
Если вы все знаете о нагрузочном тестировании и как правильно к нему подготовиться, то вам статья будет не интересна. Статья рассчитана на тех, кто хочет понять как строить “правильные” профили для тестирования и на что необходимо обращать внимание при подготовке сценария. Речь будет идти о Web-системах с Web-интерфейсом.
Я работаю в области тестирования более 10 лет, так или иначе сталкиваюсь с нагрузочным тестированием. Я читал разные статьи по этому виду тестирования, посещал конференции, старался узнавать что-то новое и инновационное в данной области. В большинстве получаемой информации вы найдете инструкции к действиям по тестированию микросервисов, баз данных и прочих подсистем по отдельности. При этом если подсистемы проверены и настроены должным образом, то не уделяется должного внимания Web-системе в целом.
Что сейчас Web-система — это набор микросервисов, подсистем, баз данных и др., которые могут располагаться на разных серверах, на разных континентах. Но все они так или иначе взаимодействуют с Web-интерфейсом (как написал выше, я рассматриваю только текущий вариант).
Многие утилиты для выполнения нагрузочного тестирования имеют возможность записи трафика. Почти все утилиты записывают полученные запросы последовательно в рамках одной сессии. То есть запрос за запросом и не заботятся о том как эти запросы выполняются в браузерах.
Возьмем несколько наиболее популярных браузеров (Google Chrome, Mozilla FireFox, Internet Explorer) и попробуем открыть любой сайт. Как показала практика работы с браузерами у некоторых есть настройка какое количество соединений они могут открывать параллельно, некоторые сами регулируют данное количество. К тому же количество соединений может меняться в зависимости от используемого типа соединения.
Internet Explorer:
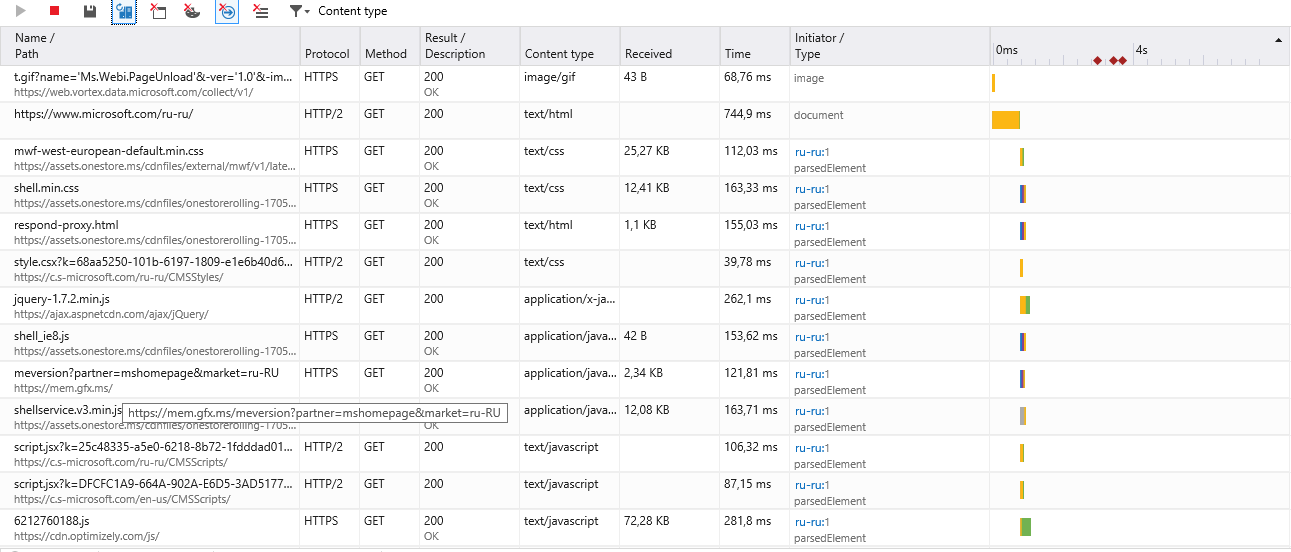
Google Chrome:
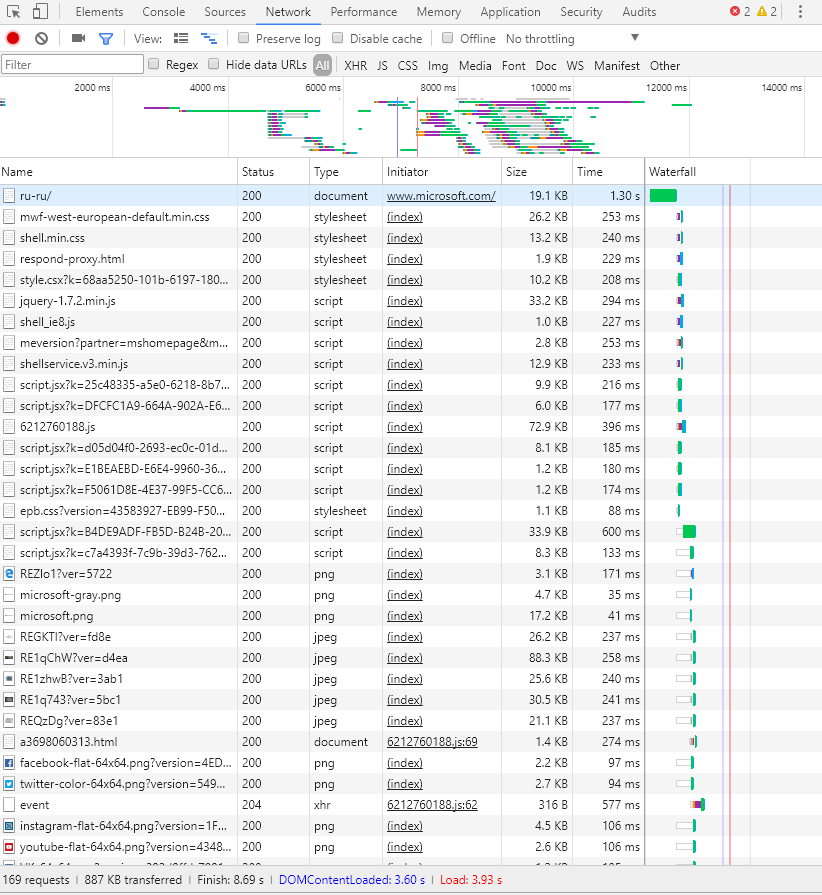
Например я видел как для одного и того же ресурса https создавалось разное количество параллельных соединений. Так Google Chrome создавал 6 соединений и все запросы обрабатывал в рамках этого количества, а вот Internet Explorer мог создавать до 20 — 30 параллельных соединений.
Мы видим, что браузеры обращаются к Web-системой в несколько потоков, они могут загружать содержимое параллельно. Но ряд утилиты выполняют только один поток для одного пользователя.
То есть фактически неправильно говорить, что один поток в утилите для тестирования производительности будет всегда соответствовать работе одного реального пользователя.
Нагрузка может быть в разы выше, чем будет генерировать используемая утилита.
Обратившись к настройкам Web-серверов, мы увидим что они определяют в основном количество рабочих процессов и количество открытых соединений. Операционная система, с которой производится нагрузка, может иметь свои собственные ограничения на количество открытых соединений, что повлияет на профиль нагрузки и он не будет связан с работой Web-системы.
Другими словами каждый виртуальный пользователь может поддерживать несколько параллельных соединений. И даже с одним пользователем можно нагрузить систему так, что она не сможет работать. Если вы используете утилиту, которая выполняет только один поток (поддерживает только одно соединение) для одного пользователям, то здесь надо понимать, что данный поток не является реальным пользователем.
Необходимо обращать внимание на то, что Web-системы могут использовать сторонние ресурсы. Это может быть аналитика, счетчики, предоставляемые шрифты, стили, javascript. В зависимости от ваших потребностей необходимо определять для себя какие именно ресурсы вам требуется тестировать. В сторонних ресурсах может инициализироваться какая-либо информация, которую вы в дальнейшем можете использовать на своей системе. Тем самым исключив сторонние ресурсы, вы не сможет симулировать полностью получаемый контент для пользователя. Необходимый перечень запросов можно определить только путем долгого анализа и глубокого понимания тестируемой системы.
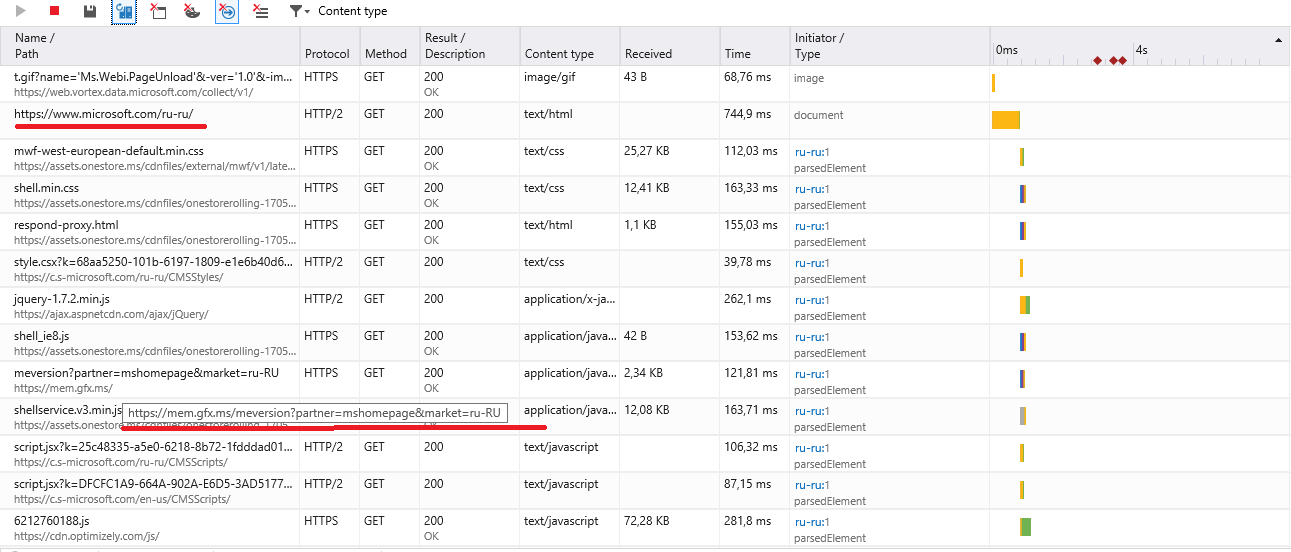
На картинке видна ситуация, когда запрос делается на ресурс, будем считать его тестируемым, который делает запрос на отличный от него. Вот здесь мы и должны решить нужен ли нам данный ресурс в нашем сценарии или он не связан с Web-системой и мы можем просто его исключить.
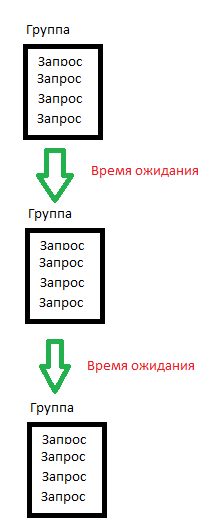
Необходимо группировать запросы по выполняемым действиям. Так можно создавать отдельные группы на открытие главной страницы, на вход в систему, на переход по ссылке и т. д. Это все нужно в основном только для того, что установить необходимые задержки между группами действий. Мы рассматриваем одного виртуального пользователя как пользователя, который реально работает с системой. Естественно при наличии 100, 200, 1000 и более реальных пользователей, каждый из них будет проводить на определенной странице разное количество времени. Следовательно трафик должен идти от виртуальных пользователей неравномерно. Поэтому между группами действий необходимы устанавливать задержки. И чем более реальными они будут, тем более реальные результаты тестирования вы будете получать.
Мы можем проигнорировать количество параллельно выполняемых соединений, сторонние ресурсы, группировки и задержки. Но в результате мы можем получить результаты тестов где видно, что система работает с 200 виртуальными пользователями (потоками), а на практике получите только 10 реальных. Или получить прямо обратные результаты, когда по графикам мы видим только 200 пользователей могут работать с системой, но с учетом разного времени использования страниц, количество используемых соединений и исключения сторонних ресурсов, мы можем получить и 500 реально работающих.
Я верю, что четкое понимание количества выполняемых соединений, правильное использование необходимого набора ресурсов и задержки между группами действий помогут вам получать более точные результаты нагрузочного тестирования, которое вы будет выполнять у себя.
Конечно это не полный список пунктов, с которых следует начинать подготовку. Есть еще множество различных аспектов, которые так или иначе влияют на тестирование производительности. Часть из них может влиять непосредственно на агента, который выполняет нагрузку и может быть никак не связан с тестируемой Web-системой.
Я работаю в области тестирования более 10 лет, так или иначе сталкиваюсь с нагрузочным тестированием. Я читал разные статьи по этому виду тестирования, посещал конференции, старался узнавать что-то новое и инновационное в данной области. В большинстве получаемой информации вы найдете инструкции к действиям по тестированию микросервисов, баз данных и прочих подсистем по отдельности. При этом если подсистемы проверены и настроены должным образом, то не уделяется должного внимания Web-системе в целом.
Что сейчас Web-система — это набор микросервисов, подсистем, баз данных и др., которые могут располагаться на разных серверах, на разных континентах. Но все они так или иначе взаимодействуют с Web-интерфейсом (как написал выше, я рассматриваю только текущий вариант).
Многие утилиты для выполнения нагрузочного тестирования имеют возможность записи трафика. Почти все утилиты записывают полученные запросы последовательно в рамках одной сессии. То есть запрос за запросом и не заботятся о том как эти запросы выполняются в браузерах.
Количество соединений и последовательность выполнения
Возьмем несколько наиболее популярных браузеров (Google Chrome, Mozilla FireFox, Internet Explorer) и попробуем открыть любой сайт. Как показала практика работы с браузерами у некоторых есть настройка какое количество соединений они могут открывать параллельно, некоторые сами регулируют данное количество. К тому же количество соединений может меняться в зависимости от используемого типа соединения.
Internet Explorer:
Google Chrome:
Например я видел как для одного и того же ресурса https создавалось разное количество параллельных соединений. Так Google Chrome создавал 6 соединений и все запросы обрабатывал в рамках этого количества, а вот Internet Explorer мог создавать до 20 — 30 параллельных соединений.
Мы видим, что браузеры обращаются к Web-системой в несколько потоков, они могут загружать содержимое параллельно. Но ряд утилиты выполняют только один поток для одного пользователя.
То есть фактически неправильно говорить, что один поток в утилите для тестирования производительности будет всегда соответствовать работе одного реального пользователя.
Нагрузка может быть в разы выше, чем будет генерировать используемая утилита.
Обратившись к настройкам Web-серверов, мы увидим что они определяют в основном количество рабочих процессов и количество открытых соединений. Операционная система, с которой производится нагрузка, может иметь свои собственные ограничения на количество открытых соединений, что повлияет на профиль нагрузки и он не будет связан с работой Web-системы.
Другими словами каждый виртуальный пользователь может поддерживать несколько параллельных соединений. И даже с одним пользователем можно нагрузить систему так, что она не сможет работать. Если вы используете утилиту, которая выполняет только один поток (поддерживает только одно соединение) для одного пользователям, то здесь надо понимать, что данный поток не является реальным пользователем.
Сторонние ресурсы
Необходимо обращать внимание на то, что Web-системы могут использовать сторонние ресурсы. Это может быть аналитика, счетчики, предоставляемые шрифты, стили, javascript. В зависимости от ваших потребностей необходимо определять для себя какие именно ресурсы вам требуется тестировать. В сторонних ресурсах может инициализироваться какая-либо информация, которую вы в дальнейшем можете использовать на своей системе. Тем самым исключив сторонние ресурсы, вы не сможет симулировать полностью получаемый контент для пользователя. Необходимый перечень запросов можно определить только путем долгого анализа и глубокого понимания тестируемой системы.
На картинке видна ситуация, когда запрос делается на ресурс, будем считать его тестируемым, который делает запрос на отличный от него. Вот здесь мы и должны решить нужен ли нам данный ресурс в нашем сценарии или он не связан с Web-системой и мы можем просто его исключить.
Группировка
Необходимо группировать запросы по выполняемым действиям. Так можно создавать отдельные группы на открытие главной страницы, на вход в систему, на переход по ссылке и т. д. Это все нужно в основном только для того, что установить необходимые задержки между группами действий. Мы рассматриваем одного виртуального пользователя как пользователя, который реально работает с системой. Естественно при наличии 100, 200, 1000 и более реальных пользователей, каждый из них будет проводить на определенной странице разное количество времени. Следовательно трафик должен идти от виртуальных пользователей неравномерно. Поэтому между группами действий необходимы устанавливать задержки. И чем более реальными они будут, тем более реальные результаты тестирования вы будете получать.
Заключение
Мы можем проигнорировать количество параллельно выполняемых соединений, сторонние ресурсы, группировки и задержки. Но в результате мы можем получить результаты тестов где видно, что система работает с 200 виртуальными пользователями (потоками), а на практике получите только 10 реальных. Или получить прямо обратные результаты, когда по графикам мы видим только 200 пользователей могут работать с системой, но с учетом разного времени использования страниц, количество используемых соединений и исключения сторонних ресурсов, мы можем получить и 500 реально работающих.
Я верю, что четкое понимание количества выполняемых соединений, правильное использование необходимого набора ресурсов и задержки между группами действий помогут вам получать более точные результаты нагрузочного тестирования, которое вы будет выполнять у себя.
Конечно это не полный список пунктов, с которых следует начинать подготовку. Есть еще множество различных аспектов, которые так или иначе влияют на тестирование производительности. Часть из них может влиять непосредственно на агента, который выполняет нагрузку и может быть никак не связан с тестируемой Web-системой.
Поделиться с друзьями
saw_tooth
На самом деле, Ваши трактования не совсем верны. В первую очередь нужно менее широко, на этапе планирования, определить что Вы хотите измерить, ведь нагрузочное тестирование это целый пул смежных и не очень задач по тестированию системы.
В контексте несущего сервера, можно полностью отбросить статику и ресурсы от третьих сторон, так как нас интересует именно состояние нашего сервера, а не то, что происходит у юзера на UI (где-то UI не догрузился, где то js запарился)
Второй момент, недостаточно получить лишь HPS график, так как он не несет реальной пользы в исследовании сервера: скриптов, базы, кешей.
Из второго момента, так же следует понимать между абсолютной нагрузкой и взвешенной. Нередко проводя тесты, и приводя какие-то обоснованные результатами доводы я слышу «Тю, чувак, та такого быть не может — мы ж тут все кешируем/прелоадим/anyway» — как пример того что многие не понимают целей лоуд теста.
И одно из последних, для реально взвешенного лоуда, нельзя полагаться на методику «размазывания запросов», она естественно дают некие приближенные цифры производительности, но лучше всего в реальной системе, на проде, иметь некоторые метрики снятые всякими статистик сервисами (гуглометрика, яндекс метрика). При таком подходе, можно иметь взвешенную цифру запросов с секунду для одного реального пользователя, а его плотность запросов — как объект для построения своих тест-сьютов для лоуда-тестинга.
В целом, при простом тестировании в первом приближении, достаточно обзавестись лог-мониторингом (CPU/RAM), базы, и просто стабильно нагружать сервер одним запросом, уверен, даже при таком подходе Вы найдете большое количество недочетов в веб-приложении, и дальнейший анализ логов, уже более точно скажет куда нужно копать, для рефакторинга… у меня в 90% случаев, после первичного просмотра, дела сразу уходят в профилирование базы, изучения запросов, выдаче slow-log и его анализа.
Nick-Monk
Фактически большинство так и теструют — каждые микросервисы отдельно. Более того, я тоже так делаю, потому что порой необходимо выделять проблемы микросервисов или кэширующих прокси серверов и т. д.
Я не предлагаю отказываться от их тестирования, я всего лишь предлагаю выполнять тестирование всей системы перед продакшеном. Конечно, нагружая сервер даже одним запросом вы можете выявить большую часть проблем.
Возьмем в качестве примера on-line кабинет организации. При входе в него начинают загружаться данные. Связь с базами данных будет работать на отлично — мы же это проверили и нагрузили. Но вот CSS или JS могу не успеть загрузиться, а следовательно внешний вид кабинета будет полностью не работоспособный. Его UI может на столько «разъехаться», что возможно дальнешее его использование пользователю не понравится и он от него откажется. Отбросив сторонние ресурсы, есть вероятность потерять пользователей на этапе ознакомления с системой. Он может просто обновить страницу и у него уже все может быть хорошо. Не все пользователи терпеливые.
saw_tooth
гм… еще раз хочу повторить свой пред. ответ: разделяйте лоад тестирование, по направлениям. Какую метрику Вы хотите знать? Ваш пример говорит лишь от отзыва части со статическими данными, которые по существу, должны вообще там крутится где-то на ngix и даже не лежать рядом с веб-приложением.
Второй момент, опять таки Ваш пример тестирует UI, а не сервер. И то что вы видите в браузере, есть следствие а не причина, более того — не самая достоверная метрика (у юзера может быть плохой канал, тупой браузер, тупой ПК). А лоад тест направлен на поиск причин на бек-енд стороне, в данном случае, можно было просто измерить время HEAD запроса и быть довольным… а если еще учитывать что, где то что-то там не догрузилось когда нужно (привет асинхронность), js запарился, страница не отрендерилась. Вины сервера тут нет, но плохой результат — на лицо. Как быть? Нужно разделять.