
В сегодняшнем посте мы предлагаем вам расшифровку доклада Андрея DreamWalker Акиньшина с DotNext 2017 Piter о памяти, в котором Андрей разбирает, как работает память с точки зрения производительности приложений. Пост получился огромный, так что запасайтесь кофе и терпением.
Весь код лежит здесь, а сама презентация — здесь.
Все мы хотим, чтобы программы, которые мы пишем, работали быстрее и кушали мало памяти. Поэтому практически всем программистам приходится заниматься перформансными работами разной степени сложности. И в ходе оптимизации главное — не хвататься за первый попавшийся кусок кода. Лучше найти узкое место программы, в которое упирается производительность. Можно сколько угодно оптимизировать другие места, но, скорее всего, эффект будет не очень заметный.
К сожалению, поиск узких мест — зачастую нетривиальная задача. Но с типом узкого места чаще всего удаётся определиться. Это может быть, например, процессор, доступ к базе данных, к диску или к сети. Один из распространённых кейсов — это доступ к основной памяти. Думаю, просто потому, что с основной памятью мы работаем чаще всего.
С точки зрения перформанса память — штука очень коварная и непонятная. Будем разбираться с тем, как она работает.

В этом докладе с DotNext 2017 Piter мы поговорим о том, что влияет на скорость работы с памятью. Обсудим как низкоуровневые хардварные штуки (CPU cache и его ассоциативность, выравнивание, store forwarding, 4K aliasing, prefetching, cache/page splits, cache bank conflicts и т.п.), так и более .NET-специфичные проблемы (pinned objects, large object heap, особенности работы кучи в полном .NET Framework и Mono).
Для начала я вам расскажу одну историю. Я понемножку помогаю писать Rider IDE и иногда занимаюсь рефакторингом кода. Как-то раз я рефакторил одну подсистему и увидел, что она написана не просто не очень хорошо, а неэффективно. И подумал: «Я же знаю, как писать эффективный код; сейчас я всё перепишу».
Переписал. Всё работает. И я решил проверить, поменялось ли хоть что-то от того, что я переписал. Первый раз я замерил время инициализации подсистемы до рефакторинга, второй раз — после рефакторинга.
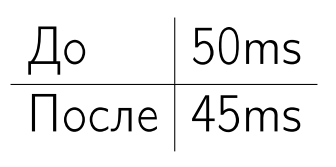
5 мс я выиграл, но одного замера мало — только по одному замеру нельзя однозначно сказать, стало ли лучше.
Я сделал 200 замеров до и 200 замеров после — получил такое распределение.

По этому распределению опять нельзя сказать, стало ли лучше.
Я распечатал эти графики и начал показывать их людям на улице, спрашивая, почему они думают, что графики такие — почему у нас вообще нет нормального распределения, а вместо этого мы получаем размазанные по перформансному пространству графики? И в глазах этих людей я видел глубокое непонимание: до меня дошло, что люди просто не знают, из чего складывается перформанс памяти. Поэтому в этом докладе мы будем разбираться, из чего складывается производительность памяти, что на неё влияет, почему мы получаем настолько большой разброс значений.
Хотелось бы научить вас писать правильные memory-бенчмарки, но на это времени нет. Зато я вам покажу 10 разных способов написать некорректные memory бенчмарки.
Но сначала маленький отказ от ответственности.

Все бенчмарки, которые я буду показывать, — чисто академические и направлены на понимание общих концепций. Если вы увидели здесь какие-то результаты тестов, это не означает, что нужно сразу бежать и переписывать продакшн код. У вас могут получиться совершенно другие результаты.
Память чувствительна к архитектуре процессора. Поэтому у нас есть три подопытные железяки. Когда я буду упоминать, например, Haswell, я не буду иметь ввиду все Haswell-процессоры в мире, а только одну конкретную модель (на скриншоте выше).
Я надеюсь, некоторые из вас знают про библиотечку BenchmarkDotNet — очень клёвая штука, чтобы писать и дизайнить бенчмарки. На основе неё я сделал все эти примеры. Если кто-то из вас не доверяет моим результатам (а у вас нет абсолютно никаких оснований мне доверять; вообще никогда не доверяйте ничему, что вам показывают или рассказывают со сцены), вы можете скачать исходники в интернете и поиграться сами.
Начнем с простого примера.
Допустим, вас не устраивает перформанс класса dictionary. Давайте напишем собственный клёвый класс dictionary.

Чтобы убедиться, что он клёвый, мы его немножко побенчмаркаем.
Положили какой-то элемент в нашу мапу. Написали stopwatch.

Как полагается, сделали много итераций, вывели время.
Помимо разнообразных прогревов, статистики, итераций и прочих проблем запуска, здесь есть две фундаментальные проблемы дизайна бенчмарка.
Первая — это доступ к памяти. Здесь мы просто берём и долбим в один элемент по кругу. Это нерелевантно. Нужно перебрать разные паттерны доступа к памяти: последовательный, случайный. На случаи, которые возникают у пользователя, тоже нужно обращать внимание; надо рассматривать какие-то предельные случаи. Далее мы обсудим, почему это важно.
Вторая фундаментальная вещь — это размер рабочей памяти. Сейчас рабочая память, грубо говоря, состоит из одного элемента. Желательно пробовать разные размерчики (маленькие, большие, близкие к размеру разных кэшей), и далее мы увидим, почему.
Все это оказывает заметное влияние.
Начнём с кэшей.
На всякий случай напомню: у нас есть процессор и основная память. К основной памяти добираться долго, поэтому придумали кэш. В кэш мы подтягиваем значение из основной памяти, а к нему доступ организуется уже быстро.
Кэш серьёзно увеличивает производительность ваших приложений. Но в бенчмаркинге он только портит жизнь. Это сплошная головная боль, потому что кэш имеет сложную архитектуру с разными уровнями. Ребята из Intel как-то там на процессоре всё это напаяли — и непонятно, как все это бенчмаркать.

Давайте рассмотрим простенький пример.

У меня есть массив байт. Размер этого массива я буду перебирать. В бенчмарке мы будем проверять, сколько стоит заинкрементить элемент массива. Но будем дергать не просто какой-то один элемент, а разные — с шагом в 64 байта. Это не случайный шаг, а типичный размер кэш-линии на современном железе. Количество итераций каждый раз одно и то же, т.е. вне зависимости от размера мы будем получать одну и ту же алгоритмическую сложность, то же количество ассемблерных инструкций. Вне зависимости от размера массива они будут совпадать с точностью до значения одной переменной. Казалось бы, как это может влиять на performance?
Давайте посмотрим для примера на Ivy Bridge и Skylake.
Пока у нас размер задействованной рабочей памяти маленький (4, 8, 16, 32 Кб), мы получаем практически одинаковые результаты.

Но до сих пор эти данные умещались в L1, типичный размер которого — 32Kb. L1 закончился, пошёл L2. И результаты у нас немного просели.

На 256 килобайтах заканчивается уже L2, начинается L3. Перформанс продолжает деградировать.

Выходим за рамки L3, и результаты уже совсем плохие.

Эта таблица иллюстрирует типичный пример бенчмаркинга, связанного с памятью.
Представьте, что у вас появилась отличная идея, как всё оптимизировать. Но она требует больших перестроений в архитектуре. Вы решили написать маленький proof of concept, чтобы померить, дают ли вообще эти оптимизации какой-нибудь результат. Написали, влезли целиком в L1. И дальше вы гоняете прогретый бенчмарк, который целиком помещается в первый уровень кэша. У вас всё хорошо. Радостные бежите и начинаете переписывать продакшн код, и всё начало тормозить. Вы говорите: «Плохие бенчмарки, не буду вообще всем этим заниматься, пойду лучше займусь багами».
Это действительно очень распространенный user case. Я его много раз видел. Когда вы переходите на уровень большого приложения, там используется много памяти, и она раскидана как-то случайно по куче, и кэш-мисы (промахи по кэшу) — очень типичная ситуация. Поэтому когда вы планируете какие-то эксперименты, важно обращать внимание на то, сколько памяти расходует ваш бенчмарк.
Я уже сказал, что у кэша есть несколько уровней. Про это все слышали, но не все до конца понимают, зачем им это надо знать. Давайте чуть подробнее посмотрим на эти уровни.
Картинка схематически изображает, как всё устроено внутри на современном железе:

У нас есть, например, четыре физических ядра. L1, L2 у каждого ядра свои, а L3 — общий для всех ядер.
Казалось бы, интересная информация, но зачем она вам нужна?
Давайте погоняем немного этот же самый бенчмарк.
Я в нём ни строчки не поменял, но сузил размер перебираемых значений моего массива данных. Теперь это 2, 4, 6 МБ. Напоминаю, что на моих машинках кэш L3 по 6 МБ.
Если запускать бенчмарк в стерильных условиях (то есть мы выключаем всё, что выключается: IDE-шку, браузер, компоненты самой системы), мы получаем хорошие результаты.

Они воспроизводимы. Разница между минимум и максимум маленькая, и этим можно пользоваться, как какими-нибудь референсными значениями; можно проводить оптимизацию.
Но давайте будем честны: никто так не тестирует. Даже я, когда готовил эту презентацию. Мне было лень на каждый бенчмарк закрывать абсолютно всё. У меня открыт Rider, IDEA, TeXstudio, запущены Dropbox, Google Drive и т.п. Вот какие результаты я получаю, когда всё это запущено.

На что нужно обратить внимание? Во-первых, очень большой разброс значений. Там теперь не 1 мс разницы, а 100-150 мс. Во-вторых, значения резко возросли. И еще важный момент: оказалось, что на 4 Мб мы тупим сильнее, чем на 6 Мб. Это случайный эффект. Если я запущу бенчмарк ещё пять раз, то получу еще пять разных результатов.
Дело в том, что сторонние приложения не всегда одинаково влияют на ваш перформанс. В обычных условиях разброс результатов небольшой, особенно когда у вас реально микробенчмарк и тестовый софт влезают в L1 и L2. Когда вы выходите на уровень L3, приходится соревноваться с другими процессами. Особенно меня удивило, что Dropbox и Google Drive очень сильно влияют на бенчмарки как раз в этом диапазоне — от 2 до 6 Мб (если что, у вас может быть по-другому).
Это действительно проблема. Многие в этом месте говорят, что мы же реальное приложение запускаем, условия там side-by-side с другими приложениями. Почему мы должны бенчмарки в стерильных условиях запускать? Потому что иначе с результатом просто невозможно работать. Последняя таблица не несёт для вас вообще никакой полезной информации. Любой бенчмарк должен быть воспроизводим. Он должен каждый раз давать вам одно и то же число с точностью до распределения. А от такого бенчмарка толку нет. Поэтому с подобными моментами нужно обращаться очень аккуратно.
Я построил картинки с распределением: нас равномерно размазало от 30 до 170 мс.

Работать с этим никак нельзя.
Давайте начнём с примера.
Я думаю, все вы можете решить такую задачку. У нас есть квадратный массив N на N, и мы хотим выбрать максимальный элемент в 0 колонке. Очень простой код — никакой магии нет.

Но вот размер массива я буду перебирать. Возьму, к примеру, 512, потому что программисты очень любят круглые числа и часто пихают их в бенчмарки, а ещё возьму 511 и 513.
На одном из этих трёх чисел — на 512 — производительность заметно ниже, чем на остальных.

Почему?
Давайте вспомним, как вообще работает процессор. У современных кэшей есть уровень ассоциативности — некоторое N. Покажу идею на примере двух-ассоциативного кэша.

Что означает, что ассоциативность кэша 2? Что каждой кэш-линии, то есть участку выровненных 64 байт в основной памяти, соответствует ровно 2 позиции в кэше, где эти 64 байта физически могут лежать. Во все остальные места они попасть просто не могут. Соответственно, для следующих 64 будут другие 2 кэш-линии и так далее. Но есть маленький нюанс, который заключается в том, что кэш — маленький, а память — большая. Как несложно догадаться, рано или поздно мы дойдем до таких линий в основной памяти, которые будут соответствовать тем же 2 кэш-линиям, что и самые первые рассматриваемые 64 байта. Такое расстояние обычно называется Critical Stride. Если вы будете перебирать много значений на расстоянии Critical Stride, они будут выбивать друг друга из кэша.
Размер Critical Stride легко посчитать: это размер кэша, деленный на его ассоциативность.

Вот несколько примеров:

Например, L1 у нас обычно 32 КБ 8-ассоциативный. Это означает, что Critical Stride будет 4 КБ. Когда мы идём с шагом 4 КБ, начинаем наступать на эту штуку, и перформанс внезапно падает. Несмотря на то, что объём рабочей памяти у нас остается маленьким, происходят постоянные кэш-промахи.
Сложность работы с Critical Stride заключается в том, что далеко не во всех ваших программах вы берётесь найти максимальный элемент в колонке. Как правило, вы пишете какой-то более сложный код, в котором сложно сказать, где вы наступили на Critical Stride, а где нет. Ещё хуже то, что gc вам постоянно каким-то образом раскидывает данные в памяти, поэтому в одних экспериментах вы можете много раз наступать на Critical Stride, а в других с тем же кодом — мало. Поэтому результаты от раза к разу могут очень сильно отличаться.
С этим не всегда можно бороться, но это полезно держать в уме на случай, если вам потребуется объяснить, почему вы получили такие результаты.
А есть ещё очень интересная особенность Skylake. Откровенно говоря, у него много интересных особенностей. Skylake — это одна из последних микро-архитектур процессоров Intel. Там ассоциативность кэша L2 понизили с 8 до 4. Почему — это совершенно отдельная история. Но если вы написали какой-нибудь микро-бенчмарк на Haswell, который учитывает всякие Critical Stride, перенесли его на другую машину, чтобы удивить друга, у него результат может не воспроизводиться, потому что Critical Stride там другой.
Есть ещё много разных особенностей у Skylake. Например, память у нас состоит из страниц. Обычно страницы примерно по 4 КБ. Попытки наступить на границу двух страниц (page split) или двух кэш-линий (caсhe line split) стоят довольно дорого. Раньше стоимость этих сплитов была 100 циклов CPU. А в Skylake разработчики немного оптимизировали архитектуру, и теперь сплиты стоят 5 циклов CPU. В реальной жизни это малорелевантно, но факт занимательный.
Можете почитать интеловские спецификации, там написано много чудесного.
Примеры становятся сложнее. Посмотрим ещё один хитрый примерчик.
У меня, как всегда, есть массив данных.

В unsafe методе первое, что я делаю — это с помощью ключевого fixed получаю указатель на массив, а затем перехожу в unsafe код.
Это очень полезный прием в memory bound бенчмарках. GC в любой момент (точнее, есть много ситуаций, когда это возможно) может перекинуть ваш массив с одного места на другое, а потом на третье и т.д. И каждый раз будет складываться какая-то новая конфигурация кэш-мисов и особенностей по памяти. Это не то, что вы хотите видеть в микро-бенчмарке, потому что результаты опять будут сильно отличаться друг от друга. Поэтому мы переходим на такой unsafe-стайл.
Я буду решать следующую задачу: буду проверять, есть ли у меня такие элементы на расстоянии дельта, для которых первое число меньше, чем второе. Для этого я указателем бегу по памяти, инкременчу указатель и сравниваю числа.
Выберем три варианта расстояния: 15, 16 и 17. И посмотрим два процессора: Skylake и Ivy Bridge.

На Skylake всё хорошо. Мы там с точностью до погрешности получаем практически идентичные результаты.
А если мы запустим бенчмарк на модели процессора, которая вышла в 2012 году, на 16 будет происходить что-то очень странное. Если мы откроем интеловский Manual по тому, как устроены процессоры, то узнаем, что на самом деле кэш-линии состоят из кэш-банков, их обычно 8 штук. Если вы читаете значение из двух разных кэш-линий, но с одинаковыми номерами кэшбэнков, у вас будут проблемы. Именно процессоры на архитектуре Sandy Bridge не умели делать это одновременно. Если у вас по коду подряд идут два чтения из таких ячеек, начиная с Haswell результат будет хороший — они смогут считаться одновременно, а в старых процессорах — нет. Если более формально, проблемы на архитектуре Sandy Bridge будут при совпадении битов со 2 по 5.
Скорее всего вы знаете, что выровненный доступ — это хорошо, а невыровненный — это плохо. Но на практике мало кто использует это знание, когда пишет программы. Однако эта штука оказывает заметное влияние, причем в достаточно простых кейсах.

Например, у меня есть две структуры: в структуре Struct3 у меня три байта, в структуре Struct8 — восемь байт. Для каждой структуры я создал небольшой массив всего на 256 элементов.
Напишем простой бенчмарк. Мы бежим по массиву и считаем сумму всех X1 и X2.

Остальные элементы — X3, X4, X5 — существуют, но они никак не используются. Мы их добавили на будущее на всякий случай, потому что когда-нибудь они точно понадобятся. Вопрос: какой из методов будет работать быстрее — S3 или S8?

Правильный ответ зависит от условий. Если мы запустим пример на полном фреймворке, типа LegacyJIT-x64, то получим, что при переходе с S3 на S8 перформанс растет в 5 раз. А на Mono — падает всего в два раза. Почему так выходит?
Тут нужно разобраться, как вообще у нас лэйаутится память в разных видах runtime.

Если мы спросим у типа marshal, какой у нас размер структуры S3, то полный фреймворк честно скажет — три байта.

А Mono думает: «Если у нас размер будет 3, то мы там будем постоянно нарываться на невыровненный доступ. Это плохо. Поэтому мы добавим дырку ещё на 5 байт, чтоб всё было выровнено».
В итоге на полном фреймворке — на LegacyJIT-x64 — данные не выровнены. Они лежат подряд, как нарисовано слева. И когда мы бегаем по бенчмарку, постоянно нарываемся на невыровненный доступ, и у нас всё тормозит. Мы переходим к S8, и доступ становится выровненным.
На Mono другой эффект. Здесь данные у нас всегда выровнены, поэтому выровненность вообще никак не влияет на performance. Но чем больше у нас байт, тем сложнее всю структуру доставать из памяти и класть, например, в стек. Мы ведь не только X1 и X2 будем доставать, чтобы всё было в стеке. Поэтому мы можем видеть практически прямо пропорциональную зависимость между количеством байт и перформансом.
Наверняка многие из вас добавляли поля в структуры, но не думали о том, что это принесёт какой-то вклад в перформанс, даже если вы их не используете. Я обычно об этом тоже не задумываюсь.
Тот же самый пример, ни строчки не поменял. Те же самые Struct3 и Struct8, только мы запустим этот бенчмарк под RyuJIT-x64.

Я специально подобрал такие условия, чтобы здесь производительность методов была одинакова.

Почему в остальных нормальных JIT-ах есть разница, а в этом нет? На RyuJIT происходит интересная вещь: если мы посмотрим на ассемблерный код, то увидим, что для S3 RyuJIT кладет все наши данные в регистры и далее использует регистры.

А для S8 кладет все данные в стек. Для S3 данные в регистре — это хорошо, но доступ не выровненный — это плохо. В S8 данные в стеке — это плохо, но зато доступ выровненный. Это хорошо. По счастливой случайности эффекты компенсировали друг друга (на самом деле я специально подбирал значения так, чтобы они компенсировали друг друга, но будем считать, что эффект обнаружен по счастливой случайности). Так бывает. Самое ужасное, что ошибка сходу незаметна. Два абсолютно одинаковых метода, которые делают одно и то же, выдают нам одинаковый результат. Но вы начнёте переносить ваши мысли на реальную систему, какие-то условия поменяются, и в итоге одна оптимизация заборет другую, и появится перформансная проблема в самом неожиданном месте.
Тут есть другой вопрос: почему здесь есть разница между S3 и S8, что это за оптимизация такая? Она называется Struct Promotion и как раз направлена на то, чтобы, если структура маленькая, всё выгружать в регистры и не трогать стек.
У struct promotion есть ряд определенных ограничений (эвристик).

Например, RyuJIT считает, что структура маленькая, если в ней четыре поля или меньше.
На такие факты завязываться очень опасно, потому что в каждой следующей версии фреймворка они могут поменяться. Завтра разработчики решат, что меньше шести полей — тоже маленькая структура. А могут решить, что оптимизация вообще не даёт прироста, и выкинут её, чтобы код стал проще. Поэтому во время оптимизации на это закладываться нельзя. Но когда вы замеряете performance, подобные оптимизации JIT (а их, на самом деле, очень много) могут всё испортить. Это опасно тем, что вы будете думать, что ваши изменения повлияли на перформанс, будете делать из этого выводы, а на самом деле просто в JIT немножко поменялась конфигурация происходящего, и он решил перекомпилировать всё по-другому.
Если простыми словами: представьте, что мы последовательно идём по памяти. CPU — умный, он об этом догадывается, т.к. умеет распознавать такие ситуации. Он может предположить, что мы и дальше будем идти последовательно, поэтому предугадывает те данные, которые нам понадобятся — префетчит их, заранее подсасывая поближе к кэшу. Это очень здорово, но, к сожалению, из-за этого получается очень большая разница в производительности между последовательным и случайным доступом.
На самом деле, на разницу производительности влияет очень много факторов, и это — один из них. Если мы пишем бенчмарки для какой-нибудь структуры данных, желательно всегда посмотреть на последовательный доступ и на рандомный. Однако с рандомным доступом тоже могут быть свои приколы.
Рассмотрим следующий примерчик.

У нас есть массив данных, и на этом массиве данных я эмулирую какую-то ссылочную структуру. Для каждого элемента int я говорю, что next — это указатель в какую-то другую ячейку. Такое упрощение. У вас могут быть какие-то ноды или граф — любая структура, где одни объекты указывают на другие. Просто чтобы обо всем этом не думать, я написал пример на массивчиках.
Я заполню ссылки и сам массив какими-то рандомными данными.

Вот, кстати, еще одна популярная ошибка тех, кто решает побенчмаркать что-нибудь со случайным доступом. Они вызывают рандом прямо внутри тела бенчмарка, видят перформансную деградацию и говорят: «Какой рандомный доступ плохой». А на самом деле просто random.Next — тоже не бесплатный, он занимает какое-то время, и желательно вызвать его заранее до бенчмарка.
У меня есть полезный метод (CPU-bound), который выполняет много инструкций.

Для примера сделал код, который проверяет, делится ли число на 13, 17, 19 и т.д. У вас может быть любой другой код, который просто выполняет много инструкций.
Далее у меня есть метод.

У него есть переменная index, которая указывает на некий текущий элемент. Я передвигаю указатель — говорю index = next[index] — и по новому индексу вытаскиваю данные из моего массива. Проверяю, хорошее мне число досталось или не очень, и считаю, сколько у меня хороших чисел.
Этот простой код можно переписать.

В новом варианте я буду получать данные заранее. Код на красном фоне — то, что было раньше; его мы выкинули. На зеленом — то, что мы написали в новом варианте. С алгоритмической точки зрения всё то же самое, но данные из массива я получаю заранее и в начале тела цикла сразу записываю подготовленный результат Y прямо в X, а только потом начинаю фетчить следующие данные.
Между этими двумя примерами есть большая разница.
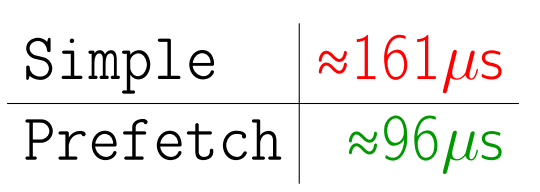
Если мы посмотрим на перформанс, метод prefetch работает заметно быстрее. Почему?
В первом случае метод IsNice должен ждать, пока мы зафетчим данные. Он не может предугадать, потому что у нас нетипичный для CPU паттерн доступа к памяти. Он должен сначала дождаться, пока мы переставим индекс, потом переставим данные, и только тогда он сможет запустить метод IsNice. А во втором случае мы сразу знаем значения X уже на уровне CPU, поэтому можем сразу запустить IsNice. Обновление индекса Y пойдет параллельно. Здесь у нас потоков нет, но работает construction level parallelism (CPU внутри себя может много всего параллелить). Отсюда и разница.
Почему нужно понимать эти prefetch-фокусы? Потому что они могут появиться просто в процессе рефакторинга. Вы немного что-нибудь поменяли в программе и таким образом изменили условия для Instruction Level Parallelism. В результате разница в перформансе появилась не из-за изменения алгоритмической сложности, а из-за того, что вы что-нибудь случайно запрефетчили. Гарантировать, что новый код ничего не префетчит, практически никогда нельзя.
Поищем веселые примеры в интеловских мануалах.

В мануалах приведен подобный пример, только мы прыгаем случайно по памяти; когда мы куда-нибудь прыгнули, нам нужно обработать две кэш-линии: сначала первую (какой-нибудь CPU consuming code), а затем вторую. И это очень обидная ситуация, потому что когда мы обрабатываем первую кэш-линию, мы знаем, что скоро нам понадобится вторая. Но процессор-то этого не знает, потому что он видит, что мы как-то рандомно прыгаем. Мы хотим дать понять CPU, что нам скоро понадобится следующая кэш-линия, чтобы он ее заранее подтянул. Для этого есть много интересных способов. Один из них предлагает компания Intel — это постучаться в область памяти не один раз, а три, т.е. перенести значения eax просто три раза подряд. Это будет условный знак для CPU, что нам нужно запрефетчить следующую кэш-линию. Человек в здравом рассудке до такого просто не догадается. Но такие оптимизации существуют.
Я очень хотел сделать пример с таким хаком на .NET, но, к сожалению, на чистом .NET не получилось, потому что JIT всё-таки, сколько бы я его не ругал, достаточно интеллектуален: если он что-то сфетчил из памяти и положил в регистр, дальше он использует регистр.
Мануал, на который я постоянно ссылаюсь, очень большой. Там написано очень много всего интересного, и никогда нельзя знать наверняка, где сработает какой-нибудь префетчинг, а где — нет. К этому тоже нужно быть хотя бы морально готовым.
Но сначала немного теории. У нас есть CPU и L1 кэш. Допустим, мы какие-то данные сохраняем в память. Мы уже знаем, что они не сразу полетят в память, а сначала осядут где-нибудь в L1. Но как это происходит? Есть ли что-нибудь между CPU и L1?

Там есть буфер. Это очень хорошая штука. Допустим, у вас есть число, и вы хотите положить его в память. Это операция не бесплатная, она занимает несколько циклов CPU, и будет здорово, если мы не будем ждать, пока данные доедут до L1-кэша, а продолжим делать какую-нибудь полезную работу. Поэтому мы кладем числа в Store Buffer и идем исполнять наши инструкции. Все работает быстро.
По аналогии есть Load Buffer.

С помощью него CPU поможет подсасывать из L1 данные, которые нам вот-вот понадобятся.
А теперь представьте такую невероятную ситуацию: вы записали что-то в память и сразу хотите прочитать. В приведённой выше схеме получается небольшая проблема, потому что нам нужно ждать, пока число через Store Buffer доедет до L1, потом CPU поймет, что число надо послать назад через Load Buffer, а мы будем сидеть и ждать. Поэтому есть механизм, который называется Store Forwarding, который умеет догадываться, что в Store Buffer у нас есть то, что нам нужно. Несмотря на то, что физически до L1 данные ещё не дошли, мы поможем выдернуть их прямо из Store Buffer и положить в Load Buffer.

Есть хитрые моменты, связанные со Store Forwarding. Благодаря этому механизму можно очень быстро проверить, что число у нас лежит в Store Buffer. Для этого используется простой хэш — от каждого числа берутся последние 12 бит адреса. И если у всех чисел последние 12 бит адреса различаются, всё хорошо. Store Forwarding отрабатывает моментально. Если не отличаются, то иногда возникают проблемки.
Теперь когда мы знаем матчасть, посмотрим ещё один пример.

Представим, что у нас есть массив данных, и мы хотим получить такой базовый оффсет, который выровнен на 4 Кб по границе страницы. Иногда очень приятно иметь выровненные данные, потому что не хочется зависеть от GC и ожидать от него любого подвоха, как он там что выровняет.
Кроме fixed, есть и другой способ запинить данные и получить адрес — это GCHandle Alloc.

С его помощью можно сказать, что объект у нас запиненный, и gc его трогать не надо. Можно получить адрес и с помощью простой магии с процентами выровнять всё это дело на 4 КБ.

Весь оффсет у нас выровнен.
Теперь мы делаем один простой вызов Array.Copy:

Мы будем копировать 16 КБ — это число, позволяющее создать какую-то нагрузку на ArrayCopy. С базового оффсета, т.е с выровненного адреса, мы будем копировать на базовый оффсет плюс 24 КБ (тоже такое очень хорошее круглое число) плюс некоторый StrideOffset. И будем перебирать сейчас StrideOffset, т.е. немного играть с Destination адресом и смотреть, что произойдет.
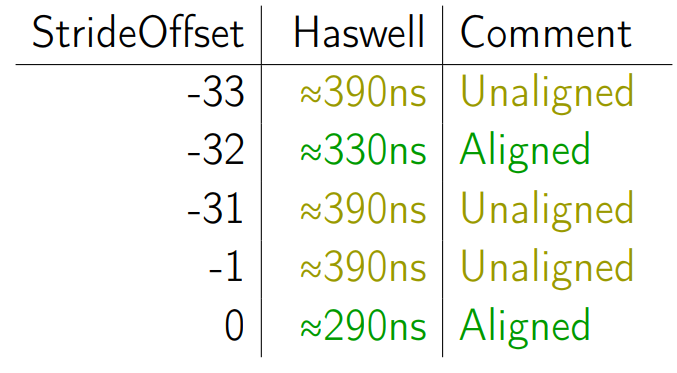
Смотреть будем на Haswell-е. И для начала возьмем StrideOffset -33. Это означает, что мы берём наши 16 Кб и копируем их на 16 Кб — 33 байта.

Наступаем на невыровненный доступ. Мы все знаем, что невыровненный доступ — это плохо.
Теперь берем StrideOffset -32. Данные более выровнены, хотя бы на 32 КБ.

Все хорошо — доступ выровнен, performance улучшился.
Перебираем числа от -31 до -1.

Если сделать много итераций и очень аккуратно всё это промерить, получаются одинаковые результаты с точностью до погрешности.
Далее, в 0 у нас совсем выровненный доступ — мы ещё и по границе страницы выровнялись.
Теперь мы попробуем сделать StrideOffset 1.
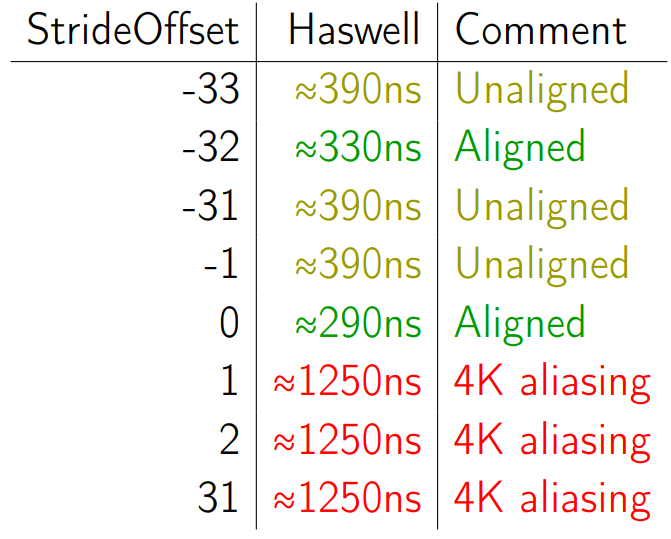
И перформанс внезапно ухудшился.
Мы копируем всё те же 16 КБ, вызываем только один единственный ArrayCopy. Всё, что мы поменяли, это Stride Offset на единичку — на 1 байт в бок сдвинули — и performance просел в пять раз. Почему так происходит?
Если совсем на пальцах: мы начинаем копировать, первый байт полетел у нас из Source Index в Destination Index — 24 КБ + 1 байт. Потом второй байт — за ним. Но второй байт находится как раз на 24 КБ раньше, чем тот, в который мы только что записали. Т.е. у нас в Store Buffer пошло какое-то значение, нам из Load Buffer нужно что-то получить, а последние 12 бит адреса у них совпадают (потому что у всего, что отличается ровно на 4 КБ, ну или на 24, совпадают последние 12 бит). И всё. Эта штука называется 4K aliasing. В интеловской документации и перформанс-счётчиках она тоже есть, и она может оказывать влияние.
Когда я про это рассказываю людям, они обычно говорят, что это точно в продакшене не встретится. Как это может возникнуть в реальном коде? А я взял Rider, открыл его и померил Intel VTune Amplifier.

Там есть 4К aliasing. Его, конечно, мало, он не сильно влияет на перформанс, по крайней мере, не до такой степени, чтобы я хотел что-то там оптимизировать. Потому что оптимизировать эту штуку почти нереально.
Иными словами, эта информация полезна, но в очень маленьком проценте случаев. Серьёзно, есть люди, которые на это наступают и которым больно, но их мало, и, скорее всего, они пишут не на .NET. Но когда мы делаем бенчмарки, мы усвоили, что нужно перебирать разные размеры, разные оффсеты. Когда мы делаем грамотный микро-бенчмаркинг, на вещи типа 4K алиасинга наступить уже вполне реально.
С ним можно бороться. Он активно проявляется, когда у нас данные не выровнены.

Можно выровнять данные, можно поменять оффсеты, можно много чего сделать — читайте интеловские доки.
Я ещё толком ничего не сказал про .NET, поэтому давайте поговорим про сборщик мусора.
Сборщик мусора — это не очень клёвая штука для того, кто хочет писать бенчмарки, потому что сборщик мусора на самом деле предоставляет вам перформансные кредиты. Вы практически мгновенно аллоцируете какую-то область памяти, это достаточно дешёвая операция. Но вы платите за это перформансные проценты в будущем. Потому что каждый раз, когда GC начинает что-то коллектить, особенно если вы построили очень сложный граф объектов, он даёт нагрузку на процессор в бекграунде, пока вы что-то делаете полезное, замедляя вас, он делает stop-the-world паузы, которые ухудшают latency и т.д. Про GC можно сделать несколько докладов о том, как он мешает жить в memory бенчмарках.
Дам общий совет: если кратко и не вникая в детали, делайте просто много-много итераций и считайте средне-размазанное влияние GC на ваш бенчмарк.
А я покажу ещё два весёлых примера, связанных с GC.
У нас в райдере есть волшебный Internal Mode, в котором появляется куча прикольных вещей.

И одна из этих прикольных вещей — Backend Memory Usage. Мы меряем, сколько у нас .NET-овская часть Rider жрёт памяти.
Здесь есть много разных показателей. В частности интересно, что у нас есть Allocated Mаnaged Memory, которая 108 МБ на этом скриншоте, а есть Working Set — 666 МБ. Это у меня сразу вызывает подозрения.
В Rider предусмотрены специальные managed-кэши, которые жрут какую-то часть памяти, когда данные не укладываются в managed, но эта часть должна быть 300-400 МБ. Т.е. эти два числа должны отличаться максимум на 400. Но вот здесь что-то явно пошло не так, и я решил проверить.
Я знаю уже, что нужно много раз мерить. Я померил много раз, посчитал среднестатистический Working Set после полной загрузки Rider, и он получился 566 МБ. Но среднестатистический — плохое слово. Большинство людей имеют количество ног больше статистического. Потому что есть безногие, есть одноногие люди. Я, как программист, морально готов к тому, что у человека может быть три или минус одна нога. Но в среднем получается немного меньше двойки. Поэтому со средним работать не очень хорошо — смотрим на распределение.

На распределении у нас вообще нет ни одного сэмпла, который бы занимал 566 Мб. Получается два максимума. Почему?
Я поймал пример, когда мы попали в правый пик и увидел следующее на снапшоте из DotMemory:

У нас есть здоровый, полностью пустой сегмент gc, а на самом конце этого сегмента — маленький запиненный объект на несколько байт, который держит весь здоровый сегмент, и из-за которого вся программа начинает жрать памяти на 200 метров больше. Как так получается?
У нас есть много кода для диагностики. В частности, мы поднимаем маленький http-server, к которому через localhost можно постучаться по специальному порту и увидеть красивые графики про то, как у нас там протокольный трафик идет с одной стороны в другую.

И вот у нас есть такой класс — HttpListener.

Внутри есть штука, которая называется SyncRequestContext. Она создаётся где-то внутри метода GetContext.

Если посмотреть на неё, то в одном месте обнаружится GCHandle.Alloc с ключиком Pinned, который мы уже знаем, и который запинивает объект размером порядка 32 байт.
Как-то у нас звёзды сошлись так, что эта штука дожила до второго поколения и там была запинена. У вас скорее всего такого не будет, но подобный феномен вполне может вылезти в другом месте.
Проблему поправили — на пустом месте Working Set стал здоровым.
Ещё один пример — про кучу больших объектов (LOH).
В полном фреймворке (Full .NET Framework и .NET Core) есть куча больших объектов, в которую попадают объекты больше 85000 байт.

Эта куча сама по себе не компактится. Можно прийти и сказать: «Куча, пожалуйста, покомпакться», — но по дефолту этого не происходит.
В масштабных приложениях куча больших объектов — это головная боль, потому что в неё попадают объекты, которые, как .NET считает, большие. Если при этом живут они недолго, в LOH остаётся дырка. Поэтому приложение жрёт очень много памяти.
Для борьбы с LOH у нас в Rider в ReSharper есть структуры, основанные на чанках — ChunkedArray.

Суть очень проста: мы хотим что-нибудь, что снаружи выглядит, как очень большой массив, а внутри на самом деле это много маленьких. Выше — очень упрощённый пример. Снаружи мы используем всё это как один массив. Внутри мы определяем размер чанка, т.е. сколько максимум может весить маленький массив, и используем эти чанки. Таким образом, во-первых, мы избегаем проблем с LOH, а во-вторых, если нам сильно захочется, можем аллоцировать большие массивы (больше 2 Гб) даже в x86 — в процессоре, с которым иногда приходится жить.
Есть вспомогательный класс чисто для бенчмарка — Node.

У Node есть ChunkedArray внутри, есть указатель на следующую ноду и очень полезный финализатор, в котором мы делаем полезную работу, например, инкрементим поле.
Простенький бенчмарк.

Мы создаем 1000 Node, каждая следующая Node, помимо того, что она содержит ChunkedArray, указывает на предыдущую, кроме каждой 50. Т.е. получается, что мы создаем 20 цепочек из 50 Node. А в конце мы коллектим весь Heap.
Начиная с 4.5.1 у нас есть специальная ручка, которая говорит: «LOH покомпакться», и она даже работает.

Устанавливаем Chunked Array 80000, чтобы ничего не попадало в LOH. Меряем это на полном фреймворке и на Mono и получаем какие-то такие результаты.

В Mono есть аналог кучи больших объектов, точнее там есть концепт больших объектов — это объекты больше 8000 байт. Но работа с кучей ведется совершенно по-другому — используются другие алгоритмы. В частности, в полном фреймворке у нас будет втык в самом конце бенчмарка, когда мы будем пытаться сколлектить всё, что попало в LOH — это дорогая операция.
А теперь мы берём и Chunksize выставляем в бесконечность, чтобы вырубить чанки вообще. Получаются такие результаты.

На полном фреймворке и на Mono всё разогналось.
Какой вывод отсюда можно сделать? По данному бенчмарку нельзя делать следующие выводы:
И вообще-то это некорректный бенчмаркинг GC, потому что пример слишком академический: не меряет ничего полезного. С помощью него я сейчас показал только то, что хотел показать. Я могу его немножечко поменять и показать, как на Mono разница в перформансе не в полтора раза, а в 100. Я могу немножечко ещё поменять и показать, что чанки на самом деле хорошие, их использовать нужно, на них всё разгоняется. Но это будут чисто академические примеры. Мерить, конечно, нужно на продакшене.
Этот пример показывает самое главное: есть эффект от того, что мы используем чанки, есть разница, попадают у нас данные в LOH или не попадает.
Как это работает на продакшене? Нужно использовать отдельно.
В Rider чанки всё ещё включены. Я порываюсь их выключить, но нельзя начать просто рефакторить легаси код. Нужно подумать, что у нас есть разные версии, что нужно поддерживать Linux, MacOS, а там своя логика аллокации памяти.
У нас есть разные runtime, разные нагрузки и сценарии. И нужно смотреть не как синтетические нагрузки выполняются, а как происходит загрузка Solution-а. Как работает навигация, какие-нибудь frequent usage. И нужно думать про целевые метрики. Потому что здесь мы на самом деле мерили пропускную способность, а она нас (здесь) не интересует. Нас не интересует, сколько раз в секунду мы можем собрать мусор. Нас интересует пользовательский опыт: через сколько времени после нажатия кнопки он увидит результаты — latency. Ещё нас интересует footprint. Пользователи почему-то не хотят, чтобы программа жрала много мегабайт, поэтому иногда даже в сторону ухудшения перформанса приходится сокращать этот самый footprint.
Забить всю имеющуюся память довольно просто. Я запускаю пару-тройку Rider, несколько копий IDEA и TeXStudio, ещё у меня там Firefox, Chrome и всё. Я оказываюсь глубоко в свопе, а в свопе работают совершенно другие перформансные законы.

Вот здесь я отлавливал один memory leak в Rider. Я оставил его вечером включенным, ушёл домой, вернулся и увидел вот такую картину: из 16 доступных Гб Rider жрет 40. Это уже пофикшено, но важный факт в том, что когда вы начинаете немножечко выходить за границу оперативной памяти, у вас начинает немножко тормозить, потому что включается диск, и какое-то время он успевает менеджить ваши страницы.
На скриншоте выше я вылез за пропускную способность моей SSD-хи. Там можно посмотреть: диск 0 — полностью загружен. Я потратил 10 минут, чтобы просто снять процессы, у меня даже курсор мышки дико тормозил. В реальности такое встречается не часто, но немножко вылезти за границы оперативки и попасть в своп — это реальный кейс. Ваши перформансные оптимизации уже там не работают.
Что нужно знать про мемори бенчмаркинг.
И еще два напоминания:
Весь код лежит здесь, а сама презентация — здесь.
Если вы любите .NET хардкор так же, как и мы, рекомендую прочитать интервью с Андреем про оптимизацию работы с памятью, которое мы делали в преддверии DotNext 2017 Piter. Ну и, само собой, посмотреть на список докладов DotNext 2017 Moscow, который пройдет 12-13 ноября.
Весь код лежит здесь, а сама презентация — здесь.
Все мы хотим, чтобы программы, которые мы пишем, работали быстрее и кушали мало памяти. Поэтому практически всем программистам приходится заниматься перформансными работами разной степени сложности. И в ходе оптимизации главное — не хвататься за первый попавшийся кусок кода. Лучше найти узкое место программы, в которое упирается производительность. Можно сколько угодно оптимизировать другие места, но, скорее всего, эффект будет не очень заметный.
К сожалению, поиск узких мест — зачастую нетривиальная задача. Но с типом узкого места чаще всего удаётся определиться. Это может быть, например, процессор, доступ к базе данных, к диску или к сети. Один из распространённых кейсов — это доступ к основной памяти. Думаю, просто потому, что с основной памятью мы работаем чаще всего.
С точки зрения перформанса память — штука очень коварная и непонятная. Будем разбираться с тем, как она работает.
В этом докладе с DotNext 2017 Piter мы поговорим о том, что влияет на скорость работы с памятью. Обсудим как низкоуровневые хардварные штуки (CPU cache и его ассоциативность, выравнивание, store forwarding, 4K aliasing, prefetching, cache/page splits, cache bank conflicts и т.п.), так и более .NET-специфичные проблемы (pinned objects, large object heap, особенности работы кучи в полном .NET Framework и Mono).
Вместо вступления
Для начала я вам расскажу одну историю. Я понемножку помогаю писать Rider IDE и иногда занимаюсь рефакторингом кода. Как-то раз я рефакторил одну подсистему и увидел, что она написана не просто не очень хорошо, а неэффективно. И подумал: «Я же знаю, как писать эффективный код; сейчас я всё перепишу».
Переписал. Всё работает. И я решил проверить, поменялось ли хоть что-то от того, что я переписал. Первый раз я замерил время инициализации подсистемы до рефакторинга, второй раз — после рефакторинга.
5 мс я выиграл, но одного замера мало — только по одному замеру нельзя однозначно сказать, стало ли лучше.
Я сделал 200 замеров до и 200 замеров после — получил такое распределение.
По этому распределению опять нельзя сказать, стало ли лучше.
Я распечатал эти графики и начал показывать их людям на улице, спрашивая, почему они думают, что графики такие — почему у нас вообще нет нормального распределения, а вместо этого мы получаем размазанные по перформансному пространству графики? И в глазах этих людей я видел глубокое непонимание: до меня дошло, что люди просто не знают, из чего складывается перформанс памяти. Поэтому в этом докладе мы будем разбираться, из чего складывается производительность памяти, что на неё влияет, почему мы получаем настолько большой разброс значений.
Хотелось бы научить вас писать правильные memory-бенчмарки, но на это времени нет. Зато я вам покажу 10 разных способов написать некорректные memory бенчмарки.
Обсуждаемые темы
- CPU cache (cache line size, associativity, …);
- Cache Bank Conflicts;
- Alignment;
- Struct Promotion;
- Prefetching;
- Store Forwarding; 4K aliasing;
- Трудности работы с GC и pinned objects;
- Large Objects Heap; Full Framework vs Mono.
Но сначала маленький отказ от ответственности.
Все бенчмарки, которые я буду показывать, — чисто академические и направлены на понимание общих концепций. Если вы увидели здесь какие-то результаты тестов, это не означает, что нужно сразу бежать и переписывать продакшн код. У вас могут получиться совершенно другие результаты.
Память чувствительна к архитектуре процессора. Поэтому у нас есть три подопытные железяки. Когда я буду упоминать, например, Haswell, я не буду иметь ввиду все Haswell-процессоры в мире, а только одну конкретную модель (на скриншоте выше).
Я надеюсь, некоторые из вас знают про библиотечку BenchmarkDotNet — очень клёвая штука, чтобы писать и дизайнить бенчмарки. На основе неё я сделал все эти примеры. Если кто-то из вас не доверяет моим результатам (а у вас нет абсолютно никаких оснований мне доверять; вообще никогда не доверяйте ничему, что вам показывают или рассказывают со сцены), вы можете скачать исходники в интернете и поиграться сами.
Замеряем время!
Начнем с простого примера.
Допустим, вас не устраивает перформанс класса dictionary. Давайте напишем собственный клёвый класс dictionary.
Чтобы убедиться, что он клёвый, мы его немножко побенчмаркаем.
Положили какой-то элемент в нашу мапу. Написали stopwatch.
Как полагается, сделали много итераций, вывели время.
Помимо разнообразных прогревов, статистики, итераций и прочих проблем запуска, здесь есть две фундаментальные проблемы дизайна бенчмарка.
Первая — это доступ к памяти. Здесь мы просто берём и долбим в один элемент по кругу. Это нерелевантно. Нужно перебрать разные паттерны доступа к памяти: последовательный, случайный. На случаи, которые возникают у пользователя, тоже нужно обращать внимание; надо рассматривать какие-то предельные случаи. Далее мы обсудим, почему это важно.
Вторая фундаментальная вещь — это размер рабочей памяти. Сейчас рабочая память, грубо говоря, состоит из одного элемента. Желательно пробовать разные размерчики (маленькие, большие, близкие к размеру разных кэшей), и далее мы увидим, почему.
Все это оказывает заметное влияние.
CPU cache
Начнём с кэшей.
На всякий случай напомню: у нас есть процессор и основная память. К основной памяти добираться долго, поэтому придумали кэш. В кэш мы подтягиваем значение из основной памяти, а к нему доступ организуется уже быстро.
Кэш серьёзно увеличивает производительность ваших приложений. Но в бенчмаркинге он только портит жизнь. Это сплошная головная боль, потому что кэш имеет сложную архитектуру с разными уровнями. Ребята из Intel как-то там на процессоре всё это напаяли — и непонятно, как все это бенчмаркать.
Давайте рассмотрим простенький пример.
У меня есть массив байт. Размер этого массива я буду перебирать. В бенчмарке мы будем проверять, сколько стоит заинкрементить элемент массива. Но будем дергать не просто какой-то один элемент, а разные — с шагом в 64 байта. Это не случайный шаг, а типичный размер кэш-линии на современном железе. Количество итераций каждый раз одно и то же, т.е. вне зависимости от размера мы будем получать одну и ту же алгоритмическую сложность, то же количество ассемблерных инструкций. Вне зависимости от размера массива они будут совпадать с точностью до значения одной переменной. Казалось бы, как это может влиять на performance?
Давайте посмотрим для примера на Ivy Bridge и Skylake.
Пока у нас размер задействованной рабочей памяти маленький (4, 8, 16, 32 Кб), мы получаем практически одинаковые результаты.
Но до сих пор эти данные умещались в L1, типичный размер которого — 32Kb. L1 закончился, пошёл L2. И результаты у нас немного просели.
На 256 килобайтах заканчивается уже L2, начинается L3. Перформанс продолжает деградировать.
Выходим за рамки L3, и результаты уже совсем плохие.
Эта таблица иллюстрирует типичный пример бенчмаркинга, связанного с памятью.
Представьте, что у вас появилась отличная идея, как всё оптимизировать. Но она требует больших перестроений в архитектуре. Вы решили написать маленький proof of concept, чтобы померить, дают ли вообще эти оптимизации какой-нибудь результат. Написали, влезли целиком в L1. И дальше вы гоняете прогретый бенчмарк, который целиком помещается в первый уровень кэша. У вас всё хорошо. Радостные бежите и начинаете переписывать продакшн код, и всё начало тормозить. Вы говорите: «Плохие бенчмарки, не буду вообще всем этим заниматься, пойду лучше займусь багами».
Это действительно очень распространенный user case. Я его много раз видел. Когда вы переходите на уровень большого приложения, там используется много памяти, и она раскидана как-то случайно по куче, и кэш-мисы (промахи по кэшу) — очень типичная ситуация. Поэтому когда вы планируете какие-то эксперименты, важно обращать внимание на то, сколько памяти расходует ваш бенчмарк.
Поговорим про CPU Cache Levels
Я уже сказал, что у кэша есть несколько уровней. Про это все слышали, но не все до конца понимают, зачем им это надо знать. Давайте чуть подробнее посмотрим на эти уровни.
Картинка схематически изображает, как всё устроено внутри на современном железе:
У нас есть, например, четыре физических ядра. L1, L2 у каждого ядра свои, а L3 — общий для всех ядер.
Казалось бы, интересная информация, но зачем она вам нужна?
Давайте погоняем немного этот же самый бенчмарк.
Я в нём ни строчки не поменял, но сузил размер перебираемых значений моего массива данных. Теперь это 2, 4, 6 МБ. Напоминаю, что на моих машинках кэш L3 по 6 МБ.
Если запускать бенчмарк в стерильных условиях (то есть мы выключаем всё, что выключается: IDE-шку, браузер, компоненты самой системы), мы получаем хорошие результаты.
Они воспроизводимы. Разница между минимум и максимум маленькая, и этим можно пользоваться, как какими-нибудь референсными значениями; можно проводить оптимизацию.
Но давайте будем честны: никто так не тестирует. Даже я, когда готовил эту презентацию. Мне было лень на каждый бенчмарк закрывать абсолютно всё. У меня открыт Rider, IDEA, TeXstudio, запущены Dropbox, Google Drive и т.п. Вот какие результаты я получаю, когда всё это запущено.
На что нужно обратить внимание? Во-первых, очень большой разброс значений. Там теперь не 1 мс разницы, а 100-150 мс. Во-вторых, значения резко возросли. И еще важный момент: оказалось, что на 4 Мб мы тупим сильнее, чем на 6 Мб. Это случайный эффект. Если я запущу бенчмарк ещё пять раз, то получу еще пять разных результатов.
Дело в том, что сторонние приложения не всегда одинаково влияют на ваш перформанс. В обычных условиях разброс результатов небольшой, особенно когда у вас реально микробенчмарк и тестовый софт влезают в L1 и L2. Когда вы выходите на уровень L3, приходится соревноваться с другими процессами. Особенно меня удивило, что Dropbox и Google Drive очень сильно влияют на бенчмарки как раз в этом диапазоне — от 2 до 6 Мб (если что, у вас может быть по-другому).
Это действительно проблема. Многие в этом месте говорят, что мы же реальное приложение запускаем, условия там side-by-side с другими приложениями. Почему мы должны бенчмарки в стерильных условиях запускать? Потому что иначе с результатом просто невозможно работать. Последняя таблица не несёт для вас вообще никакой полезной информации. Любой бенчмарк должен быть воспроизводим. Он должен каждый раз давать вам одно и то же число с точностью до распределения. А от такого бенчмарка толку нет. Поэтому с подобными моментами нужно обращаться очень аккуратно.
Я построил картинки с распределением: нас равномерно размазало от 30 до 170 мс.
Работать с этим никак нельзя.
Поговорим про CPU Cache Associativity
Давайте начнём с примера.
Я думаю, все вы можете решить такую задачку. У нас есть квадратный массив N на N, и мы хотим выбрать максимальный элемент в 0 колонке. Очень простой код — никакой магии нет.
Но вот размер массива я буду перебирать. Возьму, к примеру, 512, потому что программисты очень любят круглые числа и часто пихают их в бенчмарки, а ещё возьму 511 и 513.
На одном из этих трёх чисел — на 512 — производительность заметно ниже, чем на остальных.
Почему?
Давайте вспомним, как вообще работает процессор. У современных кэшей есть уровень ассоциативности — некоторое N. Покажу идею на примере двух-ассоциативного кэша.
Что означает, что ассоциативность кэша 2? Что каждой кэш-линии, то есть участку выровненных 64 байт в основной памяти, соответствует ровно 2 позиции в кэше, где эти 64 байта физически могут лежать. Во все остальные места они попасть просто не могут. Соответственно, для следующих 64 будут другие 2 кэш-линии и так далее. Но есть маленький нюанс, который заключается в том, что кэш — маленький, а память — большая. Как несложно догадаться, рано или поздно мы дойдем до таких линий в основной памяти, которые будут соответствовать тем же 2 кэш-линиям, что и самые первые рассматриваемые 64 байта. Такое расстояние обычно называется Critical Stride. Если вы будете перебирать много значений на расстоянии Critical Stride, они будут выбивать друг друга из кэша.
Размер Critical Stride легко посчитать: это размер кэша, деленный на его ассоциативность.
Вот несколько примеров:
Например, L1 у нас обычно 32 КБ 8-ассоциативный. Это означает, что Critical Stride будет 4 КБ. Когда мы идём с шагом 4 КБ, начинаем наступать на эту штуку, и перформанс внезапно падает. Несмотря на то, что объём рабочей памяти у нас остается маленьким, происходят постоянные кэш-промахи.
Сложность работы с Critical Stride заключается в том, что далеко не во всех ваших программах вы берётесь найти максимальный элемент в колонке. Как правило, вы пишете какой-то более сложный код, в котором сложно сказать, где вы наступили на Critical Stride, а где нет. Ещё хуже то, что gc вам постоянно каким-то образом раскидывает данные в памяти, поэтому в одних экспериментах вы можете много раз наступать на Critical Stride, а в других с тем же кодом — мало. Поэтому результаты от раза к разу могут очень сильно отличаться.
С этим не всегда можно бороться, но это полезно держать в уме на случай, если вам потребуется объяснить, почему вы получили такие результаты.
А есть ещё очень интересная особенность Skylake. Откровенно говоря, у него много интересных особенностей. Skylake — это одна из последних микро-архитектур процессоров Intel. Там ассоциативность кэша L2 понизили с 8 до 4. Почему — это совершенно отдельная история. Но если вы написали какой-нибудь микро-бенчмарк на Haswell, который учитывает всякие Critical Stride, перенесли его на другую машину, чтобы удивить друга, у него результат может не воспроизводиться, потому что Critical Stride там другой.
Есть ещё много разных особенностей у Skylake. Например, память у нас состоит из страниц. Обычно страницы примерно по 4 КБ. Попытки наступить на границу двух страниц (page split) или двух кэш-линий (caсhe line split) стоят довольно дорого. Раньше стоимость этих сплитов была 100 циклов CPU. А в Skylake разработчики немного оптимизировали архитектуру, и теперь сплиты стоят 5 циклов CPU. В реальной жизни это малорелевантно, но факт занимательный.
Можете почитать интеловские спецификации, там написано много чудесного.
Поговорим про Cache Bank Conflicts
Примеры становятся сложнее. Посмотрим ещё один хитрый примерчик.
У меня, как всегда, есть массив данных.
В unsafe методе первое, что я делаю — это с помощью ключевого fixed получаю указатель на массив, а затем перехожу в unsafe код.
Это очень полезный прием в memory bound бенчмарках. GC в любой момент (точнее, есть много ситуаций, когда это возможно) может перекинуть ваш массив с одного места на другое, а потом на третье и т.д. И каждый раз будет складываться какая-то новая конфигурация кэш-мисов и особенностей по памяти. Это не то, что вы хотите видеть в микро-бенчмарке, потому что результаты опять будут сильно отличаться друг от друга. Поэтому мы переходим на такой unsafe-стайл.
Я буду решать следующую задачу: буду проверять, есть ли у меня такие элементы на расстоянии дельта, для которых первое число меньше, чем второе. Для этого я указателем бегу по памяти, инкременчу указатель и сравниваю числа.
Выберем три варианта расстояния: 15, 16 и 17. И посмотрим два процессора: Skylake и Ivy Bridge.
На Skylake всё хорошо. Мы там с точностью до погрешности получаем практически идентичные результаты.
А если мы запустим бенчмарк на модели процессора, которая вышла в 2012 году, на 16 будет происходить что-то очень странное. Если мы откроем интеловский Manual по тому, как устроены процессоры, то узнаем, что на самом деле кэш-линии состоят из кэш-банков, их обычно 8 штук. Если вы читаете значение из двух разных кэш-линий, но с одинаковыми номерами кэшбэнков, у вас будут проблемы. Именно процессоры на архитектуре Sandy Bridge не умели делать это одновременно. Если у вас по коду подряд идут два чтения из таких ячеек, начиная с Haswell результат будет хороший — они смогут считаться одновременно, а в старых процессорах — нет. Если более формально, проблемы на архитектуре Sandy Bridge будут при совпадении битов со 2 по 5.
Поговорим про Alignment
Скорее всего вы знаете, что выровненный доступ — это хорошо, а невыровненный — это плохо. Но на практике мало кто использует это знание, когда пишет программы. Однако эта штука оказывает заметное влияние, причем в достаточно простых кейсах.
Например, у меня есть две структуры: в структуре Struct3 у меня три байта, в структуре Struct8 — восемь байт. Для каждой структуры я создал небольшой массив всего на 256 элементов.
Напишем простой бенчмарк. Мы бежим по массиву и считаем сумму всех X1 и X2.
Остальные элементы — X3, X4, X5 — существуют, но они никак не используются. Мы их добавили на будущее на всякий случай, потому что когда-нибудь они точно понадобятся. Вопрос: какой из методов будет работать быстрее — S3 или S8?
Правильный ответ зависит от условий. Если мы запустим пример на полном фреймворке, типа LegacyJIT-x64, то получим, что при переходе с S3 на S8 перформанс растет в 5 раз. А на Mono — падает всего в два раза. Почему так выходит?
Тут нужно разобраться, как вообще у нас лэйаутится память в разных видах runtime.
Если мы спросим у типа marshal, какой у нас размер структуры S3, то полный фреймворк честно скажет — три байта.
А Mono думает: «Если у нас размер будет 3, то мы там будем постоянно нарываться на невыровненный доступ. Это плохо. Поэтому мы добавим дырку ещё на 5 байт, чтоб всё было выровнено».
В итоге на полном фреймворке — на LegacyJIT-x64 — данные не выровнены. Они лежат подряд, как нарисовано слева. И когда мы бегаем по бенчмарку, постоянно нарываемся на невыровненный доступ, и у нас всё тормозит. Мы переходим к S8, и доступ становится выровненным.
На Mono другой эффект. Здесь данные у нас всегда выровнены, поэтому выровненность вообще никак не влияет на performance. Но чем больше у нас байт, тем сложнее всю структуру доставать из памяти и класть, например, в стек. Мы ведь не только X1 и X2 будем доставать, чтобы всё было в стеке. Поэтому мы можем видеть практически прямо пропорциональную зависимость между количеством байт и перформансом.
Наверняка многие из вас добавляли поля в структуры, но не думали о том, что это принесёт какой-то вклад в перформанс, даже если вы их не используете. Я обычно об этом тоже не задумываюсь.
Поговорим про Struct Promotion
Тот же самый пример, ни строчки не поменял. Те же самые Struct3 и Struct8, только мы запустим этот бенчмарк под RyuJIT-x64.
Я специально подобрал такие условия, чтобы здесь производительность методов была одинакова.
Почему в остальных нормальных JIT-ах есть разница, а в этом нет? На RyuJIT происходит интересная вещь: если мы посмотрим на ассемблерный код, то увидим, что для S3 RyuJIT кладет все наши данные в регистры и далее использует регистры.
А для S8 кладет все данные в стек. Для S3 данные в регистре — это хорошо, но доступ не выровненный — это плохо. В S8 данные в стеке — это плохо, но зато доступ выровненный. Это хорошо. По счастливой случайности эффекты компенсировали друг друга (на самом деле я специально подбирал значения так, чтобы они компенсировали друг друга, но будем считать, что эффект обнаружен по счастливой случайности). Так бывает. Самое ужасное, что ошибка сходу незаметна. Два абсолютно одинаковых метода, которые делают одно и то же, выдают нам одинаковый результат. Но вы начнёте переносить ваши мысли на реальную систему, какие-то условия поменяются, и в итоге одна оптимизация заборет другую, и появится перформансная проблема в самом неожиданном месте.
Тут есть другой вопрос: почему здесь есть разница между S3 и S8, что это за оптимизация такая? Она называется Struct Promotion и как раз направлена на то, чтобы, если структура маленькая, всё выгружать в регистры и не трогать стек.
У struct promotion есть ряд определенных ограничений (эвристик).
Например, RyuJIT считает, что структура маленькая, если в ней четыре поля или меньше.
На такие факты завязываться очень опасно, потому что в каждой следующей версии фреймворка они могут поменяться. Завтра разработчики решат, что меньше шести полей — тоже маленькая структура. А могут решить, что оптимизация вообще не даёт прироста, и выкинут её, чтобы код стал проще. Поэтому во время оптимизации на это закладываться нельзя. Но когда вы замеряете performance, подобные оптимизации JIT (а их, на самом деле, очень много) могут всё испортить. Это опасно тем, что вы будете думать, что ваши изменения повлияли на перформанс, будете делать из этого выводы, а на самом деле просто в JIT немножко поменялась конфигурация происходящего, и он решил перекомпилировать всё по-другому.
Поговорим про Prefetching
Если простыми словами: представьте, что мы последовательно идём по памяти. CPU — умный, он об этом догадывается, т.к. умеет распознавать такие ситуации. Он может предположить, что мы и дальше будем идти последовательно, поэтому предугадывает те данные, которые нам понадобятся — префетчит их, заранее подсасывая поближе к кэшу. Это очень здорово, но, к сожалению, из-за этого получается очень большая разница в производительности между последовательным и случайным доступом.
На самом деле, на разницу производительности влияет очень много факторов, и это — один из них. Если мы пишем бенчмарки для какой-нибудь структуры данных, желательно всегда посмотреть на последовательный доступ и на рандомный. Однако с рандомным доступом тоже могут быть свои приколы.
Рассмотрим следующий примерчик.
У нас есть массив данных, и на этом массиве данных я эмулирую какую-то ссылочную структуру. Для каждого элемента int я говорю, что next — это указатель в какую-то другую ячейку. Такое упрощение. У вас могут быть какие-то ноды или граф — любая структура, где одни объекты указывают на другие. Просто чтобы обо всем этом не думать, я написал пример на массивчиках.
Я заполню ссылки и сам массив какими-то рандомными данными.
Вот, кстати, еще одна популярная ошибка тех, кто решает побенчмаркать что-нибудь со случайным доступом. Они вызывают рандом прямо внутри тела бенчмарка, видят перформансную деградацию и говорят: «Какой рандомный доступ плохой». А на самом деле просто random.Next — тоже не бесплатный, он занимает какое-то время, и желательно вызвать его заранее до бенчмарка.
У меня есть полезный метод (CPU-bound), который выполняет много инструкций.
Для примера сделал код, который проверяет, делится ли число на 13, 17, 19 и т.д. У вас может быть любой другой код, который просто выполняет много инструкций.
Далее у меня есть метод.
У него есть переменная index, которая указывает на некий текущий элемент. Я передвигаю указатель — говорю index = next[index] — и по новому индексу вытаскиваю данные из моего массива. Проверяю, хорошее мне число досталось или не очень, и считаю, сколько у меня хороших чисел.
Этот простой код можно переписать.
В новом варианте я буду получать данные заранее. Код на красном фоне — то, что было раньше; его мы выкинули. На зеленом — то, что мы написали в новом варианте. С алгоритмической точки зрения всё то же самое, но данные из массива я получаю заранее и в начале тела цикла сразу записываю подготовленный результат Y прямо в X, а только потом начинаю фетчить следующие данные.
Между этими двумя примерами есть большая разница.
Если мы посмотрим на перформанс, метод prefetch работает заметно быстрее. Почему?
В первом случае метод IsNice должен ждать, пока мы зафетчим данные. Он не может предугадать, потому что у нас нетипичный для CPU паттерн доступа к памяти. Он должен сначала дождаться, пока мы переставим индекс, потом переставим данные, и только тогда он сможет запустить метод IsNice. А во втором случае мы сразу знаем значения X уже на уровне CPU, поэтому можем сразу запустить IsNice. Обновление индекса Y пойдет параллельно. Здесь у нас потоков нет, но работает construction level parallelism (CPU внутри себя может много всего параллелить). Отсюда и разница.
Почему нужно понимать эти prefetch-фокусы? Потому что они могут появиться просто в процессе рефакторинга. Вы немного что-нибудь поменяли в программе и таким образом изменили условия для Instruction Level Parallelism. В результате разница в перформансе появилась не из-за изменения алгоритмической сложности, а из-за того, что вы что-нибудь случайно запрефетчили. Гарантировать, что новый код ничего не префетчит, практически никогда нельзя.
Поищем веселые примеры в интеловских мануалах.
В мануалах приведен подобный пример, только мы прыгаем случайно по памяти; когда мы куда-нибудь прыгнули, нам нужно обработать две кэш-линии: сначала первую (какой-нибудь CPU consuming code), а затем вторую. И это очень обидная ситуация, потому что когда мы обрабатываем первую кэш-линию, мы знаем, что скоро нам понадобится вторая. Но процессор-то этого не знает, потому что он видит, что мы как-то рандомно прыгаем. Мы хотим дать понять CPU, что нам скоро понадобится следующая кэш-линия, чтобы он ее заранее подтянул. Для этого есть много интересных способов. Один из них предлагает компания Intel — это постучаться в область памяти не один раз, а три, т.е. перенести значения eax просто три раза подряд. Это будет условный знак для CPU, что нам нужно запрефетчить следующую кэш-линию. Человек в здравом рассудке до такого просто не догадается. Но такие оптимизации существуют.
Я очень хотел сделать пример с таким хаком на .NET, но, к сожалению, на чистом .NET не получилось, потому что JIT всё-таки, сколько бы я его не ругал, достаточно интеллектуален: если он что-то сфетчил из памяти и положил в регистр, дальше он использует регистр.
Мануал, на который я постоянно ссылаюсь, очень большой. Там написано очень много всего интересного, и никогда нельзя знать наверняка, где сработает какой-нибудь префетчинг, а где — нет. К этому тоже нужно быть хотя бы морально готовым.
Поговорим про 4К aliasing
Но сначала немного теории. У нас есть CPU и L1 кэш. Допустим, мы какие-то данные сохраняем в память. Мы уже знаем, что они не сразу полетят в память, а сначала осядут где-нибудь в L1. Но как это происходит? Есть ли что-нибудь между CPU и L1?
Там есть буфер. Это очень хорошая штука. Допустим, у вас есть число, и вы хотите положить его в память. Это операция не бесплатная, она занимает несколько циклов CPU, и будет здорово, если мы не будем ждать, пока данные доедут до L1-кэша, а продолжим делать какую-нибудь полезную работу. Поэтому мы кладем числа в Store Buffer и идем исполнять наши инструкции. Все работает быстро.
По аналогии есть Load Buffer.
С помощью него CPU поможет подсасывать из L1 данные, которые нам вот-вот понадобятся.
А теперь представьте такую невероятную ситуацию: вы записали что-то в память и сразу хотите прочитать. В приведённой выше схеме получается небольшая проблема, потому что нам нужно ждать, пока число через Store Buffer доедет до L1, потом CPU поймет, что число надо послать назад через Load Buffer, а мы будем сидеть и ждать. Поэтому есть механизм, который называется Store Forwarding, который умеет догадываться, что в Store Buffer у нас есть то, что нам нужно. Несмотря на то, что физически до L1 данные ещё не дошли, мы поможем выдернуть их прямо из Store Buffer и положить в Load Buffer.
Есть хитрые моменты, связанные со Store Forwarding. Благодаря этому механизму можно очень быстро проверить, что число у нас лежит в Store Buffer. Для этого используется простой хэш — от каждого числа берутся последние 12 бит адреса. И если у всех чисел последние 12 бит адреса различаются, всё хорошо. Store Forwarding отрабатывает моментально. Если не отличаются, то иногда возникают проблемки.
Теперь когда мы знаем матчасть, посмотрим ещё один пример.
Представим, что у нас есть массив данных, и мы хотим получить такой базовый оффсет, который выровнен на 4 Кб по границе страницы. Иногда очень приятно иметь выровненные данные, потому что не хочется зависеть от GC и ожидать от него любого подвоха, как он там что выровняет.
Кроме fixed, есть и другой способ запинить данные и получить адрес — это GCHandle Alloc.
С его помощью можно сказать, что объект у нас запиненный, и gc его трогать не надо. Можно получить адрес и с помощью простой магии с процентами выровнять всё это дело на 4 КБ.
Весь оффсет у нас выровнен.
Теперь мы делаем один простой вызов Array.Copy:
Мы будем копировать 16 КБ — это число, позволяющее создать какую-то нагрузку на ArrayCopy. С базового оффсета, т.е с выровненного адреса, мы будем копировать на базовый оффсет плюс 24 КБ (тоже такое очень хорошее круглое число) плюс некоторый StrideOffset. И будем перебирать сейчас StrideOffset, т.е. немного играть с Destination адресом и смотреть, что произойдет.
Смотреть будем на Haswell-е. И для начала возьмем StrideOffset -33. Это означает, что мы берём наши 16 Кб и копируем их на 16 Кб — 33 байта.
Наступаем на невыровненный доступ. Мы все знаем, что невыровненный доступ — это плохо.
Теперь берем StrideOffset -32. Данные более выровнены, хотя бы на 32 КБ.
Все хорошо — доступ выровнен, performance улучшился.
Перебираем числа от -31 до -1.
Если сделать много итераций и очень аккуратно всё это промерить, получаются одинаковые результаты с точностью до погрешности.
Далее, в 0 у нас совсем выровненный доступ — мы ещё и по границе страницы выровнялись.
Теперь мы попробуем сделать StrideOffset 1.
И перформанс внезапно ухудшился.
Мы копируем всё те же 16 КБ, вызываем только один единственный ArrayCopy. Всё, что мы поменяли, это Stride Offset на единичку — на 1 байт в бок сдвинули — и performance просел в пять раз. Почему так происходит?
Если совсем на пальцах: мы начинаем копировать, первый байт полетел у нас из Source Index в Destination Index — 24 КБ + 1 байт. Потом второй байт — за ним. Но второй байт находится как раз на 24 КБ раньше, чем тот, в который мы только что записали. Т.е. у нас в Store Buffer пошло какое-то значение, нам из Load Buffer нужно что-то получить, а последние 12 бит адреса у них совпадают (потому что у всего, что отличается ровно на 4 КБ, ну или на 24, совпадают последние 12 бит). И всё. Эта штука называется 4K aliasing. В интеловской документации и перформанс-счётчиках она тоже есть, и она может оказывать влияние.
Когда я про это рассказываю людям, они обычно говорят, что это точно в продакшене не встретится. Как это может возникнуть в реальном коде? А я взял Rider, открыл его и померил Intel VTune Amplifier.
Там есть 4К aliasing. Его, конечно, мало, он не сильно влияет на перформанс, по крайней мере, не до такой степени, чтобы я хотел что-то там оптимизировать. Потому что оптимизировать эту штуку почти нереально.
Иными словами, эта информация полезна, но в очень маленьком проценте случаев. Серьёзно, есть люди, которые на это наступают и которым больно, но их мало, и, скорее всего, они пишут не на .NET. Но когда мы делаем бенчмарки, мы усвоили, что нужно перебирать разные размеры, разные оффсеты. Когда мы делаем грамотный микро-бенчмаркинг, на вещи типа 4K алиасинга наступить уже вполне реально.
С ним можно бороться. Он активно проявляется, когда у нас данные не выровнены.
Можно выровнять данные, можно поменять оффсеты, можно много чего сделать — читайте интеловские доки.
Поговорим про GC
Я ещё толком ничего не сказал про .NET, поэтому давайте поговорим про сборщик мусора.
Сборщик мусора — это не очень клёвая штука для того, кто хочет писать бенчмарки, потому что сборщик мусора на самом деле предоставляет вам перформансные кредиты. Вы практически мгновенно аллоцируете какую-то область памяти, это достаточно дешёвая операция. Но вы платите за это перформансные проценты в будущем. Потому что каждый раз, когда GC начинает что-то коллектить, особенно если вы построили очень сложный граф объектов, он даёт нагрузку на процессор в бекграунде, пока вы что-то делаете полезное, замедляя вас, он делает stop-the-world паузы, которые ухудшают latency и т.д. Про GC можно сделать несколько докладов о том, как он мешает жить в memory бенчмарках.
Дам общий совет: если кратко и не вникая в детали, делайте просто много-много итераций и считайте средне-размазанное влияние GC на ваш бенчмарк.
А я покажу ещё два весёлых примера, связанных с GC.
У нас в райдере есть волшебный Internal Mode, в котором появляется куча прикольных вещей.
И одна из этих прикольных вещей — Backend Memory Usage. Мы меряем, сколько у нас .NET-овская часть Rider жрёт памяти.
Здесь есть много разных показателей. В частности интересно, что у нас есть Allocated Mаnaged Memory, которая 108 МБ на этом скриншоте, а есть Working Set — 666 МБ. Это у меня сразу вызывает подозрения.
В Rider предусмотрены специальные managed-кэши, которые жрут какую-то часть памяти, когда данные не укладываются в managed, но эта часть должна быть 300-400 МБ. Т.е. эти два числа должны отличаться максимум на 400. Но вот здесь что-то явно пошло не так, и я решил проверить.
Я знаю уже, что нужно много раз мерить. Я померил много раз, посчитал среднестатистический Working Set после полной загрузки Rider, и он получился 566 МБ. Но среднестатистический — плохое слово. Большинство людей имеют количество ног больше статистического. Потому что есть безногие, есть одноногие люди. Я, как программист, морально готов к тому, что у человека может быть три или минус одна нога. Но в среднем получается немного меньше двойки. Поэтому со средним работать не очень хорошо — смотрим на распределение.
На распределении у нас вообще нет ни одного сэмпла, который бы занимал 566 Мб. Получается два максимума. Почему?
Я поймал пример, когда мы попали в правый пик и увидел следующее на снапшоте из DotMemory:
У нас есть здоровый, полностью пустой сегмент gc, а на самом конце этого сегмента — маленький запиненный объект на несколько байт, который держит весь здоровый сегмент, и из-за которого вся программа начинает жрать памяти на 200 метров больше. Как так получается?
У нас есть много кода для диагностики. В частности, мы поднимаем маленький http-server, к которому через localhost можно постучаться по специальному порту и увидеть красивые графики про то, как у нас там протокольный трафик идет с одной стороны в другую.
И вот у нас есть такой класс — HttpListener.
Внутри есть штука, которая называется SyncRequestContext. Она создаётся где-то внутри метода GetContext.
Если посмотреть на неё, то в одном месте обнаружится GCHandle.Alloc с ключиком Pinned, который мы уже знаем, и который запинивает объект размером порядка 32 байт.
Как-то у нас звёзды сошлись так, что эта штука дожила до второго поколения и там была запинена. У вас скорее всего такого не будет, но подобный феномен вполне может вылезти в другом месте.
Проблему поправили — на пустом месте Working Set стал здоровым.
Поговорим про LOH
Ещё один пример — про кучу больших объектов (LOH).
В полном фреймворке (Full .NET Framework и .NET Core) есть куча больших объектов, в которую попадают объекты больше 85000 байт.
Эта куча сама по себе не компактится. Можно прийти и сказать: «Куча, пожалуйста, покомпакться», — но по дефолту этого не происходит.
В масштабных приложениях куча больших объектов — это головная боль, потому что в неё попадают объекты, которые, как .NET считает, большие. Если при этом живут они недолго, в LOH остаётся дырка. Поэтому приложение жрёт очень много памяти.
Для борьбы с LOH у нас в Rider в ReSharper есть структуры, основанные на чанках — ChunkedArray.
Суть очень проста: мы хотим что-нибудь, что снаружи выглядит, как очень большой массив, а внутри на самом деле это много маленьких. Выше — очень упрощённый пример. Снаружи мы используем всё это как один массив. Внутри мы определяем размер чанка, т.е. сколько максимум может весить маленький массив, и используем эти чанки. Таким образом, во-первых, мы избегаем проблем с LOH, а во-вторых, если нам сильно захочется, можем аллоцировать большие массивы (больше 2 Гб) даже в x86 — в процессоре, с которым иногда приходится жить.
Есть вспомогательный класс чисто для бенчмарка — Node.
У Node есть ChunkedArray внутри, есть указатель на следующую ноду и очень полезный финализатор, в котором мы делаем полезную работу, например, инкрементим поле.
Простенький бенчмарк.
Мы создаем 1000 Node, каждая следующая Node, помимо того, что она содержит ChunkedArray, указывает на предыдущую, кроме каждой 50. Т.е. получается, что мы создаем 20 цепочек из 50 Node. А в конце мы коллектим весь Heap.
Начиная с 4.5.1 у нас есть специальная ручка, которая говорит: «LOH покомпакться», и она даже работает.
Устанавливаем Chunked Array 80000, чтобы ничего не попадало в LOH. Меряем это на полном фреймворке и на Mono и получаем какие-то такие результаты.
В Mono есть аналог кучи больших объектов, точнее там есть концепт больших объектов — это объекты больше 8000 байт. Но работа с кучей ведется совершенно по-другому — используются другие алгоритмы. В частности, в полном фреймворке у нас будет втык в самом конце бенчмарка, когда мы будем пытаться сколлектить всё, что попало в LOH — это дорогая операция.
А теперь мы берём и Chunksize выставляем в бесконечность, чтобы вырубить чанки вообще. Получаются такие результаты.
На полном фреймворке и на Mono всё разогналось.
Какой вывод отсюда можно сделать? По данному бенчмарку нельзя делать следующие выводы:
- нельзя делать выводы о runtime — сравнивать Mono и полный фреймворк.
- нельзя делать вывод о том, что нам сейчас использовать в продакшене: выкидывать чанки или не выкидывать.
И вообще-то это некорректный бенчмаркинг GC, потому что пример слишком академический: не меряет ничего полезного. С помощью него я сейчас показал только то, что хотел показать. Я могу его немножечко поменять и показать, как на Mono разница в перформансе не в полтора раза, а в 100. Я могу немножечко ещё поменять и показать, что чанки на самом деле хорошие, их использовать нужно, на них всё разгоняется. Но это будут чисто академические примеры. Мерить, конечно, нужно на продакшене.
Этот пример показывает самое главное: есть эффект от того, что мы используем чанки, есть разница, попадают у нас данные в LOH или не попадает.
Как это работает на продакшене? Нужно использовать отдельно.
В Rider чанки всё ещё включены. Я порываюсь их выключить, но нельзя начать просто рефакторить легаси код. Нужно подумать, что у нас есть разные версии, что нужно поддерживать Linux, MacOS, а там своя логика аллокации памяти.
У нас есть разные runtime, разные нагрузки и сценарии. И нужно смотреть не как синтетические нагрузки выполняются, а как происходит загрузка Solution-а. Как работает навигация, какие-нибудь frequent usage. И нужно думать про целевые метрики. Потому что здесь мы на самом деле мерили пропускную способность, а она нас (здесь) не интересует. Нас не интересует, сколько раз в секунду мы можем собрать мусор. Нас интересует пользовательский опыт: через сколько времени после нажатия кнопки он увидит результаты — latency. Ещё нас интересует footprint. Пользователи почему-то не хотят, чтобы программа жрала много мегабайт, поэтому иногда даже в сторону ухудшения перформанса приходится сокращать этот самый footprint.
Забить всю имеющуюся память довольно просто. Я запускаю пару-тройку Rider, несколько копий IDEA и TeXStudio, ещё у меня там Firefox, Chrome и всё. Я оказываюсь глубоко в свопе, а в свопе работают совершенно другие перформансные законы.
Вот здесь я отлавливал один memory leak в Rider. Я оставил его вечером включенным, ушёл домой, вернулся и увидел вот такую картину: из 16 доступных Гб Rider жрет 40. Это уже пофикшено, но важный факт в том, что когда вы начинаете немножечко выходить за границу оперативной памяти, у вас начинает немножко тормозить, потому что включается диск, и какое-то время он успевает менеджить ваши страницы.
На скриншоте выше я вылез за пропускную способность моей SSD-хи. Там можно посмотреть: диск 0 — полностью загружен. Я потратил 10 минут, чтобы просто снять процессы, у меня даже курсор мышки дико тормозил. В реальности такое встречается не часто, но немножко вылезти за границы оперативки и попасть в своп — это реальный кейс. Ваши перформансные оптимизации уже там не работают.
В заключение
Что нужно знать про мемори бенчмаркинг.
- Нужно понимать общую методологию — недостаточно просто что-то написать и запустить. Нужно аккуратно дизайнить такие бенчмарки — перебирать размер рабочей памяти, паттерны доступа.
- Нужно понимать, как устроено железо и рантайм, особенно те, на которых вы работаете.
- Нужно помнить о пользовательских сценариях. Очень важно смотреть не только на бенчмарки, но и на то, как всё это ведёт себя на продакшн. Представьте чисто гипотетическую ситуацию: вы пишете плагин для какой-нибудь программки. И вы его очень хорошо оптимизировали, все быстро работает, но пользователи жалуются, что всё тормозит. Вы можете сколько угодно показывать им результаты бенчмарков, рассказывать про то, какие хорошие у вас алгоритмы и структуры данных; вы можете жаловаться, что программа, для которой вы пишите плагин в 2017 году, до сих пор 32-битная и у неё есть определённые особенности, на которых она начинает втыкать, и виноват в этом не ваш плагин. Вы даже можете написать Standalone версию вашего плагина, который делает то же, что и программка с плагином, чтобы показать, что код работает очень быстро. Но пользователи всё равно будут жаловаться, что вот ваш плагин тормозит. Поэтому когда вы смотрите на оптимизацию, очень важно тестировать не только в каком-то маленьком контексте бенчмарка. Надо смотреть, как это всё работает на продакшн системе.
И еще два напоминания:
- Этот доклад был не об оптимизациях, а о замерах. Всё то, что я рассказал, в мире оптимизации не так часто срабатывает. Не нужно пытаться оптимизировать ваши программы, чтобы там 4К алиасинга стало меньше. Но когда вы начинаете мерить, а без замеров очень сложно оптимизировать, все эти и многие другие вещи хорошо бы знать.
- В большинстве случаев всё не так уж плохо. В 80% случаев, когда у меня проблема, я снимаю snapshot, думаю: «Баг, наверное, вот тут». Меняю две строчки местами, снимаю ещё snapshot, и всё начинает работать в 10 раз быстрее, жрать в 20 раз меньше памяти, при этом я не пишу ни одного бенчмарка. Таких ситуаций большинство. В реальной жизни можно, в общем, разобраться без rocket science со всеми проблемами. Но чтобы отличить, когда вам нужно обо всём этом думать и дизайнить хорошие красивые бенчмарки, а когда можно ограничиться маленьким снапшотом, надо хотя бы концептуально представлять себе общую методологию, и как это всё работает внутри. Для этого нужно читать очень много хороших книжек, интеловские мануалы (это большое, но увлекательное чтиво), всякие хорошие статьи по перформансу. Чего я вам всем и желаю.
Весь код лежит здесь, а сама презентация — здесь.
Если вы любите .NET хардкор так же, как и мы, рекомендую прочитать интервью с Андреем про оптимизацию работы с памятью, которое мы делали в преддверии DotNext 2017 Piter. Ну и, само собой, посмотреть на список докладов DotNext 2017 Moscow, который пройдет 12-13 ноября.