

6 июня на конференции RootConf 2017, проходившей в рамках фестиваля «Российские интернет-технологии» (РИТ++ 2017), в секции «Непрерывное развертывание и деплой» прозвучал доклад «Наш опыт с Kubernetes в небольших проектах». В нём рассказывалось об устройстве, принципах работы и основных возможностях Kubernetes, а также о нашей практике использования этой системы в небольших проектах.
По традиции мы рады представить видео с докладом (около часа, гораздо информативнее статьи) и основную выжимку в текстовом виде.
Предыстория
Современная инфраструктура (для веб-приложений) прошла длинный путь эволюции от бэкенда с СУБД на одном сервере до значительного роста используемых служб, их разнесения по виртуальным машинам/серверам, перехода на облачные решения с балансировкой нагрузки и горизонтальной масштабируемостью… и до микросервисов.
С эксплуатацией современной, микросервисной, инфраструктуры есть ряд сложностей, обусловленных самой архитектурой и количеством её компонентов. Мы выделяем следующие из них:
- сбор логов;
- сбор метрик;
- supervision (проверка состояния сервисов и их перезапуск в случае проблем);
- service discovery (автоматическое обнаружение сервисов);
- автоматизация обновления конфигураций компонентов инфраструктуры (при добавлении/удалении новых сущностей сервисов);
- масштабирование;
- CI/CD (Continuous Integration и Continuous Delivery);
- vendor lock-in (речь про зависимость от выбранного «поставщика решения»: облачного провайдера, bare metal…).
Как легко догадаться из названия доклада, система Kubernetes появилась как ответ на эти потребности.
Основы Kubernetes
Архитектура Kubernetes в целом выглядит как master (может быть не один) и множество узлов (до 5000), на каждом из которых установлены:
- Docker,
- kubelet (управляет Docker),
- kube-proxy (управляет iptables).
На master находятся:
- сервер API,
- база данных etcd,
- планировщик (решает, на каком узле запускать контейнер),
- controller-manager (отвечает за отказоустойчивость).
В дополнение ко всему этому есть управляющая утилита kubectl и конфигурации, описанные в формате YAML (декларативный DSL).

С точки зрения использования Kubernetes предлагает облако, объединяющее в себе всех этих master и узлов и позволяющее запускать «строительные блоки» инфраструктуры. К таким примитивам, в том числе, относятся:
- контейнер — образ + запускаемая в нём команда;
- под (Pod; дословно переводится как «стручок») — совокупность контейнеров (может быть и один) с общей сетью, одним IP-адресом и другими общими характеристиками (общие хранилища данных, лейблы); примечание: именно поды (а не отдельные контейнеры) позволяет запускать Kubernetes;
- лейбл и селектор (Label, Selector) — набор произвольных ключей-значений, назначаемых на поды и другие примитивы Kubernetes;
- ReplicaSet — множество подов, количество которых автоматически поддерживается (при изменении числа подов в конфигурации, при падении каких-либо подов/узлов), что делает масштабирование очень простым;
- деплой (Deployment) — ReplicaSet + история старых версий ReplicaSet + процесс обновления между версиями (используется для решения задач непрерывной интеграции — деплоя);
- сервис (Service) — DNS-имя + виртуальный IP + селектор + балансировщик нагрузки (для разбрасывания запросов по подам, подходящим под селектор);
- задача (Job) — под и логика успешности выполнения пода (используется для миграций);
- cron-задача (CronJob) — Job и расписание в формате crontab;
- том (Volume) — подключение хранилища данных (к поду, ReplicaSet или Deployment) с указанием размера, типа доступа (ReadWrite Once, ReadOnly Many, ReadWrite Many), типа хранилища (поддерживаются 19 способов реализации: железных, программных, облачных);
- StatefulSet — подобное ReplicaSet множество подов, но с жёстко определёнными названиями/хостами, чтобы эти поды могли всегда общаться между собой по ним (для ReplicaSet названия каждый раз генерируются случайным образом) и иметь отдельные тома (не один на всех, как в случае ReplicaSet);
- Ingress — служба, доступная пользователям извне и разбрасывающая все запросы на сервисы по правилам (в зависимости от имени хоста и/или URL'ов).
Примеры описания пода и ReplicaSet в формате YAML:
apiVersion: v1
kind: Pod
metadata:
name: manual-bash
spec:
containers:
- name: bash
image: ubuntu:16.04
command: bash
args: [-c, "while true; do sleep 1; date; done"]apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: backend
spec:
replicas: 3
selector:
matchLabels:
tier: backend
template:
metadata:
labels:
tier: backend
spec:
containers:
- name: fpm
image: myregistry.local/backend:0.15.7
command: php-fpmЭти примитивы отвечают на все обозначенные выше вызовы за небольшими исключениями: в автоматизации обновлений конфигураций не решена проблема сборки Docker-образов, заказа новых серверов и установки узлов на них, а в CI/CD остаётся необходимость проведения подготовительных работ (установка CI, описание правил сборки Docker-образов, выкатывания YAML-конфигураций в Kubernetes).
Наш опыт: архитектура и CI/CD
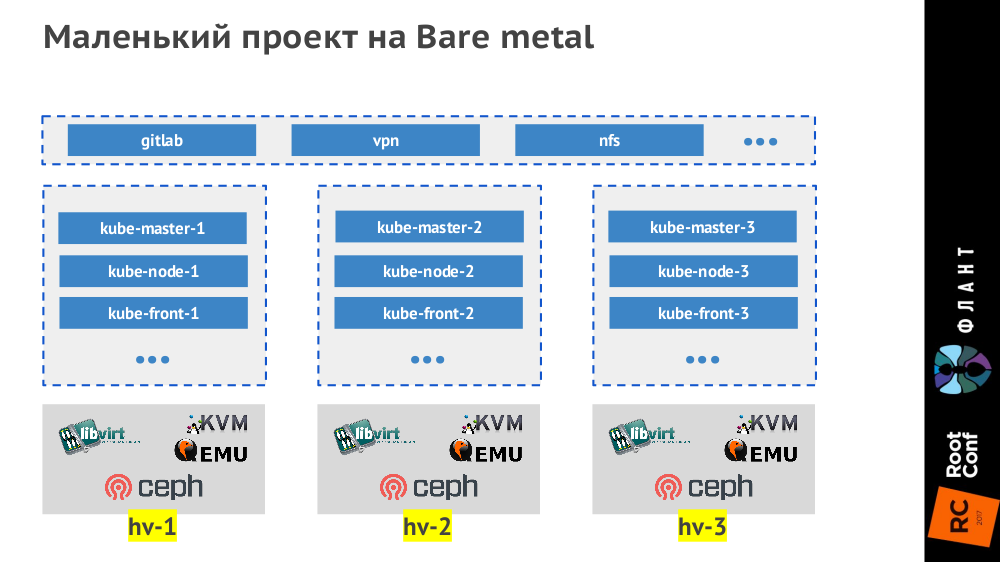
Под небольшими проектами мы подразумеваем маленькие (до 50 узлов, до 1500 подов) и средние (до 500 узлов, до 15000 подов). Самые маленькие проекты на bare metal мы делаем тремя гипервизорами, которые выглядят так:
Контроллер Ingress ставится на трёх виртуальных машинах (
kube-front-X):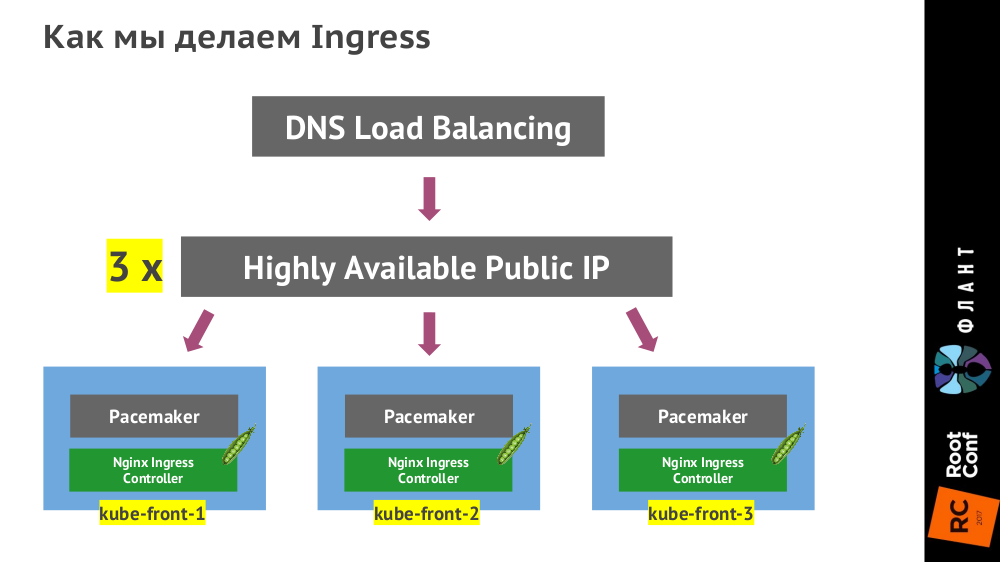
(Вместо указанного на схеме Pacemaker может быть VRRP, ucarp или другая технология — зависит от конкретного ЦОДа.)
Как выглядит цепочка Continuous Delivery:
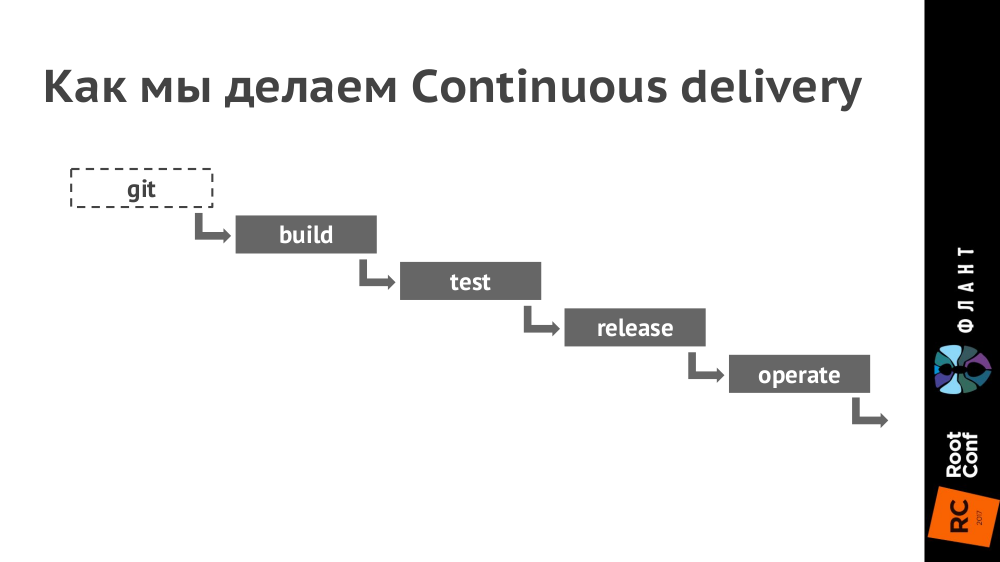
Пояснения:
- Для непрерывной интеграции используем GitLab (в ближайшие недели опубликуем статью с подробностями о практике её использования).
- В Kubernetes настраиваем окружения для каждого контура (production, staging, testing и т.п. — их количество зависит от конкретного проекта). При этом разные контуры могут обслуживаться разными кластерами Kubernetes (на разном железе и в разных облаках), а в GitLab настраивается деплой в них.
- В Git кладём Dockerfile (а точнее, мы используем для этого dapp) и каталог .kube с YAML-конфигурациями.
- При коммите (стадия build) создаём образ Docker, который отправляется в Docker Registry.
- Далее (стадия test) берём этот образ Docker и запускаем на нём тесты.
- При релизе (стадия release) YAML-конфигурации из директории .kube отдаём утилите kubectl, которая отправляет их в Kubernetes, после чего скачиваются Docker-образы и запускаются в инфраструктуре, развёрнутой по конфигурации из YAML. (Раньше мы использовали для этого Helm, но сейчас доделываем свой инструмент dapp.)
- Таким образом, за последнюю стадию (operate) полностью отвечает Kubernetes.

В случае небольших проектов инфраструктура выглядит как контейнерное облако (его реализация вторична — зависит от имеющегося железа и потребностей) с настроенным хранилищем (Ceph, AWS, GCE…) и контроллером Ingress, а также (помимо этого облака) возможно наличие дополнительных виртуальных машин для запуска сервисов, которые мы не ставим внутрь Kubernetes:

Заключение
С нашей точки зрения Kubernetes дозрел для того, чтобы его использовать в проектах любого размера. Более того, эта система даёт прекрасную возможность с самого начала сделать проект очень просто, надёжно, с отказоустойчивостью и горизонтальным масштабированием. Основной подводный камень — человеческий фактор: для небольшой команды сложно найти специалиста, который решит все нужные задачи (требует широкой технологической эрудиции), или же он будет слишком дорогим (и скоро ему станет скучно).
Видео и слайды
Видео с выступления (около часа) опубликовано в YouTube.
Презентация доклада:
Продолжение
Получив первую обратную связь по этому докладу, мы решили подготовить специальный цикл вводных статей по Kubernetes, ориентированных на разработчиков и более подробно рассказывающих об устройстве этой системы. Начнём уже в ближайшие недели — следите за обновлениями в нашем блоге!
P.S. Другие наши доклады про CI/CD
- «Собираем Docker-образы для CI/CD быстро и удобно вместе с dapp» (Дмитрий Столяров; 8 ноября 2016 на HighLoad++);
- «Практики Continuous Delivery с Docker» (Дмитрий Столяров; 31 мая 2016 на RootConf).
Комментарии (20)

grSereger
21.06.2017 10:04Спасибо за статью, подскажите, используете ли Вы kubernetes в локальной разработке? Если да, то как?
Запуск тестов в docker-образе это конечно хорошо, но как Вы тестируете взаимодействие нескольких сервисов (подов)?
Спасибо!
Borz
21.06.2017 10:10minikube?
grSereger
21.06.2017 10:28minikube — это да, но интересуют нюансы, например, как монтируются локальные директории, чтобы они были доступны в подах (при этом, желательно не плодить разны конфигурации кластера для дева и прода )?
Возможно используется helm для работы поддержания 1 конфигурации в разных контурах? Как происходит отладка приложения?
distol
21.06.2017 21:27+2minikube — это да, но интересуют нюансы, например, как монтируются локальные директории, чтобы они были доступны в подах (при этом, желательно не плодить разны конфигурации кластера для дева и прода )? Возможно используется helm для работы поддержания 1 конфигурации в разных контурах?
Пока не придумали. Работаем над этим. Есть пачка вариантов, как делаем сейчас, но все они не нравятся:
- Так-как у нас есть шеф-рецепты (dapp поддерживает), собирать одними и теми же шеф рецептами и docker-образы для прода и Vagrant'ы. Проблемы: очень долго, сложно писать универсальные рецепты.
- Запускать докер контейнеры (dapp run) в Vagrant ИЛИ использовать minikube.
- Можно собирать образ при каждом Ctrl-S. Проблемы: долго.
- Монтировать или подключаться по SSH. Проблемы: описание правил монтирования/подключения
- Разворачивать в кластере Kubernetes отдельное окружение для разработки (например давать туда доступ разработчикам, например по SSH). Проблемы: описание правил.
В целом все идет к тому, что мы будем работать над:
- Ускорением сборки и деплоя. Если сократим время сборки нового образа и деплоя в minikube до 5 секунд, уже будет вполне реально передеплоивать приложение при каждом Ctrl-S.
- Автомагией в dapp, которая будет понимать какие исходники куда добавлены (мы знаем это и так) и сама генерить маунты.
Как происходит отладка приложения?
У нашего сборщика есть специальный флаг, --dev, ну и пачка других опция для удобной отладки.

tkir
24.06.2017 02:16+3По задумке dev-режима сборщика предполагается деплоить через helm в minikube. При этом описание helm-конфигурации для development-окружения, используемый namespace — на усмотрение пользователя.
Есть команда
dapp kube minikube setup, которая:
- Стартует minikube
- Поднимает в minikube docker-registry
- Поднимает proxy в host-системе для использования docker-registry
Предполагается такой сценарий использования:
- Сборка образа в host-системе:
dapp dimg build [--dev]. - Загрузка образа в minikube docker-registry:
dapp dimg push :minikube [--dev]. - Запуск/обновление кластера:
dapp kube deploy :minikube [--dev] [+ helm values options].
Но для web-приложений в development-режиме (например) необходимы mount-ы исходников в запущенные образа, чтобы изменения исходников подхватывались уже запущенным web-сервером автоматом. Поддержки такого режима работы из коробки пока нет.

Caravus
26.06.2017 15:41Но для web-приложений в development-режиме (например) необходимы mount-ы исходников в запущенные образа, чтобы изменения исходников подхватывались уже запущенным web-сервером автоматом. Поддержки такого режима работы из коробки пока нет.
Вот тут пишут что добавили. Не то?tkir
28.06.2017 16:06В плане самой фичи mount подойдет. Т.е. mount из host в minikube + mount из minikube в docker позволят пробросить директорию в контейнер из хост-системы. Но главная проблема не в этом, а в том, чтобы этот запущенный контейнер соответствовал тем инструкциям по сборке образа приложения, которые описываются в Dappfile. Например, при изменении Gemfile.lock надо сделать bundle install. Для этого в dapp предусмотрены стадии и для пересборки стадии можно поставить триггер на изменение файла Gemfile.lock. А в случае, если изменяется не Gemfile.lock, то при сборке новой версии происходит простое и быстрое наложение патча. Так вот, если поменялись какие-то файлы, от которых зависят инструкции по сборке каких-то стадий, то образ придется пересобрать и перезапустить контейнер приложения. Но если поменялись другие файлы приложения, то новый образ собирать не надо, если исходники уже примонтированы в запущенный контейнер.
Однако сам
minikube mountмы пробовали использовать для хранения файлов docker-registry на хост-системе, а не внутри minikube на виртуалке. Но производительность этой штуки для docker-registry неприемлема.Caravus
28.06.2017 16:17Так вот, если поменялись какие-то файлы, от которых зависят инструкции по сборке каких-то стадий, то образ придется пересобрать и перезапустить контейнер приложения. Но если поменялись другие файлы приложения, то новый образ собирать не надо, если исходники уже примонтированы в запущенный контейнер.
Я видимо уже привык и просто не вижу тут проблемы. Поменялся Dockerfile — пересобрал и перезапустил.

KIVagant
26.06.2017 13:34+1> При релизе (стадия release) YAML-конфигурации из директории .kube отдаём утилите kubectl, которая отправляет их в Kubernetes, после чего скачиваются Docker-образы и запускаются в инфраструктуре, развёрнутой по конфигурации из YAML. (Раньше мы использовали для этого Helm, но сейчас доделываем свой инструмент dapp.)
Очень общая фраза. Можете рассказать, как именно вы разворачиваете новые images? Заливаете их командой set image, определяя свежий доступный образ? Используете deployment-файлы? Вызываете apply или replace?
KIVagant
26.06.2017 13:37Ещё вопрос из чайника, сталкивались ли с такой ситуацией, когда kubectl replace для deployment приводит к появлению дубликатов replicasets? Старые реплики остаются в строю, а новые с новыми images поднимаются рядом. Вероятно, это актуально для старой версии kubernetes, но не так просто обновляться в рабочем окружении.
Apply, судя по документации, должно разруливать это, но так вроде бы с самого начала нужно создавать ресурсы:
> To use 'apply', always create the resource initially with either 'apply' or 'create --save-config'.distol
26.06.2017 23:48Так, так и должно быть. Старые реплики остаются, но они нулевого размера. Посмотрите видос полностью, там рассказывается о том зачем и почему так.
elmal
1500 pod и 50 нод — не такие уж и маленькие проекты вообще то.
Кстати, а как персистентность и базы разруливаете? В качестве распределенного файлового хранилища что используете, nfs (как на слайде)?
Базы живут у вас где, внутри kubernetes (в одном экземпляре, с маппингом на хостовую файловую систему, часть нод помечены как соделжащие базы), или же во внешнем окружении есть отдельный кластер или просто отдельная машина.
distol
ceph, вроде я об этом в докладе рассказывал.
Все перечисленные варианты. Очень ждем https://github.com/kubernetes/features/issues/121 .
elmal
ceph… Ты как то тоже рассматривали как делать персистентность и ceph рассматривали. Не понравилось, что там должна обязательно быть главная нода. Я тогда думал выбрать glusterFs, но админы сказали что не факт что будет стабильно работать. В итоге сейчас админы настроили torrentSync между нодами, вроде для наших целей пока подходит.
distol
Это не совсем так. Мы от ceph используем в основном rbd, там нормальный multi master.
farcaller
Это совсем не так. Там консенсус между мониторами. Из "главных" там только первичный OSD будет "главным", но потеря OSD прозрачна для клиента.