
В настоящее время в компьютерных сетях практически повсеместно используется протокол IP. Для того, чтобы отправить IP-пакет каждый маршрутизатор ищет в свой таблице маршрутизации наилучший маршрут для адреса назначения пакета. В данной статье я хочу описать алгоритм поиска наилучшего маршрута, реализованного в ядре linux.
Обычно говорят, что все маршруты находятся в таблице маршрутизации, в которой и выполняется поиск наилучшего маршрута. Здесь может возникнуть терминологическая путаница. Дело в том, что под таблицей маршрутизации можно понимать две разные вещи, которые иногда обозначаются терминами Routing Information Base (RIB) и Forwarding Information Base (FIB). И RIB и FIB действительно хранят ip-маршруты, но предназначение этих структур и алгоритмы выбора лучших маршрутов в этих структурах отличаются.
Routing Information Base (RIB)
Маршруты на маршрутизатор могут попадать из различных источников: быть настроены статически, попадать из протоколов динамической маршрутизации OSPF, BGP и т.д. При этом из различных источников могут приходить маршруты с одним и тем-же префиксом. Из этих маршрутов нужно выбрать какой-то один и добавить его в FIB. Эта задача как раз и решается в RIB. Обычно маршрутам из разных источников присваивается разная Административная Дистанция и наилучшим считается маршрут с наименьшей Административной Дистанцией. Важно, что конкурируют между собой маршруты с одним и тем-же префиксом. Маршруты с разными префиксами между собой не сравниваются. Например, префиксы 10.0.0.0/8 и 10.0.0.0/16 это разные префиксы и в FIB попадут оба маршрута. Таким образом, в RIB выполняется поиск КОНКРЕТНОГО префикса. Поиск префиксов в RIB выполняется при добавлении или удалении маршрутов, что происходит относительно редко.
Forwarding Information Base (FIB)
FIB служит собственно для маршрутизации ip-пакетов. Здесь лучшим маршрутом считается маршрут с наиболее длинным префиксом, совпадающим с адресом назначения в ip-пакете. Совместная работа RIB и FIB показана на рисунке:
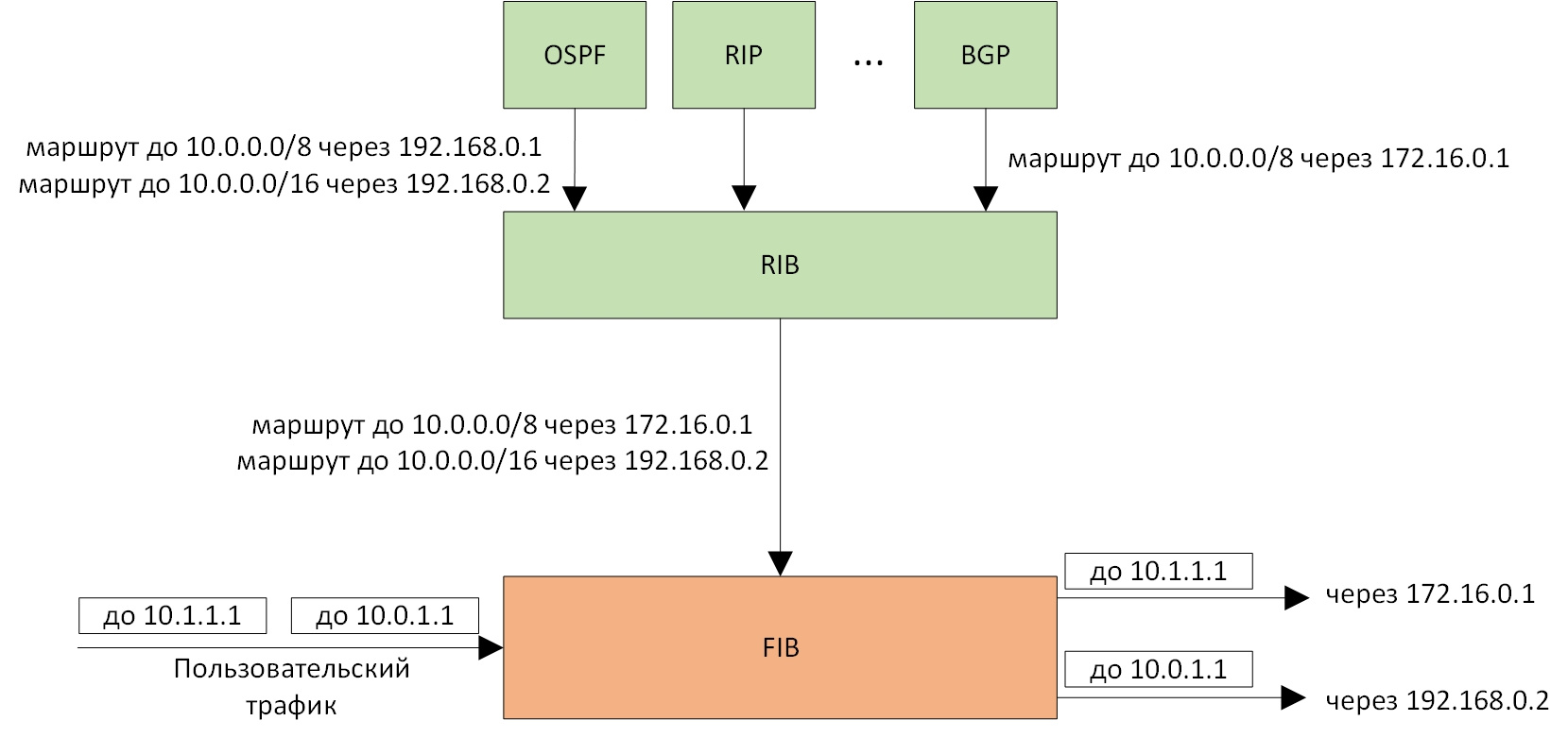
Рисунок 1. Совместная работа RIB и FIB. В RIB попадают и отбираются маршруты от разных протоколов маршрутизации. В FIB выполняется маршрутизация пакетов согласно наиболее длинным префиксам.
Поиск лучшего маршрута в FIB происходит для каждого нового ip-пакета. От того, насколько эффективно происходит поиск маршрута в FIB напрямую зависит скорость маршрутизации устройства. Поэтому поиск в FIB должен производиться максимально быстро и эффективно. В FIB может содержаться несколько сот тысяч маршрутов с разными префиксами, поэтому задача выглядит довольно нетривиальной. Для ее оптимизации было предложено много различных алгоритмов. В настоящей статье я хочу рассказать, как поиск в FIB реализован в ядре linux.
Формулировка задачи
IP-префикс обычно обозначают в виде ip-адреса и длины префикса, например: 10.0.0.0/8. Для нас будет удобнее представлять префикс в двоичном виде, оставив только левую часть, равную длине префикса и опустив его правую несущественную часть: 00001010. Маршрут по-умолчанию (т.е. префикс нулевой длины будем обозначать звездочкой *. Задача поиска выглядит следующим образом. У нас есть набор различных префиксов: *, 00, 10, 0000, 1000, 1001, 1010, 10111. Нам дается адрес назначения, который в двоичном виде выглядит, например, так: 1010110001110100010001000010111. Среди имеющихся префиксов нужно найти лучший, т.е. наиболее длинный, который совпадает с левой частью адреса назначения. В нашем примере это будет префикс 1010. К каждому префиксу привязан ip-адрес следующего маршрутизатора (next-hop), исходящий интерфейс и другая информация, достаточная отправки пакета дальше. В дальнейшем, для простоты, я буду использовать вышеуказанный набор префиксов и адреса назначения длины 6. Все нижеизложенное также применимо и для реальных ip-адресов длины 32. Как может выглядеть реальный список префиксов в FIB (в двоичном виде) можно посмотреть здесь.
Мы будем последовательно строить алгоритмы поиска лучшего префикса начиная с самого простого, постепенно улучшая их, пока не придем к алгоритму, используемому в ядре linux.
Тривиальный алгоритм
Очевидным и самым простым алгоритмом является простой перебор всех имеющихся префиксов и выбора из них лучшего. Такой алгоритм легко реализовать, но на большом количестве префиксов скорость его работы совершенно неудовлетворительна. Если в FIB у нас содержится 500000 префиксов, то нам нужно перебрать и проверить их всех.
Скорость поиска можно несколько повысить, храня префиксы в порядке убывания их длины. Тогда первый совпадающий префикс будет самым длинным и, следовательно, лучшим.
Префиксное дерево
Естественным способом организации префиксов является префиксное дерево (trie). Пример префиксного дерева для префиксов *, 00, 10, 0000, 1000, 1001, 1010, 10111 приведен на рисунке:
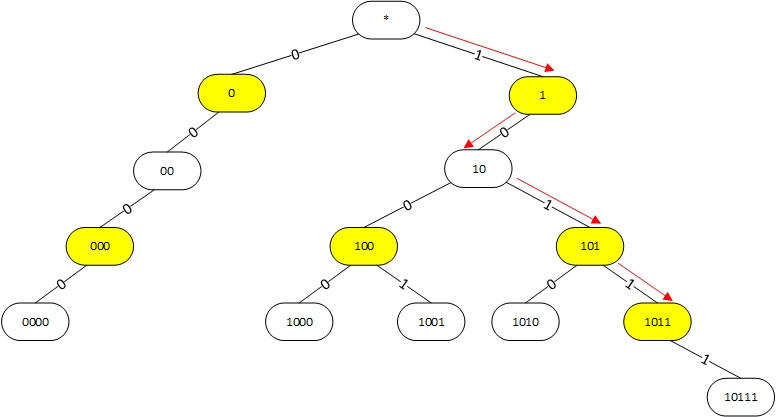
Рисунок 1. Использование префиксного дерева для поиска наиболее длинного префикса. Красными стрелками показана последовательность поиска для адреса 101100.
Белые узлы соответствуют интересующим нас префиксами. В них также хранится ссылка на информацию о том куда отправлять пакет дальше (next-hop и т.д.). Желтые узлы являются промежуточными и служат для правильной организации структуры дерева. Верхний узел является корнем дерева и соответствует префиксу 0.0.0.0/0. Для поиска лучшего префикса проверяется самый левый бит адреса назначения пакета. Если он равен 0, то спускаемся налево, если равен 1, то направо. Далее проверяем второй бит и т.д., постепенно спускаясь по дереву пока есть возможность. Спускаясь по дереву, запоминаем последний пройденный белый узел, он и будет наилучшим. Например, при поиске наилучшего префикса для адреса 101100 последовательно проходим узлы *, 1, 10, 101, 1011. Последний пройденный белый префикс равен 10, он и будет наилучшим.
Максимальное количество сравнений, очевидно, не превышает высоты дерева и для ipv4 равняется 32.
Сжатие пути
Если префиксов не очень много, то в префиксном дереве могут образовываться цепочки без ветвлений. В такой цепочке можно пропустить желтые узлы с одним дочерним префиксом, как показано на рисунке. Этот механизм называется сжатие пути (Path compression) а дерево построенное таким образом — Path compressed trie (PC-trie).
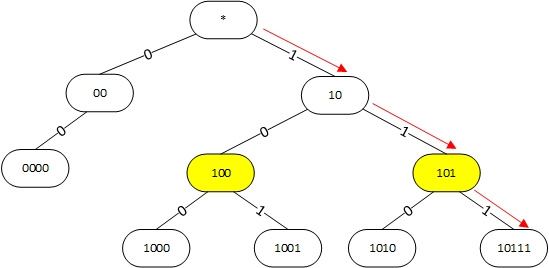
Рисунок 2. Использование Path compressed trie для поиска наиболее длинного префикса для адреса 101100.
Алгоритм поиска остается практически без изменений. Для поиска наилучшего префикса для адреса 101100 также сначала проверяем 1-й бит адреса. Поскольку он равен 1, то спускаемся вправо в префикс 10. Убеждаемся, что префикс 10 подходит. Далее проверяем 3-й бит адреса, спускаемся в узел 101, проверяем 4-й бит, и попадаем в узел 10111. Префикс 10111 не совпадает с адресом и последний посещенный нами белый префикс, как и в предыдущем случае, равен 10.
Сжатие уровня
Сжатие пути эффективно когда префиксов относительно немного. Когда же количество префиксов возрастает полезной становится другая оптимизация, называемая сжатие уровня (Level Compression). Здесь мы для некоторых узлов дерева храним не два дочерних элемента, а больше, например, 4, 8, 16 и т.д. В качестве индекса для выбора дочернего элемента используем сразу несколько битов в проверяемом адресе. Дерево использующее сжатие пути и уровня называется Level and Path Compressed Trie (LPC-Trie).
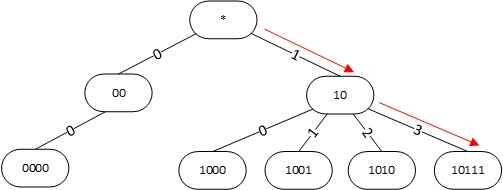
Рисунок 3. Использование Level and Path compressed trie для поиска наиболее длинного префикса для адреса 101100.
В данном случае узел 10 имеет не два дочерних узла, а четыре. Для выбора дочернего узла в адресе назначения проверяются сразу два бита: 3-й и 4-й, и используются в качестве индекса для выбора дочернего узла. Так, в адресе 101100 эти биты равны 11 (десятичное 3), т.е. после узла 10 спускаемся в дочерний узел с индексом 3, т.е. в узел 10111. Поскольку он не подходит, то наиболее длинный префикс равен 10.
Чем больше используется битов адреса назначения для нахождения очередного узла, тем меньше высота дерева и быстрее поиск. Однако при этом для некоторых индексов дочерние узлы отсутствуют и часть памяти тратится впустую.
Реализация в linux
Для проверки я брал ядро linux 4.4.60. В ядре linux для поиска лучшего префикса используется модифицированное LPC-Trie. При сжатии уровня используется максимальное количество битов, при котором количество отсутствующих дочерних узлов не превышает количество существующих дочерних узлов.
Модификация заключается в том, что все белые префиксы перемещаются в конечные узлы дерева. Промежуточные узлы используются исключительно для организации структуры дерева. В одном конечном узле может содержаться цепочка из нескольких префиксов, отличающихся друг от друга количеством нулей справа, т.е., например: 1, 10, 1000, как показано на рисунке:
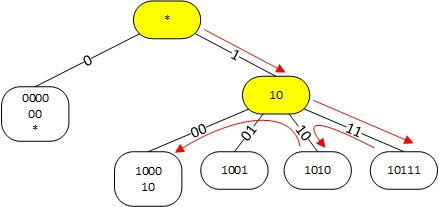
Рисунок 4. Реализация trie в Linux для поиска наиболее длинного префикса для адреса 101100.
Поиск конечного узла производится при помощи LPC-алгоритма. Затем последовательно перебираются все префиксы в конечном узле, начиная с самого длинного. Ситуация при этом усложняется тем, что в некоторых случаях наилучший маршрут оказывается пропущенным при спуске по дереву и для его нахождения необходима проверка узлов слева (backtracking). Так, для адреса 101100 мы спускаемся к узлу 10111. Поскольку в нем нет нужного префикса, мы должны проверить узел 1010 (в нем может храниться префикс 101), а затем узел 1000 и в нем находим префикс 10. К счастью, необходимость в backtracking возникает, по-видимому не очень часто и не сильно снижает скорость поиска.
Для каких целей сделана данная модификация, усложняющая и замедляющая поиск, мне не совсем понятно, возможно она облегчает построение дерева при добавлении или удалении маршрутов, а может просто является унаследованной из какого-то алгоритма.
В linux есть возможность посмотреть дерево FIB. Для этого нужно ввести команду cat /proc/net/fib_trie. При этом выдается что-то похожее на:
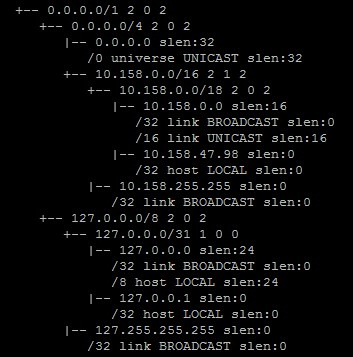
Рисунок 5. Вывод команды cat /proc/net/fib_trie
Промежуточные узлы дерева обозначены символами +--, конечные узлы символами |--. В конечных узлах видны префиксы, упорядоченные по длине.
DIR-24-8
Можно ли еще ускорить поиск наилучшего префикса? Оказывается можно, если при этом пожертвовать памятью. Если предположить, что у нас есть сколько угодно памяти, то можно организовать поиск наилучшего префикса за единственное обращение к памяти. Для этого нужно создать большой массив, в ячейках которого хранить ссылки на наилучшие префиксы, а в качестве индекса при выборе ячейки использовать адрес назначения. Для нашего примера массив будет выглядеть следующим образом:

Рисунок 6. Массив для поиска наиболее длинного префикса за одно обращение.
Чтобы найти наилучший префикс для адреса 101100 мы просто смотрим в ячейку с индексом 101100 в двоичном виде, т.е. с индексом 44, и немедленно получаем, что наилучший префикс равен 10.
Для такого хранения префиксов нужен массив с количеством ячеек 2 в степени длины адреса назначения, т.е. для адресов длины 6 понадобилось 64 ячейки, а для реальных ip-адресов длины 32 понадобится более 4 млрд. ячеек.
Для сокращения количества ячеек заметим, что в нашем случае практически все префиксы равны длине 4 или меньше. Поэтому практически для всех адресов назначения достаточно посмотреть только первые четыре бита. Модернизированная схема поиска выглядит следующим образом:

Рисунок 7. Массивы для поиска наиболее длинного префикса за максимум два обращения.
В данном случае используются два массива. Сначала поиск осуществляется в левом массиве (из 16-ти ячеек), используя в качестве индекса первые четыре бита адреса назначения. Во всех случаях, когда адрес назначения не начинается с 1011 (одиннадцать в десятичном виде) мы сразу получаем наилучший префикс. Иначе мы смотрим последние два бита адреса и используем их в качестве индекса во второй таблице (из 4-х ячеек). Видно, что для адреса 101100 мы снова получаем наилучший префикс 10. Таким образом, при поиск наилучшего префикса в большинстве случаев выполняется за одно обращение, в худшем случае за два.
В случае реальных ip-адресов может использоваться аналогичная схема. Большинство префиксов в FIB являются длины 24 или меньше. Поэтому в качестве левого массива логично использовать массив, индексируемый старшими 24-мя битами адреса (16 777 216 ячеек). Для редких случаев, когда длина хранимых префиксов оказалась длиннее 24, используются дополнительные таблицы, индексируемые последними 8-ю битами префикса (256 ячеек для каждой дополнительной таблицы).
Данный быстрый способ поиска (максимум за два обращения) называется DIR-24-8 и используется, например, в DPDK.
Обычно говорят, что все маршруты находятся в таблице маршрутизации, в которой и выполняется поиск наилучшего маршрута. Здесь может возникнуть терминологическая путаница. Дело в том, что под таблицей маршрутизации можно понимать две разные вещи, которые иногда обозначаются терминами Routing Information Base (RIB) и Forwarding Information Base (FIB). И RIB и FIB действительно хранят ip-маршруты, но предназначение этих структур и алгоритмы выбора лучших маршрутов в этих структурах отличаются.
Routing Information Base (RIB)
Маршруты на маршрутизатор могут попадать из различных источников: быть настроены статически, попадать из протоколов динамической маршрутизации OSPF, BGP и т.д. При этом из различных источников могут приходить маршруты с одним и тем-же префиксом. Из этих маршрутов нужно выбрать какой-то один и добавить его в FIB. Эта задача как раз и решается в RIB. Обычно маршрутам из разных источников присваивается разная Административная Дистанция и наилучшим считается маршрут с наименьшей Административной Дистанцией. Важно, что конкурируют между собой маршруты с одним и тем-же префиксом. Маршруты с разными префиксами между собой не сравниваются. Например, префиксы 10.0.0.0/8 и 10.0.0.0/16 это разные префиксы и в FIB попадут оба маршрута. Таким образом, в RIB выполняется поиск КОНКРЕТНОГО префикса. Поиск префиксов в RIB выполняется при добавлении или удалении маршрутов, что происходит относительно редко.
Forwarding Information Base (FIB)
FIB служит собственно для маршрутизации ip-пакетов. Здесь лучшим маршрутом считается маршрут с наиболее длинным префиксом, совпадающим с адресом назначения в ip-пакете. Совместная работа RIB и FIB показана на рисунке:
Рисунок 1. Совместная работа RIB и FIB. В RIB попадают и отбираются маршруты от разных протоколов маршрутизации. В FIB выполняется маршрутизация пакетов согласно наиболее длинным префиксам.
Поиск лучшего маршрута в FIB происходит для каждого нового ip-пакета. От того, насколько эффективно происходит поиск маршрута в FIB напрямую зависит скорость маршрутизации устройства. Поэтому поиск в FIB должен производиться максимально быстро и эффективно. В FIB может содержаться несколько сот тысяч маршрутов с разными префиксами, поэтому задача выглядит довольно нетривиальной. Для ее оптимизации было предложено много различных алгоритмов. В настоящей статье я хочу рассказать, как поиск в FIB реализован в ядре linux.
Формулировка задачи
IP-префикс обычно обозначают в виде ip-адреса и длины префикса, например: 10.0.0.0/8. Для нас будет удобнее представлять префикс в двоичном виде, оставив только левую часть, равную длине префикса и опустив его правую несущественную часть: 00001010. Маршрут по-умолчанию (т.е. префикс нулевой длины будем обозначать звездочкой *. Задача поиска выглядит следующим образом. У нас есть набор различных префиксов: *, 00, 10, 0000, 1000, 1001, 1010, 10111. Нам дается адрес назначения, который в двоичном виде выглядит, например, так: 1010110001110100010001000010111. Среди имеющихся префиксов нужно найти лучший, т.е. наиболее длинный, который совпадает с левой частью адреса назначения. В нашем примере это будет префикс 1010. К каждому префиксу привязан ip-адрес следующего маршрутизатора (next-hop), исходящий интерфейс и другая информация, достаточная отправки пакета дальше. В дальнейшем, для простоты, я буду использовать вышеуказанный набор префиксов и адреса назначения длины 6. Все нижеизложенное также применимо и для реальных ip-адресов длины 32. Как может выглядеть реальный список префиксов в FIB (в двоичном виде) можно посмотреть здесь.
Мы будем последовательно строить алгоритмы поиска лучшего префикса начиная с самого простого, постепенно улучшая их, пока не придем к алгоритму, используемому в ядре linux.
Тривиальный алгоритм
Очевидным и самым простым алгоритмом является простой перебор всех имеющихся префиксов и выбора из них лучшего. Такой алгоритм легко реализовать, но на большом количестве префиксов скорость его работы совершенно неудовлетворительна. Если в FIB у нас содержится 500000 префиксов, то нам нужно перебрать и проверить их всех.
Скорость поиска можно несколько повысить, храня префиксы в порядке убывания их длины. Тогда первый совпадающий префикс будет самым длинным и, следовательно, лучшим.
Префиксное дерево
Естественным способом организации префиксов является префиксное дерево (trie). Пример префиксного дерева для префиксов *, 00, 10, 0000, 1000, 1001, 1010, 10111 приведен на рисунке:
Рисунок 1. Использование префиксного дерева для поиска наиболее длинного префикса. Красными стрелками показана последовательность поиска для адреса 101100.
Белые узлы соответствуют интересующим нас префиксами. В них также хранится ссылка на информацию о том куда отправлять пакет дальше (next-hop и т.д.). Желтые узлы являются промежуточными и служат для правильной организации структуры дерева. Верхний узел является корнем дерева и соответствует префиксу 0.0.0.0/0. Для поиска лучшего префикса проверяется самый левый бит адреса назначения пакета. Если он равен 0, то спускаемся налево, если равен 1, то направо. Далее проверяем второй бит и т.д., постепенно спускаясь по дереву пока есть возможность. Спускаясь по дереву, запоминаем последний пройденный белый узел, он и будет наилучшим. Например, при поиске наилучшего префикса для адреса 101100 последовательно проходим узлы *, 1, 10, 101, 1011. Последний пройденный белый префикс равен 10, он и будет наилучшим.
Максимальное количество сравнений, очевидно, не превышает высоты дерева и для ipv4 равняется 32.
Сжатие пути
Если префиксов не очень много, то в префиксном дереве могут образовываться цепочки без ветвлений. В такой цепочке можно пропустить желтые узлы с одним дочерним префиксом, как показано на рисунке. Этот механизм называется сжатие пути (Path compression) а дерево построенное таким образом — Path compressed trie (PC-trie).
Рисунок 2. Использование Path compressed trie для поиска наиболее длинного префикса для адреса 101100.
Алгоритм поиска остается практически без изменений. Для поиска наилучшего префикса для адреса 101100 также сначала проверяем 1-й бит адреса. Поскольку он равен 1, то спускаемся вправо в префикс 10. Убеждаемся, что префикс 10 подходит. Далее проверяем 3-й бит адреса, спускаемся в узел 101, проверяем 4-й бит, и попадаем в узел 10111. Префикс 10111 не совпадает с адресом и последний посещенный нами белый префикс, как и в предыдущем случае, равен 10.
Сжатие уровня
Сжатие пути эффективно когда префиксов относительно немного. Когда же количество префиксов возрастает полезной становится другая оптимизация, называемая сжатие уровня (Level Compression). Здесь мы для некоторых узлов дерева храним не два дочерних элемента, а больше, например, 4, 8, 16 и т.д. В качестве индекса для выбора дочернего элемента используем сразу несколько битов в проверяемом адресе. Дерево использующее сжатие пути и уровня называется Level and Path Compressed Trie (LPC-Trie).
Рисунок 3. Использование Level and Path compressed trie для поиска наиболее длинного префикса для адреса 101100.
В данном случае узел 10 имеет не два дочерних узла, а четыре. Для выбора дочернего узла в адресе назначения проверяются сразу два бита: 3-й и 4-й, и используются в качестве индекса для выбора дочернего узла. Так, в адресе 101100 эти биты равны 11 (десятичное 3), т.е. после узла 10 спускаемся в дочерний узел с индексом 3, т.е. в узел 10111. Поскольку он не подходит, то наиболее длинный префикс равен 10.
Чем больше используется битов адреса назначения для нахождения очередного узла, тем меньше высота дерева и быстрее поиск. Однако при этом для некоторых индексов дочерние узлы отсутствуют и часть памяти тратится впустую.
Реализация в linux
Для проверки я брал ядро linux 4.4.60. В ядре linux для поиска лучшего префикса используется модифицированное LPC-Trie. При сжатии уровня используется максимальное количество битов, при котором количество отсутствующих дочерних узлов не превышает количество существующих дочерних узлов.
Модификация заключается в том, что все белые префиксы перемещаются в конечные узлы дерева. Промежуточные узлы используются исключительно для организации структуры дерева. В одном конечном узле может содержаться цепочка из нескольких префиксов, отличающихся друг от друга количеством нулей справа, т.е., например: 1, 10, 1000, как показано на рисунке:
Рисунок 4. Реализация trie в Linux для поиска наиболее длинного префикса для адреса 101100.
Поиск конечного узла производится при помощи LPC-алгоритма. Затем последовательно перебираются все префиксы в конечном узле, начиная с самого длинного. Ситуация при этом усложняется тем, что в некоторых случаях наилучший маршрут оказывается пропущенным при спуске по дереву и для его нахождения необходима проверка узлов слева (backtracking). Так, для адреса 101100 мы спускаемся к узлу 10111. Поскольку в нем нет нужного префикса, мы должны проверить узел 1010 (в нем может храниться префикс 101), а затем узел 1000 и в нем находим префикс 10. К счастью, необходимость в backtracking возникает, по-видимому не очень часто и не сильно снижает скорость поиска.
Для каких целей сделана данная модификация, усложняющая и замедляющая поиск, мне не совсем понятно, возможно она облегчает построение дерева при добавлении или удалении маршрутов, а может просто является унаследованной из какого-то алгоритма.
В linux есть возможность посмотреть дерево FIB. Для этого нужно ввести команду cat /proc/net/fib_trie. При этом выдается что-то похожее на:
Рисунок 5. Вывод команды cat /proc/net/fib_trie
Промежуточные узлы дерева обозначены символами +--, конечные узлы символами |--. В конечных узлах видны префиксы, упорядоченные по длине.
DIR-24-8
Можно ли еще ускорить поиск наилучшего префикса? Оказывается можно, если при этом пожертвовать памятью. Если предположить, что у нас есть сколько угодно памяти, то можно организовать поиск наилучшего префикса за единственное обращение к памяти. Для этого нужно создать большой массив, в ячейках которого хранить ссылки на наилучшие префиксы, а в качестве индекса при выборе ячейки использовать адрес назначения. Для нашего примера массив будет выглядеть следующим образом:
Рисунок 6. Массив для поиска наиболее длинного префикса за одно обращение.
Чтобы найти наилучший префикс для адреса 101100 мы просто смотрим в ячейку с индексом 101100 в двоичном виде, т.е. с индексом 44, и немедленно получаем, что наилучший префикс равен 10.
Для такого хранения префиксов нужен массив с количеством ячеек 2 в степени длины адреса назначения, т.е. для адресов длины 6 понадобилось 64 ячейки, а для реальных ip-адресов длины 32 понадобится более 4 млрд. ячеек.
Для сокращения количества ячеек заметим, что в нашем случае практически все префиксы равны длине 4 или меньше. Поэтому практически для всех адресов назначения достаточно посмотреть только первые четыре бита. Модернизированная схема поиска выглядит следующим образом:
Рисунок 7. Массивы для поиска наиболее длинного префикса за максимум два обращения.
В данном случае используются два массива. Сначала поиск осуществляется в левом массиве (из 16-ти ячеек), используя в качестве индекса первые четыре бита адреса назначения. Во всех случаях, когда адрес назначения не начинается с 1011 (одиннадцать в десятичном виде) мы сразу получаем наилучший префикс. Иначе мы смотрим последние два бита адреса и используем их в качестве индекса во второй таблице (из 4-х ячеек). Видно, что для адреса 101100 мы снова получаем наилучший префикс 10. Таким образом, при поиск наилучшего префикса в большинстве случаев выполняется за одно обращение, в худшем случае за два.
В случае реальных ip-адресов может использоваться аналогичная схема. Большинство префиксов в FIB являются длины 24 или меньше. Поэтому в качестве левого массива логично использовать массив, индексируемый старшими 24-мя битами адреса (16 777 216 ячеек). Для редких случаев, когда длина хранимых префиксов оказалась длиннее 24, используются дополнительные таблицы, индексируемые последними 8-ю битами префикса (256 ячеек для каждой дополнительной таблицы).
Данный быстрый способ поиска (максимум за два обращения) называется DIR-24-8 и используется, например, в DPDK.
Поделиться с друзьями
CentALT
Очень редко у кого получается описать сложные процессы простым и понятным языком. У Вас получилось, отличная статья. Спасибо.