почитать тут и посмотреть тут 1, 2 и 3.
Сам процесс поиска оптимальной модели выглядит так:
- Пробуем разные способы предобработки данных с простейшей моделью (внезапно веса простейшей dense модели из 3 слоев весят несколько гигабайт для больших фото, что не очень хорошо) и выбираем оптимальный;
- Пробуем разные архитектуры сверточных (или каких-либо других) нейросетей, выбираем оптимальную;
- При достижении какого-либо значимого бенчмарка (50%+ точности, 75% точности — выбирайте от задачи, чем больше классов, тем более мягким должен бенчмарк) — нужно проанализовать, с предсказанием каких фото и каких классов у модели возникают проблемы;
- Ансамбли и fine-tuning внешних слоев у больших архитектур нейросетей — опционально — если хотите выиграть конкурс;
- Можно попробовать подмешать в свою выборку 20-30% фото из тестовой, валидационной или просто неразмеченной части датасета (semi-supervised, код по идее работает, но у меня именно в этой задаче постоянно умирали kernel-ы, я забил);
- Повторять до бесконечности;
42/42 [==============================] - 87s - loss: 2.4055 - acc: 0.2783 - val_loss: 4.7899 - val_acc: 0.1771
Epoch 2/15
42/42 [==============================] - 90s - loss: 1.7039 - acc: 0.4049 - val_loss: 2.4489 - val_acc: 0.2011
Epoch 3/15
42/42 [==============================] - 90s - loss: 1.4435 - acc: 0.4827 - val_loss: 2.1080 - val_acc: 0.2402
Epoch 4/15
42/42 [==============================] - 90s - loss: 1.2525 - acc: 0.5311 - val_loss: 2.4556 - val_acc: 0.2179
Epoch 5/15
42/42 [==============================] - 85s - loss: 1.2024 - acc: 0.5549 - val_loss: 2.2180 - val_acc: 0.1955
Epoch 6/15
42/42 [==============================] - 84s - loss: 1.0820 - acc: 0.5858 - val_loss: 1.8620 - val_acc: 0.2849
Epoch 7/15
42/42 [==============================] - 84s - loss: 0.9475 - acc: 0.6535 - val_loss: 2.1256 - val_acc: 0.1955
Epoch 8/15
42/42 [==============================] - 84s - loss: 0.9283 - acc: 0.6665 - val_loss: 1.2578 - val_acc: 0.5642
Epoch 9/15
42/42 [==============================] - 84s - loss: 0.9238 - acc: 0.6792 - val_loss: 1.1639 - val_acc: 0.5698
Epoch 10/15
42/42 [==============================] - 84s - loss: 0.8451 - acc: 0.6963 - val_loss: 1.4899 - val_acc: 0.4581
Epoch 11/15
42/42 [==============================] - 84s - loss: 0.8026 - acc: 0.7183 - val_loss: 0.9561 - val_acc: 0.6480
Epoch 12/15
42/42 [==============================] - 84s - loss: 0.8353 - acc: 0.7064 - val_loss: 1.0533 - val_acc: 0.6145
Epoch 13/15
42/42 [==============================] - 84s - loss: 0.7687 - acc: 0.7380 - val_loss: 0.9039 - val_acc: 0.6760
Epoch 14/15
42/42 [==============================] - 84s - loss: 0.7683 - acc: 0.7287 - val_loss: 1.0038 - val_acc: 0.6704
Epoch 15/15
42/42 [==============================] - 84s - loss: 0.7076 - acc: 0.7451 - val_loss: 0.8953 - val_acc: 0.7039
А так выглядит процесс гипнотизации прогресс индикатора...
Кстати этот сниппет кода поможет вам, если вы захотите сделать semi-supervised модель в keras
# Mix iterator class for pseudo-labelling
class MixIterator(object):
def __init__(self, iters):
self.iters = iters
self.multi = type(iters) is list
if self.multi:
self.N = sum([it[0].N for it in self.iters])
else:
self.N = sum([it.N for it in self.iters])
def reset(self):
for it in self.iters: it.reset()
def __iter__(self):
return self
def next(self, *args, **kwargs):
if self.multi:
nexts = [[next(it) for it in o] for o in self.iters]
n0s = np.concatenate([n[0] for n in o])
n1s = np.concatenate([n[1] for n in o])
return (n0, n1)
else:
nexts = [next(it) for it in self.iters]
n0 = np.concatenate([n[0] for n in nexts])
n1 = np.concatenate([n[1] for n in nexts])
return (n0, n1)
mi = MixIterator([batches, test_batches, val_batches)
bn_model.fit_generator(mi, mi.N, nb_epoch=8, validation_data=(conv_val_feat, val_labels))
Но если вернуться к нашим курам, то после шага 3, проанализировав итоги модели, я увидел забавную закономерность.
Вот соотношение правильных предсказаний к числу фото
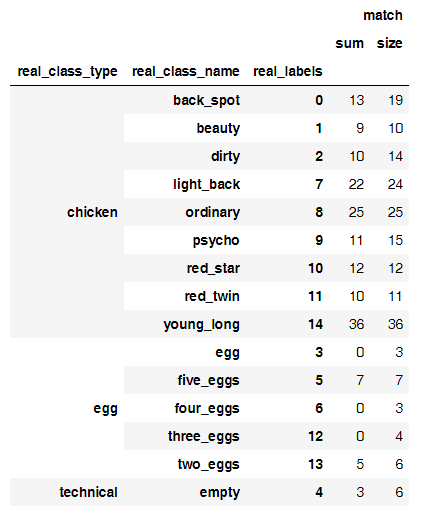
А вот основной источник неверных классификаций
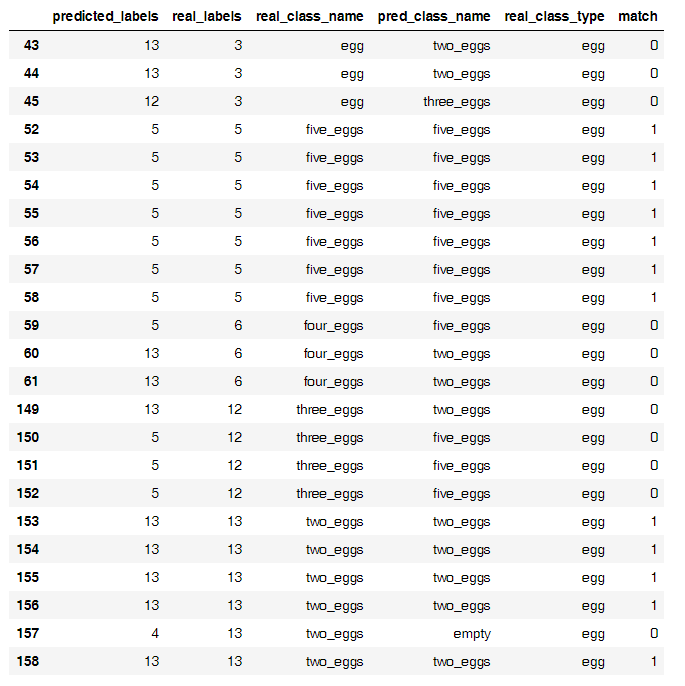
Как ни странно, на такой небольшой выборке оказалось, что нейросеть хорошо отделяет кур от яиц, но яйца считает с трудом. Я смог построить отдельную модель, которая считала яйца с 50% точностью, но не стал продолжать ее тренировать, возможно яйца проще считать так.
Поместив все яйца в один класс в итоге я и получил модель примерно с 80% точности на небольшом датасете.
3. Что пойдет на прод?
Последним штрихом остался деплой модели на прод. Тут понятное дело нужно сохранить веса и написать пару функций, которые будут крутиться в демоне в бекграунде. Но тут на помощь пришла паста из-под видео в начале статьи.
Весь код такого боевого деплоя выглядит примерно так (тут используется tensor flow в качестве бекенда).
Вот в принципе и все.
# dependencies
import numpy as np
import keras.models
from keras.models import model_from_json
from scipy.misc import imread, imresize,imshow
import tensorflow as tf?
?
In [3]:
def init(model_file,weights_file):
json_file = open(model_file,'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
#load woeights into new model
loaded_model.load_weights(weights_file)
print("Loaded Model from disk")
#compile and evaluate loaded model
loaded_model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
#loss,accuracy = model.evaluate(X_test,y_test)
#print('loss:', loss)
#print('accuracy:', accuracy)
graph = tf.get_default_graph()
?
return loaded_model,graph
?
loaded_model,graph = init('model.json','model7_20_epochs.h5')
?
In [4]:
def predict(img_file, model):
# here you should read the image
img = imread(img_file,mode='RGB')
img = imresize(img,(400,800))
#convert to a 4D tensor to feed into our model
img = img.reshape(1,400,800,3)
# print ("debug2")
#in our computation graph
with graph.as_default():
#perform the prediction
out = model.predict(img)
print(out)
print(np.argmax(out,axis=1))
# print ("debug3")
#convert the response to a string
response = (np.argmax(out,axis=1))
return response
In [6]:
chick_dict = {0: 'back_spot',
1: 'beauty',
2: 'dirty',
3: 'egg',
4: 'empty',
5: 'light_back',
6: 'ordinary',
7: 'psycho',
8: 'red_star',
9: 'red_twin',
10: 'young_long'}
?
In [7]:
prediction = predict('test.jpg',loaded_model)
print (chick_dict[prediction[0]])
[[ 2.34186242e-04 5.02209296e-04 5.61403576e-04 9.51264706e-03
2.03147720e-04 1.70257801e-04 4.71635815e-03 5.06504579e-03
1.84403792e-01 7.92831838e-01 1.79908809e-03]]
Out [9]
red_twin
In [11]:
import matplotlib.pyplot as plt
img = imread('test.jpg',mode='RGB')
plt.imshow(img)
plt.show()
Модель предсказывает верную курицу ) Ждите финального бота, который постит верных кур.
Поделиться с друзьями
Комментарии (6)

pdima
13.06.2017 12:20+140 млн параметров в одном Dense уровне не очень оптимально, если например resnet50 из кераса дотренировать, он может даже быстрее работать будет.

snakers4
13.06.2017 12:38Наверное быстрее и точность будет выше.
Но мы хотели сделать модель как бы как вещь в себе, чтобы протестить применимость в вакууме.
Я понимаю что можно обрезать пару слоев и настроить любую большую сеть, если она училась на любых животных.
Про параметры — спасибо, стало понятно почему batch norm не работал.
В следующий раз подумаю над оптимизацией.
rzykov
Спасибо, очень интересно читать. Всегда радует, когда ML находит практическое применение в реальной жизни. Ваш пример напомнил мне один проект из Норвегии https://geektimes.ru/post/287572/
snakers4
Мы скорее просто заморочились на хобби проект чтобы научиться ) Но фишка в том что мы сделали всю цепочку от курятника до сетки ))