

Проект ZFS on Linux изначально был создан для портирования существующего кода из Solaris. После закрытия его исходного кода совместно с сообществом OpenZFS проект продолжил разработку ZFS для Linux. Код может быть собран как в составе ядра, так и в виде модуля.

Сейчас пользователь может создать пул с последней совместимой с Solaris версией 28, а также с приоритетной для OpenZFS версией 5000, после которого началось применение feature flags (функциональные флаги). Они позволяют создавать пулы, которые будут поддерживаться в FreeBSD, пост-Sun Solaris ОС, Linux и OSX вне зависимости от различий реализаций.
В 2016 году был преодолён последний рубеж, сдерживавший ZFS на Linux — многие дистрибутивы включили его в штатные репозитории, а проект Proxmox уже включает его в базовую поставку. Ура, товарищи!
Рассмотрим как наиболее важные отличия, так и подводные камни, которые есть в настоящее время в версии ZFS on Linux 0.6.5.10.
Начинать знакомство с ZFS стоит с изучения особенностей CopyOnWrite (CoW) файловых систем — при изменении блока данных старый блок не изменяется, а создается новый. Переводя на русский — происходит копирование при записи. Данный подход накладывает отпечаток на производительности, зато даёт возможность хранить всю историю изменения данных.
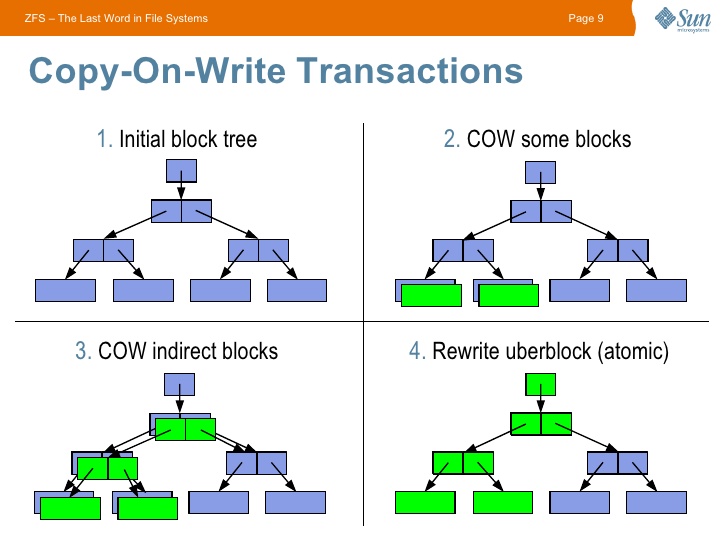
CoW подход в ZFS даёт огромные возможности: эта ФС не может иметь некорректного состояния, т.к. в случае проблем с последней транзакцией (например при отключении питания) будет использована последняя корректная.
Также сразу стоит отметить, что для всех данных считается контрольная сумма, что также оставляет свой отпечаток на производительности, но даёт гарантию целостности данных.
Кратко о главных преимуществах ZFS для вашей системы.
Защита данных:
- контрольные суммы — гарантия корректности данных;
- возможность резервирования как на уровне создания зеркал и аналогов RAID массивов, так и на уровне отдельного диска (параметр
copies); - в отличие от многих файловых систем с их fsck на уровне журнала, ZFS проверяет все данные по контрольным суммам и умеет проводить их автоматическое восстановление по команде scrub (если в пуле есть живая копия битых данных);
- первая ФС, разработчики которой честно признались во всех возможных рисках при хранении — везде при упоминании ZFS можно встретить требование оперативной памяти с поддержкой ECC (любая ФС имеет риск повреждения при отсутствии ECC памяти, просто все, кроме ZFS, предпочитают не задумываться об этом);
- ZFS создавалась с учетом ненадёжности дисков, просто помните это и перестаньте волноваться о вашем
WD GreenSeagateetc(только, если рядом трудится ещё один выживший диск).
Максимальная гибкость вашего хранилища:
- закончилось место? Замените диск на более объёмный, и ваш покорный ZFS сам займёт новоотведённое ему место (по параметру autoexpand);
- лучшая реализация снапшотов среди файловых систем для Linux. На это подсаживаешься. Инкрементально по сети, в архив,
/dev/null, да хоть раздвойте личность вашего дорогого Linux в реальном времени (clone); - нужно больше
золотаместа? 256 зебибайт хватит всем!
Структура.
В ZFS структура хранилища выглядит следующим образом:
- pool
-- vdev (virtual device) - объединяет носители (в mirror, stripe и др.)
--- block device - диск, массив, файлВ пуле может быть неограниченное количество vdev, что позволяет создать пул из двух и более mirror, RAID-Z или других сочетаний. Также доступны классические RAID10 и т.д.
Типы массивов:
Stripe — обычный RAID0.
Mirror — RAID1 на манер ZFS — реплицируются только занятые блоки, забудьте о синхронизации пустого места.
RAID-Z — создавался как замена RAID5-6, но имеет большие отличия:
— каждый блок данных — аналог отдельного массива (с динамической длинной);
— отсутствует проблема write hole;
— при ребилде создаются только данные (т.е. риск сбоя в этот момент уменьшается). Также в тестовой ветке уже находятся улучшения, которые дополнительно ускорят этот процесс.
Рекомендуется использовать RAID-Z2 (аналог RAID6). При создании RAID-Z стоит обязательно изучить эту статью, основные нюансы:
— IOPS равен самому медленному диску (создавайте RAID-Z с наименьшим количеством дисков);
— эффективность утилизации места увеличивается при бОльшем количестве дисков в массиве (требуется задать корректный recordsize, см. ссылку выше);
— в существующий массив RAID-Z нельзя добавить ещё один диск (пока), но можно заменить диски на более ёмкие. Эта проблема решается созданием нескольких массивов в рамках одного vdev.
dRAID (в разработке) — базируется на наработках RAID-Z, но при сбое позволяет задействовать на чтение-запись все диски массива.
ARC — умное кеширование в ZFS.
CoW ухудшает производительность. Для сглаживания ситуации был создан adaptive replacement cache (ARC). Его основная особенность в проработанных эвристиках для исключения вымывания кеша, в то время как обычный page cache в Linux к этому очень чувствителен.
Бонусом к ARC существует возможность создать быстрый носитель со следующим уровнем кеша — L2ARC. При необходимости он подключается на быстрые SSD и позволяет заметно улучшить IOPS HDD дисков. L2ARC является аналогом bcache со своими особенностями.
L2ARC стоит использовать только после увеличения ОЗУ на максимально возможный объём.
Также существует возможность вынести запись журнала — ZIL, что позволит значительно ускорить операции записи.
Дополнительные возможности.
Компрессия — с появлением LZ4 позволяет увеличить скорость IO за счёт небольшой нагрузки на процессор. Нагрузка настолько мала, что включение данной опции уже является повсеместной рекомендацией. Также есть возможность воспользоваться другими алгоритмами (для бекапов прекрасно подходит gzip).
Дедупликация — особенности: процесс дедупликации производится синхронно при записи, не требует дополнительной нагрузки, основное требование — ~ 320 байт ОЗУ на каждый блок данных (Используйте команду
zdb -S название_пула для симуляции на существующем пуле) или ~ 5гб на каждый 1 тб. В ОЗУ хранится т.н. Dedup table (DDT), при недостатке ОЗУ каждая операция записи будет упираться в IO носителя (DDT будет читаться каждый раз с него).Рекомендуется использовать только на часто повторяющихся данных. В большинстве случаев накладные расходы не оправданы, лучше включить LZ4 компрессию.
Снапшоты — в силу архитектуры ZFS абсолютно не влияют на производительность, в рамках данной статьи на них останавливаться не будем. Отмечу только прекрасную утилиту zfs-auto-snapshot, которая создаёт их автоматически в заданные интервалы времени. На производительности не отражается.
Шифрование (в разработке) — будет встроенным, разрабатывается с учётом всех недостатков реализации от Oracle, а также позволит штатными send/receive и scrub отправлять и проверять данные на целостность без ключа.
Основные рекомендации (TL;DR):
— Заранее продумайте геометрию массива, в настоящий момент ZFS не умеет уменьшаться, а также расширять существующие массивы (можно добавлять новые или менять диски на более объёмные);
— используйте сжатие:
compression=lz4— храните расширенные атрибуты правильно, по умолчанию хранятся в виде скрытых файлов (только для Linux):
xattr=sa— отключайте atime:
atime=off— выставляйте нужный размер блока (recordsize), файлы меньше recordsize будут записываться в уменьшенный блок, файлы больше recordsize будут записывать конец файла в блок с размером recordsize (при
recordsize=1M файл размером 1.5мб будет записан как 2 блока по 1мб, в то время как файл 0.5мб будет записан в блок размером 0.5мб). Больше — лучше для компрессии:recordsize=128K— ограничьте максимальный размер ARC (для исключения проблем с количеством ОЗУ):
echo "options zfs zfs_arc_max=половина_ОЗУ_в_байтах" >> /etc/modprobe.d/zfs.conf
echo половина_ОЗУ_в_байтах >> /sys/module/zfs/parameters/zfs_arc_max— дедупликацию используйте только по явной необходимости;
— по возможности используйте ECC память;
— настройте zfs-auto-snapshot.
Важные моменты:
— многие свойства действуют только на новые данные, к примеру при включении сжатия оно не применится к уже существующим данным. В дальнейшем возможно создание программы, применяющей свойства автоматически. Обходится простым копированием.
— консольные команды ZFS не запрашивают подтверждение, при выполнении
destroy будьте бдительны!— ZFS не любит заполнение пула на 100%, как и все другие CoW ФС, после 80% возможно замедление работы без должной настройки.
— требуется правильно выставлять размер блока, иначе производительность приложений может быть неоптимальна (примеры — Mysql, PostrgeSQL, torrents).
— делайте бекапы на любой ФС!
В настоящий момент ZFS on Linux уже является стабильным продуктом, но плотная интеграция в существующие дистрибутивы будет проходить ещё некоторое время.
ZFS — прекрасная система, от которой очень сложно отказаться после знакомства. Она не является универсальным средством, но в нише программных RAID массивов уже заняла своё место.
Я, gmelikov, состою в проекте ZFS on Linux и готов с радостью ответить на любые вопросы!
Отдельно хочу пригласить к участию, всегда рады issues и PR, а также готовы помочь вам в наших mailing lists.
Полезные ссылки:
ZFS on Linux github page
FAQ
ZFS Performance tuning
Комментарии (131)

svanichkin
19.06.2017 12:23Интересно было бы прямое глобальное сравнение скоростей (чтения/записи) для текущих файловых систем и новых… а так же о недостатках каждой.

gmelikov
19.06.2017 12:35Согласен, такое сравнение всегда интересно, но очень важно подходить к нему с учётом всех особенностей каждой ФС, на примере ZFS требуется внимательно изучить особенности Copy-on-Write.
pansa
19.06.2017 21:23+1Ага, например, ужасную деградацию скорости записи после заполнения >80%. Особо доставляет, когда массив под 100ТБ. Хоп! А 20Тб, извините, будем писать со скоростью черепахи.
Снапшоты — отлично, да, быстро. Только надо помнить, что если данные меняются быстро, то скорость заполнения раздела при наличии снапшотов шустро увеличивается.
COW очень не бесплатный, увы.gmelikov
19.06.2017 22:04Согласен, COW никогда не будет бесплатной по сравнению с классическими ФС, у них разные области.
В вашем примере могла сказаться фрагментация, ZFS по объективным причинам любит большое наличие свободного места.pansa
19.06.2017 23:01Нет, фрагментации там практически нет, т.к хранилище использовалось практически только в режиме добавления новых файлов. Возможно, поэтому дикие тормоза случились не совсем на 80%, а чуть позже. Сейчас точно не помню, с тех пор было собрано несколько новых массивов с XFS.
ZFS по объективным причинам любит большое наличие свободного места.
Так добавьте это в статью. Узнать об этом, заполнив 100Тб — крайне неприятно, правда?gmelikov
21.06.2017 08:39Спасибо, добавил.
К сожалению, серебряной пули в этом вопросе не существует, и ZFS требует подготовки перед использованием в продакшене (как, собственно, и любая другая ФС).
skeletor
20.06.2017 14:01+2Ага, например, ужасную деградацию скорости записи после заполнения >80%. Особо доставляет, когда массив под 100ТБ.
Нужно всего лишь уменьшить значение metaslab_min_alloc_size (http://skeletor.org.ua/?p=3189) и запись будет быстрее. По дефолту оно слишком большое.
Так же можно отключить/включить prefetch, nocacheflush (смотря что там происходит). Если данные не сильно важны, можно выключить sync, увеличить время сброса кеша да диск (по дефолту раз в 5 секунд).
В целом, да, zfs немного медленнее, но это не значит, что её нельзя подтюнить для более быстрой работы.
Насчёт снепшотов (из практики cиспользования zfs). Если diff между снепшототами (или снепшотом и текущим состоянием) достаточно большой (гигабайты, десятки/сотни гигабайт), то разницу начинаешь замечать: нагрузка на диски при таком же количестве iosp'ов значительно выше (логично почему). Так что, снепшоты не полностью бесплатны и это нужно учитывать.pansa
20.06.2017 23:37+1Нужно всего лишь уменьшить значение metaslab_min_alloc_size (http://skeletor.org.ua/?p=3189) и запись будет быстрее. По дефолту оно слишком большое.
Возможно, но возникают вопросы:
1) Инженеры Sun не понимали, что делали, что выбрали это значение на несколько порядков больше, чем «надо»?
2) Допустим, они ошиблись. Вы более-менее внятно понимаете — на что повлияет изменение этого параметра, где аукнется?
3) «будет быстрее» — насколько быстрее? Кто-то проводил тесты?
Это я всё к тому, что с ZFS обычно речь идет не о домашней файлопомойке, а о корпоративном хранилище, большом и ценном.
Я понимаю, что любая система требует настройки под конкретные задачи, но наобум крутить крутилки стораджа — это опасный путь. Он имеет право на жизнь, «безумству храбрых...» как говорится, но, согласитесь, не стоит рекомендовать его как серебряную пулю.
skeletor
21.06.2017 08:05+11) Точно так же как и остальные инженеры и разработчики ОС не всегда ставят некоторые параметры оптимальные и SUN здесь не исключение. Можно так же придраться к тому, почему бы по умолчанию не включать LZ4, раз оно сжимает «сжимаемые» данные и не трогает «несжимаемые».
2) Данный параметр может «аукнуться», только если у вас опять станет много свободного места (50% и более) и тогда возможно снижение скорости записи по сравнению с дефектными значениями.
3) тесты я не проводил, так как они будут очень хосто-зависимы, но из практики скажу следующее: есть у меня несколько одинаковых по железу серверов и так же однотипными данными. Так вот, падение скорости на запись наблюдается только у одного из них, и то, при достижении планки в 95%.
А насчёт серебряной пули — она действительно, если таковой не является, то явно стремиться к ней и ближе, чем любая мне известная ФС (суммарное количество преимуществ действительно намного больше, чем у других). Другое дело, что работает она как пуля только в Solaris (ни во FreeBSD, ни в Linux она не является достаточно стабильной).
Я думал точно так же как и вы и ко всему скептически относился, пока не поработал с ней плотно несколько лет. И вот тогда понимаешь, что её можно приспособить, практически под любые условия:
— нужна стабильность? пожалуйста, есть
— нужна супер скорость? да, тоже есть (подтюнил и вперёд)
— нужно что-то среднее, да тоже не вопрос.
Как уже перечисляли в статье, основные её преимущества это:
— неубиваемость. Действительно, её практически невозможно разрушить в виду особенностей строения (при каждой транзакции на диск пишутся 2 метки в начале, 2 в конце, при этом пишутся по диагонали)
— простота снепшотов (никакой lvm или btrfs не будет удобным настолько, насколько это делается в zfs)
— autoexpand — это действительно вещь и в zfs это очень просто и безболезненно.
— множество фич, которые можно тюнить.
Так же забыл добавить, что можно налету изменять размер блоков, которыми ФС пишет на диск. К примеру, если у вас на zfs postgresql (а по дефолту она пишет 8кб блоками), то нужно выставить в этой zfs тоже 8кб, тогда скорость записи значительно будет эффективнее, чем дефолтными 128кб. А если этого не знать, то можно сказать, ооо, как медленно пишет (фу, какая плохая ФС), у меня на линуксе писало быстрее.
Точно так, если вы не являетесь DBA, то вы не сможете выжать из БД максимум, и будете говорить, почему медленно работает.Scorry
21.06.2017 16:05— простота снепшотов (никакой lvm или btrfs не будет удобным настолько, насколько это делается в zfs)
Можете описать разницу с вашей точки зрения, пожалуйста?gmelikov
21.06.2017 16:07С lvm всё просто — они там не «бесплатные», накладывают большой отпечаток по производительности, сама ФС о снапшотах ничего не знает.
С btrfs — можете почитать официальную страницу btrfs gotchas, плюс в нём нет поддержки блочных устройств (в ZFS это ZVOL).Scorry
21.06.2017 16:40Извините, я по недомыслию не сократил упоминание об LVM, когда цитировал вас.Специфику создания снапшотов в LVM я представляю. Меня интересует, скорее, не разница фич (может/не может создаватьснапшот подлежащего блочного устройства), а скорее то, что вы назвали отличием снапшотов. Если сравнить снапшот субтома в btrfs и аналогичный снапшот дерева/части дерева ФС в zfs — вот, я дал команду и получил снапшот подтома — есть ли какие-то коренные отличия? То есть в данной конкретной ситуации есть, по вашему мнению, какая-либо большая удобность zfs в сравнении с btrfs?
skeletor
22.06.2017 10:38Сама специфика создания снепшота — общая и одинаковая. Реализация у всех разная. К примеру, можно провести такой тест: сделать снепшот ФС, потом создать и удалить большой файл, и так проделать несколько раз. На сколько будет отличаться снепшот в разных ФС? Вот это и будет коренным отличием (если конечно отличия будут).
А что насчёт удобства, то для это наличии многих фич + простота использования.
skeletor
22.06.2017 10:30Как минимум то, что в zfs это делается одной командой, а не как в lvm — lvcreate / lvremove. В btrfs видимо это учли, и поэтому там делается одной командой, но с добавлением subvolume.
btrfs subvolume [params]
в отличии от zfs:
zfs [params]
Мне удобнее писать меньше текста, выполняя команды. Если кому-то нравится набирать команды из 20-30 символов + иерархические ключи — можете портировать powershell.

knutov
25.06.2017 06:33то нужно выставить в этой zfs тоже 8кб, тогда скорость записи значительно будет эффективнее
А если дедупликация — то 320 байт на блок — это на вот этот record size, или там блок — что-то другое?
gmelikov
25.06.2017 08:12320 байт на recordsize.
knutov
27.06.2017 06:14Вопрос был про является ли рекордсайз блоксайзом, но я увидел
# zfs get all | grep -i size vzpool recordsize 128K default vzpool/vz3 volsize 423G local vzpool/vz3 volblocksize 16K -
Т.е. правильно ли я понимаю, что это разные вещи, и если у меня маленький средний размер файла, то мне лучше уменьшать именно recordsize ?
А на что тогда влияет volblocksize? Т.е. я понимаю, что это минимальная перезаписываемая порция данных и помню, что COW, но теперь не понимаю как вообще надо выбирать volblocksize и в зависимости от чего.
И заодним, если SSD и я очень хочу иметь много заранее очищенных блоков (и часто запускаю fstrim), а из-за COW у меня будет занято сильно больше блоков диска, чем данных — можно ли как-то управлять количеством старых копий, чтобы их было поменьше? И, например, если мне не нужны снапшоты совсем — можно ли их отключить и что-нибудь сэкономить на этом?
gmelikov
27.06.2017 09:56является ли рекордсайз блоксайзом
recordsize используется для dataset, а для ZVOL его аналогом является volblocksize, соответственно на ZVOL recordsize не влияет.
как вообще надо выбирать volblocksize и в зависимости от чего
В зависимости от размера блока ФС, которая будет находиться в ZVOL, либо от минимального размера блока, каким вы в рамках этой ФС планируете оперировать.
много заранее очищенных блоков (и часто запускаю fstrim), а из-за COW у меня будет занято сильно больше блоков диска
Пока вы не используете снапшоты, то размер ZVOL увеличиваться не будет. Если вы создадите ZVOL в режиме sparse (т.н. thin-provisioning, который в случае с COW практически бесплатен), то trim будет освобождать место и ZVOL будет занимать на пуле только занятое данными место.
можно ли их отключить и что-нибудь сэкономить на этом?
Особо не сэкономите ничего, просто не пользуйтесь.

acmnu
19.06.2017 12:26А что там с лицензией? Получилось втащить zfs в ядро Linux? А то я давно не слежу за темой.
gmelikov
19.06.2017 12:33Технически всё уже реализовано, а вопрос лицензии без проблем обходится сборкой модуля DKMS. За несколько лет ни разу проблем с ним не было.
К сожалению, интеграция в кодовую базу ядра в ближайшее время точно не произойдёт.
satter
19.06.2017 13:29в существующий массив RAID-Z нельзя добавить ещё один диск (пока)
уже запланировано? для домашнего использования очень не хватаетgmelikov
19.06.2017 13:39+1К сожалению, пока планов на эту задачу нет.
Но вопрос удобства всё же поднимается — в OpenZFS уже появилась возможность исключать диски.
wanomgn
19.06.2017 13:59>лучше включить LZ4 шифрование.
ухты… новый алгоритм шифрования… ;)))
компрессия это а не шифрование


vektory79
19.06.2017 15:21А рассматривается ли возможность ручного прогона дедубликации в отведённый даунтайм без необходимости включать его напостоянно? Есть один юзкейс (CI/DI сервера) когда происходит сильное дублирование данных и можно было бы по выходным прогонять дедубликатор (когда всё стоит и можно испоьзовать хоть всю память для этого). Но постоянно гонять никак т.к. память для работы нужна.

Daimos
19.06.2017 15:45У нас был плохой опыт использования дедупликации на ZFS в SDS NexentaStor — хранилище было заполнено от силы на 50%, но в какой-то момент времени производительность катастрофически упала, до десятков кБайт/сек.
Миграция в течение нескольких часов одной виртуалки, потом еще нескольких, ребут жесткий хранилища со включенными виртуалками под ESXi — ожила хранилка, отключение дедупликации, миграция части виртуалок на другой СХД, потом обратно — старые остались дедуплицированными, а новые уже нет.
Общее решение — пересоздание массива с нуля только.
gluko
19.06.2017 15:49+1Возможно в оперативку не влезли служебные данные нужные для дедупликации. Тогда системе пришлось сбросить это на диск, а к этой таблице нужно обращаться при каждой операции чтения и записи. Там расход примерно 8гб ОЗУ на 1 тб данных
vektory79
19.06.2017 16:19+1Ну вот в том-то и вопрос, что активация на постоянной основе спотыкается об требование памяти. Но одноразовые прогоны дедубликации по уже записанным данным может решить большинство ситуаций. Но этого как раз и не предусмотрено. Увы...
gmelikov
19.06.2017 17:26Кейс понимаю, но сейчас таких планов нет.
Сейчас требуется около 5гб ОЗУ на 1 тб данных, они требуются только в момент записи.
Acid_Jack
19.06.2017 15:31+1Тема весьма интересна.
Хотелось бы сравнить скорость работы текущей реализации ZFS в Linux (Debian 9.0) и Solaris (OpenIndiana Hipster).
gluko
19.06.2017 15:46Подскажите возможно ли после уничтожения датасета заставить ZFS вернуться к старому состоянию базы данных, где этот датасет будет еще живой чтобы спасти данные? Вроде бы есть «мифический» способ сделать это использую флаг -T и указав id транзакции до дестроя при импорте, но как бы я не старался, у меня не вышло.
Команда выглядит примерно так:
zpool import -N -o readonly=on -f -R /pool -F -T <transaction_id>
RomanStrlcpy
19.06.2017 17:25+1A deferred free means that a block has been freed but cannot be used by the pool until TXG_DEFER_SIZE transactions groups later. For example, a block that is freed in txg 50 will not be available for reallocation until txg 52 (50 + TXG_DEFER_SIZE). This provides a safety net for uberblock rollback. A pool could be safely rolled back TXG_DEFERS_SIZE transactions groups and ensure that no block has been reallocated.
TXG_DEFER_SIZE = 2. Поэтому со 100% вероятностью можно восстановить только то, что было 2 транзакции назад. А если пул заполнен, то шансов ещё меньше.gluko
19.06.2017 19:44Это понятно. К примеру мы случайно сделали destroy, затем сразу zpool export и пытаемся подключить пул со старой TXG. Проблема именно подключить… Драйвер ZFS не дает использовать старую TXG запись насколько я понял. Если есть специалисты, которые смогли найти решение данной проблемы, заклинаю, напишите как это сделать!

farcaller
19.06.2017 15:47Какие сейчас минимальные адекватные требования к оперативной памяти? Мне снапшоты zfs нравятся больше чем btrfs, но память на домашней машинке ограничена (8гб, 5 постоянно занято kvm-ками). Стоит пробовать?
vektory79
19.06.2017 16:23+1У меня в таких условиях полёт нормальный. Только надо учитывать, что ARC кеш выглядит так, как будто какое-то приложение сожрало всю память. Хотя реально эта память свободно перераспределяется под нужды приложений по требованию. Короче в моём случае работает, хоть и выглядит странно.
Использую для тестирования приложений на больших БД, которые надо долго готовить для каждого прогона. А так пересоздал снапшот и готово. Очень доволен.
gmelikov
19.06.2017 17:30Согласен с vektory79, жить можно, однако учитывайте, что ОЗУ нужно для кеширования, вы можете сказать ZFS кешировать хоть не более мегабайта (параметр zfs_arc_max), но при этом производительность на чтение будет ожидаемо ниже.
vektory79
19.06.2017 18:21Ну я ничего не указывал специально. Кеш в некоторые моменты отъедает половину оперативки. Но если я в этот момент запускаю локально приложение с прода, которое заведомо съедает всю память, то ничего летального не происходит. Кеш отдаёт память этому приложению. Ну обмен с диском начинает ожидаемо тупить. Но он и так тупил в этом случае. Ещё до установки zfs. Сейчас мне даже кажется, что после остановки приложения система быстрее вылазит из тупежей. Но конкретных замеров не делал.
Или я где-то не прав?
Andy_U
19.06.2017 16:43Не увидел в статье, а Linux умеет загружаться с ZFS, как та же самая FreeBSD?
gmelikov
19.06.2017 17:32Да, прекрасно загружается, на 2 машинах у меня нет никаких проблем. Из минусов — установка не двумя кликами.
thatsme
19.06.2017 17:57Да умеет. GRUB2 поддерживает /boot без отдельного раздела, прямо на ФС.
# zpool get bootfs
NAME PROPERTY VALUE SOURCE
zboot bootfs zboot/ROOT local
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
zboot 621G 2,03T 136K legacy
zboot/ROOT 621G 2,03T 8,98G legacy
# mount | grep boot
zboot/ROOT on / type zfs (rw,relatime,xattr,posixacl)
Кто-то спрашивал про прозводительность (всё от IOPS дисков зависит, конфигурации RAID и кол-ва шпинделей). Вот на домашней системе
Сначала смешное:
# dd if=/dev/zero of=./zerodump.useless bs=128k count=102400
102400+0 records in
102400+0 records out
13421772800 bytes (13 GB, 12 GiB) copied, 1.9465 s, 6.9 GB/s
Т.е. это на самом деле данных было записано в X раз меньше — сжатие на лету.
# zfs get all zboot/ROOT | grep compress
zboot/ROOT compressratio 1.27x — zboot/ROOT compression lz4 inherited from zboot
zboot/ROOT refcompressratio 1.55x — -------
# time cp -r American\ Gods Dark\ Matter SG-1 tmp/
real 0m34.449s
user 0m0.016s
sys 0m1.524s
# du -hs tmp
5,3G tmp
5,3G/34.449s = .1538GB/s на копирование файлов с компрессией на одной и той-же FS.
T.e. это и чтение и запись одновременно. Примечание, — компрессия для файлов-фильмов, — бесполезная трата ресурсов ЦПУ, но на производительность I/O в данном случае мало влияет.
Скорость чтения и валидации данных на диске (zpool scrub zboot/ROOT):
ссылка на скрин nmon: http://imgur.com/oNXmm3H
Диски SATA III Seagate Barracuda 1TB в конфигурации RAID-10
config:
NAME STATE READ WRITE CKSUM
zboot ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sda2 ONLINE 0 0 0
sdb2 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
sdc1 ONLINE 0 0 0
sdd1 ONLINE 0 0 0
mirror-2 ONLINE 0 0 0
sde1 ONLINE 0 0 0
sdf1 ONLINE 0 0 0
Как-то так.gmelikov
19.06.2017 18:34Примечание, — компрессия для файлов-фильмов, — бесполезная трата ресурсов ЦПУ, но на производительность I/O в данном случае мало влияет.
В случае несжимаемых данный ZFS не проводит сжатие, можете об этом не волноваться.RomanStrlcpy
19.06.2017 18:55можете ткнуть в код?
gmelikov
19.06.2017 19:03Извиняюсь, перепутал, не ZFS, а LZ4 оптимизирован с целью пропуска несжимаемых данных. Здесь можно увидеть сравнение скорости.

OmManiPadmeHum
19.06.2017 18:36-1давно интересовал вопрос: возможна ли установка linux на raw zfs?
на freebsd работает добавлением загрузчика:
dd if=/boot/zfsboot of=/dev/ada0 count=1 && dd if=/boot/zfsboot of=/dev/ada0 skip=1 seek=1024

vonbraun
19.06.2017 20:39+4Использую zfs как NAS хранилку, впринципе очень доволен. LZ4 сжатие вообще огонь, на датасторах виртуалки жмутся в среднем в 2.4 раза. Прогретый ARC от 94 — 98% чтения отдает с RAM, остальное забирает L2ARC и совсем немного приходится на hdd. Не используем дедубликацию, т.к. она имеет смысл быть при блоках 4к, а для этого требуется очень много памяти.
Пробывал варианты с
- centos7 + openzfs
- illumous — дистрибутив omnios
- solaris 11.2/11.3
В итоге остановился на конаничном — Solaris.
типовая конфигурация у нас это:
- Cisco UCS 240m4 ( cpu: 2 x E5-2699A v4, ram: 768gb, 2 x dual intel x520 10gbe, 2 x lsi sas 9200-8e )
- 216BE2C-R741JBOD / SC847E2C-R1K28JBOD
- SLOG: PX04SHB020 — очень рекомендую
- L2ARC: HUSMM1640ASS204
Тестировал fio как локально, так и экспортируюмую шару по NFSv4, так и iSCSI волум.
Linux
Плюсы:
- Нет проблем с железом / дровами
- Легко найти человека который знаком с linux
- Имеется поддержка nfsv 4.1
на этом пожалуй плюсы закончены
Минусы:
- производительность zfs меньше на процентов 15 по сравнению с тем же OmniOS, на локальных тестах + тестах по iscsi (использовал targetd lio) и на процентов 20% по сравнению с тестами по nfs.
- autoreplace для пула, т.к. каждый диск у нас видится по четырем путям, нам необходимо сконфигурировать multipathd таким образом, чтобы в названии он отоброжал физическое расположение диска — в идиале полка/слот. чтобы после замены диска он автоматически выполнял реплейс.
- т.к. я тестировал на centos7 при проблемах с производительностью мы имеет только счетчики из proc и стандартные утилиты типа iostat (в systemtap я не селен), что как мне кажется делает анализ производительности более сложным чем в случае с solaris base дистрибутивами.
- Кластер на базе Pacemaker + Corosync. Умные проверки придется пилить руками.
OmniOS
плюсы:
- Хорошая производительность как при локальных теста, так и при использовании nfs
- Имеется платный кластер — RSF-1 заточенный под кустарные схд
- Dtrace который облегчает поиск проблемных мест + множество готовых скриптов под него.
- Comstar уже интегрирован с zfs (ISCSI)
- Нет проблем с мультипазингом, MPxIO работает на ура.
- Отличное сообщество.
- FMD (fault managment daemon) — этот парень всегда пришлет письмо,
если у вас, что то сломалось (если конечно сервер и fmd еще живы). Расширяется за счет плагинов.
Минусы:
- Не на всем железе взлетит + проблема с драйверами, для современных 40гбе карточек.
- до недавнего времени была проблема с UEFI
- Админов знакомых с solaris в разы меньше.
Solaris 11.3
все плюсы из OmniOS, а так-же:
- Производительность раза в полтара выше чем у OmniOS и тем более Linux,
как я понимаю это связанно с фитчей efficiency block allocation
котарая появилас в 36-ой версии, пула если не изменяет память. - L2ARC остается горячим при переключении кластер (активной ноды) или перезагрузки
- в FMD
появились плагины io retired && zfs retired, которые отслеживают
события с I/O на диске и в случае например "дребезка" диска, помечают его
как failed и убирает из системы до выяснения обстоятельств - Sun Cluster — это парень имеет багатую историю и тесно интегрирован с
Solaris. Отлично работает, прост в использовании, вообщем нареканий нет.
Минусы:
- Сообщество на металинки достаточно "тухлое"
- Не на всем железе взлетит + проблема с драйверами, хотя дела обстоят не так
остро как с OmniOS, а если брать сервера от Oracle так проблем вообще нет. - Нет фитчи с асинхронным удалением датасетов, например датасеты размером в
50тб удаляются сутки или двое, но зато это операция не просаживает CPU как в случае с OpenZFS. - Админов знакомых с solaris в разы меньше.
- Comstar не кластирезуется из коробки, нужно допиливать.
Десклеймер: По поводу производительности, настройки openzfs на linux и
illumous я старался сделать как можно более одинаковыми. У Oracle ZFS естественно они отличались. Ну и естественно это мой личный опыт, ваше мнение/опыт могут отличаться.
По поводу использования zfs в качестве бэка для систем виртуализации, аля Linux KVM + ZFS — посмотрите проект SmartOS, он достаточно интересный и активно развивается компанией Joyent.
gmelikov
21.06.2017 08:44-1Как давно тестировали? В будущем релизе ZoL 0.7 включено множество оптимизаций производительности, которые, кстати, сразу портируются в OpenZFS (то есть проблемы уже не в реализации на Linux, основную проблему взаимодействия с ОЗУ уже решили в 0.7).
Эх, вот бы усилия Oracle да объединить с OpenZFS…vonbraun
21.06.2017 11:11+1В начале 2016 года. Я вкратце описал почему выбор пал на Солярис, также я убежден в том, что на "родной" системе zfs работает стабильнее + fmd очень удобен в части проблем с дребезгом дисков, а также автоматического создания инцидентов о возникших проблемах. Обязательно затестирую релиз 0.7 на нотнике ))
gmelikov
21.06.2017 14:52Спасибо, была интересна актуальность.
Если я правильно понял, в ZoL есть аналог fmd — ZED.
на «родной» системе zfs работает стабильнее
Не спорю, интерес именно в накладных расходах разных реализаций.
knutov
26.06.2017 06:38btw, а что с "efficiency block allocation" в ZoL?
Я что-то не смог сходу разобраться в версиях и как версия 5000 относится к линейке версий в солярисе.
gmelikov
26.06.2017 09:21btw, а что с «efficiency block allocation» в ZoL?
Уточните, какая возможность конкретно интересует (желательно ссылкой), в этом направлении многое было сделано и в Oracle, и в OpenZFS.
Я что-то не смог сходу разобраться в версиях и как версия 5000 относится к линейке версий в солярисе.
OpenZFS версия 5000 базируется на версии 28 последнего релиза с открытым исходным кодом, далее новый функционал подключается через feature flags, об этом написано в статье.
Есть пересекающийся новый функционал, но его реализации несовместимы.knutov
27.06.2017 05:26(я погуглил, но слово log не заметил, и потому родился вопрос)
Судя по гуглу — есть zpool version 36
36 Efficient log block allocation
У openzfs максимальная версия — 28, но, например, версия 37 — lz4 и lz4 у openzfs на сколько я вижу есть.
Поэтому непонятно что из того, что после 28ой версии, реально есть в 5000
skeletor
26.06.2017 11:56Нет фитчи с асинхронным удалением датасетов, например датасеты размером в
50тб удаляются сутки или двое, но зато это операция не просаживает CPU как в случае с OpenZFS.
Да, это действительно так. Если нужно удалить весь пул, то пользуюсь таким хаком: делаю zpool export, zpool create -f и всё. Новый пул создан меньше чем за минуту.
vonbraun
19.06.2017 21:40+1Рекомендую к просмотру, хоть материал и старенький, но концепция изложена полностью:
ZFS: The Last Word in File Systems — Part 1
ZFS: The Last Word in File Systems — Part 2

amarao
19.06.2017 21:53Для больших инсталляций хочу сравнение производительности с ceph'ом. Да, я знаю, что они не полностью пересекаются, но в условиях «локальное всё» их вполне можно пытаться сравнивать.
vonbraun
19.06.2017 22:11Я думаю сложно будет подобрать сопостовимые конфигурации, сравнивать по price/performance?
amarao
19.06.2017 23:26Почему? Берём то железо, какое есть. В тесте один — zfs, в тесте два — ceph. У ceph'а можно с лёгкостью сконфигрировать вариант без избыточности, то есть использовать его просто как «shared volume». И тогда уже можно тестировать производительность cephfs/rbd VS zfs.
А если же мы говорим про варианты с избыточностью, то тут вообще всё просто — в crush map задаём «использовать osd одного хоста» и смотрим на результат.
Ключевое что в ceph было бы интересно в сравнении с zfs — абсолютная толерантость к ресайзу в любую сторону. Хоть вверх, хоть вниз. Плюс возможность работать с ним как blob-хранилищем напрямую, что может быть иногда интереснее, чем fs/блочное устройство.
Но фичи ладно. Интересно было бы raw-производительность сравнить.vonbraun
20.06.2017 00:45Для больших инсталляций хочу сравнение производительности с ceph'ом
Ну если на текущем железе, то это не большая инсталяция ))
Без избыточности тестировать как мне кажется смысла тоже нет, т.к. тогда и
zfs можно собрать как raid0.
Если интересно, то в середине июля должнен получить очередное оборудование под NAS
( 2 сервера + 4-ре полки на 24-ре диска) можно попробывать на них.
По Объему схожая конфигурация это:
zfs pool (Solaris):
40 x mirror - hdd 10krpm 8 x slog - ssd 4 x l2arc - ssd
ceph (Linux 4.X)
replicated pool == 2 copies node1: 20 x osd - hdd 4 x ssd == 20 journal partitions node2: 20 x osd - hdd 4 x sdd == 20 journal partitions
Берем примерно 10% от общего полезного объема
fio --time_based --name=benchmark --size=3000g --runtime=1200 --filename=/dev/sdb --ioengine=libaio --randrepeat=0 --iodepth=128 --direct=1 --invalidate=1 --verify=0 --verify_fatal=0 --numjobs=1 --rw=write --blocksize=4k --group_reporting fio --time_based --name=benchmark --size=3000g --runtime=1200 --filename=/dev/sdb --ioengine=libaio --randrepeat=0 --iodepth=128 --direct=1 --invalidate=1 --verify=0 --verify_fatal=0 --numjobs=1 --rw=randwrite --blocksize=4k --group_reporting fio --time_based --name=benchmark --size=3000g --runtime=1200 --filename=/dev/sdb --ioengine=libaio --randrepeat=0 --iodepth=128 --direct=1 --invalidate=1 --verify=0 --verify_fatal=0 --numjobs=1 --rw=read --blocksize=4k --group_reporting fio --time_based --name=benchmark --size=3000g --runtime=1200 --filename=/dev/sdb --ioengine=libaio --randrepeat=0 --iodepth=128 --direct=1 --invalidate=1 --verify=0 --verify_fatal=0 --numjobs=1 --rw=randread --blocksize=4k --group_reporting fio --time_based --name=benchmark --size=3000g --runtime=1200 --filename=/dev/sdb --ioengine=libaio --randrepeat=0 --iodepth=128 --direct=1 --invalidate=1 --verify=0 --verify_fatal=0 --numjobs=1 --rw=readwrite --blocksize=4k --group_reporting
так?
Ключевое что в ceph было бы интересно в сравнении с zfs — абсолютная толерантость к ресайзу в любую сторону
Ну если говорить про пул, то да, уменьшить его нельзя, но если честно на своей практики и необходимости такой небыло, хотя опыт у каждого и кейсы разные. Если говорить про файловые системы, то изменение размера, это просто изменение квоты.
PS: за терминологию касательно цефа заранее извиняюсь + если тестировать будем, возможно будет полезно узнать какой то бест практис по тонкой настроки ceph.
amarao
20.06.2017 01:05Почти. Я бы использовал librados напрямую: --ioengine=rbd, плюс, если мы говорим про трушный бенчмарк, то --fsync=1. Я наблюдал как добавление fsync'а многие хранилки убивало к чертям в район сотен иопсов (с десятков тысяч).
Плюс на ceph'е лучше всё-таки blustore использовать, они его объявили production-ready этой весной.

Dorlas
19.06.2017 21:55+4Большое спасибо за статью!
Вставлю свои 5 копеек: Использую ZFS в связке с OwnCloud-сервером (как средство сихронизации пользовательских данных с Windows-машин на сервер через OwnCloud-клиент) + Samba + снапшоты.
Для себя, как администратора, сделал доступ к папке с данными через скрытый ресурс.
И через настройки Samba объяснил, как интерпретировать снапшоты ZFS:
[USERDATA$]
comment =
path = /owncloud/
public = yes
writable = no
guest ok = yes
guest only = yes
read only = yes
hosts allow = 192.168.0.2
create mask = 0777
directory mask = 0777
vfs objects = shadow_copy2
shadow: format = auto-%Y-%m-%d_%H.%M
shadow: sort = desc
shadow: snapdir = .zfs/snapshot
shadow: localtime = yes
Что мне это дало — на любом каталоге я могу вызвать в Explorer контекстное меню и выбрать пункт: Предыдущие версии. Вижу все предыдущие версии (zfs-auto-snap то работает), могу тут же их открыть и найти нужный файл нужной версии.
В добавок к этому в самом OwnCloud есть версионность и корзина.
В общем вариант, неубиваемый вирусами шифровальщиками — как бы на машине они не поработали (клиенткой) — на сервере все равно исходный вариант останется. Либо в OwnCloud, либо в ZFS.kravit
21.06.2017 16:42О да!!! очень интересно!!! Я тоже хочу поднять OwnCloud. Сделайте статью с нуля по использованию ZFS+OwnCloud+Samba+снапшоты.Буду ждать!!!


farwayer
19.06.2017 22:24+1А ту замечательную «особенность», когда при заполнении диска на 100% становится невозможно удалять файлы, в новой версии пофиксили? ;) Это такой знатный троллинг.
А вообще это единственная ФС, которая позволила мне стабильно зашарить раздел между Linux и OSX.gmelikov
20.06.2017 09:04Вроде и тогда были методы почистить диск, сейчас уже не воспроизводится. Вообще CoW имеет свои особенности, это да =)
Drugok
20.06.2017 16:59Обновил zfs до 0.6.5.9-5 на debian jessie
tank/rc-544 50G 50G 0 100% /var/www/rc-544/data
При 100% забитом разделе при попытке удалить файл получаю ошибку:
rm: cannot remove ‘backupland.com.log’: Disk quota exceeded
Проблема обходится
cat /dev/null > backupland.com.log
после чего появляется чутка места и после можно уже удалить файл
Но мне кажется это какой-то мегакостыль, есть нормальное решение проблемы?gmelikov
20.06.2017 17:02Давайте вспомним, что это CoW, да, ей даже при удалении надо сначала записать.
Плюс добавлю, что не рекомендуется заполнять пул больше, чем на 80%, дальше начнутся проблемы с фрагментированием. Последнее, что стоит делать с CoW — заполнять её на 100%, уже на 90% мониторинг обязан орать.Drugok
20.06.2017 17:15На основном пуле место свободно с большим запасом:
NAME USED AVAIL REFER MOUNTPOINT
tank 17.6T 7.81T 1.48T /home
создаю я подпул так:
/sbin/zfs create tank/rc-544 -o mountpoint=/var/www/rc-544/data -o quota=51200M
50 гиг это же не размер раздела, а квота по сути.
Или нужно делать quota+20%, а ограничивать через refquota?gmelikov
20.06.2017 17:29Нашёл тикет, касающийся данного вопроса. Проблема квалифицирована не как баг, соответственно у неё нулевой приоритет.
К сожалению, ZFSonLinux развивается в основном за счёт энтузиастов с упором на продакшн, удобства для десктопов только начинают получать какое-то внимание. Всегда рады пулл реквестам!
acmnu
23.06.2017 12:07Последнее, что стоит делать с CoW — заполнять её на 100%, уже на 90% мониторинг обязан орать.
Иногда события развиваются очень стремительно. Например чекаут корневой дериктории svn, с разворотом 1500 тегов, сделаных CI.

VGusev2007
20.06.2017 13:06gmelikov, насколько я понимаю, четверть из ARC отводится под метаданные для L2ARC. Я хотел бы использовать как можно больше l2arc, и как можно меньше отводить под ARC.
Насколько оправдано на сервере виртуализации, использовать 2gb ARC (с настройками по-умолчанию) + 80GB l2arc? Каким образом в подобной ситуации (с минимальным размером ARC) достигнуть максимума использования l2arc?
Спасибо!
gmelikov
20.06.2017 13:14Вот пример расчёта количества ОЗУ, требуемого для L2ARC.
Я бы советовал потратить деньги на ОЗУ, L2ARC на малых конфигурациях не особо вам поможет. Также стоит учесть, что пока L2ARC не сохраняет состояние между перезагрузками, и каждый раз требует «прогрева».VGusev2007
20.06.2017 13:54пока L2ARC не сохраняет состояние между перезагрузками, и каждый раз требует «прогрева».
Вы уверены? Насколько я понял что это уже исправлено. Мои беглые тесты, показали, что l2arc — используется после перезагрузки. Вроде на баг треккере уже закрыты тикеты которые вопрошали об этом.gmelikov
20.06.2017 14:00Был бы рад ошибиться, но эта возможность ещё не опубликована. В ZFSonLinux появится только после публикации патча Nexenta.
VGusev2007
20.06.2017 14:25Кажется, да, Вы не ошибаетесь. :( В общем, zfs on linux по-прежнему расстраивает (патч был представлен ещё в 2015 году).
По калькулятору совсем не понял схему рассчётов, что-то зависит от размера блока записи, от типа записи. Но, я если честно (в силу отсутствия опыта и понимания всей картины в целом), не могу правильно аплицировать это на виртуализаию (в моём случае proxmox). Как будет вести запись вирт. машина — не знаю. Да и машины — разные.
Пока хочу попробовать под ARC отвести 2-3 гб., после чего смотреть процент попадания в l2arc. К сожалению, сервера не имеют физической возможности расширения ОЗУ.
Как Вы считаете, подобный подход имеет право на жизнь?gmelikov
20.06.2017 14:46патч был представлен ещё в 2015 году
Стоит уточнить, что стабильный патч Nexenta ещё не выпущен.
Расчёт простой — на каждый блок в L2ARC нужно ~200байт ОЗУ, для виртуализации скорее всего вы будете использовать zvol с volblocksize=8kb, соответственно на 100гб L2ARC потребуется около 2.5гб ОЗУ, на практике будет меньше.
Если у вас уже есть ssd, то проведите бенчмарк, иначе для начала просто настройте ограничение на ARC и попробуйте. Главное правильно настроить proxmox, volblocksize должен соответствовать блоку гостевой системы.
Производительность будет зависеть от особенностей ваших данных, если горячие данные поместятся в ваши 3гб ОЗУ, то это лучше, чем L2ARC.VGusev2007
20.06.2017 15:11Огромная благодарность за развернутый ответ. Осталось развеять только один вопрос. Что конкретно означает фраза:
на 100гб L2ARC потребуется около 2.5гб ОЗУ
Эта область ОЗУ сама будет забираться из ARC? Или максимально отводимая область под l2arc, будет регулироваться параметром: vfs.zfs.arc_meta_limit?
gmelikov
21.06.2017 08:50https://github.com/zfsonlinux/zfs/issues/1420#issuecomment-16831663
Да.
Вот интересная информация по этой теме.
Добавлю, что в релизе 0.7 требования к ОЗУ сильно оптимизированы, и в вашем случае может помочь (но он ещё в стадии тестирования, без бекапов ставить не рекомендую).VGusev2007
21.06.2017 15:19Добрый день, огромная благодарность за уделенное внимание! Крайне приятно общаться с разработчиком напрямую.
Если я верно понял, то у товарища из треда не удалялся mirror устройство, после чего, он получил объяснение, что это может происходить из-за не достатка памяти в ARC и слишком большого l2arc.
В следствии чего, он получил рекомендацию или увеличить ОЗУ для arc, или уменьшить разделы l2arc.
Если я Вас понял верно, то для 4GB RAM отведенного под ARC, мне следует ограничить l2arc размером в 60GB, тогда, в среднем, у меня будет уходить для l2arc не более 2gb RAM + 1 GB будет оставаться для собственно ARC и 1 GB под vfs.zfs.arc_meta_limit. При этом, vfs.zfs.arc_meta_limit мне не следует трогать.
Все ли верно понимаю?
Релиз 0.7, пока мне рановато применять, так-как планирую zfs в продуктивную установку.gmelikov
21.06.2017 15:31не удалялся mirror устройство
Я дал ссылку на комментарий основного контрибьютора Brian Behlendorf, в котором он разъяснял требования к ОЗУ, касающиеся первого поста в тикете (проблема с производительностью при увеличении L2ARC). Проблема с mirror не касается обсуждаемого нами.
Все ли верно понимаю?
Всё верно, l2arc можете увеличивать по надобности без даунтайма, если ssd позволяет. arc_meta_limit стоит трогать только если выделенный объём l2arc не заполнится.
VGusev2007
21.06.2017 17:45Благодарю! Последнее что мне не до конца ясно, это от чего я должен отталкиваться при расчетах размера l2arc устройства. От размера ARC, или от размера arc_meta_limit?
Если от arc_meta_limit, выходит:
ARC = 4GB
arc_meta_limit (25% от 4GB) = 1GB
volblocksize = 8kb
По формуле выходит 40GB — максимальный размер l2arc, если отталкиваюсь от arc_meta_limit.
Как понять сколько у меня реально испольузется l2arc? Всё же, arc_meta_used, насколько я понял, косвенный параметр.
За сим откланяюсь, больше не буду приставать с вопросами. Ответы на эти вопросы ищу с 2013 года, но так внятности не получил. По этому очень рад возможности спросить у компетентного разработчика!
Вообще, это тянет на отдельную статью на Хабре.
Ведь есть ещё вопрос по размеру zlog, там я понял чуть проще, размер должен быть таков, чтобы максимум за 5-10 секунд туда успела влезть вся запись с режимом sync.
Спасибо!
gmelikov
22.06.2017 09:05Да, arc_meta_limit ограничивает максимальное количество метаданных в кеше, а записи о l2arc являются метаданными.
Статистика по заполнению l2arc есть, к примеру в Linux можно посмотреть
cat /proc/spl/kstat/zfs/arcstats
Рекомендую без донастроек проверить заполняемость, и только после этого по надобности тюнить arc_meta_limit, т.к. 200 байт ОЗУ на 1 блок l2arc — максимальный расчёт, а не фактический.

romy4
20.06.2017 17:04А что касаемо установки from scratch для новых систем? С какими дистрибами оно уже в поставке?
gmelikov
21.06.2017 08:52Если вы имеете в виду установку root раздела системы на ZFS, то пока она включена только в инсталлятор Proxmox. При этом сам пакет с ZFS уже есть во многих репозиториях (Debian, Ubuntu, Arch, Gentoo, Fedora, Centos), ручками ставится без проблем.

Anansy
23.06.2017 09:37В ZFS новичок, рискнул попробовать на паре серверов, когда оно стало наконец «искаропки» в Proxmox.
На ZFS-зеркало из пары шпиндельных HDD 500GB максимально дефолтно накатил под i5/16GB для экспериментов.
А в Hetzner сложнее — нет у них автоматизированной процедуры и возможности поставить Proxmox корнем на ZFS без заказа консолей и прочих извратов. В итоге хост поставил на BTRFS-зеркало небольшое, а 200GB под виртуалки разбил вручную, сверяясь с дефолтными параметрами экспериментальной машинки. Вроде конфиги не отличаются. Но Хетцнер — это пара Xeon-ов и Интеловские SSD.
И вот вопрос. Почему оно выдаёт такие низкие значения IO?
i5/16GB/2xHDD:
CPU BOGOMIPS: 23947.04 REGEX/SECOND: 1604707 HD SIZE: 300.58 GB (rpool/ROOT/pve-1) FSYNCS/SECOND: 83.9
2xXeon/32GB/2xSSD
CPU BOGOMIPS: 54394.40 REGEX/SECOND: 2948181 HD SIZE: 68.60 GB (rpool/data) FSYNCS/SECOND: 36.28
Это включенная компрессия LZ4 так влияет или CoW или что-то ещё? Без ZFS вроде (на старом Promox) сотни FSYNCS выдавало… но в целом серверу скорости хватает, а плюшки (снапшоты для бэкапов, сжатие) наверное перевешивают.
Может, не стоит заморачиваться? Или всё же что-то неверно настроено, и даже не руками, а дефолты Proxmox?gmelikov
23.06.2017 09:43Вот тред на форуме Proxmox, в котором есть отзывы о том, что эти измерения не сходятся с фактической производительностью.
Если вам не критично потерять информацию за последние 5-10 секунд, то вы можете выставить настройку пула sync=disabled, в таком случае ZFS не будет сбрасывать информацию на диск по команде программ, а делать это с определённой периодичностью. Но это повышает производительность за счёт риска потерять записанную информацию за последние 30 секунд (при этом сама ФС на диске битой не будет, можете не переживать).rPman
23.06.2017 21:03в подавляющем большинстве случаев такая потеря — битые файлы, база данных и т.п.
gmelikov
23.06.2017 21:46Ну при сбое питания вы в любом случае теряете последние данные, файлы, как и БД, и так и так не допишутся. Только ZFS пишет транзакционно, то есть риск повреждения уже минимален, если блок не дозаписался (причина поломки БД), то при загрузке будет использован предыдущий корректный.
Да, риск проблем с ПО при сбое питания есть всегда, в этом не спорю, но ФС в этом случае не повредится.
kravit
23.06.2017 09:51Eсть отличная статья — перенос корневой ФС на ZFS с шифрованием и созданием RAIDZ.
Разбираемся в ZFSgmelikov
23.06.2017 10:06Пролистал, в этой статье есть злые советы, которые хотят съесть ваши данные:
— RAID-Z1 не рекомендуется к использованию, лучше использовать RAID-Z2, который выдержит отказ 2 дисков;
— параметр copies=3 никак не спасает от выхода из строя 2х дисков из 3х в RAID-Z1.
knutov
27.06.2017 06:33И еще вопрос про iSCSI (btw, спасибо вам огромное, что отвечаете здесь на вопросы)
Сценарий — очень много мелких файлов, которые постоянно используются + много больших архивов, которые один раз пишутся (скорость, с которой они пишутся, не имеет значения) и часто больше даже не читаются. Хочется скорость (SSD) и сэкономить денег. Таких серверов много.
Будет ли хорошим такое решение:
Сделать один отдельный NAS с обычными 3.5 дисками (+ arc побольше и l2arc какой-то), подцеплять его по iSCSI на рабочий сервер по гигабитной(!) сети (помним — хочется сэкономить, а скорость работы с большими файлами не важна), а на рабочих серверах поставить SSD под l2arc, размером как все мелкие файлы для этого сервера + какой-то запас?
Правильно ли я думаю, что в этом случае все данные будут в локальном l2arc и скорость работы с ними будет такая же, как если бы они были на локальном диске?
Будет ли оставаться l2arc кеш между рестартами сервера? ZOL последней версии. Если не будет, то будет ли в следующей 0.7 ?
gmelikov
27.06.2017 10:23(+ arc побольше и l2arc какой-то),
l2arc с записью не поможет, он только на чтение, для ускорения записи можете посмотреть ZIL, или просто отключить sync=disabled, но только в случае хорошего резервирования по питанию (риск потери данных за последние 30 секунд). Т.к. сеть у вас гигабитная, то проще всего просто поставить побольше оперативки на NAS и всё, скорее всего вы упрётесь в гигабит даже на 1 диске (если включите sync=disabled).
а на рабочих серверах поставить SSD под l2arc
Я пользуюсь в основном локально ZFS, но, насколько я знаю, такая схема невозможна (ZFS у вас на стороне NAS).
Если вы в основном пишете, то кеш со стороны клиента особо смысла не имеет.
Будет ли оставаться l2arc кеш между рестартами сервера? ZOL последней версии. Если не будет, то будет ли в следующей 0.7 ?
Пока он не постоянный, патч уже есть, но когда он будет включён в stable ветку — точно сказать невозможно. Думаю, что через год.
спасибо вам огромное, что отвечаете здесь на вопросы
Всегда рад помочь!
gmelikov
27.06.2017 10:31очень много мелких файлов, которые постоянно используются
Ой, извините, пропустил. В таком случае будет работать стандартный кеш Linux на стороне клиента, тут стоит изучить скорее ISCSI.
На NAS можно использовать L2ARC и ZIL, но лучше начать с увеличения RAM до максимально возможного и использования ARC. Советы по поводу sync выше менее актуальны.
knutov
27.06.2017 16:07насколько я знаю, такая схема невозможна (ZFS у вас на стороне NAS).
Идея была — на NAS сделать ZVOL, его отдать по iSCSI, на клиенте это будет блочное устройство, на которое можно сделать ZFS со стороны клиента, и тогда, вроде бы, к ZFS должно быть можно сделать l2arc и ZIL. Или я неправильно думаю?
gmelikov
27.06.2017 16:21Такая реализация возможна, но, по моему, в ней получается много уровней абстракции.
ZVOL -> ISCSI -> EXT4 по моему будет более производительной, но при канале в 1гбит\сек ваш вариант может дать выигрыш.
Хотя меня и не покидает чувство, что это не правильно.knutov
28.06.2017 07:14ZVOL -> ISCSI -> EXT4
Тогда придется делать еще bcache/flashcache. Но это, возможно, и лучше — кеш будет оставаться между ребутами. Вот только их новые версии с OpenVZ не совместимы :(
gmelikov
Дополнительно стоит добавить, что на подходе версия 0.7, в которую включено огромное количество изменений, проведена работа по синхронизации кодовой базы с OpenZFS, а также внесены значительные изменения во взаимодействие с памятью.
rPman
Подскажите пожалуйста, OpenZFS может выступить iscsi initiator? сможет ли с таким томом работать windows? возможна ли загрузка с такого тома. Для меня вообще стало новостью что iscsi может расшарить не блочное устройство.
bormental
iSCSI может, но не своими средствами. Сначала нужно сделать zvol — вид датасета, предоставляющий интерфейс блочного устройства.
Делается легко, например:
Где 30G — объем.
Затем такое блочное устройство нужно "расшарить" с помощью isci-tartet.
Снэпшоты и прочие радости ZFS доступны и для zvol.
rPman
вау, спасибо!
интересно, как у этого метода с производительностью.
загрузка операционной системы с такого тома возможна?
bormental
Я только немного экспериментировал с iSCSI, поэтому о производительности такого use-case не могу глубоко рассуждать.
Но, в общем, производительность сильно зависит от конфигурации vdev.
Например, принято считать, что для ZRAID* — это производительность самого медленного в массиве HDD.
Страйп зеркал будет быстрее.
И еще скорость сильно проседает, если много операций синхронной записи. Тут либо ZIL, либо sync=disabled (если приемлемо) помогут.
Так же от параметра volsize и паттерна IO приложения зависит…
В общем, вооружившись fio и его конфигурацией, похожей на паттерн Вашего приложения, можно тюнить...
gmelikov
В RAID-Z IOPS самого медленного диска, последовательная запись в норме.
knutov
О, а подскажите, в сценарии, когда ZVOL, SSD и потому ext4 — при использовании ZVOL очень резко снижается количество свободного места (по сравнении с без ZVOL или просто ext4) и это очень чувствительно на ссд, которые и так маленькие. Нельзя ли на это как-то влиять?
gmelikov
Что вы имеете в виду?
Опишите полностью вашу установку, геометрию пула (mirror, raid-z).
knutov
Один ссд. Совсем один. На нем zvol. Размером на весь диск, для теста (потому что нам нужно одновременно сжатие и ext4), на zvol — ext4.
gmelikov
Если не создаются снапшоты, то место не должно съедаться больше, чем без zfs. Также можете попробовать на ext4 провести trim, после этого zfs отобразит только занятое место, скорее всего это вас смущает (zfs под занятым местом в zvol понимает любой когда-либо аллоцированный блок, не освобождённый).
Подскажите, а зачем вам ext4 в такой конфигурации?
knutov
Мы привязаны к OpenVZ. OpenVZ привязана к ext4. При этом у нас очень хорошо сжимаемые данные и deduplication ratio за 100, поэтому хочется уровнем ниже ext4 иметь сжатие и дедупликацию. Правда на дедупликацию при блок сайз = 4к не всегда есть память (некоторые ссд за терабайт, в некоторых серверах 32гб памяти и нельзя поставить больше)
Сравниваю получившийся размер раздела после создания (т.е. диск пустой, раздел делается на весь диск).
Судя по логам, которые нашел сходу, у меня получалось так:
Тесты на ссд на 480 гигабайт.
Если просто ext4, то df -h показывает size = 441G
Если
то получившийся size похоже то ли 440, то ли ~420.
Если
то size в df -h оказывался 383G
В цифрах могут быть ошибки, делал заметки по ходу тестирования, но порядок разницы примерно такой. Если нужно — могу найти сервер с свободным ссд и проверить снова.
gmelikov
Скорее всего у вас сочетание ashift=9 и несоответствующего ext4 volblocksize.
Выставьте нужный ashift вашему ssd, очень маловероятно, что он 9 (512 байт на блок), к тому же некоторые производители указывают не фактический размер блока.
Т.к. Стандартный размер блока ext4 4kb, то создавать zvol лучше с таким же размером блока.
В основном это может быть влияние выставленного вами ashift.
knutov
Посчитал.
Кстати, у ссд дисков (по крайней мере наших) размер сектора таки 512 байт. Все, конечно, наверное, знают, что любая запись там перезаписывает блок на 128к, но все же.
Статистика по размерам файлов (какие лучше выбрать параметры для блок сайз и прочего исходя из этого?)
Как все это считалось в красивом оформлении — https://gist.github.com/knutov/453fa860e4f574ac01413273cf79392f
И кстати, как я должен был угадать размер ZVOL, если я хотел сделать его на весь диск, и почему потом получилось больше?
Прокомментируйте пожалуйста это, возможно я делаю что-то неправильно?
gmelikov
Не спорю, просто рекомендую проверить, в списках рассылки ZFS эта тема уже поднималась, есть некоторые модели дисков, у которых заявленное производителем не сходится с фактическим.
По приведённой вами ссылке я вижу другую цифру — То есть для ext4 по умолчанию доступно тоже меньше. Прошу точно описывать исходные данные, иначе диалог неконструктивен.
Момент, который стоит учитывать в расчётах — метаданные. Естественно вы не заполните все 430гб сырого места пула. Чем больше будет volblocksize, тем меньше метаданных будет. Точный расчёт их размера произвести не так просто, т.к. они тоже сжимаются. Ссылка на тему. Т.к. вы используете -V (резервируете место), то ZFS съедает нужное количество места для гарантированной возможности записи зарезервированного места.
Плюс, как уже во многих комментариях и статье упоминалось, ZFS не предназначена для заполнения на 100%, что также ведёт к рекоммендациям не выделять всё место под ZVOL, при максимальном заполнении будут накладные расходы.
Функционал ZFS требует метаданных большего размера, чем другие ФС, контрольные суммы, снапшоты и другой функционал требует хранения, и чем меньше блок, тем больше метаданных будет.
knutov
Если я не указываю ashift (ashift=0) то zfs сам выбирает ashift=9.
Да, с размером блока недоработка была, поправил https://gist.github.com/knutov/453fa860e4f574ac01413273cf79392f
Но — размер блока ext4 и размер инода — разные вещи.
В тесте у ext4 везде размер блока оставлен по умолчанию ( -b 4096 ). В случае с ZVOL при блоксайзе 4к это 398 гигабайт вместо 440.
А вот если сделать блоксайз равный размеру инода (16к) — тогда да, получаем 417 гигабайт ext4 на zvol против 440 у ext4 без zfs, что лучше, но все равно — вы выше утверждали
а судя по тестам — это не так и без ZFS места намного больше.
Учитывая, что у меня SSD — вряд ли можно получить какую-то разницу в скорости работы при разных размерах чего угодно, по крайней мере на чтение. По этому, помня, что я хочу дефрагментацию и у 65% файлов размер менее 1 килобайта — разве не логичнее использовать более маленький volblocksize?
gmelikov
Спасибо, перепутал, но в данном случае не критично. Если вас устроит, что при запросе с диска ZFS будет выбирать блок до 16кб для любого маленького файла (а с учётом сжатия он в любом случае будет меньше), то увеличение blocksize=16k для вас целесообразно.
Извините, погорячился с утверждением, более корректно — ZFS требует дополнительного места под метаданные, в остальном всё так же.
Верно, рекомендую провести тестирование производительности и убедиться.
На дефрагментацию вообще не смотрите, до заполнения 80% диска она вас не потревожит, и пусть вас не смущает показатель fragmentation у zpool — он показывает приблизительную фрагментацию метаданных, не более.
Тут критично, каким блоком будет записывать эти файлы ext4, плюс сжатие поможет компенсировать эту проблему.
С одной стороны — да, но в ZFS чем больше размер блока — тем лучше для производительности и сжатия, и хуже для дедупликации. Что вам приоритетнее, то и стоит выбрать.
knutov
Миллионы мелких файлов делятся на два типа — часть из них создается одномоментно — в момент разворачивания дистрибутива Битрикса. Если писать их на диск не сразу, то — наверное запись как-то агрегируется и они будут писаться блоками по 16к? Я ведь правильно думаю, что в одном блоке может быть больше одного файла?
Второй тип мелких файлов — кеш битрикса. Он не дедуплицируем, но сжимаем. Но многие файлы вообще по 200 байт. Вот тут мы сможем, видимо, получить большой выигрыш, если откажемся от ext4 — на чистом зфс вроде бы можно для отдельных каталогов дедупликацию отключить и поэкономить память.
gmelikov
В рамках ZFS — да, но у вас дополнительно есть EXT4. Это, кстати, ухудшит дедупликацию, т.к. она проводится на уровне блоков.
Эх, вам бы от ext4 отказаться бы. На чистом ZFS случай битрикса можно очень классно настроить.
А вам точно нужна дедупликация ради ядра битрикса? Оно весит не так много и отлично сжимается. Или в планах ещё что-то?
knutov
Да с радостью бы, но у нас еще и OpenVZ, который жестко привязан...
У нас на каждом диске их несколько сотен.
Мы сейчас используем бекапы с LZ4 и дедупликацией (borgbackup) — там просто фантастические цифры по сжатию, очень впечатляет.