
 Эта статья представляет собой адаптацию разделов 2 и 3 из главы 9 моей книги «Глубинное обучение с Python» (Manning Publications).
Эта статья представляет собой адаптацию разделов 2 и 3 из главы 9 моей книги «Глубинное обучение с Python» (Manning Publications).Статья рассчитана на людей, у которых уже есть значительный опыт работы с глубинным обучением (например, тех, кто уже прочитал главы 1-8 этой книги). Предполагается наличие большого количества знаний.
Ограничения глубинного обучения
Глубинное обучение: геометрический вид
Самая удивительная вещь в глубинном обучении — то, насколько оно простое. Десять лет назад никто не мог представить, каких потрясающих результатов мы достигнем в проблемах машинного восприятия, используя простые параметрические модели, обученные с градиентным спуском. Теперь выходит, что нужны всего лишь достаточно большие параметрические модели, обученные на достаточно большом количестве образцов. Как сказал однажды Фейнман о Вселенной: «Она не сложная, её просто много».
В глубинном обучении всё является вектором, то есть точкой в геометрическом пространстве. Входные данные модели (это может быть текст, изображения и т. д.) и её цели сначала «векторизируются», то есть переводятся в некое первоначальное векторное пространство на входе и целевое векторное пространство на выходе. Каждый слой в модели глубинного обучения выполняет одно простое геометрическое преобразование данных, которые идут через него. Вместе, цепочка слоёв модели создаёт одно очень сложное геометрическое преобразование, разбитое на ряд простых. Эта сложная трансформация пытается преобразовать пространство входных данных в целевое пространство, для каждой точки. Параметры трансформации определяются весами слоёв, которые постоянно обновляются на основании того, насколько хорошо модель работает в данный момент. Ключевая характеристика геометрической трансформации — то, что она должна быть дифференцируема, то есть мы должны иметь возможность узнать её параметры через градиентный спуск. Интуитивно, это означает, что геометрический морфинг должен быть плавным и непрерывным — важное ограничение.
Весь процесс применения этой сложной геометрической трансформации на входных данных можно визуализировать в 3D, изобразив человека, который пытается развернуть бумажный мячик: смятый бумажный комочек — это многообразие входных данных, с которыми модель начинает работу. Каждое движение человека с бумажным мячиком похоже на простую геометрическую трансформацию, которую выполняет один слой. Полная последовательность жестов по разворачиванию — это сложная трансформация всей модели. Модели глубинного обучения — это математические машины по разворачиванию запутанного многообразия многомерных данных.
Вот в чём магия глубинного обучения: превратить значение в векторы, в геометрические пространства, а затем постепенно обучаться сложным геометрическим преобразованиям, которые преобразуют одно пространство в другое. Всё что нужно — это пространства достаточно большой размерности, чтобы передать весь спектр отношений, найденных в исходных данных.
Ограничения глубинного обучения
Набор задач, которые можно решить с помощью этой простой стратегии, практически бесконечен. И все же до сих пор многие из них вне досягаемости нынешних техник глубинного обучения — даже несмотря на наличие огромного количества вручную аннотированных данных. Скажем, для примера, что вы можете собрать набор данных из сотен тысяч — даже миллионов — описаний на английском языке функций программного обеспечения, написанных менеджерами продуктов, а также соответствующего исходного года, разработанного группами инженеров для соответствия этим требованиям. Даже с этими данными вы не можете обучить модель глубинного обучения просто прочитать описание продукта и сгенерировать соответствующую кодовую базу. Это просто один из многих примеров. В целом, всё что требует аргументации, рассуждений — как программирование или применение научного метода, долговременное планирование, манипуляции с данными в алгоритмическом стиле — находится за пределами возможностей моделей глубинного обучения, неважно сколько данных вы бросите в них. Даже обучение нейронной сети алгоритму сортировки — невероятно сложная задача.
Причина в том, что модель глубинного обучения — это «лишь» цепочка простых, непрерывных геометрических преобразований, которые преобразуют одно векторное пространство в другое. Всё, что она может, это преобразовать одно множество данных X в другое множество Y, при условии наличия возможной непрерывной трансформации из X в Y, которой можно обучиться, и доступности плотного набора образцов преобразования X:Y как данных для обучения. Так что хотя модель глубинного обучения можно считать разновидностью программы, но большинство программ нельзя выразить как модели глубинного обучения — для большинства задач либо не существует глубинной нейросети практически подходящего размера, которая решает задачу, либо если существует, она может быть необучаема, то есть соответствующее геометрическое преобразование может оказаться слишком сложным, или нет подходящих данных для её обучения.
Масштабирование существующих техник глубинного обучения — добавление большего количества слоёв и использование большего объёма данных для обучения — способно лишь поверхностно смягчить некоторые из этих проблем. Оно не решит более фундаментальную проблему, что модели глубинного обучения очень ограничены в том, что они могут представлять, и что большинство программ нельзя выразить в виде непрерывного геометрического морфинга многообразия данных.
Риск антропоморфизации моделей машинного обучения
Один из очень реальных рисков современного ИИ — неверная интерпретация работы моделей глубинного обучения и преувеличение их возможностей. Фундаментальная особенность человеческого разума — «модель психики человека», наша склонность проецировать цели, убеждения и знания на окружающие вещи. Рисунок улыбающейся рожицы на камне вдруг делает нас «счастливыми» — мысленно. В приложении к глубинному обучению это означает, например, что если мы можем более-менее успешно обучить модель генерировать текстовые описания картинок, то мы склонны думать, что модель «понимает» содержание изображений, также как и генерируемые описания. Нас затем сильно удивляет, когда из-за небольшого отклонения от набора изображений, представленных в данных для обучения, модель начинает генерировать абсолютно абсурдные описания.

В частности, наиболее ярко это проявляется в «состязательных примерах», то есть образцах входных данных сети глубинного обучения, специально подобранных, чтобы их неправильно классифицировали. Вы уже знаете, что можно сделать градиентное восхождение в пространстве входных данных для генерации образцов, которые максимизируют активацию, например, определённого фильтра свёрточной нейросети — это основа техники визуализации, которую мы рассматривали в главе 5 (примечание: книги «Глубинное обучение с Python»), также как алгоритма Deep Dream из главы 8. Похожим способом, через градиентное восхождение, можно слегка изменить изображение, чтобы максимизировать предсказание класса для заданного класса. Если взять фотографию панды и добавить градиент «гиббон», мы можем заставить нейросеть классифицировать эту панду как гиббона. Это свидетельствует как о хрупкости этих моделей, так и о глубоком различии между трансформацией со входа на выход, которой она руководствуется, и нашим собственным человеческим восприятием.
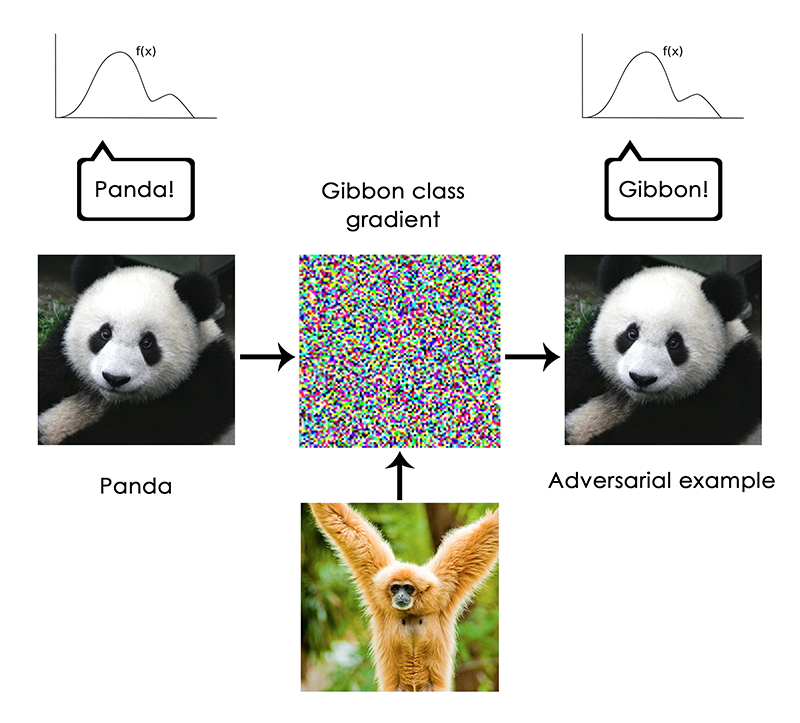
В общем, у моделей глубинного обучения нет понимания входных данных, по крайней мере, не в человеческом смысле. Наше собственное понимание изображений, звуков, языка, основано на нашем сенсомоторном опыте как людей — как материальных земных существ. У моделей машинного обучения нет доступа к такому опыту и поэтому они не могут «понять» наши входные данные каким-либо человекоподобным способом. Аннотируя для наших моделей большое количество примеров для обучения, мы заставляем их выучить геометрическое преобразование, которое приводит данные к человеческим концепциям для этого специфического набора примеров, но это преобразование является лишь упрощённым наброском оригинальной модели нашего разума, таким, какое разработано исходя из нашего опыта как телесных агентов — это как слабое отражение в зеркале.

Как практикующий специалист по машинному обучению, всегда помните об этом, и никогда не попадайте в ловушку веры в то, что нейросети понимают задачу, которую выполняют — они не понимают, по крайней мере не таким образом, какой имеет смысл для нас. Они были обучены другой, гораздо более узкой задаче, чем та, которой мы хотим их обучить: простому преобразованию входных образцов обучения в целевые образцы обучения, точка к точке. Покажите им что-нибудь, что отличается от данных обучения, и они сломаются самым абсурдным способом.
Локальное обобщение против предельного обобщения
Кажется, существуют фундаментальные отличия между прямым геометрическим морфингом со входа на выход, который делают модели глубинного обучения, и тем способом, как люди думают и обучаются. Дело не только в том, что люди обучаются сами от своего телесного опыта, а не через обработку набора учебных образцов. Кроме разницы в процессах обучения, есть фундаментальные отличия в природе лежащих в основе представлений.
Люди способны на гораздо большее, чем преобразование немедленного стимула в немедленный отклик, как нейросеть или, может быть, насекомое. Люди удерживают в сознании сложные, абстрактные модели текущей ситуации, самих себя, других людей, и могут использовать эти модели для предсказания различных возможных вариантов будущего, и выполнять долговременное планирование. Они способны на объединение в единое целое известных концепций, чтобы представить то, что они никогда не знали раньше — как рисование лошади в джинсах, например, или изображение того, что бы они сделали, если бы выиграли в лотерею. Способность мыслить гипотетически, расширять свою модель ментального пространства далеко за пределы того, что мы напрямую испытывали, то есть, способность делать абстракции и рассуждения, пожалуй, определяющая характеристика человеческого познания. Я называю это «предельным обобщением»: способность приспосабливаться к новым, никогда не испытанным ранее ситуациям, используя очень мало данных либо вовсе не используя никаких данных.
Это резко отличается от того, что делают сети глубинного обучения, что я бы назвал «локальным обобщением»: преобразование входных данных в выходные данные быстро прекращает иметь смысл, если новые входные данные хотя бы немного отличаются от того, с чем они встречались во время обучения. Рассмотрим, для примера, проблему обучения подходящим параметрам запуска ракеты, которая должна сесть на Луну. Если бы вы использовали нейросеть для этой задачи, обучая её с учителем или с подкреплением, вам бы понадобилось дать ей тысячи или миллионы траекторий полёта, то есть нужно выдать плотный набор примеров в пространстве входящих значений, чтобы обучиться надёжному преобразованию из пространства входящих значений в пространство исходящих значений. В отличие от них, люди могут использовать силу абстракции для создания физических моделей — ракетостроение — и вывести точное решение, которое доставит ракету на Луну всего за несколько попыток. Таким же образом, если вы разработали нейросеть для управления человеческим телом и хотите, чтобы она научилась безопасно проходить по городу, не будучи сбитой автомобилем, сеть должна умереть много тысяч раз в различных ситуациях, прежде чем сделает вывод, что автомобили опасны, и не выработает соответствующее поведение, чтобы их избегать. Если её перенести в новый город, то сети придётся заново учиться большей часть того, что она знала. С другой стороны, люди способны выучить безопасное поведение, не умерев ни разу — снова, благодаря силе абстрактного моделирования гипотетических ситуаций.

Итак, несмотря на наш прогресс в машинном восприятии, мы всё ещё очень далеки от ИИ человеческого уровня: наши модели могут выполнять только локальное обобщение, адаптируясь к новым ситуациям, которые должны быть очень близки к прошлым данным, в то время как человеческий разум способен на предельное обобщение, быстро приспосабливаясь к абсолютно новым ситуациям или планируя далеко в будущее.
Выводы
Вот что вы должны помнить: единственным реальным успехом глубинного обучения к настоящему моменту является способность транслировать пространство X в пространство Y, используя непрерывное геометрическое преобразование, при наличии большого количества данных, аннотированных человеком. Хорошее выполнение этой задачи представляет собой революционно важное достижение для целой индустрии, но до ИИ человеческого уровня по-прежнему очень далеко.
Чтобы снять некоторые из этих ограничений и начать конкурировать с человеческим мозгом, нам нужно отойти от прямого преобразования со входа в выход и перейти к рассуждениям и абстракциям. Возможно, подходящей основой для абстрактного моделирования различных ситуация и концепций могут быть компьютерные программы. Мы говорили раньше (примечание: в книге «Глубинное обучение с Python»), что модели машинного обучения можно определить как «обучаемые программы»; в данный момент мы можем обучать только узкое и специфическое подмножество всех возможных программ. Но что если бы мы могли обучать каждую программу, модульно и многократно? Посмотрим, как мы можем к этому придти.
Будущее глубинного обучения
Учитывая то, что мы знаем о работе сетей глубинного обучения, их ограничениях и нынешнем состоянии научных исследований, можем ли мы прогнозировать, что произойдёт в среднесрочной перспективе? Здесь несколько моих личных мыслей по этому поводу. Имейте в виду, что у меня нет хрустального шара для предсказаний, так что многое из того, что я ожидаю, может не воплотиться в реальность. Это абсолютные спекуляции. Я разделяю эти прогнозы не потому что ожидаю, что они полностью воплотятся в будущем, а потому что они интересны и применимы в настоящем.
На высоком уровне вот основные направления, которые я считаю перспективными:
- Модели приблизятся к компьютерным программам общего предназначения, построенных поверх гораздо более богатых примитивов, чем наши нынешние дифференцируемые слои — так мы получим рассуждения и абстракции, отсутствие которых является фундаментальной слабостью нынешних моделей.
- Появятся новые формы обучения, которые сделают это возможным — и позволят моделям отойти просто от дифференцируемых преобразований.
- Модели будут требовать меньшего участия разработчика — не должно быть вашей работой постоянно подкручивать ручки.
- Появится большее, систематическое повторное использование выученных признаков и архитектур; мета-обучаемые системы на основе повторно используемых и модульных подпрограмм.
Вдобавок, обратите внимание, что эти рассуждения не относятся конкретно к обучению с учителем, которое до сих пор остаётся основой машинного обучения — также они применимы к любой форме машинного обучения, включая обучение без учителя, обучение под собственным наблюдением и обучение с подкреплением. Фундаментально неважно, откуда пришли ваши метки или как выглядит ваш цикл обучения; эти разные ветви машинного обучения — просто разные грани одной конструкции.
Итак, вперёд.
Модели как программы
Как мы заметили раньше, необходимым трансформационным развитием, которое можно ожидать в области машинного обучения, является уход от моделей, выполняющих чисто распознавание шаблонов и способных только на локальное обобщение, к моделям, способным на абстракции и рассуждения, которые могут достичь предельного обобщения. Все нынешние программы ИИ с базовым уровнем рассуждений жёстко запрограммированы людьми-программистами: например, программы, которые полагаются на поисковые алгоритмы, манипуляции с графом, формальную логику. Так, в программе DeepMind AlphaGo бoльшая часть «интеллекта» на экране спроектирована и жёстко запрограммирована экспертами-программистами (например, поиск в дереве по методу Монте-Карло); обучение на новых данных происходит только в специализированных подмодулях — сети создания ценностей (value networks) и сети по вопросам политики (policy networks). Но в будущем такие системы ИИ могут быть полностью обучены без человеческого участия.
Как этого достичь? Возьмём хорошо известный тип сети: RNN. Что важно, у RNN немного меньше ограничений, чем у нейросетей прямого распространения. Это потому что RNN представляют собой немного больше, чем простые геометрические преобразования: это геометрические преобразования, которые осуществляются непрерывно в цикле
for. Временной цикл for задаётся разработчиком: это встроенное допущение сети. Естественно, сети RNN всё ещё ограничены в том, что они могут представлять, в основном, потому что каждый их шаг по-прежнему является дифференцируемым геометрическим преобразованием и из-за способа, которым они передают информацию шаг за шагом через точки в непрерывном геометрическом пространстве (векторы состояния). Теперь представьте нейросети, которые бы «наращивались» примитивами программирования таким же способом, как циклы for — но не просто одним-единственным жёстко закодированным циклом for с прошитой геометрической памятью, а большим набором примитивов программирования, с которыми модель могла бы свободно обращаться для расширения своих возможностей обработки, таких как ветви if, операторы while, создание переменных, дисковое хранилище для долговременной памяти, операторы сортировки, продвинутые структуры данных вроде списков, графов, хеш-таблиц и многого другого. Пространство программ, которые такая сеть может представлять, будет гораздо шире, чем могут выразить существующие сети глубинного обучения, и некоторые из этих программ могут достичь превосходной силы обобщения.Одним словом, мы уйдём от того, что у нас с одной стороны есть «жёстко закодированный алгоритмический интеллект» (написанное вручную ПО), а с другой стороны — «обученный геометрический интеллект» (глубинное обучение). Вместо этого мы получим смесь формальных алгоритмических модулей, которые обеспечивают возможности рассуждений и абстракции, и геометрические модули, которые обеспечивают возможности неформальной интуиции и распознавания шаблонов. Вся система целиком будет обучена с небольшим человеческим участием либо без него.
Родственная область ИИ, которая, по моему мнению, скоро может сильно продвинуться, это программный синтез, в частности, нейронный программный синтез. Программный синтез состоит в автоматической генерации простых программ, используя поисковый алгоритм (возможно, генетический поиск, как в генетическом программировании) для изучения большого пространства возможных программ. Поиск останавливается, когда найдена программа, соответствующая требуемым спецификациям, часто предоставляемым как набор пар вход-выход. Как видите, это сильно напоминает машинное обучение: «данные обучения» предоставляются как пары вход-выход, мы находим «программу», которая соответствует трансформации входных в выходные данные и способна к обобщениям для новых входных данных. Разница в том, что вместо значений параметров обучения в жёстко закодированной программе (нейронной сети) мы генерируем исходный код путём дискретного поискового процесса.
Я определённо ожидаю, что к этой области снова проснётся большой интерес в следующие несколько лет. В частности, я ожидаю взаимное проникновение смежных областей глубинного обучения и программного синтеза, где мы будем не просто генерировать программы на языках общего назначения, а где мы будем генерировать нейросети (потоки обработки геометрических данных), дополненные богатым набором алгоритмических примитивов, таких как циклы
for — и многие другие. Это должно быть гораздо более удобно и полезно, чем прямая генерация исходного кода, и существенно расширит границы для тех проблем, которые можно решать с помощью машинного обучения — пространство программ, которые мы можем генерировать автомтически, получая соответствующие данные для обучения. Смесь символического ИИ и геометрического ИИ. Современные RNN можно рассматривать как исторического предка таких гибридных алгоритмо-геометрических моделей.
Рисунок: Обученная программа одновременно полагается на геометрические примитивы (распознавание шаблонов, интуиция) и алгоритмические примитивы (аргументация, поиск, память).
За пределами обратного распространения и дифференцируемых слоёв
Если модели машинного обучения станут больше похожи на программы, тогда они больше почти не будут дифференцируемы — определённо, эти программы по-прежнему будут использовать непрерывные геометрические слои как подпрограммы, которые останутся дифференцируемыми, но вся модель в целом не будет такой. В результате, использование обратного распространения для настройки значений весов в фиксированной, жёстко закодированной сети не может оставаться в будущем предпочтительным методом для обучения моделей — по крайней мере, нельзя ограничиваться только этим методом. Нам нужно выяснить, как наиболее эффективно обучать недифференцируемые системы. Нынешние подходы включают генетические алгоритмы, «эволюционные стратегии», определённые методы обучения с подкреплением, ADMM (метод переменных направлений множителей Лагранжа). Естественно, градиентный спуск больше никуда не денется — информация о градиенте всегда будет полезна для оптимизации дифференцируемых параметрических функций. Но наши модели определённо будут становится всё более амбициозными, чем просто дифференцируемые параметрические функции, и поэтому их автоматизированная разработка («обучение» в «машинном обучении») потребует большего, чем обратное распространение.
Кроме того, обратное распространение имеет рамки end-to-end, что подходит для обучения хороших сцепленных преобразований, но довольно неэффективно с вычислительной точки зрения, потому что не использует полностью модульность глубинных сетей. Чтобы повысить эффективность чего бы то ни было, есть один универсальный рецепт: ввести модульность и иерархию. Так что мы можем сделать само обратное распространение более эффективным, введя расцепленные модули обучения с определённым механизмом синхронизации между ними, организованном в иерархическом порядке. Эта стратегия частично отражена в недавней работе DeepMind по «синтетическим градиентам». Я ожидаю намного, намного больше работ в этом направлении в ближайшем будущем.
Можно представить будущее, где глобально недифференцируемые модели (но с наличием дифференцируемых частей) будут обучаться — расти — с использованием эффективного поискового процесса, который не будет применять градиенты, в то время как дифференцируемые части будут обучаться даже быстрее, используя градиенты с использованием некоей более эффективной версии обратного распространения
Автоматизированное машинное обучение
В будущем архитектуры модели будут создаваться обучением, а не писаться вручную инженерами. Полученные обучением модели автоматически работают вместе с более богатым набором примитивов и программоподобных моделей машинного обучения.
Сейчас бoльшую часть времени разработчик систем глубинного обучения бесконечно модифицирует данные скриптами Python, затем долго настраивает архитектуру и гиперпараметры сети глубинного обучения, чтобы получить работающую модель — или даже чтобы получить выдающуюся модель, если разработчик настолько амбициозен. Нечего и говорить, что это не самое лучшее положение вещей. Но ИИ и здесь может помочь. К сожалению, часть по обработке и подготовке данных трудно автоматизировать, поскольку она часто требует знания области, а также чёткого понимания на высоком уровне, чего разработчик хочет достичь. Однако настройка гиперпараметров — это простая поисковая процедура, и в данном случае мы уже знаем, чего хочет достичь разработчик: это определяется функцией потерь нейросети, которую нужно настроить. Сейчас уже стало обычной практикой устанавливать базовые системы AutoML, которые берут на себя большую часть подкрутки настроек модели. Я и сам установил такую, чтобы выиграть соревнования Kaggle.
На самом базовом уровне такая система будет просто настраивать количество слоёв в стеке, их порядок и количество элементов или фильтров в каждом слое. Это обычно делается с помощью библиотек вроде Hyperopt, которые мы обсуждали в главе 7 (примечание: книги «Глубинное обучение с Python»). Но можно пойти намного дальше и попробовать получить обучением соответствующую архитектуру с нуля, с минимальным набором ограничений. Это возможно с помощью обучения с подкреплением, например, или с помощью генетических алгоритмов.
Другим важным направлением развития AutoML является получение обучением архитектуры модели одновременно с весами модели. Обучая модель с нуля каждый раз мы пробуем немного разные архитектуры, что чрезвычайно неэффективно, поэтому действительно мощная система AutoML будет управлять развитием архитектур, в то время как свойства модели настраиваются через обратное распространение на данных для обучения, таким образом устраняя всю чрезмерность вычислений. Когда я пишу эти строки, подобные подходы уже начали применять.
Когда всё это начнёт происходить, разработчики систем машинного обучения не останутся без работы — они перейдут на более высокий уровень в цепочке создания ценностей. Они начнут прикладывать гораздо больше усилий к созданию сложных функций потерь, которые по-настоящему отражают деловые задачи, и будут глубоко разбираться в том, как их модели влияют на цифровые экосистемы, в которых они работают (например, клиенты, которые пользуются предсказаниями модели и генерируют данные для её обучения) — проблемы, которые сейчас могут позволить себе рассматривать только крупнейшие компании.
Пожизненное обучение и повторное использование модульных подпрограмм
Если модели становятся более сложными и построены на более богатых алгоритмических примитивах, тогда эта повышенная сложность потребует более интенсивного повторного их использования между задачами, а не обучения модели с нуля каждый раз, когда у нас появляется новая задача или новый набор данных. В конце концов, многие наборы данных не содержат достаточно информации для разработки с нуля новой сложной модели и станет просто необходимо использовать информацию от предыдущих наборов данных. Вы же не изучаете заново английский язык каждый раз, когда открываете новую книгу — это было бы невозможно. К тому же, обучение моделей с нуля на каждой новой задаче очень неэффективно из-за значительного совпадения между текущими задачами и теми, которые встречались раньше.
Вдобавок, в последние годы неоднократно звучало замечательное наблюдение, что обучение одной и той же модели делать несколько слабо связанных задач улучшает её результаты в каждой из этих задач. Например, обучение одной и той же нейросети переводить с английского на немецкий и с французского на итальянский приведёт к получению модели, которая будет лучше в каждой из этих языковых пар. Обучение модели классификации изображений одновременно с моделью сегментации изображений, с единой свёрточной базой, приведёт к получению модели, которая лучше в обеих задачах. И так далее. Это вполне интуитивно понятно: всегда есть какая-то информация, которая частично совпадает между этими двумя на первый взгляд разными задачами, и поэтому общая модель имеет доступ к большему количеству информации о каждой отдельной задаче, чем модель, которая обучалась только на этой конкретной задаче.
Что мы делаем на самом деле, когда повторно применяем модель на разных задачах, так это используем предобученные веса для моделей, которые выполняют общие функции, вроде извлечения визуальных признаков. Вы видели это на практике в главе 5. Я ожидаю, что в будущем будет повсеместно использоваться более общая версия этой техники: мы не только станем применять ранее усвоенные признаки (веса подмодели), но также архитектуры моделей и процедуры обучения. По мере того, как модели будут становиться более похожими на программы, мы начнём повторно использовать подпрограммы, как функции и классы в обычных языках программирования.
Подумайте, как выглядит сегодня процесс разработки программного обеспечения: как только инженер решает определённую проблему (HTTP-запросы в Python, например), он упаковывает её как абстрактную библиотеку для повторного использования. Инженеры, которым в будущем встретится похожая проблема, просто ищут существующие библиотеки, скачивают и используют их в своих собственных проектах. Таким же образом в будущем системы метаобучения смогут собирать новые программы, просеивая глобальную библиотеку высокоуровневых повторно используемых блоков. Если система начнёт разрабатывать похожие подпрограммы для нескольких разных задач, то выпустит «абстрактную» повторно используемую версию подпрограммы и сохранит её в глобальной библиотеке. Такой процесс откроет возможность для абстракции, необходимого компонента для достижения «предельного обобщения»: подпрограмма, которая окажется полезной для многих задач и областей, можно сказать, «абстрагирует» некий аспект принятия решений. Такое определение «абстракции» похоже не понятие абстракции в разработке программного обеспечения. Эти подпрограммы могут быть или геометрическими (модули глубинного обучения с предобученными представлениями), или алгоритмическими (ближе к библиотекам, с которыми работают современные программисты).
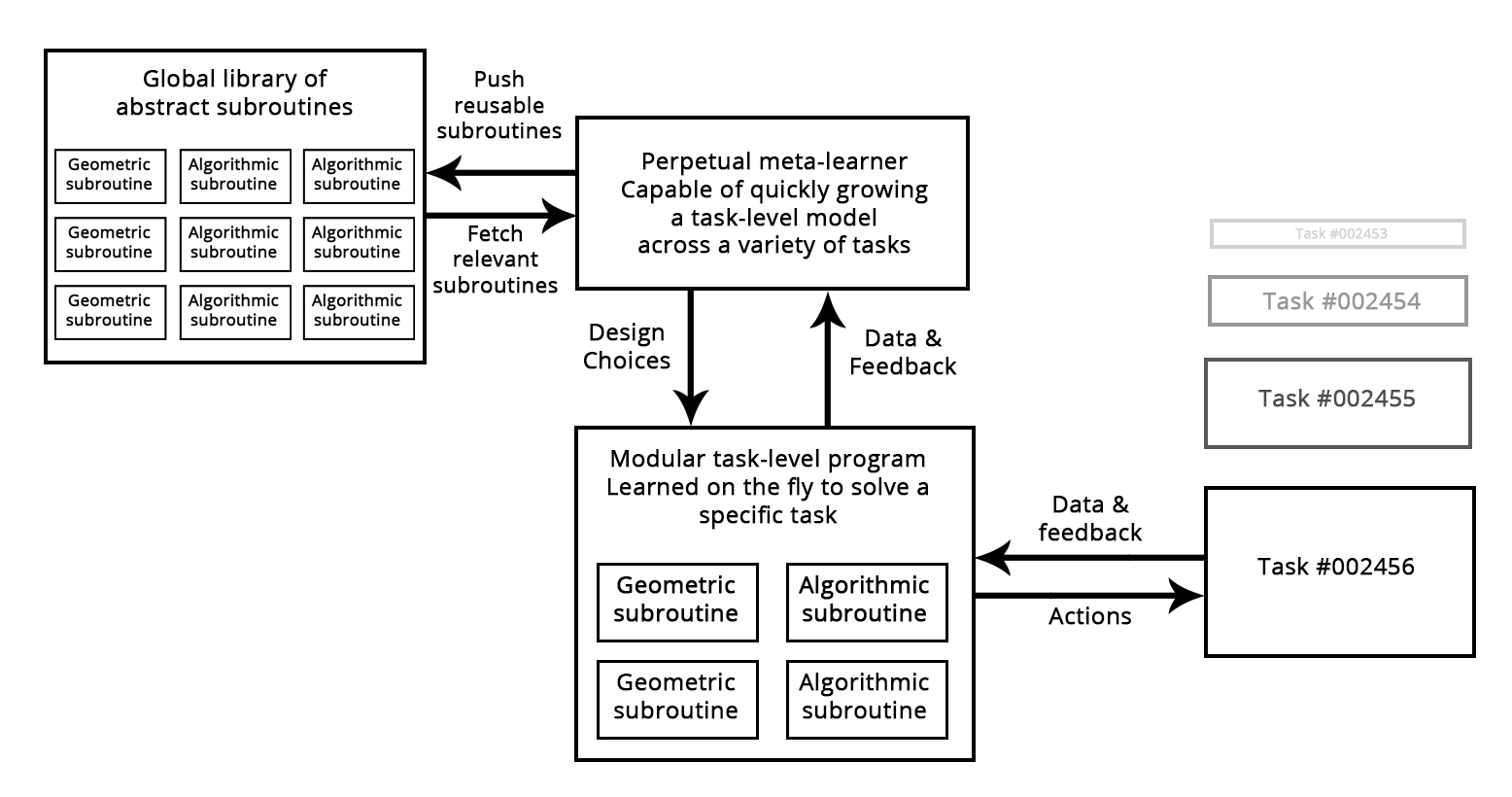
Рисунок: Метаобучаемая система, способная быстро разработать специфические для задачи модели с применением повторно используемых примитивов (алгоритмических и геометрических), за счёт этого достигая «предельного обобщения».
В итоге: долговременное видение
Вкратце, вот моё долговременное видение для машинного обучения:
- Модели станут больше похожи на программы и получат возможности, которые простираются далеко за пределы непрерывных геометрических преобразований исходных данных, с чем мы работаем сейчас. Возможно, эти программы будут намного ближе к абстрактным ментальным моделям, которые люди поддерживают о своём окружении и о себе, и они будут способны на более сильное обобщение благодаря своей алгоритмической природе.
- В частности, модели будут смешивать алгоритмические модули с формальными рассуждениями, поиском, способностями к абстракции — и геометрические модули с неформальной интуицией и распознаванием шаблонов. AlphaGo (система, потребовавшая интенсивного ручного программирования и разработки архитектуры) представляет собой ранний пример, как может выглядеть слияние символического и геометрического ИИ.
- Они будут выращиваться автоматически (а не писаться вручную людьми-программистами), с использованием модульных частей из глобальной библиотеки повторно используемых подпрограмм — библиотеки, которая эволюционировала путём усвоения высокопроизводительных моделей из тысяч предыдущих задач и наборов данных. Как только метаобучаемая система определила общие шаблоны решения задач, они преобразуются в повторно используемые подпрограммы — во многом как функции и классы в современном программировании — и добавляются в глобальную библиотеку. Так достигается способность абстракции.
- Глобальная библиотека и соответствующая система выращивания моделей будет способна достичь некоторой формы человекоподобного «предельного обобщения»: столкнувшись с новой задачей, новой ситуацией, система сможет собрать новую работающую модель для этой задачи, используя очень малое количество данных, благодаря: 1) богатым программоподобным примитивам, которые хорошо делают обобщения и 2) обширному опыту решения похожих задач. Таким же образом, как люди могут быстро изучить новую сложную видеоигру, потому что у них есть предыдущий опыт многих других игр и потому что модели на основе предыдущего опыта являются абстратктными и программоподобными, а не простым преобразованием стимула в действие.
- По существу, эту непрерывно обучающуюся систему по выращиванию моделей можно интерпретировать как Сильный Искусственный Интеллект. Но не ждите наступления какого-то сингулярного робоапокалипсиса: он является чистой фантазией, которая родилась из большого списка глубоких недоразумений в понимании интеллекта и технологий. Впрочем, этой критике здесь не место.
Комментарии (11)

alexeykuzmin0
09.08.2017 17:30Такое ощущение, что автор не понимает того, о чем пишет.
Естественно, сети RNN всё ещё ограничены в том, что они могут представлять
Известно, что рекуррентные нейронные сети Тьюринг-полны (объяснение на stack exchange, в нем есть ссылки на научные статьи). То есть, для любой программы можно подобрать рекуррентную нейронную сеть конечного размера (в статье рассматривалась сеть из около 1000 элементов), которая ее реализует. Собственно, все предложения о том, что неплохо бы еще расширить выразительную способность RNN, которые приведены после этой фразы, можно вообще не читать.
dmalkr
11.08.2017 13:55Что RNN Тьюринг-полны, понятно. А есть конструктивный способ получить нужную RNN-сеть по спецификации?
Автор, наверное, имел ввиду RNN-сети И методы их обучения. Есть ли на сегодняшний день методы обучения RNN-сетей, которые бы позволяли получить сети по спецификциям? Нет. Нужны другие методы.
> которые приведены после этой фразы, можно вообще не читать
Так что продолжаем чтение ;)
mrThreeElephants
10.08.2017 22:38+2Потрясающая статья.
Хотелось бы задать вопрос касательно Тьюринговской проблемы остановки: если мы используем генетические алгоритмы которые по-разному комбинируют примитивные алгоритмические конструкции для создания програмных модулей, а критерием завершенности такого модуля является соответствие входных и выходнях значений спецификации — то каким образом будут отбраковываться зависающие решения, например с бесконечными циклами?dmalkr
11.08.2017 13:46+1Наверное, достаточно подождать N тактов: если программа не выдала результат, то она отбрасывается.
Понятно, что N может как-то зависеть от спецификации. Например, если сети нужно сгенерировать функцию сортировки, то N может быть пропорционально квадрату размера входа.
yurij_volkov
Спасибо за статью, но всё же она скорее разочаровала, чем наоборот.
1. На фразе «для большинства задач либо не существует глубинной нейросети,… » мне резко вспомнилась теорема Колмогорова, дающая обратное вашему утверждение.
2. Вы сказали, что для её чтения нужен «значительный опыт» работы с DL, в статье же 90% воды, которую дают в рамках самого введения в DL.
3. Упомянуть об RNN стоило в тот момент, когда вы говорили, что сети в отличии от человеческого интеллекта не способны на «долгосрочное планирование»( LSTM, GRU, ...)
artbataev
Если Вы про теорему о суперпозиции, то она говорит о приближении непрерывной функции. Автор говорит, что – то есть как раз о том случае, когда теорема не работает.
alexeykuzmin0
Теорема о суперпозиции говорит о точном выражении непрерывной функции (см вики). Насколько я понимаю, любая функция, множество точек разрыва которой имеет меру 0, может быть с произвольной наперед заданой близостью (в смысле интегральной меры) приближена некоторой непрерывной функцией.
Учитывая, что я никогда не слышал о реальных промышленных задачах, в которых фигурировали бы функции с множеством точек разрыва меры более 0, а также то, что обычно нам подходит сколь угодно близкое решение, а не только точное, проблемы здесь нет.
dmalkr
Теоремы утверждают существование, но не приводят конструктивного способа построить глубинную нейросеть по набору примеров.
Так что всё правильно написано. Пусть и в «популярном», а не строгом математическом смысле.
molnij
по п1:
вы просто не дочитали, или недопривели цитату, там дальше самое главное идёт «практически подходящего размера»
Это как с машиной тьюринга — класс теоретически разрешимых через неё задач достаточно широк и иногда это удобный способ доказательства разрешимости какой-либо проблемы, но никто не спешит решать практические задачи с помощью машины Тьюринга.
Мне навскидку кажется что нетрудно показать эквивалентность инструментария нейросетей и например вычислимых по тьюрингу функций (вроде базис для частично рекурсивных функций строится без особых проблем). И после этого можно говорить, что многие задачи теоретически разрешимы, но размерность сети, получаемой влоб для этой разрешимости мягко говоря будут далеки от практического применения