
Для бизнес-приложений работа с данными — это очень важный архитектурный вопрос. Так или иначе, но вся работа приложения строится вокруг данных. Причем, если в некоторых классах программных систем данные носят вспомогательный характер, то в бизнес-приложениях данные являются основным содержанием решаемых задач.
Здесь (в этой статье) мы говорим не о техническом аспекте хранения и манипулирования данными, а об описании данных как способе проектирования приложения. Почему же данные так важны для бизнес-приложений?
Потому, что они описывают саму предметную область. Какие сущности имеются в бизнесе, как они связаны между собой. Данные очень хорошо описывают и саму решаемую задачу. Ведь при проектировании приложений нас не интересуют абсолютно все данные, а интересуют те данные (и их взаимосвязи), которые тем или иным способом влияют на решаемую задачу (включая некоторый запас развития системы в потенциально интересных направлениях). Например, если мы автоматизируем процесс развития персонала, то нас будет интересовать по сотрудникам образование, история работы. Но мы не будем отражать информацию по размерам одежды и обуви. Но, если, например, мы хотим автоматизировать учет спецодежды, то это становится уже интересным. Хотя, пытливый проектировщик может и тут поставить вопрос. Где развитие персонала, там и мотивация. А где мотивация, там и, возможно, изготовление одежды с фирменной символикой. Здесь видно, что количество данных в природе бесконечно, и искусство моделирования данных во многом определяет искусство проектирования приложений.
Конечно, очень важное место в бизнес-приложениях занимают и процессы. Хотя очень хочется (и нам, и разработчикам других платформ для разработки бизнес приложений) больший вес в проектировании приложений возложить на процессы, но данные все равно остаются наиболее значимым аспектом предметной области. И именно на отражении данных строится основная модель приложений.
Сделаем только небольшую оговорку. Под данными здесь понимаются и данные, сопровождающие процессы. То есть, получается, что процессы тоже косвенно выражаются через модель данных.
В платформе 1С:Предприятие есть и механизмы для отражения именно процессов, но это тема отдельной статьи.
Существует несколько традиционных парадигм работы с данными.
Прежде всего – есть классическая реляционная модель. В ней данные описываются в виде реляционных таблиц (обычно хранимых в реляционных DBMS). Эта парадигма хотя и совсем не новая, но вполне актуальная.
Есть объектная парадигма. В ней данные описываются в виде объектов языка программирования и каким-то образом сохраняются в базе данных. Это может быть реляционная или объектная база данных. В первом случае возможности моделирования определяются DBMS, во втором случае — используемым ORM.
Есть еще методики и подходы, которые применяются реже (при создании бизнес-приложений). Например, подход, основанный на слабоструктурированных данных.
Теперь, собственно, о том подходе, который мы выбрали для платформы 1С:Предприятия. Для него нет официально принятого названия. Назовем его «модель типов прикладных объектов». Суть подхода в том, что платформа предлагает разработчику некоторый набор типов прикладных объектов. Каждый тип предназначен для отражения в модели приложения некоторой категории сущностей предметной области. Разработчик приложения при отражении предметной области решаемой задачи в модели приложения должен выбрать подходящие типы объектов и с помощью них описать модель данных. На самом деле при этом он описывает не только модель данных, но и, во многом, модель самого приложения. Но об этом чуть позже.
Что представляет собой тип прикладных объектов?
Это некоторый заложенный в платформу шаблон (можно еще считать его абстрактным классом), определяющий множество различных аспектов работы с сущностью предметной области.
Типы прикладных объектов проявляются и при разработке (в design-time) и при работе системы (в run-time). В design-time это мета-модель описания объектов в метаданных и классы для манипулирования данными в программной модели. В run-time это различные аспекты поведения системы при работе с объектами этого типа. Например, поведение механизма блокировок.
В 1С:Предприятии существует несколько типов прикладных объектов.
Для примера возьмем три типа:
- Справочники
- Документы
- Регистры накопления
Справочники предназначены для отражения в системе некоторой условно постоянной информации (списков сотрудников, товаров, клиентов…).
Документы отражают некоторые события предметной области (продажу, прием сотрудника на работу, перечисление денег в банк). Иногда они называются по названиям печатных форм («платежное поручение», «приказ о приеме на работу», …). Но это только для удобства понимания. По сути, это именно тип события, а не печатной формы.
Регистры накопления предназначены для отражения в приложении некоторой системы учета. Например, учета хранения денежных средств или товаров на складах.
Посмотрим, что все-таки входит в «комплект» возможностей, предоставляемый типами прикладных объектов
Прежде всего, конечно, тип прикладного объекта описывает модель данных и обеспечивает отображение данных на реляционную модель хранения. Но это только небольшая часть того, что он определяет.
Например, для справочника:
- существует несколько стандартных реквизитов (полей), заложенных сразу в платформу (ссылка-идентификатор, код, наименование, ссылка на родителя для иерархического справочника, …)
- можно описать свои (произвольные) реквизиты (поля)
- можно описать табличные части, которые представляют собой тесно связанные сущности (containment) или еще их можно считать вложенными таблицами
Для документа — похоже, но есть стандартный реквизит Дата, отражающий положение события относительно других событий на оси времени, а также признак «Проведен», определяющий, отражается документ в системе учета или является черновиком.
Для регистра накопления поля делятся на измерения, ресурсы и реквизиты. Измерения описывают систему координат модели учета (например, товар, склад), ресурсы – показатели (например, количество, сумма), реквизиты – просто дополнительные поля (не влияющие на модель учета, но комментирующие записи движений).
Почему мы оперируем типами прикладных объектов, а не оперируем, например, просто таблицами (или просто сущностями – entity)?
Это очень важный момент. Таблицы имеют много преимуществ. Они ближе к простейшему моделированию в реляционной модели, они не ограничивают разработчика рамками заложенных типов. Но таблицы и не дают тех возможностей, которые дает выбранный нами подход.
Суть выбранного нами подхода в том (если говорить простыми словами), что в нашем подходе сама система (платформа) «много чего знает» про описанные объекты и «много чего умеет с ними делать». На основании этих знаний и умений система автоматически обеспечивает работу более десятка разных механизмов, работающих прямо или косвенно с этими объектами. То есть, получается, что разработчик приложения выбирает тип объекта и описывает конкретный объект, а платформа, зная тип и описание конкретного объекта, сама обеспечивает множество различных полезных функций и механизмов. Это достигается за счет того, что на уровне типа объекта определена семантика объектов данного типа (назначение объекта «по крупному»), а модель метаданных позволяет уточнить семантику конкретного объекта за счет различных свойств и специализированных моделей, описывающих различные аспекты жизнедеятельности.
Перечислим только некоторые из них:
- Прежде всего, конечно, это создание структур данных для хранения и автоматическое преобразование структуры при изменении модели
- Набор классов в объектной модели для манипулирования данными (чтения, записи, поиска)
- Механизм объектно-реляционного преобразования
- Набор типичных процедур обработки данных. Например, для документов это автоматическая нумерация, для регистра это расчет итогов, получение среза остатков на конкретный момент времени, и т.д.
- Отражение в системе прав. Так как система знает о назначении объекта, то знает и какие права для него будут актуальны
- Визуализация (отражение в интерфейсе). Опять же, зная о назначении и роли объектов, система сама конструирует и команды в интерфейсе приложения для доступа к объектам этого типа, и формы для просмотра и редактирования, и команды для различных действий с объектом.
- Обмен данными. На основании знания семантики данных платформа предоставляет стандартный механизм для асинхронного обмена измененными данными как среди родственных приложений (узлов распределенной базы), так и между разнородными приложениями (написанными как на 1С:Предприятии, так и на других технологиях)
- Объектные и транзакционные блокировки. Для правильного построения системы блокировки нужно знание о назначении данных и о взаимосвязях.
- Механизм характеристик (дополнительных полей, определяемых пользователем)
- Автоматически предоставляемый REST интерфейс (по стандарту OData)
- Выгрузку-загрузку данных в XML, JSON
- Кроме того, автоматически работают такие механизмы как: полнотекстовый поиск, журналирование доступа к данным, и т.д.
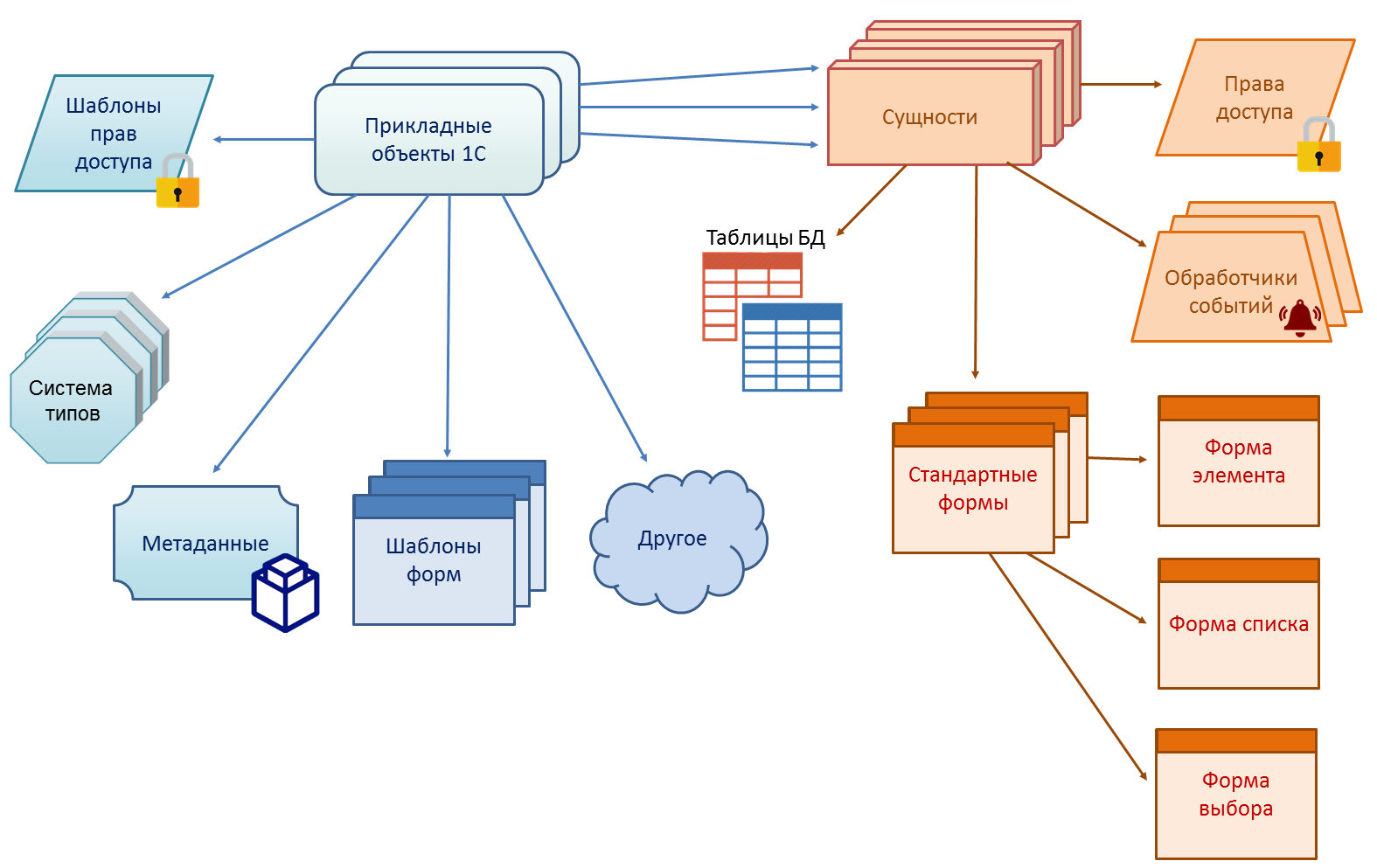
На схеме изображены далеко не все механизмы платформы, которые работают на основе прикладных объектов, а только некоторые.
В каком-то смысле типы прикладных объектов пересекаются с аспектно-ориентированным подходом. Так как все перечисленные возможности — это некоторые предопределенные аспекты, в которых отражаются типы прикладных объектов. Можно сказать, что типы прикладных объектов это не просто шаблоны, а параметризованные шаблоны. Параметризация осуществляется за счет набора свойств метаданных. Выбрав значение свойства, разработчик параметризует шаблон выбранного типа прикладного объекта и уточняет тем поведение объекта в конкретном аспекте. Например, он может выбрать тип нумерации документа (в пределах года, квартала, месяца…) и система будет автоматически обеспечивать присвоение и контроль номеров с заданной периодичностью.
Типы прикладных объектов обеспечивают знание о семантике не только самих сущностей, но и о семантике их взаимосвязей. Например, существует стандартная связь между документами и регистрами, отражающая то, как в предметной области события отражаются в модели учета. Определив такую связь, разработчик сразу получает готовую функциональность по совместному времени жизни документа и связанных с ним записей регистра.
Отдельно стоит сказать о важных предметно ориентированных аспектах.
Например, для справочников есть возможность одним флажком включить поддержку иерархии. При этом система обеспечит поддержку иерархических справочников во всем: в пользовательском интерфейсе, в отчетах, в объектной модели.
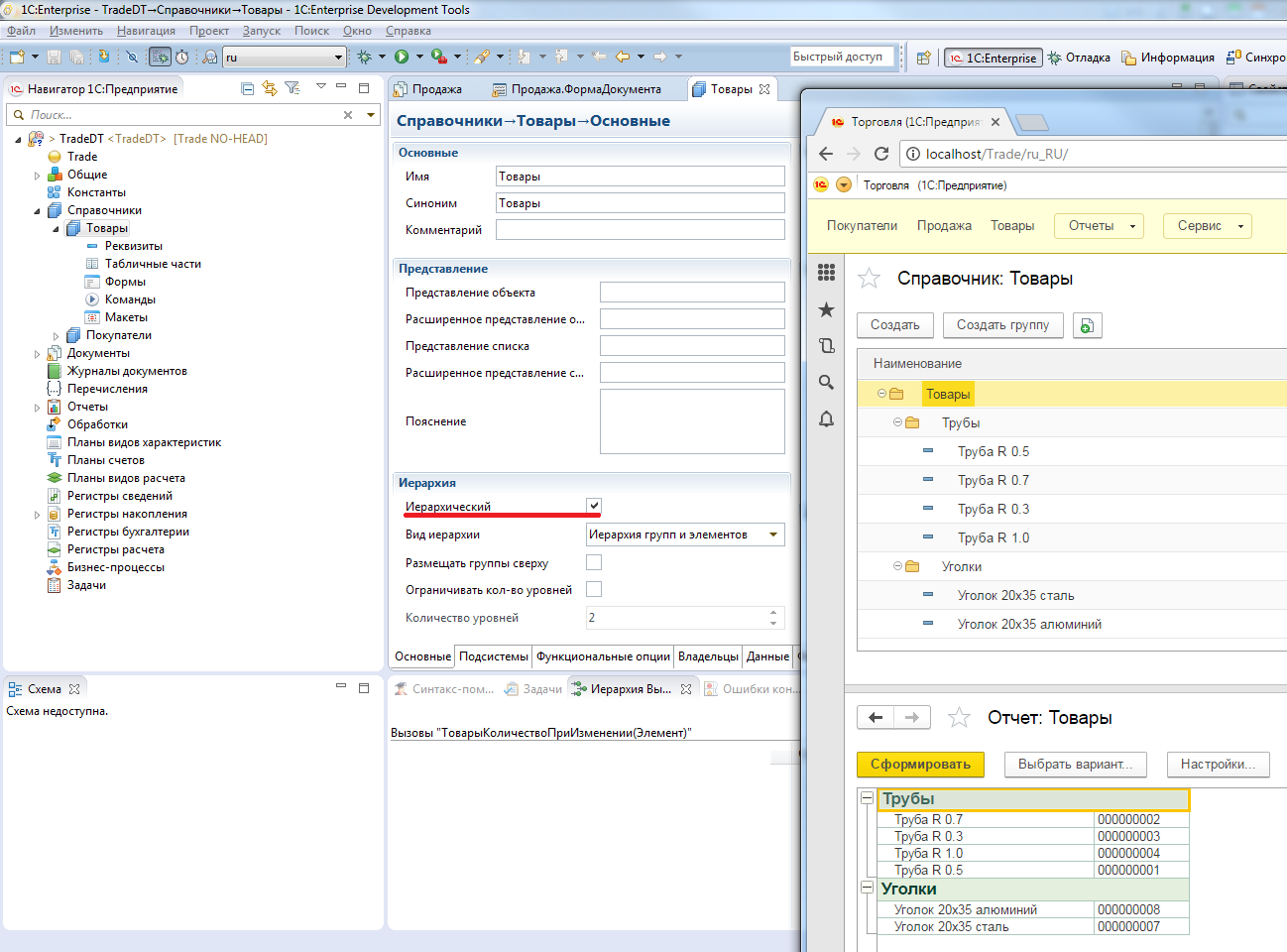
Установка одного свойства справочника «Иерархический справочник» сразу поддерживает иерархию в пользовательском интерфейсе, в отчетах, в объектной модели.
Для документов существуют такие возможности, как журналы, объединяющие несколько типов документов, сквозная нумерация в разрезе периодов и т.д.
Для регистров накопления наиболее важной возможностью является автоматическое хранение рассчитанных итогов и готовые виртуальные таблицы для доступа к итогам в различных разрезах и с учетом периодичности.
То есть, по сути, в типы прикладных объектов заложена существенная часть универсальных (типовых) механизмов бизнес-логики приложения, характерных для соответствующей категории данных предметной области.
Получается, что разработчик собирает приложение из объектов выбранных типов, как из деталей конструктора. Причем, если бывают конструкторы с «абстрактными» деталями, то в нашем конструкторе детали уже с «назначением» — колеса, окна, двери…
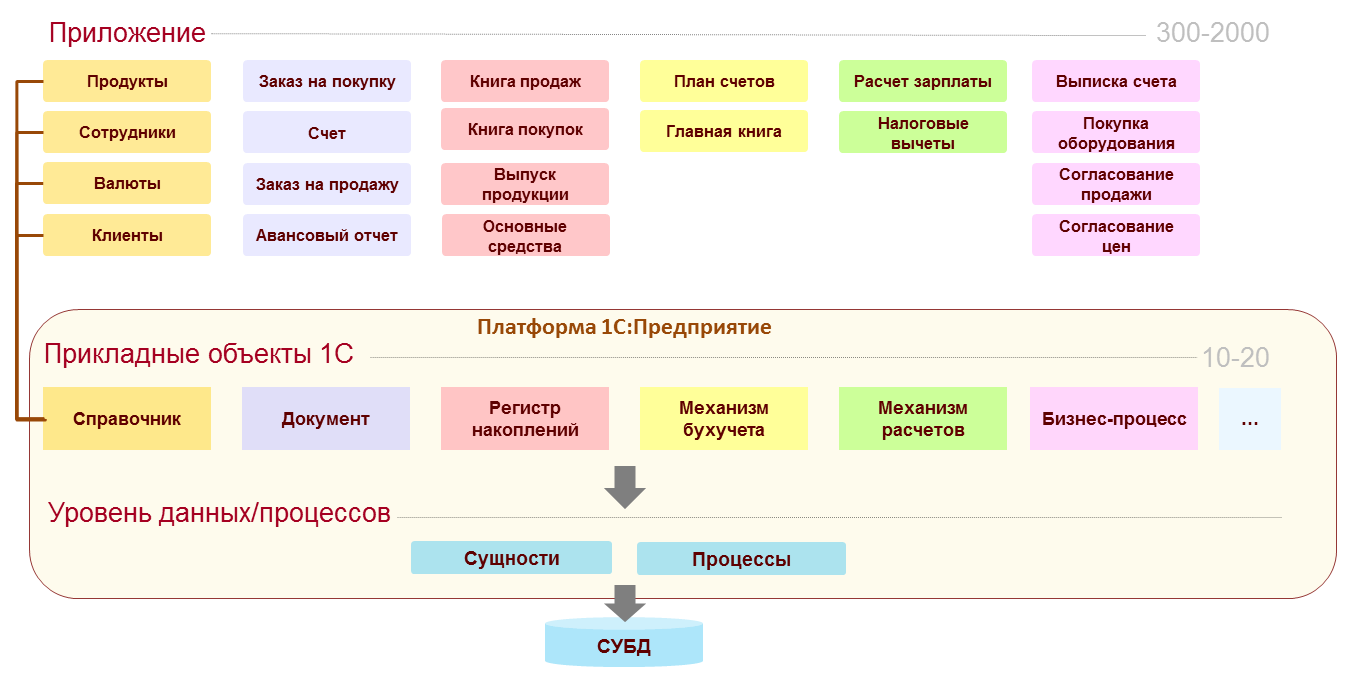 На основе типа «Справочник» разработчик строит справочники продуктов, сотрудников, валют, клиентов; на основе типа «Документ» — документы «Заказ на покупку», «Счет», «Заказ на продажу» и т.д.
На основе типа «Справочник» разработчик строит справочники продуктов, сотрудников, валют, клиентов; на основе типа «Документ» — документы «Заказ на покупку», «Счет», «Заказ на продажу» и т.д.Еще стоит сказать про методологическую ценность такого подхода. Все разработчики оперируют некоторым набором понятий, который помогает им лучше понимать суть приложений, упрощает общение. Открыв незнакомый проект 1С:Предприятия разработчик сразу видит знакомые понятия и может быстро разобраться в том какую роль в системе играет тот или иной объект. Например, чтобы понять суть приложения, стоит посмотреть на состав регистров – обычно она отражает основное назначение приложения. Если открыть структуру таблиц или, тем более, структуру классов незнакомого приложения написанного на инструментах, оперирующих таблицами и классами, то понимания будет существенно меньше.
Но, что еще важно, такой подход сближает язык разработчиков и представителей бизнеса (или аналитиков). Про необходимость наличия такого языка хорошо сказано в книге «Предметно-ориентированное проектирование (DDD). Структуризация сложных программных систем» Эрика Эванса. Типы прикладных объектов достаточно быстро становятся понятными не-программистам, и это позволяет обсуждать аналитикам, заказчикам и разработчикам основную функциональность проекта на одном языке. Часто можно встретить представителей бизнеса или аналитиков, которые не владеют программированием, но могут поставить задачу в терминах типов прикладных объектов 1С:Предприятия.
Что еще интересно. Этот подход обеспечивает постоянное развитие системы. Мы добавляем в платформу новые механизмы, и они сразу начинают работать для уже существующих объектов (без усилий разработчика приложений или с минимальными усилиями). Например, недавно мы разработали механизм хранения истории данных (версионирования). Так как система знает в общем виде о семантике данных, то разработчику достаточно поставить флажок, что он хочет хранить историю данных конкретного объекта, и платформа обеспечивает все, что нужно, от хранения истории, до визуализации — отображения пользователю истории изменений в виде различных отчетов. Когда ранее мы разработали механизм стандартного REST интерфейса (на основе стандарта OData), то во всех приложения сразу появился готовый REST интерфейс. Разработчикам ничего не пришлось для этого дорабатывать.
Почему мы не делаем еще и «просто таблицы» (в дополнение к готовым типам прикладных объектов)? Это непростой вопрос. Мы сами себе его периодически задаем.
С одной стороны это кажется заманчивым. Так мы бы закрыли все спорные случаи, когда предметная область не идеально ложится в заготовленный нами набор типов прикладных объектов. Можно было сказать разработчикам – «ну вот тебе просто таблица – и делай в ней все, как сам хочешь». Но с другой стороны это приведет к тому, что все наши стандартные механизмы будут пребывать «в растерянности» — как им обходиться с этими таблицами? Ведь они не будут знать семантику этих данных и не смогут понять, как с ними правильно работать. Ну, то есть с ними можно работать «как-то». Строго говоря, у нас есть такой опыт в части внешних источников. Для внешних источников мы описываем у себя именно таблицы (не указывая предметную направленность). И система с ними работает некоторым универсальным образом – при этом не поддерживается часть функциональности.
Пока мы все-таки стараемся удержаться от введения «просто таблиц», чтобы обеспечить чистоту модели и возможность добавлять новую функциональность, опираясь на знание о семантике всех данных. Если каких-то возможностей не будет хватать, то вначале мы все-таки будем рассматривать то, как можно развить состав типов прикладных объектов. Но, конечно, это вопрос дискуссионный, и мы будем продолжать про него думать.
Таким образом, возможности, которые предоставляет в готовом виде платформа 1С:Предприятия, и то повышение уровня абстракции, которое ценится прикладными разработчиками, во многом опираются именно на набор типов прикладных объектов. Это является одним из наиболее существенных отличий 1С:Предприятия от других средств разработки и одним из главных инструментов, обеспечивающих быструю и унифицированную разработку.
Комментарии (56)

Anderson
25.07.2017 12:26Лично нам зачастую не хватает просто таблиц. Платформа не дает возможности писать запросы на изменение (update). Даже регистр сведений при работе с ним как с набором записей (когда условие отбора можно свести к равенству) при записи делает в СУБД не update, а delete и insert. Соответственно при длительном выполнении операции другие сеансы видят то пропадающие, то появляющиеся данные.
erwins22
25.07.2017 12:38это не связано с версионностью базы данных?
Anderson
25.07.2017 12:42не думаю. в профайлере видим delete from… после этого записи исчезают. после завершения insert записи появляются. пишется набор записей с >10К записей
upd: чтение в другом сеансе не в транзакции. соответственно управляемые блокировки не используются (да и не хочется ожидание)ThinkingStone
25.07.2017 14:52Т.е. в другом сеансе режим read uncommited. Если не ошибаюсь, платформа так умеет только в режиме автоматических блокировок, а этот режим в типовых давно не используется. Да и вообще, deprecated :)
Anderson
25.07.2017 15:03Так ведь блокировки работают только в транзакции. Если чтение выполняется не в транзакции, блокировка не устанавливается
ThinkingStone
25.07.2017 15:28У вас, видимо, read_committed_snapshot не используется. В таком случае да, будет грязное чтение. Иначе при открытии справочника, например, все бы «повисло»

OlegZH
25.07.2017 13:38Может быть, это и хорошо. Определённые ограничения на действия программиста должны обеспечить целостность конструкции. Другое дело, что это оборачивается не такой эффективностью вычислений, какой можно было бы добиться при помощи явного составления прямых запросов к БД и применения оптимизации. За всё приходится платить.
Но!
Всегда есть вероятность того, что при ином построении конфигурации какие-то вещи станет выполнять проще. Возникает вопрос: а что это за задача такая, где необходимо переписывать содержимое регистра?Anderson
25.07.2017 13:48Задача специфическая (как и всегда :-)). По многим филиалам заполняется срез определенных данных и стекается в центральный офис. Срез удобнее формировать, т.к. для конкретной задачи история не важна, а само получение данных из вспомогательных занимает слишком продолжительное время. Записывать этот срез
удобнее набором записей, а не по записи. Вот и получается, что в момент обновления пользователь в динамическом списке видит, что данные пропали.OlegZH
25.07.2017 14:10+1Зачем здесь нужно переписывать содержимое регистра? Зачем нужен UPDATE?
Anderson
25.07.2017 15:00Не совсем понял вопрос… Данные обновляются периодически. update решил бы проблему с тем, что запрос на чтение не возвращает данные до того момента как будет выполнена запись.
Это касается и перепроведения документов, в случае очистки движений. запрос в другом сеансе видит исчезновение записейOlegZH
25.07.2017 21:51Я думал, что такие проблемы решаются на уровне СУБД. По моим (правда, сильно устаревшим) представлениям, регистры более всего «заточены» именно под постоянное добавление новых данных. Да, регистры сведений предусматривают перезапись. Но без полного и точного описания Вашей конкретной ситуации, трудно понять, что лучше всего следует делать. Может быть, Вам нужны периодические регистры (регистры с отметкой времени в качестве одного из измерений), чтобы запросы всегда получали актуальную информацию на момент запроса? Может быть, и отмена проведения не потребуется — я не знаю.
OlegZH
25.07.2017 14:08Что еще интересно. Этот подход обеспечивает постоянное развитие системы. Мы добавляем в платформу новые механизмы, и они сразу начинают работать для уже существующих объектов (без усилий разработчика приложений или с минимальными усилиями). Например, недавно мы разработали механизм хранения истории данных (версионирования). Так как система знает в общем виде о семантике данных, то разработчику достаточно поставить флажок, что он хочет хранить историю данных конкретного объекта, и платформа обеспечивает все, что нужно, от хранения истории, до визуализации — отображения пользователю истории изменений в виде различных отчетов.
Здорово. А как это выглядит на практике? Речь идёт, например, о конкретном справочнике, или об объекте, который описывается отдельной строкой-записью в этом справочнике?Пока мы все-таки стараемся удержаться от введения «просто таблиц», чтобы обеспечить чистоту модели и возможность добавлять новую функциональность, опираясь на знание о семантике всех данных. Если каких-то возможностей не будет хватать, то вначале мы все-таки будем рассматривать то, как можно развить состав типов прикладных объектов. Но, конечно, это вопрос дискуссионный и мы будем продолжать про него думать.
Не надо вводить «просто таблицы». Лучше попытаться вести новые типы данных (объекты конфигурации): «НаборДанных» (для хранения самих неструкутрированных изначально данных), «МодельДанных» (для описания принципов хранения: «ключ-значение», «документ», «расширяемая запись» и т.д. и т.п.) и «РегистрМетаданныхНаборовДанных» (для описания конкретных обрабатываемых в системе данных). Для решения каждой задачи создаётся свой набор данных, выбирается для него модель, формируется своя схема данных, которая отражается в регистре. Возможно, здесь потребуется принципиально новый объект конфигурации, вроде того, который был нужен Almet'у: справочник со свойствами регистра. Здесь нужна возможность доступа по ключу (по определённой системе «разрезов»), но и возможность ссылки на объект справочника. Получается, что мы, как бы, сначала заглядываем к регистр (со связкой ключей-измерений), чтобы узнать уникальный линейный код объекта, и уже из простого линейного справочника берём всё остальное.Таким образом, возможности, которые предоставляет в готовом виде платформа 1С: Предприятия и то повышение уровня абстракции, которое ценится прикладными разработчиками, во многом опираются именно на набор типов прикладных объектов. Это является одним из наиболее существенных отличий 1С: Предприятия от других средств разработки и одним из главных инструментов, обеспечивающих быструю и унифицированную разработку.
А кто они, конкуренты? Тут одно из двух: либо конкурентов нет, потому как 1С — практически единственная компания, которая использует подход, основанный на типологии прикладных объектов, либо такой подход используется другими компаниями, но в других областях, и, поэтому, прямой конкуренции не получается. Выбранный подход кажется вполне естественным. Вроде бы, все должны заниматься этим. Может быть, всему виною ниша, выбранная 1С, и заблуждение большинства пользователей и разработчиков, что подход 1С — это удел только учётных систем? Ведь, самый главный вопрос разработки программного обеспечения — это то, какова модель управления данными. Если есть подход у правлению, то он общезначим и относится ко всем случаям и ситуациям. ЯТД.
PeterG
25.07.2017 14:11Здорово. А как это выглядит на практике? Речь идёт, например, о конкретном справочнике, или об объекте, который описывается отдельной строкой-записью в этом справочнике?
Об объекте, который описывается отдельной строкой-записью. В статье довольно подробно описано.OlegZH
25.07.2017 21:59Спасибо. Очень информативно.

babylon
26.07.2017 07:05-41C к сожалению, традиционно страшно близок индустриальной к массовке и как следствие, находясь всегда в хвосте современных трендов, выбирает морально устаревшие архитектурные решения. А лучшим решением является — $mol: reactive micromodular ui-framework. Причём Tree уделывает JSON и XML на один два и три, используя контекстную типизацию. Чего у них нет… по нотации :)))
PeterG
26.07.2017 09:41Есть успешные примеры реализации бизнес-софта на этом лучшем архитектурном решении?
babylon
27.07.2017 10:05-3Не имею понятия. Имелась ввиду идейная составляющая.
Как можно не использовать таблицы ??? Таблица не versus модели. Заголовком вы показали или скрыли: О)))) свой уровень одинэсника. ПТУ отдыхает.
PeterG
27.07.2017 10:20+2Не имею понятия. Имелась ввиду идейная составляющая.
Идея может казаться сколь угодно прекрасной, но если с помощью её нет успешных реализаций требуемых задач — есть сомнения, что идея подходит для решения задач из данной предметной области.
Как можно не использовать таблицы ??? Таблица не versus модели. Заголовком вы показали или скрыли: О)))) свой уровень одинэсника. ПТУ отдыхает.
Не буду отвечать — не хочу опускаться с уровня своего ПТУ до вашего уровня.
PeterG
25.07.2017 15:02+1А кто они, конкуренты?
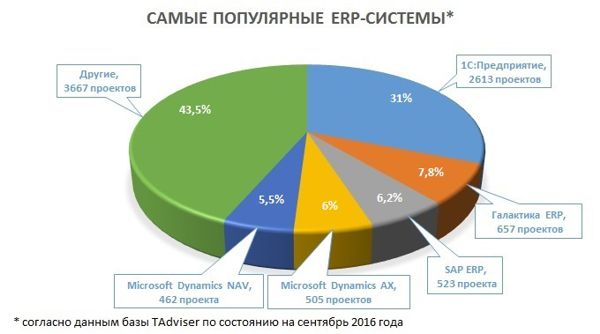
Давайте посмотрим сюда. Например, на диаграмму из первой ссылки: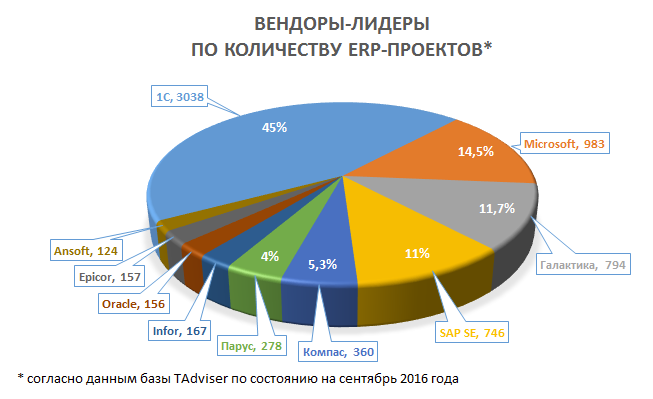
Собственно, вот и конкуренты.
А используют ли они подход, основанный на типологии прикладных объектов, или какой-то другой — конкурентами они от этого быть не перестанут.OlegZH
25.07.2017 22:05Картинка красивая, но вызывает чувства противоречивые. С одной стороны, хочется присоединиться к лидеру. С другой — потеснить его. Если говорит серьёзно, то с чем в этом списке присутствует Microsoft? Как это у них называется? Аксапта? Навижн? А Oracle? Ещё я слышал когда-то о Компасе. У них тоже, вроде, есть какая-то своя типология объектов предметной области?
PeterG
25.07.2017 22:36Если говорит серьёзно, то с чем в этом списке присутствует Microsoft?
Есть Navision; недавно появилась облачная версия.
Есть Axapta.
Есть еще Solomon и Great Plains, но об их внедрениях в России я пока не слышал.
Есть еще Microsoft CRM, но тут речь про ERP продукты, CRM к ним вроде бы не относится. Хотя составители графика могли и CRM учесть.
А Oracle?
Есть Oracle E-Business Suite, есть еще Oracle Commerce, Oracle Retail, Micros и т.д…
Ещё я слышал когда-то о Компасе.
Про Компас знаю пока очень мало. Если у вас есть ссылки на профильные материалы — буду благодарен.
Про продукты Epicor знаю побольше — ранее работал в этой компании. Типологии предметной области (по крайней мере в Epicor и iScala) нет, подход к разработке прикладного кода скорее классический.
PeterG
27.07.2017 14:51А вот картинка — с какими продуктами компании присутствуют на рынке (из этой статьи):
Serginio1
25.07.2017 15:26Кстати о таблицах и запросах. Почему не используется стандарт SQL. Сейчас запросы не соответствуют даже SQL-92. Exists. Есть только IN. Нет скалярных подзапросов. Уже куча языков поддерживает OFFSET,FETCH итд.
Кроме того при записи документов регистров не используется аналог Merge. А именно удаляется весь старый набор, даже если там изменена одна запись и записывается новый набор.Serginio1
25.07.2017 15:30Просто если взят тот же Linq to EF с их ограничениями на модель, но там язык более продвинутый Linq to EF. Практика использования. Часть III

ZEEGIN
25.07.2017 17:50При проведении документов поведение удаления движений можно настраивать.
— Удалять автоматически при отмене проведения
— Удалять автоматически
— Не удалять автоматически
Стандарты SQL описывают запросы к реляционным базам, а запросы 1С — запросы к объектно ориентированной модели данных. Не правильно их сравнивать по возможностям.
Есть хоть один практически необходимый пример использования OFFSET или FETCH? Или может быть Вы с помощью запросов сделать пытаетесь то, что решается архитектурно иначе?Serginio1
26.07.2017 11:19Еще раз про удаление.
У тебя есть набор в котором изменена 1 запись. Как этот набор запишется?
OFFSET или FETCH нужны для постраничного получения данных для сайтов и прочих выборок
Serginio1
26.07.2017 11:23Кстати я не зря привел ссылку на Linq to EF. Там как раз идеология та же самая, а возможностей больше. При этом в отличии от 1С обращение к выборкам результата еще и типизировано.
Хотелось бы еще и аннотацию типов как в TypeScript

Noa69
25.07.2017 16:28+1Интересная картина получается, модель затачивается исключительно под «быструю разработку», принося в жертву производительность, и даже возможность как бы то ни было повлиять на эту производительность программными методами, вынуждая закидывать проблемы деньгами: «купите железо еще быстрее».
И самое интересное что этот подход работает: железо дешевле и проще приобрести чем разработчиков.ZEEGIN
25.07.2017 19:22+1Так этот подход не только у 1С. Посмотрите лекции Яндекса по python. Сейчас вся разработка сводится к быстрому получению результата и вводу его в продакшн, потому что бизнес требует быстрых и частых изменений, потому и для систем учета это особенно важно. Ну а если железо не помогает узкие места производительности можно вынести во внешние компоненты 1С, которые можно написать, например, на C++. Ну а проблемы с параллельностью обработки данных (например взаимоблокировки) вполне успешно и средствами 1С решаются.
OlegZH
25.07.2017 22:20На мой чисто субъективный взгляд, возможность совместить быструю разработку и высокую производительность можно будет успешно решить только, если часть технологической платформы встроить в операционную систему (что кажется довольно логичным). Монолитность программного обеспечения порождает проблемы. Но ещё никто не сказал, что нельзя сделать само отображение предметной области на объектную модель данных эффективнее чем это сделано, например, в 1С.
В случае с 1С, правда, срабатывает ещё и такой аргумент: лучше медленная, но прозрачная и, значит, управляемая система с устоявшейся терминологией и устоявшимся рынком поддержки, чем шустрая система с постоянно меняющейся терминологией и без толковой службы поддержки. Я могу ошибаться, но, я думаю, что консерватизм нередко заставляет отказываться от более эффективного в пользу более привычного.
Arch0n
26.07.2017 10:27Конкуренты из SAP кстати так и делает, но об этом не принято говорить. Потому что там выходит в десятки раз дороже железки.
Я когда имел неосторожность работать в конторе которая внедряла в первую очередь SAP и 1С чтобы было… Там были постоянные гонения на 1С. На SAP стояли мощнейшие сервера, а под 1С предлагали использовать файловые сервера и еще постоянно сверху письма шли мол что это отдел 1С забил весь файловый сервер… Купили бы для 1С сервера как для SAP проблем бы не было. Как будто нам было охота на медленном файловом сервере гонять базы. А потом все ноют что 1С якобы медленная.

AMaxKaluga
25.07.2017 22:18Есть планы про расширению функционала отборов в наборах записей?
Сейчас условие сравнения только на равенство и только для измерений, хотя поля могут быть проиндексированы.
Из-за этого часто приходится делать запрос и молотить построчно через менеджер записи.
obelisk79
26.07.2017 09:46Я сильно далек от 1С, но хорошо знаю EMF. Смотрю вы на Эклипс перешли, так для моделей данных там как раз EMF имеется. Мэппинг в БД для него есть, сериализации разные тоже. Generic работа чере eSet/eGet/etc методы и т.д.
Arch0n
26.07.2017 11:10+2«Я сильно далек от 1С» я вот наоборот далек от «eSet/eGet/etc», но запомнил как пол года будучи уже 1Сником разрабатывал складскую программу на Дельфи под Файрбёрд. Так вот я потратил где-то 2 недели.
Но когда я попробовал повторить все то же самое на 1С у меня ушло 4 часа. И все благодаря объектной модели 1С (тогда ее семерки). В те времена было вообще не принято в 1С знать как реально лежат данные. И вы хотите чтобы наоборот замедлилась разработка, но зато по было все по стандартам из других языков программирования?

ErshoffPeter
26.07.2017 09:46мы говорим не о техническом аспекте хранения и манипулирования данными, а об описании данных как способе проектирования приложения
— а как оптимизировать доступ к данным при большом их количестве? Понятно, что вы упростили жизнь себе, как архитекторам системы, но усложнили жизнь DBA и эксплуатантам!ZEEGIN
26.07.2017 11:52А чем усложнили то? И террабайтные базы 1С работают вполне себе шустро. Я бы сказал, что в некоторых моментах dba проще, чем с другими системами, т.к. им не надо задумываться об индексах, о полнотекстовом поиске, это все в зоне ответственности архитекторов 1С. Так же как и оптимизация планов выполнения запросов и установка управлчемых блокировок.
ErshoffPeter
26.07.2017 12:23Насколько я знаю, вопросы оптимизации запросов в базах 1С стоят остро. Размер базы ещё не определяет потенциальные проблемы с быстродействием.Прежде всего проблемы с кастомными отчётами, выгрузками в хранилище данных и так далее.
OlegZH
26.07.2017 14:50+1Почему-то вспоминается совет-наставление, которое давали на курсах по 1С: структура регистров должна быть заточена под будущие отчёты: каковы отчёты, таковы и должны быть регистры. Если есть возможность предусмотреть специальный регистр, который помогает составлять некоторый отчёт, то этот регистр обязательно нужно создавать. Ну и, конечно, никому не помешает универсальный совет: составляйте изначально максимально оптимальные запросы к базе данных. Если есть возможность сделать внешнее соединение, то его обязательно нужно сделать. Была бы таблица (например, регистр), а соединение найдётся.
ZEEGIN
26.07.2017 15:37Пишите запросы для отчетов и выгрузок оптимально. Не можете написать оптимально? Меняйте архитекутуру хранения данных, чтобы написать оптимально.
90% проблем быстродействия связаны с некомпетентностью людей, предлагающих кастомные решения.

kxl
27.07.2017 01:29+2мой совет — улучшайте встроенный язык, всё равно ни один бухгалтер в конфигуратор не полезет, а простота языка должна остаться в прошлом… и отучите разработчиков типовых конфигураций писать процедуры на несколько сотен, а то и тысяч строк!

Neikist
27.07.2017 12:38+2+1 Все таки не хватает функций первого класса и анонимных функций, концепция для прикладного программиста проста (если не мудрить), но возможностей дает очень много…


x_shader
27.07.2017 10:15А как, например, из регистра накоплений производится выгрузка в таблицы фактов DWH? Это проблема интерфейса на стороне Data Integration Tool, которым будут забирать данные, или у вас есть что-то готовое для прямой интеграции (не через файлы и т.п.)?
Сорри, не сталкивался с 1С.ZEEGIN
27.07.2017 11:02Выгружать данные в какую либо отчетную систему непосрндственно не кажется правильным. Ведь та структура данных, которая положена в 1С, сделана такой для внутренних отчетов или механизмов контроля учета (например остатков) самого 1С. Отчетной системе, консолидирующей данные из разных источников, в т.ч. из 1С, может требоваться иная структура данных для формирования своих отчетов. В первую очередь следует провести сопоставление данных и формально описать правило конвертации одной строки записи 1С в строку записи таблицы DWH. Создать в 1С план обмена, в который будет включен узел, соответствующий базе данных отчетов. Включить для этого плана обмена регистрацию изменений для выгружаемой таблицы. Таким образом все новые или удаленные записи будут записаны к отправке. Далее каким либо образом DWH будет инициировать обмен, запрашивая, есть ли для нее новые данные в 1С, например можно поднять веб-сервис SOUP или HTTP прям из 1С. 1С в ответ будет формировать пакет данных, требуемый для базы отчетов. Каждый пакет должен иметь уникальный номер и после загрузки база отчетов должна послать коммит подтверждения загрузки в себя данных, после чего 1С сможет удалять у себя данные из таблицы изменений (снимать записи с регистрации) отправленные по тому номеру сообщения, который приняла база отчетов. Где будет происходить конвертация строк, в 1С или в базе отчетов не так важно, это скорее зависит от того, где дешевле выполнять доработки ззаказчику при необходимости расширить функционал.
Все перечисленные работы вполе реально сделать в одиночку за неделю. Включая составление документации и пром. тестирование.
x_shader
27.07.2017 17:14>> В первую очередь следует провести сопоставление данных и формально описать правило конвертации одной строки записи 1С в строку записи таблицы DWH.
Здесь же речь об одной строке записи прикладного объекта 1С?
>> Создать в 1С план обмена, в который будет включен узел, соответствующий базе данных отчетов. Включить для этого плана обмена регистрацию изменений для выгружаемой таблицы. Таким образом все новые или удаленные записи будут записаны к отправке.
А есть где-то описание механизма на стороне 1С? Best practice какой-нибудь? С чего стоит начать разбираться в вопросе ETL-щику, который не работал с 1С? Хочется понимать, как люди это делают правильно.
Google говорит, народ инициирует на стороне 1С выгрузку в буферную таблицу/файл, а оттуда уже забирает в DWH. Но все-равно придется как-то бить на серии «новые/обновленные/старые записи».ZEEGIN
27.07.2017 17:51Здесь же речь об одной строке записи прикладного объекта 1С?
Да. Надо для одной строки записи (справочник, документ, регистр сведений или накопления или что-то еще) определить какие его измерения, реквизиты, ресурсы как должны перейти в колонки таблицы базы отчетов. Учитывая типы измерений, будет ли потеря данных, например при конвертации строк размерностью 130 символов в строки размерностью 100, или трита (булево+null) в простое булево и т.д. — это задача аналитика, который должен знать какие данные нужны для формирования отчета в базе отчетов.Не очень понятно зачем делать какие-то буферные таблицы или файлы, когда сама платформа предлагает для этого механизм планов обмена. На низком уровне происходит так:
Если нужно выпонять какой-то тип обмена с другой системой, разработчик создает новый план обмена и включает в него те объекты 1С, которые должны передаваться в другую систему. Для каждого такого объекта платформа сама создаст таблицу изменений, в которую будет включен идентификатор записи (для справочников и документов, например — это ссылка, а для регистров — это ключ записи) и будет включен узел, в который необходимо отправить данные.
При записи объекта (например при изменении номенклатуры или создании нового документа) если для объекта есть таблица изменений, то он будет там зарегистрирован к отправке (само по себе это платформа выполняет автоматически, однако программно регистрировать и снимать с регистрации тоже можно).
Если есть несколько разных отчетных баз одного типа, то для них достаточно сделать один план обмена в котором уже в режиме предприятия создать несколько узлов, для каждой отчетной базы свой узел. Система благодаря своей структуре таблицы изменений для каждого узла будет регистрировать данные отдельно.
План обмена так же включает в себя по умолчанию номера принятых и отправленных сообщений, это необходимо для подтверждения доставки. Чтобы избежать таких случаев, когда данные в отчетную систему были отправлены, но при этом отчетная база их не приняла. При следующем обмене отправляться будут в том числе и те записи, которые отчетная база не приняла ранее, чтобы гарантировать целостность передачи. Для этого и вводится дополнительная операция — коммит подтверждения доставки. Когда 1С отправляет какие-либо данные она в таблице изменений сохраняет тот номер пакета сообщения, который она отправила и в дальнейшем когда отчетная система пришлет коммит о том, что она этот номер сообщения приняла, 1С может со спокойной совестью снять все данные с регистрации, отправленные по этому номеру сообщения.
Если обмен является двухсторонним, то обычно коммитом является получение пакета из другой базы, если обмен односторонний (как это с выгрузкой в отчетную базу) достаточно реализовать операцию подтверждения).
Сам способ отправки может быть любым. Можно создать регламентное задание, которое будет из 1С по расписанию выгружать данные в стороннюю систему, можно выгружать в файлы, можно записывать непосредственно в базу приемник (все равно какая, 1С может записывать и MySQL, MSSQL, Postgres, Oracle, IBM DB2, вообще во все, для чего есть драйвер подключения к этой базе.
Но делать непосредственные выгрузки так же как инициировать обмен из 1С — это не самая хорошая практика, лучше, когда данные запрашивает та система, которой эти данные нужны. Так же как записывать куда то в стороннее хранилище данные непосредственно тоже не очень правильно, ведь структура данных и в 1С и в сторонней базе может со временем измениться, бизнес требует частых доработок. Потому правильным считается приведение сначала к общему формату обмена, и после отправку и приемку.
Опять же что это будет за формат — не очень важно для 1С, это может быть XML, JSON, какой-то бинарный файл или просто текстовый (тот же CSV) формат, главное чтобы приемная база могла его понять и формат был согласован.
Протокол отправки то же не очень важен, сторонняя система может просто стучаться по COM, на 1С может быть реализован веб-сервис по формату SOAP или сразу передавать ответ, выполнив запрос к 1С по HTTP, ровно как и выгружать в файл на диск или ftp. Тут скорее надо определить что из этого доступно в базе которая хочет интегрироваться с 1С.
Все механизмы подробно описаны в книжке
Профессиональная разработка в системе 1С: Предприятие 8
Так же многие нюансы описаны в книжке
Настольная книга 1С: Эксперта по технологическим вопросам
iliabvf
04.08.2017 15:17Интересно в 1С обращают внимание на море новых технологий и о том как они упращают разработку? Я не говорю про Java/C#, ведь есть уже JS фреймворки, объединяющие фронтенд и бэкенд. Что произойдет когда разработка бизнесс приложений на JS станет легче 1С Предприятия? Я не говорю о гитхабе и open-source сообществе, которые являются двигателем прогресса…
Понятно что на данный момент 1С прекрасно справляется со своими задачами, но что будет дальше? Ведь даже сам по себе язык 1С никак не эволюционировал, а работа с DB запрещена пользовательским соглашением. Все этот как бы идет против течения мирового тренда.PeterG
04.08.2017 15:41Что произойдет когда разработка бизнесс приложений на JS станет легче 1С Предприятия?
Значит, у нас появятся конкуренты.
Одного я уже знаю — Haulmont c платформой CUBA. На мой взгляд, там все еще на порядок сложнее разрабатывать бизнес-приложения, чем на 1С. Возможно, со временем это изменится.
Я не говорю о гитхабе и open-source сообществе, которые являются двигателем прогресса…
Enterprise Development Tools позволяет хранить исходные коды конфигураций в Github. Или вы имеете в виду что-то другое?
Все этот как бы идет против течения мирового тренда.
А в какую сторону течет мировой тренд? Можете обрисовать?erwins22
04.08.2017 19:14+1Язык 1с неплох пока не столкнешься с фоновыми заданиями.
отсутствие await и лямбд делает программирование «сексуально» не привлекательным, особенно для мобильных приложений или той же Розницы с колбеками.
Кроме того пора уже идти в сторону необязательной типизации «функция а(в как строка) как строка»
и дать механизм аналогичный тексовым запросам ввиде функции filter, map, fold (LINQ), не как сейчас сделано «для галочки», а удобно и с поддержкой среды и добавить туда например добавление нарастающего итога благо это есть во всех новых языках, а одинесников избавит от кучи кода и т д.
Кроме того хотелось бы иметь механизм правил обмена реализованный в мобильном приложении, да я извращенец, но когда надо быстро что то наклепать не хочется полдня заниматься "____".
Almet
1С конечно хороший продукт для разработки прикладных учетных программ, но бесполезен при создании чего-то особенного, например, нельзя создать собственный объект, например, справочник со свойствами регистров, приходится выкручиваться через «связку» этих объектов
Provlax
Почему вам нужно что-то особенное создавать на 1С? Система же, как раз для разработки прикладных учетных программ. Никто вроде не заявляет, что она универсальная и ставить ей это в минус как минимум странно.
OlegZH
Да, 1С специально предназначен для для разработки прикладных учетных программ. Хотя, если смотреть на продукты 1С, то становится ясно, что на базе одной и той же технологической платформы можно создавать конфигурации для довольно широкого круга задач. Довольно много вещей хорошо укладывается в «прокрустово ложе» заданных объектов конфигурации (справочников, документов, регистров, обработок).
Ваш вопрос относительно справочника со свойствами регистра обоюдоострый.
С одной стороны, всё это упирается в необходимость менять технологическую платформу. Это возможно. Либо нужно вводить дополнительный уровень абстракции, чтобы иметь собственный «конфигуратор» для технологической платформы. Либо существенно дополнить список допустимых объектов теми объектами, которые естественным образом возникают при решении задач, отличных от задач учёта. Состав объектов конфигурации завязан на учётные задачи, но работу по выявлению новых объектов конфигурации можно продолжить и довести до своего логического конца. Но, боюсь, это приведёт к необходимости делать такую продвинутую технологическую платформу частью операционной системы.
Представьте, что будет, если сделать операционную системы чем-то вроде 1С. Это будет означать, что прикладные программисты будут иметь дело только с объектами конфигурации (им не надо будет иметь дело даже с файлами, если операционная система сама будет документно-ориентированной!).
С другой стороны, Ваше желание совместить в одном объекте разные функции разрушает сам подход к организации объектов конфигурации. Смысл подхода заключается именно в том, чтобы каждый объект решал свою задачу. Если хотите, то тут возникает что-то вроде ортогонализации Грамма-Шмидта, которая позволяет перейти от любой линейно независимой системы векторов к ортонормированной системе, в которой скалярные произведения записываются наиболее просто без смешения разноименных элементов. Если бы кто-нибудь сумел проделать аналогичный процесс в программировании, то мы могли бы собирать любые приложения из кубиков-компонентов.